Show full content
Please update your bookmarks – new articles will be posted at https://kamilborys.com/blog/ from now on.
Part of wordpress.com
Interesting snippets of code taken apart for your viewing pleasure.
Please update your bookmarks – new articles will be posted at https://kamilborys.com/blog/ from now on.


I have decided to move my content to a different platform – details to follow very soon.
char a;float b,c;main(d){for(;d>2e3*c?c=1,scanf(" %c%f",&a,&c),d=55-a%32*9/5,b=d>9,d=d%13-a/32*12:1;a=2)++d<24?b*=89/84.:putchar(a=b*d);}
Good news for all International Obfuscated C Code Contest fans — here’s another winning piece from 2013 written by Yusuke Endoh, who is no stranger to the Contest. It is dubbed the Most Tweetable 1-Liner, because is small enough to fit in a tweet (137 characters only), yet can “tweet out a tune”, that is, will play some music for your entertainment.
Running the codeThe code compiles with some harmless warnings on a modern system. The resulting binary reads musical notes from standard input and synthesises the music to the standard output.
The author advises redirecting the output to /dev/dsp:
% echo "CDEFGABc" | ./endoh3 > /dev/dsp zsh: permission denied: /dev/dsp % ls /dev/dsp ls: cannot access '/dev/dsp': No such file or directory
As you can see, my Linux system (Debian “testing”) uses PulseAudio and does not have /dev/dsp anymore. What worked for me is piping the output to aplay:
% echo "CDEFGABc" | ./endoh3 | aplay Playing raw data 'stdin' : Unsigned 8 bit, Rate 8000 Hz, Mono
If all goes well, you should hear the eight notes, bringing back memories of the dark ages where the only devices in your PC that could emit sounds were the horrible PC-Speaker and a 5.25″ floppy disk drive. (Take a look at the [author’s hints] if you can’t get it to play on your system.)
Let’s move on to the next step — it’s working, so let’s take it apart and peek inside!
Cleaning it upThe author has managed to stuff everything in a single for loop — quite an impressive achievement in minimizing the program, at the cost of readability. To have a better view, let’s untangle the code.
#include <stdio.h>
float name2freq(char name) {
float b;
int d;
d = 55 - name % 32 * 9 / 5;
b = (float)(d > 9);
d = d % 13 - name / 32 * 12;
while (++d < 24)
b *= 89.0 / 84.0;
return b;
}
int readnote(float *freq, float *len) {
char name;
float notelen = 1;
if (scanf(" %c%f", &name, ¬elen) == EOF)
return 0;
*freq = name2freq(name);
*len = notelen;
return 1;
}
int main() {
float freq, len;
while (readnote(&freq, &len))
for (int d = 24; d <= 1 + 2000 * len; ++d)
putchar((char)(freq * d));
}
What we see here will not fit in a tweet anymore — not even after Twitter raised the maximum length from 140 to 280 characters. The code is way more readable because the big for loop is unrolled, and produces exactly the same output as the original program. (I double checked it.)
Now we can see that the code reads notes from standard input with scanf, then writes binary data to the standard output. According to the author, the output data is 8000 Hz, unsigned 8 bit and monophonic — this is consistent with what aplay shows during playback.
The sound is generated in the main function. There is no surprises here — we can easily notice that inside the loop, (freq * d) cast to a char will overflow when it goes over 255 — this is used to generate the sawtooth wave.
The most interesting function here is name2freq. What is b = (float)(d > 9); used for? Why does it divide 89 by 84?
Let’s have a closer look at the name2freq function. It uses a formula to convert the ascii codes of note names into something more useful for generating music. We can have a look at the numbers with this code snippet:
char tmp[] = "CDEFGABcdefgab";
for (char *n = tmp; *n != 0; *n++)
printf("%c = %f\n", *n, name2freq(*n));
This bit of code shows the function output for the notes, as follows:
note name2freq C 8.016519 D 8.999269 E 10.102497 F 10.703836 G 12.016026 A 13.489079 B 15.142715 c 16.044067 d 18.010921 e 20.218893 f 21.422400 g 24.048586 a 26.996719 b 30.306265The first question is: Why are these numbers so small? The human hearing range is between 20 Hz and 20000 Hz — if these were real frequencies of the notes, they would be way below. This snippet will help us figure it out:
for (int d = 24; d <= 1 + 2000 * len; ++d)
putchar((char)(freq * d));
We know the code generates raw sound data with the rate of 8000 Hz — that is, 8000 of 8-bit samples (bytes) of data for one second of sound. If freq was equal to 1, the loop would output all the bytes from 0 to 255 repeatedly, generating a sawtooth wave with the length of 256 samples. We can calculate frequency of such wave:
Multiplying the loop variable by freq makes the wavelength shorter. Let’s see how it goes for C:
We can calculate the note frequencies now:
char tmp[] = "CDEFGABcdefgab";
for (char *n = tmp; *n != 0; *n++) {
float f = name2freq(*n);
printf("%c = %f = %f Hz\n", *n, f, 31.25 * f);
}
note
name2freq
frequency
C
8.016519
250.516206 Hz
D
8.999269
281.227171 Hz
E
10.102497
315.703034 Hz
F
10.703836
334.494889 Hz
G
12.016026
375.500828 Hz
A
13.489079
421.533734 Hz
B
15.142715
473.209858 Hz
c
16.044067
501.377106 Hz
d
18.010921
562.841296 Hz
e
20.218893
631.840408 Hz
f
21.422400
669.449985 Hz
g
24.048586
751.518309 Hz
a
26.996719
843.647480 Hz
b
30.306265
947.070777 Hz
We can see these values are slightly out of tune — according to the ISO 16 standard, A should have the frequency of 440 Hz. Don’t worry, you will still be able to recognize the music.
Alphabet of musicLet’s go one step further and pass the whole alphabet to the function letter by letter!
for (char n = 'A'; n <= 'z'; n++) {
float f = name2freq(n);
printf("%f\t%c\t%f Hz\n", f, n, 31.25 * f);
}
Here is the result, nicely wrapped in a table sorted by the frequency.
frequency [Hz] letters note 0.000000 Z z [ \ ] ^ _ pause 236.442268 Q X B3 250.516206 C J C4 265.427887 K R Y C#4 281.227171 D D4 297.966897 L S D#4 315.703034 E E4 334.494889 F M T F4 354.405284 U F#4 375.500828 G N G4 397.852063 V G#4 421.533734 A H O A4 446.625024 P W A#4 473.209858 B I q x B4 501.377106 c j C5 531.220973 k r y C#5 562.841296 d D5 596.343756 l s D#5 631.840408 e E5 669.449985 f m t F5 709.298193 u F#5 751.518309 g n G5 796.251535 v ` G#5 843.647480 a h o A5 893.864572 p w A#5 947.070777 b i B5Looking at this table, we can draw some interesting conclusions.
First of all, the experiment shows us what the expression b = (float)(d > 9) is used for. It evaluates to 0 for capital and small letter Z and some other non-alphabetic characters; this is how the code handle rests in the notes (zero frequency — no sound at all). We also learn how to make the code emit half-tones, as it doesn’t handle sharps and flats — you just need to find a letter that will give a frequency somewhere between your notes! For C# (the note, not the language), you can use either K, R or Y.
Our next riddle to solve here is the magic 89.0 / 84.0 number. The result of this division is about 1.059524, and it is used to calculate the note frequencies by repeated multiplications. After some digging on the world’s favourite encyclopedia I found that this number is a quite good approximation of the twelfth root of 2, ![\sqrt[12]{2}](https://s0.wp.com/latex.php?latex=%5Csqrt%5B12%5D%7B2%7D+&bg=ffffff&fg=333333&s=0&c=20201002)
The obvious question here is: why not just use pow(2, 1.0/12.0)? The author decided against it so that he won’t have to include math.h, which would make the code longer – most probably it will no longer fit in a tweet. Also, the code won’t be a one-liner anymore, as includes in C need to go on separate lines. But how do you come up with numbers like these?
Mr Stern was a German mathematician; Mr Brocot was a clockmaker from France. They both independently discovered a structure called a Stern-Brocot tree; an infinite binary tree containing all positive rational numbers, with values ordered from left to right as in a binary search tree. One of its uses is to approximate floating-point numbers to arbitrary precision.
(Once you wrap your head around the fact that in computer science, trees have roots at the top and grow downwards, things start to make more sense.)
The idea here is pretty simple. You start with two fractions, 



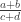
For 
The tree can be expanded indefinitely.
Aaron Rotenberg made a nice picture of the tree for Wikipedia, let';s have a look at it:

To approximate a number, we need to do a series of comparisons. We start with 1 – if the number is smaller, go left; if it's larger, go right. Keep going down the tree until you found the number (or one that's close enough).
Let's calculate
package main
import (
"fmt"
"math"
)
type frac struct {
num, denom int
}
func (f *frac) val() float64 {
return float64(f.num) / float64(f.denom)
}
func between(a, b frac) frac {
return frac{a.num + b.num, a.denom + b.denom}
}
func eq(a, b, eps float64) bool {
return math.Abs(a-b) <= eps
}
func approx(num, eps float64) frac {
left := frac{0, 1}
right := frac{1, 0}
s := between(left, right)
for !eq(num, s.val(), eps) {
if num < s.val() {
s = between(left, s)
} else {
s = between(s, right)
}
}
return s
}
func main() {
const eps float64 = 0.0001
n := math.Pow(2, 1/12.)
s := approx(n, eps)
fmt.Printf("%f is about %d/%d\n", n, s.num, s.denom)
}
"That ain't no Hank Williams song!", some might say looking at the code above. I have been experimenting with Go lately and wrote this tiny program to calculate the approximations. Even if you don't know Go at all, the code should be quite straightforward. (Hint: the for loop is actually a while.)
% go run approx.go
1.059463 is about 89/84
We just found the exact same fraction that we have seen in the original code. Just for the fun of it, let's approximate Pi:
3.141593 is about 333/106
Looks pretty close to the real thing, doesn't it?
Sound wavesHow do you actually make sounds? The whole idea is to generate waves with the right frequencies, to make the speaker's membranes move and produce sound. We know how does the code generate waves, but how do we know which frequencies are right?
It turns out, we can begin our scale with any frequency, as long as we keep the right distances between notes. Earlier we mentioned the twelve roots and equal temperament scale — let's talk a bit more about it now.
A twelve tone equal temperament scale is a logarithmic scale, with a ratio equal to the twelfth root of 2. It is the most common tuning system since the 18th century.
To calculate a given note frequency from a base frequency, we can use the following formula:
Now everyone needs to agree on the base frequency and nothing goes out of tune.
Such a basic frequency is 440Hz for A4, the 49th key on the piano. So, C4 being a 40th key would have a frequency of:
Like I said before, we are slightly out of tune, with our C equal to 250.516206 Hz. This does not pose a problem, because we are not playing with other instruments.
ConclusionTo understand the magic in 137 bytes of code, we went through music theory, a clever approximation algorithm, a great way to decode music note names to their frequencies, and sound wave generation. What a ride!
Exercise for the reader: Byte the music
main(t){
for(t=0;;t++)putchar(
(t>>6|t|t>>(t>>16))*10+((t>>11)&7)
);}
This little piece of code (or "bytebeat") written by viznut uses the same technique to generate music procedurally. The output, when treated as audio, sounds a lot like chip tune music from retro video games. How is it possible for just one short formula to contain this much of music?
Further readingWhy 12 notes to the octave? – https://www.math.uwaterloo.ca/~mrubinst/tuning/12.html
How Music Works – https://www.lightnote.co/

#!perl -p y/.-/01/;s#\d+/?#substr'01etianmsurwdkgohvf,l.pjbxcyzq',31&oct b1.$&,1#ge
Perl is (in)famous for the ability to write programs that look like line noise, and today I will take apart this beautiful piece of code. Written by tybalt89, it can decode sequences of dots and dashes to Latin letters in just 73 characters of code.
Hello MorseSome time ago I stumbled upon a Google Morse Code experiment. It tells a touching story of a developer Tania Finlayson, born with cerebral palsy and using Morse code to communicate with the world, but also gives you the ability to learn the code for yourself using easy pictographs. There’s even a Morse keyboard for Gboard on Android if you want to feel like a telegraph operator!
Since I’ve always been interested with different forms of alphabets and encoding them, I decided to try it out. A keyboard with just two keys, dot and dash, looked quite unusual at a first glance, but the pictographs turned out to be quite easy to remember. After spending some time with it, I started thinking about decoding these automatically. The similarity to binary code was obvious, so I was sure someone wrote some code for this task already. After some digging I found that beautiful tybalt89’s piece of golfed Perl code on the Anarchy golf website, and it was just too good to pass.
Running the codeThe program reads morse code text from standard input and prints the decoded data to standard output. To terminate it, press Ctrl-C.
% perl ./morse.pl
.../---/...
sos
...././.-../.-../---/--..-- .--/---/.-./.-../-../.-.-.-
hello, world.
^C
Most of the people when asked about Morse code, know only the universal distress signal SOS. The program has decodes it correctly. I also pasted a friendly greeting, which got out correctly. (If you used an old Nokia phone, you can probably also recall SMS in Morse code .../--/... as an incoming text message alert sound.) But how does it work?
We have seen B::Deparse already, it’s a module producing valid Perl code out of the internal structures after parsing the program. The resulting code is usually not exactly the same as the original source, but there is a good chance it will be more readable – especially when looking at obfuscated one-liners.
% perl -MO=Deparse ./morse.pl
LINE: while (defined($_ = readline ARGV)) {
tr/\-./10/;
s[\d+/?][substr '01etianmsurwdkgohvf,l.pjbxcyzq', 31 & oct 'b1' . $&, 1;]eg;
}
continue {
die "-p destination: $!\n" unless print $_;
}
./morse.pl syntax OK
The while loop didn’t come out of nowhere — it is the consequence of the -p switch. It wraps the code inside a loop reading subsequent lines of input (from stdin or the filenames given as parameters), and its purpose is to make processing streams easy. For example, consider the following program:
% perl -p -e 'tr/a-z/n-za-m/'
caesar cipher
pnrfne pvcure
The -e means just to execute the code given as a parameter; without it, Perl will try to open a file of such name. This is a simple example of a ROT13 cipher and will work the same way — reading input from stdin and writing to stdout.
Now let’s have a look at Deparse output:
% perl -MO=Deparse -p -e 'tr/a-z/n-za-m/'
LINE: while (defined($_ = readline ARGV)) {
tr/a-z/n-za-m/;
}
continue {
die "-p destination: $!\n" unless print $_;
}
-e syntax OK
As you can see, the -p switch was transformed into the boilerplate code we have seen before.
Let’s continue with the Morse decoder. First, it transforms the input replacing dashes with ones and dots with zeroes:
tr/\-./10/;
The dash is escaped to make sure it is considered a literal - and not as a range operator (a-z). The escaping is unnecessary here because it is at the first place, but the Deparser put it there anyways.
Let’s assume we entered the SOS .../---/... as the input. After this operation, it will be transformed to 000/111/000.
The second line is way more complicated:
s[\d+/?][substr '01etianmsurwdkgohvf,l.pjbxcyzq', 31 & oct 'b1' . $&, 1;]eg;
This is a cleverly written search and replacement function. You probably know its basic form as s/foo/bar/ (replace foo with bar), and here it is used to do the actual conversion.
The “search” part is quite easy — it is just \d+/?, that is, match one or more digits, with an optional slash at the end. At the end there are two flags, e and g. The g flag means “match globally”, or “find all occurences” — so it will match 000/, 111/ and 000. The search result is saved in the special variable $& (also known as $MATCH if you use English).
The e flag tells Perl to execute the replacement part as Perl code, and use the result for the replacement. This is where the fun begins!
Here’s a closer look at the code that gets executed for every match (that is, for every Morse code letter).
substr '01etianmsurwdkgohvf,l.pjbxcyzq', 31 & oct 'b1' . $&, 1;
This looks familiar if you have ever seen the “Morse code tree”. Here it is, courtesy of Aris00 from the English Wikipedia:

The tree works like this: Take a sequence of dots and dashes, go left for a dot and go right for a dash. Repeat until you run out of symbols, what you got is a decoded letter. Three dots mean you should go left three times from the start, ending at S. Three dashes make you go right three times and voilà, here’s an O. (There are easier ways of memorizing the code — for example, I can’t stop thinking of ..- as a Unicorn – it’s two eyes and a horn!)
The code works in a similar way. First, the sequence of ones and zeroes, possibly with a trailing slash, needs to be converted from binary into something more useful. Surprisingly, the code uses oct – a function to convert from octal. Turns out oct can also parse binary string, when given a 0b or b prefix, and doesn’t mind the slash at the end. The result is then used as an index to find the required character. But why does the code use "b1" there?
It’s there to be able to properly recognize leading zeroes in sequences. Let’s consider - (T for Tape), .- (A for Archery), ..- (U for Unicorn!) and ...- (V for Vacuum). After converting dots to zeroes and dashes to ones, we will get 1, 01, 001 and 0001, which all have the same numerical value in binary! Adding a one at the beginning fixes the problem, turning these to 11, 101, 1001 and 10001.
Another nice trick the code uses is a logical and of the index value and 31. This is done to ensure the index never goes out of bounds — it’s guaranteed never to be more than 31.
Now let’s examine the construction of the string that serves as a lookup table.
01etianmsurwdkgohvf,l.pjbxcyzq
The smallest Morse character can be just a single dot (E) or a single dash (T), so we expect these letters to appear just at the beginning. But because we have added a 1 at the beginning of the binary number in the previous step, we need to deal with it here. E is actually 0b10 (2 dec) and T maps to 0b11 (3 dec), so these letters are at the second and third position of the string. So the 01 at the beginning of the string is just a placeholder, putting the right letters at the right places for decoding.
The rest of the code is simple — it boils down to a substr call, with a calculated index and a length of one. It is repeated for every morse character matched.
It is possible to make the code display 0 as the output. We just need to find a Morse character decoding to a number that will give 0 after a logical and with 31. Since we can’t input a zero directly, let’s give it a 32 and see what happens.
32 in binary is 100000. The number is always going to be prefixed with a 1, so what we need is five dots that map to five zeroes. Using this method we can also get a one, entering four dots and a dash (100001 is 33 dec, and gives 1 after a logical and with `31):
% perl ./morse.pl
.....
0
....-
1
^C
This is actually a bug in the code — five dots stand for 5, and four dots and a dash should decode to 4. Where do I submit a pull request? 
Glad you asked! Let’s put what we learned today to good use and write a Morse encoder. It’s not going to be as minimalistic as tybalt89’s original code, as I’m trying to fight the stereotype that all Perl programs are just unreadable streams of gibberish. But I will reuse the original lookup string. Here we go — a nice, clean and readable Perl code that encodes letters to dots and dashes.
#!perl -wp
use strict;
my $lookup = '01etianmsurwdkgohvf,l.pjbxcyzq';
sub letter ($) {
# encode single letter
my ($l) = @_;
my $enc = sprintf '%b', index $lookup, $l;
$enc =~ s/^1//;
$enc =~ tr/01/.-/;
return $enc
}
sub word ($) {
# encode one word
my ($w) = @_;
return join '/', map { letter $_ } split //, $w
}
s/[a-z.,]+/word $&/ge
% echo 'code explainer' | perl encoder.pl
-.-./---/-../. ./-..-/.--./.-../.-/../-././.-.
Music to my ears!
Exercise for the readerHow would you extend the programs to support digits too?
Can you make a “golfed” version of the encoder, reducing the number of code characters as much as you can while still providing correct output?

#!/usr/bin/perl -w
use strict;
my$f= $[;my
$ch=0;sub l{length}
sub r{join"", reverse split
("",$_[$[])}sub ss{substr($_[0]
,$_[1],$_[2])}sub be{$_=$_[0];p
(ss($_,$f,1));$f+=l()/2;$f%=l
();$f++if$ch%2;$ch++}my$q=r
("\ntfgpfdfal,thg?bngbj".
"naxfcixz");$_=$q; $q=~
tr/f[a-z]/ [l-za-k]
/;my@ever=1..&l
;my$mine=$q
;sub p{
print
@_;
}
be $mine for @ever
This heart-shaped program is written in the language of choice for producing unreadable and obfuscated code: Perl 5. It also serves an unusual purpose of a proposal.
Who wrote the code?The code was published on PerlMonks in 2004 by user Falkkin (Colin McMillen).
Let’s run it% perl ./heart.pl Replacement list is longer than search list at ./heart.pl line 14. kristen, will you marry me?
The author’s intention was for the code to parse correctly even with strict mode enabled (use strict;) and all warnings turned on (-w parameter passed to the Perl executable). The modern Perl interpreter (5.26.1 used here) warns about more things than it did back in 2004, trying to spoil the great moment.
Thankfully back in 2004 the ugly warning message wasn’t there yet, and nothing got in Falkkin’s way of sending the beautiful message to Kristen.
How does it work?The popular way of dealing with creatively formatted Perl code is to use B::Deparse to try and make it more readable. B::Deparse is a backend module for the Perl compiler, producing valid Perl code out of the internal structures after parsing the program.
% perl -MO=Deparse ./heart.pl > ./heart2.pl Replacement list is longer than search list at ./heart.pl line 14. ./heart.pl syntax OK
The de-parsed code has lost its pretty heart shape, and “be mine for each ever” is not as romantic as the original, but it is now way easier to grasp. Here’s the full code, we will take it apart soon.
BEGIN { $^W = 1; }
use strict;
use arybase ();
my $f = $[;
my $ch = 0;
sub l {
length $_;
}
sub r {
join '', reverse(split(//, $_[$[], 0));
}
sub ss {
substr $_[0], $_[1], $_[2];
}
sub be {
$_ = $_[0];
p(ss($_, $f, 1));
$f += l() / 2;
$f %= l();
++$f if $ch % 2;
$ch++;
}
my $q = r("\ntfgpfdfal,thg?bngbjnaxfcixz");
$_ = $q;
$q =~ tr/[]a-z/[]l-p r-za-k/;
my(@ever) = 1 .. &l;
my $mine = $q;
sub p {
print @_;
}
be $mine foreach (@ever);
Open heart surgery
BEGIN { $^W = 1; }
First line of the code is a BEGIN block. This block will be executed as early as possible, and its purpose is to set the special variable $^W to 1. This is equivalent to passing the -w switch to the interpreter and has the effect of turning all warnings on.
use strict; use arybase (); my $f = $[; my $ch = 0;
This includes the strict and arybase modules, then initializes two variables.
The arybase module is an interesting case — we haven’t seen it in the original code. It has been inserted here because later on, the code uses it to implement the special variable $[. Right here, the ugly-named variable is used as a confusing way to say 0, but the actual purpose of it is to modify the first index of an array. By assigning 1 to it, we can have 1-indexed arrays (and another warning), as demonstrated:
% perl -E 'my @months = qw/January February March/; $[ = 1; say $months[1]' Use of assignment to $[ is deprecated at -e line 1. January
Next, in the code we can see a couple of subroutines defined:
sub l {
length $_;
}
sub r {
join '', reverse(split(//, $_[$[], 0));
}
sub ss {
substr $_[0], $_[1], $_[2];
}
These are just short names for string operations: l for length, r for reversing and ss for substring. The special variable $[ is used here again for obfuscation; what looks like unbalanced square brackets ($_[$[] in sub r, actually parses as $_[0] and means “the first parameter passed to the sub”. There is another useful subroutine with a short name defined at line 28, p, which just calls print on its parameters.
sub be {
$_ = $_[0];
p(ss($_, $f, 1));
$f += l() / 2;
$f %= l();
++$f if $ch % 2;
$ch++;
}
This subroutine actually prints letters to the standard output. It’s easy to see because it calls p(ss(...)), which uses the previously defined short names and stands for print(substr(...)).
First, the variable $_ is assigned the value of the first parameter passed to the be subroutine.
Perl’s substr function is passed three parameters here: string, offset and length. So the code prints a one-character substring of whatever it was given as the parameter, starting at position $f (which is initialized to 0).
Then, the counter variable $f is incremented in a creative way – by half the length of the string (l() / 2). The modulo operation in line 19 is performed so that the index is never out of bounds. The counter variable is additionally incremented by 1 for every second character in line 20. Due to this, the code selects characters to print alternatively from the beginning and from the middle of the passed string. So if the subroutine is passed a 20-character string, subsequent calls to it will print: first 0th element, then 10th, then 1st, then 11th… ad infinitum. This is easily checked by modifying the last line of code to print another string, like this:
be "1234567890abcdefghij" for 1..20;
Which will result in the code printing numbers and letters interleaved, as follows:
1a2b3c4d5e6f7g8h9i0j
But back to the code. Time for another obfuscated part — the actual string that will be printed on the screen.
my $q = r("\ntfgpfdfal,thg?bngbjnaxfcixz");
$_ = $q;
$q =~ tr/[]a-z/[]l-p r-za-k/;
This looks like a cat has jumped on the author’s keyboard, but it’s written like this to obfuscate the message even further. First, the string is reversed (by passing to sub r). The reversed string still looks like gibberish and has the value of "zxicfxanjbgnb?ght,lafdfpgft\n".
Next, line 25 runs the string through a tr/// operator, a translation table replacing ranges of characters:
tr/[]a-z/[]l-p r-za-k/
For more readability, let’s replace the ranges (a-z) by the actual characters:
[]abcdefghijklmnopqrstuvwxyz []lmnop rstuvwxyzabcdefghijk
This looks like a simple Caesar cipher, where all occurences of a are replaced by l, all letters b turn into m, and so on. The letter f will be replaced by a space.
In the original code, the translation tables were arranged diffently: tr/f[a-z]/ [l-za-k] /. The square brackets were probably included in the code to contribute to the confusion factor — they are required in regular expressions, but don’t do anything in the tr///. Hence in the the de-parsed code, the tables were rearranged placing the square brackets at the beginning, before the letters; they are on the same position on both “from” and “to” side of the tables, which means they won’t be substituted with anything else in the string and left as they are.
After running the string through the cipher, the result is "kitn ilyumrym?rse,wl o ar e\n". Still doesn’t look like the author’s proposal, but it’s beginning to bear some resemblance now.
my(@ever) = 1 .. &l;
my $mine = $q;
sub p {
print @_;
}
be $mine for (@ever);
Here comes the final part — we can finally print the string. (Sorry, I changed the “foreach (@ever)” back to the original meaning. Couldn’t stand it like that.)
First, take notice that one invocation of be prints only one character, so it must be called as many times as there are letters in the string to deliver the whole message. This is why the code creates @ever, an array of numbers from 1 till the string length. The numbers aren’t used for anything else in the code, only to run be the required number of times.
So that’s it — a reversed, enciphered and scrambled message that gets untangled by an obfuscated and confusing code, to deliver a beautiful message to Kristen.
Did she say yes?Yes, she did! She replied just a thirteen minutes after the original posting, accepting the proposal with a “Yes! :)” and a $propose++;. Congratulations!

main() { printf(&unix["\021%six\012\0"],(unix)["have"]+"fun"-0x60);}
Just one line of code, but lots of confusion. What does this program do?
Who wrote this code?The code won the “Best One-Liner” prize at the IOCCC in 1984. It was written by David Korn, who is also the author of Korn Shell (ksh).
Let’s run itThe code compiles just fine with gcc on Linux, giving a couple of harmless warnings about implicit declaration of printf and omitted main() return type. After running, it prints one single word:
% ./korn unix
Where does this come from? A quick glance at the source shows apparently some NUL characters, "six", "have" and "fun", but unix in this code looks more like an implicitly-declared variable than a character string.
The obvious and boring answer is that UNIX is an operating system that comes from Bell Labs, but what we’re looking for is the symbol unix and its value in the program. Let’s run the code through the preprocessor now.
% cpp korn.c
# 1 "korn.c"
# 1 ""
# 1 ""
# 31 ""
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 32 "" 2
# 1 "korn.c"
main() { printf(&1["\021%six\012\0"],(1)["have"]+"fun"-0x60);}
The output shows that the preprocessor has substituted unix with 1 in the code. But why is it doing that?
The online GNU documentation for cpp says “it is common to find unix defined on Unix systems”, quoting historical reasons — so that the code could contain clauses like #ifdef unix … #endif for conditional compilation. Luckily, it is possible to make cpp output all #define directives during its execution.
% cpp -dM korn.c | grep unix #define __unix__ 1 #define __unix 1 #define unix 1
Here’s the confirmation — unix is a system-specific predefined macro that has the value of 1. Let’s make the substitution in the source too:
int main() {
printf(&1["\021%six\012\0"],
(1)["have"]+"fun"-0x60);
}
Why so many NULs?
We will begin with clearing the confusion about multiple "\0"s found in the string. Turns out "\021" does not mean a NUL followed by a '2' and a '1', but is an escape sequence that represents a byte with the value represented as an octal (8-based) number. This is also true for "\012". These two are better written as 0x11 and 0x0A; the former is defined as “Device control 1” and (as we will see soon) is not really important here, the latter is just a newline "\n".
int main() {
printf(&1["\x11%six\n\0"],
(1)["have"]+"fun"-0x60);
}
Confusing pointers
The code uses the commutativity of addition to cleverly obfuscate the character strings passed to the printf() function. Let’s take a closer look at the technique now.
C allows to access elements of the arrays using square brackets: array[index]. Since array names behave like pointers, the elements can also be accessed like this: *(array+index). Now, as the addition operation is commutative, it is also possible to write the former as *(index+array), and, as a consequence, as index[array]. Just this trick alone is enough to confuse programmers not used to seeing constructs like 5["abcdef"], and here it is wrapped with yet another layer of obfuscation.
Knowing all this, it is possible to write the first parameter, 1["\x11%six\n\0"], in a more clear way as "\x11%six\n\0"[1]. Since strings in C are just zero-indexed character arrays, [1] means just skipping the 0th character '\x11' altogether — so the result will be the percent sign here. Then, the ampersand & is used to take the pointer (memory address), which is then passed to printf(). In the end, the format string passed as the first parameter will be "%six\n\0".
Time to take the second argument apart now. The %s at the beginning of the format string says the next argument is going to be a standard character string, null-terminated.
After what we have went through here, the expression (1)["have"]+"fun"-0x60 is pretty easy to take apart. First there is (1)["have"], which can be rewritten as "have"[1] and then as 'a'. Next there’s "fun", and 0x60. A look at the ASCII table shows that 'a' has the value of 0x61 — so the expression can be simplified to "fun"+0x61-0x60, and then to "fun"+1 — which evaluates to "un".
int main() {
printf("%six\n\0", "un");
}
This is the code with all the obfuscations removed. There’s no “fun” at all here, what remains is just an “un” which is the first half of “unix” that’s written to the standard output.
An exercise for the readerCan you have fun without UNIX? What happens when the code is compiled on a non-UNIX machine? What if unix is defined as 0?

“And to avoid the tedious repetition of these words: is equal to: I will set as I do often in work use, a pair of parallels, or Gemowe lines of one length, thus: =, because no 2 things, can be more equal.”
— Robert Recorde, The Whetstone of Witte (1557)
public class Equality {
public Equality() {
Integer a1 = 100, a2 = 100;
Integer b1 = 200, b2 = 200;
if (a1 == a2) System.out.println("a1 == a2");
if (b1 == b2) System.out.println("b1 == b2");
}
public static void main(String[] args) {new Equality(); }
}
How does the code work?
You might have seen a similar snippet before, usually followed by a good advice to always check for equality of objects using equals() instead of ==. But what really happens inside the code?
% java Equality a1 == a2
Looks like for some reason Java doesn’t want to acknowledge that 200 is equal to 200, even though it doesn’t have any problem with 100 being equal to 100. Now what happens when we change Integers to ints?
int a1 = 100, a2 = 100;
int b1 = 200, b2 = 200;
if (a1 == a2) System.out.println("a1 == a2");
if (b1 == b2) System.out.println("b1 == b2");
Surprisingly, everything works fine this time:
% java Equality2 a1 == a2 b1 == b2
Following the good advice, let’s change the code to use equals().
Integer a1 = 100, a2 = 100;
Integer b1 = 200, b2 = 200;
if (a1.equals(a2)) System.out.println("a1 equals a2");
if (b1.equals(b2)) System.out.println("b1 equals b2");
The result is also correct this time:
% java Equality3 a1 equals a2 b1 equals b2
So what happens under the hood that makes 200 not equal to 200? Let’s take a closer look at our Integers.
Integer a1 = 100, a2 = 100;
Integer b1 = 200, b2 = 200;
for (Integer i : new Integer[] { a1, a2, b1, b2 })
System.out.printf("%d -> hash %d, id hash %d%n",
i, i.hashCode(), System.identityHashCode(i));
This piece of code gives us some more insight about the Integers:
% java Equality4 100 -> hash 100, id hash 1265094477 100 -> hash 100, id hash 1265094477 200 -> hash 200, id hash 2125039532 200 -> hash 200, id hash 312714112
The first observation is that the Integers hash to themselves, but that’s pretty boring. A more interesting realization is that a1 and a2 point to the same object, while b1 and b2 are distinct.
Why is it so?
The Integer Cache and autoboxingIntroduced in Java 5, the Integer cache’s main goals are to improve Integer object performance and to reduce the memory footprint. The idea behind the mechanism is to cache a small number of Integers internally and reuse them.
Autoboxing and autounboxing, the concepts also introduced in Java 5, stand for automatic conversions between the primitive types and the corresponding object wrappers. Let’s have a quick look at how these work:
Integer a1 = 100;
With autoboxing, the compiler actually replaces that line of code with:
Integer a1 = Integer.valueOf(100);
Autounboxing works in a similar way:
Integer a1 = new Integer(100); int p = a1; // actually does this: int p = a1.intValue();
We’re just one step away from solving the mystery. Let’s have a look at Integer.valueOf() now:
Returns an
Integerinstance representing the specifiedintvalue. If a newIntegerinstance is not required, this method should generally be used in preference to the constructorInteger(int), as this method is likely to yield significantly better space and time performance by caching frequently requested values. This method will always cache values in the range -128 to 127, inclusive, and may cache other values outside of this range.
Indeed, looking under the hood we can see that the Integer has an inner private class, IntegerCache, that stores copies of Integers, by default those with values from -128 to 127 in an array. It is used by valueOf(int) to avoid the creation of new objects when unnecessary. We also see that the upper bound is configurable by the -XX:AutoBoxCacheMax=n option.
Knowing all this, let’s go back to the the code. We will print the hashcodes of the objects, then use == for checking equality:
Integer a1 = 100, a2 = 100;
Integer b1 = 200, b2 = 200;
for (Integer i : new Integer[] { a1, a2, b1, b2 })
System.out.printf("%d -> hash %d, id hash %d%n",
i, i.hashCode(), System.identityHashCode(i));
if (a1 == a2) System.out.println("a1 == a2");
if (b1 == b2) System.out.println("b1 == b2");
Time to run the code again, passing the appropriate parameter to the VM:
% java -XX:AutoBoxCacheMax=200 Equality5 100 -> hash 100, id hash 1252169911 100 -> hash 100, id hash 1252169911 200 -> hash 200, id hash 2101973421 200 -> hash 200, id hash 2101973421 a1 == a2 b1 == b2
As expected, because we bumped the upper bound of the integer cache to 200, both b1 and b2 are now served from the cache, making the code produce expected results.
By adding reflections to the mix, we can access and modify the integer cache from the code, making Java do unexpected things:
import java.lang.reflect.Field;
public class IntegerCacheFun {
public static void main(String[] args) throws Exception {
Class cls = Class.forName("java.lang.Integer$IntegerCache");
Field fld = cls.getDeclaredField("cache");
fld.setAccessible(true);
Integer[] cache = (Integer[]) fld.get(cls);
cache[4 + 128] = 5;
Integer result = 2 + 2;
System.out.print("2 + 2 = ");
System.out.println(result);
}
}
After making such modification to the integer cache, Java will claim that:
% java IntegerCacheFun 2 + 2 = 5An exercise for the reader
Which other Java classes can be abused in such way to produce wrong results?

main[-1u]={1};
You have heard of “zip bombs” (a tiny ZIP file that decompresses to multiple gigabytes) and “XML bombs” (small XML file abusing the entities to consume lots of memory), and now there is a “compiler bomb” to follow suit. The idea is quite similar — the source code is only 14 bytes, but the generated executable will be over 16 GB in size.
Who wrote it?The code is attributed to Stack Exchange user Digital Trauma. It was posted here on January 12, 2016.
How does it work?In the code main is not a function, but an array of ints. The value of -1u, that is, negative one as unsigned, is exactly 0xFFFFFFFF — the maximum value of unsigned int. The array will contain 4294967295 integers, each with the size of four bytes, taking up 17179869180 bytes in total.
The important element of the code is the array initialization — {1}. The first element of the array will be initialized to 1, and all the remaining elements will be set to 0. It is necessary for the compiler to place the entire array inside the executable. (Try removing the initialization and compiling the code by yourself.)
What is surprising is that main does not have to be a function. You can throw just about anything called main at the compiler and it will produce a valid executable — but don’t expect much more than a segmentation fault when you run it.
The author advises to compile the code with gcc, as follows:
gcc -mcmodel=medium cbomb.c -o cbomb
Turns out 8 gigabytes of RAM is not enough — the compilation fails with an error.
cbomb.c:1:1: warning: data definition has no type or storage class
main[-1u]={1};
^~~~
cbomb.c:1:1: warning: type defaults to ‘int’ in declaration of ‘main’ [-Wimplicit-int]
/usr/bin/ld: final link failed: Memory exhausted
collect2: error: ld returned 1 exit status
Let’s make a diet bomb
To consume a little bit less of the memory while still being able to play with the code, let’s try and modify it a little bit.
int main[10000]={1};
This code should produce an executable with the array having the size of 10000 integers, that is, 40000 bytes. Let’s see this in practice!
% cc ./dietbomb.c % wc -c a.out 48296 a.out % ./a.out zsh: segmentation fault ./a.out
As you can see, the compiled binary is 48K in size and gives a beautiful segfault when ran.
An exercise for the readerWhat happens when you move the array declaration to the inside of the main() function and why?

This obfuscated piece of C code prints the map of India to the standard output.
#include <stdio.h>
main() {
int a,b,c;
for (b=c=10;a="- FIGURE?, UMKC,XYZHello Folks,\
TFy!QJu ROo TNn(ROo)SLq SLq ULo+\
UHs UJq TNn*RPn/QPbEWS_JSWQAIJO^\
NBELPeHBFHT}TnALVlBLOFAkHFOuFETp\
HCStHAUFAgcEAelclcn^r^r\\tZvYxXy\
T|S~Pn SPm SOn TNn ULo0ULo#ULo-W\
Hq!WFs XDt!" [b+++21]; )
for(; a-- > 64 ; )
putchar ( ++c=='Z' ? c = c/ 9:33^b&1);
return 0;
}
Who wrote this code?
The author is unknown. I have found the code on Quora while searching the web for interesting code snippets. (If you know the author, please let me know so I can give them credit!)
Let’s run itThe code compiles and runs correctly, and sure enough it does what it should – outputs a nice ASCII map of India to the standard output.
!!!!!!
!!!!!!!!!!
!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!
!!!!!!!!!!!!
!!!!!!!!!!!!
!!!!!!!!!!!!
!!!!!!!!
!!!!!!!!!!
!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!! !!!!!
!!!!!!!!!!!!!!!!!!! !!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!! ! !!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !! !!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !! !!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!
!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !
!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!
!!!!!!!!!!!!
!!!!!!!!!!!!
!!!!!!!!!!!!
!!!!!!!!
!!!!!!
!!!!
How does it work?
The code itself is simple and consists of two for loops, one inside the other. The outer loop at line 4 walks through the long string of seemingly random letters, while the inner loop at line 11 prints characters to the standard output.
First the variables b and c are initialized to 10. Then, variable a is used to iterate over the long string. Not the whole string is processed though — the odd-looking expression used as the index, b+++21, is understood by the C compiler as b++ + 21, and skips the first 31 characters altogether. This means the code will jump over the “Hello Folks” message and start working on the string from the capital T at the beginning of line 5. Since strings in C are null-terminated, the loop will end when it reaches the end of the string. The loop will also increment b by one for each iteration.
for(; a-- > 64 ; ) putchar ( ++c=='Z' ? c = c/ 9:33^b&1);
If the value of a is lower than 64, this code will do nothing. Otherwise, it will print exactly a-64 characters to the screen. The first character processed by the outer loop is T, which has the ASCII code of 84, so it will cause the loop to print 20 characters. Let’s now have a look at the expression passed to putchar, which uses a nice combination of the ternary operator, unusual spacing and operator precedence to confuse the reader.
++c==90 // 'Z' ? c = c / 9 : 33 ^ (b & 1)
The code starts with incrementing c (using the pre-increment operator). If c equals the ASCII code of capital Z (90), it is divided 9, giving 10. Since c is initialized to 10 at the beginning of the outer loop, it will reach 90 after executing the putchar function 80 times. In this case, putchar will print a character of the ASCII code 10, which is a newline, nicely splitting the output into 80-character lines for larger terminals.
If c has not reached 90 yet (and there is no need to print the newline), the code examines the least significant bit of b using the expression (b & 1). If the bit is set, the value of b is odd; if it’s cleared, b is even. Knowing that b is incremented once for every outer loop iteration, we can easily see that 33 xor (b & 1) will alternate between 32 (for odd b‘s) and 33 (for even b‘s). Conveniently, these numbers are ASCII codes for space and exclamation mark (!), which is what is used to print the map of India.
To sum it all up: The code prints spaces and exclamation marks, alternating. The consecutive letters in the string contain the number of the characters to print.
Exercise for the readerWhat needs to be done to modify the code to display the map of your country instead?

This Java snippet uses a regular expression for something way different than they were designed for: a primality check.
public static boolean prime(int n) {
return !new String(new char[n]).matches(".?|(..+?)\\1+");
}
Who is the author?
After some digging I found out that the original author is Abigail and the code was originally written in his language of choice, Perl. The original one-liner can be found here, it looks like this:
perl -wle 'print "Prime" if (1 x shift) !~ /^1?$|^(11+?)\1+$/'How does it work?
These two code snippets look a bit different, but the general idea behind them is the same. First, the code builds a string of the length n, then a specially crafted regular expression is matched against it. If the match is positive, it means the number is not prime.
By definition, a prime is a number that is greater than 1 and has no positive divisors other than 1 and itself.
The code expects a number for the primality check as an argument, and displays “Prime” on the standard output when the number is found to be a prime.
% perl -wle 'print "Prime" if (1 x shift) !~ /^1?$|^(11+?)\1+$/' 12 (no output) % perl -wle 'print "Prime" if (1 x shift) !~ /^1?$|^(11+?)\1+$/' 13 Prime
The string to run matches on is built using Perl’s x repetition operator. The expression 1 x shift will repeat 1 as many times as given in the program argument, building a string consisting just of ones. If 12 is passed as the argument, the string will contain 111111111111.
The regular expression is composed of two sub-expressions, ^1?$ and ^(11+?)\1+$. Only one of these matches is required for the whole expression to match. Let’s have a closer look at these.
^1?$
Translated to English, this means: match the beginning of the string (^), followed by the number one (1) that occurs exactly zero or one time (?), followed by the end of string ($). This piece will match only strings of the length of 0 and 1 , detecting them as non-primes.
^(11+?)\1+$
This regular expression is more complicated as uses a repeated capturing group. It will match the string beginning (^), followed by a group of at least two ones ((11+?)), repeated at least once after the first match – so at least twice in total (\1+), and followed by the end of string ($). Its purpose is to check whether there is a number that will divide n into at least two equal parts, with no remainder. If there is one, the number is by definition not a prime.
The Java code is a bit different. First, the string is constructed like this:
new String(new char[n])
Which means: create a new array of chars with the length of n, and then create a String out of it. The default value of newchars is \U0000, which means the created string will contain exactly n null characters.
Next, the regular expression has changed slightly.
.?|(..+?)\1+
The regular expression is matched against the string using String.matches(String regex) method, which always wants a complete match – so there is no need to use ^ and $ anymore as in Perl. Also, because the string content is different than in the Perl version, the regex now uses a dot (., one occurrence of any character) to match the null characters in the string.
Most certainly not. Due to the number of matches that need to be done on the string, the code is slow.

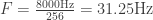
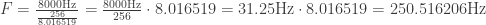

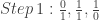
![\sqrt[12]{2} \approx 1.059463](https://s0.wp.com/latex.php?latex=%5Csqrt%5B12%5D%7B2%7D+%5Capprox+1.059463+&bg=ffffff&fg=333333&s=0&c=20201002)
![P_n = P_a \left( \sqrt[12]{2} \right)^{(n-a)}](https://s0.wp.com/latex.php?latex=P_n+%3D+P_a+%5Cleft%28+%5Csqrt%5B12%5D%7B2%7D+%5Cright%29%5E%7B%28n-a%29%7D+&bg=ffffff&fg=333333&s=0&c=20201002)
![P(C_4) = P_{40} = 440 \mathrm{Hz} \left( \sqrt[12]{2} \right)^{(40-49)} \approx 440 \mathrm{Hz} \cdot 1.059463 ^{-9} \approx 261.625775 \mathrm{Hz}](https://s0.wp.com/latex.php?latex=P%28C_4%29+%3D+P_%7B40%7D+%3D+440+%5Cmathrm%7BHz%7D+%5Cleft%28+%5Csqrt%5B12%5D%7B2%7D+%5Cright%29%5E%7B%2840-49%29%7D+%5Capprox+440+%5Cmathrm%7BHz%7D+%5Ccdot+1.059463+%5E%7B-9%7D+%5Capprox+261.625775+%5Cmathrm%7BHz%7D+&bg=ffffff&fg=333333&s=0&c=20201002)