J'ai fait l'erreur il y a 2 ans de penser que la vente de mon SaaS, Redsmin.com (je parle de son histoire ici), serait naturelle. Malgré les demandes reçues au fil du temps, rien ne me convenait. Il y a 3 mois, j'ai décidé de me prendre en main ce qui a eu pour résultat une vente de Redsmin jeudi dernier (20 août 2020). Cet article retrace les étapes que j'ai suivies.
1 - Attendre un miracle
Cela faisait 2 ans (juillet 2018) que je laissais Redsmin en roue libre. Pas de mise à jour fonctionnelle, juste un peu de support à raison d'un email par semaine environ. Le MRR variant de mois en mois entre 1 700$ et 2 800$, cela me convenait et j'espérais recevoir des propositions intéressantes.
La bonne nouvelle est que j'ai bien reçu des propositions, la mauvaise nouvelle est qu'elles ne m'intéressaient pas. Offre de partenariats, prise de participation, AcquiHire...
Je n'étais pas proactif quant à la communication et la gestion de la mise en vente de Redsmin et le projet stagnait.
Bref, j'attendais un miracle, tout comme on peut attendre d'obtenir un travail en restant chez soi. Les chances de succès sont très limitées.
2 - Se prendre en main, publier l'annonce sur des marketplaces
Le 11 mai 2020, je décide de rechercher les techniques pour vendre son SaaS. Je réalise qu'il existe des marketplaces spécialisées pour cela.
Je crée une fiche profil pour Redsmin.com sur indiemaker.co, la fiche est validée le jour même par le site.
Deux semaines plus tard, le 22 mai, je découvre microacquire.com. Rebelote, création d'une fiche profil qui sera validée 4 jours plus tard par le site.
3 - Attendre les propositions
12 jours plus tard, j'ai pu recevoir la première demande de mise en contact via Indiemaker. Concernant MicroAcquire il a suffi de 5 jours d'attente.
Au total, c'est 28 prises de contact qui ont eu lieu (19 via MicroAcquire, 9 via IndieMaker). Ces contacts ont découvert la fiche du SaaS majoritairement grâce à la newsletter dédiée de ces deux sites ainsi qu'une mise en avant par les webmestres.
4 - Constituer un dossier de vente
Les potentiels acheteurs vont avoir besoin de plus que vos beaux yeux pour prendre la décision d'aller plus loin.
Il est donc nécessaire de créer et de partager un dossier qui contiendra un ensemble d'informations communicable à l'extérieur.
Je suis parti sur un dossier par mois. Chaque dossier contenant des exports de données relatives au mois ou aux 6 derniers mois, suivant la métrique.
Plutôt que de m'embêter à réaliser des exports partiels de la base de données et de Stripe. J'ai préféré utiliser les offres gratuites de ProfitWell et ChartMogul pour agréger et réaliser des exports.
J'obtenais ainsi très facilement les informations suivantes pour chaque mois :
- MRR over the past 6 months
- MRR per plans
- MRR per countries
- MRR movements
- MRR breakdown (new business, expansion, contraction, churn, reactivation) over the past 6 months
- ARR
- Subscribers count over the past 6 months
- Churn/retention cohorts
- Cash-flow
- Freemium: free/paid ratio
- Customer Lifetime Value
À ceci il faut ajouter un export de votre comptabilité interne (profit & loss).

Ce dossier étant dans dropbox il ne me restait plus qu'à partager le lien, suite aux mises en relation.
Rétrospectivement, j'aurais dû d'abord constituer un dossier avant de soumettre les fiches. Même s'il ne faut pas plus de quelques heures pour créer une première version.
5 - Maintenir un document de Q&A
Les questions des potentiels acheteurs sont souvent les mêmes. Je ne sais pas vous, mais je n'aime pas trop me répéter. J'ai donc ajouté un fichier Q_and_A.txt qui répertorie l'intégralité des questions que j'avais pu recevoir ainsi que leurs réponses associées donc voici un extrait :
- How much effort do you need to maintain this product?
- What are the unique values of your SaaS product, compared to your competitors, like XXX ?
- If you have time to make some dev effort, what functions will you add?
- What does the overall tech stack of the prod look like?
- It seems the maintenance cost is low, why do you still sell it?
- What is included in the sell and more importantly what is not included?
- …
Sur les 28 mise en relations, j'ai pu ainsi partager l'accès au dossier de vente à 10 d'entre eux.
6 - Filtrer les propositions
Suite au partage du dossier de vente, j'ai pu recevoir 5 propositions (conversion : 17%).
Je considérais une proposition comme intéressante si elle respectait les critères suivants :
- un maintien du service pour les clients et utilisateurs existants
- une vente intégralement en cash
- le montant correspondait à mes attentes
Pour ces raisons, j'ai donc rejeté les propositions suivantes :
- acquihire (acquisition + recrutement pour continuer à maintenir Redsmin)
- apport + entrée au capital de Redsmin
- un peu de cash + une commission sur les nouvelles ventes
- un peu de cash + un second versement en fonction des résultats après 1 an
Sur ces 5 propositions, en suivant mes critères, deux ce sont avérées intéressantes. Vu que le premier y allait presque au chantage, j'ai donc continué avec le second acheteur nous avons à ce moment là échangé sur le facteur multiplicateur.
7 - Méthode EBITDA et facteur multiplicateur
Pour estimer la valeur d'un SaaS plusieurs méthodes existent mais la plus connue et sans doute l'EBITDA (Earnings Before Interest, Taxes, Depreciation and Amortization). En France nous parlons d'EBE (Excédent Brut d'Exploitation).
EBITDA = Chiffre d'affaires - Charges d'exploitation
Redsmin est un SaaS et son business model est un modèle de souscription majoritairement mensuel. Pour évaluer le chiffre d'affaires dans ces cas là, on se base sur un MRR médian (par exemple sur les 6 derniers mois) reporté sur 1 an.
Ensuite l'EBITDA est multiplié par le fameux facteur multiplicateur afin d'obtenir le montant final de la vente.
L'intérêt de la méthode EBITDA et facteur multiplicateur est qu'elle donne un repère à l'acheteur ainsi qu'au vendeur. En résumé : on ne peut pas fake son EBE/EBITDA (cette affirmation est à prendre avec des pincettes, je ne suis loin d'être un expert).
Il ne reste plus alors qu'à jouer sur le facteur multiplicateur pour trouver un terrain d'entente.
Bref, connaissant le modeste MRR de Redsmin, je savais pertinemment que cette vente ne me rendrait pas millionnaire 😅.
8 - LOI - Letter Of Intent
La lettre d'intention d'achat (ou Letter Of Intent en anglais) a principalement deux intérêts :
- une première définition du prix d'achat du SaaS
- la définition d'une période (e.g. 14 jours) d'exclusivité où le vendeur s'engagent à ne pas accepter d'autres propositions
Néanmoins la LOI n'engage habituellement pas l'acheteur, il faut donc encore montrer patte blanche !
9 - Due Diligence
Pour résumer, l'objectif de cette étape (appelée Due Diligence) est de vérifier que le vendeur (moi) ne bullshit pas sur les chiffres. Dans notre cas la Due Diligence s'est déroulée via un échange Google Meet (l'acheteur était anglais et d'un autre pays) et un partage d'écran, en 1 heure c'était plié.
Au programme :
- Parcours du code et explication macro via GitLab et GitHub.
- Objectif : démontrer que le code n'est pas dégueux, qu'il y a des tests, une intégration continue (CI) et parfois même du déploiement continu (CD), bref, que l'application est toujours maintenable.
- Parcours des revenus via Stripe.
- Objectif : prouver que je ne bullshit pas sur les exports et sur les chiffres.
- Parcours des données de visites via Google Analytics.
10 - Asset Purchase Agreement, Asset Transfer, Non Compete Agreement, NonDisclosure Agreement
À cette étape il faut définir un inventaire des assets à transférer (comptes Stripe, Analytics, Google Apps, GitLab, GitHub, npm, Tumblr, Netlify, OVH, Clever Cloud, MongoDB Atlas, RedisLabs, Uservoice, …), sous quelle modalité, avec quel pré-requis...
L'échange se concentre en parallèle sur le contrat d'Asset Purchase Agreement. Dans mon cas nous avons itéré 7 fois afin de bien spécifier les clauses légales.
En parallèle nous avons chacun ouvert un compte sur Escrow.com (oui, la compréhension VF du nom ne rassure pas !). Escrow est une plateforme agissant en tant que tiers de confiance pour assurer la transaction.
11 - Négocier l'accompagnement
Nous sommes partis sur un accompagnement de 30 jours intégré au contrat de vente. Puis une facturation à l'heure pour du conseil après ces 30 jours.
Rétrospectivement, j'aurais peut-être dû négocier l'accompagnement sur une durée de 15 jours. La bonne nouvelle cependant est que pour cet accompagnement à la transition il n'y a qu'un engagement de moyen (en mode best-effort) et pas de résultat. No stress.
12 - Signature
Après plus de 60 échanges emails qui ont eu lieu avec l'acheteur sur 2 mois pour répondre aux questions et de nous aligner sur le contenu du contrat de vente, nous étions fin prêt à signer.

Parce que dans notre cas les documents de travails étaient tous des PDF, j'ai dû faire un suivi des changements... à l'ancienne :
13 - Réaliser le transfert des assets
Le transfert de tous les assets, la migration des applications et des accès ont été réalisé en quelques heures, sans downtime pour les utilisateurs.
14 - Attendre l'argent (rends l'argent !) et payer ses impôts
Pas la peine de faire un dessin sur cette dernière partie :).
Ainsi se termine ces 3 mois. "Qui ose gagne. Là où se trouve une volonté, il existe un chemin." disait Churchil.
Si tu lis jusqu'ici c'est sans doute que les SaaS, l'indiehacking, ou simplement le développement en général te passionne. J'ai une bonne nouvelle pour toi, il y a un slack pour ça, rejoins-nous ! Il est temps de mon côté de te laisser, les autres chapitres du livre NoBullshit Tech-Lead ne sortirons pas tout seul 😅 !






































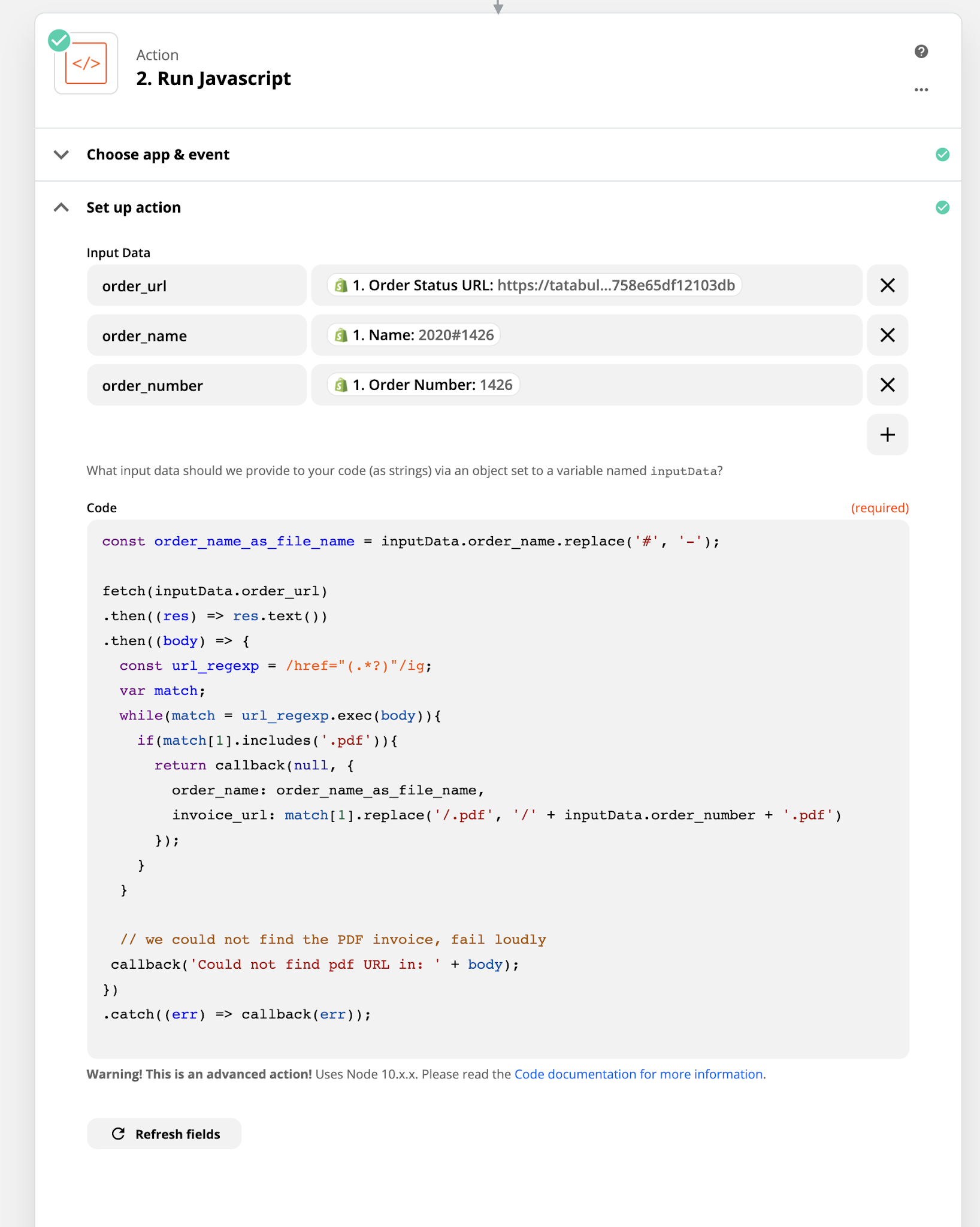
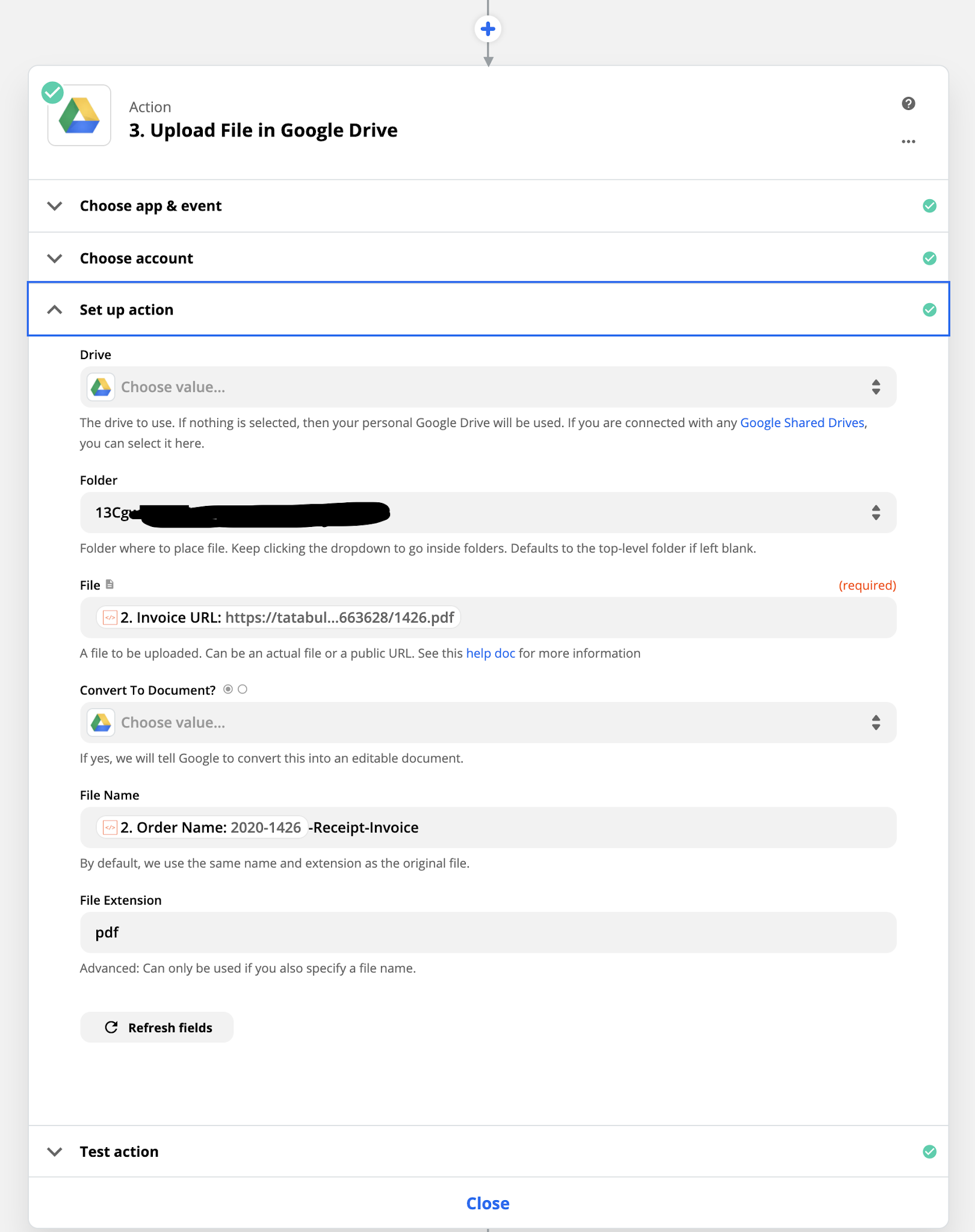
 Step 2: Add some glue code
Step 2: Add some glue code