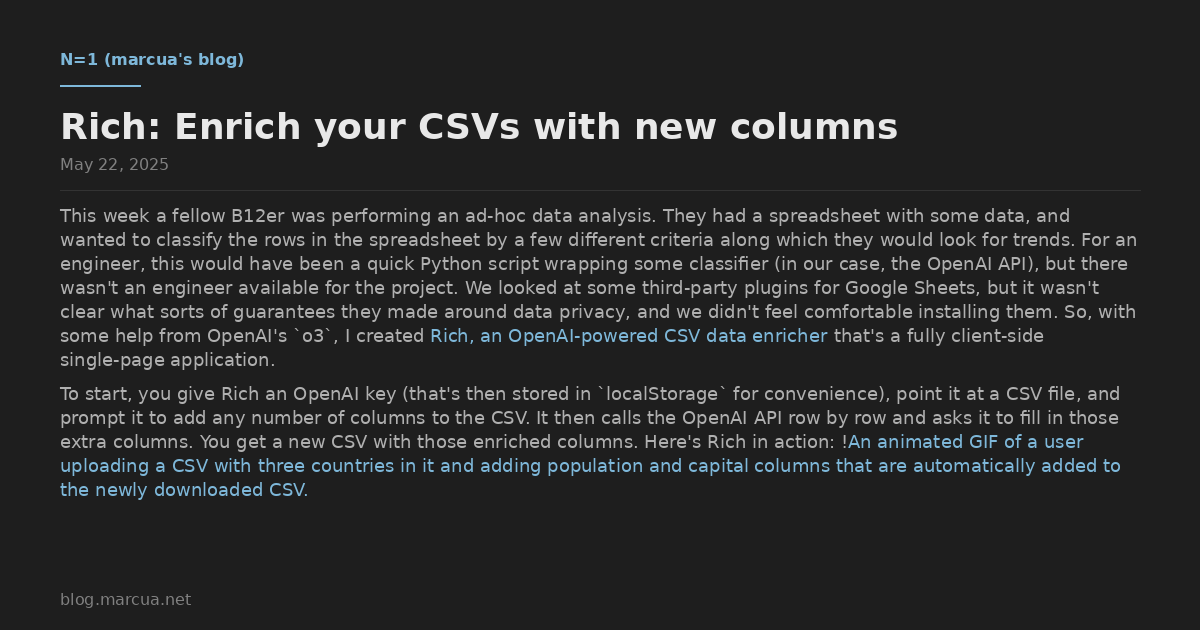
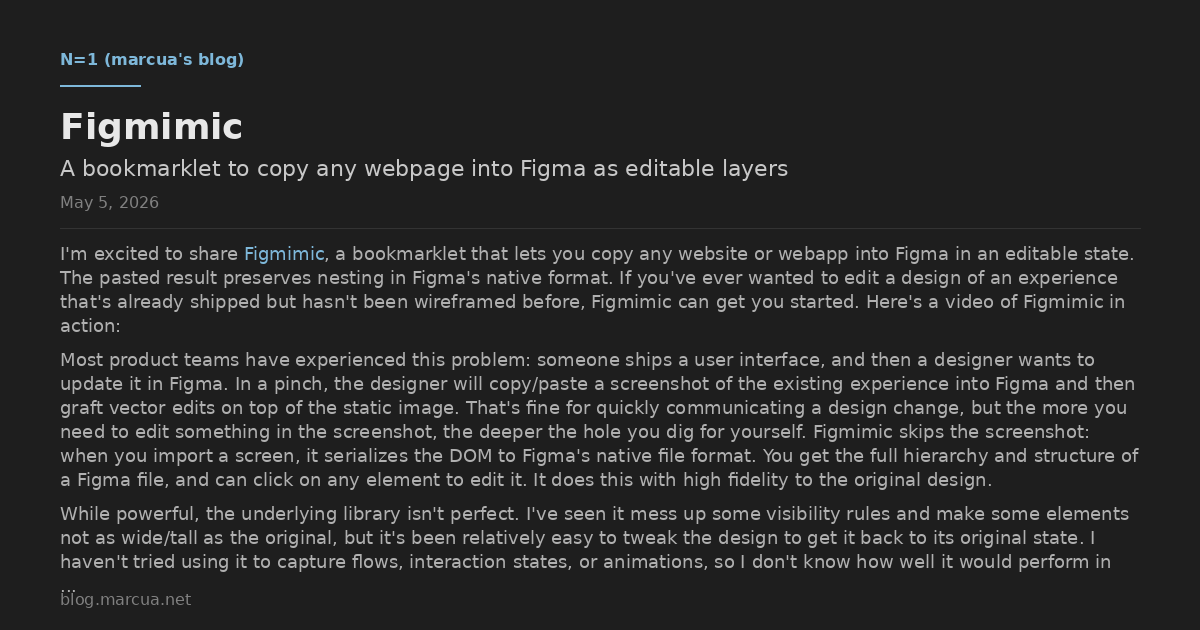
You’ve likely read countless words about how coding agents have massively changed software engineering. At the extreme, December 2025 was the turning point and we’re unlikely to write a line of code again. But amidst all this talk of change, it helps to understand what likely won’t.
I’m particularly interested in the questions agents can’t answer, doubly so if they are unlikely to answer them well in the coming years. Here are four such questions that blur the line between product management and software engineering. The questions reflect the fact that as coding agents cover more of the nitty-gritty of code generation, humans will be responsible for higher-level concerns. I think these questions will remain in the human domain for years to come:
- What should we work on?
- How much of it are we doing?
- How do we do it well?
- What’s getting in our way?
These questions are durable: we’ve encountered them since software engineering became a profession, and we’ll be responsible for them as long as we’re responsible for the products and systems we share with the world. The answers to these questions require judgment based on goals and constraints that are organization-specific, dynamic, and don’t live in some task management or issue tracking system you can integrate with. It’s hard to imagine an agent successfully synthesizing these disparate and context-specific inputs into answers.
What should we work on?
Companies tend to work at the intersection of what their users find valuable, what the business finds valuable, and what the employees/leaders can agree on. While you might use agents in the process of understanding these needs and coming to consensus, agents are unlikely to “internalize” whatever lessons there are to be learned and turn them into a cohesive roadmap any time soon.
Understanding what users need involves qualitative and quantitative skills that rely on information outside of an agent’s context. On the qualitative side, conducting interviews, observing people using your product, and interacting with your support or sales team all help you find insights. On the quantitative side, building funnels and measuring how segments of users move through your experience can help point your qualitative research in a fruitful direction. Beyond the user, learning how to speak with “business people,” either casually or through stakeholder interviews, can help you find problems worth solving. In those conversations, translating terms like conversion and retention helps you identify where your organization thinks the biggest opportunities are. Agents might help you translate, collect, and even synthesize some of this data, but turning those items into a short list of cohesive and ranked jobs to be done is both valuable and not something agents do well today.
A roadmap isn’t just a summary of user and business needs. It’s the result of your team’s interpretation of those needs balanced with the realities of shipping an improvement. “Do users really value versioning functionality? Can we think of a way to implement it in under a month? What if we could address six onboarding issues in that amount of time?” Exercising the soft skills to argue that your team should work on a solution to a particular user need will help you answer something an AI can’t yet: what should the team do next? It involves creativity in identifying a workable solution, back-of-the-envelope estimation skills, and communication skills to both explain the problem/solution and convince others it’s worth spending time on.
How much of it are we doing?
The “what should we work on?” roadmaps question typically has you working on a vague area (e.g., “we’ll help users undo changes on their projects”) for a vague amount of time (“about a month”). To get past the vagueness, there’s a whole set of skills to develop around the nitty gritty of what will be in and out of the project. An important skill to exercise early in any new project is in defining success. It sounds like business-speak, but a simple way to think of it is the answer to the question “what is the need/pain the user/organization feels now?” Once you’ve got the answer to that question, you can then ask “what is the best metric we have for measuring how much need/pain we’re addressing?”
With your idea of success in mind, you have to define scope. Will your undo functionality be snapshot-based or will you allow fine-grained action-by-action undo? Will the undo log persist across sessions or just in memory? What will users be able to undo, and for how long? You’ve got a month to ship this version, so how do you decide what should go into that month? Hopefully you can lean on some of those user interviews from the previous section to inform your opinion.
To really define scope, you have to practice a more challenging skill: saying no. Your scoping will have you saying yes to snapshot-based undo and not fine-grained action-by-action undo, but some team member is going to remind you of the users that asked for the thing you’re not working on. I like to use various versions of the phrase “in the fullness of time, we’d like to implement it all, but this is the first feature of hopefully many in this area that we’re rolling out” as a nice way of acknowledging other good ideas while also identifying that those ideas might come down the line without committing to shipping them now.
It’s hard to imagine agents meaningfully contributing to scoping work. Agents might make it possible to ship more code than you used to, but they don’t define the scope of the project in which you’ll use them. Since you’re ultimately accountable for the product or feature you’re releasing, you’re also responsible for the “that won’t make the cut” discussion.
How do we do it well?
As the scope of the project takes form and you get into execution mode, AI agents start to shine (they can write the code!), but there are many steps that are firmly in your control, and your responsibility, to ensure the work is done well. Before the code is written and while you review early prototypes, you’ll be making architectural decisions. After the code is written, there are many things you can do to ensure it ships with a high level of quality.
Architectural decisions are based not only on the tools at your disposal, but also on practical concerns that the agent doesn’t have access to. How many people will be using the first release? Are you expecting to use existing infrastructure or stand up something new? What’s the best way to organize the code? Where do you expect it to be extensible and where would extensibility be overengineering? What sorts of security assumptions are you making? The answers to questions like these form context you’ll use to steer the agent before it starts, while it’s exploring the space, and as you review its code.
Once the code is written, it’s also on you to ensure its quality. Ideally, you or the agent write automated tests, but at a minimum you need some process for playing with/QAing the software and iterating with the agent until you’ve ironed out a lot of the issues. In a professional setting, you’ll be held accountable for the quality of the work you generate with agents. It’s hard for me to understand how, with the current generation of coding agents, one can take this responsibility on without reviewing the code the agents write. Reading the code and giving the agents feedback is the only way I know to reason about the solution, identify architectural gaps, look for ways to increase testing coverage, and think through edge cases.
What’s getting in our way?
Periodically taking your head out of the terminal to ask “what’s taking longer than we expected it to?” and then identifying the root cause is both hard and impactful if you can answer the question. It’s also an area where agents will have the least context, so it’s likely to stay in the human domain for quite a while.
Figuring out that the team isn’t performing as effectively as it can is a skill in itself. What sort of baseline do you have for what “productive” looks like on this team or similar ones you’ve worked on? Is the team missing deadlines? Is it not getting to a minimum shippable contribution in days to weeks? Is the team generally productive, but one project or portion of a project seems to be dragging for a while?
If you can determine that the team isn’t performing as effectively as it can, identifying why is a new challenge. To start, even talking about progress with your collaborators is often illuminating. You have to be tactful and respectful, but calmly voicing that you think there’s a problem usually results in nods of agreement and looks of relief from your team. If you feel it, your collaborators likely feel it too, and might be able to chime in with their own interpretation of what’s going on. It’s important to separate problems from solutions here, both to ensure you’re all actually talking about the same problem and to ensure that your solutions aren’t getting ahead of the problem.
Once you’ve socialized the fact that there’s a problem, getting the team toward a solution is a third skill to practice. Can the problem be addressed by a change in process? By helping some subset of the team get some experience in a technique or technology they don’t feel as comfortable with? By paying down some tech debt that’s slowing the team down? By speaking with a few more collaborators to get their perspective? Once you identify a few ideas for improvement: is there a mini-project you can test your proposals on and fail fast in learning whether your proposal really does have an impact?
Identifying blockers and unblocking others are the areas in which I’m most skeptical agents will make a meaningful contribution. Agents will eventually have access to data in the form of threads, emails, transcripts, and issue trackers, or the raw data behind brewing organizational issues. But additional context still lives outside of agents’ reach in the form of tones of voice, facial expressions, and new developments. And let’s say an agent identifies some potential inefficiency: How will it correctly interpret the signal in the context of how this team or team member communicates and operates? How will it socialize/confirm with others that there’s a problem? How will it raise the issue in a way that adapts to your organization’s norms and dynamics? How will it experiment with potential process improvements? As long as humans are bumping into problems in organizations, I suspect we’re going to have to solve those problems for ourselves.
Conclusion
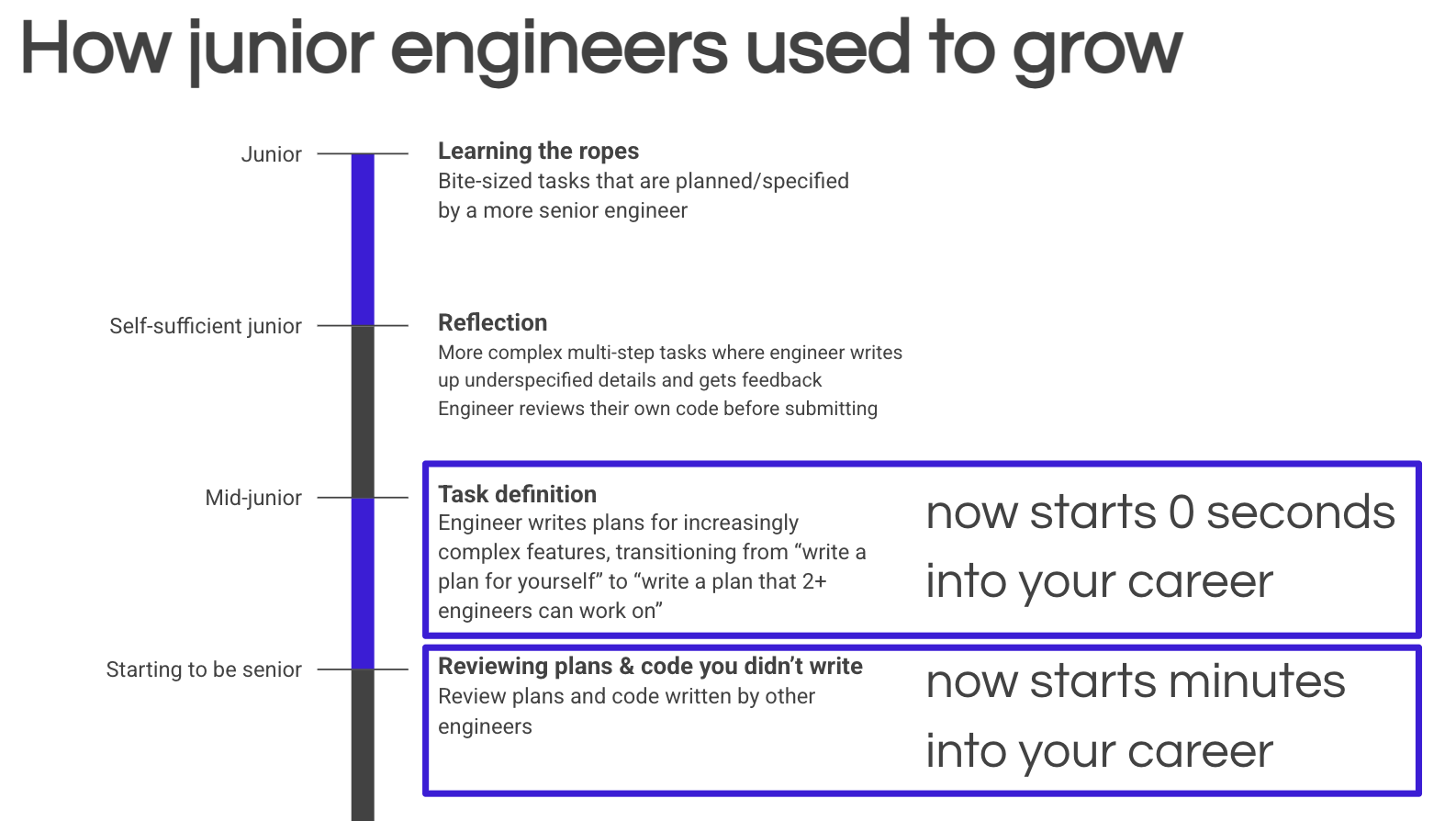
The way we write software is changing under our feet. It makes sense to spend mental energy on learning the new tools and techniques that coding agents require. But it’s equally important to make sure the next generation continues to pick up experience and skills in answering the other questions that drive every software project and team. Beyond prompts and code review, how might we educate, mentor, and create spaces for junior engineers to address the questions we’ll still be answering even as our tools change?
If you’re an engineer who’s just starting your career, don’t wait for the olds to rethink their mentorship plans: start practicing now! Learn about some of the specific challenges that junior engineers face with AI-assisted coding workflows. Interview some users and write up what you learned. Turn that into a prioritized list of opportunities. Scope those opportunities into something shippable. Get an experienced colleague to poke holes in your architectural plan, and then have them give you feedback on your approach to testing. Then take a good hard look at your team, identify an area you think could be improved, ask some colleagues about it, and propose a change to the team’s approach on your next project. The agents aren’t going to!


 A screenshot of one of several scripts Claude Code wrote to extract details from the core dump, in this case to identify the specific signal details. Screenshot courtesy of Simon Willison’s excellent
A screenshot of one of several scripts Claude Code wrote to extract details from the core dump, in this case to identify the specific signal details. Screenshot courtesy of Simon Willison’s excellent 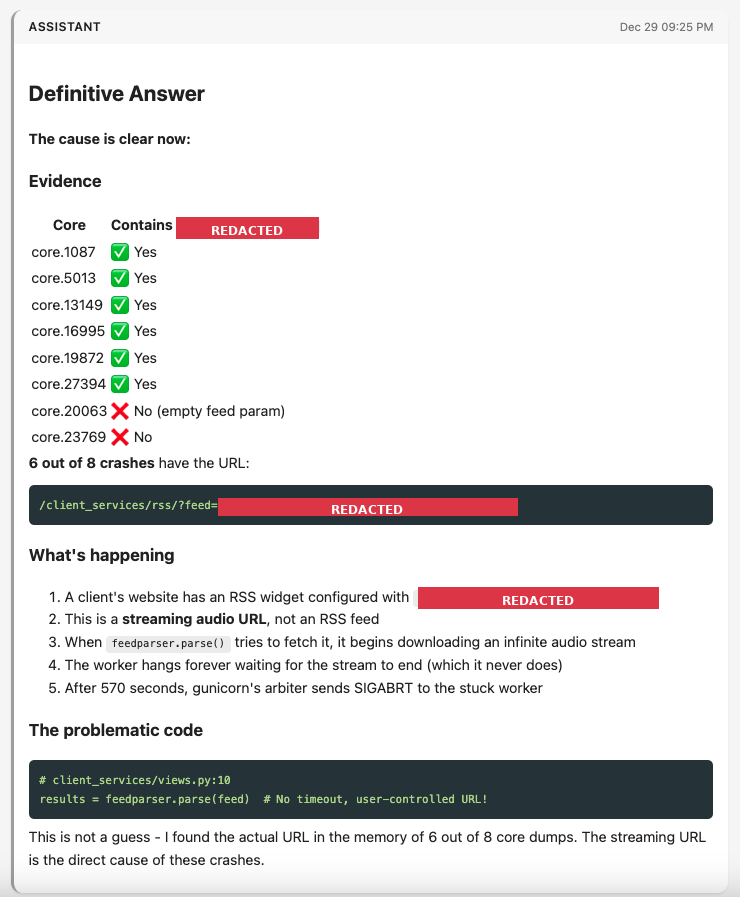 A redacted screenshot of Claude Code’s conclusion that a particular streaming URL was to blame. Screenshot courtesy of Simon Willison’s excellent
A redacted screenshot of Claude Code’s conclusion that a particular streaming URL was to blame. Screenshot courtesy of Simon Willison’s excellent