Welcome back to Audio 101! We explore the audio world in simple words here, while shooting down myths. Last time, we looked at codecs, uncompressed lossless, and compressed lossless. I hope you're all cleared up on those topics. Today, we'll learn about bitrates, human hearing, lossy audio, and transparency. Lossy audio is one of the most controversial topics in the audio world, full of misinformation.
Bitrate is the amount of data used to store one second of audio. Kilobits are the units used most commonly. A bit holds one binary value: 0 or 1. A kilobit is 1000 bits. In an audio file, if we allocate 320 kilobits of data per second of audio, that's 320kbps (kilobits per second) bitrate audio. A 16-bit, 44.1 kHz FLAC file would have 1,411 kbps.
Now that that's out of the way, lossy audio. What even is lossy audio?
Lossy audio, or lossy codecs to be precise, are optimized for human hearing. As we've all read in school, the human hearing range is from 20 Hz to 20 kHz. This is not the full picture.
Our hearing starts rapidly declining after 15 kHz. We start out with good hearing as kids. As we age, it gets worse. I bet most of you reading this can't hear above 17 kHz. Your audio gear and the environment you're in do play a part, but it's not as massive a difference as you'd think. You can test your hearing (and your audio setup) at this site.
You can hear some sounds better than others. Some sounds are simpler, some more complex. That's what lossy codecs optimize for. They calculate which parts you're least likely to hear and dump them. Lossless codecs store everything, regardless of human hearing constraints.
In lossy compression, we have a concept called transparency. Transparency is the threshold/point at which lossy audio becomes indistinguishable from lossless audio. Everyone has different hearing, different setups, etc., so when we say transparent, we mean for 99.9%.
You can verify if typical lossy audio is transparent to you by taking a double-blind ABX test. You must do 20 rounds per song and get a score of >90% to pass an ABX test. You can take a quick test at this site.
From this point on, when I talk about lossy audio, assume that I mean transparent lossy audio. Also assume that I'm talking about quality purely from a listening context. Unless I explicitly state otherwise.
Lossy codecs include MP3, AAC, Vorbis, Opus, etc. Each codec differs in which parts it decides to keep and which to dump. Some codecs reach transparency at lower bitrates than others. In other words, unlike lossless codecs, some lossy codecs are better than others. It's a competition!
Let's bust some myths.
"You can hear more instruments in lossless audio." Myth. Lossy encoders don't "remove" instruments.
"Lossy audio sounds obviously distorted." Myth. "Lossless audio is clearly better." Myth. "Lossless audio sounds way cleaner". Myth.
Modern codecs are highly efficient. The differences are extremely subtle. To tell the difference, you have to study how different codecs compress different sounds. You have to study how compression artefacts sound. Most don't have the hearing or the high-end setups needed.
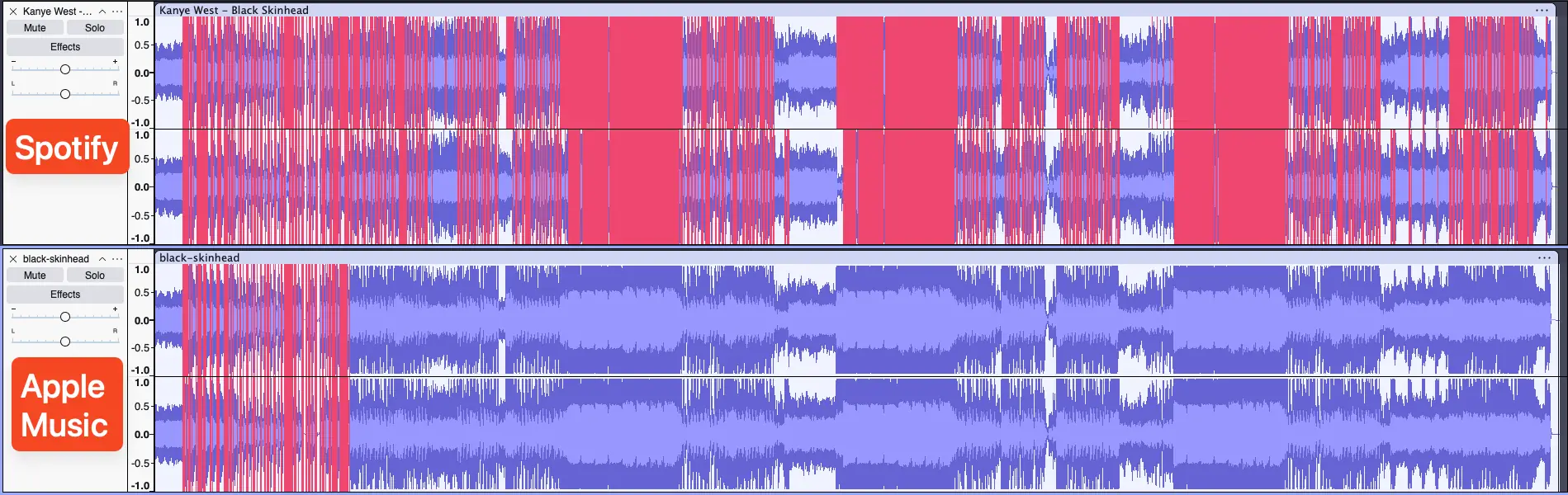
A good teacher gives good homework, and I'm not me without bashing Apple Music every now and then. Go listen to the first 10 seconds Black Skinhead on Apple Music, in your hi-res lossless 48-bit 192 kHz ALAC quality or whatever. Compare it to Spotify or YouTube Music. You don't even need premium for Spotify or YTM, the quality they offer for free is fine. Do it right now.

What's that? AM sounds worse? The drums are distorted to hell and back? Shocked? "There's no way Apple Music's lossless quality sounds worse than Spotify's 160kbps Vorbis!" Oh, but it can. Because lossy audio doesn't matter as much as you've been made to believe. (Also, the real reason is Apple Music is the worst DSP when it comes to picking masters.)
Two to three decades ago, lossy codecs weren't good at deciding what to keep and what to dump. This is where all the "lossy bad, lossless good" arguments and myths come from. It used to be true. There were stricter bandwidth constraints too, so bitrates were typically low. They struggled even at high bitrates. Lossy codecs have gotten way better since then.
One more factor that contributes to this problem is that converting a lossy file to another lossy file degrades quality, unlike lossless files. We call this generational loss. BUT, there are some codecs that don't have this problem anymore for inter-codec conversions. That is, if you take a lossy AAC file and convert it to another lossy AAC file, there's no perceivable loss in quality.
An audiophile conducted an experiment back in 2013. He converted the same file over and over 100 times to check for quality loss. Apple's AAC implementation and Nero's AAC implementation were both proven to have near-zero perceivable difference from the source file, after 100 passes.
This means, generational loss is not something to worry about if you're using AAC. It sounded almost exactly the same to audiophiles with a proper setup, after 100 passes, in 2013. It's definitely not distinguishable after a single pass to me and you, especially with encoders we have today. We'll look at spectrals later in this post.
Wait, Apple AAC and Nero AAC? There are two AAC implementations? Yes. Lossy codecs can have multiple implementations. For example, there are 9 different implementations of AAC (Apple's being the best), and that's not even getting into different object types. All you need to know is that implementations can vary a lot for the same codec. Newer versions of the same implementations are better.
Following along so far? We have pictures down below!
Most modern codecs reach transparency at 192kbps to 256kbps. This includes MP3, Vorbis, AAC, etc. Opus, the "new" kid on the block, needs much less. It's one of the most efficient codecs we have. YouTube uses Opus at ~140kbps for its videos. But what do I mean by ~140kbps? Is it not fixed?
We have three modes for bitrates: CBR (constant bitrate), VBR (variable), and ABR (average). With CBR, the bitrate remains constant throughout the file. No matter how simple or how complex the sound is, if you tell it to encode in 320kbps, it will. With VBR, you set a target quality, and the bitrate will vary throughout the file to achieve that quality. Bitrate goes down when the audio is simple, goes up when it is complex. ABR is a mix of both. It's inferior and largely irrelevant, so I won't get into it. Most encoders don't use it. VBR is the most efficient.
Spotify offers 320kbps OGG Vorbis (enable "very high" in audio quality settings), Apple Music offers 256kbps AAC, YouTube Music offers 256kbps AAC and Opus ~140kbps (enable "always high" in audio quality settings).
That's enough text. Boring. Let's look at some pictures!
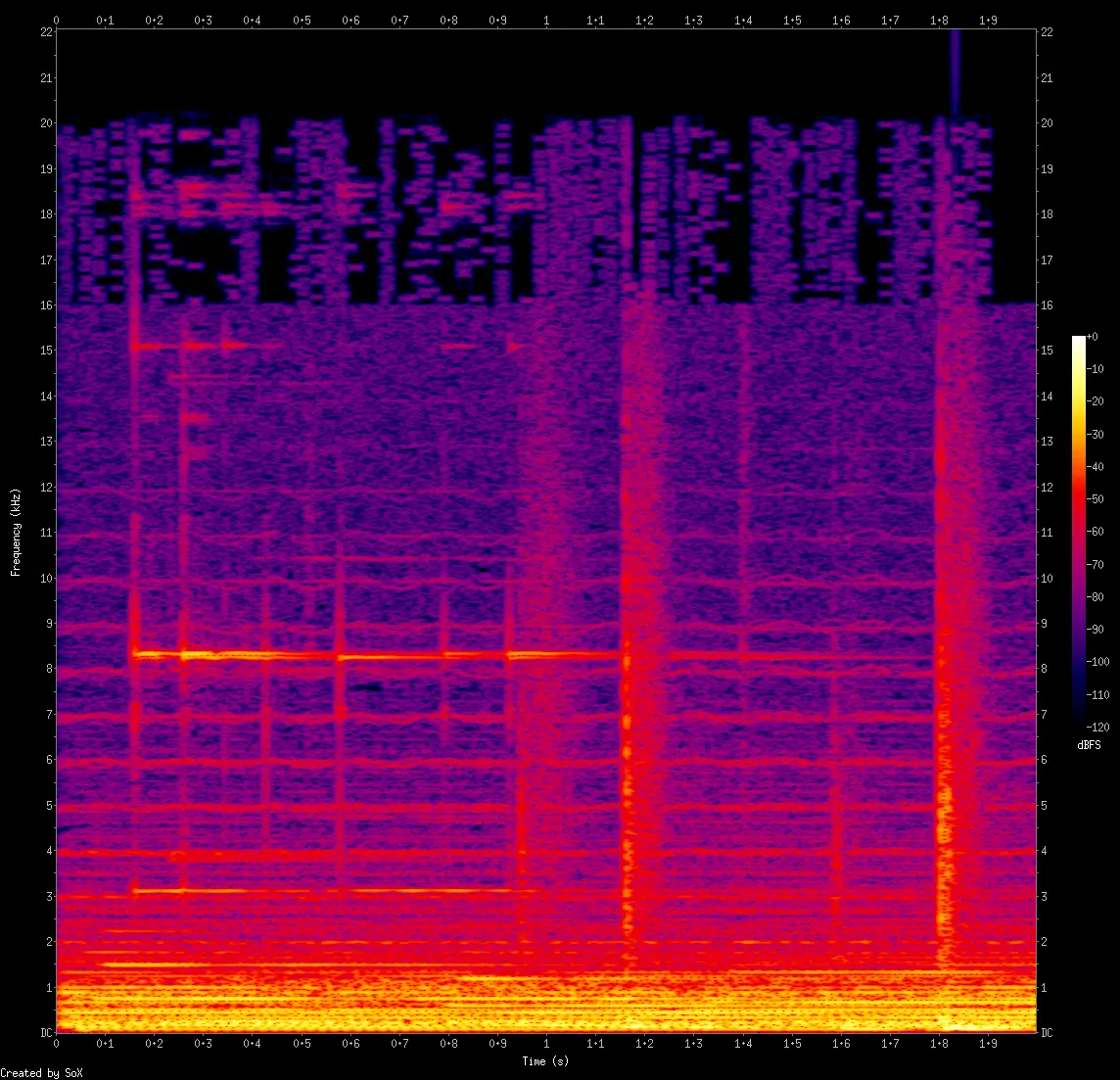
The song I'm choosing today is The Great Gig in the Sky by Pink Floyd (specifically the 1983 Japan Black Triangle CD master). It's an audiophile favourite. We're going to look at spectrograms (spectrals for short). What are they? It's a big topic, one that I'll cover in a future issue. But for now, all you need to know is that they're a way to visualize the audio data. Black is silence. The brighter the colour, the louder the sound in that region.
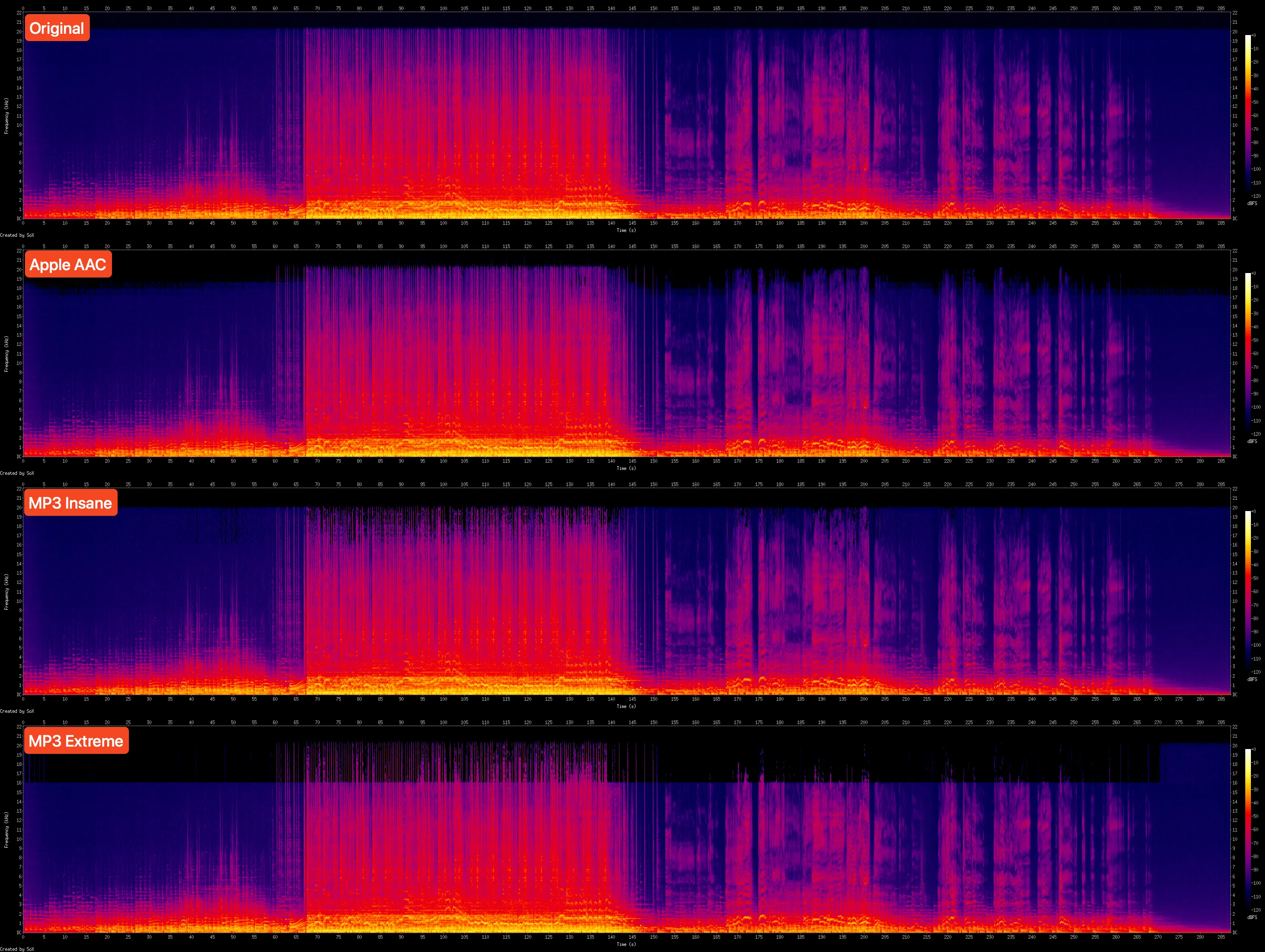
Zoom in and check the upper regions of each spectral. See how Apple's AAC encoder optimizes it. Compare LAME MP3's 320kbps CBR (--preset insane) to ~256kbps VBR mode (--preset extreme). Keep in mind that your hearing drops rapidly past 16 kHz; it needs to be really loud beyond that point for you to even barely hear.
MP3 has a clear cutoff at 16 kHz. It only retains the loudest data beyond that point. You can see it's not perfect, but it won't matter to most of our population. Apple AAC handles it way better than LAME MP3 (insane preset), all while using lower bitrates. But both are indistinguishable to most.
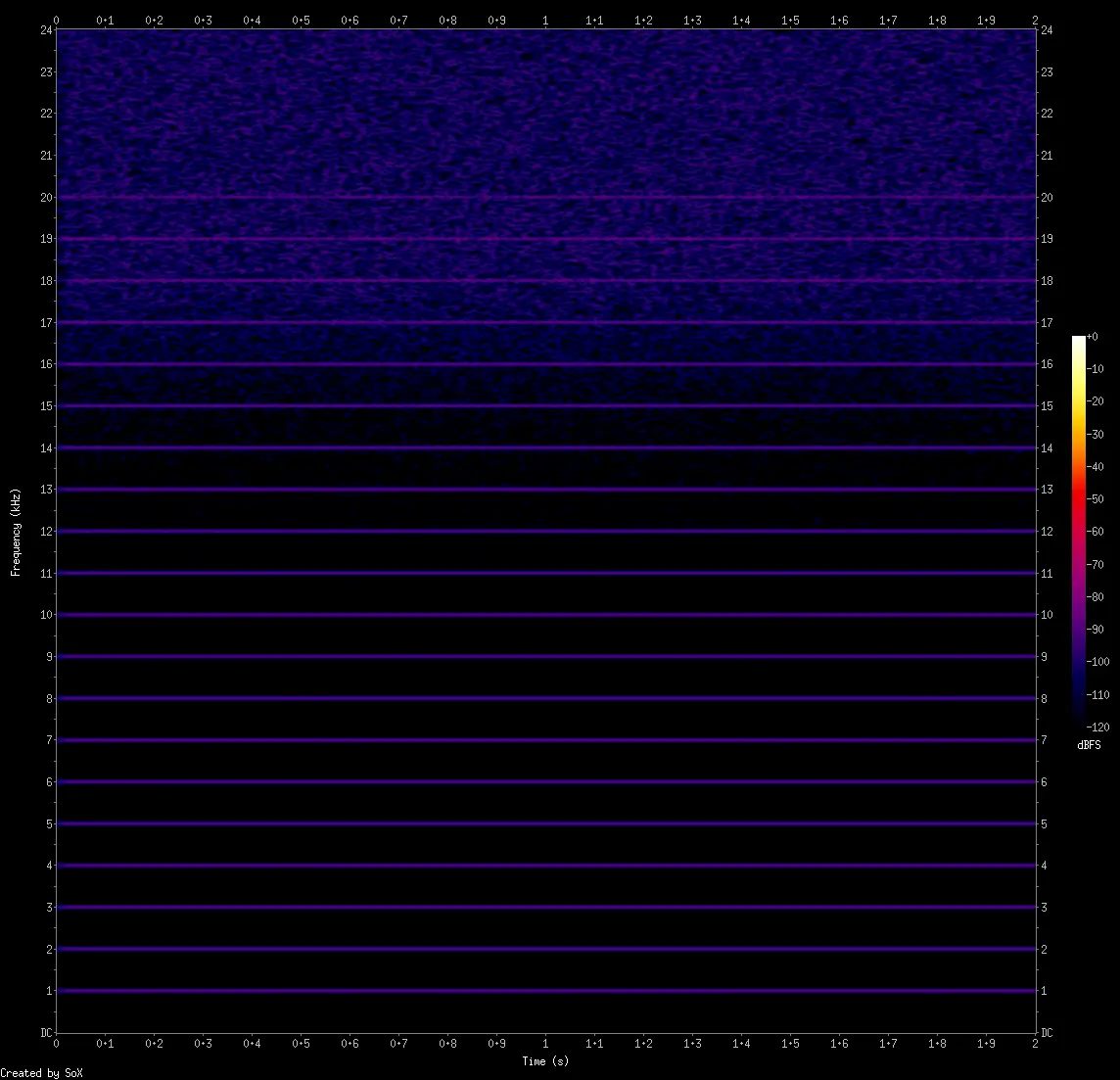
Opus spectrals:
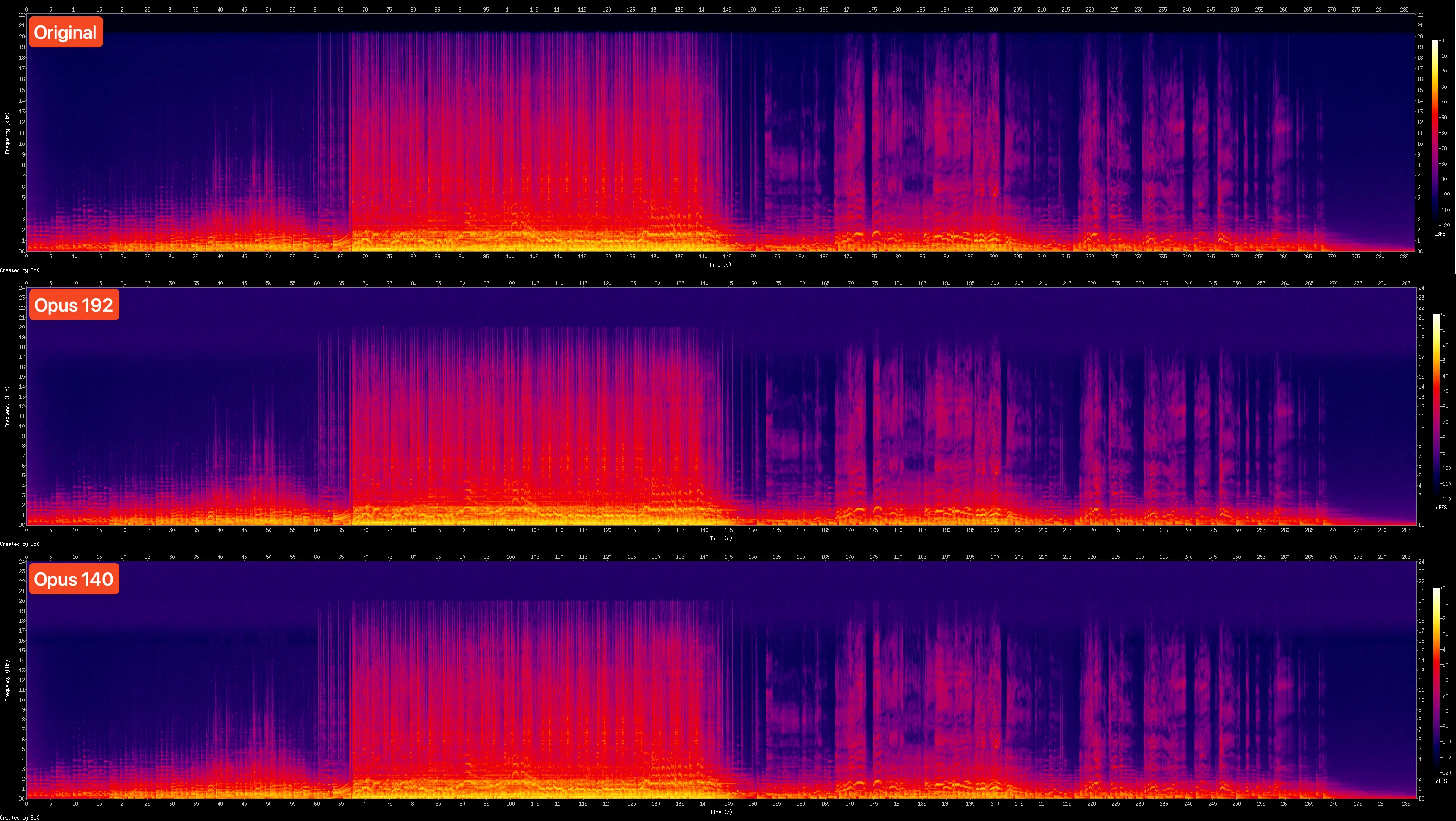
Opus resamples everything to 48 kHz, that's why you see the y-axis extended to 24 kHz. Opus is clearly far more efficient than Apple AAC. So why do I not use it for my delimited music uploads? Raw efficiency is not the only aspect. Compatibility, computational cost, generational loss, they're all important factors.
Bluetooth supports AAC. Anything you play over Bluetooth will always get transcoded (converted) to its codec, regardless of the source codec being the same. AAC has no perceivable generational loss, so that's a major win.
Before you come at me, yes, Spotify's OGG Vorbis gets transcoded as well. There is generational loss, but it's not perceivable.
Here's a spectrogram comparison of a song ripped from Spotify (OGG Vorbis 320kbps) vs. the same song transcoded to Apple AAC at 256kbps. That's the bitrate at which AAC caps out for Bluetooth.
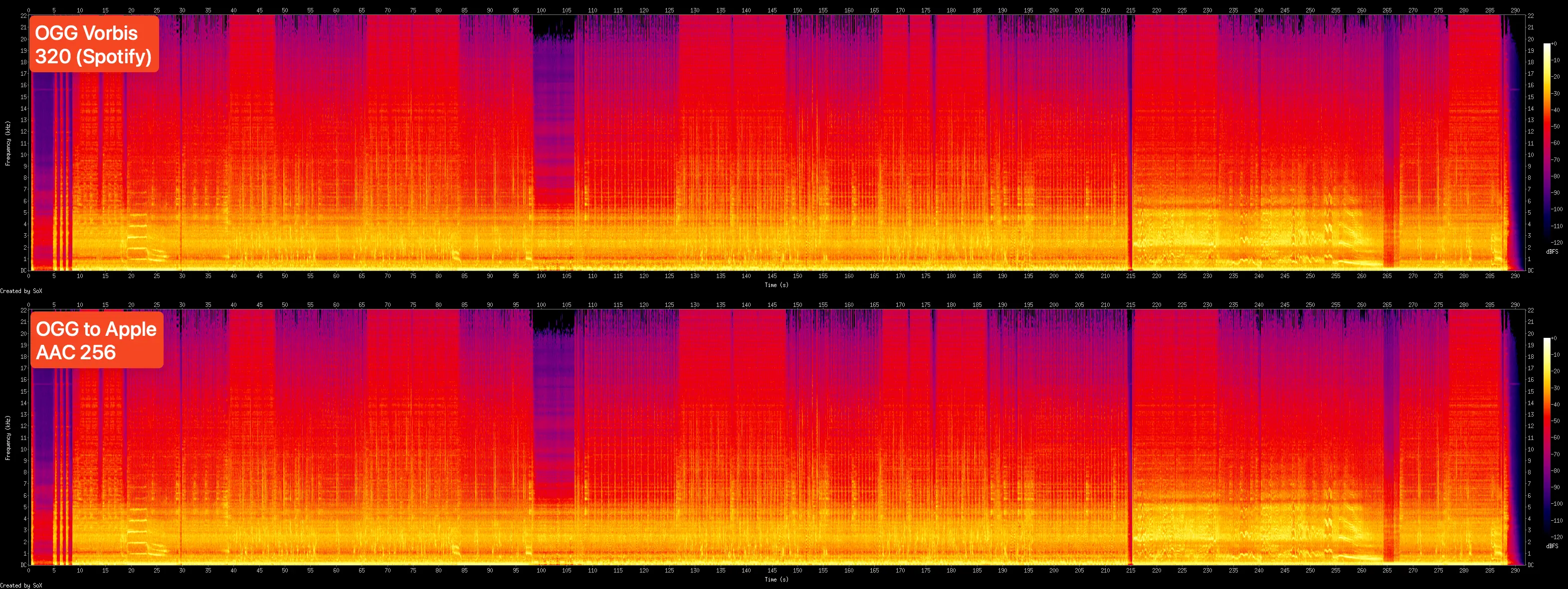
If you use ANY Bluetooth audio device, never engage in lossless vs lossy arguments because your gear is stupid. It doesn't matter even if it supports LDAC; it's not stable, and there will be transfer loss. Oh, and, all Apple Airpods models only support 256kbps AAC. "I can clearly hear the difference between lossless and lossy on my Airpods Pro!" You cannot.
When I took questions for this post, Unghost asked me, "If internet speeds are getting faster and storage is getting cheaper, why do we still need lossy audio?" Excellent question.
For storage and archival, you should always use lossless formats. I talked about this in the previous issue. As for the network aspect, think about latency. As I said earlier, FLAC files have a bitrate of 1,411 kbps or more. If I'm streaming this, it will be at least 4 times slower than a 256kbps AAC or a 320 OGG Vorbis stream.
Internet might be cheap for us, but imagine the bandwidth and load that streaming services have to bear. At least 4 times what they're handling currently. That is not cheap. On-device cache will be bigger, too. I can store 5 albums in lossy formats instead of 1 album in lossless format (again, for listening/streaming and not for archival).
Why should they, or you, bother with lossless audio and all the problems that come with it, when lossy audio is indistinguishable for 99.9% of users? It's cheaper and efficient, all while sounding the same. I've already talked about hi-res lossless (>44.1 kHz) audio introducing noise at the upper frequencies. 24-bit audio is completely useless for listening, too. Check my profile's highlights if you're curious.
If you're an outlier who can pass a double-blind ABX test, you shouldn't be using a streaming service in the first place. You have the hearing (and clearly, expensive audio gear) to appreciate the better masters that CDs tend to have. Heck, you probably remaster your favourite albums yourself.
So, which one is better, lossless or lossy? Considering only audio-quality and leaving out every other factor, then yes, lossless is obviously better. The real questions come up when you consider all the other factors.
Is your hearing that good? Do you have expensive, high-end hardware? Do you have a pristine, clinical environment? Are you always listening to music in that environment? Do you know what to look out for to differentiate lossless and lossy audio? Have you proven to yourself that you can, by passing a 20-round ABX test with >90% scores?
Lossy audio is way more than good enough for you. If you can't tell the difference, what does it matter? If you need me to tell you which one is better, what does it matter? At the end of the day, if you're loving the music and can't tell the difference, it doesn't matter.
To summarize all of this: your hearing is not as good as you think. Lossy codecs take advantage of this fact and optimize for it. Opus is the most efficient codec, Apple AAC is the best overall. You don't have skin in the game if you have Bluetooth. Airpods only support 256kbps AAC, and for good reason. Lossy audio has many practical benefits over lossless audio. If you can pass a double-blind ABX test for lossless vs lossy codecs, you shouldn't be using streaming services.
TLDR: Stick to Spotify.
Until next time! Cheers! <3