Show full content

Did you ever have to maintain multiple versions of a REST API because the change you needed to make would break existing clients? Does your native app have to call multiple REST endpoints to get all the data it needs? This blog post is about how we addressed these common problems using GraphQL and our transition to GraphQL Federation at RetailMeNot.
RetailMeNot, part of Ziff Media, Inc, makes everyday life more affordable for shoppers. We are a leading savings destination providing online and in-store coupons and cashback offers to our users. Today, we serve millions of monthly active users from our desktop, mobile web, native (iOS & Android) apps, and browser extension (Deal Finder™) experiences.
For the last 10 years, RetailMeNot’s engineering teams have built several highly performant, scalable, and efficient systems to bring savings data to our users through our experiences. And like many companies, RetailMeNot used REST APIs to serve the data. However, as the company and the systems grew, we started to experience problems like versioning, over-fetching, and under-fetching with REST APIs. For more details on the classic problems that arise from REST services and how GraphQL solves them, see this blog post. For an introduction to GraphQL, see this blog post.
How it started: A Monolithic GraphIn 2019, we took a step back to rethink where we are headed in terms of our tech stack and how to best serve future experiences. We decided to rewrite our native Android and iOS apps and the backend that supports them. In addition to this, we also built a brand new browser extension (Deal Finder™) and re-wrote several parts of our core website.
As we started to rebuild our native apps, we wanted to solve the above problems we faced with REST APIs. GraphQL seemed like a great solution for this.
Enter GraphQL. In our first iteration with GraphQL, we built a GraphQL monolith.

The GraphQL Monolith at RetailMeNot was a single GraphQL Server used by our Native Android, iOS, desktop, and mobile web clients. A single team (Graph API team) was responsible for “gatekeeping” and defining standards for this new RetailMeNot data graph.
To allow the client teams to develop and iterate faster, they were given autonomy to contribute to this monolith and expand the graph based on their needs. This, however, soon overwhelmed the Graph API team, and they became a bottleneck for getting new changes published to the graph. It was clear that we needed a new solution where the client teams could have the autonomy to expand the unified graph at their own pace and not be limited by a centralized team.
Escaping the Monolith with GraphQL Federation:Enter GraphQL Federation.
The premise behind Federation is that each subgraph team is responsible for building and maintaining their portion of the unified graph schema. This allows the subgraph teams to iterate faster as they are decoupled from the rest of the graph.
Setting up a reliable and highly scalable federated GraphQL architecture is not easy. There are several things to consider:
- How to prevent a subgraph from introducing a breaking change to the graph?
- How to make sure the GraphQL gateway always reflects the most up-to-date schema?
- How to monitor the health and performance of all the queries that are served from the graph?
To help us address these concerns, we partnered with Apollo GraphQL and leveraged their Managed Federation architecture.
In order to maintain backward compatibility and ensure zero downtime during the migration from a monolithic architecture to a federated architecture, it was very critical for us to adopt an “incremental migration” approach.
Here are the incremental steps that we took for this migration:
- First, we transformed the existing GraphQL schema in the monolithic service to support federation specifications. This allowed us to support both the federation spec and schema stitching in the same service. Here are the open-source libraries that provide support for federation spec.
- We then set up a new Gateway service that simply forwarded the traffic to the monolithic service.
- Using a weighted routing technique, we then controlled the amount of traffic that would hit the new Gateway service vs the monolithic service. Once we were confident with the changes and validations in our lower environments (stage/pre-production), we then switched over to 100% of our traffic going through the Gateway service in the production. At this point, our monolithic service was completely behind the gateway.
- Finally, we started to break apart the schema in our monolithic service (which now became a subgraph) and migrated the entities over to more cohesive and smaller subgraph services.
Here is what the GraphQL architecture at RetailMeNot looks like today:
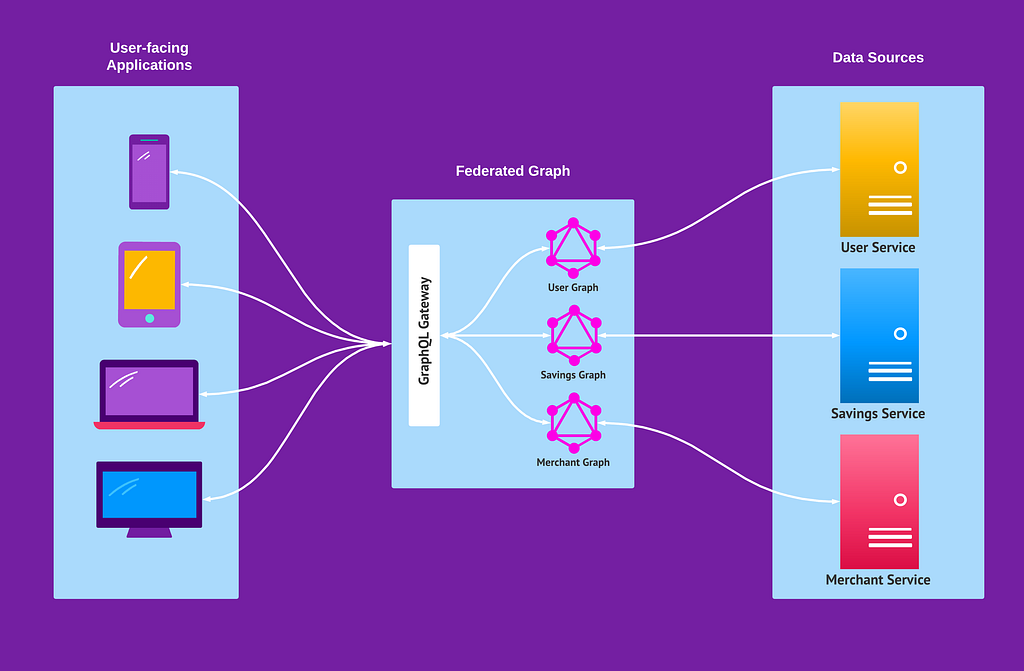
Currently, our unified data graph at RetailMeNot consists of several fully federated and highly cohesive subgraph services that are being actively worked on by different teams independently.
Adoption and lessons learned:
We had a very quick adoption of the new federated architecture internally. Multiple teams wanted to join the new federated graph immediately after it was available. This was a huge win for the Graph API team. However, as we began to incorporate new subgraph services across various teams into the federated graph, it became a bit of a wild west with subgraph design and maintenance inconsistencies. Here are some of the lessons we learned from our early adopting teams:
- Use a standard naming convention
- Standardize a schema review process
- Be very intentional about field nullability
- Document the schema definition
- Always prioritize clients’ needs
Graph Stewardship:
To address the above lessons we learned, we set up a “virtual” guild. This virtual guild consists of one member from each subgraph team. The main responsibilities of this guild are:
- Setting up best practices for RetailMeNot’s unified graph and enforcing them
- Reviewing schema changes from each sub-graph and providing feedback
- Helping onboard new subgraph teams
- Sharing what they learn with broader teams at RetailMeNot and drive GraphQL adoption across the company
So, how did moving to a federated architecture help us?
- Faster product iteration: The user-facing application teams can move much faster as the bottleneck from a single “GraphQL API team” is removed.
- Concern-based separation: Moving to a federated architecture enabled different teams to work on different product areas without affecting/blocking each other while contributing to a single graph.
- Similar tech-stack across services: Moving to a federated architecture helped us standardize the tech-stack across multiple services at RetailMeNot. This also led to high collaboration across teams.
- Developer experience: With standardized tooling and a common tech stack, developer experience has been improved a lot.
Here are some of the responses to the same question above from a few members of our organization:
“Federation enabled our teams to iterate over the deliverables with minimal dependencies. Teams have clear ownership and this has empowered the product and UX teams to iterate over new features, evaluate the market reach, and keep customers happy.”
“By utilizing Federated GraphQL, we have been able to improve the cohesion of our backend services and hide the migration of subgraph responsibilities from our client applications.”
“Federation allowed our teams to iterate on features faster and more independently, while at the same time pushing us to improve cross-team communication and collaboration in order to effectively manage the unified graph.”
“At an org level, GraphQL and federation specifically forced us to come to a mutual understanding of the data types and terminology that are used across our different services. Because of this, we were able to have meaningful conversations more quickly.”
Finally,
RetailMeNot + GraphQL Federation = Greatness
A big thanks to everyone who helped me put this blog together. Special thanks to the members of the GraphQL guild at RetailMeNot, the teams at Apollo GraphQL, and the broader GraphQL community for helping us reach where we are.
Interested in solving complex problems at scale? Check out our careers page or reach out directly if you have any questions.
About Ziff Media, Inc:
Ziff Media, Inc. is a portfolio of leading digital properties in tech, culture, and shopping. Our brands include Mashable, PCMag, RetailMeNot, Offers.com, BlackFriday.com, BestBlackFriday.com, ExtremeTech, AskMen, and TechBargains.
RetailMeNot 💜 GraphQL Federation was originally published in Ziff Media Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.