If you’re a game developer, please take notes and implement decent security measures, your users deserve it. The fire starter It all started a week ago. I was really tired of constantly dealing with x86-64, and decided it was time for a change. It was time to attack ARM. “Mobile gaming is where it’s at” […]
Show full content
If you’re a game developer, please take notes and implement decent security measures, your users deserve it.
The fire starter
It all started a week ago. I was really tired of constantly dealing with x86-64, and decided it was time for a change. It was time to attack ARM.
“Mobile gaming is where it’s at” right? Let’s dive into the world of mobile gaming!
I’m pretty sure you all know how mobile games usually copy each other’s format, or when a new game pops up it’s usually a mobile version of a console/PC game that already had a big user base.
But shit, was I surprised to learn there’s a lot going on under the hood, and different mobile games could be running on the wildest type of engine, from natively compiled games, to Unity games, to even JS or LUA games!
The target
After some research on the topic, and a small game mod I made for a small “text game”, I thought it could be fun to go for some bigger targets:
It’s basically a money grab, copy paste game, with a very slim player base (looking around the logs I later found out most players login once during events or at signup time, then never login again). The whole game is centered around the shop mechanic, and just getting a single “good” monster requires either months of playing non stop, or a very deep pocket.
The whole game is a Frankenstein’s monster made of other games pieces, and in general a very boring and clichè game, mostly dead by the time I started working on it.
Why this game?
There were a couple reasons for my choice:
don’t be a paster (looking at the code it was clear as daylight they had no idea what they were doing)
a good developer will keep good security practices in the back of his mind anytime he’s writing a line of code
And even though cocos2d-x type of games encrypt their source code files, they decided it wasn’t worth it for some reason, and just left them unencrypted and unobfuscated, free for anyone to read.
They were so nice they even left comments inside game files for me to learn more! How nice.
Target shifting
You could’ve probably guessed that my first target was not, in fact, the game servers, but a simple game mod to allow for easier battles.
It all changed as soon as I started visiting the links listed inside their source code:
Whilest using IPs to connect to your game servers instead of a DNS server to resolve them dynamically is not inherently bad from a security standpoint, it’s surely something that stands out, and that will prompt any security researcher into looking further into it.
And I was indeed right.
By exploring the urls, and changing the paths visited, you could find pretty easily the admin panels (yes I found 2).
A quick google search led me to BearAdmin, a php web administration panel. He would surely not be using some easily guessable credentials, right?
Wrong.
By using admin/admin I one-shotted the login and got “super-administrative” access privileges, which basically meant I had access to the GM panel and issue admin commands.
What could I do?
To list a few:
Add game currency.
Delete game currency
Send arbitrary global inbox rewards and messages
Ban/unban/mute/unmute any user, given that I knew it’s ingame ID (here game ID was translated as “numero di conto”)
But that’s not all
I was satisfied, but I really wanted to try and dig deeper, maybe even go for RCE (spoiler: I managed to find their servers, but not to get into them).
By doing the same type of work for all other IPs inside the game files I was able to also find their ticket managment panel (again, default credentials, this time even easier to find since they were listed in the panel’s public github repo), which lead to a very interesting conversation between me and myself inside game tickets.
Going for SQLi and Buffer Overflows I finally got some other sensitive information, this time regarding the server itself, which could’ve probably lead to remote code execution/unauthorized remote access.
Other requests like this lead to PATH and addresses leakage, which mixed with server info one could find from the admin panels, was enough to pose a serious threat to more than just game currency.
Key takeaways
Given the nature of the company’s games, I am quite sure their other games have similar problems, which further confirms my point that one should not blindly paste code and ship it to production as long as it’s not crashing more than 80% of the times.
One should not rely on the game to hide vulnerable endpoints, but instead make sure that even internal endpoints are always protected, since every point inside the network could potentially be remotely accessible given at least one vulnerable node to exploit.
Check out the code on my GitHub! Disclaimer: I am looking for a job! If you are interested in hiring me feel free to send me an email at paciaronimarco2@gmail.com! A brief introduction You may be wondering why would I attempt such a thing in the first place? I mean, hacker news is a staple […]
Disclaimer: I am looking for a job! If you are interested in hiring me feel free to send me an email at paciaronimarco2@gmail.com!
A brief introduction
You may be wondering why would I attempt such a thing in the first place? I mean, hacker news is a staple of the cyber security (and in general IT) community, therefore one should not attempt such actions, right?
If nothing else, it being a staple should mean that its security and integrity should be preserved better than anything else.
This was also my first time entering the website, therefore I really wanted to see how much they care about their users, as I usually do.
The problem
A friend of mine once told me:
“I’m not really a second page type of guy”,
and it heavily resonated with me. Being on the first page is oftentimes the only deciding factor between being seen and just being tossed down the well of forgotten memories.
Therefore one might argue that a person with the power to decide what stays on the front page is basically an Anubis of the news, who can decide what might be worthy of being known.
Anubis weighting one’s heart before “entering” the afterlife
How I did it
After a while of being in the field you’ll almost instantly get a sense of what might be feasible. In this case, upon glazing my eyes for the first time on the Hacker News website, I had a very strong desire to try and penetrate the website.
I immediately opened BurpSuite and starting exploring the website, and my first target was in fact checking if they implemented weak security practices, like not using prepared SQL statements, or insecure object references, which seem to be, at least in my experience, the most common issues with simple websites like this.
Nonetheless I did not spend much time poking around, since the website is extremely simple, therefore finding a vulneraility is usually quite straightforward if one knows what to look for.
The real deal
One should not give up so easily. Even assuming no vulnerabilities (at least not ones you’d find in less than a day) exist in the website at the time of writing this post, one should always remember that not being able to execute code or retrieve sensitive information, is usually not enough to feel safe!
Obviously you and me are very similar:
we both like cybersecurity
we both like to stay up to date with news
we both want to be spoon-fed (up to a certain extent at least)
This directly translates in us users being in the algorithm’s power.
Therefore being able to exploit the algoritm is, in my opinion, a different kind of vulnerability that security researchers should really keep in mind.
I started off experimenting with the login and register functionalities, and soon I found out they are under the same endpoint (bad) and have the exact same protection mechanism, just a recaptcha v2 that is asked for when:
The IP has already registered not long ago
The IP comes from a known VPN provider
The IP comes from previously flagged locations
Also seems to do some cookie/header tracking
Whilst this tracking method is extremely weird in my opinion, even if it worked perfectly (which it doesn’t seem to do with decent proxies), the “wall” put forth to stop bots is so weak that it is cheaper to bypass the recaptcha than it is to buy good proxies.
This meant that I was easily able to generate more than a thousand of accounts in less than an hour, while spending the equivalent of your morning coffee (captcha + proxies).
Some of the code I used and the method is described in one of my other posts, so feel free to check that out if you want more details on that.
The new target
At this point I did some research on Hacker News and how the algorithm worked to push pages up onto the top page.
This repository was quite useful to get a first good view of how the system worked internally, and I learnt about karma, flagging, and even downvoting, as well as moderation!
I was surprised to learn that they actually had a decent algorithm for detecting possibly fraudolent and/or irrelevant content, as well as a weighted voting system, where the vote of a couple users with lots of karma are more important than hundreds of votes from low karma users.
There is also a concept of momentum, which means that newer posts have a higher chance to move around a lot, and after some time the momentum completely disappears, and the post relevance starts decaying, some at a higher rate than others, directly proportional to the post’s age.
This was older posts will get eventually substituted by more relevant ones.
I failed miserably
It didn’t matter how much I tried, the posts I tried to get high in the rankings really couldn’t do much but get shadowbanned from the platform, due to the low karma and age of my accounts.
It’s at this point that it really clicked to me that if I couldn’t push something up, I could probably take it down with me, and that’s exactly what I tried to do.
One of the first tests
I started upvoting other random posts, since for some reason the upvoting system is not affected by the shadowban, and therefore is not deleted.
Instead this upvote will have an almost zero value (if not negative), and a lot of those will eventually trigger the algorithm in pushing your post as down as possible.
This way it is possible to take any new post and trigger the algorithm into shadowbanning it, making it impossible for the post to reach high rankings, as well as (probably) lowering the author’s credibility in the eyes of the algorithm.
Go big or go home
It’s cool that I can make a bot to sit on the new page and exploit the algorithm to preventively push down posts I do not like, but I want more.
I wanted to try and take down something from the top page of Hacker News, and so I did it.
The post’s ranking before starting the experiment
At this point all I had to do was to do every action the algorithm would deem as suspicious:
Vote a lot
Vote fast
And soon the post would skyrocket to 250 upvotes!
This initially had the effect of pushing the post up a bit, probably due to it attracting more attention given the high vote count, but it was all part of the plan!
The flagging system
Apparently users with more than 31 karma will have the ability to flag a post, for any reason, and this highly triggers the algorithm into further checking it out, as well as probably triggering moderators to do something about it.
The setup was perfect, and the users would be the ones giving it the final blow!
The high vote to comment ratio immediately triggered some users into commenting about it, and started raising suspicion, due to vote manipulation being a big no-no on Hacker News
The first comment after a couple minutes
At this point I just had to let the script run, and wait.
Eventually some users started noticing, commenting, and even flagging the post, that after some hours vanished from the top page of Hacker News .
The end result
Can this be avoided?
The most careful readers will probably already have noticed a very big, or may I say Massive red flag:
votes of suspicious users are still displayed normally, even though they do not count as much as a normal user’s vote, if not at all.
This is a very bad design choice since posts have a shadowban mechanic that instantly triggers at post creation, and therefore there was no real reason not to follow the same logic for upvotes.
A better approach would have been to assign a “virtual score” to posts, that actually follow the weight the algorithm gives to each vote, meaning that votes like mine would not register (following the shadowban principle Hacker News adheres to).
Additional notes
Another very important point that you might have already thought about if you read my previous post on botting, is registration/login.
The main takeaway here is that the best deterrent is cost. The main drive for bot development is usually money, therefore a developer’s target shouldn’t be to stop all bots, as it will never be possible, but rather to make botting slow and expensive, to the point where the cost becomes more than what the final objective is worth.
Bots are not always bad It might be tempting to just straight up set up a big firewall with lots and lots of rules to try and block each and every bot trying to access your website. You might want to try some “quick and dirty” hacks, such as checking the header’s order to determine […]
Show full content
Bots are not always bad
It might be tempting to just straight up set up a big firewall with lots and lots of rules to try and block each and every bot trying to access your website.
You might want to try some “quick and dirty” hacks, such as checking the header’s order to determine if the request was sent using a cheap python script, or you might be tempted to check the IP, and just blacklist it.
Whilst these choices are not inherently bad, I would strongly advice anyone dealing with a large user base, to use a WAF, instead of trying to reinvent the wheel.
The reason for this is that Google, as well as other search engines, use web crawlers to indexThe Internet, therefore blindly blocking such bots would definetely hurt your business (I mean it’s all about money, right?).
Nonetheless a major part of such bots, and their interactions, are made with malicious intent, and based on the type of website/web app you own or develop, you might need to always, and I mean always assume a flock of bots is attacking/scanning your domain at any time of the day (which is true anyways).
How can a WAF help me?
You may be asking yourself.
The inexperienced devs in here won’t probably know that Cloudflare offers a very nice Web app firewall, which is used to track issues, prevent DDoS attacks, detect and block exploits, and much, much more!
For any of you interested in web security, the name cloudflare should ring a bell for you.
An example of twitter post
Such posts are pretty common on Twitter, and are extremely easy to find too (just search for “cloudflare payload”).
This shows how much Cloudflare’s WAF has been recognized as a true obstacle for security researchers, and attackers alike.
Cloudflare’s WAF provides an extremely nice feature that was previously cited, which is exploit prevention.
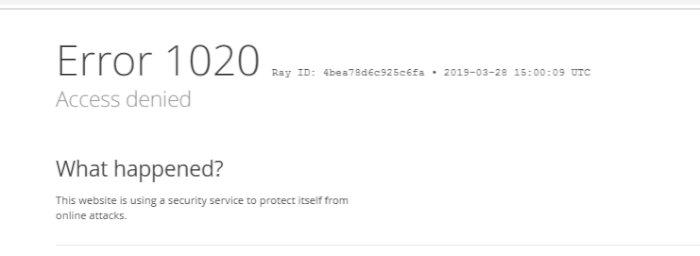
Basically before sending the request to your backend, if activated, Cloudflare’s WAF will analyze its contents, and if it deems the payload as “suspicious”, it could drop the request and return an error code.
Example or error message from Cloudflare
The tweet above demonstrates how much the community is interested in bypassing it to deliver their specially crafted payload to the backend servers.
Is it all really necessary?
Yes… and no.
This type of prevention based protection is a must in today’s world, but it’s surely not a valid excuse to push unsafe code to production!
It’s really up to the developers to choose which rules to apply on their domains. Some might choose to rely a lot on cloudflare, which could be nonetheless a terrible blunder.
SecurityTrails is a web app dedicated to finding current and previous DNS records for specific domains and their subdomains. Multiple times in the past I have found various small websites still having their old dns records out in the wild, which means their backend is exposed, and they might need to pay for the excessive reliance on the WAF for exploit protection.
Are you sponsored by Cloudflare?
No, but if someone working there is reading this, feel free to drop an email in my inbox, I’m open for work :).
Now back to the real deal, Botting.
As some research suggests, it is highly probable that 40 to 60 percent of internet traffic comes from automation. While this may be alarming for some, it’s really not.
A lot of this traffic, whilst still being malicious, is very rudimental, and most bots, even today, just try to bruteforce known exploits on every domain and machine they can interact with, which means that the most of the times simply having an updated system, and keeping track of the latest CVEs will prevent most attacks from working.
Why should I worry then?
Because I say so, obviously.
Because even if software exploits are “easily” avoidable, botting will still be a big issue even with 0 real exploits.
Besides a lot of NFT related posts, most probably a loss of trust by the users towards the platform itself. When any user with some basic python skills has the ability to automate actions, like following, commenting, and upvoting/liking, the value of such actions turns into a heated discussion topic.
Surely no one would want to highlight some specific type of content for millions of people at a time!
Time to code a PoC!
This article may have been sent to you by a colleague (could be an hint), or you may have found it randomly online.
Nonetheless I’d expect some of you to be interested in seeing how some of these bots are made.
Back in January 2022 I started developing my own application dedicated to web automation, called DiskoAIO, which was made primarily for NFT people (who could’ve guessed).
That, with some other minor applications I made in the past, really are the embodiment of your average botting application:
The application is made with some “higher-level” language
Looks > performance
But surely the project has greatly helped me understand why bot prevention might be one of the most important parts needed to keep a business alive in the long run.
Now back to the main topic.
Step 1: find some library to do most of the work for you
In this case nothing special is really needed, since there’s not many protection in my selected websites, besides a single recaptcha v2 (might want to switch to v3) that appears sporadically during login and registration, both of which are under the same endpoint, and therefore makes me think there is some code cluttering in the backend.
We will pick requests for, well… requests. And 2captcha’s library for any recaptcha keys we might need, since they are extremely cheap. We’ll also use a User-Agent library to get us various User-Agent headers to use!
import requests
import random
from fake_useragent import UserAgent
from twocaptcha import TwoCaptcha
solver = TwoCaptcha('YOUR_API_KEY_HERE')
out = open('cookies.txt', 'a')
ua = UserAgent()
Account generators have always been an hot topic in the botting community, as obviously an account will be necessary to do most of interactions with web apps nowadays.
Now, by using a proxy such as BurpSuite or simply the browser’s built in developer tools tab, we can create a new account and log the request for further inspection.
Sample request on BurpSuite
Now all we have to do is to copy the headers for our bot to use, as well as the data needed for the body.
Now all that’s left is to send the actual request and profit:
res = s.post('https://your.domain.com/login', data=data, allow_redirects=False, proxies=proxies,
headers=headers)
if res.status_code == 302:
cookie = res.headers["Set-Cookie"].split(';')[0]
print('Created account: ' + cookie)
out.write(cookie + "\n")
else:
data["g-recaptcha-response"] = solver.recaptcha(sitekey="THE_WEBSITE_SITEKEY", url="https://your.domain.com/login")["code"]
res = s.post('https://your.domain.com/login', data=data, allow_redirects=False, proxies=proxies,
headers=headers)
if res.status_code == 302:
cookie = res.next.headers["Cookie"].split('user=')[-1]
print('Created account: ' + cookie)
out.write("user=" + cookie + "\n")
else:
print('There was an error creating an account')
After the request went through, if we had a 302 as a response, it meant that the account was generated correctly, otherwise a recaptcha v2 would need to be completed, and its key sent in the body.
With this method I was able, with a couple dollars and about 20 minutes to let the script run, to generate about 1500 accounts on the targeted platform, and save the account’s access cookies to a file for later use.
Step 3: automate
For this last step I won’t provide further code, since the method to generate each request for various endpoints is the same used above.
If you really want some reference you can find some very old code in here, which is part of the old wrapper I made around Twitter (not really) private APIs.
They may look difficult to reverse engineer at first, since they are usually full of seemingly random values, but after further inspection, and some experience, you can tell which of them are used to detect bots, and which are only used to track usage for business reasons.
Key takeaways for developers
Please consider implementing custom detection vectors for automation, based not only on single requests but on overall account behaviour, which is in fact one of the most efficient deterrents in the long run.
Here I will list some detection mechanisms that you may want to look into. Some have been omitted, like TLS fingerprinting, since those are basic checks usually done by the WAF itself, if configured properly.
Always ask for basic email verification, and possibly keep a list of trusted email providers if you want to avoid custom domains and temp mails
Ask for phone verification if the account is deemed as suspicious, and keep a list of known sms providers numbers
Ask for phone verification each time the account’s “suspect” level increases through their actions, to block disposable numbers
Ask for either email or sms verification each time the login info differs substantially from the old login data (location, time not logged in, etc.)
Divide the login and/or registration procedure into different steps, each with its own tracking info (if in doubt login into your Microsoft account and check out how many requests are necessary just for that)
Have an active security team dedicated for your web app
Final notes
I have been personally invested into the world of botting, and I think it’s fascinating how it’s not really a software-to-software attack, as it’s more a software-to-people type of attack, that will (inadvertently or not) eventually cause severe issues withing the user base.
If you found this article interesting, and you’re looking for a young developer/security researcher, feel free to contact me via my personal email paciaronimarco2@gmail.com.














 .
.