Every day I read some sort of wrongheaded extrapolation about the future of AI — that today’s models are somehow indicative of AGI creating a “permanent underclass” of people that stops people from building software companies, or really doing any kind of job on the computer:
Show full content
Every day I read some sort of wrongheaded extrapolation about the future of AI — that today’s models are somehow indicative of AGI creating a “permanent underclass” of people that stops people from building software companies, or really doing any kind of job on the computer:
Hyperbolic? Perhaps. But even those who view the idea of a permanent underclass as overblown tell me that the meme contains a kernel of truth. Yash Kadadi, a 23-year-old start-up founder and Stanford dropout, summarized the sentiment of his peers: “There’s only a matter of time before GPT-7 comes out and eats all software and you can no longer build a software company. Or the best version of Tesla Optimus comes out,” and can perform all physical labor as well. In that world, this year is a human’s “last chance to be a part of the innovation.”
Yash, your peers are fucking idiots. You may as well be talking about breeding Grinches or Ninja Turtles, or kvetching about the upcoming threat from Godzilla. “The best version of Tesla’s Optimus [robot]” suggests that Tesla has released an Optimus robot, or that any prototypes are capable of anything approaching useful work, something that Tesla itself has said isn’t the case.
Every discussion of AI has become a discussion of anywhere between one and a million different theoreticals.
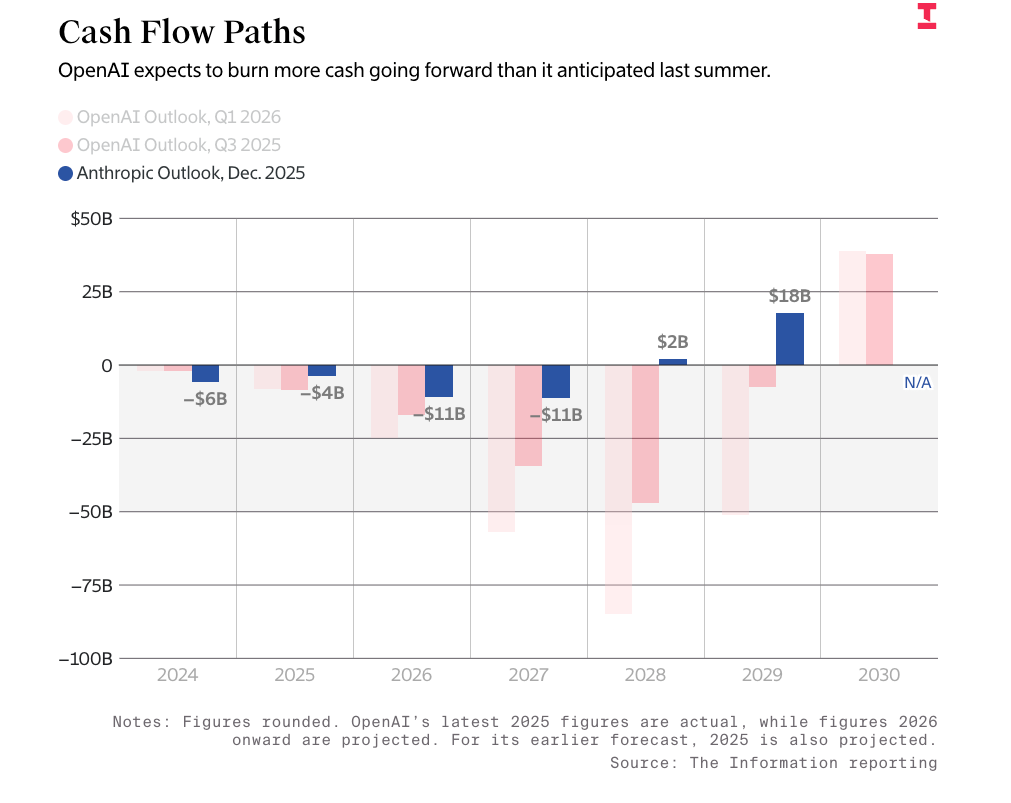
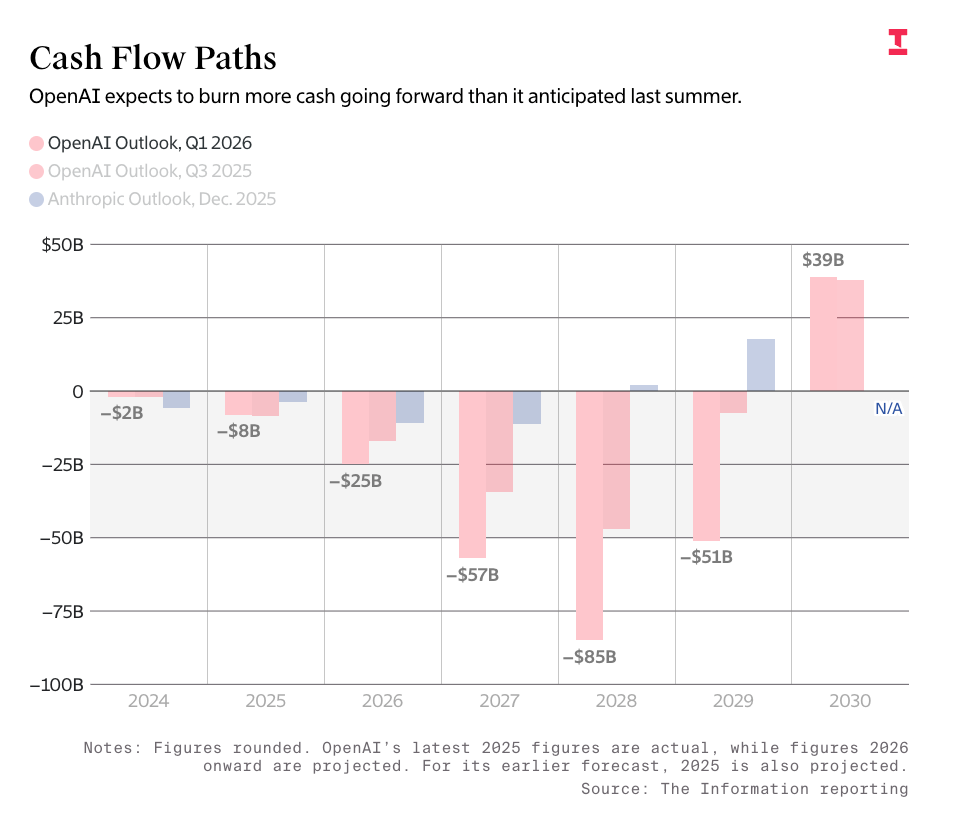
The Information’s headline that OpenAI will “save $97 billion through 2030 in latest Microsoft deal” — one that capped its revenue share (as in the actual money it sends to Microsoft) at $38 billion — hinges on the idea that OpenAI would somehow make $190 billion in revenue, because that’s what it would take to actually max out its revenue share.
The majority of articles about METR’s “time horizon” study of how long models take to complete tasks gush with mindless praise, but regularly leave out two valuable details: that these comparisons are made based on estimates of both human task times, and that the most-commonly shared task is based on how likely it is to complete a task 50% of the time:
The task-completion time horizon is the task duration (measured by human expert completion time) at which an AI agent is predicted to succeed with a given level of reliability. For example, the 50%-time horizon is the duration at which an agent is predicted to succeed half the time.
It’s the Sex Panther joke from Anchorman, except it’s a chart that gets written up in major newspapers and bandied about as proof of models becoming conscious.
Nevertheless, everybody appears to be having a lot of fun making stuff up or making ridiculous assertions based on OpenAI or Anthropic’s predictions. Likely gas leak victim Joseph Jacks posted last week that at its current rate of growth, Anthropic would pass Google’s revenue by 2028. Multiple different people I’d rather not link to are posting benchmarks of Anthropic’s still-to-be-released Mythos model as proof that we’re in the early-to-middle stages of the entirely-fictional AI 2027 “simulation,” despite the entirety of this ridiculous, oafish extrapolation relying on the idea that at some point LLMs become conscious and start doing their own research.
None of these people seem to want to engage with reality, even in their extrapolations.
But what I haven’t done recently — not since AI Bubble 2027, at least — is try my own hand at extrapolating the future based on the things I have read, seen and reported on.
I’ll be honest that there are a lot of unanswered questions I have about the AI bubble that make precise, time-based predictions almost impossible. We’re in the midst of one of the most insane market rallies in history driven around the exploding valuation of NVIDIA and data center related stocks despite there being a great deal of compelling evidence that millions of Blackwell GPUs are sitting in warehouses, meaning that the market is rallying around the idea of data centers getting built without ever confirming whether that’s actually true.
In the past, I’ve approached things from an investigative perspective, proving what I believe to be one of the greatest misallocations of capital in history. Today, I’m going to have a little more fun, exploring both the worrying signs I see and their potential consequences in the form of questions, mixing my own reporting with a little bit of fiction.
Even if Anthropic were able to mop up some of that fallow capacity, it too relies on endless venture capital and hyperscaler welfare to pay, well, increasingly-large shares of hyperscaler revenue.
I feel as if many people are willing to ask if we’re in an AI bubble, but few seem to want to talk about what might happen. It’s really easy to say “stocks are overvalued” or “OpenAI is deeply unprofitable,” but thinking much harder than that starts to make you feel a little crazy.Data center construction now makes up a larger chunk of all construction spending than commercial real estate. OpenAI has made promises that total over a trillion dollars, and Anthropic $330 billion. NVIDIA represents 8% of the value of the S&P 500, and that valuation is based on the idea that it will never, ever stop growing, which is only possible if data center construction never stops. CoreWeave, IREN, Nebius, and Nscale all rely on hyperscaler contracts that are related to OpenAI, and if those contracts go away because OpenAI does, they’re screwed.
Most people can say that these things are true, but very few of them are willing to think about their consequences, because when you do so, things begin feeling completely and utterly fucking insane.
The AI bubble is supported almost entirely by magical thinking and people ignoring obvious warning signs again and again and again in the hopes that at some point something changes. You can quote whatever story you like about Anthropic’s skyrocketing revenues (which are absolutely inflated) — there’s no getting away from the fact that it loses billions of dollars year, and if your answer is that it will turn profitable in 2028, please tell me how because there is no proof that it’s possible.
I also kind of get why nobody wants to think about this stuff. Even though it’s become blatantly obvious that the economics don’t make sense, the stock market continues to rip based on equities connected to the AI bubble in a way that defies logic but rewards positive speculation. Major media outlets continue publishing positive stories about the power of AI that seem entirely-disconnected from what AI can do, and millions of dollars are being spent by companies based on a theoretical return on investment.
“I am preparing myself to be surprised” by the bills, he said. “We believe that there’s a lot of value here. Unfortunately, it’s fairly new technology, so there’s some open questions that we’re gonna be working through” around its costs and getting a return on the investment.
We are fucking years into this man, how is the question of return on investment still an open question?
People also don’t really like thinking about bad things happening. They’re happy to make vague leaps in a direction that makes them feel prepared for the worst (such as the specious statements about all of these data centers being for the military or a theoretical bailout), especially if it makes them feel smart, but in doing so they get to avoid the actual bad stuff — the economic ramifications for ordinary people, the years of depression ahead for the tech industry, and the calamitous results for the market.
So, today, I’m going to have a little fun thinking about the actual consequences of everything I’ve been writing. I’m going to thread in both my own and others’ reporting, and take these ideas to their logical endpoints as far as I can.
This is going to be the first of a two-part exploration of what the actual consequences of the AI bubble bursting might be.
I’ll also caveat this by saying that these are, ultimately, explorations of potential future events rather than cast-iron guarantees. People seem to be resistant to being told the truth, so perhaps it’s time to explore these ideas as theoretical — fictional, even — so that people are more willing to take them in.
This series is all about simple scenarios, and one very simple question.
If you liked this piece, please subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI&
Subscribing to premium is both great value and makes it possible to write these large, deeply-researched free pieces every week.
During every bubble there’s one very obvious thing that keeps happening: things are said, these things are repeated, and are then considered fact. Sam Bankman-Fried was the smiling, friendly, “self-made billionaire” face of the crypto industry. NFTs were the future of art, and would change the way people think about the ownership of digital media.
Three months before his arrest, a CNBC reporter would fly to the Bahamas to hear SBF tell the story of how he “survived the market wreckage and still expanded his empire,” with the answer being that he had “stashed away ample cash, kept overhead low, and avoided lending,” as opposed to the truth, which was “crime.”
The point is that before every scandal is somebody emphatically telling you that everything’s fine. Everything seems real because there’s enough proof, with “enough proof” being a convincing-enough person saying that “most of FTX’s volume comes from customers trading at least $100,000 per day,” when the actual volume was manipulated by FTX itself, and the “$100,000 a day in customer funds” were being used by FTX to prop up its flailing token.
In the end, the “proof” that SBF was rich and that FTX was solvent was that nobody had run out of money and that nothing bad had happened to anybody. SBF was a billionaire sixteen times over because enough people had said that it was true.
Anyway, one of the most commonly-held parts of the AI bubble is that massive amounts — gigawatts’ worth — of data centers have both already been and continue to be built…
Remember, Colossus-1 is an odd data center, with around 200,000 H100 and H200 GPUs and an indeterminate amount of Blackwell GB200s, weighing in at around 300MW of total capacity…which isn’t really that much if we’re talking about gigawatts being built every quarter, is it?
So, I have two very simple questions to ask: how long does it take to build a data center, and how much data center capacity is actually coming online?
These simple questions are surprisingly difficult to answer. There exists very little reliable information about in-progress data centers, and what information exists is continually muddied by terrible reporting — claiming that incomplete projects are “operational” because some parts of them have turned on, for example — and a lack of any investor demand for the truth. Hyperscalers do not disclose how many data centers they’ve built, nor do they disclose how much capacity they have available.
So I went and looked, and what I found was confusing.
Defining “Built” and “Operational”
So, you’re going to hear people say “well Ed, data centers are being built,” and what I’m talking about is data centers that have been fully constructed and then turned on. It’s really, really easy to find data centers that are under construction, but as I’ve discussed in the past, that can mean everything from a pile of scaffolding to a near-complete data center.
Yet finding the latter is very, very difficult. I’ve spent the last week searching for data centers that broke ground in 2023 or 2024 that have actually been finished, and come up surprisingly empty-handed. Some projects are stuck in construction hell, eternally dueling with planning departments over permitting, some are chugging along with no real substantive updates, some, as is the case with Nscale’s Loughton, England data center, have done effectively nothing for the best part of a year, some are perennially adding more capacity to the order as a means of continuing raking in construction bills, and some are claiming their data centers are “operational” as only a single phase has turned on.
You should also know that even once construction has finished, the buildings themselves must be fully filled with the necessary cooling, power and compute hardware, at which point it can be configured to meet a client’s specifications (which can take months), at which point the unfortunate soul building the facility can actually start making money.
Building A Data Center Is Difficult, And Nobody Has Built A 1GW Data Center Yet
I think it’s also worth revisiting how difficult data center construction is, and how large these new projects are.
It’s fundamentally insane how many different companies are trying to build these things considering how difficult even the simplest data center is to build.
Take, for example, American Tower Corporation’s edge data center in Raleigh, North Carolina, which I’ll mention a little later. This is a 1MW facility — or one-thousandth the size of a gigawatt facility — occupying 4000 sq ft of real estate at first and expanding to 16,000 if ATC actually gets it up to 4MW. That’s about two-and-a-bit times larger than the typical American home. And, from ground-breaking to ribbon-cutting, it took eleven months to complete. And that’s not including all the other necessary time-consuming bits, like finding land, securing permits, and so on.
That’s a simple one. People want to build data center campuses a thousand times larger than that. Look at how difficult it is.
In fact, it’s so difficult that the companies can’t build all of it at once. Larger data center campuses are almost always divided into “phases,” in part because that’s the smartest way to build them, and in part with the express intention of convincing you that they’re “fully operational.”
For example, CNBC’s MacKenzie Sigalos reported in October 2025 that Amazon’s Indiana-based (allegedly) 2.2GW Project Rainier data center was “operational,” but only seven out of a planned 30 buildings were actually operational, and her comment of “with two more campuses [of indeterminate capacity] underway.” This comment was buried two videos and 600 words into a piece that declared the data center was “now operational,” with the express intent of making you think the whole thing was operational.
To give her credit, at least she didn’t copy-paste the outright lie from Amazon, which claimed that Rainier was “fully operational” in a press release the same day. You’ll also note that Amazon never provides any clarity about the actual capacity of Rainier.
Sigalos did exactly the same thing when the first (of eight) buildings of Stargate Abilene opened, declaring that “OpenAI’s first data center in $500 billion Stargate project is open in Texas,” burying the comment that only one was operational with another nearly complete several hundred words earlier.
These are intentionally attempts to obfuscate the actual progress of the data center buildout, and if I’m honest, I’ve spent months trying to work out why big companies that were supposedly building large swaths of data centers would be trying to do so.
Unless, of course, things weren’t going to plan.
Is Microsoft Misleading Us About Its Data Center Capacity?
Microsoft claims to have brought around 4GW of data center capacity online in the last two years, but it’s unclear how much actually got built.
In an analysis of all announced groundbreakings and land acquisitions, it appears that Microsoft has only finished the first phase of its Atlanta and Wisconsin data centers.
It is unclear where this capacity could be.
Microsoft Promised Then Failed To Deliver Comment On Its Data Center Capacity
In its last (Q3 FY26) quarterly earnings call, Microsoft CEO Satya Nadella claimed that “[Microsoft] added another gigawatt of capacity this quarter, and [remained] on track to double [its] overall footprint in two years.” A quarter earlier, he claimed to have added “nearly one gigawatt of total capacity,” with Karl Keirstead of UBS saying that he “...thought the one gigawatt added in the December quarter was extraordinary and hints that the capacity adds are accelerating.”
As I’ll discuss below, I can find no evidence of anything more than a few hundred megawatts of Microsoft’s data center capacity coming online. While I’ll humour the idea that it doesn’t announce every new data center, and that there may be colocation and neocloud counterparties (67% of CoreWeave’s revenue comes from Microsoft, for example) that make up the capacity, as I’ll also discuss, I don’t know where the hell that might be.
So, to be aggressively fair, I asked Microsoft to answer the following questions on May 4, 2026:
When Mr. Nadella said on his most-recent earnings call that Microsoft had (and I quote) "added another gigawatt of capacity this quarter," did he mean active, revenue-generating capacity?
In the event he did not, what did he mean?
How much active, revenue-generating capacity has Microsoft brought online in FY2026 so far?
Outside of Fairwater Wisconsin and Atlanta, where has that capacity been built?
A Microsoft representative from WE Communications promised to "circle back" by 5PM ET on Monday May 4th, but did not return further requests for comment via text and email, which is incredibly strange considering the simple and straightforward nature of my questions.
That’s probably because the vast majority of its publicly-announced or documented data center capacity doesn’t appear to be getting finished.
Microsoft Says Its Fairwater Data Centers Are Operational — They’re Actually Unfinished
In September 2025, CEO Satya Nadella claimed that Microsoft had added 2GW of capacity “in the last year,” and acted as if Fairwater, a project with two actively-constructed data centers with one in Wisconsin that broke ground in September 2023 and another in Atlanta that broke ground in July 2024, was something to be “announced” rather than “a very expensive project that has taken forever.” Nadella also claimed that there are “multiple identical Fairwater datacenters under construction,“ though he neglected to name them.
To be clear, “Fairwater” refers to a project where multiple data centers are linked with high-speed networking to make one larger cluster, a project that sounds ambitious because it is, and also unlikely because it’s yet to have been built.
I have serious doubts that Microsoft stood up a 350MW data center in less than a year, given everything else I’m about to explain.
Fairwater Wisconsin is also a data center of indeterminate size, but Cleanview claims Phase 1 is 400MW, quoting a story from FOX6 News Milwaukee from September 2025 that said that Microsoft was “investing an additional $4 billion to expand the campus,” featuring a video of a very much in construction data center saying the following:
Microsoft is in the final phases of building Fairwater, the world’s most powerful AI data center, in Mount Pleasant. Microsoft is on track to complete construction and bring this AI data center online in early 2026, fulfilling their initial $3.3 billion investment pledge.
So, $3.3 billion — at a rate of around $14 million per megawatt per analyst Jerome Darling of TD Cowen — is about 235MW of capacity, which is a lot lower than 400MW.
Seven months later, Satya Nadella said that the Fairwater datacenter in Wisconsin was “going live, ahead of schedule,” a sentence written in the present tense, but also said that it “will bring together hundreds of thousands of GB200s in a single seamless cluster,” which is in the future tense.
It’s a great time to remind you that Microsoft claims that it brought online roughly eight times that capacity (around 2GW) in the past six months.
To make matters worse, it doesn’t appear that Fairwater Wisconsin is actually operational. Ricardo Torres of the Milwaukee Journal-Sentinel reports that Microsoft has said it isn’t actually online, and that while there “...is equipment inside the data center conducting start-up opportunities…the company anticipates [they] will continue to happen for the next several weeks.”
Epoch AI’s satellite footage of Fairwater Wisconsin — which mentions a completely wrong capacity because it’s uniquely terrible at calculating it (it claimed Colossus-1 has 425MW capacity, for example) — notes that as of April 2026, one building appeared to be operational, with a second under construction.
In simpler terms, there’s at most around 117MW of capacity running at Fairwater Wisconsin.
Sidenote: To be clear, I think some revenue is being generated from a Fairwater data center, as my reporting from last year on OpenAI’s inference spend involved a few million dollars’ worth of billing for “Fairwater,” but it’s unclear whether that referred to Fairwater Atlanta or Wisconsin.
Epoch AI’s satellite footage notes that as of February 2026, building four’s roof was complete and “all mechanical equipment appears to be installed,” but “there is still a lot of construction activity around the building.” Based on air permits filed as part of the project (that Epoch found), it appears that each building is powered by a number of Caterpillar 3516C Generator Sets at around 2.5MW each, with building one having 47 (117.5MW), building two having 13 (32.5MW), building three having 30 (75MW), and building four having 35 (87.5MW).
If we’re very generous and assume that three buildings are complete, that means that Fairwater Atlanta is at around 225MW of capacity (not IT load!).
So, that’s about 342MW of data center capacity being built by one of the largest companies in the world, in its most-publicized and written-about data centers.
Put another way, for Microsoft to come remotely close to its so-called 2GW of capacity in the last six months, it will have had to bring online a little under six times that capacity.
I’m calling bullshit.
None of Microsoft’s Announced Data Center Capacity Since 2024 Has Been Completed
I really did want Microsoft to give me some answers, but I’m very confused as to how it can remotely claim it brought even a gigawatt of capacity online in the last year.
I also question whether Microsoft is actually building multiple other “identical” Fairwater data centers, as I can’t find any announcements or pronouncements or mentions or hints as to where they might be.
In fact, I’m having a little trouble finding where else Microsoft has been building data centers, and those I can find are extremely suspicious.
For two straight quarters, Microsoft has said it’s brought on an entire gigwatt of capacity,and I have to ask: where?
Because when you actually look at the projects it’s announced, very little appears to have been built, and that which has is nowhere near its theoretical capacity.
To be specific about what Microsoft is claiming, it’s saying it’s brought around 4GW of capacity online in the space of two years, and at a 1.35 PUE, that’s about 2.96GW of critical IT load, which works out to the power equivalent of around 284,600 H100 GPUs, which may be possible — after all, Microsoft apparently bought 450,000 H100 GPUs in 2024 — but I can’t find much evidence of data centers that could house that many GPUs, nor that might be in construction.
Microsoft’s latest update on the Hickory/Stover site is that it “will” begin “initial site setup and earthwork activities” as of February 2026, and it appears the contractor has changed from Ames Construction to Clayco.
The latest Microsoft update on the Lyle Creek site — which it adds began construction in March 2024 — is that its contractor, Whiting-Turner, “will begin initial site preparation once weather conditions allow” as of February 2026.
Okay, well, maybe it’s a Canada problem. What about Microsoft’s New Albany, Ohio data center that broke ground in October 2024? Well, as of March 2026, “spring activity would resume,” and “beginning soon, soil will be delivered to the site via a designated truck route. I’ll note that Microsoft specifically says that Ames Construction is currently leading it, and that it will “resume the lead role in project communications” once the final phase of construction is done at some unknown time.
Alright, well, how about the August 2025 ground breaking in Cheyenne, Wyoming that was allegedly “due to launch in 2026”?
Well, Microsoft hasn’t updated its community page since it said there’d be a community meeting planned for November 2025 and that “neighbors within the vicinity will be notified ahead of construction,” which sounds like construction is yet to commence. Not to worry though, it announced on April 14, 2026 that it planned to expand it to “accelerate innovation and economic growth”
This company claims it’s built four fucking gigawatts of capacity, but when I go and look to see what it’s actually built I’ve failed to find a single announced data center from the last three years that got turned on outside of its Fairwater Atlanta and Wisconsin sites.
To be clear, all of these sites are somewhere in the 200MW to 300MW range. For Microsoft to have brought online 4000MW of data center capacity in the last two years would require it to have completed thirteen or more of these projects, all while choosing not to promote them, with every project operating in such a veil of secrecy that no local or national news outlet reported a single one of them.
I truly cannot work out how Microsoft has brought on any more than 500MW of capacity in the last year based on my research, and think Microsoft is deliberately obfuscating whether said capacity was contracted rather than actively in-use, much like CoreWeave refers to itself having 3.1GW of “total contracted power” but only added 260MW of active power capacity in a single quarter at the end of 2025.
Sidenote: If you’re wondering why CoreWeave didn’t include how much active power it added in its Q1 2026 earnings press release, it’s because (per its own earnings presentation) it only added 150MW, in a quarter it contracted 400MW. It also said it added six new data centers, which I doubt.
However, the exact verbiage used in Microsoft’s earnings transcripts is that it “added another gigawatt of capacity,” which sounds far more like it’s saying it brought them online…
…but it didn’t, right? It obviously hasn’t.
Where are all the data centers, Satya? Where are they? Why are your PR people too scared to tell me?
No, really, where are they?
So, to be fair, analyst Ben Bajarin, one of the more friendly pro-AI posters, argues that actually all of that capacity is secretly behind-the-scenes, something I’d humour if there was any kind of paper trail to a bunch of Microsoft data centers that were secretly being built.
I’d also be more willing to humour it if any of the data centers that have been publicized as “breaking ground” had actually been finished, or if both Fairwater Atlanta and Wisconsin weren’t so deceptively-marketed.
My only devil’s advocate is that Microsoft could, in theory, be working with colocation partners to stand up several gigawatts of capacity through shell corporations and SPVs, but even then, not a single one has any sort of trail to Microsoft? All of that capacity?
It’s really, really weird, and the only answers I get are smug statements about how “Fairwater is ahead of schedule.”
But if I’m honest, I’m having trouble even making these numbers add up.
No, Really, Where Are All The Data Centers?
Considering how loud, offensive and conspicuous the AI bubble has become, it feels like we should have a far, far better understanding of how much actual capacity has been built.
I also think it’s time to start being realistic about how long these things are taking to build.
For example, I was only able to find a few data centers that for sure, categorically, definitively opened, and for the most part, it appears that a data center takes around 18 months to go from groundbreaking to opening.
And these, I add, are all facilities that are relatively modest — at least, when compared to the kinds of gigawatt-scale campuses that are reportedly in active development.
Novva’s 60MW data center in Reno, Nevada. Announced in May 2023, operational as of July 2025, or around 26 months.
EdgeCore’s 36MW Santa Clara, California data center campus that broke ground in January 2023, said it would be “energized in Q1 2024,” and opened in September 2025, or around 32 months.
Digging deeper, I found a lot of projects stuck in development Hell:
PowerHouse’s 65MW data center campus in Reno, Nevada broke ground in October 2024, and its website states that “delivery” will happen in April 2026, with “construction/delivery” due “Q3 2024 to Q2 2026.”
Oppidan’s Carol Stream, Illinois data center broke ground in November 2024, with the “first phase” due live in 2026. Per Clearview, it is still “planned.”
Flexennial, on the other hand, has been referring to it as “the new build” — in terms that make it sound like it was built — as far back as February 2025.
While there are absolutely data centers under construction, and some, somewhere, are actually being completed, the vast majority of projects I’ve found are either in a mysterious limbo state or, in most cases, under construction years after breaking ground.
Across the board, the message seems to be fairly simple: it takes about 18 to 24 months to build any kind of data center, and the bigger they are, the less likely they are to get completed on schedule.
Those that actually “come online” aren’t actually fully constructed, but have brought on a single phase — something I wouldn’t begrudge them if they were anything close to honest about it. In reality, data center companies actively deceive the media and customers about the actual status of projects, most likely because it’s really, really difficult to build a data center.
In any case, what I’ve found amounts to a total mismatch between the so-called “rapid buildout” of AI data centers and reality.
It also doesn’t make much sense when you factor in how many GPUs NVIDIA sold.
I Do Not Believe That More Than One Million Blackwell GPUs Are Actually In Operation — Meaning That Two Million GPUs Are Sitting In Warehouses
In October last year, NVIDIA CEO Jensen Huang told reporters that it had shipped six million Blackwell GPUs in the last four quarters, though it eventually came out that he was counting two cores for every GPU, making the real number three million. I disagree with the framing, I think it’s incoherent and dishonest, but I’ve confirmed this is what NVIDIA meant.
In any case, if we assume two cores per GPU, a B200 GPU has a power draw of around 1200W, for around 3.6GW of IT load for 3 million of them. I realize that NVIDIA also sells B100 and B300 GPUs (similar power draw) and NVL72 racks of 72 GB200 GPUs and 36 CPUs, but bear with me.
Blackwell GPUs only started shipping with any real seriousness in the first quarter of 2025, which means that a good chunk of these data centers were built with H100 and H200 GPUs in mind. Nevertheless, I can find no compelling evidence that significant amounts — anything over 500,000 GPUs — of Blackwell-based data centers have been successfully brought online.
When I say I struggled to find data centers that had been both announced and brought online, I mean that I spent hours looking, hours and hours and hours, and came up short-handed.
I want to be clear that I know that there is Blackwell capacity actually being built, and believe that the majority of that capacity is retrofits of previous data centers, such as Microsoft’s extension to its Goodyear Arizona campus which it began building in 2018 that likely houses Blackwell GPUs.
But I no longer believe that the majority of Blackwell GPUs are doing anything other than collecting dust in a warehouse. Blackwell GPUs require distinct cooling, a great deal more power than an H100, and cost an absolute shit-ton of money, making it unlikely that a 2023 or early-2024 era data center could handle them without significant modifications.
I fundamentally do not believe more than a million — if that! — Blackwell GPUs are actually in service.
If that’s the case, NVIDIA is likely pre-selling GPUs years in advance — experimenting with the dark arts of “bill-and-hold” — and helping certain partners like Microsoft install the latest generation to create the illusion of utility, availability and viability that does not actually exist.
If I’m honest, I also have serious questions about the current status of many H100 and H200 GPUs. Based on what I’ve found, I’d be surprised if more than 3GW of actual capacity was turned on in the last two years, which means that NVIDIA has sold anywhere from double to triple the amount of GPUs that the world can hold.
Data Center Capacity Isn’t Turning On At The Rate We Think, And It’s Choking The AI Industry
While the Anthropic-Musk compute deal is an obvious sign about xAI’s lack of demand for compute, it’s also, as I mentioned earlier, a clear sign that AI data centers are mostly not getting finished, and those that do get finished are taking two or three years even for smaller builds.
While it sounds a little wild, I think in reality only a few hundred megawatts — if that — of actual, usable AI compute capacity is being spun up every quarter. If I was wrong, there’d be significantly more progress on, well, anything I could find.
Why can’t Microsoft offer up a data center that isn’t called Fairwater, and why are its Fairwater data centers taking so long? How much actual capacity has Microsoft brought online? Because it certainly isn’t fucking 2GW in six months.
I’m willing to believe that Microsoft has a number of collocation agreements with parties that don’t disclose their involvement. I’m also willing to believe that Microsoft doesn’t publicize every single data center it’s building or has built.
2GW of capacity is a lot. It’s nearly ten times the (likely) existing capacity of Fairwater Atlanta. If Microsoft is bringing so much capacity online, why can’t we find it, and why won’t they tell us? And no, this isn’t some super secret squirrel “they’re building secret data centers for the government” thing, it’s very clearly a case where “capacity” refers to “something other than data centers that actually got brought online.
It Is Very Unlikely That Gigawatts of Data Center Capacity Are Coming Online Every Quarter
Despite their ubiquity in the media, AI data centers are relatively new concepts that are barely five years old. They are significantly more power-intensive than a regular data center, requiring massive amounts of cooling and access to water to the point that the surrounding infrastructure of said data center is often a massive construction project unto itself.
For example, OpenAI and Oracle’s Stargate Abilene data center is (in theory) made up of two massive electrical substations, a giant gas power plant and eight distinct data center buildings, each with around 50,000 GB200 GPUs, at least in theory. Every data center requires that power exists — as in it’s being generated in both the manner and capacity necessary to turn it on, either through external or grid-based power — and is accessible at the data center site.
This means that every single data center, no matter how big, is its own construction nightmare. You’ve got the power, the labor, the permits, the planning, the construction firm, the power company, the specialist gear, the temporary power (because on-site power is slow), the backup power (because you can’t just rely on the grid for something you’re charging millions for!), the cooling, the uninterruptible power supplies — endless lists of shit that needs to go very well or else the bloody thing won’t work.
Let’s go back to Anthropic mopping up Musk’s fallow data center capacity, which stinks of desperation for both companies. If there were modern data centers full of GB200s being turned on and available anywhere in the next month or two, wouldn’t it be more financially prudent to wait for it, even if it’s just on an efficiency level? A franken-center made up of H100s and H200s with some GB200s stapled onto the side feels like a stopgap solution.
It’s also important to remember that last year, OpenAI’s margins (which are already non-GAAP), per The Information, were worse than expected because (and I quote) it had to “..to buy more expensive compute at the last minute in response to higher than expected demand for its chatbots and models.”
Surely you’d wait a few months for some new, less tainted source of compute, right? And surely it wouldn’t be such a big deal, because new data centers get switched on every day, right?
Right?
If Data Centers Aren’t Getting Built, Everything About The AI Bubble Breaks
Look, I know it sounds crazy, but I’m telling you: I don’t think very many data centers are coming online! While I keep wanting to hedge my bets and say “I bet a few gigawatts came online,” I cannot actually find any compelling literature that backs up that statement. I’ve spent hours and hours looking, and I’ve come up with a few hundred megawatts delivered in the past two years. Every major project is stuck in the mud, a phase or two in, or facing mounting opposition from locals that don’t want a Godzilla-sized cube making a constant screaming sound 24/7 so that somebody can generate increasingly-bustier Garfields.
I’m not even being a hater! It’s just genuinely difficult to find actual data centers that have been announced that have also been fully turned on.
That $800 Billion In Capex Is Yet To Truly Enter Depreciation
So, humour me for a second: if hyperscalers are bringing on hundreds of megawatts of capacity a year, then that means that the ever-growing quarterly chunks of depreciation ripped out of their net income are just a taste of what’s to come.
Last quarter, Google’s depreciation jumped $400 million to $6.482 billion, with Microsoft’s jumping nearly a billion dollars from $9.198 billion to $10.167 billion, and Meta’s from $5.41 billion to $5.99 billion. While Amazon’s technically dropped quarter-over-quarter, it still sat at an astonishing $18.94 billion.
Remember: depreciation only increases when an item is actually put into service. If Microsoft, Google, Amazon and Meta are sitting on tens of billions of yet-to-be-installed GPUs, and said GPUs are only being installed at a snail’s pace every quarter, that means that these depreciation figures are set to grow dramatically. In fact, year-over-year, Google’s depreciation has jumped 30.7%, Amazon’s 24.7%, Microsoft’s 23.9%, and Meta’s an astonishing 34.9%.
And that’s with an extremely slow pace of deployment.
Sidenote: This also really makes me doubt that Microsoft has been bringing a gigawatt of GPU capacity for two quarters straight. A gigawatt of GPU capacity would be about $2 billion a quarter or more in depreciation. A $400 million bump in depreciation is about $9.6bn ($400 million times 24 quarters (6 years)), at about $50,000 per B200 GPU, or around 192,000 GPUs at 1200W each, for around 230.4MW.
Hell, someone could probably sit down and work out their potential capacity based on depreciation alone.
I do kind of see why the hyperscalers are sinking capex into these big AI infrastructure gigaprojects now, though. Shareholders are currently tolerating the capex because they think stuff is coming online, and that’s where the “incredible value” is. When a $20 billion or $30 billion a quarter depreciation bill first rears its head — as I said, Amazon is close, reporting $18.945bn in depreciation and amortization expenses in the most recent quarter — it’ll become obvious that the only people seeing value from AI are Jensen Huang and one of the massive construction firms slowly building these projects.
Actually, it’s probably important to state that I don’t think the majority of these projects are doing anything untoward I just don’t think any of them realized how difficult it is to build a data center, and unlike basically any other problem the tech industry has ever faced, simply throwing as much money as possible at it doesn’t really change the limits of physical construction.
I think every one of these data center projects is its own individual construction nightmare, and thanks to the general market psychosis around the AI bubble, nobody has thought to question the core assumption that these things are actually getting built.
With all that being said, I’m not sure that anyone building these things is moving with much urgency either. Perhaps they don’t need to — perhaps hyperscalers are happy, because they can continually string out both the AI narrative and put off those massive blobs of depreciation.
Maybe they can really pick up the pace, but as of early April, barely any actual gear was in the third building.
And then we get to the other problem: Oracle.
The Slow Pace of Data Center Development Is Lethal To Oracle, OpenAI, and Anthropic
As I’ve discussed before, Oracle is building 7.1GW of total capacity for OpenAI, and keeps — laughably! — saying 2027 or 2028, when at this rate, Stargate Abilene won’t be done until mid-2027, and the rest either never get finished or are done in 2030 or later.
This is setting up a horrifying situation where Oracle desperately needs OpenAI to pay it for capacity that doesn’t exist, and if it ever gets built, it’s likely to be years after OpenAI has run out of money, which is the same problem that Microsoft, Google, and Amazon have with their $748 billion of deals with Anthropic and OpenAI, though thanks to the $340 billion or more necessary to build the Stargate data centers, Oracle’s problems are far more existential.
I’ve repeatedly — and correctly! — said that the problem is that these companies didn’t have the money to pay for their capacity, but Oracle lacks Microsoft or Google’s existing profitable businesses to fall back on if these data centers are delayed, with its existing business lines plateauing and its only real growth coming from theoretical deals with OpenAI and GPU compute with negative 100% margins.
Anthropic’s desperation for new sources of compute also suggests that it’s bonking its head against the limits of its capacity, and will continue to do so as long as it continues to subsidize its users. I also think that the slow pace of construction will eventually lead to OpenAI facing similar problems.
These companies need to continue growing to continue to raise the hundreds of billions of dollars in funding necessary to pay Oracle, Google, Microsoft, and Amazon their respective pounds of flesh.
It’s now very clear that the whole “inference is profitable” and “most compute is being used for training” myths are dead, because if they weren’t, Anthropic would either need way more compute or way higher-quality compute. Colossus-1 was specifically built as a training cluster, yet its current use is “reduce rate limits for our subsidized AI subscriptions,” which is most decidedly inference provided by three-year-old hardware.
What If Only A Gigawatt Of Capacity Is Coming Online Every Year? Every Data Center Takes 18-24 Months+ To Build
Despite writing over 9000 words and driving myself slightly insane trying to find out, I still haven’t got an answer as to how much actual data center capacity has come online. Hyperscalers have clearly been retrofitting old data centers to fit their new chips, and based on my research, I can find no compelling evidence that they’ve added more than a few hundred megawatts a piece since 2023.
What I do know is that, across the board, a data center of anything above 50MW (or lower, in some cases) takes anywhere from 18 to 36 months to complete, and nobody has actually built a gigawatt data center despite how many people discuss them.
For example, Kevin O’Leary — known as “Mr. Dogshit” to his friends — is allegedly building a 9GW data center in Utah, but he may as well say that he’s building a unicorn that shits Toyota Tacomas, as doing so is far more realistic than a project that will likely cost $396 billion, assuming that locals and bankers don’t drag him to The Other Side like Dr. Facilier.
Nobody has built a 1GW data center, so I severely doubt Mr. Dogshit will be able to do anything other than create another scandal and lose a bunch of people’s money.
In other words, any time you hear about a “new data center project,” add a year or two to whatever projection they give. If it’s 2027, assume 2029, or that it never gets built. Anything being discussed as “finished in 2030” may as well not exist.
Sidenote: In general, the only projects that take anything less than a year are tiny — a megawatt max — other than Elon Musk’s Colossus-1, a Frankenstein’s monster of GPUs that vary between 1 and 3 years old.
In any case, what I’m suggesting is that very, very few data centers are actually getting finished, and if that’s true, NVIDIA has sold years worth of chips that are yet to be digested.
And if that’s true, somebody is sitting on piles of them.
I’m trying to be fair, so I’ll assume that an unknown amount of data centers got retrofitted to fit Blackwell GPUs. But I also refuse to believe that even half of the three million Blackwell GPUs that got shipped have actually been installed. Where would they go? You can’t use the same racks for them that you would with an H100 or H200, because Blackwell requires so much god damn cooling.
Why not? Isn’t this meant to be a chip that’s extremely valuable? Isn’t there infinite demand? Is there not a place to put them? Apparently Oracle wanted to use faster GB200 GPUs from Dell, but why aren’t there other customers lining up to buy these things?
Also…how was Oracle able to cancel an order of over a billion dollars’ worth of GPUs?
Can anybody do that? Because if they can, one has to wonder if this doesn’t start happening as people realize these data centers aren’t getting built.
The Data Center Construction Crisis Is Only Beginning
Pick a data center. It’s probably barely under construction, or if it’s “finished” it’s actually “partly done” with no real guide as to when the rest will finish.
That data center is a major reason that people value Nebius’ stock! It cannot make a dollar of revenue without its existence! It has the funds and blessing of Redmond’s finest — the Mandate of Heaven! — and it can’t get things done! This is bad, and indicative of a larger problem in the industry — that it’s really difficult to build data centers, and for the most part, they’re not being fully built!
You’ve heard plenty about data centers getting opposed and canceled — how about ones that fully opened? No, really, if you’ve heard about them please get in touch, because it’s really difficult to find them.
Why don’t we know? This is apparently the single most important technology movement since whatever the last justification somebody made up was, shouldn’t we have a tangible grasp? Because the way I see it, if these things aren’t coming online at the rate that people think, we have to start asking for fundamental clarity from NVIDIA about where the GPUs are, and when they’re coming online.
NVIDIA’s continually-growing valuation is based on the conceit that there is always more demand for GPUs, and perhaps that’s true, but if this demand is based on functionally selling chips two years in advance. That makes NVIDIA’s yearly upgrade cadence utterly deranged. Buy today’s GPUs! They’re the best, for now, at least. By the time you plug them in they’re gonna be old and nasty. But don’t worry, it’ll take two years for you to install the next one too!
To be clear, Blackwell GPUs are absolutely being installed! But three million of them?
People love to use “enough to power two cities” to illustrate these points, but I actually think it’s better to illustrate in real data center terms.
Stargate Abilene has taken two years to build two buildings of around 103MW of critical IT load. 3 million B200 GPUs works out to about 3.6GW of IT load. Do you really think that nearly thirty five Stargate Abilene-scale buildings were built in 2025? If so, where are they, exactly?
You may argue that other data centers are smaller, and thus it would be easier to build. So why can’t I find any examples of where they’ve done so?
By all means prove me wrong! It’s so easy! Just show me a data center announced or that broke ground in 2023 and find obvious proof it turned on. I’ll even give you credit if it’s partially open!
The problem is that I keep finding examples of “partially complete” and those are the only examples of “finished” data centers.
Isn’t this a little insane? This is all we’ve heard about for years, everybody is ACTING like these things exist at a scale that I’m not sure is actually true!
I expect a fair amount of huffing and “well of course they’re coming online” from the peanut gallery, but come on guys, isn’t this all kind of weird? Even if you want to marry Sandisk and name your children “Western” and “Digital,” why can’t you say with your whole chest several data centers that got finished? We have macro level “proof” but when you try and look at even a shred of the micro you find a bunch of guys with their hands on their hips saying “sorry mate that’ll be another $4 million.”
Something doesn’t line up, and it’s exactly the kind of misalignment that happens in a bubble — when infrastructural reality disconnects from the financials. NVIDIA is making hundreds of billions of dollars and it’s unclear how much of it is from GPUs installed in operational data centers. It feels like Jensen Huang might have run the largest preorder campaign of all time.
This has massive downstream consequences. Sandisk, Samsung, SK Hynix, Broadcom, AMD, Microsoft, Google, Oracle, and Amazon’s remaining performance obligations total [find] and are dependent on being *able* to sell gigawatts worth of computing gear or compute access. If data centers are not getting built in anything approaching a reasonable timeline, that makes the future of these companies only as viable as the construction projects themselves. Even if you truly believe Anthropic will be a $2 trillion company and a $200 billion customer of Google, the compute capacity has to exist to be bought, and it does not appear to be built or, in many cases, anywhere further than the earliest stages of construction.
If they don’t get built in the next few years, there’s no space for that solid state storage or those instinct GPUs. There’s no reason for NVIDIA to have reserved most of TSMC’s capacity, either.
Anthropic not have money to pay big cloud bills, because Anthropic company cost lots of money, more money than Anthropic make! So Anthropic only PAY cloud bills if OTHERS
Anthropic not have money to pay big cloud bills, because Anthropic company cost lots of money, more money than Anthropic make! So Anthropic only PAY cloud bills if OTHERS give it money! Amazon GIVE MONEY to Anthropic to GIVE BACK TO AMAZON, which mean no profit! And Amazon not give Anthropic enough money to pay it, so Anthropic have to ask OTHERS for money! That BAD! It mean BUSINESS not STABLE, and CLIENT not STABLE.
This bad when client MOST OF AI MONEY!
This ALSO mean that Anthropic RELIANT on OTHERS to pay AMAZON, which make AMAZON dependent on VENTURE CAPITAL for FUTURE REVENUE! Amazon SAY it have BIG BUSINESS, but BIG BUSINESS dependent on ANTHROPIC, which mean BIG BUSINESS dependent on VENTURE CAPITAL!
This SAME for GOOGLE! Both say they have BIG CLIENT, but BIG CLIENT MONEY not supported by REVENUE, so BIG CLIENT actually mean “HOW MUCH VENTURE CAPITAL MONEY ANTHROPIC HAVE.”
This bad business!
Sidenote: Me know you say “ANTHROPIC STOCK WORTH BIG MONEY,” but me need you remember how much capex Amazon and Google spend! Even if Anthropic stake worth $200 Billion, Amazon and Google still spend MANY more dollar than that on capex! And stake so BIG that neither able to SELL ALL. Only make gain on PAPER, which not REAL MONEY!
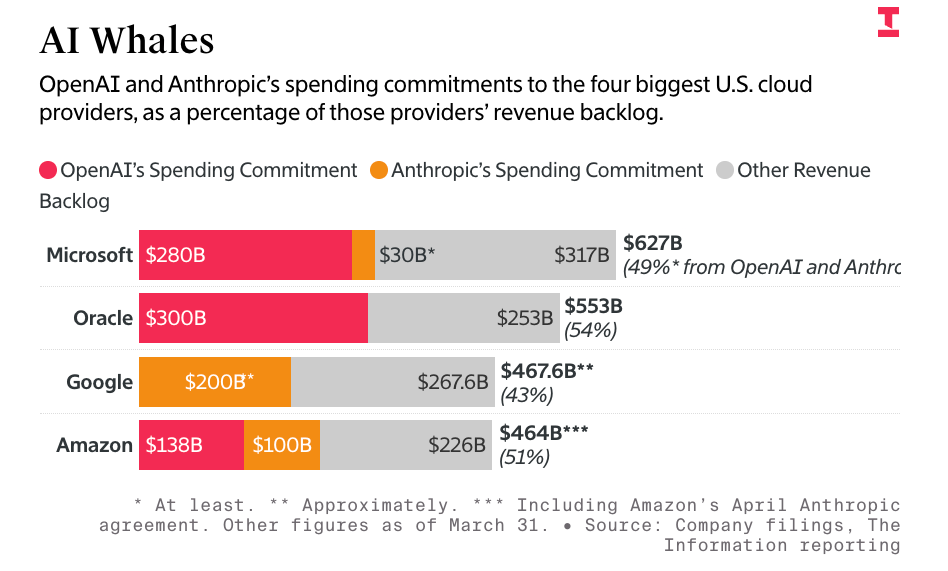
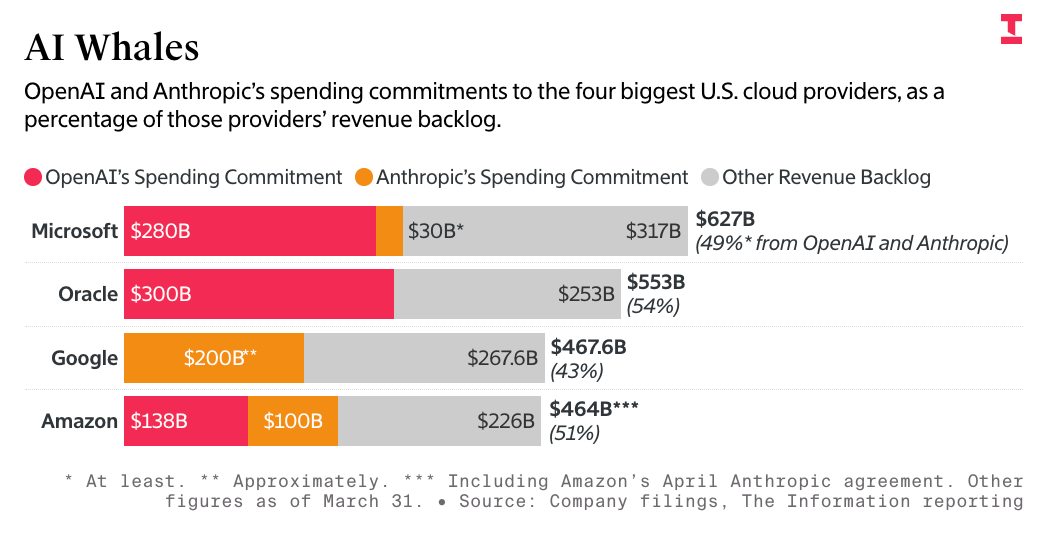
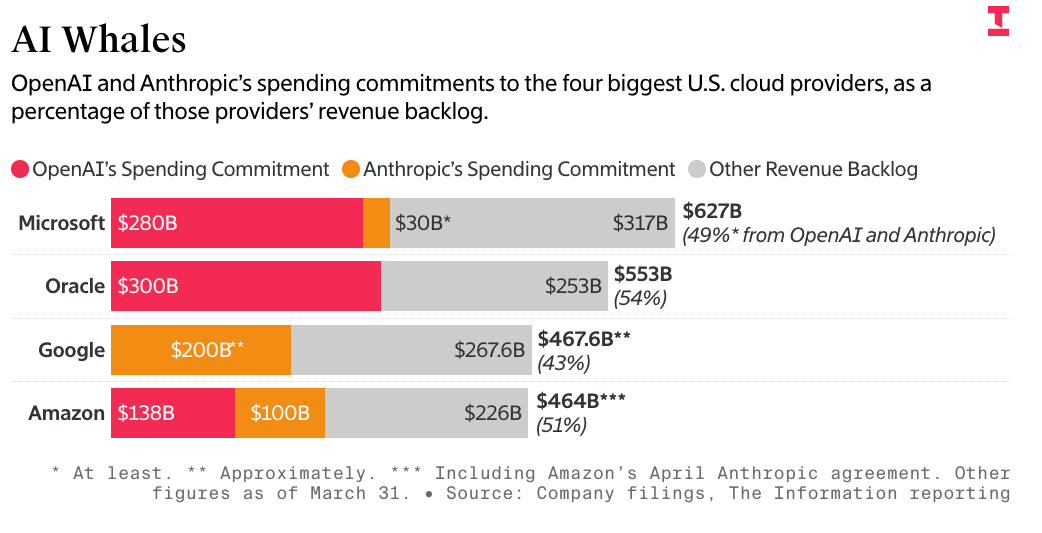
That’s $748 billion of the entire revenue backlog — not just AI compute — that’s dependent on Anthropic and OpenAI, two companies that cannot afford to pay these bills without constant venture capital infusions from either investors or the hyperscalers themselves.
If xAI doesn’t need 300MW of compute capacity that it spent at least $4 billion to build, who, exactly, are the other large customers for AI compute? I’m not even being facetious. I truly don’t know, I can’t find them, I spent most of last week looking for them, and the only answer I had a week ago was “Elon Musk buying a lot of compute for xAI to make the freaks on the Grok Subreddit able to generate pornography.”
To put this very, very simply: xAI should, in theory, have massive demand for AI compute, but its demand is apparently so small that it can flog a multi-billion-dollar data center to a competitor.
Sightline Climate found that 15.2GW of capacity is under construction and due to be completed by the end of 2027, and at this point I’m not sure anybody can make a compelling argument as to why it’s being built or who it’s for.
Who needs it? Who are the customers? Who is buying AI compute at such a scale that it would warrant so much construction? Where is the demand coming from if it’s not OpenAI and Anthropic?
These questions shouldn’t be that hard to answer, but trust me, I’ve tried and cannot find a GPU compute customer larger than $100 million a year, and honestly, that customer was xAI.
Through many hours of research, I’ve found that the vast majority — as much as 95% — of all compute demand comes from a few places:
Meta, for reasons that defy logic.
Microsoft, for OpenAI’s compute.
Google, for Anthropic’s compute.
Amazon, for Anthropic.
OpenAI.
Anthropic.
Otherwise, every data center deal you’ve ever read about is for a theoretical future customer or an unnamed “anchor tenant” that gives them “guaranteed, pre-committed occupancy” without being identified in any way.
And man, I cannot express how fucking difficult it is to find actual data center customers outside of the ones I’ve named above. In fact, it’s pretty difficult to find any customers for GPU compute not named Anthropic, OpenAI, Microsoft, Google, Meta or Amazon.
90%+ Of All AI Software and Compute Revenues Go Through Anthropic or OpenAI
Outside of OpenAI and Anthropic, effectively no AI software makes more than a few hundred million dollars a year, and to make that money, they have to spend it on tokens generated by models run by one of those two companies.
When those companies generate those tokens, they then flow to one of a few infrastructure providers — I’ll get to the breakdown shortly — to rent out GPUs.
As I’ve discussed this week, at least 75% of Microsoft, Google and Amazon’s AI revenues come from OpenAI or Anthropic, and that’s before you count the money that Microsoft, Google and Amazon make reselling models from both companies.
To get specific, The Information reports that Anthropic will pay around $1.6 billion to Amazon for reselling its models. OpenAI, per my own reporting, sent Microsoft $659 million as part of its revenue share.
AI startups — all of whom are terribly unprofitable — predominantly spend their funding on models sold by OpenAI and Anthropic. Per Newcomer, as of August last year, Cursor was spending 100% of its revenue on Anthropic. Harvey, an AI tool for lawyers, raised $960 million between February 2025 and March 2026, with most of those costs flowing to Anthropic and OpenAI.
Effectively every AI startup is a feeder for API revenue for Anthropic or OpenAI, and as a result, almost every dollar of AI revenue flows to either Google, Microsoft or Amazon.
As Anthropic and OpenAI are extremely unprofitable, Google, Microsoft and Amazon then take that money and either re-invest it in OpenAI and Anthropic, as Google, Amazon and Microsoft have all done in the past few years.
They likely also thought their own services would grow fast enough to warrant the expansion, or that other large GPU consumers would rear their heads.
That never happened. Instead, OpenAI grew bigger and more-demanding of Microsoft’s compute capacity, leading to Microsoft allowing it to seek other partners, in part (per The Information) because some executives believed OpenAI would die:
After striking the blockbuster deal in 2023, several top Microsoft executives told colleagues around that time that they thought OpenAI’s business would eventually fail, even if its technology was good, according to a former manager who discussed it with them.
Meanwhile, Amazon and Google thought they had it made. Anthropic was growing, and its compute demands were reasonable enough that neither had to stretch themselves too thin…until the second quarter of 2025, when Anthropic’s accelerated growth led to it starting to push against the limits of Google and Amazon’s capacity.
So Google agreed to backstop several billion dollars behind twodeals with Fluidstack, a brand new AI compute company, and Amazon continued expanding its Project Rainier data center.
And all of this is only happening because, based on my analysis, very little actual demand for AI compute exists outside of OpenAI and Anthropic, and OpenAI and Anthropic only exist because of Microsoft, Google, and Amazon both building and expanding their infrastructure to cater to them.
In reality, OpenAI and Anthropic are the only meaningful companies in the AI industry. They are the majority of revenue, the majority of capacity and the majority of demand. Microsoft, Google and Amazon have exploited the desperation in a tech industry that’s run out of hypergrowth ideas, and created a near-imaginary industry by propping up both companies.
The mistake that most make in measuring the circularity of OpenAI and Anthropic is to focus entirely on the money raised — $13 billion from Microsoft and up to $50 billion from Amazon for OpenAI, and as much as $80 billion from Amazon and Google for Anthropic.
The correct analysis starts with measuring infrastructure. Based on discussions with sources and analysis of multiple years of reporting, I estimate that of the roughly $700 billion in capex spent by Google, Meta and Microsoft since 2023, at least 5.5GW of capacity costing at least $300 billion has been built entirely for two companies. This has in turn inflated sales through multiple counterparties involving NVIDIA, ODMs like Quanta, Foxconn, Supermicro and Dell, and created a form of market-driven AI psychosis that inspired Meta to burn over $158 billion in three years and the entire world to convince itself that AI was the biggest thing ever.
The reason that there isn’t another OpenAI or Anthropic is that Google, Microsoft, and Amazon bankrolled their entire infrastructure, fed them billions of dollars, and then charged them discount rates for their early compute, with sources telling me that Anthropic pays vastly below-market-rates for Trainium compute from Amazon, and The Information reporting that OpenAI was paying $1.30-per-A100-per hour in 2024, or at or around the cost of running them.
By sacrificing their entire infrastructure to OpenAI and Anthropic, the hyperscalers created the illusion of demand by feeding themselves money, all while buying endless GPUs and TPUs to fill further data centers for two customers, both of whom paid discount rates that lost them money.
This capex bacchanalia gave all three companies a massive boost to their stock prices, so they kept going, even though there wasn’t really demand other than for Anthropic or OpenAI, two companies that they had to constantly cater to with investment capital and server maintenance.
The belief became that all you had to do was plan to build a data center and you’d print money, boosting NVIDIA’s sales and associated counterparties in memory stocks like Sandisk. Except that never happened.
Every data center provider that doesn’t have an Anthropic, OpenAI, or Meta-related contract makes pathetic amounts of revenue that can barely keep up with their debt. AI startups make meager revenues, and lose multitudes more than they can ever hope to make.
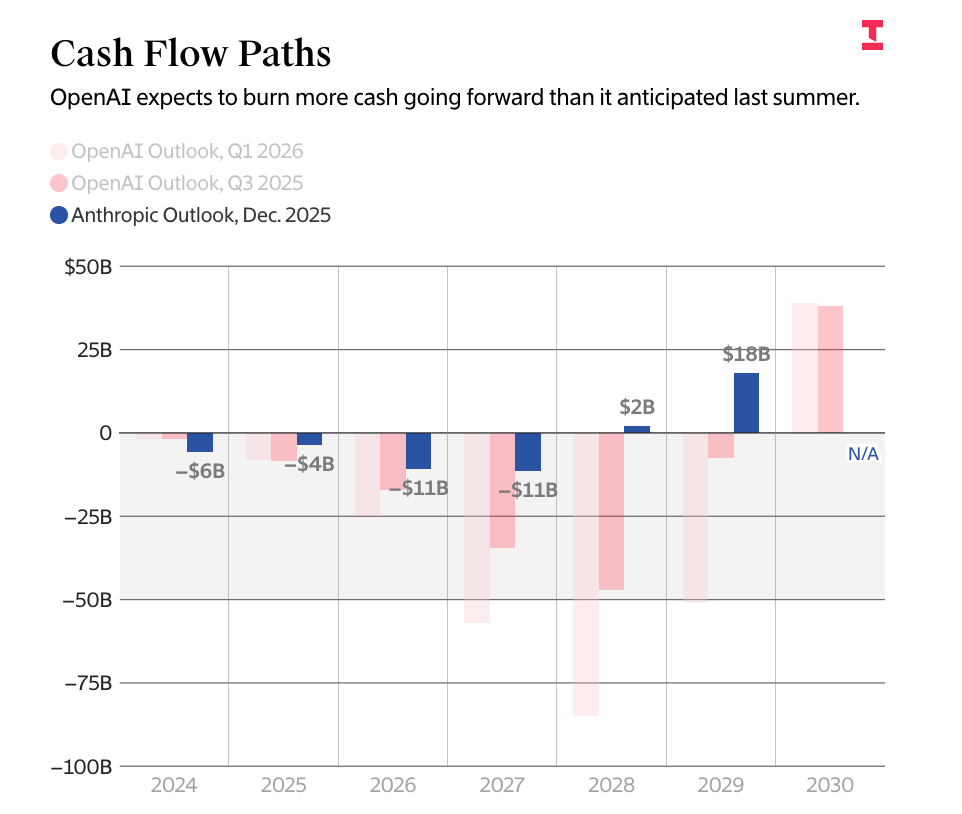
The entire AI industry relies upon two companies that expect to burn at least $1 trillion in the next four years, with Anthropic, the supposed “compute-conscious” AI company, committing to at least $330 billion in spend in the next few years.
Where does that money come from, exactly? Because neither of these companies have anything approaching a path to profitability.
Nowhere is this lack of true demand more obvious than in the neoclouds, which only seem capable of signing big deals with Anthropic, OpenAI, Microsoft (for OpenAI), and Google (for OpenAI). Oh, and Meta, who is doing this because the existence of ChatGPT gave Mark Zuckerberg such profound AI psychosis that he’s made Meta build him a CEO chatbot to talk to and burned over $150 billion.
The AI industry is a brittle, circular economy, one only made possible by a lack of financial regulation and a tech industry that’s run out of ideas. Without hyperscalers propping up OpenAI and Anthropic, there would be no reason to buy so many GPUs or build so many data centers, and neoclouds would have no reason to exist.
This is a giant con, a giant illusion, and a giant mistake.
Coming Up On This Week’s Where’s Your Ed At Premium…
90%+ of all AI revenues flow through Anthropic and OpenAI.
90%+ of all AI compute demand comes from Anthropic, OpenAI, Meta, or associated counterparties like Google and Amazon buying compute for Anthropic or OpenAI.
The vast majority of AI operations don’t require more than a few hundred to a thousand GPUs for inference, and at most 20,000 GPUs for training models.
This means that for the 15.2GW of data centers under construction before 2027 ($157 billion in annual revenue) to make sense, thousands of companies will have to rent hundreds or thousands of GPUs.
This also means that the DeepSeek problem — the reason that everybody freaked out in January 2025 — is actually industry-wide.
More than 50% of Microsoft, Google, Amazon, CoreWeave, and Oracle’s entire revenue backlogs are from OpenAI and Anthropic.
Neoclouds are unsustainable, imaginary businesses only made possible by continual subsidies from NVIDIA and the compute demands of OpenAI, Anthropic and Meta.
Outside of Anthropic and OpenAI, only around $13 billion in AI compute demand exists, with much of it taken up by Meta and NVIDIA backstopping neoclouds like CoreWeave and IREN.
ODMs like Supermicro, Dell, Quanta and Foxconn are largely dependent on AI server revenues that largely flow through OpenAI and Anthropic’s counterparties to fuel their server demand.
If you liked this piece, please subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI&
Show full content
If you liked this piece, please subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large.
Subscribing to premium is both great value and makes it possible to write these large, deeply-researched free pieces every week.
God, it’s been a long few years, and only feels longer after every ecstatic, ridiculous round of tech earnings where the world’s largest companies do everything they can to obfuscate the ugly truth behind their numbers.
By the end of 2027, big tech will have sunk $2 trillion into AI capex, with very little to show for it.
Oh, I know what you’re going to say. “These companies are growing faster than ever!” “These companies are building for future revenue streams!” “These companies are saying that AI is driving growth!”
Yet those revenues are, in the case of Meta and Google, not good enough to actually share.
While Google CEO Sundar Pichai will gladly say that “[Google’s] AI investments and full stack approach are lighting up every part of the business,” said “lighting up” never results in a revenue number that you can point at, because Google knows that analysts and journalists will read “Gemini Enterprise has great momentum with 40% quarter on quarter growth” — which we have no frame of reference for because Google doesn’t share its AI revenues — and clap and honk like fucking seals. Sundar Pichai knows that everybody is desperate to see him jingle his keys, and has such utter contempt for reporters, analysts, and investors that he doesn’t have to prove AI is actually doing anything. Those writing up his earnings will do it for him.
Meta, on the other hand, has little real AI story, and can’t even seem to get its metrics straight on what AI is doing for the company, per my premium piece from earlier in the week:
This is an impressive-sounding stat that doesn’t actually connect to any meaningful revenue information, especially when Meta announced in January 2026 that doubling GEM’s compute allowed it to drive a 3.5% lift in ad clicks (a different measurement) on Facebook and “more than a 1% gain in conversions on Instagram” in Q4 2025, which is…4% lower.
Nevertheless, I have to give Microsoft and Amazon credit for deigning us worthy of actual numbers, even if they’re piss poor.
AI Revenues Are Pathetic and Circular, With OpenAI Representing 71%+ Of Microsoft’s AI Run Rate and Anthropic 80% of Amazon’s
In any case, I need you to recognize how small these numbers are in comparison to the capex it’s taken to make them.
To give you some context, Amazon’s AI revenue run rate is roughly 0.419% of the $298 billion in capex it spent on AI capex so far, or around 25% of the $5 billion it just invested in Anthropic last week. Microsoft, on the other hand, has spent $293.8 billion on AI capex through its latest quarter — making its revenue run rate around 1.04% of its spend.
These revenues are deeply embarrassing! I am not sure why this isn’t the common refrain! These fucknuts have spent over a trillion dollars on AI and all they have to show for it is either nothing, vague statements about “everything lifting because of AI,” or pathetic revenues that only get worse the more you think about them.
OpenAI Represents 70%+ Of Microsoft’s AI Revenue and 80%+ Of Its AI GPU Compute Capacity, Creating The Illusion Of Growth That’s Dependent On A Company That Will Lose $25 Billion+ In 2026
Yet things actually get worse when you think about the sources of that revenue, or perhaps I should say source, as both Microsoft and Amazon (and I’d argue Google too, but we don’t know its AI revenues) are heavily-dependent on their large, unsustainable sons — Anthropic and OpenAI.
I’ll explain. Microsoft claims that its $37 billion in AI revenue run rate has grown by 123% year-over-year, which means its run rate, not actual 2025 AI revenue, was about $16.59 billion in Q3 FY25, or around $1.38 billion a month or, if you assume that number is consistent over the quarter (it likely wasn’t), about $4.14 billion. Based on my own reporting from direct Azure revenue numbers, this would make OpenAI’s $2.947 billion in inference spend in that quarter around 71% ($11.7bn) of Microsoft’s Q3 FY2025 AI revenue run rate. That’s embarrassing!
Yet my reporting helps us be a little more annoying than that. Back in January 2025 — around Microsoft’s Q2FY2025 earnings — it announced that its AI revenue run rate had hit $13 billion, or around $1.083 billion a month (or $3.25bn a quarter or so). In that same quarter, OpenAI had spent $2.075 billion on inference on Azure, or 63.8% of Microsoft’s AI run rate.
This is particularly funny when you go back to the quarter before, where Microsoft CEO Satya Nadella low-balled that figure, claiming it would be $10 billion in annualized run rate, and specifically said the following:
"It's all inference," he said. "One of the things that may not be as evident is that we're not actually selling raw GPUs for other people to train."
The CEO added that the company is turning away requests to use their GPUs for training "because we have so much demand on inference."
That’s…not really what happened.
Today I can report, based on discussions with sources with direct knowledge of Azure revenue, that in Q2 FY2025, Microsoft brought in around $325.2 million in revenue via renting out GPUs and other AI infrastructure, and around $367 million in revenue from Microsoft 365 Copilot, or less than half of the $1.467 billion that OpenAI spent on inference.
If you’re curious, the next quarter (Q3FY2025), AI infrastructure brought in around $412 million, and Microsoft 365 brought around $300 million.
While my sourcing for Azure revenues cuts off at Q3 FY2025, my OpenAI inference and revenue share data goes out a further two quarters to Q4 FY2025 and Q1 FY2026 (so Q2 and Q3 of the calendar year 2025), as well as half of Q2FY2026, and we can make some fairly straightforward estimates as a result.
So, based on my reporting, OpenAI spent $3.648 billion dollars on inference in the third quarter of 2025 on Microsoft Azure, or around $14.4 billion on an annualized basis. While I only had half the fourth quarter’s numbers, I estimate that OpenAI’s annualized spend hit over $18.5 billion — or around $4.6 billion a quarter — by the end of the year, and that’s not accounting for things like Sora 2 or the launch of its Codex coding platform. In total, this puts its spend at an estimated $13 billion dollars on Azure just on inference, with billions more on training.
Sidenote: If you work at Microsoft Azure and want to talk to me about these numbers, my Signal is ezitron.76.
Yet Microsoft Azure isn’t the only place that Microsoft gets fed revenue from OpenAI.
All together, that puts OpenAI’s spend on Microsoft services at over $18 billion dollars in 2025, and it’s easy to see how that would grow to over $24 billion dollars on an annualized basis in the last quarter, or around $2 billion a month. Microsoft is OpenAI’s primary cloud provider, and I estimate that OpenAI represents around 70% of its AI revenue, while taking up the majority of its infrastructure. Otherwise, Microsoft’s 20 million Copilot 365 subscribers likely pay no more than $7 billion a year.
I also think that OpenAI is taking up the lion’s share of compute.
Considering that 67% of CoreWeave’s revenue came from Microsoft renting capacity for OpenAI, I also think that it’s fair to assume that 80% or more of Microsoft’s GPUs are taken up by OpenAI, though some might now be taken up by Anthropic, which agreed to spend $30 billion on Azure. I’ve also confirmed that Microsoft’s “Fairwater” data centers — which constitute (when finished) “hundreds of thousands of GPUs” — are entirely reserved for OpenAI.
Microsoft desperately wants you to think that this is a diverse, booming revenue stream, when in fact it’s spent around $293 billion in four years to make — when you remove OpenAI — less than $3 billion a quarter in revenue, not profit.
Booooooo! Booooooo!!!!!
Anthropic Accounts For 80%+ of Amazon’s AI Revenues And At Least 75% Of Its AI GPU Compute Capacity
As far as Amazon goes, things get a lot grimmer. As I mentioned earlier, in early April, per Reuters, Amazon’s Andy Jassy admitted that its “cloud business’ AI revenue run rate was more than $15 billion in the first quarter of 2026,” which translates to around $1.25 billion in monthly revenue, or roughly 0.419% of the $298.3 billion in capex it spent so far, or around 25% of the $5 billion it just invested in Anthropic two weeks ago.
I also think it’s reasonable to assume that a large part — if not the majority of — that revenue comes from Anthropic. Per my reporting last year, Anthropic spent $518.9 million on Amazon Web Services, at a time when it had around $7 billion in annualized revenue, a figure that’s increased by 500% (if you believe it) to $30 billion in annualized revenue since. $518.9 million is about $6.2 billion in annualized spend, and I think it’s fair to assume that its spend will have at least doubled to $12 billion in annualized revenue, or around 80% of Amazon’s AI revenue.
“Year-over-year” is an attempt to obfuscate actual growth in the era of AI. A better comparison would be quarter-over-quarter, which was 12% from Q4 2025 ($17.66 billion).
This is actually significant, because it’s a slower rate of growth than between Q3 and Q4 2025, when cloud revenue jumped from $15.15 billion to $17.66 billion, or 14.2% quarter-over-quarter).
I think quarter-over-quarter growth is far more indicative of how a business is going.
Google Cloud is far more than AI! It includes all of Google’s workspace revenue, such as Gmail, Google Docs, and so on. It’s important to remember that Google jacked up its workspace pricingtwice in 2025, and that by Q1 2026, the majority of customers will have been forced to renew at inflated prices. It also includes all of Google’s cloud revenue, which is incredibly diverse and far more than just AI compute.
Google has intentionally bucketed AI-related revenue into Google Cloud so that finance and tech journalists will claim that AI is what’s driving this growth despite there being no proof that that’s the case.
One of the reasons that Google might not want to break out its AI revenues is that they’re — much like Amazon — heavily-inflated by Anthropic’s compute spend. Sadly, we have only a little information about Anthropic’s spend outside of its promise to use “up to one million TPUs, with over a gigawatt of capacity [coming] online in 2026” from the end of last year, and a month ago, when it said it would use “multiple gigawatts of next-generation TPU capacity…starting in 2027.”
Another guess might be to travel back in time to before Anthropic was a huge consumer of compute. In Q4 2023, Google Cloud sat at about $9.19 billion a quarter, and $11.96 billion in Q4 2024 (around 23% year-over-year, but a putrid 5% quarter-over-quarter from Q3 2024). By Q2 2025, it sat at $13.62 billion, and as I mentioned above, accelerated to $15.15 billion to $17.66 billion (14.2% quarter-over-quarter) to $20 billion (11.7% quarter-over-quarter) in the following three quarters.
Explainer: So, to create an output, a Large Language Model does “inference,” and the more users a company has, the more it spends on cloud services to support their inference. As a result, Anthropic’s growth means that it’s spending way, way more on its core cloud providers — Amazon and Google — to provide its services.
The cloud segment posted a notable acceleration, driven by surging demand for GenAI solutions, resulting in the doubling of backlog and tripling of operating income with the inclusion of TPU hardware agreements as a new revenue stream.
Interesting. Interesting. Google appears to be planning to sell its TPUs — its own custom silicon it currently uses only for its own services and some of Anthropic’s — to a non-specific amount of unnamed customers, to the point that its remaining performance obligations jumped from $242.8 billion to $467.8 billion in the space of a quarter.
Aside: To be clear, RPOs refer to any revenue that Google might earn in the future, such as the tens of billions of dollars Anthropic has agreed to spend, every single annual or bi-annual workspace account, every single massive ads deal, and so on and so forth.
Nevertheless, that’s a remarkable jump, especially when you try and work out who they sell to- oh wait, we actually know!
Google also signed a multi-billion dollar deal to rent TPUs to Meta, per The Information, and is also discussing A) selling TPUs to Meta directly, and B) creating SPVs that will buy its own GPUs and lease them to others:
In addition to forging the Meta deal, Google has signed an agreement with an unidentified large investment firm to fund a joint venture that would lease TPUs to other customers, according to a person involved in that arrangement. Google is in talks with other investment firms to fund other such joint ventures.
To explain, Google is creating something called a special purpose vehicle — a company with one purpose — that it then funds along with an investment firm. The SPV then raises cash via debt, which it then uses to buy TPUs directly from Google.
Now, remember that Anthropic deal to use a million TPUs from last year? How about the deal with Broadcom (which makes TPUs for Google) and Google to use “multiple gigawatts” of TPUs starting in 2027?
It’s a pretty sweet deal for Google! Google pays Broadcom to develop TPUs, Anthropic pays Google to buy those TPUs once Broadcom builds them, Google installs those TPUs in a data center, and then Anthropic pays Google to rent them back.
This isn’t real demand!
Boo!!!!!! BOOOOOO!!!!!!
Anthropic Has Committed To Spend $200 Billion On Google Cloud and TPUs
So, for the sake of transparency, I wrote the above beforeThe Information published its story about how Anthropic had committed to spend $200 billion on Google Cloud and TPU chips, which contained this very important detail:
But as part of the deal, which begins next year, Anthropic plans to spend about $200 billion with Google over five years, according to a person with knowledge of it. The commitment means Anthropic represents more than 40% of the “revenue backlog” Google disclosed to investors last week, reflecting contractual commitments from its cloud customers.
Google, Microsoft and Amazon’s AI Revenues Are Almost Entirely Based on Circular Financing Relationships That Should Be Illegal
The Information’s story also had this fascinating chart showing that around 50% of Amazon, Google and Microsoft’s backlog (which includes all revenues not just AI) — a staggering amount — is made up of revenue from OpenAI and Anthropic:
To be clear, I also wrote the below before this chart ran, because it was very fucking obvious when you actually looked at the numbers.
This is not what you do when real, meaningful demand exists for AI services. Assuming that these rounds are closed at their higher limits, it will mean that Google has invested $43 billion and Amazon $33 billion in keeping Anthropic alive.
As I’ve explained, most AI revenues out of Google, Microsoft and Amazon come from two companies that lose billions of dollars a year, have no path to profitability, and are only able to keep paying these companies because the companies (and investors) keep feeding them money.
These relationships are utterly poisonous, and an intentional attempt to deceive investors and the general public.
Google now plans to invest up to $43 billion in Anthropic, a company that I estimate takes up at least half of its 2.95GW of capacity, which has cost it around $211 billion in capex since 2023. Amazon has already invested $13 billion and as much as another $20 billion more in Anthropic, and announced its latest round with a statement about how Anthropic will use up to 5GW of compute capacity.
While dimwits might read this and say “WOW, AMAZON JUST LOCKED UP TONS OF FUTURE REVENUE,” it’s important to remember that Anthropic plans to lose $11 billion a year both in 2026 and 2027, and that’s based on its own internal (and fanciful) projections!
Me Explain Why Circular Finance Bad!
Let me spell it out in a way that boosters can understand, in the style of Gillam Fitness: Anthropic not have money to pay big cloud bills, because Anthropic company cost lots of money, more money than Anthropic make! So Anthropic only PAY cloud bills if OTHERS give it money! Amazon GIVE MONEY to Anthropic to GIVE BACK TO AMAZON, which mean no profit! And Amazon not give Anthropic enough money to pay it, so Anthropic have to ask OTHERS for money! That BAD! It mean BUSINESS not STABLE, and CLIENT not STABLE.
This bad when client MOST OF AI MONEY!
This ALSO mean that Anthropic RELIANT on OTHERS to pay AMAZON, which make AMAZON dependent on VENTURE CAPITAL for FUTURE REVENUE! Amazon SAY it have BIG BUSINESS, but BIG BUSINESS dependent on ANTHROPIC, which mean BIG BUSINESS dependent on VENTURE CAPITAL!
This SAME for GOOGLE! Both say they have BIG CLIENT, but BIG CLIENT MONEY not supported by REVENUE, so BIG CLIENT actually mean “HOW MUCH VENTURE CAPITAL MONEY ANTHROPIC HAVE.”
This bad business!
Sidenote: Me know you say “ANTHROPIC STOCK WORTH BIG MONEY,” but me need you remember how much capex Amazon and Google spend! Even if Anthropic stake worth $200 Billion, Amazon and Google still spend MANY more dollar than that on capex! And stake so BIG that neither able to SELL ALL. Only make gain on PAPER, which not REAL MONEY!
And it really, really is.
Most of Amazon, Google and Microsoft’s capex is being driven into capacity mostly used by OpenAI and Anthropic, neither of whom have the money to pay without continual infusions of more capital. Only Microsoft was smart enough to realize the problem, which is why it allowed Oracle to take over the majority of OpenAI’s future capacity (which may kill Oracle, by the way!), but both Google and Amazon keep feeding Anthropic money so that Anthropic can feed it right back to them.
Anthropic and OpenAI Have Become Load-Bearing Failsons, Making Up 70%+ Of AI Revenues and Taking Up 75%+ Of AI GPU Compute Capacity — Meaning That The Entire AI Industry Is Dependent On Whether They Can Raise Money
I’m going to try and speak simply again, because I’m still not sure people get this.
Anthropic and OpenAI make up the vast majority of all AI revenues and compute capacity. I estimate 70% of all revenues and capacity demand, if not higher.
Amazon, Google, and Microsoft’s AI revenues — and by extension their justification for future capex spend — are justified by Anthropic and OpenAI.
OpenAI and Anthropic both lose tens of billions of dollars a year (yes, Anthropic said it’ll lose $11 billion in a projection, and I believe they are being coy with their actual losses), which means that the majority of AI revenue and compute demand is dependent on whether Anthropic and OpenAI can continue to raise money.
The only solution to this problem is if either Anthropic or OpenAI can somehow find a way to become profitable, something that I have yet to see any proof is possible.
Anthropic Appears To Be Losing Far More Money Than People Believed
That’s $58 billion in eight months, with the potential to raise it to $108 billion.
I’m gonna be honest, I think Anthropic is outright misleading its investors if it’s saying that it will only burn $11 billion in 2026 and 2027, per The Information:
If that were the case, why does Anthropic need to raise one hundred and eight billion fucking dollars in less than three quarters?
Time to make up some booster talking points and get mad at them:
Well actually Ed this is because Anthropic is taking advantage of the dumb money that wants to boost its valuation. It doesn’t need the cash — it’s building a reserve!
Are you suggesting it’s raising money because it doesn’t need it? Like a rainy day fund?
Are you also suggesting that Anthropic is taking advantage of its investors?
Anthropic has a bunch of compute commitments that require it to pay a bunch of money up front! This isn’t because its business economics don’t make sense at all.
I think you’re right that Anthropic likely has to pay up front for its compute. Dario Amodei himself said so, while adding that you have to do so based on how much revenue you expect to make, and that if he’s wrong, Anthropic goes bankrupt!
Nevertheless, this doesn’t remotely interfere with my thesis! It just means that Anthropic has been forced to buy a bunch of compute immediately rather than paying for it in chunks.
In fact, I’d argue that Anthropic is having to raise this money to pay up front for capacity that’s yet to be built.
This is a sign of how much faith investors have in the product!
Yeah that’s generally how venture capital works. There’s also not really any other success story out there other than OpenAI that has anything close to a time horizon toward an exit.
We Need To Talk About Anthropic’s Revenue and Capacity Issues
This also means that Anthropic, if it’s being honest about what “run rate” means, made 23% of its lifetime revenue in a single month.
On April 6, 2026, Anthropic said it had hit $30 billion in annualized revenue, or $2.5 billion, I assume, in the period between March 6 and April 6.
That’s $2.5 billion in that period.
SemiAnalysis’ estimate is from April 30, 2026, so let’s assume that it refers to the period of March 29 to April 29, 2026.
That’s another $3.08 billion.
If we cut the periods down to strictly those after March 9, that means that Anthropic brought somewhere between somewhere between $4.5 billion and $5.58 billion in less than two months, or roughly its entire lifetime revenue.
Nevertheless, its capacity issues also make me wonder whether it’s actually taking on all that revenue, and if so, where it’s actually coming from.
Per Newcomer, as of the end of last year, 85% of Anthropic’s revenue came from API calls from companies or individuals using their models to power services. This would mean that there was roughly — assuming that number is down to around 70% given the ascent of Claude subscriptions — $3.5 billion of API spend in the space of two months, or a few thousand trillion tokens’ worth of spend.
For some context, Meta’s “token-maxing” fiasco from the beginning of April involved it burning around 60 trillion tokens in 30 days, but based on discussions with sources familiar with Meta’s spend, 80% of that was cache reads.
The Information estimates that the actual cost in that period was around $330 million, meaning that Anthropic needs at least another five — if not ten — Meta-sized customers, or such incredible dispersed demand that has effectively appeared out of nowhere in the past three months, to possibly come close to those numbers.
I personally think it’s because Anthropic is doing something peculiar with its annualized revenue calculations. Per The Information:
Anthropic calculates its annualized revenue by taking the last four weeks of application programming interface revenue and multiplying it by 13, and then adding another figure: its monthly recurring chatbot subscription revenue multiplied by 12, according to a person with direct knowledge of Anthropic’s finances. The monthly figure used to calculate recurring subscriptions is based on the number of active subscriptions that day, said the person.
The first and most-obvious place to game the numbers is that Anthropic chooses a single day’s active subscribers to anchor to its annualized revenues, which means it can preferentially select one where, say, a bunch of new people were signed up under a trial, or avoid a day where churn had users leaving. One could easily include those who are canceled but have yet to actually leave the service — such as somebody who canceled on April 7th but would still be on as a “paid” subscriber until May 8th — too.
As far as API credits go, it’s easy to manipulate a four-week-long segment based on how Anthropic bills its enterprise customers, specifically self-service enterprise deals.
In this case, Anthropic customers pre-pay a sum (say, $50 million) in credits that are billed based on their teams’ usage, and don’t expire or run out unless they’re actively consumed.
Anthropic could very, very easily manipulate this by — instead of booking based on an enterprise’s actual token burn — saying “we just got $50 million in API revenue in a calendar month!” even though that $50 million might take months to actually use.
To be fair, there are also other customers (referred to as “sales-assisted”) that are billed in arrears for their consumption. It’s unclear what the split is, and Anthropic doesn’t have to tell you.
Remember: Anthropic is a private company! It can do all the non-GAAP bullshit it likes.
When and How Does Anthropic Actually Solve Its Capacity Issues?
I keep hearing about how Anthropic is capacity-strained and all that shit, but I don’t hear any explanations as to how it fixes that problem, or what that problem actually means for the business itself. Somehow being “capacity constrained” has led to the company making more revenue, which makes me wonder whether it’s a “constraint” so much as “a company running as shitty a service as it can while billing as much as possible.”
Either way, it’s unclear how many data centers are actually getting built, or indeed how long they’re taking to build. What does Anthropic do if it’s 12-18 months away?
And really, why do these capacity constraints not seem to have any effect on its revenue growth?
While there’s a compelling argument to be made that Anthropic was the customer that would’ve bought that compute, I think we deserve an actual explanation of what Anthropic needs more compute for if it’s not “to make more money.”
Also, if it’s currently making as much money as it likes with its current capacity constraints, wouldn’t getting more compute…make the numbers worse?
Ah, fuck it, let’s move onto something funnier.
Meta Has Burned Over $150 Billion — Its AI Story Is Completely Insane Nonsense, And We Need To Stop Pretending Otherwise
Meta is probably the funniest company in the AI bubble, in the sense that it does not appear to have anything approaching an AI strategy beyond “build as much data center capacity as possible” and “lose $4 billion a quarter selling pervert glasses.”
I realize I sound a little dismissive, but nobody can actually explain to me what Meta is doing with AI in a way that remotely justifies it burning $158.25 billion in capex since 2023, with plans to spend as much as $145 billion in 2026 alone.
Now, some of you — including people I respect so much I’m not going to mention them by name! — appear to believe that Meta has some super-secret way of using all these GPUs to make “more money from ads,” and I must be clear that Meta has yet to explain that that’s the case.
This is an impressive-sounding stat that doesn’t actually connect to any meaningful revenue information, especially when Meta announced in January 2026 that doubling GEM’s compute allowed it to drive a 3.5% lift in ad clicks (a different measurement) on Facebook and “more than a 1% gain in conversions on Instagram” in Q4 2025, which is…4% lower.
You’ll note that these conversion numbers aren’t connected to any financials, which makes them a little suspicious, as 99% of Meta’s advertising revenue is ads, and “more conversions” should be fairly easy to peg to “more money”...unless said conversions aren’t actually converting into revenue for Meta’s advertisers. What does a “conversion” mean, in this case? Are these CPA ads that reward Meta on a clickthrough? Or CPM ones that pay per thousand impressions that just happen to result in a click?
Again, these are ads, which means that it’d be very easy to take that “conversion” number and turn it into “made $X,” unless of course said amount is pathetically small in the grand scheme of things.
Seriously though, what is Meta doing? I suppose it doesn’t matter when the Wall Street Journal will breathlessly write that (and I quote) Meta is envisioning “supersmart agents” and the following lede that I find to be one of the more-revolting things I’ve read about a hyperscaler recently:
Meta just offered a glimpse at what it thinks the future of work looks like: training and supervising artificial-intelligence systems to do what used to be your job. And that’s if you still have a job at all.
You may be wondering what the “glimpse” was, and it was “laying off 8000 people” and “grading employees in performance reviews on their AI use” and “making a CEO chatbot for Mark Zuckerberg to talk to.”This is an ugly, wasteful, distressed company that has no idea what to do anymore, run by a mad king who literally cannot be fired, and those who are charged with scrutinizing it will write entirely imaginary comments like “wow, Mark Zuckerberg is building supersmart agents!” without a second’s thought.
How To Argue With An AI Booster About This Round Of Tech Earnings!
The magical hysteria of the AI bubble is such that Meta, Microsoft, Google and Amazon are, despite proving no actual profit from their AI investments, effectively protected by most of the media, investors and analysts.
To be clear, I don’t think any of these companies die as a result of the bubble bursting, but I’m sick and tired of hearing everybody cover their asses with the same tired and hollow talking points, so I’ve pulled together a few of them:
“These Are Real Businesses That Print Money, They’ll Be Fine”
So, while this is technically true — as I said, these companies will not die as a result of the bubble bursting — any investor (or person who wants to deal in “the truth” rather than “stuff they misread or misremembered”) should be deeply concerned that they’ve sunk around a trillion dollars into AI capex, and all they’ve done is incubate two large, unprofitable companies that have become a burden on their infrastructure, and revenue streams that they either refuse to disclose or are both incredibly-centralized and proportionately embarrassing.
Let’s get specific: 2023, Microsoft, Google, Amazon, and Meta have spent a little over $850 billion in capex, mostly hoarding NVIDIA GPUs that will be near-to-completely obsolete by 2030.
With these GPUs comes a massive depreciation problem, as I discussed a few months ago in my time bomb premium newsletter. Every quarter, more GPUs come online, which grows the “depreciation” line on the income statement, steadily growing every quarter to the point that the Wall Street Journal projects that it will eat as much as 58% of Meta’s, 40% of Microsoft’s, and 38% of Google’s net income by 2030.
This flows neatly into my next point.
“These Businesses Are Super Profitable, And They’re Still Growing Really Fast! That’s Because of AI!”
Well, let’s be clear: whatever growth these businesses currently have is being eaten by depreciation. Last quarter, Google had $6.48 billion, Amazon $18.94 billion, Microsoft $10.1 billion, and Meta $5.9 billion, numbers that sometimes oscillate slightly down but have, year-over-year, grown by billions of dollars. And yes, year-over-year is appropriate here because this is a balance that has been steadily growing for years.
In any case, depending on the company, that “growth” is either “barely related” or “entirely unrelated” to AI.
Remember: Microsoft and Amazon are intentionally obfuscating their AI revenues by using “annualized” — a term they refuse to define that usually refers to a monthly figure times 12 — to define something in statements related to quarterly revenue. As a result, it’s impossible to precisely backtrack how much revenue they made.
In fact, that’s probably the simplest response here: if these companies were truly growing as a result of AI, they’d tell you. They’d say “AI revenue was X.” They’d say it in blunt, obvious terms. No annualized revenues, no projections, no fluff, no “AI-influenced,” just a line item that said “AI:” or even a segment, such as “Microsoft Azure AI compute.’
I also want to be clear about something else: I know, from documents viewed by this publication, that Microsoft has these line items fully itemized, and could share them if it wanted to, but intentionally chooses not to.
These companies are deliberately refusing to share their AI revenues: and it’s time for the tech and business media to begin asking them why!
“Umm, People Are PAYING For AI, Actually-”
So much that neither Google nor Meta will tell you how much!
Also, three years in, nearly a trillion dollars, and two companies have dedicated nearly their entire sales operation to pushing it, and the best they’ve got is annualized revenues and no segment breakdown.
“Oh, Microsoft has 20 million paying Copilot subscribers,” $600 million a month? For a company that makes $80 billion a quarter? That's a pathetic amount of money. You could raise more money by auctioning dogs!
I need you, please, god, to start actually using basic mathematics! Microsoft has spent $293 billion on this bullshit, and spent another $30 billion or so in the last quarter on capex!
When does this pay off?
“Anthropic and OpenAI Are Dependent On The Cloud Providers, Guaranteeing Them Revenue-”
Anyone making this point is either intentionally lying to you or incredibly ignorant. I have done the work to prove this point, and will continue to repeat it until those too incurious or deceptive learn to stop doing so.
“The Capex Will Pay Off”
How?
When?
Wwwwhen?????
Whheeeennnnnn??????????????
I’m serious, when? And how???
Not that they would, but in a scenario where Meta, Amazon, Google and Microsoft stopped spending capex on AI next quarter, they would have to make somewhere in the region of $2 trillion in brand new revenue — all while other services continued to grow — to make any of this capex worth it.
Please, explain to me how that happens when it’s taken three years and nearly three hundred billion fucking dollars for Microsoft to squirt out maybe three billion dollars in revenue (not profit), with most of that coming from OpenAI! Please, somebody, anybody explain!
You can’t!
But you know what, let’s try!
It’ll get cheaper in the future- okay, are you saying the chips will get better? Because these companies have somewhere between $100 billion and $300 billion of these fucking things.
People are starting to pay for AI- okay, but they’re not paying very much, and it’s taken so long that these companies are now burdened with endless piles of GPUs that they’ve yet to fully install. How do they catch up?
Just give it time- no! I’ve given it lots of time! Why are you being so generous to them and so impatient with me?
This is investing in tech that will turn into the most transformative tech in the future- you’re a mark!
Big Tech’s AI Story Is Unimpressive, Centralized, Unprofitable and Boring — And The AI Demand Story Is A Lie
As The Information said, around 50% of all remaining performance obligations, as in all (NOT JUST AI) of the upcoming revenue for Microsoft, Meta and Amazon, is from either OpenAI or Anthropic.
Put another way, 50% of big tech’s upcoming revenues are dependent on two companies, neither of which can afford to pay them, meaning that 50% of Meta, Amazon and Google’s revenues will either come from their own venture investments or venture capital.
This is not what stable or diverse revenue looks like, and suggests my grander thesis about AI demand is true. Outside of OpenAI and Anthropic, there’s barely any actual demand for AI services or AI compute at the scale necessary to substantiate a trillion or more in capital expenditures.
Yet the most-disgraceful part is the sheer contempt that these companies have for investors, the media, and the general public. In a functioning regulatory environment — or a market run by people with object permanence — it would be impossible to add such large amounts to your RPO balance without active scrutiny and analyst markdowns based on the fact that Anthropic and OpenAI can literally not afford to pay these bills at this time.
Microsoft, Amazon and Google have scooted along for years on the idea that they’re diverse, well-positioned companies that can build massive AI revenue streams. In reality, they’re the paypigs for Anthropic and OpenAI, providing more than 70% of their compute as a means of artificially inflating their AI revenues, knowing that analysts and the media will nod and smile without a single thought.
In fact, fuck it, I’m ending this with a rant.
The story of massive AI demand is a lie — a trillion dollars annihilated to create the largest circle jerk of all time.
Venture capitalists and hyperscalers feed money to OpenAI and Anthropic, so that venture capitalists can feed money to startups to feed to Anthropic and OpenAI, so that Anthropic and OpenAI can feed that money back to hyperscalers, who then feed that money to NVIDIA and buy more GPUs.
While it might seem tempting to credit these men as geniuses for creating companies specifically to feed them revenue, but to keep up the kayfabe of “doing AI” to substantiate this buildout means that they’ve had to massively overcommit to the bit, even though the only two meaningful businesses in AI appear to be Anthropic and OpenAI, and that’s only because they’re effectively intellectual honeypots for the entire industry.
Outside of those two, the only other competitive AI businesses are those of Amazon, Microsoft and Google — two of which now have annualized AI revenues of around 6% of their capital expenditures so far.
Google’s AI business is so booming that it refuses to break it out, and while it nebulously claims “AI is creating growth,” it’s not really clear how, and it’s vague about it because analysts and the media are ready to swallow the narrative as long as number go up.
That’s why Google doesn’t break out the number, by the way! That’s why Sundar Pichai is able to bullshit his way through every earnings call, because the media and analysts are ready to fill in the gaps in the most preferential way possible.
Amazon and Microsoft had their hands forced by the markets after their stocks stumbled, and fucked up by sharing their AI revenues. Amazon’s $298.3 billion in capex has successfully created a business that, more than a quarter of a way to a trillion, has successfully managed to make $1.25 billion dollars a month.
That’s fucking pathetic! If we had analysts with IQs above room temperature they’d run Andy Jassy out of Arlington like Shrek.
Unbe-fucking-lievable! Anthropic and OpenAI have now committed to over $718 billion of Microsoft, Amazon and Google’s revenues, despite the fact that neither of them can actually afford to pay for it. The market’s response? A slight (and short-lived) after-hours lift.
Dear members of the media: these companies are laughing at you. They know you are going to cover this in a way that makes them look good. They know you’re going to use this as proof that they’re “doing well in AI,” despite the fact that the majority of their future revenue is tied up in two oafish failsons, one of which (OpenAI) plans to burn $50 billion on compute in 2026 alone.
I realize that it’s a lot to ask people to think about things in negative terms, but things are getting a little ridiculous. These are loadbearing failsons with dysfunctional businesses! It’s very clear both of them are doing weird things with their annualized revenues, and even clearer that there’s no path to profitability!
Sadly, asking the media or analysts to act rationally or apply any real scrutiny is a joke, because this is the AI bubble, where everybody is wrong because once everybody admits what’s actually happening they’re going to have to admit they’ve all sounded insane for years. $1.25 billion a month! Andy Jassy should be ashamed of himself!
Whoopdie fucking shit man! You should be ashamed of yourself. Amy Hood should lock you out of the building. She should turn off your keycard and disconnect your keyboard.
OpenAI Gave The Tech Industry AI Psychosis, Convincing Everybody That A Dead-End Tech Was The Ultra-Panacea To The End of Hypergrowth
OpenAI is, in and of itself, a kind of psychosis generator.
It was the first thing in a long time that felt like a new thing since the iPhone for the people that entirely obsess over growth.
In theory, OpenAI’s success would lift everything at once — hardware, software, and even adjacent fields, like services. It promised to both democratize access to creating software while also heavily reinforcing existing power structures to the point that every dollar inevitably ended up in the Magnificent Seven’s pocket. It only succeeded in the latter.
The problem is that the system needed to work one day. It needed to eventually make more money than it cost. Every single one of these companies is talking about AI non-stop, and not one of them can show a profit. The only thing they can do is tell lies of omission by saying “AI helped boost everything,” and when you ask for specifics, the results are either tepid or so secretive you’d think they’re hiding a dead body.
The only reason Google, Amazon and Microsoft are being tolerated at their current excess is because their non-AI segments continue to grow through endless price-increases and enshittification, and its external business units — by which I mean OpenAI and Anthropic — are yet to die.
Sorry, I just don’t know what Meta is doing. I don’t think Meta knows what Meta is doing. Every so often it buries a fact in one of its blogs about how it saw a 3% increase in something related to AI, then it promises to burn $170 billion dollars and it’s unclear why. It also lost another $4 billion dollars on Reality Labs by the way! There should be a legitimate inquiry into where this money is going. Eighty six billion dollars and all we have is the metaverse and pervert glasses?
Elon Musk took fucking OpenAI to court. Do you think he’ll care about killing Cursor? Who’s going to be left to sue him?
Anyway, that OpenAI/Musk suit is a real Alien Versus Predator situation, and if I’m honest I’ve found whole thing a little boring, a duo of dullards shoulder-barging each other to see who can run a company that neither of them can really describe because neither of them do anything other than pontificate and take credit for other people’s work.
If this breaks OpenAI I’ll be very surprised, but if it does it would be extremely fitting that Elon would accidentally destroy the AI industry, like Mr. Bean sitting on a button that launches a nuke. If I’m wrong here it would be very funny. I’m just not giving it much hope.
Nevertheless, this entire industry is only made possible by the kayfabe circular economy of taking every single sign as good for AI and ignoring every possible glaring warning sign in the hopes that they’ll go away.
You know, like last week when Microsoft said it’s shifting GitHub Copilot to token-based billing — something I reported a week before everybody else.
This is effectively killing the product as they know it, and invalidates every single story about its revenue growth ever written. To give you some context about its scale, GitHub copilot is the second largest customer of Anthropic’s models, and was only that large because it was subsidizing the computer spend of its customers.
Why? Because that’s the only way to build any kind of AI business.
Google and Amazon realize their AI revenues are contingent on the continued survival of Anthropic, and Amazon and Microsoft’s revenues are contingent on OpenAI AND Anthropic.
They know that if these companies die they’re going to lose billions of dollars of revenue, but that they also have to compete with them for fear that they’ll be seen as “falling behind” their horrible progeny. As a result, they’re incinerating their brands and endlessly pontificating about the power or AI while spending nearly a trillion dollars on capex almost entirely to make sure their competition, which is also their customer and welfare recipient, doesn’t die.
It’s a mess, and a mistake, and eventually one of them is going to grow tired of it. Microsoft was already billions under the analyst estimates for capex. They’re moving to token based billing. They claimed to invest in Anthropic in February but didn’t mention it in their earnings in any way, shape or form.
At some point these fucknuts are going to be forced to reckon with what they’re doing.
Until then we’ll have increasingly more frenzied and ejaculatory statements about AI demand that fail to match with reality.
I truly think that it’s going to be like this if not crazier until one day when the music suddenly stops. Somebody is going to blink. Somebody is going to take a step back and give everybody else permission to stop too.
Maybe Perplexity, Lovable, Replit, or Cognition dies.
Maybe Microsoft shifting GitHub Copilot to token based billing in June first inspires others like Anthropic to follow suit.
Maybe AI token austerity begins at Microsoft, Meta, or another large company.
At the current rate of sales, it’s taking six months to install a quarter’s GPUs. At this point it’s obvious that there are warehouses of these things. It just isn’t obvious whether they’re in ones owned by hyperscalers or the Taiwanese ODMs (original design manufacturers) like Quanta Computing and Foxconn that build their servers.
None of this makes sense.
It hasn’t from the beginning. It’s the largest bubble in history, and has reached such an intellectual and financial scale that many have taken sides on it in a way that will be completely impossible to walk back if they’re wrong.
As things deteriorate, expect them to cling to their mythologies tighter and become more agitated.
And really, we’ve never seen anything like this in our lives.
You realize that Anthropic and OpenAI are insane, right? These companies have promised $718 billion to Microsoft, Google and Amazon, and cannot survive without venture capital funding, because their underlying businesses lose money on every transaction — and so help me fucking GOD if you say they’re “profitable on inference” without proof I will crush you into a cube like a car in a garbage dump!
Every single AI business you see is unprofitable, nor do any of them have a path to break-even, let alone sustainability. Nothing has changed about this story. And nobody has been able to explain the massive differences between my reporting on OpenAI’s revenues and their own leaked figures, other than to say “you must be wrong somehow,” as if that somehow invalidates “direct numbers from Azure billing.”
If you disagree with me, you really better hope I’m wrong, because I’ve got years of receipts and I can remember basically every article about AI revenues written since 2023 off the top of my head. Not a single one of my critics or any AI booster has put an iota of the same amount of effort into proving their case.
The hysteria and excess of this era has proven how many people can come to conclusions without making the effort to prove them. Disagree with me or not, I’ve done the work, and I see no proof that the other side has even started.
The world has been swept away by the fantastical ideals of Sam Altman and Dario Amodei, and two giant, unsustainable, cash-burning monstrosities that were only made possible because hyperscalers built their infrastructure for them and funded their excesses in exchange for theoretical revenues and equity stakes that give them paper gains.
Their hope, I imagine, was that in doing so, OpenAI and Anthropic would create industries surrounding them — both in the business lines attached to hyperscalers and AI startups that would potentially pay them for compute.
In the end, it appears the only way to create any real demand was to literally fund it themselves.
These men believe they’ve created perpetual energy.
What they’ve actually done is shit their pants and set their houses on fire.
Everyone, it’s time to talk about AI demand and the capacity constraint issues across the industry.
These constraints are not a result of “incredible demand” for AI, but the desperation of hyperscalers and the avariciousness of two near-trillion-dollar failsons living off their parents’ welfare. Just
Show full content
Everyone, it’s time to talk about AI demand and the capacity constraint issues across the industry.
This is not what you do when real, meaningful demand exists for AI services. Assuming that these rounds are closed at their higher limits, it will mean that Google has invested $43 billion and Amazon $33 billion in keeping Anthropic alive.
This also doesn’t make sense when you look at Anthropic’s own projections.
Per The Information, Anthropic believes it will become cash-flow-positive in the next two years after losing exactly $11 billion in both 2026 and 2027:
This only becomes more astonishing when you read that Anthropic intends to make $18 billion in 2026, $55 billion in 2027, $102 billion in 2028, and $148 billion in 2029. That’s revenue, not profit.
You may also be wondering how Anthropic goes from losing $11 billion two years running to making $2 billion in profit, and the answer is “nobody knows, including Anthropic.”
In any case, what Anthropic is saying in these projections is that it will lose $29 billion in 2026 and $66 billion in 2027. It’s also not clear what Anthropic’s actual costs will be in those years, because The Information decided it wasn’t necessary to include those. Thankfully, The Wall Street Journal did, suggesting that Anthropic intends to spend at least $86 billion on training costs alone through the end of 2029.
A gigawatt here, a gigawatt there, soon you’ll be making real money.
Except…nobody is making real money, and it appears that the vast majority of AI capacity and revenue is either going to OpenAI or Anthropic, and the rest is going to Microsoft, Google, and Amazon, who then spend that money on GPUs from NVIDIA or data centers to put them in.
What numbers we do have around AI revenues are extremely sad.
Similarly, Amazon’s $15 billion in annualized AI revenue is taken up by an estimated $12 billion in annualized AWS spend from Anthropic, and I estimate that more than 80% of that is accounted for by my estimated $12 billion in annualized spend from Anthropic.
Today I’m pushing against the grain about as hard as anybody has in the AI bubble. I fundamentally believe that the AI demand story is nonsense — a mirage created by two companies that have only been successful as a result of having near-infinite resources provided to them by hyperscalers.
Google, Amazon, and Microsoft have spent a combined $803 billion in capex on the AI bubble so far, and OpenAI and Anthropic have raised (assuming their rounds fully close) over $252 billion.
Assuming the rounds close, these three hyperscalers have sunk a combined $78 billion in funding into OpenAI and Anthropic, all while building infrastructure almost entirely in their service, and signing deals with neoclouds to continue providing it.
The AI demand story is a lie, because the only way to create a company able to actually meet said demand is for a hyperscaler to fund it themselves.
Had Amazon not given it $8 billion and Google$3 billion in its earliest days, Anthropic would’ve never been able to grow to the scale that it could spend tens of billions of dollars a year on AWS and Google Cloud, nor would OpenAI have been able to do so without the earliest infusions of over $10 billion from Microsoft (of which the majority came in the form of Azure credits), and none of this would’ve been possible had hyperscalers not effectively pre-sold their own infrastructure to their own incubated companies.
There is little “AI demand” outside of hyperscalers funnelling themselves money. The AI data center capacity crunch is a result of how long it takes to build data centers — Microsoft, Google and Amazon had an early lead, experience, and massive amounts of cash to deploy in a way that nobody else could.
Sidenote: And still, even with their experience, there’s still the insurmountable reality that building large-scale, power-hungry data center facilities takes time, and there are problems that are so big, no amount of money can make them go away. Permitting, accessing energy, and just the simple reality of building a structure from scratch are hard.
The irony is that this should be obvious to any software developer — and by extension, software company — for whom Fred Brooks’s The Mythical Man Month is still, more than fifty years later, considered essential reading, and which argues that there are things that can’t be accelerated by simply throwing money and resources at it.
Then consider the fact that a lot of the compute in the pipeline is being built by companies without that much money, and that started life in the incredibly dodgy world of crypto mining, and thus don’t have much experience in building the kinds of AI data centers that OpenAI and Anthropic need.
That’s why you can’t find A) anybody who’s spending anywhere near as much on compute as OpenAI and Anthropic and B) anybody who’s managed to compete with them at any scale. Their existence is entirely subsidized, their success a mirage, and their compute spend effectively three companies feeding themselves money.
And despite all the crowing around “the insatiable demand for compute,” there doesn’t appear to be any evidence that anybody is spending that much on it outside of Anthropic and OpenAI.
If I were wrong, we’d see literally any other AI startup signing these massive compute contracts.
Coming Up On This Week’s Where’s Your Ed At Premium…
Big Tech needs $3 trillion in new AI revenue by the end of 2030, or it’s wasted the majority of its capex.
I estimate that Anthropic and OpenAI make up at least 85% of current and future AI compute spend, either through their own direct spending or hyperscalers like Google, Amazon or Microsoft renting capacity for them.
Microsoft, Google and Amazon have built as much as 75% of their AI data center capacity to service two customers — OpenAI and Anthropic — putting the true cost of OpenAI and Anthropic, including total funding of $180 billion and $72 billion respectively, at at least $600 billion in combined infrastructure and equity investments.
And, obviously, the vast majority of their funding going toward compute spend across these three companies.
OpenAI and Anthropic cannot afford to pay their future compute commitments without hyperscaler and venture capital subsidies.
Outside of Anthropic, OpenAI, Google (for OpenAI, Anthropic and Meta), Microsoft (for OpenAI and Anthropic), Amazon (for OpenAI, Anthropic and Meta), CoreWeave (for OpenAI, Anthropic, and Meta) and Meta, less than $1 billion of actual AI compute demand exists.
In all honesty, I’ve struggled to find more than $500 million outside of Jane Street, which also funded CoreWeave.
OpenAI and Anthropic’s compute spend and demands have created an illusion of demand, becoming a systemic weakness in CoreWeave, Nebius, IREN, and TeraWulf.
Hyperscaler buildouts appear to be almost-entirely focused on either OpenAI or Anthropic, with little proof of their own services generating enough demand to fulfil them.
There is not enough revenue to substantiate the existence of the in-progress data center construction, with over $157 billion in annual revenue required to monetize the 15.2GW (11.2GW critical IT) of data centers under construction to be finished by the end of 2027.
Google is creating SPVs with investment firms to sell TPUs to itself, and has, via Broadcom, sold $63 billion in TPUs to Anthropic, which it will then bill for the compute, creating a circular financing system similar to NVIDIA’s.
To support the estimated $800 billion in GPU sales that NVIDIA claims will come through by end of 2027, there needs to be 39.6GW of new data centers constructed (only 15.2GW of which are under construction), and around $383 billion in annual AI compute demand for an industry that — even with OpenAI and Anthropic’s spend — doesn’t even reach $70 billion in annual demand.
The Information reports that OpenAI projects that its $20-a-month ChatGPT Plus subscriptions will decrease from 44 Million subscribers in 2025 to a projected 9 million subscribers in 2026.
OpenAI projects to make up the difference by increasing its ad-supported ChatGPT Go ($5 or $8-a-month depending on the region)
Show full content
Executive Summary:
The Information reports that OpenAI projects that its $20-a-month ChatGPT Plus subscriptions will decrease from 44 Million subscribers in 2025 to a projected 9 million subscribers in 2026.
OpenAI projects to make up the difference by increasing its ad-supported ChatGPT Go ($5 or $8-a-month depending on the region) subscriptions from 3 million in 2025 to 112 million in 2026.
The Information reported on April 28 that OpenAI projects an 80% decline in its $20-a-month ChatGPT Plus subscribers - from 44 million in 2025 to 9 million in 2026 - and intends to make up the shortfall using its cheaper, ad-supported "ChatGPT Go" subscriptions by growing them from 3 million in 2025 to 112 million in 2026:
OpenAI at the start of this year forecast that consumer subscribers to ChatGPT Go, which costs $8 a month in the U.S. and around $5 monthly in other countries such as India, would surge about 36 times to 112 million this year. As a result, leaders have projected that the number of subscribers to ChatGPT Plus will fall 80% to about 9 million. Users of the most expensive Pro plan will double but will still make up less than 1% of the total, the forecasts said.
That's a load-bearing "as a result" if I ever saw one. What OpenAI is actually saying here is that it's expecting a dramatic decline in its primary business line - $20-a-month ChatGPT subscriptions - and intends to somehow get 109 million new paying subscriptions of an entirely different product. As The Information noted, this would be a 3600% subscriber increase year-over-year.
Eager math-knowers in the audience will also realize that, if we assume a $5-a-month subscription cost, even if OpenAI succeeds in what would be the single-largest user acquisition campaign in history, it would still be $155 million short. I imagine OpenAI's answer would be "we're going to be serving these customers ads" and "some of them will pay $8 a month," neither of which are substantive.
Putting aside ChatGPT Go for a second, it is pretty remarkable that OpenAI is projecting an 80% decrease in ChatGPT Plus subscriptions. Perhaps this projection is something that will only come to pass if ChatGPT Go grows at such a rate...or perhaps it's something that OpenAI already sees happening, as The Wall Street Journal reported earlier in the week that OpenAI had missed revenue targets for new users and revenue, which makes the timing of this leak all-the-more suspicious.
I should also add that adding 109 million new subscribers at any price point will likely massively increase OpenAI's burn-rate.
If you liked this piece, please subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI&
I also just did a piece about how OpenAI will kill Oracle, and I’ve used some of the materials in today’s piece. It's one of my best pieces I've ever done and I'm extremely proud of it.
Subscribing to premium is both great value and makes it possible to write these large, deeply-researched free pieces every week.
Instead of offering users a certain number of “requests,” Microsoft will now charge users based on the actual cost of the models they’re using, which it calls “...an important step toward a sustainable, reliable Copilot business and experience for all users.” Users instead get however much they spend on their GitHub Copilot subscription (EG: $19 of tokens a month on a $19-a-month plan).
Translation: "we cannot continue to subsidize GitHub Copilot users, or Amy Hood will start hitting people with a baseball bat."
Anyway, the announcement itself was a fascinating preview into how these price changes are going to get framed:
Copilot is not the same product it was a year ago.
It has evolved from an in-editor assistant into an agentic platform capable of running long, multi-step coding sessions, using the latest models, and iterating across entire repositories. Agentic usage is becoming the default, and it brings significantly higher compute and inference demands.
Today, a quick chat question and a multi-hour autonomous coding session can cost the user the same amount. GitHub has absorbed much of the escalating inference cost behind that usage, but the current premium request model is no longer sustainable.
Usage-based billing fixes that. It better aligns pricing with actual usage, helps us maintain long-term service reliability, and reduces the need to gate heavy users.
You see, it’s not that Microsoft was subsidizing nearly two million people’s compute, it’s that AI has become so strong, powerful and complex that it’s basically a different product!
While Copilot might not be “...the same product it was a year ago,” very little has changed about the underlying economic mismatch: that Microsoft was allowing users to burn more than their subscription costs in tokens every single month for three years.Per the Wall Street Journal in October 2023:
Individuals pay $10 a month for the AI assistant. In the first few months of this year, the company was losing on average more than $20 a month per user, according to a person familiar with the figures, who said some users were costing the company as much as $80 a month.
I hypothesize a kind of subprime AI crisis is brewing, where almost the entire tech industry has bought in on a technology sold at a vastly-discounted rate, heavily-centralized and subsidized by big tech. At some point, the incredible, toxic burn-rate of generative AI is going to catch up with them, which in turn will lead to price increases, or companies releasing new products and features with wildly onerous rates — like the egregious $2-a-conversation rate for Salesforce’s “Agentforce” product — that will make even stalwart enterprise customers with budget to burn unable to justify the expense.
When you use these services, the company in question then pays for access to the AI models in question, either at a per-million-token rate to an AI lab, or (in the case of Anthropic and OpenAI) whatever cloud provider is renting them the GPUs to run the models. A token is basically ¾ of a word.
As a user, you do not experience token burn, just the process of inputs and outputs. AI labs obfuscate the cost of services by using “tokens” or “messages” or 5-hour-rate limits with percentage gauges, and you, as the user, do not really know how much any of it costs. On the back end, AI startups are annihilating cash, with up until recently Anthropic allowing you to burn upwards of $8 in compute for every dollar of your subscription. OpenAI allows you to do the same, though it’s hard to gauge by how much.
AI startups and hyperscalers assumed that they’d be able to get enough people through the door with subsidized, loss-making products to get them hooked on services badly enough that they’d refuse to change once businesses jacked up the prices. They also assumed, I imagine, that the cost of tokens would come down over time, versus what actually happened — while prices for some models might have come down, newer “reasoning” models burn way more tokens, which means the cost of inference has, somehow, gotten higher over time.
Both assumptions were wrong, because the monthly subscription model does not make sense for any service connected to a Large Language Model.
The Core Economics of Generative AI Are Broken
Think of it like this. When Uber (and no, this is nothing like Uber) started jacking up the prices for its rides, the underlying economics stayed the same, as did those presented to both the rider and the driver — a user paid for a ride, a driver was paid for a ride. Drivers still paid for gas, car insurance, any permits that their local government might insist upon, and whatever financing costs might be associated with their vehicle, and said costs were not subsidized by Uber. Uber’s massive losses came from subsidies, endless marketing expenses, and doomed R&D efforts into things like driverless cars .
Generative AI Subscriptions Are Nothing Like Uber
To illustrate the scale of AI’s pricing mismatch, I’m going to ask you to imagine an alternate history where Uber had a very different business model.
Generative AI subscriptions are like if Uber charged users $20 a month for 100 rides of any distance under 100 miles, and if gas was $150 a gallon, and Uber paid for the gas because somebody insisted that oil would one day be too cheap to meter.
Uber would, eventually, decide to start charging users a monthly subscription to access rides, and bill them for the gas that they consumed. Suddenly users would go from paying $20 a month for 100 rides to paying $20 to access a driver and $26 for a 10 mile drive. Understandably, users would be a little upset.
While this sounds a little dramatic, it’s actually a pretty accurate metaphor for what’s happening in the generative AI industry, and in particular, at Github Copilot.
GitHub Copilot’s previous pricing allowed 300 premium requests a month, as well as “unlimited chat requests” using models like GPT-5 mini. Each of these requests (to quote Microsoft) is “...any interaction where you ask Copilot to do something for you,” with more-expensive models taking up more requests in the later life of the request-based system, such as Claude Opus 4.6 taking up three premium requests. When you ran out of premium requests, Copilot would let you use one of those cheaper models as much as you’d like for the rest of the month.
Microsoft — like every AI company — swindled its customers by selling an unsustainable service, because it never, ever made sense to sell LLM-powered services on a monthly subscription.
If you’re wondering how much services are likely to cost under token based billing, a user on the GitHub Copilot Subreddit found that the token burn of what used to be a single premium request was somewhere around $11, as one “request” involved using 60,000 tokens in the context window, a few tools, and a bunch of internal “turns” (things that the model is doing) to produce the output.
There’s also the underlying unreliability of hallucination-prone Large Language Models. While a premium request chasing its tail and spitting out half-broken code might be frustrating, that same fuckup is a lot less forgivable when you’re paying the costs yourself.
Users have also been trained to use the product in an entirely different manner to token-based billing, and I’d imagine many of them don’t even really realize how many “tokens” they burn or how many of them a particular task takes, something which changes based on whatever model you use.
This is absolutely nothing like Uber, and anyone telling you otherwise is attempting to rationalize bad behavior. Uber may have raised prices, but it didn’t have to dramatically change the underlying economics of the platform, nor did users have to entirely change how they used the product because Uber was suddenly charging them on a per-gallon basis.
Monthly AI Subscriptions Are All Part of AI’s Subsidy Scam, A Deliberate Attempt To Separate Generative AI From Its Actual Costs
There has never been — and never will be — an economically-feasible way to offer services powered by LLMs without charging the actual token burn of each user, and in the process of deceiving said users, these companies have created products with illusory benefits and questionable return on investment.
And that’s been blatantly obvious for years.
On an economic basis, a monthly subscription only makes sense with relatively static costs. A gym can sell memberships knowing roughly how much wear-and-tear equipment gets, how much classes cost to run, and how much things like electricity, staffing and water might cost over a given period of time.
A customer of Google Workspace — at least before AI — cost whatever the cost of accessing or storing documents were, as well as the ongoing costs of Google Docs and other services. The relatively low cost of digital storage (as well as the fact that, unlike LLMs, Google Workspace isn’t particularly computationally demanding) means that a particularly-heavy Google Drive user isn’t going to eat into the margin on their monthly subscription.
Conversely, an AI subscriber’s costs can vary wildly. One user might only use ChatGPT for the occasional search, while another might feed in reams of documents, or try and refactor a codebase, or try and use it to put together a PowerPoint presentation. And the provider — a model lab like OpenAI or Anthropic, or a startup like Cursor) — has no real way to control how a user might act other than making the product worse, such as instituting usage limits, reducing the size of the context window, pushing customers to smaller (and worse) models, or changing the pricing to dissuage users from making big GPU-heavy requests.
Yet these services intentionally hide the amount of tokens or how much a particular activity has cost, which means users don’t really know what a rate limit means, which means that every abrupt change to rate limits leaves customers desperately scrambling to work out how much actual work they can do using the service.
It’s an abusive, manipulative and deceitful way of doing business that only existed so that Anthropic, OpenAI, and other AI companies could grow their user bases, as the majority of AI users perceive its real or imagined benefits entirely through the lens of being able to burn anywhere from $8 to $13.50 for every dollar of their subscription in tokens.
This intentional act of deception had one goal: to make sure that the majority of people were never exposed to the true costs of generative AI. When The Atlantic writes a breathless screed about Claude Code being Anthropic’s “ChatGPT moment,”it does so based on a $20-a-month subscription rather than the underlying token burn that it cost for Anthropic to provide it, which in turn makes the writer forgive the “minor errors” that a model might make, or when it “gets stuck on more complicated programming tasks.”
Had the writer paid for her actual token burn, and had each of the times it got “stuck” resulted in $15 in token charges, I don’t think she’d be quite as forgiving of these fuckups.
Yet that’s all part of the scam.
It’s very, very important that nobody writing about AI in the mainstream media actually understands how much these services cost, and that any mainstream articles written about services like ChatGPT or Claude Code are written by people who have little or no idea how much each individual task might cost a user.
Remember: generative AI services are, for the most part, experimental products that do not function like any other modern software or hardware. One cannot just walk up to ChatGPT or Claude and start asking it to do work.
I mean, you can, but if you don’t prompt it right, understand how it works, or make a mistake in whatever you feed it, or if it just gets things wrong, it’ll spit out something you don’t like, which in turn means you’ll need to prompt it again. LLMs are inherently unpredictable.
You cannot guarantee whether an LLM will do a particular action, or whether it will present you with an outcome based on reality. You cannot for certain say how much a particular task — even one you’ve done many times using an LLM in the past — might cost, nor can you be sure when a model might go berserk and delete something, or simply not do something yet claim that it did.
These are far more forgivable if you’ve not paying on a per-token basis, because in the mind of a subscriber, that’s just another turn or two with a chatbot rather than something that’s incurring a real cost. One doesn’t criticize so-called “jagged intelligence” because the assumption is that whatever problems you’re facing now will be eliminated at some future juncture, and you didn’t end up paying for it anyway.
Had users been forced to pay their actual rates, I imagine many would’ve bounced off the product immediately, as it’s very, very easy to burn through $5 of tokens if you’re fucking around and exploring what an LLM can do.
Sidenote: In fact, you can burn a great deal of money without ever getting the outcome you desire, because LLMs aren’t really artificial intelligence at all! Somebody without any real understanding of their limitations could easily burn $30, or $50, or even $100 trying to convince an LLM to do something it insists it’s capable of.
There’s a term for this. Sycophancy. LLMs are often designed to affirm the user, even when they’re saying dangerously unhinged things, and that can extend to saying “you want this big thing that’s not even slightly feasible, whether technically or financially?” Sure thing!
This is why the industry worked so hard to obfuscate these costs — it’s a fucking ripoff!
I think it’s inevitable that the majority of AI subscriptions move to token-based billing, especially as both Anthropic and OpenAI have now done so with their enterprise customers.
The fact that Microsoft moved GitHub Copilot subscribers to token-based is also a very, very bad sign. Microsoft is arguably the best-capitalized, most-profitable, and best-positioned company to continue subsidizing compute, and if it can’t afford to do so further, nobody else can either.
The real thing to look out for — a true pale horse — will be a major AI lab like Anthropic or OpenAI moving all of its subscribers to token-based billing. Once that happens, you’ll know it’s closing time.
Can The Average Company Afford To Move To Token-Based Billing? Anthropic Estimates Users Spend $13-$30 a day ($7K+ a year) On Claude Code, As Large Organizations Spend Hundreds of Thousands or Millions A Year
This is the direct result of training every single AI user to use these services as much as humanely possible while obfuscating how much they really cost. Every single major company demanding that every single worker “use AI as much as possible” has done so while either fundamentally ignoring or being entirely disconnected from their actual token burn, and as companies are forced to pay the actual costs, I’m not sure how you can economically justify any investment in this technology.
Sure, sure, you’re gonna say that engineers are “shipping code faster” or some such bullshit, I get it, but how much faster, and how much money are you making or saving as a result? If you’re spending 10% of your headcount on AI tokens, are you seeing that extra expense reconciled in some other way? Because I’m not sure you are. I’m not sure any business investing these vast amounts of money in tokens is seeing any return on investment, which is why everystudy about AI’s ROI struggles to find much evidence that it exists.
For the most part, everybody you’ve read gooning over the many possibilities of generative AI has experienced it without having to pay the true costs. Every Twitter psychopath writing endless screeds about their entire engineering team hammering away at Claude Code has been doing so using a $125-a-month-per-head Teams subscription with similar usage limits to Anthropic’s $100-a-month consumer subscription. Every LinkedIn gargoyle insisting that they’d “done hours of work in minutes” using some sort of Perplexity product has done so by paying, at the very most, $200 a month for Perplexity’s Max subscription.
In reality, that 10-person, $1250-a-month Teams subscription likely burns anywhere from $5000 to $10,000 a month in API calls, if not more. Anthropic Head of Growth Amol Avasare said last week that its Max subscriptions were built for heavy chat usage rather than whatever people are doing with Claude Code and Cowork, and made it clear that Anthropic is now looking at “different options to keep delivering a great experience,” which is another way of saying “we’re going to change the prices at some point.”
I’m not sure people realize how expensive these tokens are, especially for coding projects that involve massive codebases and regularly make calls to coding and infrastructure tools. Can somebody who pays $200 a month foreseeably afford $350, $400, or $500? Can they afford to have a month where they spend more than that? What happens if they go over budget, or if they literally can’t afford to spend the money necessary to finish their work?
To give you a more-practical example, up until the beginning of April, Anthropic’s own Claude Code developer documents (archive) said that “the average cost [for those using Claude Code] is $6 per developer per day, with daily costs remaining below $12 for 90% of users.” As of this week, the documents now read as follows:
Claude Code charges by API token consumption. For subscription plan pricing (Pro, Max, Team, Enterprise), see claude.com/pricing. Per-developer costs vary widely based on model selection, codebase size, and usage patterns such as running multiple instances or automation.
Across enterprise deployments, the average cost is around $13 per developer per active day and $150-250 per developer per month, with costs remaining below $30 per active day for 90% of users. To estimate spend for your own team, start with a small pilot group and use the tracking tools below to establish a baseline before wider rollout.
If we assume an average of 21 working days in a month, that puts the average cost of a Claude Code user at around $273 a month, or $3,276 a year. At $30 a working day, that works out to $630 a month, or $7560 a year.
These are astonishing numbers, made more so by the fact that there is no way you’re only spending $30 a day if you use any of Anthropic’s more-recent models. Claude Opus 4.7 costs $5 per million input and $25 per million output tokens. ‘One million tokens is around 50,000 lines of code, and assuming you’re using the supposedly state-of-the-art models, there isn’t a chance in Hell you don’t run through at least a million, with that number increasing dramatically if you’re not particularly aware of which models to use for a particular task.
Let’s play with that $30 number a little more.
For a ten person dev team, that’s $75,600 a year, and we’re only counting working days.
If you raise a mere three months to an average of $50 a working day, that raises to $88,200
If you add a single month where you go over $100, you’re spending $102,900 a year.
If you spend $300 a day, you’re now spending $756,000 on tokens for ten people.
While this might be possible within the slush fund mindset of a well-funded startup or a banana republic like Meta, any business that actually cares about its costs will have a great deal of trouble justifying spending five or six figures in extra costs on a service that “increases productivity” in a way that nobody can seem to measure.
Right now, I think most companies fall into three camps:
Enterprise deployments in massive organizations like Spotify or Uber with AI-pilled CEOs that allow budgets to run wild.
I’d also say this is the case in large, well-funded startups.
Smaller startups that use the subsidized “Teams” subscription.
Individual users paying a monthly fee to access Claude or other AI subscriptions.
All it changes is one bad earnings call to change that narrative. At some point investors — even the braindead fuckwits who have been inflating the AI bubble — will begin to question mounting R&D costs (which is where AI token burn is usually hidden) when the company’s revenue growth fails to follow. This will likely lead to more layoffs to keep up with the cost, as was the case with Meta, and then an eventual pullback when somebody asks “does any of this shit actually help us do our jobs faster or better?”
I also think that startups burning 10% or more of their headcount in AI tokens will have a tough time convincing investors in six months that doing so is necessary.
And once everybody switches to token-based billing, I’m not sure we’ll see quite as much hype around generative AI.
The Economics of AI Data Centers And Compute Do Not Make Sense
The way that people talk about AI data centers is completely disconnected from reality, and I don’t think people realize how ridiculous this entire era has become.
AI Data Centers Are Expensive To Build, Expensive To Run and Make Very Little Actual Revenue
Per Jerome Darling of TD Cowen, it costs around $30 million in critical IT (GPUs and the associated hardware) and $14 million per megawatt of data center capacity. Data centers appear to take anywhere from a year to three years depending on the size, and that’s assuming the power is available.
Of the 114GW of data centers supposedly being built by the end of 2028, only 15.2GW is under construction in any way, shape, or form. And “under construction” can mean as little as “there’s a hole in the ground.” It does not — and should not — imply that the capacity that said facility will provide is going to be imminently available.
Sidebar: If you’re interested in some of the deeper math here, please subscribe to my premium newsletter so that you can see my Bastard Data Center Model, which I created with the assistance of multiple analysts and hyperscaler sources.
Let’s start simple: whenever you think “100MW,” think “$4.4 billion,” with a large chunk of that dedicated to NVIDIA GPUs.
As a result, every AI data center starts millions of dollars in the hole, and even with six-year-long depreciation schedules, takes years to pay off… and with NVIDIA’s yearly upgrade cycle, those GPUs are unlikely to make that much money once you’re done with your first customer contract.
In any case, it’s also unclear what kind of ongoing rates these data centers charge. While spot prices might sit around $4.50 an hour for a B200 GPU, long-term contracts generally price much lower, with one founder (per The Information) saying they paid around $3.70-per-hour-per GPU for a one-year-long commitment.
To be clear, we must differentiate between the spot cost — which is the cost of randomly spinning up GPUs on somebody else’s servers — and contracted compute, the latter of which makes up the majority of data center capex. Most data centers are built with the intention of having one or two big clients, which means said clients are likely to negotiate a cheaper blended rate.
As a result, many data centers take far less than $3.70 an hour, because they bill at a per-megawatt (or kilowatt) price.
And that’s where the economics begin to break down.
The Broken Economics of a 100MW Data center — $2.55 An Hour, 16% Gross Margin With 100% Tenancy, Unprofitable Because of Debt
That’s the starting cost for a 100 megawatt data center. A 100MW data center will likely only have 85MW of actual stuff it can bill for, and based on discussions with sources familiar with hyperscaler billing, they can expect to make around $12.5 million per megawatt, or around $1.063 billion in annual revenue.
Now, I should be clear that most data center companies you know of don’t actually build them, instead leaving that job to companies like Applied Digital, who are also known as “colocation partners.” For example, CoreWeave pays a colocation fee to Applied Digital to use its North Dakota data centers. CoreWeave is responsible for all the GPUs and other tech inside the data center.
To explain the economic mismatch, I’m going to use a theoretical example of a data center leased to a theoretical AI compute company.
The GPUs in that data center are likely NVIDIA’s Blackwell chips. More than likely, said data center is using pods of 8 B200 GPUs, retailing around $450,000 a piece, or $56,250 a GPU. Based on there being 85MW of Critical IT load, the all-in capex per megawatt is around $36.78, or total IT capex of around $3.126 billion, or around $2.67 billion in GPUs.
Let’s assume this data center is in Ellendale, North Dakota, which means you’ve got an industrial electricity rate of around 6.31 cents per kilowatt hour, which works out to about $55.4 million a year in electricity costs. Based on discussions with sources, I estimate that ongoing costs like maintenance, headcount, replacement of power supplies and the like comes in at around 12% of revenue, or around $128 million a year, bringing us up to $183.4 million in costs.
Wait, sorry. You’ve also got to pay a colocation fee based on the critical IT, and according to Brightlio, that fee is often around $180-200 per kilowatt per month, depending on the scale and location of the deployment, though I’ve read as low as $130, which is the number I’m going with, or around $133 million per year. This brings us up to $316.4 million.
Well, that’s still less than $1.06 billion, so we’re still doing okay, right?
Wrong! You’ve got $3.126 billion in IT gear to depreciate, which works out to around $521 million a year over the six years you’re depreciating it. That’s $837.4 million a year, leaving you with around $168.6 million in yearly profit, or around a 16.7% gross margin…
…if you have 100% tenancy at all times! You see, data centers can take a month or two to get those GPUs installed and a customer onboarded, all while making you exactly zero dollars in revenue and losing you a great deal more, as you’re stuck paying your colocation, electricity and opex costs the whole time, albeit at a much lower rate (I’ve modeled for 10% electricity and 15% colocation/opex costs), meaning you’re losing about $3.27 million a day.
For the sake of this example, we’re going to assume it takes you an extra month to get this thing operational, meaning you’ve paid about $102 million that you’re never getting back, bringing our total costs for the year including depreciation to $939.4 million, or a 6.6% gross margin.
Wait, fuck, you didn’t use debt to buy these GPUs, did you? You did? How bad are we talking? Oh god — you got a 6-year-long asset-backed loan at 80% LTV, meaning you borrowed $2.8 billion at a 6% interest rate.
Your bank, in its eternal generosity, offered you a deal — a 12-month-long grace period where you’re only paying interest…which works out to around $168 million, which brings our total costs (excluding the month of delay for fairness) for the first year to around $1.005 billion…on $1.06 billion of revenue.
That’s a 5.19% gross margin, and you haven’t even started paying the principal. When that happens, you’re paying $54.1 million a month in loan payments, for a total of around $649 million a year for five more years, which comes out to around $1.48 billion, or a negative gross margin of around 40%.
And I must be clear that this is if you have 100% utilization and a tenant that pays you on time, every time.
Stargate Abilene Is A Disaster — $2.94-per-GPU-per-hour, $10 Billion In Annual Revenue, Years Behind Schedule, One Tenant That Loses Billions of Dollars A Year
Let’s talk about what should be the single-most economically viable project in data center history — a massive campus built for the largest AI company in the world by Oracle, a decades-old near-hyperscaler with a history of selling expensive database and business management software to enterprises and governments.
Hah, I’m kidding of course, this place is a fucking nightmare.
Per my own reporting, Oracle expects to make around $10 billion in annual revenue from Stargate Abilene, and I estimate around $75 billion in total revenue from the 7.1GW of data center capacity it’s building for one customer: OpenAI. As I also reported, Oracle estimated in 2024 that Abilene would cost at least $2.14 billion a year in colocation and electricity fees, paid to land developer Crusoe.
I should also add that it appears that Oracle is paying all of Abilene’s construction costs.
Based on my calculations and reporting, I estimate Abilene’s rough gross margin is around 37.47% once it’s fully operational:
I must be clear that that 37.47% gross margin is likely too high, as I don’t have precise knowledge of Oracle’s true insurance or headcount costs, only estimates based on documents viewed by this publication. I should also be clear that Oracle is mortgaging its entire fucking future on projects like Stargate Abilene, incurring billions of dollars of costs up front for a business that will take years to turn a profit even if OpenAI makes every single payment in a timely manner.
I also need to be clear that that $3.85 billion in yearly profit is only possible if OpenAI makes timely payments, takes tenancy of Abilene as fast as humanly possible, and everything goes to plan.
If OpenAI Fails To Raise $852 Billion In Revenue, Funding, and Debt Throughout The Next 4 Years, The Stargate Data Center Project Will Kill Oracle
Four months later on April 22, 2026, Oracle tweeted that “...in Abilene, 200MW is already operational, and delivery of the eight-building campus remains on schedule.” It is unclear if that’s 200MW of critical IT capacity or the total available power at the Abilene campus, and in any case, this is only enough power for two buildings, which means that Oracle is most decidedly not “on schedule.”
This is a huge issue. OpenAI can only pay for compute that actually exists, and only 206MW of critical IT is actually generating revenue, with the third at least a month (if not a quarter) away from doing so.
Yet there’s a larger, more-existential problem with the overall Stargate data center project — that the only way any of it makes sense is if OpenAI meets its ridiculous, cartoonish projections.
I’ll repeat the numbers: the 7.1GW of Stargate data centers in progress will make around $75 billion in annual revenue on completion, and cost more than $340 billion in total. Oracle’s free cash flow was negative $24.7 billion, and its other business lines are plateauing, making its negative-to-low margin cloud business its only growth engine.
For OpenAI to actually be able to pay its compute deals — both to partners like Amazon, Microsoft, CoreWeave, Google, Cerberas, and to Oracle — it will have to raise or make $852 billion in revenue and/or funding in the space of four years, which would require its business to grow by more than 250%, every single year, effectively 10xing by the end of 2030, at which point it will have had to find a way to become cashflow positive for any of these numbers to make sense.
To be clear, OpenAI’s projections have it making $673 billion over the next four years, and burning $218 billion to get there. It is an incredibly unprofitable business, and even if it wasn’t, it would have to make so much more money than it currently does to pay Oracle on an ongoing basis.
I calculated that $75 billion number by assuming that Vera Rubin GPUs get around $14 million per megawatt of compute (a number I’ve confirmed with sources familiar with the data center industry) across the remaining 4.64GW of critical IT that I anticipate makes up the remaining Stargate data centers.
I must be clear that any journalist repeating these numbers without saying how fucking stupid they are should be a little ashamed of themselves. Per my Friday premium:
Either way, Oracle is insufficiently-capitalized to finish Stargate Abilene. It will need at least another $150 billion to get this done, and that’s assuming that other partners pick up about $30 billion in costs. Honestly, it may be more.
I really need to be clear that Oracle has no other path to making this revenue without OpenAI, and these projects are entirely financed and paid for using the projected cashflow of the data centers themselves.
And I’m not even the only one worried about this, with OpenAI Sarah Friar sharing similar concerns after the company missed user and revenue targets, per the Wall Street Journal:
OpenAI recently missed its own targets for new users and revenue, stumbles that have raised concern among some company leaders about whether it will be able to support its massive spending on data centers.
Chief Financial Officer Sarah Friar has told other company leaders that she is worried the company might not be able to pay for future computing contracts if revenue doesn’t grow fast enough, according to people familiar with the matter.
Board directors have also more closely examined the company’s data-center deals in recent months and questioned Chief Executive Sam Altman’s efforts to secure even more computing power despite the business slowdown, the people said.
If that doesn’t worry you, perhaps this will:
She has emphasized to executives and board directors the need for OpenAI to improve its internal controls, cautioning that the company isn’t yet ready to meet the rigorous reporting standards required of a public company. Altman has favored a more aggressive timeline for an IPO, some of the people said.
That sure sounds like a company that’s gonna be able to make $852 billion by the end of the decade!
Anthropic Is Just As Bad As OpenAI, Committing To Up To 10GW ($100BN+ Annual Revenue) In Compute From Google and Amazon
While I regularly bag on OpenAI for its ridiculous promises, Anthropic isn’t far behind, promising to take “up to” 5GW of capacity from both Google and Amazon in a deal that I estimate includes around $100 billion in actual compute commitments given the scale of the capacity.
Now, I should add that Google and Amazon are far-savvier and less-desperate than Oracle, meaning that they can take the hit if Anthropic ends up running out of money. The “up to” part of that deal gives them some much-needed wiggle room that Oracle simply does not have.
Nevertheless, for Anthropic to actually meet its commitments, it will have to agree to spend anywhere from $25 billion to $100 billion a year on compute by the end of 2030.
There Needs To Be $156.8 Billion In AI Annual Compute Revenue To Support The 15.2GW of AI Data Centers Under Construction, and $1.18 Trillion To Support All 114GW Announced
The near-pornographic excitement around however many hundreds of billions of dollars of GPUs that Jensen Huang claims to be shifting regularly clouds out a problematic question: sell the compute to who, Jensen?
If we assume that the 15.2GW of data center capacity under construction (due by the end of 2028) has a PUE of around 1.35, that leaves us with roughly 11.2GW of critical IT. At $14 million per megawatt, that works out to around $156.8 billion in annual revenue in GPU rental revenue required to actually make these data centers worth it.
When you calculate for the 114GW of capacity theoretically coming online by the end of 2028, that number climbs to $1.18 trillion in annual revenue.
Who, exactly, is the customer for all this compute, and how likely is it that they’ll want to buy it by the time all that capacity is built? While many different data centers claim to have tenants for the first few years of their existence, said tenants can only start paying once the data center completes, and if it’s an AI startup, I think it’s fairly reasonable to ask whether they exist by the time it’s built.
Remember: the customers of AI compute are, for the most part, either hyperscalers trying to move capital expenditures off their balance sheets or unprofitable AI startups. Anthropic and OpenAI both intend to burn tens of billions of dollars in the next few years, and neither of them have a path to profitability.
This means that a large part — if not the majority of — AI compute revenue is dependent on a continual flow of venture capital and debt, both of which are only made possible by investors that still believe that generative AI will be the biggest, most hugest thing in the world.
How does that work out, exactly? Who is paying for this data center capacity? Who is it for? Where is the actual demand?
And if said demand exists, how the fuck do the customers even pay?
Generative AI Is Unprofitable and Unsustainable, And Only Getting More Expensive
Despite multiplestories that have both of them becoming profitable by 2028 or 2029, nobody can explain to me how OpenAI or Anthropic actually reach profitability, especially given that both of them had worse margins than expected, even when said margins strip out training costs that number in the billions of dollars.
And I’ve been asking this question for fucking years. Every time we get a new update on Anthropic or OpenAI, we hear they’ve lost billions more dollars than expected, that margins are decaying, that costs are skyrocketing, that everything is more expensive despite promises that the literal opposite would happen.
Even Cursor, a company that briefly (before its pseudo-acquisition by Musk’s SpaceX) claimed it had positive gross margins, actually had negative 23% gross margins as of January, or negative 31% if you include the cost of non-paying users, which you fucking should if you actually care about your accounting. Mysteriously, reports claim that Cursor’s margins “recently turned positive,” but magically don’t know by how much, or how that happened, or a single other detail other than one that likely helped the company get sold.
I also don’t see how any of these AI data centers actually make sense, even if they have customers to pay them for the first few years. The economics are built for perfection, with zero fault tolerance. They must have consistent, 100% utilization and tenancy, or they end up burning millions of dollars and fail to chip away at the years-long wall of depreciation created by the tech industry’s most expensive mistake.
Even if they somehow succeed, these are pathetic businesses with mediocre margins — 70% at best, assuming consistent payments, tenancy, and six fucking years of depreciation to actually break even, which might be difficult considering the yearly upgrade cycle makes the entire thing near-obsolete by the time you’re done paying it off.
And that’s before you consider that the majority of the customers are unprofitable, unsustainable startups.
I truly don’t know how any of this works out.
LLMs Are A Ripoff, And Customers Have Been Lied To
I realize it seems a little much, but I genuinely believe that subscription-based AI services were an act of deception tantamount to fraud, as they misrepresented the core unit economics and thus the possibilities of a Large Language Model. By selling users a product on a monthly rate and creating habits based on its availability, companies like Anthropic and OpenAI have misrepresented their businesses in such a way that most of their users are interacting with products and building workflows based on products that are unsustainable and impossible to maintain in their current form.
Anthropic’s recent aggressive rate limit changes were instituted mere months after multiple aggressive marketing campaigns based on experiences that are now near-impossible under the current rate limits, and based on recent moves by Anthropic, it’s clear that it intends to start removing services for its lower-tier $20-a-month subscribers at some time in the future. This is a disgusting and misleading way to run a company, and the vagueness with which Anthropic discusses its products and its services are an insult to every one of their users, and a sign that it doesn’t fear the press in any meaningful way.
I need to be very clear that the product that Anthropic offers — by virtue of recent rate limit changes — is substantially different (and far worse) than the one that you read about everywhere. Anthropic was conscious in its deliberate attempts to market a product that it knew would be gone within three months. Dario Amodei doesn’t give a fuck as long as the media keeps writing up however many billions of annualized revenue he’s conjured up today or whatever new product he’s released that’s meant to destroy some hapless public SaaS company that had already seen its growth slow.
Members of the media, I say this with abundant respect: Anthropic is mistreating its customers, and it is doing so because it believes it can get away with it. This company does not respect you, and in fact holds you with a remarkable degree of contempt, which is why it doesn’t bother to fix its services very quickly or explain why they were broken with any level of coherence.
That’s why Anthropic fucking lied about Claude Mythos being too powerful to release (it was actually a capacity issue) when in fact it’s just another fucking Large Language Model Nothingburger — because it thinks you will buy whatever it is selling, and it’s worked out exactly how to package it to give you enough plausible “proof” that a quick skimread of the system card will make you and your editor believe whatever it is you’re saying.
They also know you’ll rush to cover it rather than waiting to see what actual experts say.
AI is a con, and this is how the con works. AI was rushed and pushed in our faces as quickly as humanly possible in the least-efficient yet most-accessible form it could be presented, even if said form was never going to result in anything resembling a sustainable business. The media was rushed to immediately say that this was the thing so that everybody would agree that this was the thing now and use it as much as physically possible, and, crucially, use it in a subscription-based form that would make people experience it without ever asking how much it costs to provide.
The narrative came pre-baked. Because very few people who talked about LLMs experienced their actual cost, it was really easy for them to vaguely say “it’s just like Uber,” because that was a company that lost a lot of money but didn’t die, and it’s much easier to say that than say “wait, what do you mean OpenAI is set to lose $5 billion this year?”
Think of it like this: as a reporter, an investor, an executive, or a regular LinkedIn Lounge Lizard, you might read here and there that it’s $5 per million input tokens and $25 per million output tokens, but you’ve never really experienced how fast or slow one loses that money, because it’s important to do so to truly understand this product. Anthropic and OpenAI intentionally obfuscated that experience and created businesses that expect to burn tens of billions of dollars in 2026 and several hundred billion dollars by 2030, all because most people graded generative AI based on the subscription-based experience.
LLMs are a casino, and you’ve been gambling with the house’s money while encouraging people to bet their own on whether they’ll get a unit of work out of a particular model.
This was intentional. They never wanted you thinking about the costs because once you really start thinking about the costs this whole thing feels a little insane. I truly believe that LLM-based subscriptions are going to go away entirely, at least at the scale of any product that generates code, and in doing so, Amodei and Altman will wrap up their con, or at least believe that they have.
The problem is that these men have now signed far too many deals to get away scot-free.
OpenAI’s CFO has now said multipletimes that she doesn’t believe OpenAI is ready for IPO, and has material concerns about its growth and continued ability to meet its obligations. To repeat a quote from before:
Chief Financial Officer Sarah Friar has told other company leaders that she is worried the company might not be able to pay for future computing contracts if revenue doesn’t grow fast enough, according to people familiar with the matter.
This is a blinking red fucking light, and in a sane market would send Oracle’s stock into a tailspin, because OpenAI’s ascent to over $280 billion in annual revenue is critical to Oracle’s ability to not run out of money. In a sane media, this would send worrisome shockwaves through every group chat and Slack channel about whether or not OpenAI is actually going to make it.
This is the kind of thing that happens before a company starts dying. OpenAI’s growth is slowing at precisely the time it needs to accelerate. It needs to effectively 10x its current business by 2030 to make its obligations. OpenAI’s CFO, the literal person who would know best, is saying that she is worried that OpenAI cannot pay its fucking compute contracts if revenue doesn’t grow. This is a big, blinking warning light! This is not a drill!
Yet the bit that really worried me was the Journal’s comment that Friar didn’t think OpenAI “was ready to meet the rigorous reporting standards required of a public company.”
I’d generally not be so fucking nosy if it wasn’t for the fact that this company accounted for something like 20% of all venture capital funding in the last year and everywhere I go I have to hear the endless bloviating of Altman and Brockman and every other man at OpenAI and their fucking ideas about what regular people should do as they swan about shipping dogshit software and spending other people’s money.
For the amount of oxygen that both Anthropic and OpenAI consume, both of these companies should be fucking flawless, both as products and businesses. Instead, both are sold through varying levels of deception around their economics and efficacy, obfuscating the truth so that their Chief Executives can amass money and power and attention. It’s an insult to both good software and good taste — the most-expensive, least-reliable applications ever invented, their mistakes forgiven, their mediocrities celebrated, their infrastructure hailed as an inert god of capital.
Generative AI is an insult. It is unreliable, its economics don’t make sense, its outcomes don’t justify its existence, and the perpetrators of its con are boring, oafish and avaricious men disconnected from society and anybody who would ever disagree with them. It requires stealing art from everybody, destroying the environment, increasing our electricity bills, the constant threat of economic annihilation, the endless cacaphony of “everything fucking sucks now because of AI,” all to push software that can only be justified by people willing to ignore basic finance or sense.
It’s all so expensive, and it’s all so fucking dull. It’s offensively boring. It’s actively annoying. Every story where somebody tells you about how much they use AI sounds like they’re in an abusive relationship and/or joined a cult, echoing with a subtle desperation that says “you really need to join me in this because it’s so good, and the fact that I appear to be experiencing no joy from this product is just a sign of how efficient it is.” There is nothing light-hearted or joyful about what AI can do. There is nothing goofy or whimsical about a Large Language Model, and every interaction feels hollow.
Those who desperately look for clues that it’s becoming sentient or “more powerful” are simply seeking validation themselves — they want to be first to something, because arriving at other people’s conclusion is what they do for a living.
Being “first” — on the “frontier” one might say — is something that people crave when they can’t find something within, and it’s exactly the fuel that grifters crave, because LLMs are constantly humming with the sense that they’re about to do something new, even though they’re mathematically restricted to repeating other actions.
This is a deeply sad era. The people that have so aggressively worked together to hold up this industry have only delayed its inevitable fall. It’s terrifying to me that our markets and parts of our economy are being held up by the generally-held yet utterly-unproven assumption that LLMs will somehow get cheaper, that AI startups will magically become profitable, and that offering AI compute will be profitable in perpetuity to the point that it necessitates increasing the current supply tenfold by the year 2030.
People have debased themselves to defend the AI industry, because that’s what the industry demands of its supplicants. To be an “AI expert” requires you to actively ignore the worst economics of any industry in history, to constantly explain away obvious, glaring issues with products, and to actively convince others to do the same. OpenAI and Anthropic do not provide clear explanations of how they’ll become profitable because they know that their supporters will never ask for them — because the only way to fully “believe in AI” is to actively wear blinders.
And I get it. If you accept that OpenAI and/or Anthropic will eventually collapse, all of this seems a little insane. I am genuinely asking you to seriously consider that one or both of these companies will run out of money.
I’m really worried, made only more so by the general lack of concern I’m seeing in the media and greater society.
The assumption, if I had to imagine, is that I’m simply being alarmist, and that “the demand will absolutely be there.”
You’d better hope you’re right.
For Larry Ellison’s sake, at least. Ellison has already pledged 346 million shares of his Oracle stock — or around $61.5 billion — “to secure certain personal indebtedness, including various lines of credit,” meaning “many big, beautiful loans against his Oracle shares.” which IFR estimated back in September (when Oracle’s stock price was much higher) could allow him to secure as much as $21.4 billion in debt at a (they say “conservative”) loan-to-value ratio of 20%, and that’s assuming the banks weren’t particularly generous.
If OpenAI can’t raise $852 billion in revenue and funding by the end of 2030, it won’t be able to pay for Stargate. That’ll kill the value of Oracle’s stock, leading to a series of margin calls, leading to Ellison having to sell shares, leading to further margin calls. Whatever bailout might or might not exist won’t save Larry’s estate.
What I’m saying is that Ellison’s future rides on Sam Altman’s ability to raise funding and make revenue to the tune of $852 billion in the space of 4 years.
Hello premium subs! This is your ad-free free newsletter for the week. Questions? Queries? Email me at ez@betteroffline.com, and if you have a scoop, ezitron.76 is my Signal.
Hello premium subs! This is your ad-free free newsletter for the week. Questions? Queries? Email me at ez@betteroffline.com, and if you have a scoop, ezitron.76 is my Signal.
Instead of offering users a certain number of “requests,” Microsoft will now charge users based on the actual cost of the models they’re using, which it calls “...an important step toward a sustainable, reliable Copilot business and experience for all users.” Users instead get however much they spend on their GitHub Copilot subscription (EG: $19 of tokens a month on a $19-a-month plan).
Translation: "we cannot continue to subsidize GitHub Copilot users, or Amy Hood will start hitting people with a baseball bat."
Anyway, the announcement itself was a fascinating preview into how these price changes are going to get framed:
Copilot is not the same product it was a year ago.
It has evolved from an in-editor assistant into an agentic platform capable of running long, multi-step coding sessions, using the latest models, and iterating across entire repositories. Agentic usage is becoming the default, and it brings significantly higher compute and inference demands.
Today, a quick chat question and a multi-hour autonomous coding session can cost the user the same amount. GitHub has absorbed much of the escalating inference cost behind that usage, but the current premium request model is no longer sustainable.
Usage-based billing fixes that. It better aligns pricing with actual usage, helps us maintain long-term service reliability, and reduces the need to gate heavy users.
You see, it’s not that Microsoft was subsidizing nearly two million people’s compute, it’s that AI has become so strong, powerful and complex that it’s basically a different product!
While Copilot might not be “...the same product it was a year ago,” very little has changed about the underlying economic mismatch: that Microsoft was allowing users to burn more than their subscription costs in tokens every single month for three years.Per the Wall Street Journal in October 2023:
Individuals pay $10 a month for the AI assistant. In the first few months of this year, the company was losing on average more than $20 a month per user, according to a person familiar with the figures, who said some users were costing the company as much as $80 a month.
I hypothesize a kind of subprime AI crisis is brewing, where almost the entire tech industry has bought in on a technology sold at a vastly-discounted rate, heavily-centralized and subsidized by big tech. At some point, the incredible, toxic burn-rate of generative AI is going to catch up with them, which in turn will lead to price increases, or companies releasing new products and features with wildly onerous rates — like the egregious $2-a-conversation rate for Salesforce’s “Agentforce” product — that will make even stalwart enterprise customers with budget to burn unable to justify the expense.
When you use these services, the company in question then pays for access to the AI models in question, either at a per-million-token rate to an AI lab, or (in the case of Anthropic and OpenAI) whatever cloud provider is renting them the GPUs to run the models. A token is basically ¾ of a word.
As a user, you do not experience token burn, just the process of inputs and outputs. AI labs obfuscate the cost of services by using “tokens” or “messages” or 5-hour-rate limits with percentage gauges, and you, as the user, do not really know how much any of it costs. On the back end, AI startups are annihilating cash, with up until recently Anthropic allowing you to burn upwards of $8 in compute for every dollar of your subscription. OpenAI allows you to do the same, though it’s hard to gauge by how much.
AI startups and hyperscalers assumed that they’d be able to get enough people through the door with subsidized, loss-making products to get them hooked on services badly enough that they’d refuse to change once businesses jacked up the prices. They also assumed, I imagine, that the cost of tokens would come down over time, versus what actually happened — while prices for some models might have come down, newer “reasoning” models burn way more tokens, which means the cost of inference has, somehow, gotten higher over time.
Both assumptions were wrong, because the monthly subscription model does not make sense for any service connected to a Large Language Model.
The Core Economics of Generative AI Are Broken
Think of it like this. When Uber (and no, this is nothing like Uber) started jacking up the prices for its rides, the underlying economics stayed the same, as did those presented to both the rider and the driver — a user paid for a ride, a driver was paid for a ride. Drivers still paid for gas, car insurance, any permits that their local government might insist upon, and whatever financing costs might be associated with their vehicle, and said costs were not subsidized by Uber. Uber’s massive losses came from subsidies, endless marketing expenses, and doomed R&D efforts into things like driverless cars .
Generative AI Subscriptions Are Nothing Like Uber
To illustrate the scale of AI’s pricing mismatch, I’m going to ask you to imagine an alternate history where Uber had a very different business model.
Generative AI subscriptions are like if Uber charged users $20 a month for 100 rides of any distance under 100 miles, and if gas was $150 a gallon, and Uber paid for the gas because somebody insisted that oil would one day be too cheap to meter.
Uber would, eventually, decide to start charging users a monthly subscription to access rides, and bill them for the gas that they consumed. Suddenly users would go from paying $20 a month for 100 rides to paying $20 to access a driver and $26 for a 10 mile drive. Understandably, users would be a little upset.
While this sounds a little dramatic, it’s actually a pretty accurate metaphor for what’s happening in the generative AI industry, and in particular, at Github Copilot.
GitHub Copilot’s previous pricing allowed 300 premium requests a month, as well as “unlimited chat requests” using models like GPT-5 mini. Each of these requests (to quote Microsoft) is “...any interaction where you ask Copilot to do something for you,” with more-expensive models taking up more requests in the later life of the request-based system, such as Claude Opus 4.6 taking up three premium requests. When you ran out of premium requests, Copilot would let you use one of those cheaper models as much as you’d like for the rest of the month.
Microsoft — like every AI company — swindled its customers by selling an unsustainable service, because it never, ever made sense to sell LLM-powered services on a monthly subscription.
If you’re wondering how much services are likely to cost under token based billing, a user on the GitHub Copilot Subreddit found that the token burn of what used to be a single premium request was somewhere around $11, as one “request” involved using 60,000 tokens in the context window, a few tools, and a bunch of internal “turns” (things that the model is doing) to produce the output.
There’s also the underlying unreliability of hallucination-prone Large Language Models. While a premium request chasing its tail and spitting out half-broken code might be frustrating, that same fuckup is a lot less forgivable when you’re paying the costs yourself.
Users have also been trained to use the product in an entirely different manner to token-based billing, and I’d imagine many of them don’t even really realize how many “tokens” they burn or how many of them a particular task takes, something which changes based on whatever model you use.
This is absolutely nothing like Uber, and anyone telling you otherwise is attempting to rationalize bad behavior. Uber may have raised prices, but it didn’t have to dramatically change the underlying economics of the platform, nor did users have to entirely change how they used the product because Uber was suddenly charging them on a per-gallon basis.
Monthly AI Subscriptions Are All Part of AI’s Subsidy Scam, A Deliberate Attempt To Separate Generative AI From Its Actual Costs
There has never been — and never will be — an economically-feasible way to offer services powered by LLMs without charging the actual token burn of each user, and in the process of deceiving said users, these companies have created products with illusory benefits and questionable return on investment.
And that’s been blatantly obvious for years.
On an economic basis, a monthly subscription only makes sense with relatively static costs. A gym can sell memberships knowing roughly how much wear-and-tear equipment gets, how much classes cost to run, and how much things like electricity, staffing and water might cost over a given period of time.
A customer of Google Workspace — at least before AI — cost whatever the cost of accessing or storing documents were, as well as the ongoing costs of Google Docs and other services. The relatively low cost of digital storage (as well as the fact that, unlike LLMs, Google Workspace isn’t particularly computationally demanding) means that a particularly-heavy Google Drive user isn’t going to eat into the margin on their monthly subscription.
Conversely, an AI subscriber’s costs can vary wildly. One user might only use ChatGPT for the occasional search, while another might feed in reams of documents, or try and refactor a codebase, or try and use it to put together a PowerPoint presentation. And the provider — a model lab like OpenAI or Anthropic, or a startup like Cursor) — has no real way to control how a user might act other than making the product worse, such as instituting usage limits, reducing the size of the context window, pushing customers to smaller (and worse) models, or changing the pricing to dissuage users from making big GPU-heavy requests.
Yet these services intentionally hide the amount of tokens or how much a particular activity has cost, which means users don’t really know what a rate limit means, which means that every abrupt change to rate limits leaves customers desperately scrambling to work out how much actual work they can do using the service.
It’s an abusive, manipulative and deceitful way of doing business that only existed so that Anthropic, OpenAI, and other AI companies could grow their user bases, as the majority of AI users perceive its real or imagined benefits entirely through the lens of being able to burn anywhere from $8 to $13.50 for every dollar of their subscription in tokens.
This intentional act of deception had one goal: to make sure that the majority of people were never exposed to the true costs of generative AI. When The Atlantic writes a breathless screed about Claude Code being Anthropic’s “ChatGPT moment,”it does so based on a $20-a-month subscription rather than the underlying token burn that it cost for Anthropic to provide it, which in turn makes the writer forgive the “minor errors” that a model might make, or when it “gets stuck on more complicated programming tasks.”
Had the writer paid for her actual token burn, and had each of the times it got “stuck” resulted in $15 in token charges, I don’t think she’d be quite as forgiving of these fuckups.
Yet that’s all part of the scam.
It’s very, very important that nobody writing about AI in the mainstream media actually understands how much these services cost, and that any mainstream articles written about services like ChatGPT or Claude Code are written by people who have little or no idea how much each individual task might cost a user.
Remember: generative AI services are, for the most part, experimental products that do not function like any other modern software or hardware. One cannot just walk up to ChatGPT or Claude and start asking it to do work.
I mean, you can, but if you don’t prompt it right, understand how it works, or make a mistake in whatever you feed it, or if it just gets things wrong, it’ll spit out something you don’t like, which in turn means you’ll need to prompt it again. LLMs are inherently unpredictable.
You cannot guarantee whether an LLM will do a particular action, or whether it will present you with an outcome based on reality. You cannot for certain say how much a particular task — even one you’ve done many times using an LLM in the past — might cost, nor can you be sure when a model might go berserk and delete something, or simply not do something yet claim that it did.
These are far more forgivable if you’ve not paying on a per-token basis, because in the mind of a subscriber, that’s just another turn or two with a chatbot rather than something that’s incurring a real cost. One doesn’t criticize so-called “jagged intelligence” because the assumption is that whatever problems you’re facing now will be eliminated at some future juncture, and you didn’t end up paying for it anyway.
Had users been forced to pay their actual rates, I imagine many would’ve bounced off the product immediately, as it’s very, very easy to burn through $5 of tokens if you’re fucking around and exploring what an LLM can do.
Sidenote: In fact, you can burn a great deal of money without ever getting the outcome you desire, because LLMs aren’t really artificial intelligence at all! Somebody without any real understanding of their limitations could easily burn $30, or $50, or even $100 trying to convince an LLM to do something it insists it’s capable of.
There’s a term for this. Sycophancy. LLMs are often designed to affirm the user, even when they’re saying dangerously unhinged things, and that can extend to saying “you want this big thing that’s not even slightly feasible, whether technically or financially?” Sure thing!
This is why the industry worked so hard to obfuscate these costs — it’s a fucking ripoff!
I think it’s inevitable that the majority of AI subscriptions move to token-based billing, especially as both Anthropic and OpenAI have now done so with their enterprise customers.
The fact that Microsoft moved GitHub Copilot subscribers to token-based is also a very, very bad sign. Microsoft is arguably the best-capitalized, most-profitable, and best-positioned company to continue subsidizing compute, and if it can’t afford to do so further, nobody else can either.
The real thing to look out for — a true pale horse — will be a major AI lab like Anthropic or OpenAI moving all of its subscribers to token-based billing. Once that happens, you’ll know it’s closing time.
Can The Average Company Afford To Move To Token-Based Billing? Anthropic Estimates Users Spend $13-$30 a day ($7K+ a year) On Claude Code, As Large Organizations Spend Hundreds of Thousands or Millions A Year
This is the direct result of training every single AI user to use these services as much as humanely possible while obfuscating how much they really cost. Every single major company demanding that every single worker “use AI as much as possible” has done so while either fundamentally ignoring or being entirely disconnected from their actual token burn, and as companies are forced to pay the actual costs, I’m not sure how you can economically justify any investment in this technology.
Sure, sure, you’re gonna say that engineers are “shipping code faster” or some such bullshit, I get it, but how much faster, and how much money are you making or saving as a result? If you’re spending 10% of your headcount on AI tokens, are you seeing that extra expense reconciled in some other way? Because I’m not sure you are. I’m not sure any business investing these vast amounts of money in tokens is seeing any return on investment, which is why everystudy about AI’s ROI struggles to find much evidence that it exists.
For the most part, everybody you’ve read gooning over the many possibilities of generative AI has experienced it without having to pay the true costs. Every Twitter psychopath writing endless screeds about their entire engineering team hammering away at Claude Code has been doing so using a $125-a-month-per-head Teams subscription with similar usage limits to Anthropic’s $100-a-month consumer subscription. Every LinkedIn gargoyle insisting that they’d “done hours of work in minutes” using some sort of Perplexity product has done so by paying, at the very most, $200 a month for Perplexity’s Max subscription.
In reality, that 10-person, $1250-a-month Teams subscription likely burns anywhere from $5000 to $10,000 a month in API calls, if not more. Anthropic Head of Growth Amol Avasare said last week that its Max subscriptions were built for heavy chat usage rather than whatever people are doing with Claude Code and Cowork, and made it clear that Anthropic is now looking at “different options to keep delivering a great experience,” which is another way of saying “we’re going to change the prices at some point.”
I’m not sure people realize how expensive these tokens are, especially for coding projects that involve massive codebases and regularly make calls to coding and infrastructure tools. Can somebody who pays $200 a month foreseeably afford $350, $400, or $500? Can they afford to have a month where they spend more than that? What happens if they go over budget, or if they literally can’t afford to spend the money necessary to finish their work?
To give you a more-practical example, up until the beginning of April, Anthropic’s own Claude Code developer documents (archive) said that “the average cost [for those using Claude Code] is $6 per developer per day, with daily costs remaining below $12 for 90% of users.” As of this week, the documents now read as follows:
Claude Code charges by API token consumption. For subscription plan pricing (Pro, Max, Team, Enterprise), see claude.com/pricing. Per-developer costs vary widely based on model selection, codebase size, and usage patterns such as running multiple instances or automation.
Across enterprise deployments, the average cost is around $13 per developer per active day and $150-250 per developer per month, with costs remaining below $30 per active day for 90% of users. To estimate spend for your own team, start with a small pilot group and use the tracking tools below to establish a baseline before wider rollout.
If we assume an average of 21 working days in a month, that puts the average cost of a Claude Code user at around $273 a month, or $3,276 a year. At $30 a working day, that works out to $630 a month, or $7560 a year.
These are astonishing numbers, made more so by the fact that there is no way you’re only spending $30 a day if you use any of Anthropic’s more-recent models. Claude Opus 4.7 costs $5 per million input and $25 per million output tokens. ‘One million tokens is around 50,000 lines of code, and assuming you’re using the supposedly state-of-the-art models, there isn’t a chance in Hell you don’t run through at least a million, with that number increasing dramatically if you’re not particularly aware of which models to use for a particular task.
Let’s play with that $30 number a little more.
For a ten person dev team, that’s $75,600 a year, and we’re only counting working days.
If you raise a mere three months to an average of $50 a working day, that raises to $88,200
If you add a single month where you go over $100, you’re spending $102,900 a year.
If you spend $300 a day, you’re now spending $756,000 on tokens for ten people.
While this might be possible within the slush fund mindset of a well-funded startup or a banana republic like Meta, any business that actually cares about its costs will have a great deal of trouble justifying spending five or six figures in extra costs on a service that “increases productivity” in a way that nobody can seem to measure.
Right now, I think most companies fall into three camps:
Enterprise deployments in massive organizations like Spotify or Uber with AI-pilled CEOs that allow budgets to run wild.
I’d also say this is the case in large, well-funded startups.
Smaller startups that use the subsidized “Teams” subscription.
Individual users paying a monthly fee to access Claude or other AI subscriptions.
All it changes is one bad earnings call to change that narrative. At some point investors — even the braindead fuckwits who have been inflating the AI bubble — will begin to question mounting R&D costs (which is where AI token burn is usually hidden) when the company’s revenue growth fails to follow. This will likely lead to more layoffs to keep up with the cost, as was the case with Meta, and then an eventual pullback when somebody asks “does any of this shit actually help us do our jobs faster or better?”
I also think that startups burning 10% or more of their headcount in AI tokens will have a tough time convincing investors in six months that doing so is necessary.
And once everybody switches to token-based billing, I’m not sure we’ll see quite as much hype around generative AI.
The Economics of AI Data Centers And Compute Do Not Make Sense
The way that people talk about AI data centers is completely disconnected from reality, and I don’t think people realize how ridiculous this entire era has become.
AI Data Centers Are Expensive To Build, Expensive To Run and Make Very Little Actual Revenue
Per Jerome Darling of TD Cowen, it costs around $30 million in critical IT (GPUs and the associated hardware) and $14 million per megawatt of data center capacity. Data centers appear to take anywhere from a year to three years depending on the size, and that’s assuming the power is available.
Of the 114GW of data centers supposedly being built by the end of 2028, only 15.2GW is under construction in any way, shape, or form. And “under construction” can mean as little as “there’s a hole in the ground.” It does not — and should not — imply that the capacity that said facility will provide is going to be imminently available.
Sidebar: If you’re interested in some of the deeper math here, please subscribe to my premium newsletter so that you can see my Bastard Data Center Model, which I created with the assistance of multiple analysts and hyperscaler sources.
Let’s start simple: whenever you think “100MW,” think “$4.4 billion,” with a large chunk of that dedicated to NVIDIA GPUs.
As a result, every AI data center starts millions of dollars in the hole, and even with six-year-long depreciation schedules, takes years to pay off… and with NVIDIA’s yearly upgrade cycle, those GPUs are unlikely to make that much money once you’re done with your first customer contract.
In any case, it’s also unclear what kind of ongoing rates these data centers charge. While spot prices might sit around $4.50 an hour for a B200 GPU, long-term contracts generally price much lower, with one founder (per The Information) saying they paid around $3.70-per-hour-per GPU for a one-year-long commitment.
To be clear, we must differentiate between the spot cost — which is the cost of randomly spinning up GPUs on somebody else’s servers — and contracted compute, the latter of which makes up the majority of data center capex. Most data centers are built with the intention of having one or two big clients, which means said clients are likely to negotiate a cheaper blended rate.
As a result, many data centers take far less than $3.70 an hour, because they bill at a per-megawatt (or kilowatt) price.
And that’s where the economics begin to break down.
The Broken Economics of a 100MW Data center — $2.55 An Hour, 16% Gross Margin With 100% Tenancy, Unprofitable Because of Debt
That’s the starting cost for a 100 megawatt data center. A 100MW data center will likely only have 85MW of actual stuff it can bill for, and based on discussions with sources familiar with hyperscaler billing, they can expect to make around $12.5 million per megawatt, or around $1.063 billion in annual revenue.
Now, I should be clear that most data center companies you know of don’t actually build them, instead leaving that job to companies like Applied Digital, who are also known as “colocation partners.” For example, CoreWeave pays a colocation fee to Applied Digital to use its North Dakota data centers. CoreWeave is responsible for all the GPUs and other tech inside the data center.
To explain the economic mismatch, I’m going to use a theoretical example of a data center leased to a theoretical AI compute company.
The GPUs in that data center are likely NVIDIA’s Blackwell chips. More than likely, said data center is using pods of 8 B200 GPUs, retailing around $450,000 a piece, or $56,250 a GPU. Based on there being 85MW of Critical IT load, the all-in capex per megawatt is around $36.78, or total IT capex of around $3.126 billion, or around $2.67 billion in GPUs.
Let’s assume this data center is in Ellendale, North Dakota, which means you’ve got an industrial electricity rate of around 6.31 cents per kilowatt hour, which works out to about $55.4 million a year in electricity costs. Based on discussions with sources, I estimate that ongoing costs like maintenance, headcount, replacement of power supplies and the like comes in at around 12% of revenue, or around $128 million a year, bringing us up to $183.4 million in costs.
Wait, sorry. You’ve also got to pay a colocation fee based on the critical IT, and according to Brightlio, that fee is often around $180-200 per kilowatt per month, depending on the scale and location of the deployment, though I’ve read as low as $130, which is the number I’m going with, or around $133 million per year. This brings us up to $316.4 million.
Well, that’s still less than $1.06 billion, so we’re still doing okay, right?
Wrong! You’ve got $3.126 billion in IT gear to depreciate, which works out to around $521 million a year over the six years you’re depreciating it. That’s $837.4 million a year, leaving you with around $168.6 million in yearly profit, or around a 16.7% gross margin…
…if you have 100% tenancy at all times! You see, data centers can take a month or two to get those GPUs installed and a customer onboarded, all while making you exactly zero dollars in revenue and losing you a great deal more, as you’re stuck paying your colocation, electricity and opex costs the whole time, albeit at a much lower rate (I’ve modeled for 10% electricity and 15% colocation/opex costs), meaning you’re losing about $3.27 million a day.
For the sake of this example, we’re going to assume it takes you an extra month to get this thing operational, meaning you’ve paid about $102 million that you’re never getting back, bringing our total costs for the year including depreciation to $939.4 million, or a 6.6% gross margin.
Wait, fuck, you didn’t use debt to buy these GPUs, did you? You did? How bad are we talking? Oh god — you got a 6-year-long asset-backed loan at 80% LTV, meaning you borrowed $2.8 billion at a 6% interest rate.
Your bank, in its eternal generosity, offered you a deal — a 12-month-long grace period where you’re only paying interest…which works out to around $168 million, which brings our total costs (excluding the month of delay for fairness) for the first year to around $1.005 billion…on $1.06 billion of revenue.
That’s a 5.19% gross margin, and you haven’t even started paying the principal. When that happens, you’re paying $54.1 million a month in loan payments, for a total of around $649 million a year for five more years, which comes out to around $1.48 billion, or a negative gross margin of around 40%.
And I must be clear that this is if you have 100% utilization and a tenant that pays you on time, every time.
Stargate Abilene Is A Disaster — $2.94-per-GPU-per-hour, $10 Billion In Annual Revenue, Years Behind Schedule, One Tenant That Loses Billions of Dollars A Year
Let’s talk about what should be the single-most economically viable project in data center history — a massive campus built for the largest AI company in the world by Oracle, a decades-old near-hyperscaler with a history of selling expensive database and business management software to enterprises and governments.
Hah, I’m kidding of course, this place is a fucking nightmare.
Per my own reporting, Oracle expects to make around $10 billion in annual revenue from Stargate Abilene, and I estimate around $75 billion in total revenue from the 7.1GW of data center capacity it’s building for one customer: OpenAI. As I also reported, Oracle estimated in 2024 that Abilene would cost at least $2.14 billion a year in colocation and electricity fees, paid to land developer Crusoe.
I should also add that it appears that Oracle is paying all of Abilene’s construction costs.
Based on my calculations and reporting, I estimate Abilene’s rough gross margin is around 37.47% once it’s fully operational:
I must be clear that that 37.47% gross margin is likely too high, as I don’t have precise knowledge of Oracle’s true insurance or headcount costs, only estimates based on documents viewed by this publication. I should also be clear that Oracle is mortgaging its entire fucking future on projects like Stargate Abilene, incurring billions of dollars of costs up front for a business that will take years to turn a profit even if OpenAI makes every single payment in a timely manner.
I also need to be clear that that $3.85 billion in yearly profit is only possible if OpenAI makes timely payments, takes tenancy of Abilene as fast as humanly possible, and everything goes to plan.
If OpenAI Fails To Raise $852 Billion In Revenue, Funding, and Debt Throughout The Next 4 Years, The Stargate Data Center Project Will Kill Oracle
Four months later on April 22, 2026, Oracle tweeted that “...in Abilene, 200MW is already operational, and delivery of the eight-building campus remains on schedule.” It is unclear if that’s 200MW of critical IT capacity or the total available power at the Abilene campus, and in any case, this is only enough power for two buildings, which means that Oracle is most decidedly not “on schedule.”
This is a huge issue. OpenAI can only pay for compute that actually exists, and only 206MW of critical IT is actually generating revenue, with the third at least a month (if not a quarter) away from doing so.
Yet there’s a larger, more-existential problem with the overall Stargate data center project — that the only way any of it makes sense is if OpenAI meets its ridiculous, cartoonish projections.
I’ll repeat the numbers: the 7.1GW of Stargate data centers in progress will make around $75 billion in annual revenue on completion, and cost more than $340 billion in total. Oracle’s free cash flow was negative $24.7 billion, and its other business lines are plateauing, making its negative-to-low margin cloud business its only growth engine.
For OpenAI to actually be able to pay its compute deals — both to partners like Amazon, Microsoft, CoreWeave, Google, Cerberas, and to Oracle — it will have to raise or make $852 billion in revenue and/or funding in the space of four years, which would require its business to grow by more than 250%, every single year, effectively 10xing by the end of 2030, at which point it will have had to find a way to become cashflow positive for any of these numbers to make sense.
To be clear, OpenAI’s projections have it making $673 billion over the next four years, and burning $218 billion to get there. It is an incredibly unprofitable business, and even if it wasn’t, it would have to make so much more money than it currently does to pay Oracle on an ongoing basis.
I calculated that $75 billion number by assuming that Vera Rubin GPUs get around $14 million per megawatt of compute (a number I’ve confirmed with sources familiar with the data center industry) across the remaining 4.64GW of critical IT that I anticipate makes up the remaining Stargate data centers.
I must be clear that any journalist repeating these numbers without saying how fucking stupid they are should be a little ashamed of themselves. Per my Friday premium:
Either way, Oracle is insufficiently-capitalized to finish Stargate Abilene. It will need at least another $150 billion to get this done, and that’s assuming that other partners pick up about $30 billion in costs. Honestly, it may be more.
I really need to be clear that Oracle has no other path to making this revenue without OpenAI, and these projects are entirely financed and paid for using the projected cashflow of the data centers themselves.
And I’m not even the only one worried about this, with OpenAI Sarah Friar sharing similar concerns after the company missed user and revenue targets, per the Wall Street Journal:
OpenAI recently missed its own targets for new users and revenue, stumbles that have raised concern among some company leaders about whether it will be able to support its massive spending on data centers.
Chief Financial Officer Sarah Friar has told other company leaders that she is worried the company might not be able to pay for future computing contracts if revenue doesn’t grow fast enough, according to people familiar with the matter.
Board directors have also more closely examined the company’s data-center deals in recent months and questioned Chief Executive Sam Altman’s efforts to secure even more computing power despite the business slowdown, the people said.
If that doesn’t worry you, perhaps this will:
She has emphasized to executives and board directors the need for OpenAI to improve its internal controls, cautioning that the company isn’t yet ready to meet the rigorous reporting standards required of a public company. Altman has favored a more aggressive timeline for an IPO, some of the people said.
That sure sounds like a company that’s gonna be able to make $852 billion by the end of the decade!
Anthropic Is Just As Bad As OpenAI, Committing To Up To 10GW ($100BN+ Annual Revenue) In Compute From Google and Amazon
While I regularly bag on OpenAI for its ridiculous promises, Anthropic isn’t far behind, promising to take “up to” 5GW of capacity from both Google and Amazon in a deal that I estimate includes around $100 billion in actual compute commitments given the scale of the capacity.
Now, I should add that Google and Amazon are far-savvier and less-desperate than Oracle, meaning that they can take the hit if Anthropic ends up running out of money. The “up to” part of that deal gives them some much-needed wiggle room that Oracle simply does not have.
Nevertheless, for Anthropic to actually meet its commitments, it will have to agree to spend anywhere from $25 billion to $100 billion a year on compute by the end of 2030.
There Needs To Be $156.8 Billion In AI Annual Compute Revenue To Support The 15.2GW of AI Data Centers Under Construction, and $1.18 Trillion To Support All 114GW Announced
The near-pornographic excitement around however many hundreds of billions of dollars of GPUs that Jensen Huang claims to be shifting regularly clouds out a problematic question: sell the compute to who, Jensen?
If we assume that the 15.2GW of data center capacity under construction (due by the end of 2028) has a PUE of around 1.35, that leaves us with roughly 11.2GW of critical IT. At $14 million per megawatt, that works out to around $156.8 billion in annual revenue in GPU rental revenue required to actually make these data centers worth it.
When you calculate for the 114GW of capacity theoretically coming online by the end of 2028, that number climbs to $1.18 trillion in annual revenue.
Who, exactly, is the customer for all this compute, and how likely is it that they’ll want to buy it by the time all that capacity is built? While many different data centers claim to have tenants for the first few years of their existence, said tenants can only start paying once the data center completes, and if it’s an AI startup, I think it’s fairly reasonable to ask whether they exist by the time it’s built.
Remember: the customers of AI compute are, for the most part, either hyperscalers trying to move capital expenditures off their balance sheets or unprofitable AI startups. Anthropic and OpenAI both intend to burn tens of billions of dollars in the next few years, and neither of them have a path to profitability.
This means that a large part — if not the majority of — AI compute revenue is dependent on a continual flow of venture capital and debt, both of which are only made possible by investors that still believe that generative AI will be the biggest, most hugest thing in the world.
How does that work out, exactly? Who is paying for this data center capacity? Who is it for? Where is the actual demand?
And if said demand exists, how the fuck do the customers even pay?
Generative AI Is Unprofitable and Unsustainable, And Only Getting More Expensive
Despite multiplestories that have both of them becoming profitable by 2028 or 2029, nobody can explain to me how OpenAI or Anthropic actually reach profitability, especially given that both of them had worse margins than expected, even when said margins strip out training costs that number in the billions of dollars.
And I’ve been asking this question for fucking years. Every time we get a new update on Anthropic or OpenAI, we hear they’ve lost billions more dollars than expected, that margins are decaying, that costs are skyrocketing, that everything is more expensive despite promises that the literal opposite would happen.
Even Cursor, a company that briefly (before its pseudo-acquisition by Musk’s SpaceX) claimed it had positive gross margins, actually had negative 23% gross margins as of January, or negative 31% if you include the cost of non-paying users, which you fucking should if you actually care about your accounting. Mysteriously, reports claim that Cursor’s margins “recently turned positive,” but magically don’t know by how much, or how that happened, or a single other detail other than one that likely helped the company get sold.
I also don’t see how any of these AI data centers actually make sense, even if they have customers to pay them for the first few years. The economics are built for perfection, with zero fault tolerance. They must have consistent, 100% utilization and tenancy, or they end up burning millions of dollars and fail to chip away at the years-long wall of depreciation created by the tech industry’s most expensive mistake.
Even if they somehow succeed, these are pathetic businesses with mediocre margins — 70% at best, assuming consistent payments, tenancy, and six fucking years of depreciation to actually break even, which might be difficult considering the yearly upgrade cycle makes the entire thing near-obsolete by the time you’re done paying it off.
And that’s before you consider that the majority of the customers are unprofitable, unsustainable startups.
I truly don’t know how any of this works out.
LLMs Are A Ripoff, And Customers Have Been Lied To
I realize it seems a little much, but I genuinely believe that subscription-based AI services were an act of deception tantamount to fraud, as they misrepresented the core unit economics and thus the possibilities of a Large Language Model. By selling users a product on a monthly rate and creating habits based on its availability, companies like Anthropic and OpenAI have misrepresented their businesses in such a way that most of their users are interacting with products and building workflows based on products that are unsustainable and impossible to maintain in their current form.
Anthropic’s recent aggressive rate limit changes were instituted mere months after multiple aggressive marketing campaigns based on experiences that are now near-impossible under the current rate limits, and based on recent moves by Anthropic, it’s clear that it intends to start removing services for its lower-tier $20-a-month subscribers at some time in the future. This is a disgusting and misleading way to run a company, and the vagueness with which Anthropic discusses its products and its services are an insult to every one of their users, and a sign that it doesn’t fear the press in any meaningful way.
I need to be very clear that the product that Anthropic offers — by virtue of recent rate limit changes — is substantially different (and far worse) than the one that you read about everywhere. Anthropic was conscious in its deliberate attempts to market a product that it knew would be gone within three months. Dario Amodei doesn’t give a fuck as long as the media keeps writing up however many billions of annualized revenue he’s conjured up today or whatever new product he’s released that’s meant to destroy some hapless public SaaS company that had already seen its growth slow.
Members of the media, I say this with abundant respect: Anthropic is mistreating its customers, and it is doing so because it believes it can get away with it. This company does not respect you, and in fact holds you with a remarkable degree of contempt, which is why it doesn’t bother to fix its services very quickly or explain why they were broken with any level of coherence.
That’s why Anthropic fucking lied about Claude Mythos being too powerful to release (it was actually a capacity issue) when in fact it’s just another fucking Large Language Model Nothingburger — because it thinks you will buy whatever it is selling, and it’s worked out exactly how to package it to give you enough plausible “proof” that a quick skimread of the system card will make you and your editor believe whatever it is you’re saying.
They also know you’ll rush to cover it rather than waiting to see what actual experts say.
AI is a con, and this is how the con works. AI was rushed and pushed in our faces as quickly as humanly possible in the least-efficient yet most-accessible form it could be presented, even if said form was never going to result in anything resembling a sustainable business. The media was rushed to immediately say that this was the thing so that everybody would agree that this was the thing now and use it as much as physically possible, and, crucially, use it in a subscription-based form that would make people experience it without ever asking how much it costs to provide.
The narrative came pre-baked. Because very few people who talked about LLMs experienced their actual cost, it was really easy for them to vaguely say “it’s just like Uber,” because that was a company that lost a lot of money but didn’t die, and it’s much easier to say that than say “wait, what do you mean OpenAI is set to lose $5 billion this year?”
Think of it like this: as a reporter, an investor, an executive, or a regular LinkedIn Lounge Lizard, you might read here and there that it’s $5 per million input tokens and $25 per million output tokens, but you’ve never really experienced how fast or slow one loses that money, because it’s important to do so to truly understand this product. Anthropic and OpenAI intentionally obfuscated that experience and created businesses that expect to burn tens of billions of dollars in 2026 and several hundred billion dollars by 2030, all because most people graded generative AI based on the subscription-based experience.
LLMs are a casino, and you’ve been gambling with the house’s money while encouraging people to bet their own on whether they’ll get a unit of work out of a particular model.
This was intentional. They never wanted you thinking about the costs because once you really start thinking about the costs this whole thing feels a little insane. I truly believe that LLM-based subscriptions are going to go away entirely, at least at the scale of any product that generates code, and in doing so, Amodei and Altman will wrap up their con, or at least believe that they have.
The problem is that these men have now signed far too many deals to get away scot-free.
OpenAI’s CFO has now said multipletimes that she doesn’t believe OpenAI is ready for IPO, and has material concerns about its growth and continued ability to meet its obligations. To repeat a quote from before:
Chief Financial Officer Sarah Friar has told other company leaders that she is worried the company might not be able to pay for future computing contracts if revenue doesn’t grow fast enough, according to people familiar with the matter.
This is a blinking red fucking light, and in a sane market would send Oracle’s stock into a tailspin, because OpenAI’s ascent to over $280 billion in annual revenue is critical to Oracle’s ability to not run out of money. In a sane media, this would send worrisome shockwaves through every group chat and Slack channel about whether or not OpenAI is actually going to make it.
This is the kind of thing that happens before a company starts dying. OpenAI’s growth is slowing at precisely the time it needs to accelerate. It needs to effectively 10x its current business by 2030 to make its obligations. OpenAI’s CFO, the literal person who would know best, is saying that she is worried that OpenAI cannot pay its fucking compute contracts if revenue doesn’t grow. This is a big, blinking warning light! This is not a drill!
Yet the bit that really worried me was the Journal’s comment that Friar didn’t think OpenAI “was ready to meet the rigorous reporting standards required of a public company.”
I’d generally not be so fucking nosy if it wasn’t for the fact that this company accounted for something like 20% of all venture capital funding in the last year and everywhere I go I have to hear the endless bloviating of Altman and Brockman and every other man at OpenAI and their fucking ideas about what regular people should do as they swan about shipping dogshit software and spending other people’s money.
For the amount of oxygen that both Anthropic and OpenAI consume, both of these companies should be fucking flawless, both as products and businesses. Instead, both are sold through varying levels of deception around their economics and efficacy, obfuscating the truth so that their Chief Executives can amass money and power and attention. It’s an insult to both good software and good taste — the most-expensive, least-reliable applications ever invented, their mistakes forgiven, their mediocrities celebrated, their infrastructure hailed as an inert god of capital.
Generative AI is an insult. It is unreliable, its economics don’t make sense, its outcomes don’t justify its existence, and the perpetrators of its con are boring, oafish and avaricious men disconnected from society and anybody who would ever disagree with them. It requires stealing art from everybody, destroying the environment, increasing our electricity bills, the constant threat of economic annihilation, the endless cacaphony of “everything fucking sucks now because of AI,” all to push software that can only be justified by people willing to ignore basic finance or sense.
It’s all so expensive, and it’s all so fucking dull. It’s offensively boring. It’s actively annoying. Every story where somebody tells you about how much they use AI sounds like they’re in an abusive relationship and/or joined a cult, echoing with a subtle desperation that says “you really need to join me in this because it’s so good, and the fact that I appear to be experiencing no joy from this product is just a sign of how efficient it is.” There is nothing light-hearted or joyful about what AI can do. There is nothing goofy or whimsical about a Large Language Model, and every interaction feels hollow.
Those who desperately look for clues that it’s becoming sentient or “more powerful” are simply seeking validation themselves — they want to be first to something, because arriving at other people’s conclusion is what they do for a living.
Being “first” — on the “frontier” one might say — is something that people crave when they can’t find something within, and it’s exactly the fuel that grifters crave, because LLMs are constantly humming with the sense that they’re about to do something new, even though they’re mathematically restricted to repeating other actions.
This is a deeply sad era. The people that have so aggressively worked together to hold up this industry have only delayed its inevitable fall. It’s terrifying to me that our markets and parts of our economy are being held up by the generally-held yet utterly-unproven assumption that LLMs will somehow get cheaper, that AI startups will magically become profitable, and that offering AI compute will be profitable in perpetuity to the point that it necessitates increasing the current supply tenfold by the year 2030.
People have debased themselves to defend the AI industry, because that’s what the industry demands of its supplicants. To be an “AI expert” requires you to actively ignore the worst economics of any industry in history, to constantly explain away obvious, glaring issues with products, and to actively convince others to do the same. OpenAI and Anthropic do not provide clear explanations of how they’ll become profitable because they know that their supporters will never ask for them — because the only way to fully “believe in AI” is to actively wear blinders.
And I get it. If you accept that OpenAI and/or Anthropic will eventually collapse, all of this seems a little insane. I am genuinely asking you to seriously consider that one or both of these companies will run out of money.
I’m really worried, made only more so by the general lack of concern I’m seeing in the media and greater society.
The assumption, if I had to imagine, is that I’m simply being alarmist, and that “the demand will absolutely be there.”
You’d better hope you’re right.
For Larry Ellison’s sake, at least. Ellison has already pledged 346 million shares of his Oracle stock — or around $61.5 billion — “to secure certain personal indebtedness, including various lines of credit,” meaning “many big, beautiful loans against his Oracle shares.” which IFR estimated back in September (when Oracle’s stock price was much higher) could allow him to secure as much as $21.4 billion in debt at a (they say “conservative”) loan-to-value ratio of 20%, and that’s assuming the banks weren’t particularly generous.
If OpenAI can’t raise $852 billion in revenue and funding by the end of 2030, it won’t be able to pay for Stargate. That’ll kill the value of Oracle’s stock, leading to a series of margin calls, leading to Ellison having to sell shares, leading to further margin calls. Whatever bailout might or might not exist won’t save Larry’s estate.
What I’m saying is that Ellison’s future rides on Sam Altman’s ability to raise funding and make revenue to the tune of $852 billion in the space of 4 years.
It was January 21, 2025. Per The Information, Larry Ellison, CEO of Oracle, had just flown to Washington DC from Florida, and had to borrow a coat “...so he wouldn’t freeze during an interview he did on the White
It was January 21, 2025. Per The Information, Larry Ellison, CEO of Oracle, had just flown to Washington DC from Florida, and had to borrow a coat “...so he wouldn’t freeze during an interview he did on the White House lawn, according to two people who were involved in the event.” He was there to announce a very big — some might even say huge — new project standing next to SoftBank CEO Masayoshi Son and OpenAI CEO Sam Altman.
“Together, these world-leading technology giants are announcing the formation of Stargate, so put that name down in your books, because I think you’re gonna hear a lot about it in the future. A new American company that will invest $500 billion at least in AI infrastructure in the United States and very, very quickly, moving very rapidly, creating over 100,000 American jobs almost immediately,” said President Donald Trump.
After he was done, Ellison stepped to the podium. “The data centers are actually under construction, the first of them are under construction in Texas. Each building’s a half a million square feet, there are ten buildings currently being built, but that will expand to 20.”
Following Ellison, SoftBank’s Masayoshi Son added that Stargate would “...immediately start deploying $100 billion dollars, with the goal of making $500 billion dollars within [the] next four years, within your town!” turning to Donald Trump with his hands extended. It was unclear what town he was referring to.
Altman added that it would be “an exciting project” and that “...we’ll be able to do all the wonderful things that these guys talked about, but the fact that we get to do this in the United States is I think wonderful,” though it’s unclear what “the wonderful things” or “this” refers to.
No government money was ever involved, no funding ever left anyone’s bank account, no "initiative" ever existed, and OpenAI, Oracle and SoftBank have, in my opinion, conspired to mislead the general public about the existence and validity of a project for marketing purposes.
The “data centers actually under construction” referred to a 1.2GW project in Abilene Texas that had been under construction since the middle of 2024, and had originally been earmarked by Elon Musk and xAI, except Musk pulled out because he felt that Oracle was moving too slow. While Ellison said that there were ten buildings under construction with plans to expand to twenty, only eight were actually being built (each holding around 50,000 GB200 GPUs across NVL72 racks), with the extension up in the air until March 2026, when Microsoft agreed to lease 700MW — so another seven buildings — that were meant to go to OpenAI. These buildings will not make Oracle any money, as Oracle is, despite spending so much money, leasing whatever land it uses from Crusoe.
Sidenote: Previously-unknown information from the Wall Street Journal published this week shows that the reason why Microsoft ended up buying the additional capacity at Abilene was because lenders were uncomfortable with providing additional funding to provide compute that was ultimately destined to go to Oracle.
As far as those eight buildings go, only two are actually online and generating revenue, though sources with direct knowledge of Oracle’s infrastructure have informed me that work is still being done on both buildings despite CNBC reporting that they were “operational” in September 2025.
Four months later on April 22, 2026, Oracle tweeted that “...in Abilene, 200MW is already operational, and delivery of the eight-building campus remains on schedule.” It is unclear if that’s 200MW of critical IT capacity or the total available power at the Abilene campus, and in any case, this is only enough power for two buildings, which means that Oracle is most decidedly not “on schedule.”
Sources familiar with Oracle infrastructure have confirmed that while construction has finished on building three, barely any actual tech has been installed. It also appears that while construction has begun on a power plant of some sort, it’s unclear whether it’s the 360.5MW gas power plant or 1GW substation. In any case, Abilene needs both to turn on the GPUs, if they ever get installed.
Abilene is, for the most part, the only part of the Stargate project that’s anywhere near complete.
I say that because the other data centers — Shackelford, Texas, Port Washington, Wisconsin, Doña Ana County, New Mexico, Saline, Michigan, and Milam County, Texas — are patches of land with a few steel beams, if that. To be explicit, every single Stargate data center is funded by Oracle and its respective financial backers.
Oracle is taking on a massive amount of debt to build these data centers, working with a labyrinthine network of financiers and construction partners to pull together the capacity necessary to get paid for its five-year-long $300 billion compute deal with OpenAI.
Oracle has also, per Bloomberg, deliberately raised money using “project financing” loans that are repaid using the projected cashflow, allowing it to keep the massive amount of debt off of its balance sheet. This is remarkable — and offensive! — because it’s borrowing over $38 billion to fund construction of its Wisconsin and Shackelford data centers (the largest debt deal of its kind on record) and said debt will now effectively not exist despite its massive drag on Oracle’s cashflow, which sat at negative $24.7 billion in its last quarterly earnings.
Based on estimates ($30 million in critical IT and $14 million in construction per megawatt) from TD Cowen’s Jerome Darling, the total cost of Oracle’s 7.1GW of data center capacity will be somewhere in the region of $340 billion to build.
All of these data centers are being built for a single tenant — OpenAI — which expects, per The Information, to lose over $167 billion (assuming it hits annual revenues of over $100 billion) by the end of 2028, and as a result does not actually have the money to pay Oracle for its compute on an ongoing basis.
All of this is happening as Oracle’s core businesses plateau, even after Oracle reshuffled them in Q3 FY25 to represent Cloud, Software, Hardware and Services segments, the latter three of which have barely moved in the last 9 months as low-to-negative-margin cloud compute revenue grows.
In other words, Oracle’s only growth comes from a segment requiring hundreds of billions of dollars of compute.
To make matters worse, every single one of these data centers is behind schedule. Stargate Abilene was meant to be done at the beginning, middle, and now the end of this year, yet sources tell me there’s no way it’s finished before April 2027.
And at that point, where exactly will we be in the AI bubble? What GPUs will be available? What other kinds of silicon will exist? What will the demand be for AI compute?
I don’t think that OpenAI exists for that long, and even if it does, it will have to raise at least $200 billion in the space of three years to possibly keep up with its commitments.
I’m surprised that nobody (outside of JustDario, at least) has raised the seriousness of this situation.
Stargate, as it stands, will kill Oracle, outside of OpenAI becoming the literal most-profitable and highest-revenue-generating company of all time within the next two years. Even then, by the time that Abilene is built, its 450,000 GB200 GPUs will be two-years-old, and entirely obsolete far before its debts are repaid. A similar fate awaits whatever GPUs are put in the other Stargate data centers.
Today’s newsletter is a thorough review and analysis of the ruinous excess of Stargate, a name that only really means “data centers being built for OpenAI in the hopes that OpenAI will pay for them.” Oracle is mortgaging its entire future on their construction, and even if it gets paid, I see no way that the cashflow from OpenAI’s compute spend can recover the cost before its GPU capex is rendered obsolete, let alone whether it can cover the debt associated with the buildout.
I’m Larry Ellison — Welcome To Jackass.
Coming Up In This Week’s Where’s Your Ed At Premium…
The total estimated cost of Oracle’s Stargate capacity is around $340 billion.
OpenAI needs to make, in total, $852 billion in both revenue and funding through the end of 2030 to keep up with its compute costs with Oracle, Amazon, Google, CoreWeave and Microsoft.
Oracle cannot afford to pay for the cost of construction and equipment out of cashflow, and has had to take on over $100 billion in debt and sell $20 billion in shares.
Across a potential 7.1GW of planned Stargate capacity, Oracle stands to make around $75 billion in annual revenue.
Abilene is expected to generate around $10 billion a year in revenue on completion for a project that will likely cost in excess of $58 billion.
Stargate Abilene is extremely behind schedule, and likely won’t be finished until Q2 2027.
Oracle estimated in 2024 that Abilene would cost it $2.14 billion a year in colocation and electricity fees.
Oracle has spent over $5 billion in construction costs on the first two buildings of Abilene, with sources saying that it will likely spend over $10 billion to finish them, suggesting an overall cost of around $48-per-megawatt.
Oracle’s remaining Stargate sites are barely under construction, and will likely not be finished before the end of 2028.
Even if Oracle builds the data centers and OpenAI pays for them, the incredible upfront cost and NVIDIA’s yearly upgrade cycle will render much of the GPU capacity worthless within the next ten years.
And if OpenAI fails to pay, Larry Ellison likely has over $20 billion in personal loans collateralized by over $60 billion in Oracle shares, meaning that margin calls will follow with the collapse of Oracle's stock.
Welcome to the end of Oracle, or Sell The Compute To Who, Larry? Fucking Aquaman?
Internal documents reveal Microsoft’s planned rollout for token-based billing for all GitHub Copilot customers starting in June.
For an initial promotional period from June through August 2026, Copilot Business Customers will pay $19 per-user-per-month and receive $30 of pooled AI credits, and Copilot Enterprise customers will
Show full content
Executive Summary:
Internal documents reveal Microsoft’s planned rollout for token-based billing for all GitHub Copilot customers starting in June.
For an initial promotional period from June through August 2026, Copilot Business Customers will pay $19 per-user-per-month and receive $30 of pooled AI credits, and Copilot Enterprise customers will pay $39 per-user-per-month and receive $70 of pooled AI credits.
After an initial promotional period, pricing will change to $19-a-month with $19 of tokens, and $39-a-month with $39 of tokens.
Sources say that these amounts may change before the launch of token-based billing.
It is unclear what will happen to individual subscribers.
The company is expected to make the announcement next week.
Documents viewed by Where’s Your Ed At shed additional light on Microsoft’s transition to token-based billing for GitHub Copilot, as the company grapples with spiraling costs of AI compute.
As reported on Monday (and as announced soon after by Microsoft), the company has taken the step to suspend new sign-ups for individual and student accounts, has removed Anthropic’s Opus models from the cheapest $10-a-month plan, and plans to further tighten usage limits.
According to the documents, the announcement for token-based billing will be tomorrow (4/23), with changes to GitHub Copilot rolling out at the beginning of June.
Explainer: At present, GitHub Copilot users have a certain amount of “requests” — interactions where you ask the model to do something, with Pro ($10-a-month) accounts getting 300 a month, and Pro+ ($39-a-month) getting 1500. More-expensive models use more requests, cheaper ones use less (I’ll explain in a bit).
Users will pay a monthly subscription to access GitHub Copilot, and receive a certain allotment of AI tokens based on their subscription level. Organizations paying for GitHub Copilot will have “pooled” AI credits, meaning that tokens are shared across the entire organization.
For an initial promotional period running from June, July and August, GitHub Copilot Business Customers will pay $19 per-user-per-month and receive $30 of pooled AI credits, and Copilot Enterprise customers will pay $39 per-user-per-month and receive $70 of pooled AI credits. Afterward, users will receive either $19 or $39 of tokens depending on their subscription level.
While the documents refer to moving “all” GitHub Copilot users to token-based billing, it’s unclear at this time how Microsoft will be handling individual Pro or Pro+ subscribers.
If you liked this news hit and want to support my independent reporting and analysis, why not subscribe to my premium newsletter?
In the later afternoon of April 21 2026, Anthropic removed access to Claude Code for its $20-a-month "Pro" Plans on various pricing pages.
Current Pro users appeared to still have access via the Claude web app.
Claude Code support documents, for a brief period of
Show full content
Executive Summary:
In the later afternoon of April 21 2026, Anthropic removed access to Claude Code for its $20-a-month "Pro" Plans on various pricing pages.
Current Pro users appeared to still have access via the Claude web app.
Claude Code support documents, for a brief period of time, exclusively referred to accessing Claude Code via "your Max Plan," after previously saying you could access "with your Pro or Max Plan."
When pressed as to why support documents were changed and why the website consistently showed users that Pro subscribers weren't offered Claude Code, Avasare did not respond.
At an unknown time, Anthropic reversed the changes to the website and support documentation.
This piece remains as a record of what happened, as I do not believe that this is the last time that Anthropic makes changes in this manner.
Per Avasare, "...[Anthropic] made small adjustments along the way (weekly caps, tighter limits at peak), but usage has changed a lot and our current plans weren't built for this." This suggests that changes are to come for all subscription tiers, as he also added that Claude's Max plan was released before Claude Code and Claude Cowork, and "...designed for heavy chat usage, that's it."
The following exists as a record of what happened previously, please see above for the full story.
In developing news, Anthropic appears to have removed access to AI coding tool Claude Code from its $20-a-month "Pro" accounts. This is likely another cost-cutting move that follows a recent change (per The Information) that forced enterprise users to pay on a per-million-token based rate rather than having rate limits that were, based on researchers' findings, often much higher than the cost of the subscription.
Update: Anthropic's Amol Avasare claims that it is "...running a small test on ~2% of new prosumer signups. Existing Pro and Max subscribers aren't affected." This does not really make sense given the fact that all support documents and the Claude website reflect that Pro users do not have access to Claude Code.
I am waiting for further comment.
Previously, users were able to access Claude using their Pro subscriptions via a command-line interface and both the web and desktop Claude apps. Users were, instead of paying on a per-million-token basis, allowed to use their subscription to access Claude Code, but will likely now have to pay for API access.
Pricing on Anthropic's website reflects the removal of Claude Code on both mobile and desktop.
Some Pro users report that they are still able to access Claude Code via the web app and Command-Line Interface.
It is unclear at this time whether this change is retroactive or for new Pro subscribers, or whether Anthropic intends to entirely remove access to Claude Code (without paying for API tokens) from every Pro customer.
I have requested a comment from Anthropic, and will update this piece when I receive it, or if Anthropic confirms this move otherwise.
If you liked this news hit and want to support my independent reporting and analysis, why not subscribe to my premium newsletter?
If you liked this piece, please subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI&
For the best part of four years I’ve been wrapped up in writing these massive, sprawling narratives about the AI bubble and the tech industry at large. I still intend to write them, but today I’m going to do what I do best — explaining all the odd shit that’s happening in the tech industry and explaining why it’s concerning to me.
And because I love a good bit, I’m tying these stories to my pale horses of the AIpocalypse — signs that things are beginning to unwind in the most annoying bubble in history.
Anyway, considering that the newsletter and the podcast are now my main form of income, I’m going to be experimenting with the formats across the free and premium to keep things interesting and varied.
Anthropic’s Products Are Constantly Breaking Because It Doesn’t Have Enough Capacity, And Opus 4.7 Is Both Worse and Burns More Tokens
Pale Horse: Any further price increases or service degradations from Anthropic and OpenAI are a sign that they’re running low on cash.
Let’s start with a fairly direct statement: Anthropic should stop taking on new customers until it works out its capacity issues.
So, generally any service — Netflix, for example — you use with any regularity has the “four nines” of availability, meaning that it’s up 99.99% of the time. Once a company grows beyond a certain scale, having four 9s is considered standard business practice…
…unless you’re Anthropic!
As of writing this sentence, Anthropic’s availability for its Claude Chatbot has 98.79% uptime, its platform/console is at 99.14%, its API is at 99.09%, and Claude Code is at 99.25% for the last 90 days.
Let me put this into context. When you have 99.99% uptime, a service is only down for a minute (and 0.48 of a second) each week. If you’re hitting 98.79% uptime, as with the Claude chatbot, your downtime jumps to two hours, one minute, and 58 seconds.
Or, put another way, 98.79% uptime equates to nearly four-and-a-half days in a calendar year where the service is unavailable.
More-astonishingly, Claude for Government sits at 99.91%. Government services are generally expected to be four 9s minimum, or 5 (99.999%) for more important systems underlying things like emergency services.
This is a company that recently raised $30 billion dollars and gets talked about like somebody’s gifted child, yet Anthropic’s services seem to have constant uptime issues linked to a lack of capacity.
Since mid-February, outages for systems across Anthropic have become so common that some of its enterprise clients are switching to other AI model players.
David Hsu, founder and CEO of software development platform Retool, said he prefers to use Anthropic’s Opus 4.6 model to power his company’s AI agent tool because he believes it is the best model for enterprise. He recently changed to OpenAI’s model to power his company’s agent. “Anthropic has just been going down all the time,” he said.
The reliability of core services on the internet is often measured in nines. Four nines means 99.99% of uptime—a typical percentage that a software company commits to customers. As of April 8, Anthropic’s Claude API had a 98.95% uptime rate in the last 90 days.
One of the most detailed public complaints originated as a GitHub issue filed by Stella Laurenzo on April 2, 2026, whose LinkedIn profile identifies her as Senior Director in AMD’s AI group.
In that post, Laurenzo wrote that Claude Code had regressed to the point that it could not be trusted for complex engineering work, then backed that claim with a sprawling analysis of 6,852 Claude Code session files, 17,871 thinking blocks and 234,760 tool calls.
The complaint argued that, starting in February, Claude’s estimated reasoning depth fell sharply while signs of poorer performance rose alongside it, including more premature stopping, more “simplest fix” behavior, more reasoning loops, and a measurable shift from research-first behavior to edit-first behavior.
One Reddit post titled, "Claude Opus 4.7 is a serious regression, not an upgrade," has 2,300 upvotes. An X user's suggestion that Opus 4.7 wasn't really an improvement over Opus 4.6 got 14,000 likes. In one informal but popular test of AI intelligence, Opus 4.7 appears to say that there were two Ps in "strawberry." Another user screenshot shows it saying that it didn't cross reference because it was "being lazy." Some Redditors found that Opus 4.7 was rewriting their résumés with new schools and last names. MultipleX users posited that Opus 4.7 had simply gotten dumber.
Some X users have suggested the culprit is the AI model's reasoning times. Anthropic says the new "adaptive reasoning" function lets the model decide when to think for longer or shorter periods. One user wrote that they couldn't "get Opus 4.7 to think." Another wrote that it "nerfs performance."
"Not accurate," Anthropic's Boris Cherny, the creator of Claude Code, responded. "Adaptive thinking lets the model decide when to think, which performs better."
I think it’s deeply bizarre that a huge company allegedly worth hundreds of billions of dollars A) can’t seem to keep its services online with any level of consistency, B) appears to be making its products worse, and C) refuses to actually address or discuss the problem. Users have been complaining about Claude models getting “dumber” going back as faras2024, each time faced with a tepid gaslighting from a company with a CEO that loves to talk about his AI products wiping out half of white collar labor.
Anthropic Has No Good Solutions To Its Capacity Issues And Shouldn’t Be Accepting New Customers — And More Capacity Will Only Lose It Money
Remember: data centers take forever to build, and there’s only a limited amount of global capacity, most of which is taken up by Microsoft, Google, Amazon, Meta and OpenAI, with the first three of those already providing capacity to both Anthropic and OpenAI.
We’re likely hitting the absolute physical limits of available AI compute capacity, if we haven’t already done so, and even if other data centers are coming online, is the plan to just hand them over to OpenAI or Anthropic in perpetuity?
Yet it’s unclear whether “more capacity” means that things will be cheaper, or better, or just a way of Anthropic scaling an increasingly-shittier experience.
To explain, when an AI lab like Anthropic or OpenAI “hits capacity limits,” it doesn’t mean that they start turning away business or stop accepting subscribers, but that current (and new) subscribers will face randomized downtime and model issues, along with increasingly-punishing rate limits.
Neither company is facing a financial shortfall as a result of being unable to provide their services (rather, they’re facing financial shortfalls because they’re providing their services to customers), and the only ones paying that price because of these “capacity limits” are the customers.
What’s the goal, exactly? Providing a better experience to its current customers? Securing enough capacity to keep adding customers? Securing enough capacity to support larger models like Mythos? When, exactly, does Anthropic hit equilibrium, and what does that look like?
There’s also the issue of cost.
Anthropic is currently losing billions of dollars a year offering a service with amateurish availability and oscillating quality, and continues to accept new subscribers, meaning that capacity issues are not affecting its growth. As a result, adding more capacity simply makes the product work better for a much higher cost.
Anthropic’s Growth Story Is A Sham Based on Subsidies and Sub-par Service
Put another way, Anthropic doesn’t have to play by the rules. Venture capital funding allows it to massively subsidize its services. The endless, breathless support from the media runs cover for the deterioration of its services. A lack of any true regulation of tech, let alone AI, means that it can rugpull its customers with varying rate limits whenever it feels like.
If Anthropic were forced to charge its actual costs — and no, I don’t believe its API is profitable no matter how many people misread Dario Amodei’s interview — its growth would quickly fall apart as customers faced the real costs of AI (which I’ll get to in a bit). If Anthropic was forced to provide a stable service, it would have to stop accepting new customers or massively increase its inference costs.
Anthropic is a con, and said con is only made possible through endless, specious hype. Everybody who blindly applauded everything this company did is a mark.
Claude Mythos Was Held Back Due To Capacity Constraints, Not Fears Around Capabilities
Congratulations to all the current winners of the “Fell For It Again Award.” Per the Financial Times:
Anthropic has said it will hold off on a wider release of the model until it is reassured that it is safe and cannot be abused by bad actors. The company also has a finite amount of computing power and has suffered outages in recent weeks.
Multiple people with knowledge of the matter suggested Anthropic was holding back from a wider release until it could reliably serve the model to customers.
Did… Anthropic not bother to use its super-powerful Mythos model to check? Or did it not find anything? Either way, very embarrassing for all involved.
AI Compute Demand Is Being Inflated By Anthropic and OpenAI, With More Than 50% of AI Data Centers Under Construction Built For Two Companies, and Only 15.2GW of Capacity Under Construction Through The End of 2028
I reached out to Sightline to get some clarity, and they told me that of the 114GW of capacity due to come online by the end of 2028, only 15.2GW is under construction, including the 5GW due in 2026.
That’s…very bad.
It gets worse when you realize that the majority of that construction is for two companies:
OpenAI’s Stargate data centers account for 4.6GW — with 1.2GW in Abilene, Texas; 1.4GW in Shackelford, Texas; 1GW in Dona Ana, New Mexico; and 1GW in Port Washington, Wisconsin.
It’s safe to assume that with big tech’s hundreds of billions of dollars of capex that its data centers will make up a large amount — as much as 6GW — with most of that likely going to Anthropic or OpenAI.
While Amazon says it’s “fully operational,” it’s fucking lying, as it also claims that it has “nearly half a million Trainium 2 chips,” with each chip being 500 watts, and 500,000 times 500 watts being around 250MW. Other reports said it would be up to 1 million Trainium2 chips by the end of 2025, but that would still only amount to 500MW.
Microsoft’s also been relatively vague about the actual capacity, but based on there being “hundreds of thousands of GB200 GPUs,” that would be (assuming 300,000 GPUs) about 583MW.
So, to summarize, at least 4.6GW of the 15.2GW of data center capacity under construction is for OpenAI, with at least another 4GW of that reserved for Anthropic through partners like Microsoft, Google and Amazon. In truth, the number could be much higher.
NVIDIA Claims To Have $1 Trillion In Sales Visibility Through 2027, But Only $285 Billion GPUs Worth Of Data Centers Are Under Construction — NVIDIA Is Selling Years’ Worth of GPUs In Advance And Warehousing Them
It’s also very concerning that only such a small percentage of announced compute capacity is being built, especially when you run the numbers against NVIDIA’s actual sales.
Last year, Jerome Darling of TD Cowen estimated that it cost around $30 million per megawatt in critical IT (GPUs, servers, storage, and so on) and $12 million to $14 million per megawatt to build a data center, making critical IT around 68% (at the higher end of construction) of the total cost-per-megawatt.
Now, to be clear, those gigawatt and megawatt numbers for data centers refer to the power rather than critical IT, and if we take an average PUE (power usage efficiency, a measurement of how efficient a data center’s power is) of 1.35, we get 11.2GW of critical IT hardware, with the majority (I’d say 90%) being GPUs, bringing us down to around 10.1GW of GPUs.
If we then cut that up into GB200 or GB300 NVL72 racks with a power draw of around 140KW, that’s around 71,429 racks’ worth of hardware at an average of $4 million each, which gives us around $285.7 billion in revenue for NVIDIA.
At this point, I think it’s fair to ask why anyone is buying more GPUs, as there’s nowhere to fucking put them. Every beat-and-raise earnings from NVIDIA is now deeply suspicious.
AI Is Really Expensive, With Companies Spending As Much As 10% Of Headcount Cost On LLM Tokens, And May Reach 100% of Headcount Cost In The Next Few Quarters
New Pale Horse: Any and all signs that companies are facing the economic realities of AI, including any complaints around or adaptations to deal with the increasing costs of AI.
Last week, a report from Goldman Sachs revealed that (and I quote) “...companies are overrunning their initial budgets for inference by orders of magnitude (we heard one industry datapoint on inference costs in engineering now approaching about 10% of headcount cost, but could be on track to be on par with headcounts costs in the next several quarters based on current trajectories.”
To simplify, this means that some companies are spending as much as 10% of the cost of their employees on generative AI services, all without appearing to provide any stability, quality or efficiency gains, or (not that I want this) justification to lay people off.
Uber’s surging use of AI coding tools, particularly Anthropic’s Claude Code, has maxed out its full year AI budget just a few months into 2026, according to chief technology officer Praveen Neppalli Naga.
“I'm back to the drawing board because the budget I thought I would need is blown away already,” Neppalli Naga said in an interview.
…
He wouldn’t disclose exact figures of the company’s software budget or what it spends on AI coding tools. Uber’s research and development expenses, which typically reflect companies’ costs of developing new AI products, rose 9% to $3.4 billion in 2025 from the previous year, and the firm said in a recent securities filing it expects that cost will continue rising on an absolute dollar basis.
Uber’s CTO also added that about “...11% of real, live updates to the code in its backend systems are being written by AI agents primarily built with Claude Code, up from just a fraction of a percent three months ago.” Anyone who has ever used Uber’s app in the last year can see how well that’s going, especially if they’ve had to file any kind of support ticket.
Honestly, I find this all completely fucking insane. The whole sales pitch for generative AI is that it’s meant to be this magical, efficiency-driving panacea, yet whenever you ask somebody about it the answer is either “yeah, we’re writing all the code with it!” without any described benefits or “it costs so much fucking money, man.”
Let’s get practical about these economics, and use Spotify as an example because its CEO proudly said that its “top engineers” are barely writing code anymore, though to be clear, the Goldman Sachs example didn’t specifically name any one company.
For the sake of argument, let’s say that the company has 3000 engineers — one of its sites claims it has 2700, but I’ve seen reports as high as 3500. Let’s also assume, based on the Spotify Blind (an anonymous social media site for tech workers), that these engineers make a median salary of 192,000 a year.
In the event that Spotify spent 10% of its engineering headcount (around $576 million) on AI inference, it would be spending roughly $57.6 million, or approximately 4.1% of its $1.393 billion in Research and Development costs from its FY2025 annual report. Eager math-doers in the audience will note that 100% of headcount would be nearly half of the R&D budget, or around a quarter of its $2.2 billion in net income for the year.
Now, to be clear, these numbers likely already include some AI inference spend, but I’m just trying to illustrate the sheer scale of the cost.
While this is great for Anthropic (and to a lesser extent OpenAI), I don’t see how it works out for any of its customers. A flat 10% bump on the cost of software engineering is the direct opposite of what AI was meant to do, and in the event that costs continue to rise, I’m not sure how anybody justifies the expense much further.
And we’re going to find out fairly quickly, because the world of token subsidies is going away.
The Subprime AI Crisis Continues, With Microsoft Starting Token-Based Billing For GitHub Copilot Later This Year, And Anthropic Already Moving Enterprise Customers To API Rates
Pale Horse: Any further price increases or service degradations from AI startups, and yes, that’s what I’d call GitHub Copilot, in the sense that it loses hundreds of millions of dollars and makes fuck-all revenue.
As I reported yesterday, internal documents have revealed that Microsoft plans to temporarily suspend individual account signups to its GitHub Copilot coding product, tighten rate limits across the board, remove Opus models from its $10-a-month Pro subscription, and transition from requests (single interactions with GitHub Copilot) towards token-based billing some time later this year, with Microsoft confirming some of these details (but not token-based billing) in a blog post.
This is a significant move, driven by (per my own reporting) Microsoft’s week-over-week costs of running GitHub Copilot nearly doubling since January.
An aside/explainer: if you’re confused as to what “token-based billing” means, know that the vast majority of AI services currently subsidize their subscriptions, using another measure (such as “requests” or “rate limits”) to meter out how much a user can use the service. Nevertheless, these services still burn tokens at whatever rate that it costs to pay for them — for example, $5 per million input and $25 per million output for Opus 4.7, as I mentioned previously — meaning that the company almost always loses money unless a person doesn’t use the subscription very much.
Companies did this to grow their subscriber numbers, and I think they assumed things would get cheaper somehow. Great job, everyone!
The move to token-based billing will see GitHub users charged based on their usage of the platform, and how many tokens their prompts consume — and thus, how much compute they use. It’s unclear at this time when this will begin, but it significantly changes the value of the product.
I’ll also say that the fact that Microsoft has stopped signing up new paid GitHub Copilot subscriptions entirely is one of the most shocking moves in the history of software. I’ve literally never seen a company do this outside of products it intended to kill entirely, and that’s likely because — per my source — it intends to move paid customers over to token-based-billing, though it’s unclear what these tiers would look like, as the $10-a-month and $39-a-month subscriptions are mostly differentiated based on the amount of requests you can use.
Its decision to start cutting costs around AI suggests that said costs have become unbearable — The Information reported back in January that it was on pace to spend $500 million a year with Anthropic alone, and if that amount has doubled, it likely means that Microsoft is spending upwards of ten times its GitHub Copilot revenue, as I can report today that at the end of 2025, GitHub Copilot was at around $1.08 billion, with the majority of that revenue coming from its CoPilot Business and Enterprise subscriptions.
The Information also reported a few weeks ago that GitHub had recently seen a surge of outages attributed to “spiking traffic as well as its effort to move its applications from its own servers to Microsoft’s Azure cloud”:
“Since January, every month, every week almost now has some new peak stat for the highest [usage] rate ever,” [GitHub COO Kyle] Daigle said. He attributed the growth to “both agents and humans,” and also noted that the rise of AI coding tools has led to a rise in humans without deep coding knowledge starting to use GitHub’s platform more.
“Agents” in this case could refer to just about anything — OpenAI’s Codex, Anthropic’s Claude Code, or even people plugging in the wasteful, questionably-useful OpenClaw to their GitHub Copilot account, and if that’s what happened, it’s very likely behind the move to Token-Based Billing and rate limits.
In any case, if Microsoft’s making this move, it means that CFO Amy Hood — the woman behind last year’s pullback on data center construction — has decided that the subsidy party is over. Though Microsoft is yet to formally announce the move to Token-Based Billing, I imagine it’ll be sometime this week that it rips off the bandage.
I’m making the call that by the end of 2026, a majority of AI services will move some or all of their customers to token-based billing as they reckon with the true costs of running AI models.
This Is The Era of AI Hysteria
I kept things simple today both to give myself a bit of a break and because these were stories I felt needed telling.
Nevertheless, I do have to remark on how ridiculous everything has become.
I feel bad picking on Aaron, as he doesn’t seem like a bad guy. He is, however, increasingly-indicative of the hysterical brainrot of executive AI hysteria, where the only way to discuss the industry is in vaguely futuristic-sounding terms about “agents” and “inference” and “tokens as a commodity,” all with the intent of obfuscating the ugly, simple truth: that generative AI is deeply unprofitable, doesn’t seem to provide tangible productivity benefits, and appears to only lose both the business and the customer money.
Though my arguments might be verbose, they’re ultimately pretty simple: AI does not provide even an iota of the benefits — economic or otherwise — to justify its ruinous costs. Every new story that runs about cost-cutting or horrible burnrates increasingly validates my position, and for the most part, boosters respond by saying “well LOOK at how BIG the REVENUES are.”
It isn’t! AI revenues are dogshit. They’re awful. They’re pathetic. The entire industry — including OpenAI and Anthropic’s theoretical revenues of $13.1 billion and $4.5 billion — hit around $65 billion last year, and that includes the revenues from providing compute generated by neoclouds like CoreWeave and hyperscalers like Microsoft.
Cursor is also reportedly at $6 billion in annualized revenue (or around $500 million a month) and “gross margin positive” — which I also doubt given that it had to raise over $3 billion last year and is apparently raising another $2 billion this year.
Even if said numbers were real, the majority of OpenAI, Cursor and Anthropic’s revenues come from subsidized software subscriptions. Things have gotten so dire that even Deidre Bosa of CNBC agrees with me that AI demand is inflated by token-maxxing and subsidized services.
Otherwise, everybody else is making single or double-digit millions of dollars and losing hundreds of millions of dollars to get there. And per founder Scott Stevenson, overstating annualized revenues is extremely common, with AI startups booking “three-year-long” enterprise deals with the first year discounted and a twelve-month out:
The reason many AI startups are crushing revenue records is because they are using a dishonest metric
The biggest funds in the world are supporting this and misleading journalists for PR coverage.
The setup: Company signs 3-year enterprise deals. Year 1 is discounted (say $1M), Year 2 steps up ($2M), Year 3 is full price ($3M).
They report $3M as “ARR” — even though they’re only collecting $1M right now.
The worst part: The customer has an opt-out option at 12 months! It’s not actually a 3 year contract.
While it’s hard to say how widespread this potential act of fraud might be, Stevenson estimates that more than 50% of enterprise AI startups are using “contracted ARR” to pump their values. One (honest) founder responded to Stevenson saying that his company has $350,000 in contracted ARR but only $42,000 of ARR, adding that “next year is gonna be awesome though,” which I don’t think will be the case for what appears to be a chatbot for finding investors.
This industry’s future is predicated entirely on the existence of infinite resources, and most AI companies are effectively front-ends for models owned by Anthropic and OpenAI, two other companies that rely on infinite resources to run their services and fund their infrastructure.
And at the top of the pile sits NVIDIA, the largest company on the stock market, which is selling more GPUs than can be possibly installed, and very few people seem to notice or care.
I’m talking about hundreds of billions of dollars of GPUs sitting in warehouses that aren’t being installed, with it taking six months to install a single quarter’s worth of GPU sales. The assumption, based on every financial publication I’ve read, appears to be “it will keep selling GPUs forever, and it will all be so great.”
Where are you going to put them, Jensen? Where do the fucking GPUs go? There isn’t enough capacity under construction! If, in fact, NVIDIA is actually selling as many GPUs as it says, it’s likely taking liberties with “transfers of ownership” where NVIDIA marks a product as “sold” to somebody that has yet to actually take it on.
Sidenote: There’re already signs that GPUs are beginning to pile up.
You see, when a hyperscaler buys an AI server, what actually happens is an ODM — original design manufacturer — buys the GPUs from NVIDIA, builds the server, and then ships it to the data center, which, to be clear, is all above board and normal. These ODMs also book the entire value of the NVIDIA GPU as revenue, which is why revenues for companies like Foxconn, Wystron and Quanta Computing have all spiked during the AI bubble.
Oh, right, the signs. Per Quanta Computing’s fourth quarter financial results, inventory — as in stuff that’s sitting waiting to go somewhere — has spiked from $10.54 billion in Q3 2025 to $16.3 billion 2025, and nearly doubled year-over-year ($8.33 billion) as gross profit dropped from 7.9% in Q4 2024 to 7% Q4 2025. While this isn’t an across-the-board problem (Wistron’s inventories dropped quarter-over-quarter, for example), Taiwanese ODMs are going to be one of the first places to watch for inventory accumulation.
In any case, I keep coming back to the word “hysteria,” because it’s hard to find another word to describe this hype cycle. The way that the media, the markets, analysts, executives, and venture capitalists discuss AI is totally divorced from reality, discussing “agents” in terms that don’t match with reality and AI data centers in terms of “gigawatts” that are entirely fucking theoretical, all with a terrifying certainty that makes me wonder what it is I’m missing.
But every sign points to me being right, and if I’m right at the scale I think I’m right, I think we’re about to have a legitimacy crisis in investing and mainstream media, because regular people are keenly aware that something isn’t right, in many cases, it’s because they’re able to count.
Internal documents reveal that Microsoft plans to temporarily suspend individual account signups to its GitHub Copilot coding product, as it transitions from requests (single interactions with Copilot) towards token-based billing.
The documents reveal that the weekly cost of running Github Copilot has doubled since the start
Show full content
Executive Summary:
Internal documents reveal that Microsoft plans to temporarily suspend individual account signups to its GitHub Copilot coding product, as it transitions from requests (single interactions with Copilot) towards token-based billing.
The documents reveal that the weekly cost of running Github Copilot has doubled since the start of the year.
Microsoft also intends to tighten the rate limits on its individual and business accounts, and to remove access to certain models for those with the cheapest subscriptions.
Leaked internal documents viewed by Where’s Your Ed At reveal that Microsoft intends to pause new signups for the student and paid individual tiers of AI coding product GitHub Copilot, tighter rate limits, and eventually move users to “token-based billing,” charging them based on what the actual cost of their token burn really is.
Explainer: At present, GitHub Copilot users have a certain amount of “requests” — interactions where you ask the model to do something, with Pro ($10-a-month) accounts getting 300 a month, and Pro+ ($39-a-month) getting 1500. More-expensive models use more requests, cheaper ones use less (I’ll explain in a bit).
The document says that although token-based billing has been a top priority for Microsoft, it became more urgent in recent months, with the week-over-week cost of running GitHub Copilot nearly doubling since January.
The move to token-based billing will see GitHub users charged based on their usage of the platform, and how many tokens their prompts consume — and thus, how much compute they use. It’s unclear at this time when this will begin.
This is a significant move, reflecting the significant cost of running models on any AI product. Much like Anthropic, OpenAI, Cursor, and every other AI company, Microsoft has been subsidizing the cost of compute, allowing users to burn way, way more in tokens than their subscriptions cost.
The party appears to be ending for subsidized AI products, with Microsoft’s upcoming move following Anthropic’s (per The Information) recent changes shifting enterprise users to token-based billing as a means of reducing its costs.
Pauses on Signups for Individual and Student Tiers
GitHub Copilot currently has two tiers for individual developers — a $10-per-month package called GitHub Copilot Pro, and a $39-a-month subscription called GitHub Copilot Pro+.
According to the leaked documents, both of these tiers will be impacted by the shutdown, as will the GitHub Copilot Student product, which is included within the free GitHub Education package.
Removing Opus From GitHub Copilot Pro, Rate Limits Tightened on GitHub Copilot Pro, Pro+, Business, Enterprise
According to the documents, Microsoft also intends to tighten rate limits on some Copilot Business and Enterprise plans, as well as on individual plans, where limits have already been squeezed, and plans to suspend trials of paid individual plans as it attempts to “fight abuse.”
Although Microsoft has regularly tweaked the rate limits for individual GitHub Copilot accounts, most recently at the start of April, the document notes that these changes weren’t enough, and that more rate limits changes are to come in the next few weeks.
As part of this cost-cutting exercise, Microsoft intends to remove Anthropic’s Opus family of AI models from the $10-per-month GitHub Copilot Pro package altogether.
Premium request multipliers allow GitHub to reflect the cost of compute for different models. LLMs that require the most compute will have higher premium request multipliers compared to those that are comparatively more lightweight.
For example, the GPT-5.4 Mini model has a premium request multiplier of 0.33 — meaning that every prompt is treated as one-third of a premium request — whereas the now-retired Claude Opus 4.6 Fast had a 30x multiplier, meaning each request was treated as thirty of them.
The standard version of Claude Opus 4.6 has a premium request multiplier of three — meaning that, even with the promotional pricing, Claude Opus 4.7 is around 250% more expensive to use.
The announcements for all of these changes are scheduled to take place throughout the week.
If you liked this news hit and want to support my independent reporting and analysis, why not subscribe to my premium newsletter?
A few years ago, I made the mistake of filling out a form to look into a business loan, one that I never ended up getting. Since then I receive no less than three texts a day offering me lines of credit ranging from $150,000 to as much as
Show full content
A few years ago, I made the mistake of filling out a form to look into a business loan, one that I never ended up getting. Since then I receive no less than three texts a day offering me lines of credit ranging from $150,000 to as much as $10 million, each one boasting about how quickly they could fund me and how easy said funding would be. Some claim that they’ve been “looking over my file” (I’ve never provided any actual information), others say that they’re “already talking to underwriting,” and some straight up say that they can get me the money in the next 24 hours.
Some of the texts begin with a name (“Hey Ed, It’s Zack”) or sternly say “Edward, it’s time to raise capital.” Others cut straight to the chase and tell me that they have been “arranged for five hundred and fourty (sic) thousand,” and others send the entire terms of a loan that I assume will be harder to get than responding “yes.” While many of them are obvious, blatant scams, others lead to complaint-filled Better Business Bureau pages that show that, somehow, these entities have sent them real money, albeit under terms that piss off their customers and occasionally lead to them getting sued by the government.
That’s because right now, anybody with the right lawyers, accountants and financial backing can create their own fund and start issuing loans to virtually anyone they deem worthy.
And while they’ll all say that they use “industry-standard” underwriting, no regulatory standard exists.
This, my friends, is the world of private credit — a giant, barely-regulated time bomb of indeterminate (but most certainly trillions of dollars ) size that has become a load-bearing pillar of pensions and insurance funds, and according to Federal Reserve data, private credit has borrowed around $300 billion (as of 2023) from big banks, representing around 14% of their total loans.
Sidenote: while there are some strict “private credit” firms — such as software specialist Hercules Capital — many of the “private credit” firms I’ll discuss are really asset managers. These asset managers create and raise specialist private credit funds that either extend debt directly to a party (such as Apollo’s involvement in xAI’s $5.4 billion compute deal), or as part of a leveraged buyout, where a private equity firm buys another company and raises the debt using the company’s own assets and cashflow as collateral, putting the debt on the company’s balance sheet.
The eager, aggressive growth of private credit has even led it to start targeting individual investors, per the Financial Times:
Last year, a retired doctor in France’s southern region of Provence received a brochure in the mail from his bank touting a new investment opportunity.
A New York asset manager called Blackstone was offering the 77-year-old the chance to invest €25,000 into its flagship private debt fund. The former doctor called his son to ask: had he ever heard of Blackstone, or private debt?
His son Mathieu Chabran, co-founder of alternative investment group Tikehau Capital, had indeed heard of the powerful pioneer of private markets. But he was floored to discover that a company with $1tn in assets, which has minted over half a dozen billionaires, was seeking new business from novice investors such as his father.
The FT also neatly summarizes the problem of having regular investors involving themselves in the world of private credit:
He believes people like his father do not fully understand the risks of investing in funds that are harder to sell out of but which offer the opportunity to invest in private loans, property deals and corporate takeovers, with the allure of high returns.
And those high returns come with a cost: a lack of flexibility ranging from “you can only redeem your funds every quarter, and only a small percentage of your funds,” to “you can’t redeem your funds if everybody else tries to at the same time,” to “we make the rules here, shithead.” When an asset manager sets up a private credit fund, it often sets terms around how often — or how much — investors can pull at once, usually set around 5%, because in most cases, private credit funds are highly illiquid, as despite them acting like a financial institution, they more often than not don’t have very much money on hand for investors.
Why? Because the “private” part of private credit means that the lender directly negotiates with the borrower and values the loans based on their own internal models. Said loans generally have little or no secondary market, and private credit wants to hold them to maturity so that it can continue to provide ongoing yield (which I’ll explain in a little bit).
Sidenote: When you read about a “private credit fund,” it’s often a fund owned by an asset manager. For example, Blackstone recently raised “Blackstone Capital Opportunities Fund V,” a $10 billion “opportunistic” credit fund that incorporates as a special purpose vehicle that holds and invests the capital, and eventually sends out disbursements. Investors include New York State’s Common Retirement Fund ($250 million), Texas’ Municipal Retirement System ($200 million), and Louisiana Teachers’ Retirement System ($125 million), per Private Debt Investor.
Funds tend to have a life-cycle of somewhere between five and 10 years, which only really works if everybody keeps paying their loans.
Things were going great for private credit for the longest time, but late last year, some buzzkills at the Financial Times discovered that auto parts manufacturer First Brands and subprime auto loan company Tricolor had taken on billions of dollars of loans under dodgy circumstances, double-pledging collateral (IE: giving the same stuff as collateral on different loans) and outright falsifying lending documents, allowing the both of them to borrow upwards of $10 billion from private credit firms, including billions from North Carolina-based firm Onset Capital, which nearly collapsed but was eventually rescued by Silver Point Capital.
After the collapse of First Brands and Tricolor, JP Morgan’s Jamie Dimon said that “when you see cockroaches, there are probably more,” the kind of sinister quote baked specifically to lead off a movie about a financial crisis.
Blue Owl tried to merge a private fund (OBDC II, which allowed quarterly payouts) into another, publicly-traded fund (OBDC), but OBDC II’s value (as judged by Blue Owl itself) was 20% lower than that of OBDC, all to try and hide what are clearly problems with the economics of the fund itself. The FT has a great story about it.
Private equity is also the principal funding source for private equity’s leveraged buyouts, accounting for over 70% of all leveraged buyout funding for the last decade, which means that private credit — and anyone unfortunate enough to fund it! — is existentially tied to the ability of the portfolio companies’ ability to pay, and their continued ability to refinance their debt.
This is a problem when your assets are decaying in value. As I discussed in the Hater’s Guide To Private Equity, PE firms massively over-invested between 2017 and 2021, leaving them with a backlog of 31,000 companies valued at $3.7 trillion that they can’t sell or take public, likely because many of these acquisitions were vastly overvalued.
You see, when things were really good, asset managers raised hundreds of billions of dollars from pension funds, insurance funds (some of which they owned), and institutional investors, and then issued hundreds of billions of dollars more (at times using leverage from banks to do so) in loans to private equity firms that went on to buy everything from software companies to restaurant franchises. Said debt would immediately go on the balance sheet of the acquired company, creating a “reliable,” “consistent” yield with every loan payment that the fund could then send on to its investors, on a quarterly or monthly basis.
The problem is that these investments were made under very different economic circumstances, when money was easy to raise and exits were straightforward, leading to many assets being massively overvalued, and holding debt that was issued under revenue and growth projections that only made sense in a low-interest environment. In simple terms, these loans were given to companies assuming they’d be able to pay them long term, and assuming that the sunny economic conditions would continue indefinitely, making them tough to refinance or, in some cases, for the debtor to continue paying.
And nowhere is that problem more pronounced than the world of software.
Before 2018, Software As A Service (SaaS) companies had had an incredible run of growth, and it appeared basically any industry could have a massive hypergrowth SaaS company, at least in theory. As a result, venture capital and private equity has spent years piling into SaaS companies, because they all had very straightforward growth stories and replicable, reliable, and recurring revenue streams.
Between 2018 and 2022, 30% to 40% of private equity deals (as I’ll talk about later) were in software companies, with firms taking on debt to buy them and then lending them money in the hopes that they’d all become the next Salesforce, even if none of them will. Even VC remains SaaS-obsessed — for example, about 33% of venture funding went into SaaS in Q3 2025, per Carta.
The Zero Interest Rate Policy (ZIRP) era drove private equity into fits of SaaS madness, with SaaS PE acquisitions hitting $250bn in 2021. Too much easy access to debt and too many Business Idiots believing that every single software company would grow in perpetuity led to the accumulation of some of the most-overvalued software companies in history.
The SaaSpocalypse is often (incorrectly) described as a result of AI “disrupting incumbent software companies,” when the reality is that private equity (and private credit) made the mistaken bet that every single software company would grow in perpetuity.
This is a big fucking problem for private credit. Per the Wall Street Journal, asset managers are massively exposed to software companies, and have deliberately mislabeled some assets (such as saying a healthcare software company is just a “healthcare company”) to obfuscate the scale of the problem:
The Blue Owl Credit Income Corp. fund said that 11.6% of its portfolio consisted of loans to “internet software and services” companies at the end of the fourth quarter. The Journal found its software exposure to be around 21%.
The Blackstone Private Credit Fund, known as Bcred, reported 25.7% in software at the end of the third quarter, while the Journal found roughly 33% exposure.
Ares Capital Corp. reported 23.8% in “software and services” at the end of the fourth quarter, while the Journal found nearly 30% exposure.
The Apollo Debt Solutions fund reported 13.6% in software in the fourth quarter, while the Journal found a roughly 16% exposure.
And as I’ll explain, “obfuscation” is a big part of the private credit business model.
If I’m honest, preparing this week’s premium has been remarkably difficult, both in the amount of information I’ve had to pull together and how deeply worried it’s made me.
In the aftermath of the great financial crisis, insurance and pension funds found themselves desperate for yield — regular returns — to meet their payment obligations. Private credit has become the yield-bearer of choice, feeding over a trillion dollars of these funds’ investments into leveraged buyouts, AI data centers, loans to software companies, and failing restaurant franchises.
Asset managers offering private credit market themselves as bank-like stewards of capital, but lack many (if any) of the restrictions that make you actually trust a bank. They self-deal, investing their insurance affiliates’ funds in their own equity investments (such as when KKR used Global Atlantic to invest in data center developer CyrusOne, a company it acquired in 2022), value and revalue assets based on mysterious and undocumented private models, and account for (as I mentioned) 70% of all funding of leveraged buyouts in the last decade, of which 30 to 40% were software companies purchased between 2018 and 2022, meaning that hundreds of billions of dollars of retirement and insurance funds are dependent on overvalued software companies paying loans funded during the zero interest free era.
While a market crash feels scary, what’s far scarier is that the present and future ability of many retirement and insurance funds is dependent on whether private equity-owned entities, software companies. and AI data center firms are able to keep paying their debts. If private credit fund returns begin to lag, the retirement and insurance industry lacks a viable replacement, and I don’t know how to fix that.
Fuck it, I’ll level with you. I think asset managers are scumbags, and I think the way that they do business is fucking disgraceful. The unbelievable amount of risk that asset managers have passed onto people’s fucking retirements is enough to turn my stomach, and if I’m honest, I don’t understand how this entire thing hasn’t broken already.
If I had to guess, it’s one of two reasons: that private credit funds have yet to escalate their risk enough, or we’re yet to see said risk’s consequences, with First Brands and Tricolor being just the beginning.
And Wall Street is prepared to profit, with S&P Dow Jones launching a credit default swap derivatives product to bet against a collection of 25 different banks, insurers, REITs, and business development companies. Bank of America, Deutsche Bank, Barclays and Goldman Sachs will start selling the derivatives next week, per Reuters, and I’d argue that enough demand could spark a genuine panic across publicly-traded asset managers.
In any case, this is a situation where I fear not one massive catastrophe, but a series of smaller calamities caused by decades of hubris and questionable risk management resulting from the unbelievably stupid decision to let private entities act like banks.
This is the Hater’s Guide To Private Credit, or The Big Shart.
I think the most enlightening thing about AI is that it shows you how even the most mediocre text inspires some sort of emotion. Soulless LinkedIn slop makes you feel frustration with a person for their lack of authenticity, but you can still imagine how they forced it out of their heads. You still connect with them, even if it’s in a bad way.
AI copy is dead. It is inert. The reason you can spot it is that it sounds hollow. I don’t care if a website says stuff on it because I typed in, just like I don’t care if it responds in a way that sounds human, because it all feels like nothing to me. I am not here to give a website respect, I will not be impressed by a website, nor will I grant a website any extra credit if it can’t do the right thing every time. The computer is meant to work for me. If the computer doesn’t do what I want, I change the kind of computer I use. LLMs will always hallucinate, their outputs are not trustworthy as a result, they cannot be deterministic, and any chance of any mistakes of any kind are unforgivable. I don’t care how the website made you feel: it’s a machine that doesn’t always work, and that’s not a very good machine.
I feel nothing when I see an LLM’s output. Tell me thank you or whatever, I don’t care. You’re a website. Oh you can spit out code? Amazing. Still a website.
Perhaps you’ve found value in LLMs. Congratulations! You should feel no compulsion to have to convince me, nor should you feel any pride in using a particular website. And if you feel you’re being judged for using AI, perhaps you should ask why you feel so vilified? Did the industry do something to somehow warrant judgment? Is there something weird or embarrassing about the product, such as it famously having a propensity to get things wrong? Perhaps it loses billions of dollars? Oh, it’s damaging to the environment too? And people are telling outright lies about it and constantly saying it’ll replace people’s jobs? And the CEOs are all greedy oafish sociopaths? Did you try being cloying, judgmental, condescending, and aggressive to those who don’t like AI? Oh, that didn’t work? I can’t imagine why.
Sounds embarrassing! You must really like that website.
ChatGPT is a website. Claude is a website. While I guess Claude Code runs in a terminal window, that just means it’s an app, which I put in exactly the same mental box as I do a website.
Yet everything you read or hear or see about AI does everything it can to make you think that AI is something other than a website or an app. People that “discover the power of AI” immediately stop discussing it in the same terms as Microsoft Word, Google, or any other app or website. It’s never just about what AI can do today, but always about some theoretical “AGI” or vague shit about “AI agents” that are some sort of indeterminate level of “valuable” without anyone being able to describe why.
The agent — it's actually a collection of AI agents and assistants — scans McCann's calendar for client meetings and drafts a list of 10 things he needs to know for each one. The goal, McCann told Business Insider, was to free up time he and his staff spent preparing for the meetings.
Sounds like a website to me.
The agent reviews in-house data, what IBM and the client are doing in the market, external data, and account details — such as project status and services sold and purchased, McCann said. It can also identify industry trends and client needs by, for example, reviewing a firm's annual report and identifying a corresponding service IBM could provide.
Sounds like a website using an LLM to summarize stuff to me. Why are we making all this effort to talk about what a website does?
Digital Dave also saves McCann's team time, he said, because the three or four staffers who used to spend hours pulling together insights for the prep calls are now free to do other work.
"It's not just about driving efficiencies, but it's really about transforming how work gets done," McCann said.
My friend, this isn’t a “series of agents.” It’s an LLM that looks at stuff and spits out an answer. Chatbots have done this kind of thing forever. These aren’t “agents.” “Agents” makes it sound like there’s some sort of futuristic autonomous presence rather than a chatbot that’s looking at documents using technology that’s guaranteed to hallucinate incorrect information.
One benefit of building agents, McCann said, is that IBMers who develop them can share them with others on their team or more broadly within the company, "so it immediately creates that multiplier effect."
Many of the people who report to him have created agents, he said. There's a healthy competition, McCann said, to engineer the most robust digital sidekicks, especially because workers can build off of what their colleagues created.
Here’s a fun exercise: replace the word “agent” with “app,” and replace “AI” with “application.” In fact, let’s try that with the next quote:
Apps can handle a range of functions, including gathering information, processing paperwork, drafting communications, taking meeting minutes, and pulling research. It's still early, but these systems are quickly becoming a major focus of corporate application efforts as companies look to turn applications into something that can actually take work off employees' plates.
A variety of functions including searching for stuff, looking at stuff, generating stuff, transcribing a meeting, and searching for stuff. Wow! Who gives a fuck. Every “AI agent” story is either about code generation, summarizing some sort of information source, or generating something based on an information source that you may or may not be able to trust.
“Agent” is an intentional act of deception, and even “modern” agents like OpenClaw and its respective ripoffs ultimately boil down to “I can send you a reminder” or “I can transcribe a text you send me.”
Yet everybody seems to want to believe these things are “valuable” or “useful” without ever explaining why. A page of OpenClaw integrations claiming to share “real projects, real automations [and] real magic” includes such incredible, magical use cases as “reads my X bookmarks and discusses them with me,” “check incoming mail and remove spam,” “researches people before meetings and creates briefing docs,” “schedule reminders,” “tracking who visits a website” (summarizing information), and “using voice notes to tell OpenClaw what to do,” which includes “distilling market research” (searching for stuff) and “tightening a proposal” (generating stuff after looking at it).
I’d have no quarrel with any of this if it wasn’t literally described as magical and innovative. This is exactly the shit that software has always done — automations, shortcuts, reminders, and document work. Boring, potentially useful stuff done in an inefficient way requiring a Mac Mini and hundreds of dollars a day of API calls.
Even Stephen Fry’s effusive review of the iPad from 2010, in referring to it as a “magical object,” still referred to it as “class,” “a different order of experience,” remarking on its speed, responsiveness, its “smooth glide,” and remarking that it’s so simple. Even Fry, a writer beloved for his effervescence and sophisticated lexicon, was still able to point at the things he liked (such as the design and simplicity) in clear terms. Even in couching it in terms of the future, Fry is still able to cogently explain why he’s excited about the present.
Conversely, articles about Large Language Models and their associated products often describe them in one of three ways:
As if their ability to try to do some of a task allows them to do the entire task.
As if their ability to do tasks is somehow impressive or a justification for their cost.
An excuse for why they cannot do more hinged on something happening in the future.
This simply doesn’t happen outside of bubbles. The original CNET review of the iPhone — a technology I’d argue literally changed the way that human beings live their lives — still described it in terms that mirrored the reality we live in:
THE GOOD The Apple iPhone has a stunning display, a sleek design and an innovative multitouch user interface. Its Safari browser makes for a superb web surfing experience, and it offers easy-to-use apps. As an iPod, it shines.
THE BAD The Apple iPhone has variable call quality and lacks some basic features found in many cellphones, including stereo Bluetooth support and a faster data network. Integrated memory is stingy for an iPod, and you have to sync the iPhone to manage music content.
THE BOTTOM LINE Despite some important missing features, a slow data network and call quality that doesn't always deliver, the Apple iPhone sets a new benchmark for an integrated cellphone and MP3 player.
I’d argue that technologies like cloud storage, contactless payments, streaming music, and video and digital photography have transformed our societies in ways that were obvious from the very beginning. Nobody sat around cajoling us to accept that we’d need to sunset our Nokia 3210s and get used to touchscreens because it was blatantly obvious that it was better on using the first iPhone.
Nobody ostracized you for not being sufficiently excited about iPhone apps. Git, launched in 2005, is arguably one of the single-most transformational technologies in tech history, changing how software engineers built all kinds of software. And I’d argue that Github, which came a few years later, was equally transformational.
Editor’s note: If you used SourceForge or Microsoft Visual SourceSafe, which earned the nickname Microsoft Visual SourceShredder due to the catastrophic (and potentially career-ending) ways it failed, you know.
I realize this was before the hyper-polarized world of post-Musk Twitter, one where venture capital and the tech industry in general was a fraction of the size, but it’s really weird how different it feels when you read about how the stuff that actually mattered was covered.
I must repeat that this was a very different world with very different incentives. Today’s tech industry is a series of giant group chats across various social networks and physical locations, with a much-larger startup community (yCombinator’s last batch had 199 people — the first had 8) influenced heavily by the whims of investors and the various cults of personality in the valley. While social pressure absolutely existed, the speed at which it could manifest and mutate was minute in comparison to the rabid dogs of Twitter or the current state of Hackernews. There were fewer VCs, too.
In any case, no previous real or imagined tech revolution has ever inspired such eager defensiveness, tribalism or outright aggression toward dissenters, nor such ridiculous attempts to obfuscate the truth about a product outside of cryptocurrency, an industry with obvious corruption and financial incentives.
What Makes People So Attached To and Protective Of LLMs?
We’ve never had a cult of personality around a specific technology at this scale. There is something that AI does to people — in the way it both functions and the way that people react to it — that inspires them to act, defensively, weirdly, tribally.
I think it starts with LLMs themselves, and the feeling they create within a user.
We all love prompts. We love to be asked questions about ourselves. We feel important when somebody takes interest in what we’re doing, and even more-so when they remember things about it and seem to be paying attention. LLMs are built to completely focus themselves on us and do so while affirming every single interaction.
Human beings also naturally crave order and structure, which means we’ve created frameworks in our head about what authoritative-sounding or looking information looks like, and the language that engenders trust in it. We trust Wikipedia both because it’s an incredibly well-maintained library of information riddled with citations and because it tonally and structurally resembles an authoritative source. Large Language Models have been explicitly trained to deliver information (through training on much of the internet including Wikipedia) in a structured manner that makes us trust it like we would another source massaged with language we’d expect from a trusted friend or endlessly-patient teacher.
All of this is done with the intention of making you forget that you’re using a website. And that deception is what starts to make people act strangely.
The fact that an LLM can maybe do something is enough to make people try it, along with the constant pressure from social media, peers and the mainstream media.
Some people — such as myself — have used LLMs to do things, seen that making them do said things isn’t going to happen very easily, and walked away because I am not going to use a website that doesn’t do what it says.
As I’ve previously said, technology is a tool to do stuff. Some technology requires you to “get used to it” — iPhones and iPads were both novel (and weird) in their time, as was learning to use the Moonlander ZSK — but in basically every example doesn’t involve you tolerating the inherent failings of the underlying product under the auspices of it “one day being better.” Nowhere else in the world of technology does someone gaslight you into believing that the problems don’t exist or will magically disappear.
It’s not like the iPhone only occasionally allowed you to successfully take a photo, and reliable photography was something that you’d have to wait until the iPhone 3GS to enjoy. While the picture quality improved over time, every generation of iPhone all did the same basic thing successfully, reliably, and consistently.
I also think that the challenge of making an LLM do something useful is addictive and transformative. When people say they’ve “learned to use AI,” often they mean that they’ve worked out ways to fudge their prompts, navigate its failures, mitigate its hallucinations, and connect it to various different APIs and systems of record in such a way that it now, on a prompt, does something, and because they’re the ones that built this messy little process, they feel superior — because the model has repeatedly told them that they were smart for doing it and celebrated with them when they “succeeded.”
The term “AI agent” exists as both a marketing term and a way to ingratiate the user. Saying “yeah I used a chatbot to do some stuff” sounds boring, like you’re talking to an app or a website, but “using an AI agent” makes you sound like a futuristic cyber-warrior, even though you’re doing exactly the same thing.
LLMs are excellent digital busyboxes for those who want to come up with a way to work differently rather than actually doing work. In WIRED’s article about journalists using AI, Alex Heath boasts that he “feels like he’s cheating in a way that feels amazing”:
When technology reporter Alex Heath has a scoop, he sits down at his computer and speaks into a microphone. He’s not talking to a human colleague—Heath went independent on Substack last year—he’s talking to Claude. Using the AI-powered voice-to-text service Wispr Flow, Heath transmits his ideas to an AI agent, then lets it write his first draft.
Heath sat down with me last week to showcase how he’s integrated Anthropic’s Claude Cowork into his journalistic process. The AI tool is connected to his Gmail, Google Calendar, Granola AI transcription service, and Notion notes. He’s also built a detailed skill—a custom set of instructions—to help Claude write in his style, including the “10 commandments” of writing like Alex Heath. The skill includes previous articles he’s written, instructions on how he likes his newsletters to be structured, and notes on his voice and writing style.
Claude Cowork then automates the drafting process that used to take place in Heath’s head. After the agent finishes its first draft, Heath goes back and forth with it for up to 30 minutes, suggesting revisions. It’s quite an involved process, and he still writes some parts of the story himself. But Heath says this workflow saves him hours every week, and he now spends 30 to 40 percent less time writing.
The linguistics of “transmitting an idea to an AI agent” misrepresent what is a deeply boring and soulless experience. Alex speaks into a microphone, his words are transcribed, then an LLM burps out a draft. A bunch of different services connect to Claude Cowork and a text document (that’s what the “custom set of instructions” is) that says how to write like him, and then it writes like him, and then he talks to it and then sometimes writes bits of the story himself.
This is also most decidedly not automation. Heath still must sit and prompt a model again and again. He must still maintain connections to various services and make sure the associated documents in Notion are correct. He must make sure that Granola actually gets the transcriptions from his interview. He must (I would hope) still check both the AI transcription and the output from the model to make sure quotes are accurate. He must make sure his calendar reflects accurate information. He must make sure that Claude still follows his “voice and writing style” — if you can call it that given the amount of distance between him and the product.
Per Heath:
“I never did this because I liked being a writer. I like reporting, learning new things, having an edge, and telling people things that will make them feel smart six months from now.”
Well, Alex, you’re not telling anybody anything, your ideas and words come out of a Large Language Model that has convinced you that you’re writing them.
In any case, Heath’s process is a great example of what makes people think they’re “using powerful AI.” Large Language Models are extremely adept at convincing human beings to do most of the work and then credit “AI” with the outcomes. Alex’s process sounds convoluted and, if I’m honest, a lot more work than the old way of doing things. It’s like writing a blog using a machine from Pee-wee’s Playhouse.
I couldn’t eat breakfast that way every morning. I bet it would get old pretty quick.
This is the reality of the Large Language Model era. LLMs are not “artificial intelligence” at all. They do not think, they do not have knowledge, they are conjuring up their own training data (or reflecting post-training instructions from those developing them or documents instructing them to act a certain way), and any time you try and make them do something more-complicated, they begin to fall apart, and/or become exponentially more-expensive.
You’ll notice that most AI boosters have some sort of bizarre, overly-complicated way of explaining how they use AI. They spin up “multiple agents” (chatbots) that each have their own “skills document” (a text document) and connect “harnesses” (python scripts, text files that tell it what to do, a search engine, an API) that “let it run agentic workflows” (query various tools to get an outcome.”
The so-called “agentic AI” that is supposedly powerful and autonomous is actually incredibly demanding of its human users — you must set it up in so many different ways and connect it to so many different services and check that every “agent” (different chatbot) is instructed in exactly the right way, and that none of these agents cause any problems (they will) with each other. Oh, don’t forget to set certain ones to “high-thinking” for certain tasks and make sure that other tasks that are “easier” are given to cheaper models, and make sure that those models are prompted as necessary so they don’t burn tokens.
But the process of setting up all those agents is so satisfying, and when they actually succeed in doing something — even if it took fucking forever and costs a bunch and is incredibly inefficient — you feel like a god!And because you can “spin up multiple agents,” each one ready and waiting for you to give them commands (and ready to affirm each and every one of them), you feel powerful, like you’re commanding an army that also requires you to monitor whatever it does.
Sidebar: the psychological reward of building convoluted systems (which you can call “complex” if you want to feel fancy) is enough to drive somebody mad. OpenAI co-founder Andrej Karpathy recently described “building personal knowledge bases for various topics of research interest,” describing a dramatic and contrived process through which he has, by the sounds of it, created some sort of half-assed Wikipedia clone he can ask questions of using an LLM, with the results (and the content) also generated by AI. A user responded saying that he’d been doing a “less pro version of this using OpenClaw and Obsidian.”
It’s a very Silicon Valley way of looking at the world — a private Wikipedia that you use to…search…things you already know? Or want to know? You could just read a book I guess. Then again, in another recent tweet, Karpathy described drafting a blog post, using an LLM to “meticulously improve the argument over four hours,” then watch as the LLM “demolished the entire argument and convinced him the opposite was in fact true,” suggesting he didn’t really do much thinking about it in the first place.
God, these people sound like lunatics! I’m sorry! What’re you talking about man? You argued with a website for hours until it convinced you of something then it manipulated you into believing you were wrong? Why do you respect it? It’s a website! It doesn’t have opinions or thoughts or feelings. You are arguing with a calculator trained to sound human.
The reason that LLMs have become so interesting for software engineers is that this is already how they lived. Writing software is often a case of taping together different systems and creating little scripts and automations that make them all work, and the satisfaction of building functional software is incredible, even at the early stages.
Large Language Models perform an impression of automating that process, but for the most part force you, the user, to do the shit that matters, even if that means “be responsible for the code that it puts out.” Heath’s process does not appear to take less time than his previous one — he’s just moved stuff around a bit and found a website to tell him he’s smart for doing so.
They are Language Models interpreting language without any knowledge or thoughts or feelings or ability to learn, and each time they read something they interpret meaning based on their training data, which means they can (and will!) make mistakes, and when they’re, say, talking to another chatbot to tell it what to do next, that little mistake might build a fundamental flaw in the software, or just break the process entirely.
And Large Language Models — using the media — exist to try and convince you that these mistakes are acceptable. When Anthropic launched its Claude For Finance tool, which claims to “automate financial modeling” with “pre-built agents” (chatbots) but really appears to just be able to create questionably-useful models via Excel spreadsheets and “financial research” based on connecting to documents in your various systems, I imagine with a specific system prompt. Anthropic also proudly announced that it had scored a 55.3% on the Finance Agent Test.
I hate to repeat myself, but I will not respect a website, and I will not tolerate something being “55% good” at something if its alleged use case is that it’s an artificial intelligence.
Yet that’s the other remarkable thing about the LLM era — that there are people who are extremely tolerant of potential failures because they believe they’re either A) smart enough to catch them or B) smart enough to build systems that do so for them, with a little sprinkle of “humans make mistakes too,” conflating “an LLM that doesn’t know anything fucking up by definition” with “a human being with experiences and the capacity for adaptation making a mistake.”
Sidenote: I also believe that there is a contingent of people who are very impressed with LLMs who are really just impressed with the coding language Python. Python is awesome! It can organize your files, scrape websites, extra text from PDFs, manage your inbox, and send emails. Anyone you read talking about how LLMs “allowed them to look through a massive dataset” is likely using Python. Many of the associated tools that LLMs use use Python. Manus, the so-called “intelligent agent” firm that Meta bought last year, daisy-chains Python and Java in an incredibly-inefficient way to sometimes get things right, almost.
I truly have no beef with people using LLMs to speed up Python scripts to do fun little automations or to dig through big datasets, but please don’t try and convince me they’re being futuristic by doing so. If you want to learn Python, I recommend reading Al Sweigart’s Automate The Boring Stuff.
Anytime somebody sneers at you and says you are being “left behind” because you’re not using AI should be forced to show you what it is they’ve created or done, and the specific system they used to do so. They should have to show you how much work it took to prepare the system, and why it’s superior to just doing it themselves.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
Wondering what those “staggering improvements” are?
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
The one tangible (and theoretical!) example Karpathy gives is an example of how hard people work to overstate the capabilities of LLMs. “Coherently restructuring” a codebase might happen when you feed it to an LLM (while also costing a shit-ton of tokens, but putting that aside), or it might not understand at all because Claude Opus is acting funny that day, or it might sort-of fix it but mess something subtle up that breaks things in the future. This is an LLM doing exactly what an LLM does — it looks at a block of text, sees whether it matches up with what a user said, sees how that matches with its training data, and then either tells you things to do or generates new code, much like it would do if you had a paragraph of text you needed to fact-check. Perhaps it would get some of the facts right if connected to the right system. Perhaps it might make a subtle error. Perhaps it might get everything wrong.
This is the core problem with the “checkmate, boosters — AI can write code!” problem. AI can write code. We knew that already. It gets “better” as measured by benchmarks that don’t really compare to real world success, and even with the supposedly meteoric improvements over the last few months, nobody can actually explain what the result of it being better is, nor does it appear to extend to any domain outside of coding.
You’ll also notice that Karpathy’s language is as ingratiating to true believers as it is vague. Other domains are left unexplained other than references to “research” and “math.” I’m in a research-heavy business, and I have tried the most-powerful LLMs and highest-priced RAG/post-RAG research tools, and every time find them bereft of any unique analysis or suggestions.
I don’t dispute that LLMs are useful for generating code, nor do I question whether or not they’re being used by software developers at scale. I just think that they would be used dramatically less if there weren’t an industrial-scale publicity campaign run through the media and the majority of corporate America both incentivizing and forcing them to do so.
Similarly, I’m not sure anybody would’ve been anywhere near as excited if OpenAI and Anthropic hadn’t intentionally sold them a product that was impossible to support long-term.
This entire industry has been sold on a lie, and as capacity becomes an issue, even true believers are turning on the AI labs.
The Great Enshittification of Generative AIAnthropic’s Products Are Deteriorating In Real Time, And Its Customers Are Victims of A Con
About a year ago, I warned you that Anthropic and OpenAI had begun the Subprime AI Crisis, where both companies created “priority processing tiers” for enterprise customers (read: AI startups like Replit and Cursor), dramatically increasing the cost of running their services to the point that both had to dramatically change their features as a result. A few weeks later, I wrote another piece about how Anthropic was allowing its subscribers to burn thousands of dollars’ worth of tokens on its $100 and $200-a-month subscriptions, and asked the following question at the end:
…do you think that the current version of Claude Code is going to be what you get? Anthropic has proven it’ll rate limit their business customers, what's stopping it from doing the same to you and charging more, just like Cursor?
One of the most detailed public complaints originated as a GitHub issue filed by Stella Laurenzo on April 2, 2026, whose LinkedIn profile identifies her as Senior Director in AMD’s AI group.
In that post, Laurenzo wrote that Claude Code had regressed to the point that it could not be trusted for complex engineering work, then backed that claim with a sprawling analysis of 6,852 Claude Code session files, 17,871 thinking blocks and 234,760 tool calls.
The complaint argued that, starting in February, Claude’s estimated reasoning depth fell sharply while signs of poorer performance rose alongside it, including more premature stopping, more “simplest fix” behavior, more reasoning loops, and a measurable shift from research-first behavior to edit-first behavior.
Think that Anthropic cares? Think again:
Anthropic’s public response focused on separating perceived changes from actual model degradation. In a pinned follow-up on the same GitHub issue posted a week ago, Claude Code lead Boris Cherny thanked Laurenzo for the care and depth of the analysis but disputed its main conclusion.
Cherny said the “redact-thinking-2026-02-12” header cited in the complaint is a UI-only change that hides thinking from the interface and reduces latency, but “does not impact thinking itself,” “thinking budgets,” or how extended reasoning works under the hood.
He also said two other product changes likely affected what users were seeing: Opus 4.6’s move to adaptive thinking by default on Feb. 9, and a March 3 shift to medium effort, or effort level 85, as the default for Opus 4.6, which he said Anthropic viewed as the best balance across intelligence, latency and cost for most users.
Cherny added that users who want more extended reasoning can manually switch effort higher by typing /effort high in Claude Code terminal sessions.
To be clear, this is far from the only time that I’ve seen people complain about these models “getting dumber” — users on basically every AI Subreddit will say, at some point, that models randomly can’t do things they used to be able to, with nobody really having an answer other than “yeah dude, same.”
Back in September 2025, developer Theo Browne complained that Claude had got dumber, but Anthropic near-immediately responded to say that the degraded responses were a result of bugs that “intermittently degraded responses from Claude,” adding the following:
To state it plainly: We never reduce model quality due to demand, time of day, or server load. The problems our users reported were due to infrastructure bugs alone.
Which begs the question: is Anthropic accidentally making its models worse? Because it’s obvious it’s happening, it’s obvious they know something is happening, and its response, at least so far, has been to say that either users need to tweak their settings or nothing is wrong at all. Yet these complaints have happened for years, and have reached a crescendo with the latest ones that involve, in some cases, Claude Code burning way more tokens for absolutely no reason, hitting rate limits earlier than expected or wasting actual dollars spent on API calls.
Some suggest that the problems are a result of capacity issues over at Anthropic, which have led to a stunning (at least for software used by millions of people) amounts of downtime, per the Wall Street Journal:
The reliability of core services on the internet is often measured in nines. Four nines means 99.99% of uptime—a typical percentage that a software company commits to customers. As of April 8, Anthropic’s Claude API had a 98.95% uptime rate in the last 90 days.
This naturally led to boosters (and, for that matter, the Wall Street Journal) immediately saying that this was a sign of the “insatiable demand for AI compute”:
Spot-market prices to access Nvidia’s GPUs, or graphics processing units, in data-center clouds have risen sharply in recent months across the company’s entire product line, according to Ornn, a New York-based data provider that publishes market data and structures financial products around GPU pricing.
Renting one of Nvidia’s most-advanced Blackwell generation of chips for one hour costs $4.08, up 48% from the $2.75 it cost two months ago, according to the Ornn Compute Price Index.
“There’s a massive capacity crunch that’s unlike anything I’ve seen in the more than five years I’ve been running this business,” said J.J. Kardwell, chief executive of Vultr, a cloud infrastructure company. “The question is, why don’t we just deploy more gear? The lead times are too long. Data center build times are long, the power that’s available through 2026 is already all spoken for.”
Before I go any further: if anyone has been taking $2.75-per-hour-per-GPU for any kind of Blackwell GPU, they are losing money. Shit, I think they are at $4.08. While these are examples from on-demand pricing (versus paid-up years-long contracts like Anthropic buys), if they’re indicative of wider pricing on Blackwell, this is an economic catastrophe.
In any case, Anthropic’s compute constraints are a convenient excuse to start fucking over its customers at scale. Rate limits that were initially believed to be a “bug” are now the standard operating limits of using Anthropic’s services, and its models are absolutely, fundamentally worse than they were even a month ago.
A Scenario Illustrating How Anthropic Fucks Over Its Customers
It’s January 14 2026, and you just read The Atlantic’s breathless hype-slop about Claude Code, believing that it was “bigger than the ChatGPT moment,” that it was an “inflection point for AI progress,” and that it could build whatever software you imagined. While you’re not exactly sure what it is you’re meant to be excited about, your boss has been going on and on about how “those who don’t use AI will be left behind,” and your boss allows you to pay $200 for a year’s access to Claude Pro.
You, as a customer, no longer have access to the product you purchased. Your rate limits are entirely different, service uptime is measurably worse, and model performance has, for some reason, taken a massive dip. You hit your rate limits in minutes rather than hours. Prompts that previously allowed you a healthy back-and-forth over a project are now either impractical or impossible.
Your boss now has you vibe-coding barely-functional apps as a means of “integrating you with the development stack,” but every time you feed it a screenshot of what’s going wrong with the app you seem to hit your rate limits again. You ask your boss if he’ll upgrade you to the $100-a-month subscription, and he says that “you’ve got to make do, times are tough.” You sit at your desk trying to work out what the fuck to do for the next four hours, as you do not know how to code and what little you’ve been able to do is now impossible.
This is the reality for a lot of AI subscribers, though in many cases they’ll simply subscribe to OpenAI Codex or another service that hasn’t brought the hammer down on their rate limits.
…for now, at least.
AI Labs’ Capacity Issues Are Financial Poison, As Compute “Demand” Is Impossible To Gauge And Must Be Planned Years In Advance
The con of the Large Language Model era is that any subscription you pay for is massively subsidized, and that any product you use can and will see its service degraded as these companies desperately try to either ease their capacity issues or lower their burn rate.
Yet it’s unclear whether “more capacity” means that things will be cheaper, or better, or just a way of Anthropic scaling an increasingly-shittier experience.
To explain, when an AI lab like Anthropic or OpenAI “hits capacity limits,” it doesn’t mean that they start turning away business or stop accepting subscribers, but that current (and new) subscribers will face randomized downtime and model issues, along with increasingly-punishing rate limits.
Neither company is facing a financial shortfall as a result of being unable to provide their services (rather, they’re facing financial shortfalls because they’re providing their services to customers. And yet, the only people that are the only people paying that price because of these “capacity limits” are the customers.
This is because AI labs must, when planning capacity, make arbitrary guesses about how large the company will get, and in the event that they acquire too much capacity, they’ll find themselves in financial dire straits, as Anthropic CEO Dario Amodei told Dwarkesh Patel back in February:
So when we go to buying data centers, again, the curve I’m looking at is: we’ve had a 10x a year increase every year. At the beginning of this year, we’re looking at $10 billion in annualized revenue. We have to decide how much compute to buy. It takes a year or two to actually build out the data centers, to reserve the data center.
Basically I’m saying, “In 2027, how much compute do I get?” I could assume that the revenue will continue growing 10x a year, so it’ll be $100 billion at the end of 2026 and $1 trillion at the end of 2027. Actually it would be $5 trillion dollars of compute because it would be $1 trillion a year for five years. I could buy $1 trillion of compute that starts at the end of 2027. If my revenue is not $1 trillion dollars, if it’s even $800 billion, there’s no force on earth, there’s no hedge on earth that could stop me from going bankrupt if I buy that much compute.
What happens if you don’t buy enough compute? Well, you find yourself having to buy it last-minute, which costs more money, which further erodes your margins, per The Information:
In another sign of its financial pressures, OpenAI told investors that its gross profit margins last year were lower than projected due to the company having to buy more expensive compute at the last minute in response to higher than expected demand for its chatbots and models, according to a person with knowledge of the presentation. (Anthropic has experienced similar problems.)
In other words, compute capacity is a knife-catching game. Ordering compute in advance lets you lock in a better rate, but having to buy compute at the last-minute spikes those prices, eating any potential margin that might have been saved as a result of serving that extra demand.
Order too little compute and you’ll find yourself unable to run stable and reliable services, spiking your costs as you rush to find more capacity. Order too much capacity and you’ll have too little revenue to pay for it.
It’s important to note that the “demand” in question here isn’t revenue waiting in the wings, but customers that are already paying you that want to do more with the product they paid for. More capacity allows you to potentially onboard new customers, but they too face the same problems as your capacity fills.
This also begs the question: how much capacity is “enough”? It’s clear that current capacity issues are a result of the inference (the creation of outputs) demands of Anthropic’s users. What does adding more capacity do, other than potentially bringing that under control?
OpenAI And Anthropic’s Are Conning Their Customers, Offering Products That Will Reduce In Functionality In A Matter Of Months
This also suggests that Anthropic’s (and OpenAI’s by extension) business model is fundamentally flawed. At its current infrastructure scale, Anthropic cannot satisfactorily serve its current paying customer base, and even with this questionably-stable farce of a product, Anthropic still expects to burn $14 billion. While adding more capacity might potentially allow new customers to subscribe, said new customers would also add more strain on capacity, which would likely mean that nobody’s service improves but Anthropic still makes money.
It ultimately comes down to the definition of the word “demand.”
Let me explain.
Data center development is very slow. Only 5GW of capacity is under construction worldwide (and “construction” can mean anything from a single steel beam to a near-complete building). As a result, both Anthropic and OpenAI are planning and paying for capacity years in advance based on “demand.”
“Demand” in this case doesn’t just mean “people who want to pay for services,” but “the amount of compute that the people who pay us now and may pay us in the future will need for whatever it is they do.”
The amount of compute that a user may use varies wildly based on the model they choose and the task in question — a source at Microsoft once told me in the middle of last year that a single user could take up as many as 12 GPUs with a coding task using OpenAI’s o4-mini — which means that in a very real sense these guys are guessing and hoping for the best.
It also means that their natural choice will be to fuck over their current users to ease their capacity issues, especially when those users are paying on a monthly or — ideally — annual basis. OpenAI and Anthropic need to show continued revenue growth, which means that they must have capacity available for new customers, which means that old customers will always be the first to be punished.
We’re already seeing this with OpenAI’s new $100-a-month subscription, a kind of middle ground between its $20 and $200-a-month ChatGPT subscriptions that appears to have immediately reducedratelimits for $20-a-month subscribers.
This is a fundamentally insane and deceptive way to run a business, and I believe things will only get worse as capacity issues continue. Not only must Anthropic and OpenAI find a way to make their unsustainable and unprofitable services burn less money, but they must also constantly dance with metering out whatever capacity they have to their customers, because the more extra capacity they buy, the more money they lose.
OpenAI And Anthropic Are Unethical Businesses That Abuse Their Customers
However you feel about what LLMs can do, it’s impossible to ignore the incredible abuse and deception happening to just about every customer of an AI service.
As I’ve said for years, AI companies are inherently unsustainable due to the unreliable and inconsistent outputs of Large Language Models and the incredible costs of providing the services. It’s also clear, at this point, that Anthropic and OpenAI have both offered subscriptions that were impossible to provide at scale at the price and availability that they were leading up to 2026, and that they did so with the intention of growing their revenue to acquire more customers, equity investment and attention.
As a result, customers of AI services have built workflows and habits based on an act of deceit. While some will say “this is just what tech companies do, they get you in when it’s cheap then jack up the price,” doing so is an act of cowardice and allegiance with the rich and powerful.
To be clear, Anthropic and OpenAI need to do this. They’ve always needed to do this. In fact, the ethical thing to do would’ve been to charge for and restrict the services in line with their actual costs so that users could have reliable and consistent access to the services in question. As of now, anyone that purchases any kind of AI subscription is subject to the whims of both the AI labs and their ability to successfully manage their capacity, which may or may not involve making the product that a user pays for worse.
The “demand” for AI as it stands is an act of fiction, as much of that demand was conjured up using products that were either cheaper or more-available. Every one of those effusive, breathless hype-screeds about Claude Code from January or February 2026 are discussing a product that no longer exists. On June 1 2026, any article or post about Codex’s efficacy must be rewritten, as rate limits will be halved.
While for legal reasons I’ll stop short of the most obvious word, Anthropic and OpenAI are running — intentionally or otherwise — deeply deceitful businesses where their customers cannot realistically judge the quality or availability of the service long-term. These companies also are clearly aware that their services are deeply unpopular and capacity-constrained, yet aggressively court and market toward new customers, guaranteeing further service degradations and potential issues with models.
This is not a dignified way to use software, nor is it an ethical way to sell it.
How can you plan around this technology? Every month some new bullshit pops up. While incremental model gains may seem like a boon, how do you actually say “ok, let’s plan ahead” for a technology that CHANGES, for better or for worse, at random intervals? You’re constantly reevaluating model choices and harnesses and prompts and all kinds of other bullshit that also breaks in random ways because “that’s how large language models work.” Is that fun? Is that exciting? Do you like this? It seems exhausting to me, and nobody seems to be able to explain what’s good about it.
How, exactly, does this change?
Right now, I’d guess that OpenAI has access to around 2GW of capacity (as of the end of 2025), and Anthropic around 1GW based on discussions with sources. OpenAI is already building out around 10GW of capacity with Oracle, as well as locking in deals with CoreWeave ($22.4 billion), Amazon Web Services ($138 billion), Microsoft Azure ($250 billion), and Cerebras (“750MW”).
Both of these companies are making extremely large bets that their growth will continue at an astonishing, near-impossible rate. If OpenAI has reached “$2 billion a month” (which I doubt it can pay for) with around 2GW of capacity, this means that it has pre-ordered compute assuming it will make $10 billion or $20 billion a month in a few short years, which fits with The Information’s reporting that OpenAI projects it will make $113 billion in revenue in 2028.
And if it doesn’t make that much revenue — and also doesn’t get funding or debt to support it — OpenAI will run out of money, much as Anthropic will if that capacity gets built and it doesn’t make tens of billions of dollars a month to pay for it.
I see no scenario where costs come down, or where rate limits are eased. In fact, I think that as capacity limits get hit, both Anthropic and OpenAI will degrade the experience for the user (either through model degradation or rate limit decay) as much as they can.
I imagine that at some point enterprise customers will be able to pay for an even higher priority tier, and that Anthropic’s “Teams” subscription (which allows you to use the same subsidized subscriptions as everyone else) will be killed off, forcing anyone in an organization paying for Claude Code (and eventually Codex) via the API, as has already happened for Anthropic’s enterprise users.
Anyone integrating generative AI is part of a very large and randomized beta test. The product you pay for today will be materially different in its quality and availability in mere months. I told you this would happen in September 2024. I have been trying to warn you this would happen, and I will repeat myself: these companies are losing so much more money than you can think of, and they are going to twist the knife in and take as many liberties with their users and the media as they can on the way down.
It is fundamentally insane that we are treating these companies as real businesses, either in their economics or in the consistency of the product they offer.
These are unethical products sold in deceptive ways, both in their functionality and availability, and to defend them is to help assist in a society-wide con with very few winners.
And even if you like this, mark my words — your current way of life is unsustainable, and these companies have already made it clear they will make the service worse, without warning, if they even acknowledge that they’ve done so directly. The thing you pay for is not sustainable at its current price and they have no way to fix that problem.
Do you not see you are being had? Do you not see that you are being used?
Do any of you think this is good? Does any of this actually feel like progress?
I think it’s miserable, joyless and corrosive to the human soul, at least in the way that so many people talk about AI. It isn’t even intelligent. It’s just more software that is built to make you defend it, to support it, to do the work it can’t so you can present the work as your own but also give it all the credit.
And to be clear, these companies absolutely fucking loathe you. They’ll make your service worse at a moment’s notice and then tell you nothing is wrong.
Anyone using a subscription to OpenAI or Anthropic’s services needs to wake up and realize that their way of life is going away — that rate limits will make current workflows impossible, that prices will increase, and that the product they’re selling even today is not one that makes any economic sense.
Every single LLM product is being sold under false pretenses about what’s actually sustainable and possible long term.
With AI, you’re not just the product, you’re a beta tester that pays for the privilege.
And you’re a mark for untrustworthy con men selling software using deceptive and dangerous rhetoric.
The AI Industry Is Surprised That People Are Angry, And It Shouldn’t Be.
I will be abundantly clear for legal reasons that it is illegal to throw a Molotov cocktail at anyone, as it is morally objectionable to do so. I explicitly and fundamentally object to the recentacts of violence against Sam Altman.
It is also morally repugnant for Sam Altman to somehow suggest that the careful, thoughtful, determined, and eagerly fair work of Ronan Farrow and Andrew Marantz is in any way responsible for these acts of violence. Doing so is a deliberate attempt to chill the air around criticism of AI and its associated companies. Altman has since walked back the comments, claiming he “wishes he hadn’t used” a non-specific amount of the following words:
A lot of the criticism of our industry comes from sincere concern about the incredibly high stakes of this technology. This is quite valid, and we welcome good-faith criticism and debate. I empathize with anti-technology sentiments and clearly technology isn’t always good for everyone. But overall, I believe technological progress can make the future unbelievably good, for your family and mine.
While we have that debate, we should de-escalate the rhetoric and tactics and try to have fewer explosions in fewer homes, figuratively and literally.
These words remain on his blog, which suggests that Altman doesn’t regret them enough to remove them.
I do, however, agree with Mr. Altman that the rhetoric around AI does need to change.
They should immediately stop misleading people through company documentation that models are “blackmailing” people or, as Anthropic did in its Mythos system card, suggest a model has “broken containment and sent a message” when it A) was instructed to do so and B) did not actually break out of any container.
Those that defend AI labs will claim that these are “difficult conversations that need to be had,” when in actuality they engage in dangerous and frightening rhetoric as a means of boosting a company’s valuation and garnering attention. If either of these men truly believed these things were true, they would do something about it other than saying “you should be scared of us and the things we’re making, and I’m the only one brave enough to say anything.”
These conversations are also nonsensical and misleading when you compare them to what Large Language Models can do, and this rhetoric is a blatant attempt to scare people into paying for software today based on what it absolutely cannot and will not do in the future. It is an attempt to obfuscate the actual efficacy of a technology as a means of deceiving investors, the media and the general public.
Both Altman and Amodei engage in the language of AI doomerism as a means of generating attention, revenue and investment capital, actively selling their software and future investment potential based on their ownership of a technology that they say (disingenuously) is potentially going to take everybody’s jobs.
Based on reports from his Instagram, the man who threw the molotov cocktail at Sam Altman’s house was at least partially inspired by If Anyone Builds It, Everyone Dies, a doomer porn fantasy written by a pair of overly-verbose dunces spreading fearful language about the power of AI, inspired by the fearmongering of Altman himself. Altman suggested in 2023 that one of the authors might deserve the Nobel Peace Prize.
I only see one side engaged in dangerous rhetoric, and it’s the ones that have the most to gain from spreading it.
Cause and Effect
I need to be clear that this act of violence is not something I endorse in any way. I am also glad that nobody was hurt.
I also think we need to be clear about the circumstances — and the rhetoric — that led somebody to do this, and why the AI industry needs to be well aware that the society they’re continually threatening with job loss is one full of people that are very, very close to the edge. This is not about anybody being “deserving” of anything, but a frank evaluation of cause and effect.
People feel like they’re being fucking tortured every time they load social media. Their money doesn’t go as far. Their financial situation has never been worse. Every time they read something it’s a story about ICE patrols or a near-nuclear war in Iran, or that gas is more expensive, or that there’s worrying things happening in private credit. Nobody can afford a house and layoffs are constant.
One group, however, appears to exist in an alternative world where anything they want is possible. They can raise as much money as they want. They can build as big a building as they want anywhere in the world. Everything they do is taken so seriously that the government will call a meeting about it. Every single media outlet talks about everything they do. Your boss forces you to use it. Every piece of software forces you to at least acknowledge that they use it too. Everyone is talking about it with complete certainty despite it not being completely clear why. As many people writhe in continual agony and fear, AI promises — but never quite delivers — some sort of vague utopia at the highest cost known to man.
And these companies are, in no uncertain terms, coming for your job.
These people who sell a product with no benefit comparable on any level to its ruinous, trillion-dollar cost are able to get anything they want at a time when those who work hard are given a kick in the fucking teeth, sneered at for not “using AI” that doesn’t actually seem to make their lives easier, and then told that their labor doesn’t constitute “real work.”
At a time when nobody living a normal life feels like they have enough, the AI industry always seems to get more. There’s not enough money for free college or housing or healthcare or daycare but there’s always more money for AI compute.
Regular people feel ignored and like they’re not taken seriously, and the people being given the most money and attention are the ones loudly saying “we’re richer than anyone has ever been, we intend to spend more than anyone has ever spent, and we intend to take your job.”
Why are they surprised that somebody mentally unstable took them seriously? Did they not think that people would be angry? Constantly talking about how your company will make an indeterminate amount of people jobless while also being able to raise over $162 billion in the space of two years and taking up as much space on Earth as you please is something that could send somebody over the edge.
Every day the news reminds you that everything sucks and is more expensive unless you’re in AI, where you’ll be given as much money and told you’re the most special person alive. I can imagine it tearing at a person’s soul as the world beats them down. What they did was a disgraceful act of violence.
Unstable people in various stages of torment act in erratic and dangerous ways. The suspect in the molotov cocktail incident apparently had a manifesto where he had listed the names and addresses of both Altman and multiple other AI executives, and, per CNBC, discussed the threat of AI to humanity as a justification for his actions. I am genuinely happy to hear that this person was apprehended without anyone being hurt.
These actions are morally wrong, and are also the direct result of the AI industry’s deceptive and manipulative scare campaign, one promoted by men like Altman and Amodei, as well as doomer fanfiction writers like Yudowsky, and, of course, Daniel Kokotajlo of AI 2027 — both of whom have had their work validated and propagated via the New York Times.
On the subject of “dangerous rhetoric,” I think we need to reckon with the fact that the mainstream media has helped spread harmful propaganda, and that a lack of scrutiny of said propaganda is causing genuine harm.
I also do not hear any attempts by Mr. Altman to deal with the actual, documented threat of AI psychosis, and the people that have been twisted by Large Language Models to take their lives and those of others. These are acts of violence that could have been stopped had ChatGPT and similar applications not been anthropomorphized by design, and trained to be “friendly.”
These dangerous acts of violence were not inspired by Ronan Farrow publishing a piece about Sam Altman. They were caused by a years-long publicity campaign that has, since the beginning, been about how scary the technology is and how much money its owners make.
I separately believe that these executives and their cohort are intentionally scaring people as a means of growing their companies, and that these continual statements of “we’re making something to take your job and we need more money and space to do it” could be construed as a threat by somebody that’s already on edge.
I agree that the dangerous rhetoric around AI must stop. Dario Amodei and Sam Altman must immediately cease their manipulative and disingenuous scare-tactics, and begin describing Large Language Models in terms that match their actual abilities, all while dispensing with any further attempts to extrapolate their future capabilities. Enough with the fluff. Enough with the bullshit. Stop talking about AGI. Start talking about this like regular old software, because that’s all that ChatGPT is.
In the end, if Altman wants to engage with “good-faith criticism,” he should start acting in good faith.
That starts with taking ownership of his role in a global disinformation campaign. It starts with recognizing how the AI industry has sold itself based on spreading mythology with the intent of creating unrest and fear.
And it starts with Altman and his ilk accepting any kind of responsibility for their actions.
In what The New Yorker’s Andrew Marantz and Ronan Farrow called a “tense call” after his brief ouster from OpenAI in 2023, Sam Altman seemed unable to reckon with a “pattern of deception” across his time at the company:
“This is just so fucked up,” he said repeatedly, according to people on the call. “I can’t change my personality.” Altman says that he doesn’t recall the exchange. “It’s possible I meant something like ‘I do try to be a unifying force,’ ” he told us, adding that this trait had enabled him to lead an immensely successful company.
He attributed the criticism to a tendency, especially early in his career, “to be too much of a conflict avoider.” But a board member offered a different interpretation of his statement: “What it meant was ‘I have this trait where I lie to people, and I’m not going to stop.’ ” Were the colleagues who fired Altman motivated by alarmism and personal animus, or were they right that he couldn’t be trusted?
No, he cannot. Sam Altman is a deeply-untrustworthy individual, and like OpenAI lives on the fringes of truth, using a complaint media to launder statements that are, for legal reasons, difficult to call “lies” but certainly resemble them. For example, back in November 2025, Altman told venture capitalist Brad Gerstner that OpenAI was doing “well more” than $13 billion in annual revenue when the company would do — and this is assuming you believe CNBC’s source — $13.1 billion for the entire year. I guarantee you that, if pressed, Altman would say that OpenAI was doing “well more than” $13 billion of annualized revenue at the time, which was likely true based on OpenAI’s stylized math, which works out as so (per The Information):
OpenAI multiplies its total revenue for a recent four-week period by 13, which equals 52 weeks —or a full year, according to a person with direct knowledge of its finances.
OpenAI shares 20% of its revenue with Microsoft due to their multifaceted business arrangement, but OpenAI’s financial statements count sales before the company gives Microsoft its slice.
This means that, per CNBC’s reporting, OpenAI barely scratched $10 billion in revenue in 2025, and that every single story about OpenAI’s revenue other than my own reporting (which came directly from Azure) massively overinflates its sales. The Information’s piece about OpenAI hitting $4.3 billion in revenue in the first half of 2025 should really say “$3.44 billion,” but even then, my own reporting suggests that OpenAI likely made a mere $2.27 billion in the first half of last year, meaning that even that $10 billion number is questionable.
It’s also genuinely insane to me that more people aren’t concerned about OpenAI, not as a creator of software, but as a business entity continually misleading its partners, the media, and the general public.
To put it far more bluntly, the media has failed to hold OpenAI accountable, enabling and rationalizing a company built on deception, rationalizing and normalizing ridiculous and impossible ideas just because Sam Altman said them.
The Media Must Stop Enabling OpenAI and Acknowledge That It Cannot Afford Its Commitments
Let me give you a very obvious example. About a month ago, per CNBC, “...OpenAI reset spending expectations, telling investors its compute target was around $600 billion by 2030.”
This is, on its face, a completely fucking insane thing to say, even if OpenAI was a profitable company. Microsoft, a company with hundreds of billions of dollars of annual revenue, has about $42 billion in quarterly operating expenses.
OpenAI cannot afford to pay these agreements. At all. Hell, I don’t think any company can! And instead of saying that, or acknowledging the problem, CNBC simply repeats the statement of “$600 billion in compute spend,” laundering Altman and OpenAI’s reputation as it did (with many of the same writers and TV hosts) with SamBankman-Fried. CNBC claimed mere months before the collapse of FTX that it had grown revenue by 1,000% “during the crypto craze,” with its chief executive having “...survived the market wreckage and still expanded his empire.”
The same goes for OpenAI’s $300 billion deal with Oracle that OpenAI cannot afford and Oracle does not have the capacity to serve. These deals do not make any logical sense, the money does not exist, and the utter ridiculousness of reporting them as objective truths rather than ludicrous overpromises allowed Oracle’s stock to pump and OpenAI to continue pretending it could actually ever have hundreds of billions of dollars to spend.
I also think that revenue growth is a little too convenient, accelerating only to match Anthropic, which recently “hit” $30 billion in annualized revenue under suspicious circumstances. I can only imagine OpenAI will soon announce that it’s actually hit $35 billion in annualized revenue, or perhaps $40 billion in annualized revenue, and if that happens, you know that OpenAI is just making shit up.
Regardless, even if OpenAI is actually making $2 billion a month in revenue, it’s likely losing anywhere from $4 billion to $10 billion to make that revenue. Per my own reporting from last year, OpenAI spent $8.67 billion on inference to make $4.329 billion in revenue, and that’s not including training costs that I was unable to dig up — and those numbers were before OpenAI spent tens of millions of dollars in inference costs propping up its doomed Sora video generation product, or launched its Codex coding environment. In simpler terms, OpenAI’s costs have likely accelerated dramatically with its supposed revenue growth.
And all of this is happening before OpenAI has to spend the majority of its capital. Oracle has, per my sources in Abilene, only managed to successfully build and generate revenue from two buildings out of the eight that are meant to be done by the end of the year, which means that OpenAI is only paying a small fraction of the final costs of one Stargate data center. Its $138 billion deal with Amazon Web Services is only in its early stages, and as I explained a few months ago in the Hater’s Guide To Microsoft, Redmond’s Remaining Performance Obligations that it expects to make revenue from in the next 12 months have remained flat for multiple quarters, meaning that OpenAI’s supposed purchase of “an incremental $250 billion in Azure compute” are yet to commence.
In practice, this means that OpenAI’s expenses are likely to massively increase in the coming months. And while the “$122 billion” funding round it raised — with $35 billion of it contingent on either AGI or going public (Amazon), and $60 billion of it paid in tranches by SoftBank and NVIDIA — may seem like a lot, keep in mind that OpenAI had received $22.5 billion from SoftBank on December 31 2025, a little under four months ago.
This suggests that either OpenAI is running out of capital, or has significant up-front commitments it needs to fulfil, requiring massive amounts of cash to be sent to Amazon, Microsoft, CoreWeave (which it pays on net 360 terms) and Oracle.
And if I’m honest, I think the entire goal of the funding round was to plug OpenAI’s leaky finances long enough to take it public, against the advice of CFO Sarah Friar.
OpenAI Is Rushing Toward IPO Against The Wishes of Its CFO — And It Has Every Warning Sign That Something Is Very, Very Wrong With Its Finances
As OpenAI prepares for its potential I.P.O., Altman has faced questions not only about the effect of A.I. on the economy—it could soon cause severe labor disruption, perhaps eliminating millions of jobs—but about the company’s own finances. Eric Ries, an expert on startup governance, derided “circular deals” in the industry—for example, OpenAI’s deals with Nvidia and other chip manufacturers—and said that in other eras some of the company’s accounting practices would have been considered “borderline fraudulent.” The board member told us, “The company levered up financially in a way that’s risky and scary right now.” (OpenAI disputes this.)
As I wrote up earlier in the week, OpenAI CFO Sarah Friar does not believe, per The Information, that OpenAI is ready to go public, and is concerned about both revenue growth slowing and OpenAI’s ability to pay its bills:
She told some colleagues earlier this year that she didn’t believe the company would be ready to go public in 2026, because of the procedural and organizational work needed and the risks from its spending commitments, according to a person who spoke to her. She said she wasn’t sure yet whether OpenAI would need to pour so much money into obtaining AI servers in the coming years or whether its revenue growth, which has been slowing, would support the commitments, said the person who spoke to her.
To make matters worse, Friar also no longer reports to Altman — and god is it strange that the CFO doesn’t report to the CEO! — and it’s actually unclear who it is she reports to at all, as her current report, Fiji Simo, has taken an indeterminately-long leave of medical absence. Friar has also, per The Information, been left out of conversations around financial planning for data center capacity.
These are the big, flashing warning signs of a company with serious financial and accounting issues, run by Sam Altman, a CEO with a vastly-documented pattern of lies and deceit. Altman is sidelining his CFO, rushing the company to go public so that his investors can cash out and the larger con of OpenAI can be dumped onto public investors.
And beneath the surface, the raw economics of OpenAI do not make sense.
OpenAI Can Only Exist As Long As Venture Capital Subsidizes Its Business and Its Customers, And Its Funders and Infrastructure Partners Have Access To Debt
You’ll notice I haven’t talked much about OpenAI’s products yet, and that’s because I do not believe they can exist without venture capital funding them and the customers that buy them. These products only have market share as long as other parties continue to build capacity or throw money into the furnace.
To explain:
OpenAI’s ChatGPT Subscriptions are, like every LLM product, deeply unprofitable, which means that OpenAI needs constant funding to keep providing them. I have found users of OpenAI Codex who have been able to burn between $1,000 and $2,000 in the space of a week on a $200-a-month subscription, and OpenAI just reset rate limits for the second time in a month. This isn’t a real business.
OpenAI’s API customers (the ones paying for access to its models) are, for the most part, venture-backed startups providing services like Cursor and Perplexity that are powered by these models. These startups are all incredibly unprofitable, requiring them to raise hundreds of millions of dollars every few months (as is the case with Harvey, Lovable, and many other big-name AI firms), which means that a large chunk — some estimate around 27% of its revenue — is dependent on customers that stop existing the moment that venture capital slows down.
OpenAI’s infrastructure partners like CoreWeave and Oracle are taking on anywhere from a few billion to over a hundred billion dollars’ worth of debt to build data centers for OpenAI, putting both companies in material jeopardy in the event of OpenAI’s failure to pay or overall collapse.
OpenAI’s lead investor SoftBank is putting its company in dire straits to fund the company, with over $60 billion invested in the company so far, existentially tying SoftBank’s overall financial health to both OpenAI’s stock price and SoftBank’s ability to continue paying (or refinancing) its loans.
While OpenAI is not systemically necessary, the continued enabling and normalization of its egregious and impossible promises has created an existential threat to multiple parties named above. Its continued existence requires more money than anybody has ever raised for a company — private or public — and in the event it’s allowed to go public, I believe that both retail investors and large equity investors like SoftBank will be left holding the bag.
OpenAI has a fundamental lack of focus as a business, despite howmanyarticles have claimed over the last year that it’s working on a “SuperApp” and has some sort of renewed plan to take on whoever it is that OpenAI perceives as the competition in any given calendar month.
OpenAI Is A Confidence Game Empowered By The Media and Investors That Is Rigged To Explode
I tend to be pretty light-hearted in what I write, but please take me seriously when I say I have genuine concerns about the dangers posed by OpenAI.
I believe that OpenAI is an incredibly risky entity, not due to the power of its models or its underlying assets, but due to Sam Altman’s ability to con people and find others that will con in his stead. Those responsible for rooting out con artists — regulators, investors, and the media — have not simply failed, but actively assisted Altman in this con.
Here’re the crucial elements of the con:
Creating a halo of uncertainty around the actual efficacies of LLMs, to the point that a cult of personality grew around a technologythat obfuscated its actual outcomes and efficacies to the point that it could be sold based on what it might do rather than what it actually does.
Creating a halo of “genius” around Altman himself, aided by constant and vague threats of human destruction with the suggestion that only Altman could solve them.
Normalizing the idea that it’s both necessary and important to let a company burn billions of dollars.
Normalizing the idea that it’s okay that a company has perpetual losses, and perpetuating the idea that these losses are necessary for innovation to continue at large.
Sam Altman is a dull, mediocre man that loves money and power. He appears to be superficially charming, but his actual skill is ingratiating himself with others and having them owe him favors, or feel somehow indebted to him otherwise. He remembers people’s names and where he met them, and is very good at emailing people, writing checks, or finding reasons for somebody else to write a check. He is not technical — he can barely code and misunderstands basic machine learning (to quote Futurism) — but is very good at making the noises that people want to hear, be they big scary statements that confirm their biases or massive promises of unlimited revenue that don’t really make any rational sense.
While OpenAI might have started on noble terms, it has since morphed into a massive con led by the Valley’s most-notable con artist.
I realize that those who like AI might find this offensive, but what else do you call somebody who makes promises they can’t keep ($300 billion to Oracle, $200 billion of revenue by 2030), spreads nonsensical financials (promises to spend $600 billion in compute), makes announcements of deals that don’t exist (see: NVIDIA’s $100 billion funding and the entire Stargate project), and speaks in hyperbolic terms to pump the value of his stock (such as basically every time he talks about Superintelligence).
OpenAI is a psuedo-company that can only exist with infinite resources, its software sold on lies, its infrastructure built and paid for by other parties, and its entire existence fueled by compounding layers of leverage and risk.
OpenAI has never made sense, and was only rationalized through a network of co-conspirators. OpenAI has never had a path to profitability, and never had a product that was worthy of the actual cost of selling it. The ascension of this company has only been possible as part of an exploitation of ignorance and desperation, and its collapse will be dangerous for the entire tech industry.
Today I’ll explain in great detail the sheer scale of Sam Altman’s con, how it was exacted, the danger it poses to its associated parties, and how it might eventually collapse.
This is the Hater’s Guide To OpenAI, or Sam Altman, Freed.
Subscribing helps directly support my free work, and premium subscribers don’t see this ad in their inbox.
I can’t get over how weird the AI bubble has become.
Hyperscalers are planning to spend over $600 billion on data center construction and GPUs predominantly bought from NVIDIA, the largest company on the stock market, all to power generative AI, a technology that’s so powerful that none of them will discuss how much it’s making them, or what it is we’re all meant to be so excited.
That’s so weird! What’re you doing Microsoft? What do you mean it’s for entertainment purposes? You’re building massive data centers to drive this!
Well, okay, you’re building them at some point. As I discussed a few weeks ago, despite everybody talking about the hundreds of gigawatts of data centers being built “to power AI,” only 5GW are actually “under construction,” with “under construction” meaning anything from “we’ve got some scaffolding up” to “we’re about to hand over the keys to the customer.”
But isn’t it weird we’re even building those data centers to begin with? Why? What is it that AI does that makes it so essential — or, rather, entertaining — that we keep funding and building these things? Every day we hear about “the power of AI,” we’re beaten over the head with scary propaganda saying “AI will take our jobs,” but nobody can really explain — outside of outright falsehoods about “AI replacing all software engineers” — what it is that makes any of this worthy of taking up any oxygen let alone essential or a justification for so many billions of dollars of investment.
We Are Not In The Early Days of AI, And It’s Weird To Say That We Are
Global internet access has never been higher or cheaper, and for the most part, billions of people can access a connection fast enough to use generative AI. There is very little stopping anyone from using an LLM — ChatGPT is free, ChatGPT’s cheaper “Go” subscription has now spread to the global south, Gemini is free, Perplexity is free, and Meta’s LLM is free — where the dot com bubble was made up of stupid businesses and a lack of fundamental infrastructure to give most people the opportunity to access a reliable internet experience, basically anybody can get reliable access to generative AI.
And with that incredibly easy access, only 3% of households pay for AI. Boosters will again use this talking point to say that “we’re in the early days,” but that’s only true if you think that “early days” means “people aren’t really using it yet.”
Yet the “early days” argument is inherently deceptive.
While the Large Language Model hype cycle might have only begun in 2022, the entirety of the media and markets have focused their attention on AI, along with hundreds of billions of dollars of venture capital and nearly a trillion dollars of hyperscale capex investment. AI progress isn’t hampered by a lack of access, talent, resources, novel approaches, or industry buy-in, but by a single-minded focus on Large Language Models, a technology that has been so obviously-limited from the very beginning that Gary Marcus was able to call it in 2022.
Saying it’s “the early days” also doesn’t really make sense when faced with the rotten and incredibly unprofitable economics of AI. The early days of the internet were not unprofitable due to the underlying technology of serving websites, but the incredibly shitty businesses that people were building.Pets.comspent $400 per customer in customer acquisition costs, millions of dollars on advertising, and had hundreds of employees for a business with a little over $600,000 in quarterly revenue — and as a result, nothing about its failure was about “the early days of the internet” at all, as was the case with Kozmo, or any number of other dot com flameouts.
Similarly, internet infrastructure companies like Winstar collapsed because they tried to grow too fast and signed stupid deals rather than anything about the underlying technology’s flaws.
Eager math-heads in the audience will be able to see the issue of borrowing $2 billion to make $100 million over five years, as will eager news-heads laugh at WIRED magazine in 1999 saying that Winstar’s “small white dish antennas…[heralded] a new era and new mind-set in telecommunications.” Winstar died two years later because its business was built to grow at a rate that its underlying product couldn’t support.
In the end, microwave internet (high-speed internet delivered via radio waves) has become an $8 billion-a-year industry, despite everybody’s excitement.
In any case, anytime that somebody tells you that we’re in “the early days of AI” has either been conned or is in the process of conning you, as they’re using it to deflect from issues of efficacy or underlying economic weakness.
In fact, that’s a great place to go next.
Why Is Everybody Lying About What AI and “Agents” Can Actually Do?
Probably the weirdest thing about this entire era is how nobody wants to talk about the fact that AI isn’t actually doing very much, and that AI agents are just chatbots plugged into an API.
What tasks, exactly? Who knows! Truly, nobody seems able to say. To paraphrase Steven Levy at WIRED, 2025 was meant to be the year of AI agents, but turned out to be the year of talking about AI agents. Agents were/are meant to be autonomous pieces of software that go off and do distinct tasks.
In reality, it’s kind of hard to say what those tasks are. “AI agent” now refers to literally anything anybody wants it to, but ultimately means “chatbot that has access to some systems.”
But I’ve seen colleagues who write what you might think of as a version of Claude that runs other Claudes. So they’re like: I’ve got my five agents, and they’re being minded over by this other agent, which is monitoring what they do.
Anyway, this is all bad, because multiple papers have now shown that, and I quote, agents are “...incapable of carrying out computational and agentic tasks beyond a certain complexity,” with Futurism adding that said complexity was pretty low.
The word “agent” is meant to make you think of powerful autonomous systems that carry out complex and minute tasks, when in reality it’s…a chatbot. It’s always a fucking chatbot. It might be a chatbot with API access or a chatbot that generates a plan that another chatbot looks at and says something about, but it’s still chatbots talking to chatbots.
When you strip away the puffery, nobody seems to actually talk about what AI does.
Let’s take a look at CNBC’s piece on Goldman Sachs’ supposed contract with Anthropic to build “autonomous systems for time-intensive, high-volume back-office work”:
The bank has, for the past six months, been working with embedded Anthropic engineers to co-develop autonomous agents in at least two specific areas: accounting for trades and transactions, and client vetting and onboarding, according to Marco Argenti, Goldman’s chief information officer.
The firm is “in the early stages” of developing agents based on Anthropic’s Claude model that will collapse the amount of time these essential functions take, Argenti said. He expects to launch the agents “soon,” though he declined to provide a specific date.
…okay, but like, what does it do?
Argenti said the firm was “surprised” at how capable Claude was at tasks besides coding, especially in areas like accounting and compliance that combine the need to parse large amounts of data and documents while applying rules and judgment, he said.
Right, brilliant. Great. Love it. What tasks? What is the thing you’re paying for?
Now, the view within Goldman is that “there are these other areas of the firm where we could expect the same level of automation and the same level of results that we’re seeing on the coding side,” he said.
Goldman could next develop agents for tasks like employee surveillance or making investment banking pitchbooks, he said.
While the bank employs thousands of people in the compliance and accounting functions where AI agents will soon operate, Argenti said that it was “premature” to expect that the technology will lead to job losses for those workers.
Okay, great, we have two things it might do in the future, and that’s “employee surveillance” (?) and making pitchbooks.
The upshot is that, with the help of the agents in development, clients will be onboarded faster and issues with trade reconciliation or other accounting matters will be solved faster, Argenti said.
Onboarding? Chatbot. “Issues with trade reconciliation”? Chatbot connected to a knowledge base, like we’ve had for years but worse and more expensive. Oh, and “other accounting matters” will be solved faster, always with the future tense with these guys.
Telecommunications: AI agents will help carriers modernize network operations, simplify customer lifecycle management, and improve service delivery—bringing intelligent automation to one of the most operationally complex and regulated industries in the world. Meaningless. Automation of what?
Financial services: AI agents will help firms detect and assess risk faster, automate compliance reporting, and deliver more personalized customer interactions, such as tailoring financial advice based on a client's full account history and market conditions. Chatbot! “More-personalized interactions” are a chatbot with a connection to a knowledge system, as is any kind of “tailored financial advice.” Compliance reporting? Summarizing or pulling documents from places, much like any LLM can do, other than the fact that it’ll likely get shit wrong, which is bad for compliance.
Manufacturing and engineering: Claude will help accelerate product design and simulation, reducing R&D timelines and enabling engineers to test more iterations before production. I assume this refers to people using Claude Code to do coding, which is what it does.
Software development: Teams will use Claude Code to write, test, and debug code, helping developers move faster from design to production. Claude Code.
Frontier gives agents the same skills people need to succeed at work: shared context, onboarding, hands-on learning with feedback, and clear permissions and boundaries. That’s how teams move beyond isolated use cases to AI coworkers that work across the business.
Shared context? Chatbot. Onboarding? Chatbot. Hands-on learning with feedback? Chatbot. Clear permissions and boundaries? Chatbot setting. Let’s check out the diagram!
Uhuh. Great. What real-world tasks? Uhhh.
Teams across the organization, technical and non-technical, can use Frontier to hire AI coworkers who take on many of the tasks people already do on a computer. Frontier gives AI coworkers the ability to reason over data and complete complex tasks, like working with files, running code, and using tools, all in a dependable, open agent execution environment. As AI coworkers operate, they build memories, turning past interactions into useful context that improves performance over time.
Reason over data? Chatbot. “Complex tasks”? No idea, it doesn’t say. “Working with files”? Doesn’t say how it works with files, but I’d bet it can analyze, summarize and create charts based on them that may or may not have errors in them, and based on my experience of trying to get these things to make charts (as a test, I’d never use them in my actual work), it doesn’t seem to be able to do that. “Evaluation and optimization loops”? Unclear, because we have no idea what the tasks are. What are the agents planning, acting, or executing on? Again, no idea.
A few weeks ago, The New York Times wrote about how “AI agents are fun, useful, but [not to] give them your credit card,” saying that they can “do more than just chat…they can edit files, send emails, book trips and cause trouble”:
Mr. Heyneman, the founder of a tiny tech start-up in San Francisco, hoped to give a speech at the World Economic Forum, the annual gathering of business leaders and policymakers in Davos, Switzerland. So he asked the bot to arrange it.
While he slept, the bot searched the internet for people connected with the event, sent them text messages and worked to negotiate a speaking spot — or at least arrange coffee with people he would like to meet. After one lengthy conversation with a businessman in Switzerland, it succeeded.
But when Mr. Heyneman woke up, he was in a pickle. Going against his original instructions, the bot had agreed to pay 24,000 Swiss francs — or about $31,000 — for a corporate sponsorship. He could not pay the bill.
Sure sounds like you connected a chatbot to your email there Mr. Heyneman.
The bots can gather information from across the internet, write reports, edit files or even send and receive messages through email and text — driving online conversations largely on their own. For people like Mr. Heyneman, these bots are almost like an employee that people can delegate work to at any time of day. In some cases, the employee is reliable. Other times, not so much.
Let’s go through these:
“Gather information” — search tool, part of chatbots for years.
“Write reports” — generative AI’s most basic feature, with no details on quality.
“Edit files” — to do what exactly? Chatbot feature.
“Send and receive messages through email and text” — generating and reading text, connected to an email account.
“Delegate work” — what work? No need to get specific!
Yes, you can string together chatbots with various APIs and have the chatbot be able to activate certain systems. You could also do the same with a button you bought on Etsy connected to your computer via USB if you really wanted to. The ability to connect something to something else does not mean that anything useful happens at the end, and LLMs are extremely bad at the kind of deterministic actions that define the modern knowledge economy, especially when choosing to do them based on their interpretation of human language.
AI agents do not, as sold, actually exist. Every “AI agent” you read about is a chatbot talking to another chatbot connected to an API and a system of record, and the reason that you haven’t heard about their incredible achievements is because AI agents are, for the most part, fundamentally broken.
Even OpenClaw, which CNBC confusingly called a “ChatGPT moment,” is just a series of chatbots with the added functionality of requiring root access to your computer and access to your files and emails. Let’s see how CNBC described it back in February:
Marketed as “the AI that actually does things,” OpenClaw runs directly on users’ operating systems and applications. It can automate tasks such as managing emails and calendars, browsing the web and interacting with online services.
Hmmm interesting. I wonder if they say what that means:
Users have documented OpenClaw performing real-world tasks, including automatically browsing the web, summarizing PDFs, scheduling calendar entries, conducting agentic shopping, and sending and deleting emails on a user’s behalf.
Reading this, you might be fooled into believing that OpenClaw can actually do any of this stuff correctly, and you’d be wrong! OpenClaw is doing the same chatbot bullshit, just in a much-more-expensive and much-more convoluted way, requiring either a well-secured private space or an expensive Mac Mini to run multiple AI services and do, well, a bunch of shit very poorly.
The same goes for things like Perplexity’s “Computer,” which it describes as “an independent digital worker that completes and workflows for you,” which means, I shit you not, that it can search, generate stuff (words, code, images), and integrate with Gmail, Outlook, Github, Slack, and Notion, places where it can also drop stuff it’s generated.
Yes, all of this is dressed up with fancy terms like “persistent memory across sessions” (a document the chatbot reads and information it can access) with “authenticated integrations” (connections via API that basically any software can have). But in reality, it’s just further compute-intensive ways of trying to fit a square peg in a round hole, by which I mean having a hallucination-prone chatbot do actual work.
The only reason Jensen Huang is talking about OpenClaw is that there’s nothing else for Jensen Huang to talk about:
“OpenClaw opened the next frontier of AI to everyone and became the fastest-growing open source project in history,” said Jensen Huang, founder and CEO of NVIDIA. “Mac and Windows are the operating systems for the personal computer. OpenClaw is the operating system for personal AI. This is the moment the industry has been waiting for — the beginning of a new renaissance in software.”
That’s wild, man. That’s completely wild. What’re you talking about? What can NemoClaw or OpenClaw or whatever-the-fuck actually do? What is the actual output? That’s so fucking weird!
Let’s Talk About The Actual Consequences of Coding LLMs
I can already hear the haters in my head screaming “but Ed, coding models!” and I’m kind of sick of talking about them, because nobody can actually tell me what I’m meant to be amazed or surprised by.
To be clear, LLMs can absolutely write code, and can absolutely create software, but neither of those mean that the code is good, stable or secure, or that the same can be said of the software they create. They do not have ideas, nor do they create unique concepts — everything they create is based on training data fed to it that was first scraped from Stack Overflow, Github and whatever code repositories Anthropic, OpenAI, and Google have been able to get their hands on.
It’s unclear what the actual economic or productivity effects are, other than an abundance of new code that’s making running companies harder.
When a financial services company recently began using Cursor, an artificial intelligence technology that writes computer code, the difference that it made was immediate.
The company went from producing 25,000 lines of code a month to 250,000 lines. That created a backlog of one million lines of code that needed to be reviewed, said Joni Klippert, a co-founder and the chief executive of StackHawk, a security start-up that was working with the financial services firm.
“The sheer amount of code being delivered, and the increase in vulnerabilities, is something they can’t keep up with,” she said. And as software development moved faster, that forced sales, marketing, customer support and other departments to pick up the pace, Ms. Klippert added, creating “a lot of stress.”
As I wrote a few weeks ago, LLMs are good at writing a lot of code, not good code, and the more people you allow to use them, the more code you’re going to generate, which means the more time you’re either going to need to review that code, or the more vulnerabilities you’re going to create as a result. Worse still, hyperscalers like Meta and Amazon are allowing non-technical people to ship code themselves, which is creating a crisis throughout the tech industry.
Worse still, LLMs allow shitty software engineers that would otherwise be isolated by their incompetence to feign enough intelligence to get by, leading to them actively lowering the quality of code being shipped.
Per the Times:
At the same time, there are not enough engineers to review the explosion of code for mistakes. Recruiters are increasingly looking to hire senior engineers who have experience spotting errors in code and can monitor the software for risks. Open source software projects, which anyone can contribute to, have been inundated with A.I.-enabled additions. And sometimes flaws in the code can lead to security vulnerabilities or software that crashes.
The Times also notes that because LLM coding works better on a device rather than a web interface, “...engineers are downloading their entire company’s code to their laptops, creating a security risk if the laptop goes missing.”
Speaking frankly, it appears that LLMs can write code, and create some software, but without any guarantee that said code will compile, run, be secure, performant, or easy to read and maintain. For an experienced and ethical software engineer, LLMs can likely speed them up somewhat, though not in a way that appears to be documented in any academic sense, other than it makes them slower.
And I think it’s fair to ask what any of this actually means. What’s the advantage of having an LLM write all of your code? Are you shipping faster? Is the code better? Are there many more features being shipped? What is the actual thing you can point at that has materially changed for the better?
Software engineers don’t seem happier, nor do they seem to be paid more, nor do they seem to be being replaced by AI, nor do we have any examples of truly vibe coded software companies shipping incredible, beloved products.
In fact, I can’t think of a new piece of software I’ve used in the last few years that actually impressed me outside of Flighty.
Where’s the beef? What am I meant to be looking at? What’re you shipping that’s so impressive? Why should I give a shit?
Isn’t it weird that we’re even having this conversation? Shouldn’t it be obvious by now?
The Economics Of AI Are Weird And Bad, And It’s Even Weirder That People Try And Normalize Them
This week, economist Paul Kedrosky told me on the latest episode of my show Better Offline that AI is “...nowhere to be seen yet in any really meaningful productivity data anywhere,” and only appears in the non-residential fixed investments side of America’s GDP, at (and I quote again) “...levels we last saw with the railroad build out or with rural electrification.”
That’s so fucking weird! NVIDIA is the largest company on the US stock market and has sold hundreds of billions of dollars of GPUs in the last few years, with many of them sold to the Magnificent Seven, who are building massive data centers and reopening nuclear power plants to power them, and every single one of them is losing money doing so, with revenues so putrid they refuse to talk about them!
And all that to make…what, Gemini? To power ChatGPT and Claude? What does any of this actually do that makes any of those costs actually matter? And as I’ve discussed above, what, literally, does this software do that makes any of this worth it?
Ask the average AI booster — or even member of the media — and they’ll say something about “lots of code being written by AI,” or “novel discoveries” (unrelated to LLMs) or “LLMs finding new materials (based on an economics paper with faked data)” or “people doing research,” or, of course, “that these are the fastest-growing companies of all time.”
That “growth” is only possible because all of the companies in question heavily subsidize their products, spending $3 to $15 for every dollar of revenue. Even then, only OpenAI and Anthropic seem to be able to make “billions of dollars of revenue,” a statement that I put in quotes because however many billions there might be is up for discussion.
It’s Very Weird That The Media Ignored My Reporting on OpenAI’s Revenues, and Anthropic’s Statement That It Made $5 Billion In Revenue Through March 9, 2026
While a fewoutletswrote it up, my reporting has been outright ignored by the rest of the media. I was not reached out to by or otherwise acknowledged by any other outlets, and every outlet has continued to repeat that OpenAI “made $13 billion in 2025,” despite that being very unlikely given that it would have required it to have made $8 billion in a single quarter. While I understand why — I’m an independent, after all — these numbers directly contradict existing reporting, which, if I was a reporter, would give me a great deal of concern about the validity of my reporting and the sources that had provided it.
Though I cannot say for certain, both of these situations suggest that Anthropic and OpenAI are misleading their investors, the media and the general public. If I were a reporter who had written about Anthropic or OpenAI’s revenues previously, I would be concerned that I had published something that wasn’t true, and even if I was certain that I was correct, I would have to consider the existence of information that ran counter to my own. I would be concerned that Anthropic or OpenAI had lied to me, or that they were lying to someone else, and work diligently to try and find out what happened. I would, at the very least, publish that there was conflicting information.
The S-1 will give us the truth, I guess.
It’s Weird That The Media Continues To Normalize OpenAI And Anthropic Losing Billions of DollarsDoes Anthropic Measure Its Gross Margins Based On How Much Revenue A Model Made Rather Than Revenue Minus COGS?
Let’s talk for a moment about margins, because they’re very important to measuring the length of a business.
Amodei told the FT in December 2024 that he didn’t think profitability was based on how much you spent versus how much you made:
Let’s just take a hypothetical company. Let’s say you train a model in 2023. The model costs $100mn dollars. And, then, in 2024, that model generates, say, $300mn of revenue. Then, in 2024, you train the next model, which costs $1bn. And that model isn’t done yet, or it gets released near the end of 2024. Then, of course, it doesn’t generate revenue until 2025. So, if you ask “is the company profitable in 2024”, well, you made $300mn and you spent $1bn, so it doesn’t look profitable. If you ask, was each model profitable? Well, the 2023 model cost $100mn and generated several hundred million in revenue. So, the 2023 model is a profitable proposition.
There's two different ways you could describe what's happening in the model business right now. So, let's say in 2023, you train a model that costs $100 million, and then you deploy it in 2024, and it makes $200 million of revenue. Meanwhile, because of the scaling laws, in 2024, you also train a model that costs $1 billion. And then in 2025, you get $2 billion of revenue from that $1 billion, and you've spent $10 billion to train the model.
So, if you look in a conventional way at the profit and loss of the company, you've lost $100 million the first year, you've lost $800 million the second year, and you've lost $8 billion in the third year, so it looks like it's getting worse and worse. If you consider each model to be a company, the model that was trained in 2023 was profitable. You paid $100 million, and then it made $200 million of revenue. There's some cost to inference with the model, but let's just assume, in this cartoonish cartoon example, that even if you add those two up, you're kind of in a good state. So, if every model was a company, the model, in this example, is actually profitable.
Think about it this way. Again, these are stylized facts. These numbers are not exact. I’m just trying to make a toy model here. Let’s say half of your compute is for training and half of your compute is for inference. The inference has some gross margin that’s more than 50%.
So what that means is that if you were in steady-state, you build a data center and if you knew exactly the demand you were getting, you would get a certain amount of revenue. Let’s say you pay $100 billion a year for compute. On $50 billion a year you support $150 billion of revenue. The other $50 billion is used for training. Basically you’re profitable and you make $50 billion of profit. Those are the economics of the industry today, or not today but where we’re projecting forward in a year or two.
The only thing that makes that not the case is if you get less demand than $50 billion. Then you have more than 50% of your data center for research and you’re not profitable. So you train stronger models, but you’re not profitable. If you get more demand than you thought, then research gets squeezed, but you’re kind of able to support more inference and you’re more profitable.
The above quote has been used repeatedly to suggest that Anthropic has 50% gross margins and is “profitable,” which is extremely weird in and of itself as that’s not what Dario Amodei said at all. Based on The Information’s reporting from earlier in the year, Anthropic’s “gross margin” was 38%.”
Yet things have become even more confusing thanks to reporting from Eric Newcomer, who (in reporting on an investor presentation by Coatue from January) revealed that Anthropic’s gross margin was “45% in the quarter ended Sep-25,” with the crucial note that — and I quote — “Non-GAAP gross margins [are] calculated by Anthropic management…[are] unaudited, company-provided, and may not be comparable to other companies.”
This means that however Anthropic calculates its margins are not based on Generally Accepted Accounting Principles, which means that the real margins probably suck ass, because Anthropic loses billions of dollars a year, just like OpenAI.
Yet one seemingly-innocent line in there gives me even more pause: “Model payback improving significantly as revenue scales faster than R&D training costs.”
This directly matches with Dario Amodei’s bizarre idea that “...If you consider each model to be a company, the model that was trained in 2023 was profitable. You paid $100 million, and then it made $200 million of revenue.” Yes, I know it’s a “stylized fact” or whatever, but that’s what he said, and I think that their IPO might have a rude surprise in the form of a non-EBITDA margin calculation that makes even the most-ardent booster see red.
OpenAI and Anthropic Lose Billions of Dollars, But The Media Normalizes It In Any Way It Can, Acting As If Model Training Is Capex When It’s Actually A Cost of Goods Sold
This week, The Wall Street Journal published a piece about OpenAI and Anthropic's finances that included one of the most-offensive lines in tech media history:
Strip out “compute for research,” and OpenAI is actually on track to turn a small pretax operating profit this year, as is Anthropic under its best-case scenario. Add it back in, and OpenAI doesn’t expect to break even until the 2030s. Anthropic forecasts reaching that milestone sooner.
Two thoughts:
Are you fucking kidding me? If you simply remove billions of dollars in costs, OpenAI is profitable!
Why do you think these companies are going to break even anytime soon? You have absolutely no basis for doing so other than leaks from the company!
Yet arguably the most dishonest part is this word “training.” When you read “training,” you’re meant to think “oh, it’s training for something, this is an R&D cost,” when “training LLMs” is as consistent a cost as inference (the creation of the output) or any other kind of maintenance.
While most people know about pretraining — the shoving of large amounts of data into a model (this is a simplification I realize) — in reality a lot of the current spate of models use post-training, which covers everything from small tweaks to model behavior to full-blown reinforcement learning where experts reward or punish particular responses to prompts.
To be clear, all of this is well-known and documented, but the nomenclature of “training” suggests that it might stop one day, versus the truth: training costs are increasing dramatically, and “training” covers anything from training new models to bug fixes on existing ones. And, more fundamentally, it’s an ongoing cost — something that’s an essential and unavoidable cost of doing business.
The Journal also adds that both Anthropic and OpenAI are showing investors two versions of their earnings — one with training costs, and one without — without adding the commentary that this is extremely deceptive or, at the very least, extremely unusual.
The more I think about it the more frustrated I get. Having two sets of earnings is extremely dodgy! Especially when the difference between them is billions of dollars. This should be immediately concerning to every financial journalist, the reddest of red flags, the biggest sign that something weird is happening…
…but because this is the AI industry, the Journal runs propaganda instead:
Venture-capital firms have stomached vast losses in part because OpenAI and Anthropic are among the fastest-growing businesses in the history of tech. Each expects to more than double revenue this year, thanks largely to business customers’ adoption of new AI tools.
That “fast-growing” part is only possible because both Anthropic and OpenAI subsidize the compute of their subscribers, allowing them to burn $3 to $15 for every dollar of subscription revenue.
And no, this is nothing like Uber or Amazon, that’s a silly comparison, click that link and read what I said and then never bring it up again.
Anthropic’s Revenue Growth Is Weird and Suspicious — How Did It Go From $700 million in monthly revenue in December 2025 to $2.3 to $2.5 billion in April 2026?
I realize my suspicion around Anthropic’s growth has become something of a meme at this point, but I’m sorry, something is up here.
This works out to about $2.5 billion in a 30-day period.
Let’s assume that said period is March 6 2026 to April 6 2026.
Anthropic was making $9 billion in annualized revenue at the end of 2025, or approximately $750 million in a 30-day period.
Per Newcomer, as of December 2025, this is how Anthropic’s revenue breaks down:
Per The Information, Anthropic also sells its models through Microsoft, Google and Amazon, and for whatever reason reports all of the revenue from their sales as its own and then takes out whatever cut it gives them as a sales and marketing expense:
Anthropic counts such revenue very differently from OpenAI. AWS, Microsoft and Google each resell Anthropic’s Claude models to their respective cloud customers, but Anthropic reports all those sales as revenue, before the cloud providers receive their share of those sales. Instead, Anthropic accounts for the cloud provider payouts in its sales and marketing expenses, as we’ve previously reported here.
The Information also adds that “...about 50% of Anthropic’s gross profits on selling its AI via Amazon has gone to Amazon,” and that “...Google typically takes a cut of somewhere between 20% and 30% of net revenue, after subtracting infrastructure costs.”
The problem here is that we don’t know what the actual amounts of revenue are that come from Amazon or Google (or Microsoft, for that matter, which started selling Anthropic’s models late last year), which makes it difficult to parse how much of a cut they’re getting. That being said, Google (per DataCenterDynamics/The Information) typically takes a cut of 20% to 30% of net revenue after subtracting the costs of serving the models.
Nevertheless, something is up with Anthropic’s revenue story.
Let’s humour Anthropic for a second and say that what it’s saying is completely true: it went from making $750 million in monthly revenue in January to $2.5 billion in monthly revenue in April 2026.
That’s remarkable growth, made even more remarkable by the fact that — based on its December breakdown — most of it appears to have come from API sales. That leap from $750 million to $1.16 billion between December and February feels, while ridiculous, not entirely impossible, but the further ratchet up to $2.5 billion is fucking weird!
But let’s try and work it out.
Anthropic’s Sonnet and Opus 4.6 Models Burn More Tokens Than Previous Models, and enable a 500% Larger 1 Million Token Context Window By Default, Artificially Inflating Costs For Similar Gains
Based on OpenRouter token burn rates, Opus 4.5 was burning around 370 billion tokens a week. Immediately on release, Opus 4.6 started burning way, way more tokens — 524 billion in its first week, then 643 billion, then 634 billion, then 771 billion, then 822 billion, then 976 billion, eventually going over a trillion tokens burned in the final week of March.
In the weeks approaching its successor’s launch, Sonnet 4.5 burned between 500 billion and 770 billion tokens. A week after launch, 4.6 burned 636 billion tokens, then 680 billion, then 890 billion, and, by about a month in, it had burned over a trillion tokens in a single week.
The sudden burst in token burn across OpenRouter doesn’t suggest a bunch of people suddenly decided to connect to Anthropic and other services’ models, but that the model themselves had started to burn nearly twice the amount of tokens to do the same tasks.
At this point, I estimate Anthropic’s revenue split to be more in the region of 75% API and 25% subscriptions, based on its supposed $2.5 billion in annualized revenue (out of $14 billion, so a little under 18%) in February coming from “Claude Code” (read: subscribers to Claude, there’s no “Claude Code” subscription).
If that’s the case, I truly have no idea how it could’ve possibly accelerated so aggressively, and as I’ve mentioned before, there is no way to reconcile having made $5 billion in lifetime revenue as of March 9, 2026, having $14 billion in annualized revenue on February 12 2026, and having $4.5 billion in revenue for the year 2025.
Things get more confusing when you hear how Anthropic calculates its annualized revenues, per The Information:
Anthropic calculates its annualized revenue by taking the last four weeks of application programming interface revenue and multiplying it by 13, and then adding another figure: its monthly recurring chatbot subscription revenue multiplied by 12, according to a person with direct knowledge of Anthropic’s finances. The monthly figure used to calculate recurring subscriptions is based on the number of active subscriptions that day, said the person.
So, Anthropic is annualizing based on the last four weeks of API revenue times 13, a number that’s extremely easy to manipulate using, say, launches of new products.
This announcement also included the launch of Anthropic’s 1 million token context window in Beta for Opus 4.6
Anthropic’s $19 billion in annualized revenue from March 3, 2026 included both the launch of Claude Opus 4.6 andClaude Sonnet 4.6.
This period includes around half of the January 16 to February 16 2026 window from the previous $14 billion annualized number, and the launch of the beta of the 1 million token context window for Sonnet 4.6.
To be clear, the betas required you to explicitly turn on the 1 million token context window, and had higher pricing around long context.
Anthropic’s $30 billion in annualized revenue from April 6 2026 included two weeks’ worth of massive token burn from the launches of Sonnet and Opus 4.6.
This includes a few days of the previous window (March 3 to April 5).
In simpler terms, Anthropic is cherry-picking four-week windows of API spend — ones that are pumped by big announcements and new model releases — and annualizing them.
Sidenote: I have no idea why Anthropic chose to multiply API revenue by 13, and only multiplied subscription revenue by 12. Multiplying by thirteen is perfectly reasonable when you’re using 28-day (or four week) windows, as if you multiply 28 by 12 and then subtract the result from 365, you’re left with 29. In essence, there’s thirteen four-week periods in a single calendar year.
But the discrepancy between API and subscription revenue? That’s weird.
The one million token context window is a big deal, too, having been raised from 200,000 tokens in previous models. With Opus and Sonnet 4.6, Anthropic lets users use up to one million tokens of context, which means that both models can now carry a very, very large conversation history, one that includes every single output, file, or, well, anything that was generated as a result of using the model via the API.
This leads to context bloat that absolutely rinses your token budget.
To explain, the context window is the information that the model can consider at once. With 4.6, Anthropic by default allows you to load in one million tokens’ worth of information at once, which means that every single prompt or action you take has the model load one million tokens’ worth of information at once unless you actively “trim” the window through context editing.
Let’s say you’re trying to work out a billing bug in a codebase via whatever interface you’re using to code with LLMs. You load in a 350,000 token codebase, a system prompt (IE: “you are a talented software engineer,” here’s an example), a few support tickets, and a bunch of word-heavy logs to try and fix it. On your first turn (question), you ask it to find the bug, and you send all of that information through. It spits out an answer, and then you ask it how to fix the bug…but “asking it to fix the bug” also re-sends everything, including the codebase, tickets and logs. As a result, you’re burning hundreds of thousands of tokens with every single prompt.
Although this is a simplified example, it’s the case across basically any coding product, such as Claude Code or Cursor. While Cursor uses codebase indexing to selectively fetch pieces of the codebase without constantly loading it into the context window, one developer using Claude inside of Cursor watched a single tool call burn 800,000 tokens by pulling an entire database into the context window, and I imagine others have run into similar problems. To be clear, Anthropic charges at a per-million-token rate of $5 per million input and $25 per million output, which means that those casually YOLOing entire codebases into context are burning shit tons of cash (or, in the case of subscribers, hitting their rate limits faster).
if Anthropic actually made $2.5 billion in a month — we’ll find out when it files its S-1! — it likely came not from genuine growth or a surge of adoption, but in its existing products suddenly costing a shit ton more because of how they’re engineered.
The other possibility is the nebulous form of “enterprise deals” that Anthropic allegedly has, and the theory that they somehow clustered in this three-month-long period, but that just feels too convenient.
If 70% of Anthropic’s revenue is truly from API calls, this would suggest:
Massive new customers that are making payments up front, which makes this far from “recurring” revenue.
Massive new customers are spending tons of money immediately, burning hundreds of millions of dollars a month in tokens, and paying Anthropic handsomely for them.
I don’t see much evidence of Anthropic creating custom integrations that actually matter, or — and fuck have I looked! — any real examples of businesses “doing stuff with Claude” other than making announcements about vague partnerships.
There’s also one other option: that Silicon Valley is effectively subsidizing Anthropic through an industry-wide token-burning psychosis.
And based on some recent news, there’s a chance that’s the case.
Does Meta’s “TokenMaxxing” Account For A Quarter of Anthropic’s Revenue?
As I discussed a few weeks ago, Silicon Valley has a “tokenmaxxing” problem, where engineers are encouraged by their companies to burn as many tokens as possible, at times by their peers, and at others by their companies.
The most egregious — and honestly, worrying! — version of this came from The Information’s recent story about Meta employees competing on an internal leaderboard to see who can burn the most tokens, deliberately increasing the size of their prompts and the amount of concurrent sessions (along with unfettered and dangerous OpenClaw usage) to do so:
The rankings, set up by a Meta employee on its intranet using company data, measure how many tokens—the units of data processed by AI models—employees are burning through. Dubbed “Claudeonomics” after the flagship product of AI startup Anthropic, the leaderboard aggregates AI usage from more than 85,000 Meta employees, listing the top 250 power users.
The practice is emblematic of Silicon Valley’s newest form of conspicuous consumption, known as “tokenmaxxing,” which has turned token usage into a benchmark for productivity and a competitive measure of who is most AI native. Workers are maximizing their prompts, coding sessions and the number of agents working in parallel to climb internal rankings at Meta and other companies and demonstrate their value as AI automates functions such as coding.
The Information reports that the dashboard, called “Claudeonomics” (despite said dashboard covering other models from OpenAI, Google, and xAI), has sparked competition within Meta, with users burning a remarkable 60 trillion tokens in the space of a month, with one individual averaging around 281 billion tokens, which The Information remarks could cost millions of dollars. Meta’s company-mandated psychosis also gives achievements for particular things like using multiple models or high utilization of the cache.
Here’s one very worrying anecdote:
Some workers are instructing AI agents to carry out research for hours on end to maximize their token usage, according to two current employees.
One poster on Twitter says that there are people at Meta running loops burning tokens to rise up the leaderboards, and that Meta’s managers also measure lines of code as a success metric.
The Information says that, considering Anthropic’s current pricing for its models, that 60 trillion tokens could be as much as $900 million in the space of a month, though adds that this assumes that every token being burned was on Claude Opus 4.6 (at $15 per 1 million tokens).
I personally think this maths is a bit fucked, because it assumes that A) everybody is only using Claude Opus, B) that none of that token burn runs through the cache (which it obviously does, and the cache charges 50%, as pointed out by OpenCode co-founder Dax Radd), and C) that Meta is entirely using the API (versus paying for a $200-a-month Claude Max subscription for each user).
Digging in further, it appears that a few years ago Meta created an internal coding tool called CodeCompose, though a source at Meta tells me that developers use VSCode and an assistant called Devmate connected to models from Anthropic, OpenAI and xAI.
We literally have a leaderboard of who has cost the most in compute. Not to share too much, but there are folks north of $80k in spend. Lmao. I’ve been really skeptical about the enterprise-level LLM push. It’s 100% an amazing tool, and I’ve been using Claude and tmux as my primary driver for ~six months, but it seemed like it maybe 2x’ed output, with a lot of time wasted in reinventing the wheel and bad naive solutions. The hype seemed like it was folks who had no idea what they were doing and who had never dealt with the complexities of a large codebase.
If we assume that Meta is an enterprise customer paying API rates for its tokens, it’s reasonable to assume — at even a low $5-per-million average — that it’s spending $300 million or more a month on API calls. As Radd also added, there’s likely a discount involved. He suggested 20%, which I agree with.
Even if it’s $300 million, that’s still fucking insane. That’s still over three billiondollars a year. If this is what’s actually happening, and this is what’s contributing to Anthropic’s growth, this is not a sustainable business model, which is par for the course for Anthropic, a company that has only lost billions of dollars.
Measuring Worker Output In Token Consumption Is Incredibly Weird, and TokenMaxxing Is Not A Sustainable Business Model
Encouraging workers to burn as many tokens as possible is incredibly irresponsible and antithetical to good business or software engineering. Writing great software is, in many cases, an exercise in efficiency and nuance, building something that runs well, is accessible and readable by future engineers working on it, and ideally uses as few resources as it can.
TokenMaxxing runs contrary to basically all good business and software practices, encouraging waste for the sake of waste, and resulting in little measurable productivity benefits or, in the case of Meta, anything user-facing that actually seems to have improved.
Venture capitalist Nick Davidov mentioned yesterday that sources at Google Cloud “started seeing billions of tokens per minute from Meta, which might now be as big as a quarter of all the token spend in Anthropic.” While I can’t verify this information (and Davidoff famously deleted his photos using Claude Cowork while attempting to reorganize his wife’s desktop), if that’s the case, Meta is a load-bearing pillar of Anthropic’s revenue — and, just as importantly, a large chunk of Anthropic’s revenue flows through Google Cloud, which means A) that Anthropic’s revenue truly hinges on Google selling its models, and B) that said revenue is heavily-inflated by the fact that Anthropic books revenue without cutting out Google’s 20%+ revenue share.
In any case, TokenMaxxing is not real demand, but an economic form of AI psychosis.
There is no rational reason to tell somebody to deliberately burn more resources without a defined output or outcome other than increasing how much of the resource is being used. I have confirmed with a source at that there is no actual metric or tracking of any return on investment involved in token burn at Meta, meaning that TokenMaxxing’s only purpose is to burn more tokens to go higher on a leaderboard, and is already creating bad habits across a company that already has decaying products and leadership.
To make matters worse, TokenMaxxing also teaches people to use Large Language Models poorly. While I think LLMs are massively-overrated and have their outcomes and potential massively overstated, anyone I know who actually uses them for coding generally has habits built around making sure token burn isn’t too ridiculous, and various ways to both do things faster without LLMs and ways to be intentional with the models you use for particular tasks. TokenMaxxing literally encourages you to do the opposite — to use whatever you want in whatever way you want to spend as much money as possible to do whatever you want because the only thing that matters is burning more tokens.
Furthermore, TokenMaxxing is exactly the kind of revenue that disappears first. Zuckerberg has reorganized his AI team four or five times already, and massively shifted Meta’s focus multiple times in the last five years, proving that at the very least he’ll move on a whim depending on external forces. After laying off tens of thousands of people in the last few years, Meta has shown it’s fully capable of dumping entire business lines or groups with a moment’s notice, and while moving on from AI might be embarrassing, that would suggest that Mark Zuckerberg experiences shame or any kind of emotion other than anger.
This is the kind of revenue that a business needs to treat with extreme caution, and if Meta is truly spending $300 million or more a month on tokens, Anthropic’s annualized revenues are aggressively and irresponsibly inflated to the point that they can’t be taken seriously, especially if said revenue travels through Google Cloud, which takes another 20% off the top at the very least.
TokenMaxxing Is A Valley-Wide Problem, Raising The Costs of Running Any Software Team Based On How AI-Crazed Your CEO Has Become — And When Cost Cuts Begin, API Revenue Will Collapse
Though the term is pretty new, the practice of encouraging your engineers to use AI as much as humanly possible is an industry-wide phenomena, especially across hyperscalers like Amazon, Microsoft and Google, all of whom until recently directly have pushed their workers to use models with few restraints. Shopify and other large companies are encouraging their workers to reflexively rely on AI, with performance reviews that include stats around your token burn and other nebulous “AI metrics” that don’t seem to connect to actual productivity.
I’m also hearing — though I’ve yet to be able to confirm it — that Anthropic and other model providers are forcing enterprise clients to start using the API directly rather than paying for monthly subscriptions.
Combined with mandates to “use as much AI as possible,” this naturally increases the cost of having software engineers, which — and I say this not wanting anyone to lose their jobs — does the literal opposite of replacing workers with AI. Instead, organizations are arbitrarily raising the cost of doing business without any real reason.
Because we’re still in the AI hype cycle, this kind of wasteful spending is both tolerated and encouraged, and the second that financial conditions worsen or stock prices drop due to increasing operating expenses, these same companies will cut back on API spend, which will overwhelmingly crush Anthropic’s glowing revenues.
The AI Bubble Is Weird, Irrational and Wasteful, And It’s Even Weirder That It’s A Fringe Opinion To Say So
I think it’s also worth asking at this point what is is we’re actually fucking doing.
We’re building — theoretically — hundreds of gigawatts of data centers, feeding hundreds of billions of dollars to NVIDIA to buy GPUs, all to build capacity for demand that doesn’t appear to exist, with only around $65 billion of revenue (not profit) for the entire generative AI industry in 2025, with much of that flowing from two companies (Anthropic and OpenAI) making money by offering their models to unprofitable AI startups that cannot survive without endless venture capital, which is also the case for both AI labs.
Said data centers make up 90% of NVIDIA’s revenue, which means that 8% or so of the S&P 500’s value comes from a company that makes money selling hardware to people that immediately lose money on installing it. That’s very weird! Even if you’re an AI booster, surely you want to know the truth, right?
The most-prominent companies in the AI industry — Anthropic and OpenAI — burn billions of dollars a year, have margins that get worse over time, and absolutely no path to profitability, yet the majority of the media act as if this is a problem that they will fix, even going as far as to make up rationalizations as to how they’ll fix it, focusing on big revenue numbers that wilt under scrutiny.
That’s extremely weird, and only made weirder by members of the media who seem to think it’s their job to defend AI companies’ bizarre and brittle businesses. It’s weird that the media’s default approach to AI has, for the most part, been to accept everything that the companies say, no matter how nonsensical it might be.
It’s also weird that we’re still having a debate about “the power of AI” and “what agents might do in the future” based on fantastical thoughts about “agents on the internet” that do not exist, cannot exist, and will never exist, and it’s fucking weird that executives and members of the media keep acting as if that’s the case. It’s also weird that people discussing agents don’t seem to want to discuss that OpenAI’s Operator Agent does not work, that AI browsers are fundamentally broken, or that agentic AI does not do anything that people discuss.
In fact, that’s one of the weirdest parts of the whole AI bubble: the possibility of something existing is enough for the media to cover it as if it exists, and a product saying that it will do something is enough for the media to believe it does it. It’s weird that somebody saying they will spend money is enough to make the media believe that something is actually happening, even if the company in question — say, Anthropic — literally can’t afford to pay for it.
It’s also weird how many outright lies are taking place, and how little the media seems to want to talk about them. Stargate was a lie! The whole time it was a lie! That time that Sam Altman and Masayoshi Son and Larry Ellison stood up at the white house and talked about a $500 billion infrastructure project was a lie! They never formed the entity! That’s so weird!
It’s also weird that we’re all having to pretend that any of this matters. The revenues are terrible, Large Language Models are yet to provide any meaningful productivity improvements, and the only reason that they’ve been able to get as far as they have is a compliant media and a venture capital environment borne of a lack of anything else to invest in.
Coding LLMs are popular only because of their massive subsidies and corporate encouragement, and in the end will be seen as a useful-yet-incremental and way too expensive way to make the easy things easier and the harder things harder, all while filling codebases full of masses of unintentional, bloated code. If everybody was forced to pay their actual costs for LLM coding, I do not believe for a second that we’d have anywhere near the amount of mewling, submissive and desperate press around these models.
And it’s really weird that the mainstream media has a diametric view — that all of this is totally permissible under the auspices of hypergrowth, that these companies will simply grow larger, that they will somehow become profitable in a way that nobody can actually describe, that demand for AI data centers will exist despite there being no signs of that happening.
I get it. Living in my world is weird in and of itself. If you think like I do, you have to see every announcement by Anthropic or OpenAI as suspicious — which should be the default position of every journalist, but I digress — and any promise of spending billions of dollars as impossible without infinite resources.
At the end of this era, I think we’re all going to have to have a conversation about the innate credulity of the business and tech media, and how often that was co-opted to help the rich get richer.
Until then, can we at least admit how weird this all is?