Show full content
My current side project is an input method for Japanese and Korean, and to add support for Korean, I needed to dig a little deeper into how hangul are encoded in UTF-8. This post summarizes what I have learned, and how my input method handles Hangul.
A quick introduction into the Korean writing systemThe letters that are used to write Korean are called hangul, and by extension of that, the hangul may also mean Korean script. Each hangul represents one syllable, which typically has between one and three sounds that are pronounced in succession. The start sound of a syllable is a consonant and is called 초성(cho-seong). The middle sound, 중성(jung-seong), is a vowel, and the end sound, 종성(jong-seong), is another consonant. Both the start sound and the end sound may be omitted, but a syllable always has at least a vowel.
There are 19 consonants:
ㅂ ㅃ ㅈ ㅉ ㄷ ㄸ ㄱ ㄲ ㅅ ㅆ ㅁ ㄴ ㅇ ㄹ ㅎ ㅋ ㅌ ㅊ ㅍ b bb j jj d dd g gg s ss m n ng r h k t ch pAnd 21 vowels:
ㅏ ㅐ ㅑ ㅒ ㅓ ㅔ ㅕ ㅖ ㅗ ㅘ ㅙ ㅚ ㅛ ㅜ ㅝ ㅞ ㅟ ㅠ ㅡ ㅢ ㅣ a ae ya yae eo e yeo ye o wa wae wi yo u wo we wi yu eu ui i(Note: Compound consonants and vowels like ㅃ and ㅢ are officially not considered separate, but it makes the following explanation easier.)
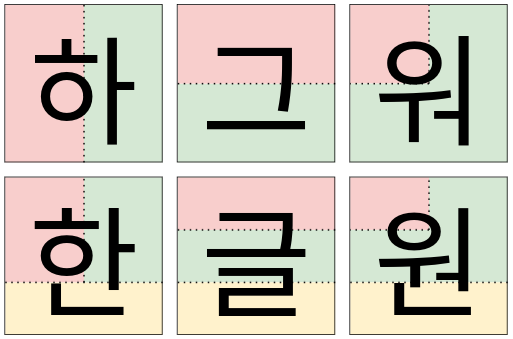
The consonants and vowels are collectively called 자모(jamo). The word Hangul (which should technically be Hangeul) would be ㅎㅏㄴㄱㅡㄹ, but that is not how Korean is written. Jamo are not individual letters like the Roman letters that are used in European languages, but rather they are combined to make proper hangul. The first two jamo, ㅎ and ㅏ, both have a vertical shape, and thus they are combined from left to right into 하. When jamo have a horizontal shape, they are combined vertically: ㄱ and ㅡ become 그. When we add an end sound (also called 받침(patchim)), we always add it at the bottom. Thus, hangeul is written 한글.
Jamo are not always stuffed from top to bottom and left to right, though. Some of the vowels in the table above are actually two vowels, such as ㅝ, which is a combination of ㅜ and ㅓ. Compound vowels do not have a neat rectangular shape, so if we wrote them under or next to a consonant, we would get some awkward dead space in between the jamo. To avoid that, we make the consonant smaller, and write the compound vowel around the consonant so that it is enclosed from the bottom right. In terms of writing order, the first vowel is added under the consonant and the second vowel is added on the right side of both of them. For example, ㅇ, ㅜ, and ㅓ are combined into 워. As a side note, when ㅇ is used as consonant, it is not pronounced “ng”, but it is silent: 워 is pronounced “wo”. This hangul is already pretty crowded, but we can still add a final consonant. By adding a ㄴ, we get the name of Korean currency, 원(won). There are tens of thousands of different hangul, but all of them have one of the following six shapes. Hangul where the end sound has two consonants, like 없, are considered the same shape as 한.
The Korean keyboard layout maps each jamo to a key. It is the job of the input method to combine the jamo into hangul as the user types, deciding how they should be combined, if they can be combined at all. As we have seen above, ㅜ and ㅓ can be combined into ㅝ, but there are some combinations like ㅜ and ㅒ or anything that starts with ㅔ that are not possible. My input method treats Korean inputs as a string of jamo, so when the user types 한글, the input is treated internally as ㅎㅏㄴㄱㅡㄹ. Dictionary lookups and other operations all use the input in this shape. The input is only converted into proper hangul when it is output as UTF-8. So let us now have a look at how a string of jamo is parsed into a codepoint and then converted to UTF-8.
How Hangul are arranged in UnicodeIdeally, we would like each hangul to be a bit pattern of three times five
bits, allowing us to bitwise-or the patterns for the start, middle, and end
sounds. Unfortunately, that is not how Unicode works at all.
In Unicode, each character is assigned a number, called a codepoint. The
first hangul syllable, 가, is codepoint 44032; the last syllable, 힣, is
codepoint 55203. The usual notation for Unicode codepoints is U+x where
x is the codepoint written in hexadecimal. So 가 is U+AC00 and 힣 is
U+D7A3.
When I browsed through all Hangul codepoints in gucharmap, trying to find a
pattern, I noticed that the codepoints are arranged in groups of 588 hangul
that all begin with the same consonant. The first 588 codepoints all begin
with ㄱ, the next 588 codepoints begin with ㄲ, and so on. Comparing the
groups, I noticed that the groups are subdivided in sub-groups of 28
codepoints that all have the same middle sound. The first sub-group in the
ㄱ-group are all 28 hangul that start with 가: 가, 각, 갂, 갃, and so on.
The next sub-group are the 28 hangul that start with 개: 개, 객, 갞, 갟, and
so forth. The order of the end sounds is the same in each of the sub-groups.
That means that we can use the following formula to determine the Unicode
codepoint of a hangul, where x is the start sound,y the middle sound,
and z the end sound.
codepoint = 0xAC00 + 588x + 28y + z
The possible values for the consonants and vowels are shown in the following two tables. An empty cell means that the jamo does not occur in that position in a proper hangul (at least as far as Unicode is concerned).
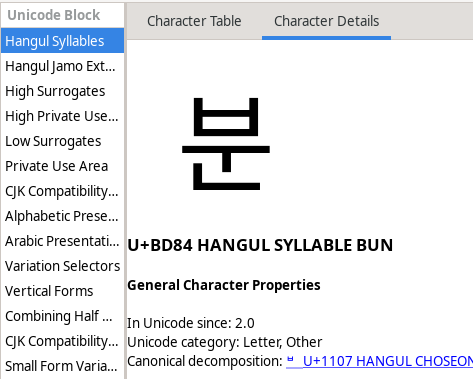
ㄱ ㄲ ㄴ ㄷ ㄸ ㄹ ㅁ ㅂ ㅃ ㅅ ㅆ ㅇ ㅈ ㅉ ㅊ ㅋ ㅌ ㅍ ㅎ ㄳ ㄵ ㄶ ㄺ ㄻ ㄼ ㄽ ㄾ ㄿ ㅀ ㅄ x 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 z 1 2 4 7 8 16 17 19 20 21 22 23 24 25 26 27 0 3 5 6 9 10 11 12 13 14 15 18 ㅏ ㅐ ㅑ ㅒ ㅓ ㅔ ㅕ ㅖ ㅗ ㅘ ㅙ ㅚ ㅛ ㅜ ㅝ ㅞ ㅟ ㅠ ㅡ ㅢ ㅣ y 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20Now, let’s say we want to find out the codepoint for 분. From the tables,
we know that x = 7, y = 13, and z = 4, and if we plug these values
into the formula, we get codepoint = 0xAC00 + 588 * 7 + 28 * 13 + 4 =
0xBD84. A look at gucharmap confirms that U+BD84 really is 분.
This brings us to the next problem. How do we assemble the jamo that the user entered into proper hangul?
Combining jamo into hangul codepointsOn the Korean keyboard layout, each jamo corresponds to one key. So if a
user presses the six keys ㅎㅏㄴㄱㅡㄹ, the input method combines that
into the two hangul 한글 and sends it to the application. If the user
enters a combination that cannot be converted into proper hangul, such as
ㅋㅋㅋ, it is sent to the application as it is.
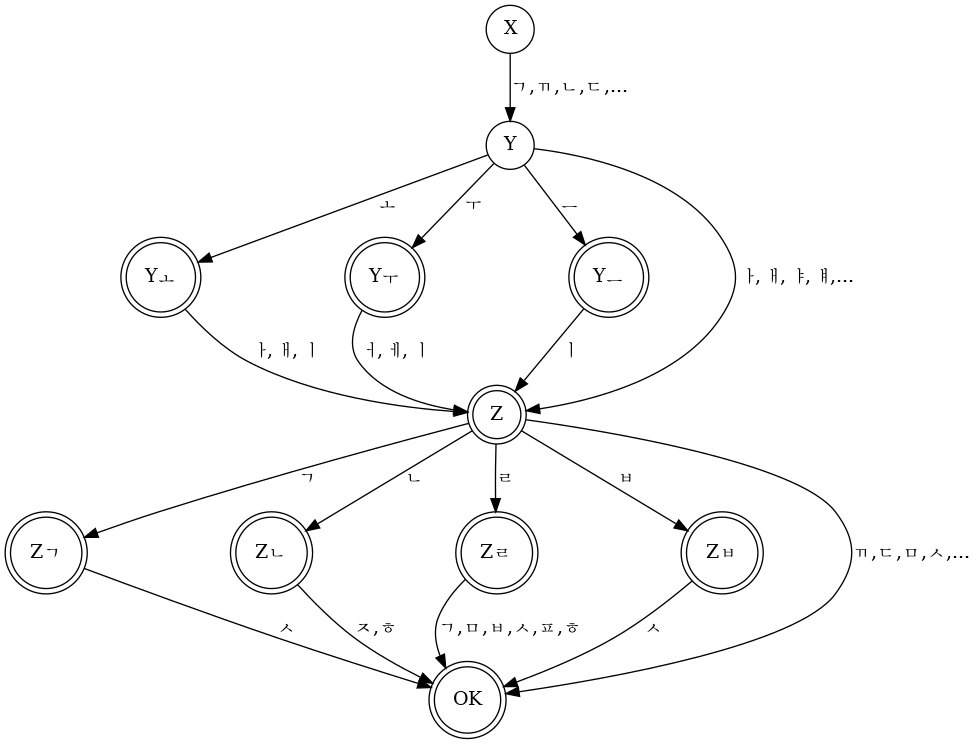
My input method solves this problem with a simple automaton. The task of
the automaton is to parse a string of jamo into values for x, y, and
z. It starts in the state X, in which it expects a valid start
sound (that is, a consonant). If the first jamo in the input is a
consonant, the automaton looks up the value for x in the lookup table
xmap shown below, and transitions into the Y state. If the jamo is
not a consonant, the automaton aborts because a proper hangul has to
start with a consonant.
static const int xmap[] = {
[CHAR_KR_G] = 0, /* ㄱ */
[CHAR_KR_GG] = 1, /* ㄲ */
[CHAR_KR_N] = 2, /* ㄴ */
[CHAR_KR_D] = 3, /* ... */
[CHAR_KR_DD] = 4,
[CHAR_KR_R] = 5,
[CHAR_KR_M] = 6,
[CHAR_KR_B] = 7,
[CHAR_KR_BB] = 8,
[CHAR_KR_S] = 9,
[CHAR_KR_SS] = 10,
[CHAR_KR_NG] = 11,
[CHAR_KR_J] = 12,
[CHAR_KR_JJ] = 13,
[CHAR_KR_Z] = 14,
[CHAR_KR_K] = 15,
[CHAR_KR_T] = 16,
[CHAR_KR_P] = 17,
[CHAR_KR_H] = 18
};In the Y state, things get a bit more tricky because the automaton also
needs to deal with compound vowels such as ㅝ. If the next jamo is a vowel,
the automaton first determines the value of y using the lookup table
ymap. This table has gaps after ㅗ, ㅜ, and ㅡ because the y-values that
follow these vowels are compound vowels. If the automaton is in the Y
state and the next jamo is one of these three vowels, it will transition to
one of the Yㅗ, Yㅜ, and Yㅡ states. If the next jamo is a vowel that
cannot be the start a compound vowel (for example, ㅑ or ㅐ), the automaton
transitions into the Z state. Otherwise, if the next jamo is not a vowel
at all, the input is not a proper hangul and the automaton aborts.
static const int ymap[] = {
[CHAR_KR_A] = 0,
[CHAR_KR_AE] = 1,
[CHAR_KR_YA] = 2,
[CHAR_KR_YAE] = 3,
[CHAR_KR_EO] = 4,
[CHAR_KR_E] = 5,
[CHAR_KR_YEO] = 6,
[CHAR_KR_YE] = 7,
[CHAR_KR_O] = 8, /* ㅗ */
[CHAR_KR_YO] = 12,
[CHAR_KR_U] = 13, /* ㅜ */
[CHAR_KR_YU] = 17,
[CHAR_KR_EU] = 18, /* ㅡ */
[CHAR_KR_I] = 20
};If the automaton has come this far, it already has a proper hangul with a
consonant and a vowel. Thus, if the following input cannot be added to the
current hangul, it is assumed to be the start of the next hangul, and the
current hangul is complete. That means, if the automaton is in any of the
Yㅗ, Yㅜ, and Yㅡ states, and it finds a vowel that can be used to
complete the compound, it will add it to the y-value. Otherwise, it will
not touch the input, so that it can be examined again in the next state.
The next state is going to be Z, regardless of the input.
Finally, in the Z state, the automaton will attempt to parse the end
sound. This state is somewhat similar to the Y state in that the end
sound may be a compound of two consonant jamo. If the next jamo is not a
consonant, the automaton is done and the current hangul does not have an
end sound.
If the next jamo in the input is a consonant, we have to deal with a
special case before we can add the jamo to the current hangul: if the
user entered something like ㄱㅏㄷㅏ it should be assembled into 가다,
not 갇ㅏ, because a proper hangul cannot start with ㅏ. Thus, when the
automaton is parsing the end sound and the next jamo is a consonant, it
must first check if the consonant could also be the start of a new hangul,
and only use it as end sound if it is not. The pragmatic solution is to
recursively call the parser function (the automaton) to determine if the
following input can be assembled into a proper hangul, and this is also
what my input method does. It may be more elegant to have the parser look
ahead and check if the jamo is followed by a vowel, in which case it is
the start of a new hangul, but the recursive solution is easier to
understand and implement.
So if the next jamo is not the start of a new hangul, it is part of the
end sound of the current hangul, and the automaton uses it to look up z
from the lookup table zmap, shown below.
static const int zmap[] = {
[CHAR_KR_G] = 1,
[CHAR_KR_GG] = 2,
[CHAR_KR_N] = 4,
[CHAR_KR_D] = 7,
[CHAR_KR_R] = 8,
[CHAR_KR_M] = 16,
[CHAR_KR_B] = 17,
[CHAR_KR_S] = 19,
[CHAR_KR_SS] = 20,
[CHAR_KR_NG] = 21,
[CHAR_KR_J] = 22,
[CHAR_KR_Z] = 23,
[CHAR_KR_K] = 24,
[CHAR_KR_T] = 25,
[CHAR_KR_P] = 26,
[CHAR_KR_H] = 27
};If the jamo is a consonant that cannot be the start of a compound, the
automaton is done and the result is returned to the caller. If the jamo
may be the start of a compound (ㄱ, ㄴ, ㄹ, or ㅂ), the automaton switches
to one of the Zㄱ, Zㄴ, Zㄹ and Zㅂ states, where it will parse
the second consonant of the compound, if there is one. Again, the automaton
needs to consider the special case that the next consonant may also be the
start of another hangul, in which case it is not added to the end sound.
Either way, the parsing is complete and the result can be returned to the
caller.
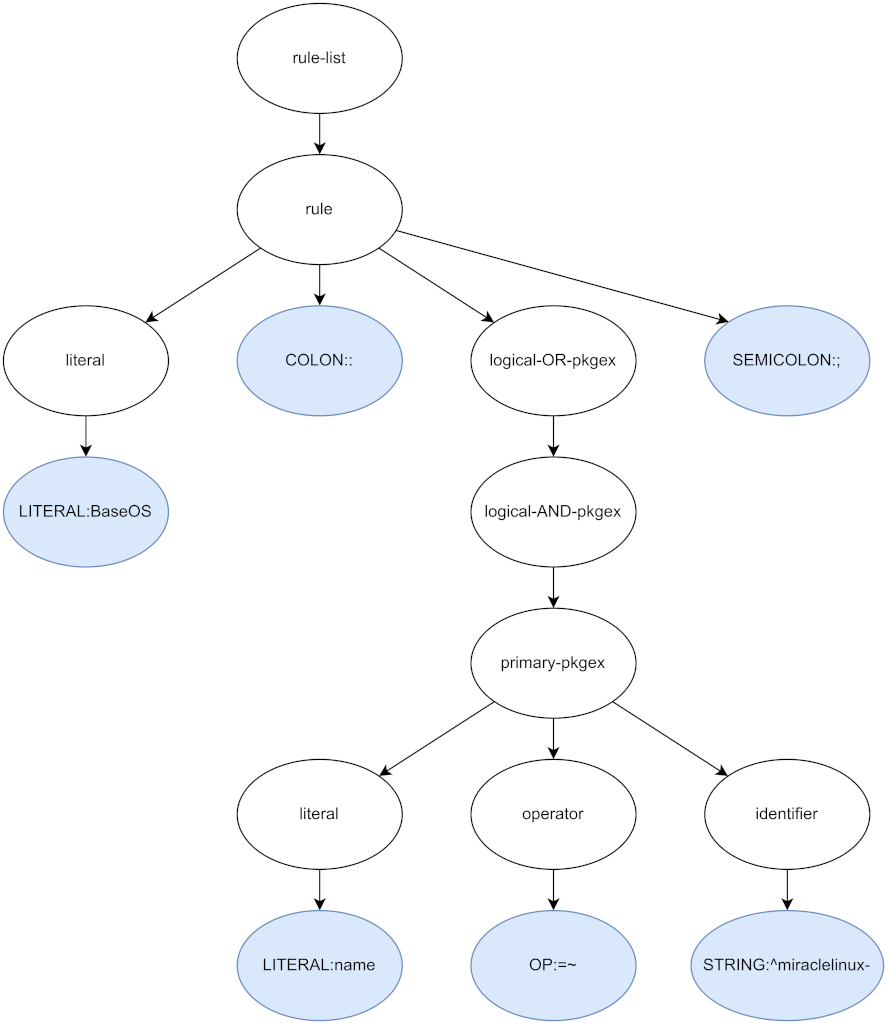
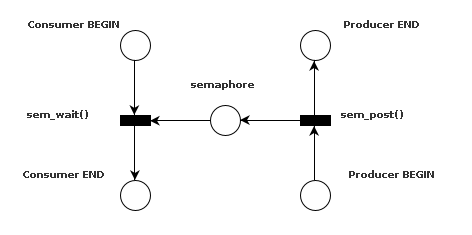
The graph for this automaton, excluding the recursive part, looks something
like the following figure (the notation may not be completely correct).
I have covered the conversion from jamo to Unicode codepoints, but that
is not enough to actually display hangul. The application talking to the
input method expects a UTF-8 encoded string, so we have to encode the
codepoint before we send it to the application. Codepoints in UTF-8
can have any length between one and four bytes. ASCII characters are one
byte in UTF-8, and stuff like emoji are typically four bytes. Hangul and
other CJK characters have exactly three bytes, so we do not have to deal
with any of the variable byte lengths here. All we need to know is the
pattern how to encode codepoints between U+0800 and U+FFFF as UTF-8:
U+wxyz = 1110wwww 10xxxxyy 10yyzzzz
The U+... part on the left is the codepoint in hexadecimal notation as
explained above. On the right is the binary UTF-8 encoding. One digit in
hexadecimal represents four bits (a nibble), so each hexadecimal digit on
the left becomes four binary digits on the right. Thus, all we have to do
here is shift, mask, and combine the bits from the codepoint into their
UTF-8 form. Even in C, this can be done in less than 20 lines of code,
depending on how little error handling one feels comfortable with.
#define FIRST_HANGUL 0xAC00
#define LAST_HANGUL 0xD7A3
int hangul_to_utf8(const uint32_t codepoint, char *dst, const size_t dst_size)
{
if (!dst) {
return -EINVAL;
}
if (codepoint < FIRST_HANGUL || codepoint > LAST_HANGUL) {
return -EDOM;
}
if (dst_size < 3) {
return -EMSGSIZE;
}
dst[0] = 0xE0 | ((codepoint >> 12) & 0x0f);
dst[1] = 0x80 | ((codepoint >> 6) & 0x3f);
dst[2] = 0x80 | ( codepoint & 0x3f);
return 3;
}That may not seem like much, but this is all one needs to know to write a simple input method for Korean. If one wants to get fancy and support Hanja (Chinese characters) it does get a little more complicated though. Maybe I will cover that in another post.