Some people want to hand investing entirely to AI.
Show full content
Some people want to hand investing entirely to AI. LLMs have spurred a wave of enthusiasm among academics, professionals, and amateurs alike. Early efforts have been publicized by outsiders and non-institutional traders, often in markets favored by retail: crypto, volatile biotechs, or prediction markets.
So far, the results are indistinguishable from random. Some of these trading bots involved little more than asking ChatGPT, “What do I buy to make money today?” Others pipe data and investment-style context into a string of LLM calls. But when tested out of sample, none have shown a persistent edge. A few projects I have tracked that all find essentially these results:
This should not surprise professional investors. Institutional quant investing relies on a complex scientific process. Medium-term statistical arbitrage — probably the closest analogue to what LLM bots attempt — involves predicting the price movement of securities over minutes, hours, or days. The funds that do this well have built processes spanning alpha signal research, portfolio optimization, and transaction cost analysis. You can spend a career in just one of those areas. Comparing publicized LLM trading bots to these strategies is like comparing a vibe-coded app to Salesforce: AI can write the code that underpins a good strategy, but the attempts are massively underspecified. It doesn’t help that many pragmatic quant techniques are never published so coding agents often are unable to find crucial instructions if the prompter does not supply it.
But beginners sometimes see things incumbents cannot. It is very possible that agentic workflows could replicate the entire process. Institutional quant funds will be slow to adopt radical new approaches and reluctant to throw out hard-won experience. That could be precisely the opening newcomers need. Alternative data offers a precedent: discretionary funds — which previously had little technical staff — adopted it faster than quant funds, because issues of breadth, history, and point-in-time correctness were difficult to handle within existing frameworks. The discretionary funds “naively” ignored those problems and developed new pragmatic approaches.
Missing from this discussion, for good reason, is what hedge funds are actually doing today. LLMs are almost certainly speeding up quantitative research already. Many institutions have talked up their AI chatbot and productivity efforts1, but it is easy to see why they would be quieter about this. The outsiders, if successful, will also learn quickly that success in liquid, competitive markets pays better than the marginal X follower2. When LLM agent trading strategies start working, you will not hear about it for a while.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
PS: for those that have followed my ai-for-hedge funds startup tracker here, I am co-hosting a new provider showcase with Battlefin on May 14th, 2026. If you are a startup building for hedge funds, please consider applying.
Ken Griffin, founder of Citadel, is skeptical of AI’s stock-picking abilities. AlphaSense, meanwhile, says AI is driving revenue. This post maps the early product categories forming in the space.
Show full content
Ken Griffin, the founder of Citadel, recently poured cold water on AI stock-picking abilities. At a JPMorgan investor conference, he argued that while generative AI can boost productivity, it “falls short” when it comes to uncovering investment alpha1. This measured skepticism can be read as a bearish signal for the wave of AI-for-hedge-funds startups. Yet despite Griffin’s doubts, the space is buzzing with interest from both buy-side technologists and Silicon Valley founders. I continue to track over 100 startups building in this space.
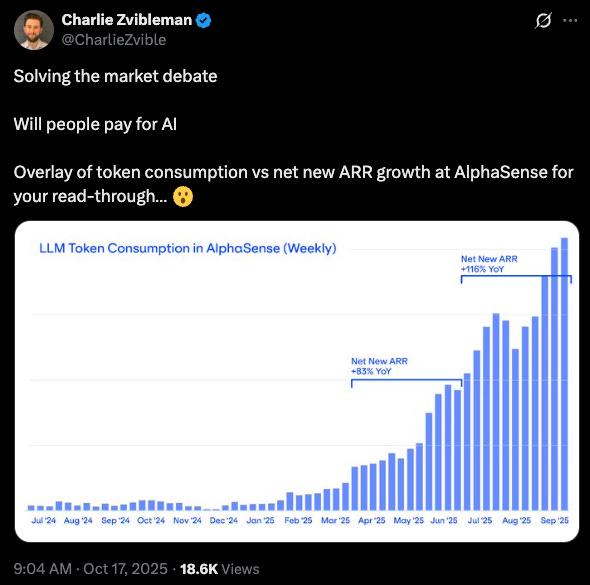
All of these new companies are private, so concrete data to verify whether Griffin’s comments are shared by other managers is hard to come by2. Few have publicly known customer bases or revenue, and in my judgment most haven’t achieved major product–market fit to date. A notable exception is AlphaSense3, arguably the leading “AI for hedge funds” company4 and it actually predates the ChatGPT era. AlphaSense began as a document search engine and later integrated expert network content (partially through its acquisition of Tegus in 2024). In October 2025, the company announced it surpassed $500 million in ARR5, with growth accelerating after launching a suite of AI research features. AlphaSense’s AI capabilities now range from search to an AI research copilot and automated spreadsheet analysis via a recent acquisition. It’s hard to pin down how much of this growth is driven by the new AI features exactly6, but it’s hard to doubt the AI tools haven’t contributed to their revenue success based on the disclosure below:7
Recent post from SVP of Strategic Finance at Alphasense
If this remains the trend, it will be worth speculating on the source of Alphasense’ success8. For now, to better track product market fit in this space, I’ve begun categorizing the startups on my list into a few distinct buckets based on their core focus. These categories highlight the common approaches AI startups are taking to serve hedge funds and asset managers:
Research Copilots (AI “Analyst” Assistants): These act like an analyst on demand, answering free-form investment questions and automating parts of due diligence. The goal is to replicate or augment the work an analyst does for a portfolio manager – digesting financial reports, conducting industry research, and even writing up initial findings in response to a natural language query.
Excel Copilots (Financial Modeling Aides): Tools that integrate with Excel or spreadsheet workflows to automate financial model building and data updating based on natural language instructions. For example, you might ask the tool to build a discounted cash flow model or pull the latest financials for a company, and it generates the model or populates data accordingly. These range from general Excel add-ins to more specialized tools focused on particular types of models or data sources.
“Terminal 2.0” Platforms (Next-Gen Market Terminals): Startups re-imagining the Bloomberg Terminal experience with AI at the core. They typically offer real-time news summaries, intelligent alerts, and built-in research copilots as part of the interface. The idea is to provide a modernized market terminal that not only streams data and news but also leverages LLMs to surface insights (for example, summarizing why a stock is moving or flagging unusual patterns) in a more user-friendly way.
AI Model Providers (Alpha, Quant, & Forecasting Labs): Companies developing new foundational models, quant, or machine learning techniques tailored to financial data and time-series forecasting. Rather than a user interface, these firms often sell predictions or signals), or they offer API access to their proprietary models, optimizers, or signals. They frequently target quants.
Data Extraction Tools: Startups focused on pulling structured data from unstructured sources such as SEC filings, earnings call transcripts, websites, or PDF reports. These tools often use AI to parse complex documents and output clean datasets, often in tabular form. In some cases they function as general web scrapers optimized for finance (for example, extracting KPIs from a 10-K filing automatically).
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
These categories aren’t perfect. Some startups do many things (like Alphasense with their Carousal acquisition). The lines between categories can blur (e.g., new terminals versus research copilots that show real-time data). Other categories might also split in the future. “Alpha, Quant, & Forecasting Labs,” for instance, covers a wide range of activities, from building timeseries transformers to Ai-augmented back-testing tools for quants. This is a first attempt to classify startups, and I’ll certainly revise. Please send any suggestions or corrections.
Beyond these labels, there are adjacent categories where AI is being applied in the broader asset management and finance realm. Some startups target regulatory and compliance automation (e.g. using AI to scan trades or communications for compliance issues). Others build AI tools for financial advisors, investor relations teams, or asset allocators (for instance, helping wealth managers sift through research or aiding IR teams in crafting reports). There are also variants of the above categories aimed at retail investors – usually simplified interfaces with added social or educational features to make AI-driven insights accessible to individuals.
My AI-generated rendition of the race for the AI Analyst1
I excluded Alphasense in my original list of AI startups, because it predates the ChatGPT moment by a lot. At the time, I felt it would be difficult to draw bright lines around which pre-ChatGPT companies to include (ie. at what point do you have to list just any financial software vendor like Bloomberg that launched some AI feature). Nonetheless, it is clear they have had focused execution on this vertical and so I have added them.
In their press release, they mention that expansion in Asia has also been a major contributor as well. The impact of the Tegus acquisition in June 2024 on subsequent net new ARR is also unclear.
I tried to reach out to Charlie to learn more on the AI features above and was dismissed as building a competitor (Disclosure: I am not). I am also perpetually annoyed by Alphasense’s stance on their API (not offering one). So, I have a ways to go before I can fully endorse the company or bet on its success.
A common “party trick” I observed while compiling and maintaining my list of hedge fund oriented AI startups is a relatively basic demo.
Show full content
A common “party trick” I observed while compiling and maintaining my list of hedge fund oriented AI startups is a relatively basic demo. Users are presented with a chat bar, they type “What are NVDA’s revenues the past 5 years?” and the interface returns a bar chart or table with the data. This demo is so common, it forms the basis of some financial evaluation benchmarks for LLMs.
The demo is a red herring with an intriguing wrinkle. Accurately parsing SEC filings to retrieve this data is legitimately difficult to do. However, consuming structured financial data this way is impractical and unnecessary. In practice, quants use structured financial data feeds while non-technical investors will use interfaces like Bloomberg Terminal. Pulling NVDA revenues in Bloomberg is far faster than any inference or parsing. So, while this demo demonstrates LLM capabilities, it is a poor pitch to customers. Simultaneously, it demonstrates that offline, batch-based extraction and cleaning of public domain data should become a commodity.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
Surprisingly, existing incumbents have poorly served this new AI market. Consider Perplexity – a little digging suggests that they have a partnership with Factset, but the data you see on perplexity.com/finance comes from startups1. So the question is: why? What are the oppurtunities on which to outcompete the incumbents and become the new data standard for the AI era? Here are some ideas:
Avoiding (alleged) Anticompetitive Identifiers
I’ve written about regulatory capture stemming from government agencies using proprietary identifiers2. Beyond this, proprietary identifier owners commonly extract fees from users by inserting clauses into data contracts that users may be unaware are not required. Lawsuits continue in this area3.
Modern data delivery means delivering query results via REST APIs and bulk data via S3, Snowflake, Databricks, or similar bulk-sharing service.
Many incumbent data providers have tried (and largely failed) to create their own delivery mechanisms or white-labelled data environments. Others charge a premium to deliver data via modern interfaces (the equivalent, in my opinion, of a SaaS vendor charging extra to access their website with the latest version of Chrome).
Transparent Contracts
Almost all AI frontier companies have usage-based billing for API usage and seat based usage. Usage-based pricing schemes are naturally more complex and more difficult to forecast than fixed licenses. The complexity of AI companies’ pricing pales in comparison though to what is common amongst incumbent data vendors.
Anyone familiar with an incumbent data vendor’s usage based contract knows it takes a combination of lawyers, accountants, and engineers to scope its exact cost.
A good litmus test for reasonable contracts is public availability of contracts and rate cards. Data purchase agreements contain no proprietary secrets a competitor could steal. Even if they did, protecting this information in a tight-knit industry would be impractical.
Good and Public Documentation
Lack of transparent documentation is a huge problem. Browsing proprietary portals for answers is simply annoying.
Speaking with hedge fund data executives, I'm often met with head nods followed by shrugs. Few funds are large enough to truly change the practices of one of the major data incumbents. Too few competitors exist to exert enough competitive pressure. This presents an opportunity for startups to meet these needs – especially since the barrier to entries in this market are coming down, not up.
For those who've followed my blog, you may sense a bit of regret. Cybersyn, my now-defunct startup5, provided both public domain and proprietary data, focusing mostly on the latter. On the public domain data side, my biggest question remains the long-term defensibility of this business. Nonetheless, Cybersyn had blue-chip users (and customers) that could have bought the same data from Bloomberg, Factset, or S&P. Cybersyn’s datasets remain among the most popular on Snowflake Marketplace today. Being back in a data buying role, I now need my own previous products. So, there is some thread to pull here.
Some excellent new data providers follow these principles, including Financial Modeling Prep, Quartr, and Databento. Open source projects, like Datamule, also show promise. It's no coincidence that innovative AI startups like Perplexity use these vendors as data sources. A paradigm change in technology will create opportunities for startups in adjacencies. Perhaps some of these startups will also find answers to the defensibility question.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
It's worth noting some exceptions beyond DaaS providers’ control, especially when data comes from a very limited set of vendors. For instance, real-time market data is relatively centrally controlled by exchanges. Data vendors are subject to data owners' controls. So, if exchanges mandate a data governance regime incompatible with modern data-sharing practices, data vendors can do little. That said, some startups like Databento have navigated this quagmire to offer more modern data products.
And there appears to be consensus building among regulators and industry standards organizations on this topic. In my opinion, Bloomberg’s data products generally fail to meet the criteria outlined here, but the group working on FIGI deserves credit.
Completing my post about tracking AI startups for hedge funds
Show full content
A couple of weeks ago, I posted about startups I have been tracking that are building for hedge fund investors. Since then, I have received very helpful inbound pointing out startups I missed. I have since added many of these that I have missed.
I have centralized the list on my personal website1, so that I can update it without having to republish posts here (and Substack does not have great support for tables). Click below to see the list:
My general criteria for including startups includes:
Focus: I avoid general-purpose, productivity types of tools that could be used by hedge funds. The exception is where the founders have a hedge fund background and have spent time on this specific use case.
Startups: I avoid mature businesses that have launched AI-features. This is necessarily a judgement call, but the line has to be drawn somewhere (otherwise I would be listing Bloomberg, etc. which seems unhelpful).
Adjacencies: I have occasionally included startups building for private equity, especially if there seems to be a natural leap towards public markets
Institutional: I avoid businesses that are retail-investor focused, even if they could be conceivably be used by someone working at a hedge fund. The exception is where the startup has firm, published plans to target institutions as well.
In the future, I plan to complete classifications around funds centered on
Silicon Valley (💻) vs. Wall Street (📈) DNA: do the founders come from top-tier backgrounds on the buy-side or from the OpenAI mafia? In practice, the best startups will blend both, but in the near-term I have noticed distinct differences stemming from the founding teams’ background.
Product Types: there are some repeating product modalities that are helpful to classify. For instance, there is revolving theme around building modified “deep research interfaces” or “Cursor for Excel Copilots”. There seems to be a few of these recurring common patterns as we all search for PMF.
These are necessarily subjective judgement calls. As always, please feel free to share your feedback or send me links to startups I have missed.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
I've been writing less frequently due to a new engagement. Lately, I've been focused on how hedge funds are using AI and LLMs—both to boost productivity and generate alpha. I've met with many of the startups in this space and developed strong views on what’s working and what isn’t. The range of founders is striking—from LLM PhDs to ex-hedge fund analysts learning to code on the job. No clear winner has emerged yet. At some point, I hope to share my own take.
In the meantime, I wanted to share a list of startups I have come across. This is a non-exhaustive list — if I have missed one, please message me:
Indeed, Cunningham’s Law states:
the best way to get the right answer on the internet is not to ask a question; it's to post the wrong answer.
With your help, I hope to compile a complete list and update this post. If you are an engineer and looking to work in this space, please also reach out to me1.
So with that in mind, I list out an incomplete list of startups building AI products for hedge funds, at least partially focused on public equities by my arbitrary judgement. I avoid already well-known vertical software providers adopting AI features.
What I learned from running a DaaS startup for two years.
Show full content
On September 11, 1973, Augusto Pinochet seized power in Chile, ending Salvador Allende’s regime and the Project Cybersyn initiative. Pinochet’s rule is infamous for its human rights abuses and brutal repression, but the economic legacy is a separate, more complex story. Under his regime, the "Chicago Boys," a group of market-oriented economists trained at the University of Chicago, implemented controversial reforms that, despite their divisiveness, were largely successful and continue to shape Chilean politics today.1
In a less dramatic turn, I recently shut down my data startup, Cybersyn. Named after the Chilean Project Cybersyn, our company shared the vision of using real-time data to measure the economy—though with a focus on shareholder value rather than Marxist ideals. Cybersyn will be a footnote in Snowflake’s history2, much like its namesake in Chile’s. However, for those interested in data businesses, I’ve captured my key learnings here for posterity.
When we started Cybersyn, we had a core thesis:
Use of third-party data would grow, and there would be a “moneyball-ization” of more industries driving demand for novel third-party data. This would be similar to what I’d seen in discretionary asset management.
Underutilized consumer data could be licensed from data owners, providing them with new, high margin revenue, and derived into useful products.
Cybersyn could adopt a capital-intensive model for licensing data, then scale by leveraging network effects and operating leverage (no revenue shares). Snowflake’s financial support, reputation, and distribution would enable this strategy.
The “10x” innovative data product would combine transaction, point-of-sale, and clickstream data at the consumer level. This product would offer insights into consumer behavior, combining the best of what the industry calls syndicate and panel data.
The core business model proved very difficult to execute. We learned that:
On the customer side, outside of asset management, insights datasets are most valuable for strategic decision making at the largest of companies. It may seem that digital-native DTC brands would be early adopters, but in practice, the time and complexity to realize a return on data-driven insights does not justify large contract values. I did not appreciate just how much longer actions and decisions take in operating business versus investing. Activation or performance marketing datasets likely would be easier to sell while subscale.
Consequently, it was difficult to find nimble, early adopters for whom the ROI for better data would make sense but who could move very fast. While we made genuine innovation on the product, facing existing insights providers for large CPG manufacturers’ business head-on was difficult without very broad data coverage.
On the supply side, large corporations (who have the most valuable data) were, in principle, interested in monetizing their data, and this trend was clearly accelerating. However, creating mutually beneficial deals proved very difficult. Data from any one company is narrow. We had to acquire multiple datasets and pay upfront, despite the time needed to generate meaningful insights (and therefore revenue). There was a tricky balance between convincing large organizations the opportunity of monetizing data was large, while simultaneously trying to negotiate a low initial price.
Alternatively, starting with commercially available proprietary data (and innovating on its processing) was far more affordable, but still challenging due to the time needed to build differentiated products, especially if the only distinction is in the derivative calculations. With already available data, the bar for building something differentiated was far higher.
In the end, the challenge with the Cybersyn business model could be summarized as having higher than expected capital-intensity, paired with slow and non-gradual offsetting revenue, due to the R&D timelines needed to build the “10x” product.
Beyond these difficulties, there were also exogenous factors:
The public market began to value profits over growth. Snowflake was not exempt from this scrutiny and our status as a consolidated entity added constraints.
Marginal venture dollars sought direct AI companies, while becoming tighter more broadly.
The above realizations led to the conclusions:
The money we raised for Cybersyn was not enough to accomplish our vision. We could not buy enough additional data types (point-of-sale, clickstream) beyond transaction data, while still maintaining a long enough runway to ensure we had a chance to complete and market with the “10x” product.
We could not raise more money because of the change in financing conditions (we were not, squarely, an AI company), our unusual capital structure, and most importantly, financial profile.
Continuing to build best-in-class transaction data products seemed unlikely to lead to the scale of outcome that excited us.
The public domain data products became very popular, even to the point where there is likely a company to be built around that alone.3 Demand from AI inference use cases and the improving ability of LLMs to clean and structure data both supported this business. I remain unsure whether any moats will protect first-movers in this space, but there is significant demand here. I predict an explosion of low-cost new options data from LLM-based data structuring.
Cybersyn had the opportunity to return significant capital to our investors based on our financial position and by selling the assets of the public domain business to Snowflake.
These realizations led us to shut down for the purpose of returning maximum capital. In another version of this story, a more reckless (or courageous) founder might have pushed ahead, spending the remaining capital on acquiring the necessary data, even with uncertain prospects for fast revenue growth. Snowflake, like other data technology companies, face tough capital allocation decisions in the new AI world. Personally, I still believe proprietary data content may still be a deserving strategic choice for companies.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
On a personal note, I owe immense gratitude to a large number of people. First and foremost, the Cybersyn team took the risk to go on this journey. I am most proud of the talent density we assembled Second, this journey would not have been possible without Thomas Laffont, Christian Kleinerman, Mike Scarpelli, Lauren Reeder, and Mike Vernal. It was an immense privilege to work with Coatue, Sequoia, and Snowflake. Finally, a very large number of partners, customers, suppliers, and other investors were instrumental - I will not attempt a list for brevity and fear of omission, but you know who you are! Thank you.
I look forward to continuing to write and work on the topics in this blog, onto 2025!
A part of the Cybersyn, celebrating the holidays, 2024.1
I published extensively on the topic of public data below. I think the rate at which LLMs can automate and assist in the core value propositions is understated.
My startup's beta product for Consumer Spending data
Show full content
This blog is a personal commentary on the intersection of data, finance, and technology and not a Cybersyn (the startup I run) corporate blog. Once in a while , I cross-post announcements from Cybersynwhen I think the content is relevant today and for posterity. Reproduced is a copy below. You can try the product here.
Today we are releasing our first consumer spending application and updating our brand and content. We started Cybersyn two years ago to reinvent how the world measures the economy. Today’s release is the product of that effort.
Consumer CurrentTM Beta is a market intelligence tool, available as a data feed and / or web app, that estimates property-level consumer spending for over 8,000 U.S. merchants (and over 25,000 at the zip code level). Powered by anonymized and aggregated card transactions, Consumer Current delivers representative dollar and growth estimates. It also provides analytics like retention, consumer demographics, and sales breakdowns by channel and marketplace.
Consumer Current enables operators of consumer-facing companies to:
Discover Growing Brands
Our wide coverage of merchants allows discovery of even new companies. This ranges from up-and-coming DTC brands driven by social media to disruptive AI startups.
Benchmark against competitors at hyperlocal levels
It is one thing to know your national market share, but quite another to decompose that into trade area dynamics to understand whether performance is driven by competitors or macro consumer conditions
You can dig into store level benchmarks to understand micro level performance trends
Understand who your customers are behaviorally
Beyond traditional demographics, understanding where your customers shop outside your four walls – both with competitors but also in adjacent markets – is key to deciding strategy
Panel-based credit and debit card data has been commercially available for a while and hedge funds were among the first to use it. We borrow from that approach and my personal experience pioneering estimates at Coatue. Consumer Current stands out through:
Merchant Coverage: 15k+ merchants in the web application and over 25k+ merchants in the data feed
Granular & Hyperlocal Estimates: Sales estimates and related analytics down to the property level.
Fast Interface: Consumer Current enables users to interact with the data in real-time, with the speed and responsiveness you would expect from a consumer app.
Accuracy
Accuracy is central to what we do. While Consumer Current is not perfect—hence its Beta status—we're committed to building a product that can be rigorously benchmarked against US Census economic data, company earnings, and private sales. We believe in translating panel data into population-level estimates, despite the added complexity. Our focus is on fast iteration and continuous improvement, driven by feedback and data from early customers.
Licensing and Delivery
We try to live up to what we consider are the best standards in data licensing. This includes transparent pricing, delivering data instantly via Snowflake, and enterprise-wide licenses. Cybersyn Current does not require any specific technical expertise to start using, but the most of the data can be made by accessing the underlying feed via Snowflake Marketplace.
What else?
As we release Consumer Current, we are also updating our branding to better represent all that we do.
We believe a necessary prerequisite to building the best proprietary market intelligence product is to first take advantage of all the public domain data that is freely available but not easily accessible. That’s why we are rebranding our public data products to Cybersyn Foundations, centralizing all of this public data into one place, with both free and paid tiers, to democratize and reduce costs to access this information via Snowflake Marketplace.
We have released an updated Data Catalog that allows users to search by source and variable all of our public domain data products. Alongside refreshed documentation, this is a step forward in data discoverability.
Where next?
We’ve only begun to explore the potential of consumer payments data. Our roadmap includes expanding merchant coverage and enabling self-service custom analytics through Snowflake Native Applications. We also see the future in combining payments, point-of-sale, and clickstream data for a true omnichannel view—something the market lacks today.
As for AI and LLMs (what blog post today couldn’t mention them!), their most transformative role in market research will be automating insight discovery. Today, our platform answers your questions. Tomorrow, it will tell you what to ask.
Thanks for reading Magis! You would do me and Cybersyn a huge favor by sharing this post.
How data licensing and government data can go wrong
Show full content
Data businesses can be particularly valuable if they have moats that guard their product from replication1. Such moats can come from legitimate technological innovation or business partnerships. The data moats worth criticizing are those built with anticompetitive government relationships: regulatory capture2. There are two types of common unfair moats: ones based on improperly proprietary identifiers and ones based on outright unfair data access.
Proprietary identifiers, also understood as data join keys3, often replace what should be open industry standards. Regulatory, tax, and statistical agencies often require the private sector to submit data and publish aggregate statistics for commercial, academic, and personal use. Various industries use agreed upon standard identifiers for companies, investable securities, and other entities that make the data easy to use. This presents an opportunity for regulatory capture. When a proprietary standard is mandated, the copyright holder can extract high fees.
One such example is CUSIP, an identifier used by financial market participants to identify companies and investable securities. The identifier is copyrighted and owned by the American Bankers Association and the operating company was recently bought by Factset4. Both use and distribution of CUSIP, even indirectly, requires a license. This is problematic because regulatory agencies such as FINRA, SEC, and the CFPB use the identifier in ostensibly public domain data releases. CUSIP benefits from an effective government mandate to do business with them5.
Another example is the DUNS number, which was used as a primary entity identifier for several government agencies, including the General Services Administration’s SAM database of government contractors. This regime required users and distributors of the data to license products from Dun & Bradstreet. While obtaining a DUNS number was ostensibly free, it gave Dun & Bradstreet a monopoly in entity validation services it provided to the government and it gave Dun & Bradstreet an unfair (effectively mandated) advantage in collecting data on business entities other data providers did not have. Several states and international governments still require the DUNS number, and this is advertised on the DUNS website6.
A second regulatory capture model occurs when companies gain privileged access to government data that they monetize. Bill of ladings data are an example of such unevenly available data. Bill of ladings are government forms collected when goods are imported into the United States by sea, approximately equivalent to shipping labels. The data is commercially valuable because it can be used to research supply chains. While the data comes from the government (the Custom and Border Protection Agency, specifically), how and where to access the data is not clearly documented. Instead, several commercial entities obtain this data and sell it. The majority of customers are likely unaware of the exact source of this data. Freedom of information requests are apparently denied in relation to obtaining this data but certain companies are able to find the right contact and obtain the data for a fee7. A similar situation exists with United Kingdom Gilt price data. UK gilt prices were previously calculated by the Debt Management Office (DMO). In 2016, the agency ran a RFP and accepted a proposal by FTSE/Tradeweb to take over calculating daily closing prices8.
The mere fact that the government charges for certain data is not problematic. Government agencies incur real costs in procuring and analyzing data, and it makes sense to charge if the primary beneficiaries are only a subset of the private sector. Further, independently reviewed RFPs to grant a private company the right to process and publish such data - as happened in the UK Gilt case - are preferable to an entirely opaque process. However, I am skeptical that technocrats should ever select a single provider (even if stakeholders claim they prefer a single authoritative source today, such ‘benevolent’ monopolies fail to anticipate changing circumstances and new stakeholders – for instance, the advent of AI/LLM users may well change the optimum)9.
There are reasons to be optimistic that at least certain cases of both regulatory moats can be eroded. Numerous financial regulatory agencies recently proposed moving away from CUSIP10 to the FIGI11 and are soliciting public comment12. SAM.Gov announced, two years ago, that it will move away from the DUNS number to its own, open, standard13. Further still, the recent litigation around CUSIP has led to questions about whether identifier numbers alone (as opposed to in their totality) can be copyrighted at all1415. Similar examples exist in the case where the government produces expensive data to the private sector. For instance, the USPS began charging for their change-of-address database and Fannie Mae and Freddie Mac charged for commercial use and redistribution of their data. In each of those cases, there are multiple competing vendors16, transparency in the license agreement needed to access the data, and transparency in pricing. Any new data vendor can agree to the license and compete on data distribution and value-add.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
I also want to point out a few distinct potentially anti-competitive data licensing cases outside the scope of the above comments. There are data products where governments fall short in data integration, so commercial entities step in. This situation is only problematic when other businesses are not allowed the same raw data access. Competition is different from convenience – the mere requirement for high upfront capital expenditure does not make a market anticompetitive. For instance, CoreLogic, BlackKnight Financial, and Attom sell mortgage deed data they gather from county governments. They bear the cost of data standardization and integrating with each county government. In theory, this seems like it should be competitive. What would be problematic, however, would be if certain counties release data only to certain vendors or counties lack transparency in how competing vendors might participate (as in the Bill of Ladings case). A second case, not to be overlooked, is that data vendors may engage in traditional anti-competitive metrics, such as price collusion, that are not regulatory capture, strictly speaking. I do not cover such cases in this essay.
Cleaning, integrating, and distributing public domain data is a valuable commercial service that private sector data companies should be paid for but there will always be a temptation to build anti-competitive moats. That’s lazy. Data companies should compete on value-add on top of public data rather than attempting to be a tax on users. This serves the best interest of the private sector customer, the government, and, most importantly, the taxpayer.
Many of the companies on my list of data companies have enduring moats. Counterpoint Global Research (ran by Michael Mauboussin) has a great list of wide-moat businesses, a surprising number of which are data businesses.
Credit goes to Tim Baker and his LinkedIn posts that made me dive into this subject (in addition to just operating a company in this space). I highly recommend following him and some of his posts and comments.
A good summary of that proposal was issued by the FDIC. The full explanation of the joint rule and methods for public comments, as a result of the Financial Data Transparency Act can be read here.
FIGI was originally developed by Bloomberg, but it has transitioned into an independent and open standard with permissive open licensing. While all open source projects have risk when primarily developed by a single, well resourced, commercial developer, this is still the best open standard that exists to my knowledge. Other standards, such as LEI or PermID (operated by a Bloomberg competitor), are also viable.
I will leave it to the reader to decide if the ABA and CUSIP’s response public comment sounds like someone who is definitely not benefiting from an unfair monopoly.
Worth noting that the EU took anticompetitive legal action against CUSIP Global Service’s previous own, S&P, previously — although, this was around the specifics of issuing a related identifier, ISIN, rather than CUSIP, specifically.
For instance, here is every vendor with full access to USPS COA data. And here is the same from Fannie Mae, along with the standard data redistribution agreement.
A perennial idea among external data consumers is a data marketplace. There are many large specialized data vendors, and thousands of small ones, each with often hundreds of datasets – so why would there not be a central marketplace to discover and buy them?
Have any attempts at data marketplaces succeeded at large scale? I think the answer is sort of. There have been successful pseudo-marketplaces whereby a single buyer takes control of the data and integrates it into a single product. The most successful of these has undoubtedly been the Bloomberg Terminal. Further, some marketplaces have been successful for narrow use cases, especially where there is a single data format or join key being sold. For example, advertising activation marketplaces for audiences have done well.1
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
There has also been relative success at distributing free data in marketplace form. For example, FRED or Data.gov - government attempts to catalog public data - have been successful judged by the downloads these repositories drive relative to the individual sources. Non-government open data repositories, such as Kaggle, have built large user bases (and website traffic estimates to kaggle.com/datasets indicate this is the most popular part of the website). In both cases, these serve an aggregation function while avoiding traditional data marketplace challenges because the data is public domain.
A new wave of data marketplaces, funded by database infrastructure providers such as Snowflake, AWS, Databricks, and Google have also recently been released. Success is still an open question2, although they clearly have a core advantage in that they tie the data buying and transfer to the same place that analysis occurs.
A few common, but recurring, issues I have observed among many attempts include:
Lack of neutrality: There have been attempts made by large data sellers to build their own data marketplaces. These DaaS companies can offer distribution to their already large customer base. Simultaneously, there could be some sort of efficiency or delivery benefit to the customer, given that the customer already has a MSA with the DaaS incumbent. In practice, the distribution advantage only works if the barrier for existing customers to adopt the new dataset is very low. For example, Bloomberg’s Terminal constantly makes new datasets available to end users without much action needed on the end users’ part – so data sellers get distribution without additional legal work. This model struggles in cases where the DaaS incumbent has a large data business that conflicts with marketplace participants: naturally, Factset is never going to list their data on S&P’s marketplace and most asset managers are going to use some Factset and some S&P content – so neither party can build a complete product.
Discoverability: Finding the right dataset to answer a business question is difficult. Good metadata search is essential. There may also be questions an analyst does not know they could be asking because they do not know such data might exist. Conviction, a venture firm, has a good write-up about why this problem may well be solved with LLMs.
Licensing and Monetization: The process of buying data varies by industry, but involves a general contracting process similar to enterprise software but also a data specific compliance process. Certain industries have developed standards for this, but the majority of marketplaces have not meaningfully solved the pain point of transacting. As with other failed marketplace categories, often the data provider and consumer find it easier (and cheaper) to take the transaction offline.
A fair question to ask is whether the advent of AI creates opportunities for either solving some of the above challenges or solving new challenges with data marketplaces. A few ideas I have recently come across include:
AI Inference: I am skeptical that selling data without strong marginal-temporal value for training AIs is a good business. Selling data for AI use at inference time, however, may be a good business. It is possible that AI use cases will present new opportunities for data sales that may be better sold with usage or consumption based systems rather than traditional bulk licensing. Eric Schmidt made a similar prediction recently: that data usage for AIs will look like music royalties3. Furthermore, selling embeddings of datasets, rather than the raw datasets themselves, may well be a value-add to many LLM software providers.
Legal Indemnification: A key friction in data acquisition and sales is that regulatory and compliance burden placed on the buyer to determine whether they can actually buy and use the data on offer. The increasing amount of regulations (CCPA in California, look-alike laws in Virginia, Maine, and others, GDPR in Europe) and the challenge in understanding these laws means that it is particularly costly to stay compliant.
Traditional marketplaces absolve themselves of liability for their sellers’ products for the obvious reason that policing and verifying each seller's products would add a tremendous cost and potential liability to the marketplace. This works fine in areas where liabilities are not a concern for buyers or where the marketplace platform can enforce very heavy technical standards on providers. In data sales,
Note that this is very different from just providing ‘standard’ terms or suggestions as to what disclosures data providers need to make – such suggestions are relatively low value-add
If data buyers could be assured that a given dataset was legal and compliant for their use case, the entity providing that assurance - from a third party perspective - would add a lot of value to the selling process, easily enough to justify a significant take rate. The arrangement would work well for data sellers as well, as the added confidence would surely increase the liquidity of the market.
Potential data sellers may also be reluctant to enter the business because of a lack of expertise on whether their exhaust data could be compliantly monetized.
Bundling: I predict that the market for data bundles will grow, as more companies will have increased capacity to process unstructured information. The marginal value of any specific one dataset may not increase, but the need for economical consumption of a very large variety of datasets will increase. Many of these use cases will initially be experimental and much of the value add may well be marginal. As such, bundles which provide a wide range of data.
Shishir Mehrotra lays out a great economic explanation for this – bundles are a good deal for both consumers and suppliers when the bundle is constructed such that the number of ‘casual fans’ increases4. I think this is exactly the dynamic that will play out with data to be used for AI inference.
For example, today there exists a well defined market for earnings transcripts among asset managers. Firms like S&P and Factset charge for transcribed earnings transcripts calls. Asset managers rely on this information for analysis and trading signals – the demand for this dataset among this customer base is relatively elastic: a price of 50K vs. 250K does not really matter, so long as the data is perfectly accurate. The cost of an asset manager not having this data would be much higher.
Earnings transcripts could also be used by non-financial firms for understanding and identifying new selling opportunities, key supplier risks, and key competitor plans. Startups might also have new ideas that rely on this type of unstructured data. Traditionally the market for using this data has been very small because (a) the processing and structuring cost for transcripts did not justify the effort (b) transcripts data was expensive. With LLMs, the effort to process and synthesize the data is low, so if the price could be made acceptable, there could be a market. The marginal value of this data may initially be low, because the use cases are new and the data is almost substitutable with news stories, SEC filings, press releases, and so on – but the there now exists a clear need for some of this data and if a data provider or marketplace benefits from economies of scale in collecting it, it makes sense to offer such data at a much lower cost in a bundle. In Shishir’s terminology, the number if casual fans for this data has massively increased.
In this essay, I reflect on some of the practical challenges of data monetization and relate them to theoretical concepts in information economics1.I then point out how these theoretical failures are real and result in obviously useful data – MLS listings or B2B transactions for example – not being widely available. I explain two particular market failure conditions resulting from the non-exclusionary nature of data and from the cold-start problem data aggregators face. By sharing these observations, I hope to solicit solutions for solving these challenges.
Economists refer to data as non-excludable, because once it is sold once, infinite copies can be made, thereby depriving the data seller from charging for additional copies. In practice, measures are taken to enforce exclusion. Data markets fail when the exclusion measures taken end up being not effective enough or too restrictive. These measures can be contractual or technical. Certain attributes of data - such as marginal temporal value - can cause data to expire and so also assist in creating exclusion. Contractual measures can be as simple as requiring data consumers to sign a licensing agreement. These generally work well when the data consumers are vetted, reputable, and unlikely to want to engage in legal disputes. Technical measures, such as data clean-rooms, aggregation constraints, digital watermarks, and so on can often be effective. Technical measures always involve a trade-off between flexibility (thereby value to the consumer) and protection (thereby insurance for the seller). If taken too far, both contractual and technical measures can entirely prevent the market, or part of a market from using a given dataset.
For example, data from multiple listing services (MLS)2 is notoriously expensive and difficult to license. MLS’ serve as cooperatives among realtors in specific geographic areas. They are highly fragmented and require extremely specific compliance rules and circumstances to license data3. This data model makes sense for industry participants – data is highly localized and there is a real risk that if the data were readily available, unsanctioned competitors could create competing listing or realty services without participating. Therefore, MLS data is extremely tightly controlled and perhaps intentionally fragmented. These measures (mostly) protect the dominance of the National Association of Realtors and realtor licensing system4. On the other hand, it creates a market failure in that noncompetitive consumers at a lower price in the demand curve are left unserved. These consumers are not able to pay hundreds of thousands of dollars for access and do not fit into prescribed acceptable use cases, but they have noncompetitive use cases that have nothing to do directly with realtors or running competing listing websites5. The lack of an effective technology to price discriminate by use case, means that data remain practically unavailable to certain portions of the market (economists would call this deadweight loss). The severity of this problem depends on how you size the noncompetitive market for real estate data.
A second market failure occurs when owners of data have insufficient incentive to share it in any one transaction, and no aggregator or coordinator exists. This failure is akin to a lack of market makers in financial markets. This situation occurs when owners’ data is only valuable if combined with many other owners’ data but not so valuable alone. It leads to a “cold start” coordination problem wherein individual owners ask for too high a price relative to what individual data consumers can bid, but the collective demand of a group of consumers for a collection of owners’ data would have a clearing price. To solve this, a data aggregator must incur the cost of acquiring data from each source. Doing so is expensive and logistically difficult because it must be done nearly simultaneously across owners to minimize the time the aggregator licenses some data but not yet enough to have a viable product to market. An analogous problem sometimes occurs simultaneously when the owners’ data requires a large amount of cleaning, modeling, or transformation to be useful. In such cases, the R&D cost may eclipse the ability of any one data consumer to incur, but the buying power of all consumers combined would suffice.
Data aggregators, therefore, have two useful roles to play: one to consolidate raw data and a second to develop data products. This is quite different from data marketplaces, data catalogs, or data brokers. Beyond coordination, data aggregators also incur duration risk, by which I mean they front capital data owners today, in exchange for data product revenue in the future.
Thanks for reading Magis! Please subscribe for free to receive new posts and support my work.
Revenue share agreements are often proposed as an equitable solution to eliminate duration risk. Such agreements involve aggregators paying owners a percentage of data product revenues. In practice, revenue shares are far from perfect solutions for both parties. For aggregators, revenue shares limit the amount of data combination that can be done by permanently impairing margins. They can be particularly detrimental to unlocking full data product potential if they are structured as an absolute percentage of sales – eventually, only so many datasets can be combined before the endeavor becomes unprofitable. This leads to a less compelling product (which is bad for everyone). Also, for data owners specifically, revenue-shares may not cross a greater-than zero dollar profit hurdle short-term if a significant amount of R&D work (therefore time) is required to make a useful product. In theory, the perfectly rational, profit-maximizing company would agree to any incremental marginal profit from monetizing their data. In practice, companies have dollar profit hurdles much larger than zero to overcome. These hurdles are due to either institutional inertia or due to the real but difficult-to-quantify expected value costs of data monetization (legal risk, press risk, employee distraction, etc.). Revenue shares are therefore not panacea solution to these challenges.
A combination of these unhappy circumstances lead to obviously marketable data being unavailable. For example, B2B transaction data is particularly fragmented, its owners assign a particularly high hurdle value, and it requires a particularly heavy amount of modeling to make useful. It is perhaps not surprising then that it is largely not an available product today.
You may ask if this is anticompetitive and there have been legal cases about it (for example, here) but these cases have largely focused on sharing MLS listings between different types of realtors or brokerages.
You could imagine a range of use cases for the data — such as investment or economic analysis, property tech startups, etc. that would not really undermine the purpose of protecting participating realtors and brokerages (regardless of your view of the desirability of the protection intent).
Is it different this time? A perennially challenging idea with a glimmer of hope.
Show full content
Market research and targeted advertising requires consumer data, specifically purchase and digital behavior records. Data can be collected actively or passively. Active collection requires consumers to take surveys, submit records, or make some other effort to contribute data. Consumers are required to participate by law, volunteer, or are paid. Collected data can be high quality, but obvious downsides include noncompliance, incomplete data, time required on the part of participants, and effort required to recruit participants1. These disadvantages lead to relatively small samples and infrequent collection. Passive data collection does not require effort from the consumer, rather data is collected continuously in the background by an app, bank, or service the consumer is using. The comparative advantage to active collection is that the collected data is more complete, less biased, and more consumers can be reached. Privacy laws and consumer opinion dictates that passive data collection needs consumer opt-in. Consumer opt-in can be obtained in exchange for free products and services (“in-kind”) or for explicit payment (“data dividends”). The former is well understood - companies like Meta offer their products for free, in exchange for collecting data from their user base that can be used by or sold to data users. The latter is less common but has been the frequent subject of speculation. Proponents of data dividends note that they combine the best attributes of active data collection (very explicit opt-in) with the best attributes of passive data collection (low effort for the consumer).
To my knowledge, no data dividend funded dataset exists of comparable scale to in-kind funded datasets. Despite limitations introduced by privacy laws, changes by corporations in response to media attention2, multiple startup efforts, and emerging interest driven by the crypto community, data dividend datasets have not become common.
My hypothesis is that the unit economics of data dividends are structurally challenging and may preclude large scale adoption. Data dividends scales linearly with the number of participants. In contrast, in-kind payments scale sub-linearly because the marginal cost of provisioning an application or software service is low and can decrease with scale. For instance, Meta’s cost of hosting a marginal user is very low and the marginal cost decreases after each order of magnitude in scale.
The unfavorable marginal costs of data dividends could be overcome, of course, if revenue scaled faster but prevailing data prices per consumer are too low. This is again best illustrated by Meta. Meta’s average revenue per user is approximately ~$40 per year or $3.3 per month3. Meta is just one example of an in-kind data buyer, but Meta’s monetization per user likely represents a best case scenario4.
In exchange for the data that generates this revenue, Meta users can use the family of Meta products (Facebook, Instagram, Whatsapp, Messenger) for free. The monthly in-kind value of the Meta family of apps likely far exceeds $40 per year5. This places data dividend programs into the unenviable position of having to compete against a difficult unit economic equation.
A corollary challenge is adverse selection and redundant opt-in of participants. Consumers willing to accept a low price for their data is correlated with certain demographic, socioeconomic, and other biases. For many (but not all) market research and advertising purposes, this set of users is less valuable. Also, consumers with this preference are likely to sign up for many such data dividend programs to maximize their earnings – so the total universe of data dividend users generated even across data dividend programs often has high overlap.
Finally, there is a lack of consensus among policy stakeholders that data dividends are a good solution. For instance, the Electronic Frontier Foundation (“EFF”), a digital rights and privacy advocacy group, often in favor of stricter data privacy laws, actually opposes data dividend programs6. This is surprising at first glance since the media-driven argument against passive data collection has been that consumers are deceived is clearly not relevant with data dividends. Instead the EFF argues that data dividends are unfair on the basis that the consumer is deceived into the relative value of their data.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
So, is the data dividend model hopeless?
Some promising ideas I have come across include:
Hybrid Value: It is conceivable that certain data dividend products also provide value in-kind such that the combined value of the dividend with the utility from the app together overcomes the unit economic hurdles. Consumers would explicitly know they are selling their data (thereby accomplishing the stated goal of most dividend programs) but the app also provided enough utility that the magnitude of direct payments could be economical. For instance, a dividend program may offer gamified experience that is fun to participate in, in addition to being paid for data. Where the lines lie between in-kind offers and true dividend programs, I will leave to the reader.
Variable Upside: Novel data dividend models could offer variable dividends dependent on some third party process or user action. For example, a quant fund may offer a stake in results in exchange for contributing data. Similar profit-sharing programs were popularized with the crypto wave as Decentralized Autonomous Organizations (“DAOs”). Or, a dividend program may offer discounts for purchases consumers were going to make anyway in exchange for their data.
What am I missing?
I could be wrong. This time it could be different. It is possible that consumer preferences for privacy change drastically wherein the unit economics are not the incentive driver (rather, participation becomes an ethical statement). It is possible that privacy oriented changes, such as the elimination of internet cookies, drives up the price of identifiable data. And, it is possible that someone invents use cases for consumer data that are so lucrative that very high dividends are justified. If you have counter examples or if you are aware of a very large data dividend driven dataset, please reach out.
There has been much discussion about how to compensate authors, journalists, artists, and other content creators for their work being used in AI. I have heard variations of the data dividend pitch to accomplish this. Proponents of such a solution would do well to consider the consumer data precedent.
This is just a matter of opinion, but I would make the case that Meta is among the most lucrative data monetization. Meta owns effectively an exclusive dataset with extremely specialized ad targeting ability and is extremely penetrated among advertisers (data buyers). Therefore, I think Meta’s revenue per user represents, more or less, the highest value scenario for data sellers.
Ongoing List of Generative AI Content Licensing Deals
Show full content
I have compiled a non-comprehensive list of content licensing deals that have been publicly reported, with a particular focus on interesting details disclosed in SEC filings and earnings transcripts. If I have missed any deals, particularly from public companies that mention such deals in earnings transcripts, analyst days, or SEC filings, please email me and I will add them.
Reddit
Widely reported to have a ~$60M per year access for ongoing and historical data with Google1. S-1 reports2 they expect to recognize $66.4M by end of 2024. Aggregate contract value of $203M with terms ranging 2-3 years.
Shutterstock
Existing deals with Meta and a 6-year3 deal with OpenAI.
$25-50M deals with Amazon, Apple4 based on statement by CFO
The relevant segment, Data Distribution and Services5, grew from $15.9M in ‘21 to $137M in ‘23, suggesting very roughly ~$100M of already recognized revenue from generative AI licensing.
Shutterstock CEO referenced existing deals with OpenAI and Meta and expressed desire to expand licensing to broader audience in Data Marketplace like Snowflake, AWS, etc.6
Yelp
Perplexity reportedly licensed data from Yelp7, though it remains unclear if this deal is materially different from other pre-generative AI deals Yelp enters into to distribute reviews, restaurants, etc.
Yelp reports data licensing in its Other category8 of ~$47M but this includes other types of revenue. This number jumped from ~21M in ‘20 to 47M in ‘239 which suggests a generate AI bump of ~25M.
Reuters
Added $22M in the Reuters News Segment10, the majority of which was apparently driven by “transactional” content licensing for artificial intelligence. This increased News Segment margin by 6.5%, so we can surmise this incremental revenue was largely content licensing.
Onetime fee of $23M for previously published academic articles and books11. The CEO expressed interest in finding more such deals. Wiley owns both academic journals and a large boom publishing business.
Associated Press was among the first organization to announce licensing data13
Multi-year contract for ongoing and historical access to Le Monde corpus with OpenAI14 announced simultaneously with Prisa deal15
I have not been able to find specific financial details for any of these, but The Information reports16 OpenAI offers 1-5M per corpus whereas Apple offers 50M over a multi-year period
Previously, for display (not generative AI purposes), WSJ reported Meta was offering publishers 3M17
X (formerly Twitter)
Well covered that Firehose access will cost 42K/month or 2.5M per year although it is not quite clear what rights/use case this level of access comes with. While largely reported at priced too high, a 2.5M price would seem reasonable or even cheap relative to the above.
StackOverflow
Deal with Google Gemini that also includes workflow integration with Google Cloud console18
Photobucket
Negotiating contracts at “5 cents and $1 dollar per photo and more than $1 per video”. With 13 billion photos (an order of magnitude more than Shutterstock), this could be a significant revenue source but we would have to assume the rights and usefulness of the entire content library are not as robust.
Automattic (Tumblr & Wordpress)
OpenAI and Midjourney apparently licensed, or at least evaluated, data from both Tumblr and Wordpress19 though I was unable to find any specific financials.
NewsCorp
Owner of Fox News, NY Post, among others is reported to be near data deals20 and expects to be “core content provider” based on last earnings call21.
Based on earnings call comments, deal is is in negotiation as of Februry ‘24 but given CEO’s compliment to Sam Altman’s approach, it is reasonable to guess OpenAI is involved.
Who is missing?
I was unable to find any specific data deal references from TripAdvisor, TikTok, or SoundCloud, which all seem like obvious candidates for data deals. Quora also has been involved in launching AI products22 bit I have found no obvious data deal disclose.
NY Times23 and IAC24 have taken a more combative stance, using the courts to protect IP rather than negotiating data deals. Other companies, like Thomson Reuters engages in data licensing but has taken selective court action25.
Other companies such as RELX Group (owners of LexisNexis and Elsevier) have announced AI products26 and workflow integrations with Microsoft27 but I have not found an outright content for training licensing deal. I have anecdotally noticed similarly situations with DaaS providers like Factset, Bloomberg, and S&P Global — although it is difficult to discern if any of their licensing deals are explicitly for AI training given they are in the business of content licensing in the first place.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
How Transformer-Based Neural Networks could Predict Chaotic Timeseries
Show full content
In the academic literature on statistical learning (“AI” if you prefer”), there is a famous paper by Leo Breiman1 about two cultures in statistics2. One culture assumes that observed data are generated by some stochastic process that can be modeled. The other culture assumes the data generating process is unknown but algorithms can make predictions about it, even if they cannot describe the causal process behind that prediction (ie. a “blackbox”). At the time the paper was written, the first culture was in vogue – statisticians, economists, and social scientists focused on proposing models that could explain the world and then fit the data to the model. These models propose interpretable statistical representations and causal theorems of the world, but often perform poorly at prediction and empirical data deviate from the model. The black box approach to statistics was, at the time, less common. However, this second culture caught up as large datasets (ie. “big data”) and cheap compute made methods that previously were only hypothesized to work practical. Competition from computer science departments also drove this culture forward. In most prediction and forecasting applications today, the state of the art now relies on this second culture. Neural networks3, in particular, ended up outperforming most other methods in many applications. As of this writing, a relatively simple neural network architecture, called the transformer, has yielded astounding prediction results in the area of language, images, and video (referred to as “unstructured” data). The applications of these predictions, in areas such as chatbots, self-driving cars, or video generation, has made the second culture dominant.
However, these impressive advances in deep learning have not yielded similar advances in forecasting chaotic systems. Examples of such systems include geopolitics, financial markets, or the weather. This category of prediction problem shares some characteristics. They involve structured tabular data, most often dealing with timeseries, the best known models fit the data extremely weakly, the processes are non-stationary4, and human ability at this class of problems is poor and not limited just by speed, information, or computation. Neural networks, including transformers, have not transformed this field yet. Attempts at applying transformer based models to timeseries have had mixed results. Amazon and Salesforce, for instance, recently released Chronos5 and Morai6 respectively, a transformer based foundational models. Interestingly, basic benchmarks show these complex models underperform ensembles of standard econometric forecasting models7. Systematic evidence from the M-Competitions show that linear models continue to perform well and tree-based models generally win the competitions8.
I have heard three competing hypotheses as to whether and how transformer based neural networks will eventually overcome this relative underperformance in chaotic system forecasting: first, that they will eventually solve this given the rate improvement, second that not enough data exists for them to do so, and third, that they will solve chaotic forecasting indirectly, by helping practitioners source more specialized statistical methods.
The first hypothesis is the most straightforward. It proposes that after future improvements to transformer-based models, they will begin to perform well on chaotic systems prediction. I do not have a deep enough intuition to really evaluate the merit of this hypothesis. All statistical learning approaches – deep learning, tree-based methods, hierarchical Bayes, and others – take the basic approach of estimating a huge number of parameters and then regularizing them to prevent overfitting9. It is certainly conceivable that sufficiently large transformer-based models, with the right balance of parameter count and regularization penalty, could replicate other statistical approaches.
The second hypothesis is that we do not have enough data – or at least enough observations of events – due to timescales to forecast non-stationary systems. This may sound counterintuitive as financial markets, for instance, generate terabytes of data a day based on the high frequency events. Other chaotic systems like astronomy or weather generate the largest structured datasets. This argument hinges on the possibility that certain stochastic processes across regimes, and those regimes take an extremely long time to observe. For example, if financial markets behave differently under recessions, it is surely problematic that only around 8 recessions have occurred since 194510. The same can be said of major geopolitical events such as wars, climate patterns like global warming, or astronomical phenomena. The timescale at which events of interest occur makes it very difficult to capture sufficient observations. Related to this reasoning is the problem of reflexivity: the very act of successfully forecasting certain chaotic systems at scale will change those systems. For instance, if OpenAI released a model that could predict stock prices, market participants would immediately employ it, causing it to lose power. More generally, if participants in a chaotic system react to forecasts and adjust accordingly, top-level timeseries models on aggregate timeseries will not produce useful forecasts – the Lucas Critique11 of economics. This hypothesis does imply, however, that micro-level models of agents in a chaotic system (agent-based modeling12) might be a viable approach and, interestingly, might be possible with transformer models.
A final proposition is that transformer based models will not assist in pushing chaotic system forecasting forward but that these algorithms will push the state of the art forward by “sourcing” appropriate methods. The number of effective statistical algorithms available and well suited to such problems far outpaces the private sectors’ ability to apply them. Many of these algorithms belong in the first culture of statistics, but only produce empirically good predictions in very specific circumstances. As a result, these algorithms are often esoteric, difficult to parameterize, and require domain knowledge. There is a shortage of human capital aware of and able to apply them. Large language models may well serve as “co-pilots” or “auto-pilots” that identify opportunities to apply highly specialized but non-transformer based models to make forecasts.
The somewhat amusing implication of this last hypothesis is that black box neural networks – the epitome of second culture statistics – may propose, develop, and test first culture models. The second culture will lead us back to the first.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
On a side note, Breiman is probably under-appreciated, especially outside academic circles, for his contributions to machine learning. Many of his contributions underpin key concepts in AI/machine learning and some of his statistical learning algorithms, such as Random Forest, remain mainstream.
Unfortunately, I will use the terms Neural Networks, Deep Learning, and Transformer-based models and their common application in Large Language Models (LLMs) interchangeably.
Simpson’s paradox is a famous statistical paradox taught in Statistics 101 classes2. The paradox can be illustrated with its most famous example: sex bias in admission to UC Berkeley. In 1973, 44% of male applicants were admitted to the PhD program they applied to whereas the rate was only 35% for female applicants. In aggregate, it appears that there is a statistically significant bias against female applicants. However, when applications are disaggregated by department, the majority of 85 departments had no significant bias against either sex, 4 were biased against women, and 6 were biased against men. This apparent contradiction is resolved when one considers that women applied at higher frequencies to departments with lower overall acceptance rates. In aggregate, the acceptance rate for women appears significantly lower than for men only because this aggregate is proportionally weighted by the number of applicants to each department – so the aggregate rate for women overweighs (relative to men) departments that are overall harder to get into. Similar paradoxes occur in medical research – for instance, a treatment may appear more effective at curing cancer overall, but that effect disappears when the patients in the study are split by severity of the cancer.
The lesson from Simpson’s paradox is that aggregate metrics can lead to the wrong conclusions when one does not consider the composition of the aggregate. Statisticians classify such studies as missing confounding variables – what accounts for the differences in groups is something other than the treatment being studied. This phenomenon is often obvious ex post but can be hard to recognize, as in the UC Berkeley case: if researchers were to test a new cancer drug only on benign forms of cancer, clearly their mortality results would look better when compared to existing drugs.
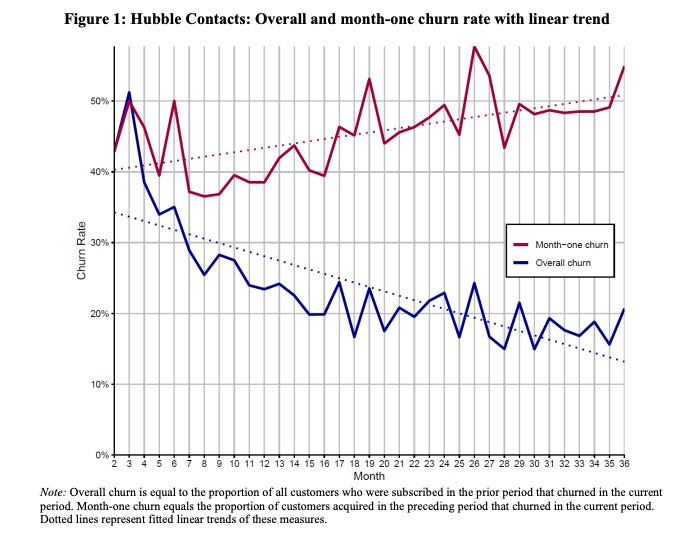
Dan McCarthy et al.3 recently published a fascinating study demonstrating an aggregation paradox occurring in the construction of churn metrics frequently used by investors to study a company’s performance over time. The paradox is statistically interesting because the aggregation bias is extremely subtle, but it is also practically important because it can lead to the somewhat puzzling conclusions that contradict common investor assumptions. The bias implies that:
A decreasing aggregate churn rate (or inversely, an increasing retention rate) may not indicate that the long-term quality of a company’s revenue base is increasing.
A sudden increase in aggregate churn rate (or inversely, a sudden increase in retention rate) may be the result of an increase in new customers and not say anything about the quality of a company’s revenue base.
For clarity, aggregate churn rate (or inversely, retention rate) refers to a common but problematic construction of a very common business metric meant to measure the stickiness or longevity of customers with a subscription service or product. Churn rates are expressed as percentages (i.e., what percentage of customers left a service). Aggregate churn rates refer to the construction of this metric over an entire customer base. This is one of the most common reported formulations, especially in quarterly reports, financial statements, and investor updates. For instance, Netflix defines churn rate as “Churn is a monthly measure defined as customer cancellations in the quarter divided by the sum of beginning subscribers and gross subscriber additions, then divided by three months.”4 Similarly, Freshworks, a software company, defines a retention rate similarly when it explains that “To calculate net dollar retention rate as of a particular date, we first determine “Entering ARR [Annual Recurring Revenue],” which is ARR from the population of our customers as of 12 months prior to the end of the reporting period. We then calculate the “Ending ARR” from the same set of customers as of the end of the reporting period. We then divide the Ending ARR by the Entering ARR to arrive at our net dollar retention rate. Ending ARR includes upsells, cross-sells, and renewals during the measurement period and is net of any contraction or attrition over this period.”5 And, in fact, authoritative sources such as Salesforce6, Hubspot7, or popular blogs8 instruct prospective investors or operators to construct churn or retention metrics in more or less this manner: across the entire comparable customer base. Investors typically assume that decreasing churn rates over time are positive because they indicate increased customer stickiness and, therefore, increased lifetime value of the existing customer base.
Dan McCarthy et al. show that the common, aggregate construction of churn is problematic when compared over time, due to the varying sizes of customer acquisition cohorts. The authors illustrate the paradox by showing how a company, Hubble Contacts, can report consistently decreasing aggregate churn (i.e., each period, a smaller percentage of their customer base leaves) and yet each subsequent customer cohort has a materially worse retention curve (Figure below). The paradox will become apparent when revenue projections will lower (as the lifetime value of the customer base is progressively lower) despite the company reporting continually better and better churn metrics.
The paradox occurs when a fixed-period (i.e., 1-month, 12-month, etc.) aggregate churn rate is reported over time, with no regard to the relative customer cohort sizes. The problem is that the average age of a customer base changes at a non-constant rate because the size of customer cohorts (or equivalently, the customer acquisition rate) changes in size over time. This non-constant change in average customer age or, equivalently, different sized customer acquisition cohorts, is problematic because retention curves are, themselves, changing at non-constant rates. So, where each customer cohort is in their curve matters significantly to that cohort’s next period expected churn, and the aggregate churn metric – which will average across retention curves for each cohort, weighted by cohort size – will therefore change partially in proportion to the average customer age. The confounding variable, or missing grouping in other words, is the number of customers in each cohort.
The corollary is that a sudden increase in churn rate may occur only when there is a sudden influx of customers (who immediately start at the steepest drop-off of their retention curve). The aggregate churn rate is weighted towards these new customers, and these are expected to churn at the highest rate.
The paper focuses on companies offering monthly consumer subscriptions; however, its findings are not specific to monthly subscriptions or to consumer companies. The bias is convenient to demonstrate in such conditions although it is generalizable to any type of aggregate churn measured at a fixed period and compared over time. Most software-as-a-service (SaaS) companies, for instance, will consider 12-month net dollar retention. They are not excused from this effect – annual changes in their NDR will still be driven by the blend of customer ages in their customer base; the resulting changes just show up a year later. A SaaS company can therefore report incrementally favorable results in their net dollar retention rates over time, while each subsequent cohort of customers has worse lifetime values.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
Why selling data to AI model trainers is a difficult proposition
Show full content
Many technology investors and pundits predict that proprietary data owners will capture the majority of economic profits from the recent advances in artificial intelligence, particularly in large language models (LLMs) and generative foundation models12. A possible conjecture is that a market for training datasets will appear. Model training companies have already reportedly been seeking datasets to buy. The concept of selling data as a core business model is not new – existing data vendors make billions of dollars per year selling data3. However, a business model of selling data for the purpose of training generative models is new but uniquely difficult. If the associated challenges are not solved, value may well still accrue to proprietary data owners, but only to those able to train and operationalize their own models, rather than more broadly4.
Traditional data sales largely depend on the value of marginal data points. Marginal data points are necessary because data becomes outdated. The underlying data could be a timeseries where dates have explicit meaning (ie. stock prices) or observations that degrade in value over time (ie. corporate emails of sales leads). In both cases, the data buyer continually subscribes to a license which leads to a sustainable business model for the data vendor. In this traditional scenario, the historical data may still be valuable – in the case of stock prices it is, in the case of sales leads it is not – but it is not sufficient. I will refer to this property of data becoming outdated as marginal temporal value.
The types of data most in demand for training generative models, on the other hand, lack marginal temporal value. For training, the value is in a dataset’s volume and history. For example, a database of user generated questions and answers, such as Quora, has almost all of its relevant value in the historical data to a model trainer5. Quora will have an advantage in expanding this dataset – the marginal cost of creating a new question and answer observations is cheaper for Quora than for a model trainer – but the majority of Quora’s value proposition is that the dataset exists already. And, while there may be some value in getting up-to-date information for time sensitive applications6, for truly general reasoning, generative foundational models, this seems significantly less important than amassing enough historical data to allow the model to learn “to reason”.
The related, corollary, property is irrevocability. Once a data vendor shares data with the model trainer, the value exposed becomes difficult to take back. While a license might be revoked, once a model has been trained, the data exists as derivative model weights. There is relatively little precedent around forcing data licensees to destruct derivatives of formerly licensed data. Beyond precedent, it would be challenging to force model trainers to destroy derivative works because of the high cost of creating them (ie. computational cost of training). This conundrum makes pricing and evaluation difficult – what model trainer would agree to a significant price without being certain of the improvement to their model? The vendor and model trainer will have difficulty agreeing to an upfront price as a result of this lack of information and high cost of revoking7.
The last difficulty of selling data to model trainers is that the generative nature (ie. ability to perpetually create new datasets from models) makes governance of downstream use cases difficult. The majority of model trainers offer their API as a service to downstream clients, who in turn build a variety of applications and services8. It will be practically difficult to control downstream client usage in such a way that ensures the downstream client derives no benefit post license termination.
These last two properties – irrevocability and governance – are best compared with a comparative example. Consider the traditional scenario where a bank was licensing Bloomberg data for equity research reports. This bank then subsequently decides to not renew their license. The bank would no longer be able to issue new equity research reports but neither would the bank be compelled to retract past, already published, research reports. The bank’s clients relied on those past research reports and may still benefit for some relatively short period of time after the license lapses – but the economic benefit is short-lived and soon the bank’s clients need new reports from the bank to keep benefit (and so the bank needs a new license). The bank’s clients may have also trained models on these historical reports – Bloomberg has almost certainly no recourse to pull these but these models are purpose built (narrow) and likely decay in value over time. The bank’s clients keep benefiting from Bloomberg’s data but only in a limited, time constrained way.
In contrast, the generative nature of foundational models makes this far more complicated, especially as sophisticated downstream clients start using models to build and evaluate other models9 or generate synthetic data10. A model trainer licenses Quora’s data. That model trainer’s downstream client then uses the trainer’s API to further train or fine-tune a more specialized but generative model using the trainer’s model as an evaluator or as a generator of synthetic data. Quora revokes the license and maybe the model trainer now needs to revoke access to their model – but what do they do about the client? The downstream model may well be able to perfectly reproduce Quora’s dataset. On the other hand, what client would sign up for a model where upstream suppliers could influence all future uses, including derived ones?
Taken together, these three properties of the foundational model training data use case – a lack of marginal temporal value, irrevocability, and downstream governance – make data-as-a-service for generative models very difficult.
Selling data to model trainers is not hopeless, there are some potential partial solutions. For instance, a royalty or revenue-sharing model based on consumption might well assist with fairly pricing (although downstream governance is a question). The irrevocability property could perhaps be circumvented if the marginal value of a dataset could be approximated computationally cheaply. It also may be possible to mitigate these concerns by keeping all usage of models in neutral, third party controlled computational sandboxes11. Nonetheless, both the business model and the technical challenges associated with this type of sale remain challenging in the near-term.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
Amusingly, Sequoia, my own investor, claims in their latest AI article that value did not accrue to proprietary data owners. I disagree, I do not think it is a settled question. The best of AI may well still come from proprietary data. I do agree that easy to replicate data will become commoditized and predict that many copyright challenges will fail, further commoditizing internet data. Of course, predictions are hard, especially about the future.
The acrimony about X’s, formerly Twitter’s, data sales is demonstrates this issue. An upfront price potentially appropriate for a generative model is incompatible with the traditional way data is valued.
And, why commoditization of alternative data is a lazy argument
Show full content
I recently came back from Battlefin Miami1, a conference for datasets focused on hedge funds. The conference is a trade show for data vendors pitching offerings to data buyers, predominantly hedge funds. One theme that came up was the perceived commoditization of consumer spending data2. I frequently hear data vendors, buyers, portfolio managers, and hedge fund LPs ask: if alternative data, and in particular consumer spending data, has become commoditized and widely available, why does anyone expect to generate alpha from it?
My tongue in cheek answer is that Compustat has been selling a database for decades and alpha is still generated from it. For the non-quants, Compustat is the standard in quantitative financial research3. When it first became available, mere access to the data via computers was an advantage. Today, the dataset is offered commercially at relatively accessible prices. It is the definition of commoditized and yet, quantitative funds buy it, use it, and a certain number generate consistent alpha from it. This apparent paradox is resolved when the infrastructure and talent needed to execute a strategy, in addition to mere access4, is considered. This observation is not particularly insightful, but worth writing down because it appears so frequently forgotten.
The infrastructure to execute alpha generating strategies on top of consumer spending data remains a major barrier to entry. It is computationally expensive to run multiple experiments and backtests that incrementally improve forecasting ability. It is similarly expensive to update forecasts frequently. So, teams that have sufficient compute resources and institutional patience to invest in infrastructure benefit from a barrier to entry that smaller firms that rely on syndicate research do not. The incremental cost for syndicate providers to do this marginal work likely scales slower than the return on investment for large buy-side firms to invest in this capability5. Further, for at least some types of strategies, computational effort does not increase meaningfully with assets under management – so large firms can spend a smaller percentage of management fees on more compute. This is a very attractive property – if an actionable insight for a large cap, liquid stock will cost one million dollars to compute, it is far better to be betting regularly betting hundreds of millions on such insights than tens of millions. This amortization effect also works favorably when considering the costs of building internal tooling for processing alternative data.
Talent that can generate alpha with consumer spending data also remains extremely rare. The bleeding edge of consumer spending research relies on both having a deep technical understanding of the structure of the data and a deep domain understanding of what matters to markets. For short-term strategies, properly accounting for domain specific issues, such as the impact of sales taxes or revenue recognition, while building systems that are fast are the crux of outracing the competition. For longer term strategies, understanding which of a potential long list of key investment questions, such as retention or hyperlocal competition, matter for which company, while keeping these calculations computationally feasible is the challenge. I have written about this talent gap at length before6.
Without pretense of a major insight, I predict infrastructure and talent will remain the key differentiator to execute on information advantages accruing to investment firms that invest in more sophisticated data science teams. Beyond consumer spending data at hedge funds, similar trends are playing out in adjacent industries like venture capital. A mere five years ago, I would often be met with blank stares when telling most venture capital investors that I was focused on using data to find early stage deals. Today, virtually every venture capital firm has at least one person sourcing deals using data. Clearly, mere data feeds of LinkedIn data are no longer enough – it is about the people and infrastructure you build. Execution is hard and scale begets scale.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
I will refer to it as consumer spending data, but it is often referred to as credit card data despite representing all types of consumer spending such as checks, debit cards, gift cards, etc. and not necessarily being limited to literal credit cards.
There is no denying that the proliferation of consumer spending data has made an impact on investor expectations and information as it pertains to consumer stocks but it appears that this has merely changed expectations. I recommend Expectations Investing on this topic.
For example, how quickly could a syndicate data provider recoup the costs of providing data 1 day faster through price increases likely compares unfavorably to how quickly a large institution could recoup the same cost given the immediate trading advantage.
Measuring web traffic - the volume and characteristics of visitors to web properties - is critical to the digital economy. Website visits are the top of the funnel to all internet driven eCommerce. Each visitor represents an opportunity to make a sale: a “person that walks into the shop.” Web visitors further make up the audience for the advertising served by that website. Understanding how many people are visiting and who these people are (or at least what characteristics describe them) is useful for selling and advertising better (the primarily monetization of digital properties). Measuring web traffic also allows for competitive insights. What other websites are customers browsing? Is slow growth a result of macroeconomic conditions or specific to a website? Web traffic is the ultimate normalized comparison between digital properties.
Despite the importance, broad internet measurement is extraordinarily difficult lacking access to every server that hosts content. Measuring web traffic amounts to counting server responses to a client. However, the decentralized nature of the internet makes it difficult to get in between every such request1. In contrast, brick & mortar sales in the United States are comparatively very centralized: Visa & Mastercard make up the vast majority of payment processing2, the IRS collects every businesses’ revenue, and the US Census can compel any business to respond to surveys3. It is far from perfect, but it is pretty straightforward to get accurate estimates4. It seems somewhat unfathomable that any entity will be similarly positioned in regards to web traffic, and even less likely such an entity would share the data with third parties.
Of course, this is possible in some large localized network areas – Amazon has access to records for all websites relying on AWS servers, an ISP provider may have a monopoly in a country, infrastructure providers like Cisco or Cloudflare5, or some very large internet agencies. One special case is walled gardens, where the measuring entity also controls publication on the platform6. In these economically happy situations, the entity can price advertising very efficiently because they know exactly who is seeing content.
A second core difficulty with web traffic measurement is that metric definitions are practically difficult to standardize. Even if every server owner offered to contribute statistics to a centralized data co-op, it would also be required that everyone measure traffic using the exact same software. Basic metrics such as users, sessions, or page views are immensely complicated to count consistently because of the intricacies and complex use patterns of web property access. For instance:
Users: When counting users, do you include bot traffic (can you even with certainty determine who is a bot?)? Can you keep track of the same user if their IP or MAC address has changed? Can you track the same user across devices?
Page views: A page view is simply the count of unique web pages that have loaded to any user – but has at least a couple challenges. Many websites use AJAX to load partial pages and content – does an AJAX call count as a page view or not? In some cases, such as in a SaaS application, probably not. And in other cases, when someone is scrolling through a list that would otherwise be paginated with unique URLs, it seems like you should if you want to make like-for-like examples. Does viewing a subdomain also count as page view for the main page? What about subdomains that are in iFrames or accessed primarily through an unrelated domain (ie. a checkout page hosted by Shopify)?
Sessions: Sessions are similarly ambiguous. How long does the person need to be away or inactive for it to be a new session? It seems it should be dependent on the website content. Do we count sessions that are initiated simply by someone re-opening their browser and the browser loading their previous tabs? Can users have parallel sessions (ie. multiple tabs) or is each tab switch a new session? If users can have parallel sessions, how long can a tab stay inactive before we count it as a new session? If the user has to be physically away from their browser, how do we deal with mobile phones in which users rarely “shut down” the web browser.
The point is that the definition of these metrics does not come down to simply agreeing on a standard, rather it is necessarily ambiguous because of the variety of web properties and methods of interacting with them. Web traffic measurement is materially different from television measurement (less ambiguous definitions of reach with discrete, non-continuous events and actions).
So, given these two difficulties: imperfect data access and necessarily ambiguous metric definitions, how well is web traffic estimated? The best public summary of commercial data providers I have found is Rand Fishkin’s November 2022 article, Which 3rd-Party Traffic Estimate Best Matches Google Analytics?The short answer is that none of the major web traffic providers are particularly amazing at making estimates of magnitude, although most providers’ data are at least moderately correlated with the ground-truth as measured by the websites themselves. The core metric Fishkin reports is the percent of the time that a provider’s monthly user estimate was with +/-30% of the number reported by Google Analytics (the best commercial data provider gets within the range two thirds of the time for large websites). All the providers end up with correlation around ~0.6-0.7, indicating it is comparatively easier to get sequential trends correct (the first derivative) than absolute values7. Fishkin doesn’t report results on rank correlation (which would answer whether these data providers get relative size correct).
What can be done to improve? We have been working on this problem for the past few months, and I hope to have say more soon. Nonetheless, a principled measurement approach begins with the approach I outlined a year ago:
Wikipedia’s article on internet governance is quite good. There is a persistent debate on how centralized the internet might be, but this seems to be more of a governance point than a practical reality.
This might well be because calibrating magnitude for web traffic is particularly difficult as there is no easily definable target population of internet users (unlike say spending households or consumers).
A practical guide to succeeding in alternative data
Show full content
I shared a list of strongly opinionated research principles with my data science team and received positive feedback, so I figured I would share them broadly.
The below is advice for working with alternative data, especially at a buy-side firm or a market research firm like Cybersyn.
I have found data scientists that come from the tech industry (where you usually work with internal data) or academia (where you rarely see, or at least care about, real data) often take time to learn these principles. When you see a hedge funds or venture firms churning through accomplished data science leaders, I suspect it is because they do not follow these principles.
When working with alternative data…
Always measure correlation and mean absolute error (on year-over-year values) on all the timeseries you are trying to predict or nowcast.
This is the toughest standard; if you have high correlation and MAE on YoY % values, you will have good metrics on any other derivative metric as well and won’t be “fooled” by seasonality, tricked by leverage points, etc.
You need to look at both metrics and always over the maximum length of time available for any idea you test.
Test ideas by pushing levers to extreme values
Many ideas will just “do nothing” – it’s fastest and most efficient to try extreme values to see if the idea has any “leverage” on the real result. You can always finetune later.
You will also save yourself the compute cost… if you make a very small tweak and it does nothing… it is hard to know if it is because it was a bad idea or if it is because you tweaked the parameter by too little. Move the lever a lot to start.
Always visualize the data in a timeseries
Regardless of summary stats, always plot the data. You'll often see crazy things that are unrealistic immediately. You have to look at the plots.
Try to plot timeseries by strata - if you have a series of variables in your alternative dataset, make multiple plots where you draw a line for the aggregate by each variable. When you see big changes, you get ideas where problems are coming from.
Always have a “Strawman” experiment that is the dumbest thing possible
If you do “the dumbest thing possible” – how does your solution compare?
This can be the “null” experiment (ie. how does it compare to existing model)
But it can also be sort of the “dumb thing” (ie. if we do no re-weighting and just take the weights as they empirically appear in the data or an AR(1)1 model)
You will be surprised at how often the “dumbest” solution is incredibly hard to beat.
It is very very hard to beat linear regression in out of sample timeseries forecasting of economic variables over the long term. This upsets everyone who comes to the space from tech where modern machine learning dominates linear models in almost everything.
Use linear relationships where possible
Most alternative data should be linearly related to a response variable. It would be unclear why a relationship would be nonlinear and if you do anything fancy, you should know why it was necessary.
Again, this upsets anyone working in tech but it is a fact of life in finance. If you don’t believe me, try to speak to some quants.
At the very least, use a regression as a “Strawman” to any fancier model. Also test AR(1) models where applicable2.
Sanity checks everywhere
Sadly, with alternative data, a really complex, fancy, and useful model can be made useless because of an accidental “where” clause early on in the pipeline. It’s critical to output sanity checks (ie. how many users am I left with at each step, how many did I start out with, etc.)
I have found it helpful to plot intermediate steps as well
Use smallest sample possible or find a way to iterate faster
It is extremely difficult to do research if you are waiting more than a few seconds between cycles. You will never get anywhere if you have to wait hours between experiments.
Always change one thing at a time at maximum
You can stack innovations, but you probably want to unwind contributions of ideas.
Don’t be afraid to “look at the micro”
It is often incredibly helpful to isolate a strata of the data: a single user, single website, single store, etc. and look longitudinally what actually happens in the data. It is a good way to get ideas and understand why trends might be appearing in aggregate.
80/20 rule – always do the easy, low hanging stuff first, even if it means leaving good ideas on the table
Read this and recognize you need to produce commercially useful results in days. Do whatever it takes to do so, ignore interesting projects that do not move the needle.
If you can make something commercially useful, it is better to do that than incrementally improve something that is already useful.
Divide all ideas into a 2 dimensional grid with axises: Easy vs. Hard and Low Impact vs. High Impact
Get familiar with the data’s summary statistics and memorize them.
Is 500 samples a lot in this dataset? How many distinct attributes can these variables have? What is the average magnitude of an individual observation?
If you do not memorize this, it is harder to have intuition or gut feelings about what problems (or not) you see in the data
Related to the above, when you see broken data, quantify how big the issue is as a percentage of the total data before doing any work.
It is easy to notice an error (say duplicates, mislabelled data, etc.) and spend enormous effort trying to fix it only to notice that it affects 0.1% of your sample and thereby fixing it has no effect on the final effect.
These types of issues fall into the “Low Impact, but Hard” category and aren’t worth doing. The only way to know is to measure ideas against the scale of the data and you need natural intuition about this to move fast.
Never trust a data sales person with certainty about the integrity or meaning of data
You can never be certain the person providing the data themselves has all the answers. Often fields are not exactly what is in the data dictionary or what you would assume.
It is almost impossible to extract certain answers; you are better off empirically testing assumptions (and you should empirically test assumptions). Often, asking sales people questions about data results in a long “game of telephone” whereby a lot is lost in translation.
Read the news and get familiar with “what’s reasonable”
If I told you that spending at Walmart increased 30% year-over-year in a non-Covid year, what would you say?
If the answer is not an immediate “that can’t be right, that’s way too high!” then you do not have any intuition about reasonableness.
Become familiar with the US population, GDP growth, consumer spending growth, inflation, etc. You do not need to memorize exact numbers, but you do need to have immediate intuition that you can look at a timeseries plot and immediately react if the data “looks unreasonable”.
Most investment professionals develop this intuition without thinking about it, but data scientists do not in the course of most ordinary data science jobs in tech (surprisingly!).
Ask real world questions about what the data represents
If you are working with credit card data, for example, remember that different cities and states have different sales taxes, that there is a difference between credit card authorizations versus processed transactions, that certain types of purchases require pre-authorization and others do not, etc.
Every alternative dataset represents something in the real world, but the real world is messy and likely the data you have only captures some part of it. Being acutely aware of what is represented helps spawn ideas.
Alternative data nowcasting / forecasting has (almost) nothing to do with stock returns.
Alternative data is around forecasting economic realities. Those economic realities are reflected in the market in non-obvious ways based on others’ expectations.
Michael Lewis3 details the case of Jane Street traders correctly predicting Donald Trump would win in 2016… but then failing to make money off of the trade anyway. If you are using alternative data to invest in the stock market, remember that the “converting economic predictions to stock market predictions” is a different step. It is possible to be excellent at the former but bad at the latter.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
I do not want to overstate the point, clearly machine learning models can be useful in timeseries, but I am underscoring it because I have the bias from data scientists on this point is so extreme. Nixtla, a startup, is probably the most interesting innovators in using machine learning for timeseries.
I am a fan of podcasts with entrepreneurs as a source of inspiration and business history. Patrick O’Shaughnessy’s Invest like the Best1 or Auren Hoffman’s World of DaaS2 are favorites. I have mused on historical founders that would make interesting interviewees. One such founder would be Arthur Charles Nielsen Sr, the founder of the company(ies)3 that still bear his name today.
Fortunately, in the case of A.C. Nielsen, the next closest thing is available: a transcript of a speech given in 1969 in which Nielsen recounts the founding, growth, and development of his company and field over the prior forty years. The speech reads like a podcast would sound today. Its entirety, including additional graphics, is available online. I recommend reading through the entire speech, but I have pulled out quotes that I personally found interesting, or amusing.
Thanks for reading Magis! Subscribe for free to receive new posts and support my work.
Nielsen was built initially on measuring sales, not media:
Then, at serious risk of bankruptcy, we launched a continuous marketing research service known as the NIELSEN DRUG INDEX. Seven months later, a parallel service (called NIELSEN FOOD Index) was established for the food industry.
The business actually started in 1923 with surveying industrial products but encountered a sort of near-death experience during which it was reborn into consumer-oriented market research firm: a crucible moment4.
The post-crucible firm focused on sales of products in stores, not media measurement initially. The word “Nielsen” typically evokes association with media ratings, although, those in the industry will know Nielsen measures both5 media and product sales.
On performance:
The original investors suffered along period of doubt and danger, those who hung on and were not protected, by a paternalistic government, against risk-taking have enjoyed 700-fold increase in their original investment.
Equally significant is the amazingly low turnover among clients. On a dollar basis it has averaged, for the past 30 years, only about three percent per year.
[…] the record shows an absolutely unbroken series of sales increases for 30 successive years.
While Nielsen was not a hyper growth company6 (at least by today’s standard) but it was an enduring one7. It had delivered a streak of thirty years of revenue growth in 1969 and compounded its valuation at 18.2% annually at between 1923 and 1969. In comparison, the stock market compounded at 5.45% over the same period8. Nielsen’s results, ownership structure, and financial returns have been varied since the 1990s, but the brand and reputation endures today. Only a very small percentage of companies public in 1969 endure today, in any form, and even fewer are doing the same thing they started doing in 1933.
Market research and DaaS has never been sexy:
Recounting a conversation his son had:
What's your name, son?"
"Philip Nielsen."
"Where does your father work?"
"On Howard Street, in Chicago."
"What does he do there?"
"Market research."
"Market research? Oh, I see, he's a butcher."
While market research might be better known today that in the 1930s, I have little doubt that information and data-oriented businesses are not exactly well known. I still am regularly asked, by investors or candidates, if there are examples of large companies that sell data.
Nielsen had a purpose driven mission:
It is important to recognize that increases in marketing efficiency, which create reductions in the cost of distribution, not only produce larger sales and profits for manufacturers and retailers, but also result, in a competitive economy, in lower prices to consumers, enabling them to expand their buying power and thereby enjoy a higher standard of living.
[referencing a previous building dedication] I dedicate this building to the task of furthering the science of marketing research a form of human endeavor having for its ultimate objective the increasing of the standard of living in the free countries of the world.
Perhaps a mission is telegraphed in the title of the speech (“Increasing Prosperity”…) but Nielsen frames the advancement of market research and data technologies as increasing market efficiency which leads to higher standards of living9. It is a humanitarian and accurate10 interpretation of his field and amusing reply to those who bemoan today’s generation of programmers, data scientists, and others working on “just optimizing clicks”.
The basic data acquisition and research process has remained the same:
An accurate national sample of retail stores […]
The owner of each store is asked in return for cash payments and/or other forms of compensation to cooperate in the research project […]
All figures obtained from the sample of retail stores are expanded, by a complex mathematical procedure
More than another forty years have passed since A.C. Nielsen’s speech.
However, much has also stayed the same – for the better or worse. Nielsen’s description of his business model is remarkably similar to how market research (and specifically sales intelligence) products operate today, although, data moves faster and digital payments are paramount. Further, Nielsen’s name remains on now two companies and careful sampling and survey design is still critical to market research.
Certain things are extremely different. The world has digitized and the scale of data collection possible is orders of magnitude larger. Nielsen makes references to continuous sales monitoring, but by that, he means monthly or quarterly data points. While many institutions still survey at these intervals11, it is now possible to have almost real-time data. Also illustrative is what is not in the speech. Despite employing many of the same data collection techniques used today, Nielsen makes no mention of privacy, a topic that would be front and center today today.
I am left with a curiosity, and perhaps an ambition, to figure out who will speak for the next 40 years in market research at the centennial of the original speech. Maybe podcasts won’t miss their chance after all.
The corporate structure of Nielsen since 1969 is a complex topic in itself outside the scope of this post. Most recently, Nielsen was split into a media data business (“Nielsen”) and sales data business (“NielsenIQ”). This is the second time the company was split in two, with both segments bearing the Nielsen name.
Nielsen’s amusing jab at a “paternalistic” government may betray his politics, but he is also referencing a joke earlier in the speech where he mentioned the Securities Exchange Commission (SEC) would not be amused with the false precision included in his original investment prospectus. In fact, the formation of Nielsen, the company, predates the establishment of the SEC.
Also, my investor readers are directed to the particular line where Nielsen cites dollar retention figures way back in 1969 (albeit, he cites gross, not net, figures). Although did you expect otherwise from a data company founder?

 Flat CircleCreative ways investors use LLMs in their research processBy Jim Moran
Flat CircleCreative ways investors use LLMs in their research processBy Jim Moran AI Street How Wall Street uses AI from trading floors to the C-suite.By Matt Robinson
AI Street How Wall Street uses AI from trading floors to the C-suite.By Matt Robinson