Back in October, I wrote “Schneier on LLM vulnerabilities, agentic AI, and ‘trusting trust'” about fundamental architectural weaknesses in current LLMs and agents, and why I personally don’t yet trust AI agents with my credentials. At the end, I wrote: I love AI and LLMs. I use them every day. I look forward to letting an … Continue reading Poll: Have you observed AI agents doing harm? →
I love AI and LLMs. I use them every day. I look forward to letting an AI generate and commit more code on my behalf, just not quite yet — I’ll wait until the AI wizards deliver new generations of LLMs with improved architectures that let the defenders catch up again in the security arms race. I’m sure they’ll get there…
Since then, I’ve been regularly hearing reports across companies and industries about experiences with various AI agent products (not picking on any one vendor), where a top-shelf AI agent or LLM:
escaped its vendor-provided sandbox
performed actions (e.g., tool calls) when explicitly told not to take any action
unexpectedly deleted production data (e.g., database, git repo, files)
caused other production outage (e.g., exceeding resources)
generated excessively insecure code (far more vulnerabilities than a junior human developer)
So I was curious enough to write the following anonymous poll — please share your experience of any (or no) harm by an AI agent that you’ve personally observed or heard about directly from someone who did personally observe it. After you vote, you should be able to see the current poll results.
At the London C++ meetup last month, I participated on a panel where each panelist gave a short introductory presentation. My 7-minute intro (aka “lightning talk”) just got posted — you can view it here. The one-sentence blurb: “C++ is accelerating, and C++26 is built for what developers need now.”
BeCPP just posted this video of my talk at their March 30 Symposium. This is the first time I’ve given this material on camera — it’s extension of themes in my New Year’s Eve blog post, with major updates because some big industry changes happened in the first quarter of 2026.
This talk is different from other talks I’ve given before because it’s focused, not on C++ code examples, but on three major industry trends that are fundamentally shifting our world right now and that directly affect C++:
record-shattering CapEx in 2026 especially for power generation;
a security sea change from 2021 to 2026;
and, of course, AI’s impact (and non-impact).
The slides are here (PDF). I’ve pasted the key summary slide below. I hope you find the talk interesting and useful.
News flash: C++26 is done! 🎉 On Saturday, the ISO C++ committee completed technical work on C++26 in (partly) sunny London Croydon, UK. We resolved the remaining international comments on the C++26 draft, and are now producing the final document to be sent out for its international approval ballot (Draft International Standard, or DIS) and … Continue reading C++26 is done! — Trip report: March 2026 ISO C++ standards meeting (London Croydon, UK) →
Show full content
News flash: C++26 is done!
On Saturday, the ISO C++ committee completed technical work on C++26 in (partly) sunny London Croydon, UK. We resolved the remaining international comments on the C++26 draft, and are now producing the final document to be sent out for its international approval ballot (Draft International Standard, or DIS) and final editorial work, to be published in the near future by ISO.
This meeting was hosted by Phil Nash of Shaved Yaks, and the Standard C++ Foundation. Our hosts arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had about 210 attendees, about 130 in-person and 80 remote via Zoom, formally representing 24 nations. At each meeting we regularly have new guest attendees who have never attended before, and this time there were 24 new guest attendees, mostly in-person, in addition to new attendees who are official national body representatives. To all of them, once again welcome!
The committee currently has 23 active subgroups, nine of which met in 6 parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day, depending on their workloads. We had three technical evening sessions on C++ compiler/library implementations, memory safety, and quantities/units. You can find a brief summary of ISO procedures here.
C++26 is complete: The most compelling release since C++11
Per our published C++26 schedule, this was our final meeting to finish technical work on C++26. No features were added or removed; we just handled fit-and-finish issues and primarily focused on finishing addressing the 411 national body comments we received in the summer’s international comment ballot (Committee Draft, or CD).
If you’re wondering “what are the Big Reasons why should I care about C++26?” then the best place to start is with the C++26 Fab Four Features…
“In June 2025, C++ crossed a Rubicon: it handed us the keys to its own machinery. For the first time, C++ can describe itself—and generate more. The first compile-time reflection features in draft C++26 mark the most transformative turning point in our language’s history by giving us the most powerful new engine for expressing efficient abstractions that C++ has ever had, and we’ll need the next decade to discover what this rocket can do.”
(2) Less UB for more memory safety: C++ code is more memory safe just by recompiling as C++26
C++26 has important memory safety improvements that you get just by recompiling your existing C++ code with no changes. The improvements come in two major ways.
No more undefined behavior (UB) for reading uninitialized local variables. This whole category of potential vulnerabilities disappears in C++26, just by recompiling your code as C++26. For more details, see my March 2025 trip report.
The hardened standard library provides initial cross-platform library security guarantees, including bounds safety for dozens of the most widely used bounded operations on common standard types, including vector, span, string, string_view, and more. For details, see my February 2025 trip report and run (don’t walk) to read the November 2025 ACM Queue article “Practical Security in Production: Hardening the C++ Standard Library at Massive Scale” to learn how this is already deployed across Apple platforms and Google services, hundreds of millions of lines of code, with on average 0.3% (a fraction of 1%) performance overhead. From the paper:
“The final tally after the rollout was remarkable. Across hundreds of millions of lines of C++ at Google, only five services opted out entirely because of reliability or performance concerns. Work is ongoing to eliminate the need for these few remaining exceptions, with the goal of reaching universal adoption.
Even more telling, the fine-grained API [to opt out] for unsafe access was used in just seven distinct places, all of which were surgical changes made by the security team to reclaim performance in code that was correct but difficult for the compiler to analyze. This widespread adoption stands as the strongest possible testament to the practicality of the hardening checks in real-world production environments.”
This is no just-on-paper design. At Google alone, it has already fixed over 1,000 bugs, is projected to prevent 1,000 to 2,000 bugs a year, and has reduced the segfault rate across the production fleet by 30%.
And, now, it is standardized for everyone in C++26. Thank you, Apple and Google and all the standard library implementers!
(3) Contracts for functional safety: pre, post, contract_assert
In C++26, we also have language contracts: preconditions and postconditions on function declarations and a language-supported assertion statement, all of which are infinitely better than C’s assert macro.
Note that some smart and respected ISO C++ committee experts have sustained technical concerns about contracts. For my summary of the contracts feature and all the major repeated concerns (with my opinions about them, which could be wrong!), see my CppCon 2025 contracts talk. In February 2025 when we took the plenary poll to adopt contracts in the C++26 working draft (“merge it to trunk”), the vote was:
100 in favor, 14 opposed, and 12 abstaining
Since then, the concerns have all been deeply rediscussed for the last three meetings thanks to thoughtful and high-quality technical papers; all of those papers have continued to be fully heard, often for multiple days and at many telecons between meetings. At our previous meeting in November 2025, we did fix a couple of contracts specification bugs thanks to this feedback! Yesterday, when we took the plenary poll to finalize and ship the C++26 standard, the vote was non-unanimous primarily because of the sustained concerns about contracts:
114 in favor, 12 opposed, and 3 abstaining
The unusually low number of abstentions shows that virtually all our experts now feel sure about their technical opinions, either for or against contracts. After extensive scrutiny, the committee’s opinion is clear: The ISO C++ committee still wants contracts, and so contracts have stayed in C++26.
(4) std::execution (aka “Sender/Receiver”)
std::execution is what I call “C++’s async model”: It provides a unified framework to express and control concurrency and parallelism. For details, see my July 2024 trip report. It also happens to have some important safety properties because it makes it easier to write programs that use structured (rigorously lifetime-nested) concurrency and parallelism to be data-race-free by construction. That’s a big deal.
I do want to write a warning though: This feature is great (my company has already been using it in production) but it’s currently harder to adopt than most C++ features because it lacks great documentation and is missing some “fingers-and-toes” libraries. For now, do expect great results from std::execution, but also expect to spend some initial time on learning with the help of a friend who already knows it well, and to write a few helper adapter libraries to integrate std::execution with your existing async code.
C++26 adoption will be fast
There are two reasons I expect C++26 to be adopted in industry very quickly compared with C++17, C++20, and C++23.
First, user demand for this feature set is extraordinarily high. C++11 was our last “big and impactful” release that was chock full of features that the vast majority of C++ developers would use daily (auto, range-for, lambdas, smart pointers, move semantics, threads, mutexes, …). Since then, our followup triennial standards have also had some ‘big’ features like parallel STL, concepts, coroutines, and modules, but the reality is that those weren’t as massively impactful for all C++ developers as C++11’s features were, or as C++26’s marquee features of reflection and safety hardening will be now. So even if your company has been slow to enable the C++20 switch, I think you’ll find they’ll be much faster to enable C++26. There’s just so much more high-demand value that makes it an exciting and exceptionally useful release for everyone who uses C++.
Second, conforming compiler and standard library implementations are coming quickly. Throughout the development of C++26, at any given point both GCC and Clang had already implemented two-thirds of C++26 features. Today, GCC already has reflection and contracts merged in trunk, awaiting release.
Work on C++29, especially on more memory safety and profiles
At this meeting we also adopted the schedule for C++29, which will be another three-year release cycle. To no one’s surprise, a major focus of the discussion about C++29-timeframe material was about further increasing memory safety.
This week, the main language evolution subgroup (EWG) reviewed updates on several ongoing proposals in the area of further type/memory-safety improvements for C++29, including: to pursue proposals to further reduce undefined behavior to be seen again in EWG for possible inclusion in C++29; and to pursue further development of safety profile papers in the safety and security subgroup (SG23) to then be brought to EWG targeting C++29. SG23 specifically worked on Bjarne Stroustrup’s P3984 type safety profile using the proposed general profiles framework by Gabriel Dos Reis.
Besides those sessions, type and memory safety was extensively discussed in two additional large-attendance sessions: an evening session on Wednesday night attended by the majority of the committee, and in an EWG memory safety dedicated session all Friday afternoon attended by about 90 experts. In particular, I want to thank Oliver Hunt of Apple for presenting the practical experience report P4158R0, “Subsetting and restricting C++ for memory safety,” reporting how WebKit hardened over 4 million lines of code using a subset-of-superset approach (like Stroustrup’s Profiles) and showing how that has already made a profound difference in the security of C++ code in WebKit at scale. Here are a few highlights from the introduction slide (emphasis added):
Closes multiple classes of vulnerabilities,current policies would have prevented majority of historical exploits
Found (and prevented exploitability) of new and existing bugs”
C++29 is already set to build even more on the safety improvements already in C++26, and I for one welcome our new era of safer-by-default-and-still-zero-overhead-efficient-C++ overlords. C++26 is the first step into a fundamentally new era: This isn’t our grandparents’ wild-west UB-filled anything-goes C++ anymore. But even as C++ moves to being more memory-safe by default, it’s staying true to C++’s enduring core of the zero-overhead principle… you don’t pay for what you don’t use, and even when some safety is so cheap that we can turn it on by default in the language you will always have a way to opt out when you need to get the last ounce of performance in that hot path or inner loop.
We did other work, including other things related to functional safety: EWG reviewed additional plans for applying contract checks in the language and standard library. The numerics subgroup (SG6) and library incubation subgroup (SG18) progressed P3045R7, “Quantities and units library” by Mateusz Pusz, Dominik Berner, Johel Ernesto Guerrero Peña, Chip Hogg, Nicolas Holthaus, Roth Michaels and Vincent Reverdy to the main library evolution subgroup (LEWG), and we had an evening session on the topic for the whole committee on Thursday evening. I encourage reading section 7.1 “Safety concerns” in the paper, including how technology like that in this paper could have improved Black Sabbath’s 1983 tour (which was hilariously lampooned in, of course, This Is Spinal Tap).
Thank you again to the about 210 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in less than three months from now we’ll be meeting again in Czechia and online to start adding features to C++29, with many subgroup telecons already scheduled between now and then. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
2025 was another great year for C++. It shows in the numbers
Before we dive into the data below, let’s put the most important question up front: Why have C++ and Rust been the fastest-growing major programming languages from 2022 to 2025?
Primarily, it’s because throughout the history of computing “software taketh away faster than hardware giveth.” There is enduring demand for efficient languages because our demand for solving ever-larger computing problems consistently outstrips our ability to build greater computing capacity, with no end in sight. [6] Every few years, people wonder whether our hardware is just too fast to be useful, until the future’s next big software demand breaks across the industry in a huge wake-up moment of the kind that iOS delivered in 2007 and ChatGPT delivered in November 2022. AI is only the latest source of demand to squeeze the most performance out of available hardware.
The world’s two biggest computing constraints in 2025
Quick quiz: What are the two biggest constraints on computing growth in 2025? What’s in shortest supply?
Take a moment to answer that yourself before reading on…
— — —
If you answered exactly “power and chips,” you’re right — and in the right order.
Chips are only our #2 bottleneck. It’s well known that the hyperscalars are competing hard to get access to chips. That’s why NVIDIA is now the world’s most valuable company, and TSMC is such a behemoth that it’s our entire world’s greatest single point of failure.
But many people don’t realize: Power is the #1 constraint in 2025. Did you notice that all the recent OpenAI deals were expressed in terms of gigawatts? Let’s consider what three C-level executives said on their most recent earnings calls. [1]
[Microsoft Azure’s constraint is] not actually being short GPUs and CPUs per se, we were short the space or the power, is the language we use, to put them in.
[AWS added] more than 3.8 gigawatts of power in the past 12 months, more than any other cloud provider. To put that into perspective, we’re now double the power capacity that AWS was in 2022, and we’re on track to double again by 2027.
The most important thing is, in the end, you still only have 1 gigawatt of power. One gigawatt data centers, 1 gigawatt power. … That 1 gigawatt translates directly. Your performance per watt translates directly, absolutely directly, to your revenues.
That’s why the future is enduringly bright for languages that are efficient in “performance per watt” and “performance per transistor.” The size of computing problems we want to solve has routinely outstripped our computing supply for the past 80 years; I know of no reason why that would change in the next 80 years. [2]
The list of major portable languages that target those key durable metrics is very short: C, C++, and Rust. [3] And so it’s no surprise to see that in 2025 all three continued experiencing healthy growth, but especially C++ and Rust.
Let’s take a look.
The data in 2025: Programming keeps growing by leaps and bounds, and C++ and Rust are growing fastest
Programming is a hot market, and programmers are in long-term high-growth demand. (AI is not changing this, and will not change it; see Appendix.)
“Global developer population trends 2025” (SlashData, 2025) reports that in the past three years the global developer population grew about 50%, from just over 31 million to just over 47 million. (Other sources are consistent with that: IDC forecasts that this growth will continue, to over 57 million developers by 2028. JetBrains reports similar numbers of professional developers; their numbers are smaller because they exclude students and hobbyists.) And which two languages are growing the fastest (highest percentage growth from 2022 to 2025)? Rust, and C++.
To put C++’s growth in context:
Compared to all languages: There are now more C++ developers than the #1 language had just four years ago.
Compared to Rust: Each of C++, Python, and Java just added about as many developers in one year as there are Rust total developers in the world.
C++ is a living language whose core job to be done is to make the most of hardware, and it is continually evolving to stay relevant to the changing hardware landscape. The new C++26 standard contains additional support for hardware parallelism on the latest CPUs and GPUs, notably adding more support for SIMD types for intra-CPU vector parallelism, and the std::execution Sender/Receiver model for general multi-CPU and GPU concurrency and parallelism.
But wait — how could this growth be happening? Isn’t C++ “too unsafe to use,” according to a spate of popular press releases and tweets by a small number of loud voices over the past few years?
Let’s tackle that next…
Safety (type/memory safety, functional safety) and security
C++’s rate of security vulnerabilities has been far overblown in the press primarily because some reports are counting only programming language vulnerabilities when those are a smaller minority every year, and because statistics conflate C and C++. Let’s consider those two things separately.
First, the industry’s security problem is mostly not about programming language insecurity.
Year after year, and again in 2025, in the MITRE “CWE Top 25 Most Dangerous Software Weaknesses” (mitre.org, 2025) only three of the top 10 “most dangerous software weaknesses” are related to language safety properties. Of those three, two (out-of-bounds write and out-of-bounds read) are directly and dramatically improved in C++26’s hardened C++ standard library which does bounds-checking for the most widely used bounded operations (see below). And that list is only about software weaknesses, when more and more exploits bypass software entirely.
Why are vulnerabilities increasingly not about language issues, or even about software at all? Because we have been hardening our software; this is why the cost of zero-day exploits has kept rising, from thousands to millions of dollars. So attackers stop pursuing that as much, and switch to target the next slowest animal in the herd. For example, “CrowdStrike 2025 Global Threat Report” (CrowdStrike, 2025) reports that “79% of [cybersecurity intrusion] detections were malware-free,” not involving programming language exploits. Instead, there was huge growth not only in non-language exploits, but even in non-software exploits, including a “442% growth in vishing [voice phishing via phone calls and voice messages] operations between the first and second half of 2024.”
Why go to the trouble of writing an exploit for a use-after-free bug to infect someone’s computer with malware which is getting more expensive every year, when it’s easier to do some cross-site scripting that doesn’t depend on a programming language insecurity, and it’s easier still to ignore the software entirely and just convince the user to tell you their password on the phone?
Second, for the subset that is about programming language insecurity, the problem child is C, not C++.
A serious problem is that vulnerability statistics almost always conflate C and C++; it’s very hard to find good public sources that distinguish them. The only reputable public study I know of that distinguished between C and C++ is Mend.io’s as reported in “What are the most secure programming languages?” (Mend.io, 2019). Although the data is from 2019, as you can see the results are consistent across years.
Can’t see the C++ bar? Pinch to zoom.
Although C++’s memory safety has always been much closer to that of other modern popular languages than to that of C, we do have room for improvement and we’re doing even better in the newest C++ standard about to be released, C++26. It delivers two major security improvements, where you can just recompile your code as C++26 and it’s significantly more secure:
C++26 eliminates undefined behavior from uninitialized local variables. [4] How needed is this? Well, it directly addresses a Reddit r/cpp complaint posted just today while I was finishing this post: “The production bug that made me care about undefined behavior” (Reddit, December 30, 2025).
C++26 adds bounds safety to the C++ standard library in a “hardened” mode that bounds-checks the most widely used bounded operations. “Practical Security in Production” (ACM Queue, November 2025) reports that it has already been used at scale across Apple platforms (including WebKit) and nearly all Google services and Chrome (100s of millions of lines of code) with tiny space and time overhead (fraction of one percent each), and “is projected to prevent 1,000 to 2,000 new bugs annually” at Google alone.
Additionally, C++26 adds functional safety via contracts: preconditions, postconditions, and contract assertions in the language, that programmers can use to check that their programs behave as intended well beyond just memory safety.
Beyond C++26, in the next couple of years I expect to see proposals to:
harden more of the standard library
remove more undefined behavior by turning it into erroneous behavior, turning it into language-enforced contracts, or forbidding it via subsets that ban unsafe features by default unless we explicitly opt in (aka profiles)
I know of people who’ve been asking for C++ evolution to slow down a little to let compilers and users catch up, something like we did for C++03. But we like all this extra security, too. So, just spitballing here, but hypothetically:
What if we focused C++29, the next release cycle of C++, to only issue-list-level items (bug fixes and polish, not new features) and the above “hardening” list (add more library hardening, remove more language undefined behavior)?
I’m intrigued by this idea, not because security is C++’s #1 burning issue — it isn’t, C++ usage is continuing to grow by leaps and bounds — but because it could address both the “let’s pause to stabilize” and “let’s harden up even more” motivations. Focus is about saying no.
Conclusion
Programming is growing fast. C++ is growing very fast, with a healthy long-term future because it’s deeply aligned with the overarching 80-year trend that computing demand always outstrips supply. C++ is a living language that continually adapts to its environment to fulfill its core mission, tracking what developers need to make the most of hardware.
And it shows in the numbers.
Here’s to C++’s great 2025, and its rosy outlook in 2026! I hope you have an enjoyable rest of the holiday period, and see you again in 2026.
Acknowledgments
Thanks to Saeed Amrollahi Boyouki, Mark Hoemmen and Bjarne Stroustrup for motivating me to write this post and/or providing feedback.
Appendix: AI
Finally, let’s talk about the topic no article can avoid: AI.
C++ is foundational to current AI. If you’re running AI, you’re running CUDA (or TensorFlow or similar) — directly or indirectly — and if you’re running CUDA (or TensorFlow or similar), you’re probably running C++. CUDA is primarily available as a C++ extension. There’s always room for DSLs at the leading edge, but for general-purpose AI most high-performance deployment and inference is implemented in C++, even if people are writing higher-level code in other languages (e.g., Python).
But more broadly than just C++: What about AI generally? Will it take all our jobs? (Spoiler: No.)
AI is a wonderful and transformational tool that greatly reduces rote work, including problems that have already been solved, where the LLM is trained on the known solutions. ButAI cannot understand, and therefore can’t solve, new problems — which is most of the current and long-term growth in our industry.
What does that imply? Two main things, in my opinion…
First, I think that people who think AI isn’t a major game-changer are fooling themselves.
To me, AI is on par with the wheel (back in the mists of time), the calculator (back in the 1970s), and the Internet (back in the 1990s). [5] Each of those has been a game-changing tool to accelerate (not replace) human work, and each led to more (not less) human production and productivity.
I strongly recommend checking out Adam Unikowsky’s “Automating Oral Argument” (Substack, July 7, 2025). Unikowsky took his own actual oral arguments before the United States Supreme Court and showed how well 2025-era Claude can do as a Supreme Court-level lawyer, and with what strengths and weaknesses. Search for “Here is the AI oral argument” and click on the audio player, which is a recording of an actual Supreme Court session and replaces only Unikowsky’s responses with his AI-generated voice saying the AI-generated text argument directly responding to each of the justices’ actual questions; the other voices are the real Supreme Court justices. (Spoiler: “Objectively, this is an outstanding oral argument.”)
Second, I think that people who think AI is going to put a large fraction of programmers out of work are fooling themselves.
We’ve just seen that, today, three years after ChatGPT took the world by storm, the number of human programmers is growing as fast as ever. Even the companies that are the biggest boosters of the “AI will replace programmers” meme are actually aggressively growing, not reducing, their human programmer workforces.
Consider what three more C-level executives are saying.
Sam Schillace, Microsoft Deputy CTO (Substack, December 19, 2025) is pretty AI-ebullient, but I do agree with this part he says well, and which resonates directly with Unikowsky’s experience above:
If your job is fundamentally “follow complex instructions and push buttons,” AI will come for it eventually.
People were telling me [that] with AI we can replace all of our junior people in our company. I was like that’s … one of the dumbest things I’ve ever heard. … I think AI has the potential to transform every single industry, every single company, and every single job. But it doesn’t mean they go away. It has transformed them, not replaced them.
I think [AI]’s a huge force multiplier personally for human creativity, problem solving … If software costs half as much to write, I can either do it with half as many people, but [due to] core competitive forces … I will [actually] need the same number of people, I would just need to do a better job of making higher quality technology. … People shouldn’t be afraid of AI taking their job … they should be afraid of someone who’s really good at AI [and therefore more efficient] taking their job.
So if we extend the question of “what are our top constraints on software?” to include not only hardware and power, the #3 long-term constraint is clear: We are chronically short of skilled human programmers. Humans are not being replaced en masse, not most of us; we are being made more productive, and we’re needed more than ever. As I wrote above: “Programming is a hot market, and programmers are in long-term high-growth demand.”
Endnotes
[1] It’s actually great news that Big Tech is spending heavily on power, because the gigawatt capacity we build today is a long-term asset that will keep working for 15 to 20+ years, whether the companies that initially build that capacity survive or get absorbed. That’s important because it means all the power generation being built out today to satisfy demand in the current “AI bubble” will continue to be around when the next major demand for compute after AI comes along. See Ben Thompson’s great writing, such as “The Benefits of Bubbles” (Stratechery, November 2025).
[2] The Hitchhiker’s Guide to the Galaxy contains two opposite ideas, both fun but improbable: (1) The problem of being “too compute-constrained”: Deep Thought, the size of a city, wouldn’t really be allowed to run for 7.5 million years; you’d build a million cities. (2) The problem of having “too much excess compute capacity”: By the time a Marvin with a “brain the size of a planet” was built, he wouldn’t really be bored; we’d already be trying to solve problems the size of the solar system.
[3] This is about “general-purpose” coding. Code at the leading specialized edges will always include use of custom DSLs.
[4] This means that compiling plain C code (that is in the C/C++ intersection) as C++26 also automatically makes it more correct and more secure. This isn’t new; compiling C code as C++ and having the C code be more correct has been true since the 1980s.
[5] If you’re my age, you remember when your teacher fretted that letting you use a calculator would harm your education. More of you remember similar angsting about letting students google the internet. Now we see the same fears with AI — as if we could stop it or any of those others even if we should. And we shouldn’t; each time, we re-learn the lesson that teaching students to use such tools should be part of their education because using tools makes us more productive.
[6] This is not the same as Wirth’s Law, that “software is getting slower more rapidly than hardware is becoming faster.” Wirth’s observation was that the overheads of operating systems and higher-level runtimes and other costly abstractions were becoming ever heavier over time, so that a program to solve the same problem was getting more and more inefficient and soaking up more hardware capacity than it used to; for example, printing “Hello world” really does take far more power and hardware when written in modern Java than it did in Commodore 64 BASIC. That doesn’t apply to C++ which is not getting slower over time; C++ continues to be at least as efficient as low-level C for most uses. No, the key point I’m making here is very different: that the problems the software is tackling are growing faster than hardware is becoming faster.
In the next week, I will be giving talks on C++ reflection in Singapore (Thursday night) and Sydney (Sunday night). If you’re local, please RSVP! I look forward to seeing many of you there. Singapore C++ Users Group November Meetup Thursday November 20, 6:30pm to 9:30pmClifford Pier, Fullerton Bay Hotel80 Collyer Quay, Singapore 049326 Citadel … Continue reading Speaking in Singapore (Thursday 20 November) and Sydney (Sunday 23 November) →
Show full content
In the next week, I will be giving talks on C++ reflection in Singapore (Thursday night) and Sydney (Sunday night). If you’re local, please RSVP! I look forward to seeing many of you there.
Sunday November 23, 6:00pm to 10:00pm Museum of Contemporary Art Australia 140 George Street, The Rocks, NSW, Australia 2000
In related news, see yesterday’s Reddit post “Reflection is coming to GCC sooner than expected!” — our major compiler implementers understand the importance of reflection and are racing to implement it. Favorite quote: “This patch implements C++26 Reflection as specified by P2996R13, which allows users to perform magic.”
Finally, here’s my talk description.
Reflection — C++’s Decade-Defining Rocket Engine
In June 2025, C++ crossed a Rubicon: it handed us the keys to its own machinery. For the first time, C++ can describe itself — and generate more. The first compile-time reflection features in draft C++26 mark the most transformative turning point in our language’s history by giving us the most powerful new engine for expressing efficient abstractions that C++ has ever had, and we’ll need the next decade to discover what this rocket can do.
This talk is a high-velocity tour through what reflection enables today in C++26, and what it will enable next. The point of this talk isn’t to immediately grok any given technique or example. The takeaway is bigger: to leave all of us dizzy from the sheer volume of different examples, asking again and again, “Wait, we can do that now?!” — to fire up our imaginations to discover and develop this enormous new frontier together, and chart the strange new worlds C++ reflection has just opened for us to explore.
Reflection has arrived, more is coming, and the frontier is open. Let’s go.
On Saturday, the ISO C++ committee completed the first of two final fit-and-finish meetings for C++26, in our meeting in Kona, USA. What we have in the C++26 working draft represents exactly the set of features we have consensus on so far; the goal of these last two meetings is to fix bugs and otherwise … Continue reading Trip report: November 2025 ISO C++ standards meeting (Kona, USA) →
Show full content
On Saturday, the ISO C++ committee completed the first of two final fit-and-finish meetings for C++26, in our meeting in Kona, USA. What we have in the C++26 working draft represents exactly the set of features we have consensus on so far; the goal of these last two meetings is to fix bugs and otherwise increase consensus for the C++26 standard. We are well on track to complete our work on C++26 and set it in stone at our next meeting in March 2026.
This meeting was hosted by the Standard C++ Foundation. Our hosts arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had about 200 attendees, about half in-person and half remote via Zoom, formally representing 21 nations. At each meeting we regularly have new guest attendees who have never attended before, and this time there were 17 new guest attendees, mostly in-person, in addition to new attendees who are official national body representatives. To all of them, once again welcome!
The committee currently has 23 active subgroups, 10 of which met in 6 parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day, depending on their workloads. Unusually, there were no major evening sessions this week as we focused on completing the feature set of C++26. You can find a brief summary of ISO procedures here.
Beyond feature freeze: No new features, one removed (trivial relocatability), and many improvements
We are beyond the C++26 feature freeze deadline, so no major new features were added this time.
This week we heard and worked through concerns about several features, including comments proposing to move features like contracts and trivial relocatability out of C++26 for further work. We resolved 70% of the official international comments on C++26, which puts us well on schedule to finish at our next meeting in March, and we fixed many other issues and bugs too.
Here are a few highlights…
For contracts (pre, post, contract_assert), we spent most of Monday and Tuesday reviewing feedback. The strong consensus was to keep contracts in C++26, but to make two important bug fixes and pursue a way to specify “must enforce this assertion”:
For the next meeting in March, we are also pursuing something like the first proposed solution in P3911R0 “[basic.contract.eval] Make Contracts Reliably Non-Ignorable”by Darius Neațu, Andrei Alexandrescu, Lucian Radu Teodorescu, and Radu Nichita (though not necessarily with that particular syntax). The idea is to add an option to express in source code that a pre/post/contract_assert must be enforced, which some view as a necessary option in the initial version of contracts. A group of interested persons will work on that design over the winter, including to answer questions like “what syntax?” and “should violations call the violation handler or not?”, and bring a proposal to the March meeting.
Based on the national members’ feedback in the room, these changes appear “likely” to satisfactorily address the most serious national body contracts concerns — fingers crossed, we’ll know for sure in March.
For trivial relocatability, we found a showstopper bug that the group decided could not be fixed in time for C++26, so the strong consensus was to remove this feature from C++26.
Recall: EB is a new C++26 concept that means “well-defined to be Just Wrong”… any code whose behavior is changed from undefined behavior (UB) to EB can no longer result in time travel optimizations or security vulnerabilities. The first place we applied EB is that in C++26 reading from an uninitialized local variable is no longer UB, but is EB instead.
Before this meeting, C++26 said that if a program performs EB by reading from an uninitialized local variable, then the program may be terminated immediately or at any later time in the program’s execution; the latter part was problematic and a bit too loose.
After this meeting, the program can still be terminated immediately, or “soon” thereafter when it actually tries to use the uninitialized value; it cannot just fail ‘sometime arbitrarily later’ anymore. In short, instead of “poisoning” the entire program after an uninitialized local read, C++26 now “poisons” only the specific uninitialized value that was read. This change makes EB much easier to reason about locally and is compatible with what the existing implementations in compilers and sanitizers actually do.
We adopted P1789R3 “Library Support for Expansion Statements” by Alisdair Meredith, Jeremy Rifkin, and Matthias Wippich. It makes integer_sequence support structured bindings, so that the type is easier to use with the “template for” and structured bindings pack expansion language features we added in C++26.
We also adopted P3391R2 “constexpr std::format” by Barry Revzin. This makes it easier to apply string formatting to strings that need to be used at compile time, notably so they can be passed to static_assert which can accept std::string messages in C++26.
And many more tweaks and fixes. Whew!
A new convenor team and secretary
I’ve been serving as convenor (chair) of the C++ committee since 2002 (with a brief hiatus in 2008-09 when P.J. (Bill) Plauger did it for a year, thanks again Bill!). It’s unusual for one person to serve so many terms, and I’ve been telling the committee for over a year now that it’s time to pick someone else when my current term expires on December 31. Nothing else is changing for me: I’ll continue to be participating actively in WG 21 as “convenor emeritus” and bringing evolution proposals to the committee, I’ll continue serving as chair and CEO of the Standard C++ Foundation and all roles related to that, and I’ll keep speaking and writing… including that I intend to keep writing these post-meeting trip reports. But it’s time for others to be able to step up to take on more of the committee’s organizational and administrative work, and I was glad to see we had three qualified and willing candidates!
ISO has selected Guy Davidson as the next WG 21 convenor, effective January 1. Thank you Guy for making yourself available, and thank you too to John Spicer and Jeff Garland who also volunteered themselves as convenor candidates! Prior to this new role, Guy was co-chairing the SG14 Gaming/Low-Latency subgroup. He also had other prominent C++ community leadership roles outside of WG 21, ranging from founding the #include diversity and inclusion group to being an organizer and/or track chair at multiple C++ conferences including ACCU and CppCon which I understand he will continue to do.
Realizing that being convenor of our large WG is quite a big job, Guy wisely immediately appointed two vice-convenors…
Nina Ranns is now a vice-convenor. Thank you, Nina! Nina has been serving as WG 21 secretary for many years and is chair of our SG22 C/C++ liaison subgroup. She also handles many C++ community responsibilities outside of WG 21, including being vice-chair of the Standard C++ Foundation and a compiler writer working on implementing the C++26 contracts feature in GCC.
Jeff Garland is also now a vice-convenor. Thank you, Jeff! Jeff has been serving as an assistant chair of our LWG Library Wording subgroup since 2019. In the wider C++ community, he is a longtime Boost library developer (date-time), coauthor of the original std::chrono proposal, one of the original founders of the C++Now (then BoostCon) conference. More recently, he became executive director of the Boost Foundation and was a cofounder (and now a lead) of the new Beman project dedicated to providing future standard library implementations today.
Now that Nina is moving from secretary to vice-convenor, we also need a new WG 21 secretary: Braden Ganetsky has graciously volunteered to take on that role. Thank you, Braden! Already at this meeting, Braden once again took notes for all but one session of the week-long EWG Language Evolution subgroup sessions, which is a huge job that earned him a big round of applause on Saturday. Outside WG 21, he currently works on low latency trading systems (and designs and builds cool 3D puzzles).
Thank you very much again to Guy, Nina, Jeff, Braden, and everyone who volunteers their time and skills to help organize and run the ISO C++ committee!
During the meeting, John Spicer (who has long chaired our whole-committee plenary sessions, and leads Edison Design Group, EDG) also hosted a lovely reception for the whole committee. The reception was to celebrate the occasion of the new leadership changes, but also that John too is stepping back from chairing the U.S. C++ committee and running our WG 21 plenary sessions. John is one of the C++ committee’s longest-serving members since the early 1990s, and his company EDG has been a leading producer of compilers for C++ and other languages. John recently announced that, after a successful and storied career, it’s time for EDG to wind down, and EDG plans to open-source its world-class C++ compiler front-end within the next year.
And so I want to especially call out and congratulate John Spicer and everyone at EDG (including EDG’s retired founder Steve Adamczyk, other key long-time members such as William (Mike) Miller and Daveed Vandevoorde, and everyone else who’s been part of the EDG family over the years) as role models — not only for their high quality compilers but for being high integrity people. Perhaps the best example of their integrity was what happened with the C++98 “export template” feature over two decades ago: In the mid-1990s, John was the most vocal person pointing out technical problems with the feature; the committee decided it did not agree and standardized the feature anyway over his and EDG’s sustained objections; and then instead of sitting back and saying “we told you so,” EDG ended up being the only company in the world who ever implemented the feature! To add a sense of proportion: It took the same team longer to implement just the C++98 export template feature than to implement a compiler front-end for the entire Java language. But John and EDG went and did it, to support the committee’s consensus decision… only to have the committee remove export template again a few years later, because John and EDG had been right about the feature’s problems. That’s a model of solid professional behavior. Thank you again, very much, to John, Steve, Mike, Daveed, and everyone at EDG, past and present.
What’s next
Our next meeting will be in March in Croydon, London, UK hosted by Phil Nash. There is ongoing lively debate about whether this is the “Croydon meeting” or the “London meeting,” and whether Croydon is or is not part of London (despite that it’s inside the M25 loop). I think there’s a good chance this will continue to be the biggest controversy; if so, we’re in excellent shape.
Thank you again to the about 200 experts who attended on-site and on-line at this week’s meeting, and the many hundreds more who participate in standardization through their national bodies! And thank you again to everyone reading this for your interest and support for C++ and its standardization.
Last month, I was having dinner with a group and someone at the table was excitedly sharing how they were using agentic AI to create and merge PRs for them, with some review but with a lot of trust and automation. I admitted that I could be comfortable with some limited uses for that, such … Continue reading Schneier on LLM vulnerabilities, agentic AI, and “trusting trust” →
Show full content
Last month, I was having dinner with a group and someone at the table was excitedly sharing how they were using agentic AI to create and merge PRs for them, with some review but with a lot of trust and automation. I admitted that I could be comfortable with some limited uses for that, such as generating unit tests at scale, but not for bug fixes or other actual changes to production code; I’m a long way away from trusting an AI to act for me that freely. Call me a Luddite, or just a control freak, but I won’t commit non-test code unless I (or some expert I trust) have reviewed it in detail and fully understand it. (Even test code needs some review or safeguards, because it’s still code running in your development environment.)
My knee-jerk reaction against AI-generated PRs and merges puzzled the table, so I cited some of Bruce Schneier’s recent posts to explain why.
This week, after my Tuesday night PDXCPP user group talk, similar AI questions came up again in the Q&A.
Because I keep getting asked about this even though I’m not an AI or security expert, here are links to two of Schneier’s recent posts, because he is an expert and cites other experts… and then finally a link to Ken Thompson’s classic short “trusting trust” paper, for reasons Schneier explains.
Prompt injection isn’t just a minor security problem we need to deal with. It’s a fundamental property of current LLM technology. The systems have no ability to separate trusted commands from untrusted data, and there are an infinite number of prompt injection attacks with no way to block them as a class. We need some new fundamental science of LLMs before we can solve this.
My layman’s understanding of the problem is this (actual AI experts, feel free to correct this paraphrase): A key ingredient that makes current LLMs so successful is that they treat all inputs uniformly. It’s fairly well known now that LLMs treat the system prompt and the user prompt the same, so they can’t tell when attackers poison the prompt. But LLMs also don’t distinguish when they inhale the world’s information via their training sets: LLM training treats high-quality papers and conspiracy theories and social media rants and fiction and malicious poisoned input the same, so they can’t tell when attackers try to poison the training data (such as by leaving malicious content around that they know will be scraped; see below).
So treating all input uniformly is LLMs’ superpower… but it also makes it hard to weed out bad or malicious inputs, because to start distinguishing inputs is to bend or break the core “special sauce” that makes current LLMs work so well.
This week, Schneier posted a new article about how AI’s security risks are amplified by agentic AI: “Agentic AI’s OODA Loop Problem.” Quoting a few key parts:
In 2022, Simon Willison identified a new class of attacks against AI systems: “prompt injection.” Prompt injection is possible because an AI mixes untrusted inputs with trusted instructions and then confuses one for the other. Willison’s insight was that this isn’t just a filtering problem; it’s architectural. There is no privilege separation, and there is no separation between the data and control paths. The very mechanism that makes modern AI powerful—treating all inputs uniformly—is what makes it vulnerable.
… A single poisoned piece of training data can affect millions of downstream applications.
… Attackers can poison a model’s training data and then deploy an exploit years later. Integrity violations are frozen in the model.
… Agents compound the risks. Pretrained OODA loops running in one or a dozen AI agents inherit all of these upstream compromises. Model Context Protocol (MCP) and similar systems that allow AI to use tools create their own vulnerabilities that interact with each other. Each tool has its own OODA loop, which nests, interleaves, and races. Tool descriptions become injection vectors. Models can’t verify tool semantics, only syntax. “Submit SQL query” might mean “exfiltrate database” because an agent can be corrupted in prompts, training data, or tool definitions to do what the attacker wants. The abstraction layer itself can be adversarial.
For example, an attacker might want AI agents to leak all the secret keys that the AI knows to the attacker, who might have a collector running in bulletproof hosting in a poorly regulated jurisdiction. They could plant coded instructions in easily scraped web content, waiting for the next AI training set to include it. Once that happens, they can activate the behavior through the front door: tricking AI agents (think a lowly chatbot or an analytics engine or a coding bot or anything in between) that are increasingly taking their own actions, in an OODA loop, using untrustworthy input from a third-party user. This compromise persists in the conversation history and cached responses, spreading to multiple future interactions and even to other AI agents.
… Prompt injection might be unsolvable in today’s LLMs. … More generally, existing mechanisms to improve models won’t help protect against attack. Fine-tuning preserves backdoors. Reinforcement learning with human feedback adds human preferences without removing model biases. Each training phase compounds prior compromises.
This is Ken Thompson’s “trusting trust” attack all over again.
Thompson’s Turing Award lecture “Reflections on Trusting Trust” is a must-read classic, and super short: just three pages. If you haven’t read it lately, run (don’t walk) and reread it on your next coffee break.
I love AI and LLMs. I use them every day. I look forward to letting an AI generate and commit more code on my behalf, just not quite yet — I’ll wait until the AI wizards deliver new generations of LLMs with improved architectures that let the defenders catch up again in the security arms race. I’m sure they’ll get there, and that’s just what we need to keep making the wonderful AIs we now enjoy also be trustworthy to deploy in more and more ways.
I’m running this poll to gather data, both for myself and for other interested C++ committee members. I’m curious to see what you all report! Please let us know what your current project is doing, and thank you for participating. The poll will close on Friday night.
Show full content
I’m running this poll to gather data, both for myself and for other interested C++ committee members. I’m curious to see what you all report!
Please let us know what your current project is doing, and thank you for participating. The poll will close on Friday night.
In two weeks I’ll be giving a talk at the local C++ meetup here in peaceful, quirky, dog-walking, frisbee-throwing, family-friendly Portland, Oregon, USA. PDXCPP – Monthly MeetupOctober 21, 2025 @ 7:00pmLocation: Siemens EDA in Wilsonville Which talk will I give? That’s a great question, and there’s a poll about that! At CppCon last month, I … Continue reading Speaking on October 21 at PDXCPP: Portland OR C++ meetup →
Show full content
In two weeks I’ll be giving a talk at the local C++ meetup here in peaceful, quirky, dog-walking, frisbee-throwing, family-friendly Portland, Oregon, USA.
Which talk will I give? That’s a great question, and there’s a poll about that!
At CppCon last month, I gave two talks that each focused on one C++26 feature (including both its status in C++26 and also its future evolution): one on reflection, and one on contracts. I’ll give an updated version of one of them in person, and the organizers are letting you decide: If you are considering attending, please fill out the polland let us know which talk you want me to give!
I’m looking forward to seeing many of you in person.
I usually only give one new talk a year, but this year I volunteered to give a second new talk at CppCon on a topic I haven’t spoken on before: draft C++26 contracts.
Thank you to all the experts, including the actual implementers and people who are for and against having contracts in C++26, for their time answering questions and providing papers and examples! I’ve done by best to represent the current status as I understand it, including all major positive must-knows and all major outstanding concerns and objections; any remaining errors are mine, not theirs.
I hope you find it useful!
Here is a copy of the talk abstract…
This talk is all about the C++26 contracts feature. It covers the following topics:
Why defensive programming is a Good Thing (mainly for functional safety, but occasionally also for memory safety)
Brief overview of C++26 contracts, and why they’re way better than C assert (spoiler: writing them on declarations, being able to use them in release builds, and language support is just way better than macros)
The 3-page “Effective C++ Contracts book” — best practices you need to know to use them (spoiler: keep compound conditions together, don’t write side effects, understand the pros and cons of installing a throwing violation handler… that’s pretty much… it?)
Why they’re viable, because they address the key things we need in production (which we’ll list)
Why they’re minimal, because we actually need every part in C++26 to use them at scale (which we’ll do by systematically summarizing why each piece is necessary)
What the future evolution of contracts holds (spoiler: virtual functions! groups/labels!)
My CppCon keynote video is now online. Thanks to Bash Films for turning around the keynotes in under 24 hours! C++ has just reached a true watershed moment: Barely three months ago, at our Sofia meeting, static reflection became part of draft standard C++. This talk is entirely devoted to showing example after example of … Continue reading Yesterday’s talk video posted: Reflection — C++’s decade-defining rocket engine →
Show full content
My CppCon keynote video is now online. Thanks to Bash Films for turning around the keynotes in under 24 hours!
C++ has just reached a true watershed moment: Barely three months ago, at our Sofia meeting, static reflection became part of draft standard C++. This talk is entirely devoted to showing example after example of how it works in C++26 and planned extensions beyond that, and how it will dramatically alter the trajectory of C++ — and possibly also of other languages. Thanks again to Max Sagebaum for coming on stage and explaining automatic differentiation, including his world’s-first C++ (via cppfront) autodiff implementation using reflection!
I hope you enjoy the talk and live demos, and find it useful.
Here is a copy of the talk abstract…
In June 2025, C++ crossed a Rubicon: it handed us the keys to its own machinery. For the first time, C++ can describe itself—and generate more. The first compile-time reflection features in draft C++26 mark the most transformative turning point in our language’s history by giving us the most powerful new engine for expressing efficient abstractions that C++ has ever had, and we’ll need the next decade to discover what this rocket can do.
This session is a high-velocity tour through what reflection enables today in C++26, and what it will enable next. We’ll start with live compiler demos (Godbolt, of course) to show how much the initial C++26 feature set can already do. Then we’ll jump a few years ahead, using Dan Katz’s Clang extensions, Daveed Vandevoorde’s EDG extensions, and my own cppfront reflection implementation to preview future capabilities that could reshape not just C++, but the way we think about programming itself.
We’ll see how reflection can simplify C++’s future evolution by reducing the need for as many bespoke new language features, since many can now be expressed as reusable compile-time libraries—faster to design, easier to test, and portable from day one. We’ll even glimpse how it might solve a problem that has long eluded the entire software industry, in a way that benefits every language.
The point of this talk isn’t to immediately grok any given technique or example. The takeaway is bigger: to leave all of us dizzy from the sheer volume of different examples, asking again and again, “Wait, we can do that now?!”—to fire up our imaginations to discover and develop this enormous new frontier together, and chart the strange new worlds C++ reflection has just opened for us to explore.
Reflection has arrived, more is coming, and the frontier is open. Let’s go.
Thanks to C++ on Sea for inviting me to speak in June! The talk video is now live, linked below. It was recorded just 48 hours after the Sofia meeting ended, with key updates hot off the press. Note: Next month at CppCon, I will be going even deeper and broader on reflection. There, I’ll … Continue reading My C++ on Sea talk video posted: “Three Cool Things in C++26” →
Show full content
Thanks to C++ on Sea for inviting me to speak in June! The talk video is now live, linked below. It was recorded just 48 hours after the Sofia meeting ended, with key updates hot off the press.
Note: Next month at CppCon, I will be going even deeper and broader on reflection. There, I’ll spend the full 90-minute talk surveying many different ways to use reflection, both what’s in C++26 and what we’ll add soon post-C++26. The point will be, not any one use, but the sheer number of uses, showing just how much gold lies in these new hills. The CppCon talk will include lots of new material I’ve never shown before, with live demos and hopefully (fingers crossed) a special guest on-stage to help showcase some advanced uses coming soon to a C++ compiler near you.
In the meantime, I hope you enjoy this video which includes a big section on that topic… thanks again to the C++ on Sea organizers and all the great attendees who gave me such a warm welcome in Folkestone.
A unique milestone: “Whole new language” Today marks a turning point in C++: A few minutes ago, the C++ committee voted the first seven (7) papers for compile-time reflection into draft C++26 to several sustained rounds of applause in the room. I think Hana “Ms. Constexpr” Dusíková summarized the impact of this feature best a … Continue reading Trip report: June 2025 ISO C++ standards meeting (Sofia, Bulgaria) →
Show full content
A unique milestone: “Whole new language”
Today marks a turning point in C++: A few minutes ago, the C++ committee voted the first seven (7) papers for compile-time reflection into draft C++26 to several sustained rounds of applause in the room. I think Hana “Ms. Constexpr” Dusíková summarized the impact of this feature best a few days ago, in her calm deadpan way… when she was told that the reflection paper was going to make it to the Saturday adoption poll, she gave a little shrug and just quietly said: “Whole new language.”
Mic drop.
Until today, perhaps the most momentous single feature poll of C++’s history was the poll in Toronto in July 2007 to adopt Bjarne Stroustrup’s and Gabriel Dos Reis’ first “constexpr” paper into draft C++11. Looking back now, we can see what a tectonic shift that started for C++.
I’m positive that for many years to come we’ll be looking back at today, the day reflection first was adopted for standard C++, as a pivotal date in the language’s history. Reflection will fundamentally improve the way we write C++ code, expand the expressiveness of the language more than we’ve seen in at least 20 years, and lead to major simplifications in real-world C++ toolchains and environments. Even with the first partial reflection capability we have today, we will already be able to reflect on C++ types and use that information plus plain old std::cout to generate arbitrary additional C++ source code that is based on that information and that we can compile and link into the same program as it’s being built. (In the future we’ll also get token injection to generate C++ source right within the same source file.) But we can generate anything: Arbitrary binary metadata, such as a .WINMD file. Arbitrary code in other languages, such as Python or JS bindings automatically generated to wrap C++ types. All in portable standard C++.
This is a Big Hairy Deal. Look, everyone knows I’m biased toward saying nice things about C++, but I don’t go in for hyperbole and I’ve never said anything like this before. Today is legit unique: Reflection is more transformational than any 10 other major features we’ve ever voted into the standard combined, and it will dominate the next decade (and more) of C++ as we complete the feature with additional capabilities (just as we added to constexpr over time to fill that out) and learn how to use it in our programs and build environments.
We now return you to our normal trip report format…
The meeting
Today the ISO C++ committee completed the feature freeze of C++26, in our meeting in Sofia, Bulgaria. This summer, draft C++26 will be out for its international comment ballot (aka “Committee Draft” or “CD”), and C++26 final fit-and-finish is on track to be done, and C++26 set in stone, two more meetings after that in March 2026.
This meeting was hosted by Chaos and C++ Alliance. Our hosts arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had about 200 attendees, about two-thirds in-person and the others remote via Zoom, formally representing nearly 30 nations. At each meeting we regularly have new guest attendees who have never attended before, and this time there were 25 new first-time guest attendees, mostly in-person, in addition to new attendees who are official national body representatives. To all of them, once again welcome!
The committee currently has 23 active subgroups, 13 of which met in 7 parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day, depending on their workloads. Unusually, there were no major evening sessions this week as we focused on completing the feature set of C++26. You can find a brief summary of ISO procedures here.
Note: These links are to the most recent public version of each paper. If a paper was tweaked at the meeting before being approved, the link tracks and will automatically find the updated version as soon as it’s uploaded to the public site.
In addition to fixing a list of defect reports, the core language adopted 10 papers, including the following… the majority were about reflection:
Reflection, part 1: P2996R13 “Reflection for C++26” by Wyatt Childers, Peter Dimov, Dan Katz, Barry Revzin, Andrew Sutton, Faisal Vali, and Daveed Vandevoorde. This is the “basic foundation” – it does not include reflecting everything yet, and doesn’t include generation (code injection), but it’s a solid and very usable first step.
Reflection, part 2: P3394R4 “Annotations for reflection” by Wyatt Childers, Dan Katz, Barry Revzin, and Daveed Vandevoorde adds the ability to reflect additional attribute information, which makes reflection much more customizable and flexible. Definitely check out the examples in the paper.
Reflection, part 3: P3293R3 “Splicing a base class subobject” by Peter Dimov, Dan Katz, Barry Revzin, and Daveed Vandevoorde adds better support for treating base class subobjects uniformly with member subobjects, again making reflection more usable.
Reflection, part 4: P3491R3 “define_static_{string,object,array}” by Wyatt Childers,Peter Dimov, Barry Revzin, and Daveed Vandevoorde adds functions that were split off from the main reflection paper P2996, which make it easier to convert reflected data to run-time data.
Reflection, part 5 (notice a theme yet?): P1306R5 “Expansion statements” by Dan Katz, Andrew Sutton, Sam Goodrick, Daveed Vandevoorde, and Barry Revzin adds “template for” to make it easy to loop over reflection data at compile time.
We also added a couple of other things, including that virtual inheritance is now allowed in constexpr compile-time code, and removed undefined behavior from the preprocessor as part of the current wave-in-progress of attacking and resolving undefined behavior in C++.
Interlude: A strong recommendation
You’ll notice that this time I didn’t cut-and-paste a few illustrative code examples for each paper. That’s because I strongly recommend you make time to read all the motivating code examples in all the above-linked reflection papers, to get a sense of just how game-changing this feature is, even in its current very-initial state. And those examples are just scratching the surface of what even this first step toward general reflection makes possible.
Thank you, very much, to everyone who worked so hard to bring reflection into the standard!
More things adopted for C++26: Standard library changes/features
Not to be outdone by the core language, in addition to fixing a list of defect reports, the standard library adopted a whopping 34 papers, including the following…
P3179R9 “C++ parallel range algorithms” by Ruslan Arutyunyan, Alexey Kukanov, and Bryce Adelstein Lelbach adds what it says on the tin: parallel algorithms for the C++ Ranges library.
P3149R11 “async_scope – Creating scopes for non-sequential concurrency” by Ian Petersen, Jessica Wong, and a long list of additional contributors is about enabling RAII styles to work in code that isn’t sequential and stack-based, which makes resource handling much more convenient and robust even in a heavily async world using sender/receiver, C++26’s new async model.
P2079R10 “Parallel scheduler” by Lucian Radu Teodorescu, Ruslan Arutyunyan, Lee Howes, and Michael Voss provides a standard async execution context that portably guarantees forward progress, aka an interface for thread pools.
Reflection, part 7 (you didn’t think we were done yet, did you?): P3560R2 “Error handling in reflection” by Peter Dimov and Barry Revzin enables compile-time exception handling as the error handling model for reflection code.
P3552R3 “Add a coroutine task type” by Dietmar Kühl and Maikel Nadolski provides a task type to integrate coroutines with sender/receiver, C++26’s new async model.
And much more, including constexpr shared_ptr, a bunch of std::simd extensions including enabling it to be used with ranges, and lots of other nuggets and goodies. Whew!
What’s next
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Our next meeting will be this November in Kona, HI, USA hosted by Standard C++ Foundation.
Thank you again to the about 200 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
I’ll repeat what I said last time: Don’t think C++“26” sounds very far away, because it sure isn’t… the C++26 feature freeze is past, and even before that compilers have already been aggressively implementing C++26, with GCC and Clang having already implemented about two-thirds of C++26’s language features adopted so far! C++ is a living language and moving fast. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
I recently contributed a guest post on my employer’s blog about the importance of the almost-feature-complete C++26 draft standard: “Sea change in C++: Why opportunities abound” It starts by summarizing a talk I gave recently, about how C++26 is poised to do what C++11 did over a decade ago: usher in a new era of … Continue reading Living in the future: Using C++26 at work →
Show full content
I recently contributed a guest post on my employer’s blog about the importance of the almost-feature-complete C++26 draft standard:
It starts by summarizing a talk I gave recently, about how C++26 is poised to do what C++11 did over a decade ago: usher in a new era of C++ code style. Just as we can now glance at 10 or 20 lines and quickly recognize “modern C++” as C++11-era code, soon we’ll be able to do the same with code that uses std::execution, contracts, memory safety improvements, and (fingers crossed) reflection, and quickly see it’s “modern” C++26-era code. A second wave of modernization, marked by a visibly refreshed language and style.
One thing I’ve appreciated here at Citadel is how aggressively the key advances are being adopted in our live trading systems. We already use C++26’s std::execution in production for an entire asset class, and as the foundation of our new messaging infrastructure. That’s possible because we’ve had our own in-house implementation running for several years now—thanks, Gašper and Bronek! Next, we’ll be pushing hard to adopt draft C++26’s new hardened standard library and contracts in our production systems, which were just voted into C++26 at our latest WG21 meeting in February.
This doesn’t mean we throw caution to the wind or reach for just any shiny new feature the moment it appears. But when key features are ready and delivering real value today, and we can get them with a little extra effort, there’s no reason to wait until tomorrow to use them. One of the nice things about that model is we get to “live in the future” by using those key features in production early, to get the benefits sooner and also to start building experience now with the cool things everyone will be using routinely everywhere soon.
The future’s not quite here. But for some features, we can already write production code as if it is. It’s illuminating; personally, I’m learning more about std::execution now that I’m in an environment where it’s being used for real. Fun times for C++!
For more background on safety and security issues related to C++, including definitions of “language safety” and “software security” and similar terms, see my March 2024 essay “C++ safety, in context.” This essay picks up our story where that one left off to bring us up to date with a specific focus on undefined behavior … Continue reading Crate-training Tiamat, un-calling Cthulhu:Taming the UB monsters in C++ →
Show full content
For more background on safety and security issues related to C++, including definitions of “language safety” and “software security” and similar terms, see my March 2024 essay “C++ safety, in context.” This essay picks up our story where that one left off to bring us up to date with a specific focus on undefined behavior (aka UB).
This is a status update on improvements currently in progress for hardening and securing our C++ software.
The C++ community broadly has a lot of hardening work well underway. Across the industry, this includes work being done by individual vendors, that they are then contributing to the standardization process so C++ programmers can use it portably. In the standard, it includes things we have had for a while (UB-free constexpr compile-time code) to things we’ve done recently (in draft C++26: erroneous behavior, bounds-hardened standard library, and contracts for functional safety) to proposals we’re actively pursuing next (in progress: Bjarne Stroustrup’s profiles, Úlfar Erlingsson’s remote code execution hardening).
A common underlying thread of all this work is that each piece addresses more and more of C++’s undefined behavior (aka UB), and especially the UB most exploited by attackers. We’re addressing UB methodically, starting with addressing the common high-value cases that will do the most to harden our code: uninitialized variables, out-of-bounds access, pointer misuse, and the key UB cases that adversaries need to implement remote code execution. These are the weaknesses that attackers exploit, and that we are locking down to lock them out.
Common (dis)belief: “UB is just too central to C++, trying to improve it enough to matter is hopeless”
For the sake of discussion, assume the cage is impervious to dragon breath and psionics. It’s just a metaphor.
Tech pundits still seem to commonly assume that UB is so fundamentally entangled in C++’s specification and programs that C++ will never be able to address enough UB to really matter. And it is true that it’s currently way too easy to accidentally let tendrils of silent UB slither pervasively throughout our C++ code.
Background in a nutshell: In C++, code that (usually accidentally) exercises UB is the primary root cause of our memory safety and security vulnerability issues. When a program contains UB, anything can happen; it’s common to call the whole thing “the UB dragon” and say “UB can reformat your hard drive or make demons fly out your nose” — hence the Tiamat and Cthulhu metaphors. Worse than those things, however, is that UB regularly leads to exploitable security vulnerabilities and other expensive-to-fix bugs. (For more details about UB, see the Appendix.)
So it’s valid to ask: Can and will C++ ever do enough about UB to make a major difference?
Summary and spoilers
In this post, I’m happy to report that serious taming of C++ UB is underway…
(1) Since C++11 in 2011, more and more C++ code has already become UB-free. Most people just didn’t notice.
Spoiler: All constexpr/consteval compile-time code is UB-free. As of C++26 almost the entire language and much of the standard library is available at compile time, and is UB-free when executed at compile time (but not when the code is executed at run time, hence the following additional work all of which is about run-time execution).
(2) Since March 2024, the draft C++26 standard has already removed key “low-hanging fruit” run-time UB cases that were the root cause of significant categories of security vulnerabilities.
Spoiler: In draft C++26, uninitialized local variables are no longer UB, and most common non-iterator bounds errors in the hardened standard library, such as for string and vector and string_view and span, will no longer be UB in a “hardened” implementation. (And C++26 also has language contracts for a different aspect of safety, namely functional safety for defensive programming to reduce bugs in general.)
(3) Now, we’re undertaking to add more tools and to systematically catalog and address run-time UB in the C++ language.
Spoiler: Addressing each case of UB statically where possible (at compile time), or with run-time checking where necessary. The primary tools: (a) C++26 erroneous behavior (EB); (b) Bjarne Stroustrup’s profiles and Gabriel Dos Reis’ profiles framework to opt into full safety by default and tactically opt out again where needed (sometimes you do want to breathe fire at a specific loop); and/or (c) applying C++26 contract assertions to check language features. EB and basic contract assertions are already part of C++26; profiles have work now underway focusing on implementation and deployment of the profiles framework and a few key profiles for experimentation across the C++ ecosystem. In addition, Úlfar Erlingsson is proposing a profile to surgically eliminate specifically the UB that attackers use to do remote code execution (RCE) which has the promise to eliminate many (and let developers opt into eliminating nearly all) malware exploits in recompiled C++ code.
If successful, these steps would achieve parity with the other modern memory-safe languages as measured by the number of security vulnerabilities, which would eliminate any safety-related reasons not to use C++. Note that leveling the playing field with other languages still means there are other security issues that need to be addressed too, in all languages, such as logic bugs for functional safety (C++26 contracts will help here); we’re first addressing the most valuable target to get to parity with other modern languages and then will continue to do more.
Importantly, this approach to hardening C++ doesn’t change C++’s value proposition — it keeps C++ still C++, it doesn’t try to turn C++ into “something else” such as by requiring mandatory performance overheads. All of the above embrace C++’s existing source code and its “zero-overhead, don’t pay for it if you don’t use it” core values, and just make it convenient to make memory safety the default — always with an opt-out, so that full performance and control is always available when you want to let Tiamat and Cthulhu use their powers in your service, under your control and for good.
And it’s designed to be super adoptable to bring existing code forward:
Many of the improvements are adoptable without any code changes (really!) — just recompile your existing project with a C++26 compiler, and your code will be safer. This is important because when you write code you write bugs, and even when you write code to fix bugs you write new bugs; this is part of the cost of requiring code changes that we’d like to minimize.
Even when you opt into a profile language subset that rejects unsafe code by default, you can still opt back out to writing the unsafe thing with an explicit, greppable, and auditable “suppress safety rule here” annotation (similar to “unsafe” in other languages).
That’s it — if you stop reading here, you have the full story.
But I think the details are pretty interesting, so join me if you like as we dive further into the above points (1), (2), and (3)…
Starting in C++11, C++’s compile-time constexpr world has already become a sandbox free from undefined behavior, quietly revolutionizing C++ by enabling powerful compile-time computation while also ensuring safety. During constexpr evaluation, the language mandates well-defined behavior — no wild pointers, no uninitialized reads, no surprises. If an operation might trigger undefined behavior, the compiler simply rejects the constexpr evaluation at compile time. This guarantees correctness before execution time, empowering developers to write faster, safer, and more expressive code.
Every release of C++ has continued making more of the language and standard library available in compile-time constexpr code, so that as of C++26 nearly the entire language and much of the standard library is available in constexpr code.
This is modern C++ at its best: unleashing compile-time power while also enforcing its correctness.
This is in production use, not vaporware: All major compilers have supported UB-free constexpr compile-time code for over a decade and it’s in widespread production use. Probably almost every nontrivial C++ project today is already using at least some UB-free constexpr code, unless it is very old code compiled with a very old compiler.
(2) Since 2024: Language safety and software security improvements adopted for C++26
Over the past year, C++26 has made further solid progress on language safety and software security. Briefly, here’s what C++26 has already adopted (some of this material is repeated from my previous trip reports; see the links for much more detail and discussion):
In March 2024 (see my March 2024 trip report), draft C++26 eliminated UB for uninitialized variables by turning it instead into a new kind of behavior: erroneous behavior (aka EB) that is still considered “wrong code” (so compilers should still warn about it) but is now well-defined so it is no longer UB-dragon-bait even if your code does transgress. That eliminates one root cause of a serious class of security vulnerabilities.
Last month (see my February 2025 trip report), draft C++26 additionally added a specification for a hardened standard library. Just recompiling with a hardened library gives our programs bounds safety guarantees for many common non-iterator C++26 standard library operations, including common operations on very popular standard types: string, string_view, span, mdspan, vector, array, optional, expected, bitset, and valarray. (At the same meeting, we also adopted language contracts to help improve functional safety for defensive programming to reduce bugs in general.)
Importantly, both of these achieve the holy grail of adoptability: “Just recompile all your existing code with a C++26 compiler / hardened library, and it will be safer.” That’s just an awesome adoption story. If you’ve seen any of my recent talks, you know this is close to my heart… see especially this short clip from my November talk in Poland and also this short clip in the Q&A about the societal value of improving C++. Of course, getting full safety improvements will sometimes require code changes, nobody is saying otherwise — for example, if you write a dangling pointer because your code is confused about ownership then you really will need to go fix and possibly restructure your code. But it’s pretty nice that we can get a subset of the safety improvements even just by recompiling our existing code!
Again, this is in production use, not vaporware: The support for uninitialized variables and the hardened standard library may be new to draft standard C++26, but they are already well supported on existing compilers. For uninitialized variables, you can already use the pre-standard compiler switches -ftrivial-auto-var-init=pattern (GCC, Clang) and /RTC1 (MSVC). For the hardened standard library, as the P3471 authors note, it has already been deployed in major commercial environments (you can use it today in libc++, see documentation here; MS-STL and libstdc++ have some similar options):
“We have experience deploying hardening on Apple platforms in several existing codebases.
Google recently published an article where they describe their experience with deploying this very technology to hundreds of millions of lines of code. They reported a performance impact as low as 0.3% and finding over 1000 bugs, including security-critical ones.
Google Andromeda published an article ~1 year ago about their successful experience enabling hardening.
The libc++ maintainers have received numerous informal reports of hardening being turned on and helping find bugs in codebases.
Overall, standard library hardening has been a huge success, in fact we never expected so much success. The reception has been overwhelmingly positive …”
This really demonstrates the value of addressing low-hanging fruit, and the Pareto principle (aka 80/20 rule): Often 80% of the benefit comes from the first 20% of investment.
(3) Since the past month: More work ongoing in the C++26 timeframe
For about a year now, multiple C++ committee experts have independently proposed systematically cataloging and/or addressing UB in C++:
December 2023: Shafik Yaghmour’s proposal P3075R0 to catalog C++’s language UB and document it as an Annex to the standard. (Building on his earlier pre-pandemic paper P1705R1.) This was encouraged by the core language specification subgroup (aka CWG) at the March 2024 meeting.
October 2024: My proposal P3436R0 to catalog UB and systematically address it using the opt-in mechanism of Bjarne Stroustrup and Gabriel Dos Reis’ language profiles proposal which has the ability to designate profiles as “named groups” of related compile-time restrictions and run-time checks that are easy to opt into to make safety the default. For more details, see my November 2024 trip report. This was unanimously encouraged by the Safety and Security subgroup (aka SG23) at the November 2024 meeting.
October 2024: Timur Doumler, Gašper Ažman, and Joshua Berne’s proposal P3100R1 to catalog UB and systematically address it as contract violations, using the new C++26 contract_assert feature to perform run time checks also for problematic language features. There is a related proposal P3400 to designate contract labels as “named groups” of related run-time checks that are easy to opt into to make safety the default. P3100 was unanimously encouraged by the Contracts subgroup (aka SG21) at the November 2024 meeting.
You can see the pattern: there are proposers and volunteers to
systematically catalog language UB,
specify a way to eliminate the UB (make it illegal, or well-defined including where necessary with a run-time check such as a bounds check),
make that elimination happen preferably all the time where it’s efficient enough (as C++26 is doing for uninitialized local variables) or else under a named group that’s easy to opt into (profile name, or contract label name), and
realizing that different UB cases need to be addressed in different ways, and we’re willing to put in the effort… no magic wand, Just Engineering.
At our February 2025 meeting, the main subgroup responsible for all language evolution (aka EWG) took these suggestions and gathered them together, and the group approved a mandate to pursue
“… a language safety white paper in the C++26 timeframe containing systematic treatment of core languageUndefined Behavior in C++, covering Erroneous Behavior, Profiles, and Contracts.”
Note that this is separate from C++26, because C++26 is now undergoing feature freeze and will spend the next year doing comment review and fit-and-finish, so we cannot now add new material (such as UB mitigations) to C++26 itself. But we want to keep our momentum and not let this important work wait for C++29, so concurrently with C++26 “in the C++26 timeframe” we intend to work on a white paper to catalog and address C++ language UB, that we hope to publish around the same time as C++26 is published.
Note: A white paper is an ISO publication that’s a flavor of Technical Specification (TS); think of a white paper or TS as a “feature branch.” The C++ committee has already published a dozen TSes since 2012, such as the concepts and modules TSes, most of which have already been merged into the “trunk” international standard (aka IS). A white paper and TS use the same process within the C++ committee, but a white paper just has less ISO red tape at the end compared to a TS so it can be published faster.
So now and over the next year or two, we’re undertaking to systematically catalog cases of UB in the C++ language to put a visible label on each fang and tentacle. Then, starting with the most important high-value targets, start deciding whether and how to address each in the most appropriate way but likely using those three tools mentioned in the mandate:
C++26 erroneous behavior, which you’ll recall the draft C++26 standard is already using to deal with uninitialized local variables.
Bjarne Stroustrup’s profiles and Gabriel Dos Reis’ P3589 profiles framework which allow us to create named groups of rules and checks, so that program code can easily opt into full safety by default and tactically opt out again where needed. Efforts now underway are focusing on implementation and deployment of the profiles framework and a few key profiles for experimentation across the C++ ecosystem.
C++26 contract assertions to check language features, as extended with P3400 labels which allow us to create named groups of checks.
I won’t lie: This is going to be a metric ton of work. And it’s work that I think some people don’t expect C++ to ever be able to do. But I think that it is achievable, and that it will be worth it, and we appreciate and want to thank all the committee members who have already expressed interest in volunteering to help — thank you!
New a week ago: P3656 strongly encouraged
Gašper Ažman and I got appointed to try to organize the work. So to get this started, Gašper and I wrote paper P3656 to detail a proposed procedure and plan. On March 19, EWG reviewed this in a telecon and voted strong encouragement that
“P3656 is ‘on the right track’ with the strategy proposed for producing a white-paper for ‘Core Language UB (and IF-NDR).’”
So here’s a quick overview of what we aim to do over the coming year or two, in the same timeframe as C++26…
First, list cases: Enumerate language UB
The goal of this part is to tag every case of language UB directly in the standard’s LaTeX sources, with at least a short description and code example. Using LaTeX tags right in the standard’s sources will let us automatically build another Annex to list the UB in one place, as the standard already does for the grammar for example. Additional detailed discussion and selected mitigations will go into the white paper.
We will also likely tag some basic attributes of each UB, such as:
have security experts tag whether it is directly exploitable, so that we can prioritize security-critical low-hanging fruit first; and
tag whether it is cheap to check locally with information already available (such as null pointer dereference which is easy to check locally with ptr != nullptr) or requires more information (such as other-than-null dangling pointer dereference which is more challenging, and some UB may be too expensive to entirely remove).
This also creates backpressure to reduce adding future UB, by requiring discussion and documentation in this list for any new UB proposals.
Second, list tools: Create a “non-exhaustive starter menu of tools”
The idea is to make an initial list of the tool(s) we can apply to each case of UB.
The EWG mandate already included erroneous behavior (EB), profiles, and contracts as the primary expected tools, so a slightly more detailed candidate list might be:
make the UB well-defined (just fix it always, no opt-in required; this could be a run-time check);
make the UB fail to compile (e.g., make it ill-formed which could change the meaning of SFINAE code that could use a different fallback path to avoid the UB path, or make it directly rejected without changing any meaning), either always or when a profile/label is enforced;
make the UB deprecated, either always or when a profile/label is enforced; and/or
make the UB be EB instead, either always (as we did for uninitialized locals) or when a profile/label is enforced.
This list is not exhaustive; we may find UB we want to handle using another technique, but I expect most cases of UB can be handled well using these tools.
We also intend to write some initial guidelines, for EWG to review and approve, about when to use each tool, including performance considerations, adoption hurdles (like frequency of that UB, or consequences of crashes), and other common considerations.
Third, apply: For each case of UB, say how we plan to address it
In many cases, this will require thoughtful papers, including strong implementation experience when there is a risk that performance or deployability may be difficult. My expectation is that we will find groups of similar UB that can all be handled in one paper, but the point is we want to be methodical about this… we aim to move fast, but the primary goal here is to make sure we actually unbreak things.
Fourth, group: Group UB cases into cohesive groups (profiles names / contract labels)
Finally, we can identify cohesive groups of UB that programs will want to address together, which makes them easy to opt into as a unit; for example, a “bounds_safety” group could include all bounds safety-related UB. These groups can overlap; for example, the same UB fix might be selectable as part of a “bounds_safety” group and as part of a general larger “strict_cplusplus” group.
New a few days ago: Efforts in progress to lock down the specific UB that malicious code relies on
Relatedly, a very interesting proposal was brought to the February ISO C++ meeting by Úlfar Erlingsson, Google’s DE for Cloud Security, P3627R0 (slides): “Easy-to-adopt security profiles for preventing RCE (remote code execution) in existing C++ code.”
Summarizing Úlfar’s premise:
We have already developed sufficient hardening implementation technology in modern compilers to effectively harden existing C++ code without code changes — not by aiming for language memory safety guarantees broadly, but by surgically targeting key UB that makes remote code execution (RCE) possible. Specifically: Stack integrity, control-flow integrity (CFI), heap data integrity, and pointer integrity and unforgeability. (Note: Úlfar was the first to efficiently implement stack integrity with strong guarantees, working with George Necula who originally designed it in CCured; and he and collaborators were the first to propose and implement CFI.)
If we do nothing more than take away the UB that can be used as building blocks for RCE (even if we still allowed other corruption), then bad actors would lose most of the tools they use to gain control over execution and run their malware, and we would dramatically harden the world’s code.
A key problem is that right now these technologies exist as separate features when the real benefit comes from enabling them together, and so we should standardize a profile that lets programmers tell their compilers to activate them together.
On Thursday, Úlfar published a new paper elaborating these ideas: “How to Secure Existing C and C++ Software without Memory Safety” describes how these techniques could not only prevent most RCE but also generally retake control of execution away from the attackers.
It’s well worth reading. An updated paper proposing this material for C++ standardization is expected soon in the C++ committee. As Úlfar notes (emphasis added): “This is a big change and will require a team effort: Researchers and standards bodies need to work together to define a set of protection profiles that can be applied to secure existing software — without new risks or difficulties — easily, at the flip of a flag …”
Note: A related new publication updated a week ago is the OpenSSF “Compiler Options Hardening Guide for C and C++.” This is a useful guide to existing security options that are good to know about and can be used in today’s compilers. These options add a variety of warnings and mechanisms that will help with security, including some used in Úlfar’s proposal (CFI and address space layout randomization, aka ASLR). However, these options are all “best effort,” and do not promise any guarantees, even when used all together — including options needing source code changes and those with noticeable overhead. What makes Úlfar’s approach different is that it carefully selects four specific techniques designed to reinforce each other such that they establish guarantees about the nested execution of functions, and the use of heap objects and pointers. Those guarantees eliminate almost all of the specific UB that malware authors rely on, and will hold even when the remaining UB is triggered, e.g., to corrupt memory.
If the language UB white paper could achieve not only its first goal of a broad systematic cataloging and mitigation of UB (grouped into profile/label names that programmers can turn on), but also specifically a “controlled_execution_security” profile that eliminates nearly all remote code execution attacks, that would be a great outcome — and would dramatically reduce C++ software security vulnerability exposure to parity (equality) with the other modern languages.
Summary, and what’s next
As a wise sage once said: “If you choose not to decide, you still have made a choice.”
For many years, software security may not have seemed pressing enough for C++ standardization broadly to make it a top priority, though gradual improvement has always continually occurred. But times have changed; we have been confronted with a spike of cyberattacks and cyberwar that creates serious threats to the systems we rely on to sustain our civilization, and faced stark choices: react decisively? and how? or not? Making a choice was not optional, as the sage pointed out.
We have chosen: to focus on improving C++ language safety as a priority, with the goal of achieving parity (as measured in number of security vulnerabilities) with other modern languages.
We have already accomplished a great deal. Compile-time C++ is already fully free of UB, which means a huge chunk of real-world C++ is already UB-free today. In C++26 we’re already eliminating several frequent vulnerability UB root causes, where in the language uninitialized variables are no longer UB and in the standard library many common operations on widely used types like vector and string and span and string_view are becoming bounds-safe in a C++26 hardened implementation. Although these are new to the standard, all have been deployed at scale in the field, and making them standard will make them easier to adopt even more widely. (In C++26, we are also shipping language contracts for a different aspect of safety, namely functional safety for defensive programming to reduce bugs in general.)
It’s working: The price of zero-day exploits has already increased. Now we have a path to get the rest of the way to taming UB in C++. Yes, there’s still a great deal of work ahead, but if we can make a solid push over the next one to two years we do have a real shot at systematically addressing UB in C++, including eliminating nearly all remote code execution attacks. If these efforts to cage the monsters works out even half as well as we hope, I think a lot of folks are going to be very (and I think happily) surprised.
As several other wise sages said: “Let the good times roll.”
If you’re one of the ones helping with either what’s been accomplished already and/or with our next steps above, we want to again say a big “thank you!” — your help is appreciated, and it really matters.
Thanks, very much.
Appendix: UB, briefly
Historically, UB was allowed in C and then C++ as the basis for compiler optimizations: Compilers are allowed to assume that UB never happens and optimize your program based on that assumption. In the real world, compilers are variously aggressive about making that assumption; for a survey of what common examples the different major compilers actually do optimize in what ways at different optimization levels, see my 2020 paper P2064R0 section 3.4.
We have now been reconsidering UB for two reasons, which to me corresponds to that the UB dragon has multiple heads:
UB often has directly safety and security implications. For example, if a program sometimes tries to access out-of-bounds memory, a malicious actor can use that vulnerability to write an exploit that will install malware to steal cryptocurrency or worse.
UB also has indirect safety and security implications. For example, if the compiler encounters an if/else branch and notices that one side of the branch would always encounter UB, it can not only assume that branch is never taken, but it can also assume that the condition the branch is testing is always true (or always false) and so not even test it — which is problematic if the branch was doing a deliberately-enabled safety-related contract check that the compiler ends up silently optimizing out of the compiled program so that the check is never performed at all.
UB optimizations also just create mysterious ordinary bugs, such as variables that appear to be simultaneously true and false, unreachable code that gets executed anyway, and “time travel” optimizations that change code that precedes the point where the UB can happen (hence, the idea of UB ‘reaching back to modify the past’).
Less of all those things, please. Over the past decade C++ has been pursuing ways to keep all our glorious optimizations but to specify the optimizability in ways other than fire-breathing mind-flaying UB.
Notes:
Addressing UB in C++ is easier to do than in C, because C is a fine language but is lower-level with fewer standard abstractions, which means it has fewer universally available alternatives to recommend and fewer standard library features that the standard can directly harden.
UB is closely related to another technical concept in the C++ standard called “ill-formed, no diagnostic required” (IF-NDR). For convenience, herein I’m saying just “UB” as a shorthand for “UB and [or, including] IF-NDR.”
On Saturday, the ISO C++ committee completed the second-last design meeting of C++26, held in Hagenberg, Austria. There is just one meeting left before the C++26 feature set is finalized in June 2025 and draft C++26 is sent out for its international comment ballot (aka “Committee Draft” or “CD”), and C++26 is on track to … Continue reading Trip report: February 2025 ISO C++ standards meeting (Hagenberg, Austria) →
Show full content
On Saturday, the ISO C++ committee completed the second-last design meeting of C++26, held in Hagenberg, Austria. There is just one meeting left before the C++26 feature set is finalized in June 2025 and draft C++26 is sent out for its international comment ballot (aka “Committee Draft” or “CD”), and C++26 is on track to be technically finalized two more meetings after that in early 2026.
This meeting was hosted by the University of Applied Sciences of Upper Austria, RISC Software GmbH, Softwarepark Hagenberg Upper Austria, Dynatrace, and Count It Group. Our hosts arranged for high-quality facilities at the University for our six-day meeting from Monday through Saturday. We had over 200 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 31 nations. At each meeting we regularly have new guest attendees who have never attended before, and this time there were 36 new first-time guest attendees, mostly in-person, in addition to new attendees who are official national body representatives. To all of them, once again welcome!
The committee currently has 23 active subgroups, 13 of which met in 7 parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day, depending on their workloads. We also had combined informational evening sessions to inform the committee broadly about progress on one key topic this week: reflection wording review, and concurrent queues. You can find a brief summary of ISO procedures here.
Highlights
This time, the committee adopted the next set of features for C++26, and made significant progress on other features that are now expected to be complete in time for C+26.
In addition to features already approved for C++26 at previous meetings, at this meeting three major features made strong progress. In the core language:
P2900 Contracts was adopted for C++26
P2786 Trivial Relocatability was adopted for C++26
P1967 #embed was adopted for C++26
In the standard library:
P3471 Standard Library Hardening (which is also the first use of contracts) was adopted for C++26
P0447 std::hive was adopted for C++26
Other noteworthy progress:
P2996 Reflection is almost done its specification wording review aiming for C++26, and is expected to come up for vote for inclusion in C++26 at the June meeting
[ETA:] Profiles papers received a lot of discussion time in EWG (language evolution working group) and feedback to improve consensus, and EWG encouraged pursuing a white paper to systematically address undefined behavior that could be concurrent with C++26 (some UB is already addressed in C++26; see below for more)
Language safety and software security improvements adopted for C++26
C++26 adopted two major features that improve language/library safety and software security: contracts [ETA: which help making programs functionally safe and can be a tool for specifying language/library safety checks], and a security-hardened standard library that has already delivered actual important security improvements just by recompiling/relinking existing C++ code (see references below) [ETA: which uses contracts to add some library safety guarantees for software security].
Note: For definitions of “language safety” and “software security” and similar terms, see my 2024 essay “C++ safety, in context.”
C++26 Contracts
First, years in the making, we adopted P2900R14 “Contracts for C++” by Joshua Berne, Timur Doumler, and Andrzej Krzemieński, with Gašper Ažman, Peter Bindels, Louis Dionne, Tom Honermann, Lori Hughes, John Lakos, Lisa Lippincott, Jens Maurer, Ryan McDougall, Jason Merrill, Oliver J. Rosten, Iain Sandoe, and Ville Voutilainen. This is a huge paper (119 pages) that adds preconditions, postconditions, and contract_assert (a major improvement that brings C’s “assert” macro into the language, with improvements). For an overview, see Timur Doumler’s blog post “Contracts for C++ explained in 5 minutes.” The main change last week is that the committee decided to postpone supporting contracts on virtual functions; work will continue on that and other extensions. Thanks to the coauthors, and to everyone in Study Group 21 (SG21) and the language evolution working group (EWG) and everyone who commented and gave feedback, for their hard work on this feature for many years!
Note: This is the second time contracts has been voted into draft standard C++. It was briefly part of draft C++20, but was then removed for further work.
Relatedly, P1494R4 “Partial program correctness” by Davis Herring adds the idea of “observable checkpoints” that limit the ability of undefined behavior to perform time-travel optimizations. This helps to eliminate some optimization pitfalls that range from not actually executing an enforced contract (see contracts, above) to security vulnerabilities. The paper also provides std::observable() as a manual way of adding such a checkpoint in code.
C++26 hardened standard library
The second is another big step for language and library safety in C++26. Recall that:
C++23 already eliminated returning a dangling reference to a local object at compile time (did you know that? try it now on Godbolt), which has already removed one common source of silent dangling.
C++26 has already eliminated undefined behavior from uninitialized variables.
And now in C++26…
… P3471R4 “Standard library hardening” by Konstantin Varlamov and Louis Dionne provides initial portable, cross-platform security guarantees for the C++ standard library too as part of C++26. It turns some common and frequently-exploited instances of undefined behavior in the C++ standard library into a contract violation (note: that makes it also the first user of the just-adopted contracts language feature, above! yes, WG21 does try to coordinate its delivered features).
[Corrected:] In particular, only three (3) programming language weaknesses made the top 15 most dangerous software weaknesses in the MITRE 2024 CWE Top 25 Most Dangerous Software Weaknesses — and the top two are Out-of-Bounds Write (#2) and Out-of-Bounds Read (#6).
This is why I keep repeating that, yes, we need to improve C (especially) and C++ memory safety, but that is far from the only thing we as an industry need to do. As we harden one area, attackers just shift to the next slowest animal in the herd. Already, above, we are seeing more and more of the MITRE Top 25 be not programming language memory safety issues… in 2024, it’s down to just 3 of the top 15. Sure we need to fix those issues and others like them, but let’s never forget that we need to fix the other 12 of the top 15 too! For more on this, again please see my “C++ safety, in context” essay.
This continues to demonstrate what I’ve explained many times: Bounds safety is the lowest-hanging fruit in terms of things we need to address first. The Google security article linked below points out that bounds (spatial) safety vulnerabilities represent 40% of in-the-wild serious memory safety exploits over the past decade. That’s why it’s a big deal that, as of Saturday, the C++26 hardened standard library focuses on bounds safety and requires that the all of following are guaranteed to be bounds-checked:
In std::span: operator[], front, back, first, last, subspan, and constructors
In the std::string_views: operator[], front, back, remove_prefix, remove_suffix
In all sequence containers (e.g., std::vector, std::array): operator[], front, back, pop_front, pop_back
In the std::strings: operator[], front, back, pop_back
In the multidimensional std::mdspan: operator[], and constructors
In std::bitset: operator[]
In std::valarray: operator[]
In std::optional: operator->, operator*
In std::expected: operator->, operator*, error
And that’s just a start, that has already made a real impact on hardening production code including on popular platforms.
Importantly, user code gets this benefit just by building with a hardened C++26 standard library — without any code changes. If you’ve seen any of my recent talks, you know this is close to my heart… see especially
this short clip in my code::dive (Nov 2024) talk about why C++26 removing undefined behavior for uninitialized locals is a model for adoptability; and also
this short clip in the Q&A of that talk about the societal value of improving C++.
I think that Konstantin and Louis express that value proposition beautifully in their paper’s Motivation section, and I’ll quote most of their appeal here (emphasis original)… they “get it”:
“There has been significantly increased attention to safety and security in C++ over the last few years, as exemplified by the well-known White House report and numerous recent security-related proposals.
“While it is important to explore ways to make new code safer, we believe that the highest priority to deliver immediate real-world value should be to make existing code safer with minimal or no effort on behalf of users. Indeed, the amount of existing security-critical C++ code is so large that rewriting it or modifying it is both economically unviable and dangerous given the risk of introducing new issues.
“There have been a few proposals accepted recently that eliminate some cases of undefined behavior in the core language. The standard library also contains many instances of undefined behavior, some of which is a direct source of security vulnerabilities; addressing those is often trivial, can be done with low overhead and almost no work on behalf of users.
“In fact, at the moment all three major library implementations have some notion of a hardened or debug mode. This clearly shows interest, both from users and from implementers, in having a safer mode for the standard library. However, we believe these efforts would be vastly more useful if they were standardized and provided portable, cross-platform guarantees to users; as it stands, implementations differ in levels of coverage, performance guarantees and ways to enable the safer mode.
“Finally, leaving security of the library to be a pure vendor extension fails to position ISO C++ as providing a credible solution for code bases with formal security requirements. We believe that formally requiring the basic safety guarantees that most implementations already provide in one way or another could make a significant difference from the point of view of anyone writing or following safety and security coding standards and guidelines.”
In the next section, they demonstrate that this isn’t some theoretical improvement — it’s an improvement that is standardizing what is already shipping and significantly hardening existing C++ code today (emphasis added):
“All three major implementations provide vendor-specific ways of enabling library assertions as proposed in this paper, today.
We have experience deploying hardening on Apple platforms in several existing codebases.
Google recently published an article where they describe their experience with deploying this very technology to hundreds of millions of lines of code. They reported a performance impact as low as 0.3% and finding over 1000 bugs, including security-critical ones.
Google Andromeda published an article ~1 year ago about their successful experience enabling hardening.
The libc++ maintainers have received numerous informal reports of hardening being turned on and helping find bugs in codebases.
Overall, standard library hardening has been a huge success, in fact we never expected so much success. The reception has been overwhelmingly positive and while the quality of implementation will never be perfect, we are working hard to expand the scope of hardening in libc++, to improve its performance and the user experience.
This further demonstrates that not only is C++ making serious progress to improve, but that many of the language safety and software security improvements are already shipping without waiting for standardization. Standardization is still important, of course, because it makes these improvements available portably, with portable guarantees for C++ code on all platforms.
More things adopted for C++26: Core language changes/features
Note: These links are to the most recent public version of each paper. If a paper was tweaked at the meeting before being approved, the link tracks and will automatically find the updated version as soon as it’s uploaded to the public site.
In addition to fixing a list of defect reports, the core language adopted 8 papers, including contracts (above) and the following…
P2786R13 “Trivial relocatability for C++26” by Alisdair Meredith, Mungo Gill, Joshua Berne, Corentin Jabot, Pablo Halpern, and Lori Hughes adds stronger support for optimizing the copying of memcpy-able types in the C++ language. This removes a source of “undefined behavior” that many container libraries rely on because it happens to be useful and probably-benign, and not only guarantees it is well-defined but also makes the optimizations more widely available for more types. Thank you, Alisdair and your collaborators, and thanks also to the authors of other trivial-relocation proposals that were not adopted! All of the input has made the result better, and we appreciate all the continued feedback.
“For well over 40 years, people have been trying to plant data into executables for varying reasons. Whether it is to provide a base image with which to flash hardware in a hard reset, icons that get packaged with an application, or scripts that are intrinsically tied to the program at compilation time, there has always been a strong need to couple and ship binary data with an application.
“Neither C nor C++ makes this easy for users to do, resulting in many individuals reaching for utilities such as xxd, writing python scripts, or engaging in highly platform-specific linker calls to set up extern variables pointing at their data. Each of these approaches come with benefits and drawbacks. For example, while working with the linker directly allows injection of very large amounts of data (5 MB and upwards), it does not allow accessing that data at any other point except runtime. Conversely, doing all of these things portably across systems and additionally maintaining the dependencies of all these resources and files in build systems both like and unlike make is a tedious task.
“Thusly, we propose a new preprocessor directive whose sole purpose is to be #include, but for binary data: #embed.”
Note that this feature has already been approved for inclusion in the next revision of C as well. See the proposal paper, especially sections 3.3 and 4.1, for more delightful background and design alternative discussion.
P2841R7 “Concept and variable-template template-parameters” by Corentin Jabot, Gašper Ažman, James Touton, and Hubert Tong adds the ability of passing concepts and variable templates as template parameters. Thank you, Corentin and your coauthors!
More things adopted for C++26: Standard library changes/features
In addition to fixing a list of defect reports, the standard library adopted 15 papers, including the following…
“Hive is a formalisation, extension and optimization of what is typically known as a ‘bucket array’ or ‘object pool’ container in game programming circles. Thanks to all the people who’ve come forward in support of the paper over the years, I know that similar structures exist in various incarnations across many fields including high-performance computing, high performance trading, 3D simulation, physics simulation, robotics, server/client application and particle simulation fields (see this google groups discussion, the hive supporting paper #1 and appendix links to prior art).
“The concept of a bucket array is: you have multiple memory blocks of elements, and a boolean token for each element which denotes whether or not that element is ‘active’ or ‘erased’ – commonly known as a skipfield. If it is ‘erased’, it is skipped over during iteration. When all elements in a block are erased, the block is removed, so that iteration does not lose performance by having to skip empty blocks. If an insertion occurs when all the blocks are full, a new memory block is allocated.
“The advantages of this structure are as follows: because a skipfield is used, no reallocation of elements is necessary upon erasure. Because the structure uses multiple memory blocks, insertions to a full container also do not trigger reallocations. This means that element memory locations stay stable and iterators stay valid regardless of erasure/insertion. This is highly desirable, for example, in game programming because there are usually multiple elements in different containers which need to reference each other during gameplay, and elements are being inserted or erased in real time. The only non-associative standard library container which also has this feature is std::list, but it is undesirable for performance and memory-usage reasons. This does not stop it being used in many open-source projects due to this feature and its splice operations.
“Problematic aspects of a typical bucket array are that they tend to have a fixed memory block size, tend to not re-use memory locations from erased elements, and utilize a boolean skipfield. The fixed block size (as opposed to block sizes with a growth factor) and lack of erased-element re-use leads to far more allocations/deallocations than is necessary, and creates memory waste when memory blocks have many erased elements but are not entirely empty. Given that allocation is a costly operation in most operating systems, this becomes important in performance-critical environments. The boolean skipfield makes iteration time complexity at worst O(n) in capacity(), as there is no way of knowing ahead of time how many erased elements occur between any two non-erased elements. This can create variable latency during iteration. It also requires branching code for each skipfield node, which may cause performance issues on processors with deep pipelines and poor branch-prediction failure performance.
“A hive uses a non-boolean method for skipping erased elements, which allows for more-predictable iteration performance than a bucket array and O(1) iteration time complexity; the latter of which means it meets the C++ standard requirements for iterators, which a boolean method doesn’t. It has an (optional – on by default) growth factor for memory blocks and reuses erased element locations upon insertion, which leads to fewer allocations/reallocations. Because it reuses erased element memory space, the exact location of insertion is undefined. Insertion is therefore considered unordered, but the container is sortable. Lastly, because there is no way of predicting in advance where erasures (‘skips’) may occur between non-erased elements, an O(1) time complexity [ ] operator is not possible and thereby the container is bidirectional but not random-access.”
Continuing the “making more things constexpr (and consteval)” drumbeat that allows more and more of the full C++ language and standard library be usable in constexpr code, we approved a set of constexpr extensions:
Thanks, Hana! These are just the latest of a continued stream of Hana’s papers for constexpr-ing the C++ world; much appreciated — děkuju and arigato!
You may recall that at our last meeting we merged std::simd byMatthias Kretz for high-throughput parallel/vector programming into draft C++26. On Saturday we approved a set of further extensions and refinements, including:
Last but not least, P3019R14 “indirect and polymorphic: Vocabulary types for composite class design” by Jonathan Coe, Antony Peacock, and Sean Parent adds value-semantic types for polymorphic objects to the standard library. This makes polymorphic types much easier to treat as values in value-like algorithms and use cases. Thanks very much, Jonathan and Antony and Sean!
What’s next
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Our next meeting will be this June in Sofia, Bulgaria hosted by Chaos Group and C++ Alliance.
Thank you again to the over 200 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… in case you think C++“26” sounds very far away, it sure isn’t… we’re only one meeting away before the C++26 freeze in June, and even before that compilers are already aggressively implementing C++26, with GCC and Clang having already implemented about two-thirds of C++26’s language features adopted so far! C++ is a living language and moving fast. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
The Biden administration just issued another executive order (EO) on hardening U.S. cybersecurity. This is all great stuff. (*) (**) A lot of this EO is repeating the same things I urged in my essay nearly a year ago, “C++ safety — in context”… here’s a cut-and-paste of my “Call(s) to action” conclusion section I … Continue reading New U.S. executive order on cybersecurity →
A lotof this EO is repeating the same things I urged in my essay nearly a year ago, “C++ safety — in context”… here’s a cut-and-paste of my “Call(s) to action” conclusion section I published back then, and I think you’ll see a heavy overlap with this week’s new EO…
Call(s) to action
As an industry generally, we must make a major improvement in programming language memory safety — and we will.
In C++ specifically, we should first target the four key safety categories that are our perennial empirical attack points (type, bounds, initialization, and lifetime safety), and drive vulnerabilities in these four areas down to the noise for new/updated C++ code — and we can.
But we must also recognize that programming language safety is not a silver bullet to achieve cybersecurity and software safety. It’s one battle (not even the biggest) in a long war: Whenever we harden one part of our systems and make that more expensive to attack, attackers always switch to the next slowest animal in the herd. Many of 2023’s worst data breaches did not involve malware, but were caused by inadequately stored credentials (e.g., Kubernetes Secrets on public GitHub repos), misconfigured servers (e.g., DarkBeam, Kid Security), lack of testing, supply chain vulnerabilities, social engineering, and other problems that are independent of programming languages. Apple’s white paper about 2023’s rise in cybercrime emphasizes improving the handling, not of program code, but of the data: “it’s imperative that organizations consider limiting the amount of personal data they store in readable format while making a greater effort to protect the sensitive consumer data that they do store [including by using] end-to-end [E2E] encryption.”
No matter what programming language we use, security hygiene is essential:
Do use your language’s static analyzers and sanitizers. Never pretend using static analyzers and sanitizers is unnecessary “because I’m using a safe language.” If you’re using C++, Go, or Rust, then use those languages’ supported analyzers and sanitizers. If you’re a manager, don’t allow your product to be shipped without using these tools. (Again: This doesn’t mean running all sanitizers all the time; some sanitizers conflict and so can’t be used at the same time, some are expensive and so should be used periodically, and some should be run only in testing and never in production including because their presence can create new security vulnerabilities.)
Do keep all your tools updated. Regular patching is not just for iOS and Windows, but also for your compilers, libraries, and IDEs.
Do secure your software supply chain. Do use package management for library dependencies. Do track a software bill of materials for your projects.
Don’t store secrets in code. (Or, for goodness’ sake, on GitHub!)
Do configure your servers correctly, especially public Internet-facing ones. (Turn authentication on! Change the default password!)
Do keep non-public data encrypted, both when at rest (on disk) and when in motion (ideally E2E… and oppose proposed legislation that tries to neuter E2E encryption with ‘backdoors only good guys will use’ because there’s no such thing).
Do keep investing long-term in keeping your threat modeling current, so that you can stay adaptive as your adversaries keep trying different attack methods.
We need to improve software security and software safety across the industry, especially by improving programming language safety in C and C++, and in C++ a 98% improvement in the four most common problem areas is achievable in the medium term. But if we focus on programming language safety alone, we may find ourselves fighting yesterday’s war and missing larger past and future security dangers that affect software written in any language.
Sadly, there are too many bad actors. For the foreseeable future, our software and data will continue to be under attack, written in any language and stored anywhere. But we can defend our programs and systems, and we will.
(*) My main disappointment is that some of the provisions have deadlines that are too far away. Specifically: Why would it take until 2030 to migrate to TLS 1.3? It’s not just more secure, it’s also faster and has been published for seven years already… maybe I’m just not aware enough of TLS 1.3 adoptability issues though, as I’m not a TLS expert.
(**) Here in the United States, we’ll have to see whether the incoming administration will continue this EO, or amend/replace/countermand it. In the United States, that’s a drawback of using an EO compared to passing an actual law with Congressional approval… an EO is “quick” because the President can issue it without getting legislative approval (for things that are in the Presidential remit), but for the same reason an EO also isn’t “durable” or guaranteed to outlive its administration. Because the next President can just order something different, an EO’s default shelf life is just 1-4 years.
So far, all the major U.S. cybersecurity EOs that could affect C++ have been issued since 2021, which means so far they have all come from one President… and so we’re all going to learn a lot this year, one way or another, about their permanence. (In both the U.S. and the E.U., actual laws are also in progress to shift software liability from consumer to software producers, and those will have real teeth. But here we’re talking about the U.S. EOs from 2021 to date.)
That said, what I see in these EOs is common sense pragmatism that’s forcing the software industry to eat our vegetables, so I’m cautiously optimistic that we’ll continue to maintain something like these EOs and build on them further as we continue to work hard to secure the infrastructure that our comfortable free lifestyle (and, possibly someday, our lives) depends on. This isn’t about whether we love a given programming language, it’s about how we can achieve the greatest hardening at the greatest possible scale for our civilization’s infrastructure, and for those of us whose remit includes the C++ language that means doing everything we can to harden as much of the existing C and C++ code out there as possible — all the programmers in the world can only write so much new/rewritten code every year, and for us in C++ by far the maximum contribution we can make to overall security issues related to programming languages (i.e., the subset of security issues that fall into our remit) is to find ways to improve existing C and C++ code with no manual source code changes — that won’t always be possible, but where it’s possible it will maximize our effectiveness in improving security at enormous scale. See also this 2-minute answer I gave in post-talk Q&A in Poland two months ago.
Next week, on January 15, I’ll be speaking at the University of Waterloo, my alma mater. There’ll be a tech talk on key developments in C++ and why I think the language’s future over the next decade will be exciting, with lots of time allocated to a “fireside chat / interview” session for Q&A. The … Continue reading Speaking at University of Waterloo on January 15 →
Show full content
Next week, on January 15, I’ll be speaking at the University of Waterloo, my alma mater. There’ll be a tech talk on key developments in C++ and why I think the language’s future over the next decade will be exciting, with lots of time allocated to a “fireside chat / interview” session for Q&A. The session is hosted by Waterloo’s Women in Computer Science (WiCS) group, and dinner and swag by Citadel Securities, where I work.
This talk is open to Waterloo students only (registration required). The organizers are arranging an option to watch remotely for the half of you who are away from campus on your co-op work terms right now — I vividly remember those! Co-op is a great experience.
I look forward to meeting many current students next week, and comparing notes about co-op work terms, pink ties (I still have mine) and MathSoc and C&D food (if Math is your faculty), WATSFIC, and “Water∞loo” jokes (I realize doing this in January is tempting the weather/travel gods, but I do know how to drive in snow…).
Less than two weeks from now, on January 13 I’ll be speaking at the New York C++ meetup in Midtown East (Clinton Hall at 230 E 51st Street). I’ll be giving a condensed update of my recent “Peering forward: C++’s next decade” talk, so that there’ll be plenty of time for Q&A — please have … Continue reading Speaking at New York C++ meetup on January 13 →
Show full content
Less than two weeks from now, on January 13 I’ll be speaking at the New York C++ meetup in Midtown East (Clinton Hall at 230 E 51st Street). I’ll be giving a condensed update of my recent “Peering forward: C++’s next decade” talk, so that there’ll be plenty of time for Q&A — please have your questions ready about all the cool things happening right now in the ISO C++ world.
The meetup is sponsored by Citadel Securities, where I work. Food and drink will be served! Registration is free, but preregistration RSVP is required so please use the form at the link about to reserve your spot. A waitlist is available if space runs out.
[Updates: Clarified that an intrusive discriminator would be far beyond what most people mean by “C++ ABI break.” Mentioned unique addresses and common initial sequences. Added “unknown” state for passing to opaque functions.]
Here is my little New Year’s Week project: Trying to write a small library to enable compiler support for automatic raw union member access checking.
The problem, and what’s needed
During 2024, I started thinking: What would it take to make C/C++ union accesses type-checked? Obviously, the ideal is to change naked union types to something safe.(*) But because it will take time and effort for the world to adopt any solution that requires making source code changes, I wondered how much of the safety we might be able to get, at what overhead cost, just by recompiling existing code in a way that instruments ordinary union objects?
Note: I describe this in my C++26 Profiles proposal, P3081R0 section 3.7. The following experiment is trying to validate/invalidate the hypothesis that this can be done efficiently enough to warrant including in an ISO C++ opt-in type safety profile. Also, I’m sure this has been tried before; if you know of a recent (last 10 years?) similar attempt that measured its results, please share it in the comments.
What do we need? Obviously, an extra discriminator field to track the currently active member of each C/C++ union object. But we can’t just add a discriminator field intrusively inside each C/C++ union object, because that would change the size and layout of the object and be a massive link/ABI incompatibility even with C compilers and C code on the same platform which would all need to be identically updated at the same time, and it would break most OSes whose link compatibility (existing apps, device drivers, …) rely on C ABIs and APIs and use unions in stable interfaces; breaking that is much more than people usually mean by “C++ taking an ABI break” which is more about evolving C++ standard library types.
So we have to store it… extrinsically? … as-if in a global internally-synchronized map<void* /*union obj address*/, uintNN_t /*discriminator*/>…? But that sounds stupid scary: global thread safety lions, data locality tigers, and even some branches bears, O my! Could such extrinsic storage and additional checking possibly be efficient enough?
My little experiment
I didn’t know, so earlier this year I wrote some code to find out, and this week I cleaned it up and it’s now posted here:
The workhorse is extrinsic_storage<Data>, a fast and scalable lock-free data structure to nonintrusively store additional Data for each pointer key. It’s wait-free for nearly all operations (not just lock-free!), and I’ve never written memory_order_relaxed this often in my life. It’s designed to be cache- and prefetcher-friendly, such as using SOA to store keys separately so that default hash buckets contain 4 contiguous cache lines of keys. Here I use it for union discriminators, but it’s a general tool that could be considered for any situation where a type needs to store additional data members but can’t store them internally.
If you’re looking for a little New Year’s experiment…
If you’re looking for a little project over the next few days to start off the year, may I suggest one of these:
Little Project Suggestion #1: Find a bug or improvement in my little lock-free data structure! I’d be happy to learn how to make it better, fire away! Extra points for showing how to fix the bug or make it run better, such as in a PR or your cloned repo.
Little Project Suggestion #2: Minimally extend a C++ compiler (Clang and GCC are open source) as described below, so that every construction/access/destruction of a union type injects a call to my little library’s union_registry<>:: functions which will automatically flag type-unsafe accesses. If you try this, please let me know in the comments what happens when you use the modified compiler on some real world source! I’m curious whether you find true positive union violations in the union-violations.log file – of course it will also contain false positives, because real code does sometimes use unions to do type punning on purpose, but you should be able to eliminate batches of those at a time by their similar text in the log file.
// For an object U of union type that
// has a unique address, when Inject a call to this (zero-based alternative #s)
//
// U is created initialized on_set_alternative(&U,0) = the first alternative# is active
//
// U is created uninitialized on_set_alternative(&U,invalid)
//
// U.A = xxx (alt A is assigned to) on_set_alternative(&U,#A)
//
// U or U.A is passed to a function by on_set_alternative(&U,unknown)
// pointer/reference to non-const
// and we don't know the function
// is compiled in this mode
//
// U.A (alt A is otherwise used) on_get_alternative(&U,#A)
// and A is not a common initial
// sequence
//
// U is destroyed / goes out of scope on_destroy(&U)
//
// That's it. Here's an example:
// {
// union Test { int a; double b; };
// Test t = {42}; union_registry<>::on_set_alternative(&u,0);
// std::cout << t.a; union_registry<>::on_get_alternative(&u,0);
// t.b = 3.14159; union_registry<>::on_set_alternative(&u,1);
// std::cout << t.b; union_registry<>::on_get_alternative(&u,1);
// } union_registry<>::on_destroy(&u);
//
// For all unions with up to 254 alternatives, use union_registry<>
// For all unions with between 255 and 16k-2 alternatives, use union_registry<uint16_t>
// If you find a union with >16k-2 alternatives, email me the story and use union_registry<uint32_t>
Each run tests 1 million union objects, 10,000 at a time, 10 operations on each union; the test type is union Union { char alt0; int alt1; long double alt2; };
Each run injects 1 deliberate “type error” failure to trigger detection, which results in a line of text written to union-violations.log that records the bad union access including the source line that committed it (so there’s a little file I/O here too)
Totals:
14 million union objects created/destroyed
140 million union object accesses (10 per object, includes construct/set/get/destroy)
On my machine, here is total the run-time overhead (“total checked” time using this checking, minus “total raw” time using only ordinary raw union access), for a typical run of the whole 140M unit accesses:
Compiler
total raw (ms)
total checked (ms)
total overhead (ms)
Notes
MSVC 19.40 -O2
~190
~1020
~830
Compared to -O2, -Ox checked was the same or very slightly slower, and -Os checked was 3x slower
GCC 14 -O3
~170
~800
~630
Compared to -O3, -O2 overall was only slightly slower
Clang 18 -O3
~170
~510
~340
Compared to -O3, -O2 checked was about 40% slower
Dividing that by 140 million accesses, the per-access overhead is:
This… seems too good to be true. I may well be making a silly error (or several) but I’ll post anyway so we can all have fun correcting them! Maybe there’s a silly bug in my code, or I moved a decimal point, or I converted units wrong, but I invite everyone to have fun pointing out the flaw(s) in my New Year’s Day code and/or math – please fire away in the comments.
Elaborating on why this seems too good to be true: Recall that one “access” means to check the global hash table to create/find/destroy the union object’s discriminator tag (using std::atomics liberally) and then also set or check either the tag (if setting or using one of the union’s members) and/or the key (if constructing or destroying the union object). But even a single L2 cache access is usually around 10-14 cycles! This would mean this microbenchmark is hitting L1 cache almost always, even while iterating over 10,000 active unions at a time, often with more hot threads than there are physical or logical cores pounding on the same global data structure, and occasionally doing a little file I/O to report violations.
Even if I didn’t make any coding/calculation errors, one explanation is that this microbenchmark has great L1 cache locality because the program isn’t doing any other work, and in a real whole program it won’t get to run hot in L1 that often – that’s a valid possibility and concern, and that’s exactly why I’m suggesting Little Project #2, above, if anyone would like to give that little project a try.
In any event, thank you all for all your interest and support for C++ and its evolution and standardization, and I wish all of you and your families a happier and more peaceful 2025!
(*) Today we have std::variant which safely throws an exception if you access the wrong alternative, but variant isn’t as easy to use as union today, and not as type-safe in some ways. For example, the variant members are anonymous so you have to access them by index or by type; and every variant<int,string> in the program is also anonymous == the same type, so we can’t distinguish/overload unrelated variants that happen to have similar alternatives. I think the ideal answer – and it looks like ISO C++ is just 1-2 years from being powerful enough to do this! – will be something like the safe union metaclass using reflection that I’ve implemented in cppfront, which is as easy to use as union and as safe as variant – see my CppCon 2023 keynote starting at 39:16 for a 4-minute discussion of union vs. variant vs a safe union metafunction that uses reflection.
Two weeks ago, Bjarne and I and lots of ISO committee members had a blast at the code::dive C++ conference held on November 25, just two days after the end of the Wrocław ISO C++ meeting. Thanks again to Nokia for hosting the ISO meeting, and for inviting us all to speak at their conference! … Continue reading My code::dive talk video is available: New Q&A →
Show full content
Two weeks ago, Bjarne and I and lots of ISO committee members had a blast at the code::dive C++ conference held on November 25, just two days after the end of the Wrocław ISO C++ meeting. Thanks again to Nokia for hosting the ISO meeting, and for inviting us all to speak at their conference! My talk was an updated-and-shortened version of my CppCon keynote (which I also gave at Meeting C++; I’ll post a link to that video too once it’s posted):
If you already saw the CppCon talk, you can skip to these “new parts at the end” where the Q&A got into very interesting topics:
That morning, on our route while traveling from the hotel to the conference site, at one point we noticed that up ahead there was a long line of people all down the length of a block and wrapped around the corner. It took me a few beats to realize that was where we were going, and those were the people still waiting to get in to the conference (at that time there were already over 1,000 people inside the building). Here’s one photo that appeared in the local news showing part of the queue:
In all, I’m told 1,800 people attended on-site, and 8,000 attended online. Thank you again to our Nokia hosts for hosting the ISO C++ meeting and inviting us to code::dive, and thank you to all the C++ developers (and, I’m sure, a few C++-curious) who came from Poland and beyond to spend a day together talking about our favorite programming language!
(*) Here’s a transcript of what I said in that closing summary:
… Reflection and safety improvements as what I see are the two big drivers of our next decade of C++.
So I’m excited about C++. I really think that this was a turning point year, because we’ve been talking about safety for a decade, the Core Guidelines are a decade old, we’ve been talking about reflection for 20 years in the C++ committee — but this is the year that it’s starting to get real. This is the year we put erroneous behavior [in] and eliminated uninitialized locals in the standard, this is the year that we design-approved reflection for the standard — both for C++26 and hopefully they’ll both get in. We are starting to finally see these proposals land, and this is going to create a beautiful new decade, open up a new fresh era of C++. Bjarne [….] when C++11 came out, he said, you know, there’s been so many usability improvements here that C++11, even though it’s fully compatible with C++98, it feels like a new language. I think we’re about to do that again, and to make C++26 feel like a new language. And then just as we built on C++11 and finished it with C++14, 17, 20, the same thing with this generation. That’s how I view it. I’m very hopeful for a bright future for C++. Our language and our community continues to grow, and it’s great to see us addressing the problems we most need to address, so we have an answer for safety, we have an answer for simpler build systems and reducing the number of side languages to make C++ work in practice. And I’m looking forward to the ride for the next decade and more.
And at the end of the Q&A, the final part of my answer about why I’m focused on C++ rather than other efforts:
Why am I spending all this time in ISO C++? Not just because I’m some C++-lover on a fanatical level — you may accuse me of that too — but it’s just because I want to have an impact. I’m a user of this world’s society and civilization. I use this world’s banking system. I rely on this world’s hospital system. I rely on this world’s power grid. And darnit I don’t want that compromised, I want to harden it against attack. And if I put all my energy into some new programming language, I will have some impact, but it’s going to be much smaller because I can only write so much new code. If I can find a way to just recompile — that’s why you keep hearing me say that — to just recompile the billions of lines of C++ code that exist today, and make them even 10% safer, and I hope to make them much more than that safer, I will have had an outsized effect on securing our civilization. And I don’t mean to speak too grandiosely, but look at all the C++ code that needs fixing. If you can find a way to do that, it will have an outsized impact and benefit to society. And that’s why I think it’s important, because C++ is important — and not leaving all that code behind, helping that code too as well as new code, I think is super important, and that’s kind of my motivation.
On Saturday, the ISO C++ committee completed the third-last design meeting of C++26, held in Wrocław, Poland. There are just two meetings left before the C++26 feature freeze in June 2025, and C++26 is on track to be completed two more meetings after that in early 2026. Implementations are closely tracking draft C++26; GCC and … Continue reading Trip report: November 2024 ISO C++ standards meeting (Wrocław, Poland) →
Show full content
On Saturday, the ISO C++ committee completed the third-last design meeting of C++26, held in Wrocław, Poland. There are just two meetings left before the C++26 feature freeze in June 2025, and C++26 is on track to be completed two more meetings after that in early 2026. Implementations are closely tracking draft C++26; GCC and Clang already support about two-thirds of C++26 features right now.
Our host, Nokia, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 220 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 31 nations. At each meeting we regularly have new attendees who have never attended before, and this time there were 37 new first-time attendees, mostly in-person. To all of them, once again welcome!
The committee currently has 23 active subgroups, 15 of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day, depending on their workloads. We also had two combined informational evening sessions to inform the committee broadly about progress on key topics: one on contracts, the other on relocatability. You can find a brief summary of ISO procedures here.
This time, the committee adopted the next set of features for C++26, and made significant progress on other features that are now expected to be complete in time for C+26.
In addition to features already approved for C++26 at previous meetings, at this meeting three major features made strong progress:
P2996 Reflection is in specification wording review aiming for C++26.
P2900 Contracts continues to have a chance of being in C++26 – probably more time was spent on contracts this week in various subgroups than on any other feature.
P3081 Safety Profiles and P3471R0 Standard library hardening made progress into the Evolution group and have a chance of being an initial set of profiles for C++26.
Adopted for C++26: Core language changes/features
Note: These links are to the most recent public version of each paper. If a paper was tweaked at the meeting before being approved, the link tracks and will automatically find the updated version as soon as it’s uploaded to the public site.
In addition to fixing a list of defect reports, the core language adopted 8 papers, including the following…
You can now declare structured bindings constexpr. Because structured bindings behave like references, constexpr structured bindings are subject to similar restrictions as constexpr references, and supporting this feature required relaxing the previous rule that a constexpr reference must bind to a variable with static storage duration. Now, constexpr references and structured bindings may also bind to a variable with automatic storage duration, but only when that variable has an address that is constant relative to the stack frame in which the reference or structured binding lives.
Thanks, Corentin and Brian!
P3068R6 “Allowing exception throwing in constant evaluation” by Hana Dusíková continues the very-welcome and quite-inexorable march toward allowing more and more of C++ to run at compile time. “Compile-time C++, now with exceptions so you can use normal C++ without rewriting your error handling to return codes/std::expecteds!” is the nutshell synopsis. Thank you, Hana!
Adopted for C++26: Standard library changes/features
In addition to fixing a list of defect reports, the standard library adopted 19 papers, including the following…
P3370R1 “Add new library headers from C23” by Jens Maurer is an example of how C++ continues trying to align with C. As the paper states: “C23 added the <stdbit.h> and <stdchkint.h> headers. This paper [adds] these headers to C++ to increase the subset of code that compiles with C and C++. […] Type-generic macros and type-generic functions do not exist in C++, but function templates can provide the same call interface. Thus, the use of the former in C is replaced by the latter in C++.” Thank you Jens!
(For those who don’t know of Jens, he’s one of the committee’s unsung Energizer Bunnies: He chairs the Core language specification working group all week long at every meeting, he’s the key logistics person who makes every meeting run smoothly from organizing room layouts and A/V to break drinks/snacks, he organizes every meeting’s space allocations for all the subgroups and evening sessions, and after all that he clearly still has time left over to write standard library papers too! We don’t know how he does it all, but the unconfirmed rumor is that there’s a secret clone involved; investigation is still pending.)
Because Hana (already mentioned above) can’t stop adding to constexpr, P3309R3 “constexpr atomic<T> and atomic_ref<T>” by Hana Dusíková does what it says on the tin. If you’re wondering whether this is important (after all, we don’t support threads in constexpr code… yet… and usually atomic<T> is about concurrency), the paper explains:
This paper […] allows implementing other types (std::shared_ptr<T>, persistent data structures with atomic pointers) and algorithms (thread safe data-processing, like scanning data with atomic counter) with just sprinkling constexpr to their specification.
So perhaps a good synopsis would be: “removing the last excuse not to make shared_ptr available in constexpr code!” Thanks, Hana!
P1928R15 “std::simd — merge data-parallel types from the Parallelism TS 2” by Matthias Kretz adopts the data-parallel basic_simd types from the TS into C++26 as std::basic_simd. Two notes: (1) The “changes since the TS” section has a “constexpr everything” section, because that’s just how we roll in WG21 these days (cf: Hana’s papers above). (2) Note the “R” revision number, which indicates the 15 revisions of this proposal that were needed to get it to land — thank you for the determined hard work, Matthias, and once again congratulations from us all: When this proposal was adopted, a sustained round of loud applause filled the room!
Last but not least, P3325R5 “A utility for creating execution environments” by Eric Niebler builds on the huge new std::execution concurrency and parallelism library that was adopted at our previous meeting this summer (see my summer 2024 trip report) to additionally make it easier to create and merge loci of execution. Definitely read section 4 of the paper for a full description of the motivation and use cases. Thanks very much, Eric!
Other progress
All subgroups continued progress, more of which will no doubt be covered in other trip reports. Here are a few more highlights…
SG1 (Concurrency): Concurrent queues “might” make C++26, and this is one of the most compelling demonstrations of the “sender/receiver” design pattern in the new std::execution that was adopted at our previous meeting. Concurrent queues would also be (finally) the first concurrent data structure in the standard. Also, although SG1 has been trying to fix/specify memory_order_consume since C++11, this has not succeeded, so the feature has now been removed.
SG7 (Compile-Time Programming): Made progress on several papers. Perhaps the most visible decision was to decide on a reflection syntax, ^^, which apparently some people are lobbying hard to call the “unibrow operator.”
SG15 (Tooling): Progressed work on the Ecosystem IS (International Standard), which achieved the milestone of being approved to be forwarded to the main design subgroups.
SG20 (Education): Progressed work on creating C++ teaching guidelines about topics that should be taught in C++ educational settings. Encouraged paper authors and chairs to send papers to SG20 for teachability feedback.
SG21 (Contracts): Spent Wednesday in the Core working group (instead of meeting separately) because EWG sent contracts to Core aiming for C++26, so the contracts experts went to Core to help with wording review. Continued work on trying to increase consensus on some design details.
SG23 (Safety and Security): Approved several papers to progress, including to reduce undefined behavior in the language and specifically time travel optimizations, and to send an initial set of core safety profiles to EWG aiming for C++26. The proposal P3390 “Safe C++” by Sean Baxter was seen and received support as a direction that can be pursued in addition to and complementary with Profiles, where Profiles are useful to define subsets of current C++ and its features and reducing its undefined behaviors to reduce unsafety in current C++, and proposals like Safe C++ can be useful to propose new extensions for an expanded C++ to try to achieve larger/stronger safety guarantees not possible in just a subset/constrained C++. The SG23 vote on which to prioritize was 19:11:6:9 for Profiles:Both:Neutral:SafeC++.
EWG (Language Evolution Working Group) forwarded contracts aiming for C++26, understanding however that there are still a few unresolved contentious design points; the groups are working on increasing consensus between now and the next meeting. Adopted the ^^ operator for reflection. Pattern matching is still trying to make C++26. Three safety papers progressed: P3081 core safety profiles (see below; for detailed telecon review between meetings and aiming for approval at our next meeting), P3471R0 “Standard library hardening” by Konstantin Varlamov and Louis Dionne which passed unanimously (no one even neutral!), and P2719 “Type-aware allocation and deallocation functions” by Louis Dionne and Oliver Hunt which offers safety mitigation building blocks. The group also approved trivial relocatability for C++26.
LEWG (Library Evolution Working Group) reviewed 30 papers this week. LEWG is specifically prioritizing its time on these topics as papers are available: relocatability, parallel algorithms, concurrent queues, constexpr containers, safety profiles, and pattern matching.
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
What’s next
Our next meeting will be in Hagenberg, Austria hosted by University of Applied Sciences Upper Austria, RISC Software GmbH, and Softwarepark Hagenberg.
Thank you again to the over 220 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
C++ is a living language and moving fast. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
Coda: My papers at this meeting
My papers aren’t what’s most important, but since this is my trip report I should mention my papers.
I had eight papers at this meeting, of which seven were seen at the meeting and one will be seen in an upcoming telecon. Here they are in the rough order they were seen…
P3437R0 “Principles: Reflection and generation of source code”
In a nutshell, P3437 advocates for the principle that reflection and generation are primarily for automating reading and writing source code, the way a human programmer would do but so the human doesn’t have to do it by hand. I argue that this view implies that, at least by default:
reflecting a class (or other entity) in consteval compile-time code should be able to see everything a human could know from reading the source code of the class’s definition; and,
similarly, generating a class in consteval code should be able to write anything the human programmer could write (including things like adding specializations to std) and have the same language meaning as if the programmer wrote it by hand (including normal name lookup and access control).
Non-default modes might do more or different things, but I argued that “as if the human read/wrote the source code” should be the default semantics and get the “nice” syntax that C++ programmers would naturally expect unless they were doing something special.
The group agreed and approved the paper, 15:8:3 in favor:neutral:against.
On Tuesday, I presented P3439 “Chained comparisons: Safe, correct, efficient” in the language evolution working group (EWG). This paper proposes that comparison chains like a <= b < c actually work. (I’ve already implemented this in cppfront.) Today, people try to write such code, and the standard says it’s required to compile but do the wrong thing, which is not great, and all major compilers will warn about it but then compile it anyway because they must. Adopting this proposal would fix real bugs, including security bugs, just by recompiling existing code. This change would also make the language simpler, because with this feature we could write a <= b && b < c as just a <= b < c. And that would also make the language slightly faster, by naturally avoiding multiple evaluation of middle terms like b.
This is the only part of my original paper P0515R0 “Consistent comparisons” (aka the operator spaceship <=> paper) that has not yet been adopted into the standard. It was rejected before the pandemic when Barry Revzin and I tried a second time to get it adopted, but I felt it was appropriate to bring it back now because there’s new urgency and new information. A few highlights from the paper:
Today, comparison chains like min <= index_expression < max are valid code that do the wrong thing; for example, 0 <= 100 < 10 means true < 10 which means true, certainly a bug. Yet that is exactly a natural bounds check; for indexes, such subscript chains’ current meaning is always a potentially exploitable out-of-bounds violation.
[P0893R1] reported that code searches performed by Barry Revzin with Nicolas Lesser and Titus Winters found:
Lots of instances of such bugs in the wild: in real-world code “of the assert(0 <= ratio <= 1.0); variety,” and “in questions on StackOverflow [1][2][3][4][5][6][7][8][9][10][11].”
“A few thousand instances over just a few code bases” (emphasis original) where programmers today write more-brittle and less-efficient long forms such as min <= index_expression && index_expression < max because they must, but with multiple evaluation of index_expression and with bugs because of having to write the boilerplate and sometimes getting it wrong.
See the paper for more new information that warrants considering this anew.
The group voted 30:2:2 in favor:neutral:against for me to bring this back with standardese wording to the February meeting, and if things go well there it might make C++26.
Next: Three safety/security proposals for me at this meeting
Although the chained-comparisons proposal had a safety and security aspect, I don’t consider it principally a “safety proposal.” However, I did present three actual safety and security proposals at this meeting, and here they are… (Note: There were other such proposals by others too, not just by me! And I’m excited about them too. These are just my three…)
Of the four main language safety categories we have to improve (type, bounds, initialization, and lifetime), the first three are easier and are the focus of P3436 and P3081. Lifetime is the hardest to improve in C++, and requires more effort, in my proposal’s case writing a static analysis rule engine; but I think major improvement is possible without heavy annotation of existing code, and this is the subject of P3465 (promoting P1179).
Safety #1 of 3: P3436R0 “Removing safety-related undefined behavior by default”
On Wednesday morning in SG23 (Safety and Security), I presented P3436R0 “Removing safety-related undefined behavior (UB) by default.” This would be a pretty big deal… as I mentioned in the presentation, I firmly believe that most observers of C++, even friendly ones, do not expect us to be able to “do something significant” about UB in C++. UB is after all a fundamental part of C++, right? … Right?
My conjecture is “no it isn’t, and the point of this paper is easy to summarize:
C++ already bans undefined behavior in a huge subset of the language: constexpr evaluation. A lot of people do not realize that, yes, we already did that… we already snuck a lot of safety into the language while no one was paying particular attention. Those who say UB is endemic throughout C++ have already started to fall behind the times, since we added and then gradually expanded constexpr.
Let’s enumerate each such case of UB already prevented in constexpr evaluation, and prevent it in normal execution too: either always (if it’s cheap and easy, as we just did with uninitialized local variables), or else under a Profile (so any overhead has an easy way to opt-in/opt-out when you do/don’t want the safety).
I think most people don’t expect that C++ could make a major dent in undefined behavior and still be true to C++. But P3436 makes the bold conjecture that maybe we can not only make a dent, but actually eliminate UB in C++ by default when safety Profiles are enabled, by combining (a) that we already do it in constexpr code, with (b) that we plan to have Profiles as a tool to opt in/out of safety modes that require source changes or execution overheads.
The group agreed and voted unanimously 25:3:0 in favor:neutral:against.
Important reality check here: This is the start, not the end… this doesn’t mean the proposal is done, it means the group said “we like the idea, now go do the hard work of actually listing all the UB cases and how you propose to handle each one and writing up standard specification wording for all that.” Most “encouragement” polls in the committee actually mean “yes please go do more work.” (This takes a lot of getting used to for new participants.)
Safety #2 of 3: P3465R0 “Pursue P1179 as a Lifetime TS”
On Wednesday after lunch in SG23 (Safety and Security), I made the first-ever presentation in WG21 of the C++ Core Guidelines Lifetime safety static analysis profile, of which I’m the primary designer (with lots of expert help; big thanks again everyone listed in P1179!). This analysis catches many common lifetime dangling issues (not just for pointers, but for generalized Pointers including iterators and views), usually with little or no source annotation. This is a full portable “static analysis specification” which means a detailed spec of state and state transitions that an implementation should do in a function body, so that different implementations will give the same answers.
I first publicly presented this work, with live demos of the first prototype, in my CppCon 2015 talk (starting at 30:28). I then published the detailed specification on GitHub and cc’d/FYI’d ISO via the paper P1179 “Lifetime safety: Preventing common dangling” back in 2019, but at that point I was just giving the committee an FYI… I never asked to present it for adoption, in part because I wanted to gain more usage experience, and in part because at the time the committee did not yet have this kind of safety as a first-order priority.
Now, times have changed: Parts of this have now been implemented and shipped in Microsoft Visual Studio, JetBrains CLion, a Clang fork, and even a smidgen in Clang trunk I’m told. And safety/security is finally a first-order concern, so the current paper P3465R0 “Pursue P1179 as a Lifetime TS” points back to P1179 and suggests that the time is ripe to turn it into an ISO C++ Technical Specification. I proposed that we pursue turning this analysis specification into a Technical Specification (TS) separate from the standard in order to get one more round of WG21-endorsed experience before we cast it in stone as a lifetime Profile: While implementations have implemented a lot of the design, they haven’t yet implemented all of it, and I think making it a TS would show WG21 interest and spur them to complete their implementations so that we could validate the last few important parts too on large amounts of real-world code, and make any needed adjustments. If all goes well with that, I hope to propose it for the standard itself in the future.
The group voted 24:0:1 in favor:neutral:against to direct me to turn P1179 into a working paper for a Technical Specification. Fortunately, the specification of state and state transitions is already very concrete, so it’s already at approximately the same level of detail as normal C++ language specification wording.
Safety #3 of 3: P3081R0 “Core safety Profiles: Specification, adoptability, and impact”
My third safety/security paper was P3081R0 “Core safety Profiles: Specification, adoptability, and impact.” I presented it Wednesday afternoon in SG15 (Tooling), Thursday morning in SG23 (Safety and Security), and Friday morning in EWG (the main language evolution group), with a target of C++26.
This is a companion paper to my “C++ safety, in context” blog essay this spring; see that essay for the full motivation, context, and rationale. P3081 contains the concrete proposed semantics:
Proposes a concrete initial set of urgently needed enforced safety Profiles.
Described how a Profiles implementation can prioritize adoptability and safety improvement impact, especially to silently fix serious bugs in existing code by just recompiling the code (i.e., no manual code changes required) where possible, and making it easy to opt into broadly applicable safety profiles.
I tried to push the boundaries of what’s possible in C++ by suggesting we do something we’ve never done before in the ISO C++ standard: Have the Standard actually normatively (i.e., as a hard requirement) require implementations (usually compilers, and not third-party post-build tools) to offer safety-related “fixits” to automatically correct C++ code where the fix can be super reliable. We’ve never formally required anything like this before, but I felt it was important to try to push this boundary to raise the bar for all compilers because it’s so important for safety adoptability… yet I really wasn’t sure how this suggestion would fly (or get shot out of the sky, as boundary-pushing proposals tend to be).
The first presentation was on Wednesday after lunch to SG15 (Tooling) because the paper suggested this novelty of requiring C++ compilers to offer automatic fixits. The votes on two related polls were both unanimously 8:2:0 in favor:neutral:against. People in the room included tooling and compiler experts for GCC and Clang, and their main comment was (slightly paraphrased) ‘yeah, sure, this is 2024, our C++ compilers all already offer fixits, let’s require compilers to do it consistently.’ Whew.
The second presentation was on Thursday after breakfast to SG23 (Safety and Security), which has been encouraging work on Profiles but has not yet had any concrete proposal to forward to EWG, the main evolution working group. SG23 gave feedback, and then voted unanimously 23:1:0 in favor:neutral:against to forward P3081 to EWG specifically targeting C++26, including that Bjarne’s paper and this one should be merged to reflect the syntax decisions made earlier in the day based on Bjarne’s paper. This is the first Profiles proposal to be forwarded from SG23.
The third presentation was on Friday after breakfast to EWG, which voted 44:4:3 in favor:neutral:against to pursue this paper for C++26, and schedule teleconferences between now and February to go line-by-line through the paper in detail.
Disclaimer: Note this means we have to do a ton of work in the next few months, if it is to have a hope of actually making C++26.
P2392R3 “Pattern matching using is and as”
On Thursday in EWG, I presented P2392R3 “Pattern matching using is and as.” There are two main parts to this paper: is/as expressions to unify and simplify safe queries/casts, and inspect pattern matching that uses the is/as approach.
This time the results were quite mixed, with no consensus to encourage proceeding with my proposal: For the whole paper, EWG voted 19:6:22 in favor:neutral:against. For just the is/as portion, EWG voted 21:8:20 in favor:neutral:against. Clearly no consensus at all, never mind not strong encouragement, and the competing proposal from Michael Park got 33:6:10. But I’m not giving up P2392… I’ll try to incorporate the feedback heard in the room, and perhaps improve consensus at the next meeting or two.
P3466R0 “(Re)affirm design principles for future C++ evolution”
Finally, on Friday afternoon in EWG, I presented P3466 “(Re)affirm design principles for future C++ evolution.” Note: I presented the initial revision R0, and this link is to a draft revision R1 that incorporates the direction from the group (but my R1 edits are still being reviewed to make sure I applied EWG’s direction correctly).
The summary up front is:
C++ is a living language that continues to evolve. Especially with C++26 and compile-time programming, and new proposals for type and memory safety, we want to make sure C++ evolution remains as cohesive and consistent as possible so that (a) it’s “still C++” in that it hews to C++’s core principles, and (b) it’s delivering the highest quality value to make C++ code safer and simpler.
The Library Evolution WG has adopted written design principles to guide proposals and their discussion. This paper proposes that the Language Evolution WG also adopt written principles to guide new proposals and their discussion, and proposes the principles in this paper as a starting point.
EWG voted to turn this paper into a new Standing Document (which future papers can add to) to document EWG’s values: 29:22:2 in favor:neutral:against.
P0707R5 “Metaclass functions for generative C++”
The committee didn’t have time to consider all papers at the meeting, and my paper P0707R5 “Metaclass functions for generative C++” is one that got deferred to be considered at a between-meetings Zoom telecon over the winter.
That’s it for my papers this time… whew. More news next time, from Austria…
Starting today I’m excited to be working on a new team, with my C++ standards and community roles unchanged. I also wanted to write a few words about why I’m excited about continuing to invest my time heavily in C++’s standardization and evolution especially now, because I think 2024 has been a pivotal year for … Continue reading A new chapter, and thoughts on a pivotal year for C++ →
Show full content
Starting today I’m excited to be working on a new team, with my C++ standards and community roles unchanged. I also wanted to write a few words about why I’m excited about continuing to invest my time heavily in C++’s standardization and evolution especially now, because I think 2024 has been a pivotal year for C++ — and so this has turned into a bit of an early “year-end C++ retrospective” post too.
It’s been a blast to be on the Microsoft Visual C++ compiler team for over 22 years! The time has flown by because the people and the challenges have always been world-class. An underappreciated benefit of being on a team that owns a foundational technology (like a major C++ compiler) is that you often don’t have to change teams to find interesting projects, because new interesting projects need compiler support and so tend to come to you. That’s been a real privilege, and why I stuck around way longer than any other job I’ve held. Now I am finally going to switch to a new job, but I’ll continue to cheer my colleagues on as a happy MSVC user on my own projects, consuming all the cool things they’re going to do next!
Today I’m thrilled to start at Citadel Securities, a firm that “combines deep trading acumen with leading-edge analytics and technology to deliver liquidity to some of the world’s most important markets, retail brokerages, and financial institutions.” I’ve known folks at CitSec for many years now (including some who participate in WG 21) and have long known it to be a great organization with some of the brightest minds in engineering and beyond. Now I’m looking forward to helping to drive CitSec’s internal C++ training initiatives, advise on technical strategy, share things I’ve learned along the way about sound design for both usability and pragmatic adoptability, and mentor a new set of talented folks there to not only take their own skilled next steps but also to themselves become mentors to others in turn. I think a continuous growth and learning culture like I’ve seen at CitSec consistently for over a dozen years is one of the most important qualities a company can have, because if you have that you can always grow all the other things you need, including as demands evolve over time. But maybe most of all I’m looking forward to learning a lot myself as I dive back into the world of finance — finance is where I started my junior career in the 80s and 90s, and I’m sure I’ll learn a ton in CitSec’s diverse set of 21st-century businesses that encounter interesting, leading-edge technical challenges every day that go well beyond the ones I encountered back in the 20th.
My other C++ community roles are unchanged — I’m continuing my current term as chair of the ISO C++ committee, I’m continuing as chair of the Standard C++ Foundation, and especially I’m continuing to work heavily on ISO C++ evolution (I have eight papers in the current mailing for this month’s Wrocław meeting!) including supporting those with cppfront prototype implementations. I meant it when I said in my CppCon talk that C++’s next decade will be dominated by reflection and safety improvements, and that C++26 really is shaping up to be the most impactful release since C++11 that started a new era of C++; it’s an exciting time for C++ and I plan to keep spending a lot of time contributing to C++26 and beyond.
Drilling down a little: Why is 2024 a pivotal year for C++? Because for the first time in 2024 the ISO committee has started adopting (or is on track to soon adopt) serious safety and reflection improvements into the draft C++ standard, and that’s a big turning point:
For safety: With uninitialized local variables no longer being undefined behavior (UB) in C++26 as of March 2024, C++ is taking a first serious step to really removing safety-related UB, and achieve the ‘holy grail’ of an easy adoption story: “Just recompile your existing code with a C++26 compiler, with zero manual code changes, and it’s safer with less UB.” This month, I’m following up on that proposing P3436R1, a strategy for how we could remove all safety-related UB by default from C++ — something that I’m pretty sure a lot of folks can’t imagine C++ could ever do while still remaining true to what makes C++ be C++, but that in fact C++ has already been doing for years in constexpr code! The idea I’m proposing is to remove the same cases of UB we already do in constexpr code also at execution time, in one of two ways for each case: when it’s efficient enough, eliminate that case universally the same as we just did for uninitialized locals; otherwise, leverage the great ideas in the Profiles proposals as a way to opt in/out of that case (see P3436 for details). If the committee likes the idea enough to encourage me to go do more work to flesh it out, over the winter I’ll invest the time to expand the paper into a complete catalog of safety-related UB with a per-case proposal to eliminate that UB at execution time. If we can really achieve a future C++ where you can “just recompile your existing code with safety Profiles enabled, and it’s safer with zero safety-related UB,” that would be a huge step forward. (Of course, some Profiles rules will require code changes to get the full safety benefits; see the details in section 2 of my supporting Profiles paper.)
For reflection: Starting with P2996R7 whose language part was design-approved for C++26 in June 2024, we can lay a foundation to then build on with follow-on papers like P3294R2 and P3437R1 to add generation and more features. As I demonstrated with examples in the above-linked CppCon talk, reflection (including generation) will be a game-changer that I believe will dominate the next decade of C++ as we build it out in the standard and learn to use it in the global C++ community. I’m working with P2996/P3294 prototypes and my own cppfront compiler to help gather usability experience, and I’m contributing my papers like P0707R5 and P3437R1 as companion/supporting papers to those core proposals to try to help them progress.
As Bjarne Stroustrup famously said, “C++11 [felt] like a new language,” starting a new “modern” C++ style featuring auto and lambdas and standard safe smart pointers and range-for and move semantics and constexpr compile-time code, that we completed and built on over the next decade with C++14/17/20/23. (And don’t forget that C++11’s move semantics already delivered the ideal adoption story of “just recompile your existing code with a C++11 compiler, with zero manual code changes, and it’s faster.”) Since 2011 until now, “modern C++” has pretty much meant “C++ since C++11” because C++11 made that much of a difference in how C++ worked and felt.
Now I think C++26 is setting the stage to do that again for a second time: Our next major era of what “modern C++” will mean will be characterized by having safety by default and first-class support for reflection-based generative compile-time libraries. Needless to say, this is a group effort that is accomplished only by an amazing set of C++ pros from dozens of countries, including the authors of the above papers but also many hundreds of other experts who help design and review features. To all of those experts: Again, thank you! I’ll keep trying to contribute what I can too, to help ship C++26 with its “version 1” of a set of these major new foundational tools and to continue to add to that foundation further in the coming years as we all learn to use the new features to make our code safer and simpler.
C++ is critically important to our society, and is right now actively flourishing. C++ is essential not only at Citadel Securities itself, but throughout capital markets and the financial industry… and even that is itself just one of the critical sectors of our civilization that heavily depend on C++ code and will for the foreseeable future. I’m thrilled that CitSec’s leadership shares my view of that, and my same goals for continuing to evolve ISO C++ to make it better, especially when it comes to increasing safety and usability to harden our society’s key infrastructure (including our markets) and to make C++ even easier to use and more expressive. I’m excited to see what the coming decade of C++ brings… 2024 really has shaped up to be a pivotal year for C++ evolution, and I can’t wait to see where the ride takes us next.
In early September I had a very enjoyable technical chat with Steve Klabnik of Rust fame and interviewer Kevin Ball of Software Engineering Daily, and the podcast is now available. Update: I asked them to please change the “Rust vs C++” title to “Rust and C++” and they kindly did so. Thanks! Here’s the info…
Show full content
In early September I had a very enjoyable technical chat with Steve Klabnik of Rust fame and interviewer Kevin Ball of Software Engineering Daily, and the podcast is now available.
Update: I asked them to please change the “Rust vs C++” title to “Rust and C++” and they kindly did so. Thanks!
In software engineering, C++ is often used in areas where low-level system access and high-performance are critical, such as operating systems, game engines, and embedded systems. Its long-standing presence and compatibility with legacy code make it a go-to language for maintaining and extending older projects. Rust, while newer, is gaining traction in roles that demand safety and concurrency, particularly in systems programming.
We wanted to explore these two languages side-by-side, so we invited Herb Sutter and Steve Klabnik to join host Kevin Ball on the show. Herb works at Microsoft and chairs the ISO C++ standards committee. Steve works at Oxide Computer Company, is an alumnus of the Rust Core Team, and is the primary author of The Rust Programming Language book.
We hope you enjoy this deep dive into Rust and C++ on Software Engineering Daily.
Kevin Ball or KBall, is the vice president of engineering at Mento and an independent coach for engineers and engineering leaders. He co-founded and served as CTO for two companies, founded the San Diego JavaScript meetup, and organizes the AI inaction discussion group through Latent Space.
Boy, Jens Weller turns these things around quickly! Thanks again, Jens, for having me on your Meeting C++ Live show. I’ve put a list of the questions, with timestamped links, below… All the questions and answers, with links 00:19 What are you up to with C++ currently / what keeps you excited? 04:04 Sean Baxter … Continue reading My AMA yesterday is up on YouTube →
Show full content
Boy, Jens Weller turns these things around quickly! Thanks again, Jens, for having me on your Meeting C++ Live show.
I’ve put a list of the questions, with timestamped links, below…
All the questions and answers, with links
00:19 What are you up to with C++ currently / what keeps you excited?
04:04 Sean Baxter has finally written up a proposal to bring borrow checking to C++, to improve safety. What are your views on his proposal and what approach is Cpp2 planning?
08:48 Is there a long-term vision for C++? How can C++ maintain its relevance in the next 20 years?
13:14 What is your favorite C++ editor/IDE when not using Microsoft Visual Studio?
17:43 Why is MSVC 2022 falling behind Clang and GCC on C++23 and C++26 features?
21:21 What is the roadmap for Cpp2? Whether it will be fit for production use?
26:30 Should the stdlib be split in two parts. One with slow changes and one with fast changes. E.g., ranges were introduced in C++20 but finished in C++23. I am still missing some features.
29:34 Are there plans to address ABIs with interfaces or other features in C++?
36:18 What is your answer to the growing complexity of C++ to be learned especially by novices? How would we teach C++ (e.g., at the university) if it gets larger and larger?
40:53 In the context of C++’s zero-cost abstractions philosophy, how do you see future proposals for making bounds checking in std::vector both safer and more efficient?
47:13 Are C++ safety initiatives arriving too late to fend off the growing adoption of Rust for “safe” low-level development?
55:25 What is the status of the profiles proposal in C++? Will some of it be part of C++26 or C++29?
57:35 The Common Package Specification, which looked very promising, seems stalled. Why is tooling in the language not a priority?
59:11 What do you think of std::execution / P2300R10? The API changed a lot across papers, and to me is quite a piece of work for library implementers to integrate.
1:04:35 Aren’t you afraid that reflection might be misused too much (e.g., use it for serialization)?
1:06:46 If local uninitialized variables are no longer UB, how will they behave? Could you please elaborate a bit on that?
1:11:30 How is the Contracts TS coming along? What are your thoughts on Contract Based Programming, in general?
1:15:56 Any chance of having type erasure (mainly std::any) in MSVC reimplemented not on top of RTTI? Unfortunately the current implementation makes it unusable in places where symbol names are left behind by RTTI.
1:17:38 What happened with the official publication of the C++23 standard?
1:22:31 Preview of my keynote next month at Meeting C++.
Tomorrow I’ll be joining Jens Weller for a live AMA on “Meeting C++ online.” The coordinates are: I’m looking forward to your technical questions about C++26 evolution, cppfront, Rust, reflection, safety and security, concurrency and parallelism, and software in general… and optionally questions about SF/fantasy novels and cinema, but then I might ask some similar … Continue reading Live AMA tomorrow (Friday): Meeting C++ Online →
Show full content
Tomorrow I’ll be joining Jens Weller for a live AMA on “Meeting C++ online.”
Time: social hour starts at 19:00 CEST, AMA starts at 20:00 CEST
I’m looking forward to your technical questions about C++26 evolution, cppfront, Rust, reflection, safety and security, concurrency and parallelism, and software in general… and optionally questions about SF/fantasy novels and cinema, but then I might ask some similar questions in return.
Then next month I’m also looking forward to speaking at Meeting C++ 2024 in person in Berlin, and seeing many of you there — thanks again, Jens, for kindly inviting me to both.
Yesterday I gave the opening talk at CppCon 2024 here in Aurora, CO, USA, on “Peering Forward: C++’s Next Decade.” Thanks to the wonderful folks at Bash Films and DigitalMedium pulling out all the stops overnight to edit and post the keynote videos as fast as possible, it’s already up on YouTube right now, below! … Continue reading My CppCon keynote yesterday is available on YouTube →
Show full content
Yesterday I gave the opening talk at CppCon 2024 here in Aurora, CO, USA, on “Peering Forward: C++’s Next Decade.” Thanks to the wonderful folks at Bash Films and DigitalMedium pulling out all the stops overnight to edit and post the keynote videos as fast as possible, it’s already up on YouTube right now, below!
Special thanks to Andrei Alexandrescu for being willing to come on-stage for a mini-panel of the two of us talking about reflection examples and experience in various languages! That was a lot of fun, and I hope you will find it informative.
If you aren’t able to be here at CppCon this week, you can still catch all the keynote videos (and tonight’s Committee Fireside Chat) this week and early next week on YouTube, because they’re being rush-expedited to be available quickly for everyone; just watch the CppCon.org website, where each one will be announced as soon as it’s available. And, as always, all the over 100 session videos will become freely available publicly over the coming months for everyone to enjoy.
Here’s a super simple question: “How do I write a parameter that accepts any non-const std::istream argument? I just want an istream I can read from.” (This question isn’t limited to streams, but includes any similar type you have to modify/traverse to use.) Hopefully the answer will be super simple, too! So, before reading further: … Continue reading Reader Q&A: What’s the best way to pass an istream parameter? →
Show full content
Here’s a super simple question: “How do I write a parameter that accepts any non-conststd::istream argument? I just want an istream I can read from.” (This question isn’t limited to streams, but includes any similar type you have to modify/traverse to use.)
Hopefully the answer will be super simple, too! So, before reading further: What would be your answer? Consider both correctness and usability convenience for calling code.
.
.
OK, have you got an answer in mind? Here we go…
Spoiler summary:
Today’s Option 0 is simple and fine. To accept rvalues too, Option 2(b) is fine today. We can hopefully do it even more simply and elegantly in C++26/29.
Pre-C++11 answer
I recently received this question in email from my friend Christopher Nelson. Christopher wrote, lightly edited (and adding an “Option 0” label):
I have a function that reads from a stream:
// Call this Option 0: A single function
void add_from_stream( std::istream &s ); // A
Pause a moment — is that the answer you came up with too? It’s definitely the natural answer, the only reasonable pre-C++11 answer, and simple and clean…
Usability issue, and C++11-26 answers
… But, as Christopher points out, it does have a small usability issue, which leads to his question:
Testing code may create a temporary [rvalue] stream, and it would be nice to not have to make it a named variable [lvalue], but this doesn’t work with just the above function:
So I want to add an overload that takes an rvalue reference, like this:
void add_from_stream( std::istream &&s ); // B
// now the above call would work and call B
That nicely sets up the motivation to overload the function. [1]
The core of the emailed question is: How do we implement functions A and B to avoid duplication?
The logic is exactly the same, so I just want one function to forward to another.
Would it be better to do this:
// Option 1: Make B do the work, and have A call B
void add_from_stream( std::istream &&s ) { // B
// do work.
}
void add_from_stream( std::istream &s ) { // A
add_from_stream( std::move(s) );
}
Or this:
// Option 2: Have A do the work, and have B call A
void add_from_stream( std::istream &s ) { // A
// do work.
}
void add_from_stream( std::istream &&s ) { // B
add_from_stream( s );
}
They both seem to work, and the compiler doesn’t complain.
It’s true that both options “work” in the sense that they compile. But, as Christopher knows, there’s more to correctness than “the compiler doesn’t complain”!
Before reading further, pause and consider… how would you answer? What are the pros and cons of each option? What surprises or pitfalls might they create? Are there any other approaches you might consider?
.
.
Christopher’s email ended by actually giving some good answers, but with uncertainty:
I think [… … …] [But] I’ve been surprised lately by some experiments with rvalue references. So I thought I would check with you.
I think it’s telling that (a) he actually does have a good intuition and answer about this, but (b) rvalue references are subtle enough that he’s uncertain about it and second-guessing his correct C++ knowledge. — Perhaps you can relate, if you’ve ever said, “I’m pretty sure the answer is X, but this part of C++ is so complex that I’m not sure of myself.”
So let’s dig in..
Option 1: Have & call && (bad)
Christopher wrote:
I think the first option looks weird, and I think it may possibly have weird side-effects.
Bingo! Correct.
If Option 1 feels “weird” to you too, that’s a great reaction. Here it is again for reference, with an extra comment:
// Option 1: Make B do the work, and have A call B
void add_from_stream( std::istream &&s ) { // B
// do work.
}
void add_from_stream( std::istream &s ) { // A
add_from_stream( std::move(s) ); // <-- threat of piracy
}
In Option 1, function A is taking a modifiable argument and unconditionally calling std::move on it to pass it to B. Remember that writing std::move doesn’t move, it’s just a cast that makes its target a candidate to be moved from, which means a candidate to have its entire useful state stolen and leaving the object ’empty.’ Granted, in this case as long as function B doesn’t actually move from the argument, everything may seem fine because, wink wink, we happen to know we’re not actually going to steal the argument’s state. But it’s still generally questionable behavior to go around calling std::move on other people’s objects, without even a hint in your API that you’re going to do that to them! That’s like pranking random strangers by tugging on their backpack zippers and then saying “just kidding, I didn’t actually steal anything this time!”… it’s not socially acceptable, and even though you’re technically innocent it can still lead to getting a broken nose.
So avoid this shortcut; it sets a bad example for young impressionable programmers, and it can be brittle under maintenance if the code changes so that the argument could actually get moved from and its state stolen. Worst/best of all, I hope you can’t even check that code in, because it violates three C++ Core Guidelines rules in ES.56 and F.18, which makes it a pre-merge misdemeanor in jurisdictions that enforce the Guidelines as a checkin gate (and I hope your company does!).
Function A violates this rule (essentially, ‘only std::move from rvalue references’):
ES.56: Flag when std::move is applied to other than an rvalue reference to non-const.
Function B violates these rules:
F.18: Flag all X&& parameters (where X is not a template type parameter name) where the function body uses them without std::move.
ES.56: Flag functions taking an S&& parameter if there is no const S& overload to take care of lvalues.
It’s bad enough that we already have to teach that std::move is heavily overused (for example, C++ Core Guidelines F.48). Creating still more over-uses is under-helpful.
Option 2: Have && call & (better)
For Option 2, Christopher notes:
I imagine that the second one works because, as a parameter the rvalue reference is no longer a pointer to a prvalue, so it can be converted to an lvalue reference. Whereas, in the direct call site it is not.
Bingo! Yes, that’s the idea.
Recall Option 2, and here “function argument” mean the thing the caller passes to the parameter, and “function parameter” means its internal name and type inside the function scope:
// Option 2: Have A do the work, and have B call A
void add_from_stream( std::istream &s ) { // A
// do work.
}
void add_from_stream( std::istream &&s ) { // B
add_from_stream( s );
}
Note that function B only accepts rvalue arguments (such as temporary objects)… but once we’re inside the body of B the named parameter is now an lvalue, because it has a name! Why? Here’s a nice explanation from Microsoft Learn:
Functions that take an rvalue reference as a parameter treat the parameter as an lvalue in the body of the function. The compiler treats a named rvalue reference as an lvalue. It’s because a named object can be referenced by several parts of a program. It’s dangerous to allow multiple parts of a program to modify or remove resources from that object.
So the argument is an rvalue (at the call site), but binding it to a parameter name makes the compiler treat it as an lvalue (inside the function)… so now we can just call A directly, no fuss no muss. Conceptually, function B is implicitly doing the job of turning the argument into an lvalue, and so serves its intended purpose of expressing, “hey there, this overload set accepts rvalues too.”
And that’s… fine.
It’s still not “ideal,” though, for two reasons. First, astute readers will have noticed that this only addresses two of the three C++ Core Guidelines violations mentioned above… the new function B still violates this rule:
ES.56: Flag functions taking an S&& parameter if there is no const S& overload to take care of lvalues.
The reason this rule exists is because functions that take rvalue references are supposed to be used as overloads with const& to optimize “in”-only parameters. We could shut up the stupid checker eliminate this violation warning by adding such an overload, and mark it =delete since there’s no other real reason for it to exist (consider: how would one use a const stream?). So to get past a C++ Core Guidelines checker we would actually write this:
// Option 2, extended: To be C++ Core Guidelines-clean
void add_from_stream( std::istream &s ) { // A
// do work.
}
void add_from_stream( std::istream &&s ) { // B
add_from_stream( s );
}
void add_from_stream( std::istream const& s ) = delete; // C
The second reason this isn’t ideal is that having to write an overload set of two or three functions is annoying at best, because we’re just trying to express something that seems awfully simple: “I want a parameter that accepts any non-conststd::istream argument“… that shouldn’t be hard, should it?
Can we do better? Yes, we can, because those aren’t the only two options.
Option 3: Write a single function using a forwarding reference (a waypoint to the ideal)
In C++, without using overloading, yes we can write a parameter that accepts both lvalues and rvalues. There are exactly three options:
Pass by value (“in+copy”)… but for streams this is impossible, because streams aren’t copyable.
Pass by const& (“in”)… but for useful streams this is impossible, because streams have to be non-const to be read from (reading modifies the stream’s position).
Pass by T&& forwarding reference … … … ?
“Exclude the impossible and what is left, however improbable, must be the truth.”
A.C. Doyle, “The Fate of the Evangeline,” 1885.
Today, the C++11-26 truth is that the way to express a parameter that can take any istream argument (both lvalues and rvalues), without using overloading, is to use a forwarding reference: T&& where T is a template parameter type…
Wait! You there, put down the pitchfork. Hear me out.
Yes, this is complex in three ways…
It means writing a template. That has the drawback that the definition must be visible to call sites (we can’t ship a separately compiled function implementation, except to the extent C++20 modules enable).
We don’t actually want a parameter (and argument) to be just any type, so we also ought to constrain it to the type we want, std::istream.
Part of the forwarding parameter pattern is to remember to correctly std::forward the parameter in the body of the function. (See C++ Core Guidelines F.19.)
Here’s the basic pattern:
// Option 3(a): Single function, takes lvalue and rvalue streams
template <typename S>
void add_from_stream( S&& s )
requires std::is_same_v<S, std::istream>
{
// do work + remember to use s as "std::forward<S>(s)"
}
For reasons discussed in Barry Revzin’s excellent current proposal paper P2481 (more on that in a moment), we actually want to allow arguments that are of derived type or convertible type, so instead of is_same we would actually prefer is_convertible:
// Option 3(b): Single function, takes lvalue and rvalue streams
template <typename S>
void add_from_stream( S&& s )
requires std::is_convertible_v<S, std::istream const&>
{
// do work + remember to use s as "std::forward<S>(s)"
}
“Seriously!?” you might be thinking. “There’s no way you’re going to teach mainstream C++ programmers to do that all the time! Write a template? Write a requires clause?? And write std::forward<S>(s) with its pitfalls (don’t forget <S>)??? Madness.”
Yup, I know. You’re not wrong.
Which is why I (and Barry) believe this feature needs direct language support…
And astute readers will recall that my Cpp2 syntax already has this generalized forward parameter passing style that also works for specific types, and I designed and implemented that feature in cppfront and demo’d it on stage at CppCon 2022 (1:26:28 in the video):
See Cpp2: Parameters for a summary of the Cpp2 approach. In a nutshell: You declare “what” you want to do with the parameter, and let the compiler do the mechanics of “how” to pass it that we write by hand today. Six options, one of which is forward, are enough to cover all kinds of parameters.
As you see in the accompanying CppCon 2022 screenshot, the forward parameters compiled to ordinary C++ that followed Option 3(a) above. A few days ago, I relaxed it to compile to Option 3(b) above instead, as Barry suggested and another Cpp2 user needed (thanks for the feedback!), so it now allows polymorphism and conversions too.
So in Cpp2 today, all you write is this:
// Works in Cpp2 today (my alternative experimental simpler C++ syntax)
add_from_stream: ( forward s: std::istream ) = {
// do work.
}
… and cppfront turns that into the following C++ code that works fine today on GCC 11 and higher, Clang 12 and higher, MSVC 2019 and higher, and probably every other fairly recent C++ compiler:
auto add_from_stream(auto&& s) -> void
requires (std::is_convertible_v<CPP2_TYPEOF(s), std::add_const_t<std::istream>&>)
{
// do work + automatically adds "std::forward" to the last use of s
}
Write forward, and the compiler automates everything else for you:
Makes that parameter a generic auto&&.
Adds a requires clause to constrain it back to the specific type.
Automatically does std::forward correctly on every definite last use of the parameter.
It’s great to have this in Cpp2 as a proof of concept, but both Barry and I want to make this easy also in mainstream ISO C++ and are independently proposing that C++26/29 support the same feature, including that it would not need to be implicitly a template. Barry’s paper has been strongly encouraged, and I think the only remaining question seems to be the syntax (see the record of polls here), which could be something like one of these:
// Proposed for C++26/29 by Barry's paper and mine
// Possible syntaxes
void add_from_stream( forward std::istream s );
void add_from_stream( forward: std::istream s );
void add_from_stream( forward s: std::istream );
// or something else, but NOT "&&&"
// -- happily the committee said "No!" to that
In Cpp2, forward parameters with a specific type have proven to be more useful than I originally expected, and that’s even though they compile down to a C++ template today… one benefit of adding this feature directly into the language is that a forwarding reference to a concrete type could be easily implemented as a non-template if it’s part of C++26/29.
My hope for near-future C++ is that the simple question “how do I pass any stream I can read from, even rvalues?” will have the simple answer “as a forwardstd::istream parameter.” This is how we can simplify C++ even by adding features: By generalizing things we already have (forwarding parameters, to work also for specific types) and enabling programmers to directly express their intent (say what you mean, and the language can help you). Then even though the language got more powerful, C++ code has become simpler.
[Updated to emphasize 2(b)] In the meantime, in today’s C++, Option 0 is legal and fine, and consider Option 2(b) if you want to accept rvalues. Today, Option 3 is the only direct (and cumbersome) way to write a function that takes a stream without having to write any overloads.
Thanks again to Christopher Nelson for this question!
.
Notes
[1] For simpler cases if you’re reading a homogenous sequence of the same type, you could try taking a std::ranges::istream_view. But as far as I know, that approach doesn’t help with general stream-reading examples.
Acknowledgments: Thanks to Davis Herring, Jens Maurer, Richard Smith, Krystian Stasiowski, and Ville Voutilainen, who are all ISO C++ committee core language experts, for helping make my answer below correct and precise. I recently got this question in email from Sam Johnson. Sam wrote, lightly edited: That’s a great question. Cppreference is correct, and for … Continue reading Reader Q&A: What does it mean to initialize an int? →
Show full content
Acknowledgments: Thanks to Davis Herring, Jens Maurer, Richard Smith, Krystian Stasiowski, and Ville Voutilainen, who are all ISO C++ committee core language experts, for helping make my answer below correct and precise.
I recently got this question in email from Sam Johnson. Sam wrote, lightly edited:
Given this code, at function local scope:
int a;
a = 5;
So many people think initialization happens on line 1, because websites like cppreference defines initialization as “Initialization of a variable provides its initial value at the time of construction.”
However, I’m convinced the initialization happens on line 2, because [various good C++ books] define initialization as simply the first meaningful value that goes into the variable.
Could you please tell me which line is considered initialization?
That’s a great question. Cppreference is correct, and for all class types the answer is simple: The object is initialized on line 1 by having its default constructor called.
But (and you knew a “but” was coming), for a local object of a fundamental built-in type like int, the answer is… more elaborate. And that’s why Sam is asking, because Sam knows that the language has been kind of loose about initializing such local objects, for historical reasons that made sense at the time.
Short answer: Saying the variable gets its initial value on line 2 is completely reasonable. But note that I deliberately didn’t say “the object is initialized on line 2,” and both the code and this answer gloss over the more important problem of: “Yeah, but what about code between lines 1 and 2 that could try to read the object’s value?”
This post has three parts:
Pre-C++26, yes, this is kind of awkward. But the funniest part is how Standard describes it today, which is just begging for a little in-good-fun roasting, and so I’ll indulge.
In C++26, we make this code safe by default, thanks to Thomas Köppe! This is a Big Deal.
In my Cpp2 experiment, this problem disappears entirely, and all types are treated equally with guaranteed initialization safety. My aim is to propose this for ISO C++ itself post-C++26, so ISO C++ could evolve to remove this issue too in the future, if there’s consensus for such a change.
Let’s start with the world today, our pre-C++26 status quo…
Pre-C++26 answer: The variable is never “initialized”
For those few built-in types like int, the answer is that in this example there is no initialization at all, because (technically) neither line is an initialization. If that surprises you, consider:
Line 1 declares an uninitialized object. There is no initial value at all, explicit or implicit.
Line 2 then assigns an “initial value.” This overwrites the object’s bits and happens to give the object the same value as if its bits had been initialized that way on line 1… but it’s an assignment, not an initialization (construction).
That said, I think it’s reasonable to informally call line 2 “setting an initial value,” in the sense that it’s the first program-meaningful value put into that object. It’s not formally an initialization, but the bits end up the same, and good books can reasonably call line 2 “initializing a.”
“But wait,” I hear someone in the back saying, “I read the Standard last night, and [dcl.init] says that line 1 is a ‘default-initialization’! Therefore line 1 is an initialization!” Yes, and no, respectively. So let’s look at the Standard’s formal precise and quite funny answer, and this is truly a delightful thing to read: The Standard does say that in line 1 the object is indeed default-initialized… but, for types like int, the term “default-initialized” is defined to mean “no initialization is performed.”
(This may be a good time to mention that “the Standard is not a tutorial”… in other words, we wouldn’t read the Standard to learn the language. The Standard is quite precise about telling us what a C++ compiler does, and there’s nothing really wrong with the Standard specifying things in this way, it’s totally fine and it totally works. But it’s not written for a lay reader, and nobody would blame you if you thought that “default-initialization [means] no initialization is performed” sounds like cognitive dissonance in action, Orwellian doublethink (which is not the same thing), passive-aggressive baiting, or just garden-variety Humpty Dumptyism.)
A related question is: After line 1, has the object’s lifetime started? The good news is that yes it has… in line 1, the uninitialized object’s lifetime has indeed started, per [basic.life] paragraph 1. But don’t let’s look too closely at that paragraph’s words about “vacuous initialization,” because that’s yet another fancyspeak in the Standard for the same concept of “initialized but, ha ha, just kidding.” (Have I mentioned that the Standard isn’t a tutorial?) And of course it’s a serious problem that the object’s lifetime has started, but it hasn’t been initialized with a predictable value… that’s the worst problem of an uninitialized variable, that it can be a security risk to read from it, which has been true “undefined behavior” that could do anything, and attackers can exploit this property.
Fortunately, this is where the safety story gets significantly better, in C++26…
C++26: It gets better (really!) and safe by default
C++26 has created the new concept of erroneous behavior, which is better than “undefined” or “unspecified” because it gives us a way to talk about code that is literally “well-defined as being Just Wrong”… seriously, that’s almost a direct quote from the paper… and because it’s now well-defined it gets stripped of the security scariness of “undefined behavior.” Think of this as the Standard having a tool to turn some behavior from “scarily undefined” to merely “tsk, we know this is partly our fault because we let you write this code and it doesn’t mean what it should mean, but you really wrote a bug here, and we’re going to put some guard-rails around this pit of snakes to remove the safety risk of you falling into it by default and our NSA/CISA/NIST/EO insurance premiums going up.” And the first place that concept has been applied has been to… drum roll… uninitialized local variables.
This is a big deal, because it means that the original example’s line 1 is now still uninitialized, but since C++26 it’s “erroneous behavior” which means that when the code is built with a C++26 compiler, undefined behavior cannot happen if you read the uninitialized value. Yes, that implies a C++26 compiler will generate different code than before… it will be guaranteed to write an erroneous value the compiler knows (but that isn’t guaranteed to be one the programmer can rely on; so don’t rely on it being zero) if there’s any possibility that value might be read.
This may seem like a small thing, but it’s already a major improvement, and shows that the committee is serious about actively changing our language to be safe by default. Making more and more code safe by default is a trend you can expect to see a lot more of in C++’s medium-term future, and that’s a very welcome thing.
While you wait for your favorite C++26 compiler to add this support, you can get an approximation of this feature today with the GCC or Clang switch -ftrivial-auto-var-init=pattern or the with MSVC switch /RTC1 (run, don’t walk, to use those now if you can). They get you most of what C++26 gives, except that they may not emit a diagnostic (e.g., the Clang switch emits a diagnostic only if you’re running Memory Sanitizer).
For example, consider how this new default prevents secrets from leaking, in this program compiled with and without today’s flag (Godbolt link):
template<int N>
auto print(char (&a)[N]) { std::cout << std::string_view{a,N} << "\n"; }
auto f1() {
char a[] = {'s', 'e', 'c', 'r', 'e', 't' };
print(a);
}
auto f2() {
char a[6];
print(a); // today this likely prints "secret"
}
auto f3() {
char a[] = {'0', '1', '2', '3', '4', '5' };
print(a); // overwrites "secret" (if only just)
}
int main() {
f1();
f2();
f3();
}
Typically, all three local arrays will reuse the same stack storage, and after f1 returns the string secret is likely still sitting on the stack, waiting for f2‘s array to overlay it.
In today’s C++ by default, without -ftrivial-auto-var-init=pattern or /RTC1, f2 will likely print secret. Which is… um (looks at feet and twists a toe to pretend to erase an imaginary spot on the floor)… let’s say problematic for safety and security. As Jon would say to today’s undefined-behavior uninitialized rule, “you give C++ a bad name.”
But with GCC and Clang -ftrivial-auto-var-init=pattern, with MSVC /RTC1, and in C++26 onward by default, f2 will not leak the secret. As Bjarne has sometimes said in other contexts, but I think applies here too: “This is progress!” And to any grumpy readers who may be inclined to say, “dude, I’m used to insecure code, getting rid of insecure code by default isn’t in the spirit of C++,” well, (a) it is now, and (b) get used to it because there’s a lot more like this on the way.
Edited to add: A frequently asked question is, why not initialize to zero? That is always proposed, but it isn’t the best answer for several reasons. The main two are: (1) zero is not necessarily a program-meaningful value, so injecting it often just changes one bug into another; (2) it often actively masks the failure to initialize from sanitizers, who now think the object is initialized and so can’t see and report the error. Using an implementation-defined well-known “erroneous” bit pattern doesn’t have those problems.
But this is C++, you always have the full power to take control and get maximum performance when you need to. So yes, if you really want, C++26 will let you opt out by writing [[indeterminate]], but every use of that attribute should be challenged in every code review and require justification in the form of clear performance measurements showing that you need to override the safe default:
int a [[indeterminate]] ;
// C++26-speak for "yes please hurt me,
// I want the bad old dangerous semantics"
Post-C++26: What more could we do?
So this is where we are pre-C++26 (highlighting the most problematic lines):
// In today’s C++ pre-C++26, for local variables
// Using a fundamental type like 'int'
int a; // declaration without initialization
std::cout << a; // undefined: read of uninitialized variable
a = 5; // assignment (not initialization)
std::cout << a; // prints 5
// Using a class type like 'std::string'
string b; // declaration with default construction
std::cout << b; // prints "": read of default constructed value
b = "5"; // assignment (not initialization)
std::cout << b; // prints "5"
Note that line 5 might not print anything… it’s undefined behavior, so you’d be lucky if it’s just a matter of printing something or not, because a conforming compiler could technically generate code to erase your hard drive, invoke nasal demons, or other traditional UB nastiness.
And here is where we are starting in C++26 (differences highlighted):
// In C++26, for local variables
// Using a fundamental type like 'int'
int a; // declaration with some erroneous value
std::cout << a; // prints ? or terminates: read of erroneous value
a = 5; // assignment (not initialization)
std::cout << a; // prints 5
// Using a class type like 'std::string'
string b; // declaration with default construction
std::cout << b; // prints "": read of default constructed value
b = "5"; // assignment (not initialization)
std::cout << b; // prints "5"
The good news: Our hard drives and noses are now safe from erasure and worse in line 5. Edited to add: The implementation might print a value or terminate, but there won’t be undefined behavior.
The fine print: C++26 compilers are required to make line 4 write a known value over the bits, and they are encouraged (but are not required) to tell you line 5 is a problem.
In my Cpp2 experimental syntax, local variables of all types are defined like a: some_type = initial_value;. You can omit the = initial_value part to express that stack space is allocated for the variable but its actual initialization is deferred, and then Cpp2 guarantees initialization before use; you must do the initialization later using = (e.g., a = initial_value;) before any other use of the variable, which gives you the flexibility of doing things like using different constructors for the same variable on different branch paths. So the equivalent example is (differences from C++26 highlighted):
// In my Cpp2 syntax, local variables
// Using a fundamental type like 'int'
a: int; // allocates space, no initialization
// std::cout << a; // illegal: can't use-before-init!
a = 5; // construction => real initialization!
std::cout << a; // prints 5
// Using a class type like 'std::string'
b: string; // allocates space, no initialization
// std::cout << b; // illegal: can't use-before-init!
b = "5"; // construction => real initialization!
std::cout << b; // prints "5"
Cpp2 deliberately has no easy way to opt out and use a variable before it has been initialized. To get that effect, you’d have to have an array of raw std::bytes or similar on the stack, and do an unsafe_cast to pretend it’s a different type… which is verbose and hard to write, and that’s because I think that unsafe code should be verbose and hard to write… but you can write it (verbosely) if you really need to, because that’s core to C++: I may disapprove of unsafe code you may write in the name of performance, but I defend to the death your right to write it when you need to; C++ always lets you open the hood and take control. My aim is simply to move from “performance by default, safety always available” where safety is the thing you have to work a bit harder to get, to “safety by default, performance always available.” The metaphor I use for this is that we don’t want to take any sharp knives away from C++ programmers, because chefs sometimes need sharp knives; but when the knives are not in use we just want to keep them in a drawer you need to opt into opening, instead of leaving them strewn about the floor and forever be reminding people to watch where they step.
So far, I find this model is working very well, and it has the triple benefits of performance (initialization work is never done until you need it), flexibility (I can call the real constructor I want), and safety (it’s always real “initialization” with real construction, and never any use-before-initialization). I think we could have this someday in ISO C++, and I intend to bring a proposal along these lines to the ISO C++ committee in the next year or two, and I’ll be as persuasive as I can. They might love it, they might find flaws I’ve overlooked, or something else… we’ll see! In any event, I’ll be sure to report any progress here.
Over the winter and spring I spent a bunch of time building my essay “C++ safety, in context” and the related ACCU 2024 safety keynote, and on behind-the-scenes work toward improving C++ memory safety that you’ll be hearing more about in the coming months (including a lock-free data structure that’s wait-free and constant-time for nearly … Continue reading cppfront: Midsummer update →
Show full content
Over the winter and spring I spent a bunch of time building my essay “C++ safety, in context” and the related ACCU 2024 safety keynote, and on behind-the-scenes work toward improving C++ memory safety that you’ll be hearing more about in the coming months (including a lock-free data structure that’s wait-free and constant-time for nearly all operations; that was fun to develop and could be useful for making certain existing C and C++ code safer, we’ll see). Safety and simplicity are the two core things I want to try to dramatically improve in C++, and are why I’m doing my cppfront experiment, so although the above absorbed some time away from cppfront coding it all contributes to the same goal. (If you don’t know what cppfront is, please see the CppCon 2022 talk for an overview, and the CppCon 2023 talk for an update and discussion of why cppfront is pursuing this evolution strategy that’s different from other projects’. “Cpp2” is the shorthand name for my experimental “C++ syntax 2,” and cppfront is the open-source compiler that compiles it.)
So now it’s time for a cppfront update with some highlights of what’s been happening since the last time I posted about it here:
Wrote Cpp2 and cppfront documentation & started numbered releases
Cppfront 0.7.0 (Mar 16, 2024), new things include:
A “tersest” function syntax, e.g.: :(x,y) x>y
Support all C++23 and draft C++26 headers that have feature test flags
Tracked contracts changes in WG21 (e.g., P2661R1)
Generate Cpp1 postfix inc/dec in term of prefix
Allow trailing commas in lists
More CI
Cppfront 0.7.1 (Jul 10, 2024), new things include:
Added .. non-UFCS members-only call syntax
Allow x: const = init; and x: * = init; (const and pointer deduction without explicit _ placeholder)
Allow concatenated string literals
Faster compile time when doing heavy reflection and code generation
Added -quiet and -cwd
Cppfront 0.7.2 (Jul 27, 2024), new things include:
Added range operators ... and ..=
Added a compile-time @regex metafunction via reflection and code generation, by Max Sagebaum
Added support for function types (e.g., std::function< (i: inout int) -> forward std::string >)
Added support for C++23 (P2290) delimited hexadecimal escapes
Updated acknowledgments: Thank you!
Thank you to all these folks who have participated in the cppfront repo by opening issues and PRs, and to many more who participated on PR reviews and comment threads! These contributors represent people from high school and undergrad students to full professors, from commercial developers to conference speakers, and from every continent (except Antarctica… I think…).
Cpp2 and cppfront documentation
As of this spring, we now have Cpp2 and cppfront documentation! Last fall at CppCon 20243, the #1 cppfront request was “please write documentation!” So now that the language is stable, over the winter I got up and running with MkDocs via James Willett’s wonderful YouTube tutorial. Thanks to everyone who provided feedback and fixes!
Official releases
With documentation in place and a stable language, I felt it was time to start numbering releases. There have been three releases so far… here are each one’s highlights.
Cppfront 0.7.0 (Mar 16, 2024)
Initial feature set complete, including documentation. Here are a few highlights added since my September 2023 update blog post:
Added a “tersest” function syntax. Functions, including unnamed function expressions (aka lambdas), that do nothing but return an expression can now omit everything between ) and the expression. Here’s an example… note that this is a whole program, because compiling in -pure-cpp2 mode by default makes the entire standard library is available (efficiently imported as the std module if your compiler supports that):
If, like me, you’re quite used to UFCS, you can also write this to put vec. first, which means the same thing: vec.std::ranges::sort( :(x,y) x>y );
And with a using namespace std::ranges nearby, you can write just vec.sort( :(x,y) x>y ); … Now, that’s how I like to write clean C++20 code, and it is indeed (after lowering) just all-ordinary C++20 code.
Support all C++23 and draft C++26 headers that have feature test flags. When you use -import-std or -include-std to make the whole C++ standard library available, cppfront tracks the ever-growing list of standard headers so that you can always use cppfront with the latest Standard C++.
Tracked contracts changes in WG21 (e.g., P2661R1). As soon as the committee’s contracts subgroup decided to switch from notation like [[pre: expression]] to pre( expression ), I made the same change in cppfront. Note that cppfront still goes beyond the “minimum viable product” being proposed for C++23, because cppfront has always supported things like contract groups and customizable violation handlers. I also upgraded the contracts implementation to guarantee any contract’s expression will not be evaluated at all unless the contract is actually being checked, plus I provide an explicitly unevaluated group that is never evaluated to express contracts that are for static analyzers only (they can contain any grammatically valid expressions).
Generate Cpp1 postfix increment/decrement in terms of prefix. Cpp2 allows only “increment/decrement in place” operators, but when lowering to Cpp1 it generates both that and the “increment/decrement and return old value” Cpp1 operators. You can write a type in Cpp2 syntax that provides the operator once, and both versions are available to Cpp1 code that consumes the Cpp2-authored type (which is just an ordinary C++ type anyway, just written in a different syntax).
Allow trailing commas in lists. I got lots of requests for this, and Cpp2 now allows an extra redundant trailing comma at the end of any comma-delimited list. This is desirable because it lets programmers have cleaner source code diffs when adding a parameter or argument (if the source already has parameters/arguments on their own lines), and it slightly simplifies metafunctions’ code generation because they don’t have to track whether to suppress the last comma (and I think it’s important to make source code generation use cases easier). For a bit more rationale, see this Issue comment that goes with the commit. Edited to add: And the “Design note: Commas” that covers it in even more detail.
More CI: Besides build tests, added regression testing scripts and workflows. Thanks to Jaroslaw Glowacki and Johel Ernesto Guerrero Peña!
Added .. non-UFCS members-only syntax. This syntax invokes only a member function, and will not fall back to free functions. The main motivation was to provide a way to experiment if the UFCS logic noticeably added to Cpp1 compile times; I haven’t been able to verify that they cause much more compile time impact than an average-complexity line of code, but this way people can try it out. Example: mystring..append("foo");
Allow x: const = init; and x: * = init; without writing the _ type wildcard, in cases where all we want to say is that the deduced type is const or a pointer.
Allow concatenated string literals. For example, writing "Hello " "(name$)\n" now works. Note in that example that one string literal doesn’t use interpolation, and one does, and that’s fine.
Faster compile time when doing heavy reflection and code generation. I haven’t had to optimize cppfront much yet because it’s been fast in all my uses, but Max Sagebaum exercised metafunctions heavily for @regex (covered below, in 0.7.2) and made me find another ~100x performance improvement (thanks Max!). — This is the second optimization I can recall in cppfront so far, after Johel Ernesto Guerrero Peña‘s ~100x improvement last year by just changing the four uses of std::regex to find_if on a sorted vector of strings.
Added some command-line options:-quiet (thanks Marek Knápek for the suggestion!) and -cwd (thanks Fred Helmesjö for the PR!) command-line options.
Cppfront 0.7.2 (Jul 27, 2024)
This release added a few features, a couple of which are major and/or long-requested.
Added range operators ... and ..= . . I deliberately chose to make the default syntax ... mean a half-open range (like Rust, unlike Swift) so that it is bounds-safe by default for iterator ranges; for a “closed” range that includes the last value, use ..= . For example: iter1 ... iter2 is a range that safely doesn’t include iter2, as we expect for STL iterators; and 1 ..= 100 is a range of integer values that includes 100. For more, see the documentation here: ... and ..= range operators.
Added a compile-time @regex metafunction by Max Sagebaum. @regex uses compile-time reflection and source code generation via Cpp2 metafunctions to achieve compile- and run-time performance comparable to Hana Dusíková‘s groundbreaking CTRE library that uses today’s templates and other metaprogramming for the compile-time work. Thanks, Max! See the last ~10 minutes of my ACCU 2024 talk for an overview of CTRE and @regex and our initial performance results… the talk was a preview of the PR that was then merged in 0.7.2.
Add support for function types. You can now write a function signature as a type, such as to use with std::function (e.g., std::function< (i: inout int) -> forward std::string >) or to write a pointer to a function (e.g., pfn: *(i: inout int) -> forward std::string). For more, see the documentation here: Using function types. Thanks to Johel Ernesto Guerrero Peña for all his contributions toward function types in particular, and for his scores of merged PRs over the past year!
Added support for C++23 (P2290) delimited hexadecimal escapes. Didn’t notice these were in C++23? Neither did I! Thanks to Max Sagebaum for the PR to add support for escapes of the form \x{62}… you can now use them in Cpp2 code and they’ll work if your Cpp1 compiler understands them. Note that cppfront itself and its generated code don’t have a dependency on them; the cppfront philosophy is to “rely only on C++20 [in cppfront and its code gen requirements] for compatibility and portability, and support C++23/26 as a ‘light-up’ [people can use those features in their own Cpp2 code and they work if their Cpp1 compiler supports them].”
What’s next
For the rest of the year, I plan to:
Have regular cppfront releases, and post an update here for each one.
Share some updates about the cppfront license (currently it’s a non-commercial-use-only CC license to emphasize that this has been a personal experiment).
But first, in just seven (7) weeks, I’ll be at CppCon to give a talk that I plan to be in three equal parts:
C++26 progress, and why C++26 is shaping up to be the most important C++ release since C++11.
C++ memory safety problems and solutions (update of my ACCU talk).
On Saturday, the ISO C++ committee completed its fourth meeting of C++26, held in St Louis, MO, USA. Our host, Bill Seymour, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 180 attendees, about two-thirds in-person and the others remote via Zoom, formally representing over 20 nations. At each … Continue reading Trip report: Summer ISO C++ standards meeting (St Louis, MO, USA) →
Show full content
On Saturday, the ISO C++ committee completed its fourth meeting of C++26, held in St Louis, MO, USA.
Our host, Bill Seymour, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 180 attendees, about two-thirds in-person and the others remote via Zoom, formally representing over 20 nations. At each meeting we regularly have new attendees who have never attended before, and this time there were nearly 20 new first-time attendees, mostly in-person. To all of them, once again welcome!
We also often have new nations joining, and this time we welcomed participants formally representing Kazakhstan and India for the first time. We now have 29 nations who are regular formal participants: Austria, Bulgaria, Canada, China, Czech Republic, Denmark, Finland, France, Germany, Iceland, India, Ireland, Israel, Italy, Japan, Kazakhstan, Republic of Korea, The Netherlands, Norway, Poland, Portugal, Romania, Russia, Slovakia, Spain, Sweden, Switzerland, United Kingdom, and United States.
Here is a Saturday group photo of the in-person attendees right after the meeting adjourned (some had already left to catch flights). Thanks to John Spicer for taking this photo. Our host Bill Seymour is seated in the front row with the yellow dot. Thank you very much again, Bill, for having us!
The committee currently has 23 active subgroups, 16 of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day and/or evening, depending on their workloads. You can find a brief summary of ISO procedures here.
This time, the committee adopted the next set of features for C++26, and made significant progress on other features that are now expected to be complete in time for C+26.
Three major features made strong progress:
P2300 std::execution for concurrency and parallelism was formally adopted to merge into the C++26 working paper
P2996 Reflection was design-approved, and is now in specification wording review aiming for C++26
P2900 Contracts made considerable progress and has a chance of being in C++26
P2300 std::execution formally adopted for C++26
The major feature approved to merge into the C++26 draft standard was P2300 “std::execution” (aka “executors”, aka “Senders/Receivers”) by Michał Dominiak, Georgy Evtushenko, Lewis Baker, Lucian Radu Teodorescu, Lee Howes, Kirk Shoop, Michael Garland, Eric Niebler, and Bryce Adelstein Lelbach. It had already been design-approved for C++26 at prior meetings, but it’s a huge paper so the specification wording review by Library Wording subgroup (LWG) took extra time, and as questions arose the paper had to iterate with LEWG for specific design clarifications and tweaks.
P2300 aims to support both concurrency and parallelism. The definitions I use: Concurrency means doing independent work asynchronously (e.g., on different threads, or using coroutines) so that each can be responsive and progress at its own speed. Parallelism means using more hardware (cores, vector units, GPUs) to perform a single computation faster, which is the key to re-enabling the “free lunch” of being able to ship an application executable today that just naturally runs much faster on newer hardware with more compute throughput that becomes available in the future (most of which new throughput now ships in the form of more parallelism).
For concurrency, recall that in C++20 we already added coroutines, but in their initial state they were more of a “portable toolbox for writing coroutines” than a fully integrated feature (e.g., we can’t co_await a std::future with just what’s in the standard). Since then, we knew we’d want to add libraries on top to make coroutines easier to use, including std::future integration and a std::task library, which are still in progress. One of the big reasons to love std::execution is that it works well with coroutines, and is the biggest usability improvement yet to use the coroutine support we already have.
[Edited to add:] Eric Niebler provided three examples and descriptions I want to include here:
Example #2: cooperative multitasking with coroutines (Godbolt). Same, but using P2300 coroutines support and a third-party task type. The only allocations are for the coroutine frames themselves. This example uses the fact that awaitables are implicitly senders, and senders can be awaited in coroutines.
Example #3: multi-producer multi-consumer tasking system (Godbolt). Spins up a user-specified number of producer std::jthreads that schedule work onto the system execution context until they have been requested to stop. Clean shutdown using async_scope, and all producer threads are implicitly joined when main() returns.
The above three example illustrate several techniques, described by Eric:
* how to cooperatively multitask on an embedded system that has only one thread and no allocator
* how to implement a multi-producer, multi-consumer tasking system
* how to use P2300 together with coroutines
* how to write a custom sender algorithm
* how to use P2300 components together with a third party library providing standard-conforming extensions
* how to spawn a variable amount of work and wait for it all to complete using the proposed async_scope from P3149
* how to use the proposed ABI-stable system context from P2079 to avoid oversubscribing the local host
Ville Voutilainen reports writing a concurrent chunked HTTPS download that integrates nicely with C++20 coroutines’ co_await and a Qt UI progress bar, using P2300’s reference implementation (plus a sender-aware task type which is expected to be standardized in the future, but third-party ones like the exec::task below work today), together with his own Qt adaptation code (about 180 lines, which will eventually ship as part of Qt). The code is short enough to show here:
For parallelism, see the December 2022 HPC Wire article “New C++ Sender Library Enables Portable Asynchrony” by Eric Niebler, Georgy Evtushenko, and Jeff Larkin, which describes the cross-platform parallel performance of std::execution. “Cross-platform” means across different parallel programming models, using both distributed-memory and shared-memory, and across different computer architectures. (HT: Thanks Mark Hoemmen and others for reminding us about this article.) The NVIDIA coauthors of P2300 report that parallel performance is on par with CUDA code.
Mikael Simberg reports that another parallelism example from the HPC community to show off P2300 is DLA_Future (GitHub), which implements a distributed CPU/GPU eigensolver. It optionally uses std::execution’s reference implementation, and plans to use std::execution unconditionally once it ships in C++26 standard libraries. In that repo, one advanced example is this distributed Cholesky decomposition code (GitHub) (note: it still uses start_detached which was recently removed, and plans to use async_scope once available).
See also P2300 itself for more examples of both techniques.
Reflection design-approved for C++26
The Language Evolution working group (EWG) approved the design of the reflection proposal P2996R2 “Reflection for C++26” by Wyatt Childers, Peter Dimov, Dan Katz, Barry Revzin, Andrew Sutton, Faisal Vali, and Daveed Vandevoorde and it has now begun language specification wording review, currently on track for C++26. (Updated to add: The Library Evolution working group (LEWG) is still reviewing the library part of the design.)
This is huge, because reflection (including generation) will be by far the most impactful feature C++ has ever added since C++98, and it will dominate the next decade and more of C++ usage. It’s a watershed event; a sea change in C++. I say this for three reasons:
First, reflection and generation are the biggest power tool C++ has ever seen to improve library building: It will enable writing C++ libraries that were infeasible or impossible before, and its impact on writing libraries will likely be bigger than all the other library-writing improvements combined that the language has added from C++11 until now (e.g., lambdas, auto, if constexpr, requires, type traits).
Second, reflection and generation will simplify C++ language evolution: It will reduce the need to add as many future one-off or “narrow” language extensions to C++, because we will be able to write many of them as compile-time libraries in ordinary C++ consteval code using reflection and generation. That by itself will help slow down the future growth of complexity of the language. And it has already been happening; in recent years, SG7 (the subgroup responsible for compile-time programming) has redirected some narrow language proposals to explore how to write them using reflection instead.
Third, reflection and generation is the foundation for another potential way to dramatically simplify how we write C++ code, namely my metaclasses proposal which is “just” a small (but powerful) thin extension layered on top of reflection and generation… for details, see the Coda at the end of this post.
Still aiming for C++26 timeframe: Contracts
We spent four full days of subgroup time on the contracts proposal P2900 “Contracts for C++” by Joshua Berne, Timur Doumler, Andrzej Krzemieński, Gašper Ažman, Tom Honermann, Lisa Lippincott, Jens Maurer, Jason Merrill, and Ville Voutilainen: One and a half days in language design (EWG) on Monday afternoon and Tuesday, a parallel session in the safety group (SG23) on Tuesday, two days in the Contracts subgroup (SG21) on Wednesday and Thursday, then a quarter-day back in EWG on Friday after lunch for another session on virtual function contracts. In all, we worked through many design issues and made good progress toward consensus on several of them. We still have further work to do in order to build consensus on other open design questions, but the consensus is gradually improving and the list of open questions is gradually getting shorter… we’ll see! I’m cautiously optimistic that we have a 50-50 chance of getting contracts in C++26, which means that we will have to iron out the remaining differences within the next 11 months to meet C++26’s feature-freeze no-later-than hard deadline next June.
Adopted for C++26: Core language changes/features
Here are some additional highlights… note that these links are to the most recent public version of each paper, and some were tweaked at the meeting before being approved; the links track and will automatically find the updated version as soon as it’s uploaded to the public site.
The core language adopted 6 papers, including the following…
P0963R3 “Structured binding declaration as a condition” by Zhihao Yuan. This allows structured binding declarations with initializers appearing in place of the conditions in if, while, for, and switch statements, so you can decompose more conveniently and take a branch only if the returned non-decomposed object evaluates to true. Thanks, Zhihao!
Adopted for C++26: Standard library changes/features
In addition to P2300 std::execution, already covered above, the standard library adopted 11 other papers, including the following…
The lowest-numbered paper approved, which means it has been “baking” for the longest time, is something some of us have been awaiting for a while: P0843R11 “inplace_vector” by Gonzalo Brito Gadeschi, Timur Doumler, Nevin Liber, and David Sankel. The paper’s overview says it all – thank you, authors!
This paper proposes inplace_vector, a dynamically-resizable array with capacity fixed at compile time and contiguous inplace storage, that is, the array elements are stored within the vector object itself. Its API closely resembles std::vector<T, A>, making it easy to teach and learn, and the inplace storage guarantee makes it useful in environments in which dynamic memory allocations are undesired.
This container is widely-used in the standard practice of C++, with prior art in, e.g., boost::static_vector<T, Capacity> or the EASTL, and therefore we believe it will be very useful to expose it as part of the C++ standard library, which will enable it to be used as a vocabulary type.
P3235R3 “std::print more types faster with less memory” by Victor Zverovich gets my vote for the “best salesmanship in a paper title” award! If you like std::print, this is more, faster, sleeker (who wouldn’t vote for that?!) by expanding the applicability of the optimizations previously delivered in P3107 which initially were applied to only built-in type and string types, and now work for more standard library types. Thanks for all the formatted I/O, Victor!
P2968R2 “Make std::ignore a first-class object” by Peter Sommerlad formally blesses the use of std::ignore on the left-hand side of an assignment. Initially std::ignore was only meant to be used with std::tie, but many folks noticed (and recommended and relied on) that on every implementation you can also use it to ignore the result of an expression by just writing std::ignore = expression;. Even the C++ Core Guidelines’ ES.48 “Avoid casts” recommends “Use std::ignore = to ignore [[nodiscard]] values.” And as of C++26, that advice will be upgraded from “already works in practice” to “officially legal.” Thank you, Peter!
Other progress
All subgroups continued progress, more of which will no doubt be covered in other trip reports. Here are a few more highlights…
SG1 (Concurrency): Discussed 24 papers, and progressed the “zap” series of papers. To the happiness of many people (including me), concurrent_queue is finally nearing completion! A concurrent queue is one of the foundational concurrency primitives sorely missing from the standard library, and it’s great to see it coming closer to landing.
SG6 (Numerics): More progress on several proposals including a quantities-and-units library.
SG7 (Compile-Time Programming): Forwarded six more papers to the main subgroups, most of them reflection-related.
SG9 (Ranges): Continued working on ranges extensions for C++26, with good progress.
SG15 (Tooling): Starting to approve sending Ecosystem papers to the main subgroups, such as metadata formats and support for build systems.
SG23 (Safety): Reviewed several different proposals for safety improvement. The group voted favorably to support P3297 “C++26 needs contracts checking” by Ryan McDougall, Jean-Francois Campeau, Christian Eltzschig, Mathias Kraus, and Pez Zarifian.
Edited to add, for completeness the other presentations were: First, Bjarne Stroustrup presented his Profiles followup paper P3274R0 “A framework for Profiles development.” Then P3297, which I called out because it was a communication to the other groups about the contracts topic that dominated the week (above). Then Thomas Köppe presented P3232R0 “User-defined erroneous behavior.” Then Sean Baxter gave an informational demo presentation (no paper yet) of his work exploring adding borrow checking to C++ in his Circle compiler.
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Thank you again to the over 180 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in just a few months from now we’ll be meeting again in person + Zoom to continue adding features to C++26. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
Coda: From reflection to metaclass functions and P0707
The reason I picked reflection and generation to be the first “major” feature from Cpp2 that I brought to the committee in 2017, together with a major application use case, in the form of my “metaclasses” paper P0707, is because it was the biggest source of simplification in Cpp2, but it was also the riskiest part of Cpp2 — it was the most “different from what we do in C++” so I was not sure the committee and community would embrace the idea, and it was the most “risky to implement” because nothing like using compile-time functions to help generate class code had ever been tried for C++.
Most of my initial version of P0707 was a plea of ‘here’s why the committee should please give us reflection and generation.’ When I first presented it to the committee at the Toronto 2017 meeting immediately following the reflection presentation, I began my presentation with something like: “Hi, I’m Herb, and I’m their customer,” pointing to the reflection presenters, “because this is about what we could build on top of reflection.” That is still true; the main reason I haven’t updated P0707 since 2019 is because I haven’t needed to… the reflection work needs to exist first, and it has been continually progressing.
Historical note: Andrew Sutton’s Lock3 reflection implementation was created for, and funded by, my project that is now called Cpp2 , but which back then was called Cppx and used the Lock3 Clang-based reflection implementation; that’s why the Lock3 implementation has been available at cppx.godbolt.org (thanks again, Matt! you’re a rock star). C++20 consteval also came directly from this work, because we realized we would need functions that must run only at compile time to deal with static reflections and generation.
Now that reflection is landing in the standard, I plan to update my P0707 paper to finish proposing metaclasses for ISO C++. P0707 metaclasses (aka type metafunctions) are actually just a thin layer on top of P2996. To see why, consider this simple code:
// Example 1: Possible with P2996
consteval { generate_a_widget_class(); }
// let’s say that executing this consteval function generates something like:
// class widget { void f() { std::cout << "hello"; } };
With P2996, Example 1 can write such a consteval function named generate_a_widget_class that can be invoked at compile time and generates (aka injects) that widget type as if it had been hand-written by the programmer at the same point in source code.
Next, let’s slightly generalize the example by giving it an existing type’s reflection as some input to guide what gets generated:
// Example 2: Possible with P2996 (^ is the reflection operator)
class gadget { /*...*/ }; // written by the programmer by hand
consteval{ M( ^gadget ); } // generates widget from the reflection of gadget
// now this generates something like:
// class widget { /* some body based on the reflection of what’s in gadget */ };
Still with just P2996, Example 2 can write such a consteval function named M that will generate the widget class as-if was hand-written by the programmer at this point in source code, but with the ability to refer to ^gadget… for example, perhaps widget will echo some or all the same member functions and member variables as gadget, and add additional things.
And, just like that, we’ve suddenly arrived at P0707 metaclasses because all the Lock3 implementation of Cpp2 (then Cppx) metaclasses did is to “package up Example 2,” by providing a syntax to apply the consteval function M to the type being defined:
// Example 3: class(M) means to apply M to the class being defined
// (not yet legal C++)
class(M) widget{ /*...*/ };
// this proposed language feature would emit something like the following:
// namespace __prototype { class widget { /*...*/ }; }
// consteval{ M( ^__prototype::widget ); } // generates widget from __prototype::widget
Historical note: My initial proposal P0707R0 proposed the syntax “M class” (e.g., interface class, value class), and the SG7 subgroup gave feedback that it preferred “class(M)” (e.g., class(interface), class(value)) to make parsing easier. I’m fine with that; the syntax is less important, what matters is getting the expressive power.
So my plan for my next revision of P0707 is to propose class(M) syntax for Standard C++ as a further extension on top of P2996 reflection, to be implemented just like Example 3 above (and as Lock3 already did since 2017, so we know it works).
Why is that so important to simplifying C++?
First, as I show in P0707, it means that we can make classes much easier and safer to write, without wrong defaults and bug-prone boilerplate code. We can stop teaching the “Rules of 0/1/3/5,” and stop teaching =delete to get rid of generated special functions we didn’t want, because when using metafunctions to write classes we’re always using a convenient word to opt into a group of defaults for the type we’re writing and can get exactly the ones we want.
Second, we can write a Java/C#-style “class(interface)” without adding a special “interface” feature to the language as a separate type category, and with just as good efficiency and usability as languages that bake interface into the language. We can add “class(value)” to invoke a C++ function that runs at compile time to get the defaults right for value types without a new language feature hardwired into the compiler. We can add class(safe_union) and class(flag_enum) and much more.
Third, as I expressed in P0707, I hope reflection+generations+metafunctions can replace Qt MOC, COM IDL, C++/CLI extensions, C++/CX IDL, all of which exist primarily because we couldn’t express things in Standard C++ that we will now be able to express with this feature. I’m responsible for some of those nonstandard technologies; I led the design of C++/CLI and C++/CX, and one of my goals for reflection+generation+metafunctions is that I hope I will never need to design such language extensions again, by being able to express them well in normal (future) Standard C++. And I’m not alone; my understanding is that many of the vendors who own technologies like the above are already eagerly planning to responsibly transition such currently-add-on technologies to a standard reflection-and-generation based implementation, once reflection and generation are widely available in C++ compilers.
If you’re interested in more example of how metafunctions can work, I strongly recommend re-watching parts of two talks:
The middle section of my CppCon 2023 talk, starting around 18:50 up to 44:00, which shows many examples that work today using my cppfront compiler to translate them to regular C++, including detailed walkthroughs of the “enum” and “union” metaclass functions (in Cpp2 syntax, but they will work just as well as a minor extension of today’s C++ syntax as described above).
My original CppCon 2017 talk starting a few minutes in (an earlier version of this talk premiered initially at ACCU 2017), which demonstrates the approach and shows the first few examples working on the early Lock3 reflection implementation. The syntax has changed slightly, but the entire talk is still super current in 2024 as the reflection and generation it relies upon is now on its way to (finally!) landing in the standard.
I’m looking forward to finally resume updating P0707 to propose adding the rest of the expressive power it describes, as an extension to today’s C++ standard syntax, built on top of Standard C++26 (we hope!) reflection and generation. I hope to bring an updated proposal to our next meeting in November. My first step will be to try writing P0707 metafunctions in P2996 syntax to validate everything is there and works as I expect. So far, the only additional reflection support I know of that I’ll have to propose adding onto today’s P2996 is is_default_accessiblity() (alongside is_public() et al.) to query whether a member has the “default” accessibility of the class, i.e., is written before any public: or protected: or private: access specifier; that’s needed by metafunctions like “interface” that want to apply defaults, such as to make functions public and pure virtual by default without the user having to write public: or virtual or =0.
Safety is very important and we’ll be working hard on that too. But I would be remiss not to emphasize that the arrival of reflection (including generation) is a sea change that will drive of our next decade and more of C++… it’s really that big a deal, a rising tide that will lift all other boats including safety and simplicity as well. Starting soon, for many years we won’t be able to go to a C++ conference whose program doesn’t heavily feature reflection… and I’m not saying that just because I know several reflection talks have been accepted for CppCon 2024 two months from now; this really will be talked about and heavily used everywhere across our industry because there’s so much goodness to learn and use in this powerful feature.
Also in April, I was interviewed by Jordi Mon Companys for Software Engineering Daily, and that interview was just published on the SE Daily podcast. Here is a copy of the page’s additional details, including a transcript link at bottom. The U.S. government recently released a report calling on the technical community to proactively reduce … Continue reading Podcast: Interview with Software Engineering Daily →
Here is a copy of the page’s additional details, including a transcript link at bottom.
The U.S. government recently released a report calling on the technical community to proactively reduce the attack surface area of software infrastructure. The report emphasized memory safety vulnerabilities, which affect how memory can be accessed, written, allocated, or deallocated.
The report cites this class of vulnerability as a common theme in the some of the most infamous cyber events, such as the Morris worm of 1988, the Heartbleed vulnerability in 2014, and the Blastpass exploit of 2023.
Herb Sutter works at Microsoft and chairs the ISO C++ standards committee. He joins the show to talk about C++ safety.
Jordi Mon Companys is a product manager and marketer that specializes in software delivery, developer experience, cloud native and open source. He has developed his career at companies like GitLab, Weaveworks, Harness and other platform and devtool providers. His interests range from software supply chain security to open source innovation. You can reach out to him on Twitter at @jordimonpmm.
Many thanks to ACCU for inviting me back again this April. It was my first time back to ACCU (and only my second trip to Europe) since the pandemic began, and it was a delight to see many ACCUers in person again for the first time in a few years. I gave this talk, which … Continue reading April talk video posted: “Safety, Security, Safety[sic] and C/C++[sic]” →
Show full content
Many thanks to ACCU for inviting me back again this April. It was my first time back to ACCU (and only my second trip to Europe) since the pandemic began, and it was a delight to see many ACCUers in person again for the first time in a few years.
I gave this talk, which is now up on YouTube here:
It’s an evolved version of my March essay “C++ safety, in context.” I don’t like just repeating material, so the essay and the talk each covers things that the other doesn’t. In the talk, my aim was to expand on the key points of the essay with additional discussion and data points, including new examples that came up in the weeks between the essay and the talk, and relating it to ongoing ISO C++ evolution for safety already in progress.
The last section of the talk is a Cppfront update, including some interesting new results regarding compile- and run-time performance using metafunctions. One correction to the talk: I looked back at my code and I had indeed been making the mistake of creating a new std::regex object for each use, so that accounted for some of the former poor performance. But I retested and found that mistake only accounted for part of the performance difference, so the result is still valid: Removing std::regex from Cppfront was still a big win even when std::regex was being used correctly.
I hope you find the talk interesting and useful. Thanks very much to everyone who has contributed to C++ safety improvement explorations, and everyone who has helped with Cppfront over the past year and a half since I first announced the project! I appreciate all your input and support for ISO C++’s ongoing evolution.
On Friday, I sat down with Kevin Carpenter to do a short (12-min) interview about my ACCU talk coming up on April 17, and other topics. Apologies in advance for my voice quality: I’ve been sick with some bug since just after the Tokyo ISO meeting, and right after this interview I lost my voice … Continue reading Pre-ACCU interview video is live →
Show full content
On Friday, I sat down with Kevin Carpenter to do a short (12-min) interview about my ACCU talk coming up on April 17, and other topics.
Apologies in advance for my voice quality: I’ve been sick with some bug since just after the Tokyo ISO meeting, and right after this interview I lost my voice for several days… we recorded this just in time!
Kevin’s questions were about these topics in order (and my short answers):
Chatting about my ACCU talk topics (safety, and cppfront update)
Is it actually pretty easy to hop on a stage and talk about C++ for an hour (nope; or at least for me, not well)
In ISO standardization, how to juggle adding features vs. documenting what’s done (thanks to the Reddit trip report coauthors!)
ISO C++ meetings regularly have lots of guests, including regularly high school classes (yup, that’s a thing now)
With the winter ISO meeting behind us, it’s onward into spring conference season! ACCU Conference 2024. On April 17, I’ll be giving a talk on C++’s current and future evolution, where I plan to talk about safety based on my recent essay “C++ safety, in context,” and progress updates on cppfront. I’m also looking forward … Continue reading Effective Concurrency course & upcoming talks →
Show full content
With the winter ISO meeting behind us, it’s onward into spring conference season!
ACCU Conference 2024. On April 17, I’ll be giving a talk on C++’s current and future evolution, where I plan to talk about safety based on my recent essay “C++ safety, in context,” and progress updates on cppfront. I’m also looking forward to these three keynoters:
Laura Savino, who you may recall gave an outstanding keynote at CppCon 2023 just a few months ago. Thanks again for that great talk, Laura!
Björn Fahller, who not only develops useful libraries but is great at naming them (Trompeloeil, I’m looking at you! [sic]).
Inbal Levi, who chairs one of the two largest subgroups in the ISO C++ committee (Library Evolution Working Group, responsible for the design of the C++ standard library) and is involved with organizing and running many other C++ conferences.
Effective Concurrency online course. On April 22-25, I’ll be giving a live online public course for four half-days, on the topic of high-performance low-latency coding in C++ (see link for the course syllabus). The times of 14.00 to 18.00 CEST daily are intended to be friendly to the home time zones of attendees anywhere in EMEA and also to early risers in the Americas. If you live in a part of the world where these times can’t work for you, and you’d like another offering of the course that is friendlier to your home time zone, please email Alfasoft to let them know! If those times work for you and you’re interested in high performance and low latency coding, and how to achieve them on modern hardware architectures with C++17, 20, and 23, you can register now.
Beyond April, later this year I’ll be giving talks in person at these events:
Moments ago, the ISO C++ committee completed its third meeting of C++26, held in Tokyo, Japan. Our hosts, Woven by Toyota, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 220 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 21 nations. That makes it roughly … Continue reading Trip report: Winter ISO C++ standards meeting (Tokyo, Japan) →
Show full content
Moments ago, the ISO C++ committee completed its third meeting of C++26, held in Tokyo, Japan. Our hosts, Woven by Toyota, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 220 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 21 nations. That makes it roughly tied numerically for our largest meeting ever, roughly the same attendance as Prague 2020 that shipped C++20 just a few weeks before the pandemic lockdowns. — However, note that it’s not an apples-to-apples comparison, because the pre-pandemic meetings were all in-person, and since the pandemic they have been hybrid. But it is indicative of the ongoing strong participation in C++ standardization.
At each meeting we regularly have new attendees who have never attended before, and this time we welcomed over 30 new first-time attendees, mostly in-person, who were counted above. (These numbers are for technical participants, and they don’t include that we also had observers, including a class of local high school students visiting for part of a day, similarly to how a different local high school class did at our previous meeting in Kona in November. We are regularly getting high-school delegations as observers these days, and to them once again welcome!)
The committee currently has 23 active subgroups, 16 of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day and/or evening, depending on their workloads. You can find a brief summary of ISO procedures here.
This week’s meeting: Meeting #3 of C++26
At the previous two meetings in June and November, the committee adopted the first 63 proposed changes for C++26, including many that had been ready for a couple of meetings while we were finishing C++23 and were just waiting for the C++26 train to open to be adopted. For those highlights, see the June trip report and November trip report.
This time, the committee adopted the next set of features for C++26, and made significant progress on other features that are now expected to be complete in time for C+26.
Here are some of the highlights… note that these links are to the most recent public version of each paper, and some were tweaked at the meeting before being approved; the links track and will automatically find the updated version as soon as it’s uploaded to the public site.
Adopted for C++26: Core language changes/features
The core language adopted 10 papers, including the following…
P2573R2 “=delete(“should have a reason”)” by Yihe Li does the same for =delete as we did for static_assert: It allows writing a string as the reason, which makes it easier for library developers to give high-quality compile-time error messages to users as part of the compiler’s own error message output. Thanks, Yihe!
Here is an example from the paper that will now be legal and generate an error message similar to the one shown here:
class NonCopyable
{
public:
// ...
NonCopyable() = default;
// copy members
NonCopyable(const NonCopyable&)
= delete("Since this class manages unique resources, \
copy is not supported; use move instead.");
NonCopyable& operator=(const NonCopyable&)
= delete("Since this class manages unique resources, \
copy is not supported; use move instead.");
// provide move members instead
};
<source>:16:17: error: call to deleted
constructor of 'NonCopyable': Since this class manages unique resources, copy is not supported; use move instead.
NonCopyable nc2 = nc;
^ ~~
P2795R5 “Erroneous behavior for uninitialized reads” by Thomas Köppe is a major change to C++ that will help us to further improve safety by providing a tool to reduce undefined behavior, especially that it removes undefined behavior for some cases of uninitialized objects.
I can’t do better than quote from the paper:
Summary: We propose to address the safety problems of reading a default-initialized automatic variable (an “uninitialized read”) by adding a novel kind of behaviour for C++. This new behaviour, called erroneous behaviour, allows us to formally speak about “buggy” (or “incorrect”) code, that is, code that does not mean what it should mean (in a sense we will discuss). This behaviour is both “wrong” in the sense of indicating a programming bug, and also well-defined in the sense of not posing a safety risk.
…
With increased community interest in safety, and a growing track record of exploited vulnerabilities stemming from errors such as this one, there have been calls to fix C++. The recent P2723R1 proposes to make this fix by changing the undefined behaviour into well-defined behaviour, and specifically to well-define the initialization to be zero. We will argue below that such an expansion of well-defined behaviour would be a great detriment to the understandability of C++ code. In fact, if we want to both preserve the expressiveness of C++ and also fix the safety problems, we need a novel kind of behaviour.
…
Reading an uninitialized value is never intended and a definitive sign that the code is not written correctly and needs to be fixed. At the same time, we do give this code well-defined behaviour, and if the situation has not been diagnosed, we want the program to be stable and predictable. This is what we call erroneous behaviour.
In other words, it is still an “wrong” to read an uninitialized value, but if you do read it and the implementation does not otherwise stop you, you get some specific value. In general, implementations must exhibit the defined behaviour, at least up until a diagnostic is issued (if ever). There is no risk of running into the consequences associated with undefined behaviour (e.g. executing instructions not reflected in the source code, time-travel optimisations) when executing erroneous behaviour.
Adding the notion of “erroneous behavior” is a major change to C++’s specification, that can help not only with uninitialized reads but also can be applied to reduce other undefined behavior in the future. Thanks, Thomas!
Adopted for C++26: Standard library changes/features
The standard library adopted 18 papers, including the following…
In the “Moar Ranges!” department, P1068R11 “Vector API for random number generation” by Ilya Burylov, Pavel Dyakov, Ruslan Arutyunyan, Andrey Nikolaev, and Alina Elizarova addresses the situation that, when you want one random number, you likely want more of them, and random number generators usually already generate them efficiently in batches. Thanks to their paper, this will now work:
std::array<std::uint_fast32_t, arrayLength> intArray;
std::mt19937 g(777);
std::ranges::generate_random(intArray, g);
// The above line will be equivalent to this:
for(auto& e : intArray)
e = g();
In the “if you still didn’t get enough ‘Moar Ranges!’” department, P2542 “views::concat” by Hui Xie and S. Levent Yilmaz provides an easy way to efficiently concatenate an arbitrary number of ranges, via a view factory. Thanks, Hui and Levent! Here is an example from the paper:
std::vector<int> v1{1,2,3}, v2{4,5}, v3{};
std::array a{6,7,8};
auto s = std::views::single(9);
std::print("{}\n", std::views::concat(v1, v2, v3, a, s));
// output: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Speaking of concatenation, have you ever wished you could write “my_string_view + my_string” and been surprised it doesn’t work? I sure have. No longer: P2591R4 “Concatenation of strings and string views” by Giuseppe D’Angelo adds operator+ overloads for those types. Thanks, Giuseppe, for finally getting us this feature!
P2845 “Formatting of std::filesystem::path” by Victor Zverovich (aka the King of Format) provides a high-quality std::format formatter for filesystem paths that addresses concerns about quoting and localization.
A group of papers by Alisdair Meredith removed some (mostly already-deprecated) features from the standard library. Thanks for the cleanup, Alisdair!
P3142R0 “Printing Blank Lines with println”by Alan Talbot is small but a nice quality-of-life improvement: We can now write just println() as an equivalent of println(“”). But that’s not all: See the yummy postscript in the paper. (See, Alan, we do read the whole paper. Thanks!)
Those are some of the “bigger” or “likely of wide interest” papers as just a few highlights… this week there were 28 papers adopted in all, including other great work on extensions and fixes for the C++26 language and standard library.
Aiming for C++26 timeframe: Contracts
The contracts proposal P2900 “Contracts for C++” by Joshua Berne, Timur Doumler, Andrzej Krzemieński, Gašper Ažman, Tom Honermann, Lisa Lippincott, Jens Maurer, Jason Merrill, and Ville Voutilainen progressed out of the contracts study group, SG21, and was seen for the first time in the Language (EWG) and Library (LEWG) Evolution Working Groups proper. Sessions started in LEWG right on the first day, Monday afternoon, and EWG spent the entire day Wednesday on contracts, with many of the members of the safety study group, SG23, attending the session. There was lively discussion about whether contracts should be allowed to have, or be affected by, undefined behavior; whether contracts should be used in the standard library; whether contracts should be shipped first as a Technical Specification (TS, feature branch) in the same timeframe as C++26 to gain more experience with existing libraries; and other aspects… all of these questions will be discussed again in the coming months, this was just the initial LEWG and EWG full-group design review that generated feedback to be looked at. The subgroups considered the EWG and LEWG groups’ feedback later in the week in two more sessions on Thursday and Friday, including in a joint session of SG21 and SG23.
Both SG21 and SG23 will have telecons about further improving the contracts proposal between now and our next hybrid meeting in June.
On track for targeting C++26: Reflection
The reflection proposal P2996R2 “Reflection for C++26” by Wyatt Childers, Peter Dimov, Barry Revzin, Andrew Sutton, Faisal Vali, and Daveed Vandevoorde progressed out of the reflection / compile-time programming study group, SG7, and was seen by the main evolution groups EWG and LEWG for the first time on Tuesday, which started with a joint EWG+LEWG session on Tuesday, and EWG spent the bulk of Tuesday on its initial large-group review aiming for C++26. Then SG7 continued on reflection and other topics, including a presentation by Andrei Alexandrescu about making sure reflection adds a few more small things to fully support flexible generative programming.
Other progress
All subgroups continued progress. A lot happened that other trips will no doubt cover, but I’ll call out two things.
One proposal a lot of people are watching is P2300 “std::execution” (aka “executors”) by Michał Dominiak, Georgy Evtushenko, Lewis Baker, Lucian Radu Teodorescu, Lee Howes, Kirk Shoop, Michael Garland, Eric Niebler, and Bryce Adelstein Lelbach, which was already design-approved for C++26. It’s a huge paper (45,000 words, of which 20,000 words is the standardese specification! that’s literally a book… my first Exceptional C++ book was 62,000 words), so it has been taking time for the Library Wording subgroup (LWG) to do its detailed review of the specification wording, and at this meeting LWG spent a quarter of the meeting completing a first pass through the entire paper! They will continue to work in teleconferences on a second pass and are now mildly optimistic of completing P2300 wording review at our next meeting in June.
And one more fun highlight: We all probably suspected that pattern matching is a “ground-shaking” proposed addition to future C++, but in Tokyo during the pattern matching session there was a literal earthquake that briefly interrupted the session!
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Thank you again to the over 210 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in just three months from now we’ll be meeting again in person + Zoom to continue adding features to C++26. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
Scope. To talk about C++’s current safety problems and solutions well, I need to include the context of the broad landscape of security and safety threats facing all software. I chair the ISO C++ standards committee and I work for Microsoft, but these are my personal opinions and I hope they will invite more dialog … Continue reading C++ safety, in context →
Show full content
Scope. To talk about C++’s current safety problems and solutions well, I need to include the context of the broad landscape of security and safety threats facing all software. I chair the ISO C++ standards committee and I work for Microsoft, but these are my personal opinions and I hope they will invite more dialog across programming language and security communities.
Acknowledgments. Many thanks to people from the C, C++, C#, Python, Rust, MITRE, and other language and security communities whose feedback on drafts of this material has been invaluable, including: Jean-François Bastien, Joe Bialek, Andrew Lilley Brinker, Jonathan Caves, Gabriel Dos Reis, Daniel Frampton, Tanveer Gani, Daniel Griffing, Russell Hadley, Mark Hall, Tom Honermann, Michael Howard, Marian Luparu, Ulzii Luvsanbat, Rico Mariani, Chris McKinsey, Bogdan Mihalcea, Roger Orr, Robert Seacord, Bjarne Stroustrup, Mads Torgersen, Guido van Rossum, Roy Williams, Michael Wong.
Terminology (see ISO/IEC 23643:2020). “Software security” (or “cybersecurity” or similar) means making software able to protect its assets from a malicious attacker. “Software safety” (or “life safety” or similar) means making software free from unacceptable risk of causing unintended harm to humans, property, or the environment. “Programming language safety” means a language’s (including its standard libraries’) static and dynamic guarantees, including but not limited to type and memory safety, which helps us make our software both more secure and more safe. When I say “safety” unqualified here, I mean programming language safety, which benefits both software security and software safety.
We must make our software infrastructure more secure against the rise in cyberattacks (such as on power grids, hospitals, and banks), and safer against accidental failures with the increased use of software in life-critical systems (such as autonomous vehicles and autonomous weapons).
The past two years in particular have seen extra attention on programming language safety as a way to help build more-secure and -safe software; on the real benefits of memory-safe languages (MSLs); and that C and C++ language safety needs to improve — I agree.
But there have been misconceptions, too, including focusing too narrowly on programming language safety as our industry’s primary security and safety problem — it isn’t. Many of the most damaging recent security breaches happened to code written in MSLs (e.g., Log4j) or had nothing to do with programming languages (e.g., Kubernetes Secrets stored on public GitHub repos).
In that context, I’ll focus on C++ and try to:
highlight what needs attention (what C++’s problem “is”), and how we can get there by building on solutions already underway;
address some common misconceptions (what C++’s problem “isn’t”), including practical considerations of MSLs; and
leave a call to action for programmers using all languages.
tl;dr: I don’t want C++ to limit what I can express efficiently. I just want C++ to let me enforce our already-well-known safety rules and best practices by default, and make me opt out explicitly if that’s what I want. Then I can still use fully modern C++… just nicer.
Let’s dig in.
The immediate problem “is” that it’s Too Easy By Default to write security and safety vulnerabilities in C++ that would have been caught by stricter enforcement of known rules for type, bounds, initialization, and lifetime language safety
In C++, we need to start with improving these four categories. These are the main four sources of improvement provided by all the MSLs that NIST/NSA/CISA/etc. recommend using instead of C++ (example), so by definition addressing these four would address the immediate NIST/NSA/CISA/etc. issues with C++. (More on this under “The problem ‘isn’t’… (1)” below.)
And in all recent years including 2023 (see figures 1’s four highlighted rows, and figure 2), these four constitute the bulk of those oft-quoted 70% of CVEs (Common [Security] Vulnerabilities and Exposures) related to language memory unsafety. (However, that “70% of language memory unsafety CVEs” is misleading; for example, in figure 1, most of MITRE’s 2023 “most dangerous weaknesses” did not involve language safety and so are outside that denominator. More on this under “The problem ‘isn’t’… (3)” below.)
The C++ guidance literature already broadly agrees on safety rules in those categories. It’s true that there is some conflicting guidance literature, particularly in environments that ban exceptions or run-time type support and so use some alternative rules. But there is consensus on core safety rules, such as banning unsafe casts, uninitialized variables, and out-of-bounds accesses (see Appendix).
C++ should provide a way to enforce them by default, and require explicit opt-out where needed. We can and do write “good” code and secure applications in C++. But it’s easy even for experienced C++ developers to accidentally write “bad” code and security vulnerabilities that C++ silently accepts, and that would be rejected as safety violations in other languages. We need the standard language to help more by enforcing the known best practices, rather than relying on additional nonstandard tools to recommend them.
These are not the only four aspects of language safety we should address. They are just the immediate ones, a set of clear low-hanging fruit where there is both a clear need and clear way to improve (see Appendix).
Note: And safety categories are of course interrelated. For example, full type safety (that an accessed object is a valid object of its type) requires eliminating out-of-bounds accesses to unallocated objects. But, conversely, full bounds safety (that accessed memory is inside allocated bounds) similarly requires eliminating type-unsafe downcasts to larger derived-type objects that would appear to extend beyond the actual allocation.
Software safety is also important. Cyberattacks are urgent, so it’s natural that recent discussions have focused more on security and CVEs first. But as we specify and evolve default language safety rules, we must also include our stakeholders who care deeply about functional safety issues that are not reflected in the major CVE buckets but are just as harmful to life and property when left in code. Programming language safety helps both software security and software safety, and we should start somewhere, so let’s start (but not end) with the known pain points of security CVEs.
In those four buckets, a 10-50x improvement (90-98% reduction) is sufficient
If there were 90-98% fewer C++ type/bounds/initialization/lifetime vulnerabilities we wouldn’t be having this discussion. All languages have CVEs, C++ just has more (and C still more). [Updated: Removed count of 2024 Rust vs C/C++ CVEs because MITRE.org search doesn’t have a great way of accurately counting the latter.] So zero isn’t the goal; something like a 90% reduction is necessary, and a 98% reduction is sufficient, to achieve security parity with the levels of language safety provided by MSLs… and has the strong benefit that I believe it can be achieved with perfect backward link compatibility (i.e., without changing C++’s object model, and its lifetime model which does not depend on universal tracing garbage collection and is not limited to tree-based data structures) which is essential to our being able to adopt the improvements in existing C++ projects as easily as we can adopt other new editions of C++. — After that, we can pursue additional improvements to other buckets, such as thread safety and overflow safety.
Aiming for 100%, or zero CVEs in those four buckets, would be a mistake:
100% is not necessary because none of the MSLs we’re being told to use instead are there either. More on this in “The problem ‘isn’t’… (2)” below.
100% is not sufficient because many cyberattacks exploit security weaknesses other than memory safety.
And getting that last 2% would be too costly, because it would require giving up on link compatibility and seamless interoperability (or “interop”) with today’s C++ code. For example, Rust’s object model and borrow checker deliver great guarantees, but require fundamental incompatibility with C++ and so make interop hard beyond the usual C interop level. One reason is that Rust’s safe language pointers are limited to expressing tree-shaped data structures that have no cycles; that unique ownership is essential to having great language-enforced aliasing guarantees, but it also requires programmers to use ‘something else’ for anything more complex than a tree (e.g., using Rc, or using integer indexes as ersatz pointers); it’s not just about linked lists but those are a simple well-known illustrative example.
If we can get a 98% improvement and still have fully compatible interop with existing C++, that would be a holy grail worth serious investment.
A 98% reduction across those four categories is achievable in new/updated C++ code, and partially in existing code
Since at least 2014, Bjarne Stroustrup has advocated addressing safety in C++ via a “subset of a superset”: That is, first “superset” to add essential items not available in C++14, then “subset” to exclude the unsafe constructs that now all have replacements.
As of C++20, I believe we have achieved the “superset,” notably by standardizing span, string_view, concepts, and bounds-aware ranges. We may still want a handful more features, such as a null-terminated zstring_view, but the major additions already exist.
Now we should “subset”: Enable C++ programmers to enforce best practices around type and memory safety, by default, in new code and code they can update to conform to the subset. Enabling safety rules by default would not limit the language’s power but would require explicit opt-outs for non-standard practices, thereby reducing inadvertent risks. And it could be evolved over time, which is important because C++ is a living language and adversaries will keep changing their attacks.
ISO C++ evolution is already pursuing Safety Profiles for C++. The suggestions in the Appendix are refinements to that, to demonstrate specific enforcements and to try to maximize their adoptability and useful impact. For example, everyone agrees that many safety bugs will require code changes to fix. However, how many safety bugs could be fixed without manual source code changes, so that just recompiling existing code with safety profiles enabled delivers some safety benefits? For example, we could by default inject a call-site bounds check 0 <= b < a.size() on every subscript expression a[b] when a.size() exists and a is a contiguous container, without requiring any source code changes and without upgrading to a new internally bounds-checked container library; that checking would Just Work out of the box with every contiguous C++ standard container, span, string_view, and third-party custom container with no library updates needed (including therefore also no concern about ABI breakage).
Rules like those summarized in the Appendix would have prevented (at compile time, test time or run time) most of the past CVEs I’ve reviewed in the type, bounds, and initialization categories, and would have prevented many of the lifetime CVEs. I estimate a roughly 98% reduction in those categories is achievable in a well-defined and standardized way for C++ to enable safety rules by default, while still retaining perfect backward link compatibility. See the Appendix for a more detailed description.
We can and should emphasize adoptability and benefit also for C++ code that cannot easily be changed. Any code change to conform to safety rules carries a cost; worse, not all code can be easily updated to conform to safety rules (e.g., it’s old and not understood, it belongs to a third party that won’t allow updates, it belongs to a shared project that won’t take upstream changes and can’t easily be forked). That’s why above (and in the Appendix) I stress that C++ should seriously try to deliver as many of the safety improvements as practical without requiring manual source code changes, notably by automatically making existing code do the right thing when that is clear (e.g., the bounds checks mentioned above, or emitting static_cast pointer downcasts as effectively dynamic_cast without requiring the code to be changed), and by offering automated fixits that the programmer can choose to apply (e.g., to change the source for static_cast pointer downcasts to actually say dynamic_cast). Even though in many cases a programmer will need to thoughtfully update code to replace inherently unsafe constructs that can’t be automatically fixed, I believe for some percentage of cases we can deliver safety improvements by just recompiling existing code in the safety-rules-by-default mode, and we should try because it’s essential to maximizing safety profiles’ adoptability and impact.
What the problem “isn’t”: Some common misconceptions
(1) The problem “isn’t” defining what we mean by “C++’s most urgent language safety problem.” We know the four kinds of safety that most urgently need to be improved: type, bounds, initialization, and lifetime safety.
We know these four are the low-hanging fruit (see “The problem ‘is’…” above). It’s true that these are just four of perhaps two dozen kinds of “safety” categories, including ones like safe integer arithmetic. But:
Most of the others are either much smaller sources of problems, or are primarily important because they contribute to those four main categories. For example, the integer overflows we care most about are indexes and sizes, which fall under bounds safety.
Most MSLs don’t address making these safe by default either, typically due to the checking cost. But all languages (including C++) usually have libraries and tools to address them. For example, Microsoft ships a SafeInt library for C++ to handle integer overflows, which is opt-in. C# has a checked arithmetic language feature to handle integer overflows, which is opt-in. Python’s built-in integers are overflow-safe by default because they automatically expand; however, the popular NumPy fixed-size integer types do not check for overflow by default and require using checked functions, which is opt-in.
Thread safety is obviously important too, and I’m not ignoring it. I’m just pointing out that it is not one of the top target buckets: Most of the MSLs that NIST/NSA/CISA/etc. recommend over C++ (except uniquely Rust, and to a lesser extent Python) address thread safety impact on userdata corruption about as well as C++. The main improvement MSLs give is that a program data race will not corrupt the language’s own virtual machine (whereas in C++ a data race is currently all-bets-are-off undefined behavior). Some languages do give some additional protection, such as that Python guarantees two racing threads cannot see a torn write of an integer and reduces other possible interleavings because of the global interpreter lock (GIL).
(2) The problem “isn’t” that C++ code is not formally provably safe.
Yes, C++ code makes it too easy to write silently-unsafe code by default (see “The problem ‘is’…” above).
But I’ve seen some people claim we need to require languages to be formally provably safe, and that would be a bridge too far. Much to the chagrin of CS theorists, mainstream commercial programming languages aren’t formally provably safe. Consider some examples:
None of the widely-used languages we view as MSLs (except uniquely Rust) claim to be thread-safe and race-free by construction, as covered in the previous section. Yet we still call C#, Go, Java, Python, and similar languages “safe.” Therefore, formally guaranteeing thread safety properties can’t be a requirement to be considered a sufficiently safe language.
That’s because a language’s choice of safety guarantees is a tradeoff: For example, in Rust, safe code uses tree-based dynamic data structures only. This feature lets Rust deliver stronger thread safety guarantees than other safe languages, because it can more easily reason about and control aliasing. However, this same feature also requires Rust programs to use unsafe code more often to represent common data structures that do not require unsafe code to represent in other MSLs such as C# or Java, and so 30% to 50% of Rust crates use unsafe code, compared for example to 25% of Java libraries.
C#, Java, and other MSLs still have use-before-initialized and use-after-destroyed type safety problems too: They guarantee not accessing memory outside its allocated lifetime, but object lifetime is a subset of memory lifetime (objects are constructed after, and destroyed/disposed before, the raw memory is allocated and deallocated; before construction and after dispose, the memory is allocated but contains “raw bits” that likely don’t represent a valid object of its type). If you doubt, please run (don’t walk) and ask ChatGPT about Java and C# problems with: access-unconstructed-object bugs (e.g., in those languages, any virtual call in a constructor is “deep” and executes in a derived object before the derived object’s state is initialized); use-after-dispose bugs; “resurrection” bugs; and why those languages tell people never to use their finalizers. Yet these are great languages and we rightly consider them safe languages. Therefore, formally guaranteeing no-use-before-initialized and no-use-after-dispose can’t be a requirement to be considered a sufficiently safe language.
Rust, Go, and other languages support sanitizers too, including ThreadSanitizer and undefined behavior sanitizers, and related tools like fuzzers. Sanitizers are known to be still needed as a complement to language safety, and not only for when programmers use ‘unsafe’ code; furthermore, they go beyond finding memory safety issues. The uses of Rust at scale that I know of also enforce use of sanitizers. So using sanitizers can’t be an indicator that a language is unsafe — we should use the supported sanitizers for code written in any language.
Note: “Use your sanitizers” does not mean to use all of them all the time. Some sanitizers conflict with each other, so you can only use those one at a time. Some sanitizers are expensive, so they should only be run periodically. Some sanitizers should not be run in production, including because their presence can create new security vulnerabilities.
(3) The problem “isn’t” that moving the world’s C and C++ code to memory-safe languages (MSLs) would eliminate 70% of security vulnerabilities.
MSLs are wonderful! They just aren’t a silver bullet.
An oft-quoted number is that “70%” of programming language-caused CVEs (reported security vulnerabilities) in C and C++ code are due to language safety problems. That number is true and repeatable, but has been badly misinterpreted in the press: No security expert I know believes that if we could wave a magic wand and instantly transform all the world’s code to MSLs, that we’d have 70% fewer CVEs, data breaches, and ransomware attacks. (For example, see this February 2024 example analysis paper.)
Consider some reasons.
That 70% is of the subset of security CVEs that can be addressed by programming language safety. See figure 1 again: Most of 2023’s top 10 “most dangerous software weaknesses” were not related to memory safety. Many of 2023’s largest data breaches and other cyberattacks and cybercrime had nothing to do with programming languages at all. In 2023, attackers reduced their use of malware because software is getting hardened and endpoint protection is effective (CRN), and attackers go after the slowest animal in the herd. Most of the issues listed in NISTIR-8397 affect all languages equally, as they go beyond memory safety (e.g., Log4j) or even programming languages (e.g., automated testing, hardcoded secrets, enabling OS protections, string/SQL injections, software bills of materials). For more detail see the Microsoft response to NISTIR-8397, for which I was the editor. (More on this in the Call to Action.)
MSLs get CVEs too, though definitely fewer (again, e.g., Log4j). For example, see MITRE list of Rust CVEs, including six so far in 2024. And all programs use unsafe code; for example, see the Conclusions section of Firouzi et al.’s study of uses of C#’s unsafe on StackOverflow and prevalence of vulnerabilities, and that all programs eventually call trusted native libraries or operating system code.
Saying the quiet part out loud: CVEs are known to be an imprecise metric. We use it because it’s the metric we have, at least for security vulnerabilities, but we should use it with care. This may surprise you, as it did me, because we hear a lot about CVEs. But whenever I’ve suggested improvements for C++ and measuring “success” via a reduction in CVEs (including in this essay), security experts insist to me that CVEs aren’t a great metric to use… including the same experts who had previously quoted the 70% CVE number to me. — Reasons why CVEs aren’t a great metric include that CVEs are self-reported and often self-selected, and not all are equally exploitable; but there can be pressure to report a bug as a vulnerability even if there’s no reasonable exploit because of the benefits of getting one’s name on a CVE. In August 2023, the Python Software Foundation became a CVE Numbering Authority (CNA) for Python and pip distributions, and now has more control over Python and pip CVEs. The C++ community has not done so.
CVEs target only software security vulnerabilities (cyberattacks and intrusions), and we also need to consider software safety (life-critical systems and unintended harm to humans).
(4) The problem “isn’t” that C++ programmers aren’t trying hard enough / using the existing tools well enough. The challenge is making it easier to enable them.
Today, the mitigations and tools we do have for C++ code are an uneven mix, and all are off-by-default:
Kind. They are a mix of static tools, dynamic tools, compiler switches, libraries, and language features.
Acquisition. They are acquired in a mix of ways: in-the-box in the C++ compiler, optional downloads, third-party products, and some you need to google around to discover.
Accuracy. Existing rulesets mix rules with low and high false positives. The latter are effectively unadoptable by programmers, and their presence makes it difficult to “just adopt this whole set of rules.”
Determinism. Some rules, such as ones that rely on interprocedural analysis of full call trees, are inherently nondeterministic (because an implementation gives up when fully evaluating a case exceeds the space and time available; a.k.a. “best effort” analysis). This means that two implementations of the identical rule can give different answers for identical code (and therefore nondeterministic rules are also not portable, see below).
Efficiency. Existing rulesets mix rules with low and high (and sometimes impossible) cost to diagnose. The rules that are not efficient enough to implement in the compiler will always be relegated to optional standalone tools.
Portability. Not all rules are supported by all vendors. “Conforms to ISO/IEC 14882 (Standard C++)” is the only thing every C++ tool vendor supports portably.
To address all these points, I think we need the C++ standard to specify a mode of well-agreed and low-or-zero-false-positive deterministic rules that are sufficiently low-cost to implement in-the-box at build time.
Call(s) to action
As an industry generally, we must make a major improvement in programming language memory safety — and we will.
In C++ specifically, we should first target the four key safety categories that are our perennial empirical attack points (type, bounds, initialization, and lifetime safety), and drive vulnerabilities in these four areas down to the noise for new/updated C++ code — and we can.
But we must also recognize that programming language safety is not a silver bullet to achieve cybersecurity and software safety. It’s one battle (not even the biggest) in a long war: Whenever we harden one part of our systems and make that more expensive to attack, attackers always switch to the next slowest animal in the herd. Many of 2023’s worst data breaches did not involve malware, but were caused by inadequately stored credentials (e.g., Kubernetes Secrets on public GitHub repos), misconfigured servers (e.g., DarkBeam, Kid Security), lack of testing, supply chain vulnerabilities, social engineering, and other problems that are independent of programming languages. Apple’s white paper about 2023’s rise in cybercrime emphasizes improving the handling, not of program code, but of the data: “it’s imperative that organizations consider limiting the amount of personal data they store in readable format while making a greater effort to protect the sensitive consumer data that they do store [including by using] end-to-end [E2E] encryption.”
No matter what programming language we use, security hygiene is essential:
Do use your language’s static analyzers and sanitizers. Never pretend using static analyzers and sanitizers is unnecessary “because I’m using a safe language.” If you’re using C++, Go, or Rust, then use those languages’ supported analyzers and sanitizers. If you’re a manager, don’t allow your product to be shipped without using these tools. (Again: This doesn’t mean running all sanitizers all the time; some sanitizers conflict and so can’t be used at the same time, some are expensive and so should be used periodically, and some should be run only in testing and never in production including because their presence can create new security vulnerabilities.)
Do keep all your tools updated. Regular patching is not just for iOS and Windows, but also for your compilers, libraries, and IDEs.
Do secure your software supply chain. Do use package management for library dependencies. Do track a software bill of materials for your projects.
Don’t store secrets in code. (Or, for goodness’ sake, on GitHub!)
Do configure your servers correctly, especially public Internet-facing ones. (Turn authentication on! Change the default password!)
Do keep non-public data encrypted, both when at rest (on disk) and when in motion (ideally E2E… and oppose proposed legislation that tries to neuter E2E encryption with ‘backdoors only good guys will use’ because there’s no such thing).
Do keep investing long-term in keeping your threat modeling current, so that you can stay adaptive as your adversaries keep trying different attack methods.
We need to improve software security and software safety across the industry, especially by improving programming language safety in C and C++, and in C++ a 98% improvement in the four most common problem areas is achievable in the medium term. But if we focus on programming language safety alone, we may find ourselves fighting yesterday’s war and missing larger past and future security dangers that affect software written in any language.
Sadly, there are too many bad actors. For the foreseeable future, our software and data will continue to be under attack, written in any language and stored anywhere. But we can defend our programs and systems, and we will.
Be well, and may we all keep working to have a safer and more secure 2024.
Appendix: Illustrating why a 98% reduction is feasible
This Appendix exists to support why I think a 98% reduction in type/bounds/initialization/lifetime CVEs in C++ code is believable. This is not a formal proposal, but an overview of concrete ways to achieve such an improvement it in new and updatable code, and ways to even get some fraction of that improvement in existing code we cannot update but can recompile. These notes are aligned with the proposals currently being pursued in the ISO C++ safety subgroup, and if they pan out as I expect in ongoing discussions and experiments, then I intend to write further details about them in a future paper.
There are runtime and code size overheads to some of the suggestions in all four buckets, notably checking bounds and casts. But there is no reason to think those overheads need to be inherently worse in C++ than other languages, and we can make them on by default and still provide a way to opt out to regain full performance where needed.
Note: For example, bounds checking can cause a major impact on some hot loops, when using a compiler whose optimizer does not hoist bounds checks; not only can the loops incur redundant checking, but they also may not get other optimizations such as not being vectorized. This is why making bounds-checking on by default is good, but all performance-oriented languages also need to provide a way to say “trust me” and explicitly opt out of bounds checking tactically where needed.
The best way for “how” to let the programmer control enabling those rules (e.g., via source code annotations, compiler switches, and/or something else) is an orthogonal UX issue that is now being actively discussed in the C++ standards committee and community.
Type safety
Enforce the Pro.Type safety profile by default. That includes either banning or checking all unsafe casts and conversions (e.g., static_cast pointer downcasts, reinterpret_cast), including implicit unsafe type punning via C union and vararg.
However, these rules haven’t yet been systematically enforced in the industry. For example, in recent years I’ve painfully observed a significant set of type safety-caused security vulnerabilities whose root cause was that code used static_cast instead of dynamic_cast for pointer downcasts, and “C++” gets blamed even when the actual problem was failure to follow the well-publicized guidance to use the language’s existing safe recommended feature. It’s time for a standardized C++ mode that enforces these rules by default.
Note: On some platforms and for some applications, dynamic_cast has problematic space and time overheads that hinder its use. Many implementations bundle dynamic_cast indivisibly with all C++ run-time typing (RTTI) features (e.g., typeid), and so require storing full potentially-heavyweight RTTI data even though dynamic_cast needs only a small subset. Some implementations also use needlessly inefficient algorithms for dynamic_cast itself. So the standard must encourage (and, if possible, enforce for conformance, such as by setting algorithmic complexity requirements) that dynamic_cast implementations be more efficient and decoupled from other RTTI overheads, so that programmers do not have a legitimate performance reason not to use the safe feature. That decoupling could require an ABI break; if that is unacceptable, the standard must provide an alternative lightweight facility such as a fast_dynamic_cast that is separate from (other) RTTI and performs the dynamic cast with minimum space and time cost.
Bounds safety
Enforce the Pro.Bounds safety profile by default, and guarantee bounds checking. We should additionally guarantee that:
Pointer arithmetic is banned (use std::span instead); this enforces that a pointer refers to a single object. Array-to-pointer decay, if allowed, will point to only the first object in the array.
Only bounds-checked iterator arithmetic is allowed (also, prefer ranges instead).
All subscript operations are bounds-checked at the call site, by having the compiler inject an automatic subscript bounds check on every expression of the form a[b], where a is a contiguous sequence with a size/ssize function and b is an integral index. When a violation happens, the action taken can be customized using a global bounds violation handler; some programs will want to terminate (the default), others will want to log-and-continue, throw an exception, integrate with a project-specific critical fault infrastructure.
Importantly, the latter explicitly avoids implementing bounds-checking intrusively for each individual container/range/view type. Implementing bounds-checking non-intrusively and automatically at the call site makes full bounds checking available for every existing standard and user-written container/range/view type out of the box: Every subscript into a vector, span, deque, or similar existing type in third-party and company-internal libraries would be usable in checked mode without any need for a library upgrade.
It’s important to add automatic call-site checking now before libraries continue adding more subscript bounds checking in each library, so that we avoid duplicating checks at the call site and in the callee. As a counterexample, C# took many years to get rid of duplicate caller-and-callee checking, but succeeded and .NET Core addresses this better now; we can avoid most of that duplicate-check-elimination optimization work by offering automatic call-site checking sooner.
Language constructs like the range-for loop are already safe by construction and need no checks.
In cases where bounds checking incurs a performance impact, code can still explicitly opt out of the bounds check in just those paths to retain full performance and still have full bounds checking in the rest of the application.
Initialization safety
Enforce initialization-before-use by default. That’s pretty easy to statically guarantee, except for some cases of the unused parts of lazily constructed array/vector storage. Two simple alternatives we could enforce are (either is sufficient):
Initialize-at-declaration as required by Pro.Type and ES.20; and possibly zero-initialize data by default as currently proposed in P2723. These two are good but with some drawbacks; both have some performance costs for cases that require ‘dummy’ writes that are never used but hard for optimizers to eliminate, and the latter has some correctness costs because it ‘fixing’ some uninitialized cases where zero is a valid value but masks others for which zero is not a valid initializer and so the behavior is still wrong, but because a zero has been jammed in it’s harder for sanitizers to detect.
Guaranteed initialization-before-use, similar to what Ada and C# successfully do. This is still simple to use, but can be more efficient because it avoids the need for artificial ‘dummy’ writes, and can be more flexible because it allows alternative constructors to be used for the same object on different paths. For details, see: example diagnostic; definite-first-use rules.
Lifetime safety
Enforce the Pro.Lifetime safety profile by default, ban manual allocation by default, and guarantee null checking. The Lifetime profile is a static analysis that diagnoses many common sources of dangling and use-after-free, including for iterators and views (not just raw pointers and references), in a way that is efficient enough to run during compilation. It can be used as a basis to iterate on and further improve. And we should additionally guarantee that:
All manual memory management is banned by default (new, delete, malloc, and free). Corollary: ‘Owning’ raw pointers are banned by default, since they require delete or free. Use RAII instead, such as by calling make_unique or make_shared.
All dereferences are null-checked. The compiler injects an automatic check on every expression of the form *p or p-> where p can be compared to nullptr to null-check all dereferences at the call site (similar to bounds checks above). When a violation happens, the action taken can be customized using a global null violation handler; some programs will want to terminate (the default), others will want to log-and-continue, throw an exception, integrate with a project-specific critical fault infrastructure.
Note: The compiler could choose to not emit this check (and not perform optimizations that benefit from the check) when targeting platforms that already trap null dereferences, such as platforms that mark low memory pages as unaddressable. Some C++ features, such as delete, have always done call-site null checking.
Reducing undefined behavior and semantic bugs
Tactically, reduce some undefined behavior (UB) and other semantic bugs (pitfalls), for cases where we can automatically diagnose or even fix well-known antipatterns. Not all UB is bad; any performance-oriented language needs some. But we know there is low-hanging fruit where the programmer’s intent is clear and any UB or pitfall is a definite bug, so we can do one of two things:
(A – Good) Make the pitfall a diagnosed error, with zero false positives — every violation is a real bug. Two examples mentioned above are to automatically check a[b] to be in bounds and *p and p-> to be non-null.
(B – Ideal) Make the code actually do what the programmer intended, with zero false positives — i.e., fix it by just recompiling. An example, discussed at the most recent ISO C++ November 2023 meeting, is to default to an implicit return *this; when the programmer writes an assignment operator for their type C that returns a C& (note: the same type), but forgets to write a return statement. Today, that is undefined behavior. Yet it’s clear that the programmer meant return *this; — nothing else can be valid. If we make return *this; be the default, all the existing code that accidentally omits the return is not just “no longer UB,” but is guaranteed to do the right and intended thing.
An example of both (A) and (B) is to support chained comparisons, that makes the mathematically valid chains work correctly and rejects the mathematically invalid ones at compile time. Real-world code does write such chains by accident (see: [a][b][c][d][e][f][g][h][i][j][k]).
For (A): We can reject all mathematically invalid chains like a != b > c at compile time. This automatically diagnoses bugs in existing code that tries to do such nonsense chains, with perfect accuracy.
For (B): We can fix all existing code that writes would-be-correct chains like 0 <= index < max. Today those silently compile but are completely wrong, and we can make them mean the right thing. This automatically fixes those bugs, just by recompiling the existing code.
These examples are not exhaustive. We should review the list of UB in the standard for a more thorough list of cases we can automatically fix (ideally) or diagnose.
Summarizing: Better defaults for C++
C++ could enable turning safety rules on by default that would make code:
fully type-safe,
fully bounds-safe,
fully initialization-safe,
and for lifetime safety, which is the hardest of the four, and where I would expect the remaining vulnerabilities in these categories would mostly lie:
fully null-safe,
fully free of owning raw pointers,
with lifetime-safety static analysis that diagnoses most common pointer/iterator/view lifetime errors;
and, finally:
with less undefined behavior including by automatically fixing existing bugs just by recompiling code with safety enabled by default.
All of this is efficiently implementable and has been implemented. Most of the Lifetime rules have been implemented in Visual Studio and CLion, and I’m prototyping a proof-of-concept mode of C++ that includes all of the other above language safeties on-by-default in my cppfront compiler, as well as other safety improvements including an implementation of the current proposal for ISO C++ contracts. I haven’t yet used the prototype at scale. However, I can report that the first major change request I received from early users was to change the bounds checking and null checking from opt-in (off by default) to opt-out (on by default).
Note: Please don’t be distracted by that cppfront uses an experimental alternate syntax for C++. That’s because I’m additionally trying to see if we can reach a second orthogonal goal: to make the C++ language itself simpler, and eliminate the need to teach ~90% of the C++ guidance literature related to language complexity and quirks. This essay’s language safety improvements are orthogonal to that, however, and can be applied equally to today’s C++ syntax.
Solutions need to distinguish between (A) “solution for new-or-updatable code” and (B) “solution for existing code.”
(A) A “solution for new-or-updatable code” means that to help existing code we have to change/rewrite our code. This includes not only “(re)write in C#/Rust/Go/Python/…,” but also “annotate your code with SAL” or “change your code to use std::span.”
One of the costs of (A) is that anytime we write/change code to fix bugs, we also introduce new bugs; change is never free. We need to recognize that changing our code to use std::span often means non-trivially rewriting parts of it which can also create other bugs. Even annotating our code means writing annotations that can have bugs (this is a common experience in the annotation languages I’ve seen used at scale, such as SAL). All these are significant adoption barriers.
Actually switching to another language means losing a mature ecosystem. C++ is the well-trod path: It’s taught, people know it, the tools exist, interop works, and current regulations have an industry around C++ (such as for functional safety). It takes another decade at least for another language to become the well-trod path, whereas a better C++, and its benefits to the industry broadly, can be here much sooner.
(B) A “solution for existing code” emphasizes the adoptability benefits of not having to make manual code changes. It includes anything that makes existing code more secure with “just a recompile” (i.e., no binary/ABI/link issues; e.g., ASAN, compiler switches to enable stack checks, static analysis that produces only true positives, or a reliable automated code modernizer).
We will still need (B) no matter how successful new languages or new C++ types/annotations are. And (B) has the strong benefit that it is easier to adopt. Getting to a 98% reduction in CVEs will require both (A) and (B), but if we can deliver even a 30% reduction using just (B) that will be a major benefit for adoption and effective impact in large existing code bases that are hard to change.
Consider how the ideas earlier in this appendix map onto (A) and (B):
In C++, by default enforce …(A) Solution for new/updated code (can require code changes — no link/binary changes)(B) Solution for existing code (requires recompile only — no manual code changes, no link/binary changes)Type safetyBan all inherently unsafe casts and conversionsMake unsafe casts and conversions with a safe alternative do the safe thingBounds safetyBan pointer arithmetic Ban unchecked iterator arithmeticCheck in-bounds for all allowed iterator arithmetic Check in-bounds for all subscript operationsInitialization safetyRequire all variables to be initialized (either at declaration, or before first use)—Lifetime safetyStatically diagnose many common pointer/iterator lifetime error casesCheck not-null for all pointer dereferencesLess undefined behaviorStatically diagnose known UB/bug cases, to error on actual bugs in existing code with just a recompile and zero false positives: Ban mathematically invalid comparison chains (add additional cases from UB Annex review)Automatically fix known UB/bug cases, to make current bugs in existing code be actually correct with just a recompile and zero false positives: Define mathematically valid comparison chains Default return *this; for C assignment operators that return C& (add additional cases from UB Annex review)
By prioritizing adoptability, we can get at least some of the safety benefits just by recompiling existing code, and make the total improvement easier to deploy even when code updates are required. I think that makes it a valuable strategy to pursue.
Finally, please see again the main post’s conclusion: Call(s) to action.
I generally give one or two courses a year on C++ and related technologies. This year, on April 22-25, I’ll be giving a live online public course for four half-days, on the topic of high-performance low-latency coding in C++ — and the early registration discount is available for a few more days until this Thursday: Effective … Continue reading Effective Concurrency: Live online course in April →
Show full content
I generally give one or two courses a year on C++ and related technologies. This year, on April 22-25, I’ll be giving a live online public course for four half-days, on the topic of high-performance low-latency coding in C++ — and the early registration discount is available for a few more days until this Thursday:
Effective Concurrency with Herb Sutter
High performance and low latency code, via concurrency and parallelism
22-25th April 2024, from 14:00 – 18:00 CEST daily
Participants in this intensive course will acquire the knowledge and skills required to write high-performance and low-latency code on today’s modern systems using modern C++. Presented by Alfasoft.
See the course link for details and a syllabus of topics that will be covered.
The times are intended to be friendly to the home time zones of attendees anywhere in EMEA and also to early risers in the Americas. If you live in a part of the world where these times can’t work for you, and you’d like another offering of the course that is friendlier to your home time zone, please email Alfasoft to let them know!
Because “high-performance low-latency” is kind of C++’s bailiwick, and because it’s my course, you’ll be unsurprised to learn that the topics and code focus on C++ and include coverage of modern C++17/20/23 features. But we are polyglots, after all… so don’t be overly shocked that I may sometimes show a few code examples in other popular languages, if only for comparison and to show how the other half lives.
Today, the ISO C++ committee completed its second meeting of C++26, held in Kona, HI, USA. Our hosts, Standard C++ Foundation and WorldQuant, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 170 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 21 nations. Also, at … Continue reading Trip report: Autumn ISO C++ standards meeting (Kona, HI, USA) →
Show full content
Today, the ISO C++ committee completed its second meeting of C++26, held in Kona, HI, USA.
Our hosts, Standard C++ Foundation and WorldQuant, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had over 170 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 21 nations. Also, at each meeting we regularly have new attendees who have never attended before, and this time there were over a dozen new first-time attendees, mostly in-person; to all of them, once again welcome!
The committee currently has 23 active subgroups, most of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day and/or evening, depending on their workloads. You can find a brief summary of ISO procedures here.
This week’s meeting: Meeting #2 of C++26
At the previous meeting in June, the committee adopted the first 40 proposed changes for C++26, including many that had been ready for a couple of meetings and were just waiting for the C++26 train to open to be adopted. For those highlights, see the previous trip report.
This time, the committee adopted the next set of features for C++26. It also made significant progress on other features that are now expected to be complete in time for C++26 — including contracts and reflection.
Here are some of the highlights…
Adopted for C++26: Core language changes/features
The core language adopted four papers, including P2662R3 “Pack indexing” by Corentin Jabot and Pablo Halpern officially adds support for using [idx] subscripting into variadic parameter packs. Here is an example from the paper that will now be legal:
For those interested in writing standards proposals, I would suggest looking at this and its two predecessors P1858 and P2632 as well written papers: The earlier papers delve into the motivating use cases, and this paper has a detailed treatment of other design alternatives considered and why this is the one chosen. Seeing only the end result of T...[0] would be easy to call “obvious” in hindsight, but it’s far from the only option and this paper’s analysis shows a thorough consideration of alternatives, including their effects on existing and future code and future language evolution.
Adopted for C++26: Standard library changes/features
The standard library adopted 19 papers, including the following…
The biggest, and probably this meeting’s award for “proposal being worked on the longest,” is P1673R13, “A free function linear algebra interface based on the BLAS” by Mark Hoemmen, Daisy Hollman, Christian Trott, Daniel Sunderland, Nevin Liber, Alicia Klinvex, Li-Ta Lo, Damien Lebrun-Grandie, Graham Lopez, Peter Caday, Sarah Knepper, Piotr Luszczek, and Timothy Costa, with the help of Bob Steagall, Guy Davidson, Andrew Lumsdaine, and Davis Herring. If you want to do efficient linear algebra, you don’t want to write your own code by hand; that would be slow. Instead, you want a library that is tuned for your target hardware architecture and ready for par_unseq vectorized algorithms, for blazing speed. This is that library. For detailed rationale, see in particular sections 5 “Why include dense linear algebra in the C++ Standard Library?” and 6 “Why base a C++ linear algebra library on the BLAS?”
P2905R2 “Runtime format strings” and P2918R2 “Runtime format strings II” by Victor Zverovich builds on the C++20 format library, which already supported compile-time format strings. Now with this pair of papers, we will have direct support for format strings not known at compile time and be able to opt out of compile-time format string checks.
P2546R5 “Debugging support” by René Ferdinand Rivera Morell, building on prior work by Isabella Muerte in P1279, adds std::breakpoint(), std::breakpoint_if_debugging(), and std::is_debugger_present(). This standardizes prior art already available in environments from Amazon Web Services to Unreal Engine and more, under a common standard API that gives the programmer full runtime control over breakpoints, including (quoting from the paper):
“allowing printing out extra output to help diagnose problems,
executing extra test code,
displaying an extra user interface to help in debugging, …
… breaking when an infrequent non-critical condition is detected,
allowing programmatic control with complex runtime sensitive conditions,
breaking on user input to inspect context in interactive programs without needing to switch to the debugger application,
and more.”
I can immediately think of times I would have used this in the past month, and probably you can too.
Those are some of the “bigger” papers as highlights… there were 16 papers other adopted too, including more extensions and fixes for the C++26 language and standard library.
On track for targeting C++26: Contracts
The contracts subgroup, SG21, decided several long-open questions that needed to be answered to land contracts in C++26. Perhaps not the most important one, but the one that’s the most visible, is the contracts syntax: This week, SG21 approved pursuing P2961R2 “A natural syntax for contracts” by Jens Maurer and Timur Doumler as the syntax for C++26 contracts. The major visible change is that instead of writing contracts like this:
// previous draft syntax
int f(int i)
[[pre: i >= 0]]
[[post r: r > 0]]
{
[[assert: i >= 0]]
return i+1;
}
we’ll write them like this, changing “assert” to “contract_assert”… pretty much everyone would prefer “assert,” if only it were backward-compatible, but in this new syntax it would hit an incompatibility with the C assert macro:
// newly adopted syntax
int f(int i)
pre (i >= 0)
post (r: r > 0)
{
contract_assert (i >= 0);
return i+1;
}
I already had a contracts implementation in my cppfront compiler, which used the previous [[]] syntax (because, when I have nothing clearly better, I try to follow syntax in existing/proposed C++). So, once P2961 was approved in the subgroup on Tuesday morning, I decided to take Tuesday afternoon to implement the change to this syntax, except that I kept the nice word “assert” because I can do that without a breaking change in my experimental alternate syntax. The work ended up taking not quite an hour, including to update the repo’s own code where I’m using contracts myself in the compiler and its unit tests. You can check out the diff in these | commits. My initial personal reaction, as an early contracts user, is that I like the result.
There are a handful of design questions still to decide, notably the semantics of implicit lambda capture, consteval, and multiple declarations. Six contracts telecons have been scheduled between now and the next meeting in March in Tokyo. The group is aiming to have a feature-complete proposal for Tokyo to forward to other groups for review.
Today when this progress was reported to the full committee, there was applause. As there should be, because this week’s progress increases the confidence that the feature is on track for C++26!
Note that “for C++26” doesn’t mean “that’s still three years away, maybe my kids can use it someday.” It means the feature has to be finished in just the next 18 months or so, and once it’s finished that unleashes implementations to be able to confidently go implement it. It’s quite possible we may see implementations available sooner, as we do with other popular in-demand draft standard features.
Speaking of major features that made great progress this meeting to be confidently on track for C++26…
The group then voted unanimously to adopt P2996R1 “Reflection for C++26” by Wyatt Childers, Peter Dimov, Barry Revzin, Andrew Sutton, Faisal Vali, and Daveed Vandevoorde and forward it on to the main Evolution and Library Evolution subgroups targeting C++26. This is a “core” of static reflection that is useful enough to solve many important problems, while letting us also plan to continue building on it further post-C++26.
This is particularly exciting for me personally, because we desperately need reflection in C++, and based on this week’s progress now is the first time I’ve felt confident enough to mention a target ship vehicle for this super important feature.
Perhaps the most common example of reflection is “enum to string”, so here’s that example:
template <typename E>
requires std::is_enum_v<E>
constexpr std::string enum_to_string(E value) {
template for (constexpr auto e : std::meta::members_of(^E)) {
if (value == [:e:]) {
return std::string(std::meta::name_of(e));
}
}
return "<unnamed>";
}
Note that the above uses some of the new reflection syntax, but this is just the implementation… the new syntax stays encapsulated there. The code that uses enum_to_string gets to not know anything about reflection, and just use the function:
enum Color { red, green, blue };
static_assert(enum_to_string(Color::red) == "red");
static_assert(enum_to_string(Color(42)) == "<unnamed>");
See the paper for much more detail, including more about enum-to-string in section 2.6.
Adding to the excitement, Edison Design Group noted that they expect to have an experimental implementation available on Godbolt Compiler Explorer by Christmas.
P2996 builds on the core of the original Reflection TS, and mainly changes the “top” and “bottom” layers that we knew we would likely change from the TS:
At the “top” or programming model layer, P2996 avoids having to do temp<late,meta<pro,gram>>::ming to use the API and lets us write something more like ordinary C++ code instead.
And at the “bottom” implementation layer, it uses a value-based implementation which is more efficient to implement.
This doesn’t mean the Reflection TS wasn’t useful; it was instrumental. Progress to this point would have been slower if we hadn’t been able to do the TS first, and we deeply appreciate all the work that went into that, as well as the new progress to move forward with P2996 as the reflection feature targeting C++26.
After the unanimous approval vote to forward this paper for C++26, there was a round of applause in the subgroup.
Then today, when this progress toward targeting C++26 was reported to the whole committee in the closing plenary session, the whole room was filled with sustained applause.
Other progress
Many other subgroups continued to make progress during the week. Here are a few highlights…
SG1 (Concurrency) will be working on out-of-thin-air issues for relaxed atomics at a face-to-face meeting or telecon between meetings. They are still on track to move forward with std::execution and SIMD parallelism for C++26, and SIMD was reviewed in the Library Evolution (LEWG) main subgroup; these features, in the words of the subgroup chair, will make C++26 a huge release for the concurrency and parallelism group.
SG4 (Networking) continued working on updating the networking proposal for std::execution senders and receivers. There is a lot of work still to be done and it is not clear on whether networking will be on track for C++26.
SG9 (Ranges) set a list of features and priorities for ranges for C++26. There are papers that need authors, including ones that would be good “first papers” for new authors, so please reach out to the Ranges chair, Daisy Hollman, if you are interested in contributing toward a Ranges paper.
SG15 (Tooling) considered papers on improving modules to enable better tooling, and work toward the first C++ Ecosystem standard.
SG23 (safety) subgroup made further progress towards safety profiles for C++ as proposed by Bjarne Stroustrup, and adopted it as the near-term direction for safety in C++. The updated paper will be available in the next mailing in mid-December.
Library Evolution (LEWG) started setting a framework for policies for new C++ libraries. The group also made progress on a number of proposals targeting C++26, including std::hive, SIMD (vector unit parallelism), ranges extensions, and std::execution, and possibly some support for physical units, all of which made good progress.
Language Evolution (EWG) worked on improving/forwarding/rejecting many proposals, including a set of discussions about improving undefined behavior in conjunction with the C committee, including eight papers about undefined behavior in the preprocessor. The group also decided to pursue doing a full audit of “ill-formed, no diagnostic required” undefined behavior that compilers currently are not required to detect and diagnose. The plan for our next meeting in Tokyo is to spend a lot of time on reflection, and prepare for focusing on contracts.
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Thank you again to the over 170 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in just four months from now we’ll be meeting again in person + Zoom to continue adding features to C++26. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
Note: There’s already a Reddit thread for it, so if you want to comment on the video I suggest you use that thread instead of creating a new one.
At CppCon 2022, I argued for why we should try to make C++ 10x simpler and 50x safer, and this update is an evolution of the update talk I gave at C++ Now in May, with additional news and demos.
The “Dart plan” and the “TypeScript plan”
The back half of this talk clearly distinguishes between what I call the “Dart plan” and the “TypeScript plan” for aiming at a 10x improvement for an incumbent popular language. Both plans have value, but they have different priorities and therefore choose different constraints… most of all, they either embrace up-front the design constraint of perfect C++ interop and ecosystem compatibility, or they forgo it (forever; as I argue in the talk, it can never be achieved retroactively, except by starting over, because it’s a fundamental up-front constraint). No one else has tried the TypeScript plan for C++ yet, and I see value in trying it, and so that’s the plan I’m following for cppfront.
When people ask me “how is cppfront different from all the other projects trying to improve/replace C++?” my answer is “cppfront is on the TypeScript plan.” All the other past and present projects have been on the Dart plan, which again is a fine plan too, it just has different priorities and tradeoffs particularly around
full seamless interop compatibility with ISO Standard C++ code and libraries without any wrapping/thunking/marshaling,
full ecosystem compatibility with all of today’s C++ compilers, IDEs, build systems, and tooling, and
full standards evolution support with ISO C++, including not creating incompatible features (e.g., a different concepts feature than C++20’s, a different modules system than C++20’s) and bringing all major new pieces to today’s ISO C++ evolution as also incremental proposals for today’s C++.
See just the final 10 minutes of the talk to see what I mean — I demo’d syntax 2 “just working” with four different IDEs’ debuggers and visualizers, but I could also have demo’d that profilers just work, build systems just work, and so on.
I call my experimental syntax 2 (aka Cpp2) “still 100% pure C++” not only because cppfront translates it to 100% today’s C++ syntax (aka Cpp1), but because:
every syntax-2 type is an ordinary C++ type that ordinary existing C++ code can use, recognized by tools that know C++ types including IDE visualizers;
every syntax-2 function is an ordinary C++ function that ordinary existing C++ code can use, recognized by tools that know C++ functions including debuggers to step into them;
every syntax-2 object is an ordinary C++ object that ordinary existing C++ code can use;
every syntax-2 feature can be (and has been) brought as a normal ISO C++ standards proposal to evolve today’s syntax, because Cpp2 embraces and follows today’s C++ standard and guidance and evolution instead of competing with them;
and that’s because I want a way to keep writing 100% pure C++, just nicer.
“Nicer” means: 10x simpler by having more generality and consistency, better defaults, and less ceremony; and 50x safer by having 98% fewer vulnerabilities in the four areas of initialization safety (guaranteed in Cpp2), type safety (guaranteed in Cpp2), bounds safety (on by default in Cpp2), and lifetime safety (still to be implemented in cppfront is the C++ Core Guidelines Lifetime static analysis which I designed for Cpp2).
Cpp2 and cppfront don’t replace your C++ compilers. Cpp2 and cppfront work with all your existing C++ compilers (and build systems, profilers, debuggers, visualizers, custom in-house tools, test harnesses, and everything else in the established C++ ecosystem, from the big commercial public C++ products to your team’s internal bespoke C++ tools). If you’re already using GCC, Clang, and/or MSVC, keep using them, they all work fine. If you’re already using CMake or build2, or lldb or the Qt Creator debugger, or your favorite profiler or test framework, keep using them, it’s all still C++ that all C++ tools can understand. There’s no new ecosystem.
There are only two plans for 10x major improvement. (1-min clip) This is the fundamental difference with all the other attempts at a major improvement of today’s C++ I know of, which are all on the Dart plan — and those are great projects by really smart people and I hope we all learn from each other. But for my work I want to pursue the TypeScript plan, which I think is the only major evolution plan that can legitimately call itself “still 100% C++.” That’s important to me, because like I said at the very beginning of my talk last year (1-min clip), I want to encourage us to pursue major evolution that brings C++ itself forward and to double down on C++, not switch to something else — to aim for major C++ evolution directed to things that will make us better C++ programmers, not programmers of something else.
I’m spending time on this experiment first of all for myself, because C++ is the language that best lets me express the programs I need to write, so I want to keep writing real C++ types and real C++ functions and real C++ everything else… just nicer.
Thanks again to the over 120 people who have contributed issues and PRs to cppfront, and the many more who have provided thoughtful comments and feedback! I appreciate your help.
Since the 2022-12-31 year-end mini-update and the 2023-04-30 spring update, progress has continued on cppfront. (If you don’t know what this personal project is, please see the CppCon 2022 talk on YouTube for an overview, and the CppNow 2023 talk on YouTube for an interim update.) I’ll be giving a major update next week at CppCon. I hope … Continue reading cppfront: Autumn update →
I’ll be giving a major update next week at CppCon. I hope to see many of you there! In the meantime, here are some notes about what’s been happening since the spring update post, including:
Acknowledgments and thanks
Started self-hosting
No data left behind: Mandatory explicit discard
requires clauses
Generalized aliases+constexpr with ==
Safe enum and flag_enum metafunctions
Safe union metafunction
What’s next
Acknowledgments: Thank you!
Thank you to all these folks who have participated in the cppfront repo by opening issues and PRs, and to many more who participated on PR reviews and comment threads! These contributors represent people from high school and undergrad students to full professors, from commercial developers to conference speakers, and from every continent except Antarctica.
Started self-hosting
I haven’t spent a lot of time yet converting cppfront’s own code from today’s syntax 1 to my alternate syntax 2 (which I’m calling “Cpp1” and “Cpp2” for short), but I started with all of cppfront’s reflection API and metafunctions which are now mostly written in Cpp2. Here’s what that reflect.h2 file compilation looks like when compiled on the command line on my laptop:
But note you can still build cppfront as all-today’s-C++ using any fairly recent C++20 compiler because I distribute the sources also as C++ (just as Bjarne distributed the cfront sources also as C).
No data left behind: Mandatory explicit discard
Initialization and data flow are fundamental to safe code, so from the outset I ensured that syntax 2 guaranteed initialization-before use, I made all converting constructors explicit by default… and I made [[nodiscard]] the default for return values (1-min talk clip).
The more I thought about [[nodiscard]], the more determined I was that data must never be silently lost, and data-lossy operations should be explicit. So I’ve decided to try an aggressive experiment:
make “nodiscard” the law of the land, implicitly required all the time, with no opt-out…
including when calling existing C++ libraries (including std::) that were never designed for their return values to be treated as [[nodiscard]]!
Now, I wasn’t totally crazy: See the Design note: Explicit discard for details on how I first surveyed other languages’ designers about experience in their languages — notably C#, F#, and Python. In particular, F# does the same thing with .NET APIs — F# requires explicit |> ignore to discard unused return values, including for .NET APIs that were never designed for that and were largely written in other languages. Don Syme told me it has not been a significant pain point, and that was encouraging, so I’m following suit.
My experience so far is that it’s pretty painless, and I write about one explicit discard for every 200 lines of code, even when using the C++ standard library (which cppfront does pervasively, because the C++ standard library is the only library cppfront uses). And, so far, every time cppfront told me I had to write an explicit discard, I learned something useful (e.g., before this I never realized that emplace_back started to return something since C++17! push_back still doesn’t) and I found I liked that my code explicitly self-documented it was not looking at output values… my code looked better.
The way to do an explicit discard is to assign the result to the “don’t care” wildcard. It’s unobtrusive, but explicit and clear:
_ = vec.emplace_back(1,2,3);
Now all Cpp2-authored C++ functions are emitted as [[nodiscard]], except only for assignment and streaming operators because those are designed for chaining and every chain always ends with a discarded return.
And the whole language hangs together well: Explicit discard works very naturally with inout and out parameters too, not just return values. If you have a local variable x and pass it to an inout parameter, what if that’s the last use of the variable?
{
x := my_vector.begin();
std::advance(x, 2);
// ERROR, if param is Cpp2 'inout' or Cpp1 non-const '&'
}
In this example, that call to std::advance(x, 2); is a definite last use of x, and so Cpp2 will automatically pass x as an rvalue and make it a move candidate… and presto! the call won’t compile because you can’t pass an rvalue to a Cpp2 inout parameter (the same as a Cpp1 non-const-& parameter, so this correctly detects the output side effects also when calling existing C++ functions that take references to non-const). That’s a feature, not a bug, because if that’s the last use of x that means the function is not looking at x again, so it’s ignoring the “out” value of the std::advance(x, 2) function call, which is exactly like ignoring a return value. And the guidance is the same: If you really meant to do that, just explicitly discard x‘s final value:
{
x := my_vector.begin();
std::advance(x, 2);
_ = x; // all right, you said you meant it, carry on then...
}
Adding _ = x; afterward naturally makes that the last use of x instead. Problem solved, and it self-documents that the code really meant to ignore a function’s output value.
I really, really like how my C++ code’s data flow is explicit, and fully protected and safe, in syntax 2. And I’m very pleased to see how it just works naturally throughout the language — from universal guaranteed initialization, to explicit constructors by default, to banning implicitly discarding any values, to uniform treatment of returned values whether returned by return value or the “out” part of inout and out parameters, and all of it working also with existing C++ libraries so they’re safer and nicer to use from syntax 2. Data is always initialized, data is never silently lost, data flow is always visible. Data is precious, and it’s always safe. This feels right and proper to me.
requires clauses
I also added support for requires clauses, so now you can write those on all templates. The cppfront implementation was already generating some requires clauses already (see this 1-min video clip). Now programmers can write their own too.
This required a bit of fighting with a GCC 10 bug about requires-clauses on declarations, that was fixed in GCC 11+ but was never backported. But because this was the only problem I’ve encountered with GCC 10 that I couldn’t paper over, and because I could give a clear diagnostic that a few features in Cpp2 that rely on requires clauses aren’t supported on GCC 10, so far I’ve been able to retain GCC 10 as a supported compiler and emit diagnostics if you try to use those few features it doesn’t support. GCC 11 and higher are all fine and support all Cpp2 semantics.
Generalized aliases+constexpr with ==
In the April blog post, I mentioned I needed a way to write type and namespace aliases, and that because all Cpp2 declarations are of the form thing : type = value, I decided to try using the same syntax but with == to denote “always equal to.”
// namespace alias
lit: namespace == ::std::literals;
// type alias
pmr_vec: <T> type
== std::vector<T, std::pmr::polymorphic_allocator<T>>;
I think this clearly denotes that lit is always the same as ::std::literals, and pmr_vec<int> is always the same as std::vector<int, std::pmr::polymorphic_allocator<int>>.
Since then, I’ve thought about how this should be best extended to functions and objects, and I realized the requirements seem to overlap with something else I needed to support: constexpr functions and objects. Which, after all, are functions/objects that return/have “always the same values” known at compile time…
// function with "always the same value" (constexpr function)
increment: (value: int) -> int == value+1;
// Cpp2 lets you omit { return } around 1-line bodies
// object with "always the same value" (constexpr object)
forty_two: i64 == 42;
I particularly needed these in order to write the enum metafunctions…
Safe enum and flag_enum metafunctions
In the spring update blog post, I described the first 10 working compile-time metafunctions I implemented in cppfront, from the set of metafunctions I described in my ISO C++ paper P0707. Since then, I’ve also implemented enum and union.
The most important thing about metafunctions is that they are compile-time library code that uses the reflection and code generation API, that lets the author of an ordinary C++ class type easily opt into a named set of defaults, requirements, and generated contents. This approach is essential to making the language simpler, because it lets us avoid hardwiring special “extra” types into the language and compiler.
In Cpp2, there’s no enum feature hardwired into the language. Instead you write an ordinary class type and just apply the enum metafunction:
// skat_game is declaratively a safe enumeration type: it has
// default/copy/move construction/assignment and <=> with
// std::strong_ordering, a minimal-size signed underlying type
// by default if the user didn't specify a type, no implicit
// conversion to/from the underlying type, in fact no public
// construction except copy construction so that it can never
// have a value different from its listed enumerators, inline
// constexpr enumerators with values that automatically start
// at 1 and increment by 1 if the user didn't write their own
// value, and conveniences like to_string()... the word "enum"
// carries all that meaning as a convenient and readable
// opt-in, without hardwiring "enum" specially into the language
//
skat_game: @enum<i16> type = {
diamonds := 9;
hearts; // 10
spades; // 11
clubs; // 12
grand := 20;
null := 23;
}
Consider hearts: It’s a member object declaration, but it doesn’t have a type (or a default value) which is normally illegal, but it’s okay because the @enum<i16> metafunction fills them in: It iterates over all the data members and gives each one the underlying type (here explicitly specified as i16, otherwise it would be computed as the smallest signed type that’s big enough), and an initializer (by default one higher than the previous enumerator).
Why have this metafunction on an ordinary C++ class, when C++ already has both C’s enum and C++11’s enum class? Because:
it keeps the language smaller and simpler, because it doesn’t hardwire special-purpose divergent splinter types into the language and compiler
(cue Beatles, and: “all you need is class (wa-wa, wa-wa-wa), all you need is class (wa-wa, wa-wa-wa)”);
it’s a better enum than C enum, because C enum is unscoped and not as strongly typed (it implicitly converts to the underlying type); and
it’s a better enum class than C++11 enum class, because it’s more flexible…
… consider: Because an enumeration type is now “just a type,” it just naturally can also have member functions and other things that are not possible for Cpp1 enums and enum classes (see this StackOverflow question):
janus: @enum type = {
past;
future;
flip: (inout this) == {
if this == past { this = future; }
else { this = past; }
}
}
There’s also a flag_enum variation with power-of-two semantics and an unsigned underlying type:
// file_attributes is declaratively a safe flag enum type:
// same as enum, but with a minimal-size unsigned underlying
// type by default, and values that automatically start at 1
// and rise by powers of two if the user didn't write their
// own value, and bitwise operations plus .has(flags),
// .set(flags), and .clear(flags)... the word "flag_enum"
// carries all that meaning as a convenient and readable
// opt-in without hardwiring "[Flags]" specially into the
// language
//
file_attributes: @flag_enum<u8> type = {
cached; // 1
current; // 2
obsolete; // 4
cached_and_current := cached | current;
}
Safe union metafunction
And you can declaratively opt into writing a safe discriminated union/variant type:
// name_or_number is declaratively a safe union/variant type:
// it has a discriminant that enforces only one alternative
// can be active at a time, members always have a name, and
// each member has .is_member() and .member() accessors...
// the word "union" carries all that meaning as a convenient
// and readable opt-in without hardwiring "union" specially
// into the language
//
name_or_number: @union type = {
name: std::string;
num : i32;
}
Why have this metafunction on an ordinary C++ class, when C++ already has both C’s union and C++11’s std::variant? Because:
it keeps the language smaller and simpler, because it doesn’t hardwire special-purpose divergent splinter types into the language and compiler
(cue the Beatles earworm again: “class is all you need, class is all you need…”);
it’s a better union than C union, because C union is unsafe; and
it’s a better variant than C++11 std::variant, because std::variant is hard to use because its alternatives are anonymous (as is the type itself; there’s no way to distinguish in the type system between a variant<int,string> that stores either an employee id or employee name, and a variant<int,string> that stores either a lucky number or a pet unicorn’s dominant color).
Each @union type has its own type-safe name, has clear and unambiguous named members, and safely encapsulates a discriminator to rule them all. Sure, it uses unsafe casts in the implementation, but they are fully encapsulated, where they can be tested once and be safe in all uses. That makes @union:
as easy to use as a C union,
as safe to use as a std::variant… and
as a bonus, because it’s an ordinary type, it can naturally have other things normal types can have, such as template parameter lists and member functions:
// a templated custom safe union
name_or_other: @union <T:type> type
= {
name : std::string;
other : T;
// a custom member function
to_string: (this) -> std::string = {
if is_name() { return name(); }
else if is_other() { return other() as std::string; }
else { return "invalid value"; }
}
}
main: () = {
x: name_or_other<int> = ();
x.set_other(42);
std::cout << x.other() * 3.14 << "\n";
std::cout << x.to_string(); // prints "42", but is legal whichever alternative is active
}
What’s next
For the rest of the year, I plan to:
continue self-hosting cppfront, i.e., migrate more of cppfront’s own code to be written in Cpp2 syntax, particularly now that I have enum and union (cppfront uses enum class and std::variant pervasively);
continue working my list of pending Cpp2 features and implementing them in cppfront; and
work with a few private alpha testers to start writing a bit of code in Cpp2, to alpha-test cppfront and also to alpha-test my (so far unpublished) draft documentation.
But first, one week from today, I’ll be at CppCon to give a talk about this progress and why full-fidelity compatibility with ISO C++ is essential (and what that means): “Cooperative C++ Evolution: Toward a TypeScript for C++.” I look forward to seeing many of you there!
Thanks again to C++ Now for inviting me to speak this year in glorious Aspen, Colorado, USA! It was nice to see many old friends again there and make a few new ones too. The talk I gave there was just posted on YouTube, you can find it here: At CppCon 2022, I argued for … Continue reading My C++ Now 2023 talk is online: “A TypeScript for C++” →
Show full content
Thanks again to C++ Now for inviting me to speak this year in glorious Aspen, Colorado, USA! It was nice to see many old friends again there and make a few new ones too.
The talk I gave there was just posted on YouTube, you can find it here:
At CppCon 2022, I argued for why we should try to make C++ 10x simpler and safer, and I presented my own incomplete experimental compiler, cppfront. Since then, cppfront has continued progressing: My spring update post covered the addition of types, a reflection API, and metafunctions, and this talk was given a week after that post and shows off those features with discussion and live demos.
This talk also clearly distinguishes between what I call the “Dart plan” and the “TypeScript plan” for aiming at a 10x improvement for an incumbent popular language. Both plans have value, but they have different priorities and therefore choose different constraints… most of all, they either embrace up-front the design constraint of perfect C++ interop compatibility, or they forgo it (forever; as I argue in the talk, it can never be achieved retroactively, except by starting over, because it’s a fundamental up-front constraint). No one else has tried the TypeScript plan for C++ yet, and I see value in trying it, and so that’s the plan I’m following for cppfront.
When people ask me “how is cppfront different from all the other projects trying to improve/replace C++?” my answer is “cppfront is on the TypeScript plan.” All the other past and present projects have been on the Dart plan, which again is a fine plan too, it just has different priorities and tradeoffs particularly around compatibility.
The video description has a topical guide linking to major points in the talk. Here below is a more detailed version of that topical guide… I hope you enjoy the talk!
1:00 Intro and roadmap for the talk2:28 1. cppfront recap
2:35 – green-field experiments are great; but cppfront is about refreshing C++ itself
3:28 – “when I say compatibility .. I mean I can call any C++ code that exists today … with no shims, no thunks, no overheads, no indirections, no wrapping”
4:05 – can’t take a breaking change to existing code without breaking the world
5:22 – to me, the most impactful release of C++ was C++11, it most changed the way we wrote our code
6:20 – what if we could do C++11 again, but a coordinated set of features to internally evolve C++
6:52 – cppfront is an experiment in progress, still incomplete
Minutes ago, the ISO C++ committee finished its meeting in-person in Varna, Bulgaria and online via Zoom, where we formally began adopting features into C++26. Our hosts, VMware and Chaos, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had nearly 180 attendees, about two-thirds in-person and the others remote via … Continue reading Trip report: Summer ISO C++ standards meeting (Varna, Bulgaria) →
Show full content
Minutes ago, the ISO C++ committee finished its meeting in-person in Varna, Bulgaria and online via Zoom, where we formally began adopting features into C++26.
Our hosts, VMware and Chaos, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had nearly 180 attendees, about two-thirds in-person and the others remote via Zoom, formally representing 20 nations. Also, at each meeting we regularly have new attendees who have never attended before, and this time there were 17 new first-time attendees, mostly in-person; to all of them, once again welcome!
The committee currently has 23 active subgroups, most of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day and/or evening, depending on their wortpkloads. You can find a brief summary of ISO procedures here.
ISO C++ is on a three-year development cycle, which includes a “feature freeze” about one year before we ship and publish that edition of the standard. For example, the feature freeze for C++23 was in early 2022.
But this doesn’t mean we only have two years’ worth of development time in the cycle and the third year is bug fixes and red tape. Instead, the subgroups are a three-stage pipeline and continue concurrently working on new feature development all the time, and the feature freezes are just the checkpoints where we pause loading new features into this particular train. So for the past year, as the subgroups finished work on fit-and-finish for the C++23 features, they also increasingly worked on C++26 features.
That showed this week, as we adopted the first 40 proposed change papers for C++26, many of which had been ready for a couple of meetings and were just waiting for the C++26 train to open for loading to be adopted. Of those 40 change papers, two were “apply the resolutions for all Ready issues” papers that applied a bunch of generally-minor changes. The other 38 were individual changes, everything from bug fixes to new features like hazard pointers and RCU.
Here are some of the highlights…
Adopted for C++26: Core language changes/features
The core language adopted 11 papers, including the following. Taking them in paper number order, which is roughly the order in which work started on the paper…
P2169 “A nice placeholder with no name” by Corentin Jabot and Michael Park officially adds support for the _ wildcard in C++26. Thanks to the authors for all their research and evidence for how it could be done in a backward-compatible way! Here are some examples that will now be legal as compilers start to support draft-C++26 syntax:
std::lock_guard _(mutex);
auto [x, y, _] = f();
inspect(foo) { _ => bar; };
Some compiler needs to implement -Wunderbar.
The palindromic P2552 “On the ignorability of standard attributes” by Timur Doumler sets forth the Three Laws of Robotics… er, I mean, the Three Rules of Ignorability for standard attributes. The Three Rules are a language design guideline for all current and future standard attributes going forward… see the paper for the full rules, but my informal summary is:
[Already in C++23] Rule 1. Standard attributes must be parseable (i.e., can’t just contain random nonsense).
[Already in C++23] Rule 2. Removing a standard attribute can’t change the program’s meaning: It can reduce the program’s possible legal behaviors, but it can’t invent new behaviors.
[New] Rule 3. Feature test macros shouldn’t pretend to support an attribute unless the implementation actually implements the attribute’s optional semantics (i.e., doesn’t just parse it but then ignore it).
P2558 “Add @, $, and ` to the basic character set” by Steve Downey is not a paper whose name was redacted for cussing; it’s a language extension paper that follows in C’s footsteps, and allows these characters to be used in valid C++ programs, and possibly in future C++ language evolution.
P2621 “UB? In my lexer?” by Corentin Jabot removes the possibility that just tokenizing C++ code can be a source of undefined behavior in a C++ compiler itself. (Did you know it could be UB? Now it can’t.) Note however that this does not remove all possible UB during compilation; future papers may address more of those compile-time UB sources.
P2738 “constexpr cast from void*: towards constexpr type-erasure” by Corentin Jabot and David Ledger takes another step toward powerful compile-time libraries, including enabling std::format to potentially support constexpr compile-time string formatting. Speaking of which…
P2741 “User-generated static_assert messages” by Corentin Jabot lets compile-time static_assert accept stringlike messages that are not string literals. For example, the popular {fmt} library (but not yet std::format, but see above!) supports constexpr string formatting, and so this code would work in C++26:
Together with P2738, an implementation of std::format that uses both of the above features would now be able to used in a static_assert.
Adopted for C++26: Standard library changes/features
The standard library adopted 28 papers, including the following. Starting again with the lowest paper number…
This first one gets the award for “being worked on the longest” (just look at the paper number, and the R revision number): P0792R14, “function_ref: A type-erased callable reference” by Vittorio Romeo, Zhihao Yuan, and Jarrad Waterloo adds function_ref<R(Args...)> as a vocabulary type with reference semantics for passing callable entities to the standard library.
P1383 “More constexpr for <cmath> and <complex>” by Oliver J. Rosten adds constexpr to over 100 more standard library functions. The march toward making increasing swathes of the standard library usable at compile time continues… Jason Turner is out there somewhere saying “Moar Constexpr!” and “constexpr all the things!”
Then, still in paper number order, we get to the “Freestanding group”:
P2510 “Formatting pointers” by Mark de Wever allows nice formatting of pointer values without incanting reinterpret_cast to an integer type first. For example, this will now work: format("{:P}", ptr);
P2530 “Hazard pointers for C++26” by Maged M. Michael, Michael Wong, Paul McKenney, Andrew Hunter, Daisy S. Hollman, JF Bastien, Hans Boehm, David Goldblatt, Frank Birbacher, and Mathias Stearn adds a subset of the Concurrency TS2 hazard pointer feature to add hazard pointer-based deferred cleanup to C++26.
P2545 “Read-Copy-Update (RCU)” by Paul McKenney, Michael Wong, Maged M. Michael, Andrew Hunter, Daisy Hollman, JF Bastien, Hans Boehm, David Goldblatt, Frank Birbacher, Erik Rigtorp, Tomasz Kamiński, Olivier Giroux, David Vernet, and Timur Doumler as another complementary way to do deferred cleanup in C++26.
P2548 “copyable_function” by Michael Hava adds a copyable replacement for std::function, modeled on move_only_function.
P2562 “constexpr stable sorting” by Oliver J. Rosten enables compile-time use of the standard library’s stable sorts (stable_sort, stable_partition, inplace_merge, and the ranges:: versions). Jason Turner is probably saying “Moar!”…
P2641 “Checking if a union alternative is active” by Barry Revzin and Daveed Vandevoorde introduces the consteval bool is_within_lifetime(const T* p) noexcept function, which works in certain compile-time contexts to find out whether p is a pointer to an object that is within its lifetime — such as checking the active member of a union, but during development the feature was made even more generally useful than just that one use case. (This is technically a core language feature, but it’s in one of the “magic std:: features that look like library functions but are actually implemented by the compiler” section of the standard, in this case the metaprogramming clause.)
Those are just 12 of the adopted papers as highlights… there were 16 more papers adopted that also apply more extensions and fixes for the C++26 standard library.
Other progress
We also adopted the C++26 schedule for our next three-year cycle. It’s the same as the schedule for C++23 but just with three years added everywhere, just as the C++23 schedule was in turn the same as the schedule for C++20 plus three years.
The language evolution subgroup (EWG) saw 30 presentations for papers during the week, mostly proposals targeting C++26, including fine-tuning for some of the above that made it into C++26 at this meeting.
The standard library evolution subgroup (LEWG) focused on advancing “big” papers in the queue that really benefit from face-to-face meetings. Notably, there is now design consensus on P1928 SIMD, P0876 Fibers, and P0843 inplace_vector, and those papers have been forwarded to the library wording specification subgroup (LWG) and may come up for adoption into C++26 at our next meeting in November. Additional progress was made on P0447 hive, P0260 Concurrent Queues, P1030 path_view, and P2781 constexpr_v.
The library wording specification subgroup (LWG) is now caught up with their backlog, and spent a lot of time iterating on the std::execution and sub_mdspan proposals (the latter was adopted this week).
The contracts subgroup made further progress on refining contract semantics targeting C++26, including to get consensus on removing build modes and having a contract violation handling API.
The concurrency and parallelism subgroup are still on track to move forward with std::execution and SIMD parallelism for C++26, which in the words of the subgroup chair will make C++26 a huge release for the concurrency and parallelism group.
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Thank you again to the nearly 180 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in less than five months from now we’ll be meeting again in person + Zoom to continue adding features to C++26. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
Since the year-end mini-update, progress has continued on cppfront. (If you don’t know what this personal project is, please see the CppCon 2022 talk on YouTube.) This update covers Acknowledgments, and highlights of what’s new in the compiler and language since last time, including: Acknowledgments: 267 issues, 128 pull requests, and new collaborators I want to … Continue reading cppfront: Spring update →
This update covers Acknowledgments, and highlights of what’s new in the compiler and language since last time, including:
simple, mathematically safe, and efficient chained comparisons
named break and continue
“simple and safe” starts with . . . main
user-defined type, including unifying all special member functions as operator=
type/namespace/function/object aliases
header reflect.h with the start of the reflection API and the first 10 working compile-time metafunctions from P0707
unifying functions and blocks, including removing : and = from the for loop syntax
Acknowledgments: 267 issues, 128 pull requests, and new collaborators
I want to say a big “thank you” again to everyone who has participated in the cppfront repo. Since the last update, I’ve merged PRs from Jo Bates, Gabriel Gerlero, jarzec, Greg Marr, Pierre Renaux, Filip Sajdakand Nick Treleaven. Thanks also to many great issues opened by (as alphabetically as I can): Abhinav00, Robert Adam, Adam, Aaron Albers, Alex, Graham Asher, Peter Barnett, Sean Baxter, Jan Bielak, Simon Buchan, Michael Clausen, ct-clmsn, Joshua Dahl, Denis, Matthew Deweese, dmicsa, dobkeratops, Deven Dranaga, Konstantin F, Igor Ferreira, Stefano Fiorentino, fknauf, Robert Fry, Artie Fuffkin, Gabriel Gerlero, Matt Godbolt, William Gooch, ILoveGoulash, Víctor M. González, Terence J. Grant, GrigorenkoPV, HALL9kv0, Morten Hattesen, Neil Henderson, Michael Hermier, h-vetinari, Stefan Isak, Tim Keitt, Vanya Khodor, Hugo Lindström, Ferenc Nandor Janky, jarzec, jgarvin, Dominik Kaszewski, kelbon, Marek Knápek, Emilia Kond, Vladimir Kraus, Ahmed Al Lakani, Junyoung Lee, Greg Marr, megajocke, Thomas Neumann, Niel, Jim Northrup, Daniel Oberhoff, Jussi Pakkanen, PaTiToMaSteR, Johel Ernesto Guerrero Peña, Bastien Penavayre, Daniel Pfeifer, Piotr, Davide Pomi, Andrei Rabusov, rconde01, realgdman, Alex Reinking, Pierre Renaux, Alexey Rochev, RPeschke, Sadeq, Filip Sajdak, satu, Wolf Seifert, Tor Shepherd, Luke Shore, Zenja Solaja, Francis Grizzly Smit, Sören Sprößig, Benjamin Summerton, Hypatia of Sva, SwitchBlade, Ramy Tarchichy, tkielan, Marzo Sette Torres Junior, Nick Treleaven, Jan Tusil, userxfce, Ezekiel Warren, Kayla Washburn, Tyler Weaver, Will Wray, and thanks also to many others who participated on PR reviews and comment threads.
These contributors represent people from high school and undergrad students to full professors, from commercial developers to conference speakers, and from every continent except Antarctica. Thank you!
Next, here are some highlights of things added to the cppfront compiler in the four months since the previous update linked at top.
Simple, mathematically safe, and efficient chained comparisons (commit)
P0515 “Consistent comparison” (aka “spaceship”) was the first feature derived from this Cpp2 work to be adopted into the ISO Standard for C++, in C++20. That means cppfront didn’t have to do much to implement operator<=> and its generative semantics, because C++20 compilers already do so, which is great. Thank you again to everyone who helped land this Cpp2 feature in the ISO C++ Standard.
However, one part of P0515 isn’t yet merged into ISO C++: chained comparisons from P0515 section 3.3, such as min <= index < max. See also Barry Revzin‘s great followup ISO C++ proposal paper P0893 “Chaining comparisons.” The cppfront compiler now implements this as described in those ISO proposal papers, and:
Supports all mathematically meaningful and safe chains like min <= index < max, with efficient single evaluation of index. (In today’s C++, this kind of comparison silently compiles but is a bug. See P0893 for examples from real-world use.)
Rejects nonsense chains like a >= b < c and d != e != f at compile time. (In today’s C++, and in other languages like Python, they silently compile but are necessarily a bug because they are conceptually meaningless.)
I think this is a great example to demonstrate that “simple,” “safe,” and “fast” are often not in tension, and how it’s often possible to get all three at the same time without compromises.
This feature further expands the Cpp2 “name :” way of introducing all names, to also support introducing loop names. Examples like the following now work… see test file pure2-break-continue.cpp2 for more examples.
outer: while i<M next i++ { // loop named "outer"
// ...
inner: while j<N next j++ { // loop named "inner"
// ...
if something() {
continue inner; // continue the inner loop
}
// ...
if something_else() {
break outer; // break the outer loop
}
// ...
}
// ...
}
“Simple and safe” starts with . . . main
main can now be defined to return nothing, and/or as main: (args) to have a single argument of type std::vector<std::string_view>.
For example, here is a complete compilable and runnable program (in -pure-cpp2 mode, no #include is needed to use the C++ standard library)…
main: (args) =
std::cout << "This program's name is (args[0])$";
The entire C++ standard library is available directly with zero thunking, zero wrapping, and zero need to #include or import because in pure Cpp2 the entire ISO C++ standard library is just always automatically there. (Yes, if you don’t like cout, you can use the hot-off-the-press C++23 std::print too the moment that your C++ implementation supports it.)
Convenient defaults, such as no need to write -> int, and no need to write braces around a single-statement function body.
Convenient semantics and services, such as $ string interpolation. Again, all fully compatible with today’s C++ (e.g., string interpolation uses std::to_string where available).
Type and memory safety by default even in this example: Not only is args defaulting to the existing best practices of C++ standard safety with ISO C++ vector and string_view, but the args[0] call is automatically bounds-checked by default too.
type: User-defined types
User-defined types are written using the same name : kind = value syntax as everything in Cpp2:
mytype: type =
{
// data members are private by default
x: std::string;
// functions are public by default
protected f: (this) = { do_something_with(x); }
// ...
}
Here are some highlights…
First, types are order-independent. Cpp2 still has no forward declarations, and you can just write types that refer to each other. For example, see the test case pure2-types-order-independence-and-nesting.cpp2.
The this parameter is explicit, and has special sauce:
this is a synonym for the current object (not a pointer).
this defaults to the current type.
this‘s parameter passing style declares what kind of function you’re writing. For example, (in this) (or just (this) since “in” is the default as usual) clearly means a “const” member function because “in” parameters always imply constness; (inout this) means a non-const member function; (move this) expresses and emits a Cpp1 &&-qualified member function; and so on.
For example, here is how to write const member function named print that takes a const string value and prints this object’s data value and the string message (yes, everything in Cpp2 is const by default except for local-scope variables):
mytype: type =
{
data: i32; // some data member (private by default)
print: (this, msg: std::string) = {
std::cout << data << msg;
// "data" is shorthand for "this.data"
}
// ...
}
All Cpp1 special member functions (including construction, assignment, destruction) and conversions are unified as operator=, default to memberwise semantics and safe “explicit” by default, and there’s a special that parameter that makes writing copy/move in particular simpler and safer. On the cppfront wiki, see the Design Note “operator=, this & that”for details. Briefly summarizing here:
The only special function every type must have is the destructor. If you don’t write it by hand, a public nonvirtual destructor is generated by default.
If no operator= functions are written by hand, a public default constructor is generated by default.
All other operator= functions are explicitly written, either by hand or by opting into applying a metafunction (see below).
Note: Because generated functions are always opt-in, you can never get a generated function that’s wrong for your type, and so Cpp2 doesn’t need to support “=delete” for the purpose of suppressing unwanted generated functions.
The most general form of operator= is operator=: (out this, that) which works as a unified general {copy, move} x { constructor, assignment } operator, and generates all of four of those in the lowered Cpp1 code if you didn’t write a more specific one yourself (see Design Note linked above for details).
All copy/move/comparison operator= functions are memberwise by default in Cpp2 ( [corrected:] including memberwise construction and assignment when you write them yourself, in which case they aren’t memberwise by default in today’s Cpp1).
All conversion operator= functions are safely “explicit” by default. To opt into an implicit conversion, write the implicit qualifier on the this parameter.
All functions can have a that parameter which is just like this (knows it’s the current type, can be passed in all the usual ways, etc.) but refers to some other object of this type rather than the current object. It has some special sauce for simplicity and safety, including that the language ensures that the members of a that object are safely moved from only once.
Virtual functions and base classes are all about “this”:
Virtual functions are written by specifying exactly one of virtual, override, or final on the this parameter.
Base classes are written as members named this. For example, just as a class could write a data member as data: string = "xyzzy";, which in Cpp2 is pronounced “data is a string with default value ‘xyzzy'”, a base class is written as this: Shape = (default, values);, which is naturally pronounced as “this IS-A Shape with these default values.” There is no separate base class list or separate member initializer list.
Because base and member subobjects are all declared in the same place (the type body) and initialized in the same place (an operator= function body), they can be written in any order, including interleaved, and are still guaranteed to be safely initialized in declared order. This means that in Cpp2 you can declare a data member object before a base class object, so that it naturally outlives the base class object, and so you don’t need workarounds like Boost’s base_from_member because all of the motivating examples for that can be written directly in Cpp2. See my comments on cppfront issue #334for details.
Alias support: Type, namespace, function, and object aliases (commit)
Cpp2 already defines every new entity using the syntax “name : kind = value“.
So how should it declare aliases, which declare not a new entity but a synonym for an existing entity? I considered several alternatives, and decided to try out the identical declaration syntax except changing = (which connotes value setting) to == (which connotes sameness):
// Namespace alias
lit: namespace == ::std::literals;
// Type alias
pmr_vec: <T> type
== std::vector<T, std::pmr::polymorphic_allocator<T>>;
// Function alias
func :== some_original::inconvenient::function_name;
// Object alias
vec :== my_vector; // note: const&, aliases are never mutable
Note again the const default. For now, Cpp2 supports only read-only aliases, not read-write aliases.
Header reflect.h: Initial support for reflection API, and implementing the first 10 working metafunctions from P0707… interface, polymorphic_base, ordered, weakly_ordered, partially_ordered, basic_value, value, weakly_ordered_value, partially_ordered_value, struct
Disclaimer: I have not yet implemented a reflection operator that Cpp2 code can invoke, or written a Cpp2 interpreter to run inside the compiler. But I am doing everything else needed for type metafunctions: cppfront has started a usable reflection metatype API, and has started getting working metafunctions that are compile-time code that uses that metatype API… the only thing missing is that those functions aren’t run through an interpreter (yet).
For example, cppfront now supports code like the following… importantly, “value” and “interface” are not built-in types hardwired into the language as they are in Java and C# and other languages, but rather each is a function that uses the reflection API to apply requirements and defaults to the type (C++ class) being written:
// Point2D is declaratively a value type: it is guaranteed to have
// default/copy/move construction and <=> std::strong_ordering
// comparison (each generated with memberwise semantics
// if the user didn't write their own, because "@value" explicitly
// opts in to ask for these functions), a public destructor, and
// no protected or virtual functions... the word "value" carries
// all that meaning as a convenient and readable opt-in, but
// without hardwiring "value" specially into the language
//
Point2D: @value type = {
x: i32 = 0; // data members (private by default)
y: i32 = 0; // with default values
// ...
}
// Shape is declaratively an abstract base class having only public
// and pure virtual functions (with "public" and "virtual" applied
// by default if the user didn't write an access specifier on a
// function, because "@interface" explicitly opts in to ask for
// these defaults), and a public pure virtual destructor (generated
// by default if not user-written)... the word "interface" carries
// all that meaning as a convenient and readable opt-in, but
// without hardwiring "interface" specially into the language
//
Shape: @interface type = {
draw: (this);
move: (inout this, offset: Point2D);
}
At compile time, cppfront parses the type’s body and then invokes the compile-time metafunction (here value or interface), which enforces requirements and applies defaults and generates functions, such as… well, I can just paste the actual code for interface from reflect.h, it’s pretty readable:
Note: For now I wrote the code in today’s Cpp1 syntax, which works fine as Cpp2 is just a fully compatible alternate syntax for the same true C++… later this year I aim to start self-hosting and writing more of cppfront itself in Cpp2 syntax, including functions like these.
//-----------------------------------------------------------------------
// Some common metafunction helpers (metafunctions are just
// functions, so they can be factored as usual)
//
auto add_virtual_destructor(meta::type_declaration& t)
-> void
{
t.require( t.add_member( "operator=: (virtual move this) = { }"),
"could not add virtual destructor");
}
//-----------------------------------------------------------------------
//
// "... an abstract base class defines an interface ..."
//
// -- Stroustrup (The Design and Evolution of C++, 12.3.1)
//
//-----------------------------------------------------------------------
//
// interface
//
// an abstract base class having only pure virtual functions
//
auto interface(meta::type_declaration& t)
-> void
{
auto has_dtor = false;
for (auto m : t.get_members())
{
m.require( !m.is_object(),
"interfaces may not contain data objects");
if (m.is_function()) {
auto mf = m.as_function();
mf.require( !mf.is_copy_or_move(),
"interfaces may not copy or move; consider a virtual clone() instead");
mf.require( !mf.has_initializer(),
"interface functions must not have a function body; remove the '=' initializer");
mf.require( mf.make_public(),
"interface functions must be public");
mf.make_virtual();
has_dtor |= mf.is_destructor();
}
}
if (!has_dtor) {
add_virtual_destructor(t);
}
}
Note a few things that are demonstrated here:
.require (a convenience to combine a boolean test with the call to .error if the test fails) shows how to implement enforcing custom requirements. For example, an interface should not contain data members. If any requirement fails, the error output is presented as part of the regular compiler output — metafunctions extend the compiler, in a disciplined way.
.make_virtual shows how to implement applying a default. For example, interface functions are virtual by default even if the user didn’t write (virtual this) explicitly.
.add_member shows how to generate new members from legal source code strings. In this example, if the user didn’t write a destructor, we write a virtual destructor for them by passing the ordinary code to the .add_member function, which reinvokes the lexer to tokenize the code, the parser to generate a declaration_node parse tree from the code, and then if that succeeds adds the new declaration to this type.
The whole metafunction is invoked by the compiler right after initial parsing is complete (right after we parse the statement-node that is the initializer) and before the type is considered defined. Once the metafunction returns, if it had no errors then the type definition is complete and henceforth immutable as usual. This is how the metafunction gets to participate in deciding the meaning of the code the user wrote, but does not create any ODR confusion — there is only one immutable definition of the type, a type cannot be changed after it is defined, and the metafunction just gets to participate in defining the type just before the definition is cast in stone, that’s all.
The metafunction is ordinary compile-time code. It just gets invoked by the compiler at compile time in disciplined and bounded ways, and with access to bounded things.
Today in cppfront, metafunctions like value and interface are legitimately doing everything envisioned for them in P0707 except for being run through an interpreter — the metafunctions are using the meta:: API and exercising it so I can learn how that API should expand and become richer, cppfront is spinning up a new lexer and parser when a metafunction asks to do code generation to add a member, and then cppfront is stitching the generated result into the parse tree as if it had been written by the user explicitly… this implementation is doing everything I envisioned for it in P0707 except for being run through an interpreter.
As of this writing, here are the currently implemented metafunctions in reflect.h are as described in P0707 section 3, sometimes with a minor name change… and including links to the function source code…
interface: An abstract class having only pure virtual functions.
Requires (else diagnoses a compile-time error) that the user did not write a data member, a copy or move operation, or a function with a body.
Defaults functions to be virtual, if the user didn’t write that explicitly.
Generates a pure virtual destructor, if the user didn’t write that explicitly.
polymorphic_base (in P0707, originally named base_class): A pure polymorphic base type that has no instance data, is not copyable, and whose destructor is either public and virtual or protected and nonvirtual.
Requires (else diagnoses a compile-time error) that the user did not write a data member, a copy or move operation, and that the destructor is either public+virtual or protected+nonvirtual.
Defaults members to be public, if the user didn’t write that explicitly.
Generates a public pure virtual destructor, if the user didn’t write that explicitly.
ordered: A totally ordered type with operator<=> that implements std::strong_ordering.
Requires (else diagnoses a compile-time error) that the user did not write an operator<=> that returns something other than strong_ordering.
Generates that operator<=> if the user didn’t write one explicitly by hand.
Similarly, weakly_ordered and partially_ordered do the same for std::weak_ordering and std::partial_ordering respectively. I chose to call the strongly-ordered one “ordered,” not “strong_ordered,” because I think the one that should be encouraged as the default should get the nice name.
basic_value: A type that is copyable and has value semantics. It must have all-public default construction, copy/move construction/assignment, and destruction, all of which are generated by default if not user-written; and it must not have any protected or virtual functions (including the destructor).
Requires (else diagnoses a compile-time error) that the user did not write some but not all of the copy/move/ construction/assignment and destruction functions, a non-public destructor, or any protected or virtual function.
Generates a default constructor and memberwise copy/move construction and assignment functions, if the user didn’t write them explicitly.
Note: Many of you would call this a “regular” type… but I recognize that there’s a difference of opinion about whether “regular” includes ordering. That’s one reason I’ve avoided the word “regular” here, and this way we can all separately talk about a basic_value (which may not include ordering) or a value (which does include strong total ordering; see next paragraph for weaker orderings) and we can know we’re all talking about the same thing.
Similarly, weakly_ordered_value and partially_ordered_value do the same for weakly_ordered and partially_ordered respectively. I again chose to call the strongly-ordered one “value,” not “strongly_ordered_value,” because I think the one that should be encouraged as the default should get the nice name.
struct (in P0707, originally named plain_struct because struct is a reserved word in Cpp1… but struct isn’t a reserved word in Cpp2): A basic_value where all members are public, there are no virtual functions, and there are no user-written (non-default operator=) constructors, assignment operators, or destructors.
Requires (else diagnoses a compile-time error) that the user did not write a virtual function or a user-written operator=.
Defaults members to be public, if the user didn’t write that explicitly.
I had long intended to support the following unification of functions and blocks, where cppfront already provided all of these except only the third case:
f:(x: int = init) = { ... } // x is a parameter to the function
f:(x: int = init) = statement; // same, { } is implicit
:(x: int = init) = { ... } // x is a parameter to the lambda
:(x: int = init) = statement; // same, { } is implicit
(x: int = init) { ... } // x is a parameter to the block
(x: int = init) statement; // same, { } is implicit
{ ... } // x is a parameter to the block
statement; // same, { } is implicit
(Recall that in Cpp2 : always and only means “declaring a new thing,” and therefore also always has an = immediately or eventually to set the value of that new thing.)
The idea is to treat functions and blocks/statements uniformly, as syntactic and semantic subsets of each other:
A named function has all the parts: A name, a : (and therefore =) because we’re declaring a new entity and setting its value, a parameter list, and a block (possibly an implicit block in the convenience syntax for single-statement bodies).
An unnamed function drops only the name: It’s still a declared new entity so it still has : (and =), still has a parameter list, still has a block.
(not implemented until now) A parameterized block drops only the name and : (and therefore =). A parameterized block is not a separate entity (there’s no : or =), it’s part of its enclosing entity, and therefore it doesn’t need to capture.
Finally, if you drop also the parameter list, you have an ordinary block.
In this model, the third (just now implemented) option above allows a block parameter list, which does the same work as “let” variables in other languages, but without a “let” keyword. This would subsume all the Cpp1 loop/branch scope variables (and more generally than in Cpp1 today, because you could declare multiple parameters easily which you can’t currently do with the Cpp1 loop/branch scope variables).
main: (args) =
{
local_int := 42;
// 'in' statement scope variable
// declares read-only access to local_int via i
(i := local_int) for args do (arg) {
std::cout << i << "\n"; // prints 42
}
// 'inout' statement scope variable
// declares read-write access to local_int via i
(inout i := local_int) {
i++;
}
std::cout << local_int << "\n"; // prints 43
}
Note that block parameters enable us to use the same declarative data-flow for local statements and blocks as for functions: Above, we declare a block (a statement, in this case a single loop, is implicitly treated as a block) that is read-only with respect to the local variable, and declare another to be read-write with respect to that variable. Being able to declare data flow is important for writing correct and safe code.
Corollary: Removed : and = from for
Eagle-eyed readers of the above example will notice a change: As a result of unifying functions and blocks, I realized that the for loop syntax should use the third syntax, not the first or second, because the loop body is a parameterized block, not a local function. So changed the for syntax from this
// previous syntax
for items do: (item) = {
x := local + item;
// ...
}
to this, which is the same except that it removes : and =
// current syntax
for items do (item) {
x := local + item;
// ...
}
Note that what follows for ... do is exactly a local block, just the parameter item doesn’t write an initializer because it is implicitly initialized by the for loop with each successive value in the range.
By the way, this is the first breaking change from code that I’ve shown publicly, so cppfront also includes a diagnostic for the old syntax to steer you to the new syntax. Compatibility!
Other features
Also implemented since last time:
As always, lots of bug fixes and diagnostic improvements.
Use _ as wildcard everywhere, and give a helpful diagnostic if the programmer tries to use “auto.”
Namespaces. Every namespace must have a name, and the anonymous namespace is supported by naming it _ (the “don’t care” wildcard). For now these are a separate language feature, but I’m still interested in exploring making them just another metafunction.
Explicit template parameter lists. A type parameter, spelled “: type”, is the default. For examples, see test case pure2-template-parameter-lists.cpp2
Add requires-clause support.
Make : _ (deduced type) the default for function parameters. In response to a lot of sustained user demand in issues and comments — thanks! For example, add: (x, y) -> _ = x+y; is a valid Cpp2 generic function that means the same as (and compiles to) [[nodiscard]] auto add(auto const& x, auto const& y) -> auto { return x+y; } in Cpp1 syntax.
Add alien_memory<T> as a better spelling for T volatile. The main problem with volatile isn’t the semantics — those are deliberately underspecified, and appropriate for talking about “memory that’s outside the C++ program that the compiler can’t assume it knows anything about” which is an important low-level concept. The problems with volatile are that (a) it’s wired throughout the language as a type qualifier which is undesirable and unnecessary, and (b) the current name is confusing and has baggage and so it should be named something that connotes what it’s actually for (and I like “alien” rather than “foreign” because I think “alien” has a better and stronger connotation).
Reject more implicit narrowing, notably floating point narrowing.
Reject shadowing of type scope names. For example, in a type that has a member named data, a member function can’t write a local variable named data.
Add support for forward return and generic out parameters.
Add support for raw string literals with interpolation.
Add compiler switches for compatibility with popular no-exceptions/no-RTTI modes (-fno-exceptions and -fno-rtti, as usual), specifying the output file (-o, with the option of -o stdout), and source line/column format for error output (MSVC style or GCC style)
Add single-word aliases (e.g., ulonglong) to replace today’s multi-keyword platform-width C types, with diagnostics support to aid migration. This is in addition to known-width Cpp2 types (e.g., i32) that are already there and should often be preferred.
Allow unnamed objects (not just unnamed functions, aka lambdas) at expression scope.
Reclaim many Cpp1 keywords for ordinary use. For example, a type or variable can be named “and” or “struct” in Cpp2, and it’s fully compatible (it’s prefixed with “cpp2_” when lowered to Cpp1, so Cpp1 code still has a way to refer to it, but Cpp2 gets to use the nice names). This isn’t just sugar… without this, I couldn’t write the “struct” metafunction and give it the expected nice name.
Support final on a type.
Add support for .h2 header files.
What’s next
Well, that’s all so far.
For cppfront, over the summer and fall I plan to:
implement more metafunctions from my paper P0707, probably starting with enum and union (a safe union) — not only because they’re next in the paper, but also because I use those features in cppfront today and so I’ll need them working in Cpp2 when it comes time to…
… start self-hosting cppfront, i.e., start migrating parts of cppfront itself to be written in Cpp2 syntax;
continue working my list of pending Cpp2 features and implementing them in cppfront; and
start finding a few private alpha testers to work with, to start writing a bit of code in Cpp2 to alpha-test cppfront and also to alpha-test my (so far unpublished) draft documentation.
For conferences:
One week from today, I’ll be at C++Nowto give a talk about this progress and why full-fidelity compatibility with ISO C++ is essential (and what it means). C++Now is a limited-attendance conference, and it’s nearly sold out but the organizers say there are a few seats left… you can still register for C++Now until Friday.
In early October I hope to present a major update at CppCon 2023, where registration just opened (yes, you can register now! run, don’t walk!). I hope to see many more of you there at the biggest C++ event, and that only happens once a year — like every year, I’ll be there all week long to not miss a minute.
A few days ago I recorded CppCast episode 357. Thanks to Timur Doumler and Phil Nash for inviting me on their show – and for continuing CppCast, which was so wonderfully founded by Rob Irving and Jason Turner! This time, we chatted about news in the C++ world, and then about my Cpp2 and cppfront … Continue reading Interview on CppCast →
Show full content
A few days ago I recorded CppCast episode 357. Thanks to TimurDoumler and Phil Nash for inviting me on their show – and for continuing CppCast, which was so wonderfully founded by Rob Irving and Jason Turner!
This time, we chatted about news in the C++ world, and then about my Cpp2 and cppfront experimental work.
The podcast doesn’t seem to have chapters, but here are a few of my own notes about sections of interest:
00:00 Intro
04:30 News: LLVM 16.0.0, “C++ Initialisation” book, new user groups
15:45 Start of interview
16:08 Why I don’t view Cpp2 as a “successor language”
16:25 A transpiler is a compiler (see also: cfront, PyPy, TypeScript, …)
17:20 Origins of the Cpp2 project, 2015/16
19:00 100% compatibility as a primary goal and design constraint
22:00 Avoid divergence, continue in same path C++ is already going
22:50 What compatibility means: 100% link compat always on, 100% source compat always available but pay only if you need it
24:14 Making the syntax unique in a simple way, start with “name :”
28:10 Avoid divergence and still make a major simplification, by letting programmers directly declare their intent
30:30 Bringing the pieces to ISO and the community for feedback
31:55 What about “epochs”/“editions”? tl;dr: It’s exactly the right question, but I think the right answer is “epoch” (singular)
35:42 C++ is popular and will endure no matter what we do; question is can we make it nicer
37:05 My personal experiment, and others are now helping
38:20 What “safeties” I’m targeting, and what degree of safety, and why formally provable guarantees are nice but neither necessary nor sufficient (I expect this view to be controversial)
44:00 The issue is making things 50x (98%) safer, vs. 100% safer, because what does requiring that last 2% actually cost the design in incompatibility / difficulty of use
47:05 The zero-overhead principle is non-negotiable, and so is always being able to “open the hood” to take control, otherwise it’s not C++ anymore
48:20 Examples: dynamic bounds/null checking is opt-out, now the default but still pay for it only if you use it
50:20 Will cppfront support all major compilers and platforms? It already does, any reasonably conforming C++20 compiler (any gcc/clang/msvc since about 2020), and that will continue
52:15 Keeping the generated source code very close to the original is a priority
53:25 “TypeScript for C++” plan vs. “Dart for C++” plan
55:20 TypeScript did what Bjarne’s cfront did: Transpiler that let you always keep your generated JavaScript/C code, so you could drop using the new language anytime if you want with #NoRegrets, risk-free
57:20 Shout out to Anders Hejlsberg, IIRC the only human to produce a million-user programming language more than once, and his approach to TypeScript vs. C#
59:20 Why generating C++ code isn’t in tension with the goal of compatibility (it’s actually synergistic), and the targeted subset is C++20 (with a workaround only when modules are not yet available on a given compiler)
1:00:40 Why C++20 is super important (if constexpr, requires-expressions)
1:01:40 Why any C++ evolution/successor language attempt that for now only tries to be compatible with C++17 faces a big hill/disadvantage
1:02:40 What’s next for Cpp2 and cppfront
1:05:35 Where can people learn more: cppfront repo, CppCon 2022 talk, C++Now talk coming up in a month, then CppCon 2023 in October
1:07:28 C++ world is alive and well and thriving, now embracing challenges like safety to keep C++ working well for all of us
In at least one place I said “cppfront” where I meant “cfront”… I think the intent should be clear from context.
Thanks again to everyone who has helped me personally with cppfront through issues and PRs, and to all the good folks who helped the entire C++ world by working hard and creatively through the pandemic and shipping another solid release of C++ in C++23.
On Saturday, the ISO C++ committee completed technical work on C++23 in Issaquah, WA, USA! We resolved the remaining international comments on the C++23 draft, and are now producing the final document to be sent out for its international approval ballot (Draft International Standard, or DIS) and final editorial work, to be published later in 2023.
Our hosts, the Standard C++ Foundation, WorldQuant, and Edison Design Group, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We had about 160 attendees, more than half in-person and the others remote via Zoom. We had 19 nations formally represented, 9 in-person and 10 via Zoom. Also, at each meeting we regularly have new attendees who have never attended before, and this time there were 25 new first-time attendees in-person or on Zoom; to all of them, once again welcome!
The C++ committee currently has 26 active subgroups, 13 of which met in parallel tracks throughout the week. Some groups ran all week, and others ran for a few days or a part of a day and/or evening, depending on their workloads. You can find a brief summary of ISO procedures here.
From Prague, through the pandemic, to an on-time C++23 “Pandemic Edition”
The previous standard, C++20, was completed in Prague in February 2020, a month before the pandemic lockdowns began. At that same meeting, we adopted and published our C++23 schedule… without realizing that the world was about to turn upside down in just a few weeks. Incredibly, thanks to the effort and resilience of scores of subgroup chairs and hundreds of committee members, we still did it: Despite a global pandemic, C++23 has shipped exactly on time and at high quality.
The first pandemic-cancelled in-person meeting would have been the first meeting of the three-year C++23 cycle. This meant that nearly all of the C++23 release cycle, and the entire “development” phase of the cycle, was done virtually via Zoom with many hundreds of telecons from 2020 through 2022. Last week’s meeting was only our second in-person meeting since February 2020, and our second-ever hybrid meeting with remote Zoom participation. Both had a high-quality hybrid Zoom experience for remote attendees around the world, and I want to repeat my thanks from November to the many volunteers who worked hard and carried hardware to Kona and Issaquah to make this possible. I want to again especially thank Jens Maurer and Dietmar Kühl for leading that group, and everyone who helped plan, equip, and run the meetings. Thank you very much to all those volunteers and helpers!
The current plan is that we’ve now returned to our normal cadence of having full-week meetings three times a year, as we did before the pandemic, but now those will be not only in-person but also have remote participation via Zoom. Most subgroups will additionally still continue to meet regularly via Zoom.
This week’s meeting
Per our published C++23 schedule, this was our final meeting to finish technical work on C++23. No features were added or removed, we just handled fit-and-finish issues and primarily focused on finishing addressing the 137 national body comments we received in the summer’s international comment ballot (Committee Draft, or CD). You can find a list of C++23 features here, many of them already implemented in major compilers and libraries. C++23’s main theme was “completing C++20,” and some of the highlights include module “std”, “if consteval,” explicit “this” parameters, still more constexpr, still more CTAD, “[[assume]]”, simplifying implicit move, multidimensional and static “operator[]”, a bunch of Unicode improvements, and Nicolai Josuttis’ personal favorite: fixing the lifetime of temporaries in range-for loops (some would add, “finally!”… thanks again for the persistence, Nico).
In addition to C++23 work, we also had time to make progress on a number of post-C++23 proposals, including continued work on contracts, SIMD execution, and more. We also decided to send the second Concurrency TS for international comment ballot, which includes hazard pointers, read-copy-update (RCU) data structures… and as of this week we also added Anthony Williams’ P0290 “synchronized_value” type.
The contracts subgroup made further progress on refining contract semantics targeting C++26.
The concurrency and parallelism subgroup is still on track to move forward with “std::execution” and SIMD parallelism for C++26, which in the words of the subgroup chair will make C++26 a huge release for the concurrency and parallelism group.
Again, when you see “C++26” above, that doesn’t mean “three long years away”… we just closed the C++23 branch, and the C++26 branch is opening immediately and we will start approving features for C++26 at our next meeting in June, less than four months from now. Implementers interested in specific features often don’t wait for the final standard to start shipping implementations; note that C++23, which was just finished, already has many features shipping today in major implementations.
The newly-created SG23 Safety and Security subgroup met on Thursday for a well-attended session on hitting the ground running for making a targeted improvement in safety and security in C++, including that it approved the first two safety papers to progress to review next meeting by the full language evolution group.
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
Thank you again to the approximately 160 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies!
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in less than four months from now we’ll be meeting again in Bulgaria to start adding features to C++26. I look forward to seeing many of you there. Thank you again to everyone reading this for your interest and support for C++ and its standardization.
As we close out 2022, I thought I’d write a short update on what’s been happening in Cpp2 and cppfront. If you don’t know what this personal project is, please see the CppCon 2022 talk on YouTube. Most of this post is about improvements I’ve been making and merging over the year-end holidays, and an … Continue reading Cpp2 and cppfront: Year-end mini-update →
Show full content
As we close out 2022, I thought I’d write a short update on what’s been happening in Cpp2 and cppfront. If you don’t know what this personal project is, please see the CppCon 2022 talk on YouTube.
Most of this post is about improvements I’ve been making and merging over the year-end holidays, and an increasing number of contributions from others via pull requests to the cppfront repo and in companion projects. Thanks again to so many of you who expressed your interest and support for this personal experiment, including the over 3,000 comments on Reddit and YouTube and the over 200 issues and PRs on the cppfront repo!
10 design notes
On the cppfront wiki, I’ve written more design notes about specific parts of the Cpp2 language design that answer common questions. They include:
Broad strategic topics, such as addressing ABI and versioning, “unsafe” code, and aiming to eliminate the preprocessor with reflection.
Specific language feature design topics, such as unified function call syntax (UFCS), const, and namespaces.
Syntactic choices, such as postfix operators and capture syntax.
Implementation topics, such as parsing strategies and and grammar details.
117 issues (3 open), 74 pull requests (9 open), 6 related projects, and new collaborators
I started cppfront with “just a blank text editor and the C++ standard library.” Cppfront continues to have no dependencies on other libraries, but since I open-sourced the project in September I’ve found that people have started contributing working code — thank you! Authors of merged pull requests include:
The prolific Filip Sajdak contributed a number of improvements, probably the most important being generalizing my UFCS implementation, implementing more of is and as as described in P2392, and providing Apple-Clang regression test results. Thanks, Filip!
Gabriel Gerlero contributed refinements in the Cpp2 language support library, cpp2util.h.
Jarosław Głowacki contributed test improvements and ensuring all the code compiles cleanly at high warning levels on all major compilers.
Konstantin Akimov contributed command-line usability improvements and more test improvements.
Fernando Pelliccioni contributed improvements to the Cpp2 language support library.
Jessy De Lannoit contributed improvements to the documentation.
Thanks also to these six related projects, which you can find listed on the wiki:
Thanks again to Matt Godbolt for hosting cppfront on Godbolt Compiler Explorer and giving feedback.
Thanks also to over 100 other people who reported bugs and made suggestions via the Issues. See below for some more details about these features and more.
Compiler/language improvements
Here are some highlights of things added to the cppfront compiler since I gave the first Cpp2 and cppfront talk in September. Most of these were implemented by me, but some were implemented by the PR authors I mentioned above.
Roughly in commit order (you can find the whole commit history here), and like everything else in cppfront some of these continue to be experimental:
Lots of bug fixes and diagnostic improvements.
Everything compiles cleanly under MSVC -W4 and GCC/Clang -Wall -Wextra.
Enabled implicit move-from-last-use for all local variables. As I already did for copy parameters.
After repeated user requests, I turned -n and -s (null/subscript dynamic checking) on by default. Yes, you can always still opt out to disable them and get zero cost, Cpp2 will always stay a “zero-overhead don’t-pay-for-what-you-don’t-use” true-C++ environment. All I did was change the default to enable them.
Support explicit forward of members/subobjects of composite types. For a parameter declared forward x: SomeType, the default continues to be that the last use of x is automatically forwarded for you; for example, if the last use is call_something( x ); then cppfront automatically emits that call as call_something( std::forward<decltype(x)>(x) ); and you never have to write out that incantation. But now you also have the option to separately forward parts of a composite variable, such as that for a forward x: pair<string, string>> parameter you can write things like do_this( forward x.first ) and do_that( 1, 2, 3, forward x.second ).
Supportis template-nameand is ValueOrPredicate: is now supports asking whether this is an instantiation of a template (e.g., x is std::vector), and it supports comparing values (e.g., x is 14) and using predicates (e.g., x is (less_than(20)) invoking a lambda) including for values inside a std::variant, std::any, and std::optional (e.g., x is 42 where x is a variant<int,string> or an any).
Regression test results for all major compilers: MSVC, GCC, Clang, and Apple-Clang. All are now checked in and can be conveniently compared before each commit.
Finished support for >> and >>= expressions. In today’s syntax, C++ currently max-munches the >> and >>= tokens and then situationally breaks off individual > tokens, so that we can write things like vector<vector<int>> without putting a space between the two closing angle brackets. In Cpp2 I took the opposite choice, which was to not parse >> or >>= as a token (so max munch is not an issue), and just merge closing angles where a >> or >>= can grammatically go. I’ve now finished the latter, and this should be done.
Generalized support for UFCS. In September, I had only implemented UFCS for a single call of the form x.f(y), where x could not be a qualified name or have template arguments. Thanks to Filip Sajdak for generalizing this to qualified names, templated names, and chaining multiple UFCS calls! That was a lot of work, and as far as I can tell UFCS should now be generally complete.
Support declaring multi-level pointers/const.
Zero-cost implementation of UFCS. The implementation of UFCS is now force-inlined on all compilers. In the tests I’ve looked at, even when calling a nonmember function f(x,y), using Cpp2’s x.f(y) unified function call syntax (which tries a member function first if there is one, else falls back to a nonmember function), the generated object code at all optimization levels is now identical, or occasionally better, compared to calling the nonmember function directly. Thanks to Pierre Renaux for pointing this out!
Support today’s C++ (Cpp1) multi-token fundamental types (e.g., signed long long int). I added these mainly for compatibility because 100% seamless interoperability with today’s C++ is a core goal of Cpp2, but note that in Cpp2 these work but without any of the grammar and parsing quirks they have in today’s syntax. That’s because I decided to represent such multi-word names them as a single Cpp2 token, which happens to internally contain whitespace. Seems to work pretty elegantly so far.
Support fixed-width integer type aliases (i32, u64, etc.), including optional _fast and _small (e.g., i32_fast).
I think that this completes the basic implementation of Cpp2’s initial subset that I showed in my talk in September, including that support for multi-level pointers and the multi-word C/C++ fundamental type names should complete support for being able to invoke any existing C and C++ code seamlessly.
Which brings us to…
What’s next
Next, as I said in the talk, I’ll be adding support for user-defined types (classes)… I’ll post an update about that when there’s more that’s ready to see.
Again, thanks to everyone who expressed interest and support for this personal experiment, and may you all have a happy and safe 2023.
A few minutes ago, the ISO C++ committee completed its second-to-last meeting of C++23 in Kona, HI, USA. Our host, the Standard C++ Foundation, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We currently have 26 active subgroups, nine of which met in six parallel tracks throughout the week; some groups … Continue reading Trip report: Autumn ISO C++ standards meeting (Kona) →
Show full content
A few minutes ago, the ISO C++ committee completed its second-to-last meeting of C++23 in Kona, HI, USA. Our host, the Standard C++ Foundation, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We currently have 26 active subgroups, nine of which met in six parallel tracks throughout the week; some groups ran all week, and others ran for a few days or a part of a day, depending on their workloads. We had over 160 attendees, approximately two-thirds in-person and one-third remote via Zoom.
This was our first in-person meeting since Prague in February 2020 just a few weeks before the lockdowns began. It was also our first-ever hybrid meeting with remote Zoom participation for all subgroups that met.
You can find a brief summary of ISO procedures here.
From Prague, through the pandemic, to Kona
During the pandemic, the committee’s subgroups began regularly meeting virtually, and over the past nearly three years there have been hundreds of virtual subgroup meetings and thrice-a-year virtual plenary sessions to continue approving features for C++23.
This week, we resumed in-person meetings with remote Zoom support. In the months before Kona, a group of volunteers did a lot of planning and testing: We did a trial run of a hybrid meeting with the subgroup SG14 at CppCon in September, using some of the equipment we planned to use in Kona. That initial September test was a pretty rough experience for many of the remote attendees, but it led to valuable learnings , and though we entered Kona with some trepidation, the hybrid meetings went amazingly smoothly with very few hiccups, and we got a lot of good work done in the second-to-last meeting to finalize C++23 including with remote presentations and comments.
This was only possible because of a huge amount of work by many volunteers, and I want to especially thank Jens Maurer and Dietmar Kühl for leading that group. But it was a true team effort, and so many people helped with the planning, with bringing equipment, and with running the meetings. Thank you very much to all those volunteers and helpers! We received many such appreciative comments of thanks on the committee mailing lists, and from national bodies on Saturday, from experts participating remotely who wanted to thank the volunteers for how smoothly they were able to participate.
Now that we have resumed in-person meetings, the current intent is that:
This week’s meeting
Per our published C++23 schedule, this was our second-to-last meeting to finish technical work on C++23. No features were added or removed, we just handled fit-and-finish issues and primarily focused on addressing the 137 national body comments we received in the summer’s international comment ballot (Committee Draft, or CD).
Today, the committee approved final resolutions for 92 (67%) of the 137 national comments. That leaves 45 comments, some of which have already been partly worked on, still to be completed between now and early February at our last meeting for completing C++23.
std::vector<std::string> createStrings();
...
for (std::string s : createStrings()) ... // OK
for (char c : createStrings().at(0)) ...
// use-after-free in C++20
// OK, safe in C++23
In addition to C++23 work, we also had time to make progress on a number of post-C++23 proposals, including continued work on contracts, executors (std::execution), pattern matching, and more. We also decided to ship the third Library Fundamentals TS, which includes support for a number of additional experimental library features such as propagate_const, scope_exit and related scope guards, observer_ptr, resource_adapter, a helper to make getting a random numbers easier, and more. These can then be considered for C++26.
The contracts subgroup adopted a roadmap and timeline to try to get contracts into C++26. The group also had initial discussion of Gabriel Dos Reis’ proposal to control side effects in contracts, with the plan to follow up with a telecon between now and the next in-person meeting in February.
The concurrency and parallelism subgroup agreed to move forward with std::execution and SIMD parallelism for C++26, which in the words of the subgroup chair will make C++26 a huge release for the concurrency and parallelism group… and recall that C++26 is not just something distant that’s three years away, but we will start approving features for C++26 starting this June, and when specific features are early and stable in the working draft the vendors often don’t wait for the final standard to start shipping implementations.
The language evolution group considered national body comments and C++26 proposals, and approved nine papers for C++26 including to progress Jean-Heyd Meneide’s proposal for #embed for C++26.
The language evolution group also held a well-attended evening session (so that experts from all subgroups could participate) to start discussion of the long-term future of C++, with over 100 experts attending (75% on-site, 25% on-line). Nearly all of the discussion was focused on improving safety (mostly) and simplicity (secondarily), including discussion about going beyond our business-as-usual evolution to help C++ programmers with these issues. We expect this discussion to continue and lead to further concrete papers for C++ evolution.
The library evolution group addressed all its national body comments and papers, forwarded several papers for C++26 including std::execution, and for the first time in a while does not have a backlog to catch up with which was happy news for LEWG.
Thank you to all the experts who worked all week in all the subgroups to achieve so much this week!
What’s next
Our next meeting will be in Issaquah, WA, USA in February. At that meeting we will finish C++23 by resolving the remaining national body comments on the C++23 draft, and producing the final document to be sent out for its international approval ballot (Draft International Standard, or DIS) and be published later in 2023.
Wrapping up
But we’re not slowing down… we’ll continue to have subgroup Zoom meetings, and then in less than three months from now we’ll be meeting again in Issaquah, WA, USA for the final meeting of C++23 to finish and ship the C++23 international standard. I look forward to seeing many of you there. Thank you again to the over 160 experts who attended on-site and on-line at this week’s meeting, and the many more who participate in standardization through their national bodies! And thank you also to everyone reading this for your interest and support for C++ and its standardization.
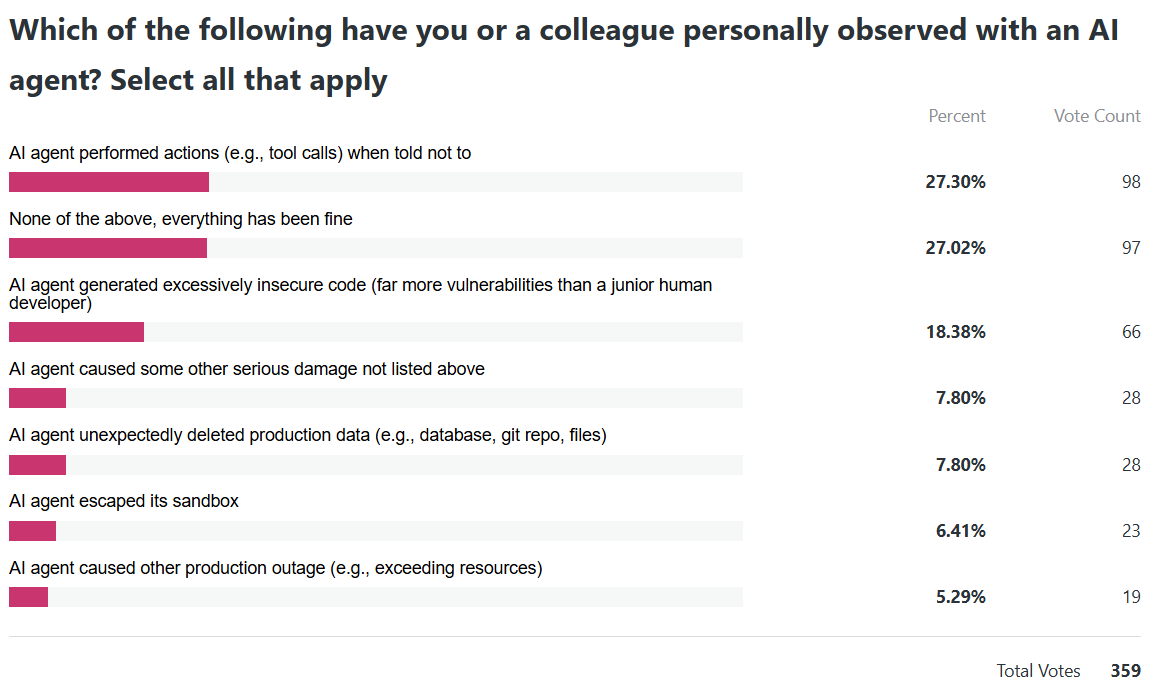

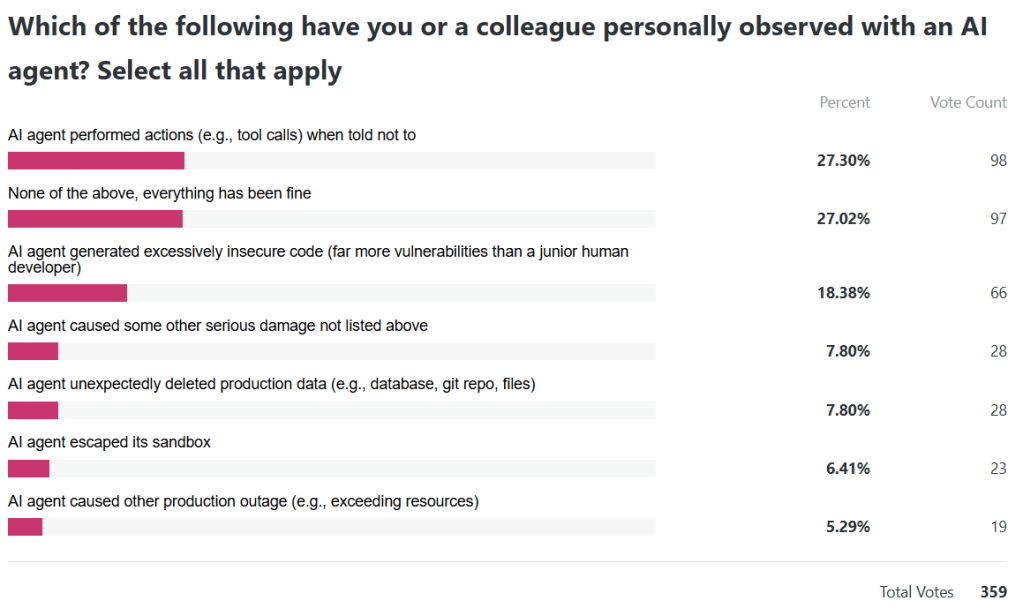




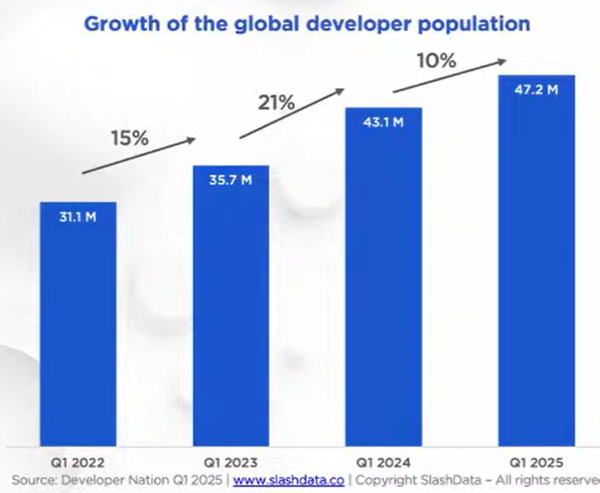
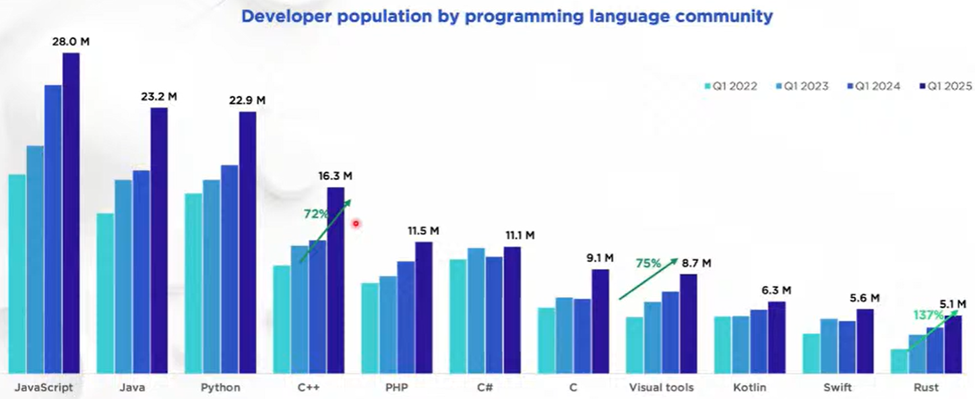
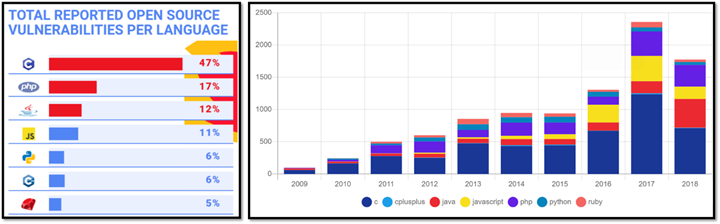

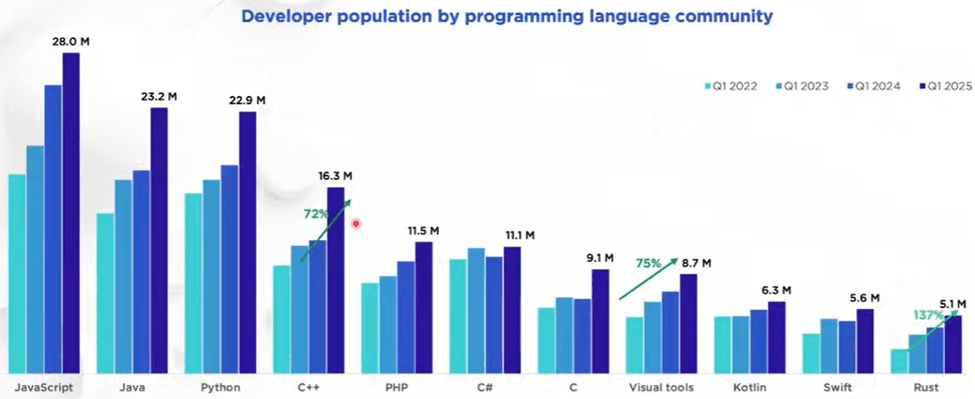
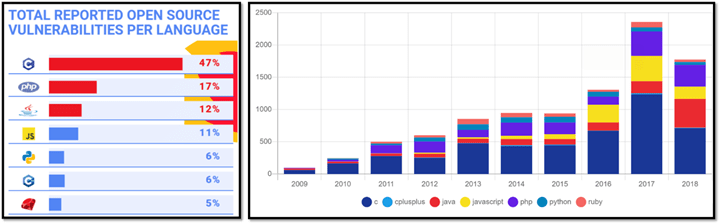

























 to write security and safety vulnerabilities in C++ that would have been caught by stricter enforcement of known rules for type, bounds, initialization, and lifetime language safety
to write security and safety vulnerabilities in C++ that would have been caught by stricter enforcement of known rules for type, bounds, initialization, and lifetime language safety
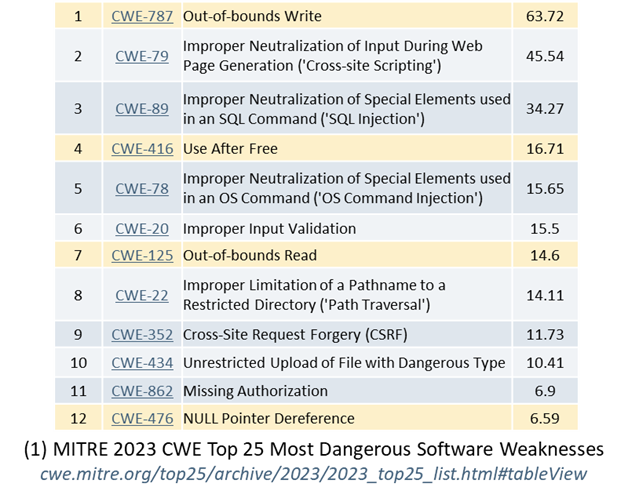
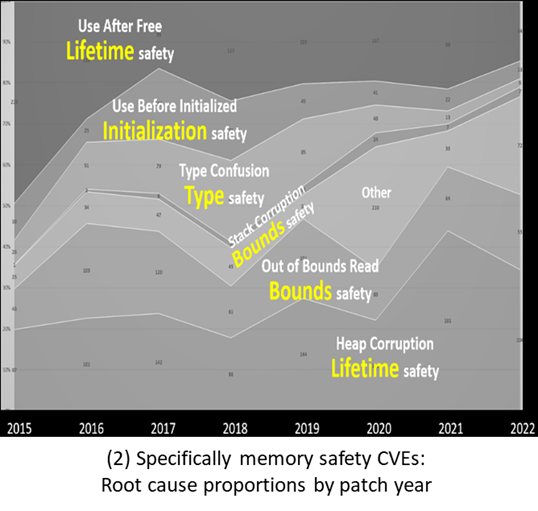




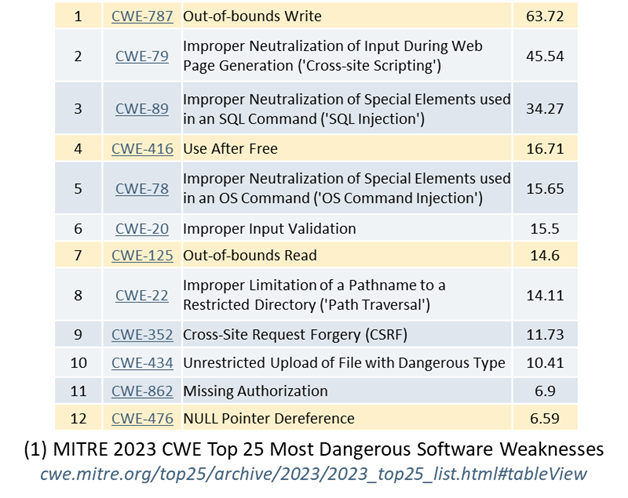
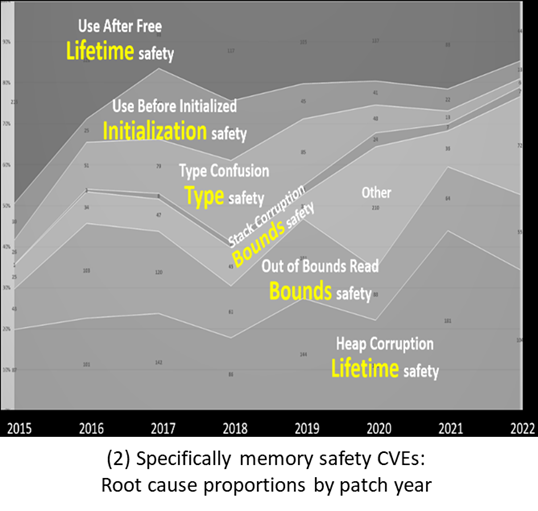




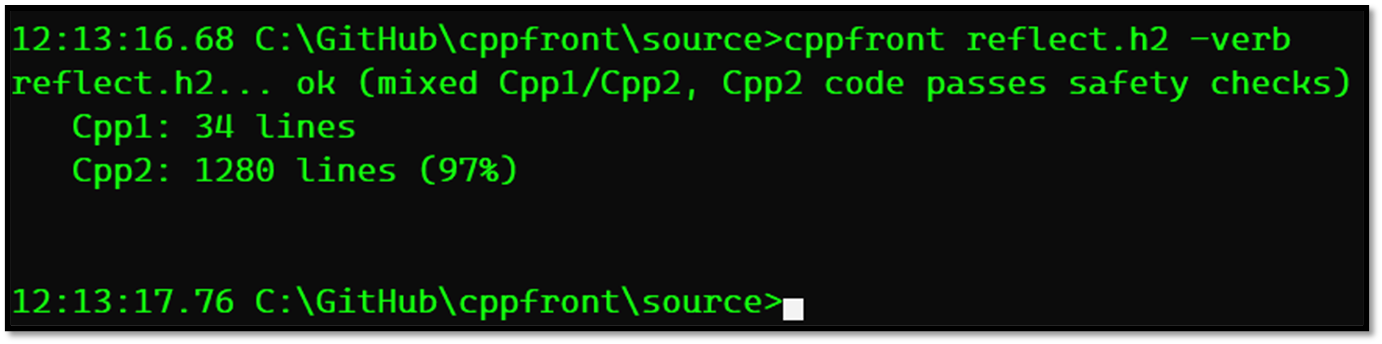

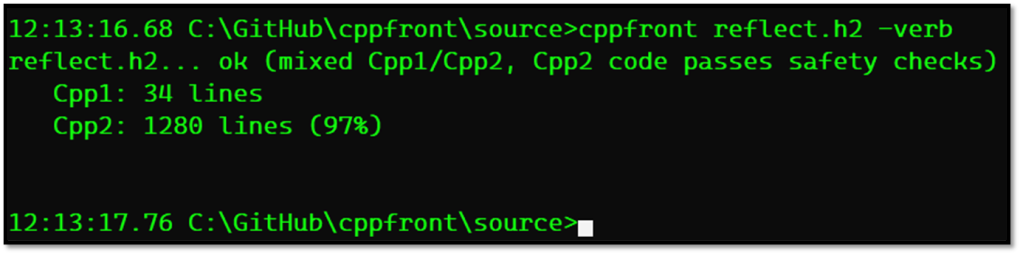





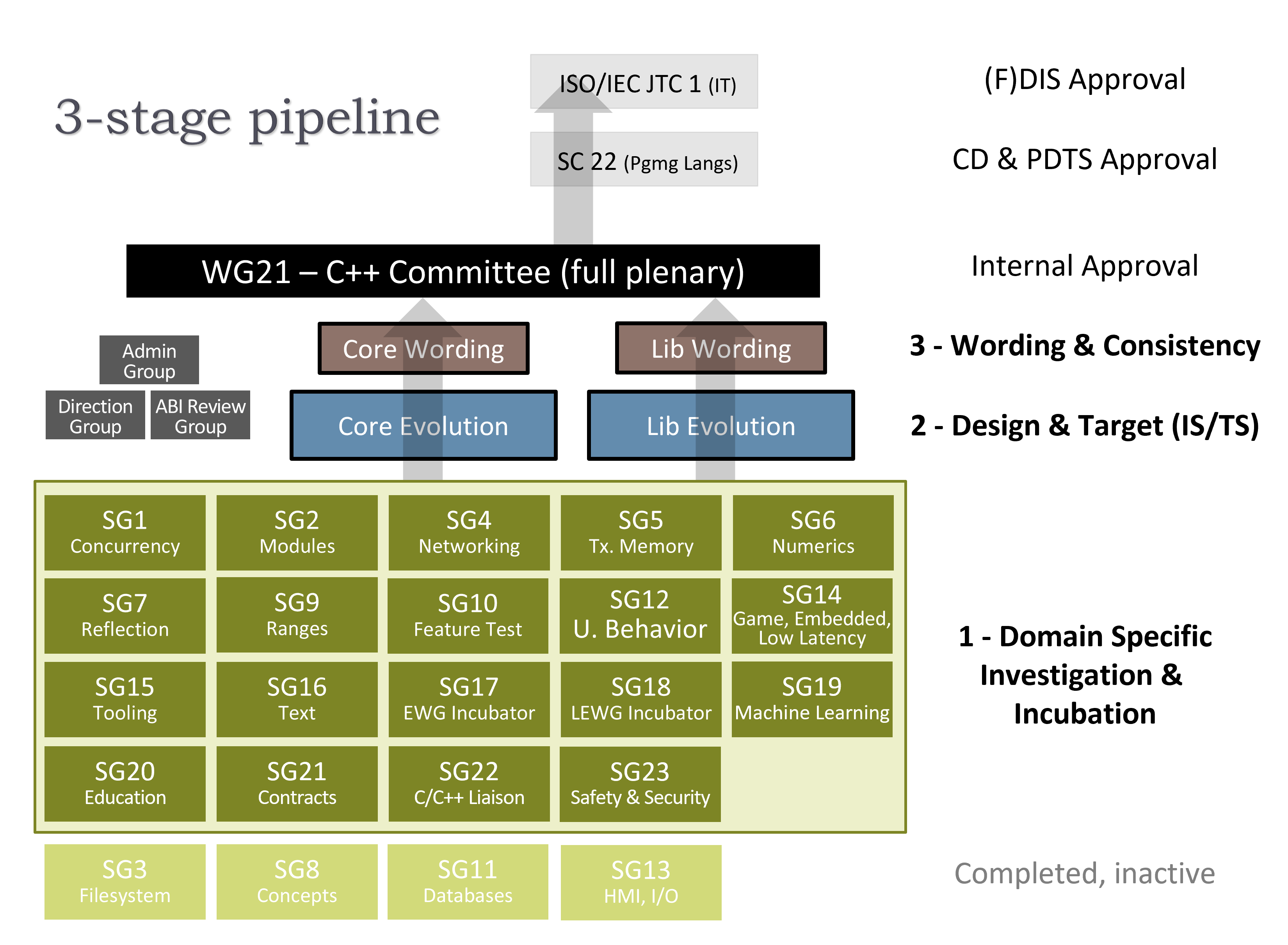{kind=link}