I recently learned from Allen Downey’s blog that Our World in Data is providing API access to their data. Our World in Data hosts datasets across several important topics, from population and demographic change, poverty and economic development, to human rights and democracy. From Nov 2024, Our World in Data “[offers] direct URLs to access data in CSV format and comprehensive metadata in JSON format” (this is what they call the Public Chart API).
See this link for full documentation on the chart data API. Allen Downey’s blog post shows how to use this API in Python; in this post I’ll show the corresponding code in R.
Downloading metadata
The chart data API page tells us what APIs are available to us. The starting point is a base URL which we denote by <base_url>. This is what’s available to us:
<base_url> – The page on the website where you can see the chart.<base_url>.csv – The data for this chart, usually what we want to download.<base_url>.metadata.json – The metadata for this chart, e.g. chart title, the units, how to cite the data sources.<base_url>.zip – The dataset, metadata, and a readme as zip file.
Let’s start by looking at the metadata for average monthly surface temperature:
library(tidyverse)
library(httr)
library(jsonlite)
# define URL and query parameters
url <- "https://ourworldindata.org/grapher/average-monthly-surface-temperature.metadata.json"
query_params <- list(
v = "1",
csvType = "full",
useColumnShortNames = "true"
)
# get metadata
headers <- add_headers(`User-Agent` = "Our World In Data data fetch/1.0")
response <- GET(url, query = query_params, headers)
metadata <- fromJSON(content(response, as = "text", encoding = "UTF-8"))
The returned metadata object is a list with a few keys:
# view the metadata keys
names(metadata)
#> [1] "chart" "columns" "dateDownloaded" "activeFilters"
The chart element gives us high-level information of the chart:
glimpse(metadata$chart)
#> List of 5
#> $ title : chr "Average monthly surface temperature"
#> $ subtitle : chr "The temperature of the air measured 2 meters above the ground, encompassing land, sea, and in-land water surfaces."
#> $ citation : chr "Contains modified Copernicus Climate Change Service information (2025)"
#> $ originalChartUrl: chr "https://ourworldindata.org/grapher/average-monthly-surface-temperature?v=1&csvType=full&useColumnShortNames=true"
#> $ selection : chr "World"
There’s more information on the dataset in metadata$columns$temperature_2m
names(metadata$columns$temperature_2m)
#> [1] "titleShort" "titleLong" "descriptionShort" "descriptionProcessing" "shortUnit" "unit"
#> [7] "timespan" "type" "owidVariableId" "shortName" "lastUpdated" "citationShort"
#> [13] "citationLong" "fullMetadata"
(Why temperature_2m? Looking at metadata$columns$temperature_2m$shortName, it seems like temperature_2m is the short name for the dataset.)
Downloading the dataset
Here is code downloading the average monthly surface temperature for just the USA:
# define the URL and query parameters
url <- "https://ourworldindata.org/grapher/average-monthly-surface-temperature.csv"
query_params <- list(
v = "1",
csvType = "filtered",
useColumnShortNames = "true",
tab = "chart",
country = "USA"
)
# get data
headers <- add_headers(`User-Agent` = "Our World In Data data fetch/1.0")
response <- GET(url, query = query_params, headers)
df <- read_csv(content(response, as = "text", encoding = "UTF-8"))
head(df)
#> # A tibble: 6 × 6
#> Entity Code year Day temperature_2m...5 temperature_2m...6
#> <chr> <chr> <dbl> <date> <dbl> <dbl>
#> 1 United States USA 1941 1941-12-15 -1.88 8.02
#> 2 United States USA 1942 1942-01-15 -4.78 7.85
#> 3 United States USA 1942 1942-02-15 -3.87 7.85
#> 4 United States USA 1942 1942-03-15 0.0978 7.85
#> 5 United States USA 1942 1942-04-15 7.54 7.85
#> 6 United States USA 1942 1942-05-15 12.1 7.85
Allen Downey notes that the last column is undocumented, and based on context is probably the average annual temperature.
Here’s a simple plot of the data:
plot(df$Day, df$temperature_2m...5, type = "l",
main = "USA ave monthly temperature",
xlab = "Date", ylab = "Temperature in C")

If you wanted the entire dataset, just use csvType = "full" in the request parameters, like so:
# define the URL and query parameters
url <- "https://ourworldindata.org/grapher/average-monthly-surface-temperature.csv"
query_params <- list(
v = "1",
csvType = "full",
useColumnShortNames = "true",
tab = "chart"
)
# same code for the http request works, see above
How do you know which filters you can apply? There is no extensive documentation of what filters you can apply, but as you click on the base URL to change the chart, the URL changes. You can then use this to infer the query parameters to add.
For example, I clicked around on the chart to get this URL: https://ourworldindata.org/grapher/average-monthly-surface-temperature?tab=chart&time=2001-05-15..2024-05-15&country=OWID_WRL~THA. The code below shows how you can download the data and reproduce the chart:
# define the URL and query parameters
url <- "https://ourworldindata.org/grapher/average-monthly-surface-temperature.csv"
query_params <- list(
v = "1",
csvType = "filtered",
useColumnShortNames = "true",
tab = "chart",
time = "2001-05-15..2024-05-15",
country = "OWID_WRL~THA"
)
# get data
headers <- add_headers(`User-Agent` = "Our World In Data data fetch/1.0")
response <- GET(url, query = query_params, headers)
df <- read_csv(content(response, as = "text", encoding = "UTF-8"))
ggplot(df) +
geom_line(aes(x = Day, y = temperature_2m...5, col = Entity)) +
labs(title = "Ave monthly temperature for World & Thailand",
x = "Date", y = "Temperature in C") +
theme_bw() +
theme(legend.position = "bottom")











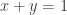



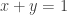












![\begin{aligned} \mathbb{P} \{ \text{intersection} | a, c, a < c \} &= \int_0^1 1 - \left[ 1 + \dfrac{(v-1)a}{u} \right] dv \\ &= \int_0^1 \dfrac{(1-v)a}{u} dv \\ &= \frac{a}{u} \left[ v - \frac{v^2}{2} \right]_0^1 \\ &= \frac{a}{2u}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BP%7D+%5C%7B+%5Ctext%7Bintersection%7D+%7C+a%2C+c%2C+a+%3C+c+%5C%7D+%26%3D+%5Cint_0%5E1+1+-+%5Cleft%5B+1+%2B+%5Cdfrac%7B%28v-1%29a%7D%7Bu%7D+%5Cright%5D+dv+%5C%5C+%26%3D+%5Cint_0%5E1+%5Cdfrac%7B%281-v%29a%7D%7Bu%7D+dv+%5C%5C+%26%3D+%5Cfrac%7Ba%7D%7Bu%7D+%5Cleft%5B+v+-+%5Cfrac%7Bv%5E2%7D%7B2%7D+%5Cright%5D_0%5E1+%5C%5C+%26%3D+%5Cfrac%7Ba%7D%7B2u%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![\begin{aligned} \mathbb{P} \{ \text{intersection when } a < c \} &= \int_0^1 \int_a^1 \frac{a}{2u} du \; da \\ &= \int_0^1 \left[ \frac{a \log u}{2} \right]_a^1 da \\ &= -\frac{1}{2} \int_0^1 a \log a \; da. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BP%7D+%5C%7B+%5Ctext%7Bintersection+when+%7D+a+%3C+c+%5C%7D+%26%3D+%5Cint_0%5E1+%5Cint_a%5E1+%5Cfrac%7Ba%7D%7B2u%7D+du+%5C%3B+da+%5C%5C+%26%3D+%5Cint_0%5E1+%5Cleft%5B+%5Cfrac%7Ba+%5Clog+u%7D%7B2%7D+%5Cright%5D_a%5E1+da+%5C%5C+%26%3D+-%5Cfrac%7B1%7D%7B2%7D+%5Cint_0%5E1+a+%5Clog+a+%5C%3B+da.++%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)







 is a non-negative random variable such that its expectation is 5 and its variance is 25. What is the maximum probability that
is a non-negative random variable such that its expectation is 5 and its variance is 25. What is the maximum probability that  ?
? , where
, where  and
and  are independent,
are independent,  , and
, and  with probability
with probability 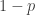 , and
, and  otherwise. The problem becomes trying to find the maximum value of
otherwise. The problem becomes trying to find the maximum value of  .
. , we have
, we have![\begin{aligned} \mathbb{E}[YZ \mid Y] &= Y \mathbb{E}[Z], \\ \mathbb{E}[(YZ)^2 \mid Y] &= \mathbb{E}[YZ^2 \mid Y] = Y \mathbb{E}[Z^2], \\ \text{Var}(YZ \mid Y) &= \mathbb{E}[(YZ)^2 \mid Y] - (\mathbb{E}[YZ \mid Y])^2 \\ &= Y \mathbb{E}[Z^2] - Y (\mathbb{E}[Z])^2 \\ &= Y \text{Var}(Z). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5BYZ+%5Cmid+Y%5D+%26%3D+Y+%5Cmathbb%7BE%7D%5BZ%5D%2C+%5C%5C+%5Cmathbb%7BE%7D%5B%28YZ%29%5E2+%5Cmid+Y%5D+%26%3D+%5Cmathbb%7BE%7D%5BYZ%5E2+%5Cmid+Y%5D+%3D+Y+%5Cmathbb%7BE%7D%5BZ%5E2%5D%2C+%5C%5C+%5Ctext%7BVar%7D%28YZ+%5Cmid+Y%29+%26%3D+%5Cmathbb%7BE%7D%5B%28YZ%29%5E2+%5Cmid+Y%5D+-+%28%5Cmathbb%7BE%7D%5BYZ+%5Cmid+Y%5D%29%5E2+%5C%5C+%26%3D+Y+%5Cmathbb%7BE%7D%5BZ%5E2%5D+-+Y+%28%5Cmathbb%7BE%7D%5BZ%5D%29%5E2+%5C%5C+%26%3D+Y+%5Ctext%7BVar%7D%28Z%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\begin{aligned} 5 &= \mathbb{E}[X] = \mathbb{E}[\mathbb{E}[YZ \mid Y]] \\ &= \mathbb{E}[Z] \mathbb{E}[Y] \\ &= (1-p) \mathbb{E}[Z], \\ \mathbb{E}[Z] &= \frac{5}{1-p}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+5+%26%3D+%5Cmathbb%7BE%7D%5BX%5D+%3D+%5Cmathbb%7BE%7D%5B%5Cmathbb%7BE%7D%5BYZ+%5Cmid+Y%5D%5D+%5C%5C+%26%3D+%5Cmathbb%7BE%7D%5BZ%5D+%5Cmathbb%7BE%7D%5BY%5D+%5C%5C+%26%3D+%281-p%29+%5Cmathbb%7BE%7D%5BZ%5D%2C+%5C%5C+%5Cmathbb%7BE%7D%5BZ%5D+%26%3D+%5Cfrac%7B5%7D%7B1-p%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\begin{aligned} 25 &= \text{Var}(X) = \mathbb{E}[\text{Var}(YZ \mid Y)] + \text{Var}(\mathbb{E}[YZ \mid Y]) \\ &= \mathbb{E}[Y \text{Var}(Z)] + \text{Var}(Y \mathbb{E}[Z]) \\ &= \text{Var}(Z) \mathbb{E}[Y] + (\mathbb{E}[Z])^2 \text{Var}(Y) \\ &= (1-p) \text{Var}(Z) + p(1-p) \left(\frac{5}{1-p} \right)^2. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+25+%26%3D+%5Ctext%7BVar%7D%28X%29+%3D+%5Cmathbb%7BE%7D%5B%5Ctext%7BVar%7D%28YZ+%5Cmid+Y%29%5D+%2B+%5Ctext%7BVar%7D%28%5Cmathbb%7BE%7D%5BYZ+%5Cmid+Y%5D%29+%5C%5C+%26%3D+%5Cmathbb%7BE%7D%5BY+%5Ctext%7BVar%7D%28Z%29%5D+%2B+%5Ctext%7BVar%7D%28Y+%5Cmathbb%7BE%7D%5BZ%5D%29+%5C%5C+%26%3D+%5Ctext%7BVar%7D%28Z%29+%5Cmathbb%7BE%7D%5BY%5D+%2B+%28%5Cmathbb%7BE%7D%5BZ%5D%29%5E2+%5Ctext%7BVar%7D%28Y%29+%5C%5C+%26%3D+%281-p%29+%5Ctext%7BVar%7D%28Z%29+%2B+p%281-p%29+%5Cleft%28%5Cfrac%7B5%7D%7B1-p%7D+%5Cright%29%5E2.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 , we have
, we have
 , i.e.
, i.e.  .
. , then the probability-generating function (PGF) of
, then the probability-generating function (PGF) of ![\begin{aligned} G(z) = \mathbb{E} [z^X] = \sum_{x=0}^\infty p(x) z^x, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+G%28z%29+%3D+%5Cmathbb%7BE%7D+%5Bz%5EX%5D+%3D+%5Csum_%7Bx%3D0%7D%5E%5Cinfty+p%28x%29+z%5Ex%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 , and
, and
 ,
,![\begin{aligned} \mathbb{E}\left[ \dfrac{X!}{(X-k)!} \right] = G^{(k)}(1^-) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5Cleft%5B+%5Cdfrac%7BX%21%7D%7B%28X-k%29%21%7D+%5Cright%5D+%3D+G%5E%7B%28k%29%7D%281%5E-%29+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\begin{aligned} \mathbb{E}[X] &= G'(1-), \\ \text{Var}(X) &= G''(1^-) + G'(1^-) - [G'(1^-)]^2. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5BX%5D+%26%3D+G%27%281-%29%2C+%5C%5C+%5Ctext%7BVar%7D%28X%29+%26%3D+G%27%27%281%5E-%29+%2B+G%27%281%5E-%29+-+%5BG%27%281%5E-%29%5D%5E2.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 points are placed uniformly at random on a circle. What’s the probability that all
points are placed uniformly at random on a circle. What’s the probability that all  . For each
. For each  , define the event
, define the event  as the event where all
as the event where all  and moving clockwise.
and moving clockwise.
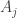 are not disjoint. That means that there is some configuration of points where the clockwise semicircle starting from
are not disjoint. That means that there is some configuration of points where the clockwise semicircle starting from  covers all points. Consider moving clockwise from
covers all points. Consider moving clockwise from  half the circle. But by the same logic, the arc reaching
half the circle. But by the same logic, the arc reaching 
 , let
, let 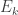 be the expected number of rolls until the total sum becomes at least
be the expected number of rolls until the total sum becomes at least  . What we want is
. What we want is 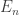 .
. , and
, and
 . Here’s the induction step going from
. Here’s the induction step going from  to
to ![\begin{aligned} E_k &= \mathbb{P}(\text{roll more than } k-1) + \sum_{i = 1}^{k-1} \mathbb{P}(\text{roll a } k - i) \cdot (1 + E_i) \\ &= \frac{n-k-1}{n} + \sum_{i=1}^{k-1} \frac{1}{n}\cdot \left[ 1 + \left(\frac{n+1}{n} \right)^{i-1} \right] \\ &= 1 + \frac{1}{n}\sum_{i=1}^{k-1} \left(\frac{n+1}{n} \right)^{i-1} \\ &= 1 + \frac{1}{n} \cdot \frac{(\frac{n+1}{n})^{k-1} - 1}{\frac{n+1}{n} - 1} \\ &= 1+ \left( \frac{n+1}{n} \right)^{k-1} - 1 \\ &= \left( \frac{n+1}{n} \right)^{k-1}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+E_k+%26%3D+%5Cmathbb%7BP%7D%28%5Ctext%7Broll+more+than+%7D+k-1%29+%2B+%5Csum_%7Bi+%3D+1%7D%5E%7Bk-1%7D+%5Cmathbb%7BP%7D%28%5Ctext%7Broll+a+%7D+k+-+i%29+%5Ccdot+%281+%2B+E_i%29+%5C%5C+%26%3D+%5Cfrac%7Bn-k-1%7D%7Bn%7D+%2B+%5Csum_%7Bi%3D1%7D%5E%7Bk-1%7D+%5Cfrac%7B1%7D%7Bn%7D%5Ccdot+%5Cleft%5B+1+%2B+%5Cleft%28%5Cfrac%7Bn%2B1%7D%7Bn%7D+%5Cright%29%5E%7Bi-1%7D+%5Cright%5D+%5C%5C+%26%3D+1+%2B+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bk-1%7D+%5Cleft%28%5Cfrac%7Bn%2B1%7D%7Bn%7D+%5Cright%29%5E%7Bi-1%7D+%5C%5C+%26%3D+1+%2B+%5Cfrac%7B1%7D%7Bn%7D+%5Ccdot+%5Cfrac%7B%28%5Cfrac%7Bn%2B1%7D%7Bn%7D%29%5E%7Bk-1%7D+-+1%7D%7B%5Cfrac%7Bn%2B1%7D%7Bn%7D+-+1%7D+%5C%5C+%26%3D++1%2B+%5Cleft%28+%5Cfrac%7Bn%2B1%7D%7Bn%7D+%5Cright%29%5E%7Bk-1%7D+-+1+%5C%5C+%26%3D+%5Cleft%28+%5Cfrac%7Bn%2B1%7D%7Bn%7D+%5Cright%29%5E%7Bk-1%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
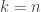 , we get
, we get
 ,
,  .
.

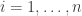 . For each observation
. For each observation  , and an observation
, and an observation  which we want to predict. Both the lasso and fused lasso model the predictions as
which we want to predict. Both the lasso and fused lasso model the predictions as
 . The lasso estimates the coefficients as the solution to the minimization problem
. The lasso estimates the coefficients as the solution to the minimization problem![\begin{aligned} \hat\beta = \underset{\beta}{\text{argmin}} \; \left[ \frac{1}{2n} \sum_{i=1}^n \left( y_i - \beta_0 - \sum_{j=1}^p \beta_j x_{ij} \right)^2 + \lambda \sum_{j=1}^p |\beta_j | \right], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Chat%5Cbeta+%3D+%5Cunderset%7B%5Cbeta%7D%7B%5Ctext%7Bargmin%7D%7D+%5C%3B+%5Cleft%5B+%5Cfrac%7B1%7D%7B2n%7D+%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+y_i+-+%5Cbeta_0+-+%5Csum_%7Bj%3D1%7D%5Ep+%5Cbeta_j+x_%7Bij%7D+%5Cright%29%5E2+%2B+%5Clambda+%5Csum_%7Bj%3D1%7D%5Ep+%7C%5Cbeta_j+%7C+%5Cright%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
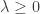 is a hyperparameter. (Note that the intercept
is a hyperparameter. (Note that the intercept 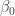 is not included in the penalty term: this is usually the case for regularized models.) The penalty term encourages the coefficients
is not included in the penalty term: this is usually the case for regularized models.) The penalty term encourages the coefficients  to shrink to zero, giving sparsity.
to shrink to zero, giving sparsity.![\begin{aligned} \hat\beta = \underset{\beta}{\text{argmin}} \; \left[ \frac{1}{2n} \sum_{i=1}^n \left( y_i - \beta_0 - \sum_{j=1}^p \beta_j x_{ij} \right)^2 + \lambda_1 \sum_{j=1}^p |\beta_j | + \lambda_2 \sum_{j=2}^p |\beta_j - \beta_{j-1} | \right], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Chat%5Cbeta+%3D+%5Cunderset%7B%5Cbeta%7D%7B%5Ctext%7Bargmin%7D%7D+%5C%3B+%5Cleft%5B+%5Cfrac%7B1%7D%7B2n%7D+%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+y_i+-+%5Cbeta_0+-+%5Csum_%7Bj%3D1%7D%5Ep+%5Cbeta_j+x_%7Bij%7D+%5Cright%29%5E2+%2B+%5Clambda_1+%5Csum_%7Bj%3D1%7D%5Ep+%7C%5Cbeta_j+%7C+%2B+%5Clambda_2+%5Csum_%7Bj%3D2%7D%5Ep+%7C%5Cbeta_j+-+%5Cbeta_%7Bj-1%7D+%7C+%5Cright%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 and
and  are hyperparameters. On top of penalizing the size of the coefficients, the fused lasso also penalizes the differences between successive coefficients. This encourages the coefficient profile (the plot of
are hyperparameters. On top of penalizing the size of the coefficients, the fused lasso also penalizes the differences between successive coefficients. This encourages the coefficient profile (the plot of  vs.
vs.  for several mass over charge ratios (
for several mass over charge ratios ( ). The goal is to find
). The goal is to find  . Assume that they are computed from z-scores
. Assume that they are computed from z-scores  (test statistics following normal distributions). Let
(test statistics following normal distributions). Let ![\mathbb{E}[\mathbf{X}] = \boldsymbol{\mu}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmathbf%7BX%7D%5D+%3D+%5Cboldsymbol%7B%5Cmu%7D&bg=ffffff&fg=333333&s=0&c=20201002) and let
and let  . Without loss of generality, assume that each test statistic
. Without loss of generality, assume that each test statistic  has variance 1. With this, we can express the p-values as
has variance 1. With this, we can express the p-values as![\begin{aligned} p_i = 2 \left[ 1 - \Phi (|X_i|) \right], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+p_i+%3D+2+%5Cleft%5B+1+-+%5CPhi+%28%7CX_i%7C%29+%5Cright%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
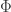 is the CDF function of the standard normal distribution.
is the CDF function of the standard normal distribution. .
. such that
such that  for all
for all  and
and  is independent of
is independent of  . The test statistic for the Cauchy combination test, proposed by Liu & Xie 2020 (Reference 1), is
. The test statistic for the Cauchy combination test, proposed by Liu & Xie 2020 (Reference 1), is![\begin{aligned} T(\mathbf{X}) = \sum_{i=1}^d w_i \tan \left[ \pi \left( 2 \Phi (|X_i|) - \frac{3}{2} \right) \right] = \sum_{i=1}^d w_i \tan \left[ \pi \left( \frac{1}{2} - p_i \right) \right]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+T%28%5Cmathbf%7BX%7D%29+%3D+%5Csum_%7Bi%3D1%7D%5Ed+w_i+%5Ctan+%5Cleft%5B+%5Cpi+%5Cleft%28+2+%5CPhi+%28%7CX_i%7C%29+-+%5Cfrac%7B3%7D%7B2%7D+%5Cright%29+%5Cright%5D+%3D+%5Csum_%7Bi%3D1%7D%5Ed+w_i+%5Ctan+%5Cleft%5B+%5Cpi+%5Cleft%28+%5Cfrac%7B1%7D%7B2%7D+-+p_i+%5Cright%29+%5Cright%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 for each
for each ![\tan \left[ \pi \left( \frac{1}{2} - p_i \right) \right]](https://s0.wp.com/latex.php?latex=%5Ctan+%5Cleft%5B+%5Cpi+%5Cleft%28+%5Cfrac%7B1%7D%7B2%7D+-+p_i+%5Cright%29+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) has the standard Cauchy distribution (see
has the standard Cauchy distribution (see  has the standard Cauchy distribution.
has the standard Cauchy distribution. ,
,  follows a bivariate normal distribution. Suppose also that
follows a bivariate normal distribution. Suppose also that ![\mathbb{E}[\mathbf{X}] = \mathbf{0}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cmathbf%7BX%7D%5D+%3D+%5Cmathbf%7B0%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Let
. Let 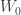 be a standard Cauchy random variable. Then for any fixed
be a standard Cauchy random variable. Then for any fixed  and any correlation matrix
and any correlation matrix  , we have
, we have
 with
with  .
.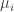 ‘s are large, or equivalently when a smaller number of
‘s are large, or equivalently when a smaller number of  ‘s are very small. We can see this intuitively: small
‘s are very small. We can see this intuitively: small ![\tan [\pi(1/2 - p_i)]](https://s0.wp.com/latex.php?latex=%5Ctan+%5B%5Cpi%281%2F2+-+p_i%29%5D&bg=ffffff&fg=333333&s=0&c=20201002) ‘s, so the test statistic will be dominated by a few very large p-values. See Section 4.2 of Reference 1 for a power comparison study.
‘s, so the test statistic will be dominated by a few very large p-values. See Section 4.2 of Reference 1 for a power comparison study. are independent
are independent  variables and
variables and  is a random vector independent of the
is a random vector independent of the 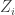 ‘s with
‘s with  , it is well-known that
, it is well-known that  also has a
also has a  has a
has a  and
and  be i.i.d.
be i.i.d.  , where
, where 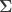 is a diagonal matrix with strictly positive entries on the diagonal. Let
is a diagonal matrix with strictly positive entries on the diagonal. Let  be a random vector independent of
be a random vector independent of  such that
such that 
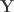 , but as long as the dependence structure for the two random vectors is the same, the linear combination of their ratios remains Cauchy-distributed! Here is the formal statement:
, but as long as the dependence structure for the two random vectors is the same, the linear combination of their ratios remains Cauchy-distributed! Here is the formal statement: into a standard
into a standard  and
and ![X = \tan \left[ \pi \left( \frac{1}{2} - U \right)\right]](https://s0.wp.com/latex.php?latex=X+%3D+%5Ctan+%5Cleft%5B+%5Cpi+%5Cleft%28+%5Cfrac%7B1%7D%7B2%7D+-+U+%5Cright%29%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) , then
, then 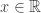 ,
,![\begin{aligned} \mathbb{P} \left\{ X \leq x \right\} &= \mathbb{P} \left\{ \tan \left[ \pi \left( \frac{1}{2} - U \right)\right] \leq x \right\} \\ &= \mathbb{P} \left\{ \frac{1}{2} - U \leq \frac{1}{\pi}\tan^{-1} x \right\} \\ &= \mathbb{P} \left\{ \frac{1}{2} - \frac{1}{\pi}\tan^{-1} x \leq U \right\} \\ &= 1 - \left[ \frac{1}{2} - \frac{1}{\pi}\tan^{-1} x \right] \\ &= \frac{1}{2} + \frac{1}{\pi}\tan^{-1} x, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb%7BP%7D+%5Cleft%5C%7B+X+%5Cleq+x+%5Cright%5C%7D+%26%3D+%5Cmathbb%7BP%7D+%5Cleft%5C%7B+%5Ctan+%5Cleft%5B+%5Cpi+%5Cleft%28+%5Cfrac%7B1%7D%7B2%7D+-+U+%5Cright%29%5Cright%5D+%5Cleq+x+%5Cright%5C%7D+%5C%5C++%26%3D+%5Cmathbb%7BP%7D+%5Cleft%5C%7B+%5Cfrac%7B1%7D%7B2%7D+-+U+%5Cleq+%5Cfrac%7B1%7D%7B%5Cpi%7D%5Ctan%5E%7B-1%7D+x+%5Cright%5C%7D+%5C%5C++%26%3D+%5Cmathbb%7BP%7D+%5Cleft%5C%7B+%5Cfrac%7B1%7D%7B2%7D+-+%5Cfrac%7B1%7D%7B%5Cpi%7D%5Ctan%5E%7B-1%7D+x+%5Cleq+U%C2%A0+%5Cright%5C%7D+%5C%5C++%26%3D+1+-+%5Cleft%5B+%5Cfrac%7B1%7D%7B2%7D+-+%5Cfrac%7B1%7D%7B%5Cpi%7D%5Ctan%5E%7B-1%7D+x+%5Cright%5D+%5C%5C++%26%3D+%5Cfrac%7B1%7D%7B2%7D+%2B+%5Cfrac%7B1%7D%7B%5Cpi%7D%5Ctan%5E%7B-1%7D+x%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 , so the LHS inside the probability is always in
, so the LHS inside the probability is always in  to get the PDF of
to get the PDF of ![\begin{aligned} f_X(x) &= \dfrac{d}{dx} \left[ \frac{1}{2} + \frac{1}{\pi}\tan^{-1} x \right] \\ &= \frac{1}{\pi (1 + x^2)}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+f_X%28x%29+%26%3D+%5Cdfrac%7Bd%7D%7Bdx%7D+%5Cleft%5B+%5Cfrac%7B1%7D%7B2%7D+%2B+%5Cfrac%7B1%7D%7B%5Cpi%7D%5Ctan%5E%7B-1%7D+x+%5Cright%5D+%5C%5C++%26%3D+%5Cfrac%7B1%7D%7B%5Cpi+%281+%2B+x%5E2%29%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=333333&s=0&c=20201002)