Show full content
In this document we discuss how to do “classical machine learning” Latent Semantic Analysis (LSA) with Raku for collections of documents, and how to generate the code for the related LSA workflows.
The Raku package, “ML::LatentSemanticAnalyzer”, [AAp12], facilitates the construction and execution of computational LSA workflows using Sparse Matrix Linear Algebra (SMLA). The design and implementation of the package are based on those of the Python package, “LatentSemanticAnalyser”, [AAp3]. (There are also corresponding implementations in R and Wolfram Language; see [AAp3, AAp1]. The Wolfram Language one was implemented first.)
Before continuing further with examples of LSA pipelines and code generation of such pipelines, a few important points:
- With the LSA package, Raku is nearly fully equipped for Machine Learning (ML).
- I would say what is missing is Quantile Regression. See the blog post “Doing Data Science with Raku”, [AA3], for more details.
- The LSA package implementation became justifiable (or possible) because of the C-implementation of one of the sparse matrix algorithms for Singular Value Decomposition (SVD)
in the Raku “native call” package “Math::SparseMatrix::Native”, [AAp6].- The package “Math::SparseMatrix”, [AAp6], is a wrapper of- or, has an adapter class to “Math::SparseMatrix::Native”.
- The native, i.e. C-implementation of SMLA is needed in order to achieve satisfactory speed of SMLA operations.
- The package “Math::SparseMatrix” provides matrices with named rows and columns which are especially convenient for implementing LSA and recommender systems based on SMLA. See [AAv6];
- Before the implementation of “ML::LatentSemanticAnalyzer” the only streamlined way to do LSA with Raku was through Retrieval Augmented Generation (RAG). See [AAp11, AAv5].
- As all other main ML workflows in Raku, [AA3, AAp9, AAv2], the code for LSA workflows can be generated with in several different ways.
- Using both grammars and Large Language Models (LLMs). (As discussed below.)
LSA workflows
The scope of the package is to facilitate the creation and execution of the workflows encompassed in this flow chart:
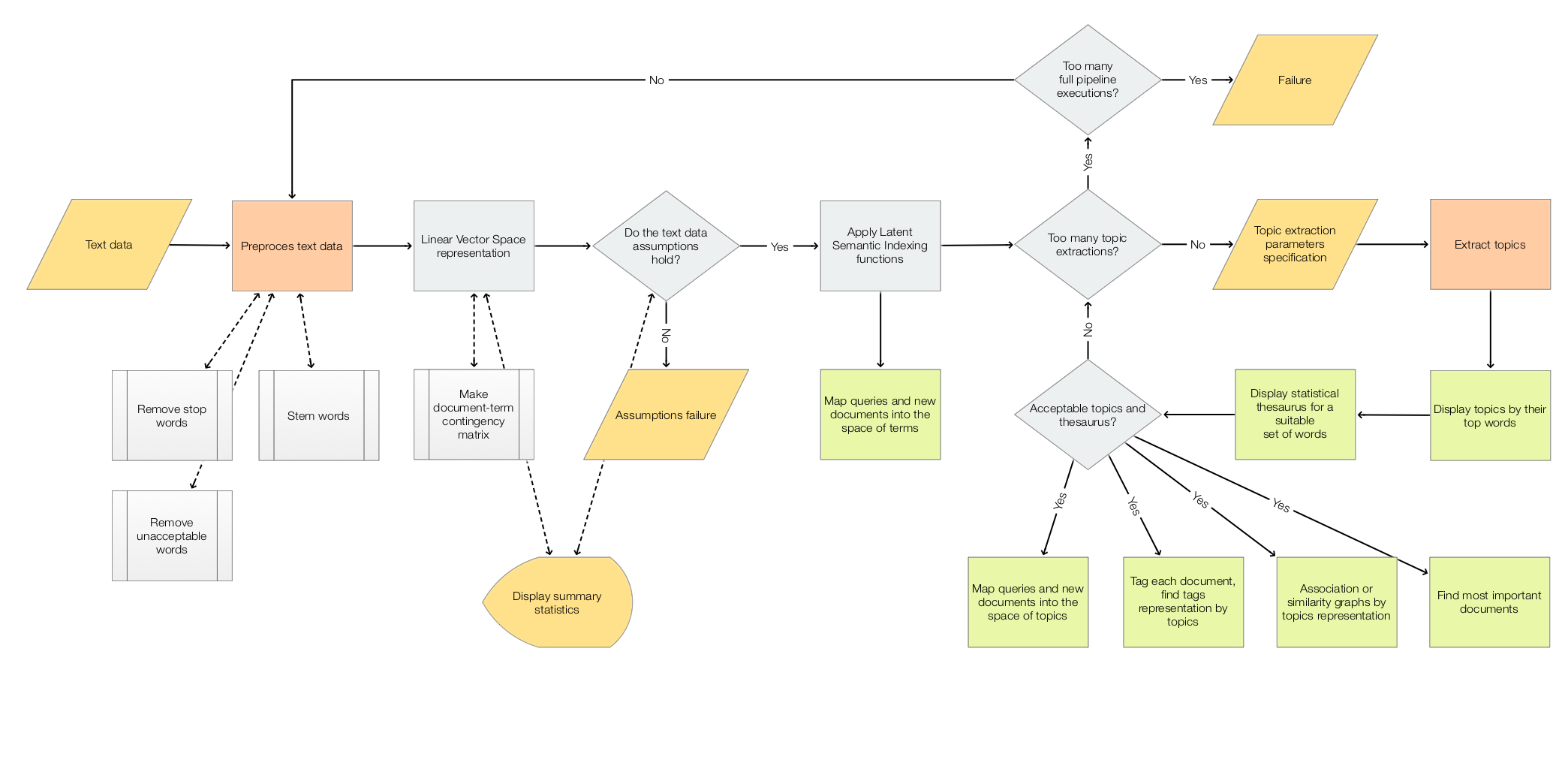
For more details see the article “A monad for Latent Semantic Analysis workflows”, [AA1].
The package provides:
- Class
ML::LatentSemanticAnalyzer - Functions for applying Latent Semantic Indexing (LSI) functions on matrix entries
- “Data loader” function for obtaining a dataset of ~580 abstracts of conference presentations
LSA pipeline example
Here is an example of an LSA pipeline that:
- Ingests a collection of texts
- Makes the corresponding document-term matrix using stemming and removing stop words
- Extracts 40 topics
- Shows a table with the extracted topics
- Shows a table with statistical thesaurus entries for selected words
use ML::LatentSemanticAnalyzer;use ML::LatentSemanticAnalyzer::Utilities;use Lingua::EN::Stem::Porter;# Collection of textsmy @dsAbstracts = ML::LatentSemanticAnalyzer::Utilities::get-abstracts-dataset();my %docs = @dsAbstracts.map(*<ID>) Z=> @dsAbstracts.map(*<Abstract>);say %docs.elems;# Remove non-stringsmy %docs2 = %docs.grep({ $_.value ~~ Str:D });say %docs2.elems;# Stemmer function (to preprocess words in the pipeline below)say &porter.WHY;# Words to show statistical thesaurus entries formy @words = <notebook computational function neural talk programming>;# Reproducible results (just within a session)srand(12);# LSA pipelinemy $lsaObj = ML::LatentSemanticAnalyzer.new .make-document-term-matrix(docs => %docs2, :stop-words, :stemming-rules, :3min-length) .apply-term-weight-functions( global-weight-func => "IDF", local-weight-func => "None", normalizer-func => "Cosine") .extract-topics(:40number-of-topics, :10min-number-of-documents-per-term, method => "SVD") .echo-topics-interpretation(:12number-of-terms, :!wide-form) .echo-statistical-thesaurus( terms => @words.map(*.&porter), :wide-form, :12number-of-nearest-neighbors, method => "cosine", :echo)Remark: See this Jupyter notebook for the execution results of the LSA pipeline above.
Related Raku packages
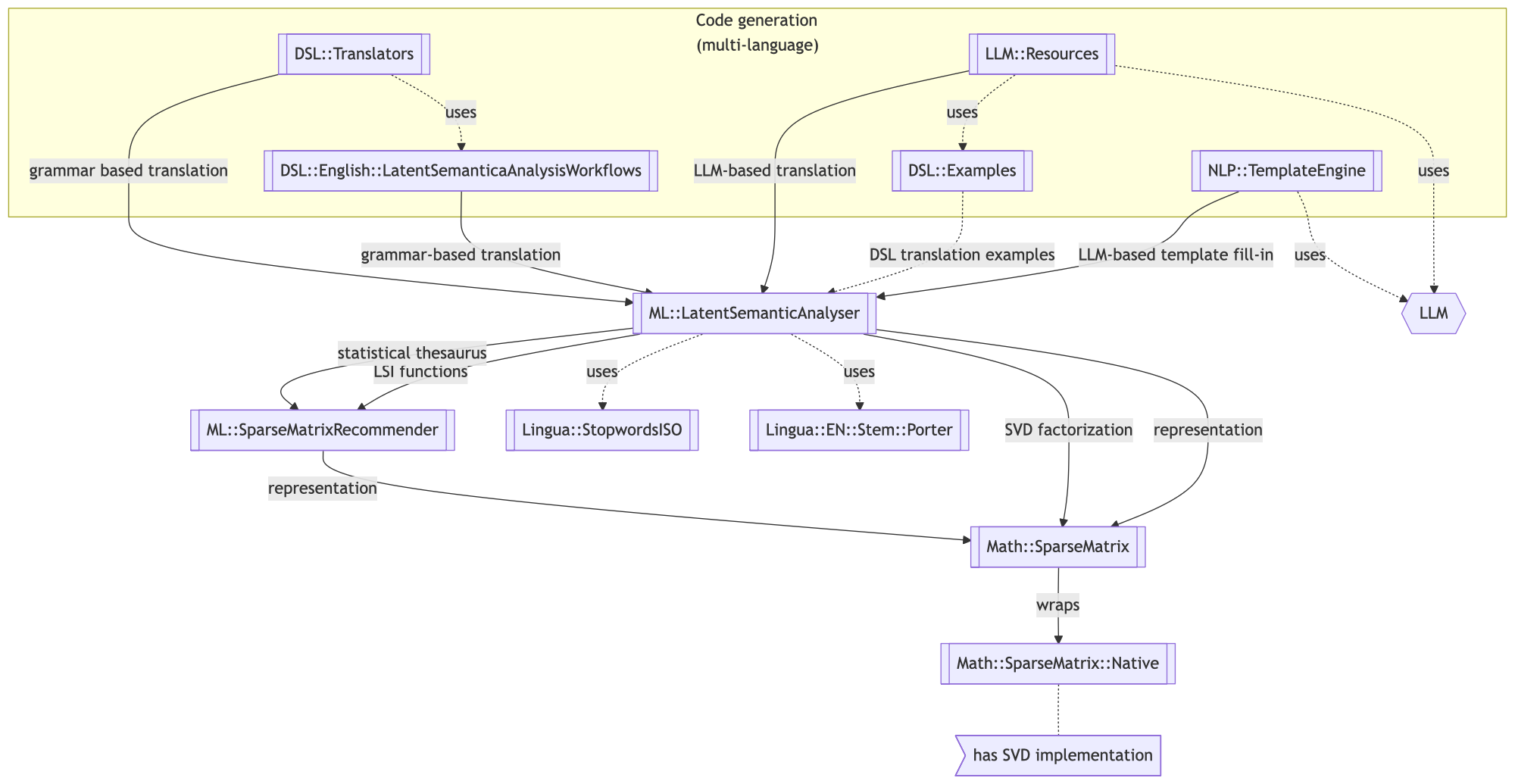
This package is based on the Raku package “Math::SparseMatrix”, [AAp5].
The package “ML::SparseMatrixRecommender”, [AAp7], also uses LSI functions — this package uses LSI methods of the class ML::SparseMatrixRecommender. The statistical thesaurus derivation with the method “cosine-distance” use ML::SparseMatrixRecommender recommender.
Several packages can be used to generate LSA workflow code (not just Raku, but other programming languages too) —
see the section “Code generation with natural language commands” below.
The following diagram summarizes the relationship between “ML::LatentSemanticAnalysis” and other Raku packages:
Related Mathematica, Python, and R packages Wolfram Language (aka Mathematica)
The Raku pipeline above corresponds to the following pipeline for the Mathematica package
[AAp1]:
lsaObj = LSAMonUnit[aAbstracts]⟹ LSAMonMakeDocumentTermMatrix["StemmingRules" -> Automatic, "StopWords" -> Automatic]⟹ LSAMonEchoDocumentTermMatrixStatistics["LogBase" -> 10]⟹ LSAMonApplyTermWeightFunctions["IDF", "None", "Cosine"]⟹ LSAMonExtractTopics["NumberOfTopics" -> 20, Method -> "NNMF", "MaxSteps" -> 16, "MinNumberOfDocumentsPerTerm" -> 20]⟹ LSAMonEchoTopicsTable["NumberOfTerms" -> 10]⟹ LSAMonEchoStatisticalThesaurus["Words" -> Map[WordData[#, "PorterStem"]&, {"notebook", "computational", "function", "neural", "talk", "programming"}]];Here is a corresponding Python pipeline with the package [AAp3]:
lsaObj = (LatentSemanticAnalyzer() .make_document_term_matrix(docs=docs2, stop_words=True, stemming_rules=True, min_length=3) .apply_term_weight_functions(global_weight_func="IDF", local_weight_func="None", normalizer_func="Cosine") .extract_topics(number_of_topics=40, min_number_of_documents_per_term=10, method="NNMF") .echo_topics_interpretation(number_of_terms=12, wide_form=True) .echo_statistical_thesaurus(terms=stemmerObj.stemWords(words), wide_form=True, number_of_nearest_neighbors=12, method="cosine", echo_function=lambda x: print(x.to_string())))The package LSAMon-R, [AAp2], implements a software monad for LSA workflows.
LSA packages comparison project
The project “Random mandalas deconstruction with R, Python, and Mathematica”, [AAr1, AA2], has documents, diagrams, and (code) notebooks for comparison of LSA application to a collection of images (in multiple programming languages.)
A big part of the motivation to make the Python package “RandomMandala”, [AAp4], was to make easier the LSA package comparison. Wolfram Language (aka Mathematica) and R have fairly streamlined connections to Python, hence it is easier to propagate (image) data generated in Python into those systems.
Code generation with natural language commands Using grammar-based interpreters
The project “Raku for Prediction”, [AAr2, AAv2, AAp9], has a Domain Specific Language (DSL) grammar and interpreters
that allow the generation of LSA code for corresponding Mathematica, Python, R, and Raku packages.
Here is Command Line Interface (CLI) invocation example that generate code for this package:
dsl-translation -t=Raku 'create from aDocs; apply LSI functions IDF, None, Cosine; extract 20 topics; show topics table'# ML::LatentSemanticAnalyzer.new(aDocs)# .apply-term-weight-functions(global-weight-func => "IDF", local-weight-func => "None", normalizer-func => "Cosine")# .extract-topics(number-of-topics => 20)# .echo-topics-table( )Here is an example using the NLP Template Engine, [AAr2, AAv3, AAp10]:
use ML::NLPTemplateEngine;concretize('create from aDocs; apply LSI functions IDF, None, Cosine; extract 20 topics; show topics table; thesaurus for bell and ringer.', lang => "Raku")# my $lsaObj = ML::LatentSemanticAnalyzer.new# .make-document-term-matrix(docs=>aDocs,# stop-words=>Whatever,# stemming-rules=>Whatever,# min-length=>3)# .apply-term-weight-functions(global-weight-func=>"IDF",# local-weight-func=>"None",# normalizer-func=>"Cosine")# .extract-topics(number-of-topics=>20, min-number-of-documents-per-term=>20, method=>"LSI", max-steps=>16)# .echo-topics-interpretation(number-of-terms=>10, wide-form=>True)# .echo-statistical-thesaurus(terms=>["bell", "ringer"],# wide-form=>True,# number-of-nearest-neighbors=>12,# method=>"cosine",# echo-function=>&put)Remark: For more LSA-code generation examples see the Jupyter notebook “Code-generation.ipynb”.
References Articles
[AA1] Anton Antonov, “A monad for Latent Semantic Analysis workflows”, (2019), MathematicaForPrediction at WordPress.
[AA2] Anton Antonov, “Random mandalas deconstruction in R, Python, and Mathematica”, (2022), MathematicaForPrediction at WordPress.
[AA3] Anton Antonov, “Day 2 – Doing Data Science with Raku”, (2025), Raku Advent Calendar at WordPress.
Python, R, and Wolfram Language packages[AAp1] Anton Antonov, Monadic Latent Semantic Analysis Mathematica package, (2017), MathematicaForPrediction at GitHub.
[AAp2] Anton Antonov,Latent Semantic Analysis Monad in R, (2019), R-packages at GitHub/antononcube.
[AAp3] Anton Antonov, LatentSemanticAnalyzer, Python package, (2021-2026), PyPI.
[AAp4] Anton Antonov, RandomMandala, Python package, (2021), PyPI.
Raku packages[AAp5] Anton Antonov, Math::SparseMatrix, Raku package, (2024-2026), GitHub/antononcube.
[AAp6] Anton Antonov, Math::SparseMatrix::Native, Raku package, (2024-2026), GitHub/antononcube.
[AAp7] Anton Antonov, ML::SparseMatrixRecommender, Raku package, (2025), GitHub/antononcube.
[AAp8] Anton Antonov, Data::Generators, Raku package, (2021-2025), GitHub/antononcube.
[AAp9] Anton Antonov, DSL::English::LatentSemanticAnalysisWorkflows, Raku package, (2020-2024), GitHub/antononcube.
[AAp10] Anton Antonov, ML::NLPTemplateEngine, Raku package, (2023-2025), GitHub/antononcube.
[AAp11] Anton Antonov, LLM::RetrievalAugmentedGeneration, Raku package, (2024-2025), GitHub/antononcube.
[AAp12] Anton Antonov, ML::LatentSemanticAnalyzer, Raku package, (2026), GitHub/antononcube.
Repositories[AAr1] Anton Antonov, “Random mandalas deconstruction with R, Python, and Mathematica” presentation project, (2022), SimplifiedMachineLearningWorkflows-book at GitHub/antononcube.
[AAr2] Anton Antonov, “Raku for Prediction” book project, (2021-2022), GitHub/antononcube.
Videos[AAv1] Anton Antonov, “TRC 2022 Implementation of ML algorithms in Raku”, (2022), Anton A. Antonov’s channel at YouTube.
[AAv2] Anton Antonov, “Raku for Prediction”, (2021), The Raku Conference (TRC) at YouTube.
[AAv3] Anton Antonov, “NLP Template Engine, Part 1”, (2021), Anton A. Antonov’s channel at YouTube.
[AAv4] Anton Antonov, “Random Mandalas Deconstruction in R, Python, and Mathematica (Greater Boston useR Meetup, Feb 2022)”, (2022), Anton A. Antonov’s channel at YouTube.
[AAv5] Anton Antonov, “Raku RAG demo”, (2024), Anton A. Antonov’s channel at YouTube.
[AAv6] Anton Antonov, “Sparse matrix neat examples in Raku”, (2024), Anton A. Antonov’s channel at YouTube.