Show full content
In this post, I'm going to explain how a humble LLM can become an all-powerful weather-checking AI agent.

You're sitting in your office, rows of desks as far as the eye can see, when a wistful question crosses your mind: "What's the weather like outside?" Unfortunately, there isn't a window in sight and your corporate security policies don't allow distracting websites like weather.com, so you're seemingly out of luck. Then, you remember: you're an ML engineer with the latest and greatest LLM running on your machine. Surely, such sophisticated technology would be able to handle this problem with ease.
You pop open a terminal, hit your local model with a prompt like "What is the current weather in Seattle?", and watch in horror as the model outputs a hallucination like "The sun has, unfortunately, exploded," or quitter talk like "I don't have that information." The outside world seems to be a mystery to both you and your LLM.The "M" in "LLM" doesn't mean "meteorologist"You've come face-to-face with the crushing reality that your LLM is not, in fact, an omnipotent techno-deity. It consists not of divine aether but, rather, carefully-tuned matrices that transform some text that you prompt it with into some other text. Through the hard work of many GPUs training it to compress the near-entirety of the internet, the text the LLM spits out is often relevant to the text you put in. It can even be factually correct, assuming relevant information appeared in its training dataset. However, that training dataset was compiled months or years ago; the LLM could possibly output the correct weather from a day in 2023, but the present conditions are entirely unknown.
More generally, an LLM's "knowledge" — that is, the set of facts it might reasonably expound upon — comes from two sources:
You are now aware of two things: the weather (rainy and overcast) and a sense of disappointment in LLMs. Can we do better than using our model as a very expensive JSON parser? What if, when you ask your LLM for the weather, it could query the National Weather Service API itself and then produce a well-formatted response? The idea would be something like this:
The AI agent software serves as the point of contact between the human user and the LLM. Typically, this looks like a chat window where the user can ask questions and view responses.
In the weather example, you would type "What is the current weather in Seattle?" into a chat window provided by the agent, and the answer would (hopefully) be shown there.Tool library
The agent maintains a library of tools that the LLM may use to interact with the outside world. These might be API endpoints or local commands. Each tool also needs a text description of what it does and a unique signature for the LLM to output when it wants to use the tool.
In the weather example, the only tool we need in the library is one like:
When the user asks the agent a question, that question doesn't get sent directly to the model. The agent first augments the question with information about any relevant tools from its library, then passes the augmented prompt to the model.
In the weather example, the prompt that gets sent to the model might look like:
The user is asking "What is the current weather in Seattle?" You can use the following tools to answer the question:
When the LLM produces a response to this prompt, the agent scans it for any requests to use one of its tools. Typically, these will be written in some special format that can easily be detected (e.g., surrounded by special <tool></tool> tokens). When one is found, the agent executes the corresponding action.
In the weather example, the LLM might output something like:
The user wants to know the current weather in Seattle. I have access to a tool that can return information about the weather. Therefore, I'm going to use this tool. <tool>nws_api Seattle</tool>
When the agent detects the <tool></tool> tokens, it would use curl to query the National Weather Service API.Re-prompting
After the agent executes the tool, it appends some result text to the LLM's input context and resumes generation. This result text might be the data returned by an endpoint, a status code, the content of an edited file, etc. This allows the LLM to use the outcome of the tool to either make further requests or conclude its process.
In the weather example, the agent would pass the JSON object containing the weather data into the model context so the LLM could use that data to produce its final response.It's all clear nowAfter a few days of sleepless work, you've set up an AI agent wrapper around your local LLM. You ask it, "What is the current weather in Seattle?" The LLM, aware of the National Weather Service API at its disposal, outputs a request to query it. The agent does so, and passes the JSON blob back to the model. The model produces its final response: "It is sunny." Though the sun's rays are far away, you feel its warmth wash over you.
You can't help but wonder: is this all AI agents can do? In the sense of "are AI agents really just tool-using lackeys for LLMs," the answer is yes. In the sense of "can AI agents only use weather-related tools," the answer is no.
Writing code is currently the most prevalent use case for AI agents. This ranges from vibe coding, where the AI agent writes code with almost no human supervision, to human augmentation, where a software engineer is actively iterating with the AI agent to make incremental changes to a codebase. Code is a great first use case for AI agents: it's text-based, which LLMs happen to read and write quite well; there's a ton of public examples of code on the internet, which LLMs have trained on and learned from; and software engineers are nerds, who tend to get excited about fancy new tools.
I'm pretty optimistic about the potential for AI agents in other domains, like finance or law, though I'm also pretty convinced that there will be many carefully-crafted domain-specific AI agent tools rather than a single one used across all. To bring a useful agent into a domain, I see three problems to solve:
You're sitting in your office, rows of desks as far as the eye can see, when a wistful question crosses your mind: "What's the weather like outside?" Unfortunately, there isn't a window in sight and your corporate security policies don't allow distracting websites like weather.com, so you're seemingly out of luck. Then, you remember: you're an ML engineer with the latest and greatest LLM running on your machine. Surely, such sophisticated technology would be able to handle this problem with ease.
You pop open a terminal, hit your local model with a prompt like "What is the current weather in Seattle?", and watch in horror as the model outputs a hallucination like "The sun has, unfortunately, exploded," or quitter talk like "I don't have that information." The outside world seems to be a mystery to both you and your LLM.The "M" in "LLM" doesn't mean "meteorologist"You've come face-to-face with the crushing reality that your LLM is not, in fact, an omnipotent techno-deity. It consists not of divine aether but, rather, carefully-tuned matrices that transform some text that you prompt it with into some other text. Through the hard work of many GPUs training it to compress the near-entirety of the internet, the text the LLM spits out is often relevant to the text you put in. It can even be factually correct, assuming relevant information appeared in its training dataset. However, that training dataset was compiled months or years ago; the LLM could possibly output the correct weather from a day in 2023, but the present conditions are entirely unknown.
More generally, an LLM's "knowledge" — that is, the set of facts it might reasonably expound upon — comes from two sources:
- The content of its training dataset
- The content of its input prompt
You are now aware of two things: the weather (rainy and overcast) and a sense of disappointment in LLMs. Can we do better than using our model as a very expensive JSON parser? What if, when you ask your LLM for the weather, it could query the National Weather Service API itself and then produce a well-formatted response? The idea would be something like this:
- You prompt the LLM, asking it for the current weather.
- The LLM, acknowledging that you want to know the weather and that it doesn't have the answer in its weights, outputs a request to query the National Weather Service API.
- The request gets executed, and the resulting JSON is passed back into the model prompt.
- The LLM, with the JSON now in its prompt, outputs the nicely-formatted answer.
The AI agent software serves as the point of contact between the human user and the LLM. Typically, this looks like a chat window where the user can ask questions and view responses.
In the weather example, you would type "What is the current weather in Seattle?" into a chat window provided by the agent, and the answer would (hopefully) be shown there.Tool library
The agent maintains a library of tools that the LLM may use to interact with the outside world. These might be API endpoints or local commands. Each tool also needs a text description of what it does and a unique signature for the LLM to output when it wants to use the tool.
In the weather example, the only tool we need in the library is one like:
- Name: National Weather Service API
- Action: curl ...
- Description: Invoke the National Weather Service API and receive information about the current weather in a specified location.
- Signature: nws_api [location]
When the user asks the agent a question, that question doesn't get sent directly to the model. The agent first augments the question with information about any relevant tools from its library, then passes the augmented prompt to the model.
In the weather example, the prompt that gets sent to the model might look like:
The user is asking "What is the current weather in Seattle?" You can use the following tools to answer the question:
- Name: National Weather Service API.
- Description: ...
- Signature: nws_api [location].
When the LLM produces a response to this prompt, the agent scans it for any requests to use one of its tools. Typically, these will be written in some special format that can easily be detected (e.g., surrounded by special <tool></tool> tokens). When one is found, the agent executes the corresponding action.
In the weather example, the LLM might output something like:
The user wants to know the current weather in Seattle. I have access to a tool that can return information about the weather. Therefore, I'm going to use this tool. <tool>nws_api Seattle</tool>
When the agent detects the <tool></tool> tokens, it would use curl to query the National Weather Service API.Re-prompting
After the agent executes the tool, it appends some result text to the LLM's input context and resumes generation. This result text might be the data returned by an endpoint, a status code, the content of an edited file, etc. This allows the LLM to use the outcome of the tool to either make further requests or conclude its process.
In the weather example, the agent would pass the JSON object containing the weather data into the model context so the LLM could use that data to produce its final response.It's all clear nowAfter a few days of sleepless work, you've set up an AI agent wrapper around your local LLM. You ask it, "What is the current weather in Seattle?" The LLM, aware of the National Weather Service API at its disposal, outputs a request to query it. The agent does so, and passes the JSON blob back to the model. The model produces its final response: "It is sunny." Though the sun's rays are far away, you feel its warmth wash over you.
You can't help but wonder: is this all AI agents can do? In the sense of "are AI agents really just tool-using lackeys for LLMs," the answer is yes. In the sense of "can AI agents only use weather-related tools," the answer is no.
Writing code is currently the most prevalent use case for AI agents. This ranges from vibe coding, where the AI agent writes code with almost no human supervision, to human augmentation, where a software engineer is actively iterating with the AI agent to make incremental changes to a codebase. Code is a great first use case for AI agents: it's text-based, which LLMs happen to read and write quite well; there's a ton of public examples of code on the internet, which LLMs have trained on and learned from; and software engineers are nerds, who tend to get excited about fancy new tools.
I'm pretty optimistic about the potential for AI agents in other domains, like finance or law, though I'm also pretty convinced that there will be many carefully-crafted domain-specific AI agent tools rather than a single one used across all. To bring a useful agent into a domain, I see three problems to solve:
- Presenting a user experience that people in that domain actually like.
- Designing a shared data layer that both the AI agent and humans in that domain can understand and manipulate.
- Building a library of minimal, explainable, and low-risk tools for the AI agent to use.




















 The two vertical rays collide with no obstacles, so the cells along them stay open-faced. The rightward ray collides with an obstacle, so everything in between is sandwiched.
The two vertical rays collide with no obstacles, so the cells along them stay open-faced. The rightward ray collides with an obstacle, so everything in between is sandwiched.














 Structure and upgrade options offered to the player.
Structure and upgrade options offered to the player.



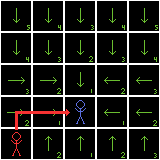
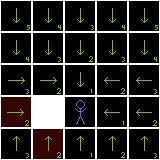
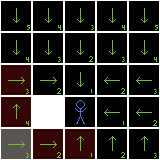
 A direction field, with two paths (in red) from different starting positions
A direction field, with two paths (in red) from different starting positions