Show full content
A year of building a video caption pipeline with 100+ professional creators, and what it taught us about scaling supervision instead of models.
By Zhiqiu Lin and Chancharik Mitra. Based on our CVPR 2026 work, Building a Precise Video Language with Human-AI Oversight (Highlight, Top 3%).
How close is today's video generator to a Hollywood cinematographer?Hollywood directors reach for certain shots because they make a scene land. They cue a specific feeling in the viewer that flat coverage cannot. Open your favorite video generator (Veo 3.1, Seedance 2, or any of the latest open-source models) and ask it for a dolly zoom of a man standing in the middle of a bustling street, the way Hitchcock used the shot to make the world feel like it is collapsing inward. Or a rack focus pulling from a coffee cup to the woman behind it, the kind of focus pull that quietly tells the audience where to look. Or a Dutch-angle shot of a nervous person staring into the void, a tilted frame that puts the viewer on edge.
Most generators will hand back something close to a generic dolly-in, or a slow-motion clip with the wrong focal subject. The output is usually visually competent, but it does not do the thing. The model has clearly seen videos that contain these techniques. It just does not know how to act on the words.
We think this is symptomatic of a broader gap. Filmmakers communicate with a shared, precise vocabulary: shot size, frame position, focus type, lens distortion, camera height, video speed. Today's vision-language models (VLMs), and the captioning datasets that feed them, mostly do not.
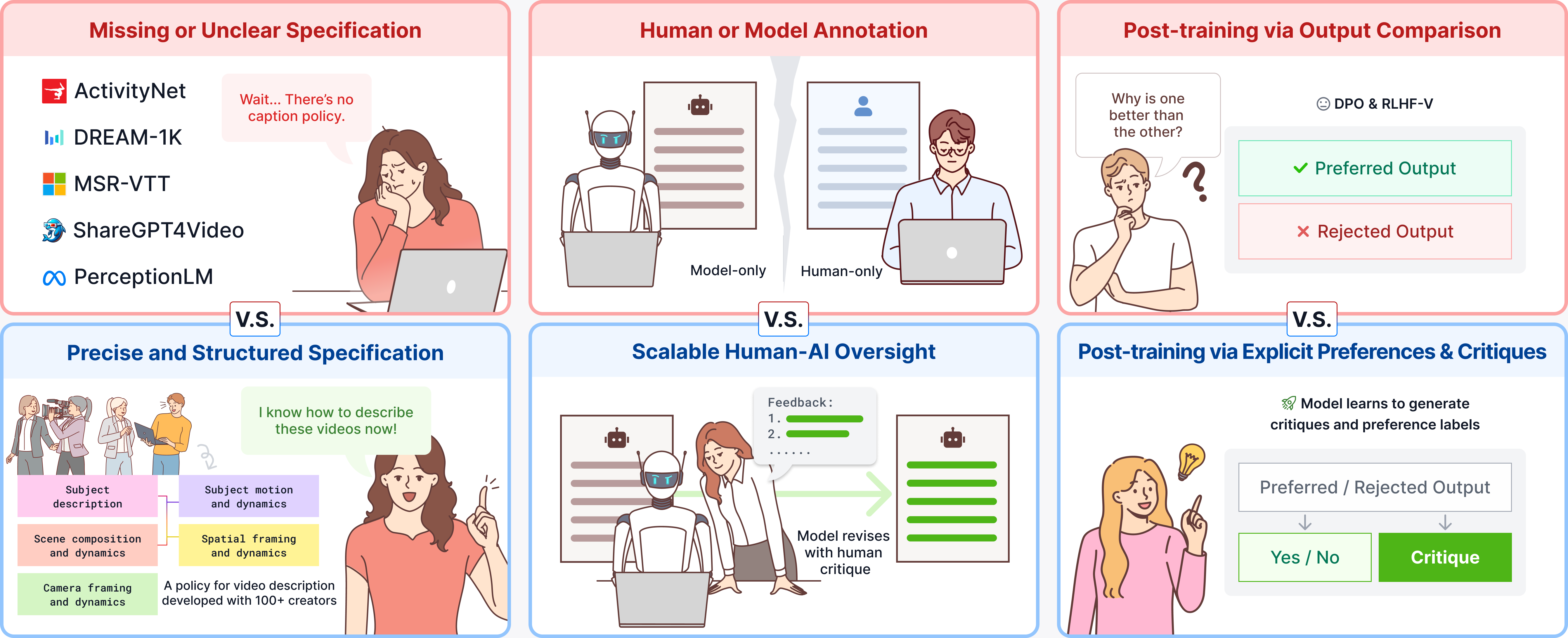
In this post we describe CHAI, a captioning pipeline (in our usage, a caption is a long, structured paragraph describing a video's content, motion, and camera work — not a subtitle track) that we built over the past year with 100+ professional video creators. The acronym stands for Critique-based Human-AI Oversight. Existing video caption datasets are typically written either by crowdworkers, who lack the cinematic vocabulary to describe a shot precisely, or by large vision-language models, whose captions read smoothly (fluent — no grammatical or stylistic errors) but routinely describe objects and motions that are not in the video (hallucinated). The central idea behind CHAI is to combine the two: the captioner model (e.g., a large video-language model such as Gemini-2.5-Pro) writes the draft, a trained human critiques it, and the model revises against that critique.
This post works through four questions:
1. Why do VLMs struggle with cinematic prompts?
2. How should humans and models divide the captioning work?
3. Does the quality of human critique change what the model can learn?
4. Do better captions in the training data give us a better video generator?
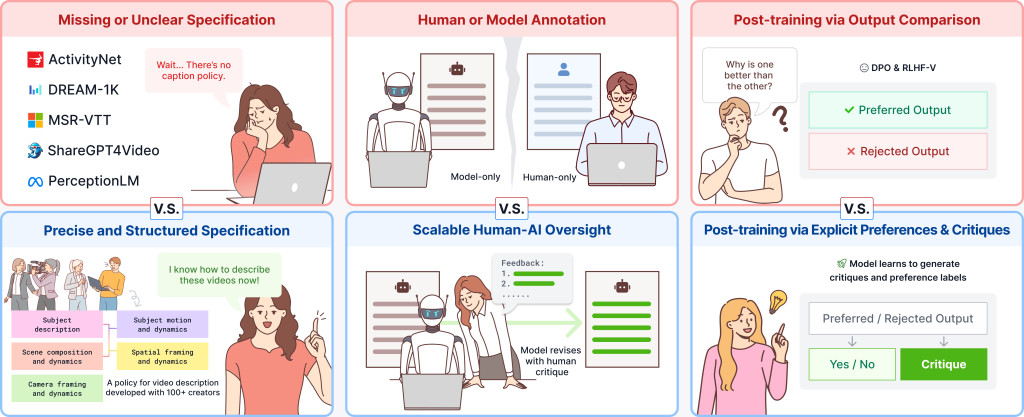
A natural first hypothesis is that this is a capacity problem — that the current generation of vision-language models is simply too small, has too little context, or has not been pretrained on enough video to handle cinematic prompts, and that the next generation will solve it. But after auditing eight popular video-text datasets from 2016 to 2025 (ActivityNet Captions, MSR-VTT, DREAM-1K, ShareGPT4Video, PerceptionLM, and others), we think the bottleneck is somewhere else. The visual content is in the videos these models train on, and modern VLMs perceive it well. What is missing is the language: the captions paired with those videos do not contain the precise vocabulary needed to describe cinematic technique. In our experiments, training larger models on more of the same data only marginally improved these issues. They appear to be problems of annotation policy, not of capacity.
Three patterns showed up over and over:
• Imprecise terminology. Captions conflate dolly-in (the camera physically moves forward) with zoom-in (the focal length changes), or describe a fisheye distortion as "circular building."
• Missing information. Captions describe what is in the frame and skip everything else: motion, camera shake, focus changes, shot size. Anything temporal, anything about the camera, gets dropped.
• Subjective descriptions. "An atmospheric shot full of tension" tells a model nothing it can ground in pixels.
A natural next thought: just hire crowdworkers to write more careful captions. We tried that. Crowdworkers still confused dolly-in with zoom-in, called wide shots "close-ups," and described fisheye distortion as "a round building." Seeing is not the same as knowing how to describe.
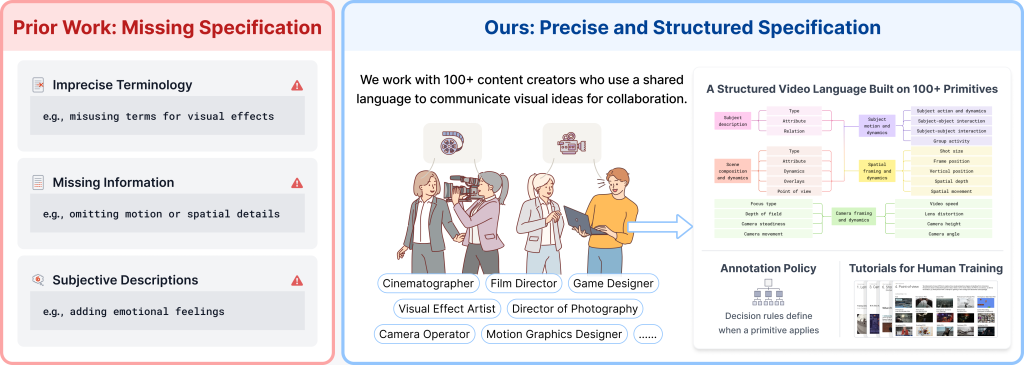
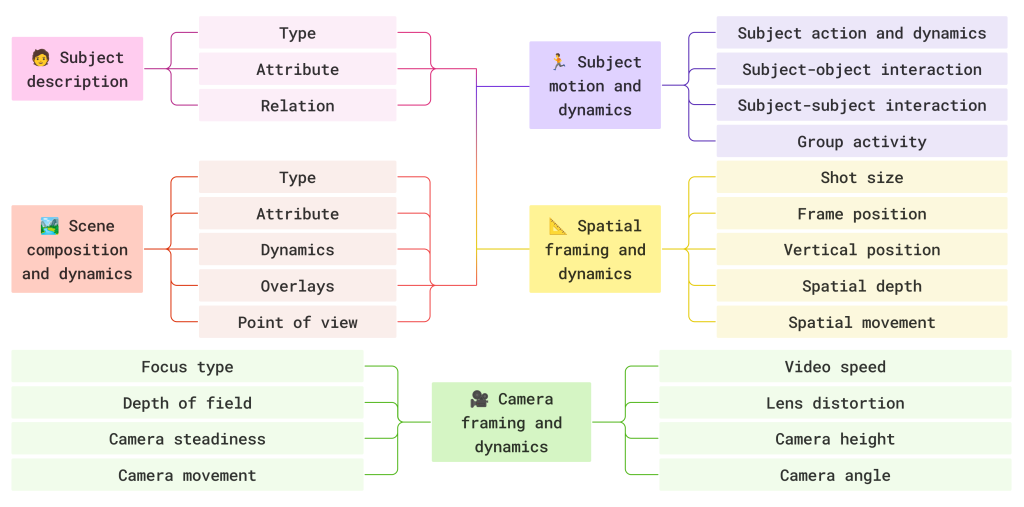
What worked, eventually, was bringing in people whose job requires this vocabulary: cinematographers, directors of photography, motion graphics designers, VFX artists, game designers, camera operators. Over the past year, we built a structured caption specification with 100+ such collaborators. The specification has five aspects:
• Subject (type, attribute, relations)
• Scene (composition, dynamics, overlays, point of view)
• Motion (subject actions, interactions, group activity)
• Spatial (shot size, frame position, depth, spatial movement)
• Camera (focus type, depth of field, steadiness, movement, video speed, lens distortion, height, angle)
All five aspects together involve roughly 200 low-level visual primitives, every one with a definition and a decision rule for when it applies. This prevents annotators from freelancing terminology, as all they have to do is tag against the spec.
Takeaway: VLMs struggle with cinematic prompts because the captions they were trained on do not contain the precise vocabulary professionals use. In our experiments, scaling models or data alone gave only marginal gains; specifying the language carefully made a much bigger difference.
Question 2: How should humans and models divide the captioning work?Once we made the spec, we still had to decide who would write the long captions. The two obvious choices, humans or models, each come with well-known limitations.
Humans alone produce captions with typos, grammatical errors, and inconsistent event ordering. They also fatigue: 200 to 400 words of careful prose per video, while looking up the spec, is exhausting and expensive.
Models alone produce captions that read beautifully but that, on a depressing fraction of clips, confidently describe objects and motions that are not there. They also frequently mix up left and right.
What we noticed in pilot studies is that the failure modes are asymmetric in a useful way. Today's LLMs write better prose than most humans. But humans, especially trained ones, are much better than LLMs at noticing visual or motion errors in a draft, the kind where the caption says "moving left" but the subject is moving right. So we built the pipeline around that asymmetry. The model drafts, the human critiques, the model revises. This is conceptually similar to Saunders et al. (2022)'s self-critiquing models for summarization, but applied to long-form video captioning where the human still does the hard part: catching grounded errors against the actual video.
Concretely, the loop:
1. Primitives. A trained annotator labels which visual and motion primitives are present in the clip.
2. Pre-caption. The model generates a long caption from those primitives, following the spec.
3. Critique. An annotator reads the pre-caption against the video and writes a critique pointing out what is wrong and what should change. The critique has to be accurate (the things it flags are wrong), complete (it does not miss errors), and constructive (it tells the model what to do, not just that something is bad).
4. Post-caption. The model revises its draft using the critique.
5. Refinement. If the post-caption is still off, the human refines the critique rather than rewriting the caption.
We tasked reviewers (top-performing annotators promoted to a quality-control role) with checking every critique and post-caption against the video. This way annotators were scored based on their accuracy, while reviewers earned rewards for catching the mistakes they found. Both precision (do not flag things that are not wrong) and recall (do not miss things that are wrong) were incentivized at the data level, before any modeling happened.
Shifting the human's job from writing to proofreading has a side benefit we underestimated: each video takes far less cognitive effort, and the resulting 200 to 400 word captions end up more accurate than what either humans or models produce alone.
Takeaway: LLMs and humans have asymmetric strengths in long-form video captioning. Designing the pipeline around that asymmetry, rather than trying to replace one with the other, gives both better captions and a more sustainable annotation process.
Question 3: Does the quality of human critique change what the model can learn?The pipeline produces a triple for every video: (pre-caption, critique, post-caption). That triple is more than just an annotated caption. It is supervision for three different post-training tasks at once:
• Captioning. Train the model to produce long, faithful captions.
• Reward modeling. Treat (pre-caption, post-caption) as a (rejected, preferred) pair.
• Critique generation. Train the model to write the critique itself, given the video and the draft.
We post-trained Qwen3-VL-8B on all three formats jointly using standard supervised fine-tuning (SFT). We also tried reinforcement learning (RL) methods like Direct Preference Optimization (DPO), but found that simple SFT on the full triplet data is the strongest. The detailed numbers are in the paper; the headline is that adding explicit preference and critique signals improves every method we tested.
We were curious whether the quality of the critique mattered to downstream performance, or whether any "this is wrong" signal would do. So we ran an ablation: take a clean CHAI critique, deliberately degrade one property at a time (accuracy, recall, constructiveness), and see how the post-trained captioner performs on each task.

Results for an 8B Qwen3-VL post-trained on each variant are presented in Table 1. Caption and Critique are BLEU-4 scores (a standard text-generation metric measuring n-gram overlap with reference text on a 0–100 scale; higher means closer to the human reference) against held-out reference captions and critiques. For the Reward task, we report binary accuracy on whether the captioner scores the post-caption higher than the pre-caption (chance = 50). Higher is better on all three.
Three things stand out:
1. Quality is not optional. Dropping any one of the three properties materially hurts every downstream task. Non-constructive critiques (the cheapest to collect, since you do not have to say what is wrong) hurt the least but still leave a large gap.
2. Existing data is mostly non-constructive. We checked the critiques in publicly released datasets like Saunders et al.'s GDC release and MM-RLHF. More than half are non-constructive in our sense ("this is wrong" with no suggested fix). That helps explain why training on those datasets leaves performance on the table.
3. An 8B model can be competitive with much larger closed models when the data is right. On the same captioning, reward, and critique benchmarks, the post-trained 8B Qwen3-VL matches or exceeds GPT-5 and Gemini-3.1-Pro on the metrics we report. The model size has not changed; the supervision signal has.
A small bonus: the same reward model also helps at inference time. Best-of-N decoding with the trained reward model continues to improve performance with no additional human labels.
Takeaway: The form of the critique is not a stylistic detail. A model jointly post-trained on captions, preferences, and critiques performs materially better on all three tasks when the critiques it is trained on are accurate, complete, and constructive — and materially worse when any one of those properties is missing.
Question 4: Do better captions in the training data give us a better video generator?A skeptical reader might say: this is all very nice, but captioning is upstream of what most people actually want, which is generation. So we tested whether the improved captioner moves the needle on a downstream video generator. We took a large corpus of professional video (films, ads, music videos, gameplay), re-captioned it with the post-trained 8B model, and used those new captions to fine-tune Wan2.2.
The fine-tuned model can act on detailed prompts (up to roughly 400 words) for techniques that off-the-shelf generators reliably get wrong:
We did not change the generator architecture or training objective. The only thing that changed was the language used to describe the videos in the training set. That was enough to teach an existing generator a class of techniques it previously could not articulate.
Takeaway: A more precise caption vocabulary upstream translates into more controllable generation downstream, with the same model architecture and training recipe. The bottleneck for cinematic control was in the supervision, not the model.
DiscussionWe started this project assuming we were going to train a captioner model. We ended up spending most of the year on the pipeline around it: what to write captions about, who should write them, who should check them, and what the checks should look like. The model contributions feel almost downstream of those choices.
Three things we wish we had appreciated earlier:
• Specification before scale. Training larger models on noisier data gave only marginal gains. Once the spec was in place, smaller models started looking very competitive.
• "Crowdsource it" is not a baseline; it is a different problem. Annotating cinematic technique correctly requires the same vocabulary the field already uses. Asking untrained workers to invent that vocabulary on the fly is not the cheap version of asking trained workers to apply it.
• Critiques are training data. The form of the critique we collect today decides how effectively models can be trained tomorrow. Datasets that record only thumbs-up / thumbs-down are leaving a lot of post-training signal on the table.
CHAI is one piece of a longer effort on precise video language. The closest companion is CameraBench (NeurIPS’25 Spotlight), our earlier benchmark on camera motion, which seeded the camera-side primitives in the spec.
ResourcesWe are releasing the specification, training tutorials, annotation platform, quality-control flow, data, code, and models. If you are working on video understanding or generation and want to use any of these, please do.
Project page: https://linzhiqiu.github.io/papers/chai/
Paper: https://arxiv.org/abs/2604.21718
Code: https://github.com/chancharikmitra/CHAI
ReferencesKrishna et al., 2017. Dense-Captioning Events in Videos (ActivityNet Captions). ICCV. arXiv:1705.00754.
Xu et al., 2016. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. CVPR.
Wang et al., 2024. Tarsier: Recipes for Training and Evaluating Large Video Description Models (DREAM-1K). arXiv:2407.00634.
Chen et al., 2024. ShareGPT4Video: Improving Video Understanding and Generation with Better Captions. NeurIPS. arXiv:2406.04325.
Cho et al., 2025. PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding. arXiv:2504.13180.
Saunders et al., 2022. Self-critiquing Models for Assisting Human Evaluators. arXiv:2206.05802.
Zhang et al., 2025. MM-RLHF: The Next Step Forward in Multimodal LLM Alignment. arXiv:2502.10391.
Lin et al., 2025. Towards Understanding Camera Motions in Any Video (CameraBench). NeurIPS Spotlight. arXiv:2504.15376.
Wan Team, 2025. Wan: Open and Advanced Large-Scale Video Generative Models (Wan2.2). arXiv:2503.20314.
Bai et al., 2025. Qwen3-VL Technical Report. arXiv:2511.21631.
All opinions expressed in this post are those of the authors and do not represent the views of CMU.