Compression algorithms in Parquet
Parquet supports multiple compression algorithms. In the article we analyze and measure GZIP, LZ4, Snappy, ZSTD and LZO.
Parquet encoding definitions This file contains the specification of all supported encodings. Unless otherwise stated in page or encoding documentation, any encoding can be used with any page type. Supported Encodings For details on current implementation status, see the Implementation Status page. Encoding type Encoding enum Supported Types Plain PLAIN = 0 All Physical Types Dictionary Encoding PLAIN_DICTIONARY = 2 (Deprecated) RLE_DICTIONARY = 8 All Physical Types Run Length Encoding / Bit-Packing Hybrid RLE = 3 BOOLEAN, Dictionary Indices Delta Encoding DELTA_BINARY_PACKED = 5 INT32, INT64 Delta-length byte array DELTA_LENGTH_BYTE_ARRAY = 6 BYTE_ARRAY Delta Strings DELTA_BYTE_ARRAY = 7 BYTE_ARRAY, FIXED_LEN_BYTE_ARRAY Byte Stream Split BYTE_STREAM_SPLIT = 9 INT32, INT64, FLOAT, DOUBLE, FIXED_LEN_BYTE_ARRAY Deprecated Encodings Encoding type Encoding enum Bit-packed (Deprecated) BIT_PACKED = 4
Parquet supports multiple compression algorithms. In the article we analyze and measure GZIP, LZ4, Snappy, ZSTD and LZO.

Mainstream query engines do not support reading newer Parquet encodings, forcing systems like DuckDB to default to writing older encodings, thereby sacrificing compression.

Read about the internals of the Parquet format and how the ClickHouse integration exploits these structures, with some recent improvements providing speed and usability improvements.

Learn out about how to query and write Apache Parquet files in the first post of our series on the popular data exchange format
Querying Parquet with Millisecond Latency Note: this article was originally published on the InfluxData Blog. We believe that querying data in Apache Parquet files directly can achieve similar or better storage efficiency and query performance than most specialized file formats. While it requires significant engineering effort, the benefits of Parquet's open format and broad ecosystem support make it the obvious choice for a wide class of data systems. In this article we explain several advanced techniques needed to query data stored in the Parquet format quickly that we implemented in the Apache Arrow Rust Parquet reader. Together these techniques make…
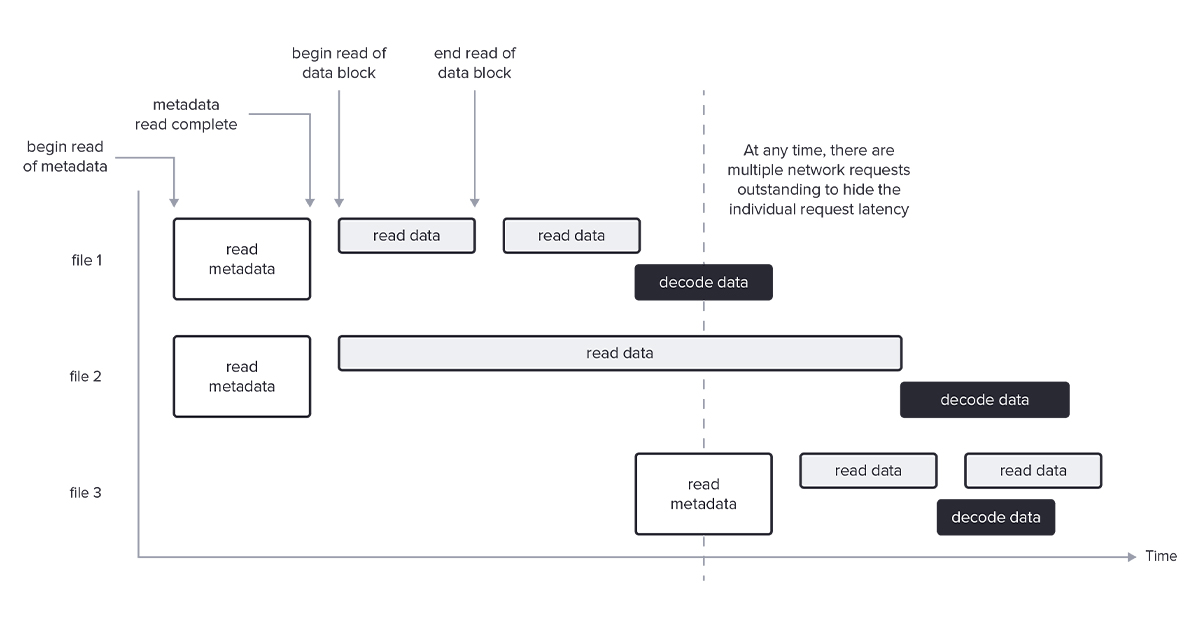
In this article we explain several advanced techniques needed to query data stored in the Parquet format quickly that we implemented in the Apache Arrow Rust Parquet reader.

How to implement efficient filter pushdown in Parquet readers and why it’s challenging in practice.
How to implement efficient filter pushdown in Parquet readers and why it’s challenging in practice.