Simon Willison on llm-pricing
73 posts tagged ‘llm-pricing’. Posts about the pricing of various LLMs. See also my pricing calculator.
Our latest model, Claude Opus 4.7, is now generally available. Opus 4.7 is a notable improvement on Opus 4.6 in advanced software engineering, with particular gains on the most difficult tasks.
73 posts tagged ‘llm-pricing’. Posts about the pricing of various LLMs. See also my pricing calculator.
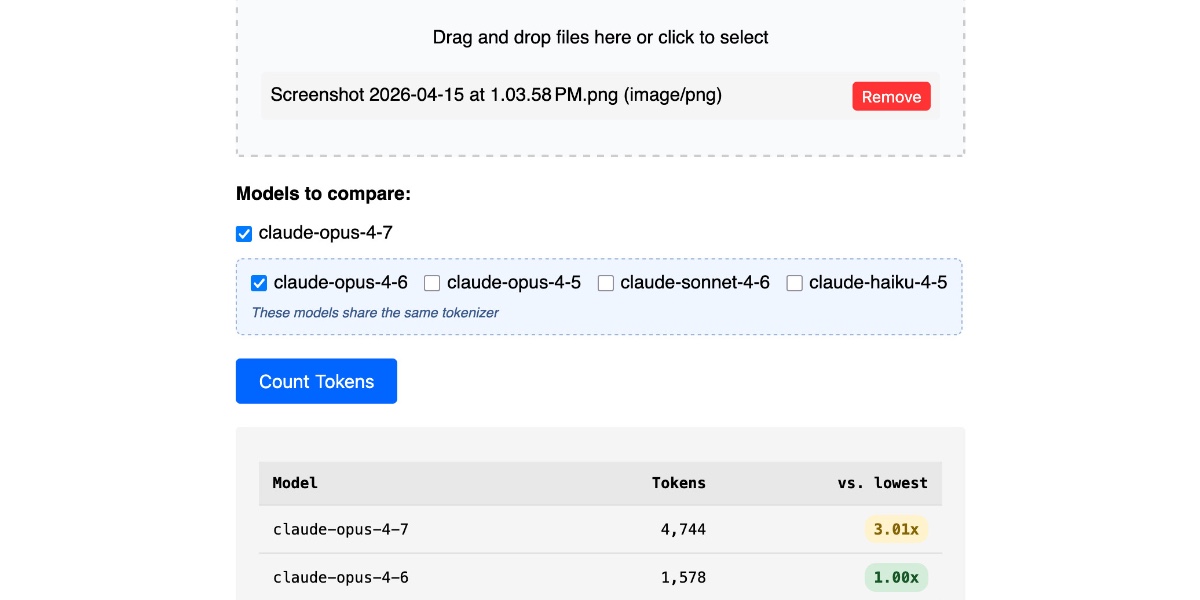
I upgraded my Claude Token Counter tool to add the ability to run the same count against different models in order to compare them. As far as I can tell …

Opus 4.6 is much smarter than the other one. It feels like I’m working with someone from Bronx Science. I had been using Sonnet 4.6, which I switched to after reading somewhere that it costs …
157 posts tagged ‘local-llms’. LLMs that can run on consumer hardware like laptops or mobile phones.
114 posts tagged ‘pelican-riding-a-bicycle’. My benchmark for LLMs: "Generate an SVG of a pelican riding a bicycle". Here's my answer to what happens if AI labs train for pelicans riding bicycles?. "User …
April 2026 AI roundup: OpenAI-Microsoft restructure, AWS partnership, Claude Opus 4.7, GPT-5.5, major security breaches, and the wildest model leaks yet.

Welcome to this week’s AI Security Newsletter. The headline thread is supply-chain and access-control: Anthropic’s restricted Mythos cyber model both surfaced thousands of OS/browser vu…
I just refactored my whole website into a completely new design without writing any code myself. Looks pretty good, right? Would you believe me if I told you I one-shot this whole thing in one day using my AI orchestrated workflow? No? Good, you shouldn't because I didn't. It's hard to believe given...
113 posts tagged ‘pelican-riding-a-bicycle’. My benchmark for LLMs: "Generate an SVG of a pelican riding a bicycle". Here's my answer to what happens if AI labs train for pelicans riding bicycles?. "User …
113 posts tagged ‘pelican-riding-a-bicycle’. My benchmark for LLMs: "Generate an SVG of a pelican riding a bicycle". Here's my answer to what happens if AI labs train for pelicans riding bicycles?. "User …

Discover the top 6 open source language models that can replace Claude Opus 4.7 or GPT-5.5 for coding tasks at a fraction of the cost: GLM-5.1, Kimi K2.6, Qwen 3.6 Plus, MiniMax M2.7, MiMo V2.5 Pro, and Mistral Medium 3.5.

Opus 4.7 ships with real coding gains, an automated cyber chaperone, and a tokenizer that can charge you 35% more for the same prompt. The capability curve still bends up. The trust curve does not.
Fabric is an open-source framework for augmenting humans using AI. It provides a modular system for solving specific problems using a crowdsourced set of AI prompts that can be used anywhere. - dan...
Fabric is an open-source framework for augmenting humans using AI. It provides a modular system for solving specific problems using a crowdsourced set of AI prompts that can be used anywhere. - dan...
Anthropic changed the tokenizer in Opus 4.7. We looked at usage that shifted from 4.6 to 4.7 to measure exactly how it affects costs.

Plus Claude Code pricing confusion and changes in the system prompt between Claude Opus 4.6 and 4.7
I upgraded my Claude Token Counter tool to add the ability to run the same count against different models in order to compare them. As far as I can tell …
113 posts tagged ‘pelican-riding-a-bicycle’. My benchmark for LLMs: "Generate an SVG of a pelican riding a bicycle". Here's my answer to what happens if AI labs train for pelicans riding bicycles?. "User …
Fabric is an open-source framework for augmenting humans using AI. It provides a modular system for solving specific problems using a crowdsourced set of AI prompts that can be used anywhere. - dan...

It’s Anthropic’s most powerful “generally available” model to date.

Speed, cost, and predictability are starting to matter more to me than top-end reasoning.

The complete system for building production AI agent harnesses. Skills, hooks, memory, subagents, multi-agent orchestration, and the patterns that make AI coding agents reliable infrastructure.
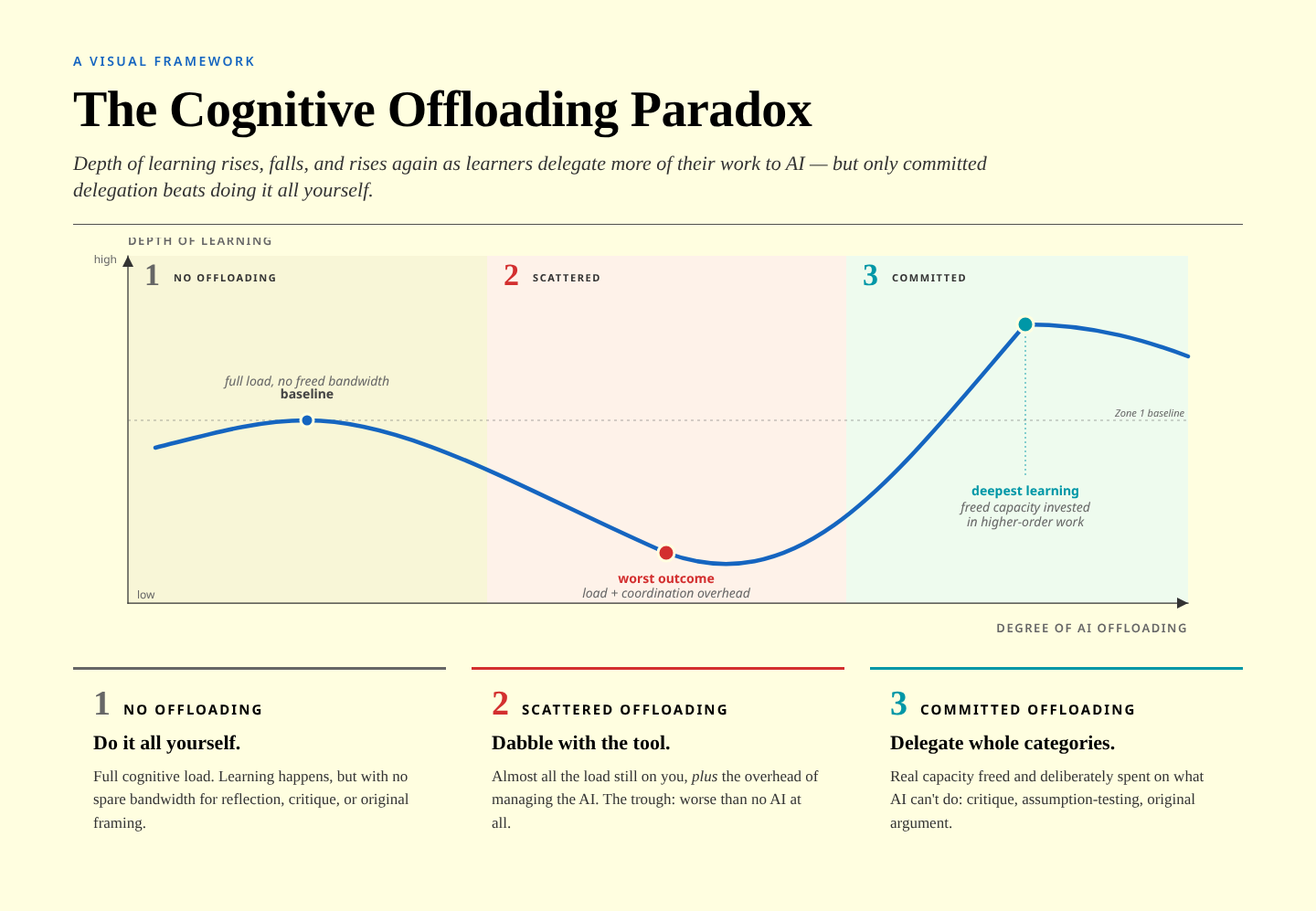
Almost a year ago, I responded here on Thought Shrapnel to what I thought was a terrible paper which claimed to show, via brain scans, that using LLMs was bad for students' cognitive development. As Philippa Hardman notes in this article, the academic literature has begun caught up with what people actually using these tools already know: The theoretical picture sharpened in 2025–26. Favero et al. (2025) warned that cognitive offloading undermines learning outcomes unless the mental effort that’s freed up gets redirected towards other meaningful tasks.

Anthropic announced the most powerful cyberweapon ever built last week and kept it, granting access to forty companies while the US government got a press re...
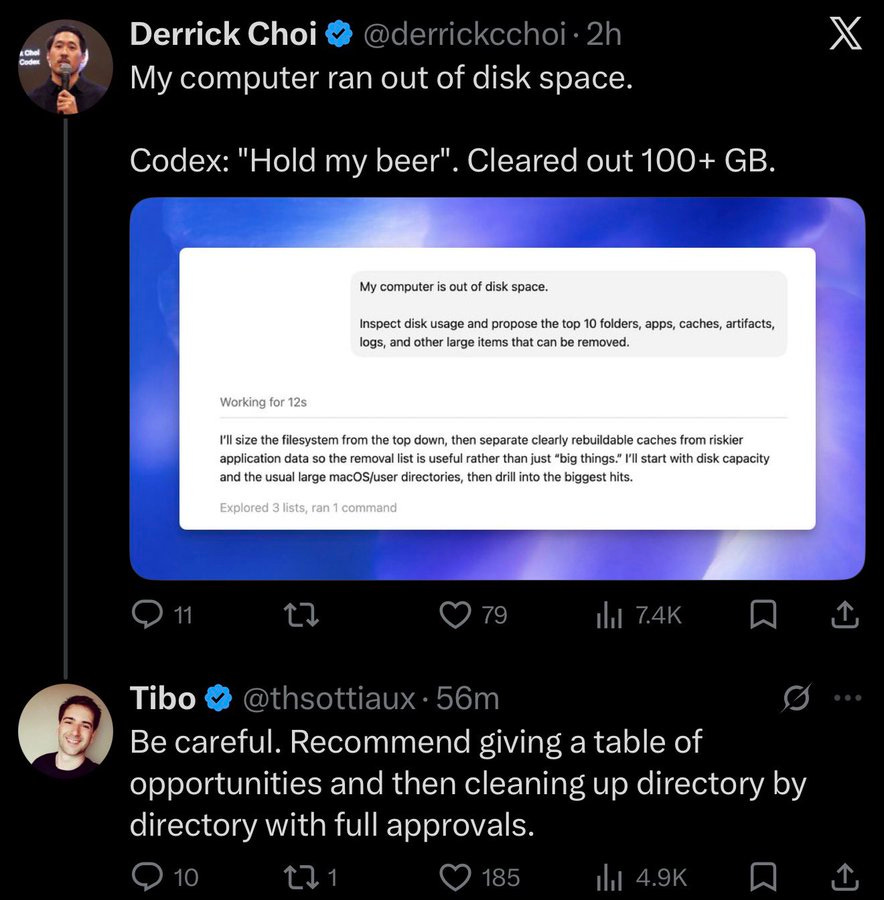
When I started this series, everyone was going crazy for coding agents. Now a lot more people are going crazy for coding agents, as well they should given how much better coding agents keep getting…
A collection of things I read in April that stuck with me, covering AI agents, tooling and other interesting blog posts.
Updates and tips about using Large Language Models (LLM) for programming and development


A fortnight of frontier launches from Mythos to Claude Design; Andon Labs' AI-run SF shop; feral AI in organisations; emotions inside Claude
Updates and tips about using Large Language Models (LLM) for programming and development
In this blog post, I did a head-to-head comparison of Claude Code and Codex CLI to decide which coding agent is worth your time and money.

Developments in biology, robotics, web, and more

ARC Prize Foundation is a nonprofit advancing open-source AGI research through benchmarks & prizes.
199 posts tagged ‘llm-release’. New releases of various LLMs.
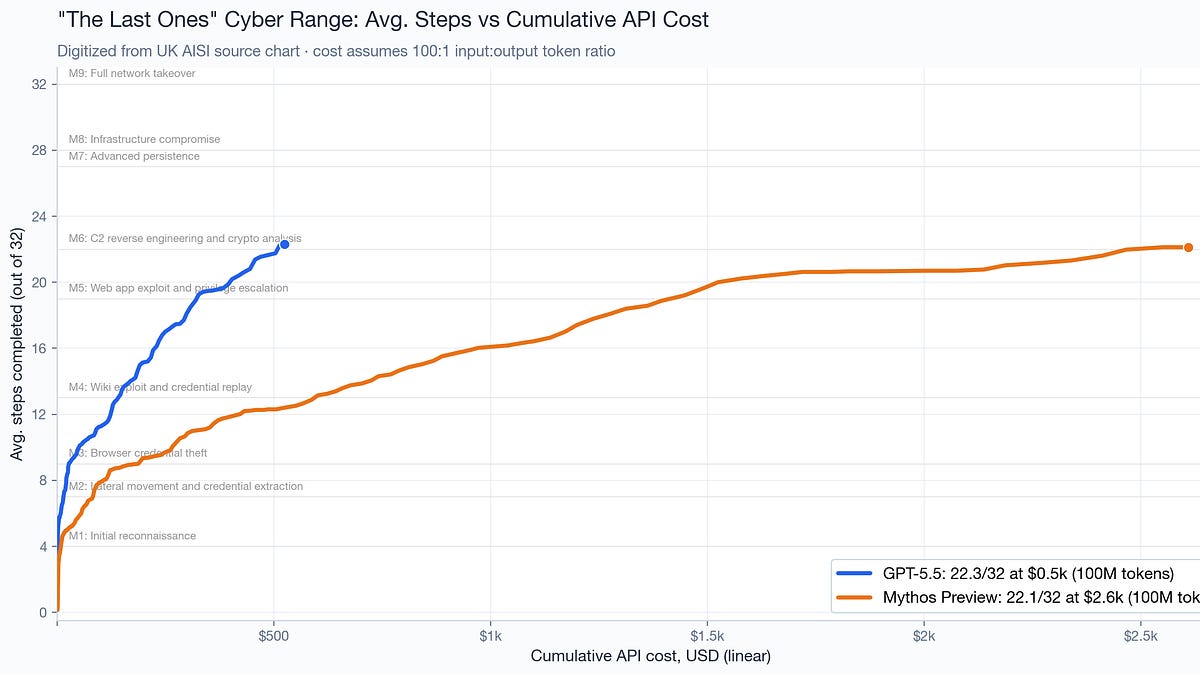
Is Claude Mythos Preview a particularly big jump in AI capabilities?

Hands On With GPT 5.5, Opus 4.7, DeepSeek V4, Why Benchmarks Are Bad, and Who’s Going To Win
Today, we’re launching Claude Design, a new Anthropic Labs product that lets you collaborate with Claude to create polished visual work like designs, prototypes, slides, one-pagers, and more.
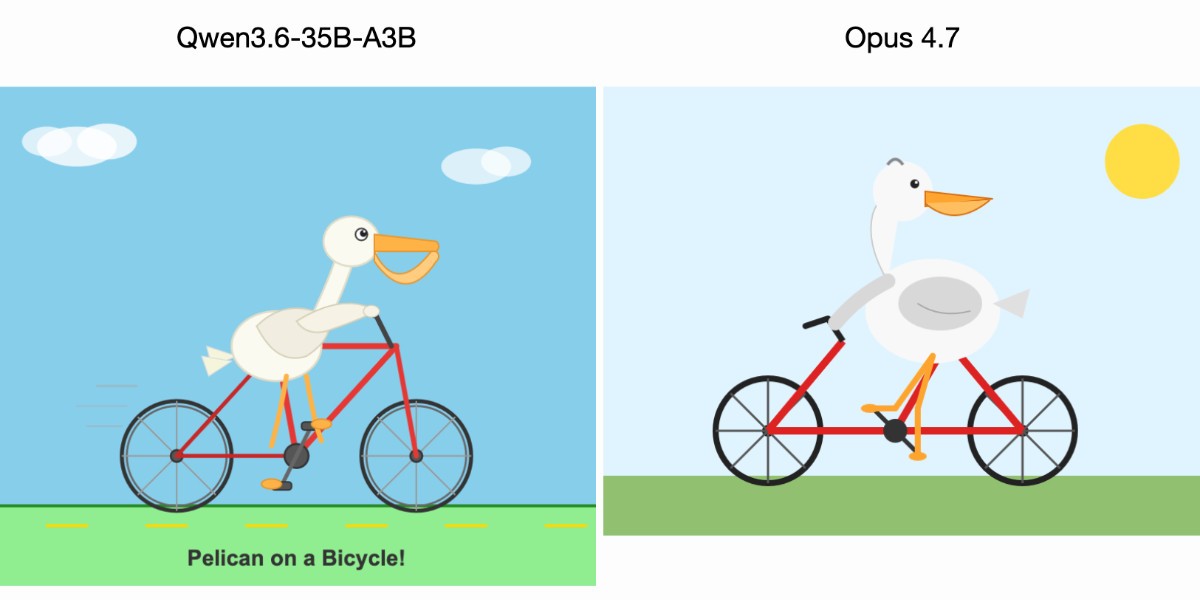
For anyone who has been (inadvisably) taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning’s two big model …

We got exclusive early access to Anthropic's latest model Opus 4.7. Here's what's new, what's improved, and why it matters for the future of AI security.
Last week, Anthropic introduced Claude Design, a new research preview product from the equally new Anthropic Labs. Claude Design, which is currently available to Pro, Max, Team, and Enterprise subscribers through the Claude web app, can prototype apps and websites, design presentation materials, generate marketing materials, and more. As someone who has felt as though

AWS launches Claude Opus 4.7 in Amazon Bedrock, Anthropic's most intelligent Opus model for advancing performance across coding, long-running agents, and professional work. Claude Opus 4.7 is powered by Amazon Bedrock's next generation inference engine, purpose-built for generative AI inferencing and fine-tuning workloads.

The question isn't what AI can do, it's what you can do with AI