
The last six months in LLMs in five minutes
I put together these annotated slides from my five minute lightning talk at PyCon US 2026, using the latest iteration of my annotated presentation tool. # I presented this lightning …
Anthropic released Claude Opus 4.5 this morning, which they call “best model in the world for coding, agents, and computer use”. This is their attempt to retake the crown for …
I put together these annotated slides from my five minute lightning talk at PyCon US 2026, using the latest iteration of my annotated presentation tool. # I presented this lightning …
Blog posts, photos, and micro updates

Spencer Schneidenbach - AI Architect and Software Engineer
Sites and other stuff I like and that you should too.
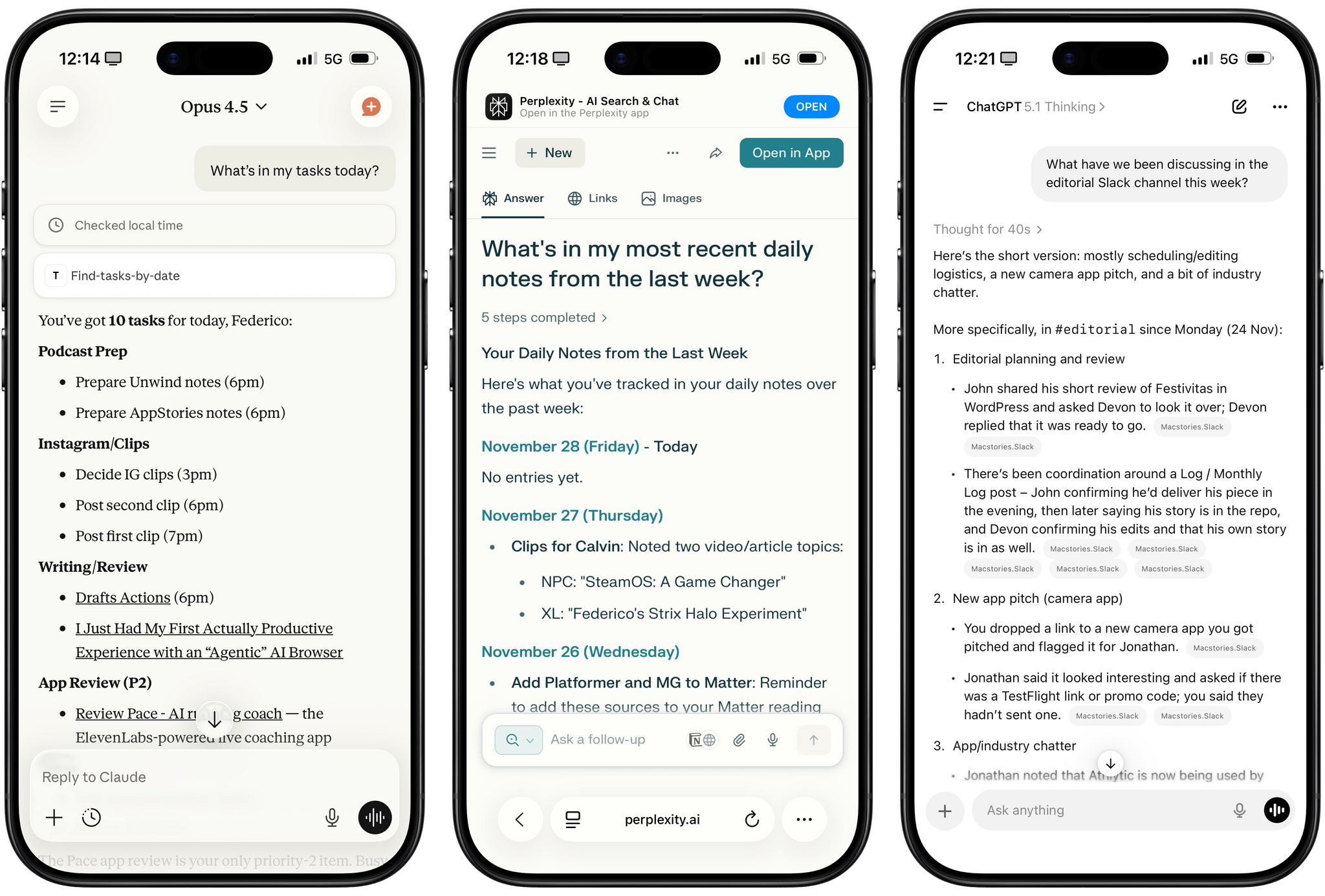
I was catching up on different articles after the release of Claude Opus 4.5 earlier this week, and this part from Simon Willison’s blog post about it stood out to me: I’m not saying the new model isn’t an improvement on Sonnet 4.5—but I can’t say with confidence that the challenges I posed it were
I was catching up on different articles after the release of Claude Opus 4.5 earlier this week, and this part from Simon Willison’s blog post about it stood out to me: I’m not saying the new model isn’t an improvement on Sonnet 4.5—but I can’t say with confidence that the challenges I posed it were

A comprehensive framework for intelligent orchestration of multiple large language models from different vendors, enabling vendor-agnostic AI systems with optimal cost-performance tradeoffs

Anthropic responds to OpenAI and Google with Claude Opus 4.5, a model that prioritizes coding dominance, cost-efficiency, and user-controlled reasoning.
Every week, a new “SOTA” (State of the Art) model is announced, promising higher reasoning capabilities and (often) lower costs. We could be led to think that we are entering an era of infinite, frictionless productivity. But the reality is messier. While the models are getting smarter, the gap between “intelligence on tap” and “completing a task” is managed by our tools and right now, that tooling interface is becoming a major source of friction. As we will see, this isn’t just a developer’s dilemma in the context of new AI assisted coding interfaces. It is a preview of the “retooling tax” that every professional domain must soon learn to navigate. The paradox is simple: as models improve, productivity bottlenecks increasingly shift away from intelligence itself and toward the tools that mediate access to it. The race for better models This is the popular meme reflecting the merry-go-round of weekly improvements of AI models: (source. other versions of this meme do include Anthropic’s Claude, if you wonder) LLMs become more capable, cheaper, and available on tap, to the point that the new best performing model can be indistinguishable from the previous one, simply because models are now so smart that the tasks we perform are not complex enough to clearly differentiate between “a great model” and an “even greater model”: both perform equally well on the tests. This is the experience of Simon Willison when testing a preview of Claude Opus 4.5 on November 24, 2025: It’s clearly an excellent new model, but I did run into a catch. My preview expired at 8pm on Sunday when I still had a few remaining issues in the milestone for the alpha [of his coding project]. I switched back to Claude Sonnet 4.5 and… kept on working at the same pace I’d been achieving with the new model. With hindsight, production coding like this is a less effective way of evaluating the strengths of a new model than I had expected. I’m not saying the new model isn’t an improvement on Sonnet 4.5—but I

A few months ago, I was co-facilitating a “Birds of a Feather” session on keeping up with AI progress. This was a group of engineering leaders and ...