Uncategorizedgithumorprogrammingsoftware development
Maybe it was an elegant one like 184bdd8e5dd39de66d48cd8b5e48d64c1a78d7ef or a more prosaic one like 8834fc4b992220d3eb2679557eccb6654453bfb1, but the result is the same. For me personally, I went as far as pinging all 300 developers on our Slack instance that I wanted adf3e0e8c5ffdc913ccf62cd3b349a1ece09f578, and a couple days later someone took it anyway. And when I asked them […]
Show full content
We’ve all had it happen to us. You wake up, roll over to grab your phone, and check your company’s commit log. And then you see it. Someone else has taken the commit id you wanted. And you’re crestfallen.
Maybe it was an elegant one like 184bdd8e5dd39de66d48cd8b5e48d64c1a78d7ef or a more prosaic one like 8834fc4b992220d3eb2679557eccb6654453bfb1, but the result is the same. For me personally, I went as far as pinging all 300 developers on our Slack instance that I wanted adf3e0e8c5ffdc913ccf62cd3b349a1ece09f578, and a couple days later someone took it anyway. And when I asked them why, why would they do something so petty and cruel, all they could say was “What is actually wrong with you?” I reported them to my mom but nothing’s happened yet.
Today I’m introducing git dibs so nobody ever takes your coveted commit hash again.
With git dibs you can call dibs on a 40 hexadecimal-character SHA-1 hash, asserting your right to use it to identify a future git commit.
Concerned about accidentally trying to use another developer’s reserved hash? We’ve got your covered! With git dibs, you can add a hook to all your git repositories that will roll back any commits that violate the social contract.
Don’t forget to vote on your favorite hashes, because we are a community.
I made something beautifully useless and I love it
For a dumb joke I took way too far, I’m pretty happy about git dibs. I was worried that spending so many hours would kill the joke for me, but I’m still laughing. It’s like one of those useless boxes with a switch that only exists to turn itself off when you activate it.
With git, you don’t have any idea what your commit ID is going to be until you actually make it, unless you are some kind of degenerate that manually constructs the git hash with git hash-object. It’s a deterministic SHA-1 hash of a bunch of stuff, least of which is a timestamp and your author information.
So the idea of “reserving a commit ID” is ludicrous.
What’s even more insane is the thought that anybody would even respect a reserved commit hash, especially one that would be used in a completely separate repo. Besides, randomly landing on someone else’s commit hash is probably on par with launching a ball bearing into space and hitting a specific quark 200 million light years away.
This all stemmed from a stupid joke I posted on my company’s Slack (they bear a lot of my stupid jokes, and if you’re one of them I thank you for your service). I was playing with git hooks and eventually wondered if you could reject a commit based on the commit hash (you can’t, you have to wait until post-commit and then rollback). So of course I decided to take it way too far and build a production-grade NodeJS website deployed to Vercel with a Postgresql database and an official Python SDK published to PyPi.
All the shenanigans
My favorite part of git dibs is that if you do reserve a commit, the system has no way of actually knowing it’s yours if you somehow manage to land on it. Effectively, all git dibs does is make it impossible to use a commit. Sorry for the inconvenience.
That’s why the favicon for the website is perfect: A green check mark for “successful reservation” hovering above a trash can. The whole ensemble has the appearance of an arrow pointing to the bottom of a trash can, which is what you’d be doing to your repo if you actually set up a git hook to reject commits someone has called “dibs” on.
I also purchased the domain reserveryourgitcommitnowdotcom.com because the site was originally “Git commit reserver” before I thought of “git dibs”. I kind of miss the name because the icon was a big “GC” that could also stand for “garbage collected”, and this partly inspired the final gitdibs favicon.
In the “latest” tab, I made sure to really sell the urgency of reserving a commit before they all ran out by showing how many were left unclaimed. I considered computing how many commits really were left unreserved until I did the math and realized that 16^40 is so unfathomably large that even if a trillion were reserved, the number didn’t change, so 1.4615016e+48 is just hardcoded into the HTML.
I added the ability to vote partially because some hex strings are legitimately cool, but mostly because I wanted to say “Your vote matters!” even though it doesn’t. There are no accounts and everything is anonymized. If you tried hard enough, you could vote as many times as you wanted.
“Service guarantees citizenship”
The “Search” page has the ability to paginate through every reserved hash in chunks of 50. This was partly me venting about the poorly-implemented SQL pagination I’ve seen, and just wanting to do it right for a change. Big nod to Marcus Winand’s Use the index Luke for teaching me a ton about SQL indexes.
An initial design allowed submissions to include contact information so you could be reached by people wanting to use your hash. I removed it because after reserving a commit, it can neither be edited nor deleted. This is by design, because we’ve all learned that the best way to scale is by using append-only data structures.
When I first deployed the backend, you couldn’t actually call dibs on a commit because of a SQL bug. I thought this was hilarious and almost kept it in there it would keep people from posting racist things. My wife suggested we could even front-run every attempt to call dibs by generating a fake name that happened to just barely call it beforehand every time. Ultimately I decided to go full bore with functional uselessness.
The site was designed with accessibility in mind, so that the 10 people who would understand the joke and find it funny (“and” is doing a lot of work there) would be able to access it. Its Lighthouse score is remarkably good. Did you know that fireworks go off when you get a perfect score?
These days when I’m reviewing a pull request it feels like I’m talking to an AI bot, because I am. When I ask questions like “Why did you decide to do it this way?” I usually get a response (from a human) that has all the tells of AI-speak. But I’m not mad at the human, I’m mad at my tools.
I can’t ask the human “Why did you decide to use this library?” because the human didn’t make that decision, the AI did. So the human is going to turn around and ask the AI, “Why did you decide to use this library?” And then paste the answer to me. Pre-AI, you asked the developer, not their manager, questions during code review, so why are we asking the manager now? Let’s cut out the middleman.
All the authors of the code should be involved in the review. What I don’t want is to ask a question, and then an AI agent is spun up to try to reverse-engineer the reason something was done. That’s completely wrong. When we ask a human why, we are interrogating their internal thought process; we need information that was not included with the pull request.
With AI, that calculus has changed.
An AI’s chain-of-thought is externally auditable. Your interactions with the AI are externally auditable. Let’s get that context into the review and into source control.
Should we commit every token produced in the making of a pull request? Absolutely not. There’s too much noise. Instead, we should take inspiration from Random Labs’ idea of episodes where agents return transcripts of successful tool calls and conclusions.
Alongside the code involved in a pull request needs to be a transcript of decisions made and why (or why not). This scales with agent swarms: a pre-pull-request step shall concatenate these decision logs and perform some final formatting.
Inline comments in code are okay but they are problematic for a few reasons:
Changes to source files, even for comments generally requires a re-run of a build pipeline: linting, compilation, and tests
These transcripts are going to be way larger than is generally acceptable for an inline comment
Comments generally talk about how code works now and not all the decisions that went into it.
Code reviews need to be wildly different than before.
When reviewers make comments, the developer’s AI needs to receive them directly and be allowed to decide whether to take action in the form of patches and replies. This is possible now with with a combination of GitHub/GitLab webhooks and their associated MCP servers. The developer can configure their AI to ask for permission first or to go ahead and do what they think is right. Very similar to what happens with Devin AI or Claude Code via GitLab Duo. The (human) developer still has the opportunity to make their own comments and changes. This will greatly reduce the time from a reviewer asking a question to getting results. How often have you made a comment that wasn’t addressed until hours or days later? Or not at all?
For reviewers, they need to be able to interrogate pull requests in the same way they interrogate codebases. Context is king, so the decision log being checked in alongside the code is vital for this purpose.
What I mean is that I need to be able to cleanly interact with a pull request in the exact same way I do now, plus I need to have a window alongside it for interacting with Codex or Claude in the same way as it’s integrated into an IDE for development. I’m not sure there’s a clean tool for this just yet, so I’m begging someone to make one. I’m sick of creating a new git branch just to squash the developer’s branch into it just so I can ask the AI its opinion.
I want to be able to privately go back and forth with AI asking questions about best practices, unknown libraries, and unfamiliar languages in the diff before I decide a code review comment is warranted.
And if a comment is warranted, then this could indicate a gap in the decision log that should be updated before the pull request is accepted.
With seamless AI integration into the review process, it should be much easier for reviewers to go so far as to suggest a straight-up patch.
And while I’m on my soapbox, please add all our design documents/decision records, architectural diagrams to source control in an LLM parseable format like Markdown or Mermaid.
Context is king.
Edit 3/26/2025
Many readers have the impression that I’m condoning or outright advocating that we delegate our entire thinking to the machine, and that’s taking things quite a bit too far. If the AI decided to accomplish a task in a certain way, and the developer carefully read through and verified that it did what they needed (with all the associated considerations for performance, security, …), then did they even need to ask themselves “Why this way instead of some other way?” Maybe. Maybe not. It gets the job done up to our standards. If a reviewer then asks “Why this approach?” Then it’s really a question for the AI, isn’t it? It wasn’t “What does this code do?”, which the developer should be able to answer.
“Why this library?” “Because it gets the job done?” Maybe the reviewer (me) should have been more specific, like “This library introduces a new third party dependency and we already can achieve something equivalent with <other thing>”, but wanting to know someone’s reasons for doing something before implying they might have done something wrong is just good manners.
“Oh I just needed something random but also human-readable” you said, as you casually called .Substring(8) on a UUID. You probably also “casually” mutilate animals like you did to that poor UUID. Great job on that name, too, Shakespeare. Item_019b1999 is going to be the next buzzword all the youths are yelling. Very human-readable. Length […]
Show full content
“Oh I just needed something random but also human-readable” you said, as you casually called .Substring(8) on a UUID.
You probably also “casually” mutilate animals like you did to that poor UUID. Great job on that name, too, Shakespeare. Item_019b1999 is going to be the next buzzword all the youths are yelling. Very human-readable.
If it wasn’t bad enough, you kept the first eight characters and not the last. Do you even know what a UUID is? Let me show you.
It’s a terrible diagram; so let me simplify that for you:
All of the randomness is that the end!
Okay, okay, the first 12 characters are actually an encoded Unix timestamp with millisecond precision, so only IDs generated within the resolution of that timestamp would collide. Let’s see what happens as you truncate the UUID.
LengthInterval where all IDs get the same valueRough human equivalent121 msCamera flash1116 msMonitor refresh10256 msSlow mosquito flaps its wings9≈ 4 sSound of a firework travels one mile8≈ 1 minToweling off body after shower7≈ 17.5 minCartoon show episode6≈ 4.5 hrCook 20lb turkey5≈ 3 dayRoof replacement4≈ 50 dayOldest fruit fly3≈ 2 yrParmesan cheese aging2≈ 12.5 yrChinese zodiac cycles through all animals1≈ 557 yrThe Ottoman empire
By truncating your UUID to 8 characters, you’ve ensured that all items generated while I was microwaving my rice have the same value. Congratulations for creating a nightmare.
Oh, but Andy, we use UUIDv4 where it’s all random
(Some libraries just call this a UUID but they really mean v4)
The reason to use a UUID is for uniqueness. If you don’t want it, generate some random bits yourself.
As you truncate your UUIDv4, here’s how many IDs you can generate until you have a greater than 50% chance of a collision.
UUID Length (chars)Number generatedRough human intuition322.7 QuintillionA third of all insects on earth (How???)31680 QuadrillionAtoms of gold worth $0.33 ($4,300/oz)30170 QaKg of mass to power the Sun for 1.3 yrs2942 Qa260k years worth of parcels shipped (161B/yr)2810.5 QaNanoseconds in 350 years272.5 QaVolume of Lake Superior (gal)26660 T2x the global real estate market ($)25165 TData center energy usage in 2023 (kWh)2441.5 TCells in a human body2310 TTrees on 3.5 earths222.5 TMeters to Uranus21650 B136 years of orders at Amazon (9k/sec)20160 BStars in the Milky Way1940 BNeurons in a Gorilla1810 BPeople on earth172.5 BPing pong balls to fill 16 Olympic pools161.3 BAll dogs15316 MMPeople in USA1479 MMTravelers passing through LAX each yea1320 MM3 days of orders at Amazon (9k/sec)1220 MM (yes)3 days of orders at Amazon (9k/sec)115 MMLEGOs produced every 3 days101.2 M30kg of white rice grains9300 kMonster energy drinks sold every 4 hours880 k9 minutes of orders at Amazon (9k/sec)720 kPickleball courts built in 202465 kPack of staples51.2 kStack of paper the height of a soda can4300 Bag of Dum Dums lollipops380People on a city bus220Seconds for a human to urinate15Your IQ if your truncate a UUID
So yeah, if you truncated your UUIDv4 to 8 characters at Amazon you’d probably get your PIP in 6 months instead of the 2 year average.
And this is just when the probability of generating UUIDs crosses the 50% threshold, which you would never even want to get close to. If you’re going to produce 100 billion UUIDs over the lifetime of your app (very realistic in modern enterprise), you want the probability of a collision to be disappearingly small, approaching 0.
For the sake of argument, let’s say that while you YOLO your way through life failing up the entire time, you decide that a 1% probability of collision is “good enough”. After truncating your UUID to 8 characters, you will hit a 1% chance of collision after just 9,300 IDs. That’s the number of steps a Spaniard takes in a day (three times as many as you).
Hell, even if you deigned to allow the UUID to retain half its original length (16 characters), you’d still have a 1% chance of collision after 150 MM, or the number of Snickers bars produced in 10 days.
And you’re still missing the point.
It’s not human readable anyway
End users don’t give a shit what your IDs look like, they’re going to copy and paste if they ever need to (which is roughly never)
Assumed user preference does not DICTATE HOW FUCKED YOUR DATABASE SHOULD BE
Use a different encoding
Did you know you can get shorter IDs without sacrificing uniqueness? UUIDs are hex-encoded (base 16) and only 4 bits of information can fit into each character. If you change your encoding to base 32, wow you can have an ID of length 26 instead of 32. If you used raw base 64, you could get down to 22 characters.
This is the idea behind the TypeID specification: a type-specific prefix followed by a base32 encoded UUID. Now you can generate IDs like Item_01kccskbjfff08mh2ttwpvjf9c which are equally human readable as before (meaning kind of but not really) without sacrificing the entire reason for its existence.
On human-readable IDs
Give up. Or at least give up on your end users easily remembering (or caring). Even random phrase generators that puke out something like “Parchment-Pellet-Closeable-Whoopee” only sound human readable at first. Without looking back, can you remember the alleged human-readable passphrase I just mentioned? Didn’t think so.
For you and all the coworkers that loathe you for truncating UUIDs, okay yeah maybe TypeIDs are helpful. These allow you to parse into stronger types like class FistId so that someone can’t accidentally use a FistId when they should have been using a FaceId. And it makes reading logs way easier.
Conclusion
Recently I reviewed some code that tried to cram an entire directory structure worth of IDs into one: {grandparent}_{parent}_{child}_{UUID}, except the entire string was only allowed to be 80 characters long. So it was truncated at the end. Fortunately (unfortunately?) two of the IDs were simple integers up to 8 digits, meaning our string could be 83 characters. So we were truncating the last 3 characters. Of the only part of the ID that made it unique in the first place. Turns out a simple UUID worked just fine and the other information could be gleaned from elsewhere.
For every character of a UUID you lop off, you are increasing the odds of a collision by four times (and the odds that I find you and lop off the end of your ring finger). It’s even worse if you’re using a UUID where the first few characters are an encoded timestamp.
Before you truncate a UUID ask yourself a few questions:
Are the extra few characters really making anything less readable?
Can I use a different encoding or a different kind of ID instead?
If you still decide you must truncate, then at least keep the last characters because they’re likely to give you better odds.
In 2016, Microsoft made a pull request to Node.js that added almost 3 million lines of code. The Node.js maintainers were actually super cool about it, since it enabled Node.js to use Microsoft’s pretty decent Javascript engine (ChakraCore) optimized for Windows. They were in a bit of a pickle, however, since they didn’t really get […]
Show full content
In 2016, Microsoft made a pull request to Node.js that added almost 3 million lines of code. The Node.js maintainers were actually super cool about it, since it enabled Node.js to use Microsoft’s pretty decent Javascript engine (ChakraCore) optimized for Windows. They were in a bit of a pickle, however, since they didn’t really get any heads up about it, and 3 million lines of code is a lot of fucking code.
Eventually, after one of the longest discussion threads to ever exist on a pull request, it was abandoned, left as a branch with the promise of staying current, and then that branch was itself abandoned in 2020. In 2021, Microsoft’s entire Javascript engine was abandoned too, although they stopped active development as early as 2018.
I’m pretty sure the pull request was too large, but what is the right size? That’s what we’re here to talk about today.
Before I get started, I want to bring some closure to the tale of Microsoft’s pull request (PR).
Should they have just merged it?
Hell no. Besides there just being too much stuff all at once, there was also the question of whether Microsoft’s code even belonged in Node.js. I’d like to point you to this blog post by my good friend Ashley Gullen (we’ve never met or interacted in any way). I’ll summarize it for you anyway since I wouldn’t be arsed to click the link either.
> 75% to 95% of the total work involved in software engineering is maintenance
And if you skim the discussion of Microsoft’s ill-fated PR, the subtext in criticism from maintainers was roughly “I don’t want to be responsible for maintaining this shit.”
Reviewability
Microsoft’s PR consisted entirely of code from an existing well-tested codebase that was surprisingly loved. But they missed perhaps the most consequential of all the -ilities, reviewability.
It doesn’t matter if your code is readable, decomposed, well-tested, and performant. If it’s not reviewable then it doesn’t get merged. Period.
I wrote a four part series in 2020 on how to make code reviewable, and I stand by it today. The first and most important step to writing reviewable code is making sure that your reviewers are on board with the intent of it beforehand (Microsoft failed here).
After you clear that hurdle, it’s just a matter of ensuring that each review is digestible by the reviewers (Microsoft failed here too). You want your review to take about ten minutes, and you don’t want to include more than 4 “things” in it.
But 4 things and 10 minutes is perhaps an average bound, if not close to an upper bound for your code reviews.
How small can you go? How small should you go?
Minimum reviewable unit
In academia, a minimum publishable unit is is the minimum amount of information that can be used to generate a publication in a peer-reviewed venue.
In software engineering we can make the analog that a minimum reviewable unit is the minimum amount of information that can be used to generate a pull request in a code review.
“Minimum publishable unit” has negative connotations because researchers who do it are seen as trying to artificially get their “pub count” up, which is a simple and easy metric that institutions use as part of making hiring and tenure decisions (reference). Gee, who would have thought that such a metric would be gamed?
However, in the field of software engineering, a minimum reviewable unit can be the optimal way to incrementally deliver value. A fortunate side effect is that delivering code this way improves the metrics that companies measure about you (“Are they good metrics? It doesn’t matter!”).
The guide for submitting patches to the Linux kernel says:
> Solve only one problem per patch.
Easy enough. If our upper bound for a code review is four things, then the lower bound should be one thing. But what the hell is one thing?
If we got pedantic with it, the minimal amount of information we could change would be one bit. For example, changing the ASCII character 'b' (binary 01100010) into 'c' (binary 01100011). How many bug fixes have you seen that were just one character?
Though if someone on my team tries to merge their next feature one character at a time, then ritualistic flaying would be too light a punishment. So one bit might be a theoretical minimum, but what is a practical minimum?
Minimum practical reviewable unit
Stanislau the plasma physicist and his intern PeeWee are writing code for the next generation nuclear fusion reactor. Stanislau keeps submitting pull requests containing an entire research paper’s worth of equations. PeeWee has but a lowly bachelor’s in mathematics with no specific domain knowledge in plasma physics (what an idiot, right?). These pull requests take hours and hours for PeeWee to review, which is completely impractical.
If Stanislau isn’t going to spend more time carefully walking PeeWee through the code, explaining and defending what each piece does, then he needs to break up his pull requests into pieces that can be reviewed in a timely fashion by his intern. On their team, “one thing” is likely closer to what PeeWee considers to be “one thing”.
Erica the staff software engineer works on a giant monolithic web app that is showing its age. She can’t merge her changes until:
The code builds from scratch (20 minutes)
The unit tests pass (20 minutes)
The king of France makes a royal decree that the code is acceptable (~6 months)
The code coverage tool reports adequate unit testing (5 minutes)
The regression tests pass (1 hr)
The manual testers sign off (6 hours)
The product owner signs off (6 hours)
It’s not uncommon for her pull requests to take an entire week to get merged into the main branch. It has become impractical for her to split her pull requests into very small pieces, because the overhead of maintaining stacked branches and multiple in-flight pull requests is just too much to cope with. As a result, each of her pull requests becomes about as large as they can reasonably be.
Until her company invests in streamlining the pipeline by, for example, splitting large independent modules into their own repositories, Erica’s situation is only going to get worse. On her team, “one practical thing” means “as much as I can reasonably put into a single review”.
Jordan works for a tech org that has dictated everyone must use feature branches instead of trunk-based development for their features. After all, feature flagging services cost money and their company is in the business of making money, not spending it on superfluous things that would make everyone’s lives easier and save them money in the long run. Also, the shitty coffee on the fourth floor costs $5. Developers are allowed to do whatever they want in their feature branches to get work done, but the rule is that once code is to be merged into the main branch it must undergo a thorough review.
It’s not just impractical for Jordan to have small pull requests, it’s impossible. Sure, they can have each commit to their feature branch reviewed, and theoretically the “big bang” merge into the main branch should just be a formality, but rules are rules. In Jordan’s company, “one thing” means “one feature”.
Finally, Alex is the senior developer on a “two-pizza team” that doesn’t actually get any pizza. Their build pipeline is really fast, and Alex only needs one other developer to sign off before they can merge a branch. Nice, right? Except Alex is inundated with six or more reviews every day. On bad days it’s as high as a dozen.
Alex’s teammates are assholes. Share the load, people. That is, unless Alex is the asshole who insists on this arrangement, but one developer would never be so conceited as to force all changes to go through them first, right?
“One thing” on Alex’s team should be very small, but the turnaround on reviews is longer than necessary because they all seem to go through one person. So, like Erica, devs will include just a little bit more in each pull request so that they don’t get sent to the end of the line.
It’s a social problem
The minimum practical reviewable is unit a social optimization problem that must take into account the specific team, project, CI/CD process, and culture. As Fred Brooks once wrote:
“The major problems of our work are not so much technological as sociological in nature.”
Ideally we want “one thing” to be fairly small, but still self-contained. Here are some best practices to ensure that this is practical:
It should be digestible by the least-expert reviewer you’ll have, because otherwise they’ll take a long time to review, and also probably miss defects.
Keep an eye on the time between when a pull request is opened and when it is merged. Pull out code from your application into other repositories where they can be consumed as libraries or even as separately-hosted services. Automate the hell out of your tests, and move the longest ones to run on a schedule that won’t stand in the way of a merge (in the TFS days we called these “rolling builds”).
Use trunk-based development so you can merge your changes into the main branch sooner. If you must use feature branches, find a way to rescope your features to be smaller, or alternatively allow for unreviewed or lightly-reviewed “big bang” merges, with requirements that merges into the feature branch were thoroughly reviewed.
If the culture just won’t allow for a streamlined review, you can try to change it, which is slow even in small companies. You do this by finding the decision makers, which is usually at the director or even CTO level, and personally reaching out. Persistently reach out. Don’t stop reaching out. The squeaky wheel gets the grease. The alternative is to spend your days shitposting in Slack instead of working while you look around for other jobs, because just generally complaining to your colleagues isn’t going to accomplish squat. It’s pretty fun to just shitpost in Slack instead of working, so I can’t fault you if you go that route.
Empirical pull request size
Until AI completely takes over, you’ll just have to live with the fact that there’s no single quantifiable answer to the size of a minimum practical reviewable unit.
Let’s look at some numbers anyway. For fun.
I went around to some popular open source libraries and measured their commit sizes. I assumed that one commit = one pull request, which is definitely not always true, but is true enough for the repos I looked at.
Empirically, how large are pull requests?
The Linux kernel
The Linux kernel contains 1.3 million commits, which is not bad for a personal project from a random computer science undergraduate.
Over 44% of all commits changed 10 lines or fewer, and 4% of all commits changed just 1 line!
The distribution of commit sizes appears to follow a power-law distribution, where the median commit size is 14 LOC, but the average of 84 LOC is skewed by the long tail of larger commits.
It added a ton of code for AMD’s Display Core Next (DCN) architecture that handles all graphics coming from the GPU to your monitor. But the size of this commit is an outlier among outliers; only 30 commits changed more than 100k lines of code, and the next largest touched only about 260k LOC (15% fewer LOC).
Suffice it to say that the maintainers of the Linux Kernel appear to have done a great job in keeping commits small and adhering to their “do one thing” mantra. Except for that one dev who added 300k LOC; I think they did two things.
PostgreSQL
Git wasn’t invented until 2005, but the maniacs at PostgreSQL used a time machine to make their first commit in 1996 (They used a tool called cvs2git to migrate their repository.)
Despite their longer git history than Linux, the PostgreSQL repository only contains about 61k commits. It, too skews heavily towards small commits, with 35% changing 10 LOC or less. It, too, appears to follow a power-law distribution.
I promise you that’s a different graph than the one I posted for Linux. Go ahead and check.
The only tell is that the median commit size of PostgreSQL is 23 LOC and its average is 359 LOC, which is also skewed heavily by outliers.
The largest commit in PostgreSQL is this one that clocks in at a whopping 515k LOC.
Use radix tree for character encoding conversions.
Replace the mapping tables used to convert between UTF-8 and other character encodings with new radix tree-based maps. Looking up an entry in a radix tree is much faster than a binary search in the old maps. As a bonus, the radix tree representation is also more compact, making the binaries slightly smaller.
[...]
I had no idea there were so many different character encodings. There’s johab, KOI8-U, SHIFT JIS and a whole mess of Windows-specific encodings. Each different conversion probably could have been added in its own commit, though.
That huge commit, too, is an outlier among outliers. There are only 24 commits over 100k LOC, and the next largest one is 30% smaller!
It’s clear that the maintainers of PostgreSQL have also maintained good commit hygiene. While its commits appear to change more LOC on average, I noticed that they also tend to include more test code on average, too, although I haven’t collected any formal data to that effect.
ChakraCore
What about Microsoft’s ChakraCore, the reason for the doomed pull request into Node.js that I discussed at the beginning of this blog post?
It appears that some enthusiasts have been trickling changes into the repository since it was abandoned by Microsoft, but it’s pretty clear that the developers were already transitioning off the project by the time Microsoft announced in 2018 that they were adopting Chromium for their browser. If I had to guess based on the data, the developers found out in July of the same year.
The total number of commits sits at 13k, although only about half are non-merge commits, which indicates a strong preference for squashing within the team. How large are these commits, though?
There’s definitely some outliers here, but overall it also appears to follow a power-law distribution in LOC changed. The median LOC is an even 30 while the average is extremely skewed to 1264. 31% of all commits changed 10 LOC or fewer.
Let’s take a closer look at that skew. There are only 3 commits that changed more than 100k LOC, and the largest commit changed 1,385,288 LOC. What happened there?
ChatGPT tells me that it’s likely a long-lived feature branch for Windows Redstone 3 (a Windows 10 release) but I can’t be fucked to verify that for myself. If true, it only reinforces my point about feature branches encouraging huge “big bang” merges (read the story about “Jordan” above).
The important thing is that it appears to be a merge commit in disguise. The next largest commit was 99% indentation changes, so let’s call it even and exclude these two as outliers. This brings the average commit size down to 987 LOC.
So how did Microsoft do? Skimming over their commits, it appears the ChakraCore developers were even more diligent about adding tests than the PostgreSQL team, so I’m unsurprised to see higher numbers. It’s been my experience that teams of professional software developers (professional as in “getting paid to do it”) generally produce larger pull requests thanks to testing requirements. It’s quite often that I find myself writing more test code than feature code.
Node.js
I’m obligated to analyze the Node.js repo after I spent the first two paragraphs of this article discussing it. Let’s look at commit sizes year-over-year.
Node.js is maintaining a strong pace of activity, averaging nearly 3k commits per year for the last five years, and 43k commits overall. Let’s take a look at the commit size distribution:
To nobody’s surprise it also follows a power-law distribution with the vast, vast majority of commits on the smaller side; 39% of commits changed 10 LOC or fewer. This pulls the median LOC changed to 19.
What’s a little strange about this repository is that the average LOC changed per commit is way higher at 686. Why is that?
The largest commit in Node.js changed a whopping 5 million lines of code:
This pull request updates the OpenSSL version that is statically linked with Node.js from OpenSSl 1.1.1 to quictls OpenSSL 3.0.0+quic.
[...]
Which appears to mostly consist of build-generated files targeting various architectures.
In fact, there are over 100 commits that change more than 100k lines, and 5 that change more than 1 million! Microsoft’s pull request doesn’t sound so large after all.
The second and third largest commits also happened to be for OpenSSL upgrades. The fourth and fifth-largest commits were related to upgrading a dependency on a localization library (ICU), and in classic C++ fashion, Node.js builds their C++ dependencies from source, meaning any time they add or upgrade a third party library, they have to bring in all its source files.
Node.js, like any other library, has dependencies on other libraries. It’s just that upgrading these dependencies in Node.js results in huge commits. The maintainers aren’t doing anything wrong here; building your dependencies from source is a totally valid dependency-management strategy in C++ codebases. It murders your already-hours-long build times, though. While such pull requests aren’t small in terms of LOC, they still feel small.
Like the other repositories we’ve looked at, I think that the Node.js maintainers have done an excellent job of writing reviewable code. Flipping through their commits, it seems as if they’ve been able to keep the median LOC changed per commit small while also adding tests with almost every change. Kudos.
21 lines of code
We looked at four fairly large open source projects to get an empirical idea of how large a pull request should be. It was hardly a comprehensive study, but both the median of medians and the average of medians come out to 21 LOC changed per commit. That means the vast, vast majority of pull requests that you see should be around this number.
It doesn’t mean that larger LOC changed is bad.
The standard deviation on LOC changed per commit was large, thanks to the power-law distribution. It was high as 31k in Node.js down to a paltry 5k in PostgreSQL. That means a commit that changes even 5k LOC is generally within a standard deviation of the average.
Ultimately what should be considered “minimal” is up to your company, team, culture, CI/CD pipeline, and tech stack. The biggest takeaway for me is that large pull requests should be rare, and exponentially rarer the larger they get.
In closing
Pull requests should ideally only change “one thing”, whatever that means to your team. Too bad the real world doesn’t fit nicely into a little box. The reality is that the size of pull requests is a reflection of your entire company. While I can’t tell you exactly how large your pull requests should be, I can recommend some strategies that will help move you towards your ideal. I talk about each of these in the “Minimum practical reviewable unit” section:
Use trunk based development; avoid feature branches
If you must use feature branches, redefine “feature” to be quite small
Break off large logical chunks of code (“bounded contexts”) into separate repositories with separate CI/CD
Define “one thing” in terms of a novice or early intermediate
Move the longest running tests into ones that are run on a schedule instead of a required step in a pull request
Commit sizes follow a power-law distribution, meaning commits that change 10 LOC should be an order of magnitude more common than commits that change 100 LOC, which should be an order of magnitude more common than commits that change 1k LOC, and so on. Large pull requests have their place, but if one comes across your desk, you should question whether it is artificially large or if it should have been broken up. Try not to be a pedantic jerk to your coworker who submitted it, though. Just try to help them do better next time.
Appendix: Data collection methodology
From each repository, I only collected commits that:
had a single parent (a.k.a “not a merge commit”)
This necessarily excludes the first commit from each repository, which I can live with
added or removed at least one line of code from its parent commit according to git diff --shortstat
A funny thing happens if you include merge commits in the analysis. In Git, a merge commit can be between any number of branches (an “octopus merge”), so the question of “how many lines changed” is ambiguous. You might also end up with a merge commit that accidentally adds a new root commit to the repository, and depending on how you diff that merge commit, it can appear like it added the entire repository to itself. This has apparently happened 4 times in the course of the Linux kernel’s development. Those are discussed in more depth here.
When I say “lines of code changed” throughout the blog post I mean the sum of lines added with the absolute value of lines removed. For example, if a commit added 1 line and removed 2 lines, the total lines of code changed is 3.
I saved the output for all commits into a comma-delimited file (.csv) with the following headers:
“Id”, “Date”, “Lines Changed”, “Lines Added”, “Lines Removed”. The Id column was the full commit hash and Date was in the format YYYY-MM-DD, e.g., 2025-03-19. Because I grabbed the date data from pygit2, it was in UTC time. The other columns I think are self-explanatory.
I analyzed the data using a mixture of pandas, numpy, and scipy. The quartiles shown in the graphs were computed using the pandas quantile function (except Q2 was calculated using mean). The “Q4” label was merely placed to the right past the “Q3” line to indicate that the remaining volume belonged in the fourth quartile.
The log-log graphs used base two instead of base ten because I felt like it showed a little more nuance in the data even though base ten probably fit the data better. Plus, like any self-respecting computer scientist, I’m a slut for powers of two.
The data for the stacked bar plots that showed commit sizes per year was computed by first computing a “Bucket” column in my DataFrame that placed each commit into one of the buckets shown in the plot’s legend based on the "Lines Changed" column. The bucket intervals were open, so the “1-10” bucket includes commits that changed 10 LOC. This was accomplished by using the Pandas cut function, after which it was grouped by year via the groupby function: (some variables are excluded for legibility)
bins = [0, 10, 20, 50, 100, 200, 500, np.inf]
bin_labels = ["1-10", "11-20", "20-50", "51-100", "101-200", "201-500", "500+"]
# df is a pandas.DataFrame
# pd is an alias for pandas
df["Bucket"] = pd.cut(df["Lines Changed"], bins=bins, labels=bin_labels, right=True)
grouped = df.groupby([pd.Grouper(key="Date", freq="YE"), "Bucket"], observed=False).size().unstack(fill_value=0)
In the above snippet, size() is a call to DataFrameGroupBy.size, which creates a new Series object that looks like this:
Date Bucket 2009-12-31 1-10 253 11-20 103 20-50 185 51-100 127 101-200 86 # ... more dates
and the following call to unstack(fill_value=0) pivots the buckets to be columns, producing a DataFrame that looks like this:
The graphs were plotted using matplotlib. Credit goes to Dr. Stephanie Valentine for providing copious input on how to present these graphs against my usual style of “eye vomit that induces fear in young children”.
Feel free to republish my figures so long as you attribute them to me.
(Featured image by Camille Couvez on Unsplash) When a measure becomes a target, it ceases to be a good measure But AndyG, doesn’t this just encourage a race to the bottom? Aren’t we sacrificing quality for speed?
Your manager calls you into a virtual meeting and, after wading through the requisite bullshit small talk, asks what you’ve been working on for the last month.
“Well I fixed that showstopper bug! And everyone agreed it had a big impact.”
“It looks like the fix was just one line of code.”
“Yeah but it took me two days to find that one line haha, you know how it goes.”
“I don’t. I went to business school.”
You’re sweating bullets now. You know this asshole already doesn’t like you, especially after last month’s town hall when you politely suggested we should have less bureaucracy instead of more.
“Well, I also designed our upcoming feature! That took a week!”
“I saw the UML diagram, it’s only 3 different boxes with arrows pointing at each other? How did that take a week?”
“Well I had to work with product on the requirements and then there was a lot of iteration with the team. You know how it goes haha.”
“I don’t. I went to business school.”
See where this is going? You need to be ready to prove it. Here’s how.
Know Prove your worth
I can’t believe I have to say this, but so many developers don’t get it. It doesn’t matter if Jane Doe from the Red Team can vouch that you worked closely with her. It doesn’t matter that your bug fix could have been published in Nature it was so transcendental. If you can’t prove you’re doing the work, you’re on the chopping block.
Why was that coworker fired for no reason? Because they weren’t doing anything! Or at least they couldn’t prove otherwise.
Your manager isn’t an idiot. Okay, well they very well may be, but the tools they use are not. They have tools that will suck up data from literally every possible source available. And these tools are getting better every year. Tools like Jellyfish, CodeClimate, Quantive, and if your organization is old and rich enough, plenty of homegrown stuff. If you’re unfortunate enough to live in the United States, they can legally install a keylogger on your laptop.
Are these tools measuring the “right” thing? It doesn’t matter! What matters is that your organization has standardized what it means to be “data-driven” with respect to performance management. Is there a qualitative aspect to performance review? Sure, but it plays a decreasingly important role. Your quantitative metrics are going to keep getting “flagged” to your boss if they’re not up to snuff regardless.
What’s a more realistic scenario here? Your manager stands up to their entire chain of command and HR and convinces them “this is all bullshit, MY developer is just a misunderstood polymath!” or that they give into the metrics and fire your ass for underperformance? Don’t bother answering, it was rhetorical. The principle of least effort already answered it (and in its honor I’ve linked the definition instead of copying it).
When a measure becomes a target, it ceases to be a good measure
Meaning that when value is assigned to a thing, then that thing will be optimized into oblivion. Like the time the French government tried to incentivize people to kill rats by offering a bounty on rat tails. People discovered that if you only cut the tail off a captured rat, it would continue breeding more rats whose tails you could harvest.
Don’t be so disillusioned to think that all metrics are bad. If management is measuring pull request (PR) throughput, is it really so bad that developers start pushing through smaller PRs? God forbid we end up delivering value faster with fewer defects, better testing, and more thorough peer review.
When your manager rolls up to you asking what you’ve accomplished, have your work artefacts ready:
Pull requests
The simplest and probably most widespread metric used to measure developers is how many pull requests they’re merging. This roughly corresponds to “Change lead time” for you poor sods who have been pounded over the head with DORA metrics.
Don’t jump the gun and dive headfirst into your next task without spending five minutes thinking about the order things can be done, otherwise you’ll hurt the metric instead of helping it. I know, I know, writing code is the fun part of the job, but if you don’t plan a little, then one thing leads to another and suddenly your pull request balloons into a two thousand line monstrosity. We’ve all been there, learn from it.
You’re already thinking,
But AndyG, doesn’t this just encourage a race to the bottom? Aren’t we sacrificing quality for speed?
That’s why we have peer review. If you’re sacrificing quality so that you can push more PRs through the pipeline, your colleagues should catch it and hold up the review. One of the reasons to incentivize smaller PRs is because reviewers statistically catch more defects this way.
If nobody is reviewing PRs with any kind of sincerity, you have bigger problems. Hell, these days you can utilize an AI code reviewer that’s auto-added to reviews so that you can at least get some feedback.
Outside of peer review, there are powerful tools for measuring the quality of the code you’re pushing, and if your organization were smart they’d be using them. Metrics like code coverage, cyclomatic complexity, cognitive complexity, and even rework can be tracked. Bugs added to your issue tracker will link back to your work items and/or pull requests.
And lastly, people be snitchin’! Your coworkers and management are gonna get pissed off if every single customer-facing incident is caused by you. Qualitative feedback matters most when everyone is sick of your shit.
Publish your notes
Remember that one line bug fix that took two days to do? Your single puny little PR for it is assigned the same value as that one the mouth breather in the cubicle next door merged, titled “Test: Assert that 1 == 1”.
You were already keeping notes while you debugged the thing, just put them somewhere that counts! Put them in the GitHub/GitLab issue discussion. Each time you have a new insight, a new theory, a new approach, or a new data point, add a comment into the discussion. This will bump up any measure of overall activity. This “activity measure” is triply important if you work remotely because otherwise your manager will start wondering if you are working two jobs because you go dark all the time. (Note: I don’t give a shit if you ARE working two jobs so long as you’re meeting or exceeding my expectations.)
Publishing your debug notes is good practice anyway. If a similar bug crops up for another developer down the line, your notes could drastically reduce the time to fix it. As a bonus for you introverts out there (everyone reading this), you can link your coworker to the discussion instead of actually having a conversation about it.
One last thing: this isn’t restricted to debugging. For feature development tasks, don’t be afraid to discuss all the different ways you thought about approaching the work before outlining what you settled on and why. Literally last week I reassigned a task to a coworker and I was glad that I had already spent the time elaborating my approach and any gotchas.
Promote TODOs to issues
Ditch your personal note-tacking apps like Obsidian or the tried-and-true plain text file when it comes to writing down things you want to do. Promote these to full-fledged issues tracked by your work tracking software (Azure DevOps, GitLab, or (shudders) Jira). Senior developers create work for themselves instead of being told what to do. Make it easy for your manager to check that box when they’re considering promotions.
Throw everything into revision control
Look, at the end of the day you need to be able to prove you were doing something other than googling meme templates to make jokes in your team channels, and anything that serves up immutable timestamps for that work is ideal.
Architecture work? Source control. Tools like Mermaid.JS or PlantUML fit nicely into git. Yes, merge your architectural diagrams into your source control. Have your architectural reviews in the same place code reviews happen.
If you’re being forced against your will to write design docs in e.g., Word (because you work at Microsoft), then the self-contained revision history will have to do. Your corporate overlords are probably sucking in that data anyway.
UI Work? Revision control. Now, I’m not a designer so I don’t know enough about UI mocking tools to say for sure how well they support the kind of revision control us developers are used to. I’m pretty sure it’s mostly dogshit though. Tools like Figma take care of their own “revision history” so that’ll have to suffice modulo any plugins that hack in something better. On the other hand, watch out for Adobe XD because it’s not enough to force you into paying $60 a month for Adobe Creative Cloud, they hate you so much that they’re also going to arbitrarily delete “old” revisions of your files because fuck you.
Closing thoughts
Your wall-of-text posts in Slack aren’t tracked. Okay, those are tracked, but by HR for compliance reasons in case y’all get sued. And HR is making damn sure that data is retained for the minimal amount of time according to law so that it can’t come up in discovery 10 years later.
If your manager can’t see it, it doesn’t exist when performance review time rolls around. That extra hour of lunch you took because you were staring off into space thinking about architecture? Didn’t happen. Your outside-of-work conversation at the bar that inevitably turned to work? The drunken ravings of a lunatic. That two hour pair programming session with the junior dev to get their stuff over the finish line? A big blank spot in your activity log.
If you spent so much time helping another dev, make sure that time gets tracked in a measurable way. Add comments to the issue or pull request as you go. Heck, co-assign the work if you’re really pulling some weight.
A rising tide lifts all boats, so definitely help your fellow devs. Just make sure that management knows it was you who lifted the tide.
Cover your ass
This post can be summarized as “cover your ass”. It’s okay to be humble when you’re talking about how you made varsity in high school. It’s foolish to be humble with managers about your performance.
When you start doing everything I’ve suggested, you’ll notice that your thoughts become better organized because they’re written down and not fighting for space in your head alongside sci-fi lore. You will delegate work easier because it’s already been prepped. You will solve bugs faster because previous bug fixes are well documented (and for the DORA bean counters out there, that is “Mean time to resolution”). And when your boss wants to squeeze in yet another feature, you can prove your plate is currently full.
Your project manager might even start making semi-accurate predications about what can be delivered over the next three months because you’re actually tracking your work.
Simply put, you will accidentally become a better developer by “gaming the system”.
I had a plumber over the other day. I was worried that my water service line might be leaking. There was a wet patch in the yard and I noticed that one of my sink’s water pressure seemed to be lower than usual. If the line had a pinhole leak in it, it could easily burst into a multi-thousand dollar flood on my hands. The joys of home ownership.
The plumber listened to my concerns and then inspected a few things: the piping where the service line enters my home, the pressure regulator, the sink in question, and even my water heater.
Afterwards, he told me it’s probably not as bad as I feared, but that I should sit down.
He produced a tablet and turned it to face me.
“Here are your options,” he started, indicating towards a group of boxes on the screen.
“First we have the ‘platinum package’. This includes replacing your pressure regulator with one that is set correctly (apparently pressure regulators can only be set once?), as well as a new water heater, a water softening system, a reverse-osmosis system, an electronic descaler, and a replacement of all your faucet aerators.”
The price was conveniently listed below: six easy monthly payments of $2,500 ($2400 if I was a “member”).
He patiently answered all of my questions about this package, although it was surprisingly hard to get an answer to “Do you think I really need all this?”
From there, we went down the line through the other options. Each cost a little less than the previous, included fewer products, and were more cleverly named than airfare classes; there was ‘premium’ followed by ‘standard’, ‘economy plus’, ‘economy’, and finally ‘band-aid’.
I asked more questions, and I was eventually able to negotiate my own “package” consisting of just what I thought I needed. For closure, no, my water service line was not leaking (probably).
And that’s how you make product give a shit about your architecture proposals.
You are the plumber
Your role as a software engineer is to play the plumber to product. The reality of the world is that product holds the money and software development is seen as a cost center to be minimized towards zero. You are selling to them.
Let’s walk through an example.
How this works
Your team successfully launched a new product for your company. It’s awesome at what it does, customers love it so far, but it’s still fairly immature.
Product comes to you and says “What our customers need next is the ability to generate reports.”
Now, having been intimately involved in the development of the product, you know how the data is stored. It’s a relational database. It’s fantastic at CRUD operations. It can perform some basic aggregation across related tables, but otherwise it’s ill-suited for something like “reporting”. Besides, product tells you that customers would love if their reports could be sorted and filtered based on customer addresses, but customer address information is actually stored in a completely separate system. And this system calls into yours, not vice-versa. And…, and…, and…
Before you freak out on product and go into all the reasons you can’t do what they want, take a step back and consider:
Product doesn’t give a shit about how your data is stored. Product cares about products
Product is looking for a result, not a distributed system design interview whiteboard session
Product is human (for now), and they understand that there are engineering considerations. That’s why they came to you in the first place. They came to you for a negotation (more on this in a minute)
In other words, product doesn’t give a shit about your architecture proposal. Yet.
Channel your inner plumber.
(Aside, you’ve earned this “problem”. You designed the system correctly to do what it needed to do in order to be a successful product. The natural order of successful products is to evolve beyond their original infrastructure.)
So here’s what you do instead of stuttering through an explanation of “indexes”, “table joins”, and “cardinality”:
You show them the “platinum package”.
This means that you gather up all the information you need to give product exactly what they want, and then you come back to them with an estimate: six easy monthly payments of $2500. Or, rather, you say “One full time mid-level engineer’s time for 6 months on our team, plus one full time engineer’s time from the Infrastructure team.”
Taken aback at such a large estimate (because they were hoping, pretty please, that it would be a single two week sprint. After all, all the data they need is “already in our system”, right?), product utters a single-word question:
“Why?”
And that is how you get product to give a shit about your architecture proposal. Suddenly they want to know all about it because they know they can’t afford a full year’s worth of engineering work.
Now you can (gently) talk to them about the difference between online transaction processing systems (OLTP) and online analysis processing systems (OLAP).
Each thing that needs to be done is a line item in your ‘platinum package’ invoice:
Define an ETL process to flatten and export our data to Snowflake
If you want, you can further break this down into the batch processes that happen, and when, where, and how often they happen, which informs data freshness guarantees
Similarly define a process to flatten and export the “customer data” from its system
Provision a new Snowflake instance
Front-end and backend work to provide the customer a way to specify what data they want and how
Translating the customer’s request into Snowflake and back
etc. (Saving reports to a document store, emailing them, running them on a schedule, etc. etc. etc.)
Be nice
During the discussion, you will patiently go into as much detail as product wants about specific line items. You will explain acronyms and technologies. You will explain costs of each to the best of your ability.
And then they can turn around and ask you “Do you really think I need all this?”.
Ah who am I kidding? Product doesn’t give a flying fuck about your opinion, you dirty code monkey. They’ll ask themselves “Do I really need all this?”
And the answer might actually be “yes”.
Sure, it’s hard, and expensive, and time-consuming to do, but that’s how businesses make money; by doing the hard, expensive, time-consuming thing for their customers so their customers don’t have to. Granted, that’s only if your company hasn’t yet started confusing “build something our customers need” with “build something that conveniently fits into a 2 week sprint” (and that’s a big “if”).
I’m not gonna hire a plumber just to wipe the gunk off my sink faucet. That shit is $87 just for them to ring your doorbell. Anyway, I digress.
It’s a negotiation
Understandably, product will want to deliver something to their customers sooner than six months, so they’ll reply with things like “What if we put off saving and emailing reports until later?” or “I didn’t realize it would take that long to get these running on a schedule and uploaded to the cloud”, or my favorite, “You are so smart and good looking and totally not a slob that eats lunch at their desk so often that their keyboard has accumulated a mass of crumbs to the point where the shift key sometimes can’t go all the way down, can’t we do everything in the platinum package in two weeks instead of six months?”
A surprising number of developers fall for that last one.
Like, most of them.
Sure, you could “just” murder your database with table-scanning queries that join every single table and hope that you’ve provisioned a beefy enough machine to handle the load “for now”. Just like your plumber could “just” fix a pipe leaking on the floor by shoving a bucket under it and telling you to empty it every week.
But you gotta take a stand on quality somewhere.
Developers fall into the same trap of thinking in terms of whatever length of time their organization parcels out work into: two week “sprints”, six week “cycles”, what have you.
And product is telling them the scope can’t budge. And you know sure as shit you ain’t getting any more team members to handle the load. What’s the only thing that can give at this point? Quality. That’s the iron triangle of software development, and you’re its latest victim.
So let me squash the idea of sacrificing quality real quick by asking you a question:
What’s worse, delivering something a customer actually hates, or delivering nothing at all?
From painful experience, I can tell you that you’ll lose customers if you choose the former. And the former happens when you sacrifice quality. You don’t want a goddamn bucket under your pipe that you have to empty, you want a new pipe.
Grow a spine and find a level of quality that you will not compromise on. For example, my plumbers won’t install any off-the-shelf parts. They’ll only install products that they supply themselves because they are confident in the quality. At least I charitably believe that instead of the alternative which is that these products are expensive as heck and yet another way to gouge me on the margins.
My point is that quality has some fixed minimum and therefore scope and time are what budges instead. If you make a big enough of a stink you might even get more budget and a bigger team, but if you manage to accomplish that please tell me how.
Now back to the show.
It’s a negotiation, redux
After you’ve decided to be a big strong boy that takes a stand on some bare modicum of quality, we can start the negotiations.
When product says things like
“What if we put off saving and emailing reports until later?”
or
“What if we dropped running reports on a schedule?”
This is when you start bringing out your ‘standard’ and ‘economy plus’ packages etc. Because you’ve already gone to the trouble of treating these things as line items in an invoice (read: estimated their effort) you can tell product how much their chosen package will cost. You can even give them estimates on when you can deliver these line items, allowing your organization to plan over a longer time horizon with deliverable dates along the way.
It gets interesting when product goes a little off-script and says something like
“What part of the desired scope can you deliver if I don’t want to pay for an OLAP system?”
Then you can get creative. You are negotiating with product on the two facets of the project that will generally change (mentioned in my rant above): scope, and time.
If I were jaded (I am), I’d say the only thing that really gets negotiated is scope because for some reason every shop out there has decided that an entire project needs to fit within the arbitrary window of time that constitutes whatever definition of “agile” they’re currently following.
If you’re reading this thinking, “No way, management at my company take a longer term view of things in favor of delivering best-in-class products”, then I implore you to include that information in a letter you send to:
His Holiness Casa Santa Marta 00120 Vatican City
So they can be canonized as the first living saint.
In many ways, you are simply helping product to ruthlessly prioritize a list of work so that the team can deliver the highest return-on-investment (ROI) within the confines of the fixed time, and budget points of the iron triangle. If there’s enough good stuff left on the table at the end, you might have accidentally planned ahead for your next project for once.
Turning it around
If you’re doing your job right, there’s plenty of crap that YOU want to do, but so far we’ve only talked about making the people with the money give it to you when THEY want to do something.
So how do you get product to give a shit about your architecture proposal when the tables are turned?
Well, your local insulation company will gladly come to you, for free, and spend an hour with really expensive thermal imaging gear to find walls that need more insulation. Free because they know that your home’s “builder grade” insulation made of bits of drywall and discarded Monster Energy cans is literally garbage. They’ll tell you that you’ll save $50 a month in heating and cooling costs if only you could give them $5,000.00 now.
You’ll quickly do the math and ask yourself a few questions:
am I really that uncomfortable?
do I plan on staying at this home for roughly another 8 years (the time it takes before I’ll recover the investment), and
if I were going to invest five grand, would it be better spent elsewhere?
Wow suddenly you’re the product team. Go take a cold shower.
The equation doesn’t change
Nothing has changed here except who came up with the idea. Be the insulation company. You still need to come up with line items in an invoice as before. You still need to negotiate time and scope. You still need to make a compelling argument about ROI. Here’s what’s not going to get your proposal greenlit:
“I want to add a couple more tests to this code the intern wrote last summer”
How the fuck is your company supposed to translate that into ROI? Try this instead:
“I noticed that (business critical feature) is under-tested, so I would classify it as high risk of having bugs in it that would be showstoppers. An outage here could cost us big $$$ not just to fix it, but also in customer churn and reputation loss.”
And even if your project gets greenlit, it may be after you make some concessions like the project can’t go on for longer than a week, or that you can’t bring in anyone else on it (that’s the negotiation part).
You have some petty cash to spend
The last point I want to make is that you probably have a little free time to do what you want at your job outside of feature work and chores like keeping third party libraries updated. Google called this “20% time” in the early 2000s (and their engineers called it “120% time”).
For the last time, the equation doesn’t change. It’s just that the same person (you) holds the money and proposes the work. You may not need to write out your line items on paper (although it would certainly help); most devs somehow keep that in their head alongside all the movie quotes they endlessly repeat in Slack.
Don’t feel obligated to immediately spend your allowance on small things like linting fixes. You can invest it each week towards something bigger like a pub/sub system so that you can pull a new microservice out of your monolith. Just make sure that the rest of the team is onboard with the bigger changes.
Summing things up
When you are elaborating work for product’s next brilliant feature that less than 1% of customers will ever use, elaborate how to do it right. The cost of time, scope, and budget fall out from there. Let product decide if they want to make that investment. Negotiate with your product team on what you can deliver and when, and never back down on quality. Easier said than done.
Harness your inner plumber. Sell that platinum package. It will make dealing with all the shit everyday a little easier.
“I’ll compose a new type that holds a Doohickey and also indicates whether the fetch operation succeeded!” If you couldn’t have a utopia in the real world, then dammit you’d have one in your obscure codebase! It shall have clean logic untarnished by dirty, filthy hobbitses error-checking. Something like this:
It’s the classic love story. Girl meets boy. Boy isn’t sure if his function will succeed, so he returns a metatype for his actual type indicating whether the operation succeeded or failed. Boy loses girl. We’ve all been there.
Here’s how it happened. Err, well, at least that second part.
You had a function for fetching Doohickeys. It looked like this:
public Doohickey GetDoohickey(string Id){/*...*/}
But pretty soon you realized that no Doohickey might exist, so you quickly revised your API to allow for a null return:
public Doohickey? GetDoohickey(string Id){/*...*/}
All was well. Fetching a Doohickey results in one of two things: null, or not-null. It’s great that C# has facilities for representing this! At least, that’s what you thought before an ominous cloud appeared overhead and a security review reminded you that not everyone has access to all Doohickeys. You recalled that the security team doesn’t reach out to say hello, they reach out to tell you to pack your shit, so you quickly add a permissions check to avoid the conversation:
public Doohickey? GetDoohickey(string Id)
{
if (!PermissionCheck())
// wtf do I return here?
// ...
}
You were stuck then, because the type returned by your function only has two states: null or not null. If you return null, a caller might interpret that the Doohickey might simply not exist and do something unmentionable. You need a third state, but C# doesn’t support a Nullable<Nullable<Doohickey>> type because it doesn’t make sense and you felt a little guilty for even considering it.
“And is it really an exceptional scenario where a user doesn’t have permission to access a Doohickey?” You asked yourself. “Do I want to go down the rabbit hole of adding try-catch handlers everywhere in the code?”
So you had a brilliant idea:
“I’ll compose a new type that holds a Doohickey and also indicates whether the fetch operation succeeded!”
With one hand giddily patting yourself on the back, you used the other to write the following (on your one-handed Dvorak):
public class GetDoohickeyResult
{
public Doohickey? TheDoohickey {get; set;}
public bool Succeeded {get; set;}
}
public GetDooHickeyResult GetDoohickey(string Id)
{
if (!PermissionCheck())
return new GetDoohickeyResult{TheDoohickey = null, Succeeded = false};
// ...
}
It wasn’t long before you realized this pattern could be applied to other things, so you created a generic type that could hold a Doohickey, a Thingamajig, a Whatchamacallit, or anything else. And you probably called that class Result<T>
public class Result<T>
{
// Note: NOT the 1982 John Carpenter horror film... but actually kind of similar
public T? TheThing {get; set;}
public bool Succeeded {get; set;}
}
public Result<DooHickey> GetDoohickey(string Id){/*...*/}
Well, congratulations for getting that far. You made half a Monad. Or as functional programmers would call it, “half a monad” (but with a snooty, holier-than-thou tone).
A regular Doohickey can be shoveled into Result<Doohickey> just fine:
Doohickey myPrecious = FetchDoohickeyFromLake();
var successfulDoohickeyResult = new Result<DooHickey>
{
TheThing = myPrecious,
Succeeded = true;
}
Most of the programming world sees this as run-of-the-mill construction, but functional programmers fall to their knees and reverently proclaim “It is return! The first law of Monads!”. Some less-religious functional programmers might shrug and call it “lifting”. (Meme-loving functional programmers say you’ve rolled a burrito).
You probably stopped your journey here. The code was good enough, tests passed, and product was already cracking the whip for you to move on because the feature-factory culture of your organization was insatiable.
But maybe you didn’t move on. Maybe you thought, “Hey, I can take this farther.” Maybe you led the hoi polloi in an anti-capitalist revolution that overthrew the fat pigs on top of the social hierarchy, ushering in a new era of peace and prosperity!
But probably you only refactored a little bit more, which is enough rebellion for one day.
That refactoring was fueled by your dislike of a bunch of if statements cluttering up your business logic:
var maybeDoohickey = GetDoohickey(id);
if (maybeDoohickey.Success)
{
// TODO: Hide in a cave
}
If you couldn’t have a utopia in the real world, then dammit you’d have one in your obscure codebase! It shall have clean logic untarnished by dirty, filthy hobbitses error-checking.
Something like this:
So you wrote the following implementation of this magical .Then function. It accepts a function that will be called only if the provided Result<Doohickey> is successful. It might return a type other than Doohickey (represented by U), but it’s always possible that both the source and destination types (T and U respectively) could be Doohickey.
public static Result<U> Then<T, U>(this Result<T> result, Func<T, U> onSuccess)
{
if (result.Success)
return new Result<U>{TheThing = onSuccess(result.TheThing), Success = true};
else
return new Result<U>{TheThing = null, Success = false};
}
(If you knew too much theory you might have chosen a silly, confusing name like Map or Select)
Shortly after that, you realized that HideInCave should return a Result<Doohickey> too:
public Result<Doohickey> HideInCave(Doohickey thePrecious){/*...*/}
Putting it gently, this really fucked your code up. Now your .Then wasn’t returning a Result<Doohickey>, it was returning a Result<Result<Doohickey>> and the compiler didn’t like it:
GetDoohickey(id) // Result<Doohickey>
.Then(HideInCave) // Result<Result<Doohickey>>
.Then(EatAFish) // compiler error, `EatAFish` does not accept a parameter of type `Result<Doohickey>`
.OnError(StealFromHobbits)
Fortunately you had a simple enough fix for it. You’d write an overload for .Then where you didn’t need to construct your own Result<U> in the success case, you’d let the Func<T, Result<U>> parameter do it for you:
public static Result<U> Then<T, U>(this Result<T> result, Func<T, Result<U>> onSuccess)
{
if (result.Success)
// this next line just returns the Result<U> from onSuccess unlike the other .Then overload
return onSuccess(result.TheThing);
else
return new Result<U>{TheThing = null, Success = false};
}
(If you knew too much theory again, you might have chosen a completely different nonsensical name for this function like Bind or SelectMany)
You code now automatically flattened Result<Result<T>> into Result<T>. Satisfied, you grabbed a nearby shop towel to wipe the grease off your elbows, chuckled at your silly hack, and moved on with your life.
But the devout functional programmer watching you (they see all) now prostrated themselves to the floor chanting in holy ecstasy “The prophecy has been fulfilled. The second law of Monads – Bind – has arrived! The reckoning is nigh!” (The meme-loving functional programmers would giggle that you unwrapped your burrito.)
If you really made it that far, congratulations, you accidentally created a real Monad. Or at least the closest approximation to one that your programming language supported.
Oh yeah, and while you were doing all that your girlfriend left you.
The End
This story is based on the reality of codebases I’ve seen in my career. Half-baked implementations of Monads that do just enough to be useful for one or two use cases, but not enough to really make the overall codebase easier to use. It is my great hope that this article de-mystifies the scary Monad word and other category theory terminology that gets thrown around with it.
The Result<T> example here is most closely associated with what might be called an Either Monad. In a “real” implementation of it, there would be a litany of other helper functions to account for all kinds of different cases, and I say that from experience writing a simple functional library to support my own work. I want to strongly dissuade you from attempting to write your own. Instead, reach for one of the established functional programming libraries out there for your programming language (For example, language-ext in C#).
Libraries can only do so much though, and when you go down this path you’ll quickly find their limitations. Before you know it, you’ll be filing issues on your language’s GitHub page, complaining about lack of functional support on StackOverflow, booting Arch Linux, sporting a top-hat and bowtie, and unironically saying “indubitably” in casual conversation. It’s a dangerous path to walk.
If there’s an if condition inside a function, consider if it could be moved to the caller instead Finally, I want to briefly return to the notion of testing: Well, the answer to that is the same as the answer to exceptions; strengthen the type returned by the function, and let callers ignore scenarios they […]
In late 2023, Alex Kladov published Push ifs up and fors down which essentially says the following (correct) statement:
If there’s an if condition inside a function, consider if it could be moved to the caller instead
Great advice, and I thoroughly agree. I’d even make a stronger argument to encode the check into the type itself. For example, if a number cannot be less than zero by the time it reaches a function, your type system should be able to prove it. But I digress.
The advice from Alex really only considers data that is entering a function, and not data that is exiting. If your function fetches data in some way, via a call to a database or some other external service, then you want to push your if checks down, not up.
Consider the following contrived example that makes a GET call over HTTP to presumably get some notion of a Student from a REST service.
public async Task<HttpResponseMessage> FetchStudentById(Guid studentId)
{
return await _httpClient.GetAsync($"{studentsUrl}/{studentId}");
}
Now every caller that calls this method needs to:
Check that the response indicates success, and
deserialize the data into a stronger type
Now, code like this doesn’t really exist. Programmers often realize this issues ahead of time. The only problem is that they often inadequately address them. Consider this slightly more realistic scenario:
public async Task<Student?> FetchStudentById(Guid studentId)
{
var response = await _httpClient.GetAsync($"{studentsUrl}/{studentId}");
// ensure 200 response code
if (response.StatusCode != StatusCode.OK)
return null;
// try to deserialize a type
try
{
var jsonResponse = await response.Content.ReadAsStringAsync();
return JsonConvert.DeserializeObject<Student>(jsonResponse);
}
catch (Exception e) // some deserialization exception
{
return null;
}
}
This is a lot better. We’ve moved our if checks down into this function so they can be done in one place instead of many. Code like this can (and does) exist in perpetuity without a ton of issues. Consider the following questions, though:
Does the caller expect that a student with the provided Id might not exist or are they checking for null everywhere after?
If I wanted to write tests against this endpoint, how could I test success and failure scenarios?
If we don’t receive a 200 back
If deserialization fails because of e.g., ill-formatted JSON or even an unexpected schema change
The scenario where an Id wasn’t found is treated the same as all failure scenarios – return null.
Too often people turn to exceptions to differentiate between actual failure and simply a not-found Student:
public async Task<Student?> FetchStudentById(Guid studentId)
{
var response = await _httpClient.GetAsync($"{studentsUrl}/{studentId}");
// throws (bad)
response.EnsureSuccessStatusCode();
// check for no student found: endpoint returns a string that says "null"
var jsonResponse = await response.Content.ReadAsStringAsync();
if (jsonResponse == "null")
return null;
// otherwise, try to deserialize, which throws upon failure (bad)
return JsonConvert.DeserializeObject<Student>(jsonResponse);
}
While we can now write tests against this endpoint to differentiate between no student found and actual failure (good), we’ve created problems for all code that calls FetchStudentById:
Callers still must ask themselves if null means failure or just a missing student, because null is so ubiquitously used for both
writing documentation that explains that yes, null, really means a missing student only goes so far; developers have to consult your ugly docs to find this out
All callers now need to wrap the call in a try...catch, unless they want the exception to crash the service
This is sometimes kind of, sort of okay because most services wrap all operations in a top level try-catch which might just log it for developers to see, and then maybe surface a generic error to any end user
The first and easiest thing issue to address is the ambiguity of a null return. You can do this by exposing two functions, one returns null and one does not*:
public async Task<Student?> FetchStudentByIdOptional(Guid studentId)
{
var response = await _httpClient.GetAsync($"{studentsUrl}/{studentId}");
// throws (bad)
response.EnsureSuccessStatusCode();
// check for no student found: endpoint returns a string that says "null"
var jsonResponse = await response.Content.ReadAsStringAsync();
if (jsonResponse == "null")
return null;
// otherwise, try to deserialize, which throws upon failure (bad)
return JsonConvert.DeserializeObject<Student>(jsonResponse);
}
public async Task<Student> FetchStudentById(Guid studentId)
{
var optionalStudent = FetchStudentByIdOptional(studentId);
if (optionalStudent == null)
throw new Exception($"No student with Id {studentId} found");
return optionalStudent!;
}
(*Note: I’d actually recommend using a type that indicates the possibility of a Student or not, via a Optional type, but it’s not realistic to ask developers to pull in a third party library to support this, or alternatively write their own. If you’re already using a language that has a Maybe monad built in, you probably already came to all these conclusions yourself because the language forced you into it.)
This is better; we’ve strengthened the type of FetchStudentById so that callers know it will never return null, and as result your codebase won’t be littered with unnecessary null checks.
Callers also know that the ...Optional method’s null means no student was found. You might adopt LINQ’s FirstOrDefault or similar terminology to communicate this even better.
However, callers are still faced with the issue of exceptions being thrown.
Finally, I want to briefly return to the notion of testing:
What if I want to write more specific tests around expected response codes or additional information being returned by an endpoint?
It’s not uncommon for endpoint to return wrapped data that indicates metadata about the response, like a list of warnings regarding the request, deprecation, or even information about api versioning
Well, the answer to that is the same as the answer to exceptions; strengthen the type returned by the function, and let callers ignore scenarios they don’t care about!
Conclusion
I’ll leave you with a a restatement of this post’s title:
*I’m pretty sure the only way to really tell if an email address is valid is to send an email to it and hopefully not get it bounced back as undeliverable. Regular expressions be damned. *In Haskell, this is only true if you ask it to
At some point, every developer writing user-facing code has asked themselves the question
“How should I validate input?”
For example, a user wants to change their email address, and you only want to process their request if their new email is indeed, roughly*, a correct email address.
[HttpPost("/set-email")]
public ActionResult SetEmail([FromBody] string? alleged_email)
{
// ???
}
And as far as the database code is concerned, an email address could come from any point in the preceding call stack. So the next question you find yourself asking is
“When do I validate input?”
If you Google “When to validate parameters” you get absurd answers like
Usually parameter checks are very cheap, even if called thousands of times. For example, test if a value is null, a string or Collection is empty (sic) a number is in a given range.
(Link)
and
if you can live with the potential performance hit, I like to validate parameters everywhere, as it makes code maintenance and refactoring a bit easier
(Link)
I contend that we should not revalidate the same parameters “thousands of times”. I hope you, dear discerning reader, agree.
*I’m pretty sure the only way to really tell if an email address is valid is to send an email to it and hopefully not get it bounced back as undeliverable. Regular expressions be damned.
Type-driven design
At this point, functional programmers chuckle, twirl their mustaches, and adjust their monocles before exclaiming “Elementary my boy, use type-driven design!”.
Your average functional programmer (generated by DALL-E)
As the functional programmer explains that type-driven design ensures program correctness by designing types where certain properties are always true, the object-oriented programmer scratches their head wondering what’s so revolutionary about that; enforcing invariants is pretty much the entire point of object-oriented programming (encapsulation and access control are the what, and invariants are the why).
What neither programmer realizes is that they’ve both been doing type-driven design wrong. But it’s not their fault. They’ve both been misled. We’ve all been misled. Misled by the allure of our languages’ constructors.
A constructors’ purpose is to ensure that when an object is created, it is done so in a valid state. Don’t take my word for it, Wikipedia plainly states as much.
What if we can’t achieve a valid state with the parameters we’re given?
Ah, and therein lies the problem. A constructor can only “return” an instance of the class type.
When you perform validation within a constructor, it’s too late to do anything but throw an exception upon failure.
public class EmailAddress
{
public EmailAddress(string alleged_email)
{
if (!EmailRegex.IsMatch(alleged_email))
throw new ArgumentException("wtf bro");
// ...
Digression on exceptions
Some languages lack the sort of exceptions you see in C++ and C#. In Go, we’re talking about “panics”, for example.
But even the word “panic” is inconsistent across languages. In Rust, a panic is not recoverable.
Like Rust, Java has unrecoverable panics, but they’re called Errors. It can be confusing because Java also has recoverable Exceptions, too.
To confuse us even more, Go also has Errors, except they are nothing like unrecoverable panics. Instead they are simply values that can be passed around like anything else. Extra confusing is that in Haskell, Exceptions are like Go errors; they’re just values. Value-based exceptions are often wrapped up in other standard language constructs. In Rust, you’d use std::result, for example.
When I mention exceptions, I’m speaking of recoverable exceptions/panics that are not values.
Friends don’t let friends use exceptions
Exceptions are less-than-ideal mechanisms for logic control. Besides the fact that a try-catch block is uglier than sin, here are some reasons to avoid them:
Exceptions are heavy performance hitters.
Exception instances almost always* store an entire stack trace
Additionally, there are often big performance overheads just to build the stack trace.
Handling exceptions is so expensive that some C++ projects disable them altogether (ref). This has caused a bit of an existential crisis in the C++ community
In C++, the common “zero cost exception” model builds compile-time information about all handlers for places where there is a throw. It is “zero (CPU) cost” until an exception is actually thrown. When that happens, though, it is extremely expensive.
In C#, exceptions trigger a stack unwinding in search of a handler, which involves examining each stack frame in the current call-stack.
*In Haskell, this is only true if you ask it to
Exceptions do not compose
(Except in languages where they do)
Exceptions “escape” the current scope, or as Chair of the C++ committee Herb Sutter says in “Zero-overhead deterministic exceptions: Throwing values”, “exceptional control flow is invisible”. This means laboriously adding nested scope upon nested scope in the form of try...catch blocks so that exceptions do not “escape” and terminate your program.
We do not want error handling to distract us from the “happy-path” logic we are expressing. Instead, we want to give the programmer flexibility to either handle an error immediately or decide to push off handling until later.
So you’re outlawing exceptions?
I’m not saying don’t ever use exceptions, I’m saying they should be a last resort. I may not always agree with the Google C++ style guide, but it does have this pearl of wisdom with regards to exceptions:
The availability of exceptions may encourage developers to throw them when they are not appropriate or recover from them when it’s not safe to do so. For example, invalid user input should not cause exceptions to be thrown.
If a user accidentally left off the domain of their email address, don’t throw an exception. If there is a disk read error or failure to allocate memory, for example, then sure, exceptions can be useful.
Doesn’t revalidate the same input (“thousands of times”), and
Gracefully handles invalid input
1. Reject invalid input early
Let’s set aside the security implications. Practically speaking, if you need to validate at all, you might as well do it right away otherwise when validation fails, you’ve wasted CPU and memory.
That’s it. I’m sure there are other arguments, but this is the most sound.
2. Don’t revalidate the same input
It’s needlessly wasteful. See #1. Even if your validation code was very lightweight, you’re at least abusing the “Don’t repeat yourself” (DRY) principle.
3. Gracefully handle invalid input
What makes error handling “graceful”?
In order for error-handling to be “graceful”, it must:
not throw exceptions, and
not bounce around between logic and error checking like so:
var resultA = FunctionA();
if (!resultA.Succeeded)
{
// error handling
}
var resultB = FunctionB(resultA.Value);
if (!resultB.Succeeded)
{
// error handling
}
// ...
Throwing exceptions almost got it right
Throwing exceptions in constructors actually satisfies conditions #1 (reject invalid input early) and #2 (don’t revalidate the same input). However, they utterly fail #3 (gracefully handle invalid input).
The workarounds that fell short
Programmers are a curious, perfection-seeking bunch. Many have recognized the issues with using constructors as validators and invented workarounds. Few got it right. In attempting to address condition #3 (gracefully handle invalid input), they relax either condition #1 (reject invalid input early); condition #2 (don’t revalidate the same input); or both.
All of the workarounds that got it wrong have one thing in common: they move the validation code outside of the class. When this happens, later consumers of the class can never be sure if the class is valid. Let’s take a look at some of these well-meaning but ultimately wrong techniques.
Error codes
Error codes are lightweight integers used to represent some error condition. The most ubiquitous error code is 1 which is returned by a process when it exits with an error. In C#, validating our email address with error codes might look like this:
public enum EmailValidationErrorCode
{
Ok = 0,
IsNull = 1,
InvalidFormat = 2
}
[HttpPost("/set-email")]
public ActionResult SetEmail([FromBody] string? alleged_email)
{
var validationResult = ValidateEmail(alleged_email);
if (validationResult != EmailValidationErrorCode.Ok)
return BadRequest();
// ...
return Ok();
}
EnumValidationErrorCode ValidateEmail(string? alleged_email)
{
if (alleged_email == null)
return EmailValidationErrorCode.IsNull;
else if (!EmailRegex.IsMatch(alleged_email))
return EmailValidationErrorCode.InvalidFormat;
return EmailValidationErrorCode.Ok;
}
Consider yourself lucky if you get enumerations like this instead of plain integers for which you need to consult a physical paper manual issued by a company that went out of business 20 years ago, whose only copy is somewhere in Grace’s old office (before she retired).
The only problem that error codes solve is that errors are now much more lightweight than exceptions. Everything else about them is awful.
They encourage a if (success) {...} else {...} programming style that is hard to read
They don’t compose
Other functions that need to consume this input CANNOT KNOW THEY RECEIVED A VALID EMAIL! They are forced to revalidate.
In other words, error codes violate condition #2 (don’t revalidate the same input) and arguably condition #3 (handle invalid input gracefully). They arguably violate condition #1 (reject invalid input early) as well, since you must remember to call the validation code, but I’ll give it a pass.
ValidationResult
People realized that error codes were seriously lacking. For one thing, they usually only indicated one type of failure. Multiple things could be wrong with input, and you don’t want the end user to get stuck in a debug whack-a-mole loop where they fix one validation error just to be presented with the next one, and so on. (Skipping over bitfield approaches) this leads us to ValidationResult approaches, which can store more than one error object. These error objects are fancy, they can have an integer code AND a human-readable string.
The slick FluentValidation library in for .NET has us declare a validator class where we can compose validation rules, even dependent rules using LINQ-like syntax:
public class EmailValidator : AbstractValidator<string>
{
public EmailValidator()
{
RuleFor(str => str).EmailAddress(EmailValidationMode.Net4xRegex);
}
}
[HttpPost("/set-email")]
public ActionResult SetEmail([FromBody] string? alleged_email)
{
var validationResult = new EmailValidator().Validate(alleged_email);
if (!validationResult.IsValid())
return BadRequest(validationResult.ToString());
// ...
return Ok();
}
These solve exactly zero of the problems I laid out with error codes. They’re fun to write though!
In fact, this actually violates another rule:
Use protection; validate before you allocate
Validator classes require us to have an instance of the class being validated before validation can run. Besides wasting an allocation for scenarios where validation fails, they make the assumption that the class being validated is basically a bag of public properties (called “POD” in C++, POJO in Java, POCO in C#, or more universally a Passive data structure).
Mithra save you if your class reads a configuration file, or calls out to a service on the network like a database. All that work for nothing. And sometimes you don’t even really have any control over that; in C++ if you derive from a base class, the base class gets constructed first (as opposed to C# where the derived class is).
Allocations are not inherently expensive; it’s all the stuff that can come with it.
(N.B. I consider Validator classes as nearly identical to the fallacious two-stage construction as popularized by MFC)
Either
Some programmers got a little wiser with their ValidationResult-esque classes. Maybe they overheard some of the older kids talking about “Monads” and decided that they were sick of writing if(success){...} else{...} everywhere. Who knows?
One day someone said, “What if instead of manually checking whether the result succeeded or failed, I could just provide the functions that should get called for either scenario?” and then proceeded to absolutely butcher an implementation of Either.
The prolific C# Youtuber Nick Chapsas eventually stumbled his way into the following implementation after 3 years and 6 videos with cringey thumbnails (1, 2, 4, 5, 6)
My criticisms of Mr. Chapsas are tongue-in-cheek; I actually appreciate all he’s done for the C# community
If you were fooled into even trying to compose with functions that returned instances of Chapsas’ Result you’d quickly see how fast it becomes unwieldy. For example, here are just three function calls in order, the first two returning Result.
var finalResult = FunctionReturningResult(arg).Match
(
successValue => OtherFunctionReturningResult(successValue)
.Match
(
anotherSuccess => FinallyASaneFunction(anotherSuccess) // I already hate myself
someFailure => SomeErrorCode(someFailure)
),
failureValue => OtherFailureCode(failureValue)
);
Brief aside on Monads
“This type is technically a union and this type is also technically a Monad” Chapsas tells viewers (ref), and he is wrong on both fronts.
Let’s demystify Monads. They’re basically interfaces: interfaces for classes that wrap other classes. Consider List. It wraps zero or more T that can be accessed sequentially. For a type to be a Monad, you must be able to:
“lift” a T into it
We can easily create a list of a single element
“map” a function to it
In C#, this is LINQ’s .Select function. We can convert a List<int> to a List<string> for example
(Monads aren’t actually required to have “map”, but many do anyway)
“bind” a function to it
in C#, this is LINQ’s .SelectMany function. It “flattens”. If you “map” a function that raises each element into its own list like so .Select(value => new List{value, value}), then you end up with effectively List<List<T>>. SelectMany (“bind”) will concatenate all internal lists to form a flattened list of List<T>.
What Nick has given us is not a Monad, but roughly a “Church encoded Either” (except Mark Seemann more cleverly implements his to simulate a union). An unfortunately it lacks a “bind” operation.
As for the claim that it’s a union, C# lacks true sum types and as a result memory is still allocated for both. An actual union only allocates enough memory to hold its largest type. Behaviorally, though, Nick’s Result<T> does act like a discriminated union.
Kudos for getting that far though, Nick. With just a little more work we could evolve this type into a full Monad. To his credit, though, he eventually recommends both dotNext’s Result and LanguageExt’s Result<A> classes instead (of which neither are Monads)
Regardless, it doesn’t matter if you used a properly-implemented Either to solve the validation problem. As soon as you “reach inside” it to grab the value (e.g., in the success case), the consuming function has no idea that the parameter was validated anyway.
Types must be self-validating, otherwise it’s the “trust me bro” approach to contracts.
ValidatedEmailAddress
Here is where I give everyone I’ve criticized about validation a pass. Validation is subtly difficult to accomplish, and even the best of the best get it wrong. As proof, let’s revisit my hero, the Reverend Mark Seemann. Even he has been blinded by constructors.
Before I begin, I want to mention that Mark Seemann has probably forgotten more category theory and functional programming than I will ever learn. The guy has written two books and runs a freakin’ course on type-driven design.
And yet he still got validation wrong (so close, though).
Mark has written quite a bit about validation (1, 2, 3, 4), and he ultimately recommends the following pattern to construct your objects:
public class EmailDto
{
public string? Email{get; init;}
public Result TryParse()
{
if (Email == null)
return null;
if (!EmailRegex.IsMatch(Email))
return null;
return new EmailAddress{Email = this.Email};
}
}
public class ValidatedEmailAddress
{
public string Email{get; init;}
}
(Where Result is a proper Either implementation).
The problem with this code is that I have a coworker named Homer S. who doesn’t pay attention to silly things like unenforced preconditions. You tell them that ValidatedEmailAddress should only be constructed as a result of EmailDTO.TryParse and it goes in one ear and out the other. Maybe you’ll get lucky and catch them submitting something like this in code review:
var validEmail = new ValidatedEmailAddress{Email = "notvalid"};
While this code handles invalid input gracefully (condition #3) it ultimately fails to avoid revalidating the same input (condition #2). Future consumers of an ValidatedEmailAddress cannot actually be certain it was validated.
Like the techniques mentioned above, it also arguably fails to reject invalid input early (condition #1); one must remember to construct a ValidatedEmailAddress via EmailDto.TryParse
I mentioned that this code got really close to the right answer, and TryParse is the clue.
Guid.TryParse
In C#, there’s a common pattern for constructing basic types from a string that looks like this:
public struct Guid
{
public static bool TryParse(string input, out Guid result)
{
// ...
}
}
If this were the only way to make a Guid (it’s not) it would satisfy the two criteria that Mark’s TryParse did not!
Let’s combine Mark Seemann’s TryParse pattern with C#’s TryParse pattern.
Smart constructors
Briefly let’s revisit our requirements for proper validation
Reject invalid input early
Don’t revalidate the same input, and
Gracefully handle invalid input
More concretely,
It should be impossible to construct an instance of the target type in an invalid state
We must not throw exceptions, and
We must be able to compose with the result of validation
Just get to the technique already!
Let’s tweak Mark’s TryParse pattern above just slightly for our EmailAddress class:
public class EmailAddress
{
private readonly string _email;
private EmailAddress(string validatedEmail)
{
_email = validatedEmail;
}
public static ValidatedResult TryParse(string maybeEmail)
{
if (maybeEmail == null)
return Validated.Fail("Email address was null")
else if (!EmailAddressRegex.IsMatch(maybeEmail))
return Validated.Fail("Email address was not in the correct format")
else
return Validated.Succeed(new EmailAddress(maybeEmail));
}
}
Does this approach satisfy our criteria?
1. Reject invalid input early
Failure to construct an EmailAddress immediately returns a ValidationResult in a failure state, which can short circuit subsequent chained calls.
2. Don’t revalidate the same input
It is impossible to create an EmailAddress instance in a bad state; the class enforces its own preconditions. Consumers can rest assured knowing they don’t need to revalidate.
3. Gracefully handle invalid input
As outlined in Mark’s blog post, we can compose with our ValidationResult class.
(Also we are not throwing exceptions.)
Personally, I prefer an error type that is a bit richer than a string (Mark Seemann does too), but the above demonstrates the gist of the technique.
Railway oriented programming
With all this in place, we can implement a railway pattern. In this pattern, error information is encapsulated and then propagated down the call chain, to be handled at the end.
We could fail either when we try to turn a string into an email address (EmailAddress.TryParse) or when we actually attempt to update the user (_db.UpdateEmailAddressForUser) if, for example, no user with that Id actually exists.
But you don’t see the error handling scattered around the codebase. Instead, each .Then examines the ValidationResult object. If said object is in an error state, the error simply propagates to the next call in the chain. Otherwise the function passed into .Then is applied. Error handling is done at the end in .Apply(MapResponse) which will return an appropriate REST response based on whether the prior code succeeded or failed.
I advise you to use function names that make sense to your team. For example, I like the name .Then, which is overloaded for a variety of scenarios. It sure beats confusing names like Map and Bind.
A little bit at a time
If I wanted to, I could break the railway pattern at any point and write imperatively:
var updatedEmailResponse = await EmailAddress.TryParse(inputStr)
.Then(async (validEmailAddress) => await _db.UpdateEmailAddressForUser(uid, validEmailAddress));
if (!updatedEmailResponse.Success)
return updatedEmailResponse.Match(/*...*/);
var webResponse = new UpdateEmailResponseForWeb(/*...*/);
return Ok(webResponse);
Sure, it’s not 100% pure, but it’s massively more useful than before. Baby steps. We can now transition our codebase from a more imperative style to a more compositional style as we see fit.
A smart constructor pattern is where you make it impossible for consumers to call the actual constructor of a type. Instead, you (the type’s author) expose a function (or functions) that can do it instead. Consumers are forced to call your function, which guarantees correct-construction of your type, and also has more flexibility to return error information than a lowly constructor.
The name “smart constructor” comes from a Haskell technique of the same name. In Haskell, smart constructors are achieved through some module export trickery, but for most “general purpose” languages, we need to follow the TryParse pattern outlined above.
(Feel free to name your smart constructor something other than TryParse)
We are working against our programming languages!
It’s not easy or intuitive to pull this off correctly. Programming languages make it easy to call constructors, and I think it should be the other way around. Maybe one day we’ll get a language (or updates to an existing language) to better support type-driven design.
Smart constructors are the best of functional and object-oriented programming
Modulo language syntax, we get to keep the fantastic invariant preservation of object-oriented design, while also benefiting from the expressivity afforded to us by monadic composition.
Closing thoughts
I did not invent smart constructors. Almost everyone I shared this article with said that they had either seen or independently reinvented this technique at some point. In 2015, Scott Wlaschin succinctly summarized the entire technique in two comments:
// Just as in C#, use a private constructor
// and expose "factory" methods that enforce the constraints
As long as I’m linking to Scott Wlaschin, I should point out that he wrote an excellent series on type-driven design in 2013. I’ve reiterated many of his points here. In fact, in that same 2015 Github gist I linked above, he demonstrates smart constructors for F#.
I suspect that smart constructors (in object-oriented code) have been around nearly as long as object-oriented code existed. They just have not been written about extensively.
I hope that I’ve helped formalize this technique and give it a handy name to refer to. Perhaps one day we’ll mention “smart constructors” as often as we say “factory pattern”.
Acknowledgements
I’m extremely grateful for the fantastic correspondence I’ve had with the following people in the course of writing this article (in alphabetical order by last name):
Nathan Bayles
Dr. Jory Denny
Timothy Gilino
Adam Homer
Ben Ketcherside
Dr. Stephanie Valentine
Appendix A: ASP.NET validation middleware
Considering my use of C# throughout this article, I would be remiss if I didn’t mention ASP.NET’s validation middleware.
When you write a web app in C# .NET, the infrastructure conveniently handles constructing your strongly-typed parameters from the weakly typed JSON/XML/Text/etc. requests you receive. If you create a class to encapsulate all of these parameters, you can annotate them with validation requirements as follows:
public record ChangeEmailRequest
(
[Required]
string UserId,
[Email]
string NewEmail
)
Before your function is invoked, ASP.NET will validate that UserId is not null, and that NewEmail has an @ character (yes, that’s really all it does). If validation fails, you can configure it to automatically return a 400 (Bad Request) with a default or custom response body, or you can explicitly check if (!ModelState.IsValid) and perform in-line handling in your controller.
This actually works really well in practice. Almost all validation only needs to happen at the point that we receive user input, and returning a bad request response right away is good (see: #1 Reject invalid input early). If you really need to, you can even access dependency-injected services in your custom-validation attributes (even if it makes testing a little weird).
Plus, when you use a record type in this way (init-only properties), it is immutable after creation. This almost satisfies condition #2 (don’t revalidate the same input).
With automatic 400 (Bad Request) responses configured, this even satisfies condition #3 (gracefully handle invalid input).
There are a few problems, though. Condition #2 (don’t revalidate the same input) is not actually satisfied; if the controller action decided to pass this parameter onto a service class (or even just a helper function), that consumer can’t be certain that validation has been performed, because the following is still possible:
var badRequest = new ChangeEmailRequest("validUserId", "InvalidEmail");
Condition #3 (gracefully handle invalid input) is not actually satisfied either. Again, it’s only satisfied at the controller action level. If you wanted to perform this validation anywhere else in the codebase (outside of maybe EntityFramework), it would look like this:
var maybeAGoodRequest = new ChangeEmailRequest(/*...*/);
var validationContext = new ValidationContext(maybeAGoodRequest, null, null);
var validationResults = new List<ValidationResult>();
bool isValid = Validator.TryValidateObject(maybeAGoodRequest, validationContext, results, true);
if (!isValid)
{
// handle error
}
else
{
// handle success
}
So ASP.NET middleware validation only works if it stays right there: executed automatically before being passed along to your controller. Any invariants that must be preserved beyond a controller action need to be put into a self-validating type (via a smart constructor).
Appendix B: Improving the smart constructor pattern
Almost all validation happens on “primitive types”; booleans, numeric types, characters, and collections of the previous. Therefore there’s a pretty finite number of ways to perform validation on them:
Enforce value is in a range
For collections, enforce a min/max length
For strings, enforce a regex match
Therefore you can encode each of these types of validation into general-purpose utility functions to be reused.
Better yet, if you have access to a code-generation tool, like the built-in source-generators in C#, then you can take this a step further by annotating your class properties with the kind of validation that should be performed on them, and then letting the source generator take care of the rest.
[AutoGenerateTryParse]
public partial class ChangeEmailRequest
(
[NotEmpty]
public string UserId {get;}
[Email]
public string NewEmail{get;}
)
Notice that this class has get-only properties and no constructors.
Then your code generator could generate the TryParse method and the private constructor for you:
public partial class ChangeEmailRequest
{
private ChangeEmailRequest(string UserId, string NewEmail)
{
this.UserId = UserId;
this.NewEmail = NewEmail;
}
public static ValidationResult<ChangeEmailRequest, List<string>>
TryParse(string UserId, string NewEmail)
{
var validationErrors = new List<string>();
if (string.IsNullOrEmpty(UserId))
validationErrors.Add("UserId field is required");
if (!EmailRegex.IsMatch(NewEmail))
validationErrors.Add("NewEmail is not a valid email");
if (validationErrors.Count > 0)
return ValidationResult.Fail(validationErrors);
return ValidationResult.Succeess(new ChangeEmailRequeest(UserId, NewEmail));
}
}
While C#’s source generators are still in pretty rough shape, writing one to take care of this boilerplate significantly reduced the lines of code in our codebase.
Appendix C: When it’s acceptable to forgo smart constructors
Smart constructors are a way to enforce that a “narrow contract” is never broken; a function (constructor in our case) may only be defined for certain inputs, and “undefined” for all others. Functional programmers call these types of functions “partial”. Smart constructors effectively wrap partial functions (constructors) in “total” functions; functions that can accept all possible values for their parameters’ types. Instead of allowing a narrow contract to be violated, our smart constructors return an error type instead.
Performance
Checking contract validity costs time and space, and some argue that this should not be necessary inside a bug-free program. In other words, (C++) developers would prefer that such checks do not happen in a production (Release) build of their software. Because obviously there are no bugs in production software.
Nonetheless, you may decide to hide your smart constructors’ checks behind a compile-time check that indicates it is for Debug-only builds. E.g., #if DEBUG in C# and #if NDEBUG in C++. You may even decide to demote your smart constructors to simple assertions for syntax’s sake.
In C++, when a contract in the language or standard library is violated, it is said to result in “undefined behavior” which is often described as “anything can happen”, from the right thing all the way to say, somehow remote starting your car. The reality is that your compiler writers decide what happens, which ranges from a possible (but not guaranteed) segmentation fault from e.g., from accessing a pointer to deallocated memory to possibly incorrect mathematical behavior from e.g., from signed integer overflow (most implementations just roll over to the negatives).
Making such assumptions about the correctness of your code can result in far more efficient assembly generation, which does actually matter sometimes. Just know that this is a conscious design decision made by the architects of a system, who have proved in other ways (usually by construction) that a narrow contract will not be violated.
Wide contracts
Opposite to “narrow contracts” are wide contracts. Functions with wide contracts have no preconditions on the values of their parameters. As you compose more and more types on top of each other, you may get to a point where you do not need to perform any additional validation because your types are already sufficiently “strong”. Consider the scenario of composing a Person type from an Email type, and other similar “strong” parameters:
public class Person
{
public Person(Email emailAddress, NonEmptyString name){...}
}
Parameter objects
The most common type of wide contract I encounter is when a type merely serves to hold all the parameters for a function. This is called a “parameter object isomorphism”, and is really common in the Vulkan API.
Thanks for reading this far. As a reward, here are some baby goats. (Photo by James Tiono on Unsplash)
Cars People 0 0 1 1 2 4 3 9 4 16 5 25 Number of people on the first N train cars
Show full content
A local pizza place has the following deals going:
2 medium (12 inch) pizzas, or
1 jumbo (18 inch) pizza
Which is the better deal?
There are entire websites dedicated to telling you which pizza deal is the better pick, and it comes down to one thing: how much pizza can you get for your value?
Do we get more pizza in the first deal or the second?
Maximum Pizza
Let’s assume that the pizzas are equally tall, no matter what size they come in. Therefore, the only thing that matters is the area of pizza.
Recall the formula for the area of a circle:
Pizzas are measured by their diameters, therefore the radius of a medium pizza is and the radius of a jumbo pizza is .
A jumbo pizza is 2.25 times the size of a medium pizza! The second deal is the best way to maximize your pizza.
"What does pizza have to do with uniformly sampling a disc?"
Everything. If you had to randomly drop a pepperoni onto the pizza on the left or the pizza on the right (below), shouldn’t the one on the right have a higher chance to get the pepperoni?
Attempting to randomly place a point on a disc pepperoni on a pizza
Let’s start with a jumbo pizza. Let’s call the radius of this pizza . Your goal is to place a pepperoni somewhere on it.
I know! First we’ll choose a radius such that .
That picture (above) isn’t quite right. It’s more accurate to say that, by choosing only a radius, we’ve merely narrowed down the possible locations of our pepperoni to the circumference of some sub-pizza with radius .
To get a point on the sub-pizza’s circumference, we need to choose some angle between and . I prefer to use radians, so it’s equivalent to say .
And that’s it! We now have enough information to place our pepperoni (We’ve used polar coordinates to describe a point on the circle).
Pepperoni placed.
A catch
We certainly succeeded in choosing some place to put a pepperoni, but was our method "fair" in that every place on the pizza had an equal chance of receiving it?
In fact, the answer is a resounding
"NO!"
If we chose (remember a jumbo pizza has a radius of ), then even though the radius was 50% of the size, the sub-pizza we chose as a result only contained 25% of the total area! Our pepperoni-placement method accidentally biases sampling towards smaller pizzas!
We need to change how we choose our radius to account for this relationship.
In a minute I’ll provide another analogy to more intuitively explain the math, but first I have a confession to make.
A confession
In 2007, I took a course on computer graphics, and one of our assignments was to make a little game using only raw OpenGL code.
The game was simple: two players take turns drawing lines between any two adjacent points in a grid, and if your line completed one or more squares,
you "owned" that square. Whoever had the most squares at the end won.
I decided to add a little flair; I rendered "fireworks" to celebrate the end of the game. The "explosion" was just a bunch of little dots randomly sampled inside a circle that grew larger, and then fell straight down, growing smaller and darker until they disappeared.
Forgive the poor resolution
My confession is that I incorrectly sampled these points inside the circle in exactly the way I just said would accidentally bias them.
Look upon my shame!
Sampling points on a disc
Please allow me to make a little analogy to better intuitively understand the math for sampling points on a disc.
Train analogy
Imagine you have a train consisting of 5 train cars. How might you fairly select a length of train at random (0 cars, 1 car, 2 cars, …, 5 cars)?
Apologies for the patronization here; it’s fairly straightforward to choose a length at random by a uniform random sampling a number between 0 and 5 (inclusive).
Okay, but what if there is 1 person in each train car, and we want to select a length of train at random such that the percentage of people in the resulting train is also selected randomly (fairly)?
I hear you, I hear you, it’s the same thing as before since there is only one person in each car, we again randomly sample a number between 0 and 5.
That is, the percentage of people is linearly correlated with the length of the train.
Let’s change it up a bit.
What if, instead of 1 person per train car, the distribution instead followed the sequence of odd numbers; the first car had 1 person, the second car 3 people, and so on (1, 3, 5, 7, 9)?
We still want to select a length of train such that the percentage of people is chosen fairly. How can we do it?
Not so easy now, is it?
Let’s step back a second and look at some concrete numbers.
If we continued to uniformly sample train car lengths and we chose five (100% of the train cars), we’d get 100% of all the people.
If we continued to uniformly sample train car lengths and we chose zero (0% of the train cars), we’d get 0% of all the people.
Hmm, so far it seems like it’s still linearly correlated? Why can’t we just continue to uniformly sample train car lengths?
Well, what happens when we choose a length of three (60% of the train cars)?
There are 9 people in the first three train cars, which is only 36% of all people, not 60%! The percentage of people is no longer linearly correlated with the percentage of train cars.
How many people are in each train length?
CarsPeople00112439416525Number of people on the first N train cars
In other words, the number of people in a train increases by the square of the number of cars.
Restated semi-formally, in a train of length , the percentage of passengers in a train of length is ().
If we wanted to uniformly sample a percentage of people and get the necessary train length, we’d set our percentages equal and solve for .
For example, if we wanted to choose 16% of the passengers, we’d have the following equation (for ).
Multiply both sides by
Take the square root of both sides to solve for :
So to get 16% of the population on the train, we’d need to take the first two train cars.
Let’s double check our math.
From before, there are 4 people in the first two train cars. There is a total of 25 people. Therefore the percentage of people in the first two train cars is .
Randomly sampling points in a disc works the exact same way, except there are an infinite number of train cars!
The train analogy doesn’t perfectly work because we’ve discretized the problem.
We can’t select, say, 50% of people because we’d need to take train cars,
and the resulting fines from OSHA violations would bankrupt me (on top of the jail time from selecting half a person).
Sampling on a disc
Like selecting a percentage of people (rather than train cars) on our train,
we should select a percentage of area (rather than radius) on our disc.
Returning to our pizza analogy, if you were to randomly select a pizza size between medium ( in) and jumbo ( in), you wouldn’t want to bias yourself to less overall pizza, would you? No! You want there to be an equal probability of all possible pizza amounts (areas)!
Therefore we can randomly sample a percentage (of area), which concretely means choosing a value in the continuous range . Now that we have a target percentage, we solve for , our radius.
We do that like we did before with the train — we assign our desired percentage to the ratio of area taken up by the resulting circle.
Let represent our randomly chosen percentage, and the radius of the disc we are sampling from. Therefore,
Take the square root of both sides
Finally multiply both sides by
Since both and are known, we’ve solved for !
It may seem counterintuitive that taking the square root of our randomly chosen percentage allowed us to bias (or rather, unbias) our sampling towards larger areas, but remember that , and consequentially results in a larger value instead of a smaller one (except for values of exactly or ).
A disc’s area does not change as a function of angle chosen, so we are free to randomly sample in the continuous range .
If you’d like to change your polar coordinates back to cartesian ones,
and
Formal derivation
Now that you’ve gotten a good intuition for how to uniformly sample a disc, you’re ready for the next step where we make the math a bit more rigorous. Feel free to skip right over this section if you feel like you understand the material well enough already.
Creation of a probability distribution
Let’s reason our way into creating a probability distribution.
Afterwards, we can use the distribution to draw samples from and show that the math comes out exactly as before.
"Every point on this disc is equally likely to be sampled"
If we split our disc of in half, we can argue that each half has an equally likely chance of being sampled, right?
We are really making an argument about area here, aren’t we? Each half has an equal chance because it has the same area.
Let’s change how we break the halves up:
The inner circle occupies the same area as the outer annulus, even though the radii ranges they cover are vastly different.
If we were to sample randomly 1000 times, we’d expect 500 samples to end up in each differently-colored area. Let’s begin making a histogram.
If we further break up the inner circle into equal areas, leaving the outer annulus intact:
We’d expect 250 samples in each.
The first inches will have only half the number of samples as the last inches. Clearly the distribution we are drawing from is not uniform in the radius parameter.
Let’s see what our histogram looks like if every bucket represented inch.
The last inch of radius on our disc is expected to receive 17x as many samples as the first inch.
If we normalized the number of samples so that the first bin received exactly 1 sample, the histogram looks a little more familiar to our train from earlier:
Returning to our previous histogram (1000 samples), we begin constructing a cumulative distribution function (cdf) by modifying our buckets such that all of them begin at 0 (meaning later buckets include earlier ones).
This tells us how many samples landed in the range from :
Because a cdf represents the probability a sample falls between , we must normalize our buckets by the total number of samples to find the probability that a randomly sampled point falls into them.
Our cdf is clearly not linear. In fact it perfectly fits the equation
Recognizing that we can generalize our formula to for some constant maximal radius .
Rewritten more formally, the random variable is the distributed between according to cdf
.
Sampling from our distribution
Now that we have a cdf, we can use a technique called inverse transform sampling
to compute a function such that
Where is our random variable, and is a value drawn from the standard uniform distribution in the range .
In other words, we will transform a sample drawn from the uniform random distribution into a sample drawn from our distribution, given our cdf.
Substituting for :
Multiplying both sides by :
And finally taking the square root of both sides:
The math comes out exactly the same as before when we treated as a percentage of area we wished to sample.
"But what about the probability distribution for our angle ?"
If you follow the same process as before, you will see that follows a uniform distribution. I’ll leave it as an exercise to the reader.
Closing thoughts
This wouldn’t be a very good blog post if I didn’t show you the difference between sampling the "wrong" way (discussed in the beginning) versus sampling the "correct" way, so here it is. The uniform random numbers used are identical between the figures, the only difference is that the "correct" way subsequently takes the square root. Notice how close to the center the samples end up being in the "wrong" way.
I didn’t think the internet had very many good resources on such a seemingly-simple topic as this. All the discussions I found were usually immediately math-heavy and not very intuitive for someone that doesn’t work with statistics every day. I purposely put the heavier math stuff in its own section near the end because I myself have trouble understanding that kind of thing. If you wanted a rigorous discussion of those things, you probably didn’t need this blog post to understand them in the first place. I hope that you are inspired by this post, and confident that if you are ever asked to code up something like this in an interview, you’d ace it. Happy coding!

































































 and the radius of a jumbo pizza is
and the radius of a jumbo pizza is  .
.


 . Your goal is to place a pepperoni somewhere on it.
. Your goal is to place a pepperoni somewhere on it.
 such that
such that  .
.

 between
between  and
and  . I prefer to use radians, so it’s equivalent to say
. I prefer to use radians, so it’s equivalent to say  .
.

 (remember a jumbo pizza has a radius of
(remember a jumbo pizza has a radius of  ), then even though the radius was 50% of the size, the sub-pizza we chose as a result only contained 25% of the total area! Our pepperoni-placement method accidentally biases sampling towards smaller pizzas!
), then even though the radius was 50% of the size, the sub-pizza we chose as a result only contained 25% of the total area! Our pepperoni-placement method accidentally biases sampling towards smaller pizzas!



 , the percentage of passengers in a train of length
, the percentage of passengers in a train of length  is
is  (
( ).
If we wanted to uniformly sample a percentage of people and get the necessary train length, we’d set our percentages equal and solve for
).
If we wanted to uniformly sample a percentage of people and get the necessary train length, we’d set our percentages equal and solve for  .
. ).
).
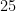


 .
. train cars,
and the resulting fines from OSHA violations would bankrupt me (on top of the jail time from selecting half a person).
train cars,
and the resulting fines from OSHA violations would bankrupt me (on top of the jail time from selecting half a person).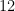 in) and jumbo (
in) and jumbo (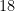 in), you wouldn’t want to bias yourself to less overall pizza, would you? No! You want there to be an equal probability of all possible pizza amounts (areas)!
in), you wouldn’t want to bias yourself to less overall pizza, would you? No! You want there to be an equal probability of all possible pizza amounts (areas)!![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) . Now that we have a target percentage, we solve for
. Now that we have a target percentage, we solve for  represent our randomly chosen percentage, and
represent our randomly chosen percentage, and 


 are known, we’ve solved for
are known, we’ve solved for  , and consequentially
, and consequentially  results in a larger value instead of a smaller one (except for values of exactly
results in a larger value instead of a smaller one (except for values of exactly  or
or  ).
).![[0, 2\pi]](https://s0.wp.com/latex.php?latex=%5B0%2C+2%5Cpi%5D&bg=ffffff&fg=000&s=0&c=20201002) .
If you’d like to change your polar coordinates back to cartesian ones,
.
If you’d like to change your polar coordinates back to cartesian ones,

 in half, we can argue that each half has an equally likely chance of being sampled, right?
in half, we can argue that each half has an equally likely chance of being sampled, right?




 inches will have only half the number of samples as the last
inches will have only half the number of samples as the last  inches. Clearly the distribution we are drawing from is not uniform in the radius parameter.
inches. Clearly the distribution we are drawing from is not uniform in the radius parameter.

![[0, r]](https://s0.wp.com/latex.php?latex=%5B0%2C+r%5D&bg=ffffff&fg=000&s=0&c=20201002) :
:
 , we must normalize our buckets by the total number of samples to find the probability that a randomly sampled point falls into them.
, we must normalize our buckets by the total number of samples to find the probability that a randomly sampled point falls into them.


 we can generalize our formula to
we can generalize our formula to  for some constant maximal radius
for some constant maximal radius ![[0, R]](https://s0.wp.com/latex.php?latex=%5B0%2C+R%5D&bg=ffffff&fg=000&s=0&c=20201002) according to cdf
according to cdf .
. such that
such that
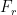 :
:
 :
:









