Show full content
Marcel Scherer, Eli Shamovich and I have recently uploaded to the arxiv our new paper “On the spectral radius of operator tuples“. In this paper we study the spectral radius function 







Marcel Scherer, Eli Shamovich and I have recently uploaded to the arxiv our new paper “On the spectral radius of operator tuples“. In this paper we study the spectral radius function

I have recently seriously written on “The Unreasonable Flakiness of Assessment in the Mathematical Sciences“, and today I want to look at our flaky business from another angle, not 100% serious, but still. Any mathematician I know is overloaded and backlogged with referee work, and if they’re not overloaded that’s because they are rejecting more than half of the “invitations” to referee papers. On the other hand, we all know the experience, of submitting a paper and essentially saying “goodbye” to the paper, knowing that next time they’ll hear about it a year or so later. It’s understandable, because the referees have too many papers to referee, so they will only start looking at our paper several months after agreeing to review it.
As authors, it seems like a good tactic to “aim slightly high” when submitting our papers, because the reward for publishing in a top journal is so much higher that it seems worth the gamble. Worst case it gets rejected, and then we can correct and aim lower until we get it through the hoop. From the point of view of the authors, the tactic of aiming a bit high first makes sense if there is no urgency in getting out another publication. From an ecological point of view, this is somewhat wasteful: because a paper rejected is a paper resubmitted somewhere else. So whenever we aim a bit high, we are actually creating more referee work for ourselves.
On the other side of the fence, as referees, we feel responsible for upholding the standards of the journals that asked our help in refereeing. But the same ecological conservation law applies: a paper rejected is a paper resubmitted somewhere else. So whenever we decide to reject a paper, we are again creating more referee work for ourselves.
Here is what I am going to do:
Following up on my commitment from the last post, I am coming back with a final report of the Brown’s Philosophy of Mathematics: A Contemporary Introduction to the World of Proofs and Pictures. I wrote midway through the book that I recommend it, because I felt that by reading it I was working myself up into debates with the author, which made reading very active. Having read the book, I feel even more enthusiastic than before to study philosophy of mathematics, so I still feel that this book should be recommended. However, I must say that I did not find it to be a well written book. Fun, yes. Enticing, sure. Entertaining even. But it doesn’t feel like any justice has been done to the subject, and I am not sure what I have learned. What bothers me is most is not that the author concentrated on his own view, not doing justice to other points of view and debunking them in a shallow way – it is actually refreshing to read a book with an opinion. What bothers me most is that the various approaches and schools are simply not explained in sufficient detail and depth (even the author’s). The author name-drops various philosophers or thinkers or various approaches, and goes into a discussion before the reader has a chance to understand really what it is about. Like a child telling his parent about a daydream, he just starts in the middle as if we can see his thoughts. In earlier parts of the books it worked fine for me, because the main characters (Russel, Hilbert, etc.) were familiar to me. Later in the book, when he discussed Lakatos, I was very happy, because I happened to read Lakatos with attention, so I could follow the hints and complete the argument using my memory. But later on in the book, for example when discussing Wittgenstein, it became harder to enjoy, since the presentation seems to assume that the reader knows who the philosopher is, recognizes his main works and understands what they are about. And when the author came to discuss Freiling’s “refutation” of the continuum hypothesis, he was writing as if we have already discussed it, without even putting it into a time frame, so it felt as if the text was not intended to be read by me.
The author’s philosophical-mathematical position is that of “liberal platonism”. Roughly, he believes that mathematical objects have their own existence, and that we can study them using many tools: intuition, computations, pictures, proofs, conjectures, analogies, … Note that proofs is just one method of study. This point of view conforms with mathematical practice, though it might not conform with the prevalent point of view of practicing mathematicians. In Brown’s own words, he “…consider[s] mathematics to be like the natural sciences where some of the most important discoveries, such as the microscope, for instance, initiated new methods of generating evidence.” We study nature by making observations and experiments, as well as by theorizing, and we study mathematics in very much the same way. Axioms in mathematics play the same role as theories in physics; whereas naive formalist views of mathematics identify truth and proof, Brown suggest that theorem being a consequence of the axioms can be used to test whether the axioms are true (or “good”).
The book treats the use of pictures as proofs or evidence for mathematical truths less than one might expect from the subtitle. But it is one of the main innovations of the book, and there is enough stuff to chew, especially in Chapters 3 and 12. I found this discussion to be the book’s most important contribution. Brown makes a very good point that a written proof in logical symbols can mislead and lead to errors no less than a picture. Moreover, none of the crises that shook the foundations of mathematics nor any of the paradoxes that forced mathematicians to rethink the axiomatic approach was the result of using pictures – they were the result of using “standard mathematics”, and in particular set theory, wrongly. Beyond these undeniable observations, Brown also makes the more radical claim that a picture can constitute a complete rigorous proof. I’ll think about it.
To summarize, this book is an interesting, eclectic and idiosyncratic introduction to the philosophy of mathematics, with an emphasis on somewhat a non-mainstream (and very compelling) point of view that mathematics deals with subsisting objects, which can be investigated and known in infinitely many ways – mathematical proof being just one. If you are going to read only a handful of books on the topic, this shouldn’t be it. But if you are planning to seriously delve into philosophy of mathematics, I recommend adding it to your reading list.
Let me end with a quote from the end of the book: “Mathematics is one of humanity’s nobler activities. Trying to make sense of it is an enormously difficult task.” Yes, I agree with that. And the more that I think about it, the harder it seems.
Is there any better escape from reality than mathematics? Sure there is: philosophy of mathematics.
I am reading “Philosophy of Mathematics: A Contemporary Introduction to the Worlds of Proofs and Pictures” by James Robert Brown.

The book advocates a flavor of a Platonistic philosophy of math. A feature of the book is an argument for the validity of pictures in proofs, not just as psychological aids but rather as “windows into Plato’s heaven”. To be more precise, if mathematics is about real objects that exist some-abstract-where then we can learn about this mathematical reality in . What I don’t like about this book is precisely what I love about it: almost every page contains some idea or opinion that I find weak or flawed, stated in unwavering confidence. I find the authors’s rebuttal of the points of views of his philosophical opponents especially enraging and unfair, and I feel compelled to go read their account. But I am enjoying my imaginary arguments with the author immensely. Half way through, I can already highly recommend this book; the book is truly thought provoking.
Why am I thinking about philosophy of math? Well, to be honest, I always am. But why am I doing it publicly? First, it is becoming urgent to do so (because of AI duh, but also because as my responsibility grows I have to get to grips with this stuff). Second, I am writing about it in order to make some commitment.
Here is a small commitment: after finishing reading I will try to blog about what I’ve learned.
Mid size commitment: I will re-read Imre Lakatos’s “Proofs and Refutations” and write a summary.
I feel like making a big commitment, too: five years from now I will design an undergraduate course that will be an Introduction to Philosophy of Mathematics. Five years should be enough to prepare.
But now I have to prepare for next semester, which according to what things look like now, will begin under fire.
Of course, this is a rant. You can tell by the title. But, for the record, let me be forward that I don’t have an idea how to solve the problem that I will be lamenting, nor do I think that I am doing a better job than everyone else at assessing mathematics done by other people. I am writing this little rant as the beginning of a thought process about how to improve things. Now that this little apology is out of the way, let me lament away.
Once in a while I compare the rigor and care that I exercise when checking whether a piece of mathematics is correct, with the methodology that I employ when evaluating the quality of mathematical output, such as when I referee a paper for a journal, or write a report for a grant funding agency, when considering job applicants and even when judging the worth of my own work. The difference is like earth and sky. I believe that I am not alone in this.
In a mathematical proof, every single claim has to follow with fool-proof logic from previously established propositions, every reference needs to be precise. How careful we are when crafting these arguments! But when assessing a paper submitted to a journal? Well, we do our best.
I read a paper carefully and convince myself that it is correct and new. But is it good enough? I squint at the paper and write: “The paper under review does not meet the standard of the Journal of A” and recommend rejection. But if this paper would have been submitted to another journal, I might have written “I recommend to publish this paper in the Journal of B“. Because JOB is somewhat less prestigious than JOA, you see. It’s not that I have read more than a couple of papers that were published in either of these two journals in the past five years, I just know that JOA is better, I can just tell that this paper does or doesn’t cut the bar. As a member of the community I seem to have some idea of how good a paper has to be in order to be published in this or that journal. And that’s that.
Recommending that their paper be rejected is not the worst thing that you can do to someone. Big deal! Submit somewhere else. But we also need to consider job applicants. And here, to our horror, we need to assess the quality of work done in a field in which we are not experts. Our chief tool – at least for screening and forming a short list – is the list of publications. We read the list very carefully, we check the timeline against the output, but most importantly, we look at journal names. If there are Top Journals in the publication list, then this applicant is considered to be promising.
Applicants are compared one against the other. In a way it is like a card game: every list of publications is like a hand that the applicant obtained. There are rules. Some rules are agreed upon universally, some are “house rules” that come in different variants. All things being equal, having more papers is better. But the quality of the venue counts much more. In the imaginary example above JOA beats JOB. In math, there are four big journals – Annals of Mathematics, Acta Mathematica, Journal of the American Math Society, and Inventiones mathematicae – and they play the role of joker cards – they beat anything. I think that these rules do make some sense, because if you use the criterion “published in the top four” for deciding if someone is an excellent mathematician, you are going to have a very low false positive error rate. Even if this method has a high false negative rate, from the point of view of top institutions doing the hiring it makes sense to use this proxy.
Most mathematicians are wary of using bibliometrics. We are not so stupid that we make judgements based on quantitative measures that can be gamed. Most of us have our own personal journal ranking system. We might all agree what the big four journals are, but then there are dozens of very selective journals and we have different opinions about how they compare one with the other. I recently decided that I want a paper in a top journal so I submitted to Journal X. Happily the paper was accepted, but then a friend told me that Journal X is not as selective as it used to be. Besides being pissed at this, I thought how did you reach this conclusion? Surely he hasn’t evaluated a significant number of papers over the years but is making an opinion based on a small sample of papers. It’s ironic: we so often use the prestige of a journal to assess the quality of a paper, that assessing the quality of a journal by a small sample of papers it published almost seems like circular reasoning.
To complicate things even more, it is also the case that different people will employ different strategies when choosing a journal to which they submit their work. So even if we try to apply uniform standards for evaluating job applicants, the job applicants will not be lending themselves to a uniform evaluation since they approach our ranking machine from different directions.
It has happened to me that an excellent paper that I submitted to a good journal came back with two contradicting referee reports. A reasonable conclusion from this experience is that whether or not a paper of given quality gets accepted to a certain journal is a random variable. Note that I am not claiming that it is a 50:50 toss up, but rather that when one submits to a journal one is making an educated bet. Sure, most papers have 0% chance of being published in Acta. But some very excellent papers were rejected from Acta, meaning that their authors could not predict that they would be rejected for certain. In some cases it could be the negative opinion of a single referee out of a handful that leads to rejection – things might have worked out differently with a little bit of luck.
Suppose you are a PhD student, and you have written what you believe to be an excellent paper. Where should you submit it? The higher you send it, the bigger the prize, you will be able to apply for jobs in more prestigious places. But the higher you send it, the greater the chances that it will eventually get rejected, and that lowers the chances of having an actual publication when you apply for a postdoc. The same dilemma arises at every step of one’s career. Different people choose different strategies, based on their personalities, connections, responsibilities and safety nets.
To be clear: when evaluating a job applicant for a position, nobody relies on blindly reading a list of publications. We look into the research, applicants are often invited to give a talk, people in the department who work in related fields might be able to weigh in. Most importantly, letters of recommendations are solicited. The letters of recommendations are written by experts in the field who can explain the novelty and difficulty of the applicant’s work, and sometimes give very delicate and valuable information, such as comparing the applicant to researchers in a similar stage.
Letters make us more informed, but the job of taking a set of applicants, each with their own set of letters of recommendation, and ranking them according to the letters is not a very well defined task with rigorous methodology. Different applicants typically have disjoint sets of letter writers, different writers have different styles, and different readers come up with different interpretations for the same letters!
Perhaps it is unavoidable that a mathematician operating outside of mathematics will feel the tension between the rigorous standards of our profession and the subjective task of assessing quality and making a value judgement. Maybe the question to ask is not whether we are being rigorous or consistent, but whether we end up making good decisions.
This document contains some excerpts from Part B2 of my ERC grant proposal. The area of NC function theory is not as widely recognized as some other areas competing for grants, I therefore thought that it would be interesting for some readers if I told the mathematical story of how I was led to enter this area.
My proposal ended up not being funded, and I thought that it might be of use to somebody out there if I made the expository parts of my proposal available online.
If I am already sharing stuff from my proposal, here is an excerpt from Part B1 of my proposal, a brief summary of my main research achievements and peer recognition. It makes me squirm to read it, but I forgive myself: one has to get into the mood of being full of oneself when writing these kinds of things. No way around it, you really have to get into the attitude when competing for grants. After all, if one is applying for millions of Euros in funding, one can’t pretend to be humble and shy.
In a recent academic assembly a colleague said something along the lines of “the AI revolution is imminent, we must act quickly or we will be left behind” which – together with the incoherent clamor coming from all directions (ministry of education, university administration, colleagues, students, social media) – has led me to realize the extent of the confusion in which higher education finds itself today.
There is no new thing under the sun. This is not the first time that we’ve seen the academic community under the spell of a collective urge to scramble and catch the future by its tail. But the current anticipation of the rise of AI seems different: this time it’s justified, this time it’s a true revolution. Okay. So before stepping out to face the storm, let’s take a deep breath and get our thoughts in order.
Students, and everyone else, will use whatever technology is available. We can’t and shouldn’t try to avoid that or outlaw it. But technology is manufactured to be easy to use. We didn’t need to teach them to use the mouse, a touch screen, or google search. I learned about Wolfram alpha from my students. I found out about Stack Exchange myself, but didn’t have to tell my students about it. For a generation, programmers have relied on code that they could cut and paste from the web for small things but – for crying loud! – no professor of CS needed to show her students how to cut and paste code from forums. Today, we are told that some – but not all! – engineers in the industry can do the work of 50 programmers by making good use of AI. Remarkable! But none of these engineers who are right now working wonders with AI was taught how to “prompt engineer” – they are adapting to a new technology while building on their domain knowledge and problem solving abilities. As we embrace the change, we should acknowledge that our responsibility as educators only grows with this change. Responsibility cannot offloaded to AI. Nothing has to be.
(This post is an updated version of an older post with another project added)
In the recent spring semester I taught the advanced course Function Theory 2, which was about a number of advanced topics in complex function theory, where “advanced” means that they are typically not covered in a first course in complex function theory (here is the info page for the course to get an idea of what is was about). For their final projects, students were required to choose one of a list of topics on which they wrote a report and gave a lecture. Some of the students agreed to share their projects online, and I am putting them up here for posterity 
Gal Goren and Yarden Sharoni asked me if they could prepare a video instead of a lecture. Even though I estimated that this would be about ten times more difficult than giving a talk, I agreed. I am very happy to share their final project here, which was beautifully done.
Perhaps it is worth saying that the video is not entirely self contained, and it does require the viewer to know stuff about holomorphic functions, meromorphic function, and specifically to know quite a lot about the Riemann zeta function. All the prerequisites for this video were taught in the lectures, however, I left the Prime Number Theorem and the most challenging facts needed about the Riemann zeta function to the project. However, in the video Gal and Yarden explain all the facts that they use, and a viewer with standard undergraduate complex analysis background that is willing to take that on faith some facts will be able to enjoy this video (Gal and Yarden are planning to prepare another video which will contain all the prerequisites, so I subscribed to their channel looking for to that).
2. What did Riemann do in his famous paper?Uri Ronen and Tom Waknine chose one of the most challenging topics offered: to read Riemann’s paper “On the number of primes less than a given magnitude” write a report on it and give it to a lecture to the class, explaining what this paper achieves. I suggested to use Edwards’s book “Riemann’s Zeta Function” which contains a translation of the paper and begins with a chapter walking the readers through the paper. The excellent reference notwithstanding, this was a very challenging project and Uri and Tom gave a masterful lecture. Here is Uri and Tom’s report:
On Riemann’s famous paper on the Zeta function – On the Number of Primes Less Than a Given MagnitudeDownload 3. Other projectsOther projects by the students (which I will not upload) were on:
Malte Gerhold, Marcel Scherer and I have recently posted our paper “Empirical bounds for dilations of free unitaries and the universal commuting dilation constant” to the arxiv. This my first paper that is in experimental mathematics. What we do in it is gather evidence for the conjecture that the universal commuting dilation constant 
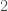
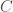







Equivalently, 

It is easy to show that 











We had the ideas and the basic code for computing dilation constants (of matrices) for a few years now. Why did we carry out the experiment only now? First, we could now compute the dilation constants for pairs 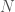
Wait, just good old fashioned optimization algorithms, no AI? No LLMs? What year is this? Well, in fact we did use LLMs (GitHub Copilot to be precise) but in a very modest way. Another reason that we have been waiting with this project all these years is that it is somewhat of a nuisance for rusty programmers like us to write scripts that run numerical experiments and handle data; we thought that it could make a nice undergraduate project (like this, but even better because it fits in with some theory). However, the pandemic, the war, and other stuff prevented me from offering a numerical undergraduate project in the past few years. A few months ago we realized that we shouldn’t wait until an undergraduate comes along to do the all the dirty work, since it can be done by ChatGPT or one of its cousins. So we used Copilot to help us quickly write scripts for performing experiments, data handling, and visualisations. This is a rather modest use of AI compared to the massive hype that I am exposed to online! I find myself being amused – and even relieved – that we use computers for our research but in the good old fashioned way, by invoking powerful optimization algorithm to compute constants that we theoretically know how to but wouldn’t be able to by hand.
More convincing, less rigorousI need to explain the title of this post, which is really a sentence that we wrote in the paper (and which I am making a big deal of because perhaps at other times in my career as a philosopher of math I would have found it paradoxical). The thing is that we can prove rigorously, that for every 


and while 



I I found the following nice history of large language models (LLMs, or in other words Chat-GPT, CLaude and all their AI kin) on Gregory Gundersen’s blog:
https://gregorygundersen.com/blog/2025/10/01/large-language-models/
I find it interesting to follow up on developments in AI and machine learning not “just” because it is THE most dramatic and exciting revolution in science and technology of the decade (so far!) but also because it is intriguing to me, as a mathematician, to see what kinds of math is needed (i) to understand what’s going on under the hood, and (ii) to have partaken in the development of it (the short story is: not very much, but still some nontrivial amount of mathematics and mathematical maturity is needed). When I write “as a mathematician” I mean both as research mathematician as well as a teacher of math – it is incredibly important that we who teach mathematics have an idea of what math is used in today’s frontiers of science and technology.
The short answer is that one needs linear algebra, calculus, multivariate calculus, algorithms and probability theory to have a basic understanding of of what’s going on below the hood in these LLMs, though for actually developing new stuff one will need a wider education and also some mathematical maturity. Needless to say, the mathematics of Machine Learning is just one very small aspect of this field.
The history I linked to has a nice reference list and several links to other interesting blog posts or essays. In particular it sent me to Richard Sutton’s (short) essay The Bitter Lesson which I’ve been hearing of lately but never read, which describes the author’s conclusion that “general methods that leverage computation are ultimately the most effective, and by a large margin”, or, to put it in my words: researchers like to try to invent ingenious algorithms to do stuff, but typically simple methods that scale well do better because eventually the computers will become fast enough so that brute force will win.
Update: after posting this, I realized that some readers may lack the background in neural networks to understand the above survey. For readers lacking any previous acquaintance with neural networks, the first three pages of this Notice’s article by Balestriero et al. is a very nice place to start.
