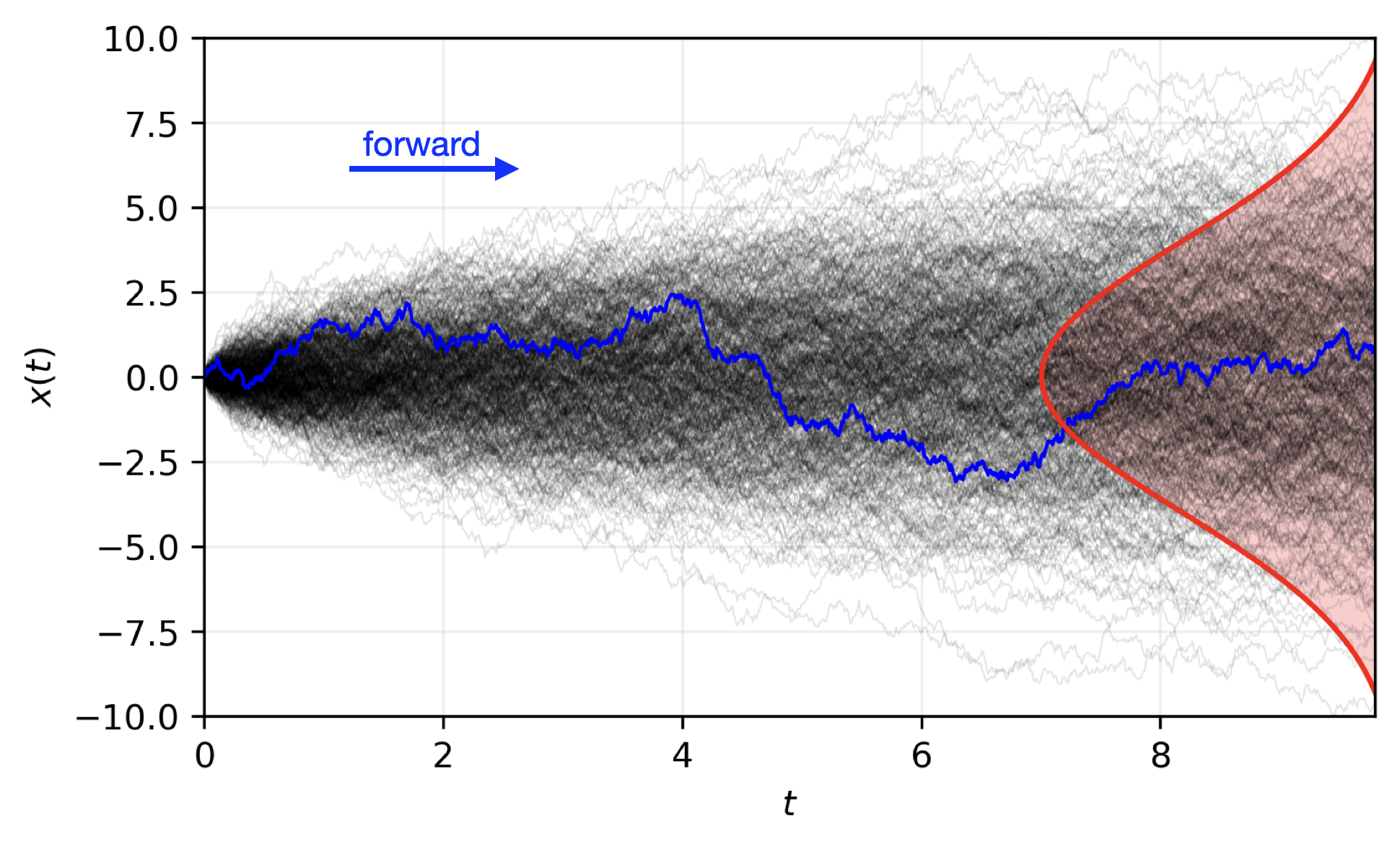
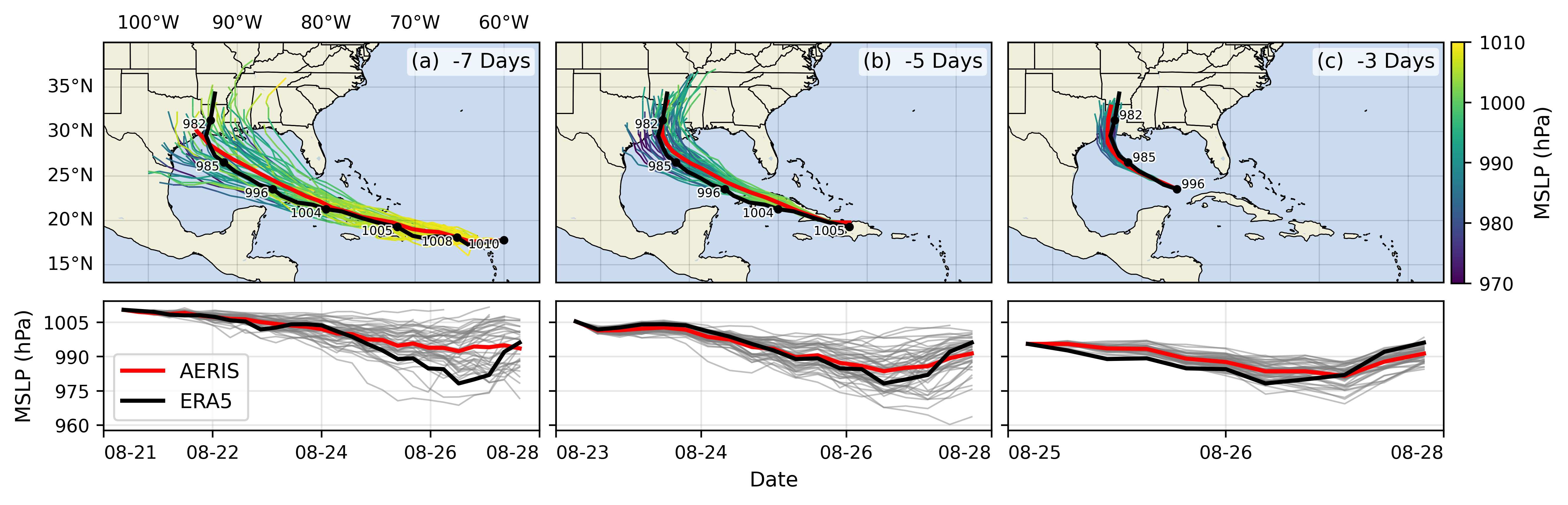
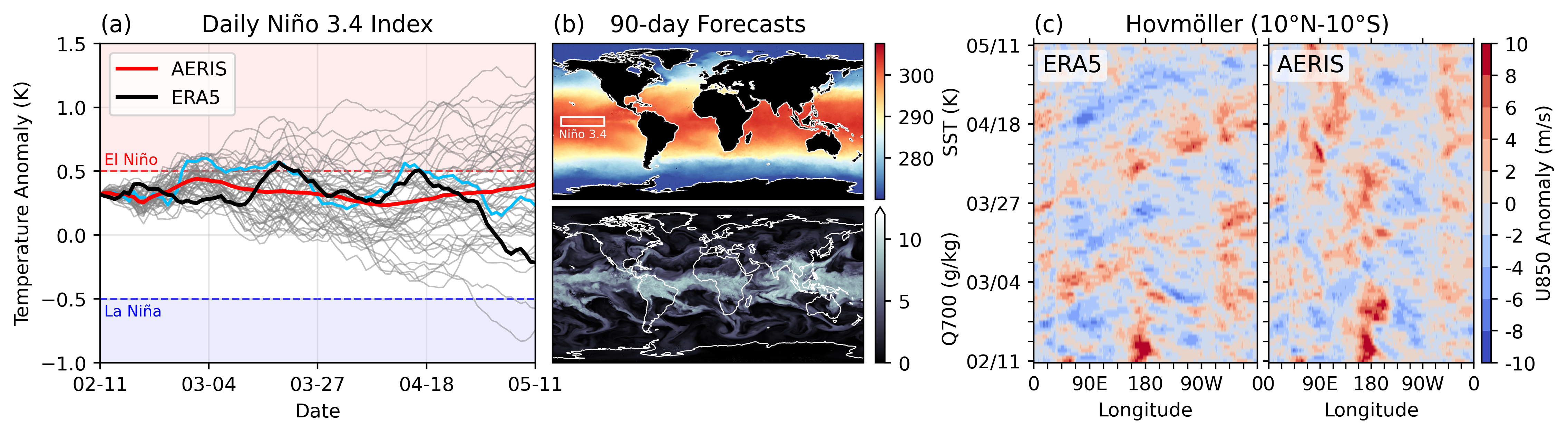
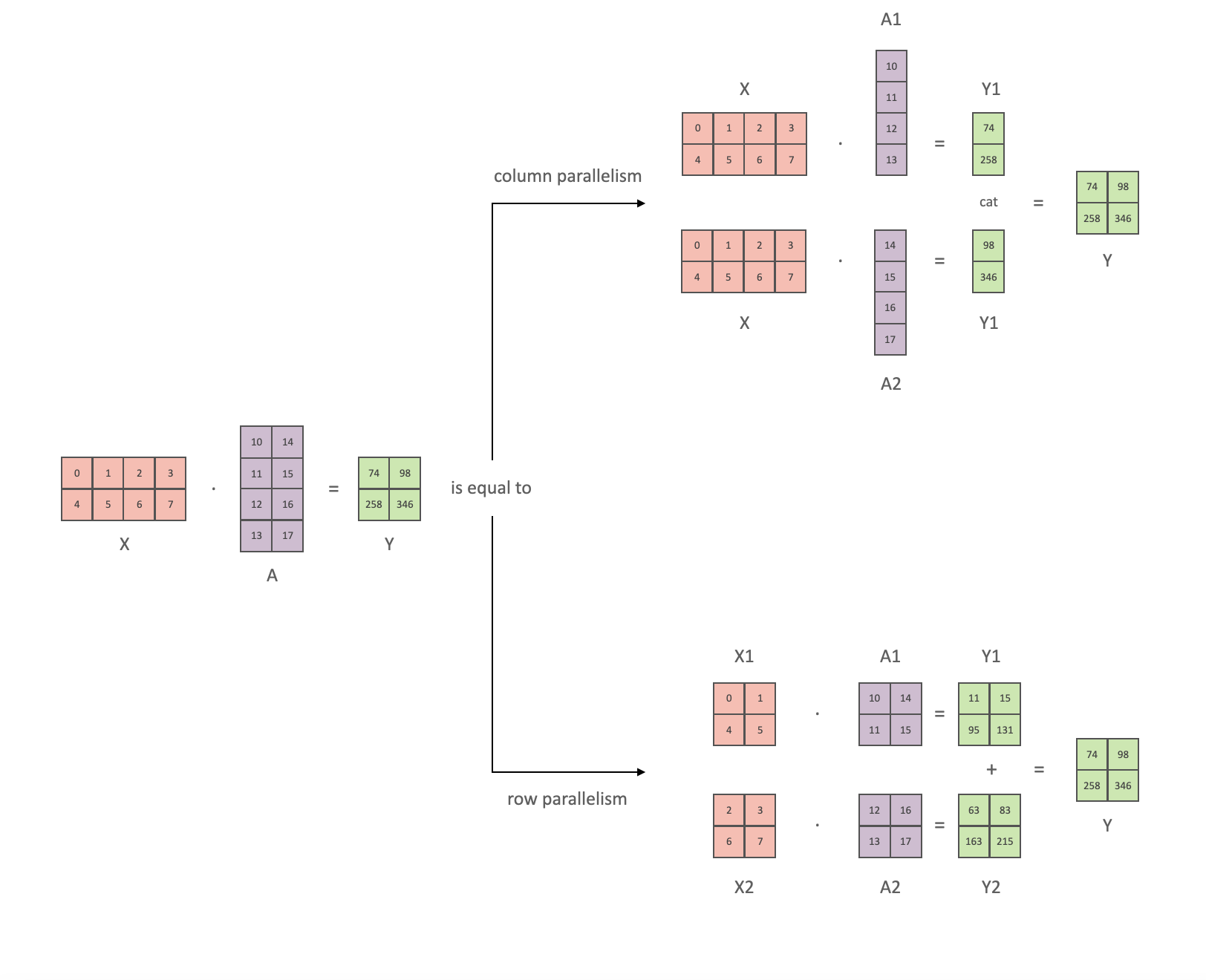
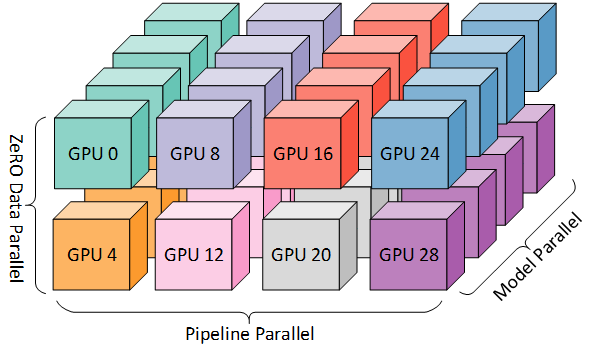
Launch:
; ezpz-launch -m torchtitan.experiments.blendcorpus.train --job.config_file torchtitan/experiments/blendcorpus/train_configs/auroraGPT_7B.toml
output:
#[09/12/25 @ 11:33:56][x4117c4s2b0n0]
; ezpz-launch -m torchtitan.experiments.blendcorpus.train --job.config_file torchtitan/experiments/blendcorpus/train_configs/auroraGPT_7B.toml
[2025-09-12-113711][I][-zsh:91] Using torchtitan/experiments/blendcorpus/train_configs/auroraGPT_7B.toml
[2025-09-12-113711][I][-zsh:91] Logs will be saved to: logs/auroraGPT_7B-2025-09-12-113711.log
[W912 11:37:15.852098275 OperatorEntry.cpp:219] Warning: Warning only once for all operators, other operators may also be overridden.
Overriding a previously registered kernel for the same operator and the same dispatch key
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
dispatch key: XPU
previous kernel: registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/aten/src/ATen/VmapModeRegistrations.cpp:37
new kernel: registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/ipex_2.8.10_xpu_rel_08_18_2025/intel-extension-for-pytorch/build/Release/csrc/gpu/csrc/gpu/xpu/ATen/RegisterXPU_0.cpp:172 (function operator())
[2025-09-12 11:37:16,879] [INFO] [real_accelerator.py:260:get_accelerator] Setting ds_accelerator to xpu (auto detect)
/opt/aurora/25.190.0/frameworks/aurora_nre_models_frameworks-2025.2.0/lib/python3.10/site-packages/neural_compressor/utils/utility.py:44: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import parse_version
[2025-09-12 11:37:30,939] [INFO] [logging.py:107:log_dist] [Rank -1] [TorchCheckpointEngine] Initialized with serialization = False
[2025-09-12 11:37:43,263749][I][ezpz/__init__:266:<module>] Setting logging level to 'INFO' on 'RANK == 0'
[2025-09-12 11:37:43,266470][I][ezpz/__init__:267:<module>] Setting logging level to 'CRITICAL' on all others 'RANK != 0'
[2025-09-12 11:37:43,273704][I][ezpz/launch:340:launch] ----[🍋 ezpz.launch][started][2025-09-12-113743]----
[2025-09-12 11:37:47,537879][I][ezpz/launch:345:launch] Job ID: 7591191
[2025-09-12 11:37:47,538702][I][ezpz/launch:346:launch] nodelist: ['x4117c4s2b0n0', 'x4117c4s6b0n0']
[2025-09-12 11:37:47,539093][I][ezpz/launch:347:launch] hostfile: /var/spool/pbs/aux/7591191.aurora-pbs-0001.hostmgmt.cm.aurora.alcf.anl.gov
[2025-09-12 11:37:47,540277][I][ezpz/pbs:188:get_pbs_launch_cmd] ✅ Using [24/24] GPUs [2 hosts] x [12 GPU/host]
[2025-09-12 11:37:47,541233][I][ezpz/launch:316:build_executable] Building command to execute by piecing together:
[2025-09-12 11:37:47,541638][I][ezpz/launch:317:build_executable] (1.) launch_cmd: mpiexec --verbose --envall --np=24 --ppn=12 --hostfile=/var/spool/pbs/aux/7591191.aurora-pbs-0001.hostmgmt.cm.aurora.alcf.anl.gov --no-vni --cpu-bind=verbose,list:2-4:10-12:18-20:26-28:34-36:42-44:54-56:62-64:70-72:78-80:86-88:94-96
[2025-09-12 11:37:47,542413][I][ezpz/launch:318:build_executable] (2.) cmd_to_launch: /lus/flare/projects/AuroraGPT/AuroraGPT-v1/Experiments/AuroraGPT-2B/tt/auroraGPT-ANL/torchtitan/venvs/aurora/torchtitan-aurora_nre_models_frameworks-2025.2.0/bin/python3 -m torchtitan.experiments.blendcorpus.train --job.config_file torchtitan/experiments /blendcorpus/train_configs/auroraGPT_7B.toml
[2025-09-12 11:37:47,543429][I][ezpz/launch:360:launch] Took: 4.27 seconds to build command.
[2025-09-12 11:37:47,543810][I][ezpz/launch:363:launch] Executing:
mpiexec
--verbose
--envall
--np=24
--ppn=12
--hostfile=/var/spool/pbs/aux/7591191.aurora-pbs-0001.hostmgmt.cm.aurora.alcf.anl.gov
--no-vni
--cpu-bind=verbose,list:2-4:10-12:18-20:26-28:34-36:42-44:54-56:62-64:70-72:78-80:86-88:94-96
/lus/flare/projects/AuroraGPT/AuroraGPT-v1/Experiments/AuroraGPT-2B/tt/auroraGPT-ANL/torchtitan/venvs/aurora/torchtitan-aurora_nre_models_frameworks-2025.2.0/bin/python3
-m
torchtitan.experiments.blendcorpus.train
--job.config_file
torchtitan/experiments/blendcorpus/train_configs/auroraGPT_7B.toml
[2025-09-12 11:37:47,545251][I][ezpz/launch:179:get_aurora_filters] Filtering for Aurora-specific messages. To view list of filters, run with EZPZ_LOG_LEVEL=DEBUG
[2025-09-12 11:37:47,545756][I][ezpz/launch:370:launch] Execution started @ 2025-09-12-113747...
[2025-09-12 11:37:47,546182][I][ezpz/launch:371:launch] ----[🍋 ezpz.launch][stop][2025-09-12-113747]----
[2025-09-12 11:37:47,546634][I][ezpz/launch:99:run_command] Caught 24 filters
[2025-09-12 11:37:47,547002][I][ezpz/launch:100:run_command] Running command:
mpiexec --verbose --envall --np=24 --ppn=12 --hostfile=/var/spool/pbs/aux/7591191.aurora-pbs-0001.hostmgmt.cm.aurora.alcf.anl.gov --no-vni --cpu-bind=verbose,list:2-4:10-12:18-20:26-28:34-36:42-44:54-56:62-64:70-72:78-80:86-88:94-96 /lus/flare/projects/AuroraGPT/AuroraGPT-v1/Experiments/AuroraGPT-2B/tt/auroraGPT-ANL/torchtitan/venvs/aurora/torchtitan-aurora_nre_models_frameworks-2025.2.0/bin/python3 -m torchtitan.experiments.blendcorpus.train --job.config_file torchtitan/experiments/blendcorpus/train_configs/auroraGPT_7B.toml
Disabling local launch: multi-node application
Connected to tcp://x4117c4s2b0n0.hsn.cm.aurora.alcf.anl.gov:7919
Launching application 422e0368-f389-4475-8131-3de313723140
cpubind:list x4117c4s2b0n0 pid 35392 rank 0 0: mask 0x1c
cpubind:list x4117c4s2b0n0 pid 35393 rank 1 1: mask 0x1c00
cpubind:list x4117c4s2b0n0 pid 35394 rank 2 2: mask 0x1c0000
cpubind:list x4117c4s2b0n0 pid 35395 rank 3 3: mask 0x1c000000
cpubind:list x4117c4s2b0n0 pid 35396 rank 4 4: mask 0x1c00000000
cpubind:list x4117c4s2b0n0 pid 35397 rank 5 5: mask 0x1c0000000000
cpubind:list x4117c4s2b0n0 pid 35398 rank 6 6: mask 0x1c0000000000000
cpubind:list x4117c4s2b0n0 pid 35399 rank 7 7: mask 0x1c000000000000000
cpubind:list x4117c4s2b0n0 pid 35400 rank 8 8: mask 0x1c00000000000000000
cpubind:list x4117c4s2b0n0 pid 35401 rank 9 9: mask 0x1c0000000000000000000
cpubind:list x4117c4s2b0n0 pid 35402 rank 10 10: mask 0x1c000000000000000000000
cpubind:list x4117c4s2b0n0 pid 35403 rank 11 11: mask 0x1c00000000000000000000000
Application 422e0368-f389-4475-8131-3de313723140 started execution
cpubind:list x4117c4s6b0n0 pid 111063 rank 12 0: mask 0x1c
cpubind:list x4117c4s6b0n0 pid 111064 rank 13 1: mask 0x1c00
cpubind:list x4117c4s6b0n0 pid 111065 rank 14 2: mask 0x1c0000
cpubind:list x4117c4s6b0n0 pid 111066 rank 15 3: mask 0x1c000000
cpubind:list x4117c4s6b0n0 pid 111067 rank 16 4: mask 0x1c00000000
cpubind:list x4117c4s6b0n0 pid 111068 rank 17 5: mask 0x1c0000000000
cpubind:list x4117c4s6b0n0 pid 111069 rank 18 6: mask 0x1c0000000000000
cpubind:list x4117c4s6b0n0 pid 111070 rank 19 7: mask 0x1c000000000000000
cpubind:list x4117c4s6b0n0 pid 111071 rank 20 8: mask 0x1c00000000000000000
cpubind:list x4117c4s6b0n0 pid 111072 rank 21 9: mask 0x1c0000000000000000000
cpubind:list x4117c4s6b0n0 pid 111073 rank 22 10: mask 0x1c000000000000000000000
cpubind:list x4117c4s6b0n0 pid 111074 rank 23 11: mask 0x1c00000000000000000000000
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
operator: aten::geometric_(Tensor(a!) self, float p, *, Generator? generator=None) -> Tensor(a!)
registered at /lus/tegu/projects/datasets/software/wheelforge/repositories/pytorch_2p8_rel_07_18_2025/pytorch/build/aten/src/ATen/RegisterSchema.cpp:6
from pkg_resources import parse_version
# [...repeated...]: TODO: Add this to the list of filters in ezpz
from pkg_resources import parse_version
[2025-09-12 11:38:05,512552][I][ezpz/__init__:266:<module>] Setting logging level to 'INFO' on 'RANK == 0'
[2025-09-12 11:38:05,515164][I][ezpz/__init__:267:<module>] Setting logging level to 'CRITICAL' on all others 'RANK != 0'
[2025-09-12 11:38:07,293955][I][ezpz/dist:1181:setup_torch_distributed] Using fw='ddp' with torch_{device,backend}= {xpu, xccl}
[2025-09-12 11:38:07,295126][I][ezpz/dist:1039:setup_torch_DDP] Caught MASTER_PORT=44635 from environment!
[2025-09-12 11:38:07,295968][I][ezpz/dist:1055:setup_torch_DDP] Using torch.distributed.init_process_group with
- master_addr='x4117c4s2b0n0.hsn.cm.aurora.alcf.anl.gov'
- master_port='44635'
- world_size=24
- rank=0
- local_rank=0
- timeout=datetime.timedelta(seconds=3600)
- backend='xccl'
[2025-09-12 11:38:07,297280][I][ezpz/dist:772:init_process_group] Calling torch.distributed.init_process_group_with: rank=0 world_size=24 backend=xccl
[2025-09-12 11:38:21,344380][I][ezpz/pbs:188:get_pbs_launch_cmd] ✅ Using [24/24] GPUs [2 hosts] x [12 GPU/host]
[2025-09-12 11:38:21,346401][I][ezpz/dist:450:print_dist_setup] [device='xpu'][rank=0/23][local_rank=0/11][node=0/1]
[2025-09-12 11:38:21,347018][W][utils/_logger:68:warning] Using [24 / 24] available "xpu" devices !!
2025:09:12-11:38:21:(35392) |CCL_WARN| value of CCL_LOG_LEVEL changed to be error (default:warn)
[2025-09-12 11:38:22,154201][I][ezpz/dist:1401:setup_torch] Using device='xpu' with backend='xccl' + 'xccl' for distributed training.
[2025-09-12 11:38:22,155050][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 0/23]
[2025-09-12 11:38:22,154185][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 6/23]
[2025-09-12 11:38:22,154353][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 7/23]
[2025-09-12 11:38:22,154299][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 9/23]
[2025-09-12 11:38:22,154355][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][11/23]
[2025-09-12 11:38:22,154185][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 1/23]
[2025-09-12 11:38:22,154184][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 5/23]
[2025-09-12 11:38:22,154350][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 8/23]
[2025-09-12 11:38:22,154312][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][12/23]
[2025-09-12 11:38:22,154495][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][10/23]
[2025-09-12 11:38:22,154339][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 4/23]
[2025-09-12 11:38:22,154312][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][13/23]
[2025-09-12 11:38:22,154312][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][15/23]
[2025-09-12 11:38:22,154312][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][16/23]
[2025-09-12 11:38:22,154379][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][17/23]
[2025-09-12 11:38:22,154398][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 2/23]
[2025-09-12 11:38:22,154319][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][18/23]
[2025-09-12 11:38:22,154284][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][19/23]
[2025-09-12 11:38:22,154325][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][20/23]
[2025-09-12 11:38:22,154382][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][22/23]
[2025-09-12 11:38:22,154502][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][14/23]
[2025-09-12 11:38:22,154391][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][21/23]
[2025-09-12 11:38:22,154451][I][ezpz/dist:1448:setup_torch] ['x4117c4s6b0n0'][23/23]
[2025-09-12 11:38:22,154411][I][ezpz/dist:1448:setup_torch] ['x4117c4s2b0n0'][ 3/23]
[2025-09-12 11:38:22,694566][I][blendcorpus/train:85:__init__] Starting job: AuroraGPT-7B Training
[2025-09-12 11:38:22,695590][I][blendcorpus/train:93:__init__] Running with args: {
"activation_checkpoint": {
"early_stop": false,
"mode": "none",
"per_op_sac_force_recompute_mm_shapes_by_fqns": [
"moe.router.gate"
],
"selective_ac_option": "op"
},
"blendcorpus": {
"append_eod": true,
"blend_sample_in_corpus": false,
"data_cache_path": "./.cache/data/auroraGPT-7B/olmo-mix-1124/",
"data_file_list": null,
"dataloader_type": "single",
"eod_token_id": 2,
"micro_batch_size": null,
"num_workers": 2,
"provide_attention_mask": false,
"seq_length": null,
"shuffle": true,
"shuffle_sample_in_corpus": true,
"split": "98,1,1"
},
"checkpoint": {
"async_mode": "disabled",
"create_seed_checkpoint": false,
"enable": false,
"enable_first_step_checkpoint": false,
"exclude_from_loading": [],
"export_dtype": "float32",
"folder": "checkpoint",
"initial_load_in_hf": false,
"initial_load_model_only": true,
"initial_load_path": null,
"interval": 10,
"keep_latest_k": 10,
"last_save_in_hf": false,
"last_save_model_only": false,
"load_step": -1
},
"comm": {
"init_timeout_seconds": 300,
"save_traces_folder": "comm_traces",
"trace_buf_size": 20000,
"train_timeout_seconds": 100
},
"compile": {
"components": [
"model",
"loss"
],
"enable": true
},
"experimental": {
"custom_args_module": "torchtitan.experiments.blendcorpus.job_config",
"custom_import": ""
},
"fault_tolerance": {
"enable": false,
"group_size": 0,
"min_replica_size": 1,
"process_group": "gloo",
"process_group_timeout_ms": 10000,
"replica_id": 0,
"semi_sync_method": null
},
"float8": {
"emulate": false,
"enable_fsdp_float8_all_gather": false,
"filter_fqns": [
"output"
],
"moe_fqns_prototype": [],
"precompute_float8_dynamic_scale_for_fsdp": false,
"recipe_name": null
},
"job": {
"config_file": "torchtitan/experiments/blendcorpus/train_configs/auroraGPT_7B.toml",
"description": "AuroraGPT-7B Training",
"dump_folder": "./outputs/AuroraGPT-7B",
"print_args": true,
"use_for_integration_test": true
},
"lr_scheduler": {
"decay_ratio": 0.8,
"decay_type": "linear",
"min_lr_factor": 0.0,
"warmup_steps": 2
},
"memory_estimation": {
"disable_fake_mode": false,
"enable": false
},
"metrics": {
"disable_color_printing": false,
"enable_tensorboard": true,
"enable_wandb": true,
"log_freq": 1,
"save_for_all_ranks": false,
"save_tb_folder": "tb"
},
"model": {
"converters": [],
"flavor": "AuroraGPT-7B",
"hf_assets_path": "./assets/hf/AuroraGPT-7B",
"name": "blendcorpus",
"print_after_conversion": false,
"tokenizer_backend": "sptoken",
"tokenizer_path": null
},
"mx": {
"filter_fqns": [
"output"
],
"moe_fqns_prototype": [],
"mxfp8_dim1_cast_kernel_choice": "triton",
"recipe_name": "mxfp8_cublas"
},
"optimizer": {
"beta1": 0.9,
"beta2": 0.95,
"early_step_in_backward": false,
"eps": 1e-08,
"implementation": "fused",
"lr": 0.0002,
"name": "AdamW",
"weight_decay": 0.1
},
"parallelism": {
"context_parallel_degree": 1,
"context_parallel_rotate_method": "allgather",
"data_parallel_replicate_degree": 1,
"data_parallel_shard_degree": -1,
"disable_loss_parallel": false,
"enable_async_tensor_parallel": false,
"enable_compiled_autograd": false,
"expert_parallel_degree": 1,
"expert_tensor_parallel_degree": 1,
"fsdp_reshard_after_forward": "default",
"module_fqns_per_model_part": null,
"pipeline_parallel_degree": 1,
"pipeline_parallel_first_stage_less_layers": 1,
"pipeline_parallel_last_stage_less_layers": 1,
"pipeline_parallel_layers_per_stage": null,
"pipeline_parallel_microbatch_size": 1,
"pipeline_parallel_schedule": "1F1B",
"pipeline_parallel_schedule_csv": "",
"pipeline_parallel_split_points": [],
"tensor_parallel_degree": 1
},
"profiling": {
"enable_memory_snapshot": false,
"enable_profiling": false,
"profile_freq": 10,
"save_memory_snapshot_folder": "memory_snapshot",
"save_traces_folder": "profile_trace"
},
"training": {
"dataset": "blendcorpus",
"dataset_path": "/flare/Aurora_deployment/AuroraGPT/datasets/dolma/dolma_v1_7_file_list_mini.txt",
"deterministic": false,
"enable_cpu_offload": false,
"gc_debug": false,
"gc_freq": 50,
"global_batch_size": -1,
"local_batch_size": 1,
"max_norm": 1.0,
"mixed_precision_param": "bfloat16",
"mixed_precision_reduce": "float32",
"seed": null,
"seq_len": 4096,
"steps": 1000
},
"validation": {
"dataset": "c4_validation",
"dataset_path": null,
"enable": false,
"freq": 5,
"local_batch_size": 8,
"seq_len": 2048,
"steps": 10
}
}
Number of ranks per node: 12
Is initialized already
[2025-09-12 11:38:22,781763][I][distributed/parallel_dims:158:_build_mesh_without_ep] Building 1-D device mesh with ['dp_shard'], [24]
[2025-09-12 11:38:22,783219][I][tools/utils:65:collect] [GC] Initial GC collection 0.00 seconds
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[2025-09-12 11:38:22,795599][I][dataset/sptoken:75:build_sentencepiece_tokenizer] [SPTokenizer] Using model path: ./assets/hf/AuroraGPT-7B
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[Tokenizer] Using backend: sptoken (SentencePiece)
[2025-09-12 11:38:22,806079][I][dataset/sptoken:36:__init__] [SPTokenizer] Loaded model: ./assets/hf/AuroraGPT-7B/tokenizer.model, vocab size: 32000
[INFO][2025-09-12 11:38:22.811010] Reading data from /flare/Aurora_deployment/AuroraGPT/datasets/dolma/dolma_v1_7_file_list_mini.txt
[INFO][2025-09-12 11:38:22.811281] Number of datasets: 9
[INFO][2025-09-12 11:38:22.811427] Global batch size: 24
[INFO][2025-09-12 11:38:22.811559] Training iterations: 1000
[INFO][2025-09-12 11:38:22.811682] Evaluation iterations: 0
[INFO][2025-09-12 11:38:22.811805] Total number of training samples: 24000
[INFO][2025-09-12 11:38:22.811932] Total number of evaluation samples: 0
[INFO][2025-09-12 11:38:22.812052] Total number of testing samples: 0
[2025-09-12 11:38:23,388839][I][data/gpt_dataset:263:_cache_indices] > loading algebraic corpus dataset index: ./.cache/data/auroraGPT-7B/olmo-mix-1124/eaaf4239bf399fe90985648264fc597b_index.npy
[2025-09-12 11:38:23,400289][I][data/gpt_dataset:270:_cache_indices] > loading algebraic corpus dataset sample index: ./.cache/data/auroraGPT-7B/olmo-mix-1124/eaaf4239bf399fe90985648264fc597b_sample_index.npy
[2025-09-12 11:38:23,401313][I][data/gpt_dataset:277:_cache_indices] > finished loading in 0.01251498400233686 seconds
[2025-09-12 11:38:23,402526][I][data/gpt_dataset:291:__init__] [BuildCorpusDataset] Caught args.shuffle_sample_in_corpus=True across 19984 samples
[2025-09-12 11:38:23,498032][I][data/gpt_dataset:263:_cache_indices] > loading arxiv corpus dataset index: ./.cache/data/auroraGPT-7B/olmo-mix-1124/9958f3591de484302ca17a2f1feeafaf_index.npy
[2025-09-12 11:38:23,502674][I][data/gpt_dataset:270:_cache_indices] > loading arxiv corpus dataset sample index: ./.cache/data/auroraGPT-7B/olmo-mix-1124/9958f3591de484302ca17a2f1feeafaf_sample_index.npy
[2025-09-12 11:38:23,506868][I][data/gpt_dataset:277:_cache_indices] > finished loading in 0.008856782980728894 seconds
[2025-09-12 11:38:23,507665][I][data/gpt_dataset:291:__init__] [BuildCorpusDataset] Caught args.shuffle_sample_in_corpus=True across 4140 samples
[2025-09-12 11:38:23,520625][I][data/blendable_dataset:131:__init__] > loading blendable dataset index: ./.cache/data/auroraGPT-7B/olmo-mix-1124/212cf8a136a93b7bc9cd575fa4c82f21_index.npy
[2025-09-12 11:38:23,527379][I][data/blendable_dataset:134:__init__] > loading blendable dataset sample index: ./.cache/data/auroraGPT-7B/olmo-mix-1124/212cf8a136a93b7bc9cd575fa4c82f21_sample_index.npy
[2025-09-12 11:38:23,532038][I][data/blendable_dataset:139:__init__] > finished loading in 0.011423073010519147 seconds
[2025-09-12 11:38:23,543427][I][data/blendable_dataset:152:__init__] > size of blendable dataset: 24124 samples
[2025-09-12 11:38:23,544235][I][blendcorpus/train:177:__init__] Using BlendCorpus dataloader.
[2025-09-12 11:38:23,544713][I][blendcorpus/train:185:__init__] Building blendcorpus AuroraGPT-7B with TransformerModelArgs(_enforced='This field is used to enforce all fields have defaults.', dim=4096, n_layers=32, n_heads=32, n_kv_heads=8, vocab_size=32000, multiple_of=256, ffn_dim_multiplier=None, norm_eps=1e-05, rope_theta=10000, max_seq_len=4096, depth_init=True, use_flex_attn=False, attn_mask_type='causal', eos_id=0)
wandb: Currently logged in as: foremans (aurora_gpt) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
wandb: Tracking run with wandb version 0.21.3
wandb: Run data is saved locally in ./outputs/AuroraGPT-7B/tb/20250912-1138/wandb/run-20250912_113823-qzle9mdw
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run snowy-sunset-14
wandb: View project at https://wandb.ai/aurora_gpt/torchtitan
wandb: View run at https://wandb.ai/aurora_gpt/torchtitan/runs/qzle9mdw
[2025-09-12 11:38:24,703889][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:24,750784][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:24,776002][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:24,848549][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:24,864781][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safeten sors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:24,964752][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,005897][I][components/metrics:155:__init__] WandB logging enabled
[2025-09-12 11:38:25,012474][I][components/metrics:124:__init__] TensorBoard logging enabled. Logs will be saved at ./outputs/AuroraGPT-7B/tb/20250912-1138
[2025-09-12 11:38:25,017569][I][components/metrics:101:build_device_memory_monitor] XPU capacity: Intel(R) Data Center GPU Max 1550 with 63.98GiB memory
[2025-09-12 11:38:25,044275][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,093814][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,126732][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,146946][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,146998][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,147707][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,148411][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,149299][I][blendcorpus/train:212:__init__] Model blendcorpus AuroraGPT-7B size: 5,933,109,248 total parameters
[2025-09-12 11:38:25,150242][I][components/loss:28:build_cross_entropy_loss] Compiling the loss function with torch.compile
[2025-09-12 11:38:25,190998][I][infra/parallelize:357:apply_compile] Compiling each TransformerBlock with torch.compile
[2025-09-12 11:38:25,220312][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,245422][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,262857][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,271332][I][infra/parallelize:122:parallelize_llama] Applied FSDP to the model
[2025-09-12 11:38:25,289336][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safetensors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,296201][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safeten sors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,296289][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safeten sors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,298835][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safeten sors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,299750][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safeten sors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,299754][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safeten sors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,299888][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safeten sors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,770147][I][blendcorpus/train:290:__init__] Peak FLOPS used for computing MFU: 2.982e+14
[2025-09-12 11:38:25,771316][I][blendcorpus/train:292:__init__] XPU memory usage for model: 1.04GiB(1.63%)
[2025-09-12 11:38:25,773314][W][protocols/state_dict_adapter:76:__init__] model.safetensors.index.json not found at hf_assets_path: ./assets/hf/AuroraGPT-7B/model.safeten sors.index.json. Defaulting to saving a single safetensors file if checkpoint is saved in HF format
[2025-09-12 11:38:25,774216][I][distributed/utils:225:maybe_enable_amp] Mixed precision training is handled by fully_shard
[2025-09-12 11:38:25,774808][I][blendcorpus/train:381:__init__] Trainer is initialized with local batch size 1, global batch size 24, gradient accumulation steps 1, sequence length 4096, total steps 1000 (warmup 2)
[2025-09-12 11:38:25,775505][I][blendcorpus/train:695:<module>] Using SDPBackend.FLASH_ATTENTION backend for SDPA
[2025-09-12 11:38:25,776216][I][blendcorpus/train:569:train] BlendCorpus dataloader advanced to consumed =0 samples (step={self.step}).
[2025-09-12 11:38:25,776915][I][blendcorpus/train:581:train] Training starts at step 1.
[2025-09-12 11:39:11,844905][I][components/metrics:442:log] step: 1 loss: 10.8919 grad_norm: 5.7773 memory: 21.74GiB(33.98%) tps: 88 tflops: 3.62 mfu: 1.21%
[2025-09-12 11:39:11,847254][I][distributed/utils:299:set_pg_timeouts] Synchronizing and adjusting timeout for all ProcessGroups to 0:01:40
[2025-09-12 11:39:13,996720][I][components/metrics:442:log] step: 2 loss: 15.4482 grad_norm: 95.7768 memory: 23.63GiB(36.93%) tps: 1,906 tflops: 78.63 mfu: 26.37%
[2025-09-12 11:39:16,148721][I][components/metrics:442:log] step: 3 loss: 18.1145 grad_norm: 177.2544 memory: 23.63GiB(36.93%) tps: 1,905 tflops: 78.60 mfu: 26.36%
[2025-09-12 11:39:18,293594][I][components/metrics:442:log] step: 4 loss: 12.2966 grad_norm: 47.6269 memory: 23.63GiB(36.93%) tps: 1,912 tflops: 78.86 mfu: 26.45%
[2025-09-12 11:39:20,423330][I][components/metrics:442:log] step: 5 loss: 12.4196 grad_norm: 55.3153 memory: 23.63GiB(36.93%) tps: 1,925 tflops: 79.42 mfu: 26.63%
[2025-09-12 11:39:22,550981][I][components/metrics:442:log] step: 6 loss: 10.8771 grad_norm: 5.3124 memory: 23.63GiB(36.93%) tps: 1,927 tflops: 79.50 mfu: 26.66%
[2025-09-12 11:39:24,670689][I][components/metrics:442:log] step: 7 loss: 10.9488 grad_norm: 41.6404 memory: 23.63GiB(36.93%) tps: 1,934 tflops: 79.80 mfu: 26.76%
[2025-09-12 11:39:26,791101][I][components/metrics:442:log] step: 8 loss: 9.9818 grad_norm: 18.3422 memory: 23.63GiB(36.93%) tps: 1,934 tflops: 79.77 mfu: 26.75%
[2025-09-12 11:39:28,911059][I][components/metrics:442:log] step: 9 loss: 9.0792 grad_norm: 9.5251 memory: 23.63GiB(36.93%) tps: 1,934 tflops: 79.79 mfu: 26.76%
[2025-09-12 11:39:31,025851][I][components/metrics:442:log] step: 10 loss: 8.4230 grad_norm: 4.9722 memory: 23.63GiB(36.93%) tps: 1,939 tflops: 79.98 mfu: 26.82%
[2025-09-12 11:39:33,138436][I][components/metrics:442:log] step: 11 loss: 8.0111 grad_norm: 4.7603 memory: 23.63GiB(36.93%) tps: 1,941 tflops: 80.07 mfu: 26.85%
[2025-09-12 11:39:35,250642][I][components/metrics:442:log] step: 12 loss: 7.8059 grad_norm: 9.0702 memory: 23.63GiB(36.93%) tps: 1,941 tflops: 80.08 mfu: 26.85%
[2025-09-12 11:39:37,361018][I][components/metrics:442:log] step: 13 loss: 7.3035 grad_norm: 5.1540 memory: 23.63GiB(36.93%) tps: 1,943 tflops: 80.15 mfu: 26.88%
[2025-09-12 11:39:39,472014][I][components/metrics:442:log] step: 14 loss: 7.1419 grad_norm: 4.1700 memory: 23.63GiB(36.93%) tps: 1,942 tflops: 80.13 mfu: 26.87%
[2025-09-12 11:39:41,584217][I][components/metrics:442:log] step: 15 loss: 6.9347 grad_norm: 4.9882 memory: 23.63GiB(36.93%) tps: 1,941 tflops: 80.08 mfu: 26.86%
[2025-09-12 11:39:43,690898][I][components/metrics:442:log] step: 16 loss: 7.3633 grad_norm: 31.0589 memory: 23.63GiB(36.93%) tps: 1,946 tflops: 80.29 mfu: 26.93%
[2025-09-12 11:39:45,799715][I][components/metrics:442:log] step: 17 loss: 7.1793 grad_norm: 13.7271 memory: 23.63GiB(36.93%) tps: 1,944 tflops: 80.21 mfu: 26.90%
[2025-09-12 11:39:47,907438][I][components/metrics:442:log] step: 18 loss: 7.2268 grad_norm: 10.9098 memory: 23.63GiB(36.93%) tps: 1,945 tflops: 80.25 mfu: 26.91%
[2025-09-12 11:39:50,018253][I][components/metrics:442:log] step: 19 loss: 6.9895 grad_norm: 6.6582 memory: 23.63GiB(36.93%) tps: 1,942 tflops: 80.13 mfu: 26.87%
[2025-09-12 11:39:52,127309][I][components/metrics:442:log] step: 20 loss: 6.7515 grad_norm: 3.5633 memory: 23.63GiB(36.93%) tps: 1,944 tflops: 80.20 mfu: 26.90%
[2025-09-12 11:39:54,237784][I][components/metrics:442:log] step: 21 loss: 6.7755 grad_norm: 3.6999 memory: 23.63GiB(36.93%) tps: 1,943 tflops: 80.15 mfu: 26.88%
[2025-09-12 11:39:56,348825][I][components/metrics:442:log] step: 22 loss: 6.9412 grad_norm: 3.5428 memory: 23.63GiB(36.93%) tps: 1,942 tflops: 80.13 mfu: 26.87%
[2025-09-12 11:39:58,460931][I][components/metrics:442:log] step: 23 loss: 6.8696 grad_norm: 2.8968 memory: 23.63GiB(36.93%) tps: 1,941 tflops: 80.08 mfu: 26.86%
[2025-09-12 11:40:00,572489][I][components/metrics:442:log] step: 24 loss: 6.6327 grad_norm: 5.1677 memory: 23.63GiB(36.93%) tps: 1,942 tflops: 80.11 mfu: 26.86%
[2025-09-12 11:40:02,683070][I][components/metrics:442:log] step: 25 loss: 6.7134 grad_norm: 3.7672 memory: 23.63GiB(36.93%) tps: 1,943 tflops: 80.14 mfu: 26.88%
[2025-09-12 11:40:04,793520][I][components/metrics:442:log] step: 26 loss: 6.5521 grad_norm: 3.4081 memory: 23.63GiB(36.93%) tps: 1,943 tflops: 80.15 mfu: 26.88%
[2025-09-12 11:40:06,906933][I][components/metrics:442:log] step: 27 loss: 6.6118 grad_norm: 2.8971 memory: 23.63GiB(36.93%) tps: 1,940 tflops: 80.04 mfu: 26.84%
[2025-09-12 11:40:09,019771][I][components/metrics:442:log] step: 28 loss: 6.7229 grad_norm: 2.6085 memory: 23.63GiB(36.93%) tps: 1,941 tflops: 80.06 mfu: 26.85%
[2025-09-12 11:40:11,135250][I][components/metrics:442:log] step: 29 loss: 6.5777 grad_norm: 2.8184 memory: 23.63GiB(36.93%) tps: 1,938 tflops: 79.96 mfu: 26.81%
[2025-09-12 11:40:13,249416][I][components/metrics:442:log] step: 30 loss: 6.5954 grad_norm: 2.7959 memory: 23.63GiB(36.93%) tps: 1,939 tflops: 80.00 mfu: 26.83%
[2025-09-12 11:40:15,364869][I][components/metrics:442:log] step: 31 loss: 6.4546 grad_norm: 3.2096 memory: 23.63GiB(36.93%) tps: 1,938 tflops: 79.96 mfu: 26.82%
[2025-09-12 11:40:17,476265][I][components/metrics:442:log] step: 32 loss: 6.6677 grad_norm: 2.1374 memory: 23.63GiB(36.93%) tps: 1,942 tflops: 80.11 mfu: 26.87%
[2025-09-12 11:40:19,590038][I][components/metrics:442:log] step: 33 loss: 6.5451 grad_norm: 2.0738 memory: 23.63GiB(36.93%) tps: 1,940 tflops: 80.02 mfu: 26.84%
[2025-09-12 11:40:21,706964][I][components/metrics:442:log] step: 34 loss: 6.7087 grad_norm: 2.5267 memory: 23.63GiB(36.93%) tps: 1,937 tflops: 79.91 mfu: 26.80%
[2025-09-12 11:40:23,826393][I][components/metrics:442:log] step: 35 loss: 6.3955 grad_norm: 1.9991 memory: 23.63GiB(36.93%) tps: 1,935 tflops: 79.81 mfu: 26.76%
[2025-09-12 11:40:25,943121][I][components/metrics:442:log] step: 36 loss: 6.4686 grad_norm: 1.5817 memory: 23.63GiB(36.93%) tps: 1,937 tflops: 79.91 mfu: 26.80%
[2025-09-12 11:40:28,062842][I][components/metrics:442:log] step: 37 loss: 6.3481 grad_norm: 2.6166 memory: 23.63GiB(36.93%) tps: 1,934 tflops: 79.79 mfu: 26.76%
[2025-09-12 11:40:30,184717][I][components/metrics:442:log] step: 38 loss: 6.4443 grad_norm: 2.5323 memory: 23.63GiB(36.93%) tps: 1,932 tflops: 79.71 mfu: 26.73%
[2025-09-12 11:40:32,305122][I][components/metrics:442:log] step: 39 loss: 6.2732 grad_norm: 2.1087 memory: 23.63GiB(36.93%) tps: 1,934 tflops: 79.77 mfu: 26.75%
[2025-09-12 11:40:34,431400][I][components/metrics:442:log] step: 40 loss: 6.1638 grad_norm: 1.6096 memory: 23.63GiB(36.93%) tps: 1,928 tflops: 79.55 mfu: 26.68%
[2025-09-12 11:40:36,558993][I][components/metrics:442:log] step: 41 loss: 6.2434 grad_norm: 2.1429 memory: 23.63GiB(36.93%) tps: 1,927 tflops: 79.50 mfu: 26.66%
[2025-09-12 11:40:38,684159][I][components/metrics:442:log] step: 42 loss: 6.2472 grad_norm: 1.9758 memory: 23.63GiB(36.93%) tps: 1,929 tflops: 79.59 mfu: 26.69%
[2025-09-12 11:40:40,811350][I][components/metrics:442:log] step: 43 loss: 6.0686 grad_norm: 2.0387 memory: 23.63GiB(36.93%) tps: 1,927 tflops: 79.52 mfu: 26.67%
[2025-09-12 11:40:42,942820][I][components/metrics:442:log] step: 44 loss: 6.0512 grad_norm: 1.7659 memory: 23.63GiB(36.93%) tps: 1,924 tflops: 79.36 mfu: 26.61%
[2025-09-12 11:40:45,071924][I][components/metrics:442:log] step: 45 loss: 5.9693 grad_norm: 3.0356 memory: 23.63GiB(36.93%) tps: 1,926 tflops: 79.44 mfu: 26.64%
[2025-09-12 11:40:47,202347][I][components/metrics:442:log] step: 46 loss: 6.1370 grad_norm: 2.2346 memory: 23.63GiB(36.93%) tps: 1,924 tflops: 79.39 mfu: 26.62%
[2025-09-12 11:40:49,335707][I][components/metrics:442:log] step: 47 loss: 6.0951 grad_norm: 2.2721 memory: 23.63GiB(36.93%) tps: 1,922 tflops: 79.29 mfu: 26.59%
[2025-09-12 11:40:51,472182][I][components/metrics:442:log] step: 48 loss: 6.1080 grad_norm: 2.3427 memory: 23.63GiB(36.93%) tps: 1,919 tflops: 79.17 mfu: 26.55%
[2025-09-12 11:40:53,607441][I][components/metrics:442:log] step: 49 loss: 5.8213 grad_norm: 2.4015 memory: 23.63GiB(36.93%) tps: 1,920 tflops: 79.22 mfu: 26.57%
[2025-09-12 11:40:53,644423][I][tools/utils:65:collect] [GC] Performing periodical GC collection 0.04 seconds
[2025-09-12 11:40:55,782338][I][components/metrics:442:log] step: 50 loss: 6.0710 grad_norm: 2.2237 memory: 23.63GiB(36.93%) tps: 1,885 tflops: 77.77 mfu: 26.08%
[2025-09-12 11:40:57,921332][I][components/metrics:442:log] step: 51 loss: 5.6129 grad_norm: 1.8282 memory: 23.63GiB(36.93%) tps: 1,917 tflops: 79.07 mfu: 26.52%
[2025-09-12 11:41:00,060512][I][components/metrics:442:log] step: 52 loss: 5.8381 grad_norm: 2.2276 memory: 23.63GiB(36.93%) tps: 1,917 tflops: 79.07 mfu: 26.52%
[2025-09-12 11:41:02,201596][I][components/metrics:442:log] step: 53 loss: 5.5789 grad_norm: 1.8904 memory: 23.63GiB(36.93%) tps: 1,915 tflops: 79.00 mfu: 26.49%
[2025-09-12 11:41:04,338853][I][components/metrics:442:log] step: 54 loss: 5.5972 grad_norm: 1.9285 memory: 23.63GiB(36.93%) tps: 1,918 tflops: 79.14 mfu: 26.54%
[2025-09-12 11:41:06,483940][I][components/metrics:442:log] step: 55 loss: 5.5264 grad_norm: 2.1031 memory: 23.63GiB(36.93%) tps: 1,911 tflops: 78.86 mfu: 26.45%
[2025-09-12 11:41:08,626486][I][components/metrics:442:log] step: 56 loss: 5.6756 grad_norm: 1.8958 memory: 23.63GiB(36.93%) tps: 1,914 tflops: 78.95 mfu: 26.48%
[2025-09-12 11:41:10,768986][I][components/metrics:442:log] step: 57 loss: 5.5827 grad_norm: 1.9008 memory: 23.63GiB(36.93%) tps: 1,914 tflops: 78.95 mfu: 26.48%
[2025-09-12 11:41:12,915983][I][components/metrics:442:log] step: 58 loss: 6.1343 grad_norm: 2.2042 memory: 23.63GiB(36.93%) tps: 1,910 tflops: 78.78 mfu: 26.42%
[2025-09-12 11:41:15,057467][I][components/metrics:442:log] step: 59 loss: 5.7517 grad_norm: 1.7251 memory: 23.63GiB(36.93%) tps: 1,914 tflops: 78.98 mfu: 26.49%
[2025-09-12 11:41:17,195890][I][components/metrics:442:log] step: 60 loss: 5.5449 grad_norm: 1.7781 memory: 23.63GiB(36.93%) tps: 1,917 tflops: 79.10 mfu: 26.53%
[2025-09-12 11:41:19,340106][I][components/metrics:442:log] step: 61 loss: 5.5037 grad_norm: 1.8137 memory: 23.63GiB(36.93%) tps: 1,912 tflops: 78.88 mfu: 26.45%
[2025-09-12 11:41:21,479998][I][components/metrics:442:log] step: 62 loss: 5.5703 grad_norm: 2.2754 memory: 23.63GiB(36.93%) tps: 1,916 tflops: 79.04 mfu: 26.51%
[2025-09-12 11:41:23,619646][I][components/metrics:442:log] step: 63 loss: 5.3396 grad_norm: 1.9820 memory: 23.63GiB(36.93%) tps: 1,916 tflops: 79.06 mfu: 26.51%
[2025-09-12 11:41:25,758931][I][components/metrics:442:log] step: 64 loss: 5.2862 grad_norm: 2.1926 memory: 23.63GiB(36.93%) tps: 1,917 tflops: 79.07 mfu: 26.52%
[2025-09-12 11:41:27,902443][I][components/metrics:442:log] step: 65 loss: 5.3883 grad_norm: 1.8266 memory: 23.63GiB(36.93%) tps: 1,913 tflops: 78.91 mfu: 26.46%
[2025-09-12 11:41:30,047189][I][components/metrics:442:log] step: 66 loss: 5.3715 grad_norm: 1.8546 memory: 23.63GiB(36.93%) tps: 1,912 tflops: 78.86 mfu: 26.45%
[2025-09-12 11:41:32,191202][I][components/metrics:442:log] step: 67 loss: 5.3473 grad_norm: 1.8945 memory: 23.63GiB(36.93%) tps: 1,912 tflops: 78.88 mfu: 26.45%
[2025-09-12 11:41:34,336648][I][components/metrics:442:log] step: 68 loss: 5.4083 grad_norm: 1.6982 memory: 23.63GiB(36.93%) tps: 1,911 tflops: 78.83 mfu: 26.44%
[2025-09-12 11:41:36,480695][I][components/metrics:442:log] step: 69 loss: 5.2105 grad_norm: 1.5840 memory: 23.63GiB(36.93%) tps: 1,912 tflops: 78.89 mfu: 26.45%
[2025-09-12 11:41:38,625671][I][components/metrics:442:log] step: 70 loss: 5.2483 grad_norm: 1.8750 memory: 23.63GiB(36.93%) tps: 1,911 tflops: 78.85 mfu: 26.44%
[2025-09-12 11:41:40,772186][I][components/metrics:442:log] step: 71 loss: 5.1239 grad_norm: 1.9717 memory: 23.63GiB(36.93%) tps: 1,910 tflops: 78.80 mfu: 26.43%
[2025-09-12 11:41:42,918729][I][components/metrics:442:log] step: 72 loss: 5.3355 grad_norm: 1.8882 memory: 23.63GiB(36.93%) tps: 1,910 tflops: 78.79 mfu: 26.42%
[2025-09-12 11:41:45,066384][I][components/metrics:442:log] step: 73 loss: 5.0560 grad_norm: 1.6971 memory: 23.63GiB(36.93%) tps: 1,909 tflops: 78.76 mfu: 26.41%
[2025-09-12 11:41:47,209176][I][components/metrics:442:log] step: 74 loss: 5.0859 grad_norm: 2.6819 memory: 23.63GiB(36.93%) tps: 1,913 tflops: 78.93 mfu: 26.47%
[2025-09-12 11:41:49,355442][I][components/metrics:442:log] step: 75 loss: 5.2856 grad_norm: 1.8572 memory: 23.63GiB(36.93%) tps: 1,910 tflops: 78.81 mfu: 26.43%
[2025-09-12 11:41:51,499099][I][components/metrics:442:log] step: 76 loss: 5.2415 grad_norm: 1.4722 memory: 23.63GiB(36.93%) tps: 1,913 tflops: 78.90 mfu: 26.46%
[2025-09-12 11:41:53,642872][I][components/metrics:442:log] step: 77 loss: 5.1465 grad_norm: 1.6991 memory: 23.63GiB(36.93%) tps: 1,913 tflops: 78.90 mfu: 26.46%
[2025-09-12 11:41:55,790222][I][components/metrics:442:log] step: 78 loss: 4.9042 grad_norm: 2.5348 memory: 23.63GiB(36.93%) tps: 1,909 tflops: 78.77 mfu: 26.41%
[2025-09-12 11:41:57,938398][I][components/metrics:442:log] step: 79 loss: 5.1845 grad_norm: 2.1790 memory: 23.63GiB(36.93%) tps: 1,908 tflops: 78.73 mfu: 26.40%
[2025-09-12 11:42:00,085052][I][components/metrics:442:log] step: 80 loss: 5.0380 grad_norm: 1.8122 memory: 23.63GiB(36.93%) tps: 1,910 tflops: 78.79 mfu: 26.42%
[2025-09-12 11:42:02,229187][I][components/metrics:442:log] step: 81 loss: 5.1028 grad_norm: 2.3178 memory: 23.63GiB(36.93%) tps: 1,912 tflops: 78.89 mfu: 26.46%
[2025-09-12 11:42:04,376585][I][components/metrics:442:log] step: 82 loss: 4.9639 grad_norm: 1.7682 memory: 23.63GiB(36.93%) tps: 1,909 tflops: 78.77 mfu: 26.42%
[2025-09-12 11:42:06,522266][I][components/metrics:442:log] step: 83 loss: 5.1079 grad_norm: 2.0751 memory: 23.63GiB(36.93%) tps: 1,911 tflops: 78.83 mfu: 26.44%
[2025-09-12 11:42:08,668032][I][components/metrics:442:log] step: 84 loss: 5.0744 grad_norm: 1.4189 memory: 23.63GiB(36.93%) tps: 1,911 tflops: 78.82 mfu: 26.43%