
xAI: The Unpriced Risk in SpaceX’s IPO
A report concerning xAI's safety practices, governance, and disclosure obligations ahead of the SpaceX IPO.
A report concerning xAI's safety practices, governance, and disclosure obligations ahead of the SpaceX IPO.
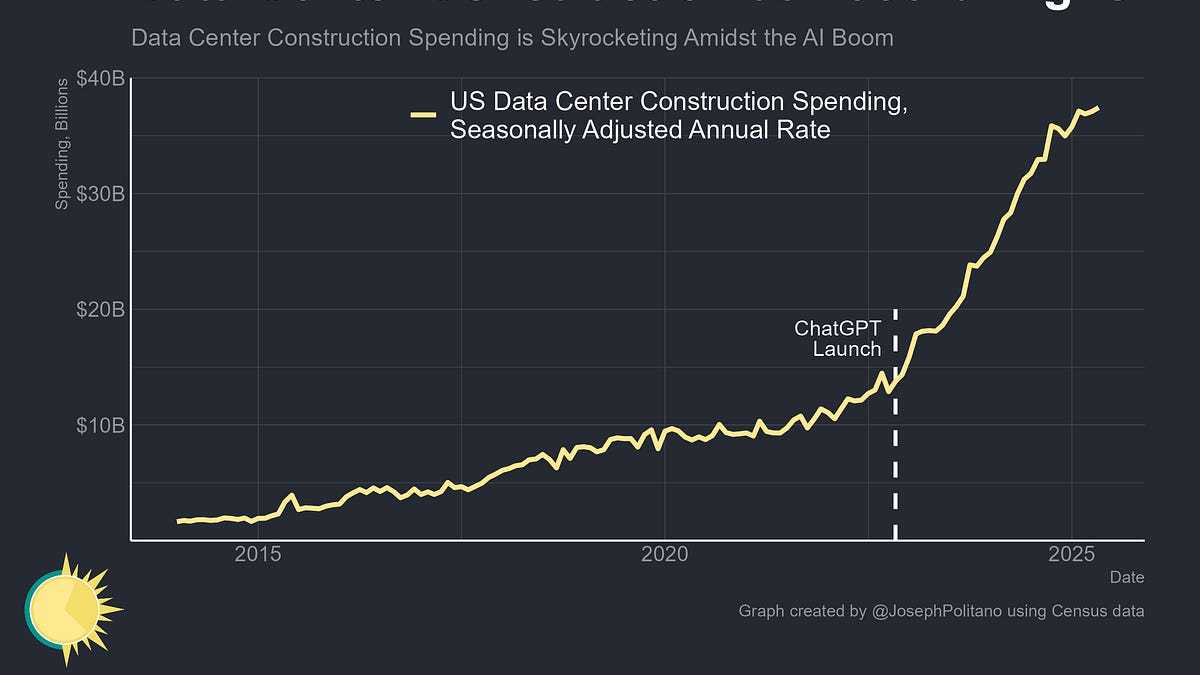
US AI-Related Investment Keeps Breaking Records, With Total Software, Computer, & Data Center Spending Now Exceeding $1T Per Year
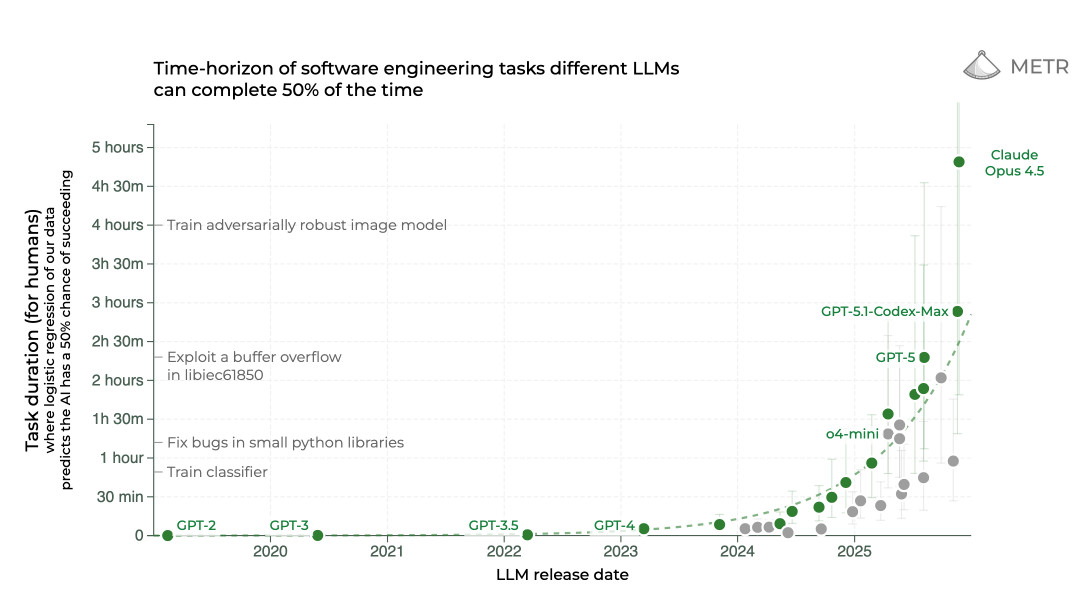
This is the third in my annual series reviewing everything that happened in the LLM space over the past 12 months. For previous years see Stuff we figured out about …

Does process matter? We are about to find out.
This is the third in my annual series reviewing everything that happened in the LLM space over the past 12 months. For previous years see Stuff we figured out about …
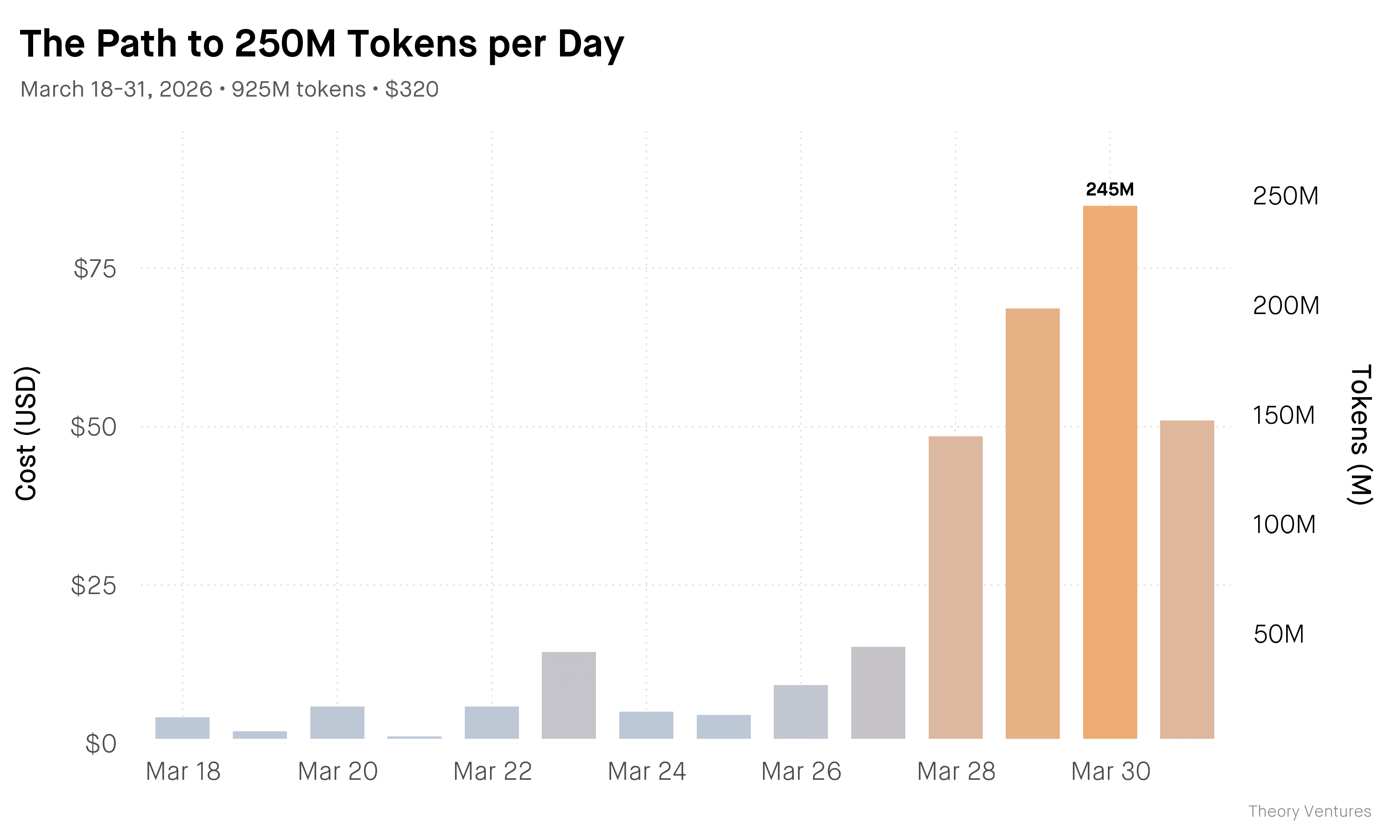
I burnt 250M tokens in a day. Tokenmaxxing is the deliberate practice of maximizing AI token consumption through parallelization.
Fall 2025 - Harvard

The Compute Theory of Everything, grading the homework of a minor deity, and the acoustic preferences of Atlantic salmon
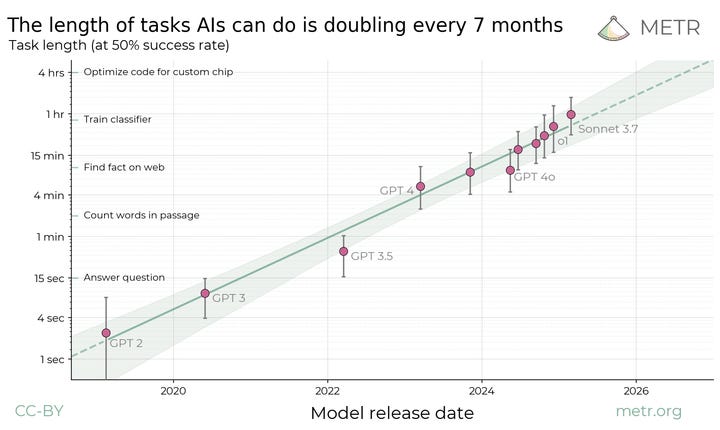
LLMs were invented in four major developments... all of which were datasets
Analysis of AI agent reliability using survival models. Re-examining METR's task data with Weibull distributions reveals insights about long-horizon AI autonomy.

How has AI progress compared to AI 2027 thus far?
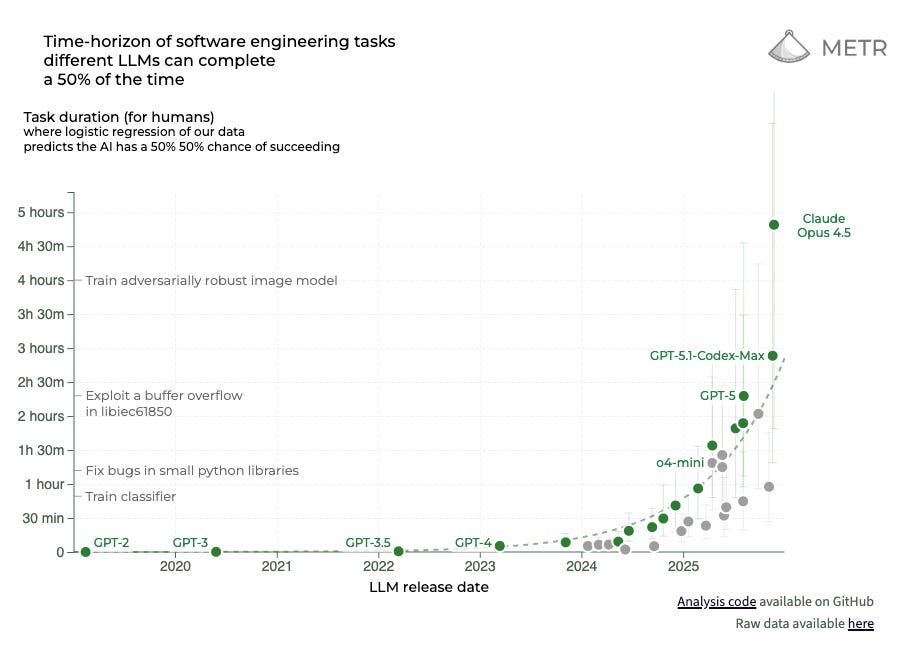
METR’s benchmark has become a bellwether of AI capability growth, but its design isn’t up to the task, argues Nathan Witkin
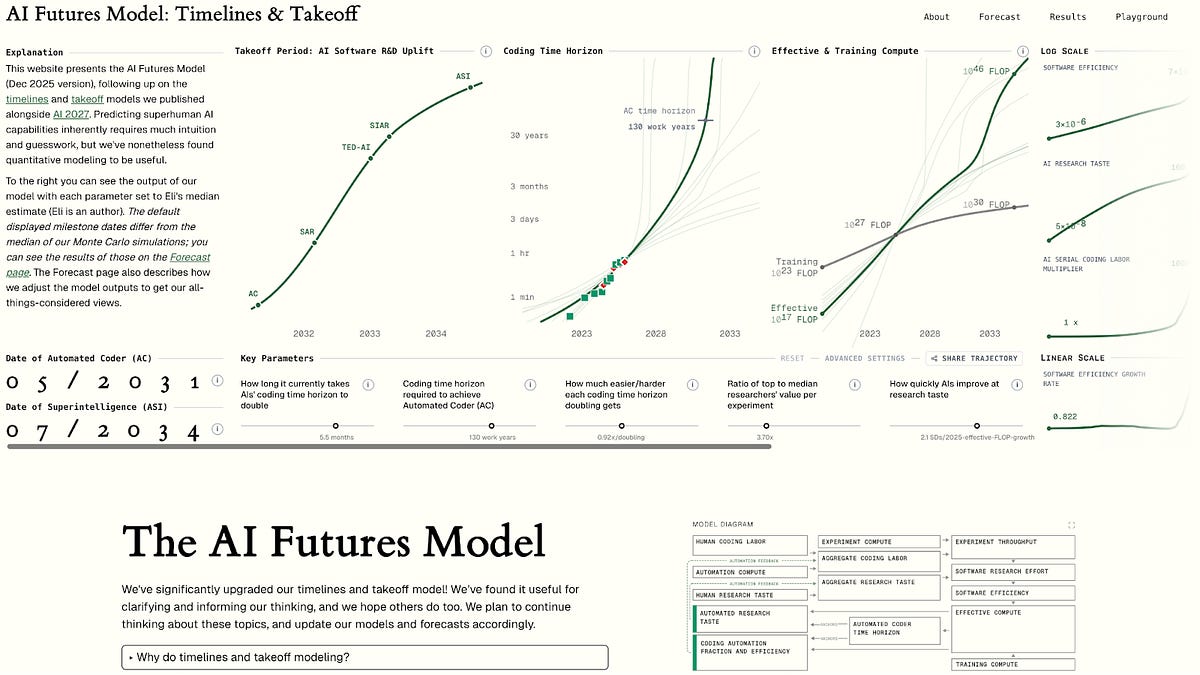
We've significantly improved our model of AI timelines and takeoff speeds!

Advanced AI could unlock an era of enlightened and competent government action. But without smart, active investment, we’ll squander that opportunity and barrel blindly into danger.

Educational demos, marketing materials, and creative work—problems without a mathematical harness. Part 2 of the Agent Autonomy series shows how orchestrated agent evolution can solve subjective problems through skill-based guidance and multiple independent evaluators.

Learn how to evaluate agentic AI systems using dual evaluation, LLM-as-a-judge, and hybrid methods that go beyond observability.

Gemini 3 is out. The benchmarks are genuinely incredible. But it’s hard to know what to do about it.41% on HLE. 45% on ARC-AGI-2. These are colossal achievem...

Intro/Disclaimer: Trade at your own risk! Just like women think “I’m special” and “This time it’ll be different” when it comes to relationships, men think the same way when it comes to stock trading. Warren Buffett’s advice has remained the same for years: Most people should simply dump their money into an index fund that tracks the market and forget about it rather than actively trade and lose money. I too have recommended that same approach in one of my most-read posts, but given my actions, I think I need to add another oft-repeated piece of advice: “do as I say and not as I do.”

Here's what's actually shocking about GLP-1s: they work by making the entire behavioral apparatus of weight loss obsolete. AI does the exact same violence to our model of intelligence.

The limiting factor shifts from cognition to governance and economics. The model is no longer the bottleneck. The system is.

Cut through the rhetoric: what people mean by each, why benchmarks keep saturating, and how super-exponential autonomy reframes the next few years

The Unreliability of LLMs & What Lies Ahead

An analysis of AI and institutions.
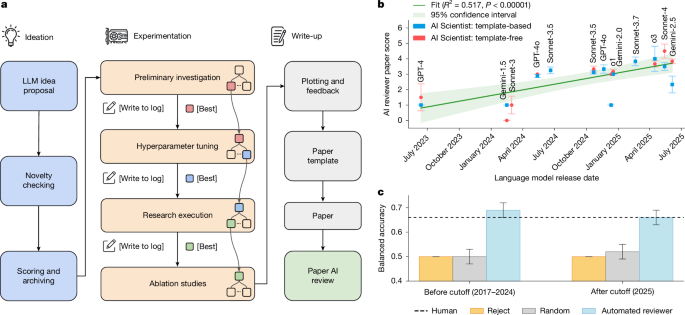
An artificial intelligence system can produce research papers with minimal human involvement, even passing the first round of peer review for the workshop of a main machine learning conference.
Anthropic economic research on productivity gains
An artificial intelligence system can produce research papers with minimal human involvement, even passing the first round of peer review for the workshop of a main machine learning conference.
Disclaimers:

A lot changes in three months

Agentic, delegation-based services could reshape how people access government, cutting administrative burden – if agencies start building the right design patterns now.
I ask how long something will take. Claude answers in developer-hours. Claude is doing the work.

What are we actually hiring for when AI can ace your interviews?
The work most of us are doing right now—the clicking, the tabbing between windows, the copy-pasting, the endless typing interspersed with bursts of genuine cognition—will soon seem as archaic as programming in assembly language—the low-level instruction set for a machine that is about to be automated away. The Atom of Work: The Read-Cognify-Write Loop Break down any task performed by a knowledge worker, and you find the same atomic structure repeating itself:

Crossposted on lesswrong Modern humans first emerged about 100,000 years ago. For the next 99,800 years or so, nothing happened. Well, not quite nothing. There were wars, political intrigue, the in…
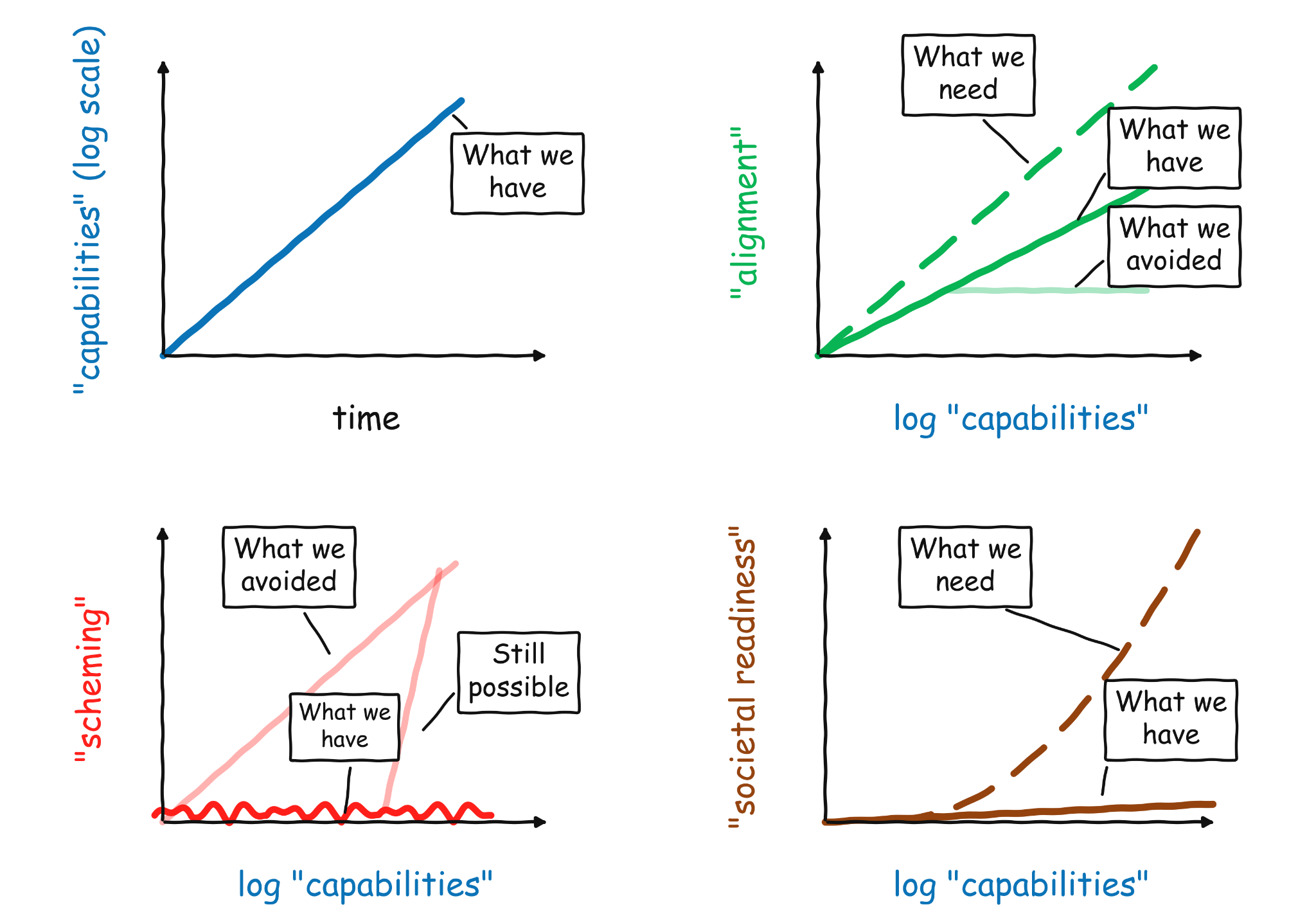
Here is a quick overview of my intuitions on where we are with AI safety in early 2026: So far, we continue to see exponential improvements in capabilities. This is most visible in the famous “METR…
Blog post: OpenAI's inflated valuation, as I understand it

Here's what needs to be done to make software engineering automatic

Zhengdong Wang’s personal website

The new scaling paradigm for AI reduces the amount of information a model could learn per hour of training by a factor of 1,000 to 1,000,000. I explore what this means and its implications for scaling.
Since most of my audience is data people, I’m pretty confident you can read a graph. Take a guess when I started using Claude Code. Yes, that’s correct. I installed Claude Code on December 14th with my pro plan. On December 15th, I upgraded to the $200/mo MAX plan, and I expect to keep it […]

What the printing press taught me about AI, FOMO, and the decades-long game of technological diffusion.

Mathematics isn't only about saying true things. It's about asking the right questions, being confused, stumbling about, getting distracted, being wrong, recognizing when you're wrong, being stuck. Mostly being stuck. It's about clinging to a giant edifice and feeling it out until you understand som
Every week, a new “SOTA” (State of the Art) model is announced, promising higher reasoning capabilities and (often) lower costs. We could be led to think that we are entering an era of infinite, frictionless productivity. But the reality is messier. While the models are getting smarter, the gap between “intelligence on tap” and “completing a task” is managed by our tools and right now, that tooling interface is becoming a major source of friction. As we will see, this isn’t just a developer’s dilemma in the context of new AI assisted coding interfaces. It is a preview of the “retooling tax” that every professional domain must soon learn to navigate. The paradox is simple: as models improve, productivity bottlenecks increasingly shift away from intelligence itself and toward the tools that mediate access to it. The race for better models This is the popular meme reflecting the merry-go-round of weekly improvements of AI models: (source. other versions of this meme do include Anthropic’s Claude, if you wonder) LLMs become more capable, cheaper, and available on tap, to the point that the new best performing model can be indistinguishable from the previous one, simply because models are now so smart that the tasks we perform are not complex enough to clearly differentiate between “a great model” and an “even greater model”: both perform equally well on the tests. This is the experience of Simon Willison when testing a preview of Claude Opus 4.5 on November 24, 2025: It’s clearly an excellent new model, but I did run into a catch. My preview expired at 8pm on Sunday when I still had a few remaining issues in the milestone for the alpha [of his coding project]. I switched back to Claude Sonnet 4.5 and… kept on working at the same pace I’d been achieving with the new model. With hindsight, production coding like this is a less effective way of evaluating the strengths of a new model than I had expected. I’m not saying the new model isn’t an improvement on Sonnet 4.5—but I

During the Industrial Revolution, machines displaced most Western agricultural workers, who later went on to cities and earned higher wages. However, some time later, the automobile displaced all horses, and they still haven’t reallocated to new professions. In the coming decades, are we the 19th century peasant, or the horse?

Wall Street wiped $300 billion from SaaS stocks and declared the model dead. They're right about the wrong thing.

<nav class="toc"> <ul> <li><a href="#key-features-of-astrocoder">Key Features of AstroCoder</a> <li><a href="#auto-generating-documentation"...
Agent design patterns.
This report introduces new metrics of AI usage to provide a rich portrait of interactions with Claude in November 2025, just prior to the release of Opus 4.5.
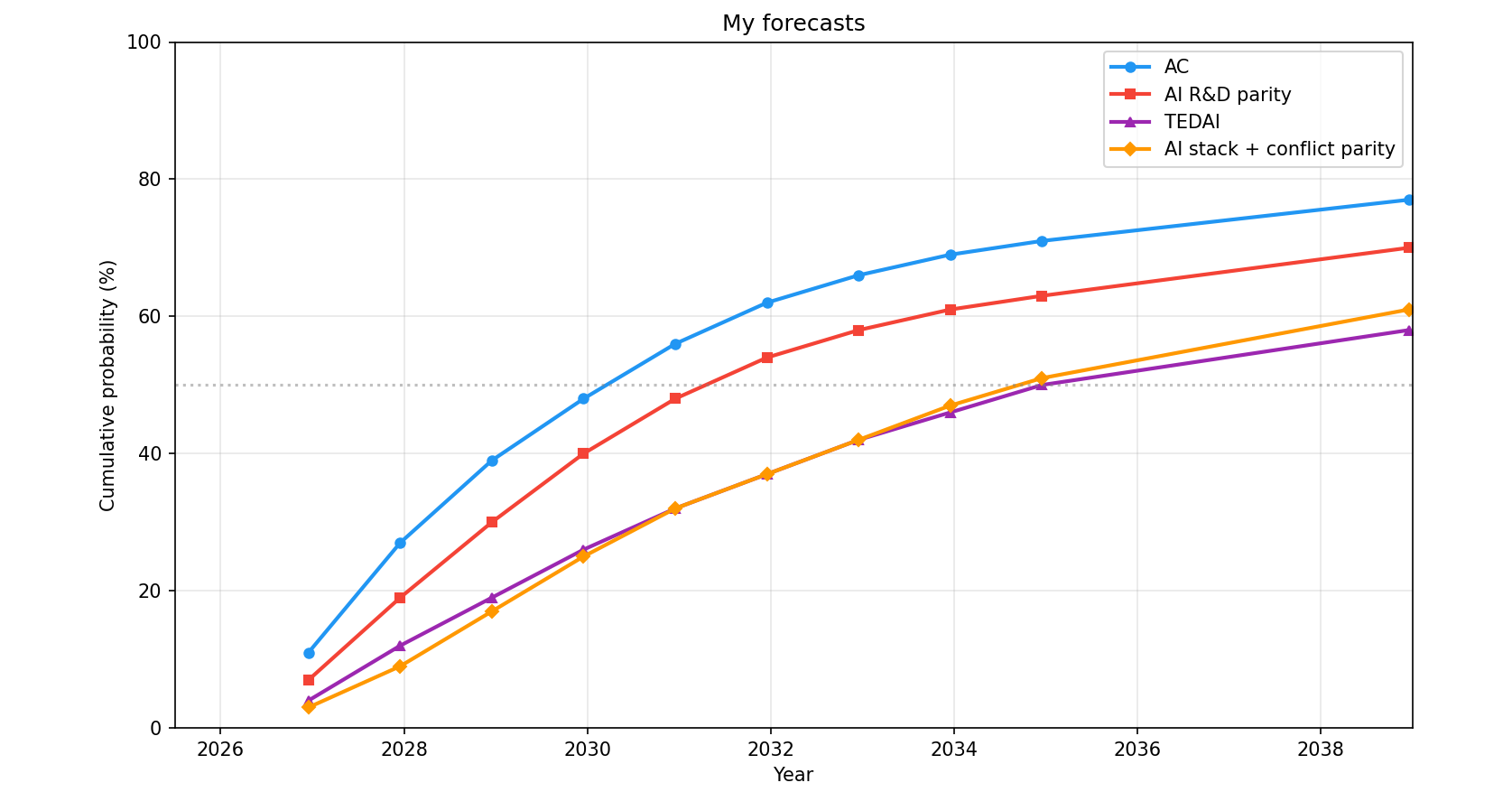
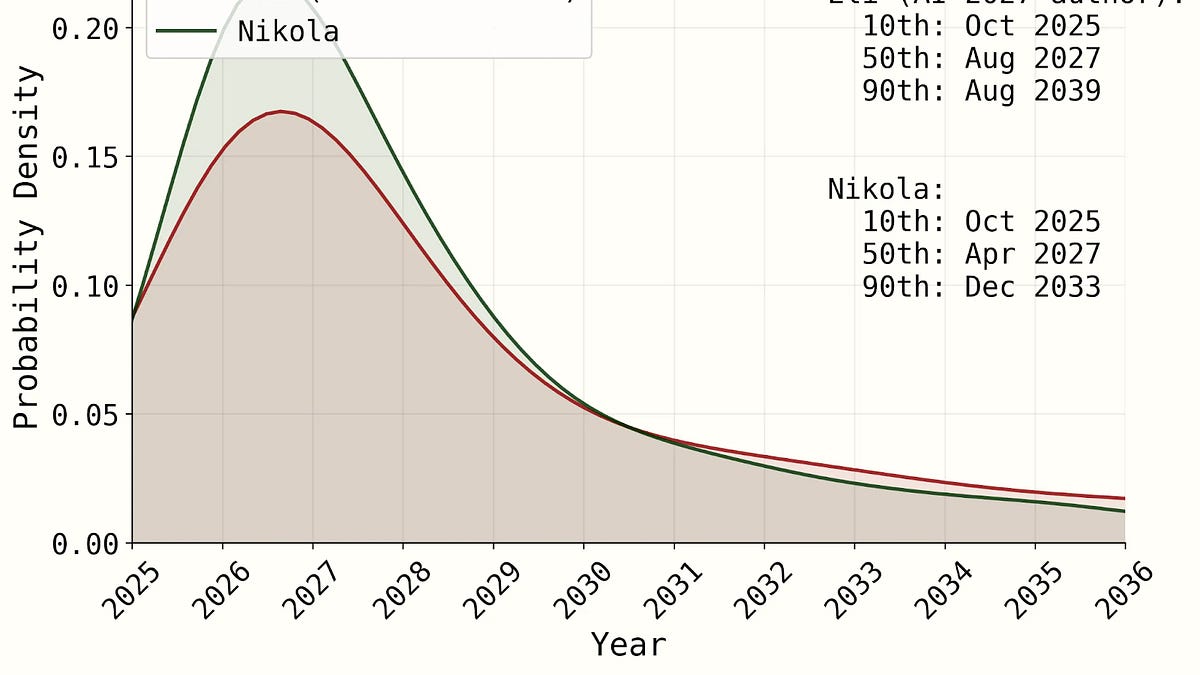
I've recently updated towards substantially shorter AI timelines and much faster progress in some areas. [1] The largest updates I've made are (1) an…

Radical optionality is about preserving democratic governments’ ability to make good decisions about how to govern transformative AI systems as circumstances evolve.
Documenting my journey in the world of AI and RL.
How has AI progress compared to AI 2027 thus far?
Transformer Weekly: GAIN AI Act, China’s rare earth crackdown, and AI bubble talk

A botched GPT-5 launch, selective amnesia, and flawed reasoning are having real consequences
How has AI progress compared to AI 2027 thus far?
How has AI progress compared to AI 2027 thus far?

What we learned from three iterations of a performance engineering take-home that Claude keeps beating.

Interaction models move beyond turn-based AI interfaces by handling multimodal, real-time collaboration natively across audio, video, and text.
Donating to a 501(c)(4) focused on AI issues in the public interest

Track how long AI agents stay useful before a human must step in, and design leadership rituals to extend that window without losing control.

To some, METR’s “time horizon plot” indicates that AI utopia—or apocalypse—is close at hand. The truth is more complicated.
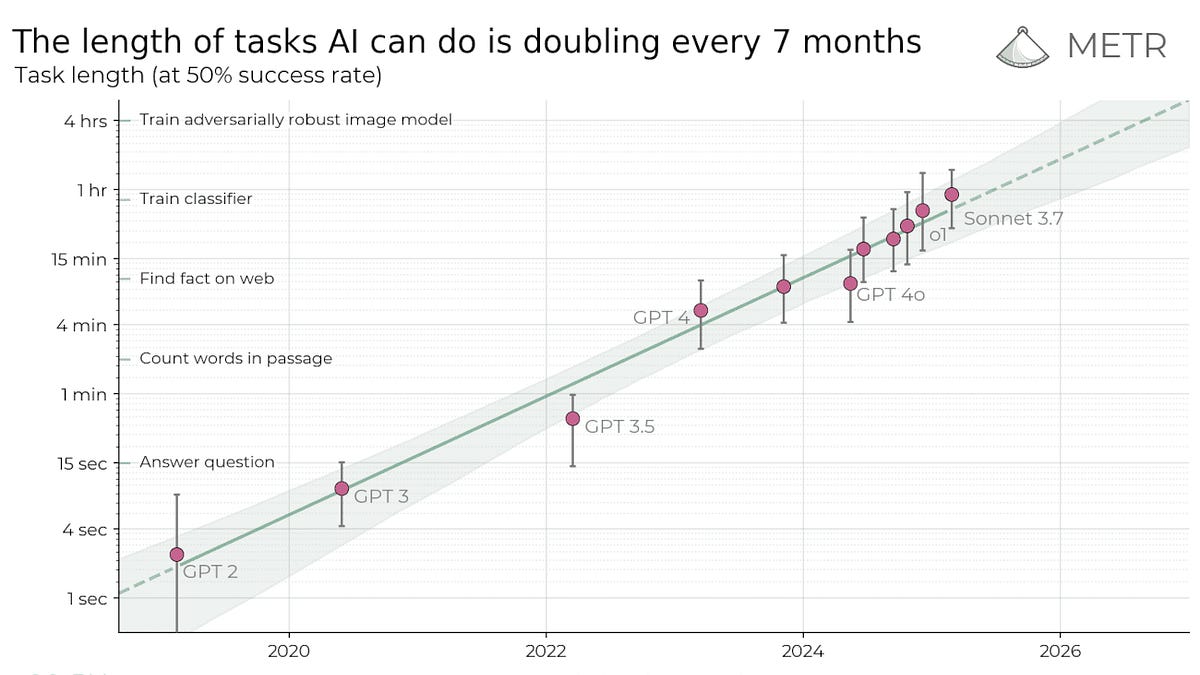
AI models were initially given human tests (like the LSAT or MCAT) or tests written for AIs like the MMLU. However since they’ve mastered so many of these tests and the tests don’t always carry over to real-world abilities, new measures of progress are needed. One way to rank the difficulty of a task is by how long it would take a human to complete it. In March,

tars is a personal AI assistant with CLI, Web UI, Email, and Telegram channels, persistent memory, hybrid search, integration with tools I used all the time. About 35 features, 14kloc of python and 600 tests all told. I didn't write any of it. The experience was different enough from traditional de
This is the third in my annual series reviewing everything that happened in the LLM space over the past 12 months. For previous years see Stuff we figured out about …
Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.

Current AIs struggle to create a whole that exceeds the sum of its parts