Basic concepts
What's the essence of probability? There are two views:
- Frequentist: Probability is an objective thing. We can know probability from the result of repeating a random event many times in the same condition.
- Bayesian: Probability is a subjective thing. Probability means how you think it's likely to happen based on your initial assumptions and the evidences you see. Probability is relative to the information you have.
Probability is related to sampling assumptions. Example: Bertrand Paradox: there are many ways to randoly select a chord on a circle, with different proability densities of chord.
A distribution tells how likely a random variable will be what value:
- A discrete distribution can be a table, telling the probability of each possible outcome.
- A discrete distribuiton can be a function, where the input is a possible outcome and the output is probability.
- A discrete distribution can be a vector (an array), where i-th number is the probability of i-th outcome.
- A discrete distribution can be a histogram, where each pillar is a possible outcome, and the height of pillar is probability.
- A continuous distribution can be described by a probability density function (PDF) fff. A continuous distribution has infinitely many outcomes, and the probability of each specific outcome is zero (usually). We care about the probability of a range: P(a<X<b)=∫abf(x)dxP(a<X<b)=\int_a^b f(x)dxP(a<X<b)=∫abf(x)dx. The integral of the whole range should be 1: ∫−∞∞f(x)dx=1\int_{-\infty}^{\infty}f(x)dx=1∫−∞∞f(x)dx=1. The value of PDF can be larger than 1.
- A distribution can be described by cumulative distribution function. F(x)=P(X≤x)F(x) = P(X \leq x)F(x)=P(X≤x). It can be integration of PDF: F(x)=∫−∞xf(x)dxF(x) = \int_{-\infty}^x f(x)dxF(x)=∫−∞xf(x)dx. It start from 0 and monotonically increase then reach 1.
- Quantile function QQQ is the inverse of cumulative distribution function. Q(p)=xQ(p) = xQ(p)=x means F(x)=pF(x)=pF(x)=p and P(X≤x)=pP(X \leq x) = pP(X≤x)=p. The top 25% value is Q(0.75)Q(0.75)Q(0.75). The bottom 25% value is Q(0.25)Q(0.25)Q(0.25).
Independent means that two random variables don't affect each other. Knowing one doesn't affect the distribution of other. But there are dependent random variables that, when you know one, the distribution of another changes.
P(X=x)P(X=x)P(X=x) means the probability of random variable XXX take value xxx. It can also be written as PX(x)P_X(x)PX(x) or P(X)P(X)P(X). Sometimes the probability density function fff is used to represent a distribution.
A joint distribution tells how likely a combination of multiple variables will be what value. For a joint distribution of X and Y, each outcome is a pair of X and Y, denoted (X,Y)(X, Y)(X,Y). If X and Y are independent, then P(X=x,Y=y)=P((X,Y)=(x,y))=P(X=x)⋅P(Y=y)P(X=x,Y=y)=P((X,Y)=(x,y))=P(X=x) \cdot P(Y=y)P(X=x,Y=y)=P((X,Y)=(x,y))=P(X=x)⋅P(Y=y).
For a joint distribution of (X,Y)(X, Y)(X,Y), if we only care about X, then the distribution of X is called marginal distribution.
You can only add probability when two events are mutually exclusive.
You can only multiply probability when two events are independent, or multiplying a conditional probability with the condition's probability.
Conditional probability
P(E∣C)P(E \vert C)P(E∣C) means the probability of EEE happening if CCC happens.
P(E∣C)=P(E∩C⏞E and C both happen)P(C)P(E∩C)=P(E∣C)⋅P(C)P(E|C) = \frac{P(\overbrace{E \cap C}^{\mathclap{\text{E and C both happen}}})}{P(C)} \quad\quad\quad\quad\quad P(E\cap C) = P(E|C) \cdot P(C)P(E∣C)=P(C)P(E∩CE and C both happen)P(E∩C)=P(E∣C)⋅P(C)
If E and C are independent, then P(E∩C)=P(E)P(C)P(E \cap C) = P(E)P(C)P(E∩C)=P(E)P(C), then P(E∣C)=P(E)P(E \vert C)=P(E)P(E∣C)=P(E).
For example, there is a medical testing method of a disease. The test result can be positive (indicate having diesase) or negative. But that test is not always accurate.
There are two random variables: whether test result is positive, whther the person actually has disease. This is a joint distribution. The 4 cases:
Test is positiveTest is negativeActually has diseaseTrue positive aaa
False negative (Type II Error) bbbActually doesn't have disease
False positive (Type I Error) cccTrue negative ddd
a,b,c,da, b, c, da,b,c,d are four possibilities. a+b+c+d=1a + b + c + d = 1a+b+c+d=1.
For that distribution, there are two marginal distributions. If we only care about whether the person actually has disease and ignore the test result, then the marginal distribution is:
ProbabilityActually has diseasea+ba+ba+b (the infect rate of population)Actually doesn't have diseasec+dc+dc+d
Similarily there is also a marginal distribution of whether the test result is positive.
False negative rate is P(Test is negative ∣ Actually has disease)P(\text{Test is negative } \vert \text{ Actually has disease})P(Test is negative ∣ Actually has disease), it means the rate of negative test when actually having disease. And false positive rate is P(Test is positive ∣ Actually doesn’t have disease)P(\text{Test is positive } \vert \text{ Actually doesn't have disease})P(Test is positive ∣ Actually doesn’t have disease).
False negative rate=P(Test is negative∣Actually has disease)=ba+b\text{False negative rate} = P(\text{Test is negative} | \text{Actually has disease}) = \frac{b}{a + b}False negative rate=P(Test is negative∣Actually has disease)=a+bb
False positive rate=P(Test is positive∣Actually doesn’t have disease)=cc+d\text{False positive rate} = P(\text{Test is positive} | \text{Actually doesn't have disease}) = \frac{c}{c + d}False positive rate=P(Test is positive∣Actually doesn’t have disease)=c+dc
Some people may intuitively think false negative rate means P(Test result is false ∣ Test is negative)P(\text{Test result is false } \vert \text{ Test is negative})P(Test result is false ∣ Test is negative), which equals P(Actually has disease ∣ Test is negative)P(\text{Actually has disease } \vert \text{ Test is negative})P(Actually has disease ∣ Test is negative), which equals bb+d\frac{b}{b+d}b+db. But that's not the official definition of false negative.
Bayes theorem allow "reversing" P(A∣B)P(A \vert B)P(A∣B) as P(B∣A)P(B \vert A)P(B∣A):
P(A∣B)=P(A∩B)P(B)=P(B∣A)⋅P(A)P(B)P(A|B) = \frac{P(A \cap B)}{P(B)} = \frac{P(B|A)\cdot P(A)}{P(B)}P(A∣B)=P(B)P(A∩B)=P(B)P(B∣A)⋅P(A)
- Prior means what I assume the distribution is before knowing some new information.
- If I see some new information and improved my understanding of the distribution, then the new distribution that I assume is posterior.
Mean
The theoretical mean is the "weighted average" of all possible cases using theoretical probabilities.
E[X]E[X]E[X] denotes the theoretical mean of random variable XXX, also called the expected value of XXX. It's also often denoted as μ\muμ.
For discrete case, E[X]E[X]E[X] is calculated by summing all theoretically possible values multiply by their theoretical probability.
The mean for discrete case:
μ=E[X]=∑x⏟consider all cases of xx⋅P(X=x)⏞probability of that case\mu = E[X] = \sum_{\underbrace{x} _ {\mathclap{\text{consider all cases of x}}}} x \cdot \overbrace{P(X=x)} ^ {\mathclap{\text{probability of that case}}}μ=E[X]=consider all cases of xx∑x⋅P(X=x)probability of that case
The mean for continuous case:
μ=E[X]=∫−∞∞x⋅p(x)dx\mu = E[X] = \int_{-\infty}^{\infty} x \cdot p(x) dxμ=E[X]=∫−∞∞x⋅p(x)dx
Some rules related to mean:
- The mean of two random variables can add up
E[X+Y]=E[X]+E[Y]E[∑iXi]=∑iE[Xi]E[X + Y] = E[X] + E[Y]\quad \quad \quad E[\sum_iX_i] = \sum_iE[X_i]E[X+Y]=E[X]+E[Y]E[∑iXi]=∑iE[Xi]
- Multiplying a random variable by a constant kkk multiplies its mean
E[kX]=k⋅E[X]E[kX] = k \cdot E[X]E[kX]=k⋅E[X]
- A constant's mean is that constant
E[k]=kE[k] = kE[k]=k
(The constant kkk doesn't necessarily need to be globally constant. It just need to be a certain value that's not affected by the random outcome. It just need to be "constant in context".)
Another important rule is that, if XXX and YYY are independent, then
E[X⋅Y]=E[X]⋅E[Y]E[X \cdot Y] = E[X] \cdot E[Y]E[X⋅Y]=E[X]⋅E[Y]
Because when XXX and YYY are independent, P(X=xi,Y=yj)=P(X=xi)⋅P(Y=yj)P(X=x_i, Y=y_j) = P(X=x_i) \cdot P(Y=y_j)P(X=xi,Y=yj)=P(X=xi)⋅P(Y=yj), then:
E[X⋅Y]=∑i,jxi⋅yj⋅P(X=xi,Y=yj)=∑i,jxi⋅yj⋅P(X=xi)⋅P(Y=yj)E[X \cdot Y] = \sum_{i,j}{x_i \cdot y_j \cdot P(X=x_i, Y=y_j)} = \sum_{i,j}{x_i \cdot y_j \cdot P(X=x_i) \cdot P(Y=y_j)}E[X⋅Y]=i,j∑xi⋅yj⋅P(X=xi,Y=yj)=i,j∑xi⋅yj⋅P(X=xi)⋅P(Y=yj)
Note that E[X+Y]=E[X]+E[Y]E[X+Y]=E[X]+E[Y]E[X+Y]=E[X]+E[Y] always work regardless of independence, but E[XY]=E[X]E[Y]E[XY]=E[X]E[Y]E[XY]=E[X]E[Y] requires independence.
For a sum, the common factor that's not related to sum index can be extraced out. So:
∑i,jf(i)g(j)=∑i(∑j(f(i)⏟irrelevant to j⋅g(j)))=∑i(f(i)∑jg(j)⏟irrelevant to i)=(∑if(i))(∑jg(j))\sum_{i,j}f(i)g(j)
= \sum_{i} \left( \sum _ {j} (\underbrace{f(i)} _ \text{irrelevant to j} \cdot g(j)) \right)
=\sum _ {i} \left( f(i) \underbrace{\sum _ {j} g(j)} _ \text{irrelevant to i} \right)
=\left(\sum _ {i} f(i)\right) \left(\sum _ {j} g(j)\right) i,j∑f(i)g(j)=i∑j∑(irrelevant to jf(i)⋅g(j))=i∑f(i)irrelevant to ij∑g(j)=(i∑f(i))(j∑g(j))
Then:
∑i,jxi⋅yj⋅P(X=xi)⋅P(Y=yj)=(∑ixiP(X=xi))⋅(∑jyjP(Y=yj))=E[X]⋅E[Y]\sum_{i,j}{x_i \cdot y_j \cdot P(X=x_i) \cdot P(Y=y_j)} = \left(\sum_ix_iP(X=x_i)\right) \cdot \left(\sum_jy_jP(Y=y_j)\right) = E[X] \cdot E[Y]i,j∑xi⋅yj⋅P(X=xi)⋅P(Y=yj)=(i∑xiP(X=xi))⋅(j∑yjP(Y=yj))=E[X]⋅E[Y]
(That's for the discrete case. Continuous case is similar.)
If we have nnn samples of XXX, denoted X1,X2,...XnX_1, X_2, ... X_nX1,X2,...Xn, each sample is a random variable, and each sample is independent to each other, and each sample are taken from the same distribution (independently and identically distributed, i.i.d), then we can estimate the theoretical mean by calculating the average. The estimated mean is denoted as μ^\hat{\mu}μ^ (Mu hat):
E^i[X]=μ^=1n∑iXi\hat{E}_i[X] = \hat{\mu} = \frac{1}{n} \sum_i{X_i}E^i[X]=μ^=n1i∑Xi
Hat ^\hat{}^ means it's an empirical value calculated from samples, not the theoretical value.
Some important clarifications:
- The theoretical mean is weighted average using theoretical probabilities
- The estimated mean (empirical mean, sample mean) is non-weighted average over samples
- The theoretical mean is an accurate value, determined by the theoretical distribution
- The estimated mean is an inaccurate random variable, because it's calculated from random samples
The mean of estimated mean equals the theoretical mean.
E[μ^]=E[1n∑iXi]=1n∑iE[Xi]=1n∑iE[X]=1nn⋅E[X]=μE[\hat{\mu}] = E[\frac{1}{n}\sum_iX_i] = \frac{1}{n} \sum_i E[X_i] = \frac{1}{n} \sum_i E[X] = \frac{1}{n} n \cdot E[X] = \muE[μ^]=E[n1i∑Xi]=n1i∑E[Xi]=n1i∑E[X]=n1n⋅E[X]=μ
Note that if the samples are not independent to each other, or they are taken from different distributions, then the estimation will be possibly biased.
Variance
The theoretical variance, Var[X]\text{Var}[X]Var[X], also denoted as σ2\sigma ^2σ2, measures how "spread out" the samples are.
σ2=Var[X]=E[(X−μ)2]\sigma ^2 = \text{Var}[X] = E[(X - \mu)^2]σ2=Var[X]=E[(X−μ)2]
If kkk is a constant:
Var[kX]=k2Var[X]\text{Var}[kX] = k^2 \text{Var}[X]Var[kX]=k2Var[X]
Var[X+k]=Var[X]\text{Var}[X + k] = \text{Var}[X]Var[X+k]=Var[X]
Var[X]=E[X2]−E[X]2\text{Var}[X] = E[X^2] - E[X]^2Var[X]=E[X2]−E[X]2
Standard deviation (stdev) σ\sigmaσ is the square root of variance. Multiplying a random variable by a constant also multiplies the standard deviation.
The covariance Cov[X,Y]\text{Cov}[X, Y]Cov[X,Y] measures the "joint variability" of two random variables XXX and YYY.
Cov[X,Y]=E[(X−E[X])(Y−E[Y])]Var[X]=Cov[X,X]\text{Cov}[X, Y] = E[(X-E[X])(Y-E[Y])]
\quad\quad\quad
\text{Var}[X]=\text{Cov}[X,X]Cov[X,Y]=E[(X−E[X])(Y−E[Y])]Var[X]=Cov[X,X]
Some rules related to variance:
Var[X+Y]=E[((X−E[X])+(Y−E[Y]))2]\text{Var}[X + Y]=
E[((X-E[X])+(Y-E[Y]))^2] Var[X+Y]=E[((X−E[X])+(Y−E[Y]))2]
=E[(X−E[X])2+(Y−E[Y])2+2(X−E[X])(Y−E[Y])]=Var[X]+Var[Y]+2⋅Cov[X,Y]= E[(X-E[X])^2 + (Y-E[Y])^2 + 2(X-E[X])(Y-E[Y])]
= \text{Var}[X] + \text{Var}[Y] + 2 \cdot \text{Cov}[X, Y]=E[(X−E[X])2+(Y−E[Y])2+2(X−E[X])(Y−E[Y])]=Var[X]+Var[Y]+2⋅Cov[X,Y]
If XXX and YYY are indepdenent, as previouly mentioned E[XY]=E[X]⋅E[Y]E[XY]=E[X]\cdot E[Y]E[XY]=E[X]⋅E[Y], then
Cov[X,Y]=E[(X−E[X])(Y−E[Y])]=E[X−E[X]]⋅E[Y−E[Y]]=0⋅0=0\text{Cov}[X, Y] = E[(X-E[X])(Y-E[Y])] = E[X-E[X]] \cdot E[Y-E[Y]] = 0 \cdot 0 = 0Cov[X,Y]=E[(X−E[X])(Y−E[Y])]=E[X−E[X]]⋅E[Y−E[Y]]=0⋅0=0
so Var[X+Y]=Var[X]+Var[Y]\text{Var}[X + Y]= \text{Var}[X] + \text{Var}[Y]Var[X+Y]=Var[X]+Var[Y]
The mean is sometimes also called location. The variance is sometimes called dispersion.
If we have some i.i.d samples but don't know the theoretical variance, how to estimate the variance? If we know the theoretical mean, then it's simple:
σ^2=1n∑i((Xi−μ)2)\hat{\sigma}^2 = \frac{1}{n} \sum_{i}((X_i - \mu)^2)σ^2=n1i∑((Xi−μ)2)
E[σ^2]=σ2E[\hat{\sigma}^2] = \sigma^2E[σ^2]=σ2
However, the theoretical mean is different to the estimated mean. If we don't know the theoretical mean and use the estimated mean, it will be biased, and we need to divide n−1n-1n−1 instead of nnn to avoid bias:
σ^2=1n−1∑i((Xi−μ^)2)\hat{\sigma}^2 = \frac{1}{n-1} \sum_{i}((X_i - \hat{\mu})^2)σ^2=n−11i∑((Xi−μ^)2)
This is called Bessel's correction. note that the more i.i.d samples you have, the smaller the bias, so if you have many i.i.d samples, then the bias doesn't matter in practice.
Originally, n samples have n degrees of freedom. If we keep the estimated mean fixed, then it will only have n-1 degrees of freedom. That's an intuitive explanation of the correction. The exact dedution of that correction is tricky:
Deduction of Bessel's correction
Firstly, the estimated mean itself also has variance
Var[μ^]=Var[1n∑iXi]=1n2Var[∑iXi]\text{Var}[\hat{\mu}] = \text{Var}\left[\frac{1}{n}\sum_iX_i\right] = \frac{1}{n^2} \text{Var}\left[\sum_iX_i\right]Var[μ^]=Var[n1i∑Xi]=n21Var[i∑Xi]
As each sample is independent to other samples. As previously mentioned, if XXX and YYY are independent, adding the variable also adds the variance: Var[X+Y]=Var[X]+Var[Y]\text{Var}[X + Y]= \text{Var}[X] + \text{Var}[Y]Var[X+Y]=Var[X]+Var[Y]. So:
Var[∑iXi]=∑iVar[Xi]=nσ2\text{Var}\left[\sum_i{X_i}\right] = \sum_i{\text{Var}[X_i]} = n\sigma^2Var[i∑Xi]=i∑Var[Xi]=nσ2
Var[μ^]=1n2Var[∑iXi]=1n2⋅nσ2=σ2n\text{Var}[\hat{\mu}] = \frac{1}{n^2} \text{Var}\left[\sum_iX_i\right] = \frac{1}{n^2} \cdot n\sigma^2 = \frac{\sigma^2}{n}Var[μ^]=n21Var[i∑Xi]=n21⋅nσ2=nσ2
As previously mentioned E[μ^]=μE[\hat{\mu}] = \muE[μ^]=μ, then Var[μ^]=E[(μ^−E[μ^])2]=E[(μ^−μ)2]=σ2n\text{Var}[\hat{\mu}] = E[(\hat{\mu} - E[\hat{\mu}])^2] = E[(\hat{\mu} - \mu)^2] = \frac{\sigma^2}{n}Var[μ^]=E[(μ^−E[μ^])2]=E[(μ^−μ)2]=nσ2. This will be used later.
A trick is to rewrite Xi−μ^X_i - \hat{\mu}Xi−μ^ to (Xi−μ)−(μ^−μ)(X_i - \mu) - (\hat{\mu} - \mu)(Xi−μ)−(μ^−μ) and then expand:
∑i((Xi−μ^)2)=∑i(((Xi−μ)−(μ^−μ))2)=∑i((Xi−μ)2−2(Xi−μ)(μ^−μ)+(μ^−μ)2)\sum_{i}((X_i - \hat{\mu})^2) = \sum _ {i}\left(((X_i - \mu) - (\hat{\mu} - \mu))^2\right)
= \sum _ i{\left(
(X_i - \mu)^2-2(X_i - \mu)(\hat{\mu} - \mu)+(\hat{\mu} - \mu)^2\right)
}i∑((Xi−μ^)2)=i∑(((Xi−μ)−(μ^−μ))2)=i∑((Xi−μ)2−2(Xi−μ)(μ^−μ)+(μ^−μ)2)
=∑i(Xi−μ)2−2(μ^−μ)∑i(Xi−μ)+n(μ^−μ)2= \sum_i{(X_i - \mu)^2}
-2 (\hat{\mu} - \mu) \sum_i{(X_i - \mu)}
+n(\hat{\mu} - \mu)^2
\quad=i∑(Xi−μ)2−2(μ^−μ)i∑(Xi−μ)+n(μ^−μ)2
Then take mean of two sides:
E[∑i((Xi−μ^)2)]=E[∑i(Xi−μ)2−2(μ^−μ)∑i(Xi−μ)+n(μ^−μ)2]E\left[ \sum _ {i}((X_i - \hat{\mu})^2) \right]=
E\left[\sum _ i{(X_i - \mu)^2}
-2 (\hat{\mu} - \mu) \sum _ i{(X_i - \mu)}
+n(\hat{\mu} - \mu)^2\right]E[i∑((Xi−μ^)2)]=E[i∑(Xi−μ)2−2(μ^−μ)i∑(Xi−μ)+n(μ^−μ)2]
=E[∑i(Xi−μ)2]−2E[(μ^−μ)∑i(Xi−μ)]+nE[(μ^−μ)2]=E\left[\sum_i{(X_i - \mu)^2}\right]
-2 E\left[(\hat{\mu} - \mu) \sum_i{(X_i - \mu)}\right]
+n E[ (\hat{\mu} - \mu)^2 ]=E[i∑(Xi−μ)2]−2E[(μ^−μ)i∑(Xi−μ)]+nE[(μ^−μ)2]
There are now three terms. The first one equals nσ2n\sigma^2nσ2:
E[∑i(Xi−μ)2]=nσ2E\left[\sum_i{(X_i - \mu)^2}\right] = n\sigma^2E[i∑(Xi−μ)2]=nσ2
note that
∑i(Xi−μ)=(∑iXi)−nμ=nμ^−nμ=n(μ^−μ)\sum_i{(X_i-\mu)} = (\sum_iX_i) - n\mu = n\hat{\mu} - n\mu = n(\hat{\mu}-\mu)i∑(Xi−μ)=(i∑Xi)−nμ=nμ^−nμ=n(μ^−μ)
So the second one becomes
−2E[(μ^−μ)∑i(Xi−μ)]=−2E[(μ^−μ)n(μ^−μ)]=−2nE[(μ^−μ)2]-2 E\left[(\hat{\mu} - \mu) \sum_i{(X_i - \mu)}\right] =
-2E[(\hat{\mu}-\mu)n(\hat{\mu}-\mu)] = -2nE[(\hat{\mu}-\mu)^2]−2E[(μ^−μ)i∑(Xi−μ)]=−2E[(μ^−μ)n(μ^−μ)]=−2nE[(μ^−μ)2]
Now the above three things become
E[∑i((Xi−μ^)2)]=nσ2−nE[(μ^−μ)2]E\left[ \sum_{i}((X_i - \hat{\mu})^2) \right]=n\sigma^2 -nE[(\hat{\mu}-\mu)^2]E[i∑((Xi−μ^)2)]=nσ2−nE[(μ^−μ)2]
E[(μ^−μ)2]E[(\hat{\mu}-\mu)^2]E[(μ^−μ)2] is also Var[μ^]\text{Var}[\hat{\mu}]Var[μ^]. As previously mentioned, it equals σ2n\frac{\sigma^2}{n}nσ2, so
E[∑i((Xi−μ^)2)]=nσ2−nσ2n=(n−1)σ2E\left[ \sum_{i}((X_i - \hat{\mu})^2) \right]=
n\sigma^2 -n \frac{\sigma^2}{n} = (n-1)\sigma^2E[i∑((Xi−μ^)2)]=nσ2−nnσ2=(n−1)σ2
So
E[∑i((Xi−μ^)2)n−1]=σ2E\left[ \frac{\sum _ {i}((X_i - \hat{\mu})^2)}{n-1} \right] = \sigma^2E[n−1∑i((Xi−μ^)2)]=σ2
Other measures of "spreadness"
Mean absolute deviation:
MeanAbsoluteDeviation[X]=E[∣X−E[X]∣]\text{MeanAbsoluteDeviation}[X] = E[ \left| X - E[X] \right| ]MeanAbsoluteDeviation[X]=E[∣X−E[X]∣]
Sometimes the E[X]E[X]E[X] is replaced by median value.
Z-score
For a random variable XXX, if we know its mean μ\muμ and standard deviation σ\sigmaσ then we can "standardize" it so that its mean become 0 and standard deviation become 1:
Z=X−μσZ = \frac{X-\mu}{\sigma}Z=σX−μ
That's called Z-score or standard score.
Often the theoretical mean and theoretical standard deviation is unknown, so z score is computed using sample mean and sample stdev:
Z=X−μ^σ^Z = \frac{X-\hat\mu}{\hat\sigma}Z=σ^X−μ^
In deep learning, normalization uses Z score:
- Layer normalization: it works on a vector. It treats each element in a vector as different samples from the same distribution, and then replace each element with their Z-score (using sample mean and sample stdev).
- Batch normalization: it works on a batch of vectors. It treats the elements in the same index in different vectors in batch as different samples from the same distribtion, and then compute Z-score (using sample mean and sample stdev).
Note that in layer normalization and batch normalization, the variance usually divides by nnn instead of n−1n-1n−1.
Computing Z-score for a vector can also be seen as a projection:
- The input x=(x1,x2,...,xn)\boldsymbol{x} = (x_1,x_2,...,x_n)x=(x1,x2,...,xn)
- The vector of ones: 1=(1,1,...,1)\boldsymbol{1} = (1, 1, ..., 1)1=(1,1,...,1)
- Computing sample mean can be seen as scaling 1n\frac 1 nn1 then dot product with the vector of ones: μ^=1nx⋅1{\hat \mu}= \frac 1 n \boldsymbol{x} \cdot \boldsymbol{1}μ^=n1x⋅1
- Subtracting the sample mean can be seen as subtracting μ^⋅1\hat {\mu} \cdot \boldsymbol{1}μ^⋅1, let's call it y\boldsymbol yy: y=x−μ^⋅1=x−1n(x⋅1)⋅1\boldsymbol y = \boldsymbol x - {\hat \mu} \cdot \boldsymbol{1} = \boldsymbol x- \frac 1 n (\boldsymbol{x} \cdot \boldsymbol{1}) \cdot \boldsymbol{1}y=x−μ^⋅1=x−n1(x⋅1)⋅1
- Recall projection: projecting vector a\boldsymbol aa onto b\boldsymbol bb is (a⋅bb⋅b)⋅b(\frac{\boldsymbol a \cdot \boldsymbol b}{\boldsymbol b \cdot \boldsymbol b}) \cdot \boldsymbol b(b⋅ba⋅b)⋅b.
- (1)2=n(\boldsymbol 1)^2 = n(1)2=n. So 1n(x⋅1)⋅1\frac 1 n (\boldsymbol{x} \cdot \boldsymbol{1}) \cdot \boldsymbol{1}n1(x⋅1)⋅1 is the projection of x\boldsymbol xx onto 1\boldsymbol 11.
- Subtracting it means removing the component in the direction of 1\boldsymbol 11 from x\boldsymbol xx. So y\boldsymbol yy is orthogonal to 1\boldsymbol 11. y\boldsymbol yy is in a hyper-plane orthogonal to 1\boldsymbol 11.
- Standard deviation can be seen as the length of y\boldsymbol yy divide by n\sqrt{n}n (or n−1\sqrt{n-1}n−1): σ2=1n(y)2\boldsymbol\sigma^2 = \frac 1 n (\boldsymbol y)^2σ2=n1(y)2, σ=1n∣y∣\boldsymbol\sigma = \frac 1 {\sqrt{n}} \vert \boldsymbol y \vertσ=n1∣y∣.
- Dividing by standard deviation can be seen as projecting it onto unit sphere then multiply by n\sqrt nn (or n−1\sqrt{n-1}n−1).
- So computing Z-score can be seen as firstly projecting onto a hyper-plane that's orthogonal to 1\boldsymbol 11 and then projecting onto unit sphere then multiply by n\sqrt nn (or n−1\sqrt{n-1}n−1).
Skewness
Skewness measures which side has more extreme values.
Skew[X]=E[(X−μ)3σ3]\text{Skew}[X] = E\left[\frac{(X - \mu)^3}{\sigma ^3}\right]Skew[X]=E[σ3(X−μ)3]
A large positive skew means there is a fat tail on positive side (may have positive extreme values). A large negative skew means fat tail on negative side (may have negative extreme values).
If two sides are symmetric, its skew is 0, regardless of how fat the tails are. Gaussian distributions are symmetric so they has zero skew. note that an asymmetric distribution can also has 0 skewness.
There is a concept called moments that unify mean, variance, skewness and kurtosis:
- The n-th moment: E[Xn]E[X^n]E[Xn]. Mean is the first moment.
- The n-th central moment: E[(X−μ)n]E[(X-\mu)^n]E[(X−μ)n]. Variance is the second central moment.
- The n-th central standardized moment: E[(X−μσ)n]E[(\frac{X-\mu}{\sigma})^n]E[(σX−μ)n]. Skewness is the third central standardized moment. Kurtosis is the fourth central standardized moment.
There is an unbiased way to estimate the thrid central moment μ3\mu_3μ3.
μ3[X]=E[(X−μ)3]μ3^=n(n−1)(n−2)∑i(Xi−μ^)3\mu_3[X] = E[(X-\mu)^3]
\quad\quad\quad\quad
\hat{\mu_3} = \frac{n}{(n-1)(n-2)} \sum_i (X_i - \hat{\mu})^3μ3[X]=E[(X−μ)3]μ3^=(n−1)(n−2)ni∑(Xi−μ^)3
The deduction of unbiased third central moment estimator is similar to Bessel's correction, but more tricky.
A common way of estimating skewness from i.i.d samples, is to use the unbiased third central moment estimator, to divide by cubic of unbiased estimator of standard deviation:
G1=μ3^σ^3=n(n−1)(n−2)∑i(Xi−μ^)3σ^3G_1 = \frac{\hat{\mu_3}}{\hat{\sigma}^3}
= \frac{n}{(n-1)(n-2)}\sum_i{\frac{(X_i - \hat{\mu})^3}{\hat{\sigma}^3}}G1=σ^3μ3^=(n−1)(n−2)ni∑σ^3(Xi−μ^)3
But it's still biased, as E[XY]E[\frac{X}{Y}]E[YX] doesn't necessarily equal E[X]E[Y]\frac{E[X]}{E[Y]}E[Y]E[X]. Unfortunately, there is no completely unbiased way to estimate skewness from i.i.d samples (unless you have other assumptions about the underlying distribution). The bias gets smaller with more i.i.d samples.
Kurtosis
Larger kurtosis means it has a fatter tail. The more extreme values it has, the higher its kurtosis.
Kurt[X]=E[(X−μ)4σ4]=E[(X−μ)4]σ4\text{Kurt}[X] = E\left[\frac{(X - \mu)^4}{\sigma ^4}\right] = \frac{E[(X-\mu)^4]}{\sigma^4}Kurt[X]=E[σ4(X−μ)4]=σ4E[(X−μ)4]
Gaussian distributions have kurtosis of 3. Excess kurtosis is the kurtosis minus 3.
A common way of estimating excess kurtosis from i.i.d samples, is to use the unbiased estimator of fourth cumulant (E[(X−E[X])4]−3Var[X]2E[(X-E[X])^4]-3Var[X]^2E[(X−E[X])4]−3Var[X]2), to divide the square of unbiased estimator of variance:
G2=(n+1)n(n−1)(n−2)(n−3)⋅∑i((Xi−μ^)4)σ^4−3(n−1)2(n−2)(n−3)G_2 = \frac{(n+1)n}{(n-1)(n-2)(n-3)} \cdot \frac{\sum_i((X_i-\hat{\mu})^4)}{\hat{\sigma}^4}
-3\frac{(n-1)^2}{(n-2)(n-3)}G2=(n−1)(n−2)(n−3)(n+1)n⋅σ^4∑i((Xi−μ^)4)−3(n−2)(n−3)(n−1)2
It's still biased.
Control variate
If we have some independent samples of XXX, can estimate mean E[X]E[X]E[X] by calculating average E^[X]=1n∑iXi\hat{E}[X]=\frac{1}{n}\sum_i X_iE^[X]=n1∑iXi. The variance of calculated average is 1nVar[X]\frac{1}{n} \text{Var}[X]n1Var[X], which will reduce by having more samples.
However, if the variance of XXX is large and the amount of samples is few, the average will have a large variance, the estimated mean will be inaccurate. We can make the estimation more accurate by using control variate.
If:
- we have a random variable Y that's correlated with X
- we know the true mean of Y: E[Y]E[Y]E[Y],
Then we can estimate E[X]E[X]E[X] using E^[X+λ(Y−E[Y])]\hat{E}[X+\lambda(Y-E[Y])]E^[X+λ(Y−E[Y])], where λ\lambdaλ is a constant. By choosing the right λ\lambdaλ, the estimator can have lower variance than just calculating average of X. The Y here is called a control variate.
Some previous knowledge: E[E^[A]]=E[A]E[\hat{E}[A]] = E[A]E[E^[A]]=E[A], Var[E^[A]]=1nVar[A]\text{Var}[\hat{E}[A]]=\frac{1}{n}\text{Var}[A]Var[E^[A]]=n1Var[A].
The mean of that estimator is E[X]E[X]E[X], meaning that the estimator is unbiased:
E[E^[X+λ(Y−E[Y])]]=E[X+λ(Y−E[Y])]=E[X]+λ(E[Y−E[Y]]⏟=0)=E[X]E[\hat{E}[X+\lambda(Y-E[Y])]] = E[X+\lambda(Y-E[Y])]
= E[X] + \lambda(\underbrace{E[Y-E[Y]]}_{=0})=E[X]E[E^[X+λ(Y−E[Y])]]=E[X+λ(Y−E[Y])]=E[X]+λ(=0E[Y−E[Y]])=E[X]
Then calculate the variance of the estimator:
Var[E^[X+λ(Y−E[Y])]]=1nVar[X+λ(Y−E[Y])]=1nVar[X+λY−λE[Y]⏟constant]\text{Var}[\hat{E}[X+\lambda(Y-E[Y])]]=\frac{1}{n}\text{Var}[X+\lambda(Y-E[Y])]
=\frac{1}{n}\text{Var}[X+\lambda Y\underbrace{-\lambda E[Y]}_\text{constant}]Var[E^[X+λ(Y−E[Y])]]=n1Var[X+λ(Y−E[Y])]=n1Var[X+λYconstant−λE[Y]]
=1nVar[X+λY]=1n(Var[X]+Var[λY]+2cov[X,λY])=1n(Var[X]+λ2Var[Y]+2λcov[X,Y])=\frac{1}{n}\text{Var}[X+\lambda Y] = \frac{1}{n}(\text{Var}[X]+\text{Var}[\lambda Y] +2\text{cov}[X,\lambda Y])
= \frac{1}{n}(\text{Var}[X]+\lambda^2 \text{Var}[Y]+2\lambda \text{cov}[X,Y])=n1Var[X+λY]=n1(Var[X]+Var[λY]+2cov[X,λY])=n1(Var[X]+λ2Var[Y]+2λcov[X,Y])
We want to minimize the variance of estimator by choosing a λ\lambdaλ. We want to find a λ\lambdaλ that minimizes Var[Y]λ2+2cov[X,Y]λ\text{Var}[Y] \lambda^2 + 2\text{cov}[X,Y] \lambdaVar[Y]λ2+2cov[X,Y]λ. Quadratic funciton knowledge tells ax2+bx+c (a>0)ax^2+bx+c \ \ (a>0)ax2+bx+c (a>0) minimizes when x=−b2ax=\frac{-b}{2a}x=2a−b, then the optimal lambda is:
λ=−cov[X,Y]Var[Y]\lambda = - \frac{\text{cov}[X,Y]}{\text{Var}[Y]}λ=−Var[Y]cov[X,Y]
And by using that optimal λ\lambdaλ, the variance of estimator is:
Var[E^[X+λ(Y−E[Y])]]=1n(Var[X]−cov[X,Y]2Var[Y])\text{Var}[\hat{E}[X+\lambda(Y-E[Y])]]=\frac{1}{n} \left( \text{Var}[X] -\frac{\text{cov}[X,Y]^2}{\text{Var}[Y]} \right)Var[E^[X+λ(Y−E[Y])]]=n1(Var[X]−Var[Y]cov[X,Y]2)
If X and Y are correlated, then cov[X,Y]2Var[Y]>0\frac{\text{cov}[X,Y]^2}{\text{Var}[Y]} > 0Var[Y]cov[X,Y]2>0, then the new estimator has smaller variance and is more accurate than the simple one. The larger the correlation, the better it can be.
Information entropy
Information entropy measures:
- How uncertain a distribution is.
- How much information a sample in that distribution carries.
If we want to measure the amount of information of a specific event, an event EEE 's amount of information as I(E)I(E)I(E), there are 3 axioms:
- If that event always happens, then it carries zero information. I(E)=0I(E) = 0I(E)=0 if P(E)=1P(E) = 1P(E)=1.
- The more rare an event is, the larger information (more surprise) it carries. I(E)I(E)I(E) increases as P(E)P(E)P(E) decreases.
- The information of two independent events happen together is the sum of the information of each event. Here I use (X,Y)(X, Y)(X,Y) to denote the combination of XXX and YYY. That means I((X,Y))=I(X)+I(Y)I((X, Y)) = I(X) + I(Y)I((X,Y))=I(X)+I(Y) if P((X,Y))=P(X)⋅P(Y)P((X, Y)) = P(X) \cdot P(Y)P((X,Y))=P(X)⋅P(Y). This implies the usage of logarithm.
Then according to the three axioms, the definition of III (self information) is:
I(E)=logb1P(E)=−logbP(E)I(E) = \log_b \frac{1}{P(E)} = - \log_b P(E)I(E)=logbP(E)1=−logbP(E)
The base bbb is relative to the unit. We often use the amount of bits as the unit of amount of information. An event with 50% probability has 1 bit of information, then the base will be 2:
I(E)=log21P(E)(in bits)I(E) = \log_2 \frac{1}{P(E)} \quad \text{(in bits)}I(E)=log2P(E)1(in bits)
Then, for a distribution, the expected value of information of one sample is the expected value of I(E)I(E)I(E). That defines information entropy HHH:
H(X)=E[I(X)]=E[log21P(X)]H(X) = E[I(X)] = E\left[\log_2\frac{1}{P(X)}\right]H(X)=E[I(X)]=E[log2P(X)1]
In discrete case:
H(X)=∑x(P(x)⋅log2(1P(x)))H(X) = \sum_x \left(P(x) \cdot \log_2\left(\frac{1}{P(x)}\right) \right)H(X)=x∑(P(x)⋅log2(P(x)1))
If there exists xxx where P(x)=0P(x) = 0P(x)=0, then it can be ignored in entropy calculation, as limx→0xlogx=0\lim_{x \to 0} x \log x = 0limx→0xlogx=0.
Information entropy in discrete case is always positive.
In continuous case, where fff is the probability density function, this is called differential entropy:
H(X)=∫Xf(x)⋅log1f(x)dxH(X) = \int_{\mathbb{X}} {f(x) \cdot \log \frac{1}{f(x)}} dxH(X)=∫Xf(x)⋅logf(x)1dx
(X\mathbb{X}X means the set of xxx where f(x)≠0f(x) \neq 0f(x)=0, also called support of fff.)
In continuous case the base is often eee rather than 2. Here log\loglog by default means loge\log_eloge.
In discrete case, 0≤P(x)≤10 \leq P(x) \leq 10≤P(x)≤1, log1P(x)>0\log \frac{1}{P(x)} > 0logP(x)1>0, so entropy can never be negative. But in continuous case, probability density function can take value larger than 1, so entropy may be negative.
- A fair coin toss with two cases has 1 bit of information entropy: 0.5⋅log2(10.5)+0.5⋅log2(10.5)=10.5 \cdot \log_2(\frac{1}{0.5}) + 0.5 \cdot \log_2(\frac{1}{0.5}) = 10.5⋅log2(0.51)+0.5⋅log2(0.51)=1 bit.
- If the coin is biased, for example the head has 90% probability and tail 10%, then its entropy is: 0.9⋅log2(10.9)+0.1⋅log2(10.1)≈0.470.9 \cdot \log_2(\frac{1}{0.9}) + 0.1 \cdot \log_2(\frac{1}{0.1}) \approx 0.470.9⋅log2(0.91)+0.1⋅log2(0.11)≈0.47 bits.
- If it's even more biased, having 99.99% probability of head and 0.01% probability of tail, then its entropy is: 0.9999⋅log2(10.9999)+0.0001⋅log2(10.0001)≈0.00150.9999 \cdot \log_2(\frac{1}{0.9999}) + 0.0001 \cdot \log_2(\frac{1}{0.0001}) \approx 0.00150.9999⋅log2(0.99991)+0.0001⋅log2(0.00011)≈0.0015 bits.
- If a coin toss is fair but has 0.01% percent of standing up on the table, having 3 cases each with probability 0.0001, 0.49995, 0.49995, then its entropy is 0.0001⋅log2(10.0001)+0.49995⋅log2(10.49995)+0.49995⋅log2(10.49995)≈1.00140.0001 \cdot \log_2(\frac{1}{0.0001}) + 0.49995 \cdot \log_2(\frac{1}{0.49995}) + 0.49995 \cdot \log_2(\frac{1}{0.49995}) \approx 1.00140.0001⋅log2(0.00011)+0.49995⋅log2(0.499951)+0.49995⋅log2(0.499951)≈1.0014 bits. (The standing up event itself has about 13.3 bits of information, but its probability is low so it contributed small in information entropy)
If X and Y are independent, then H((X,Y))=E[I((X,Y))]=E[I(X)+I(Y)]=E[I(X)]+E[I(Y)]=H(X)+H(Y)H((X,Y))=E[I((X,Y))]=E[I(X)+I(Y)]=E[I(X)]+E[I(Y)]=H(X)+H(Y)H((X,Y))=E[I((X,Y))]=E[I(X)+I(Y)]=E[I(X)]+E[I(Y)]=H(X)+H(Y). If one fair coin toss has 1 bit entropy, then n independent tosses has n bit entropy.
If I split one case into two cases, entropy increases. If I merge two cases into one case, entropy reduces. Because p1log1p1+p2log1p2>(p1+p2)log1p1+p2p_1\log \frac{1}{p_1} + p_2\log \frac{1}{p_2} > (p_1+p_2) \log \frac{1}{p_1+p_2}p1logp11+p2logp21>(p1+p2)logp1+p21 (if p1≠0,p2≠0p_1 \neq 0, p_2 \neq 0p1=0,p2=0), which is because that f(x)=log1xf(x)=\log \frac{1}{x}f(x)=logx1 is convex, so p1p1+p2log1p1+p2p1+p2log1p2>log1p1+p2\frac{p_1}{p_1+p_2}\log\frac{1}{p_1}+\frac{p_2}{p_1+p_2}\log\frac{1}{p_2}>\log\frac{1}{p_1+p_2}p1+p2p1logp11+p1+p2p2logp21>logp1+p21 , then multiply two sides by p1+p2p_1+p_2p1+p2 gets the above result.
The information entropy is the theorecical minimum of information required to encode a sample. For example, to encode the result of a fair coin toss, we use 1 bit, 0 for head and 1 for tail (reversing is also fine). If the coin is biased to head, to compress the information, we can use 0 for two consecutive heads, 10 for one head, 11 for one tail, which require fewer bits on average for each sample. That may not be optimal, but the most optimal loseless compresion cannot be better than information entropy.
In continuous case, if kkk is a positive constant, H(kX)=H(X)+logkH(kX) = H(X) + \log kH(kX)=H(X)+logk:
Y=kX(k>0)fY(y)=1kfX(yk)Y=kX \quad (k>0) \quad \quad
f_Y(y) = \frac{1}{k}f_X(\frac{y}{k})Y=kX(k>0)fY(y)=k1fX(ky)
H(Y)=∫YfY(y)⋅log1fY(y)dy=∫Y1kfX(x)log11kfX(x)d(kx)=∫XfX(x)(log1fX(x)+logk)dxH(Y) = \int_\mathbb{Y} {f_Y(y) \cdot \log\frac{1}{f_Y(y)}} dy=\int_\mathbb{Y}{\frac{1}{k}f_X(x)\log\frac{1}{\frac{1}{k}f_X(x)}} d(kx)
=\int_\mathbb{X} f_X(x) \left(\log\frac{1}{f_X(x)} + \log k \right) dxH(Y)=∫YfY(y)⋅logfY(y)1dy=∫Yk1fX(x)logk1fX(x)1d(kx)=∫XfX(x)(logfX(x)1+logk)dx
=∫XfX(x)log1fX(x)dx+(logk)∫XfX(x)dx=H(X)+logk=\int_\mathbb{X} f_X(x) \log \frac{1}{f_X(x)}dx + (\log k) \int_\mathbb{X} f_X(x) dx = H(X) + \log k=∫XfX(x)logfX(x)1dx+(logk)∫XfX(x)dx=H(X)+logk
Entropy is invariant to offset of random variable. H(X+k)=H(X)H(X+k)=H(X)H(X+k)=H(X)
Joint information entropy
A joint distribution of X and Y is a distribution where each outcome is a pair of X and Y. Its entropy is called joint information entropy. Here I will use H((X,Y))H((X,Y))H((X,Y)) to denote joint entropy (to avoid confusing with cross entropy).
H((X,Y))=E(X,Y)[log1P((X,Y))]=∑x,yP((X,Y)=(x,y))log1P((X,Y)=(x,y))H((X,Y)) = E_{(X,Y)}\left[\log\frac{1}{P((X,Y))}\right] = \sum_{x,y}P((X,Y)=(x,y)) \log \frac{1}{P((X,Y)=(x,y))}H((X,Y))=E(X,Y)[logP((X,Y))1]=x,y∑P((X,Y)=(x,y))logP((X,Y)=(x,y))1
If I fix the value of Y as yyy, then see the distribution of X:
H(X∣Y=y)=EX[log1P(X∣Y=y)]=∑xP(X=x∣Y=y)log1P(X=x∣Y=y)H(X|Y=y) = E_X\left[\log \frac{1}{P(X|Y=y)} \right]=\sum_xP(X=x|Y=y) \log\frac{1}{P(X=x|Y=y)}H(X∣Y=y)=EX[logP(X∣Y=y)1]=x∑P(X=x∣Y=y)logP(X=x∣Y=y)1
Take that mean over different Y, we get conditional entropy:
H(X∣Y)=Ey[H(X∣Y=y)]=∑x,yP(Y=y)P(X=x∣Y=y)log1P(X=x∣Y=y)H(X|Y) = E_y[H(X|Y=y)] = \sum_{x,y} P(Y=y) P(X=x|Y=y) \log\frac{1}{P(X=x|Y=y)}H(X∣Y)=Ey[H(X∣Y=y)]=x,y∑P(Y=y)P(X=x∣Y=y)logP(X=x∣Y=y)1
Applying conditional probability rule: P((X,Y))=P(X∣Y)P(Y)P((X,Y)) = P(X \vert Y) P(Y)P((X,Y))=P(X∣Y)P(Y)
=∑x,yP((X,Y))log1P(X=x∣Y=y)= \sum_{x,y} P((X,Y)) \log \frac{1}{P(X=x|Y=y)}=x,y∑P((X,Y))logP(X=x∣Y=y)1
So the conditional entropy is defined like this:
H(X∣Y)=EX,Y[log1P(X∣Y)]=∑x,yP((X,Y)=(x,y))log1P(X=x∣Y=y)H(X|Y) = E_{X,Y}\left[\log\frac{1}{P(X|Y)}\right] = \sum_{x,y} P((X,Y)=(x,y)) \log \frac{1}{P(X=x|Y=y)}H(X∣Y)=EX,Y[logP(X∣Y)1]=x,y∑P((X,Y)=(x,y))logP(X=x∣Y=y)1
P((X,Y))=P(X∣Y)P(Y)P((X, Y)) = P(X \vert Y) P(Y)P((X,Y))=P(X∣Y)P(Y). Similarily, H((X,Y))=H(X∣Y)+H(Y)H((X,Y))=H(X \vert Y)+H(Y)H((X,Y))=H(X∣Y)+H(Y). The exact deduction is as follows:
H(X∣Y)+H(Y)=EX,Y[log1P(X∣Y)]+EY[log1P(Y)]=EX,Y[log1P(X∣Y)]+EX,Y[log1P(Y)]H(X|Y) + H(Y) = E_{X,Y}\left[ \log\frac{1}{P(X|Y)} \right] +E_Y\left[\log\frac{1}{P(Y)}\right]=E_{X,Y}\left[ \log\frac{1}{P(X|Y)} \right] +E_{X,Y}\left[\log\frac{1}{P(Y)}\right]H(X∣Y)+H(Y)=EX,Y[logP(X∣Y)1]+EY[logP(Y)1]=EX,Y[logP(X∣Y)1]+EX,Y[logP(Y)1]
=EX,Y[log1P(X∣Y)+log1P(Y)]=EX,Y[log1P(X∣Y)P(Y)]=EX,Y[log1P((X,Y))]=H((X,Y))=E_{X,Y}\left[ \log\frac{1}{P(X|Y)}+\log\frac{1}{P(Y)} \right]=E_{X,Y}\left[ \log\frac{1}{P(X|Y)P(Y)}\right]=E_{X,Y}\left[ \log \frac{1}{P((X,Y))} \right] = H((X,Y))=EX,Y[logP(X∣Y)1+logP(Y)1]=EX,Y[logP(X∣Y)P(Y)1]=EX,Y[logP((X,Y))1]=H((X,Y))
If XXX and YYY are not independent, then the joint entropy is smaller than if they are independent: H((X,Y))<H(X)+H(Y)H((X, Y)) < H(X) + H(Y)H((X,Y))<H(X)+H(Y). If X and Y are not independent then knowing X will also give some information about Y. This can be deduced by mutual information which will be explained below.
KL divergence
Here IA(x)I_A(x)IA(x) denotes the amount of information of value (event) xxx in distribution AAA. The difference of information of the same value in two distributions AAA and BBB:
IB(x)−IA(x)=log1PB(x)−log1PA(x)=logPA(x)PB(x)I_B(x) - I_A(x) = \log \frac{1}{P_B(x)} - \log \frac{1}{P_A(x)} = \log \frac{P_A(x)}{P_B(x)}IB(x)−IA(x)=logPB(x)1−logPA(x)1=logPB(x)PA(x)
The KL divergence from AAA to BBB is the expected value of that regarding the probabilities of AAA. Here EAE_AEA means the expected value calculated using AAA's probabilities:
DKL(A∥B)=EA[IB(x)−IA(x)]=∑xPA(x)logPA(x)PB(x)D_{KL}(A \parallel B) = E_A[I_B(x) - I_A(x)] = \sum_x P_A(x) \log \frac{P_A(x)}{P_B(x)}DKL(A∥B)=EA[IB(x)−IA(x)]=x∑PA(x)logPB(x)PA(x)
You can think KL divergence as:
- The "distance" between two distributions.
- If I "expect" the distribution is B, but the distribution is actually A, how much "surprise" do I get on average.
- If I design a loseless compression algorithm optimized for B, but use it to compress data from A, then the compression will be not optimal and contain redundant information. KL divergence measures how much redundant information it has on average.
KL divergence is also called relative entropy.
KL divergence is asymmetric, DKL(A∥B)D_{KL}(A\parallel B)DKL(A∥B) is different to DKL(B∥A)D_{KL}(B\parallel A)DKL(B∥A). It's often that the first distribution is the real underlying distribution, and the second distribution is an approximation or the model output.
If A and B are the same, the KL divergence betweem them are zero. Otherwise, KL divergence is positive. KL divergence can never be negative, will explain later.
PB(x)P_B(x)PB(x) appears on denominator. If there exists xxx that PB(x)=0P_B(x) = 0PB(x)=0 and PA(x)≠0P_A(x) \neq 0PA(x)=0, then it can be seen that KL divergence is infinite. It can be seen as "The model expect something to never happen but it actually can happen". If there is no such case, we say that A absolutely continuous with respect to B, written as A≪BA \ll BA≪B. This requires all outcomes from B to include all outcomes from A.
Another concept is cross entropy. The cross entropy from A to B, denoted H(A,B)H(A, B)H(A,B), is the entropy of A plus KL divergence from A to B:
H(A,B)=H(A)+DKL(A∥B)=EA[IB(x)]H(A, B) = H(A) + D_{KL}(A \parallel B) = E_A[I_B(x)]H(A,B)=H(A)+DKL(A∥B)=EA[IB(x)]
H(A,B)=∑xPA(x)⋅log1PB(x)H(A, B) = \sum_x P_A(x) \cdot \log \frac{1}{P_B(x)}H(A,B)=x∑PA(x)⋅logPB(x)1
Information entropy H(X)H(X)H(X) can also be expressed as cross entropy of itself H(X,X)H(X, X)H(X,X), similar to the relation between variance and covariance.
(In some places H(A,B)H(A,B)H(A,B) denotes joint entropy. I use H((A,B))H((A,B))H((A,B)) for joint entropy to avoid ambiguity.)
Cross entropy is also asymmetric.
In deep learning cross entropy is often used as loss function. If each piece of training data's distribution's entropy H(A)H(A)H(A) is fixed, minimizing cross entropy is the same as minimizing KL divergence.
Jensen's inequality
Jensen's inequality states that for a concave function fff:
E[f(X)]≤f(E[X])E[f(X)] \leq f(E[X])E[f(X)]≤f(E[X])
The reverse applies for convex.
Here is a visual example showing Jensen's inequality. For example I have a discrete distribution with 5 cases X1,X2,X3,X4,X5X_1,X_2,X_3,X_4,X_5X1,X2,X3,X4,X5 (these are possible outcomes of distribution, not samples), corresponding to X coordinates of the red dots. The probabilities of the 5 cases are p1,p2,p3,p4,p5p_1, p_2, p_3, p_4, p_5p1,p2,p3,p4,p5 that sum to 1.
E[X]=p1X1+p2X2+p3X3+p4X4+p5X5E[X] = p_1 X_1 + p_2 X_2 + p_3 X_3 + p_4 X_4 + p_5 X_5E[X]=p1X1+p2X2+p3X3+p4X4+p5X5.
E[f(x)]=p1f(X1)+p2f(X2)+p3f(X3)+p4f(X4)+p5f(X5)E[f(x)] = p_1 f(X_1) + p_2 f(X_2) + p_3 f(X_3) + p_4 f(X_4) + p_5 f(X_5)E[f(x)]=p1f(X1)+p2f(X2)+p3f(X3)+p4f(X4)+p5f(X5).
Then (E[X],E[f(x)])(E[X], E[f(x)])(E[X],E[f(x)]) can be seen as an interpolation between five points (X1,f(X1)),(X2,f(X2)),(X3,f(X3)),(X4,f(X4)),(X5,f(X5))(X_1, f(X_1)), (X_2, f(X_2)), (X_3, f(X_3)), (X_4, f(X_4)), (X_5, f(X_5))(X1,f(X1)),(X2,f(X2)),(X3,f(X3)),(X4,f(X4)),(X5,f(X5)), using weights p1,p2,p3,p4,p5p_1, p_2, p_3, p_4, p_5p1,p2,p3,p4,p5. The possible area of the interpolated point correspond to the green convex polygon:

import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
np.random.seed(42)
def concave_function(x):
return -x**2
x_range = np.linspace(-3, 3, 1000)
y_range = concave_function(x_range)
x_points = np.random.uniform(-2.5, 2.5, 5)
x_points = np.sort(x_points)
y_points = concave_function(x_points)
average_x = np.mean(x_points)
f_of_average_x = concave_function(average_x)
average_of_f = np.mean(y_points)
plt.figure(figsize=(10, 6))
plt.plot(x_range, y_range, 'b-', linewidth=2, label='Concave function f(x)')
plt.scatter(x_points, y_points, color='red', s=50, zorder=3, label='($X_i$, $f(X_i)$)')
polygon_vertices = list(zip(x_points, y_points))
polygon = Polygon(polygon_vertices, closed=True, alpha=0.3, facecolor='green', edgecolor='green',
linewidth=2, label='Where ($E[X]$, $E[f(X)]$) can be')
plt.gca().add_patch(polygon)
inequality_text = "($E[X]$, $E[f(X)]$) is below ($E[X]$, $f(E[X])$)"
plt.text(0, min(y_range) + 1, inequality_text,
horizontalalignment='center', fontsize=12, bbox=dict(facecolor='white', alpha=0.7))
plt.grid(True, alpha=0.3)
plt.legend(loc='upper right')
plt.title("Visualization of Jensen's Inequality for a Concave Function", fontsize=14)
plt.xlabel('x', fontsize=12)
plt.ylabel('f(x)', fontsize=12)
plt.tight_layout()
#plt.show()
plt.savefig("jensen_inequality.svg")
For each point in green polygon (E[X],E[f(X)])(E[X], E[f(X)])(E[X],E[f(X)]), the point on function curve with the same X coordinate (E[X],f(E[X]))(E[X], f(E[X]))(E[X],f(E[X])) is above it. So E[f(X)]≤f(E[X])E[f(X)] \leq f(E[X])E[f(X)]≤f(E[X]).
The same applies when you add more cases to the discrete distribution, the convex polygon will have more points but still below the function curve. The same applies to continuous distribution when there are infinitely many cases.
Jensen's inequality tells that KL divergence is non-negative:
There is a trick that extracting -1 makes PAP_APA be in denominator that will be cancelled later.
DKL(A∥B)=EA[logPA(x)PB(x)]=−EA[logPB(x)PA(x)]D_{KL}(A\parallel B) = E_A\left[\log \frac{P_A(x)}{P_B(x)}\right] = - E_A\left[\log \frac{P_B(x)}{P_A(x)}\right]DKL(A∥B)=EA[logPB(x)PA(x)]=−EA[logPA(x)PB(x)]
The logarithm function is concave. Jensen's inequality gives:
EA[logPB(x)PA(x)]≤log(EA[PB(x)PA(x)])E_A\left[\log \frac{P_B(x)}{P_A(x)}\right] \leq \log \left( E_A \left[\frac{P_B(x)}{P_A(x)}\right] \right)EA[logPA(x)PB(x)]≤log(EA[PA(x)PB(x)])
Multiplying -1 and flip:
DKL(A∥B)=−EA[logPB(x)PA(x)]≥−log(EA[PB(x)PA(x)])D_{KL}(A \parallel B) = - E_A\left[\log \frac{P_B(x)}{P_A(x)}\right] \geq
-\log \left( E_A \left[\frac{P_B(x)}{P_A(x)}\right] \right)DKL(A∥B)=−EA[logPA(x)PB(x)]≥−log(EA[PA(x)PB(x)])
The right side equals 0 because:
EA[PB(x)PA(x)]=∑xPA(x)⋅PB(x)PA(x)=∑xPB(x)=1−log(EA[PB(x)PA(x)])=−log1=0E_A \left[\frac{P_B(x)}{P_A(x)}\right] = \sum_x P_A(x) \cdot \frac{P_B(x)}{P_A(x)} = \sum_x P_B(x) = 1
\quad\quad\quad
-\log \left( E_A\left[\frac{P_B(x)}{P_A(x)}\right] \right) = -\log 1 = 0EA[PA(x)PB(x)]=x∑PA(x)⋅PA(x)PB(x)=x∑PB(x)=1−log(EA[PA(x)PB(x)])=−log1=0
Estimate KL divergence
If:
- We have two distributions: AAA is the target distribution, BBB is the output of our model
- We have nnn samples from AAA: x1,x2,...xnx_1, x_2, ... x_nx1,x2,...xn
- We know the probablity of each sample in each distribution. We know PA(xi)P_A(x_i)PA(xi) and PB(xi)P_B(x_i)PB(xi)
Then how to estimate the KL divergence DKL(A,B)D_{KL}(A, B)DKL(A,B)?
Reference: Approximating KL Divergence
As KL divergence is EA[logPA(x)PB(x)]E_A\left[\log \frac{P_A(x)}{P_B(x)}\right]EA[logPB(x)PA(x)], the simply way is to calculate the average of logPA(x)PB(x)\log \frac{P_A(x)}{P_B(x)}logPB(x)PA(x):
D^KL(A∥B)=E^x∼A[logPA(x)PB(x)]=1n∑x∼AlogPA(x)PB(x)\hat{D}_{KL}(A \parallel B) = \hat E_{x \sim A}\left[\log\frac{P_A(x)}{P_B(x)}\right]=\frac{1}{n}\sum_{x \sim A} \log \frac{P_A(x)}{P_B(x)}D^KL(A∥B)=E^x∼A[logPB(x)PA(x)]=n1x∼A∑logPB(x)PA(x)
However it may to be negative in some cases. The true KL divergence can never be negative. This may cause issues.
A better way to estimate KL divergence is:
D^KL(A∥B)=E^x∼A[logPA(x)PB(x)+PB(x)PA(x)−1]\hat{D}_{KL}(A \parallel B) = \hat E_{x \sim A} \left[\log \frac{P_A(x)}{P_B(x)} + \frac{P_B(x)}{P_A(x)} - 1\right]D^KL(A∥B)=E^x∼A[logPB(x)PA(x)+PA(x)PB(x)−1]
(PA(x)=0P_A(x) = 0PA(x)=0 is impossible because it's sampled from A)
It's always positive and has no bias. The PB(x)PA(x)−1\frac{P_B(x)}{P_A(x)}-1PA(x)PB(x)−1 is a control variate and is negatively correlated with logPA(x)PB(x)\log \frac{P_A(x)}{P_B(x)}logPB(x)PA(x).
Recall control variate: if we want to estimate E[X]E[X]E[X] from samples more accurately, we can find another variable YYY that's correlated with XXX, and we must know its theoretical mean E[Y]E[Y]E[Y], then we use E^[X+λY]−λE[Y]\hat E[X+\lambda Y] - \lambda E[Y]E^[X+λY]−λE[Y] to estimate E[X]E[X]E[X]. The parameter λ\lambdaλ is choosed by minimizing variance.
The mean of that control variate is zero, because Ex∼A[PB(x)PA(x)−1]=∑xPA(x)(PB(x)PA(x)−1)=∑x(PB(x)−PA(x))=∑xPB(x)−∑xPA(x)=0E_{x \sim A}\left[\frac{P_B(x)}{P_A(x)}-1\right]=\sum_x P_A(x) (\frac{P_B(x)}{P_A(x)}-1)=\sum_x (P_B(x) - P_A(x)) =\sum_x P_B(x) - \sum_x P_A(x)=0Ex∼A[PA(x)PB(x)−1]=∑xPA(x)(PA(x)PB(x)−1)=∑x(PB(x)−PA(x))=∑xPB(x)−∑xPA(x)=0
The λ=1\lambda=1λ=1 is not chosen by mimimizing variance, but chosen by making the estimator non-negative. If I define k=PB(x)PA(x)k=\frac{P_B(x)}{P_A(x)}k=PA(x)PB(x), then logPA(x)PB(x)+λ(PB(x)PA(x)−1)=−logk+λ(k−1)\log \frac{P_A(x)}{P_B(x)} + \lambda(\frac{P_B(x)}{P_A(x)} - 1) = -\log k + \lambda(k-1)logPB(x)PA(x)+λ(PA(x)PB(x)−1)=−logk+λ(k−1). We want it to be non-negative: −logk+λ(k−1)≥0-\log k + \lambda(k-1) \geq 0−logk+λ(k−1)≥0 for all k>0k>0k>0, it can be seen that a line y=λ(k−1)y=\lambda (k-1)y=λ(k−1) must be above y=logky=\log ky=logk, the only solution is λ=1\lambda=1λ=1, where the line is a tangent line on logk\log klogk.
Mutual information
If X and Y are independent, then H((X,Y))=H(X)+H(Y)H((X,Y))=H(X)+H(Y)H((X,Y))=H(X)+H(Y). But if X and Y are not independent, knowing X reduces uncertainty of Y, then H((X,Y))<H(X)+H(Y)H((X,Y))<H(X)+H(Y)H((X,Y))<H(X)+H(Y).
Mutual information I(X;Y)I(X;Y)I(X;Y) measures how "related" X and Y are:
I(X;Y)=H(X)+H(Y)−H((X,Y))I(X;Y) = H(X) + H(Y) - H((X, Y)) I(X;Y)=H(X)+H(Y)−H((X,Y))
For a joint distribution, if we only care about X, then the distribution of X is a marginal distribution, same as Y.
If we treat X and Y as independent, consider a "fake" joint distribution as if X and Y are independent. Denote that "fake" joint distribution as ZZZ, then P(Z=(x,y))=P(X=x)P(Y=y)P(Z=(x,y))=P(X=x)P(Y=y)P(Z=(x,y))=P(X=x)P(Y=y). It's called "outer product of marginal distribution", because its probability matrix is the outer product of two marginal distributions, so it's denoted X⊗YX \otimes YX⊗Y.
Then mutual information can be expressed as KL divergence between joint distribution (X,Y)(X, Y)(X,Y) and that "fake" joint distribution X⊗YX \otimes YX⊗Y:
I(X;Y)=H(X)+H(Y)−H((X,Y))=EX[I(X)]+EY[I(Y)]−EX,Y[I((X,Y))]I(X;Y)=H(X)+H(Y)-H((X,Y))=E_X[I(X)]+E_Y[I(Y)]-E_{X,Y}[I((X,Y))]I(X;Y)=H(X)+H(Y)−H((X,Y))=EX[I(X)]+EY[I(Y)]−EX,Y[I((X,Y))]
=EX,Y[I(X)+I(Y)−I((X,Y))]=EX,Y[log1P(X)+log1P(Y)−log1P((X,Y))]=E_{X,Y}[I(X)+I(Y)-I((X,Y))] = E_{X,Y}\left[\log\frac{1}{P(X)} + \log \frac{1}{P(Y)} - \log \frac{1}{P((X,Y))} \right]=EX,Y[I(X)+I(Y)−I((X,Y))]=EX,Y[logP(X)1+logP(Y)1−logP((X,Y))1]
=EX,Y[logP((X,Y))P(X)P(Y)]=DKL((X,Y)∥(X⊗Y))=E_{X,Y}\left[\log\frac{P((X,Y))}{P(X)P(Y)} \right]
= D_{KL}((X,Y) \parallel (X \otimes Y))=EX,Y[logP(X)P(Y)P((X,Y))]=DKL((X,Y)∥(X⊗Y))
KL divergence is zero when two distributions are the same, and KL divergence is positive when two distributions are not the same. So:
- Mutual information I(X;Y)I(X;Y)I(X;Y) is zero if the joint distribution (X,Y)(X,Y)(X,Y) is the same as X⊗YX\otimes YX⊗Y, which means X and Y are independent.
- Mutual information I(X;Y)I(X;Y)I(X;Y) is positive if X and Y are not independent.
- Mutual information is never negative, because KL divergence is never negative.
H((X,Y))=H(X)+H(Y)−I(X;Y)H((X,Y))=H(X)+H(Y)-I(X;Y)H((X,Y))=H(X)+H(Y)−I(X;Y), so if X and Y are not independent then H((X,Y))<H(X)+H(Y)H((X,Y))<H(X)+H(Y)H((X,Y))<H(X)+H(Y).
Mutual information is symmetric, I(X;Y)=I(Y;X)I(X;Y)=I(Y;X)I(X;Y)=I(Y;X).
As H((X,Y))=H(X∣Y)+H(Y)H((X,Y)) = H(X \vert Y) + H(Y)H((X,Y))=H(X∣Y)+H(Y), so I(X;Y)=H(X)+H(Y)−H((X,Y))=H(X)−H(X∣Y)I(X;Y) = H(X) + H(Y) - H((X,Y)) = H(X) - H(X \vert Y)I(X;Y)=H(X)+H(Y)−H((X,Y))=H(X)−H(X∣Y).
If knowing Y completely determines X, knowing Y make the distribution of X collapse to one case with 100% probability, then H(X∣Y)=0H(X \vert Y) = 0H(X∣Y)=0, then I(X;Y)=H(X)I(X;Y)=H(X)I(X;Y)=H(X).
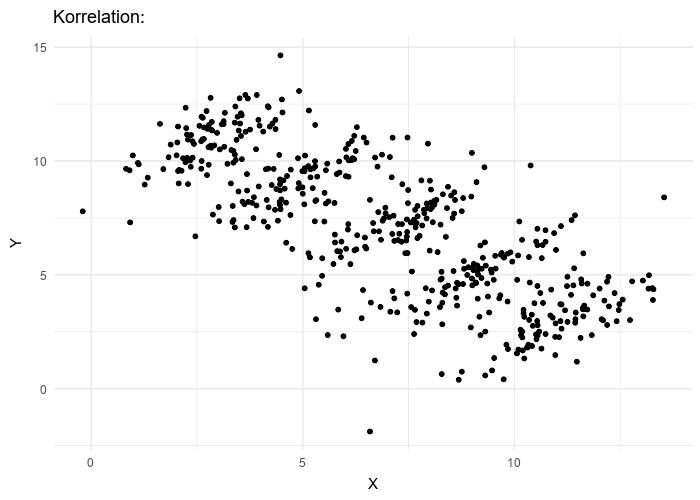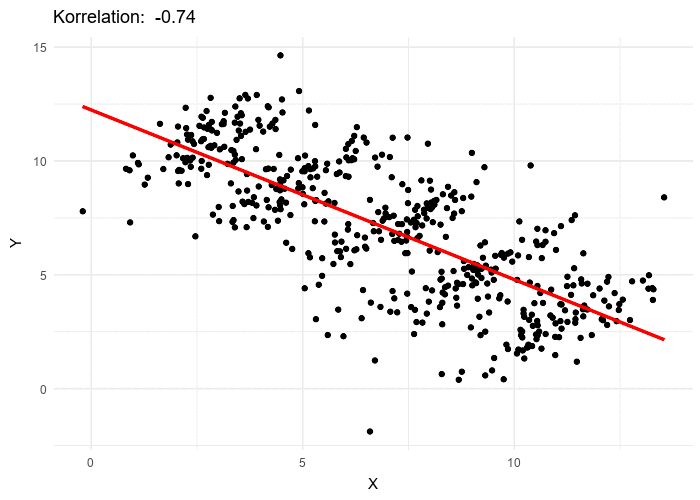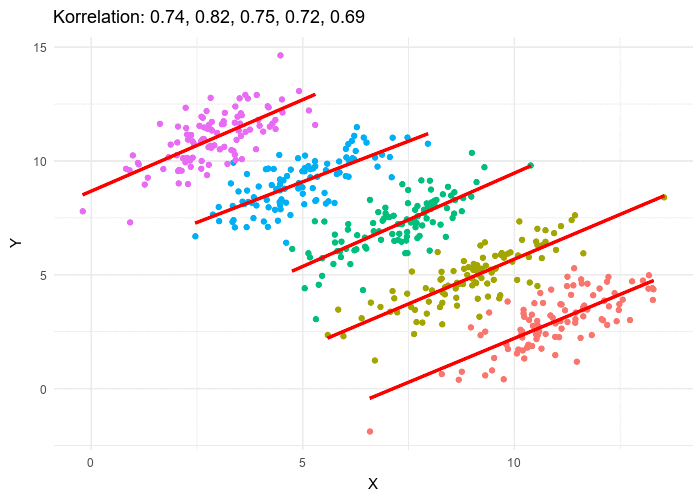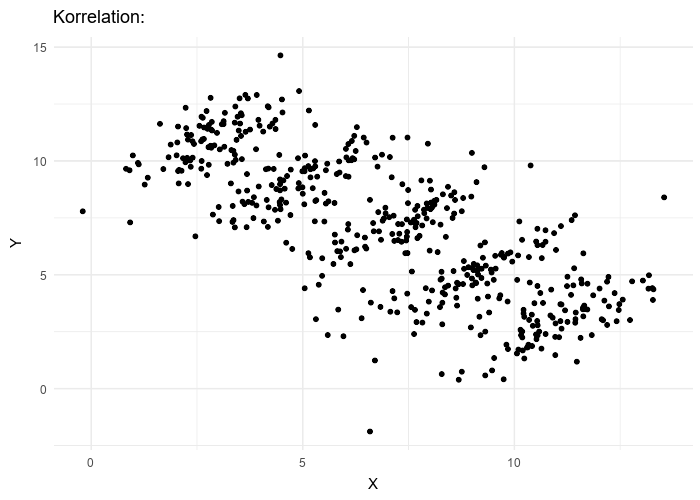
Some places use correlation factor Cov[X,Y]Var[X]Var[Y]\frac{\text{Cov}[X,Y]}{\sqrt{\text{Var}[X]\text{Var}[Y]}}Var[X]Var[Y]Cov[X,Y] to measure the correlation between two variables. But correlation factor is not accurate in non-linear cases. Mutual information is more accurate in measuring correlation.
Information Bottleneck theory in deep learning
Information Bottleneck theory tells that the training of neural network will learn an intermediary representation that:
- Minimize I(Input ; IntermediaryRepresentation)I(\text{Input} \ ; \ \text{IntermediaryRepresentation})I(Input ; IntermediaryRepresentation). Try to compress the intermediary representation and reduce unnecessary information related to input.
- Maximize I(IntermediaryRepresentation ; Output)I(\text{IntermediaryRepresentation} \ ; \ \text{Output})I(IntermediaryRepresentation ; Output). Try to keep the information in intermediary representation that's releveant to the output as much as possible.
Convolution
If we have two independent random variablex X and Y, and consider the distribution of the sum Z=X+YZ=X+YZ=X+Y, then
P(Z=z)=∑x,y, if z=x+yP(X=x)P(Y=y)P(Z=z)=\sum_{x,y, \ \text{if} \ z=x+y} P(X=x)P(Y=y)P(Z=z)=x,y, if z=x+y∑P(X=x)P(Y=y)
For each z, it sums over different x and y within the constraint z=x+yz=x+yz=x+y.
The constraint z=x+yz=x+yz=x+y allows determining yyy from xxx and zzz: y=z−xy=z-xy=z−x, so it can be rewritten as:
P(Z=z)=∑xP(X=x)P(Y=z−x)P(Z=z)=\sum_{x}P(X=x) P(Y=z-x)P(Z=z)=x∑P(X=x)P(Y=z−x)
In continuous case
fZ(z)=∫−∞∞fX(x)fY(z−x)dxf_Z(z) = \int_{-\infty}^{\infty} f_X(x) f_Y(z-x) dxfZ(z)=∫−∞∞fX(x)fY(z−x)dx
The probability density function of the sum fZf_ZfZ is denoted as convolution of fXf_XfX and fYf_YfY:
fZ=fX∗fYPZ=PX∗PYf_Z = f_X * f_Y \quad\quad\quad P_Z=P_X * P_YfZ=fX∗fYPZ=PX∗PY
The convolution operator ∗*∗ can:
- In continuous case, convolution takes two probability density functions, and give a new probability density function.
- In discrete case, convolution can take two functions and give a new function. Each function inputs an outcome and outputs the probability of that outcome.
- In discrete case, convolution can take two vectors and give a new vector. Each vector's i-th element correspond to the probability of i-th outcome.
Convolution can also work in 2D or more dimensions. If X=(x1,x2)X=(x_1,x_2)X=(x1,x2) and Y=(y1,y2)Y=(y_1,y_2)Y=(y1,y2) are 2D random variables (two joint distributions), Z=X+Y=(z1,z2)Z=X+Y=(z_1,z_2)Z=X+Y=(z1,z2) is convolution of X and Y:
fz(z1,z2)=∫−∞∞∫−∞∞fX(x1,x2)⋅fY(z1−x1,z2−x2)dx1dx2f_z(z_1,z_2) = \int_{-\infty}^\infty \int_{-\infty}^\infty f_X(x_1,x_2) \cdot f_Y(z_1-x_1,z_2-x_2) dx_1dx_2fz(z1,z2)=∫−∞∞∫−∞∞fX(x1,x2)⋅fY(z1−x1,z2−x2)dx1dx2
Convolution can also work on cases where the values are not probabilities. Convolutional neural network uses discrete version of convolution on matrices.
Likelihood
Normally when talking about probability we mean the probability of an outcome under a modelled distribution: P(outcome ∣ modelled distribution)P(\text{outcome} \ \vert \ \text{modelled distribution})P(outcome ∣ modelled distribution). But sometimes we have some concrete samples from a distribution but want to know which model suits the best, so we talk about the probability that a model is true given some samples: P(modelled distribution ∣ outcome)P(\text{modelled distribution} \ \vert \ \text{outcome})P(modelled distribution ∣ outcome).
If I have some samples, then some parameters make the samples more likely to come from the modelled distribution, and some parameters make the samples less likely to come from the modelled distribution.
For example, if I model a coin flip using a parameter θ\thetaθ, that and I observe 10 coin flips have 9 heads and 1 tail, then θ=0.9\theta=0.9θ=0.9 is more likely than θ=0.5\theta=0.5θ=0.5. That's straightforward for a simple model. But for more complex models, we need to measure likelihood.
Likelihood L(θ∣x1,x2,...,xn)L(\theta \vert x_1,x_2,...,x_n)L(θ∣x1,x2,...,xn) measures:
- How likely that we get samples x1,x2,...,xnx_1, x_2, ... , x_nx1,x2,...,xn from the modelled distribution using parameter θ\thetaθ.
- how likely a parameter θ\thetaθ is the real underlying parameter, given some independent samples x1,x2,...,xnx_1,x_2,...,x_nx1,x2,...,xn.
L(θ∣x1,x2,...xn)=f(x1∣θ)⋅f(x2∣θ)⋅...⋅f(xn∣θ)=∏if(xi∣θ)L(\theta | x_1,x_2,...x_n) = f(x_1|\theta) \cdot f(x_2|\theta) \cdot ... \cdot f(x_n|\theta) = \prod_i f(x_i|\theta)L(θ∣x1,x2,...xn)=f(x1∣θ)⋅f(x2∣θ)⋅...⋅f(xn∣θ)=i∏f(xi∣θ)
For example, if I model a coin flip distribution using a parameter θ\thetaθ, the probability of head is θ\thetaθ and tail is 1−θ1-\theta1−θ. If I observe 10 coin flip has 9 heads and 1 tail, then the likelihood of θ\thetaθ:
L(θ∣ 9 heads and 1 tail )=θ9⋅(1−θ)L(\theta | \text{ 9 heads and 1 tail }) = \theta^9 \cdot (1-\theta)L(θ∣ 9 heads and 1 tail )=θ9⋅(1−θ)
- If I assume that the coin flip is fair, θ=0.5\theta=0.5θ=0.5, then likelihood is about 0.000977.
- If I assume θ=0.9\theta=0.9θ=0.9, then likelihood is about 0.387, which is larger.
- If I assume θ=0.999\theta=0.999θ=0.999 then likelihood is about 0.00099, which is smaller than when assuming θ=0.9\theta=0.9θ=0.9.
The more likely a parameter is, the higher its likelihood. If θ\thetaθ equals the true underlying parameter then likelihood takes maximum.
By taking logarithm, multiply becomes addition, making it easier to analyze. The log-likelihood function:
logL(θ∣x1,x2,...xn)=∑ilogf(xi∣θ)\log L(\theta | x_1,x_2,...x_n) = \sum_i \log f(x_i|\theta)logL(θ∣x1,x2,...xn)=i∑logf(xi∣θ)
Score and Fisher information
The score function is the derivative of log-likelihood with respect to parameter, for one sample:
s(θ;x)=∂logL(θ∣x)∂θ=∂logf(x∣θ)∂θ=1f(x∣θ)⋅∂f(x∣θ)∂θs(\theta;x) = \frac{\partial \log L(\theta | x)}{\partial \theta}
= \frac{\partial\log f(x | \theta)}{\partial \theta} = \frac{1}{f(x|\theta)} \cdot \frac{\partial f(x|\theta)}{\partial \theta}s(θ;x)=∂θ∂logL(θ∣x)=∂θ∂logf(x∣θ)=f(x∣θ)1⋅∂θ∂f(x∣θ)
If θ\thetaθ equals true underlying parameter, then mean of likelihood Ex[L(θ∣x)]E_x[L(\theta \vert x)]Ex[L(θ∣x)] takes maximum, mean of log-likelihood Ex[logL(θ∣x)]E_x[\log L(\theta \vert x)]Ex[logL(θ∣x)] also takes maximum.
A continuous function's maximum point has zero derivative, so when θ\thetaθ is true, then the mean of score function Ex[s(θ;x)]=∂Ex[f(x∣θ)]∂θE_x[s(\theta;x)]= \frac{\partial E_x[f(x \vert \theta)]}{\partial \theta}Ex[s(θ;x)]=∂θ∂Ex[f(x∣θ)] is zero.
The Fisher information I(θ)\mathcal{I}(\theta)I(θ) is the mean of the square of score:
I(θ)=Ex[s(θ;x)2]\mathcal{I}(\theta) = E_x[s(\theta;x)^2]I(θ)=Ex[s(θ;x)2]
(The mean is calculated over different outcomes, not different parameters.)
We can also think that Fisher information is always computed under the assumption that θ\thetaθ is the true underlying parameter, then Ex[s(θ;x)]=0E_x[s(\theta;x)]=0Ex[s(θ;x)]=0, then Fisher information is the variance of score I(θ)=Varx[s(θ;x)]\mathcal{I}(\theta)=\text{Var}_x[s(\theta;x)]I(θ)=Varx[s(θ;x)].
Fisher informaiton I(θ)\mathcal{I}(\theta)I(θ) also measures the curvature of score function, in parameter space, around θ\thetaθ.
Fisher information measures how much information a sample can tell us about the underlying parameter.
Linear score
When the parameter is an offset and the offset is infinitely small, then the score function is called linear score. If the infinitely small offset is θ\thetaθ. The offseted probability density is f2(x∣θ)=f(x+θ)f_2(x \vert \theta) = f(x+\theta)f2(x∣θ)=f(x+θ), then
slinear(x)=s(θ;x)=∂f2(x∣θ)∂θ=∂logf(x+θ⏞→0)∂θ=dlogf(x)dxs_\text{linear}(x)=s(\theta;x) = \frac{\partial f_2(x|\theta)}{\partial \theta} = \frac{\partial \log f(x+\overbrace{\theta}^{\to 0})}{\partial \theta} = \frac{d\log f(x)}{dx}slinear(x)=s(θ;x)=∂θ∂f2(x∣θ)=∂θ∂logf(x+θ→0)=dxdlogf(x)
In the places that use score function (and Fisher information) but doesn not specify which parameter, they usually refer to the linear score function.
Max-entropy distributions
Recall that if we make probability distribution more "spread out" the entropy will increase. If there is no constraint, maximizing entropy of real-number distribution will be "infinitely spread out over all real numbers" (which is not well-defined). But if there are constraints, maximizing entropy will give some common and important distributions:
ConstraintMax-entropy distributiona≤X≤ba \leq X \leq ba≤X≤bUniform distributionE[X]=μ, Var[X]=σ2E[X]=\mu,\ \text{Var}[X]=\sigma^2E[X]=μ, Var[X]=σ2Normal distributionX≥0, E[X]=μX \geq 0, \ E[X]=\muX≥0, E[X]=μExponential distributionX≥m>0, E[logX]=gX \geq m > 0, \ E[\log X] = gX≥m>0, E[logX]=gPareto (Type I) distribution
There are other max-entropy distributions. See Wikipedia.
We can rediscover these max-entropy distributions, by using Largrange multiplier and functional derivative.
Largrange multiplier
To find the distribution with maximum entropy under variance constraint, we can use Largrange multiplier. If we want to find maximum or minimum of f(x)f(x)f(x) under the constraint that g(x)=0g(x)=0g(x)=0, we can define Largragian function L\mathcal{L}L:
L(x,λ)=f(x)+λ⋅g(x)\mathcal{L}(x,\lambda) = f(x) + \lambda \cdot g(x)L(x,λ)=f(x)+λ⋅g(x)
Its two partial derivatives have special properties:
∂L(x,λ)∂x=∂f(x)∂x+λ∂g(x)∂x∂L(x,λ)∂λ=g(x)\frac{\partial \mathcal{L}(x,\lambda)}{\partial x} = \frac{\partial f(x)}{\partial x} + \lambda \frac{\partial g(x)}{\partial x}
\quad\quad\quad
\frac{\partial \mathcal{L}(x,\lambda)}{\partial \lambda} = g(x)∂x∂L(x,λ)=∂x∂f(x)+λ∂x∂g(x)∂λ∂L(x,λ)=g(x)
Then solving equation ∂L(x,λ)∂x=0\frac{\partial \mathcal{L}(x,\lambda)}{\partial x}=0∂x∂L(x,λ)=0 and ∂L(x,λ)∂λ=0\frac{\partial \mathcal{L}(x,\lambda)}{\partial \lambda}=0∂λ∂L(x,λ)=0 will find the maximum or minimum under constraint. Similarily, if there are many constraints, there are multiple λ\lambdaλs. Similar things also apply to functions with multiple arguments. The argument xxx can be a number or even a function, which involves functional derivative:
Functional derivative
A functional is a function that inputs a function and outputs a value. (One of) its input is a function rather than a value (it's a higher-order function). Functional derivative (also called variational derivative) means the derivative of a functional respect to its argument function.
To compute functional derivative, we add a small "perturbation" to the function. f(x)f(x)f(x) becomes f(x)+ϵ⋅η(x)f(x)+ \epsilon \cdot \eta(x)f(x)+ϵ⋅η(x), where epsilon ϵ\epsilonϵ is an infinitely small value that approaches zero, and eta η(x)\eta(x)η(x) is a test function. The test function can be any function that satisfy some properties.
The definition of functional derivative:
∂G(f+ϵη)∂ϵ=∫∂G∂f⋅η(x)dx\frac{\partial G(f+\epsilon \eta)}{\partial \epsilon} = \int \boxed{\frac{\partial G}{\partial f}} \cdot \eta(x) dx∂ϵ∂G(f+ϵη)=∫∂f∂G⋅η(x)dx
Note that it's inside integration.
For example, this is a functional: G(f)=∫xf(x)dxG(f) = \int x f(x) dxG(f)=∫xf(x)dx. To compute functional derivative ∂G(f)∂f\frac{\partial G(f)}{\partial f}∂f∂G(f), we firstly compute ∂G(f+ϵη)∂ϵ\frac{\partial G(f+\epsilon \eta)}{\partial \epsilon}∂ϵ∂G(f+ϵη) then try to make it into the form of ∫∂G∂f⋅η(x)dx\int \boxed{\frac{\partial G}{\partial f}} \cdot \eta(x) dx∫∂f∂G⋅η(x)dx
∂G(f+ϵη)∂ϵ=∂∫x(f(x)+ϵη(x))dx∂ϵ=∫x⋅η(x)dx\frac{\partial G(f+\epsilon \eta)}{\partial \epsilon}=
\frac{\partial \int x (f(x)+\epsilon \eta(x))dx }{\partial \epsilon}=
\int x \cdot \eta(x) dx∂ϵ∂G(f+ϵη)=∂ϵ∂∫x(f(x)+ϵη(x))dx=∫x⋅η(x)dx
Then by pattern matching with the definition, we get ∂G∂f=x\frac{\partial G}{\partial f}=x∂f∂G=x.
Calculate functional derivative for G(f)=∫x2f(x)dxG(f)=\int x^2f(x)dxG(f)=∫x2f(x)dx:
G(f+ϵη)−G(f)∂ϵ=∂∫x2(f(x)+ϵη(x))−x2f(x)dx∂ϵ=∫x2η(x)dx\frac{G(f+\epsilon\eta)-G(f)}{\partial \epsilon}=
\frac{\partial\int x^2(f(x)+\epsilon\eta(x))- x^2f(x)dx}{\partial \epsilon}
= \int x^2 \eta(x) dx∂ϵG(f+ϵη)−G(f)=∂ϵ∂∫x2(f(x)+ϵη(x))−x2f(x)dx=∫x2η(x)dx
Then ∂G∂f=x2\frac{\partial G}{\partial f}=x^2∂f∂G=x2.
Calculate functional derivative for G(f)=∫(−f(x)logf(x))dxG(f) = \int (-f(x) \log f(x)) dxG(f)=∫(−f(x)logf(x))dx:
∂G(f+ϵη)∂ϵ=∂∫(−1)(f(x)+ϵη(x))log(f(x)+ϵη(x))dx∂ϵ\frac{\partial G(f+\epsilon \eta)}{\partial \epsilon} = \frac{\partial \int (-1) (f(x)+\epsilon \eta(x)) \log(f(x)+\epsilon\eta(x)) dx}{\partial \epsilon}∂ϵ∂G(f+ϵη)=∂ϵ∂∫(−1)(f(x)+ϵη(x))log(f(x)+ϵη(x))dx
=∫(−1)(η(x)log(f(x)+ϵη(x))+η(x)f(x)+ϵη(x)(f(x)+ϵη(x)))dx= \int (-1) \left( \eta(x) \log (f(x)+\epsilon \eta(x)) + \frac{\eta(x)}{f(x)+\epsilon \eta(x)} (f(x)+\epsilon \eta(x)) \right) dx=∫(−1)(η(x)log(f(x)+ϵη(x))+f(x)+ϵη(x)η(x)(f(x)+ϵη(x)))dx
=∫(−log(f(x)+ϵη(x))−1)η(x)dx= \int \left( -\log(f(x)+\epsilon \eta(x)) - 1 \right) \eta(x) dx=∫(−log(f(x)+ϵη(x))−1)η(x)dx
As log\loglog is continuous, and ϵη(x)\epsilon \eta(x)ϵη(x) is infinitely small, so log(f(x)+ϵη(x))=log(f(x))\log(f(x)+\epsilon \eta(x))=\log (f(x))log(f(x)+ϵη(x))=log(f(x)):
∂G(f+ϵη)∂ϵ=∫(−logf(x)−1)η(x)dx∂G∂f=−logf(x)−1\frac{\partial G(f+\epsilon \eta)}{\partial \epsilon} = \int (-\log f(x) - 1) \eta(x) dx
\quad\quad\quad
\frac{\partial G}{\partial f} = -\log f(x) - 1∂ϵ∂G(f+ϵη)=∫(−logf(x)−1)η(x)dx∂f∂G=−logf(x)−1
Get uniform distribution by maximizing entropy
If we constraint the variance range, a≤X≤ba \leq X \leq ba≤X≤b, then maximize its entropy using fuctional derivative
We have constraint ∫abf(x)dx=1\int_a^b f(x)dx=1∫abf(x)dx=1, which is ∫abf(x)dx−1=0\int_a^b f(x)dx-1=0∫abf(x)dx−1=0.
L(f)=∫abf(x)log1f(x)dx+λ1(∫abf(x)dx−1)\mathcal{L}(f) = \int_a^b f(x) \log \frac 1 {f(x)} dx + \lambda_1 \left(\int_a^b f(x)dx-1 \right)L(f)=∫abf(x)logf(x)1dx+λ1(∫abf(x)dx−1)
=∫ab(−f(x)logf(x)+λ1f(x))dx−λ1= \int_a^b (-f(x) \log f(x) + \lambda_1 f(x)) dx - \lambda_1=∫ab(−f(x)logf(x)+λ1f(x))dx−λ1
Compute derivatives
∂L∂f=−logf(x)−1+λ1∂L∂λ1=∫abf(x)dx−1\frac{\partial \mathcal{L}}{\partial f} = -\log f(x) -1 + \lambda_1
\quad\quad\quad
\frac{\partial \mathcal{L}}{\partial \lambda_1} = \int_a^b f(x)dx-1∂f∂L=−logf(x)−1+λ1∂λ1∂L=∫abf(x)dx−1
Solve ∂L∂f=0\frac{\partial \mathcal{L}}{\partial f}=0∂f∂L=0:
−logf(x)−1+λ1=0logf(x)=λ1−1f(x)=eλ1−1-\log f(x) -1 + \lambda_1=0
\quad\quad\quad
\log f(x) = \lambda_1 - 1
\quad\quad\quad
f(x) = e^{\lambda_1-1}−logf(x)−1+λ1=0logf(x)=λ1−1f(x)=eλ1−1
Solve ∂L∂λ1=0\frac{\partial \mathcal{L}}{\partial \lambda_1}=0∂λ1∂L=0:
∫abf(x)dx=1∫abeλ1−1dx=1(b−a)eλ1−1=1eλ1−1=1b−a\int_a^b f(x)dx=1
\quad\quad\quad
\int_a^b e^{\lambda_1-1} dx = 1
\quad\quad\quad
(b-a) e^{\lambda_1-1} = 1
\quad\quad\quad
e^{\lambda_1-1}=\frac 1 {b-a}∫abf(x)dx=1∫abeλ1−1dx=1(b−a)eλ1−1=1eλ1−1=b−a1
The result is f(x)=1b−a (a≤x≤b)f(x) = \frac 1 {b-a} \ \ \ (a \leq x \leq b)f(x)=b−a1 (a≤x≤b).
Normal distribution
The normal distribution, also called Gaussian distribution, is important in statistics. It's the distribution with maximum entropy if we constraint its variance σ2\sigma^2σ2 to be a finite value.
It has two parameters: the mean μ\muμ and the standard deviation σ\sigmaσ. N(μ,σ2)N(\mu, \sigma^2)N(μ,σ2) denotes a normal distribution. Changing μ\muμ moves the PDF alone X axis. Changing σ\sigmaσ scales PDF along X axis.
We can rediscover normal distribution by maximizing entropy under variance constraint.
Rediscover normal distribution by maximizing entropy with variance constraint
For a distribution's probability density function fff, we want to maximize its entropy H(f)=∫f(x)log1f(x)dxH(f)=\int f(x) \log\frac{1}{f(x)}dxH(f)=∫f(x)logf(x)1dx under the constraint:
- It's a valid probability density function: ∫−∞∞f(x)dx=1\int_{-\infty}^{\infty} f(x)dx=1∫−∞∞f(x)dx=1, and f(x)≥0f(x) \geq 0f(x)≥0
- The mean: ∫−∞∞xf(x)dx=μ\int_{-\infty}^{\infty} x f(x) dx = \mu∫−∞∞xf(x)dx=μ
- The variance constraint: ∫−∞∞f(x)(x−μ)2dx=σ2\int_{-\infty}^{\infty} f(x) (x-\mu)^2 dx = \sigma^2∫−∞∞f(x)(x−μ)2dx=σ2
We can simplify to make deduction easier:
- Moving the probability density function along X axis doesn't change entropy, so we can fix the mean as 0 (we can replace xxx as x−μx-\mux−μ after finishing deduction).
- log1f(x)\log\frac{1}{f(x)}logf(x)1 already implicitly tells f(x)>0f(x)>0f(x)>0
- It turns out that the mean constraint ∫−∞∞xf(x)dx=0\int_{-\infty}^{\infty} x f(x) dx = 0∫−∞∞xf(x)dx=0 is not necessary to deduce the result, so we can not include it in Largrange multipliers. (Including it is also fine but will make it more complex.)
The Largragian function:
L(f,λ1,λ2,λ3)={∫−∞∞f(x)log1f(x)dx+λ1(∫−∞∞f(x)dx−1)+λ2(∫−∞∞f(x)x2dx−σ2)\mathcal{L}(f,\lambda_1,\lambda_2,\lambda_3)=
\begin{cases}
\int_{-\infty}^{\infty} f(x) \log\frac{1}{f(x)}dx \\ + \lambda_1 \left(\int_{-\infty}^{\infty} f(x)dx-1\right) \\ + \lambda_2 \left(\int_{-\infty}^{\infty} f(x)x^2dx -\sigma^2\right)
\end{cases}L(f,λ1,λ2,λ3)=⎩⎨⎧∫−∞∞f(x)logf(x)1dx+λ1(∫−∞∞f(x)dx−1)+λ2(∫−∞∞f(x)x2dx−σ2)
=∫−∞∞(−f(x)logf(x)+λ1f(x)+λ2x2f(x))dx−λ1−λ2σ2=\int_{-\infty}^{\infty} (-f(x)\log f(x) + \lambda_1 f(x) +
\lambda_2 x^2 f(x) ) dx - \lambda_1 - \lambda_2\sigma^2=∫−∞∞(−f(x)logf(x)+λ1f(x)+λ2x2f(x))dx−λ1−λ2σ2
Then compute the functional derivative ∂L∂f\frac{\partial \mathcal{L}}{\partial f}∂f∂L
∂L∂f=−logf(x)−1+λ1+λ2x2\frac{\partial \mathcal{L}}{\partial f}
= -\log f(x) - 1 + \lambda_1 + \lambda_2 x^2∂f∂L=−logf(x)−1+λ1+λ2x2
Then solve ∂L∂f=0\frac{\partial \mathcal{L}}{\partial f}=0∂f∂L=0:
∂L∂f=0logf(x)=−1+λ1+λ2x2f(x)=e(−1+λ1+λ2x2)\frac{\partial \mathcal{L}}{\partial f}=0
\quad\quad\quad
\log f(x) = -1+\lambda_1+\lambda_2 x^2
\quad\quad\quad
f(x) = e^{(-1+\lambda_1+\lambda_2 x^2)}∂f∂L=0logf(x)=−1+λ1+λ2x2f(x)=e(−1+λ1+λ2x2)
We get the rough form of normal distribution's probabilify density function.
Then solve ∂L∂λ1=0\frac{\partial \mathcal{L}}{\partial \lambda_1}=0∂λ1∂L=0:
∂L∂λ1=0∫−∞∞f(x)dx=1∫−∞∞e(−1+λ1+λ2x2)dx=1\frac{\partial \mathcal{L}}{\partial \lambda_1}=0 \quad\quad\quad
\int_{-\infty}^{\infty} f(x)dx=1 \quad\quad\quad
\int_{-\infty}^{\infty} e^{(-1+\lambda_1+\lambda_2 x^2)} dx = 1∂λ1∂L=0∫−∞∞f(x)dx=1∫−∞∞e(−1+λ1+λ2x2)dx=1
That integration must converge, so λ2<0\lambda_2<0λ2<0.
A subproblem: solve ∫−∞∞e−kx2dx\int_{-\infty}^{\infty} e^{-k x^2}dx∫−∞∞e−kx2dx (k>0k>0k>0). The trick is to firstly compute its square (∫−∞∞e−kx2dx)2(\int_{-\infty}^{\infty} e^{-k x^2}dx)^2(∫−∞∞e−kx2dx)2, turning the integration into two-dimensional, and then substitude polar coordinates x=rcosθ, y=rsinθ, x2+y2=r2, dx dy=r dr dθx=r \cos \theta, \ y = r \sin \theta, \ x^2+y^2=r^2, \ dx\ dy = r \ dr \ d\thetax=rcosθ, y=rsinθ, x2+y2=r2, dx dy=r dr dθ :
(∫−∞∞e−kx2dx)2=∫−∞∞∫−∞∞e−k(x2+y2)dx dy=∫θ=0θ=2π∫r=0r=∞re−kr2dr dθ=2π∫0∞re−kr2dr\left( \int_{-\infty}^{\infty} e^{-kx^2}dx\right)^2
=\int_{-\infty}^{\infty}\int_{-\infty}^{\infty} e^{-k(x^2+y^2)}dx\ dy
= \int_{\theta=0}^{\theta=2\pi}\int_{r=0}^{r=\infty} r e^{-kr^2}dr\ d\theta
= 2\pi \int_{0}^{\infty} r e^{-kr^2}dr(∫−∞∞e−kx2dx)2=∫−∞∞∫−∞∞e−k(x2+y2)dx dy=∫θ=0θ=2π∫r=0r=∞re−kr2dr dθ=2π∫0∞re−kr2dr
Then substitude u=−kr2, du=−2kr dr, dr=−12krduu=-kr^2, \ du = -2kr\ dr, \ dr = -\frac{1}{2kr}duu=−kr2, du=−2kr dr, dr=−2kr1du:
=2π∫0−∞(−12k)eudu=πk∫−∞0eudu=πk= 2\pi \int_{0}^{-\infty} (-\frac{1}{2k}) e^udu=\frac{\pi}{k}\int_{-\infty}^0e^udu=\frac{\pi}{k}=2π∫0−∞(−2k1)eudu=kπ∫−∞0eudu=kπ
So ∫−∞∞e−kx2dx=πk\int_{-\infty}^{\infty} e^{-kx^2}dx=\sqrt{\frac{\pi}{k}}∫−∞∞e−kx2dx=kπ.
Put −λ2=k-\lambda_2=k−λ2=k
∫−∞∞e(−1+λ1+λ2x2)dx=e−1+λ1∫−∞∞eλ2x2=e−1+λ1π−λ2=1\int_{-\infty}^{\infty} e^{(-1+\lambda_1+\lambda_2 x^2)} dx
= e^{-1+\lambda_1} \int_{-\infty}^{\infty} e^{\lambda_2 x^2}
= e^{-1+\lambda_1} \sqrt{\frac{\pi}{-\lambda_2}} = 1∫−∞∞e(−1+λ1+λ2x2)dx=e−1+λ1∫−∞∞eλ2x2=e−1+λ1−λ2π=1
e−1+λ1=−λ2πe^{-1+\lambda_1} = \sqrt{\frac{-\lambda_2}{\pi}}e−1+λ1=π−λ2
Then solve ∂L∂λ2=0\frac{\partial \mathcal{L}}{\partial \lambda_2}=0∂λ2∂L=0:
∂L∂λ2=0∫−∞∞x2f(x)dx=σ2∫−∞∞x2e(−1+λ1+λ2x2)dx=σ2\frac{\partial \mathcal{L}}{\partial \lambda_2}=0 \quad\quad\quad
\int_{-\infty}^{\infty} x^2f(x)dx=\sigma^2 \quad\quad\quad
\int_{-\infty}^{\infty} x^2e^{(-1+\lambda_1+\lambda_2 x^2)} dx = \sigma^2∂λ2∂L=0∫−∞∞x2f(x)dx=σ2∫−∞∞x2e(−1+λ1+λ2x2)dx=σ2
It requires another trick. For the previous result ∫−∞∞e−kx2dx=πk\int_{-\infty}^{\infty} e^{-kx^2}dx=\sqrt{\frac{\pi}{k}}∫−∞∞e−kx2dx=kπ, take derivative to kkk on two sides:
∫−∞∞e(−x2)kdx=πk−12→take derivative to k∫−∞∞(−x2)e(−x2)kdx=−12πk−32\int_{-\infty}^{\infty} e^{(-x^2)k}dx=\sqrt{\pi} k^{-\frac{1}{2}}
\xrightarrow{\text{take derivative to }k}
\int_{-\infty}^{\infty} (-x^2)e^{(-x^2)k}dx = -\frac{1}{2}\sqrt{\pi} k^{-\frac{3}{2}}∫−∞∞e(−x2)kdx=πk−21take derivative to k∫−∞∞(−x2)e(−x2)kdx=−21πk−23
So ∫−∞∞x2e−kx2dx=12πk3\int_{-\infty}^{\infty} x^2e^{-kx^2}dx = \frac{1}{2}\sqrt{\frac{\pi}{k^3}}∫−∞∞x2e−kx2dx=21k3π
∫−∞∞x2e(−1+λ1+λ2x2)dx=e−1+λ1∫−∞∞eλ2x2dx=e−1+λ1⋅12π−λ23=σ2\int_{-\infty}^{\infty} x^2e^{(-1+\lambda_1+\lambda_2 x^2)} dx
=e^{-1+\lambda_1} \int_{-\infty}^{\infty} e^{\lambda_2x^2}dx
=e^{-1+\lambda_1} \cdot \frac{1}{2} \sqrt{\frac{\pi}{-\lambda_2^3}}=\sigma^2∫−∞∞x2e(−1+λ1+λ2x2)dx=e−1+λ1∫−∞∞eλ2x2dx=e−1+λ1⋅21−λ23π=σ2
By using e−1+λ1=−λ2πe^{-1+\lambda_1} = \sqrt{\frac{-\lambda_2}{\pi}}e−1+λ1=π−λ2, we get:
−λ2π⋅12π−λ23=σ21λ22=2σ2\sqrt{\frac{-\lambda_2}{\pi}} \cdot \frac{1}{2} \sqrt{\frac{\pi}{-\lambda_2^3}}=\sigma^2
\quad\quad\quad
\sqrt{\frac{1}{\lambda_2^2}}=2\sigma^2π−λ2⋅21−λ23π=σ2λ221=2σ2
Previously we know that λ2<0\lambda_2<0λ2<0, then λ2=−12σ2\lambda_2=-\frac{1}{2\sigma^2}λ2=−2σ21. Then e−1+λ1=12πσ2e^{-1+\lambda_1}=\sqrt{\frac{1}{2\pi\sigma^2}}e−1+λ1=2πσ21
Then we finally deduced the normal distribution's probability density function (when mean is 0):
f(x)=e(−1+λ1+λ2x2)=12πσ2e−12σ2x2f(x) = e^{(-1+\lambda_1+\lambda_2 x^2)} = \sqrt{\frac{1}{2\pi\sigma^2}} e^{-\frac{1}{2\sigma^2}x^2}f(x)=e(−1+λ1+λ2x2)=2πσ21e−2σ21x2
When mean is not 0, substitute xxx as x−μx-\mux−μ, we get the general normal distribution:
f(x)=12πσ2e−12σ2(x−μ)2=12πσe−12(x−μσ)2f(x)=\sqrt{\frac{1}{2\pi\sigma^2}} e^{-\frac{1}{2\sigma^2}(x-\mu)^2}
= \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{1}{2}\left( \frac{x-\mu}{\sigma} \right)^2}f(x)=2πσ21e−2σ21(x−μ)2=2πσ1e−21(σx−μ)2
Entropy of normal distribution
We can then calculate the entropy of normal distribution:
H(X)=∫f(x)log1f(x)dx=∫f(x)log(2πσ2e(x−μ)22σ2)dxH(X) = \int f(x)\log\frac{1}{f(x)}dx=\int f(x) \log( \sqrt{2\pi\sigma^2}e^{\frac{(x-\mu)^2}{2\sigma^2}})dxH(X)=∫f(x)logf(x)1dx=∫f(x)log(2πσ2e2σ2(x−μ)2)dx
=∫f(x)(12log(2πσ2)+(x−μ)22σ2)dx=12log(2πσ2)∫f(x)dx⏟=1+12σ2∫f(x)(x−μ)2⏟=σ2dx=\int f(x) \left(\frac{1}{2}\log(2\pi\sigma^2)+\frac{(x-\mu)^2}{2\sigma^2}\right)dx=\frac{1}{2}\log(2\pi\sigma^2)\underbrace{\int f(x)dx} _ {=1}+
\frac{1}{2\sigma^2}\underbrace{\int f(x)(x-\mu)^2} _ {=\sigma^2}dx=∫f(x)(21log(2πσ2)+2σ2(x−μ)2)dx=21log(2πσ2)=1∫f(x)dx+2σ21=σ2∫f(x)(x−μ)2dx
=12log(2πσ2)+12=12log(2πeσ2)=\frac{1}{2}\log(2\pi\sigma^2)+\frac{1}{2}=\frac{1}{2}\log(2\pi e \sigma^2)=21log(2πσ2)+21=21log(2πeσ2)
If X follows normal distribution and Y's distribution that have the same mean and variance, the cross entropy H(Y,X)H(Y,X)H(Y,X) have the same value: 12log(2πeσ2)\frac{1}{2}\log(2\pi e \sigma^2)21log(2πeσ2), regardless of the exact probability density function of Y. The deduction is similar to the above:
H(Y,X)=∫fY(x)log1fX(x)dx=∫fY(x)log(2πσ2e(x−μ)22σ2)dxH(Y,X)=\int f_Y(x) \log \frac 1 {f_X(x)} dx = \int f_Y(x) \log( \sqrt{2\pi\sigma^2}e^{\frac{(x-\mu)^2}{2\sigma^2}})dxH(Y,X)=∫fY(x)logfX(x)1dx=∫fY(x)log(2πσ2e2σ2(x−μ)2)dx
=∫fY(x)(12log(2πσ2)+(x−μ)22σ2)dx=12log(2πσ2)∫fY(x)dx⏟=1+12σ2∫fY(x)(x−μ)2⏟=σ2dx=\int f_Y(x) \left(\frac{1}{2}\log(2\pi\sigma^2)+\frac{(x-\mu)^2}{2\sigma^2}\right)dx=\frac{1}{2}\log(2\pi\sigma^2)\underbrace{\int f_Y(x)dx} _ {=1}+
\frac{1}{2\sigma^2}\underbrace{\int f_Y(x)(x-\mu)^2} _ {=\sigma^2}dx=∫fY(x)(21log(2πσ2)+2σ2(x−μ)2)dx=21log(2πσ2)=1∫fY(x)dx+2σ21=σ2∫fY(x)(x−μ)2dx
=12log(2πσ2)+12=12log(2πeσ2)=\frac{1}{2}\log(2\pi\sigma^2)+\frac{1}{2}=\frac{1}{2}\log(2\pi e \sigma^2)=21log(2πσ2)+21=21log(2πeσ2)
Central limit theorem
We have a random variable XXX, which has meam 0 and (finite) variance σ2\sigma^2σ2.
If we add up nnn independent samples of XXX: X1+X2+...+XnX_1+X_2+...+X_nX1+X2+...+Xn, the variance of sum is nσ2n\sigma^2nσ2.
To make its variance constant, we can divide it by n\sqrt nn, then we get Sn=X1+X2+...+XnnS_n = \frac{X_1+X_2+...+X_n}{\sqrt n}Sn=nX1+X2+...+Xn. Here SnS_nSn is called the standardized sum, because it makes variance not change by sample count.
Central limit theorem says that the standardized sum apporaches normal distribution as nnn increase. No matter what the original distribution of XXX is (as long as its variance is finite), the standardized sum will approach normal distribution.
The information of distribution of XXX will be "washed out" during the process. This "washing out information" is also increasing of entropy. As nnn increase, the entopy of standardized sum always increase (except when X follows normal distribution the entropy stays at maximum). H(Sn+1)>H(Sn)H(S_{n+1}) > H(S_n)H(Sn+1)>H(Sn) if XXX is not normally distributed.
Normal distribution has the maximum entropy under variance constraint. As the entropy of standardized sum increase, its entropy will approach maximum and it will approach normal distribution. This is similar to second law of theomodynamics.
This is called Entropic Central Limit Theorem. Proving that is hard and requires a lot of prerequisite knowledges. See also: Solution of Shannon's problem on the monotonicity of entropy, Generalized Entropy Power Inequalities and Monotonicity Properties of Information
In the real world, many things follow normal distribution, like height of people, weight of people, error in manufacturing, error in measurement, etc.
The height of people is affect by many complex factors (nurtrition, health, genetic factors, exercise, environmental factors, etc.). The combination of these complex factors definitely cannot be similified to a standardized sum of i.i.d zero-mean samples X1+X2+...+Xnn\frac{X_1+X_2+...+X_n}{\sqrt n}nX1+X2+...+Xn. Some factors have large effect and some factors have small effect. The factors are not necessarily independent. But the height of people still roughly follows normal distribution. This can be semi-explained by second law of theomodynamics. The complex interactions of many factors increase entropy of the height. At the same time there are also many factors that constraint the variance of height. Why is there a variance constraint? In some cases variance correspond to instability. A human that is 100 meters tall is impossible as it's physically unstable. Similarily a human that's 1 cm tall is impossible in maintaining normal biological function. The unstable things tend to collapse and vanish (survivorship bias), and the stable things remain. That's how the variance constraint occurs in nature. In some places, variance correspond to energy, and the variance is constrainted by conservation of energy.
Although normal distribution is common, not all distributions are normal. There are also many things that follow fat-tail distributions.
Also note that Central Limit Theorem works when nnn approaches infinity. Even if a distribution's standardized sum approach normal distribution, the speed of converging is important: some distribution converge to normal quickly, and some slowly. Some fat-tail distribution has finite variance but their standardized sum converge to normal distribution very slowly.
Multivariate normal distribution
In below, bold letter (like x\boldsymbol xx) means column vector:
x=[x1x2...xn]\boldsymbol x = \begin{bmatrix} x_1 \\ x_2 \\ ... \\ x_n \end{bmatrix}x=x1x2...xn
Linear transform: for a (column) vector x\boldsymbol{x}x, muliply a matrix AAA on it: AxA\boldsymbol xAx is linear transformation. Linear transformation can contain rotation, scaling and shearing. For row vector it's xA\boldsymbol xAxA. Two linear transformations can be combined one, corresponding to matrix multiplication.
Affine transform: for a (column) vector x\boldsymbol xx, multiply a matrix on it and then add some offset Ax+bA\boldsymbol x + \boldsymbol bAx+b. It can move based on the result of linear transform. Two affine transformations can be combined into one. If y=Ax+b,z=Cy+d\boldsymbol y=A\boldsymbol x+\boldsymbol b, \boldsymbol z=C\boldsymbol y+\boldsymbol dy=Ax+b,z=Cy+d, then z=(CA)x+(Cb+d)\boldsymbol z=(CA)\boldsymbol x +(C\boldsymbol b + \boldsymbol d)z=(CA)x+(Cb+d)
(in some places affine transformation is called "linear transformation".)
Normal distribution has linear properties:
- if you multiply a constant, the result still follow normal distribution. X∼N→ kX∼NX \sim N \rightarrow \ kX \sim NX∼N→ kX∼N
- if you add a constant, the result still follow normal distribution. X∼N→(X+k)∼NX \sim N \rightarrow (X+k) \sim NX∼N→(X+k)∼N
- If you add up two independent normal random variables, the result still follows normal distribution. X∼N,Y∼N→(X+Y)∼NX \sim N, Y \sim N \rightarrow (X+Y) \sim NX∼N,Y∼N→(X+Y)∼N
- A linear combination of many independent normal distributions also follow normal distribution. X1∼N,X2∼N,...Xn∼N→(k1X1+k2X2+...+knXn)∼NX_1 \sim N, X_2 \sim N, ... X_n \sim N \rightarrow (k_1X_1 + k_2X_2 + ... + k_nX_n) \sim NX1∼N,X2∼N,...Xn∼N→(k1X1+k2X2+...+knXn)∼N
If:
- We have a (row) vector x\boldsymbol xx of independent random variables x=(x1,x2,...xn)\boldsymbol x=(x_1, x_2, ... x_n)x=(x1,x2,...xn), each element in vector follows a normal distribution (not necessarily the same normal distribution),
- then, if we apply an affine transformation on that vector, which means multipling a matrix AAA and then adding an offset b\boldsymbol bb, y=Ax+b\boldsymbol y=A\boldsymbol x+\boldsymbol by=Ax+b,
- then each element of y\boldsymbol yy is a linear combination of normal distributions, yi=x1Ai,1+x2Ai,2+...xnAi,n+biy_i=x_1 A_{i,1} + x_2 A_{i, 2} + ... x_n A_{i,n} + b_iyi=x1Ai,1+x2Ai,2+...xnAi,n+bi,
- so each element in y\boldsymbol yy also follow normal distribution. Now y\boldsymbol yy follows multivariate normal distribution.
Note that the elements of y\boldsymbol yy are no longer necessarily independent.
What if I apply two or many affine transformations? Two affine transformations can be combined into one. So the result is still multivariate normal distribution.
To describe a multivariate normal distribution, an important concept is covariance matrix.
Recall covariance: Cov[X,Y]=E[(X−E[X])(Y−E[Y])]\text{Cov}[X,Y]=E[(X-E[X])(Y-E[Y])]Cov[X,Y]=E[(X−E[X])(Y−E[Y])]. Some rules about covariance:
- It's symmetric: Cov[X,Y]=Cov[Y,X]\text{Cov}[X,Y] = \text{Cov}[Y,X]Cov[X,Y]=Cov[Y,X]
- If X and Y are independent, Cov[X,Y]=0\text{Cov}[X,Y]=0Cov[X,Y]=0
- Adding constant Cov[X+k,Y]=Cov[X,Y]\text{Cov}[X+k,Y] = \text{Cov}[X,Y]Cov[X+k,Y]=Cov[X,Y]. Variance is invariant to translation.
- Multiplying constant Cov[k⋅X,Y]=k⋅Cov[X,Y]\text{Cov}[k\cdot X,Y] = k \cdot \text{Cov}[X,Y]Cov[k⋅X,Y]=k⋅Cov[X,Y]
- Addition Cov[X+Y,Z]=Cov[X,Z]+Cov[Y,Z]\text{Cov}[X+Y,Z] = \text{Cov}[X,Z]+\text{Cov}[Y,Z]Cov[X+Y,Z]=Cov[X,Z]+Cov[Y,Z]
Covariance matrix:
Cov(x,y)=E[(x−E[x])(y−E[y])T]\text{Cov}(\boldsymbol x,\boldsymbol y) = E[(\boldsymbol x - E[\boldsymbol x])(\boldsymbol y-E[\boldsymbol y])^T]Cov(x,y)=E[(x−E[x])(y−E[y])T]
Here E[x]E[\boldsymbol x]E[x] taking mean of each element in x\boldsymbol xx and output a vector. It's element-wise. E[x]i=E[xi]E[\boldsymbol x]_i = E[\boldsymbol x_i]E[x]i=E[xi]. Similar for matrix.
The covariance matrix written out:
Cov(x,y)=[Cov[x1,y1] Cov[x1,y2] ... Cov[x1,yn]Cov[x2,y1] Cov[x2,y2] ... Cov[x2,yn]⋮ ⋮ ⋱ ⋮Cov[xn,y1] Cov[xn,y2] ... Cov[xn,yn]]\text{Cov}( x, y)=\begin{bmatrix}
\text{Cov}[ x_1, y_1] &\ \text{Cov}[ x_1, y_2] &\ ... &\ \text{Cov}[ x_1, y_n] \\
\text{Cov}[ x_2, y_1] &\ \text{Cov}[ x_2, y_2] &\ ... &\ \text{Cov}[ x_2, y_n] \\
\vdots &\ \vdots &\ \ddots &\ \vdots \\
\text{Cov}[ x_n, y_1] &\ \text{Cov}[ x_n, y_2] &\ ... &\ \text{Cov}[ x_n, y_n]
\end{bmatrix}Cov(x,y)=Cov[x1,y1]Cov[x2,y1]⋮Cov[xn,y1] Cov[x1,y2] Cov[x2,y2] ⋮ Cov[xn,y2] ... ... ⋱ ... Cov[x1,yn] Cov[x2,yn] ⋮ Cov[xn,yn]
Recall that multiplying constant and addition can be "moved out of E[]E[]E[]": E[kX]=kE[X], E[X+Y]=E[X]+E[Y]E[kX] = k E[X], \ E[X+Y]=E[X]+E[Y]E[kX]=kE[X], E[X+Y]=E[X]+E[Y]. If AAA is a matrix that contains random variable and BBB is a matrix that's not random, then E[A⋅B]=E[A]⋅B, E[B⋅A]=B⋅E[A]E[A\cdot B] = E[A]\cdot B, \ E[B\cdot A] = B\cdot E[A]E[A⋅B]=E[A]⋅B, E[B⋅A]=B⋅E[A], because multiplying a matrix come down to multiplying constant and adding up, which all can "move out of E[]E[]E[]". Vector can be seen as a special kind of matrix.
So applying it to covariance matrix:
Cov(A⋅x,y)=E[(A⋅x−E[A⋅x])(y−E[y])T]=E[(A⋅x−A⋅E[x])(y−E[y])T]\text{Cov}(A \cdot \boldsymbol x,\boldsymbol y) = E[(A\cdot \boldsymbol x - E[A\cdot \boldsymbol x])(\boldsymbol y-E[\boldsymbol y])^T] = E[(A\cdot \boldsymbol x - A \cdot E[\boldsymbol x])(\boldsymbol y-E[\boldsymbol y])^T]Cov(A⋅x,y)=E[(A⋅x−E[A⋅x])(y−E[y])T]=E[(A⋅x−A⋅E[x])(y−E[y])T]
=A⋅E[(x−E[x])(y−E[y])T]=A⋅Cov(x,y)=A\cdot E[(\boldsymbol x - E[\boldsymbol x])(\boldsymbol y-E[\boldsymbol y])^T] = A \cdot \text{Cov}(\boldsymbol x, \boldsymbol y)=A⋅E[(x−E[x])(y−E[y])T]=A⋅Cov(x,y)
Similarily, Cov(x,B⋅y)=Cov(x,y)⋅BT\text{Cov}(\boldsymbol x, B \cdot \boldsymbol y) = \text{Cov}(\boldsymbol x, \boldsymbol y) \cdot B^TCov(x,B⋅y)=Cov(x,y)⋅BT.
If x\boldsymbol xx follows multivariate normal distribution, it can be described by mean vector μ\boldsymbol \muμ (the mean of each element of x\boldsymbol xx) and covariance matrix Cov(x,x)\text{Cov}(\boldsymbol x,\boldsymbol x)Cov(x,x).
Initially, if I have some independent normal variables x1,x2,...xnx_1, x_2, ... x_nx1,x2,...xn with mean values μ1,...,μn\mu_1, ..., \mu_nμ1,...,μn and variances σ12,...,σn2\sigma_1^2, ..., \sigma_n^2σ12,...,σn2. If we treat them as a multivariate normal distribution, the mean vector μx=(μ1,...,μn)\boldsymbol \mu_x = (\mu_1, ..., \mu_n)μx=(μ1,...,μn). The covariance matrix will be diagonal as they are independent:
Cov(x,x)=[σ12 0 ... 00 σ22 ... 0⋮ ⋮ ⋱ ⋮0 0 ... σn2]\text{Cov}(\boldsymbol x,\boldsymbol x) =
\begin{bmatrix}
\sigma_1^2 &\ 0 &\ ... &\ 0 \\
0 &\ \sigma_2^2 &\ ... &\ 0 \\
\vdots &\ \vdots &\ \ddots &\ \vdots \\
0 &\ 0 &\ ... &\ \sigma_n^2
\end{bmatrix}Cov(x,x)=σ120⋮0 0 σ22 ⋮ 0 ... ... ⋱ ... 0 0 ⋮ σn2
Then if we apply an affine transformation y=Ax+b\boldsymbol y = A \boldsymbol x + \boldsymbol by=Ax+b, then μy=Aμx+b\boldsymbol \mu_y = A \mu_x + \boldsymbol bμy=Aμx+b. Cov(y,y)=Cov(Ax+b,Ax+b)=Cov(Ax,Ax)=ACov(x,x)AT\text{Cov}(\boldsymbol y,\boldsymbol y) = \text{Cov}(A \boldsymbol x + \boldsymbol b,A \boldsymbol x + \boldsymbol b) = \text{Cov}(A \boldsymbol x, A \boldsymbol x) = A \text{Cov}(\boldsymbol x,\boldsymbol x) A^TCov(y,y)=Cov(Ax+b,Ax+b)=Cov(Ax,Ax)=ACov(x,x)AT.
Gaussian splatting
The industry standard of 3D modelling is to model the 3D object as many triangles, called mesh. It only models the visible surface object. It use many triangles to approximate curved surface.
Gaussian splatting provides an alternative method of 3D modelling. The 3D scene is modelled by a lot of mutlivariate (3D) gaussian distributions, called gaussian. When rendering, that 3D gaussian distribution is projected onto a plane (screen) and approximately become a 2D gaussian distribution, now probability density correspond to color opacity.
Note that the projection is perspective projection (near things big and far things small). Perspective projection is not linear. After perspective projection, the 3D Gaussian distribution is no longer strictly a 2D Gaussian distribution, can be approximated by a 2D Gaussian distribution.
Triangle mesh is often modelled by people. But gaussian splatting scene is often trained from photos of different perspectives of a scene.
A gaussian's color can be fixed or can change based on different view directions.
Gaussian splatting also works in 4D by adding a time dimension.
Score-based diffusion model
In diffusion model, we add gaussian noise to image (or other things). Then the diffusion model takes noisy input and we train it to output the noise added to it. There will be many steps of adding noise and the model should output the noise added in each step.
Tweedie's formula shows that estimating the noise added is the same as computing the likelihood of image distribution.
To simplify, here we only consider one dimension and one noise step (the same also applies to many dimensions and many noise steps).
If the original value is x0x_0x0, we add a noise ϵ∼N(0,σ2)\epsilon \sim N(0, \sigma^2)ϵ∼N(0,σ2), the noise-added value is x1=x0+ϵx_1 = x_0 + \epsilonx1=x0+ϵ, x1∼N(x0,σ2)x_1 \sim N(x_0, \sigma^2)x1∼N(x0,σ2).
The diffusion model only know x1x_1x1 and don't know x0x_0x0. The diffusion model need to estimate ϵ\epsilonϵ from x1x_1x1.
Here:
- p0(x0)p_0(x_0)p0(x0) is the probability density of original clean value (for image generation, it correspond to the probability distribution of images that we want to generate)
- p1(x1)p_1(x_1)p1(x1) is the probability density of noise-added value
- p1∣0(x1∣x0)p_{1 \vert 0}(x_1 \vert x_0)p1∣0(x1∣x0) is the probability density of noise-added value, given clean training data x0x_0x0. It's a normal distribution given x0x_0x0. It can also be seen as a function that take two arguments x0,x1x_0, x_1x0,x1.
- p0∣1(x0∣x1)p_{0 \vert 1}(x_0 \vert x_1)p0∣1(x0∣x1) is the probability density of the original clean value given noise-added value. It can also be seen as a function that take two arguments x0,x1x_0, x_1x0,x1.
(I use p1∣0(x1∣x0)p_{1 \vert 0}(x_1 \vert x_0)p1∣0(x1∣x0) instead of shorter p(x1∣x0)p(x_1 \vert x_0)p(x1∣x0) is to reduce confusion between different distributions.)
p1∣0(x1∣x0)p_{1 \vert 0}(x_1 \vert x_0)p1∣0(x1∣x0) is a normal distribution:
p1∣0(x1∣x0)=12πσe−12(x1−x0σ)2p_{1 \vert 0}(x_1 \vert x_0) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{1}{2}\left( \frac{x1-x_0}{\sigma} \right)^2}p1∣0(x1∣x0)=2πσ1e−21(σx1−x0)2
Take log:
logp1∣0(x1∣x0)=−12(x1−x0σ)2+log12πσ\log p_{1 \vert 0}(x_1 \vert x_0) = -\frac 1 2 \left( \frac{x_1-x_0}{\sigma} \right)^2 + \log \frac 1 {\sqrt{2\pi}\sigma}logp1∣0(x1∣x0)=−21(σx1−x0)2+log2πσ1
The linear score function under condition:
∂logp1∣0(x1∣x0)∂x1=−(x1−x0σ)⋅1σ=−x1−x0σ2\frac{\partial \log p_{1 \vert 0}(x_1 \vert x_0)}{\partial x_1} = -\left(\frac{x_1-x_0}{\sigma} \right) \cdot \frac {1} {\sigma} = -\frac{x_1-x_0}{\sigma^2}∂x1∂logp1∣0(x1∣x0)=−(σx1−x0)⋅σ1=−σ2x1−x0
Bayes rule:
p0∣1(x0∣x1)=p1∣0(x1∣x0)p0(x0)p1(x1)p_{0 \vert 1}(x_0 \vert x_1) = \frac{p_{1 \vert 0}(x_1 \vert x_0) p_0(x_0)}{p_1(x_1)}p0∣1(x0∣x1)=p1(x1)p1∣0(x1∣x0)p0(x0)
Take log
logp0∣1(x0∣x1)=logp1∣0(x1∣x0)+logp0(x0)−logp1(x1)\log p_{0 \vert 1}(x_0 \vert x_1) = \log p_{1 \vert 0}(x_1 \vert x_0) + \log p_0(x_0) - \log p_1(x_1)logp0∣1(x0∣x1)=logp1∣0(x1∣x0)+logp0(x0)−logp1(x1)
Take partial derivative to x1x_1x1:
∂logp0∣1(x0∣x1)∂x1=∂logp1∣0(x1∣x0)∂x1+∂logp0(x0)∂x1⏟=0−∂logp1(x1)∂x1\frac{\partial\log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1} = \frac{\partial \log p_{1 \vert 0}(x_1 \vert x_0)}{\partial x_1} + \underbrace{\frac{\partial \log p_0(x_0)}{\partial x_1}}_{=0} - \frac{\partial \log p_1(x_1)}{\partial x_1}∂x1∂logp0∣1(x0∣x1)=∂x1∂logp1∣0(x1∣x0)+=0∂x1∂logp0(x0)−∂x1∂logp1(x1)
Using previous result ∂logp1∣0(x1∣x0)∂x1=−x1−x0σ2\frac{\partial \log p_{1 \vert 0}(x_1 \vert x_0)}{\partial x_1} = - \frac{x_1-x_0}{\sigma^2}∂x1∂logp1∣0(x1∣x0)=−σ2x1−x0
∂logp0∣1(x0∣x1)∂x1=−x1−x0σ2−∂logp1(x1)∂x1\frac{\partial\log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1} = - \frac{x_1-x_0}{\sigma^2} - \frac{\partial \log p_1(x_1)}{\partial x_1}∂x1∂logp0∣1(x0∣x1)=−σ2x1−x0−∂x1∂logp1(x1)
Rearrange:
σ2∂logp0∣1(x0∣x1)∂x1=−x1+x0−σ2∂logp1(x1)∂x1\sigma^2 \frac{\partial\log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1} = - x_1+x_0 - \sigma^2\frac{\partial \log p_1(x_1)}{\partial x_1}σ2∂x1∂logp0∣1(x0∣x1)=−x1+x0−σ2∂x1∂logp1(x1)
x0=σ2∂logp0∣1(x0∣x1)∂x1+x1+σ2∂logp1(x1)∂x1x_0=\sigma^2 \frac{\partial\log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1}+x_1+\sigma^2\frac{\partial \log p_1(x_1)}{\partial x_1}x0=σ2∂x1∂logp0∣1(x0∣x1)+x1+σ2∂x1∂logp1(x1)
Now if we already know the noise-added value x1x_1x1, but we don't know x0x_0x0 so x0x_0x0 is uncertain. We want to compute the expectation of x0x_0x0 under that condition that x1x_1x1 is known.
E[x0∣x1]=Ex0[σ2∂logp0∣1(x0∣x1)∂x1+x1+σ2∂logp1(x1)∂x1∣x1]E[x_0 \vert x_1] = E_{x_0}\left[ \sigma^2 \frac{\partial\log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1}+x_1+\sigma^2\frac{\partial \log p_1(x_1)}{\partial x_1} \biggr\vert x_1 \right]E[x0∣x1]=Ex0[σ2∂x1∂logp0∣1(x0∣x1)+x1+σ2∂x1∂logp1(x1)x1]
=x1+Ex0[σ2∂logp0∣1(x0∣x1)∂x1∣x1]+Ex0[σ2∂logp1(x1)∂x1∣x1]= x_1 + E_{x_0}\left[\sigma^2 \frac{\partial\log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1}\biggr\vert x_1\right] + E_{x_0}\left[ \sigma^2\frac{\partial \log p_1(x_1)}{\partial x_1} \biggr\vert x_1\right]=x1+Ex0[σ2∂x1∂logp0∣1(x0∣x1)x1]+Ex0[σ2∂x1∂logp1(x1)x1]
Within it, Ex0[∂logp0∣1(x0∣x1)∂x1∣x1]=0E_{x_0}\left[ \frac{\partial\log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1} \biggr\vert x_1 \right]=0Ex0[∂x1∂logp0∣1(x0∣x1)x1]=0, because
Ex0[∂logp0∣1(x0∣x1)∂x1∣x1]=∫p0∣1(x0∣x1)⋅∂logp0∣1(x0∣x1)∂x1dx0E_{x_0}\left[ \frac{\partial\log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1} \biggr\vert x_1 \right]=
\int p_{0 \vert 1}(x_0 \vert x_1) \cdot \frac{\partial \log p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1} dx_0 Ex0[∂x1∂logp0∣1(x0∣x1)x1]=∫p0∣1(x0∣x1)⋅∂x1∂logp0∣1(x0∣x1)dx0
=∫p0∣1(x0)⋅1p0∣1(x0∣x1)⋅∂p0∣1(x0∣x1)∂x1dx0=∫∂p0∣1(x0∣x1)∂x1dx0=∂∫p0∣1(x0∣x1)dx0∂x1=∂1∂x1=0= \int p_{0 \vert 1}(x_0) \cdot \frac 1 {p_{0 \vert 1}(x_0 \vert x_1)} \cdot \frac{\partial p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1} dx_0 = \int \frac{\partial p_{0 \vert 1}(x_0 \vert x_1)}{\partial x_1} dx_0 = \frac{\partial \int p_{0 \vert 1}(x_0 \vert x_1) dx_0}{\partial x_1} = \frac{\partial 1}{\partial x_1}=0=∫p0∣1(x0)⋅p0∣1(x0∣x1)1⋅∂x1∂p0∣1(x0∣x1)dx0=∫∂x1∂p0∣1(x0∣x1)dx0=∂x1∂∫p0∣1(x0∣x1)dx0=∂x1∂1=0
And Ex0[σ2∂logp1(x1)∂x1∣x1]=σ2∂logp1(x1)∂x1E_{x_0}\left[ \sigma^2\frac{\partial \log p_1(x_1)}{\partial x_1} \biggr\vert x_1\right] = \sigma^2\frac{\partial \log p_1(x_1)}{\partial x_1}Ex0[σ2∂x1∂logp1(x1)x1]=σ2∂x1∂logp1(x1) because it's unrelated to random x0x_0x0.
So
E[x0∣x1]=x1+σ2∂logp1(x1)∂x1⏟Train diffusion model to output thisE[x_0 \vert x_1] = x_1 + \underbrace{\sigma^2\frac{\partial \log p_1(x_1)}{\partial x_1}}_{\mathclap{\text{Train diffusion model to output this}}}E[x0∣x1]=x1+Train diffusion model to output thisσ2∂x1∂logp1(x1)
That's Tweedie's formula (for 1D case). It can be generalized to many dimensions, where the x0,x1x_0, x_1x0,x1 are vectors, the distributions p0,p1,p0∣1,p1∣0p_0, p_1, p_{0 \vert 1}, p_{1 \vert 0}p0,p1,p0∣1,p1∣0 are joint distributions where different dimensions are not necessarily independent. The gaussian noise added to different dimensions are still independent.
The diffusion model is trained to estimate the added noise, which is the same as estimating the linear score.
Exponential distribution
If we have constraint X≥0X \geq 0X≥0 and fix the mean E[X]E[X]E[X] to a specific value μ\muμ, then maximizing entropy gives exponential distribution. It can also be rediscovered from Lagrange multiplier:
L(f,λ1,λ2,λ3)={∫0∞f(x)log1f(x)dx+λ1(∫0∞f(x)dx−1)+λ2(∫0∞f(x)xdx−μ)\mathcal{L}(f,\lambda_1,\lambda_2,\lambda_3)=
\begin{cases}
\int_{0}^{\infty} f(x) \log\frac{1}{f(x)}dx \\ + \lambda_1 \left(\int_{0}^{\infty} f(x)dx-1\right) \\ + \lambda_2 \left(\int_{0}^{\infty} f(x)xdx -\mu\right)
\end{cases}L(f,λ1,λ2,λ3)=⎩⎨⎧∫0∞f(x)logf(x)1dx+λ1(∫0∞f(x)dx−1)+λ2(∫0∞f(x)xdx−μ)
=∫0∞(−f(x)logf(x)+λ1f(x)+λ2xf(x))dx−λ1−λ2μ=\int_{0}^{\infty} (-f(x)\log f(x) + \lambda_1 f(x) +
\lambda_2 x f(x) ) dx - \lambda_1 - \lambda_2\mu=∫0∞(−f(x)logf(x)+λ1f(x)+λ2xf(x))dx−λ1−λ2μ
∂L∂f=−logf(x)−1+λ1+λ2x∂L∂λ1=∫0∞f(x)dx−1∂L∂λ2=∫0∞xf(x)dx−μ\frac{\partial \mathcal{L}}{\partial f}
= -\log f(x) - 1 + \lambda_1 + \lambda_2 x
\quad\quad\quad
\frac{\partial \mathcal{L}}{\partial \lambda_1}=\int_0^{\infty}f(x)dx-1
\quad\quad\quad
\frac{\partial \mathcal{L}}{\partial \lambda_2}=\int_0^{\infty} xf(x)dx-\mu∂f∂L=−logf(x)−1+λ1+λ2x∂λ1∂L=∫0∞f(x)dx−1∂λ2∂L=∫0∞xf(x)dx−μ
Then solve ∂L∂f=0\frac{\partial \mathcal{L}}{\partial f}=0∂f∂L=0:
∂L∂f=0logf(x)=−1+λ1+λ2xf(x)=e(−1+λ1+λ2x)=e(−1+λ1)⋅eλ2x\frac{\partial \mathcal{L}}{\partial f}=0
\quad\quad\quad
\log f(x) = -1+\lambda_1+\lambda_2 x
\quad\quad\quad
f(x) = e^{(-1+\lambda_1+\lambda_2 x)} = e^{(-1+\lambda_1)} \cdot e^{\lambda_2 x}∂f∂L=0logf(x)=−1+λ1+λ2xf(x)=e(−1+λ1+λ2x)=e(−1+λ1)⋅eλ2x
Then solve ∂L∂λ1=0\frac{\partial \mathcal{L}}{\partial \lambda_1}=0∂λ1∂L=0:
∂L∂λ1=0∫0∞e(−1+λ1)⋅eλ2xdx=1∫0∞eλ2xdx=e1−λ1\frac{\partial \mathcal{L}}{\partial \lambda_1}=0
\quad\quad\quad
\int_0^{\infty} e^{(-1+\lambda_1)} \cdot e^{\lambda_2 x} dx = 1
\quad\quad\quad
\int_0^{\infty} e^{\lambda_2 x} dx = e^{1-\lambda_1}∂λ1∂L=0∫0∞e(−1+λ1)⋅eλ2xdx=1∫0∞eλ2xdx=e1−λ1
To make that integration finite, λ2<0\lambda_2 < 0λ2<0.
Let u=λ2x, du=λ2dx,dx=1λ2duu = \lambda_2 x, \ du = \lambda_2 dx, dx=\frac 1 {\lambda_2} duu=λ2x, du=λ2dx,dx=λ21du,
∫0∞eλ2xdx=1λ2∫0−∞eudu=−1λ2=e1−λ1\int_0^{\infty} e^{\lambda_2 x} dx = \frac 1 {\lambda_2} \int_0^{-\infty} e^udu = -\frac 1 {\lambda_2} = e^{1-\lambda_1}∫0∞eλ2xdx=λ21∫0−∞eudu=−λ21=e1−λ1
Then solve ∂L∂λ2=0\frac{\partial \mathcal{L}}{\partial \lambda_2}=0∂λ2∂L=0:
∂L∂λ2=0∫0∞xe(−1+λ1+λ2x)dx=μ∫0∞xeλ2xdx=μe1−λ1\frac{\partial \mathcal{L}}{\partial \lambda_2}=0
\quad\quad\quad
\int_0^{\infty} x e^{(-1+\lambda_1+\lambda_2 x)} dx = \mu
\quad\quad\quad
\int_0^{\infty} x e^{\lambda_2 x} dx = \mu e^{1-\lambda_1}∂λ2∂L=0∫0∞xe(−1+λ1+λ2x)dx=μ∫0∞xeλ2xdx=μe1−λ1
∫0∞xeλ2xdx=(1λ2xeλ2x−1λ22eλ2x)0∞=1λ22\int_0^{\infty} x e^{\lambda_2 x} dx = (\frac 1 {\lambda_2} x e^{\lambda_2 x} - \frac 1 {\lambda_2^2} e^{\lambda_2x}) _0^{\infty} = \frac 1 {\lambda_2^2}∫0∞xeλ2xdx=(λ21xeλ2x−λ221eλ2x)0∞=λ221
Now we have
f(x)=e(−1+λ1)⋅eλ2x−1λ2=e1−λ11λ22=μe1−λ1f(x) = e^{(-1+\lambda_1)} \cdot e^{\lambda_2 x}
\quad\quad\quad
-\frac 1 {\lambda_2} = e^{1-\lambda_1}
\quad\quad\quad
\frac 1 {\lambda_2^2}=\mu e^{1-\lambda_1}f(x)=e(−1+λ1)⋅eλ2x−λ21=e1−λ1λ221=μe1−λ1
Solving it gives λ2=−1μ, e1−λ1=μ\lambda_2 = - \frac 1 {\mu}, \ e^{1-\lambda_1} = \muλ2=−μ1, e1−λ1=μ. Then
f(x)=1μe−1μx(x≥0)f(x) = \frac 1 \mu e^{-\frac 1 \mu x} \quad\quad (x \geq 0)f(x)=μ1e−μ1x(x≥0)
In the common definition of exponential distribution, λ=1μ\lambda = \frac 1 \muλ=μ1, f(x)=λe−λxf(x) = \lambda e^{-\lambda x}f(x)=λe−λx.
Its tail function:
TailFunction(x)=P(X>x)=∫x∞λe−λydy=(−e−λy)∣y=xy=∞=e−λx\text{TailFunction}(x) = P(X>x) = \int_x^{\infty} \lambda e^{-\lambda y}dy= \left(-e^{-\lambda y}\right) \biggr\vert_{y=x}^{y=\infty} = e^{-\lambda x}TailFunction(x)=P(X>x)=∫x∞λe−λydy=(−e−λy)y=xy=∞=e−λx
If some event is happening in fixed rate (λ\lambdaλ), exponential distribution measures how long do we need to wait for the next event, if how long we will need to wait is irrelevant how long we have aleady waited (memorylessness).
Exponential distribution can measure:
- The lifetime of machine components.
- The time until a radioactive atom decays.
- The time length of phone calls.
- The time interval between two packets for a router.
- ...
How to understand memorlessness? For example, a kind of radioactive atom decays once per 5 minutes on average. If the time unit is minute, then λ=15\lambda = \frac 1 5λ=51. For a specific atom, if we wait for it to decay, the time we need to wait is on average 5 minutes. However, if we have already waited for 3 minutes and it still hasn't decay, the expected time that we need to wait is still 5 minutes. If we have waited for 100 minutes and it still hasn't decay, the expected time that we need to wait is still 5 minutes. Because the atom doesn't "remember" how long we have waited.
Memorylessness means the probability that we still need to wait needToWait\text{needToWait}needToWait amount of time is irrelevant to how long we have already waited:
P(t≥(alreadyWaited+needToWait) ∣ t≥alreadyWaited)=P(t≥needToWait)P(t \geq (\text{alreadyWaited} + \text{needToWait}) \ \vert \ t \geq \text{alreadyWaited}) = P(t \geq \text{needToWait})P(t≥(alreadyWaited+needToWait) ∣ t≥alreadyWaited)=P(t≥needToWait)
(We can also rediscover exponential distrbution from just memorylessness.)
Memorylessness is related with its maximum entropy property. Maximizing entropy under constraints means maximizing uncertainty and minizing information other than the constraints. The only two constraints are X≥0X\geq 0X≥0, the wait time is positive, and E[X]=1λE[X]=\frac 1 \lambdaE[X]=λ1, the average rate of the event. Other than the two constraints, there is no extra information. No information tells waiting reduces time need to wait, no information tells waiting increases time need to wait. So it's the most unbiased: waiting has no effect on the time need to wait. If the radioactive atom has some "internal memory" that changes over time and controls how likely it will decay, then the waiting time distribution encodes extra information other than the two constraints, which makes it no longer max-entropy.
Pareto distribution
Rediscover Pareto distribution from 80/20 rule
80/20 rule: for example 80% of weallth are in the richest 20% (the real number may be different).
It has fractal property: even within the richest 20%, 80% of wealth are in the richest 20% within. Based on this fractal-like property, we can naturally get Pareto distribution.
If the total people count is NNN, the total wealth amount is WWW. Then 0.2N0.2N0.2N people have 0.8W0.8W0.8W wealth. Applying the same within the 0.2N0.2N0.2N people: 0.2⋅0.2N0.2 \cdot 0.2 N0.2⋅0.2N people have 0.8⋅0.8W0.8 \cdot 0.8W0.8⋅0.8W wealth. Applying again, 0.2⋅0.2⋅0.2N0.2 \cdot 0.2 \cdot 0.2 N0.2⋅0.2⋅0.2N people have 0.8⋅0.8⋅0.8W0.8 \cdot 0.8 \cdot 0.8 W0.8⋅0.8⋅0.8W welath.
Generalize it, 0.2kN0.2^k N0.2kN people have 0.8kW0.8^k W0.8kW wealth (kkk can be generalized to continuous real number).
If the wealth variable is XXX (assume X>0X > 0X>0), its probability density function is f(x)f(x)f(x), and porportion of people correspond to probability, the richest 0.2k0.2^k0.2k porportion of people group have 0.8kW0.8^kW0.8kW wealth, ttt is the wealth threshold (minimum wealth) of that group:
P(X≥t)=∫t∞f(x)dx=0.2kP(X \geq t) = \int_t^{\infty} f(x)dx = 0.2^kP(X≥t)=∫t∞f(x)dx=0.2k
Note that f(x)f(x)f(x) represents probability density function (PDF), which correspond to density of proportion of people. N⋅f(x)N\cdot f(x)N⋅f(x) is people amount density over wealth. Multiplying it with wealth xxx and integrate gets total wealth in range:
∫t∞x(N⋅f(x))dx=0.8kW∫t∞xf(x)dx=0.8kWN\int_t^{\infty} x (N \cdot f(x)) dx = 0.8^k W
\quad\quad\quad
\int_t^{\infty} x f(x) dx = 0.8^k \frac W N∫t∞x(N⋅f(x))dx=0.8kW∫t∞xf(x)dx=0.8kNW
We can rediscover Pareto distribution from these. The first thing to do is extract and eliminate kkk:
∫t∞f(x)dx=0.2k=e(log0.2)k(log0.2)k=log∫t∞f(x)dx\int_t^{\infty} f(x)dx = 0.2^k = e^{(\log 0.2)k} \quad\quad\quad (\log 0.2) k=\log\int_t^{\infty} f(x)dx∫t∞f(x)dx=0.2k=e(log0.2)k(log0.2)k=log∫t∞f(x)dx
∫t∞xf(x)dx=WN0.8k=WNe(log0.8)k(log0.8)k=logN∫t∞xf(x)dxW\int_t^{\infty} x f(x) dx = \frac W N 0.8^k = \frac W N e^{(\log 0.8)k} \quad\quad\quad
(\log 0.8)k = \log \frac{N\int_t^{\infty} x f(x) dx}{W}∫t∞xf(x)dx=NW0.8k=NWe(log0.8)k(log0.8)k=logWN∫t∞xf(x)dx
k=log∫t∞f(x)dxlog0.2=logN∫t∞xf(x)dxWlog0.8log0.8log0.2log∫t∞f(x)dx=logN∫t∞xf(x)dxWk=\frac{\log\int_t^{\infty} f(x)dx}{\log 0.2}=\frac{\log \frac{N\int_t^{\infty} x f(x) dx}{W}}{\log 0.8}
\quad\quad\quad
\frac{\log 0.8}{\log 0.2} \log\int_t^{\infty} f(x)dx = \log \frac{N\int_t^{\infty} x f(x) dx}{W}k=log0.2log∫t∞f(x)dx=log0.8logWN∫t∞xf(x)dxlog0.2log0.8log∫t∞f(x)dx=logWN∫t∞xf(x)dx
log((∫t∞f(x)dx)log0.8log0.2)=logN∫t∞xf(x)dxW\log\left(\left(\int_t^{\infty} f(x)dx\right) ^{\frac{\log 0.8}{\log 0.2}} \right) = \log \frac{N\int_t^{\infty} x f(x) dx}{W}log((∫t∞f(x)dx)log0.2log0.8)=logWN∫t∞xf(x)dx
(∫t∞f(x)dx)log0.8log0.2=NW∫t∞xf(x)dx\left(\int_t^{\infty} f(x)dx\right) ^{\frac{\log 0.8}{\log 0.2}} = \frac N W \int_t^{\infty} x f(x) dx(∫t∞f(x)dx)log0.2log0.8=WN∫t∞xf(x)dx
Then we can take derivative to ttt on two sides:
log0.8log0.2(∫t∞f(x)dx)log0.8log0.2−1(−f(t))=NW(−tf(t))\frac{\log 0.8}{\log 0.2} \left( \int_t^{\infty} f(x)dx \right)^{\frac{\log 0.8}{\log 0.2}-1} (- f(t)) = \frac N W (-t f(t))log0.2log0.8(∫t∞f(x)dx)log0.2log0.8−1(−f(t))=WN(−tf(t))
f(t)≠0f(t) \neq 0f(t)=0. Divide two sides by −f(t)-f(t)−f(t):
log0.8log0.2(∫t∞f(x)dx)log0.8log0.2−1=NWt\frac{\log 0.8}{\log 0.2} \left( \int_t^{\infty} f(x)dx \right)^{\frac{\log 0.8}{\log 0.2}-1} = \frac N W tlog0.2log0.8(∫t∞f(x)dx)log0.2log0.8−1=WNt
((∫t∞f(x)dx)log0.8log0.2−1)1log0.8log0.2−1=(Nlog0.2Wlog0.8t)1log0.8log0.2−1\left( \left( \int_t^{\infty} f(x)dx \right)^{\frac{\log 0.8}{\log 0.2}-1} \right)^{\frac 1 {\frac{\log 0.8}{\log 0.2}-1}} = \left(\frac {N\log 0.2} {W\log 0.8} t\right)^{\frac 1 {\frac{\log 0.8}{\log 0.2}-1}}((∫t∞f(x)dx)log0.2log0.8−1)log0.2log0.8−11=(Wlog0.8Nlog0.2t)log0.2log0.8−11
∫t∞f(x)dx=(Nlog0.2Wlog0.8t)1log0.8log0.2−1=(Nlog0.2Wlog0.8t)log0.2log0.8−log0.2\int_t^{\infty} f(x)dx = \left( \frac{N\log 0.2}{W\log 0.8} t \right)^{\frac 1 {\frac{\log 0.8}{\log 0.2}-1}}
= \left( \frac{N\log 0.2}{W\log 0.8} t \right)^{\frac {\log 0.2} {\log 0.8-\log 0.2}}∫t∞f(x)dx=(Wlog0.8Nlog0.2t)log0.2log0.8−11=(Wlog0.8Nlog0.2t)log0.8−log0.2log0.2
Take derivative to ttt on two sides again:
−f(t)=log0.2log0.8−log0.2(Nlog0.2Wlog0.8t)log0.2log0.8−log0.2−1⋅Nlog0.2Wlog0.8-f(t) = \frac {\log 0.2} {\log 0.8-\log 0.2} \left( \frac{N\log 0.2}{W\log 0.8} t \right)^{\frac {\log 0.2} {\log 0.8-\log 0.2} - 1} \cdot \frac{N\log 0.2}{W\log 0.8}−f(t)=log0.8−log0.2log0.2(Wlog0.8Nlog0.2t)log0.8−log0.2log0.2−1⋅Wlog0.8Nlog0.2
Now ttt is an argument and can be renamed to xxx. And do some adjustments:
f(x)=−log0.2log0.8−log0.2(Nlog0.2Wlog0.8)log0.2log0.8−log0.2⋅xlog0.2log0.8−log0.2−1f(x) = -\frac {\log 0.2} {\log 0.8-\log 0.2} \left(\frac{N\log 0.2}{W\log 0.8}\right)^{\frac {\log 0.2} {\log 0.8-\log 0.2} } \cdot x ^{\frac {\log 0.2} {\log 0.8-\log 0.2} - 1}f(x)=−log0.8−log0.2log0.2(Wlog0.8Nlog0.2)log0.8−log0.2log0.2⋅xlog0.8−log0.2log0.2−1
Now we get the PDF. We still need to make the total probability area to be 1 to make it a valid distribution. But there is no extra unknown parameter in PDF to change. The solution is to crop the range of XXX. If we set the minimum wealth in distribution to be mmm (but doesn't constraint the maximum wealth), creating constraint X≥mX \geq mX≥m, then using the previous result
∫m∞f(x)dx=1(Nlog0.2Wlog0.8m)log0.2log0.8−log0.2=1m=Wlog0.8Nlog0.2≈0.1386WN\int_m^{\infty} f(x)dx = 1 \quad\quad\quad
\left( \frac{N\log 0.2}{W\log 0.8} m \right)^{\frac {\log 0.2} {\log 0.8-\log 0.2}} = 1
\quad\quad\quad
m = \frac{W \log 0.8}{N \log 0.2} \approx 0.1386 \frac W N∫m∞f(x)dx=1(Wlog0.8Nlog0.2m)log0.8−log0.2log0.2=1m=Nlog0.2Wlog0.8≈0.1386NW
Now we rediscovered (a special case of) Pareto distribution from just fractal 80/20 rule. We can generalize it further for other cases like 90/10 rule, 80/10 rule, etc. and get Pareto (Type I) distribution. It has two parameters, shape parameter α\alphaα (correspond to −log0.2log0.8−log0.2=log5log4≈1.161-\frac {\log 0.2} {\log 0.8-\log 0.2} = \frac{\log 5}{\log 4} \approx 1.161−log0.8−log0.2log0.2=log4log5≈1.161) and minimum value mmm:
f(x)={αmαx−α−1 x≥m,0 x<mf(x) = \begin{cases}
\alpha m^\alpha x^{-\alpha-1} &\ x \geq m, \\
0 &\ x < m
\end{cases}f(x)={αmαx−α−10 x≥m, x<m
Note that in real world the wealth of one can be negative (has debts more than assets). The Pareto distribution is just an approximation. mmm means the threshold where Pareto distribution starts to be good approximation.
If α≤1\alpha \leq 1α≤1 then its theoretical mean is infinite. Of course if we have finite samples then the sample mean will be finite, but if the theoretical mean is infinite, the more sample we have, the larger the sample mean tend to be, and the trend won't stop.
If α≤2\alpha \leq 2α≤2 then its theoretical variance is infinite. Recall that centrol limit theorem require finite variance. The standarized sum of values taken from Pareto distribution whose α≤2\alpha \leq 2α≤2 does not follow central limit theorem because it has infinite variance.
Pareto distribution is often described using tail function (rather than probability density function):
TailFunction(x)=P(X>x)={mαx−α if x≥m,1 if x<m\text{TailFunction}(x) = P(X>x) = \begin{cases}
m^\alpha x^{-\alpha} &\ \text{if } x \geq m, \\
1 &\ \text{if } x < m
\end{cases}TailFunction(x)=P(X>x)={mαx−α1 if x≥m, if x<m
Rediscover Pareto distribution by maximizing entropy under geometric mean constraint
There are additive values, like length, mass, money. For additive values, we often compute arithmetic average 1n(x1+x2+..+xn)\frac 1 n (x_1 + x_2 + .. + x_n)n1(x1+x2+..+xn).
There are also multiplicative values, like asset return rate, growth ratio. For multiplicative values, we often compute geometric average (x1⋅x2⋅...⋅xn)1n(x_1 \cdot x_2 \cdot ... \cdot x_n)^{\frac 1 n}(x1⋅x2⋅...⋅xn)n1. For example, if an asset grows by 20% in first year, drops 10% in second year and grows 1% in third year, then the average growth ratio per year is (1.2⋅0.9⋅1.01)13(1.2 \cdot 0.9 \cdot 1.01)^{\frac 1 3}(1.2⋅0.9⋅1.01)31.
Logarithm allows turning multiplication into addition, and turning power into multiplication. If y=logxy = \log xy=logx, then log of geometric average of xxx is arithmetic average of yyy:
log((x1⋅x2⋅...⋅xn)1n)=1n(logx1+logx2+...+logxn)=1n(y1+y2+...+yn)\log \left((x_1 \cdot x_2 \cdot ... \cdot x_n)^{\frac 1 n}\right) = \frac 1 n (\log x_1 + \log x_2 + ... + \log x_n)=\frac 1 n (y_1 + y_2 + ... + y_n)log((x1⋅x2⋅...⋅xn)n1)=n1(logx1+logx2+...+logxn)=n1(y1+y2+...+yn)
Pareto distribution maximizes entropy under geometric mean constraint E[logX]E[\log X]E[logX].
If we have constraints X≥m>0X \geq m > 0X≥m>0, E[logX]=gE[\log X] = gE[logX]=g, using largrange multiplier to maximize entropy:
L(f,λ1,λ2)={∫m∞f(x)log1f(x)dx+λ1(∫m∞f(x)dx−1)+λ2(∫m∞f(x)logxdx−g)\mathcal{L}(f, \lambda_1, \lambda_2)= \begin{cases}\int_m^{\infty} f(x) \log \frac 1 {f(x)} dx \\\\ + \lambda_1 (\int_m^{\infty} f(x)dx-1) \\\\ + \lambda_2 (\int_m^{\infty} f(x)\log x dx - g) \end{cases}L(f,λ1,λ2)=⎩⎨⎧∫m∞f(x)logf(x)1dx+λ1(∫m∞f(x)dx−1)+λ2(∫m∞f(x)logxdx−g)
L(f,λ1,λ2)=∫m∞( −f(x)logf(x)+λ1f(x)+λ2f(x)logx )dx−λ1−gλ2\mathcal{L}(f, \lambda_1, \lambda_2) = \int_m^{\infty} (\ -f(x)\log f(x) + \lambda_1 f(x) + \lambda_2 f(x) \log x \ ) dx -\lambda_1 - g \lambda_2L(f,λ1,λ2)=∫m∞( −f(x)logf(x)+λ1f(x)+λ2f(x)logx )dx−λ1−gλ2
∂L∂f=−logf(x)−1+λ1+λ2logx\frac{\partial \mathcal{L}}{\partial f} = -\log f(x) - 1 + \lambda_1 + \lambda_2 \log x∂f∂L=−logf(x)−1+λ1+λ2logx
∂L∂λ1=∫m∞f(x)dx−1\frac{\partial \mathcal{L}}{\partial \lambda_1} = \int_m^{\infty} f(x) dx -1∂λ1∂L=∫m∞f(x)dx−1
∂L∂λ2=∫m∞f(x)logx dx−g\frac{\partial \mathcal{L}}{\partial \lambda_2} = \int_m^{\infty} f(x) \log x \ dx-g∂λ2∂L=∫m∞f(x)logx dx−g
Solve ∂L∂f=0\frac{\partial \mathcal{L}}{\partial f}=0∂f∂L=0:
−logf(x)−1+λ1+λ2logx=0- \log f(x) - 1 + \lambda_1 + \lambda_2 \log x=0−logf(x)−1+λ1+λ2logx=0
logf(x)=−1+λ1+λ2logx\log f(x) = -1+\lambda_1 + \lambda_2 \log xlogf(x)=−1+λ1+λ2logx
f(x)=e−1+λ1+λ2logxf(x) = e^{-1+\lambda_1+\lambda_2 \log x}f(x)=e−1+λ1+λ2logx
f(x)=e−1+λ1⋅(elogx)λ2=e−1+λ1⋅xλ2f(x) = e^{-1+\lambda_1} \cdot (e^{\log x})^{\lambda_2} = e^{-1+\lambda_1} \cdot x^{\lambda_2}f(x)=e−1+λ1⋅(elogx)λ2=e−1+λ1⋅xλ2
Solve ∂L∂λ1=0\frac{\partial \mathcal{L}}{\partial \lambda_1}=0∂λ1∂L=0:
e−1+λ1∫m∞xλ2dx=1∫m∞xλ2dx=e1−λ1e^{-1+\lambda_1}\int_m^{\infty} x^{\lambda_2}dx = 1\quad\quad\quad \int_m^{\infty} x^{\lambda_2}dx = e^{1-\lambda_1}e−1+λ1∫m∞xλ2dx=1∫m∞xλ2dx=e1−λ1
To make ∫m∞xλ2dx\int_m^{\infty} x^{\lambda_2}dx∫m∞xλ2dx be finite, λ2<−1\lambda_2 < -1λ2<−1.
∫m∞xλ2dx=(1λ2+1xλ2+1)∣x=mx=∞=−1λ2+1mλ2+1=e1−λ1\int_m^{\infty} x^{\lambda_2}dx= \left( \frac{1}{\lambda_2+1}x^{\lambda_2+1} \right) \biggr\vert^{x=\infty}_{x=m} =- \frac 1 {\lambda_2+1} m^{\lambda_2 + 1} = e^{1-\lambda_1}∫m∞xλ2dx=(λ2+11xλ2+1)x=mx=∞=−λ2+11mλ2+1=e1−λ1
mλ2+1λ2+1=−e1−λ1e−1+λ1=−λ2+1mλ2+1(1)\frac{m^{\lambda_2+1}}{\lambda_2+1} = -e^{1-\lambda_1} \tag{1}\quad\quad\quad e^{-1+\lambda_1}=-\frac{\lambda_2+1}{m^{\lambda_2+1}}λ2+1mλ2+1=−e1−λ1e−1+λ1=−mλ2+1λ2+1(1)
Solve ∂L∂λ2=0\frac{\partial \mathcal{L}}{\partial \lambda_2}=0∂λ2∂L=0:
∫m∞f(x)logx dx=g\int_m^{\infty} f(x) \log x \ dx=g∫m∞f(x)logx dx=g
∫m∞e−1+λ1⋅xλ2logx dx=g\int_m^{\infty} e^{-1+\lambda_1} \cdot x^{\lambda_2} \log x \ dx=g∫m∞e−1+λ1⋅xλ2logx dx=g
If we temporarily ignore e−1+λ1e^{-1+\lambda_1}e−1+λ1 and compute ∫m∞xλ2logx dx\int_m^{\infty} x^{\lambda_2} \log x \ dx∫m∞xλ2logx dx. Let u=logxu=\log xu=logx, x=eux=e^ux=eu, dx=eududx = e^ududx=eudu:
∫m∞xλ2logx dx=∫logm∞eλ2uu du=(1λ2+1ue(λ2+1)u−1(λ2+1)2e(λ2+1)u)∣u=logmu=∞\int_m^{\infty} x^{\lambda_2} \log x \ dx=\int_{\log m}^{\infty} e^{\lambda_2 u} u \ du = \left( \frac 1 {\lambda_2+1} u e^{(\lambda_2+1)u} - \frac 1 {(\lambda_2+1)^2} e^{(\lambda_2+1)u}\right) \biggr\vert_{u=\log m}^{u=\infty}∫m∞xλ2logx dx=∫logm∞eλ2uu du=(λ2+11ue(λ2+1)u−(λ2+1)21e(λ2+1)u)u=logmu=∞
Then
∫m∞xλ2logx dx=−1λ2+1(logm)e(λ2+1)logm+1(λ2+1)2e(λ2+1)logm\int_m^{\infty} x^{\lambda_2} \log x \ dx=- \frac 1 {\lambda_2+1} (\log m) e^{(\lambda_2+1)\log m} + \frac 1 {(\lambda_2+1)^2} e^{(\lambda_2+1)\log m}∫m∞xλ2logx dx=−λ2+11(logm)e(λ2+1)logm+(λ2+1)21e(λ2+1)logm
=−1λ2+1(logm)m(λ2+1)+1(λ2+1)2m(λ2+1)=- \frac 1 {\lambda_2+1} (\log m) m^{(\lambda_2+1)} + \frac 1 {(\lambda_2+1)^2} m^{(\lambda_2+1)}=−λ2+11(logm)m(λ2+1)+(λ2+1)21m(λ2+1)
So
∫m∞e−1+λ1⋅xλ2logx dx=e−1+λ1(−1λ2+1(logm)m(λ2+1)+1(λ2+1)2m(λ2+1))\int_m^{\infty} e^{-1+\lambda_1} \cdot x^{\lambda_2} \log x \ dx
= e^{-1+\lambda_1} \left(- \frac 1 {\lambda_2+1} (\log m) m^{(\lambda_2+1)} + \frac 1 {(\lambda_2+1)^2} m^{(\lambda_2+1)} \right)∫m∞e−1+λ1⋅xλ2logx dx=e−1+λ1(−λ2+11(logm)m(λ2+1)+(λ2+1)21m(λ2+1))
By using (1) e−1+λ1=−λ2+1mλ2+1e^{-1+\lambda_1}=-\frac{\lambda_2+1}{m^{\lambda_2+1}}e−1+λ1=−mλ2+1λ2+1:
=−(−logm+1λ2+1)=logm−1λ2+1=g=- (-\log m + \frac 1 {\lambda_2+1})=\log m - \frac 1 {\lambda_2+1} = g=−(−logm+λ2+11)=logm−λ2+11=g
1λ2+1=logm−gλ2+1=1logm−g\frac 1 {\lambda_2+1} = \log m - g\quad\quad\quad\lambda_2+1 = \frac 1 {\log m - g}λ2+11=logm−gλ2+1=logm−g1
e−1+λ1=−λ2+1mλ2+1=−1logm−gm1logm−ge^{-1+\lambda_1}=-\frac{\lambda_2+1}{m^{\lambda_2+1}} = - \frac{\frac 1 {\log m - g}}{m^{\frac 1 {\log m - g}}}e−1+λ1=−mλ2+1λ2+1=−mlogm−g1logm−g1
f(x)=e−1+λ1⋅xλ2=−1logm−gm1logm−gx(1logm−g−1)f(x)= e^{-1+\lambda_1} \cdot x^{\lambda_2} = - \frac{\frac 1 {\log m - g}}{m^{\frac 1 {\log m - g}}} x^{(\frac 1 {\log m - g}-1)}f(x)=e−1+λ1⋅xλ2=−mlogm−g1logm−g1x(logm−g1−1)
Let α=−1logm−g\alpha = -\frac 1 {\log m - g}α=−logm−g1, it become:
f(x)=αmαx−α−1(x>m)f(x) = \alpha m^{\alpha} x^{-\alpha-1} \quad\quad(x>m)f(x)=αmαx−α−1(x>m)
Now we rediscovered Pareto (Type I) distribution by maximizing entropy.
In the process we have λ2<−1\lambda_2 \lt -1λ2<−1. From λ2+1=1logm−g\lambda_2+1 = \frac 1 {\log m - g}λ2+1=logm−g1 we know logm−g<0\log m - g <0logm−g<0, which is m<egm < e^gm<eg.
Share of top ppp porportion
For example, if wealth follows Pareto distribution, how to compute the wealth share of the top 1%? Generally how to compute the share of the top ppp porpotion?
We firstly need to compute the threshold value ttt of the top nnn:
P(X>t)=nmαt−α=pt=(pm−α)−1α=mp−1αP(X>t) = n \quad\quad\quad m^\alpha t^{-\alpha}=p
\quad\quad\quad
t= (p m^{-\alpha})^{- \frac{1}{\alpha}} = m p^{- \frac{1}{\alpha}}P(X>t)=nmαt−α=pt=(pm−α)−α1=mp−α1
Then compute the share
Share=∫t∞xNf(x)dx∫m∞xNf(x)dx=∫t∞xf(x)dx∫m∞xf(x)dx\text{Share} = \frac{\int_t^{\infty} x N f(x)dx}{\int_m^{\infty} x N f(x)dx}=\frac{\int_t^{\infty} x f(x)dx}{\int_m^{\infty} x f(x)dx}Share=∫m∞xNf(x)dx∫t∞xNf(x)dx=∫m∞xf(x)dx∫t∞xf(x)dx
∫b∞xf(x)dx=∫b∞αm−αx−αdx=αm−α⋅(1−α+1x−α+1)∣x=bx=∞=(−αm−α1−α+1)b−α+1\int_b^{\infty} x f(x)dx = \int_b^{\infty} \alpha m^{-\alpha} x^{-\alpha}dx = \alpha m^{-\alpha} \cdot \left( \frac 1 {-\alpha+1} x^{-\alpha+1} \right) \biggr\vert_{x=b}^{x=\infty} = \left(- \alpha m^{-\alpha} \frac 1 {-\alpha+1}\right) b^{-\alpha+1}∫b∞xf(x)dx=∫b∞αm−αx−αdx=αm−α⋅(−α+11x−α+1)x=bx=∞=(−αm−α−α+11)b−α+1
To make that integration finite, we need −α+1<0-\alpha+1< 0−α+1<0, α>1\alpha > 1α>1.
Share=∫t∞xf(x)dx∫m∞xf(x)dx=(−αm−α1−α+1)t−α+1(−αm−α1−α+1)m−α+1=t−α+1m−α+1=m−α+1p−1α(−α+1)m−α+1=p1−1α\text{Share}=\frac{\int_t^{\infty} x f(x)dx}{\int_m^{\infty} x f(x)dx}= \frac{\left(- \alpha m^{-\alpha} \frac 1 {-\alpha+1}\right) t^{-\alpha+1}}{\left(- \alpha m^{-\alpha} \frac 1 {-\alpha+1}\right) m^{-\alpha+1}}= \frac{t^{-\alpha+1}}{m^{-\alpha+1}} = \frac{m^{-\alpha+1} p^{ - \frac{1}{\alpha} (-\alpha+1)}}{m^{-\alpha+1}}=p^{1- \frac{1}{\alpha}}Share=∫m∞xf(x)dx∫t∞xf(x)dx=(−αm−α−α+11)m−α+1(−αm−α−α+11)t−α+1=m−α+1t−α+1=m−α+1m−α+1p−α1(−α+1)=p1−α1
The share porpotion is irrelevant to mmm.
Some concrete numbers:
α\alphaαShare of top 20%Share of top 1%1.00199.84%99.54%1.186.39%65.79%1.16096480.00%52.81%1.276.47%46.42%1.368.98%34.55%1.558.48%21.54%244.72%10.00%2.538.07%6.31%334.20%4.64%
print("| $\\alpha$ | Share of top 20% | Share of top 1% |\n| - | - | - |\n"+ "\n".join([
"|"+ "|".join([f"{a}"] + [
f"{pow(p,1-(1/a)):.2%}" for p in [0.2,0.01]
]) + "|" for a in [1.001,1.1,1.160964,1.2,1.3,1.5,2,2.5,3]
]))
Power law distributions
A distribution is power law distribution if its tail function P(X>x)P(X>x)P(X>x) is roughly porpotional to x−αx^{-\alpha}x−α, where α\alphaα is called exponent.
P(X>x)∝x−α(roughly)P(X>x) \propto x^{-\alpha} \quad\quad \text{(roughly)}P(X>x)∝x−α(roughly)
The "roughly" here means that it can have small deviations that is infinitely small when xxx is large enough. Rigorously speaking it's P(X>x)∝L(x)x−αP(X>x) \propto L(x) x^{-\alpha}P(X>x)∝L(x)x−α where LLL is a slow varying function that requires limx→∞L(rx)L(x)=1\lim_{x \to \infty} \frac{L(rx)}{L(x)}=1limx→∞L(x)L(rx)=1 for positive rrr.
Note that in some places the power law is written as P(X>x)∝L(x)x−(α−1)P(X>x) \propto L(x) x^{-(\alpha-1)}P(X>x)∝L(x)x−(α−1). In these places the α\alphaα is 1 larger than the α\alphaα in Pareto distribution. The same α\alphaα can have different meaning in different places. Here I will use the α\alphaα that's consistent with the α\alphaα in Pareto distribution.
The lower the exponent α\alphaα, the more right-skewed it is, and the more extreme values it have.
The power law parameter estimation according to Power laws, Pareto distributions and Zipf’s law:
DistributionEstimated min value that power law starts to holdEstimated exponent α\alphaαFrequency of use of words11.20Number of citations of papers1002.04Number of hits on web sites11.40Copies of books sold in the US2 millions2.51Telephone calls received101.22Magnitude of earthquakes3.82.04Diameter of moon craters0.012.14Intensity of solar flares200
0.83Intensity of wars3
0.80Net worth of Americans$600 millions1.09Frequency of family names10000
0.94Population of US cities400001.30
Book The Black Swan also provides some estimation of power law parameter in real world:
DistributionEstimated exponent α\alphaαNumber of books sold in the U.S.1.5Magnitude of earthquakes2.8Market moves3 (or lower)Company size1.5People killed in terroist attacks2 (but possibly a much lower exponent)
Note that the estimation is not accurate because they are sensitive to rare extreme samples.
Note that there are things whose estimated α<1\alpha < 1α<1: intensity of solar flares, intensity of wars, frequency of family names. Recall that in Pareto (Type I) distribuion if α≤1\alpha \leq 1α≤1 then the theoretical mean is infinite. The sample mean tend to be higher and higher when we collect samples and the trend won't stop. If the intensity of war do follow power law and the real α<1\alpha < 1α<1, then much larger wars exists in the future.
Note that most of these things has estimated α<2\alpha < 2α<2. In Pareto (Type I) distribution if α≤2\alpha \leq 2α≤2 then its theoretical variance is infinite. Not having a finite variance makes them not follow central limit theorem and should not be modelled using gaussian distribution.
There are other distributions that can have extreme values:
- Log-normal distribution: If logX\log XlogX is normally distributed, then XXX follows log-normal distribution. Put in another way, if YYY is normally distributed, then eYe^YeY follows log-normal distribution.
- Stretched exponential distribution: P(X>x)P(X>x)P(X>x) is roughly porpotional to e−kxβe^{-kx^\beta}e−kxβ (β<1\beta < 1β<1)
- Power law with exponential cutoff: P(X>x)P(X>x)P(X>x) is roughly porpotional to x−αe−λxx^{-\alpha} e^{-\lambda x}x−αe−λx
They all have less extreme values than power law distributions, but more extreme values than normal distribution and exponential distribution.
Relation with exponential distribution
If TTT follows exponential distribution, then aTa^TaT follows Pareto (Type I) distribution if a>1a>1a>1.
If TTT follows exponential distribution, its probability density fT(t)=λe−λtf_T(t) = \lambda e^{-\lambda t}fT(t)=λe−λt (T≥0T\geq 0T≥0), its cumulative distribution function FT(t)=P(T<t)=1−e−λtF_T(t) = P(T<t) = 1-e^{-\lambda t}FT(t)=P(T<t)=1−e−λt
If Y=aTY=a^TY=aT, a>1a>1a>1, then
P(Y<y)=P(aT<y)=P(T<logyloga)=1−e−λlogyloga=1−(elogy)−λloga=1−y−λlogaP(Y<y) = P(a^T < y) = P\left(T < \frac{\log y}{\log a}\right) = 1- e^{-\lambda \frac{\log y}{\log a}}=1- (e^{\log y})^{-\frac{\lambda}{\log a}}=1-y^{-\frac{\lambda}{\log a}}P(Y<y)=P(aT<y)=P(T<logalogy)=1−e−λlogalogy=1−(elogy)−logaλ=1−y−logaλ
TailFunction(y)=P(Y>y)=1−P(Y<y)=y−λloga\text{TailFunction}(y)=P(Y>y) = 1-P(Y<y) = y^{-\frac{\lambda}{\log a}}TailFunction(y)=P(Y>y)=1−P(Y<y)=y−logaλ
Because T≥0T\geq 0T≥0, Y≥a0=1Y \geq a^0=1Y≥a0=1. Now YYY's tail function is in the same form as Pareto (Type I) distribution, where α=λloga, m=1\alpha=\frac{\lambda}{\log a}, \ m =1α=logaλ, m=1.
Lindy effect
If the lifetime of something follows power law distribution, then it has Lindy effect: the longer that it has existed, the longer that it will likely to continue existing.
If the lifetime TTT follows Pareto distribution, if something keeps living at time ttt, then compute the expected lifetime under that condition.
(The mean is weighted average. The conditional mean is also weighted average but under condition. But as the total integrated weight is not 1, it need to divide the total integrated weight.)
E[T∣T>t]=∫t∞xf(x)dx∫t∞f(x)dx=∫t∞xαm−αx−α−1dx∫t∞αm−αx−α−1dxE[T | T > t] = \frac{\int_t^{\infty} xf(x)dx}{\int_t^{\infty} f(x)dx} =
\frac{\int_t^{\infty} x \alpha m^{-\alpha} x^{-\alpha-1} dx }{\int_t^{\infty} \alpha m^{-\alpha} x^{-\alpha-1} dx}E[T∣T>t]=∫t∞f(x)dx∫t∞xf(x)dx=∫t∞αm−αx−α−1dx∫t∞xαm−αx−α−1dx
=∫t∞x−αdx∫t∞x−α−1dx=1−α+1x−α+1∣x=tx=∞1−αx−α∣x=tx=∞=−1−α+1t−α+1−1−αt−α=αα−1t= \frac{\int_t^{\infty} x^{-\alpha} dx }{\int_t^{\infty} x^{-\alpha-1} dx} = \frac{ \frac 1 {-\alpha+1} x^{-\alpha+1} |_{x=t}^{x=\infty}}{\frac 1 {-\alpha} x^{-\alpha}|_{x=t}^{x=\infty}} = \frac{-\frac 1 {-\alpha+1} t^{-\alpha+1}}{-\frac 1 {-\alpha} t^{-\alpha}} = \frac{\alpha}{\alpha-1} t=∫t∞x−α−1dx∫t∞x−αdx=−α1x−α∣x=tx=∞−α+11x−α+1∣x=tx=∞=−−α1t−α−−α+11t−α+1=α−1αt
(For that integration to be finite, −α+1<0-\alpha+1<0−α+1<0, α>1\alpha>1α>1)
The expected lifetime is αα−1t\frac{\alpha}{\alpha-1} tα−1αt under the condition that it has already lived to time ttt. The expected remaining lifetime is αα−1t−t=1α−1t\frac{\alpha}{\alpha-1} t-t= \frac{1}{\alpha-1}tα−1αt−t=α−11t. It increases by ttt.
Lindy effect often doesn't apply to physical things. Lindy effect often applies to information, like technology, culture, art, social norm, etc.
Distribution of lifetimeExpected remaining lifetime of living onesNormal distributionGet shorter as time passesExponential distributionDoes not change as time passes (memorylessness)Pareto distributionGet longer as time passes (Lindy effect)
Benford's law
If some numbers spans multiple orders of magnitudes, Benford's law says that about 30% of numbers have leading digit 1, about 18% of numbers have leading digit of 2, ... The digit ddd's porportion is log10(1+1d)\log_{10} \left(1 + \frac 1 d \right)log10(1+d1).
Pareto distribution is a distribution that spans many orders of magnitudes. Let's compute the distribution of first digit if the number follows Pareto distribution.
If xxx starts with digit ddd then d10k≤x<(d+1)10kd 10^k \leq x < (d+1) 10^kd10k≤x<(d+1)10k, k=0,1,2,...k=0, 1, 2, ...k=0,1,2,... Pareto distribution has a lower bound mmm. If we make mmm randomly distributed then analytically computing the probability of each starting digit become hard due to edge cases.
In this case, doing a Monte Carlo simulation is easier.
How to randomly sample numbers from a Pareto distribution? Firstly we know the cumulative distribution function F(x)=P(X<x)=1−P(X>x)=1−mαx−αF(x) = P(X<x) = 1-P(X>x) = 1- m^\alpha x^{-\alpha}F(x)=P(X<x)=1−P(X>x)=1−mαx−α. We can then get quantile function, which is the inverse of FFF: F(x)=p, Q(p)=xF(x)=p, \ \ Q(p) = xF(x)=p, Q(p)=x
p=1−mαx−αmαx−α=1−px−α=(1−p)m−αp=1-m^\alpha x^{-\alpha} \quad\quad\quad m^\alpha x^{-\alpha}=1-p \quad\quad\quad x^{-\alpha} = (1-p) m^{-\alpha}p=1−mαx−αmαx−α=1−px−α=(1−p)m−α
(x−α)−1α=((1−p)m−α)−1αx=m(1−p)−1αQ(p)=m(1−p)−1α(x^{-\alpha})^{- \frac{1}{\alpha}} = \left((1-p) m^{-\alpha}\right)^{- \frac{1}{\alpha}}
\quad\quad\quad x = m (1-p)^{- \frac{1}{\alpha}}
\quad\quad\quad Q(p) = m (1-p)^{- \frac{1}{\alpha}}(x−α)−α1=((1−p)m−α)−α1x=m(1−p)−α1Q(p)=m(1−p)−α1
Now we can randomly sample ppp between 0 and 1 then Q(p)Q(p)Q(p) will follow Pareto distribution.
Given xxx how to calculate its first digit? If 10≤x<10010\leq x<10010≤x<100 (1≤log10x<21 \leq \log_{10} x < 21≤log10x<2) then first digit is ⌊x10⌋\lfloor {\frac x {10}} \rfloor⌊10x⌋. If 100≤x<1000100 \leq x < 1000100≤x<1000 (2≤log10x<32 \leq \log_{10}x < 32≤log10x<3) then the first digit is ⌊x100⌋\lfloor {\frac x {100}} \rfloor⌊100x⌋. Generalize it, the first digit ddd is:
d=⌊x10⌊log10x⌋⌋d = \left\lfloor \frac {x} {10^{\lfloor \log_{10} x \rfloor}} \right\rfloord=⌊10⌊log10x⌋x⌋
Because Pareto distribution has a lot of extreme values, directly calculating the sample will likely to exceed floating-point range and give some inf. So we need to use log scale. Only calculate using logx\log xlogx and avoid using xxx directly.
Sampling in log scale:
logx=log(m(1−p)−1α)=logm−1αlog(1−p)\log x = \log \left(m (1-p)^{- \frac{1}{\alpha}}\right) = \log m - \frac{1}{\alpha} \log (1-p)logx=log(m(1−p)−α1)=logm−α1log(1−p)
Calculating first digit in log scale:
log10x=logexloge10\log_{10}x = \frac{\log_e x}{\log_e 10}log10x=loge10logex
logx10⌊log10x⌋=logx−⌊log10x⌋log10=logx−⌊logxlog10⌋log10\log \frac {x} {10^{\lfloor \log_{10} x \rfloor}} = \log x - \lfloor \log_{10} x \rfloor \log 10 = \log x - \left\lfloor \frac{\log x}{\log 10} \right\rfloor \log 10log10⌊log10x⌋x=logx−⌊log10x⌋log10=logx−⌊log10logx⌋log10
d=⌊elogx−⌊logxlog10⌋log10⌋d = \left\lfloor e^{\log x - \left\lfloor \frac{\log x}{\log 10} \right\rfloor \log 10} \right\rfloord=⌊elogx−⌊log10logx⌋log10⌋
When α\alphaα approaches 000 it accurately follows Benford's law. The larger α\alphaα the larger deviation with Benford's law.
If we fix the min value mmm as a specific number, like 333, when α\alphaα is not very close to 000 it significantly deviates with Benford's law. However if we make mmm a random value between 1 and 10 then it will be close to Benford's law.

import numpy as np
import matplotlib.pyplot as plt
def first_digit_of_log_x(log_x):
log_10_x = log_x / np.log(10)
exponent = log_x - np.floor(log_10_x) * np.log(10)
return np.floor(np.exp(exponent)).astype(int)
benford_probs = [np.log10(1 + 1/d) for d in range(1, 10)]
n_samples = 1000000
alphas = [0.001, 0.9, 1.2, 2.0]
fig, axs = plt.subplots(4, 2, figsize=(12, 10))
fig.suptitle("First digit distribution in Pareto Distributions")
def sub_plot(row, col, alpha, m, m_str):
p = np.random.uniform(0, 1, n_samples)
log_xs = np.log(m) - (np.log(1 - p)) / alpha
digits = first_digit_of_log_x(log_xs)
digit_counts = np.bincount(digits, minlength=10)[1:10]
observed_probs = digit_counts / digit_counts.sum()
axs[row, col].bar(range(1, 10), observed_probs, label='Result', color='#6075eb')
axs[row, col].plot(range(1, 10), benford_probs, 'o-', label='According to Benford\'s Law', color='#ff7c3b')
axs[row, col].set_title(f"$\\alpha$ = {alpha}, {m_str}")
axs[row, col].legend()
axs[row, col].set_xticks(range(1, 10))
axs[row, col].set_ylim(0, 0.5)
sub_plot(0,0,0.001,np.random.uniform(1, 10, n_samples),'$m \\sim U[1,10]$')
sub_plot(1,0,0.9,np.random.uniform(1, 10, n_samples),'$m \\sim U[1,10]$')
sub_plot(2,0,1.2,np.random.uniform(1, 10, n_samples),'$m \\sim U[1,10]$')
sub_plot(3,0,2.0,np.random.uniform(1, 10, n_samples),'$m \\sim U[1,10]$')
sub_plot(0,1,0.001,3.0,'$m = 3$')
sub_plot(1,1,0.9,3.0,'$m = 3$')
sub_plot(2,1,1.2,3.0,'$m = 3$')
sub_plot(3,1,2.0,3.0,'$m = 3$')
plt.tight_layout()
plt.savefig("pareto_benfords_law.svg")
Hypothesis testing
We have a null hypothesis H0H_0H0, like "the coin is fair", and an alternative hypothesis H1H_1H1, like "the coin is unfair". We now need to test how likely H1H_1H1 is true using data.
If you have some data and it's extreme if we assume null hypothesis H0H_0H0, then P-value is the probability of getting the result that's as extreme or more extreme than the data if we assume null hypothesis H0H_0H0 is true. If p-value is small then the alternative hypothesis is likely true.
If I do ten coin flips then get 9 heads and 1 tail, the probability that the coin flip is fair but still get 9 heads and 1 tail. P-value is the probability that we get as extreme or more extreme as the result, and the "extreme" is two sided, so p-value is P(9 heads 1 tail)+P(10 heads 0 tail)+P(1 heads 9 tail)+P(0 heads 10 tail)P(\text{9 heads 1 tail}) + P(\text{10 heads 0 tail}) + P(\text{1 heads 9 tail}) + P(\text{0 heads 10 tail})P(9 heads 1 tail)+P(10 heads 0 tail)+P(1 heads 9 tail)+P(0 heads 10 tail) assume coin flip is fair.
Can we swap the null hypothesis and alternative hypothesis? For two conflicting hypothesis, which one should be the null hypothesis? The key is burden of proof. The null hypothesis is the default that most people tend to agree and does not need proving. The alternative hypothesis is special and require you to prove using the data.
The lower the p value, the higher your confidence that alternative hypothesis is true. But due to randomness you cannot be 100% sure.
Caveat: Collect data until significance
If you are doing an AB test, you keep collecting data, and when there is statistical significance (like p-value lower than 0.05) you make a conclusion, this is not statistically sound. A random fluctation in the process could lead to false positive results.
A more rigorous approach is to determine required sample size before AB test. And the fewer data you have the stricter hypothesis test should be (lower p-value threshold). According to O'Brien-Fleming Boundary, the p-value threshold should be 0.001 when you have 25% data, 0.005 when you have 50% data, 0.015 when you have 75% data and 0.045 when you have 100% data.
Bootstrap
If I have some samples and I calculate values like mean, variance, median, etc. The calculated value is called statistic. The statistics themselves are also random. If you are sure "In 95% probability the real median is between 8.1 and 8.2" then [8.1,8.2][8.1,8.2][8.1,8.2] is a confidence interval with 95% confidence level. Confidence interval can measure how uncertain a statistics is.
One way of computing confidence interval is called bootstrap. It doesn't require you to assume that the statistic is normally distributed. But it do require the samples to be i.i.d.
It works by resample from the data and create many replacements of the data, then calculate the statistics of the replacement data, then get the confidence interval.
For example if the original samples are [1.0,2.0,3.0,4.0,5.0][1.0, 2.0, 3.0, 4.0, 5.0][1.0,2.0,3.0,4.0,5.0], resample means randomly select one from original data and repeat 5 times, giving things like [4.0,2.0,4.0,5.0,2.0][4.0, 2.0, 4.0, 5.0, 2.0][4.0,2.0,4.0,5.0,2.0] or [3.0,2.0,4.0,4.0,5.0][3.0, 2.0, 4.0, 4.0, 5.0][3.0,2.0,4.0,4.0,5.0] (they are likely to contain duplicates).
Then compute the statistics for each resample. If the confidence level is 95%, then the confidence interval's lower bound is the 2.5% percentile number in these statistics, and the upper bound is the 97.5% percentile number in these statistics.
Overfitting
When we train a model (including deep learning and linear regression) we want it to also work on new data that's not in training set. But the training itself is to change the model parameter to fit training data.
Overfitting means the training make the model "memorize" the training data and does not discover the underlying rule in real world that generates training data.
Reducing overfitting is a hard topic. The ways to reduce overfitting:
-
Regularization. Force the model to be "simpler". Force the model to compress data. Weight sharing is also regularization (CNN is weight sharing comparing to MLP). Add inductive bias to limit the possibility of model.
(The old way of regularization is to simply reduce parameter count, but in deep learning, there is deep double descent effect where more parameter is better.)
-
Make the model more expressive. If the model is not exprssive enough to capture real underlying rule in real world that generates training data, it's simply unable to generalize. An example is that RNN is less expressive than Transformer due to fixed-size state.
-
Make the training data more comprehensive. Reinforcement learning, if done properly, can provide more comprehensive training data than supervised learning, because of the randomness in interacting with environment.
How to test how overfit a model is?
- Separate the data into training set and test set. Only train using training set and check model performance on test set.
- Test sensitivity to random fluctation. We can add randomness to parameter, input, hyperparameter, etc., then see model performance. An overfit model is more prone to random perturbation because memorization is more "fragile" than real underlying rule.
Issues in real-world statistics
- Survivorship bias and selection bias.
- Simpson's paradox and base rate fallacy.
- Confusing correlation with causalty.
- Try too many different hypothesis. Spurious correlations
- Collect data until significance.
- Wrongly remove outliers.
- ...



 The planes that get hit in critical places never come back, thus don't get included in the stat of bullet holes, forming the regions missing bullet hole in that image.
The planes that get hit in critical places never come back, thus don't get included in the stat of bullet holes, forming the regions missing bullet hole in that image.