If you want to read this paper, I highly suggest viewing the nicely formatted PDF version available here: Zenodo Publication
A comparison of Genetic Algorithms (GA), Gradient Descent (GD) and Simulated Annealing (SA) and how they differ in effectiveness when optimizing linkage lengths of Jansen’s Linkage to achieve a desired foot trajectory
Authored by: Xander van Pelt
Table of Contents
Abstract 3
1.Introduction 3
2. Background Knowledge 6
2.1 Jansen’s Linkage 6
2.2 Gradient Descent 6
2.3 Genetic Algorithms 7
2.4 Simulated Annealing 8
2.5 Previous Comparative Studies 8
3. Methodology 9
3.1 Simulation Methodology 9
3.1.1 Linkage Representation and Foot Trajectory Computation 9
3.1.2 Target Foot Trajectory 11
3.1.3 Error measurement 12
3.1.4 Experimental Setup 14
3.2 Optimization Methods 14
3.2.1 Gradient Descent 15
3.2.2 Genetic Algorithm 16
3.2.3 Simulated Annealing 17
3.3 Hyperparameter Testing 18
3.3.1 Gradient Descent 18
3.3.2 Genetic Algorithm 21
3.3.3 Simulated Annealing 25
4. Results 28
4.1 Convergence Behavior 28
4.2 Final Performance Comparison 29
4.3 Computational Efficiency 29
4.5 Qualitative Trajectory Analysis 30
5. Discussion 31
5.1 Main Findings 31
5.2 Implications for Linkage Optimization 32
5.3 Comparison with Literature 33
5.4 Limitations 33
Works Cited 34
Abstract
Jansen’s linkage, a planar thirteen-bar mechanism designed by Theo Jansen in the 1990s, converts rotary motion into efficient walking gaits for legged robotics. This study compares three canonical optimization algorithms, Gradient Descent (GD), Genetic Algorithm (GA), and Simulated Annealing (SA), at their effectiveness for minimizing trajectory deviation from a target effector trajectory (gait).
Each algorithm optimized thirteen linkage bar lengths to minimize root mean square error (RMSE) between simulated and target foot trajectories, sampled at 180 points per crank rotation, under identical evaluation budgets of 100,000 objective function calls. Each method executed 200 independent trials with randomly initialized semi-feasible configurations.
Hyperparameter selection employed systematic grid search with statistical validation confirming robustness. ANOVA analysis revealed that run-to-run initialization variability exceeded hyperparameter-induced variance by 5-7× across all algorithms (η² < 0.03, p > 0.05), establishing that observed performance differences reflect fundamental algorithmic characteristics rather than tuning choices.
SA achieved median RMSE of 1.08 units, significantly outperforming GD (3.68 units) and GA (12.76 units). These findings establish SA’s temperature-controlled stochastic acceptance as optimal for the rugged, multimodal error landscape of inverse kinematic linkage design.
**Code: **GitHub Repository
1.Introduction {#1.introduction}
Developing robots that can navigate uneven terrain has long been a priority in robotics. Legged systems are often preferred over wheeled or tracked platforms because they adapt better to irregular ground, reduce energy use, and keep body elevation stable (Pop et al., 2011). These advantages are evident in applications such as lunar exploration (Bartsch et al., 2012) and humanitarian mine detection (Nonami et al., 2000), which show the importance of efficient leg mechanisms in modern robotics.
One candidate for efficient leg design is Jansen’s linkage, a planar 13-link, single-degree-of-freedom mechanism created by Theo Jansen in the 1990s (Jansen, n.d.a). A simple rotary input drives the entire linkage, producing a smooth walking gait. Originally designed for kinetic sculptures, the mechanism has since attracted interest in robotics, particularly for reconnaissance robots where energy efficiency and simplicity are critical, or applications which require traversal on sand, mud or other surfaces where wheels typically struggle.
![]()
Figure 1: Jansen’s linkage and linkage lengths. Path traced by crank in green, path traced by foot effector in red. (Frey, 2007)
The central challenge is to determine the set of link lengths (a-m in Figure 1) that produce a desired foot trajectory for the linkage. While multiple performance criteria, such as stride smoothness, consistency of ground contact timing, or torque uniformity, could theoretically be incorporated as additional objectives, this study restricts attention to a single-objective formulation. The trajectory is the path traced by the foot effector (red line) during a full rotation of the crank (link m, green circle). For walking robots, an effective trajectory is vital for its utility, often requiring a flat ground-contact phase and sufficient stride length and height for obstacle clearance. Optimizing the linkage therefore requires simulating trajectories for different parameter sets and searching for the one that best matches a predefined target trajectory. In this study, the target trajectory is based on Jansen’s established mechanism, shown in Figure 1. The sole optimization objective, dependent on 13 parameters which are subject to linkage length constraints, is to minimize the root mean square error (RMSE) of sampled points between the simulated trajectory and the target, a standard metric in robotics for comparing continuous motion.
We compare three popular methods of single-objective optimization: gradient descent (GD), genetic algorithms (GA) and simulated annealing (SA), and how effective they are at solving a complex, non-linear, multi-parameter issue, which Jansen’s linkage presents. Gradient descent algorithms are typically faster at finding optimal solutions due to the lower computation cost, and how they “know” the way to the optimal solution through following the gradient of the error surface (Ruder, 2016). In contrast, genetic algorithms operate through evolutionary principles, which can help them avoid local minima that might trap gradient-based methods (Alvarez, 2005). Although they require more computational effort, they can excel in solution spaces with complex topographies, as gradient descent algorithms can get stuck in suboptimal solutions (local minima) (Carr, 2014). Simulated annealing is a stochastic iterative optimization process which mimics the natural process of metallurgical annealing, where a system is allowed to explore high-energy states early in the optimization process before gradually “cooling” to settle into lower-energy configurations. Its stochastic factor allows the algorithm to escape out of local minima, without getting stuck (Yang, 2020).
The choice between these algorithms depends on factors such as the smoothness of the design space, the availability of derivatives, computational resources, and whether global or local optimization is required. For Jansen’s linkage, all approaches provide promising advantages.
This study compares canonical GD, GA and SA implementations to keep the comparison clear, ignoring techniques such as momentum, jitter or hybridization or crowding. Future works could extend this analysis by incorporating such refinements to explore performance improvements and more sophisticated optimization strategies.
2. Background Knowledge {#2.-background-knowledge}
2.1 Jansen’s Linkage {#2.1-jansen’s-linkage}
Jansen’s linkage is a single-degree-of-freedom planar mechanism that converts rotary motion into a walking gait through thirteen interconnected links. Though first designed in the early 1990s by Dutch artist Theo Jansen for his Strandbeest sculptures (Jansen, n.d.a), the mechanism has since attracted attention in robotics for its potential to enable legged systems that can traverse uneven terrain more efficiently than wheeled designs (Sengupta and Bhatia, 2017). Research has investigated optimizing its linkage parameters and extending its design to improve adaptability (e.g. Komoda and Wagatsuma, 2012). An effective gait in robots is important, making optimization a central challenge for applying Jansen’s linkage, and other linkages in practical robotics. In this study, the optimization criterion is defined as the root mean square error (RMSE) between the simulated and target trajectories, so the linkage is not tuned for stride height or stance phase specifically, but for overall path similarity to Jansen’s original design.
2.2 Gradient Descent {#2.2-gradient-descent}
Gradient Descent (GD) is an iterative optimization algorithm that updates parameters in the direction of the steepest decrease of an error function, seeking a local minimum (Cauchy, 1847). Its performance depends on the topology of the error surface and learning rate which can be difficult to choose as larger steps can cause divergence and miss local minima, while too small steps can lead to slow convergence or getting trapped in sub optimal minima (Ruder, 2016). A key limitation is the need for a differentiable error function. For mechanical optimization problems such as Jansen’s linkage, the mapping from linkage parameters to foot trajectory is highly complex, making closed-form differentiation impractical. In such cases, numerical methods like finite difference approximations are used to estimate gradients, though at a significant computational cost. Furthermore, basic GD implementations fail when the error function is discontinuous or has abrupt changes as the path down is non direct. One workaround is to smooth or regularize the objective (e.g., via interpolation), but this changes the surface being optimized. For Jansen’s linkage, some parameter sets can create geometric constraints that prevent full crank rotation, introducing discontinuities that make GD harder to apply than in smoother problems (see Section 3.1.1 for implementation details).
2.3 Genetic Algorithms {#2.3-genetic-algorithms}
Genetic Algorithms (GA) are stochastic optimization methods inspired by natural selection (Holland, 1975; Goldberg, 1989). Candidate solutions are encoded as chromosomes, evaluated by a fitness function, and evolved over generations through selection, crossover, and mutation. Unlike Gradient Descent, GAs do not require gradient information, making them attractive for problems with discontinuous or non-differentiable error functions.
In the context of Jansen’s linkage, the chromosome can directly encode the set of linkage lengths, while the fitness function needs to evaluate higher for candidates with lower RMSE. This representation allows the GA to explore a large, rugged solution space without being trapped by local minima—a common limitation of gradient-based methods. However, GAs typically converge more slowly than GD, and their effectiveness depends heavily on hyperparameters such as population size, crossover rate, and mutation rate, making proper implementation challenging. Finally, GAs are also computationally expensive, since each generation requires evaluating an entire population of candidates.
2.4 Simulated Annealing {#2.4-simulated-annealing}
Simulated Annealing (SA) is a probabilistic optimization technique, where in each iteration, the current state (which are the set of linkage lengths) has a probabilistic chance of changing to an adjacent state, depending on how much higher the energy of the next state is, and the global temperature, which gradually decreases over iterations; the algorithm will always choose a lower energy state if available. As the temperature slowly decreases, jumps which increase the energy are less likely to occur. The probability is dictated by this formula: e-E/T, where E is the increase in energy and T is the current temperature. Though the term energy is used, this refers to the cost of any given solution. This process makes SA especially effective at approximating global minimums as it has the means to escape local minima or cost surface variation while the temperature is initially high. (Yang, 2020; CMU n.d.)
Simulated annealing is widely used in mechanism synthesis in general because global-search metaheuristics perform better than local gradient-based methods on the highly multimodal, nonsmooth error landscapes characteristic of inverse-kinematic design problems. This makes it an ideal candidate for Jansen’s linkage optimization.
2.5 Previous Comparative Studies {#2.5-previous-comparative-studies}
Direct comparisons of gradient descent (GD), genetic algorithms (GA), and simulated annealing (SA) in linkage or mechanism optimization are not reported in the academic literature. However, the behaviors of all three algorithms are clear in existing literature outside of linkage and mechanism specific optimization: GD converges quickly but is vulnerable to local minima, GA converges more slowly but explores globally and handles non-differentiable objectives (Chaparro et al., 2008), and SA balances these trade-offs by maintaining a single solution while probabilistically accepting worse moves to escape local minima (Cheney et al., 2018). Some studies also suggest hybrids, like using GA or SA for global search, then GD for local refinement in general optimization problems (Khorshidi et al., 2011; Alvarez, 2005; Zhang et al., 2005).
Within mechanism design, most papers evaluate one algorithms in isolation. For example, simulated annealing has been used for four-bar linkage synthesis for path generation (Martínez-Alfaro, 2007). Interestingly, Jansen used a genetic algorithm while first optimizing his linkage for locomotion (Jansen, n.d.b).
In broader optimization contexts outside linkage optimization, comparisons have yielded mixed results depending on the problem domain. Jia and Lichti (2017) found GA performed best overall due to solution quality and fewer parameters to tune, while Cheney et al. (2018) found GA solutions consistently outperformed SA at the cost of longer computer time in thermal conductance optimization.
Nevertheless, there is a dearth of academic literature directly comparing single-objective GD, GA, and SA for reproducing motion in mechanical linkages like Jansen’s or similar. This absence leaves open the question of how the three algorithms differ in effectiveness when applied to the unique optimization challenge of Jansen’s linkage.
3. Methodology {#3.-methodology}
3.1 Simulation Methodology {#3.1-simulation-methodology}
3.1.1 Linkage Representation and Foot Trajectory Computation {#3.1.1-linkage-representation-and-foot-trajectory-computation}
Any Jansen’s linkage is represented as a list of 13 values, representing the lengths of linkages a–m, respectively:
Lany=[a, b, c, d, e, f, g, h, i, j, k, l, m]
The foot trajectory was represented as a set of Cartesian samples {(xi,yi)}i=1N taken at uniformly spaced crank angles over one full rotation. A kinematic solver implemented in Python 3.11 calculated every foot joint position per crank angle, though some parameter sets led to lockups with no valid configuration at certain crank angles.
A resolution of N=180 samples per cycle (2° increments) was chosen as a balance between accuracy and computation time. This sampling density enabled both Gradient Descent and Genetic Algorithm optimizers to evaluate candidate solutions rapidly. At this resolution, the sampled path closely matches the continuous trajectory (Figure 2), whereas fewer samples would risk missing variations and reduce RMSE reliability.
Kinematically impossible linkages, where the mechanism locks partway through rotation were handled by only calculating RMSE using crank angles where the mechanism has a valid kinematic solution. At each valid angle, the simulated foot position is compared to the corresponding target trajectory point. Invalid angles contribute to the penalty term rather than being included in the point-wise distance calculation. This weighted penalty was added directly into the RMSE calculation (see 3.1.3), and depended on the severity of mechanical constraint violation. By adding a weighted penalty, instead of assigning infinite error, the error surface remained continuous, allowing GD to be viable.
![]() Figure 2: Comparison of 10/50/100/180/360 samples (red points) of the foot trajectory against the continuous path (black line). At N=180 (highlighted), the discrete samples closely approximate the continuous trajectory, justifying this resolution for optimization.
Figure 2: Comparison of 10/50/100/180/360 samples (red points) of the foot trajectory against the continuous path (black line). At N=180 (highlighted), the discrete samples closely approximate the continuous trajectory, justifying this resolution for optimization.
3.1.2 Target Foot Trajectory {#3.1.2-target-foot-trajectory}
The trajectory created by Theo Jansen’s original linkage (Figures 2 and 3) is used as the target trajectory for all optimizers, chosen as it is well-established and achievable with the mechanism. The foot trajectory is defined at the same resolution of N=180 crank angles used in the simulation; ensuring one-to-one correspondence between points is essential for valid error measurement.
Jansen’s original linkage has the following linkage lengths:
LJansen’s=[38.0, 41.5, 39.3, 40.1, 55.8, 39.4, 36.7, 65.7, 49.0, 50.0, 61.9, 7.8, 15.0]
All candidate solutions were bounded within and chosen randomly within 100% of Jansen’s original proportions, while avoiding degenerate cases such as zero-length links by incurring a minimum value of 110-1. This maintained an appropriately sized search space for both algorithms:
Lmin=[0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]Lmax=[76.0, 83.0, 78.6, 80.2, 111.6, 78.8, 73.4, 131.4, 98.0, 100.0, 123.8, 15.6, 30.0]
Additionally, to disentangle optimization performance from initialization sensitivity, all candidate solutions start as semi-feasible initializations to avoid completely degenerate solutions which are trivially discardable and wouldn’t be considered in practical linkage optimization problems. We classify semi-feasible as satisfying ninvalidN2 (at least half of crank angles yield valid foot positions). This still requires algorithms to navigate partially infeasible regions, representing a practical and realistic optimization situation. We also implement a restart condition for GD as it often completely halts and becomes stuck in a local minimum before spending the entire evaluation budget, this way it can re-initialize outside of areas with no clear slope to feasibility. We acknowledge that these design choices do slightly favour SA and GD success over GA.
![]()
Figure 3: Theo Jansen’s original linkage and the path its foot traces.
3.1.3 Error measurement {#3.1.3-error-measurement}
RMSE served as the objective for GD, the fitness basis for GA and the energy for SA because it effectively characterizes trajectory similarity and emphasizes larger deviations (Chai and Draxler, 2014). Making it an ideal objective function for many optimization problems involving continuous motion. It also preserves physical units, making it more interpretable. Mathematically it is defined as follows, where {pi=(xi,yi)}i=1N is the target trajectory points and {pi=(xi,yi)}i=1N is the actual, and N is the number of discrete samples of foot positions as the mechanism’s crank does a full rotation. Samples are only compared at identical phases (θi) and in a fixed global coordinate frame, where the crank pivot is located at the origin (as seen in Figure 3). Crank angles that yield no kinematically feasible position are removed from {pi=(xi,yi)}i=1N and the corresponding indices i which were removed were also excluded from {pi=(xi,yi)}i=1N, to ensure the RMSE compares points at the same angle between the simulated and target trajectories.
RMSE= i=1N[(xi−xi)2+(yi−yi)2]+P2 ninvalidN
where P is a penalty factor, ninvalid is the number of unsolvable samples, and N is the total number of crank angles tested. This approach weighs the penalty based on the severity of constraint violation directly within the RMSE calculation, maintaining a smoother error landscape while discouraging infeasible solutions and ensuring RMSE keeps its units. For all trials, the penalty factor P=100 was chosen heuristically to ensure invalid solutions are ranked worse than feasible ones while maintaining gradient continuity. We acknowledge that penalty magnitude may affect convergence behavior.
Several alternative error metrics were also considered: Mean Absolute Error (MAE) captures average deviations but fails to emphasize larger errors. And Hausdorff Distance accounts only for the single largest deviation, overlooking cumulative discrepancies along the trajectory. Similarly, Fréchet Distance captures curve similarity better, but its computational cost makes it impractical for finite-difference GD optimization, because evaluation needs to be run for every iteration. The area-between-curves metric is the same. Overall, RMSE functionally aligned with the objectives of linkage optimization.
In the rest of this paper, E(L) refers to the RMSE with penalty function as defined here, where the points are generated from linkage set L.
3.1.4 Experimental Setup {#3.1.4-experimental-setup}
We used 200 runs per algorithm at identical evaluation budgets (100,000 calls) and hyperparameters (Tables 2–5), with randomly initialized starting solutions based within the bounds specified in 3.12.
To enable a relative comparison of each method, each had a budget of 100,000 objective evaluations per run, and each would terminate at the point the entire budget was spent, returning the final RMSE value. Complete iteration histories were recorded for all runs, capturing algorithm-specific metrics to facilitate convergence and behavioral analysis.
A budget of 100,000 evaluations was chosen to reflect practical linkage design scenarios where each kinematic simulation is computationally inexpensive (~1ms), allowing optimization to complete within minutes. This budget enables all three algorithms to demonstrate their convergence patterns. The focus is on final solution quality rather than convergence speed. This reflects real-world uses for linkage optimization which is usually a one-time task; given the low cost of individual evaluations, achieving the best possible trajectory match matters more than minimizing iterations.
Method
Evaluations per iteration / generation
Gradient Descent
26 (with finite central difference gradient approximation)
14 (with finite forward difference gradient approximation)
Genetic Algorithm
N Note: caching fitness values of solutions during training reduces the number of calls progressively over generations.
Simulated Annealing
1
Table 1: Optimization methods and objective function evaluations per iteration / generation.
3.2 Optimization Methods {#3.2-optimization-methods}
The final hyperparameters used for each optimization method was informed by preliminary hyperparameter analysis and testing (see section 3.3 for final values and methodology).
3.2.1 Gradient Descent {#3.2.1-gradient-descent}
A multi-start gradient descent (GD) algorithm using finite-difference gradient approximation was implemented in Python 3.11, with sequential restarts upon convergence stagnation. The method begins with a random set of 13 lengths L0. At each iteration t, the update rule is:
Lt+1 = Lt - η∇E(Lt)
where η is the learning rate and ∇E(Lt) is the gradient vector:
∇E(Lt) = [∂E∂l₁,∂E∂l₂, …,∂E∂l13]
Since deriving a gradient function for Jansen’s linkage is infeasible, the gradient was approximated using finite differences. Both central (CFD) and forward (FFD) finite differences methods of gradient approximation were tested (see 3.3.1), where FFD was found to be favorable and was used for final tests. CFD approximates gradient as follows, using 13 forward and 13 backwards points, making 26 in total per each iteration:
∂E∂lj ≈ [E(L+εej) - E(L-εej)]2ε
FFD uses 14 evaluation calls in total per each iteration, 13 for each forward point, and 1 for the current point:
∂E∂lj ≈ [E(L+εej) - E(L)]ε
where ej is the unit vector in dimension j and ε is a small perturbation.
In each iteration, if the Euclidean norm of the gradient vector ∇E(L) was less than a small value , or an iteration pushed Lt beyond the defined bounds (see 3.1.2), the optimization would restart with a new randomly generated L, making the GD effectively a multi-start approach. Termination would occur once the evaluation call budget had been exhausted.
3.2.2 Genetic Algorithm {#3.2.2-genetic-algorithm}
The genetic algorithm (GA) was implemented in Python 3.11. The fitness function was defined as Fitness(L)=1000 - E(L), ensuring a fair comparison by keeping the fitness directly proportional to the cost in GD and SA. The constant of 1000 was great enough to ensure all fitness values remained positive.
The initial population of N candidate solutions is generated:
ℒ0={L1,L2,L3, …,LN-1, LN}
Each solution Ln, is a uniform randomly generated set of 13 parameters within the bounds (see 3.1.2). All 13 linkage lengths were encoded as genes directly.
In each generation henceforth, fitness scores are calculated for every candidate. Parent candidates are then selected using stochastic universal sampling (SUS). In this method, each candidate solution occupies a segment of the interval [0,1] proportional to its fitness value. A set of N evenly spaced pointers (separated by 1/N) are placed across the interval starting from a single random offset in [0, 1/N], and any candidate whose segment contains a pointer is selected as a parent.
Then the selected parents form the next generation as follows:
- Randomly select 2 parents from the parent pool (with replacement)
- Perform single-point crossover with probability pc to generate a child. If crossover does not occur, the child is a direct copy of one of the two parents, chosen randomly
- Mutate each gene in the child with probability pm. If mutation occurs, that gene is replaced by a random value
- Add the child to the new generation
- Repeat steps 2–5 until the new generation has N candidate solutions
Termination occurred once the evaluation budget was exhausted, the solution with the best fitness score is the outputted solution. For mutation, all random values were clamped to the same ranges. Fitness values for solutions were cached to avoid redundant evaluations, which is a standard practice in evolutionary algorithms. Each generation cost approximately N objective function evaluation calls, though caching improved efficiency over generations marginally.
3.2.3 Simulated Annealing {#3.2.3-simulated-annealing}
The simulated annealing (SA) optimizer was implemented in Python 3.11. The method begins with an initial random set of 13 lengths L0 and initial temperate T0. For each generation t, a candidate solution L’ is generated by perturbing the current solution Lt:
L’=Lt+
Where is a random 13-dimensional vector whose components are independent Gaussians with mean 0 and standard deviation :
=(1, … 13), i ~ 𝒩(0, )
If the random vector pushes L beyond the defined bounds (see 3.1.2), a new, random is generated until a valid one is found. Next, we compute , the change in error between the current solution and candidate solution:
=E(L’)-E(Lt)
1 objective iteration evaluation is called per iteration, as the value of E(Lt) is cached from the previous iteration. Now, whether the candidate solution becomes the solution in the next iteration Lt+1, depends on the following conditional logic:
if <0 or exp(-Tt)>u, Lt+1=L’
otherwise, Lt+1=Lt
Where Tt is the current temperature and u is a uniformly random variable in [0,1]. After each iteration, update the temperature with cooling rate 0 <<1:
Tt+1=Tt
Termination occurs after the evaluation call budget is exhausted.
3.3 Hyperparameter Testing {#3.3-hyperparameter-testing}
Hyperparameter selection employed systematic grid search across all methods, with statistical validation confirming robustness of results. The detailed hyperparameter tuning process is detailed in sections 3.3.1 through 3.3.3. However, in the end, ANOVA analysis revealed that run-to-run initialization variability exceeded hyperparameter-induced variance by 5-7× across all algorithms (2<0.03, p>0.05), demonstrating that observed performance differences stem from fundamental algorithmic properties rather than tuning choices. This finding establishes that the observed performance differences reflect fundamental algorithmic characteristics rather than hyperparameter configurations.
3.3.1 Gradient Descent {#3.3.1-gradient-descent}
Gradient Descent
Variable
Name
Value chosen
CFD / FFD
Whether central or forward finite difference gradient approximation is used
FFD
Small perturbation value for finite gradient
0.1
η
Learning rate
0.1
t
Gradient-norm stopping threshold
110-5
Table: 2 Final Hyperparameter Configuration for Gradient Descent
For gradient approximation, the truncation error scales as O(2) for central finite difference (CFD) and O() for forward finite difference (FFD). However, FFD only uses 14 objective function evaluations per iteration, compared to CFD’s 26 evaluations, signifying a potential tradeoff between accuracy and efficiency to be explored.
We quantify the accuracy loss between using CFD and FFD through a preliminary testing process. We evaluate both CFD and FFD across nine epsilon values spanning three orders of magnitude:
{0.005, 0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1.0, 2.0}
Using the same 50 random initial parameter configurations for each combination. Each optimization run uses a fixed learning rate of 0.1 and is limited to 500 gradient descent iterations. The choice of learning rate does not affect the relative comparison between methods and epsilon values, as all configurations use the same value. For each method-epsilon pair, we compute the distribution of final RMSE values across all 50 configurations and identify the epsilon value that minimizes the median final RMSE. This approach allows us to simultaneously determine the optimal epsilon value and whether to use CFD or FFD.
![]()
Figure 4: Boxplot of final RMSE values across different values of with CFD and FFD
It was found that CFD performed best at =0.2 where the median RMSE was 5.2480 having used 12,078 evaluation calls. FFD performed best at =0.1 with the medium RMSE being 12.6% higher than CFD’s best, at 5.9103 having used 6,055 evaluation calls. However, CFD’s better accuracy came at a 199% the cost of FFD. At the fixed budget of 100,000 evaluations, FFD’s 2× efficiency enables significantly more iterations and restarts, which outweighs the per-step accuracy loss for final solution quality and gives GD more chances to restart with an initial set of parameters that lies within an exploitable basin of the objective function landscape.
The learning rate and gradient-norm was then determined. For each candidate learning rate { 0.01, 0.05, 0.1, 0.5, 1.0, 2.0}, we ran 50 trials at the full 100,000 evaluation budget and a stopping threshold of 110-5, below which the gradient provides negligible directional information. If an early stop occurred, the algorithm restarted from a new random initialization to explore different regions of the parameter space with the same evaluation call budget.
![]()
Figure 5: Learning rate effects on gradient descent performance
We settled on a value of =0.1 as it had the lowest median RMSE across 50 trials of 1.499. Although higher learning rates increased the restart frequency, they likely struggled to exploit valleys and subsequently performed worse. The smallest value tested, 0.01, also struggled, as it spent too much of the limited evaluation budget on exploiting a single valley, or many local minima and didn’t have opportunity to explore more of the solution space to find a better minimum. The wide variance explains this, as occasionally, when it did start within an ideal valley, it exploited it very well. Overall, we were biased towards the choice of =0.1 as it prioritized maximum accuracy over consistency of results compared to =1.0, which although had much lower variance, didn’t achieve the same median accuracy.
3.3.2 Genetic Algorithm {#3.3.2-genetic-algorithm}
GA inherently comes with many more hyperparameters to consider compared to GD or SA. To limit the computational burden we categorize hyperparameters into 2 categories: hyperparameters with first-order impact on performance, and secondary algorithm design choices which are less critical or have well-established best practices. Hyperparameter optimization focused exclusively on the primary tier.
Primary hyperparameters with first-order effects on performance
Variable
Name
Final Value Chosen
N
Number of candidates in each generation (population size)
100
pc
Probability of crossover
0.7
pm
Probability of mutation
0.1
Table 3: GA Primary hyperparameters with first-order effects on performance
Secondary algorithm choices with second-order effects on performance
Parameter
Implemented choice
Parent selection method
Stochastic Universal Selection (SUS)
Crossover method
One-point
Mutation type
Replace-by-Random Mutation
Table 4: GA Secondary algorithm choices with second-order effects on performance
Population size typical recommendations are 10× the problem dimension, suggesting ~130 for our 13-dimensional problem. With a fixed evaluation budget, a larger population decreases the number of generations making this choice a tradeoff between exploration and refinement. We consider the ranges around this suggested value.
Optimal values for crossover probability typically fall in between 0.6 and 0.9 for continuous problems. Whereas ranges for mutation probability are usually between 1d and 10d where d=13 for Jansen’s 13 linkages, suggesting somewhere between 0.008 and 0.077 for our problem.
Taking into account all these ranges, we settle on the following grid search:
N
pc
pm
50
0.6
0.008
130
0.7
0.043
250
0.8
0.077
500
0.9
0.1
![]()
Figure 6: Grid search testing results for GA
Figure 2 shows the result of final RMSE values for each permutation of the grid search. Although, the set of hyperparameters: N=100, pc=0.7, pm=0.1produced the lowest RMSE, a one-way ANOVA revealed that hyperparameter choice had minimal impact on final performance. Across all 64 configurations, mean RMSE was 12.78 (=1.97). Critically, within-configuration variance (=1.95) was seven times larger than between-configuration variance (=0.28), indicating that run-to-run stochasticity dominated any systematic hyperparameter effects.
Effect size analysis confirmed this finding: 2=0.019, meaning hyperparameter combinations explained only 1.9% of total variance in outcomes. The F-test (F = 0.98, df = 63/3136, p = 0.52) failed to reject the null hypothesis of equal means across configurations, confirming that the tested hyperparameter combinations were statistically indistinguishable given the inherent noise between runs.
We settled on N=100, pc=0.7, pm=0.1 given they did produce the best results, even though hyperparameter choice within the tested ranges has little effect on final RMSE.
3.3.3 Simulated Annealing {#3.3.3-simulated-annealing}
Simulated Annealing
Variable
Name
Value chosen
T0
Initial temperature
5
Cooling rate
0.9
Standard deviation of random perturbation (i)
0.2
Table 5: Final Hyperparameter Configuration for Simulated Annealing
A preliminary marginal effect sensitivity analysis was conducted with a 10,000 evaluation budget, across 20 trials per configuration to attain a rough estimate of hyperparameter values to use. Every permutation of the following grid of values were tested:
Hyperparameters values tested for sensitivity analysis
T0
1.0
10
50
0.9
0.95
0.99
0.1
2
5
![]()
Figure 7: SA Hyperparameter Sensitivity Analysis
Results revealed that the perturbation standard deviation plays an important role in dictating the explorative vs exploitativeness behaviour of the search, and that independent of T0 and , values of >0.1 consistently made performance worse, likely by preventing fine-grained local refinement. Values for T0 and had little influence on median RMSE, however a cooling rate 0.95 was slightly better than the other tested values, and an initial temperature of 10 performed marginally better than other values.
With a tighter range of variables, chosen around those found optimal in the preliminary tests (T0=10, =0.95, =0.1) A final grid search was conducted, using the full 100,000 evaluation budget across 50 trials to match the conditions of the final algorithm comparison, as the balance between exploitation and exploration governed by depends on the total budget and thus iterations the algorithm has. The following grid was searched:
Grid Search Values for SA
T0
1.0
5.0
10.0
0.9
0.95
0.99
0.03
0.05
0.1
![]()
Figure 8: Boxplot of all SA grid search permutations and RMSE results.
One-way ANOVA across all 27 configurations revealed minimal systematic effect of hyperparameter choice on SA performance. Mean RMSE was 4.09 (σ = 12.46) across all 1,350 trials. Within-configuration variance (σ = 10.45) was approximately five times larger than between-configuration variance (σ = 2.12), indicating that run-to-run stochasticity dominated systematic hyperparameter effects.
Effect size quantified this insensitivity: η² = 0.028, meaning hyperparameter combinations explained only 2.8% of total variance in outcomes. The F-test (F = 1.45, df = 26/1323, p = 0.066) failed to reject the null hypothesis of equal means across configurations at the α = 0.05 level, though the result approached marginal significance.
This pattern indicates that while hyperparameter choice has some measurable effect on SA performance, the magnitude is small compared to initialization-dependent stochasticity. The between-configuration standard deviation of σ = 2.12 confirms that switching hyperparameters changes outcomes far less than simply re-running SA with the same hyperparameters (σ = 10.45 within-configuration variance). Put differently: choosing different hyperparameters matters ~5× less than the luck of initialization.
In the end, we chose values of T0=5.0, =0.90, =0.2 as they represented the hyperparameter set with lowest median RMSE even though statistically, it was minimally significant from other configurations.
4. Results {#4.-results}
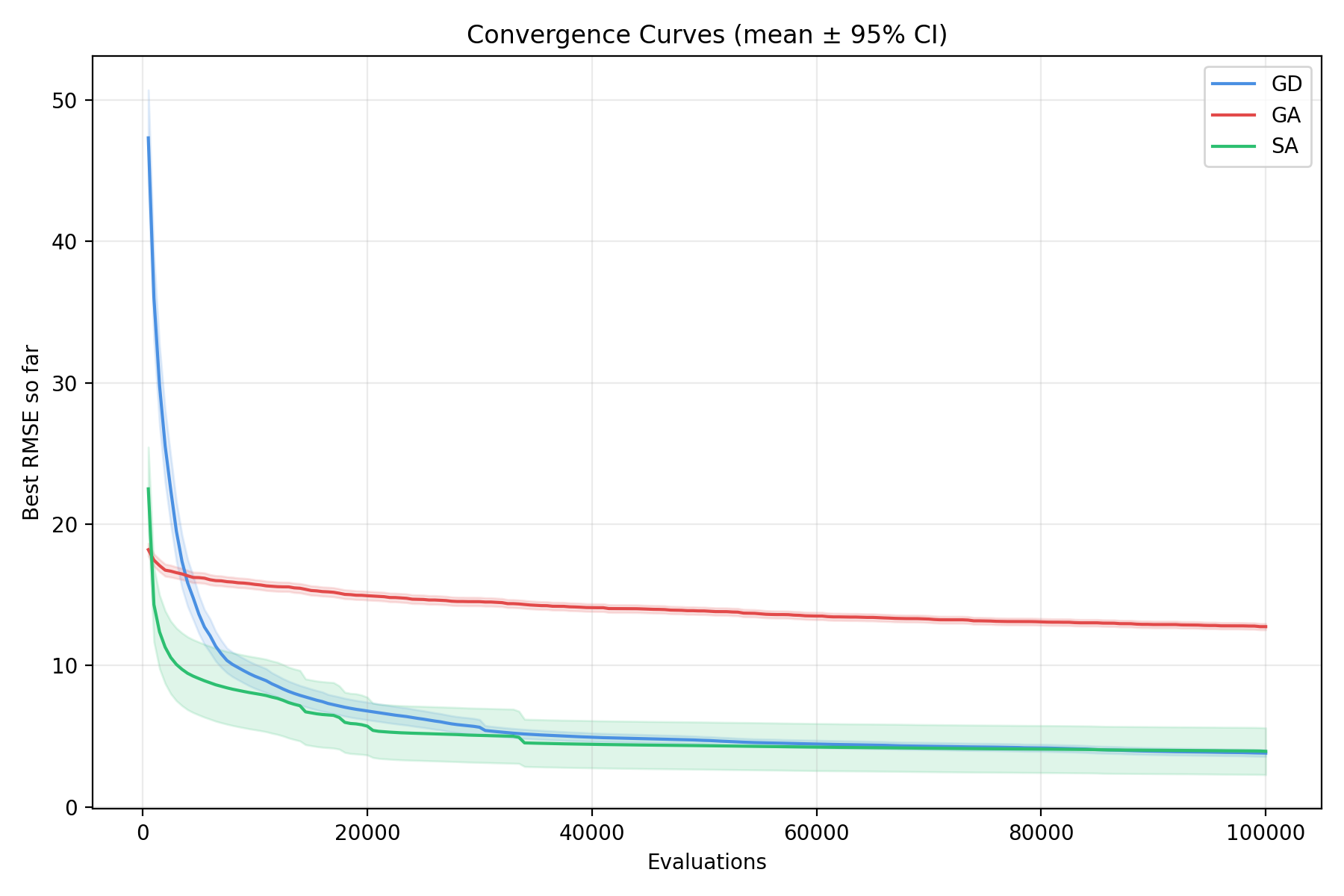
4.1 Convergence Behavior {#4.1-convergence-behavior}
![]()
Figure 9: Median convergence curves with interquartile ranges for Gradient Descent (blue), Genetic Algorithm (red), and Simulated Annealing (green) across 100 runs. GD exhibits rapid initial descent with periodic restarts, GA shows steady monotonic improvement, and SA displays characteristic high-variance exploration before gradual convergence. All algorithms operated under identical 100,000 evaluation budgets. Note: Convergence curves show different sampling densities due to varying evaluation costs per iteration, this results in making it seem
4.2 Final Performance Comparison {#4.2-final-performance-comparison}
![]()
Figure 10: Distribution of final RMSE values for Gradient Descent (blue), Genetic Algorithm (red), and Simulated Annealing (green) after exhausting the 100,000 evaluation budget. SA achieves superior median performance (1.08) compared to GD (3.68) and GA (12.76), though with greater run-to-run variability. GA exhibits the tightest distribution, indicating high consistency at the cost of solution quality. Boxes represent interquartile ranges; whiskers extend to the full range of final RMSE values.
4.3 Computational Efficiency {#4.3-computational-efficiency}
![]()
Figure 11: SA consistently outperforms GD and GA in terms of evaluations needed to reach certain RMSE thresholds. The evaluations for GD to reach <= 1 RMSE have large variance, likely due to lucky starting conditions being a large factor in success; GD is able to exploit a valley very if it happens to start in one. In general, SA shows a much more consistent budget rate, and tends to be less influenced on stochastic starting conditions.
4.5 Qualitative Trajectory Analysis {#4.5-qualitative-trajectory-analysis}
![]()
Figure 12: Shows example trajectories at RMSE values of approximately 1, 2, 3, 5, 10 and 15. For practical applications anything above 1 is considered a non-satisfactory outcome. In our comparison, this makes SA the only real acceptable optimization method, though GD does occasionally reach acceptable RMSE values, the inconsistent outputs limit practical use.
![]()
Figure 13: Median RMSE trajectories for each method.
![]()
Figure 14: Top-3 trajectories for each method. GA fails catastrophically, not being able to generate even one acceptable linkage over 200 trials.
#
5. Discussion {#5.-discussion}
5.1 Main Findings {#5.1-main-findings}
Simulated Annealing’s median RMSE of 1.08 units represents a 241% improvement over Gradient Descent (3.68 units) and 1,081% improvement over Genetic Algorithm (12.76 units). SA’s effectiveness for multimodal optimization is well-established (Yang, 2020), and this expectation is met in our testing.
GA’s largest challenge was likely the 13-dimensional continuous parameter space as it doesn’t excel in large search space solutions. Single-point crossover in high dimensions disrupts parameter coupling, often violating geometric constraints despite both parents being feasible (or mostly feasible). Premature convergence likely exacerbated this issue: once the population clustered around mediocre solutions, GA relied on lucky mutations to progress, however these mutations were rare especially with 13-dimensions. GA executed ~1,000 generations versus SA’s 100,000 iterations within the fixed budget, thus population-based breadth consumed evaluations without enabling the exploitation that SA achieved through iterative refinement.
GD’s multi-start strategy provided competitive speed when initialized in favorable valleys (lower quartile ~1.5 RMSE), but success depended on initialization luck. This is reflected in GD’s larger final RMSE variance. The forward finite difference approximation enabled 15-20 restarts per trial by halving evaluation cost per iteration. However, this constitutes random multi-start, whereas SA performs better and more consistently without this restart strategy due it’s effectiveness at escaping local minima in the problem space. A more promising implementation of multi-start GD could instead use high learning rate (η=1.0) for rapid valley probing followed by refined search (η=0.05) in promising regions. This could have improved performance by quickly assessing basin quality before committing budget to local exploitation.
The hyperparameter insensitivity finding, where initialization variance exceeded configuration effects by 5-7× across all methods (η²<0.03), demonstrates that Jansen’s linkage landscape structure dominates algorithmic tuning choices within the ranges tested.
5.2 Implications for Linkage Optimization {#5.2-implications-for-linkage-optimization}
For single-degree-of-freedom planar mechanisms with approximately 13 continuous variables to optimize, SA should be used. For more expensive simulations, at budgets of <10,000 evaluations, SA’s exploration phase cannot complete with GD. Which may be advantageous for: (1) interactive design tools requiring rapid approximate solutions, (2) refinement near known good solutions, or (3) batch runs where 50+ trials are acceptable. For vanilla GA, the catastrophic failure observed here stems from inadequate operators for continuous-parameter coupling and solution space constriction, rather than inherent algorithm weaknesses.
These findings transfer to inverse kinematics problems with similar geometric constraints, however they may not generalize to multi-objective cases. It should also be noted that the integration of a penalty term directly into the RMSE value serves as a convenient method of keeping the problem single-objective. However this may have limitations as the penalty magnitude (P=100) was chosen heuristically and may affect convergence behavior, particularly on gradient-based methods which work better with smoother error landscapes. Alternative approaches such multi-objective formulations treating validity as a separate objective may be more appropriate for problems where the boundary between feasible and infeasible regions is less well-defined.
5.3 Comparison with Literature {#5.3-comparison-with-literature}
Martínez-Alfaro (2007) demonstrated SA’s effectiveness for four-bar synthesis; this study extends this validation from 4 to 13 coupled parameters. Jansen himself used GA in the 1990s (Jansen, n.d.b), though implementation details are undocumented, he likely employed more advanced variants that our canonical implementation. Additionally, the pre-defined search space is unknown; it is possible Jansen could’ve had more tightly specified design constraints and length ranges already planned.
5.4 Limitations {#5.4-limitations}
All methods employed canonical implementations without refinements. GD lacked momentum or adaptive learning rates. Whereas GA excluded elitism and used only single-point crossover and stochastic universal sampling. SA implemented exponential cooling only. These choices demonstrated core behaviors of each algorithm but employing advanced variants is highly favored. Algorithmic rankings may also shift when comparing state-of-the-art implementations, as GD with capabilities to better escape local minima could reasonably outperform SA.
Additionally, the single-objective formulation neglects criteria critical to walking robots: ground force smoothness, torque consistency, energy efficiency. Multi-objective formulations would fundamentally change the landscape, and could favor GA or similar population-based methods for Pareto exploration.
Lastly, generalizability of these findings remains unvalidated beyond single-DOF planar linkages with approximately 13 parameters. Extensions to higher or lower dimensional problems may reveal differences, particularly for GA.
Works Cited
Alvarez, G. (2005) Can we make genetic algorithms work in high-dimensionality problems? [pdf] Available at: https://sepwww.stanford.edu/sep/gabriel/Papers/micro_GAs.pdf [Accessed 10 September 2025].
Bartsch, S., Birnschein, T., Römmermann, M., Hilljegerdes, J., Kühn, D. and Kirchner, F. (2012) ‘Development of the six-legged walking and climbing robot SpaceClimber’, Journal of Field Robotics, 29, pp. 506–532. Available at: https://doi.org/10.1002/rob.21418 [Accessed 10 September 2025].
Carnegie Mellon University, “Simulated annealing,” Machine Learning Glossary, School of Computer Science. [Online]. Available: https://www.cs.cmu.edu/afs/cs.cmu.edu/project/learn-43/lib/photoz/.g/web/glossary/anneal.html. [Accessed: Nov. 25, 2025].
Carr, J. (2014) An Introduction to Genetic Algorithms. [pdf] Available at: https://www.whitman.edu/documents/academics/mathematics/2014/carrjk.pdf [Accessed 10 September 2025].
Cauchy, A.-L. (1847) ‘Méthode générale pour la résolution des systèmes d’équations simultanées’, Comptes Rendus Hebdomadaires des Séances de l’Académie des Sciences.
Chai, T. and Draxler, R.R. (2014) ‘Root mean square error (RMSE) or mean absolute error (MAE)? – Arguments against avoiding RMSE in the literature’, Geoscience Model Development, 7, pp. 1247–1250. Available at: https://www.researchgate.net/publication/272024186_Root_mean_square_error_RMSE_or_mean_absolute_error_MAE-_Arguments_against_avoiding_RMSE_in_the_literature [Accessed 10 September 2025].
Chaparro, B.M., Thuillier, S., Menezes, L.F., Manach, P.Y. and Fernandes, J.V. (2008) ‘Material parameters identification: gradient-based, genetic and hybrid optimization algorithms’, Computational Materials Science, 44(2), pp. 339–346. Available at: https://www.sciencedirect.com/science/article/abs/pii/S0927025608001766 [Accessed 10 September 2025].
Frey, M. (2007) Strandbeest Leg Proportions. [image] Available at: https://commons.wikimedia.org/wiki/File:Strandbeest_Leg_Proportions.svg [Accessed 10 September 2025].
Goldberg, D.E. (1989) Genetic Algorithms in Search, Optimization, and Machine Learning. Addison-Wesley Professional.
Jansen, T. (n.d.a) Strandbeest. Available at: http://www.strandbeest.com [Accessed 10 September 2025].
Jansen, T. (n.d.b) Evolution - Strandbeest, Chorda. Available at: https://www.strandbeest.com/evolution?period=chorda [Accessed 10 September 2025].
Jia, F., & Lichti, D. (2017). A comparison of simulated annealing, genetic algorithm and particle swarm optimization in optimal first-order design of indoor TLS networks. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, IV-2-W4, 75–82. https://isprs-annals.copernicus.org/articles/IV-2-W4/75/2017/
Kerr, A., & Mullen, K. (2018). A comparison of genetic algorithms and simulated annealing for maximizing thermal conductivity in one-dimensional classical lattices. arXiv arXiv:1801.09328. https://arxiv.org/abs/1801.09328arxiv
Khorshidi, M., Soheilypour, M., Peyro, M., Atai, A. and Shariat Panahi, M. (2011) ‘Optimal design of four-bar mechanisms using a hybrid multi-objective GA with adaptive local search’, Mechanism and Machine Theory, 46(10), pp. 1453–1465. Available at: https://www.sciencedirect.com/science/article/abs/pii/S0094114X11000887 [Accessed 10 September 2025].
Komoda, K. and Wagatsuma, H. (2012) ‘A proposal of the extended mechanism for Theo Jansen linkage to modify the walking elliptic orbit and a study of cyclic base function’. Dynamic Walking Conference 2012, Pensacola, Florida. Available at: https://ihmc.us/dwc2012files/Komoda.pdf [Accessed 10 September 2025].
Nonami, K., Shimoi, N., Huang, Q.J., Komizo, D. and Uchida, H. (2000) ‘Development of teleoperated six-legged walking robot for mine detection and mapping of mine field’, Proceedings of the 2000 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2000), Takamatsu, Japan, vol. 1, pp. 775–779. doi: 10.1109/IROS.2000.894698.
Pop, F., Dolga, V., Ciontos, O. and Pop, C. (2011) ‘CAD design and analytical model of a twelve bar walking mechanism’, UPB Scientific Bulletin, Series D: Mechanical Engineering, 73, pp. 35–48.
Ruder, S. (2016) An overview of gradient descent optimization algorithms. [pdf] Available at: https://arxiv.org/pdf/1609.04747 [Accessed 10 September 2025].
Sengupta, S. and Bhatia, P. (2017) ‘Study of applications of Jansen’s mechanism in robot, 2016’, International Journal of Scientific Research and Development, 4(3), pp. 1–4. Available at: https://pdfs.semanticscholar.org/fed6/0b7d342d243409d032eb951f02ac415fad7a.pdf [Accessed 10 September 2025].
Yang, X.-S. (2020). Nature-inspired optimization algorithms (2nd ed., pp. 97-104). ISBN: 9780128219867
 I made this illustration to show the general architecture of both types of systems, agentic and procedural.
I made this illustration to show the general architecture of both types of systems, agentic and procedural.
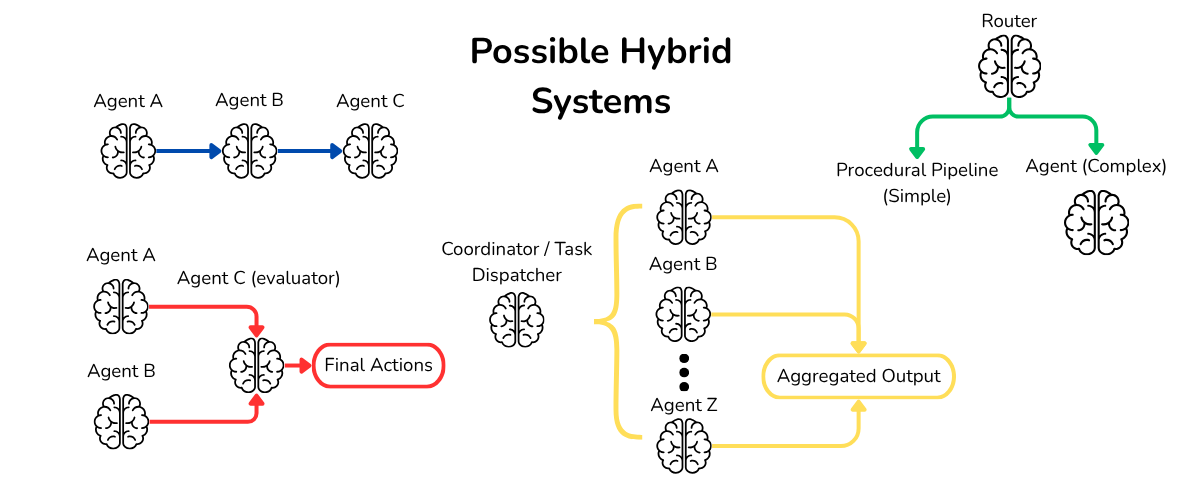 There’s really a bunch of interesting structures you can make, many mirroring real world organizational structures. I’ve illustrated just a few, ones which I’ve implemented in some form.
There’s really a bunch of interesting structures you can make, many mirroring real world organizational structures. I’ve illustrated just a few, ones which I’ve implemented in some form.




{kind=link}