A question that I am very interested in is whether it is possible to study hypergraphs with techniques that are in the spirit of spectral graph theory.
It is generally possible to “flatten” the adjacency tensor of a hypergraph into a matrix, especially if the hypergraph is  -uniform with even, and spectral properties of this matrix give information about the hypergraph, but usually a large amount of information is lost in this process, and the approach can only be applied to rather dense hypergraphs.
-uniform with even, and spectral properties of this matrix give information about the hypergraph, but usually a large amount of information is lost in this process, and the approach can only be applied to rather dense hypergraphs.
If we have a 4-uniform hypergraph with  vertices, for example, meaning a hypergraph in which each hyperedge is a set of four elements, its
vertices, for example, meaning a hypergraph in which each hyperedge is a set of four elements, its 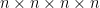 adjacency tensor can be flattened to a
adjacency tensor can be flattened to a 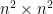 matrix. Unless the hypergraph has a number of hyperedges that is at least quadratic in , however, such a matrix is too sparse to provide any useful information via basic spectral techniques.
matrix. Unless the hypergraph has a number of hyperedges that is at least quadratic in , however, such a matrix is too sparse to provide any useful information via basic spectral techniques.
Recently, a number of results of a “spectral hypergraph theory” flavor have appeared that, instead, apply spectral graph theory techniques to the Kikuchi graph associated to a hypergraph, leading to very impressive applications such as new lower bounds for locally correctable codes.
In this post I would like to show a simple but rather magical use of this approach, that gives a proof of Feige’s conjecture concerning a “Moore bound for hypergraphs”.
In an undirected graph, the girth is the length of the shortest simple cycle, and in the previous post we told the story of trade-offs between density of the graph and girth, such as the Moore bound.
In a hypergraph, an interesting analog to the notion of girth is the size of the smallest even cover, where an even cover is a set of hyperedges such that every vertex belongs to an even number of hyperedges in the set. The reader should spend a minute to verify that if the hypergraph is a graph, this definition is indeed equivalent to the girth of the graph.
To see why this is a useful property, the hyperedges of a -uniform hypergraph with vertex set V can be represented as vectors in  in a standard way: a vector
in a standard way: a vector  represents the set
represents the set  . Under this representation, an even cover is a collection of hyperedges whose corresponding vectors have a linear dependency, so a -uniform hypergraph with vertices,
. Under this representation, an even cover is a collection of hyperedges whose corresponding vectors have a linear dependency, so a -uniform hypergraph with vertices,  hyperedges and such that there is no even cover of size
hyperedges and such that there is no even cover of size  corresponds to a construction of vectors in
corresponds to a construction of vectors in 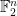 , each of Hamming weight , such that any
, each of Hamming weight , such that any  of them are linearly independent. Having large collections of sparse vectors that don’t have small linear dependencies is useful in several applications.
of them are linearly independent. Having large collections of sparse vectors that don’t have small linear dependencies is useful in several applications.
It is easy to study the size of even covers in random hypergraphs, and a number of results about CSP refutations and SoS lower bounds rely on such calculations. Feige made the following worst-case conjecture:
Conjecture 1 (Moore Bound for Hypergraphs) If a -uniform hypergraph has vertices and  hyperedges, then there must exist an even cover of size
hyperedges, then there must exist an even cover of size 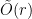
Where the “tilde” hides a polylogn multiplicative factor. For 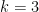 , for example, the conjecture asserts that a hypergraph with vertices and hyperedges must contain an even cover of size
, for example, the conjecture asserts that a hypergraph with vertices and hyperedges must contain an even cover of size  . For
. For  , the bound is
, the bound is  .
.
The Feige conjecture was recently proved by Guruswami, Kothari and Manohar using Kikuchi graphs and their associated matrices. In this post, we will see a simplified proof by Hsieh, Kothari and Mohanty (we will only see the even case, which is much easier to analyze, and we will not prove the case of odd , which is considerably more difficult).
1. A spectral proof of the Moore bound in graphs
We will first provide a spectral proof of the Moore bound for graphs, and then we will use Kikuchi graphs/matrices to lift the argument to hypergraphs.
To see how to use spectral arguments to reason about girth, let us start from the simple case of  -regular graphs. We want to reason about cycles in a graph, and a spectral concept immediately comes to mind: if
-regular graphs. We want to reason about cycles in a graph, and a spectral concept immediately comes to mind: if  is the adjacency matrix of the graph, then
is the adjacency matrix of the graph, then  is the number of closed walks of length in the graph. If the girth of is more than , then none of those closed walks can be, or contain, a cycle, and this restricts how many such walks can exist. All such walks happen within the local tree that surrounds the start node, and the walk can just traverse part of this local tree. Combining these observations suffices to obtain a non-trivial bound.
is the number of closed walks of length in the graph. If the girth of is more than , then none of those closed walks can be, or contain, a cycle, and this restricts how many such walks can exist. All such walks happen within the local tree that surrounds the start node, and the walk can just traverse part of this local tree. Combining these observations suffices to obtain a non-trivial bound.
First of all, if a graph is -regular, we have  and so
and so

and we claim that if the girth is more than we also have

This is because a closed walk of even length , provided that is less than the girth, can be specified by indicating the starting node, of which there are , then for every step of the walk whether we are moving one step closer or one step further from the starting node in the local tree around the node, for which we have 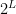 choices to enumerate, and, finally, for the
choices to enumerate, and, finally, for the 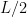 steps in which we move one step further, which edge we follow, for which we have
steps in which we move one step further, which edge we follow, for which we have  choices. When we move closer to the start node, only one edge can be followed and there are no choices to enumerate.
choices. When we move closer to the start node, only one edge can be followed and there are no choices to enumerate.
Combining the bounds and taking -th roots, we have  , which gives the weak but respectable Moore-like bound
, which gives the weak but respectable Moore-like bound

The next step is to make such an argument work for irregular graphs. We would again like to reason in terms of the trace of the power of a matrix, to relate it to counting closed walks, and to show that the count is small if the girth is large. We will need, however, to find the proper normalization, because we cannot use just the adjacency matrix any more.
If is the adjacency matrix of an irregular graph  of average degree
of average degree  and
and  is the diagonal matrix of degrees of , so that
is the diagonal matrix of degrees of , so that 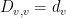 is the degree of vertex
is the degree of vertex  , a common normalization is to look at the matrix
, a common normalization is to look at the matrix  , or to the symmetric matrix
, or to the symmetric matrix  , which has the same trace and eigenvalues. This is also the transition matrix of the random walk in , so that when we study the trace of powers of this matrix we end up considering the probability that a random walk of a certain length returns to the start vertex. We also know that
, which has the same trace and eigenvalues. This is also the transition matrix of the random walk in , so that when we study the trace of powers of this matrix we end up considering the probability that a random walk of a certain length returns to the start vertex. We also know that

so that for every

If we try to analyze the trace of powers of this matrix, however, we run into some technical difficulties, that are greatly simplified by a neat trick which is not totally natural and that I will try to justify.
Let us think about the regular case as analyzed above, except that we work with  for consistency. The division by contributes a
for consistency. The division by contributes a  term to the trace of the -th power, so we “gain” a factor of
term to the trace of the -th power, so we “gain” a factor of 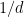 in each step. We lose it almost entirely when we do a step away from the start node, because we have to account for choices, but we gain it entirely when we take a step closer to the start node, because that is a forced move for which we do not need to enumerate choices. We end up gaining a factor of for each backward step, of which there are , and so we can cleanly say that the trace goes down by a factor of
in each step. We lose it almost entirely when we do a step away from the start node, because we have to account for choices, but we gain it entirely when we take a step closer to the start node, because that is a forced move for which we do not need to enumerate choices. We end up gaining a factor of for each backward step, of which there are , and so we can cleanly say that the trace goes down by a factor of  . We pay for the choice of the start vertex and for the choice of when to go forward and when to backward, and the overall bound is
. We pay for the choice of the start vertex and for the choice of when to go forward and when to backward, and the overall bound is  which becomes
which becomes  when we take the -th root.
when we take the -th root.
The difficulty in replicating this argument with the same cleanliness in the irregular case is that, when we are enumerating what can happen when the closed walk passes through a vertex , the gain from a backward step from is  , which could be much larger than
, which could be much larger than  , and it is not straightforward how to “average” things, because we are multiplying terms that are not independent.
, and it is not straightforward how to “average” things, because we are multiplying terms that are not independent.
It would certainly be very convenient if the normalization in a step from vertex was such that we always gain a factor that is both smaller than , to have a proper account of the backward steps, and smaller than to account for the possible forward steps.
The trick is simply to enforce that with a different normalization: instead of working with  or , we define
or , we define  and work with
and work with  and
and  . With this normalization, a step backward from contributes
. With this normalization, a step backward from contributes  which is certainly less than while the enumeration of steps forward can still not exceed a contribution of 1.
which is certainly less than while the enumeration of steps forward can still not exceed a contribution of 1.
The only concern about this new normalization is that we divide by a larger matrix and this could cause its norm to drop too much, but fortunately the norm is essentially preserved, as we can see by using the test vector  .
.
We have that the quadratic form is

while the norm squared of the test vector is

so that we have a good lower bound on the norm

To bound the trace of our normalized matrix, we perform a similar enumeration as the one we did in the regular case. We have to enumerate all closed walks  where
where  and the edge
and the edge  exists for
exists for  . We have choices for the start vertex
. We have choices for the start vertex 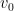 and then choices for whether, at each step, we move one step closer to the start vertex in the local tree, in a unique way, or one step forward, in one of
and then choices for whether, at each step, we move one step closer to the start vertex in the local tree, in a unique way, or one step forward, in one of  possible ways. We will denote by
possible ways. We will denote by  the set containing the unique neighbor of
the set containing the unique neighbor of  that is one step closer to the start vertex in the local tree of the start vertex, and by
that is one step closer to the start vertex in the local tree of the start vertex, and by  the set containing the
the set containing the  neighbors of
neighbors of 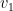 that are one step further. If
that are one step further. If  represents the binary choice of whether to move further or closer to the start vertex in the walk from node , then
represents the binary choice of whether to move further or closer to the start vertex in the walk from node , then  is the set of choices that we have to enumerate.
is the set of choices that we have to enumerate.
With this notation we can write the trace as
![\displaystyle \begin{array}{rcl} & & {\rm tr}( (\Gamma^{-1} A)^L) \\ & = & \sum_{b \in \{ 0,1\}^L} \sum_{v_0 \in [n]} \sum_{v_1 \in N_{b_0}(v_0)}\Gamma^{-1}_{v_0,v_0} \ldots \\ & & \hspace{20pt} \sum_{v_{L-1} \in N_{b_{L-2}} (v_{L-2}) }\Gamma^{-1} _ { v_{L-2} ,v_{L-2} } \cdot {\bf 1}(v_0 \in N_{b_{L-1}} (v_{L-1})) \cdot \Gamma_{v_{L-1},v_{L-1}} \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D+%26+%26+%7B%5Crm+tr%7D%28+%28%5CGamma%5E%7B-1%7D+A%29%5EL%29+%5C%5C+%26+%3D+%26+%5Csum_%7Bb+%5Cin+%5C%7B+0%2C1%5C%7D%5EL%7D+%5Csum_%7Bv_0+%5Cin+%5Bn%5D%7D+%5Csum_%7Bv_1+%5Cin+N_%7Bb_0%7D%28v_0%29%7D%5CGamma%5E%7B-1%7D_%7Bv_0%2Cv_0%7D+%5Cldots+%5C%5C+%26+%26+%5Chspace%7B20pt%7D+%5Csum_%7Bv_%7BL-1%7D+%5Cin+N_%7Bb_%7BL-2%7D%7D+%28v_%7BL-2%7D%29+%7D%5CGamma%5E%7B-1%7D+_+%7B+v_%7BL-2%7D+%2Cv_%7BL-2%7D+%7D+%5Ccdot+%7B%5Cbf+1%7D%28v_0+%5Cin+N_%7Bb_%7BL-1%7D%7D+%28v_%7BL-1%7D%29%29+%5Ccdot+%5CGamma_%7Bv_%7BL-1%7D%2Cv_%7BL-1%7D%7D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
In order to bound the above expression, we see that we have choices for  , then choices for , and for each of the steps from a vertex in which we go backward we have a term
, then choices for , and for each of the steps from a vertex in which we go backward we have a term  which is
which is  ; for each of the steps from a vertex in which we go forward we have branches, but each multiplied by
; for each of the steps from a vertex in which we go forward we have branches, but each multiplied by  so that the total contribution is less than 1.
so that the total contribution is less than 1.
Overall we can say

so that rearranging and taking -th roots we have

that is also equivalent to

which is again a respectable Moore-like bound for irregular graphs.
A final note about this spectral argument is that  can still be seen as the transition matrix of a sort of random walk, that is, one that from has a probability
can still be seen as the transition matrix of a sort of random walk, that is, one that from has a probability  of stopping, and probability
of stopping, and probability  of proceeding through each neighbor of . The trace of the -th power of
of proceeding through each neighbor of . The trace of the -th power of  computes, up to a factor of , the collision probability of the distribution of the
computes, up to a factor of , the collision probability of the distribution of the  -th step of this walk starting from a random vertex, and the negative logarithm of this probability is called the Renyi entropy of the distribution. This is all to say that this spectral argument is not totally unrelated to the argument in the previous post, in which we computed the entropy of a non-backtracking random walk started at a random vertex.
-th step of this walk starting from a random vertex, and the negative logarithm of this probability is called the Renyi entropy of the distribution. This is all to say that this spectral argument is not totally unrelated to the argument in the previous post, in which we computed the entropy of a non-backtracking random walk started at a random vertex.
2. Kikuchi matrices and hypergraphs
We now come to the magic of this post, where we define Kikuchi graphs and associated matrices, and we see how to transfer spectral graph theory techniques to hypergraphs.
If ![{H= ([n],F)}](https://s0.wp.com/latex.php?latex=%7BH%3D+%28%5Bn%5D%2CF%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) is a -uniform hypergraph with vertices, even, and if we select an integer parameter
is a -uniform hypergraph with vertices, even, and if we select an integer parameter  , the Kikuchi graph associated to
, the Kikuchi graph associated to  and
and  is a graph
is a graph 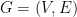 with
with  vertices defined as follows. We think of each vertex of as a set
vertices defined as follows. We think of each vertex of as a set  of vertices of ; if
of vertices of ; if  is a hyperedge of , then for every set of vertices we have the edge
is a hyperedge of , then for every set of vertices we have the edge  in , where we use
in , where we use 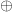 to denote symmetric difference between sets. In other words, the edges of are the pairs of sets of vertices of whose symmetric difference is a hyperedge of .
to denote symmetric difference between sets. In other words, the edges of are the pairs of sets of vertices of whose symmetric difference is a hyperedge of .
This feels a lot like a Cayley graph, and in fact it can be seen as a vertex-induced subgraph of a Cayley graph, but this would not give a very enlightening perspective on the content of this post, so we will not pursue this concept furhter.
Necessarily, in an edge 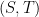 of the Kikuchi graph corresponding to an hyperedge
of the Kikuchi graph corresponding to an hyperedge  , the sets and
, the sets and  must each contain
must each contain 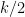 vertices of each, and so the construction as described only works for hypergraphs where the hyperedge cardinality is even. We already mentioned that everything becomes considerably more complex in the odd case, which we will not deal with.
vertices of each, and so the construction as described only works for hypergraphs where the hyperedge cardinality is even. We already mentioned that everything becomes considerably more complex in the odd case, which we will not deal with.
For each hyperedge of , there are  choices of a set containing vertices of of which are from . Overall, if has hyperedges, is going to have
choices of a set containing vertices of of which are from . Overall, if has hyperedges, is going to have

undirected edges (the factor of 2 comes from the fact that without it we would count  and
and  as two different edges while it is the same undirected edge).
as two different edges while it is the same undirected edge).
If  , then the Kikuchi graph construction is analogous to the standard “flattening” of a tensor to a matrix or of a hypergraph to a graph, and it is not immediately clear from the definitions what is gained by choosing a larger and obtaining a larger graph that only seems more redundant and more complex to analyze.
, then the Kikuchi graph construction is analogous to the standard “flattening” of a tensor to a matrix or of a hypergraph to a graph, and it is not immediately clear from the definitions what is gained by choosing a larger and obtaining a larger graph that only seems more redundant and more complex to analyze.
An important gain is that for larger the resulting graph is denser. Indeed the average degree of the Kikuchi graph is

and one can see that for  and
and  the bound
the bound

holds, showing how larger choices of yield denser graphs.
What about even covers and Feige’s conjecture? Suppose does not have even covers of size , and let us look at a length- closed walk  in , where
in , where  and the edges
and the edges  exist in for each step of the walk. Let us call
exist in for each step of the walk. Let us call 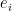 the hyperedge of corresponding to the edge , so that we have
the hyperedge of corresponding to the edge , so that we have  . The key observation is that, iterating the definitions of the edges we have
. The key observation is that, iterating the definitions of the edges we have

but we also have  and so
and so

From the multiset of hyperedges  let us repeatedly remove pairs of identical hyperedges: this process will terminate either with a set of hyperedges occurring each once, or with an empty collection of hyperedges. The former case cannot happen, however, because this set of hyperedges would be a double cover of cadinality less than , so the process must terminate with an empty set, meaning that the multiset
let us repeatedly remove pairs of identical hyperedges: this process will terminate either with a set of hyperedges occurring each once, or with an empty collection of hyperedges. The former case cannot happen, however, because this set of hyperedges would be a double cover of cadinality less than , so the process must terminate with an empty set, meaning that the multiset  is such that every hyperedge occurs an even number of times.
is such that every hyperedge occurs an even number of times.
Maybe it is not clear where we are going with this, but we have made all the key observations to be ready to prove the Feige conjecture, because we have related lack of even covers in the hypergraph with restricted properties of closed walks in the associated Kikuchi graph, and we already have spectral techniques that can be applied when we understand restrictions on closed walks in a graph.
3. Proof of the Feige Conjecture
The Feige conjecture will follow from the bounds formalized below:
Lemma 1 (Main) Let be an order , even, hypergraph with vertices and edges. Suppose that there is no even cover of size in . Construct the Kikuchi graph of with parameter , where  . Let be the adjacency matrix of , let be its diagonal matrix of degrees, let be the average degree of , define . Then
. Let be the adjacency matrix of , let be its diagonal matrix of degrees, let be the average degree of , define . Then

We already proved the first two inequalities. To deal with the last one we will enumerate the closed walks of length in .
To enumerate all length- closed walks  with , we call the hyperedge associated to the edge , and we again associate a vector
with , we call the hyperedge associated to the edge , and we again associate a vector  to each walk, but this time
to each walk, but this time 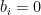 when the hyperedge is old, meaning it has already appeared in the sequence
when the hyperedge is old, meaning it has already appeared in the sequence  as some
as some 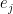 with
with  . We let
. We let  if the hyperedge is new, meaning that it appears for the first time in the sequence .
if the hyperedge is new, meaning that it appears for the first time in the sequence .
Note that now the Kikuchi graph does not necessarily have large girth: for example it is easy to see that it has a lot of length-4 cycles. From the discussion in the previous section, however, we know that the sequence is such that every hyperedge that appears in the sequence appears an even number of times and, in particular, the sequence involves at most distinct hyperedges. This will be enough to obtain the claimed upper bound on the trace.
Analogously with the notation used in the previous section, We let  be the set of neighbors of
be the set of neighbors of 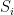 that are possible as a next step of the closed walk assuming that the step corresponds to an old hyperedge and
that are possible as a next step of the closed walk assuming that the step corresponds to an old hyperedge and  the set of neighbors of that are possible as a next step of the closed walk assuming that the step corresponds to a new hyperedge.
the set of neighbors of that are possible as a next step of the closed walk assuming that the step corresponds to a new hyperedge.
With this notation, we can write the trace as
![\displaystyle \begin{array}{rcl} & & {\rm tr}( (\Gamma^{-1} A)^L) \\ & = & \sum_{b \in \{ 0,1\}^L} \sum_{S_0 \in {[n] \choose r}} \sum_{S_1 \in N_{b_0} (S_0)} \Gamma^{-1} _{S_0,S_0} \ldots \\ & & \hspace{15pt} \sum_{S_{L-1} \in N_{b_{L-2}} (S_{L-2}) }\Gamma^{-1} _{S_{L-2}, S_{L-2} } \cdot {\bf 1}( S_0 \in N_{b_{L-1}} (S_{L-1}) ) \cdot \Gamma^{-1} _{S_{L-1}, S_{L-1} } \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D+%26+%26+%7B%5Crm+tr%7D%28+%28%5CGamma%5E%7B-1%7D+A%29%5EL%29+%5C%5C+%26+%3D+%26+%5Csum_%7Bb+%5Cin+%5C%7B+0%2C1%5C%7D%5EL%7D+%5Csum_%7BS_0+%5Cin+%7B%5Bn%5D+%5Cchoose+r%7D%7D+%5Csum_%7BS_1+%5Cin+N_%7Bb_0%7D+%28S_0%29%7D+%5CGamma%5E%7B-1%7D+_%7BS_0%2CS_0%7D+%5Cldots+%5C%5C+%26+%26+%5Chspace%7B15pt%7D+%5Csum_%7BS_%7BL-1%7D+%5Cin+N_%7Bb_%7BL-2%7D%7D+%28S_%7BL-2%7D%29+%7D%5CGamma%5E%7B-1%7D+_%7BS_%7BL-2%7D%2C+S_%7BL-2%7D+%7D+%5Ccdot+%7B%5Cbf+1%7D%28+S_0+%5Cin+N_%7Bb_%7BL-1%7D%7D+%28S_%7BL-1%7D%29+%29+%5Ccdot+%5CGamma%5E%7B-1%7D+_%7BS_%7BL-1%7D%2C+S_%7BL-1%7D+%7D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
We have choices for and  choices for
choices for 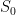 . For each step
. For each step  of the walk, if
of the walk, if  and the step uses an old hyperedge, then
and the step uses an old hyperedge, then  has at most
has at most  possibilities, corresponding to hyperedges that have been seen so far in the walk and that can be repeated. Each choice contributes a value of
possibilities, corresponding to hyperedges that have been seen so far in the walk and that can be repeated. Each choice contributes a value of  , for a total contribution that is at most
, for a total contribution that is at most  . Because all hyperedges that are used in the walk are used an even number of times, there have to be at least steps in which we have an old hyperedge. When and we have a new hyperedge at step , then
. Because all hyperedges that are used in the walk are used an even number of times, there have to be at least steps in which we have an old hyperedge. When and we have a new hyperedge at step , then  can be at most the set of all
can be at most the set of all  neighbors of , and each contributes a value of
neighbors of , and each contributes a value of  so that the total contribution is less than one. This proves the claimed upper bound
so that the total contribution is less than one. This proves the claimed upper bound

and establishes the Main Lemma.
After taking -th roots, the Main Lemma says that

We instantiate the construction to

which makes  , so that the Main Lemma implies
, so that the Main Lemma implies  . Recall that we also proved
. Recall that we also proved
which combines to

or, equivalently, we have proved the upper bound

provided that there is no even cover of size  , which is precisely the Feige conjecture.
, which is precisely the Feige conjecture.
Without all the commentary that we added, the even case of the Feige conjecture, already a significant problem that had been open and challenging for a while, is solved in half a page of simple calculations. The magic of the Kikuchi graph comes in the very simple way that even covers in the hypergraph translate to restrictions to what closed walks can look like in the associated graph, and these are restrictions that are usefully exploitable in trace arguments.
As we remarked, something else that is also very useful in the connection is that the size of the sets corresponding to vertices in the Kikuchi graph is a parameter that we can control, and it “densifies” the graph the more it is turned up.
The odd case is considerably more involved, and it is where all the major work is done, though the even case already gives a glimpse of the power of these techniques.
I would like to remark that several technical steps above are taken verbatim from the paper of Hsieh, Kothari and Mohanty, as they are already as simplified and clear as they can be. I want to thank Lucas Pesenti for having explained this proof to me.

 , and we perform a BFS in it starting from any vertex, and we stop it after no more than
, and we perform a BFS in it starting from any vertex, and we stop it after no more than 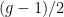 hops, then we are guaranteed to keep finding new vertices at every step of the exploration: if we had two paths of length at most
hops, then we are guaranteed to keep finding new vertices at every step of the exploration: if we had two paths of length at most  . If the graph is
. If the graph is 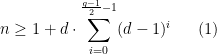
 levels of a complete
levels of a complete  .
.  ? It took about 30 years for this question to be positively resolved by Alon, Hoory and Linial.
? It took about 30 years for this question to be positively resolved by Alon, Hoory and Linial.  edges, where
edges, where  , and we would like to say that
, and we would like to say that  .
.
 , consider the distribution of a random node
, consider the distribution of a random node  .
.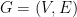 , the non-backtracking random walk is the probabilistic process where, at every step, we keep track of the vertex
, the non-backtracking random walk is the probabilistic process where, at every step, we keep track of the vertex  where we were at the previous step, and, for the next step, we choose a new vertex
where we were at the previous step, and, for the next step, we choose a new vertex  among the neighbors of
among the neighbors of  . The transition rules are that we have transitions of the form
. The transition rules are that we have transitions of the form  , where
, where  are pairs of edges of
are pairs of edges of  , where we use
, where we use 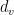 the denote the degree of a vertex
the denote the degree of a vertex  , then you will explore a random path and reach a random leaf in one of the local trees that we are interested in, so this is indeed the process that we want.
, then you will explore a random path and reach a random leaf in one of the local trees that we are interested in, so this is indeed the process that we want. , and we would like to say that the expectation over
, and we would like to say that the expectation over 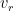 given
given  . We will now prove that and we will interleave the chain of equalities and inequalities with explanations:
. We will now prove that and we will interleave the chain of equalities and inequalities with explanations:



 given the previous vertices is just the uniform distribution of the neighbors of
given the previous vertices is just the uniform distribution of the neighbors of  with the exception of
with the exception of  , so it is a uniform distribution over
, so it is a uniform distribution over  possibilities, whose entropy is clearly
possibilities, whose entropy is clearly  . The expectation is over the process of selecting the walk. Recall that the walk process is such that, at each step, the “current vertex” always has the same distribution, so, calling
. The expectation is over the process of selecting the walk. Recall that the walk process is such that, at each step, the “current vertex” always has the same distribution, so, calling 

 , and we have
, and we have 






