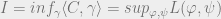Show full content
Here’s a penny to a brown god – not that I know much about him – sullen, untameable, intractable, prone to numerical issues. Patient at times, and at first recognized as a frontier god. Useful, untrustworthy and a conveyor of speech. Forgotten to some extent, but omniscient, and always there.
His rhythm was present in the nursery bedroom,
In the rank ailanthus of the April dooryard,
In the smell of grapes on the autumn table,
And the evening circle in the winter gaslight.
Recently, I have been studying HMMs with a view to working out and implementing something called the CTC loss [1, 2, 3]- a conception that forms the core of many a modern speech recognition application, most recently reincarnating here [4, 5, 6] in streaming ASR. But tangentially, I found that it might be instructive to present how Langrange Multipliers work through two simple examples in GMMs and HMMs. Both of these are properly explained in Bishop 2006 [7]. The HMM machinery in general is an extension of the GMM setup, with state transitions.
GMM example – EMHere, we look at the general scenario where our distribution of interest 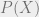





Upon inspection of the EM update above, we can see that we would like to take expectations over the 
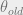


We then maximize the likelihood (or, if you will, the quantity 


The maximization with respect to 

Take derivative of the log likelihood equation with respect to



Now, in order to impose constraints on

Consider maximizing the quantity

Taking derivative with respect to

This gives, after multiplying by

This completes our demonstration for the GMM case.
HMM exampleIn this case, we have a sequential model consisting of 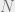
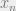

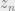

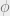


In order to do maximum likelihood estimation for the HMM, we again resort to the EM procedure to iteratively update the model parameters. The

If we plug in the expression for the joint into the logarithm, we notice that it splits into three pieces. The second and third pieces need some unrolling. Notice that in the second piece, two variables 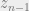

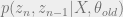

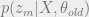

Next, we rewrite the expectations making use of the fact that

We can now put it all together to write what the

The constraints involve
 . As before, include it in the constraint as follows:
. As before, include it in the constraint as follows:
Upon differentiating, multiplying by

 to give
to give 
We can perform exactly similar set of operations for 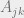

This completes our treatment of Lagrange Multipliers for HMMs
ConclusionsNot to put too fine a point on it, this is an exposition of two examples of Lagrange Multipliers from the well known PRML book by Bishop. The reason I decided to put it up was that in many texts explaining the HMM (e.g. Duda [7] – also, quite recommended), they skim over how these (and similar) terms arise in the forward-backward algorithm. This was a cause of some confusion to me when I went over them. However, it is enormously instructive (though, perhaps a bit time consuming) to work it out from first principles.
References- Alex Graves et al.: Connectionist Temporal Classification https://www.cs.toronto.edu/~graves/icml_2006.pdf
- Hunnan et al.: Deep Speech – Scaling End to End Speech Recognition https://arxiv.org/abs/1412.5567
- Hunnan: Distill blog – https://distill.pub/2017/ctc/
- RNN-Transducer – googleai blog – https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html
- RNN-Transducer – https://arxiv.org/abs/1811.06621
- RNN-Transducer – Assembly AI blog – https://www.assemblyai.com/blog/an-overview-of-transducer-models-for-asr/
- Bishop 2006 – https://www.microsoft.com/en-us/research/people/cmbishop/prml-book/
- Duda, Hart and Stork – Pattern Classification, 2nd Edition – https://www.wiley.com/en-gb/Pattern+Classification%2C+2nd+Edition-p-9780471056690











 to be minimized, as the ‘teacher’ term is constant.
to be minimized, as the ‘teacher’ term is constant. 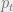 from the teacher and
from the teacher and 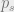 from student, and compute the cross entropy between then as shown above. This is then added to the overall loss setup.
from student, and compute the cross entropy between then as shown above. This is then added to the overall loss setup. 














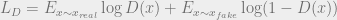
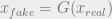 , and the strength of the adversarial term can be modulated by the fudge parameter
, and the strength of the adversarial term can be modulated by the fudge parameter  . Note also that we can draw from different (or same) minibatches of fake and real, in keeping with the notation – as otherwise, we would not need separate notation for
. Note also that we can draw from different (or same) minibatches of fake and real, in keeping with the notation – as otherwise, we would not need separate notation for 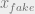 which is obtained by sending
which is obtained by sending  to the generator
to the generator 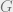 –
–  is 1 for the generator objective and 0 for the other.
is 1 for the generator objective and 0 for the other.





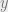 , parameterized by the model
, parameterized by the model 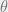 , with a gaussian likelihood.
, with a gaussian likelihood.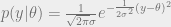
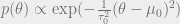
 .
.
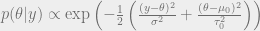

 and
and 
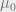 and the ‘data’ term as connoted by
and the ‘data’ term as connoted by 
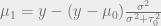


 .
.
 and
and 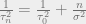
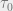 ) gets slowly weighted out by the data term. When we have a large number of data points
) gets slowly weighted out by the data term. When we have a large number of data points 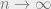 , our uncertainty term vanishes:
, our uncertainty term vanishes: 
 )
)

![\begin{aligned} \mathcal{L}_v = E_{q(z;v)}[\log p(x,z) - \log q(z;v)] = E_{q(z;v)} [f(z)] + H(q(z;v)) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathcal%7BL%7D_v+%3D+E_%7Bq%28z%3Bv%29%7D%5B%5Clog+p%28x%2Cz%29+-+%5Clog+q%28z%3Bv%29%5D+%3D+E_%7Bq%28z%3Bv%29%7D+%5Bf%28z%29%5D+%2B+H%28q%28z%3Bv%29%29+%5Cend%7Baligned%7D+&bg=eeeeee&fg=666666&s=0&c=20201002)
 by varying the variational parameters v through the surrogate distribution
by varying the variational parameters v through the surrogate distribution 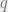 .
.![\begin{aligned} \int \nabla_v q(z;v) f(z) dz &=& \int q(z;v) \nabla_v \log q(z;v) f(z) dz \ &=& E_q(z;v) [f(z) \log q(z;v)] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cint+%5Cnabla_v+q%28z%3Bv%29+f%28z%29+dz+%26%3D%26+%5Cint+q%28z%3Bv%29+%5Cnabla_v+%5Clog+q%28z%3Bv%29+f%28z%29+dz+%5C+%26%3D%26+E_q%28z%3Bv%29+%5Bf%28z%29+%5Clog+q%28z%3Bv%29%5D+%5Cend%7Baligned%7D+&bg=eeeeee&fg=666666&s=0&c=20201002)
![E_q(z;v)[f(z) \log q(z;v)] = \frac{1}{L} \sum_{l=1}^L [f(z^l) \log q(z^l;v)]](https://s0.wp.com/latex.php?latex=E_q%28z%3Bv%29%5Bf%28z%29+%5Clog+q%28z%3Bv%29%5D+%3D+%5Cfrac%7B1%7D%7BL%7D+%5Csum_%7Bl%3D1%7D%5EL+%5Bf%28z%5El%29+%5Clog+q%28z%5El%3Bv%29%5D+&bg=eeeeee&fg=666666&s=0&c=20201002)
![\nabla_v \mathcal{L} = \nabla_v E_{q(z;v)} [f(z)] = \nabla_v \int q(z;v) f(z) dz + \cdots](https://s0.wp.com/latex.php?latex=%5Cnabla_v+%5Cmathcal%7BL%7D+%3D+%5Cnabla_v+E_%7Bq%28z%3Bv%29%7D+%5Bf%28z%29%5D+%3D+%5Cnabla_v+%5Cint+q%28z%3Bv%29+f%28z%29+dz+%2B+%5Ccdots+&bg=eeeeee&fg=666666&s=0&c=20201002)
 , but as the estimator contains variational parameters
, but as the estimator contains variational parameters  within it, we cannot carry out any sort of diffentiation operations to it with respect to
within it, we cannot carry out any sort of diffentiation operations to it with respect to  into another distribution
into another distribution  independent of
independent of 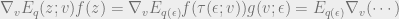
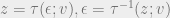 with pdfs
with pdfs  . In some cases, it is possible to find a transformation such that the reparameterized distribution is independent of the variational parameters
. In some cases, it is possible to find a transformation such that the reparameterized distribution is independent of the variational parameters 
 .
.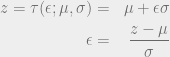
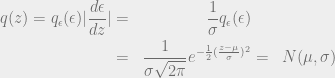

 so that
so that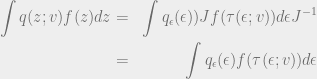

 is weakly dependent on
is weakly dependent on  has dependence on the variational parameters. In this case, the expectation will have to be evaluated term by term with chain rule
has dependence on the variational parameters. In this case, the expectation will have to be evaluated term by term with chain rule![\nabla_v E_{q(z;v)} [f(z)] = \nabla_v E_{q_\epsilon(\epsilon;v)} [f (\tau(\epsilon;v))] = \nabla_v \int q_\epsilon(\epsilon;v) f(\tau(\epsilon;v)) d\epsilon](https://s0.wp.com/latex.php?latex=%5Cnabla_v+E_%7Bq%28z%3Bv%29%7D+%5Bf%28z%29%5D+%3D+%5Cnabla_v+E_%7Bq_%5Cepsilon%28%5Cepsilon%3Bv%29%7D+%5Bf+%28%5Ctau%28%5Cepsilon%3Bv%29%29%5D+%3D+%5Cnabla_v+%5Cint+q_%5Cepsilon%28%5Cepsilon%3Bv%29+f%28%5Ctau%28%5Cepsilon%3Bv%29%29+d%5Cepsilon+&bg=eeeeee&fg=666666&s=0&c=20201002)
![\nabla_v E_{q(z;v)}[f(z)] = \int q_\epsilon(\epsilon;v) \nabla_v f(\tau(\epsilon;v)) d\epsilon + \int q_\epsilon(\epsilon;v) f(\tau(\epsilon;v))\nabla_v \log q_\epsilon(\epsilon;v) d\epsilon](https://s0.wp.com/latex.php?latex=%5Cnabla_v+E_%7Bq%28z%3Bv%29%7D%5Bf%28z%29%5D+%3D+%5Cint+q_%5Cepsilon%28%5Cepsilon%3Bv%29+%5Cnabla_v+f%28%5Ctau%28%5Cepsilon%3Bv%29%29+d%5Cepsilon+%2B+%5Cint+q_%5Cepsilon%28%5Cepsilon%3Bv%29+f%28%5Ctau%28%5Cepsilon%3Bv%29%29%5Cnabla_v+%5Clog+q_%5Cepsilon%28%5Cepsilon%3Bv%29+d%5Cepsilon+&bg=eeeeee&fg=666666&s=0&c=20201002)
![\begin{aligned} g^{rep} = E_{q_\epsilon(\epsilon;v)} \nabla_v f(\tau(\epsilon;v)) \\ g^{corr} = E_{q_\epsilon(\epsilon;v)} f(\tau(\epsilon;v)) \nabla_v \log q_\epsilon(\epsilon;v) \\ \mathcal{L}_v = g^{rep} + g^{corr} + \nabla_v H[q(z;v)] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+g%5E%7Brep%7D+%3D+E_%7Bq_%5Cepsilon%28%5Cepsilon%3Bv%29%7D+%5Cnabla_v+f%28%5Ctau%28%5Cepsilon%3Bv%29%29+%5C%5C+g%5E%7Bcorr%7D+%3D+E_%7Bq_%5Cepsilon%28%5Cepsilon%3Bv%29%7D+f%28%5Ctau%28%5Cepsilon%3Bv%29%29+%5Cnabla_v+%5Clog+q_%5Cepsilon%28%5Cepsilon%3Bv%29+%5C%5C+%5Cmathcal%7BL%7D_v+%3D+g%5E%7Brep%7D+%2B+g%5E%7Bcorr%7D+%2B+%5Cnabla_v+H%5Bq%28z%3Bv%29%5D+%5Cend%7Baligned%7D+&bg=eeeeee&fg=666666&s=0&c=20201002)
 vanishes.
vanishes. satisfying
satisfying  , we seek to find another estimator
, we seek to find another estimator  of lower variance, using an estimator
of lower variance, using an estimator  with
with  :
:

 such that
such that  .
.![\begin{aligned} \nabla_v E_{q(z;v)} [f(z)] &= E_{q(z;v)} [f(z) \nabla_v \log q(z;v)] \\ & + E_{q(z;v)}[\nabla_z f(z) h(\tau^{-1} (z;v);v)] \\ & + E_{q(z;v)} [f(z) (\nabla_z \log q(z;v) h(\tau^{-1}(z;v);v)+u(\tau^{-1}(z;v);v))] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cnabla_v+E_%7Bq%28z%3Bv%29%7D+%5Bf%28z%29%5D+%26%3D+E_%7Bq%28z%3Bv%29%7D+%5Bf%28z%29+%5Cnabla_v+%5Clog+q%28z%3Bv%29%5D+%5C%5C+%26+%2B+E_%7Bq%28z%3Bv%29%7D%5B%5Cnabla_z+f%28z%29+h%28%5Ctau%5E%7B-1%7D+%28z%3Bv%29%3Bv%29%5D+%5C%5C+%26+%2B+E_%7Bq%28z%3Bv%29%7D+%5Bf%28z%29+%28%5Cnabla_z+%5Clog+q%28z%3Bv%29+h%28%5Ctau%5E%7B-1%7D%28z%3Bv%29%3Bv%29%2Bu%28%5Ctau%5E%7B-1%7D%28z%3Bv%29%3Bv%29%29%5D+%5Cend%7Baligned%7D+&bg=eeeeee&fg=666666&s=0&c=20201002)
 , and a transformation
, and a transformation  , how do we calculate the pdf of the variable
, how do we calculate the pdf of the variable 
 (use modulus to keep sign positive)
(use modulus to keep sign positive) :
:  , with the transformation from
, with the transformation from  :
: 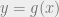 . Then the CDF of
. Then the CDF of  is given by:
is given by: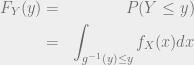
 is an increasing or decreasing function. In the case of it being an increasing function, the expression becomes:
is an increasing or decreasing function. In the case of it being an increasing function, the expression becomes: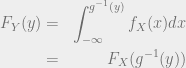
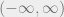 . Likewise, if
. Likewise, if  to
to 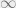 . This is because for any
. This is because for any  ,
,  in this case. This is made use of in the formula for
in this case. This is made use of in the formula for 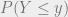 .
.
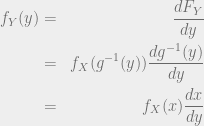
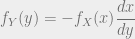

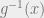 needs to exist, so the function must be one-one (i.e. have only one equivalent mapping in the inverse), and onto (no point must be left out).
needs to exist, so the function must be one-one (i.e. have only one equivalent mapping in the inverse), and onto (no point must be left out). , we have a transformation (with sloppy notation)
, we have a transformation (with sloppy notation) 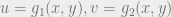 , functions that are one-one and onto, we should have an inverse transformation
, functions that are one-one and onto, we should have an inverse transformation  .
.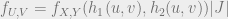

 (which could be, say, a gaussian), and then transform it into more and more expressive distributions. We do the bookkeeping by means of the transformation machinery described above.
(which could be, say, a gaussian), and then transform it into more and more expressive distributions. We do the bookkeeping by means of the transformation machinery described above.
 , which we would like to come from the same distribution as the ground truth
, which we would like to come from the same distribution as the ground truth  . This is achieved by minimizing the Wasserstein distance between
. This is achieved by minimizing the Wasserstein distance between 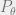 and
and  . We can propose this problem in primal space through Optimal Transport.
. We can propose this problem in primal space through Optimal Transport.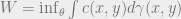
 ; i.e. we sample
; i.e. we sample  and send it through the generator, or in other words, we push forward
and send it through the generator, or in other words, we push forward  ; and
; and  . The Wasserstein distance is characterized by a particular type of joint distribution
. The Wasserstein distance is characterized by a particular type of joint distribution 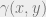 of
of  –
– 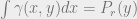 ;
;  .
. can be specified as a Euclidean distance, in which case we term this quantity a Wasserstein distance:
can be specified as a Euclidean distance, in which case we term this quantity a Wasserstein distance:
 root:
root: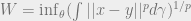
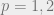 . The original Monge problem was with
. The original Monge problem was with 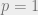 ,
,  . When we use the squared distance with
. When we use the squared distance with 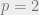 , we come across something called “Brenier’s theorem” in the Monge problem.
, we come across something called “Brenier’s theorem” in the Monge problem. (parameterized by
(parameterized by  ) that maximizes the above. The constraint, of course is that these functions should be 1-Lipshitz continuous.
) that maximizes the above. The constraint, of course is that these functions should be 1-Lipshitz continuous. , a function is Lipshitz continuous [4] if there exists a constant
, a function is Lipshitz continuous [4] if there exists a constant 
 . The question then arises as to how we can enforce this constraint. The paper’s recipe is to ‘clip’ the weights so that they lie in a ball
. The question then arises as to how we can enforce this constraint. The paper’s recipe is to ‘clip’ the weights so that they lie in a ball ![[-0.01, 0.01]^l](https://s0.wp.com/latex.php?latex=%5B-0.01%2C+0.01%5D%5El&bg=eeeeee&fg=666666&s=0&c=20201002) (
(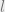 being the dimensionality). Here, we try to intuit why this might work through some simple analysis.
being the dimensionality). Here, we try to intuit why this might work through some simple analysis.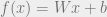
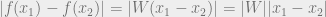
 . One way of enforcing this is to arbitrarily clip the weights to some small value. They use
. One way of enforcing this is to arbitrarily clip the weights to some small value. They use  , that are very close to each other, we get the gradient.
, that are very close to each other, we get the gradient.



 , the transport plan. The joint has the property that when we take its marginals, we get the source and target masses.
, the transport plan. The joint has the property that when we take its marginals, we get the source and target masses.
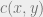 is the distance. When we take the Euclidean distance
is the distance. When we take the Euclidean distance  , we call this a Wasserstein distance. The original problem by Monge concerned itself with moving mounds of earth between points, with
, we call this a Wasserstein distance. The original problem by Monge concerned itself with moving mounds of earth between points, with  . The problem was defined such that one wanted to transport earth from a point
. The problem was defined such that one wanted to transport earth from a point 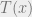 using a mass conservation condition. Apparently, this formulation posed several problems, such as non-existence (as mass cannot be split).
using a mass conservation condition. Apparently, this formulation posed several problems, such as non-existence (as mass cannot be split). . We work in the discrete setting to stay compatible with the notes in [1].
. We work in the discrete setting to stay compatible with the notes in [1]. point masses
point masses 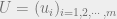 , and
, and 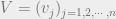 , and we would like to transport
, and we would like to transport 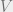 with minimum cost. The transportation plan in this case is the ‘joint’
with minimum cost. The transportation plan in this case is the ‘joint’ 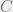 where
where 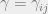 ,
,  with
with  ,
, 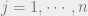 .
.
 ;
;  (
(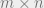 flattened into a vector), so the quantity
flattened into a vector), so the quantity  should be of dimension
should be of dimension 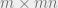 . Likewise,
. Likewise, 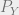 should be of dimension
should be of dimension  . We are now ready to set up the objective.
. We are now ready to set up the objective.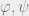 .
. are satisfied, it equals the desired expression
are satisfied, it equals the desired expression  . Otherwise, its maximum would be
. Otherwise, its maximum would be 


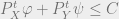 is to be viewed in a component wise sense.
is to be viewed in a component wise sense.