I occasionally get some comments and/or questions about why I have abandoned the “old ways” of Visions of Chaos for AI. I wanted to clarify a few things and have a post to point the next person who complains to. Ever since I started coding Visions of Chaos, even in the days before I even […]
Show full content
I occasionally get some comments and/or questions about why I have abandoned the “old ways” of Visions of Chaos for AI. I wanted to clarify a few things and have a post to point the next person who complains to.
Ever since I started coding Visions of Chaos, even in the days before I even released it to the public, users will have their favorite modes and be disappointed when I stop coding that feature and move on to the next thing.
If you are of the “AI Slop” crowd and have a general dislike of AI, then you see that Visions of Chaos has hundreds of machine learning modes and you are not happy. You want me to work on the older modes, be that cellular automata, fractals, shaders, reaction diffusion, etc.
Personally I find AI fascinating. The majority of my Patrons are mainly interested in the machine learning modes too. If you do have a capable GPU on your PC then I really recommend you try all of the available machine learning functionality to get an idea of what is possible.
Do not think of machine learning and AI as the one new feature in Visions of Chaos. Rather think of it as a back end to allow hundreds of interesting new modes and scripts to run inside Visions of Chaos.
If you really still have that AI slop dislike then I have now added an install option to not install any of the machine learning if you want to. If you cannot ignore that Machine Learning mode menu you can now install Visions of Chaos without ever having to see any mention of AI or machine learning.
For the rest of you, I am sure you are looking forward to the future advancements in the AI models like I am.
Local Vibe Coding “Vibe Coding” is a new term that means you create code by describing what you want in normal English. You explain to an AI what the “vibe” is you are going for and wait for the AI to do the coding for you. For a while the only was to try vibe […]
Show full content
Local Vibe Coding
“Vibe Coding” is a new term that means you create code by describing what you want in normal English. You explain to an AI what the “vibe” is you are going for and wait for the AI to do the coding for you.
For a while the only was to try vibe coding was to use one of the large cloud based paywalled AI systems. Recently I have been experimenting with some locally runnable code models that will work on a 24 GB consumer level GPU (4090 or 5090). Visions of Chaos has always been about getting all of these AI systems running locally without needing any paid for cloud subscriptions.
llama.cpp to the rescue
I have added support for llama.cpp into the latest versions of Visions of Chaos. llama.cpp runs various LLM models locally on your GPU.
Testing The Coder Capabilities
Here are some examples created using the various models. The basic prompt was to create a javascript app in a single html file. This means it can easily be shared and opened in any web browser.
If you want to see the code the AI generated for any of these examples, open them, right-click and view source, or right-click the links and download the html file.
gpt-oss:20b
The first model I tried in llama.cpp was gpt-oss:20b. This model is one of the newer “chain of thought” models. This means when you have asked it a question the AI does multiple thinking passes to process your prompt more deeply. In this way it can (in theory) give better quality answers to your prompts.
Clocks Something simple to start. “write me an html page. the contents of the page should be a clock that shows the current hour, minute and seconds in a hand drawn style. there can also be a hand drawn classic clock with hour and minute hands to also show the time that way.”
7 Segment Display Clock A 7 segment display. This took a few extra prompts for appearance, but got there in the end. Notice how the segments have that slight fade out at the edges like a real clock does from the LED fading out behind each segment.
Tic-Tac-Toe Something with simple smarts. “write me an html page that plays a game of tic tac toe. the computer should play strategic moves and not just random choices. have a restart button when the game ends. keep track of the scores for win, lose and draw games.”
Reversi More complex. The AI stated that the black strategy was to always make the move that takes the most pieces, but it still beat me just with that. Only this prompt. “write me an html page. it should be the game reversi or othello. the computer should be the black player. who goes first should be random.”
Connect Four I used to be really good at Connect Four and could only be beaten by other pro players. Nothing to be proud of as it was just the result of way too many games while drinking way too much at the pub. This AI result plays well and beat me. Although it has been years since I played seriously. The AI coded a very good strategy. “write me an html page. it should be a game of connect four with the human vs the computer. the computer should use strategies to beat the average player.”
Maze How about a maze generator. This one had a few extra prompts to change colors and layouts.
“write me an html page that creates and solves mazes. size the maze to fit the window. give options for how many pixels each maze cell is.”
Gemma4 26b
This was the best from Google for a short time before China released Qwen 3.6.
Retro Worm Game The classic worm eats the food and grows game.
Sudoku AI got this working first go. A few extra tweaks helped get it to this stage.
Qwen 3.6 35b
Reversi another Reversi from the Qwen3.6-35b model.
Mandelbrot Zoomer A realtime zoomer into the Mandelbrot set. Click and hold the point you want to zoom into. Limited precision so it does not go too deep.
2D Gravity Gravity simulator that handles 25,000 without a slow down.
Chess. This one took 4 minutes 30 seconds on a 4090 GPU. A complete working chess app with an AI to play against. This was the first result without needing any further prompts.
Although smaller than 35b, the 27b model is better at coding.
Using AI as a Code Reviewer
My next test was to give it some of my old code and see if it can help. I gave it my complete code for 2D SPH (Smoothed Particle Hydrodynamics) fluid simulations and asked if it could review the code and recommend any ways I could speed up the code.
It went off “thinking” for a few minutes and then gave me a surprisingly detailed result with ideas from simple code tweaks to reorganizing how data was aligned in memory.
Using just the simple tweaks got the code speed down from approx 13 seconds per frame to 5 seconds per frame. Those fixes were very basic “derrr, I should have seen that” type fixes, but this is code that I have spent a lot of time going over trying to improve the speed of in the past. 3 minutes with the AI and it is now almost 3 times as fast.
I did try giving the AI full control and asked it to make all the changes it thought would help. The new rewrite of the code was a mess that had more compiler errors than help.
I think when using these coder systems locally you want to minimize the code it is working on or ask it exact specifics as you go. If you are a coder already it helps. Then you can ask it more specific questions like “I have traced the slowest performance of this code to the DoTheLongHardParts function. Can you look at it and see what you can suggest to improve speeds”?
Solving My Decade Old Problem
This is where it really convinced me it was helpful. For many years now I have on and off tried to solve the problem of searching for interesting cellular automata. See this post for all the details. Once I had the gpt-oss:20b model setup I asked it to code me a search utility for “interesting”. After a few hours over two afternoons it had coded two javascript apps for 2D and 3D CA searching that do find interesting rules. When you have spent 10 years on an issue and AI solves it in a few hours it really is mind blowing and shows how that when it works it can be very useful.
Updating Web Design
For a while now I wanted to make some changes to my website. Specifically I wanted these expandable/collapsible tables that the Visions of Chaos page now has.
Before the collapsible tables the user had to scroll down a long way to get to the download link as there were so many modes and user comments listed.
With only a few passes of my CSS layout with GPT-OSS:20B I had the tables I wanted collapsible, the new blue colors, and the more rounded tables. I did still need to do a few manual tweaks, so it does help if you know the syntax the AI is writing.
It Is Not Perfect
Vibe coding is not perfect. Especially when running on the limited VRAM of a local GPU, but it is amazing for what it can do. The way it can get 95% of the app I ask for and not have a single syntax error is amazing. It may need a few extra prompts to tidy up issues and bugs.
But, like all AI, it will never say “sorry, I don’t know what that is”. Rather it assures you it can help and happily hallucinates code that works, but misses the point of what it is supposed to do.
Try It Yourself
If you have a capable 24 GB GPU (3090, 4090 or 5090) then I highly recommend you try it. It is a virtual zero cost coder you can get advice from at any time.
Download Visions of Chaos and install the llama.cpp mode. Start with the gpt-oss-20b or the gemma4-26b model. Ask it whatever you like. Feed it some code or text to review. Get it to write you a simple or not so simple game.
A tip for getting started. JavaScript apps in a single html file are good to get used to vibe coding. Try using text like the following to prompt…
Create me a javascript app in a single html file.
It should -describe what you want it to code here-
Include a debug ability that will catch and display errors or crashes as text so I can copy/paste the errors to help debugging.
For the description, be as explicit as you can. If you want your app to have a specific look, describe it. If you want some other features describe them. You can always start with a very vague description and reprompt to improve the results, but if you spend a few minutes describing what you want it can get there quicker.
For more complex apps then the request for debug text can really help. JavaScript apps will just hang when they have an error. That does not really help the AI fix the problem. “it crashes when I click the XYZ button” is not as helpful as being able to copy/paste a stack trace for the AI to see exactly what went wrong.
Visions of Chaos now supports setting up llama.cpp. llama.cpp supports Gemma4:26b. Gemma4:26b is one of the “thinking” chain of thought models and gives impressive results. I wanted to test how well it could help write scripts for short movies based on a simple prompt. These are the results. I had just finished watching The Holy […]
Show full content
Visions of Chaos now supports setting up llama.cpp. llama.cpp supports Gemma4:26b. Gemma4:26b is one of the “thinking” chain of thought models and gives impressive results. I wanted to test how well it could help write scripts for short movies based on a simple prompt. These are the results.
I had just finished watching The Holy Mountain so I wanted to try a more surreal movie. Using the Gemma4:26b model in llama.cpp I prompted it to create the prompts for 20 scenes in a surreal movie inspired by Jodorowsky and Lynch. Like Lynch I will keep the story or the point of the film a secret. Make your own conclusions, but this movie is the result of rendering the AI prompts using LTX 2.3. Gemma also created the prompts for the music that ACE-Step-xl-1.5 generated.
Next up was a qatsi style movie. I thought this was the perfect use for these AI Text-to-Video short movies. The prompt was “i want to make a new text-to-video movie in the style of the qatsi movies. 30 scenes with an overarching structure to them like Koyaanisqatsi or Baraka. can you help?” That was basically it. As the human in this creation my job was to render batches of each prompt looking for the best ones to add to the final movie.
Lastly, a more arty Sci-Fi short. The prompt this time was “i want you to help write a sci-fi text to video movie. the theme should be how humanity is destroyed by AI. starting with pre-AI times, going through the AI advancement and finally the destruction of humanity. 30 scenes of 10 second length each. the visuals should be a more arty sci-fi movie like Solaris or 2001 and not a flashy sci-fi like Star Wars.”
For this one I did have to tweak prompts more and ask the AI to change prompts as some of them either did not suit the movie or LTX had problems creating a good result from the prompt, but overall this would still be 90% of just the AI. With Gemma, you can just ask “can you change the xyz prompt for me?” and it will happily come up with a few alternatives. One prompt it originally wrote was a basic sunset I changed and one prompt was for swings in a playground swinging without anyone on them, but no matter how many times I tried LTX was not able to make normal looking swings so that needed to be changed.
All of those were generated 100% locally on a 4090 GPU. No cloud based subscriptions needed.
I was really impressed with how relatively easy this was. LTX 2.3 is the only “problem” here as it does still generate messy outputs or has trouble with certain prompts. You can see from the movies above it does a good job when it works (it is by far the best local only Text-to-Video system at the time of writing and it handles HD resolution 10 second movies easily), but the need to render large batches of a prompt waiting for that suitable result took some time. I will revisit this when LTX improves or the next great local Text-to-Video system is released.
Although these tests were following what the AI wanted as closely as possible, it could easily be used for tweaking existing ideas or giving a bunch of ideas for new movies if you have writers block.
This is Part 9. There is also Part 1, Part 2, Part 3, Part 4, Part 5, Part 6, Part 7 and Part 8. This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script. This will be the last of these Text-to-Image Summary posts. Beyond these […]
This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script.
This will be the last of these Text-to-Image Summary posts. Beyond these models all of the newer models are about the same quality results.
AuraFlow v0.1
Author: Original script by FAL
Original script: https://huggingface.co/fal
Time for 1024×1024 on a 4090: 53 seconds
Description: A new model. Very early stages and needs much more training. The following samples are cherry picked best results from a random prompt batch run.
a bronze sculpture of an evil alien 4K photo and hyperrealistic
a lush rainforest
a palace trending on pixiv and lens flare
an expressionist painting of a waterfall
an eyeball
computer generated imagery of dinosaurs
decoupage of a school of tropical fish by Daniel Maclise and Ram Chandra Shukla
digital art of an atoll
graphite pencil of a lion
metalpoint of an ocean
AuraFlow v0.2
Author: Original script by FAL
Original script: https://huggingface.co/fal
Time for 1024×1024 on a 4090: 53 seconds
Description: Updated AuraFlow model. Still being trained. The following samples are cherry picked best results from a random prompt batch run.
a cinematic painting of a beautiful woman by Anton Möller and János Saxon-Szász
a comic book panel of a large waterfall
a cute monster made of crystals and copper CryEngine and #film
a low poly render of a sea monster
a pop art painting of Harry Potter made of wood and liquid metal
a watercolor painting of Teletubbies
an archipelago by Phil Foglio and Yan Hui Flickr and rendered in Cinema4D
Dracula made of chrome and lego IMAX and hyperrealistic
humans vivid colors and IMAX
psychedelic of an eyeball made of wrought iron and vines
Flux
Author: Original script by Black Forest Labs
Original script: https://huggingface.co/black-forest-labs/FLUX.1-schnell
Time for 1024×1024 on a 4090: 25 seconds
Description: Handles text well and manages different sized images without duplicating subjects like other models can tend to do.
a cinematic painting of a cityscape
a cute creature for sale on Facebook Marketplace and psychedelic
a sea made of flowers and wood
an android filmic and psychedelic
an angry man made of liquid metal and plastic
an animation of a happy family
an attractive woman
an ugly monster
Harry Potter
The Grinch
Kolors
Author: Original script by Kolors Team
Original script: https://github.com/Kwai-Kolors/Kolors
Time for 1024×1024 on a 4090: 20 seconds
Description: Great results, very fast.
a beautiful woman
a cute girl CGSociety and filmic
a frog
a nightmare creature
a rough seascape
a shack CGSociety and 4K HD realism
an alien
an impressionist painting of the tropics
an ugly creature
kittens CryEngine and psychedelic
AuraFlow v0.3
Author: Original script by FAL
Original script: https://huggingface.co/fal
Time for 1024×1024 on a 4090: 54 seconds
Description: Third update to the AuraFlow model.
a flemish baroque of Miss Piggy by Laurits Tuxen and George Reid
a mountain path
a robot
a sea monster
an eyeball trending on Flickr and trending on ArtStation
an octopus
an ugly creature by Andre de Krayewski and Aleksander Kobzdej rendered in unreal engine and rendered in Cinema4D
an ugly woman
pixel art of Godzilla hyperrealistic and hyperrealistic
stencil of a portrait of a young boy
Stable Diffusion v3.5
Author: Original script by Stability AI
Original script: https://huggingface.co/stabilityai/stable-diffusion-3.5-large
Time for 1024×1024 on a 4090: 40 seconds
Description: Seems to create a lot of grid/dot/texture artefacts on generated images. Not too impressive compared to their earlier models.
a cubist painting of kittens
a sorceress trending on Flickr and rendered in unreal engine
a zombie rendered in Cinema4D and Flickr
abstract expressionism of a demon
an alien
an expressionist painting of a house
eyeballs by Ruth Bernhard and John Matson
Freddy Krueger
ink wash painting of a happy child
steampunk art of Teletubbies
CogView3
Author: Original script by THUDM
Original script: https://github.com/THUDM/CogView4
Time for 1024×1024 on a 4090: 42 seconds
Description: Works OK. Nothing spectacular.
a bronze sculpture of Frankenstein
a cubist painting of humans
a lush rainforest by Katsuhiro Otomo and Jörg Immendorff
a renaissance painting of a werewolf
a watercolor painting of the Sydney Harbour Bridge
an art deco painting of a knight
an ugly creature
pixel art of an attractive man
poster art of a castle
stencil of an ugly woman made of vines and liquid metal 8K 3D and 4K HD realism
CogView4
Author: Original script by THUDM
Original script: https://github.com/THUDM/CogView4
Time for 1024×1024 on a 4090: 1 minute 17 seconds
Description: Updated version 4 of the CogView model.
a fantasy land
a hyperrealistic painting of a rough seascape
a japanese painting of a cute monster
a Pixar character
a tardigrade hyperrealistic and trending on pixiv
an abstract painting of a tundra lens flare and trending on pixiv
an ugly face
egyptian art of a forest path
flesh made of silver and plastic by Elena Guro and Robert Lee Eskridge
screen printing of reflective spheres made of metal and wrought iron CryEngine and trending on ArtStation
HiDream-I1-nf4
Author: Original script by hykilpikonna
Original script: https://github.com/hykilpikonna/HiDream-I1-nf4
Time for 1024×1024 on a 4090: 1 minute 35 seconds
Description: Provides dev, full and fast model options. Full is the slowest but worth the wait for the superior results.
a cute girl
a forest path
a happy clown
a mill
a mountain Range
a movie monster made of vines and plastic vivid colors and 8K 3D
a sorcerer
an octopus
poster art of a lion made of cardboard and vines
poster art of a man
Any Others I Missed?
Do you know of any other colabs and/or github Text-to-Image systems I have missed? Let me know and I will see if I can convert them to work with Visions of Chaos for a future release. If you know of any public Discords with other colabs being shared let me know too.
EVERY PYTHON DEVELOPER OUT THERE! ALL OF YOU! PLEASE ADD EXACT VERSION NUMBERS TO YOUR REQUIREMENTS.TXT FILES! Did I convince you? Are you adding in version numbers right now? If not, read on. It has been a while since I was annoyed enough to add a new blog post in the annoyances catagory, but this […]
Show full content
EVERY PYTHON DEVELOPER OUT THERE! ALL OF YOU! PLEASE ADD EXACT VERSION NUMBERS TO YOUR REQUIREMENTS.TXT FILES!
Did I convince you? Are you adding in version numbers right now? If not, read on.
It has been a while since I was annoyed enough to add a new blog post in the annoyances catagory, but this is it.
Python Packages
Python. A constant love/hate relationship with me. Love for the most part as it allows me to add many awesome new machine learning systems to Visions of Chaos. The hate (for now) comes from version hell with packages. This is more a developer issue (all of us) and not a problem with Python itself.
When most developers create a new Python program/script/system they usually provide a requirements.txt file listing the Python packages their code needs to run. Packages are like extra libraries of code that give the script more functionality. They allow the Python code to have more commands and they make it easier for devs to code. These packages are installed with the Python pip command.
Here are a few lines from a typical requirements.txt file
The first line specifies an exact version number. That means that gradio 3.33.1 will be installed. This is good.
The next 3 lines do not specify any version numbers. This is bad. By default when a version nuimber is not specified the latest available version is used. If the same script and requirements are being used soon after the script is released then this is probably not an issue as the developer most likely used the same current versions. The problem arises as more time elapses between the release date and the user install date. numpy here is a good example. numpy has deprecated (made obsolete and unsuported) many commands and syntax over the versions. If pip installs the latest version every time, the chances are that a new version is going to break existing code. When this happens the poor end user (or me) has to go and try and work out which library broke and how to fix it (if possible).
The last line specifies a >= version number. This is just as bad as no version. This also shows an issue I had only recently (one of the reasons I wrote this blog post). Pillow now has a v10 release that breaks some of the v9.5 code. If the author had specified 9.5.0 as an exact version then there would be no problems. Pillow could advance to v136.56.3 and it would not matter as the script in question would still know to install v9.5.0.
Python Virtual Environments
When I first started adding machine learning systems to Visions of Chaos I quickly encountered version hell. Firstly if you are going to add a lot of different Python scripts you are going to run into version conflicts. Some scripts need v1 of a certain package, some need v2. To get around this you can use Python environments. Environments keep a certain set of packages and versions isolated from others. When you want to run a certain script, you activate its environment first so you know you have the right packages. Within the environments in Visions of Chaos I always specify exact version numbers for the packages. Life was good, back to work on more interesting things. No such luck.
The Real Problem
Now we really get to the annoyance. Unless EVERY developer out there specifies exact version numbers in their required packages lists any updates could cause version hell.
Visions of Chaos supports using the GPU for calculations. Without the GPU support these machine learning systems run orders of magnitude slower on the CPU. Because of different versions of pytorch with GPU support, most devs do not include GPU supported pytorch with their requirements. Makes sense to avoid lots of “it doesn’t install for me” complaints. I know what specific version of pytorch Visions of Chaos uses so what I do is, at the end of any environment setup, I will uninstall any existing CPU pytorch versions and install the GPU version I know works.
This all worked smoothly until a week ago. I had reports a lot of the modes in Visions of Chaos were not working. Scripts that ran happily for months would fail when new users installed them (great first impression for a new user to find a lot of the features do not work). Time to test. I reset the environments in question and ran the scripts. Sure enough the same errors.
What happened this time was Python package requirements without version numbers being updated outside my control.
Firstly it was pytorch. My environment setups usually end with this
That gets rid of any auto-installed CPU pytorch and installs a versioned GPU version.
BUT, when pytorch installs it also installs a bunch of its own pre-requisite packages. And when it does this it does NOT specify version numbers. So even though every line and package I install has exact versions, a dependancy from pytorch does not and that causes my scripts to fail. pytorch updated to the lastest typing_extensions package that caused script errors.
Same thing happened with the latest Pillow v10 release around the same time. Changes to v10 caused problems with v9.5.0.
Both of those issues could be fixed by adding these next lines to the end of the environment setups.
But that is only a temp fix. Any day now a non-versioned requirement of a package I install could cause this same madness all over again. I have spent 5 days now tediously reinstalling environments and debugging and fixing code, all because someone somewhere did not spend 2 minutes to put version numbers into their requirements.txt. A quick update months later, this still causes frequent problems and bug reports that I need to add tweaks to my environments to remove incompatible packages and force an older package to fix an issue in some other package somewhere out there.
To get an idea of how often this issue causes me problems, open the Visions of Chaos revision history. Every entry there that starts with “Fixed install issue” was a perfectly working script that failed due to an unversioned Python package update.
The Fix?
If it was up to me I would change pip to enforce that a version must be specified. No version, pip errors out with “You didn’t specify a version you bozo! Don’t you know how much of a hassle this can cause!” If each package specifies a version it installs fine.
All a dev has to do is before uploading their working new script is run a quick pip list command to show the packages and versions. Then they just copy those versions into their requirments.txt file. If every dev did this (and Python forced them to) this version hell would be fixed (maybe not a 100% fix, but much better than what we have now). Maybe an enforced law of version numbers is needed?
Maybe this post can also help explain to users who just see Visions of Chaos “not work” why it happens and why it is outside my control.
AnimateDiff One of the recent additions I added to Visions of Chaos was AnimateDiff. Git repository is here if you want to see the code or more info. AnimateDiff generates short 2 second movies at 8 frames per second, 16 frames total. This is due to the model being trained on a bunch of movies […]
Show full content
AnimateDiff
One of the recent additions I added to Visions of Chaos was AnimateDiff. Git repository is here if you want to see the code or more info. AnimateDiff generates short 2 second movies at 8 frames per second, 16 frames total. This is due to the model being trained on a bunch of movies that were only 2 seconds long. The generation process takes around 1m13s per movie on a 4090 and uses around 15.3 GB of GPU VRAM.
You can see some cherry picked results here. Not every result you try will be that good. I include a batch button in Visions of Chaos so you can run the same prompt over multiple random seeds to generate a bunch of outputs on the current prompt. That way you can come back after a while and look for the best result.
The first question people ask (or at least everyone who tried it in Visions of Chaos did) was “how do I make longer and larger sized videos”?
AnimateDiff Prompt Travel
In comes AnimateDiff Prompt Travel. The dev worked out how to merge the shorter 2 second clips into longer movies and it handles larger resolutions too. For the simplest usage you give a list of frame numbers and text prompts and the script does the rest. This script takes around 12.8 GB VRAM when running.
The settings for both of those movies are included with Visions of Chaos so you can create them on your own PC and tweak the prompts to anything else.
Art Games
On the Softology Discord there is the art-games channel. The purpose of the channel is for users to take another user’s Text-to-Image output, change up to two words and post the new image. This continues on and slowly evolves new subjects of the images. I took a bunch of these prompts and ran them through AnimateDiff Prompt Travel. This is the result.
These are the prompts that change every 4 seconds of movie time.
Laughing watching collapsing scifi insanity
Laughing dog watching collapsing house scifi insanity
Laughing astronaut dog watching collapsing house planet scifi insanity
Laughing astronaut above collapsing planet scifi insanity
tranquil astronaut above futuristic planet scifi insanity
tranquil dragon above futuristic planet steampunk insanity
Tranquil dragon above futuristic planet
xenomorph butterfly above futuristic city
garden airships above futuristic city
Garden spheres above futuristic city
psychedelic_spheres_above_futuristic_sky
glass spheres above a sky
glass sphere containing a galaxy
glass spheres containing a galaxy
glass spheres containing a cute creature
glass cage containing a cute spider
glass nicholas cage containing a cute spider monkey
glass wonderland landscape containing a cute spider monkey
glass wonderland landscape containing a cute spider astronaut
wonderland landscape containing a cute alien robot
Wonderland landscape containing a cute quokka
Wonderland landscape burning a cute scarecrow
large crow burning a cute scarecrow
large crow burning a cute scarecrow on halloween
large dragon burning a cute castle on halloween
Large dragon burning a Spring castle on grass
Large dragon eating a Spring roll on grass
pixar dragon eating a Spring roll on cgsociety
pixar mouse eating a Spring salad on cgsociety
beksinski mouse eating a decaying salad on cgsociety
disney mouse eating a decaying franchise on cgsociety
disney mouse driving a decaying car on cgsociety
humanoid mouse driving a cyberpunk car on cgsociety
humanoid tree driving a cyberpunk car on mars
Humanoid tree driving a green car on asphalt
bonsai tree in a green car on asphalt
rainbow tree in a green pot on asphalt
rainbow unicorn melting in a green pot on asphalt
rainbow unicorn marshmallow melting in a green pot on asphalt instagram
rainbow robot, marshmallow smoking in a green pot on instagram
Handsome robot, marshmallow bouncing in a green pot on instagram
Rainbow Robot wearing a jingasa smoking a green pot, Artwork, Golden Hour, High Contrast, 3D, Feng Shui, volumetric Light, Iridescent, Brushed Aluminum
Handsome marshmallow robot bouncing in a green suit on a piano
Bionic marshmallow robot in a green suit stomping on a piano
Bionic elephant robot in a green suit stomping on a bridge
Bionic elephant robot in a green tuxedo dancing on a bridge
bulbuous elephant male in a green tuxedo dancing on a bridge
bulbous knight male in a green armor dancing on a bridge
bulbous knight male in green armor dancing on a tank
warcraft knight male in green armor driving on a tank
warcraft knight male in green armor driving on a tesla
warcraft knight male in green armor driving on a tesla
warcraft pig male in shiny armor driving on a tesla
warcraft pig male in shiny armor flying on a dragon
warcraft pig male in shiny armor fighting a dragon
warcraft pig female in shiny armor fighting a big dragon
warcraft pig male in shiny armor fighting a dragon
lego pig female in shiny armor fighting a big pumpkin
lego cat female in black armor fighting a big pumpkin
weird cat female in black armor inside a big pumpkin
steampunk cat female in black armor inside a big warehouse
steampunk cat female in black armor inside a rich bank
fat cat aristocrat in black armor inside a rich bank
fat cat aristocrat in black armor inside a rich bank
fat cat aristocrat wombat in matte black armor inside a rich bank
fat cat aristocrat wombat in matte black suit inside a robbed bank
fat cat aristocrat wombat in matte black suit driving a robbed Cadillac
fat cat shooting rat in matte black suit driving a robbed Cadillac
fat cat shooting rat in matte black suit driving a futuristic Cadillac
fat cat rat in matte black space suit driving a futuristic Cadillac
fat cat in matte black space suit driving a futuristic Cadillac in disney
fat cat in matte black space suit driving a futuristic Cadillac book in disney
fat cat in matte black space suit driving a futuristic book in disney France
fat cat in matte black space suit driving a book in renaissance france
cat in matte black hat driving a helicopter in renaissance france
cat in matte black hat robe driving cleaning a spaceship in renaissance Mars
cat in matte black robe watering a garden in renaissance Mars
cat in matte black robe watering a garden in Arizona desert renaissance Mars
cat in matte black robe eating a cactus in Arizona desert
cat in fluffy robe eating a cactus in Arizona desert
zombie in fluffy robe eating a brain in Arizona desert
zombie in fluffy robe eating a donut in Chicago desert
zombie in fluffy bikini eating a donut in chicago street
Zombie in fluffy city eating donut in street
Zombie in city eating pizza in street
zombie in city partying in street
zombie in Rome partying in museum
Zombie in Rome studying in party
shark in Rome feasting in party
dapper shark in Rome feasting in situ
dapper koala in Sydney feasting in situ
dapper axolotl in Chinatown feasting in situ
satanic axolotl in Chinatown meditating in situ
satanic sheep in cafe meditating in situ
satanic sheep in cafe meditating in space
giant blob in cafe meditating in space
giant viking in a cafe meditating in space
scary clowns in a cafe meditating in space
hairy clowns in a car meditating in space
hairy starfish in a fishbowl meditating in space
lairy starfish in a fishbowl cogitating in space
alien starfish in a helmet cogitating in space
alien creature in a helmet cogitating in space moebius
alien monk in a kasaya cogitating in space moebius
alien monk in a kasaya cogitating in labyrinth esher
dumfounded alien child in a kasaya cogitating in labyrinth esher
alien creature in a helmet cogitating in space moebius
dumbfounded alien child in a kayak cogitating in labyrinth escher
dumbfounded alien puppet in a kayak conflagrating in labyrinth escher
dumbfounded alien puppet in a kayak conflagrating in labyrinth escher, damien hirst
disturbing alien puppet in a bubble conflagrating in labyrinth escher, damien hirst
Cute alien puppet in a bubble conflagrating in labyrinth escher, damien hirst
Tutorials
The Future of AI Movies
AI movie creation is advancing quickly like image generation did before it. It won’t be long before everyone can generate their own movies at home with finer control of the imagery produced.
A quick post showing some steps to get NeRF going in Visions of Chaos to help first time users. Step 1 – Training 1. Create a new empty directory for your trained data eg D:\Nerf Test\ 2. Create a directory under that called images eg D:\Nerf Test\images\ 3. If you have a series of images […]
Show full content
A quick post showing some steps to get NeRF going in Visions of Chaos to help first time users.
Step 1 – Training
1. Create a new empty directory for your trained data eg D:\Nerf Test\
2. Create a directory under that called images eg D:\Nerf Test\images\
3. If you have a series of images you know will work for training, put them under images. Otherwise, you can copy the images from C:\Users\YourUserName\AppData\Roaming\Visions of Chaos\Examples\MachineLearning\Instant Neural Graphics Primitives\data\nerf\fox\images\.
4. Start Visions of Chaos and select Mode->Machine Learning->Mesh Generation->Instant Neural Graphics Primitives
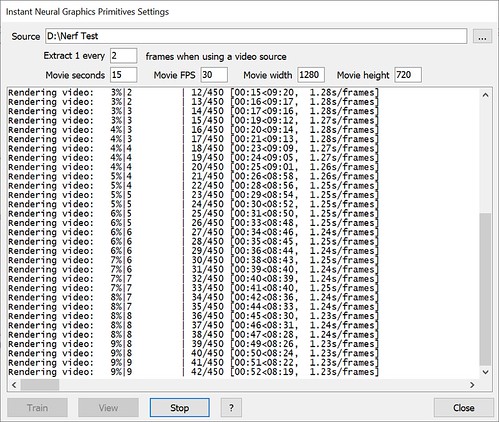
5. Set the source to be D:\Nerf Test and click Train.
6. Wait for the training to finish. For the fox images on a 3090 it took around 3 minutes.
Step 2 – Viewing
With the Source location still pointing to D:\Nerf Test you can now click View to start the viewer GUI.
If you used the fox images you will see the point cloud of the trained data like the following. Middle mouse button click and drag to slide the model around. Left click and drag to rotate.
Step 3 – Creating a Movie
Lastly you can now create a movie of a virtual camera moving around the 3D point object.
1. Let the points accumulate enough to see a reasonable image that is not too noisy.
2. Scroll down in the settings dialog and expand Snapshot.
3. Click Save.
Now to make the camera path. By default the path dialog is hidden behind the main dialog, so click and drag the main dialog out of the way.
When you have the Camera Path dialog showing, move the camera (middle click and drag, left click and drag) to the position you want your movie to start at.
1. Click Add from cam to add that point.
2. Rotate and zoom to another location and once again click Add from cam.
3. Do this another few times to create the camera key frames.
4. Once you added all the points click Save to save the path.
5. You can now close the GUI.
6. With the Source directory still set to D:\Nerf Test click Movie.
By default it will create a 15 second movie at 30 fps at a size of 1280×720. You can change these settings if you wish.
The movie frames will be created …
…and the movie will play when finished.
The movie is saved under your specified Scene directory.
Train your own images
See the fox images as an idea of images to use. You want a series of images rotating around the subject showing it from all sides you want to see in the final movie.
You can also use a movie to train from of your subject rotating. The movie frames will be extracted for you and then trained as normal.
This is Part 8. There is also Part 1, Part 2, Part 3, Part 4, Part 5, Part 6, Part 7 and Part 9. This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script. Name: Deforum Stable Diffusion v0.4 Author: Original script by Robin Rombach, Andreas […]
This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script.
Name: Deforum Stable Diffusion v0.4
Author: Original script by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
Original script: https://colab.research.google.com/github/deforum/stable-diffusion/blob/main/Deforum_Stable_Diffusion.ipynb
Time for 512×512 on a 3090: 34 seconds
Maximum resolution on a 24 GB 3090: 1280×640
Maximum resolution on an 8GB 2080: 640×576
Description: Incredible. Latest and greatest. Beats all previous Text-to-Image systems. If you only use one, use this one. Deforum builds upon Stable Diffusion with animation support. v0.4 is the latest version.
a canal
a forest path
a loft
a matte painting of a river hyperdetailed and CryEngine
a painting of the tropics
a pastel of a nightmare 4K HD realism and trending on Flickr
a photorealistic painting of Cookie Monster rendered in unreal engine and CGSociety
a tropical beach by Karl Hagedorn and Michalis Oikonomou
an etching of King Kong
concept art of Gandalf CGSociety and 4K HD realism
lovecraftian cthulhu tentacle horrors by giger and beksinski, highly textured, 8K 4K HD
roses in the rain, rosebuds, rain drops, 8K 4K HD
Name: Deforum Stable Diffusion v0.5
Author: Original script by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
Original script: https://colab.research.google.com/github/deforum/stable-diffusion/blob/main/Deforum_Stable_Diffusion.ipynb
Time for 512×512 on a 3090: 34 seconds
Maximum resolution on a 24 GB 3090: 1280×640
Maximum resolution on an 8GB 2080: 640×576
Description: Incredible. Latest and greatest. Beats all previous Text-to-Image systems. If you only use one, use this one. Deforum builds upon Stable Diffusion with animation support. v0.5 is the latest version.
a castle
a cute monster
a fine art painting of humans rendered in unreal engine and trending on pixiv
a pop art painting of Frankenstein by Kim Hwan-gi and Zha Shibiao
a sorceress by Adolf Fényes and Rodolfo Morales for sale on Facebook Marketplace and trending on ArtStation
a watercolor painting of a farm by József Breznay and John Zephaniah Bell
an eagle made of feathers and silver
an ugly face
puppies
street art of Jason Vorhees
colorful surrealism by dali, giger, beksinski and haeckel
nebula galaxy planets hubble
Name: Deforum Stable Diffusion v0.6
Author: Original script by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
Original script: https://colab.research.google.com/github/deforum-art/deforum-stable-diffusion/blob/main/Deforum_Stable_Diffusion.ipynb
Time for 512×512 on a 3090: 34 seconds
Maximum resolution on a 24 GB 3090: 1280×640
Maximum resolution on an 8GB 2080: 640×576
Description: Incredible. Latest and greatest. Beats all previous Text-to-Image systems. If you only use one, use this one. Deforum builds upon Stable Diffusion with animation support. v0.6 is the latest version.
a bedroom
a bronze sculpture of Robert DeNiro rendered in unreal engine and trending on Flickr
a chinese painting of a peacock by Agnes Lawrence Pelton and Bob Thompson
a cute girl 4K HD realism and 8K 3D
a fine art painting of a palace made of mist
a green tree frog
a lion
a storybook illustration of the Australian outback
ballpoint pen art of Frankenstein
Brad Pitt by Rhea Carmi and Robert Bechtle
beauty, 4K, 8K, HD, hyper detailed, high detail, surrealism
an oil painting by Picasso and van Gogh, 4K, 8K, HD, hyper detailed, high detail, surrealism
Name: Stable Diffusion v2
Author: Original script by Robin Rombach et al
Original script: https://github.com/Stability-AI/stablediffusion
Time for 768×768 on a 3090: 42 seconds
Maximum resolution on a 24 GB 3090: 1664×704
Maximum resolution on an 8GB 2080: Unable to run on an 8GB GPU.
Description: Uses a newly trained version of the Stable Diffusion model that renders native at 768×768. The following examples show 768×768 sized output.
a cave
a detailed painting of fear IMAX and Flickr
a digital rendering of a human made of chrome and gold
a mansion
a portrait of a sad clown
a spooky forest
a storybook illustration of a lush rainforest for sale on Facebook Marketplace and #film
an etching of a babbling brook
an oil painting of a castle in the mountains
Yoda
Name: Stable Diffusion v2.1
Author: Original script by Robin Rombach et al
Original script: https://github.com/Stability-AI/stablediffusion
Time for 768×768 on a 3090: 42 seconds
Maximum resolution on a 24 GB 3090: 1664×704
Maximum resolution on an 8GB 2080: Unable to run on an 8GB GPU.
Description: Updated Stable Diffusion model. The following examples show 768×768 sized output.
a detailed drawing of Frankenstein
a forest clearing
a frog hyperrealistic and photorealistic
a mountain cabin
a sad clown
a surrealist sculpture of eyeballs
a swamp hyperdetailed and rendered in unreal engine
a townhouse photorealistic and lens flare
an ink drawing of Al Pacino
an ugly creature
Name: Deforum Stable Diffusion v0.7
Author: Original script by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
Original script: https://colab.research.google.com/github/deforum-art/deforum-stable-diffusion/blob/main/Deforum_Stable_Diffusion.ipynb
Time for 768×768 on a 3090: 2 minutes 50 seconds
Maximum resolution on a 24 GB 3090: 2496×1088
Maximum resolution on an 8GB 2080: 640×576
Description: Now supports Stable Diffusion v2.1 model for 768×768 resolution.
a cave
a forest clearing
a lion
a pastel of Big Bird by John Blair and Christoph Ludwig Agricola CryEngine and 4K HD realism
a tributary
a watercolor painting of a western town trending on ArtStation and Tri-X 400 TX
a werewolf
an abstract painting of Gandalf
an alien forest IMAX and vivid colors
an engraving of a cute girl
a hyperrealistic matte painting of melting color, 4K, 8K, HD, high detail, hyper detailed
a hyperrealistic matte painting of a lush rainforest, 4K, 8K, HD, high detail, hyper detailed
a hyperrealistic matte painting of a magical glowing mushroom forest at night, 4K, 8K, HD, high detail, hyper detailed
Name: Kandinsky v2.1
Author: Original script by AI Forever
Original script: https://github.com/ai-forever/Kandinsky-2
Time for 768×768 on a 3090: 1 minute 14 seconds
Maximum resolution on a 24 GB 3090: 1664×704
Maximum resolution on an 8GB 2080: Unable to run on an 8GB GPU.
Description: A new alternative script to Stable Diffusion and other models. Definitely worth a try.
a cabin
a fireman
a hyperrealistic painting of an ocean by Ella Guru and Walter Emerson Baum rendered in unreal engine and photorealistic
a lineart illustration of goldfish 4K photo and vivid colors
a portrait of a beautiful young girl in a garden at dusk
a robot
an impressionist painting of a happy family
an ugly monster
Harry Potter
Spiderman
Name: DeepFloyd IF
Author: Original script by DeepFloyd AI Research Band
Original script: https://github.com/deep-floyd/IF
Time for 1024×1024 on a 3090: 1 minute 17 seconds
Maximum resolution on a 24 GB 3090: 1024×1024 only
Maximum resolution on an 8GB 2080: Unable to run on an 8GB GPU.
Description: A new alternative script to Stable Diffusion and other models. 1024×1024 native resolution is nice.
Click to see these samples in 1024×1024 resolution.
a babbling brook
a cathedral
a collage painting of a vast city lens flare and 8K 3D
a cove
a mountain cabin
a still life of a mountain path
a teddy bear
a worried man made of bones and wire
an allegory of Charmander
gorillas
Name: Kandinsky v2.2
Author: Original script by AI Forever
Original script: https://github.com/ai-forever/Kandinsky-2
Time for 1024×1024 on a 3090: 1 minute 3 seconds
Maximum resolution on a 24 GB 3090: 1664×704
Maximum resolution on an 8GB 2080: Unable to run on an 8GB GPU.
Description: An update to Kandinsky. Handles 1024×1024 resolution. Superb fast results.
a digital rendering of frogs 8K 3D and CryEngine
a gouache of a happy person made of liquid metal and metal by Emma Lampert Cooper and Zha Shibiao
a lounge room
a lush rainforest 8K 3D and for sale on Facebook Marketplace
a watercolor painting of an ugly person made of chrome and chrome
an attractive woman
an ugly face
computer graphics of fear ZBrush and filmic
impressionist of New York City trending on ArtStation and trending on Flickr
pixel art of a robot by Siona Shimshi and Nedroid
Name: SDXL 1.0
Author: Original script by Stability AI
Original script: https://github.com/Stability-AI/generative-models/tree/main
Time for 1024×1024 on a 3090: 34 seconds
Maximum resolution on a 24 GB 3090: 1664×704
Maximum resolution on an 8GB 2080: Unable to run on an 8GB GPU.
Description: The latest from Stability AI. Handles 1024×1024 resolutions by default.
a detailed painting of a Pixar character
a hyperrealistic painting of a rough seascape
a kitten wearing pajamas and sunglasses in times square
A mystical forest filled with glowing mushrooms and iridescent butterflies, where a wise old owl perched on a branch watches over a group of playful fairies as they dance under the moonlight.
a new york city street in the rain
a painting of the amazon rainforest
a portrait of a beautiful young girl in a garden at dusk
a portrait of a female cyborg by h r giger
an oil painting of an ugly creature
Lovecraftian horror
Name: PixArt-alpha
Author: Original script by PixArt-alpha
Original script: https://github.com/PixArt-alpha/PixArt-alpha
Time for 1024×1024 on a 4090: 14 seconds
Description: Another fast Text-to-Image model/script. Handles 1024×1024 resolutions by default.
a cartoon of a monkey
a cove
a cute creature made of vines and mist
a fine art painting of a colorful parrot
a kangaroo
a photorealistic painting of a clown
etching of an ugly man
impressionist of a lighthouse
scribble art of an ugly person
the country rendered in Cinema4D and hyperrealistic
Name: Playground v2
Author: Original script by playgroundai
Original script: https://huggingface.co/playgroundai/playground-v2-1024px-aesthetic
Time for 1024×1024 on a 4090: 15 seconds
Description: Stable diffusion alternate model trained from scratch. Handles 1024×1024 resolutions by default.
a cubist painting of an ugly man
a monkey made of liquid metal and feathers lens flare and psychedelic
a portrait of a young girl
a surrealist sculpture of a green tree frog
a witch made of vines and paper
an acrylic painting of a cloudy sunset
an anime drawing of a sad clown
fear
screen printing of a canyon
trypophobia
Name: Stable Cascade
Author: Original script by Stability AI
Original script: https://github.com/Stability-AI/StableCascade
Time for 1024×1024 on a 4090: 15 seconds
Description: Handles 1024×1024 resolutions by default. Fast and high quality outputs. Also handles widescreen high resolutions with minimal subject duplication.
a church 4K HD realism and trending on pixiv
a detailed matte painting of reflective spheres vivid colors and 8K 3D
a mosaic of a sorcerer by Isabel Codrington and John Harris
a photo of a cute girl
an ugly person
an ugly person by Ford Madox Brown and Al Feldstein
computer graphics of a cute creature 4K photo and trending on Flickr
digital sculpture of Big Bird
Harry Potter
Robocop
Name: PixArt-sigma
Author: Original script by PixArt-alpha
Original script: https://github.com/PixArt-alpha/PixArt-sigma
Time for 1024×1024 on a 4090: 14 seconds
Description: Updated from PixArt-alpha.
a caricature of love
a cliff
a cute girl by Ernesto Neto and Carel Weight rendered in Cinema4D and super detailed
a heart psychedelic and Flickr
a marble sculpture of Lovecraftian horror trending on ArtStation and trending on pixiv
a nightmare
a pond
an ultrafine detailed painting of an ocean by Ejnar Nielsen and Kim Deuk-sin
eyeballs made of mist and bones
watercolor of eyeballs
Stable Diffusion 3 Medium
Author: Original script by Stabiliy AI
Original script: https://huggingface.co/stabilityai/stable-diffusion-3-medium-diffusers
Time for 1024×1024 on a 4090: 15 seconds
Description: New model from Stability AI. They only released the medium size model at this stage, so results are not the best. The following samples are cherry picked best results from a many random prompt batch run.
a cinematic painting of a waterfall
a demon
a detailed matte painting of anxiety
a hyperrealistic painting of a swamp
a mountain range #film and super detailed
a sea monster
a tiger
an octopus hyperdetailed and lens flare
Hermoine Granger
scratchboard art of a crying person Flickr and 8K 3D
Any Others I Missed?
Do you know of any other colabs and/or github Text-to-Image systems I have missed? Let me know and I will see if I can convert them to work with Visions of Chaos for a future release. If you know of any public Discords with other colabs being shared let me know too.
This is Part 7. There is also Part 1, Part 2, Part 3, Part 4, Part 5, Part 6, Part 8 and Part 9. This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script. Name: Multi-Perceptor VQGAN+CLIP v4 Author: Remi Durant Original script: https://colab.research.google.com/drive/1peZ98vBihDD9A1v7JdH5VvHDUuW5tcRK Time for […]
This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script.
Name: Multi-Perceptor VQGAN+CLIP v4
Author: Remi Durant
Original script: https://colab.research.google.com/drive/1peZ98vBihDD9A1v7JdH5VvHDUuW5tcRK
Time for 512×512 on a 3090: 2 minutes 36 seconds
Maximum resolution on a 24 GB 3090: 1120×480
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Version 4 of Remi’s Multi-Perceptor VQGAN+CLIP script.
a bronze sculpture of a garden
a church by Tadeusz Kantor
a color pencil sketch of a monkey hyperdetailed
a comic book panel of a lush rainforest
a matte painting of a witch by William Geissler
a peninsula by Ei-Q CGSociety
a surrealist sculpture of hell
an eyeball made of flowers
cyberpunk art of a canyon
lineart of dense woodland
Name: V-Majesty Diffusion v1.2
Authors: Original script by Dango233 and multimodalart
Original script: https://colab.research.google.com/github/multimodalart/MajestyDiffusion/blob/main/v.ipynb
Time for 512×512 on a 3090: 3 minutes 08 seconds
Maximum resolution on a 24 GB 3090: 1664×704.
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: A new diffusion based script.
a black and white photo of war
a brownstone by Oliver Sin super detailed
a cute creature
a doctor
a drawing of a babbling brook photorealistic
a hill
a ninja by Michael Ford psychedelic
a photo of a beautiful young girl in a summer garden at dusk
a storybook illustration of a cozy den
New York City
Name: Latent Majesty Diffusion v1.3
Authors: Original script by Dango233 and multimodalart
Original script: https://colab.research.google.com/github/multimodalart/MajestyDiffusion/blob/main/latent.ipynb
Time for 512×512 on a 3090: 2 minutes 24 seconds
Maximum resolution on a 24 GB 3090: 512×512 (when using GFPGAN upscaling)
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Starts with a smaller resolution image (usually 256×256 pixels), upscales it with GFPGAN, and then does a few more diffusion passes. GFPGAN can really help get better coherency in faces.
a hyperrealistic painting of a cute creature
a hyperrealistic painting of an evil clown
a picture of a tree
a surrealist painting of kittens
an engraving of an angry woman made of voxels
an oil painting of an attractive woman by Eileen Aldridge
an ultrafine detailed painting of Bruce Willis 4K HD realism
Robert DeNiro ZBrush
Tweety Pie
Yoda
Name: Huemin JAX Diffusion v2.7
Author: Huemin
Original script: https://colab.research.google.com/github/huemin-art/jax-guided-diffusion/blob/v2.7/Huemin_Jax_Diffusion_2_7.ipynb
Time for 512×512 on a 3090: 3 minutes 55 seconds
Maximum resolution on a 24 GB 3090: 2496×1088
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Starts with a smaller resolution image (usually 256×256 pixels), upscales it with GFPGAN, and then does a few more diffusion passes. GFPGAN can really help get better coherency in faces.
a babbling brook
a mountain path Flickr
a river CGSociety
a spooky forest by John F. Peto
a storybook illustration of a mansion by Donald Roller Wilson
a surrealist sculpture of an alien forest
a watercolor painting of fear made of bones ZBrush
Name: DALL-E Mini
Author: Original script by Boris Dayma
Original script: https://colab.research.google.com/github/borisdayma/dalle-mini/blob/main/tools/inference/inference_pipeline.ipynb
Time for 512×512 on a 3090: Locked to 256×256 – 1 minute 13 seconds
Maximum resolution on a 24 GB 3090: 256×256
Maximum resolution on an 8GB 2080: 256×256
Description: Capable of rendering multiple images in one pass. Very nice results. Limited to 256×256 at this time. These examples show a 4×4 grid of 16 images for each prompt.
a fine art painting of a fire breathing dragon
a hyperrealistic painting of an ugly monster
a planet
a river
a rose
a surrealist painting of a king
an airbrush painting of satan
an engraving of a frog
an ultrafine detailed painting of fear
Darth Vader trending on pixiv
Name: Latent Majesty Diffusion v1.6
Authors: Original script by Dango233 and multimodalart
Original script: https://colab.research.google.com/github/multimodalart/MajestyDiffusion/blob/main/latent.ipynb
Time for 512×512 on a 3090: 2 minutes 07 seconds
Maximum resolution on a 24 GB 3090: 512×512 (when using GFPGAN upscaling)
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: The latest amazing update to Latent Diffusion. Awesome colors, textures, lighting, details, coherency. Highly recommended.
a colorful parrot
a detailed matte painting of puppies
a gallery
a mountain cabin by Tom Palin 4K HD realism
a renaissance painting of a spooky forest
a school of tropical fish by Jane Carpanini
an ugly creature
the Amazon Rainforest photorealistic
The Grinch
Yoda trending on Flickr
Name: Disco Diffusion v5.4
Authors: Original script by @somnai, @gandamu, @zippy731 and @devdef
Original script: https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb
Time for 512×512 on a 3090: 2 minutes 20 seconds
Maximum resolution on a 24 GB 3090: 2496×1088
Maximum resolution on an 8GB 2080: 768×768
Description: Latest version of Disco Diffusion.
a 3D render of the Grand Canyon by Dóra Keresztes
a hyperrealistic painting of a zombie made of cheese and feathers CryEngine and rendered in Cinema4D
a macro photograph of an ugly creature
a matte painting of a monument
a picture of a vast city
a skyscraper
a thunder storm
Jason Vorhees by Chen Chi
reflective spheres hyperrealistic
the country by Robert Thomas and Chen Jiru rendered in unreal engine and 4K photo
a collage painting of a lush rainforest by Doc Hammer and Alexander Ivanov hyperrealistic and CryEngine
a cubist painting of a lion and a sunset CryEngine and trending on pixiv
a fine art painting of a zombie
a gulf by I Ketut Soki and Alfons von Czibulka
a monastery trending on Flickr and #film
a morning landscape
a prairie CGSociety and CryEngine
a werewolf
ballpoint pen art of a monument
cyberpunk art of heaven filmic and CryEngine
Name: CLIP Guided k-diffusion
Author: Original script by Katherine Crowson
Original script: https://colab.research.google.com/drive/1w0HQqxOKCk37orHATPxV8qb0wb4v-qa0
Time for 512×512 on a 3090: 6 minutes 56 seconds
Maximum resolution on a 24 GB 3090: Fixed to 512×512 resolution.
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: A new script by Katherine. Seems to generate more abstract results and these example images needed a long run of random prompts to select from.
a jigsaw puzzle of paranoia by Petr Brandl and Sasha Putrya
a landscape vivid colors
a pastel of Cookie Monster by Ren Bonian and Ángel Botello for sale on Facebook Marketplace and CryEngine
a reef
a renaissance painting of Al Pacino
a statue of a submarine made of metal and crystals by James Sessions American painter and Elfriede Lohse-Wächtler
an airbrush painting of a nightmare creature vivid colors and rendered in Cinema4D
an oil painting of a cephalopod made of paper and mist
an ugly person and an area 4K HD realism and trending on pixiv
conceptual art of an ugly monster
Name: CLIP Prior + VQGAN (MSE method)
Author: Original script by Katherine Crowson
Original script: https://colab.research.google.com/drive/1yOpCY9eXvzELHppvh-o0DevhxVYOGr5i
Time for 512×512 on a 3090: 3 minutes 31 seconds
Maximum resolution on a 24 GB 3090: 832×512
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: A new script by Katherine. Can give some interesting details but coherence may suffer at larger resolutions.
a collage painting of a tiger vivid colors and photorealistic
a cove 4K photo and CryEngine
a cute creature
a glacier
a space nebula
a townhouse
a valley
an oil painting of a peacock by Wu Hong and Eve Ryder
Cthulhu
digital art of a wetland made of cheese and timber by Jacob Duck and Jacob Gerritsz Cuyp
Name: Latent Diffusion LAION_400M v2
Author: Original script by pesser
Original script: https://github.com/pesser/stable-diffusion
Time for 16 256×256 images on a 3090: 49 seconds
Maximum resolution on a 24 GB 3090: 512×512
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM
Description: Renders multiple images quickly. Coherency is best at 256×256 so these example images are 2×2 tiled results. Each took 35 seconds on a 3090.
a babbling brook
a colorful parrot
a fine art painting of a castle
a matte painting of a rose
a pencil sketch of a cave 4K photo and hyperrealistic
a photorealistic painting of Cthulhu for sale on Facebook Marketplace and Flickr
a surrealist painting of a cloudy sunset
a surrealist painting of a monkey
an illustration of of a tiger by Stanley Twardowicz and Antoni Pitxot
an impressionist painting of a cottage
Name: Stable Diffusion
Author: Original script by pesser
Original script: https://github.com/CompVis/stable-diffusion
Time for 512×512 on a 3090: 34 seconds
Maximum resolution on a 24 GB 3090: 1280×640
Maximum resolution on an 8GB 2080: 640×576
Description: Incredible. Latest and greatest. Beats all previous Text-to-Image systems. If you only use one, use this one.
a black and white photo of puppies
a cathedral rendered in unreal engine and super detailed
a city made of mist trending on ArtStation and trending on Flickr
a detailed matte painting of a lush rainforest made of crystals and feathers
a king
a polaroid photo of a clown vivid colors and 8K 3D
an airbrush painting of the Terminator CryEngine and for sale on Facebook Marketplace
an ambient occlusion render of a wetland by William Forsyth and Victorine Foot trending on pixiv and CryEngine
poster art of a farm by Frederic Leighton and Yang Borun rendered in unreal engine and 8K 3D
the Australian outback
Name: Deforum Stable Diffusion v0.3
Author: Original script by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
Original script: https://colab.research.google.com/github/deforum/stable-diffusion/blob/main/Deforum_Stable_Diffusion.ipynb
Time for 512×512 on a 3090: 34 seconds
Maximum resolution on a 24 GB 3090: 1280×640
Maximum resolution on an 8GB 2080: 640×576
Description: Incredible. Latest and greatest. Beats all previous Text-to-Image systems. If you only use one, use this one. Deforum builds upon Stable Diffusion with animation support.
a babbling brook
a forest path
a photo of a lake
a ranch by Nikolai Alekseyevich Kasatkin and Harriet Zeitlin
a watercolor painting of a rectory hyperdetailed and trending on ArtStation
Al Pacino by Lam Qua and George Frederick Harris
an angry person by Kazys Varnelis and Dóra Keresztes
Do you know of any other colabs and/or github Text-to-Image systems I have missed? Let me know and I will see if I can convert them to work with Visions of Chaos for a future release. If you know of any public Discords with other colabs being shared let me know too.
This is Part 6. There is also Part 1, Part 2, Part 3, Part 4, Part 5, Part 7, Part 8 and Part 9. This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script. Name: Augmented CLIP Guided Diffusion Author: Peter Baylies Original script: https://github.com/pbaylies/Augmented_CLIP Time […]
This post continues listing the Text-to-Image scripts included with Visions of Chaos and some example outputs from each script.
Name: Augmented CLIP Guided Diffusion
Author: Peter Baylies
Original script: https://github.com/pbaylies/Augmented_CLIP
Time for 512×512 on a 3090: 1 minutes 16 seconds
Maximum resolution on a 24 GB 3090: 1664×704
Maximum resolution on an 8GB 2080: 256×256 57 seconds
Description: Another CLIP Guided Diffusion script. Fast. Gives unique textured results.
a detailed painting of people by Nicolette Macnamara
a diagram of a nightmare creature made of gold
a nightmare creature
a painting of a cabin next to a stream in a secluded forest
a storybook illustration of Jabba The Hutt by Carle Hessay
a werewolf by A R Middleton Todd
an oil painting of Big Bird
Gandalf trending on pixiv
Lovecraftian horror
poster art of the Las Vegas strip by George Passantino
Name: Princess Generator
Author: Dango233
Original script: https://colab.research.google.com/drive/1QgH9TvQMXR3PpEGBcHnghtEcwFDXLaYE
Time for 512×512 on a 3090: 2 minutes 38 seconds
Maximum resolution on a 24 GB 3090: 1664×704
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM.
Description: The latest update to “CLIP Guided Diffusion v6” from Dango233. Can give some superb results. Worth exploring and experimenting with further.
a cloudy sunset
a fireplace by Jacob More
a happy alien by James Jarvaise
a mountain path by Stephen Pace
a raytraced image of a western town
a teddy bear
Charmander made of wood by Hua Yan
dense woodland by Marie Angel
paranoia by Floris van Dyck
portrait of Princess Victoria trending on artstation
Name: Disco Diffusion v4.1
Author: @Somnai
Original script: https://colab.research.google.com/drive/1sHfRn5Y0YKYKi1k-ifUSBFRNJ8_1sa39
Time for 512×512 on a 3090: 1 minute 57 seconds
Maximum resolution on a 24 GB 3090: 2496×1088
Maximum resolution on an 8GB 2080: 1152×512. 4 minutes 39 seconds.
Description: The latest update to Disco Diffusion. Really nice detailed outputs. Low VRAM requirments allow huge sized images. I didn’t realise I had 3 zombie themed results in this random batch.
a bronze sculpture of a zombie
a fantasy land
a pencil sketch of Cthulhu by Rudolf Koller
a pop art painting of zombies
a portrait of a young boy by Hendrick Cornelisz. van Vliet
a tree by Philips Wouwerman
a western town
a zombie
Han Solo psychedelic
vector art of the Amazon Rainforest
Name: Hypertron v2
Author: Philipuss
Original script: https://colab.research.google.com/drive/10fa8X6EsfZfda1dfhJ_BtfPZ7Te1WGoX
Time for 512×512 on a 3090: 1 minute 57 seconds
Maximum resolution on a 24 GB 3090: 1120×480.
Maximum resolution on an 8GB 2080: 256×256 2 minutes 18 seconds
Description: Version 2 of Hypertron. More models, more flavors. Works OK. Can give the “image in a sea of purple/grey” that previous MSE based scripts suffered from. Can give good results if you let it run a large random batch overnight.
a bronze sculpture of a spooky forest by Herb Aach
a diamond made of flowers
a gouache of an android by Wu Bin
a photo of a kitchen
a photorealistic painting of a cemetery
a sketch of a haunted house
a tattoo of Squirtle made of clay
an art deco painting of a human by Nicolas Lancret 8K 3D
goldfish by Elfriede Lohse-Wächtler
Lovecraftian horror by Aileen Eagleton
Name: CC12M Diffusion
Author: Katherine Crowson
Original script: https://colab.research.google.com/drive/1TBo4saFn1BCSfgXsmREFrUl3zSQFg6CC
Time for 512×512 on a 3090: 1 minute 48 seconds
Maximum resolution on a 24 GB 3090: 1664×704.
Maximum resolution on an 8GB 2080: 832×512 2 minutes 59 seconds
Description: Can support higher resolutions, but the coherance really falls apart with anything over 256×256. It handles multiple images at once, so these examples are 4 256×256 results.
a black and white photo of a lush rainforest trending on Flickr
a detailed matte painting of a factory
a hacker by Mykola Burachek
a sea monster CGSociety
a surrealist painting of a happy person
a tardigrade by Cosmo Alexander
an anime drawing of an evening landscape by Daphne Fedarb photorealistic
an art deco painting of a happy person by John Uzzell Edwards
chalk art of a bouquet of flowers
the human condition
Name: Augmented CLIP Guided Diffusion v2
Author: Peter Baylies
Original script: https://github.com/pbaylies/Augmented_CLIP
Time for 512×512 on a 3090: 2 minutes 48 seconds
Maximum resolution on a 24 GB 3090: 1664×704
Maximum resolution on an 8GB 2080: 512×512 4 minutes 56 seconds
Description: Updaterd version of the Augmented CLIP Guided Diffusion script.
a bungalow 4K HD realism
a forest fire
a lush rainforest CryEngine
a painting of a kitchen by Betye Saar
a portrait of a princess trending on artstation
a spooky forest
a tattoo of a zombie
a werewolf by David Cooke Gibson
an oil painting of a lake
an ugly man
Name: v-diffusion
Author: Katherine Crowson
Original script: https://github.com/crowsonkb/v-diffusion-pytorch
Time for 512×512 on a 3090: 3 minutes 57 seconds
Maximum resolution on a 24 GB 3090: 896×512 or 640×640.
Maximum resolution on an 8GB 2080: 128×128 1 minute 19 seconds
Description: Updated version of Velocity-Diffusion. Tends to make incoherant collage images over 256×256.
a black and white photo of a portrait of a young girl
a cityscape by Lujo Bezeredi
a cloudy sunset
a hologram of a sad face by Josef Šíma
a lounge room by Riad Beyrouti IMAX
a mountain path
a portrait of a young boy made of metal
a portrait of a young girl
a space nebula
an acrylic painting of a mountain range
Name: GLID-3
Author: Jack Qiao
Original script: https://github.com/Jack000/glid-3
Time for 512×512 on a 3090: 35 seconds
Maximum resolution on a 24 GB 3090: 768×768.
Maximum resolution on an 8GB 2080: 512×512 50 seconds
Description: Great textures and lighting. Poor image coherency.
a cemetery
a drawing of a cloudy sunset
a drawing of a human lens flare
a lake
a large waterfall made of silver
a marina
a minimalist painting of a teddy bear by Johann Ludwig Bleuler
a hyperrealistic painting of a queen made of flowers
a painting of a happy clown
a skeleton
a stained glass window 4K HD realism
a watercolor painting of a lounge room
an eagle
an ultrafine detailed painting of Harry Potter
vector art of a zombie by Oskar Kokoschka
Name: JAX CLIP Guided Diffusion v2.7
Author: nshepperd
Original script: https://colab.research.google.com/drive/1nmtcbQsE8sTjfLJ1u3Y4d6vi9ZTAvQph
Time for 512×512 on a 3090: 2 minutes 37 seconds
Maximum resolution on a 24 GB 3090: 2496×1088
Maximum resolution on an 8GB 2080: 512×512. 3 minutes 59 seconds.
Description: ANother diffusion based script. Can give very nice high detail results.
a Dalek made of feathers
a haunted house
a picture of a chateau by Odhise Paskali
a refinery
a studio by Allan Ramsay trending on ArtStation
a sunset
a thunder storm
a watercolor painting of a fire breathing dragon
a witch made of mist
the tropics by Thomas de Keyser
Name: GLID-3-XL
Author: Jack Qiao
Original script: https://github.com/Jack000/glid-3-xl
Time for 512×512 on a 3090: 1 minute 04 seconds
Maximum resolution on a 24 GB 3090: 512×512.
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM.
Description: Improved/updated version of GLID-3. Uses CLIP for better accuracy. Great textures and lighting. Poor image coherency when over 256×256.
a demon
a detailed matte painting of a bouquet of flowers
a kitchen
a photorealistic painting of a movie monster hyperrealistic
a picture of The Incredible Hulk by Kazimir Malevich
a pop art painting of an angry woman
a spooky forest
an abbey
New York City by Marie Courtois
poster art of Gandalf vivid colors
Name: ruDALL-E Aspect Ratio
Author: Alex Shonenkov
Original script: https://github.com/shonenkov-AI/rudalle-aspect-ratio
Time for 512×512 on a 3090: N/A
Maximum resolution on a 24 GB 3090: N/A
Maximum resolution on an 8GB 2080: Unable to run on 8GB VRAM.
Description: Version of ruDALL-E that generates wide and/or tall aspect ratio images. The shorter side is limited to 256 pixels. Results can be very nice. Will generate multiple images at once, so these sample images have 4 results per prompt.
a black and white photo of a werewolf
a cartoon of a swamp
a large waterfall made of metal
a lounge room
a matte painting of a townhouse
a palace made of mist
a photo of an ugly woman
a tropical beach
an evil clown
dense woodland
Any Others I Missed?
Do you know of any other colabs and/or github Text-to-Image systems I have missed? Let me know and I will see if I can convert them to work with Visions of Chaos for a future release. If you know of any public Discords with other colabs being shared let me know too.