Eurovision was on yesterday. I’ve never been interested much in the musical side
but the weird political dynamics of Eurovision voting have always fascinated me;
I tune in each year just for them and somewhat snarky commentary of Graham
Norton, the UK commentator.
As I was watching the jury votes come in, a question popped into my head: Which
country has voted the best in Eurovision? That is, which country was best at
picking the eventual top 10 and in the right order?
Strangely enough, while there’s
plentyofwork on voting blocs and bilateral biases at
Eurovision, most of it asks who votes for whom; I wanted to ask who votes
accurately. I couldn’t find anyone asking the question that way, so I decided
to do some data analysis myself.
The metric
To begin to answer this question, I first needed to formalize what “best” even
means. That is, some mathematical notion of “good” and “bad”.
In my work on Perfetto, a performance debugging tool, one question I get often
is: “how do I split a Perfetto trace into multiple files?” Instead of answering
directly, I say: “there isn’t an easy way to do that, but what’s leading you to
collect traces large enough to want to split?”
This is one of my golden rules at work. When a user asks me something “weird”:
don’t answer the first version of the question.
On the surface this might appear like I’m talking about the
XY problem, but that stops one step
short. It treats the user’s stated question as a puzzle to decode: figure out
what they really meant, answer that, move on. I think we can go much further.
Instead, the confusion that produced the wrong question is itself an opening,
and the conversation it sparks is valuable to both sides. The user walks away
with a better mental model of the tool. I walk away with a clearer picture of
where the product confuses people. And sometimes, between us, we figure out that
the product itself needs to change.
For eight years, I’ve wanted a high-quality set of devtools for working with
SQLite. Given how important SQLite is to the industry1, I’ve long been puzzled that no one has invested in building
a really good developer experience for it2.
A couple of weeks ago, after ~250 hours of effort over three months3 on evenings, weekends, and vacation days, I finally
released syntaqlite
(GitHub), fulfilling this
long-held wish. And I believe the main reason this happened was because of AI
coding agents4.
Of course, there’s no shortage of posts claiming that AI one-shot their project
or pushing back and declaring that AI is all slop. I’m going to take a very
different approach and, instead, systematically break down my experience
building syntaqlite with AI, both where it helped and where it was
detrimental.
I’ll do this while contextualizing the project and my background so you can
independently assess how generalizable this experience was. And whenever I make
a claim, I’ll try to back it up with evidence from my project journal, coding
transcripts, or commit history5.
Most SQL tools treat SQLite as a “flavor” of a generic SQL parser. They approximate the language, which means they break on SQLite-exclusive features like virtual tables, miss syntax like UPSERT, and ignore the 22 compile-time flags that change the syntax SQLite accepts.
So I built syntaqlite: an open-source parser, formatter, validator, and LSP built directly on SQLite’s own Lemon-generated grammar. It sees SQL exactly how SQLite sees it, no matter which version of SQLite you’re using or which feature flags you compiled with.
> syntaqlite fmt -e "select u.name,u.email,count(e.id) as events from users u join events e on e.user_id=u.id where u.signed_up_at>=date('now','-30 days') group by u.name,u.email having count(e.id)>10 order by events desc"
SELECT u.name, u.email, count(e.id) AS events
FROM users AS u
JOIN events AS e ON e.user_id = u.id
WHERE
u.signed_up_at >= date('now', '-30 days')
GROUP BY
u.name,
u.email
HAVING
count(e.id) > 10
ORDER BY
events DESC;
We’ve recently been looking into optimizing rendering performance of the Perfetto UI on large traces. We discovered that there was some inefficiency in our data fetching logic, especially when you’re very zoomed out.
In this case, there can be a lot of slices (spans) which are so small that they take less than one pixel of width. So for each pixel, we need to figure out “what is the event which we should draw for this pixel”. Over time we’ve come to the conclusion that the best thing to draw is the slice with the largest duration in that pixel.
We can break this into two sub-problems:
What is the range of events which correspond to each pixel?
What is the event with the maximum duration for that pixel?
We’re going to focus on 1) in this post as that’s where the slowdown was. 2) is fascinating but also surprisingly orthogonal. If you’re interested, I would suggest reading this excellent post from Tristan Hume explaining the basic algorithm we use.
All three have a very simple pitch: they will give you full access to Linux
virtual machines to act as a sandboxed developer environment in the cloud.
At first glance, the attention these have gotten is very head-scratching. The
idea of a Linux VPS has been around for more than 20 years at this point and VPS
providers like DigitalOcean and Hetzner are widely known and used in the
industry. From a technological standpoint, there’s very little revolutionary
here.
Is it price then? Well no: the hardware specs are pretty awful for what you pay.
For example, exe.dev gives you 2 CPUs and 8GB RAM shared across your whole
account for $20/month. For comparison, at Hetzner for roughly that price, you
can get a single VPS with 16 CPUs and 32GB RAM…
When I was a junior engineer, my manager would occasionally confide his frustrations to me in our weekly 1:1s. He would point out a project another team was working on and say, “I don’t believe that project will go anywhere, they’re solving the wrong problem.” I used to wonder, “But you are very senior, why don’t you just go and speak to them about your concerns?” It felt like a waste of his influence to not say anything.
So it’s quite ironic that I found myself last week explaining to a mentee why I thought a sister team’s project would have to pivot because they’d made a poor early design choice. And he rightfully asked me the same question I had years ago: “why don’t you just tell them your opinion?” It’s been on my mind ever since because I realized I’d changed my stance on it a lot over the years.
Two people. Eighteen accounts spanning checking, savings, credit cards, investments. Three currencies. Twenty minutes of work every week.
One net worth number I actually trust.
The payoff: A single, trustworthy net worth number growing over time.
No app did exactly what I needed, so I built my own personal finance system using plain-text accounting principles and a powerful Python library called Beancount. This post shows you how I handle imports, investments, multi-currency, and a two-person view.
How I got here
It all started during the 2021 tax season. I had blocked out an entire weekend and was juggling statements, trying to compute capital gains, stressing about getting the numbers mixed up. “This is chaos”, I thought. “There must be a way to simplify this with automation”. Being a software engineer, I did what felt natural and hacked together a bunch of scripts on top of a database.
Just a quick note documenting some recent changes to the blog. Nothing groundbreaking, but enough accumulated updates that I wanted to write them down.
Homepage Redesign
The homepage used to be a chronological list of articles; your classic default blog format. I’ve redesigned it into more of a two-pane “dashboard” feel. The reason? My content is quite varied: I have long essays and technical write-ups but also short TIL or notes posts (like this one!). Having a way to differentiate between them while also scanning across the titles of different types of posts felt really valuable.
I was inspired by this post which I stumbled across.
Light Mode Returns
A couple of days ago, a reader emailed me and asked if I could add a light mode to the blog because they were reading in a bright environment. Though personally I prefer dark mode, I appreciate not everyone agrees so it made sense to add.
On paper, I fit the mold he describes: I’m a Senior Staff engineer at Google. Yet, reading his work left me with a lingering sense of unease. At first, I dismissed this as cynicism. After reflecting, however, I realized the problem wasn’t Sean’s writing but my reading.
Sean isn’t being bleak; he is accurately describing how to deal with a world where engineers are fungible assets and priorities shift quarterly. But my job looks nothing like that and I know deep down that if I tried to operate in that environment or in the way he described I’d burn out within months.
Instead I’ve followed an alternate path, one that optimizes for systems over spotlights, and stewardship over fungibility.
It’s Friday at 4pm. I’ve just closed my 12th bug of the week. My brain is completely fried. And I’m staring at the bug leaderboard, genuinely sad that Monday means going back to regular work. Which is weird because I love regular work. But fixit weeks have a special place in my heart.
What’s a fixit, you ask?
Once a quarter or so, my org with ~45 software engineers stops all regular work for a week. That means no roadmap work, no design work, no meetings or standups.
Instead, we fix the small things that have been annoying us and our users:
an error message that’s been unclear for two years
a weird glitch when the user scrolls and zooms at the same time
a test which runs slower than it should, slowing down CI for everyone
The rules are simple: 1) no bug should take over 2 days and 2) all work should focus on either small end-user bugs/features or developer productivity.
If you do Linux systems programming, you will have likely pored over man pages, either on the command line or, my personal preference, using the excellent man7.org or linux.die.net.
I’ve always seen the numbers in sleep(3) and read(2) and idly wondered what they meant, but never actually bothered to look them up.
That is, until a review comment on a pull request:
// Behaves like man 2 basename
reviewer: nit: it’s not a syscall, so “man 2” is incorrect
So I looked it up. The answer was in the man(1) page (also accessible via the delightful man man command):
The table below shows the section numbers of the manual followed by the types of pages they contain.
1 Executable programs or shell commands
2 System calls (functions provided by the kernel)
3 Library calls (functions within program libraries)
(... less common section numbers)
So my colleague was right and the code should have read // behaves like man 3 basename as basename(3) is a libc library call.
Last week, I came across Don’t Build an Audience. It’s a fascinating post and has been occupying a lot of my “free thinking” time. I strongly suggest reading it as it’s well written and excellently argued.
To summarise what it tries to say:
The market for written content on the web (blog posts, articles etc) is “efficient”: in other words, great work will find its audience without you needing to build a “following” first.
“Liquidity providers” (influencers, curators, algorithms) are incentivized to share good content because it benefits them. They maintain credibility and engagement by surfacing quality work. Specifically called out are Substack, Alexey Guzey and Tyler Cowen.
You can speed up “distribution” of what you write with minimal effort. Just 30 minutes to email a few key people and posts on the “right” platforms.
Therefore, focus on creating excellent work rather than “building an audience”. If it’s truly good, the market will ensure it reaches “everyone who matters”.
I’m a very strong believer in the core message of “make cool things rather than chase followers”. It’s something I’ve done throughout my life and I have zero interest in changing that going forward.
But I don’t agree with the argument that the market is efficient for all types of written content. I think the author is over-indexing on what they write about: topics accessible for a wide audience and do not require background knowledge (e.g. philosophical musings, economic theory, social dynamics).
I write about technicaltopics. Sometimes this can be so deeply in the weeds that at most a few thousand people in the world would care about it. But it might totally change how these people work: it might teach about how to debug performance in their code, let them know about a new approach to analysing data or even inspires them build an entirely new program.
I’m a Senior Staff Software Engineer at Google working on
Perfetto, an open source suite of tools for
performance tracing and analysis. I joined Perfetto as a founding engineer in
2017 and have been part of the project ever since.
I’m passionate about performance, open-source and especially the intersection of
those two domains. I’m also generally interested in AI/LLMs and how they are
changing the software engineering industry.
If you’re interested in learning more, my public resume is
here.
Contact
Hearing from readers is one of the best parts of writing, so please reach out if
something resonates with you or you want to discuss any of the topics I write
about.
As an “SQLite consultant” for my local area of Google, I often have people come to me having written SQL like:
SELECT CAST(bar AS STRING) AS baz
FROM foo
and ask me “Why is baz always an integer?! Have I hit an SQLite bug?”.
I have to again reach for my list of “odd quirks that SQLite has that people don’t know about”. Because this is not a bug, at least according to the SQLite manual.
Instead, the correct way to write the above query is:
For tables not declared as STRICT, the affinity of a column is determined by the declared type of the column, according to the following rules in the order shown:
If the declared type contains the string “INT” then it is assigned INTEGER affinity.
If the declared type of the column contains any of the strings “CHAR”, “CLOB”, or “TEXT” then that column has TEXT affinity. Notice that the type VARCHAR contains the string “CHAR” and is thus assigned TEXT affinity.
If the declared type for a column contains the string “BLOB” or if no type is specified then the column has affinity BLOB.
If the declared type for a column contains any of the strings “REAL”, “FLOA”, or “DOUB” then the column has REAL affinity.
Otherwise, the affinity is NUMERIC.
STRING does not match any of the numbered rules and so fallback to NUMERIC affinity which, in the general case, means integer.
Due to SQLite’s staunch stance of being “backwards compatible” there’s very little chance of this paper-cut ever going away. But at least next time someone comes to me with this issue, I’ll be able to link to this post instead of writing the same thing for the nth time :)
A few weeks ago, I wrote about “The Documentation System” and how valuable I found it. As I dug deeper into researching how best to apply the principles outlined there, I came across Diátaxis. Written by the same author after they left Divio, Diátaxis is a distillation of all the principles with much more guidance in how to apply the framework (e.g. giving more examples), diving more into the philosophy and in general being a more comprehensive view into how to write great technical docs.
I’m blown away by how well the framework (and Diátaxis makes clear it is a framework not a rigid set of rules) is explained. It’s patently obvious that the author really understands technical documentation and they truly have given a gift to the industry by writing it up.
Finding Diátaxis has only made me more motivated to deeply absorb its principles and see how to best apply it to all technical documentation I refactor and/or write going forward.
The talk was recorded and is available on YouTube. Taking inspiration from Simon Willison, this post is an annotated presentation containing my slides and detailed notes on them. The talk also has a lot of UI demos: for these, I’ll have a screenshot but also a link to the relevant part of the video (videos are unbeatable for UI!).
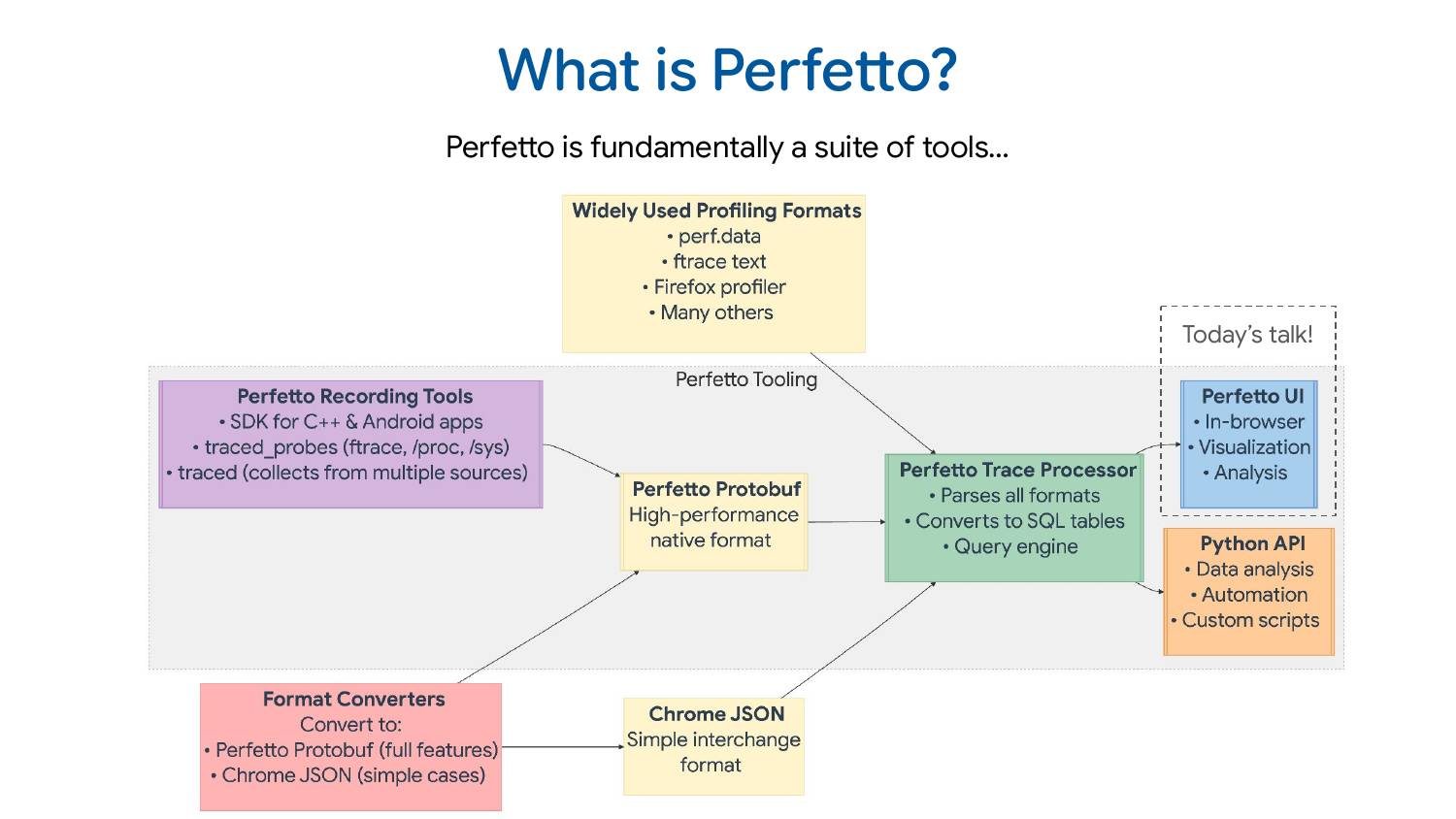
First, what is Perfetto? Perfetto is fundamentally a suite of tools: it’s not just one thing but a bunch of different tools working together to help you debug and root-cause problems. This diagram shows how everything fits together, with the core parts of the Perfetto project in the center.
The recording tools for Perfetto consist of 1) an SDK for C++ apps 2) a daemon that can collect data from ftrace, /proc, /sys, and various kernel interfaces 3) another daemon that amalgamates trace data from multiple processes into a single trace file. These tools all speak the Perfetto protobuf format, a high-performance trace format designed to be very efficient to write but not to analyze or consume directly.
That’s where the trace processor comes in. It’s a C++ library that parses the protobuf format, but also a bunch of other widely used trace formats. It exposes this data via an SQL query interface to any embedding program including Perfetto UI (which is what most of this talk is about) and also to the Python API if you want to do ad-hoc scripting or analysis in Python.
There are also very common tracing/profiling formats used by the Linux community: perf.data, ftrace text format, Firefox profiler format, and many others. Perfetto supports quite a few of those directly. There’s also the Chrome JSON format (AKA the Trace Event Format) which is a simpler interchange format. It’s not the most efficient to read or write, but it does the job for a lot of use cases.
Often people write converters. They have their own tracing format, maybe proprietary, maybe open source but something we don’t know about, and it’s very common that people convert to one of the formats we understand, most commonly our protobuf or Chrome JSON formats.
The Perfetto UI is fundamentally a web-based trace visualizer, combining timeline visualization, user-driven selection/aggregation, and SQL queries all in one interface. Because it has the trace processor as a backend, it works with a bunch of different trace formats.
It’s very important to note that even though the Perfetto UI is web-based, everything happens inside your browser and trace data never leaves your system. You can even build it and host it yourself on any static server: we’ve made it extremely easy to do so!
At the start of 2025, we actually moved our whole development to GitHub. In the past, we used to develop on Android and GitHub was just a mirror. That’s no longer the case, GitHub is actually where we develop and take pull requests.
Most of this talk, I’m going to spend actually showing you how you can use the Perfetto UI to debug performance issues on Linux. I don’t want to show you an Android trace which needs a lot of context about how the Android system works and so you think, “oh, that was cool, but I didn’t really understand what was happening.”
So to make this talk more approachable, I wrote a straightforward demo program you can look at yourself! So it’s obviously not a production system but I’ve tried to make it as representative of the sort of issues we use Perfetto for every day.
It’s a Rust program which generates a Julia set and visualizes it over time. The technologies I used: Vulkan, GPU rendering and also multi-threaded CPU computation. So how it works is that computation of various parameters is happening on background threads, and then that’s being passed to the main thread for rendering.
And then, for demonstration purposes, there is a performance bug; rendering should run at 60 FPS, but every so often, the frame rate drops dramatically. Here’s what that looks like:
The code is on GitHub and if you’re interested in following along. The traces are there as well - you don’t have to collect the traces yourself, but you can if you want. All the instructions and information is in the README.
So the first suspicion we may have is that maybe it’s some CPU problem. A lot of engineers I know would reach for perf immediately whenever they see a problem like this. The main reason is that if perf can capture the problem, they can go straight to the line of code without needing to spend time debugging using more complex approaches.
Sometimes you run into a truly inspirational piece of software that it’s a wonder even exists. I found 0x0.st recently and it very much falls into this bucket.
It’s essentially a simple, no-account, temporary file hosting site where you can just upload a file using a simple HTTP POST and the site will host it for you for between 30 days and 1 year depending on the size of the file. Uploading a file is as simple as:
curl -F 'file=@yourfile.ext' https://0x0.st
and you’ll get back a URL that you can share or use in the future.
I thought all the services like this had long since disappeared especially in the age of increasing scrutiny by government of content that websites host. It turns out though that from this discussion on HN, there are actually a bunch of similar services (transfer.sh, bashupload.com, chunk.io) but 0x0.st was the only one which I was able to access without an error.
The Perfetto UI is a fascinating project to work on because it often faces performance problems which you wouldn’t see in more “normal” webapps. I learn about all sorts of weird web features by reviewing PRs for the UI.
Two such features I just learned about:
will-change (PR): a hint, to be used sparingly, to tell the browser that a certain property of a DOM element will change in the near future.
isolation (PR):
I feel MDN didn’t do a great job of explaining so I asked Claude which gave a much more useful answer:
isolation is a CSS property that creates a new stacking context for an element. Think of a stacking context as a self-contained z-index universe. Elements within one stacking context can layer on top of each other, but their z-index values only matter relative to siblings within that same context.
The Perfetto team spent a lot of time earlier this year rewriting our documentation to be more useful for the average developer. We struggled a lot to figure out “what is the best way to structure our documentation”.
When reading Examples are the best documentation today, I came across The Documentation System, an approach to structuring developer documentation. Reading through it, I couldn’t help but marvel at how clear and concisely it laid out the ideas we were struggling to come up with from first principles.
Specifically, I really like how it breaks down documentation into four quadrants:
Tutorials: take your user through a series of steps to complete some task with your project.
How-to guides: solve a real world problem with your project.
Reference guides: give technical explanations of how things work.
Explanations: clarify a particular topic or area and how the project fits into the bigger tech landscape.
I think we got most of this right in our documentation rewrite but we definitely muddled some of these areas together, making our pages less clear than they could be. I plan on spending some time later this year correcting our docs to match this system closer.
I recently stumbled across
this post on lobste.rs
about a project called
traceboot which allows
visualizing the Linux boot process using lightweight ftrace events and Perfetto.
The author had
some commentary
about their experience trying to order tracks in Perfetto:
Ordering tracks with perfetto has been ridiculously complicated. It has taken
the majority of the time of this project! Upstream’s answers are basically
that the main user is Android (Perfetto is a Google project) so others come
second if at all. While I get the reasons to do so, I read that as a caution
against depending on it as a third-party. Google is notorious for (…)
completely killing projects
Honestly? All of these points are right:
It is really unfortunate that doing something so simple took so much effort.
It’s true that external users are supported at a lower priority than Android
users.
It’s also the case that Google has historically wound down projects when
priorities shift
The good news is that we just
landed support for trace
writers to specify explicitly how traces should be ordered with the JSON format
in Perfetto without any extreme workarounds! This feature is already available on
the “Canary” UI channel and on “Stable” within 3-4 weeks.
I’ve been using Claude Code extensively for personal projects, and similar AI
coding tools at work. Recently I came across
this excellent blog post
that resonated with a lot of my experience.
One part stuck with me though: Noah emphasizes that tools fail with LLMs when
they’re “overly complex,” with the Unix philosophy being particularly
well-suited for tool calling. But then I thought about git.
Git breaks the Unix philosophy completely. It’s sprawling, stateful, and
complex. And yet Claude Code handles it effortlessly. It composes commands that,
even after 10+ years of daily git usage, I wouldn’t think to use. It handles
rebasing, cherry-picking, complex resets—stuff that trips up experienced
developers regularly.
So if simplicity and the Unix philosophy aren’t the whole story, what else
matters?
I’ve come up with three “hallmarks” of a good tool for tool calling with LLMs.
1. It’s been around for a long time and/or is used by lots of people
One of my biggest weaknesses as a software engineer is procrastination when
facing a new project. When the scope is unclear, I have a tendency to wait until
I feel I’ve “felt out” the problem to start doing anything. I know I’ll feel
better and work much faster when I get “stuck in” but I still struggle with that
first step, overcoming the “activation energy” required to engage with the
details.
LLMs have been a game-changer for me in this respect: I can just throw a couple
of sentences at them with the shape of the problem. This leads to one of two
outcomes:
The LLM comes up with a good solution, usually in a slightly different way
than what I was thinking. I realize “oh wow the solution is much simpler than
I thought”. Straight away I start thinking about the consequences of
implementing and improving what the LLM suggested.
The LLM comes up with a solution that I intuitively recognize as “wrong”. My
immediate reaction is frustration (“How could it get it so wrong”) which
leads me to go back and forth with the model, explaining to it why its
solution could not possibly work. But in the process of arguing with the
model, my brain is churning away and generating variations or different
approaches that could work. After a while, even if the AI is still on the
wrong track, the debate will trigger a moment of inspiration where suddenly
the solution will come to me. I’ll excitedly start up a new conversation and
start working through it with the model.
The key is the emotional reaction I have immediately to the LLM’s response,
either excitement or frustration. By harnessing this immediate feedback
loop, I get my brain out of its passive, procrastination mode. It’s almost like
a jolt: either I’m thrilled because it’s simpler than I thought, or I’m spurred
to action by the urge to correct a perceived ‘wrong’ answer. This forces me to
engage with the problem in a meaningful way.
TLDR: Explain how the V4L2 M2M API works through the use-case of
implementing hardware video encoding on the Raspberry Pi. This knowledge is
generally useful as V4L2 is the de-facto generic API for hardware decoding and
encoding on Linux.
Background
My journey started at
this video on the
excellent
Craft Computing
YouTube channel which showed how to setup TinyPilot, a Python app for KVM over
IP which runs on a Raspberry Pi. Behind the scenes, TinyPilot uses
ustreamer to read frames from a HDMI
capture card and either exposes it over HTTP or writes it to shared memory.
Along with the MJPEG output, support was recently added for encoding video using
H264.
Even after messing with the source code, I could not get the H264 encoding
working on my Pi running 64-bit Ubuntu with an error message of
Can't create MMAL wrapper. Digging further, I ran into some insurmountable
roadblocks with the approach taken by ustreamer and discovered the complex state
of hardware encoding on the Pi.