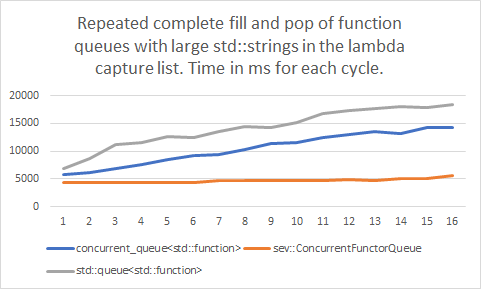
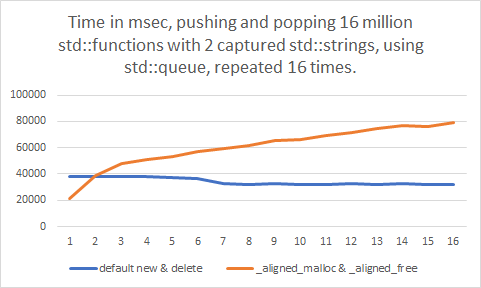
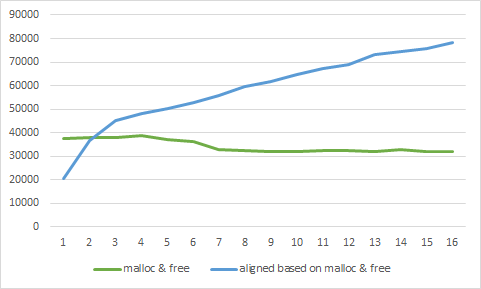
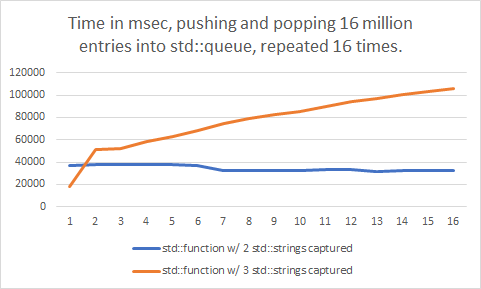
Show full content
The finest blue noise in the galaxy.
In short, alternate per-pixel between Floyd-Steinberg and Jarvis-Judice-Ninke error diffusion kernels using the lowbias32 randomizer function.

The purpose of dithering is to allow quantizing analog or higher precision data into lower bit depth while minimizing loss of information, aliasing, banding, or other artifacts. Techniques used for this generally fall under either using an ordered dithering mask (e.g. Bayer, void-and-cluster, etc.) or forms of error diffusion (Floyd-Steinberg, sigma-delta, etc.) Similarly to resampling kernels, dithering kernels for 2D processing are distinct from 1D kernels, as the signal distribution becomes spatial rather than purely linear. These techniques are relevant both for quantizing to low bit depths (e.g. printing, e-ink, embedded hardware, etc.), as well as for quantizing high-precision authored content into common file formats (e.g. floating point to 8-bit/channel).
Ordered ditheringOrdered dithering is implemented by using a pre-calculated threshold mask to decide whether to round up or down. The threshold mask is usually an 8-bit bitmap.

(Make sure your browser is displaying the images at 1:1 display pixel size to ensure proper comparison.)
Error diffusion ditheringFloyd-Steinberg and Jarvis-Judice-Ninke kernels are the two earliest 2D error diffusion kernels described in literature. Several variants exist which make adjustments purely for hardware performance reasons, but which don’t offer any quality benefits, so I will skip over these. One problem with the FS kernel are strongly noticeable patterns at certain gray levels. The JJN kernel does not suffer this problem as much, but is larger and looks much coarser, while at the same time slightly sharpening the image features.


Error diffusion is implemented by selecting the color nearest to the target color, and carrying over the remainder error to neighboring pixels. The target color is modified by adding the carried over error before quantization. A kernel, which is just a small table of numbers, describes what fraction of the error each of the neighboring pixels receive.
Color space awarenessFor color space-aware dithering, the color distance can be calculated in a perceptual color space (e.g. Oklab Lr), and the error must be accumulated in a linear color space (e.g. linear RGB). These can be distinct from the actual quantized color space (e.g. sRGB).
Conventionally, dithering test images are processed without color space conversion, treating the input as linear. We follow this convention for the 1-bit comparisons to enable direct comparison with reference literature. For multi-channel or higher bit depth outputs we apply proper color space conversion.
Perturbation and blue noiseIn 1988, Ulichney demonstrated perturbed variants of Floyd-Steinberg dithering, in particular a 30% randomization of the threshold, and a random 50% alternation between pairs within the kernel, effectively randomly switching between 4 modified variants of the Floyd-Steinberg kernel. This technique breaks up the patterns of the kernel by introducing a tiny amount of white noise. The resulting spectrum of reference gray levels was described as strongly suppressing low frequencies, with the error diffused evenly into high frequencies, and called blue noise. These techniques as described by Ulichney were not optimized as described, but demonstrate the principle and the concept of blue noise, and viable paths in improving dithering quality.


A spectrum analysis of these techniques shows a first-order blue noise curve approaching a ~6dB power density per octave, similar to the spectrum of a 1D sigma-delta ADC with TPDF (effectively, also threshold perturbation) as used in audio engineering.
To imagine blue noise, it can be explained as the more intuitive (yet fallacious) version of a coin flip, where after several heads you’re more likely to get a tails, the gambler’s false sense of fairness, or in other words, random numbers with a negative autocorrelation.
Stochastic kernel-switching (our method)Our method is a specific variant of kernel weight perturbation, which simply switches between the proven FS and JJN kernels, using the high bits of the lowbias32 hash function as randomizer. This technique is simple and unambiguous to implement, is fast, has near-perfect blue noise characteristics, eliminates pattern formation entirely, introduces less white noise than alternatives, and can be applied also to multi-level as well as non-uniform quantization.


Existing weight perturbation methods compared here include Ostromoukhov, which switches between 128 pre-calculated kernels depending on the gray level, and Zhou-Fang, which extends Ostromoukhov with positional modulation. The Ostromoukhov technique attempts to optimize an ideal kernel at every gray level to more closely approach a blue noise profile, however, this limits the practical application of this technique to quantizing from 8-bit to 1-bit, or other uniform power-of-2 ratios that match, and excludes non-uniform colorspace-aware dithering. A failure mode with Ostromoukhov is that flat gray levels in themselves are not perturbed and show patterns. Zhou-Fang expands on this technique with a new pre-calculated table along with a modulation table to further perturb the process based on the pixel position, however, this retains the same applicability limitations.


At present, the most common blue noise derived technique in dithering is using a pre-calculated ordered blue noise threshold mask, such as one generated through the void-and-cluster method. This is as cheap to implement as a Bayer matrix, and highly practical for parallel processing. However, rather than diffusing error, this technique merely masks the error using an approximation of blue noise, reducing the actual signal quality.


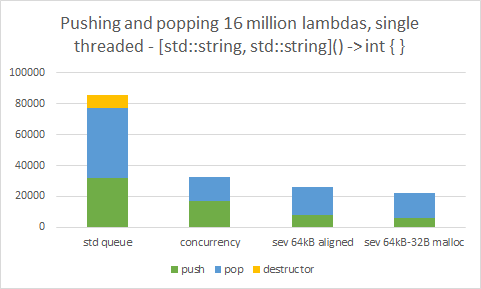
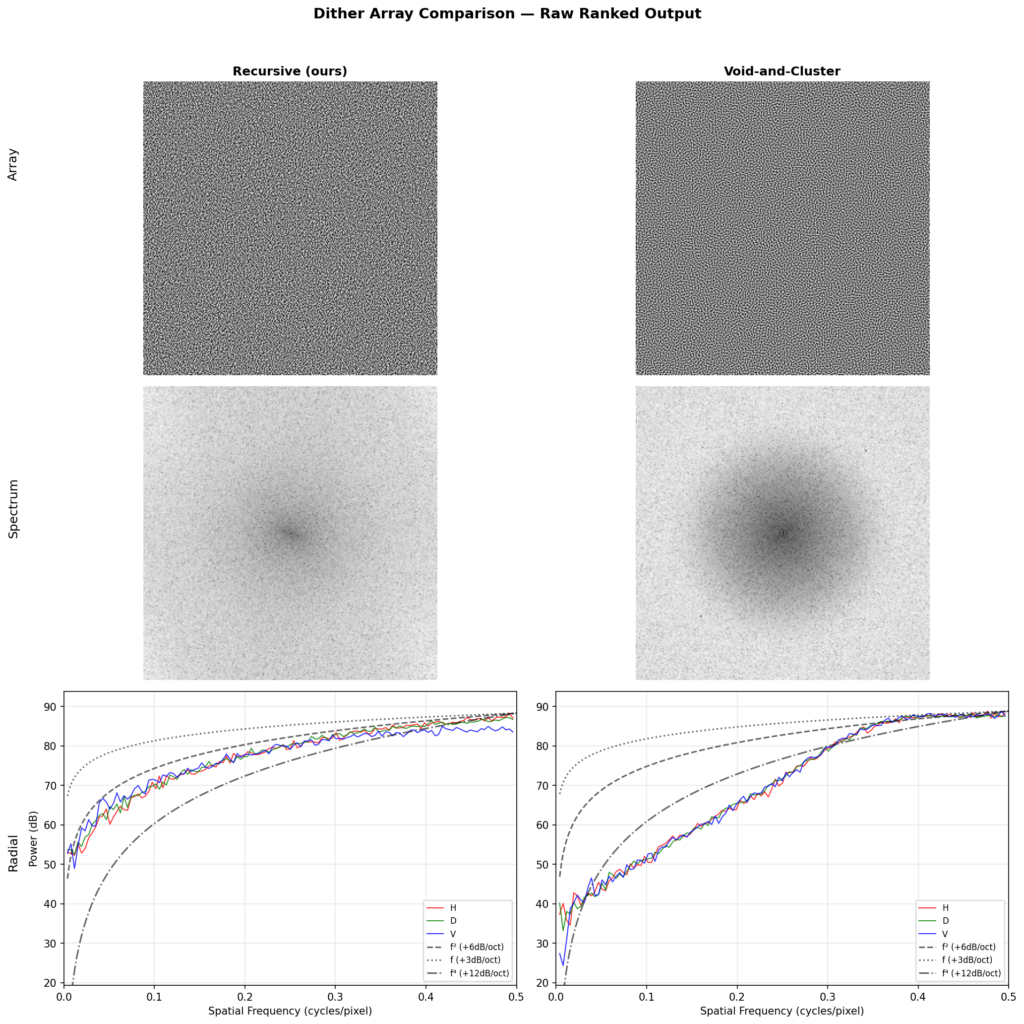
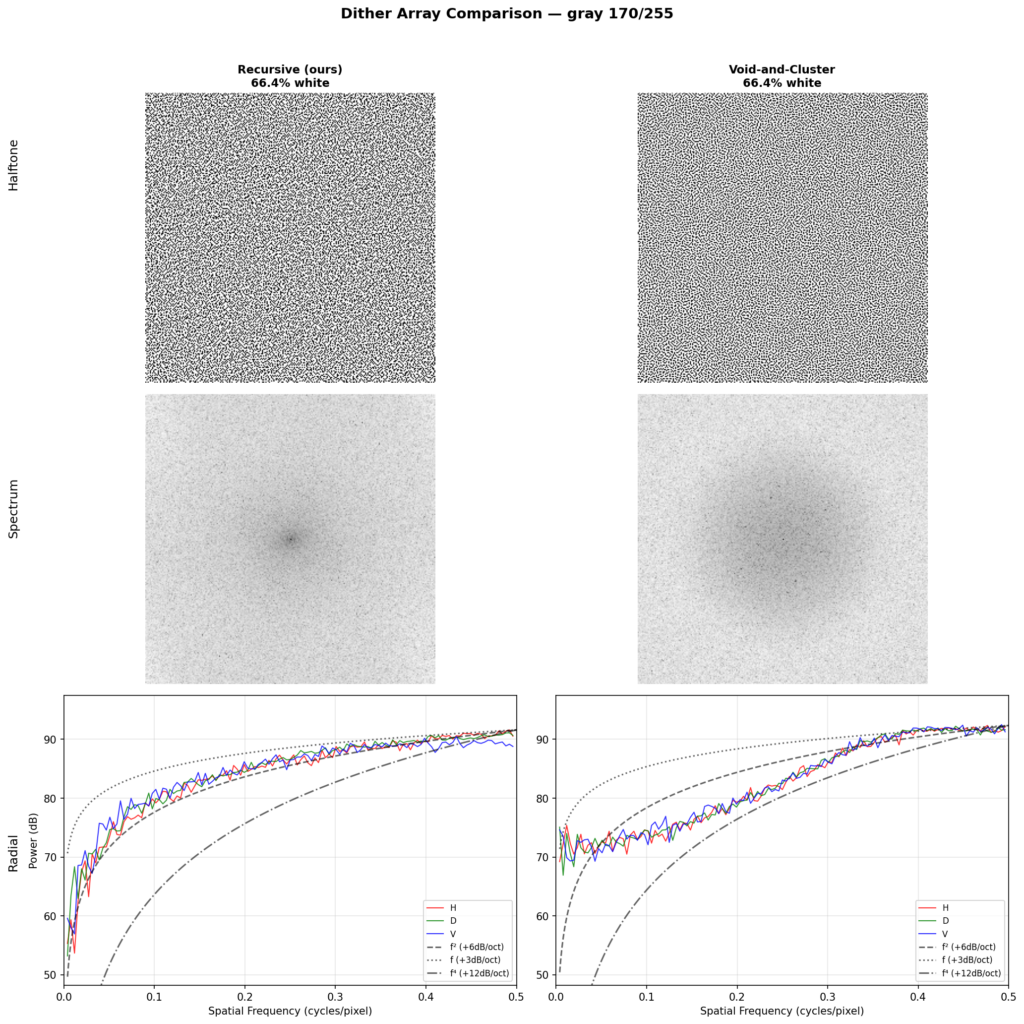
The common objective metric found in literature to compare error diffusion methods is to analyze the spectrum at various levels of gray. This reveals whether the diffusion is in fact blue noise, and the level of isotropy exhibited by it. To read the chart, basically, if the three lines (the horizontal, diagonal, and vertical analysis) align closely together, you have high isotropy. Then, the first part of the chart should just go as low as possible, and the final part of the chart should be a flat peak. The x axis shows spatial frequency from low to high, and the y axis shows power in dB. Isotropy in the lower frequencies is more crucial than in the higher frequencies, as the lower frequencies are more visible. Sharp peaks in the graph show up when patterns form.
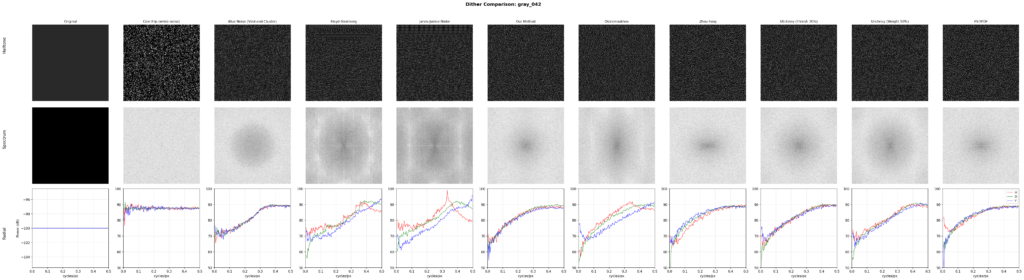
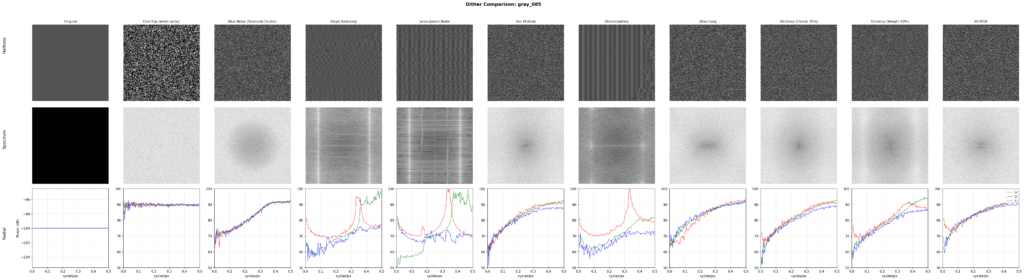
By this metric, our method nearly perfectly aligns with the theoretical ~6dB/octave blue noise curve. The methods described by Ulichney, as well as a variant of Floyd-Steinberg using TPDF for threshold perturbation, similarly approach the same curve. Ostromoukhov’s technique improves on FS, but does not fully eliminate patterns at single gray levels. Zhou-Fang is relatively clean, but the technique vertically introduces some level of noise in the lower ranges due to the modulation being position dependent.
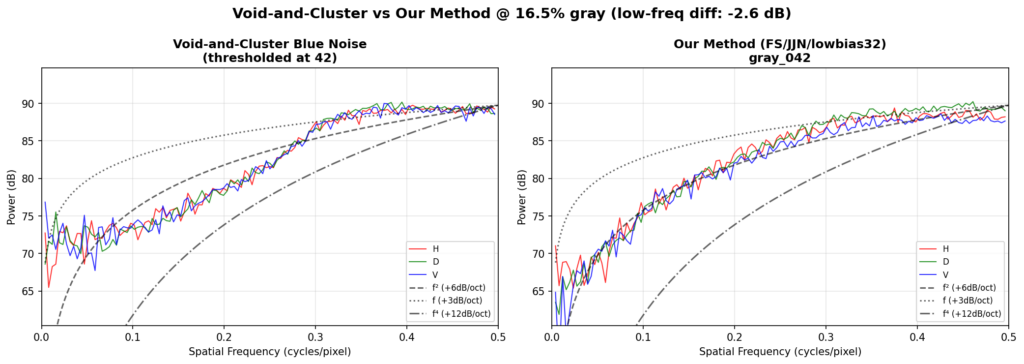
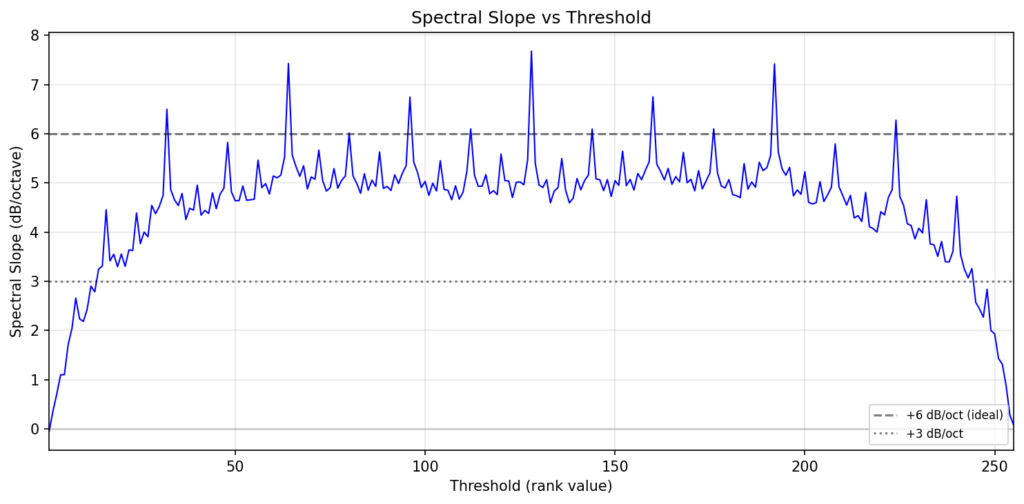
A comparison with theoretical blue noise curves shows our method maintains a consistent 6dB/oct slope across the full frequency range, whereas void-and-cluster (a well-known blue noise approximation) exhibits a steeper rolloff in the midrange that flattens at the extremes.
Ramps and steps





As there are no widely adopted objective metrics in literature for real images, we’re using an approach where the original and quantized image are analyzed in wavelet form, as wavelets happen to model error patterns quite well, and several metrics are then derived from the difference between the original and quantized output at multiple subbands. The resulting set of informal metrics is useful for relatively comparing several desirable aspects between techniques.
The measurements here are an average made from the following standard images: cameraman, lake, lena_gray_512, livingroom, mandril_gray, pirate, walkbridge, and woman_blonde. The complete test outputs can be found on GitHub.
The blueness metric measures how locally the error is getting diffused. A higher score means the error stays close to where it originated rather than spreading into visible large-scale patterns. It’s calculated by comparing the energy level of coarser bands against the finer bands. Floyd-Steinberg as expected has the most local diffusion, as it’s designed to be the smallest possible kernel. JJN, given its size, ranks much coarser. Our method sits right in-between. For comparative purposes, void-and-cluster scores low (even though it is an excellent blue noise approximation) because it doesn’t diffuse the error, it just masks.
Flatness is measured by how flat the spectrum of the error at each band is. A lower score here means there are repetitive error artifact patterns in the output. White noise scores highest in this metric, as it has no patterns. Our method and Zhou-Fang rank at the same level for this metric. Ostromoukhov ranks low here since it exhibits a lot of patterns.
Structure measures how faithfully the halftone output preserves the edges and details of the original image, calculated as a correlation between original and output wavelet coefficients across scales. This score is particularly hurt by noise or blurring smoothness getting added into the target signal. Specifically, threshold-perturbed techniques score poorly on this metric, and techniques which inherently sharpen the image score more highly. Our method scores similarly to FS and JJN. Zhou-Fang ranks low as its position-dependent modulation causes white noise along the vertical axis.
The isotropy shows how consistent the vertical, horizontal, and diagonal errors are, comparatively. Techniques with a higher base noise level do score more highly on this metric by default, so (just as with the other metrics) it needs to be read in relation to the blueness and other metrics, and cannot be considered by itself.
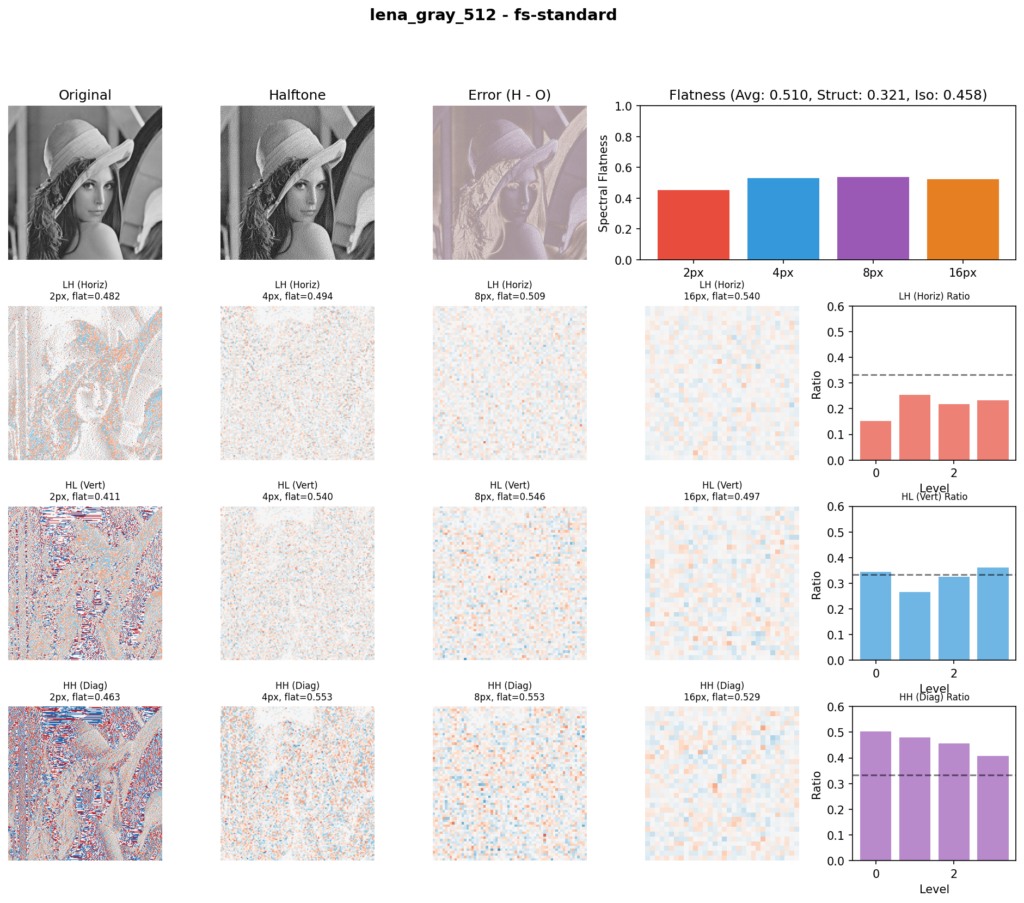
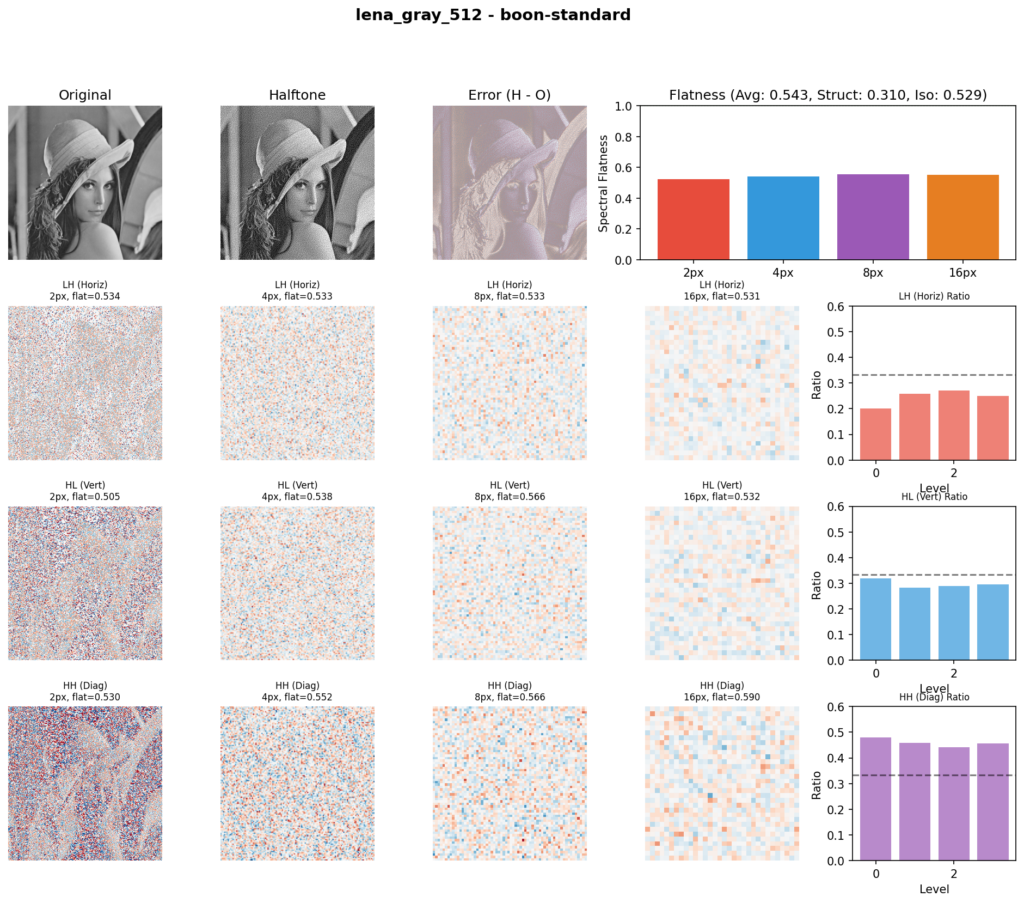
Using these metrics we can get a reasonable objective measure of different techniques. The error patterns clearly highlight themselves in the wavelet analysis. Our method strikes a competitive balance across all four metrics.
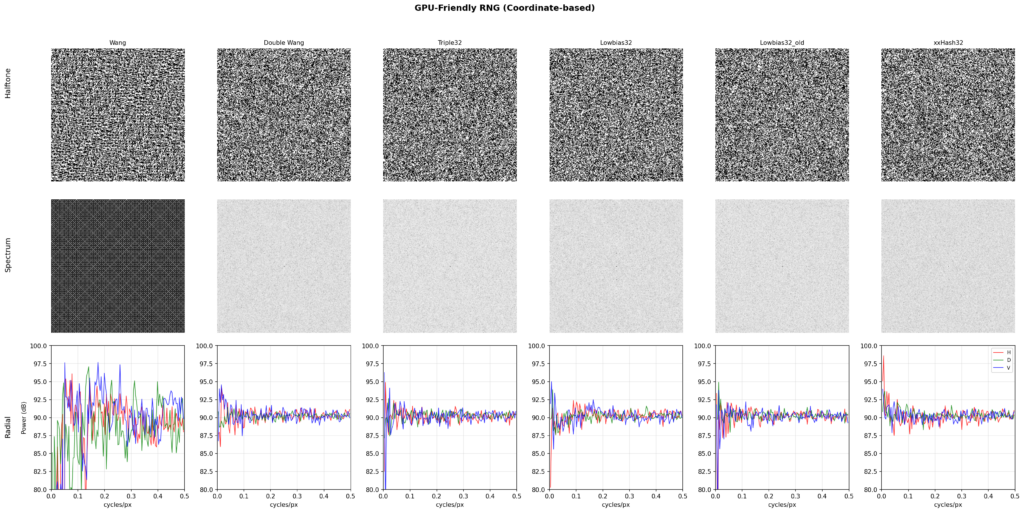
Alternative hash pairingsComparing outputs with various randomizer functions shows minimal practical difference, although the differences are measurable. Our choice here is lowbias32 for its simplicity and cleanest noise profile. Additionally, it is important to prefer the high bits over the low bits, as these have better statistical properties due to better mixing.
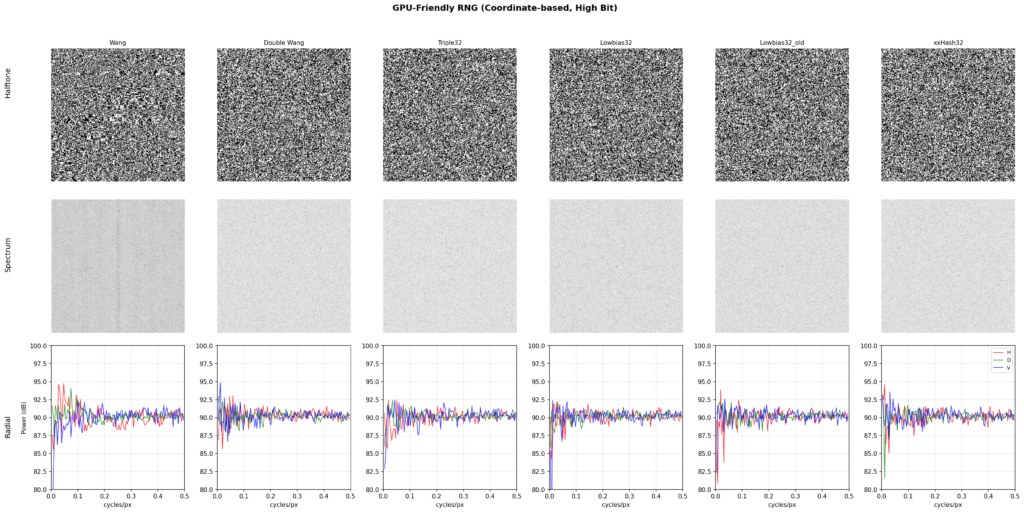
Comparison of coordinate-based pseudo-random number generators, highest (most significant) bit
Wang hash, even with its repetitive behavior when used in a 2D context, still performs adequately when compared to lowbias32, so in practice the choice of randomizer is flexible.


Several popular kernels pair well with Floyd-Steinberg. JJN pairs best with FS based on comparisons across gray levels. Pairings between kernels other than FS, however, do not work as well. It seems plausible that at least one of the kernels should be the smallest reliable kernel, and that there exists a more ideal pairing than the one presented here.
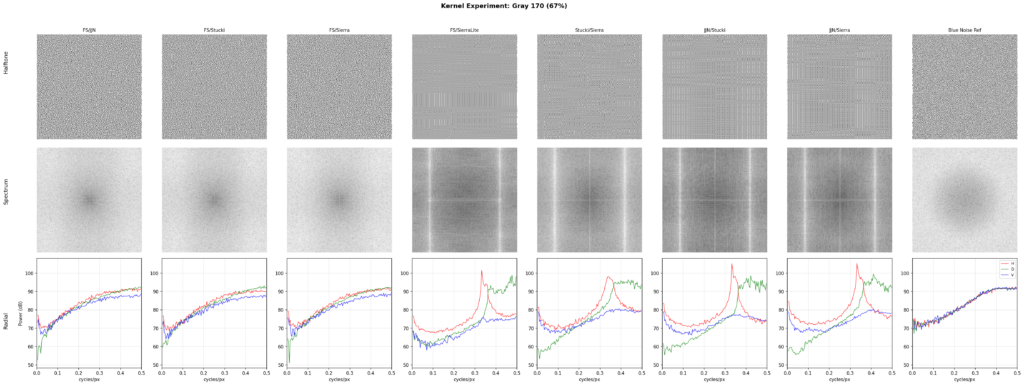
This diffusion technique is easy to implement in existing error diffusion pipelines and has a nearly ideal blue noise profile without diffusion pattern artifacts.
The random seed used for switching kernels can be changed per-frame, this allows the technique to be used for display scanout where the diffusion must temporally vary between frames. Ideally, a 3D kernel may provide more optimal temporal properties for such use cases.
Error diffusion is inherently a stateful serial process, so not straightforward to use in stateless parallel processing contexts, however it is possible to pipeline and process multiple lines simultaneously maintaining a few pixels delay between each line, by synchronizing available work between threads with atomic counters.
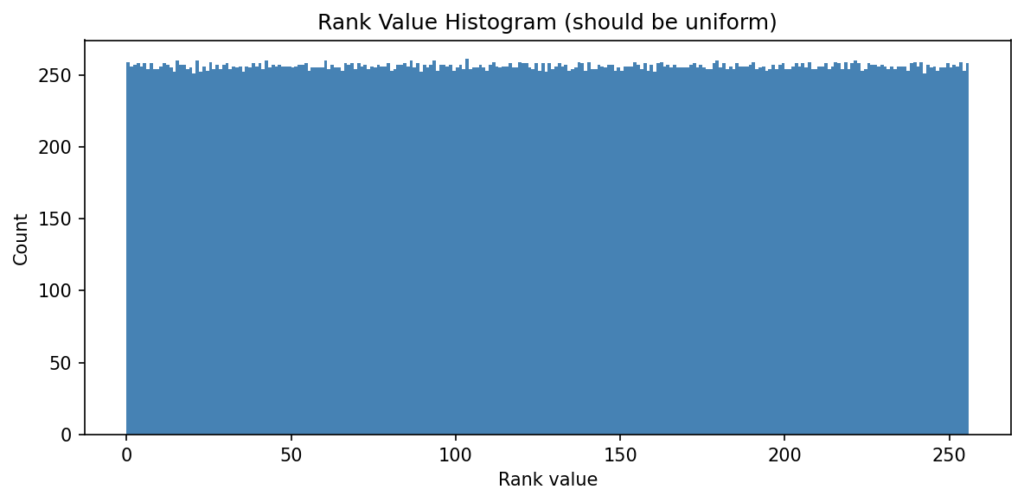
Generative ordered blue noise mappingIt is possible to generate an ordered blue noise map using error dithering as a source, by generating a halftone output for 0.5 gray, and then recursively splitting each low and high population with a new gray halftone, masking out the portions that are not part of the current population (simply setting them at 0 or 1) so the error propagates over them. This population splitting technique is repeated until we have assigned all 256 populations.


The resulting ordered blue noise has a perfectly uniform distribution, and reasonably maintains its spectral profile accross thresholds. It is plausible that a more ideal kernel pairing may maintain a more consistent spectral profile for this generative task.
- Quantizing ML image generation outputs from FP16 or FP32 to 8-bit/channel PNG
- Low bit depth image formats for embedded hardware
- Display scanout (e-ink, embedded, etc.)
- Printers
- Deterministic generative blue noise maps for procedural placement of foliage in games
- Spatial distribution for stochastic image sampling in rendering techniques
The same technique can be used for 1D quantization, as an alternative to sigma-delta with threshold perturbation dithering. Reasonable kernel pairs are found at [ 1 ] and [ 19, 5 ], [ 1 ] / [ 23, 1 ], and [ 1 ] / [ 7, 5 ] (derived from the 2D JJN kernel). This can likely be further optimized. Performance appears competitive against sigma-delta with dither, and shows less distortion at the lowest threshold ranges.
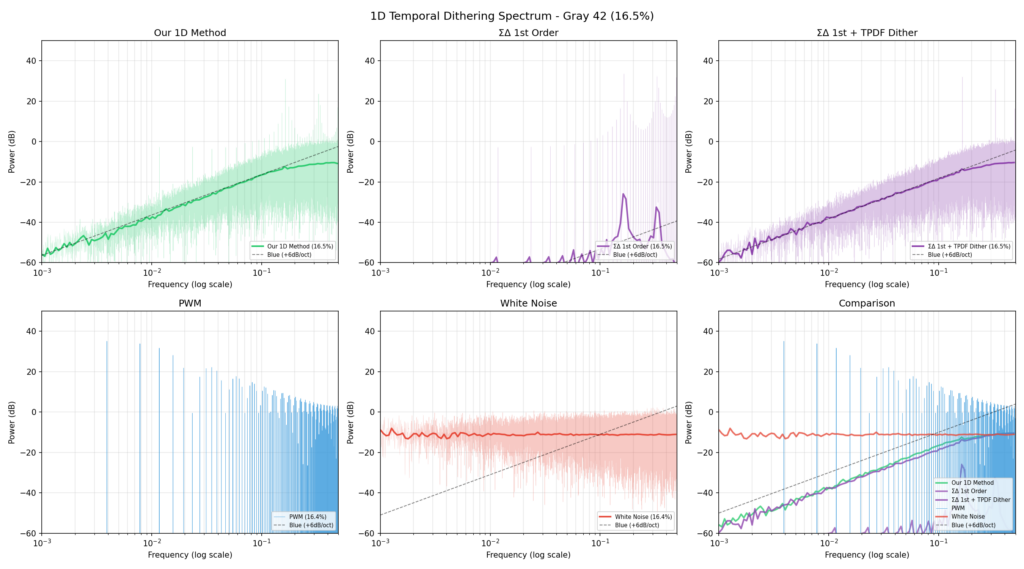
For the task of producing full-range 1D blue noise using the generative population splitting technique, we found that [ 1 ] and [ 0, 1 ] are ideal kernels. This may also offer some hint towards a more ideal 2D pairing.
Practical applications in 1D- LED dimming without flicker or strobing interference
- Audio ADC
- LLM token sampling (using generative blue noise)
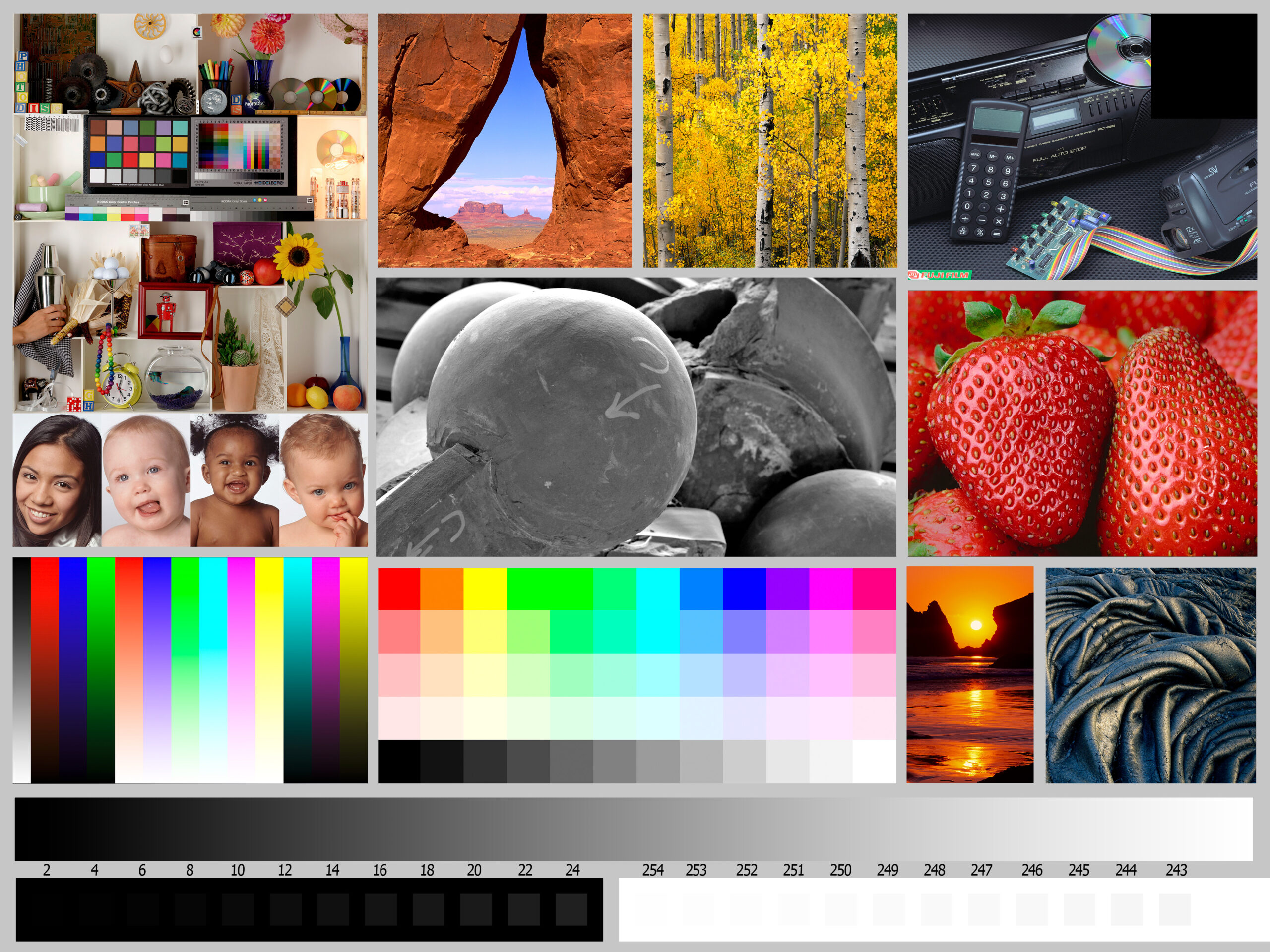
Samples created using the dithering web demo included in the CRA tool. Color space-aware dithering. Ensure you are viewing these at 1:1 pixel size, as browser scaling interpolates in display gamma space which darkens colors at high contrast edges.