Show full content
I always assumed that the recognisable 'whoosh' sound a plane or helicopter makes when passing overhead simply comes from the famous Doppler effect. But when you listen closely, this explanation doesn't make complete sense.
#planepassingwave > div { word-wrap: break-word; word-break: normal; } const regions = WaveSurfer.Regions.create(); const wavesurfer_whoosh = WaveSurfer.create({ container: '#planepassingwave', waveColor: 'rgb(25, 100, 200)', progressColor: 'rgb(0, 100, 100)', mediaControls: true, plugins: [regions], }); wavesurfer_whoosh.load('https://oona.windytan.com/blogfiles/plane-chopper-passing.mp3'); wavesurfer_whoosh.on('decode', () => { // Regions regions.addRegion({ start: 6, content: 'Plane', drag: false, }) regions.addRegion({ start: 25, content: 'Helicopter', drag: false, }) }); <div class="audiodiv"><audio controls=""><source src="https://oona.windytan.com/blogfiles/plane-chopper-passing.mp3" id="planepassingaudio"></audio></div>(Audio clipped from freesound - here and here)
A classic example of the Doppler effect is the sound of a passing ambulance constantly descending in pitch. When a plane flies overhead the roar of the engine sometimes does that as well. But you can also hear a wider, breathier noise that does something different: it's like the pitch goes down at first, but when the plane has passed us, the pitch goes up again. That's not how Doppler works! What's going on there?
Comb filtering.Let's shed light on the mystery by taking a look at the sound in a time-frequency spectrogram. Here, time runs from left to right, frequencies from top (high) to bottom (low).

We can clearly see one part of the sound (the one starting at 2500 Hz) sweeping downwards, or from high to low frequencies; this should be the Doppler effect. But there's something else happening at the bottom of the image – another pattern is moving down at first, then up again...
This sound's frequency distribution seems to form a series of moving peaks and valleys. This resembles what audio engineers would call 'comb filtering', due to its appearance in the spectrogram. When the peaks and valleys move about it causes a 'whoosh' sound; this is the same principle as in the flanger effect used in music production. But these are just jargon for the electronically created version. We can call the acoustic phenomenon the whoosh.
The comb pattern is caused by two copies of the same exact sound arriving at a slightly different times, close enough that they form an interference pattern. It's closely related to what happens to light in the double slit experiment. In recordings this often means that the sound was captured by two microphones and then mixed together; you can sometimes hear this happen unintentionally in podcasts and radio shows. So my thought process is, are we hearing two copies of the plane's sound? How much later is the other one arriving, and why? And why does the 'whoosh' appear to go down in pitch at first, then up again?
Into the cepstral domain.The cepstrum, which is the inverse Fourier transform of the estimated log spectrum, is a fascinating plot for looking at delays and echoes in complex (as in complicated) signals. While the spectrum separates frequencies, the cepstrum measures time, or quefrency – see what they did there? It reveals cyclicities in the sound's structure even if it interferes with itself, like in our case. In that it's similar to autocorrelation.
It's also useful for looking at sounds that, experientially, have a 'pitch' to them but that don't show any clear spectral peak in the Fourier transform. Just like the sound we're interested in.
Here's a time-quefrency cepstrogram of the same sound (to be accurate, I used the autocepstrum here for better clarity):

The Doppler effect is less prominent here. Instead, the plot shows a sweeping peak that seems to agree with the pitch change we hear. This delay time sweeps from around 4 milliseconds to 9 ms and back. Note that the scale: higher frequencies (shorter times) are on the bottom this time.
Now why would the sound be so correlated with itself with this sweeping delay time?
Ground echo?Here's my hypothesis. We are hearing not only the direct sound from the plane but also a delayed echo from a nearby flat surface. These two sound get superimposed and interfere before they reach our ears. The effect would be especially prominent with planes and helicopters because there is little in the way of the sound either from above or from the large surface. And what could be a large reflective surface outdoors? Well, the ground below!
Let's think about the numbers. The ground is around one-and-a-half metres below our ears. When a plane is directly overhead, the reflected sound needs to take a path that's three metres longer (two-way) than the direct path. Since sound travels 343 metres per second this translates to a difference of 9 milliseconds – just what we saw in the correlogram!
Below, I used GeoGebra to calculate the time difference (between the yellow and green paths) in milliseconds.

When the plane is far away the angle is shallower, the two paths are more similar in distance, and the time difference is shorter.
It would follow that a taller person hears the sound differently than a shorter one, or someone in a tenth-floor window! If the ground is very soft, maybe in a mossy grove, you probably wouldn't hear the effect at all; just the Doppler effect. But this prediction needs to be tested out in a real forest.
Here's what a minimal acoustic simulation model renders. We'll just put a flying white noise source in the sky and a reflective surface as the ground. Let's only update the IR at 15 fps to prevent the Doppler phenomenon from emerging.
WaveSurfer.create({ container: '#simulatedwave', waveColor: 'rgb(25, 100, 200)', progressColor: 'rgb(0, 100, 100)', url: 'https://oona.windytan.com/blogfiles/simulation1.mp3', mediaControls: true, }) <div class="audiodiv"><audio controls=""><source src="https://oona.windytan.com/blogfiles/simulation1.mp3" id="simulatedaudio"></audio></div>Whoosh!
Some everyday whooshes.The whoosh isn't only associated with planes. When it occurs naturally it usually needs three things:
- a sound with a lot of structure (preferably a hissy or breathy noise)
- an unobstructed echo from a closeby surface
- and some kind of physical movement.
I've heard this outdoors when the sound of a waterfall was reflecting off a brick wall (video); and next to a motorway when the sound barrier provided the reflection. You can hear it in some films – for instance, in the original Home Alone when Kevin puts down the pizza box after taking a whiff (video)!
You can even hear it in the sound of thunder when lightning hits quite close. Nothing is physically moving in this case; but it might be caused because a 'bang' is created simultaneously along a very long path but sound only travels so fast.
Try it yourself: move your head towards a wall – or a laptop screen – and back away from it, while making a continuous 'hhhh' or 'shhh' noise. Listen closely but don't close your eyes, you might bump your nose.
Where have you encountered the whoosh?
A simple little plot.Finally, if you have JavaScript turned on you'll see (and hear) some more stuff in this blog post. In the interactive graph below you can move the aeroplane and listener around and see how the numbers change. The 'lag' or time difference we hear (orange arrow) comes from how much farther away the reflected virtual image is compared to the real aeroplane. For instance, when it's right above, the copied sound travels 3 meters longer. In the lower right corner, the 'filter' spectrum up to 4.5 kHz is also drawn. The circles are there to visualize the direct distance.
.jxgbox {background-color: #222; } .JXGtext { color: #ddd !important; fill: #666; } body { background-color: black; } #jxgbox_licenseText { fill: #eee !important; } FAQI get many questions that point out that planes have two of something: two engines, two ends in one engine, etc... I can see how this is an inviting chain of though, but it has two problems. 1) The sound is not just associated to jet engines or even planes at all; 2) The sounds would have to be nearly identical for interference to happen. Random wind noise wouldn't created phase-coherent sounds from two independent sources. Some discussion in the comments below.



 Moving the microphone.
Moving the microphone.
 Skater calculation.
Skater calculation.


![[Image: Two spectrograms labeled 'random Youtube video' and '4K version', the former showing compression artifacts.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhxHxA1NzbJulmPxer0gk48ImmkoN4ji66G3lnAMiMYlLkE0ekgJ6VTq9umFEn97Wr5dGUIo8fzsUpC8w6DL_9yptx8BqDQe0swHSQpJ62F3f-CYlLrYNMwLsW61j4GLWbLINrLsSpvwkih9Mn7I_kbaXADf47Imt3AgK3Hxo3U-wM4JQpFkNOy9DtHQUA3/s1353/yt-vs-4k.jpg)
![[Image: A single film frame.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhC59_S2FfWRnMghfZ4QuHa4GEugXiwUtUudblRrARDPO-v171yCcH4ri_lUxGpkcWCbh1d6htKfH7CSqmMjjJpG0id9XcyMLNTz2k5yVn2jTDvWu62jhr1bl0BOugwiI2CepLB3Y20DwI2sPGV_kQvPmt1nNdwvQPFVVeHVk-9JtyuxoUyyLCiG3IhXd-e/s1100/film_scan.jpg)
![[Image: Spectrogram with fluctuating tones.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgnShT00BrqwOsAyo2lEg8GsM894ogOPfS0K1BARfwYSE_2TfpPVAYjTkdx1f1rff48an2iDaUxXdQguAdkJDbZqW5Pk06ZHylJx9iZTxmAu1ztnikQIF-rVobS5xPQZmB_QRQhTO4P_Ym4Bz5HttsqxFNw8260cjloq4UeKI7iwReipqjaBaTJnuJYZs3G/s1784/flutterpercent.png)
![[Image: Spectrum plot showing a peak at 15.0 Hz about 15 dB higher than background.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiVcLRpMLSy3_mVGx7bqA2qq5eM5OgSp_4PBNZs0ESSw0WGaYm_uNd-xOEhyWpeEy5_9itOS3Ta34aAkOTqVMf38gGuTxfbi8Ru9NNl1EaeHQxQh3OrIaF4uurbNYPz4guDRldNGc9PT0rlKgeAAxX-1uJKHQDUt9qQLAHc8I3kLwiiEoT_XhUZmTwdV_tv/s1490/15hz.png)
![[Image: GUI of a software with spectrograms and oscillogram plots.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjeHxYb1XXSjCwdDvUnGoPv0OVbnzi2W_PaxSo2_tfchJ73ArpUu6D61cFciKnrS8T5fsmgblIapbsuvmPx7tg2wSthgzbLsxvo8H8PGBncLuCemYWExdgDEdADr_Pl21gpg9PtsylusilHh9Y8I7cDCzsFPJs-nTlbSn_-NJnKNcwm_uU2cQMC5Nwpt7Yh/s1204/annotation.jpg)
![[Image: Buttons of an old device, one of them Varispeed, labeled 1981. Below, part of a GUI with the text Varispeed, labeled 2023.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi-ftP_bhx7_ijHh3uG18VJRLnLsRbKWaho5kgEz3Hu5y5m5R1pYC3BivLZunACRMAllEkv4YrMKk1ANe3YVOeyuM2rvzMEW8LoHJqyewoU8B6ABosgMbwAptHtv4VTwU0zbKB6fJP5Qx36iiDS8Pm-ok9yAd9EYUfQO06Oi8-JSQp0UIe0LPhcsV4hqP6P/s547/1981.jpg)
![[Image: A waveform in Audacity.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjRocIM1OFdKzStrX8VTZ_pZnynkIJRxVZzCKjdBIkCa9FqKFTXNrYfwUBvsO0dp0iy0FpivP1g_FQboHFDF3xgNcWd303GLKqwH3s3NB2hyphenhyphenwhXyNdi3kNUMhS07pEdQw9cbcmaRZ94IGMfwdLfqDsIj9vh4PH2Qtqpvr6kJGZipaShCdrVYg-j59Sjo9Cy/s1501/speed-variations.png)
![[Image: Two waveforms, one of them piecewise and noisy, the other one smooth and continuous.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj0n3FreUSaXNwU3f4_NacMaZACdrpp-bcD3AGkqcOLVPbVbGDs34gKuhIYvmzoW8sBSLWWJ1UwhJVefJ7HPRSFV3sw93N2oPVT5p98J54dQz6kQEiAPE_HKoej4DE4dXHtbMREBfLOX43NVzJ8LgETuGbJKS6KET1NqhfyXqmn8FOW3Pw579ivisEsNnU5/s1028/flutter-filter.png)
![[Image: Movie screenshot]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj-rof_q4SRStw6UAZpRiymm4m8SaiYjwDouDWZPEIiFYqRiKC45pmSaQ2Rh40dMz6yzsRUYrEPIWta3lOCicEgyPLUV9w4KljzS8jHH8iQ0JvhaGZqIY42Y92MJsBCuGEAQaZAI_inkwl5okdLezPlxoWDJbyUcR15Cql4wZyL5bQx5zvVBcZF__ECBsYo/s320/example-moo.jpg) After
After
![[Image: Movie screenshot]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjjuZucmQXJmuMxSCIdBgbrQKBvsv2d5RW-Kq8GB0cPQmCXGruPZUfl8v2D5zy4yRCSKZKwUuVodofx1pDjkigdDlcnxqYcpYFrlTKUPnE26IJxCkBxP9jByvT0VInbjYEhBOK0TeWElBiwweNZ_1oz3izzt7mVv4iAlGaVvpsXG75pCebzIJLy-hPmAmgL/s320/example-whistle.jpg) After
Sidetrack 1: Anything else we can find?
After
Sidetrack 1: Anything else we can find?
![[Image: Spectrogram showing a frequency range from 0 to 180 Hz.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhpgDAGqXTHKKLEf-Nsc4U2aBDg1NhpfQnoLcZt9fPXrh5LgosyzGyRckaNuA9O1Gb0XRKevcuwdFx9ZtCXGNKn5SNrrbGoMIHmNPjJW8_phqO4ZcB02wHAPpsin8q4yWw1WXI41Ly6l5tUYrm5kPC75aUH6jr1H8NIWW86Oe80bgwO5Rf8EcmCjsb_1vi5/s1074/annotated-200px.jpg)
![[Image: Spectrogram showing tones with apparent sidebands.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgmJ6HtiyVj-yVW0JA7Ae5VYVOLhNuSfVoam0-yXFdzlKW6u1LeVuulZ872Jv7i8ec3-ofsac_qnXfL78uXDvydAiiOc97mPVXO03fLrR6rOPQv4n26REMoqsqOgwRIlkv1VzxaZI0ZOmYAZWCzT_FsVv4nldRBxQDIvxZ9OgsuFUOxFUUfcHsLJmiaBdoa/s856/sidebands.jpg)





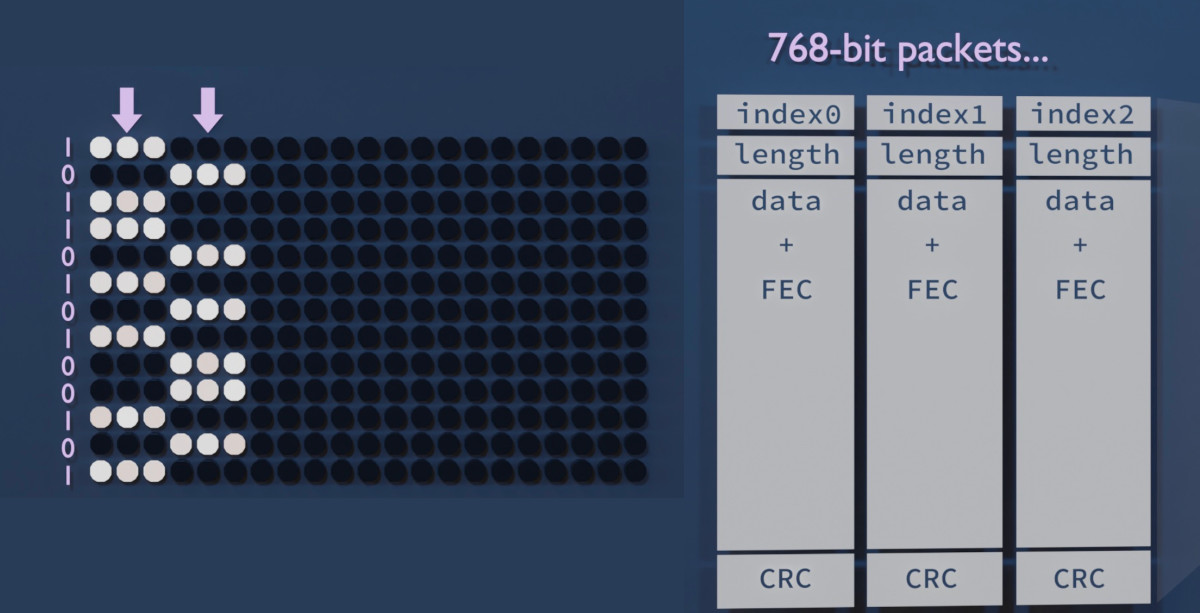








![[Image: A plot showing similar patterns that were on the disc surface.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgjfo5UWLOUu5REWu2Pywu_t1WgP6UJZ5W9DpzWU2NBuej4TthDHygkCXWka07TwdFMIpkroeqYT15OA3S19IcNU4nzb15WZ7fyyNmI6h0CE4A7VBTSXX-DhRDaGNlIYa2AG3NKQ9NGxO6_/s1024/blackpink2.png)
![[Image: A square image of the disc video texture.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjPisSQ0k9f16Mkoi7KOWCajT5YBDRJbUt0QjbR7mIWw3LZD22hyphenhyphenS9o4HTOCrkbjlEr9Q8la_GWX-CUZeotP9V8yBj7tdogf4dM351kjbrt1YTsMsc1E8vUf98ZophoMLD57qxwmPMv7vwn/s512/disc-pigpen-insync.jpg)
![[Image: Screenshot of C++ code with a list of events.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhWdBWR5I5I1mTXJs721g0ZtFf5ixXLtAqnh96HYgl_ICY1u_vgb_OmR5hqidOjSyOeo8lhomcHU6Kl4EGhHZVW7ItkV3Qx_VH0Pe8H9lThTNk0ekEKenZhRXx55glQ_mXYbsapu-uLmqGx/s479/events-screenshot.png)
![[Image: A screenshot of Blender with the device without textures.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhZGeWmeXgvDoQaLk2DzbwzbB9gftTUJqL6fJP0KPXjMdMAtsKeFbcf9tEzkso-FJHZEnjhGU5gebXX-bJ6JOZrf7K2NrQbjKuapeGXzsfBfopsSjsl2ip6SR_iF5SqRJGEcUN-DqA4sjLA/s1920/modeling-psyche4.jpg)
![[Image: A Blender texture node map.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgIF0nbsZgcGp5_hTtXkrSDtcjcyTQ0p072dWDuut948V5VK1KbZQJk9LRs6CrsFiM3EPLtez-2a7cPeGIfI-hG9D_VfqWXyrGRcwx7UXDUBm4_Y-p9-oWW_kQFWqokP2Q03raDENghfyB5/s2016/disc-shader.jpg)
![[Image: A render of the record player.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgCWvYWzuSFKzHBqwtb5aICiMpF1aJNpDntyNnTZOGh9FY4aObotdk4IB4MmasuG6uLPw2pOTtfVC4xJSTlHWrUpMPsEXQKMasaKnmDXoSHdb9TTHKtWcUIK0s6tyPR_Zu3cSNatrbaiLgw/s1920/psyche-render1.jpg)
![[Image: A screenshot of a Python script.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgoOUqggMM8fUV4EK7B4vh9P71EfJsgxbMDTzZbecqYHCO1GcFs2yPEoDCvdMP7jRljmO4wcMT8ru_mDjRZUOdFMcvj3h-UWXjvH0VX4anuZUmnHn4PYoCUTNq27zi_alHwsQeMF0etPAm_/s635/python-csv-import.jpg)
![[Image: A powered-on NES console and a MacBook on top of it, showing a Tetris title screen.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgI12MLq_5qagdxwQXzc8WOzE-N5cgtWXGSheXiG3H6qnkCWZMuGhQh_Fn88YSbqr7Owrqz8kppdC_p_I88_lEqBUj7fDoYI7-I0dy8yP7WdbcuHv62FKNssU7lpg2eNDtRV42E1WnhmxQD/s1600/IMG_6228.jpg)

![[Image: A screen showing Super Mario Bros., and a smaller picture with Oona in it.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgjgHYuaIsECDkGGbtyVixRSGVw_Dh3ukjHRBxw2EBKtdDbOADwsEJWVeUUfo3BiJ2xP-Lu9W2XTAE7NAScuX3ZL8h2EEHKGqM2LBLfe9e4ogESKxNfmoYgI4EA39TNzHYEaDN0JXZNVPTG/s450/crt-capture.jpg)
![[Image: A somewhat blurry photo of an LCD TV showing Super Mario Bros.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh_XzVzjsytlPbzIsOBJJSZgaDgbHVOi8v2waK0wMfLbhfvNsoSRqp_BjjuHYfRRYk7BKLJ1NygWGJAG_xUBnQPy2Kwi8bQJp3EaRtc4WurxPqR9CPae6oZEks2QT0zIwj0gntzH_W6u8-Y/s1600/lcd-capture.jpg)
![[Image: Oscillogram of one PAL scanline, showing hsync, colour burst, and YUV parts.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgH_zqGuJdjJwVxXRLC3zSt1nIMly-zYw0_gOm2MGJftW623qdMAIHK4o6rufDWshKSfQGn2k4UGmJ1fzGCRzjVQy7uBJfNFzYq9iSvClbvI7a4s3q1882pmnRrP1EvU0KOojvrCnO2uPhr/s400/scanline.jpg)
![[Image: A spectrogram showing the AM carrier centered in zero, with the sidebands, chroma subcarriers and audio alias annotated.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjcdduLn81WyrXsmRsfs6ZD2RNUFx__hikxP8jDtbhAksiWF_76b2dSKONlzn60JpI-KPMAFa5J5_n91vxddlj5__bGMZWL-iddItLklaZETGaBz1G-bUsoUgBojxrGoJ1khV-x7xoYGwB6/s1600/audiocarrier-annotated.jpg)
![[Image: Black-and-white screen capture of NES Tetris being played.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjwFvn_csWHfM4RW-1z0z8Qs2OWLsuQTo8H-Ks8apRdv0lc7l4E2fqfQJMtvDXcQPXy8R6lnAS0RQiHstD2QD-QVpctakfFVlg3Vc0DxktbK9z2cx0RLvhxgvLQHk0slV4LGCuLwXMjzWg6/s320/tetris-bw.jpg) Decoding colour
Decoding colour

![[Image: The three chroma channels Y, U, and V shown separately as greyscale images, together with a coloured composite of Mario and two Goombas.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgFPMVeaLGO-ll-fmPdHg7hka4GDK4dxAMxmCysom703v-_8r-Vf5zDdxMXolFrjsYdD6BR6v5J_YZ2tr7-oO3nD1ri8u48wcuwdFE5qmcXl-uOF-H9NJjURQ0GUImH9wQatyx4A6d_IzP9/s1600/chroma-preecho.jpg)
![[Image: htop screenshot show palview and airspy_rx on top, followed by some system processes.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhTTxyKTqsrUbgApxBxqtoaVRUvrj-uEXBkDHJFn1dvhGRLpmWsmtjbe3N8n9N_o0XnnALUpe5VsKpB-Qcc0uXpQQZsrGr-Lmb6nBzs-3EzM5CG6m7iFpwyCUqaQMy1rMXiaYvKXoerH6d9/s500/htop-screenshot.png)


![[Image: Photo of three different walkie-talkies.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhcIlePrhv4X5zhlMjS3-NXPCemkiHAFKtk0XImsucTQCD6s0RVHzqB2y0uBpP1JTCF6DSyrI074B8qr-PxEvvZ497giDNJo9Z28XZAxVG7AFhENmV93bcWDAqpeXmwfwj-2ZD5Q7Q05zs5/s400/puhelimet-tausta.jpg)

![[Image: A user interface with text-mode graphics, showing eight vertical lanes of timestamped information. The lanes are mostly empty, but there's an occasional colored bar with annotations like 'a1' or '62'.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEizOo72Y8CO7jCOSswHCLK4csjiubXHra8cqXLAnK9Ri12eMUsp8q43PSo14DN8Oi0TzCHvr4MnpLagOZoN-d-jwQdbf-fO1zgB_5qx-rZ0eMHktmhLLV-TOM0FHnymSyKpWLSqqxtjvcRv/s527/screenshot-pmrsquash.png)
![[Image: A diagram illustrating how an FFT is used to search for a melody. The FFT in the image is noisy and some parts of the melody can not be measured.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjS9JMtU94yhhuthNknNLnoMeR6IcUMyIeAIRdUae-iduSILXG_yBLBXbiS4DQZ7oTTTawxORfleB7eBTlbpUpXIDljXSP8nCPhB_eDf2Z2TFrAFYJpOHgYVI_V1WsV9mLVEyh22MExkHtW/s511/fft.jpg)
 Naming and classification
Naming and classification
![[Image: Two-character codes grouped into categories and paired with emoji. Four categories, namely fruit, sound, mammals, and scary. The fruit category has codes beginning with an M, and emoji for different fruit, etc.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg27GQuq2fxG2UrLqto-asPmTgLQkmh_WUJT4Il5P5N3pJdFpJ7xr7vuwxLnyKe799iDx_XTstPhtQBkUsftie-hBdZ6kiR2KIaa3l0E9IBFW32-Yc3V7FU1FrcbsOZTHWTScTwZvYCHrMt/s418/ctcss-emoji.png) Future directions
Future directions

![[Image: White concentric circles on a black background, with evenly separated lines connecting them.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEicIPnEytmyXedVbulIXkF378vzJR4EYLKX3ygpqWbJJcn-6p_AGQUB3jt2R4vKotN_0dxB5edNDpQAe4Rc1w6SKiCOyLRbKJR4USqIxof6rgvea29M71-q_0ymcPiuUHtZBZGmOSLLlRZp/s1600/spokes.png)
![[Image: A zoomed view of a circle, showing the glow effect.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjNAONoJIEObnIVGE-AbyecROvA4VkTER3ic2TDQ5nHXI5GYfvHEejAruFS33WyLTCruuN0lO2Mo4AWXOQL8iQYZLhpvQ9jExSwQmRz2diVCoU3jPWjjB7VqVJwD2Z2oRXRSzM2JHdaAAx7/s450/glow-zoomed.png)
![[Image: A zoomed view of a circle, showing the color overlay effect.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjnljOUCNrwy85yDcP0YzmqcEFu7f6W0uqegcsrFkhj4jTG9oMivCOJRrCAWgMyjYAAI0TKTXQZ-PwRMmlhrR9BpeBiFh9yFaZCUxI9MXxrIGbfCA78zvSrbs0TcLcmJwOXnCpUrBLJqWd2/s450/overlay-effect.png) Eye candy: Flicker
Eye candy: Flicker
![[Image: A zoomed view of the text 'finally' with a glow and color overlay effect.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEirmsMDeVOsnMtHYkFwICo5_uXRRFuUEnk_Cyewpe2mqHEJkIWdWt3I3rgMvDdcy0SAM5FNFoYKxekllK3zP53uhHpMLmk_C69yUSLlc_YoR0KlOAy0eaGJb7RWFvXoPS5mpO9-zAt2IdHA/s450/finally.png) Encoding the video
Encoding the video
![[Image: A pink Otamatone in front of a microphone. Next to it a screenshot of Audacity with a periodic but complex waveform in it.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEheF9HQ5A_3NXK-RZkItzL19UQsYH19clTdD9zIwcqeYbYWLDmuYtQcu08wrquO59vbbdyedkzN7Tx_ZEdHp9Rw2s8b-VlmZNVvOFn6OBEctWfa1qXjbj0qKJpcyWbZNv5eW_JdosnzZ-jA/s1600/popfilter.jpg)
![[Image: A Black Otamatone with a cable coming out of its mouth into a USB sound card. A waveform with more binary nature is displayed on a screen.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEha-l4G4z3zvNaB_4UpCaVp3G-JkeZgIYI_7q0dfXYQwygBWYMBfXmQsDt1Qvpw0hkwMNTXLjaJE2xz9U7dv-S1yTNSVL8TSH9PhVSNMhZlCCN0QH4aeilTxxOl96IHU22LsseUR7nJ0Yad/s1600/otamalineout.jpg)
![[Image: Oscillogram of a square wave.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjpR7HiGi6gtLxjIOXF1q109KtIkKXlX7cN7OAuUa27KLATtKaz0qJ0PxVN3lt3Uf7WvUWo2I3SMpPUV056zLbiDCDhlupMJot1bjHwxWs40sc7jc-x32deNcM0VZariy8N1lW6pb4AK5kk/s1600/Screen+Shot+2017-11-24+at+17.24.36.png)
![[Image: Musical notation showing a range from A1 to B7.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgV30yNuAN8hCumOCKRSM6a1eySsZbX25hZMl-irAbnntWoNPyfCxa1mB1RrRYp4ekcFdxgKsDBmTV4n1k1bOxE5RP3yMlJQNuerZxHXdZ22VBA_wsWzEMfEoKeBcDv5EWW77ZDqTlDn7BM/s400/otamatone-range.png)
![[Image: Screenshot of Baudline showing lots of frequency spikes, and next to it a CSV list of dozens of frequencies and power readings in the Vim editor.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjtmPUtBeb_Dr02WSuLA8rcxRlnvZa5aOl2ajaE2kD8i4DtsKFPihJbEkH4f3rpfEsDldTuqv_bqfHEqgyX8yi_xTANmuzXneUIKPYn6EgLJiIXqzeN2RiV5WdgzNMtQsHeXxzuz1rGu2Qz/s1600/harmopowers.png)
![[Image: Screenshot of REAPER's FIR filter editor, showing a frequency response made out of nodes and lines interpolated between them.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEinekeR8qdGsDJ5sWXxH_9G9jPzvQonFuC2tCSUu5GFzDFCfUW2T93QEIAYoTQ9gWDq-ps4YT6tw_0cK8ePiRheRynLOTBQ511rDIt62Zh5Jt2AJKW0wxbcw168nQqNWTkZzvRoPdAOYbku/s1600/Screen+Shot+2017-11-19+at+10.21.26.png)
![[Image: Two waveforms, the top one of which is a square wave and the bottom one has a slowly decaying signal starting at every square transition.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjYJqCo1whmphJf0z81cYQFYl1fEZUGrMwVWOX0Hj9tmWNOEvgSAflGjXj7KlwFm4o7glpza3Q5EWV_CIas05s6WRXcth5O8Qjq8Z0s6iRLghEmTA_UW_QaTFiidiYknipr48taEvLcroZg/s1600/Screen+Shot+2017-11-22+at+8.19.33.png)
![[Image: A screenshot of Fog Convolver.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEix0nl71C6FiN1Gal1S3F8aETwyyR4KlLG3AmKv9ULa2XqbK63uBWSvNlYSxeGoCyRPfN4Es_9MEw3qNCEdMr8RxEHuSwZfqqjrf_L4Tt8cQYMPm46JzLeScF3klY3U0ssLoKgiArTfrbia/s1600/screenshot-fogbank.jpg)
![[Image: A spectrogram in four steps, where the signal is first cut at 3 kHz, then shifted up, producing two sidebands, the upper of which is then filtered out.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgN5_Zy6ARkoMhJuBl96gzNm3WDMRfEiBqZzb1_E1eQqlQdBvClPr6LvjqGyHfxHVIs88Z0ly9zzGswfkGgqwNsYxwHSZRJ_bMmfq8NKyqaWhM8PeYDYFqKUCeTSPKL72VISb-vycG-6KAL/s1600/invert-spectro.png)

![[Image: A spectrogram showing a narrow band of speech-like harmonics, but with a constant dip in the middle of the band.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg6QjzxPReF6UXcSlkUZ0Q6w0MW2SC8M7Z6NdGfBFrBPZxoYtTQu0N8Wtk5Df5IVeVxpsjZ8K3k7Lp6HH4GzhaYGJS1Jnhu6fFOO58QrGqaF_j6rbLyPKoSqAS6vj8x2Qe2PaMRIIkY7Egl/s1600/split-point.jpg)
![[Image: A graph of the time spent in various parts of the call tree of the program, with the subtree leading to the dot product operation highlighted. It takes well over 80 % of the tree.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEilLXBUcWihSX70UpUUDN5MiA7N5j7kQMppYG43xzuJpYdZH0c0k-19GC5e7_5TfivSeOle408E0WPlnJPe1dEbMMe2OhVBfVw5Jq8ojSq5v8M59cyWGWp46-oUngwwlus8N8VY28HarmeX/s1600/deinvert-perf.png)
![[Image: Close-up shot of a miniature vinyl record, with a detail view of the grooves.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgt3gSLou9vVgUvBmkE3ED4wax1cru1J1s0FR8z1w2v59j3HqKD-l6MXafFwLk8SUS34_D5YkpPuGEDBv_4HgPwAlsrH_5dVNCqppDjuyYPS5lvUlMv72WIyiRfU4w6auJxqNW0wDCl-xVB/s1600/vinyyli-zoom.jpg)
![[Image: The photo of the circular record unwrapped into a long linear strip.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgEcWYze6gwl_Adheon9elKRD6fon9GdyWpGg_LoCzE8UtkpPVtzcfOVNNB5EWT91ZjCl5l8mDfiUeYGuVOWDYCa5k6KxHmmgDLdQmJIOHCiWBGKlJQSv9-i7dVhL3ttktCXo2-zccBkkr5/s1600/unwrapped.png)
![[Image: A zoomed-in view of the unwrapped grooves labeled and highlighted with colored lines.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgrCXDEnEGkileTPi_q5Zd8GVmEr4cxNPZBYj2zm4PXfMw4MP7v_HeI0Z024NxWeSfvObC3TXZJNFBig3xqHrB2luaHAFm-9RwYibcEacWEwfeqlFlmQJd1mMgP7EulMwK-oqbVAaQ62tmh/s1600/raidat-manuaalisesti.png)
![[Image: Parts of a few grooves shown greatly magnified. They appear either as horizontal stripes, or horizontally organized groups of distinct blobs.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi7BPvUXTmKHG6U_RrgeUoaXAKahZ67hbjVsTxb7MbfyvxA1AAf-swR0fSdSKx_PnWjHSKoXDYrf3lQiiATcOkx8tlmEBg0bhn_lQc3Bs2TBm3FNaA9aJ3MjQxNeLTh_lEDaPNh_wWRn78B/s1600/groove-center-displacement.png)
![[Image: A paper programmable music box.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi3dtNWvQ6egqAgWx-_k9__beJ6HvB4UPg6nS5DVTClY1ytN56t9x6Sw2mZdZI9eJPwpxWXi3DSd9ywFSd3jyTErBQoprIybZ1rr7c6blyFotHO5uV0JsYiJ-rulJfua0sYJhN6VkCr_VSS/s1600/IMG_6798.jpg)
![[Image: A recording setup with a microphone.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhFI67wIrNfYfUA4m244LiKXFxr1ua_6ZbA3w3B911IJX40ZcckRT5L_pl-SqgnDjIq00wqbROQQiKr3WY-h5B5K6yTHpsumwsvHI09rtyXre6pOOj5TdWQm1rUyZQlFX_sxzdz322Z09jw/s1600/IMG_7607.JPG)
![[Image: Musical notation explaining transposition by multiplication by the 12th root of 2.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhcfWi9CVTYXztYkPcGYsJzxJg9ZLbXvg5ZjInnFWXMW0EHcng-N394B2myUJju5mKhEY54OB4g9ZeOatQXe0cX-VOAdCuLecez_uLibvqIFuv4KoP_KIwHI1jaqJFdx0IFBkmJ2VegCLVK/s380/notes_12root_t.png)
![[Image: Spectrogram of the beginning of a note with the characteristic screech, centered around 12 kilohertz.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjJ5FEUZCR7qcTWZglyBnW7MmpAGYuN_19HRlgJPM7BQfHMrPkt2lDX_mwrmwVdZeB2MUO1KH-xUBbgRs0vpBjT5zLwyTo1ZDHpdPwHiOjRhdR3h0qNoE0QIKQLgsC0qA4Y7VK03HLxfTGt/s1600/screech.jpg)
![[Image: VIM screenshot of a text file containing music box markup.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg0Rm4-UqZZbjeo4nVT9jXakV-VhqLzrOg7N_h0NU-P8VTbNLgX6WiZqpTPAbe5BZYWDxxAehgdQKiKHxyX8oTyHZ5psG4mD3zDc7wTFw4bcOnetXIUnTzhkAWP2MqDFjsqVaXvR7n_tDTV/s1600/Screen+Shot+2017-07-17+at+15.22.27.png)
![[Image: Screenshot of Audacity showing an audio file over eleven hours long.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgjyjQ5aQ5C_WSBEMIuM7R_1CZyvc4zMoPWt4Egna3qhWYNKJN2iZZB-NciG3Efy8Qo-utByS1Wr6fzGtkfg8omYo2BK7JfNT-EzKHfwmSEpQBLOfQ8SaLvbqj98DLt49nnxJye2G-u6n25/s1600/Screen+Shot+2016-09-26+at+0.19.53.png)
![[Image: A graph showing frequency and power, first fluctuating but then both stabilize for a moment, where text says 'PLL locked'. Caption says 'No, I did not copy'.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhwIys3UsSSN0416QgmaXwvwEQ15s17O6sFWs9AJ0nkeKszasjvgzaEZ3dzqNAb-rlvsduwGU3yNl_1621sPnOtUE_wsdCfuAVCB8sONadQBuueNtjaJKKLU1nfBKmbvZuyfCRrthlBw68Q/s1600/plot-lock.png)
![[Image: A plot of RMS power versus frequency, with dots scattered all over, but mostly concentrated in a few clusters.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhrhYz0_IxabL_QLPuN0Rt8QzJ1uy_bkd1tLC4q1cpRzh_mMREjKb7UUnLU1Ri-rFyaWydXCrnEYymsKnkQDed51EaPYmIumgb-W8BK5KqaUOfuMq83HzPsFSDfr5wWub56L73O_heotwK5/s1600/plot12.png)
![[Image: The same clusters presented in a gradual color scheme and numbered from 1 to 12.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEixlW3cmPy8YU5-c8M8OLOs1GlGhyphenhyphenebaTp6Xc7WzVmi9goQbEYPD-CLhE6aQGfhVcLIpdkMGUrfh-Ri-ehUplQraoz8ag2Rn4r3VyVT-D35i1Oxbv14qrf6rFFrKQ76bBHmZkOwm_XxxWDD/s1600/heatmap3.png)
![[Image: A few lines from a conversation between Boa 1 and Cobra 1. Numbers in different colors are printed in front of each line.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjy9wyge-5pOtq7REJyPPznqfHLZSsuvleHEhGm5XVN9iLpGL2gN9Th6nBiedVP2iple9fuMPfF_tX6JSz-yYVjcevReNuE_Pnj5YrAm4YYc3ZeYWpMJV1XNWauB6ccyrhbeNl-KfZNN3Zn/s1600/snakes.png)
![[Image: Spectrum plots of the two signals superimposed.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjxJb8tfNcyfwlqRoibN9ffpl4QTwWtHbxI_XwUQURfVL9Sabkfj7MVufWlpiHT5q1bSgi13xowZ_YVcFHu82JkG3JcnUALlyf0qe_tMvqG7rPaAfOAp8kp8haCQfhysja4ITKwXE6j_bQn/s1600/viker-puhe.png)
![[Image: A graph of several signal properties against time.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiWhUWCDPhsTT7vtVZJibWzn4K_2SoG9EOY75kRFeLXZgK7PN8ML5O33DeD43SGMKDcErB_dvzwmC7DhzV18pHLlrrEcLsRdjfQw8o964RBjAUVHDCLIiHhExYFocZDKAgMbMXfDPUWaa1f/s1600/NZjst7F.png)
![[Image: A graph of several signal properties against time.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEibHzljSbMrQw5VMB4ErTyv3bxmE5tFl4MKbu6Y7njkCOsF8cnY07FpLUynNBXQ5owOVwwvxaGEXI1xvcp7kciC5T9DXDfJUri1rGDixvq8FcnKYBgleIstRJ4ooUSkTywe8pXk_H9oQdkp/s1600/wXmOjiN.png)
![[Image: Acme Thunderer 60.5 whistle]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjKdJ8jqWTJO_fS1ilnlhIRaRV4AYC-6mj0nVcE2udYbIZQrcnKZWdlLrOPrUVRiXXzQ-dYc3JDSQLxcHVGgxAqBdsEAng04JMQ_B-dFcIyQ9VOcjDCPd-SwVhKJT5gV1YXxr0N_tGMLCfL/s1600/IMG_4864-1.jpg)
![[Image: Display of a sound pressure meter showing 106.3 dB max.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhtsQ0g2nfQYkU_wODsX-TPDkTVARQ1cFJKzshhBrvGrdswsMmZBMlVYPA2_Sp_jsDselFLiXlqe7h5gOgBu16XAAvAa-k86D12YbPwF0hz3R92_86PyukNigOfPH9rj35yF86VqerS_Fj3/s1600/IMG_4865-1.jpg)
![[Image: Spectrogram showing a tone with frequency shifts.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEijskzqOQXlFFqsYmhyphenhyphenXNS45EpV7mbP0Vz0-9CSh8qWwKDseRnUfLx7zlB7tYR6lAU9LCAIcWLu_h2i6mCYU0ahBJk6_P8HWZbfv4GTWzek7wZXtaR0fC5LTcRKOlO6Y7I8pa6tRf7GN2Ln/s1600/acme-spektri.jpg)
![[Image: An electrode made out of transparent plastic.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi-IFvsNBn7XwU4rXB823E2AWw8EPwR64TasHFdYmCYeSdOzd7eJCk1uc41pCZVZblYPgzBtv8tyWAQfdO0JlMekMzeL_Rscoonfv_LjJOW-GwXFbwTkdnbx3EsNOuiwEIYvfvTi7lAWCmN/s1600/IMG_4855-1.jpg)
![[Image: Photo of my cheek with an electrode attached to it.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh8ZwKtWTgsN0jdLYOFdX0FEP6GkEytmI7VHseOPMYGuKlR5KvaZU9iy56ENKmiGCMB1nEEUfVj6vw369ad_ffxlIqTQwvKdl1BiRnPdV0OAoEcDE3PKItVWcPPhQL1XRYO5v-wt_6G2HHo/s1600/IMG_2923-1.jpg)
![[Image: Spectrogram.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEid_rsFra0OFNOqpe0vXgQkUkYylgUyeX_7UWwtFVB01TZk-_p3M63Hltk51RO8z3uk_caghPvRLyHwWNTNaKfWXrHfzWSDpxPOOVjWnT5lni_pi5hIAk4X51D3a1_PSuf4stmqNN1tFeSd/s1600/lihas2.jpg)
![[Image: Spectrogram with a regularly pulsating signal.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj4SM3lSCjDjXS7zIXOJFWXFRa2R-oxGCLU6RazEyh0GEnOOXooIvU2EIR_2xaRJo0k5BcSD16PdHStJR5JsyXPKsb3sE9TgWzZc2PELQkvvnIJn9sl3jprdfvx7q5H23V7wR9VzZ1sTEp0/s1600/pulsating.jpg)
![[Image: Animation of the signal indicator LEDs of an amplifier blinking in a rhythmic manner.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhVKNcorTRIpmXogOkQi4tukKw1GYDhQjfKDe0JxG1mDEsAczybHqSP9ddPGO29y2gQjdav6pXDtJ1kJLmBZuxvJSot1tK1hUOjWTeRp6zf9_goJ6usTBO5sFRtBk_Nc8571yspwN7b9K0J/s200/pulssi.gif)
![[Image: Oscillogram with strong triple-pointed spikes at regular intervals.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhlBDXiUU66rtGlYmP4tXO9T_AcIqoA_BiqR9SVyozwbMNLvNoPL5BzkaiJRBHUZErx-JKSvv4kyC5qupKQM0Aaa39IG5xW2Q3bV7bqr1GKaLxMfxxw0RGh9bJQ7_kRrw84W6xv3a3e7WnX/s1600/screenshot-ekg.png)
![[Image: A pure tone audiogram of both ears indicating no hearing loss.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgUf6rqi-WaY6GsAMciuY1RwdK1XoL1M0KzBcPXzR3XzX3mN26qru8QhMUcDK4s4jGBYfnNUEP3ITgSuAwXzZvPPevQDob5MnY8FW8levIw5Kq5xwSIsApVQBouyKAv_8a3gKu-syNzZIvL/s1600/pta.png)
![[Image: Oscillograms of a wideband signal and a sinusoid tone, and a multiplication of the two.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjD0WvVnLRiPh7HrR9y3cXDceGHJ-RiiljtpX2FE-G3SkBiFLS9rfgr5w78a9cf6MuFdW_NN9JkPT4B2vEII16_yiDRnvPummJXI5kl2oFUV_8L8VAeX4GMRgkv7bFb93xxdndcLc6w5CjO/s1600/multiply.png)
![[Image: Sennheiser earplugs connected to the microphone preamp input of a Xenyx 302 USB audio interface.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj4B5y1VkH6XtRcQ-gsZZMbs18mzyztspQqSW5kPw5CuPgWXwbkwLlRMVvwp1uLwXqrtrsD3XMRFLn6UdWRdkf-WZSl5wO2olOFTBp60mCR7c3iMBuRDWzm_g9jntBJlvFsOzen4tSXvNfA/s1600/IMG_4749-1.jpg)
![[Image: Screenshot of baudline with the result of spectral integration from 0 to 150 Hz, with nothing to note but a slight downward slope towards the higher frequencies.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj3wgd9SJLF2ipcP0qQbHXm5ySvnsQvEvirSipnvH0QkzlsC7AUi4K8EMqqhlqcqXIPz1VwOOiawMuhSlocElM30402-Y-0m7qzpUUoIC0pniwtE6Lm5QmBEYTw0Vdl3j67pxFfmIwrauDS/s1600/Screen+Shot+2015-07-11+at+17.42.31.png)
![[Image: A tweet by the bank, in Finnish. Translation: Our customers' personal data will not be made available to Google under any circumstances. Thanks to everyone who participated in the discussion! (2/2)]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhcdvnM-vdWEEJETMI5Io0tiq36nvh4Yyyd46NGsANXQsXMOy-lydxIPiip72T50DUbL4O-kxxotmawOZleC0u7g-kNp2EDZs5-HDpTtsmv8tQ0319rU7rMdVhsNdbYz4ZlfDG_I097Nb5k/s450/asiakkaidemme.png)
![[Image: Screenshot of textual output from redsea, with some parts explained.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEghDSuLUBhcKfHe0dEKhePRSEWFhrKu3tNkSLDL7rHZQUfMFDTcbS2AhNSlM2HRToqNGoq6YSdk3fIxa3fcF2cgGkfCmpmNA_QVIfaYgLN21JJ-LwF-Avf__oVdquGFti67-DKlqYrqZj6T/s1600/rds-groups.png)
![[Image: Oscillograms illustrating how the RDS subcarrier is gradually processed in redsea and finally reduced to a series of 1's and 0's.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEi0-32woZW6BB5JDgpyzAf3g6a9QG30gFenMBF9dyxaWlwVDJs3tcnuvOY8W47uLsHahxks2255_giLHj6AP7uDGm_o8CWR0JKg0EniI5Zq50bzKexdQ5PD1zwSSEasGilj7iEj0x8zg7a2/s1600/redsea-waves-all.png)
![[Image: Photo of package]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgLzWDjhxrtaQkYMEY5mWA64DopVUjJg2XKcYjY1wq9Tnf0JfnlnYT_jAhJjGfJhRdvGty4qnwiQBiG7M0KVHlzKGHFMCP0Kh7UdX9Yg6Hzl9k-fO9ThClrQx5Vrh-fQMQiRudLJA6iyIbb/s160/IMG_3605-1.jpg)
![[Image: Photo of package]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh0WZVUi88LlKBhiBmlw3DnJugciSIWORU48FXUIk5_OBp1aMvzDUV0-xC1ftarqhxy1zLKTWOSrsB3Nn8L79WGSzlZm5x68X4zXqfLjK-IkVnupFn57kA-HR3OIHDwYRm7gQ5CwFJw3OP0/s160/IMG_3667-1.jpg)
![[Image: Photo of package]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjo_JNMkqcclx0ZYVhiY4y7q9hYhsxxlI6IdFT9td71lWQnXbYoAQeFvc0E0hwF65HQqF6vjRuYlW4Z3PAcv9bmHjv7eI4-zEqTA_0xvONXgwIy6cqK4jriaE5KS93vjk3WiZ3DoyQ5QD9f/s160/IMG_3609-1.jpg)
![[Image: Photo of package]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhgh1m8g62zYfyKiLAosd0IbONX1i9vvzrd9Dk7BwbDSYA6HSjZ752s3M6ReVSFwJTKi2bMAGui4z_Q-hfYS8YUavkB_a1ZMEXukM6HyAB1QEWw3mtRAbcMn9abimPJX038No6raNod5J8g/s160/IMG_3606-1.jpg)
![[Image: Photo of package]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgu_hnwUfVbB91VIe0rcD9YcP0NM8urUYE2qNN6ZCmT2umiEm8k_b68-eiBrvZmsBRt489NmFWFzyh-EE2OpJxcQwrIvGeYvmGDPfWH4AzqkKxCJ1LFv_wG9xmrCkmOs6eJiFJfC2jbETfV/s160/IMG_3617-1.jpg)
![[Image: Photo of package]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjGCGn7_I2GlylRc5oc6ogAu3W8TE7GczyLw2sKrx4CrTzmw5zJc1n__lnSgtn2-Klpg9GAwF6sB75wX9K06DMDadP8LFehYXKcLjU1FtWGpYRAnBMKMSsTFkwgTkyUKs2glNtP2rXo6bgK/s160/IMG_3602-1.jpg)
![[Image: Photo of package]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEg9XkAxP9Pu088raQuCmkEIIFDwEcYwfb6G8japeR98RK5Kiku0S3FekMBIJi5gb3jIs7SKCVJ7QxutJ8GGUoAmHQvaJgNk3f1fNZmId51AGa3gsd9J-gkRKagi2PQiV_VLX4g2hP7Wlsri/s320/IMG_3623-1.jpg)
![[Image: Terminal screenshot showing a PGP key fingerprint and the same with all hex numbers replaced with emoji.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiSqjooSaf0To6FrwZgBLMDYJQHvR191sOKPXBI2QkiB8wQm6MVOKg2UbXH9cw3fL0v99vL2mxvdLEgJwXoZGl6_lE9LzAvKm7ccBuX__Nsv4JtwsE7dfI9C1mqdqnl29pEm78SDW1n3H8y/s480/rsa.png)
![[Image: Terminal screenshot showing a hex dump of a poem and the same with all hex numbers replaced with emoji. kissofoni; tassun kynsi neulana / musa korvista kajahtaa]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgslVegzWOtb-hUhvIKDSKCLGAo_hfuorZCNSp90FuuO8_sprWa_eYVleRlCJFJfdR0m0B7d-uz4iUHY4MbJsMFI-VPigBi3IcC6vTxL9J7pZLclC-zSbNcI-yEgEC6RSlihrTr-7npZaVN/s480/korvista.png)
![[Image: Five photos of the same directional microwave antenna, taken from different angles, and edge-detection and elliptical Hough transform results from each one, with a large and small circle for all ellipses.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEht212L91KY_9TT2hZspfeS6LE70CXC2KxPCK56Y7HVyFJmOw7QYNEKJaIVQ4XR_qggDXRS2ufY_WjMYp_A7qIxwKSjCF6A_HwMi0CmR2KRSDKVxL2zOmySCabC0qorKIKLeyMMQfWn6K71/s1600/linkitylink.png)
![[Image: Diagram showing how the ratio of the diameters of the large and small circle is proportional to the angle of the antenna in relation to the camera.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjBWQ8ZWP0iIFBS6javYIrLqtpiyKlWCRq-FPdN6myGibuaV_ntX2dkDqct5k_6dCNbObsskvlBLkaivN1oKYj9KBN6_mb65fPZvKDxShcvj6BgK0lrPUVt1ebQ8mw1KP2mV1qHyBdb-aY-/s1600/dish.png)
![[Image: Information display onboard a Helsinki train, showing a transcript of an announcement along with the time of the day, current speed and other info.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh26Tjh5ugfGUsyQTOimb0w9ppvdoNxwEWdQhP4WtSHEYTQ1f8RDCfAonikNw3n5pvlfB4JLvMg1Dpq35hJ0MMCOJi_EToLZ1fm85yRaXNZLaWSfkbTSaifvOGrmVVAgJ4HcX7NquaKy7NG/s1600/Cv6TbdL.jpg)
![[Image: Byte histogram and Poincare plot of a raw audio file, characteristic of Gaussian-distributed data encoded as four-bit samples.]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEh8Q8-T2Qr_Ecur96iJTFcsfPvxSnhl1fqfwWRf2i5jkOxNmQZEjkgjwz29e3xhHumDGS6oZBZ7esLlV1aXv7YdbIoDnIuwZATKyB0QsAO3YJLg4bD42BOZEJs_Ksj5-o4isE0MNQhN3NJf/s450/poincare-plots.png)