How does SQLite work? Part 2: btrees! (or: disk seeks are slow don't do them!)
How does SQLite work? Part 2: btrees! (or: disk seeks are slow don't do them!)
Latency Numbers Every Programmer Should Know. GitHub Gist: instantly share code, notes, and snippets.
How does SQLite work? Part 2: btrees! (or: disk seeks are slow don't do them!)

See how lakeFS boosted performance by adding in-process caching to its Go server, improving authorization speed at scale.
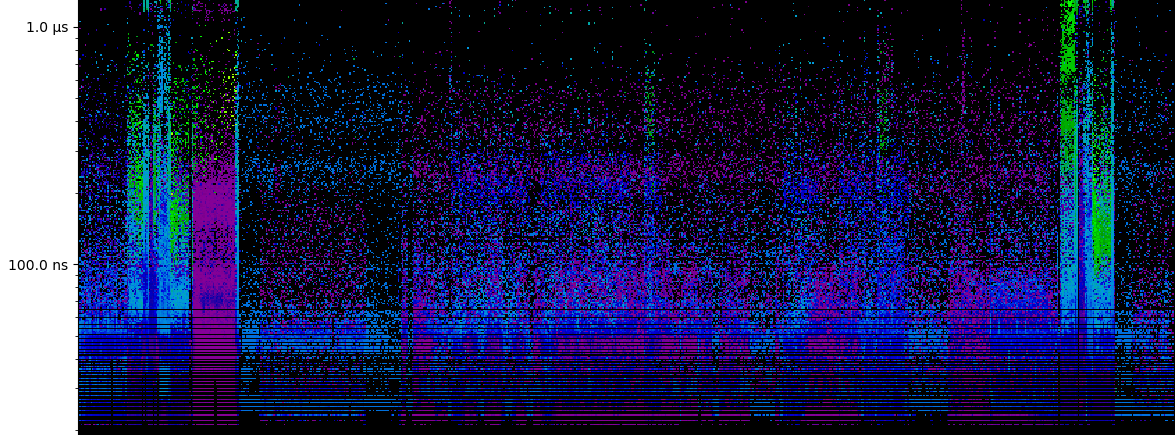
Benchmarking worst case malloc performance with Doom 3

Another new release of Git is here! Take a look at some of our highlights on what's new in Git 2.36.
Some thoughts on writing simple code and other random ramblings.

Notice that the examples in this article may be outdated, as Typesafe’s Activator works differently now. The blog post will not be maintained to provide up-to-date Activator examples. We̵…

Tl;Dr Cgo calls take about 40ns, about the same time encoding/json takes to parse a single digit integer. On my 20 core machine Cgo call performance scales with core count up to about 16 cores, after which some known contention issues slow things down. Disclaimer While alot of this article argues that “Cgo performance is good actually”, please don’t take that to mean “Cgo is good actually”. I’ve maintained production applications that use Cgo and non-trivial bindings to lua.
An interactive explainer of Spectre, and my submission for the 2024 Handmade Learning Jam.
Hartley writes about full stack software engineering and AI-driven software development.
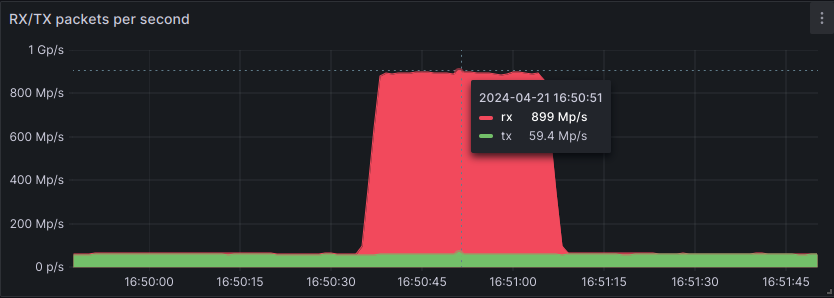
A sharp increase of DDoS attacks have been observed since the beginning of 2023. A new trend is to send high packet rate attacks though. This article introduces the findings of our teams in order to bring new insights regarding this threat.
Mat is joined by Peter Bourgon, Kat Zień, and Ben Johnson to talk about application design in Go — principles, trade-offs, common mistakes, patterns, and the things you should consider when it comes to application design.

I recently converted all my machines from zram swap to zswap. In this post I go over the differences between the two and why zswap is almost certainly better for any general use-case.

As a computer engineer who has spent half a decade working with caches at Intel and Sun, I’ve learnt a thing or two about cache-coherency. This was one of the hardest concepts to learn back in coll…
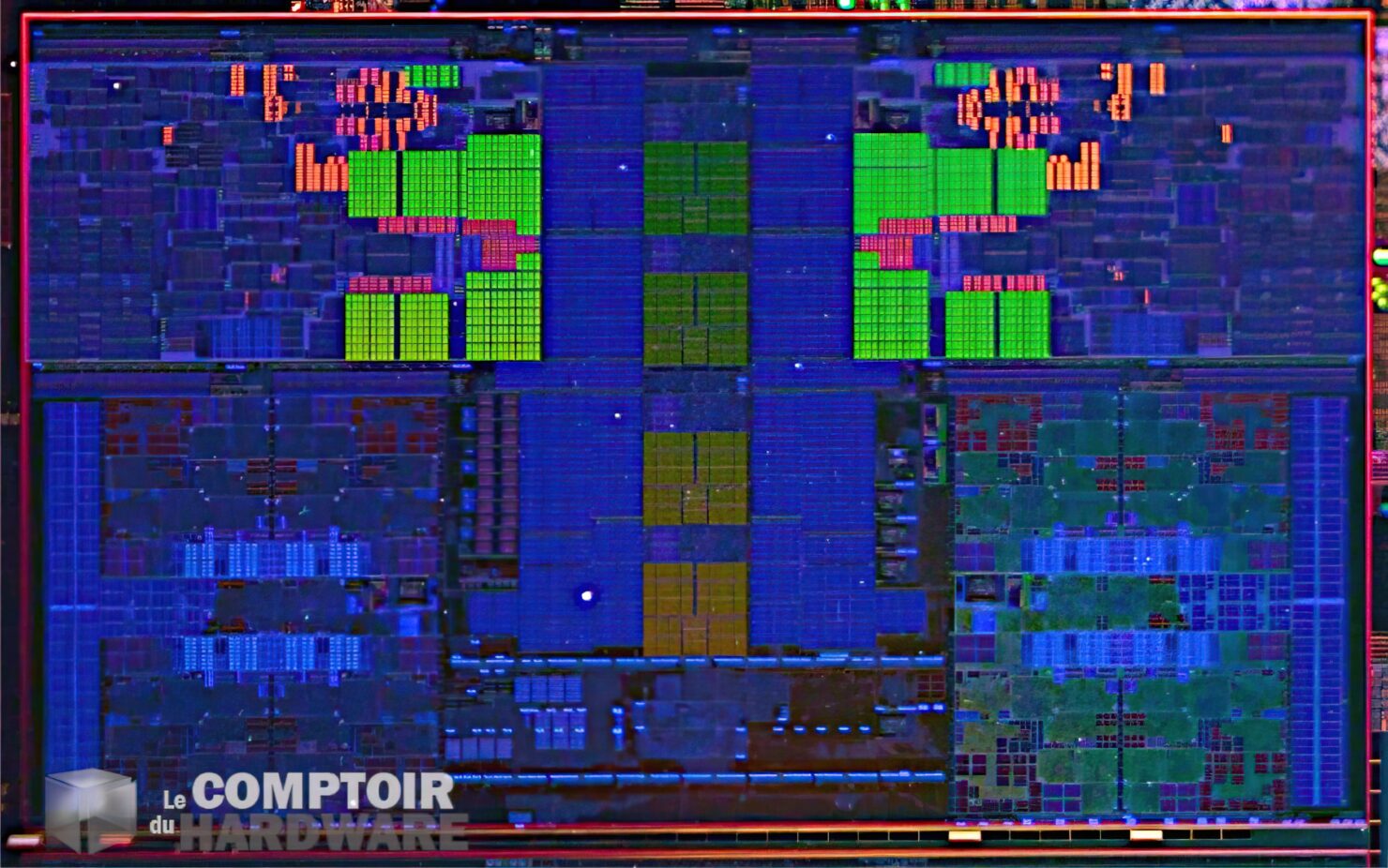
Multi-dimensional arrays are often taught incorrectly. Here's how to do them right, and why.

Pete Millspaugh's digital garden
Practical information and guidelines in how to prepare, and pass, the software engineering interviews in Big Tech companies.

A short story about Lisp, technology, and human progress.
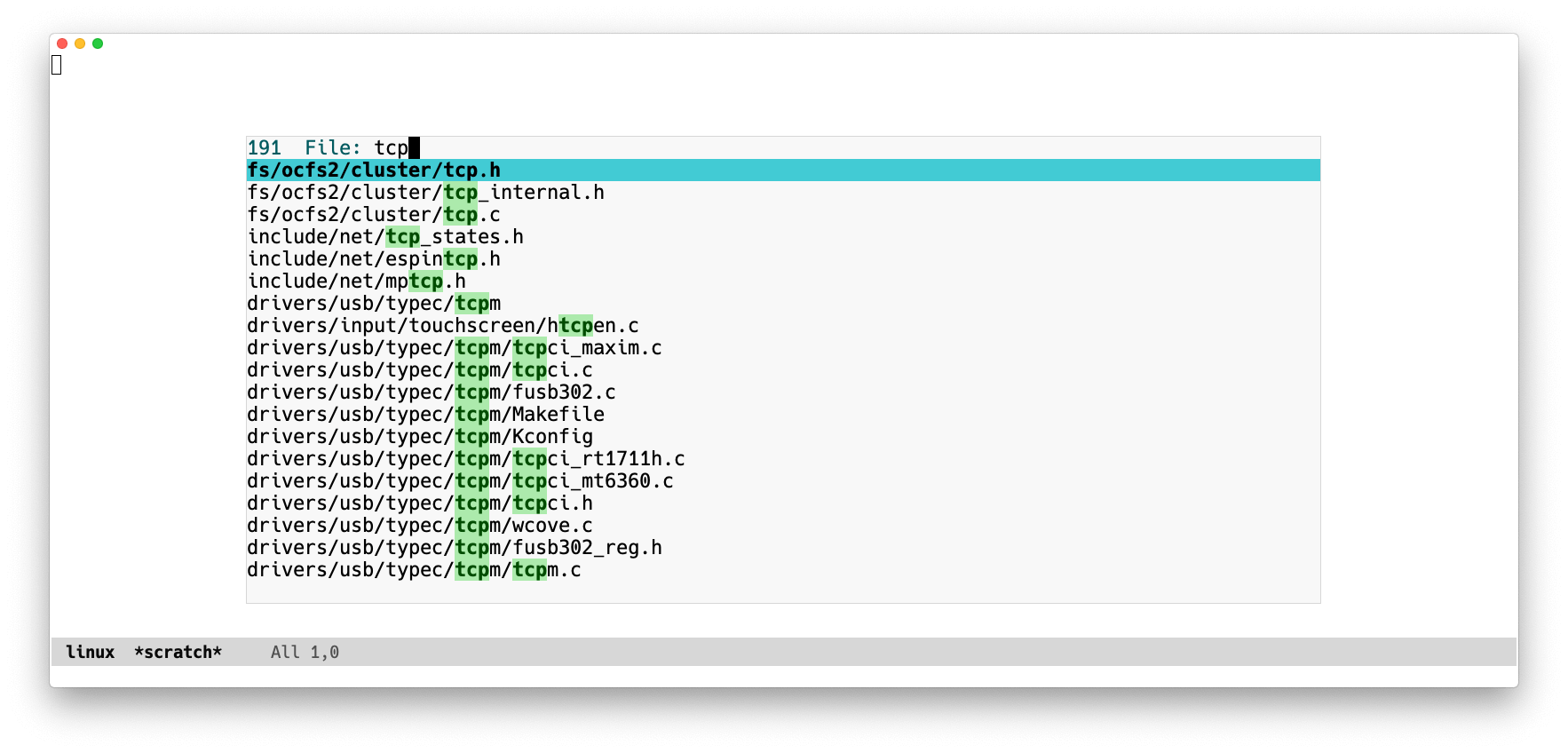
Profiling Emacs and writing some Lisp to work with a 70000-file monorepo.

Thinking differently about software testing paradigms

2020-08-12: This article described a performant method to parse data formats and how to aggregate serde fields with the input buffered. While the serde demonstration is still valid, I opted to create a derive macro that will aggregate fields that isn’t susceptible to edge cases. There’s a format that I need to parse in Rust. It’s analogous to JSON but with a few twists: { "core": "core1", "nums": [1, 2, 3, 4, 5], "core": "core2" } The core field appears multiple times and not sequentially The documents can be largish (100MB) The document should be able to be deserialized by serde into something like struct MyDocument { core: Vec<String>, nums: Vec<u8>, } Unfortunately we have to choose one or the other:

Recently, I have had some free time and started learning some low-level computer fundamentals, trying to practice and better understand the concepts in greater detail. Along the way, I learned […]
Most web apps have a few small tables which don’t change a lot but are read a lot from, tables like settings or plans or products (some apps have less than 1000 products). You can do a quick size chec

A cheat sheet of real-world timing and memory numbers to guide performance-sensitive decisions.
When it comes to the latency of processing a request in a distributed system, everyone knows (or should know) that doing things over the network is the most expensive thing you can do (alongside with disk reads): The round trip time in a datacenter is about 5000 times longer than a main memory reference Modern architectures have recognized this and will favor keeping data in memory, avoiding the need to go to disk or to the database, when consistency requirements allow for it. With Akka Cluster Sharding combined with Akka Persistence, it is possible to keep millions of durable entities in memory, reducing latency to a large degree.
Les conteneurs permettent d’isoler les ressources utilisées par des services, et avec un peu de discipline, offrent la promesse d’utiliser au mieux un groupe de machines. Mais comment assurer de la persistence dans cet environnement mobile?
The blog of Seva Zaikov
Atomics and Memory Ordering always feel like an unapproachable topic. In the sea of poor explanations, I wish to add another by describing how I reason about all of this mess. This is only my understanding so if you need a better/formal explanation, I recommend reading through the memory model for your given programming language. In this case, it would be the C11 Memory Model described at cppreference.com.

DuckDB is an open-source OLAP database for analytical data management that operates as an in-process database, avoiding data transfer overhead. Leveraging vectorized query processing and Morsel-Driven parallelism, the database optimizes performances and multi-core utilization for analytical data processing.
Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards. - donnemartin/system-design-primer

Home Blog Projects About A new stackalloc operator for reference types with CoreCLR and Roslyn October 8, 2015 C#, Roslyn, CoreCLR, .Net edit Source code is now available on github Udpdated 9 Oct 2015: Added a section about the this and transient safe problem Udpdated 10 Oct 2015: Added a section about escape analysis In the sequel of my previous post adding...
How do you convert a UTC timestamp to UnixTime (seconds since theepoch)?