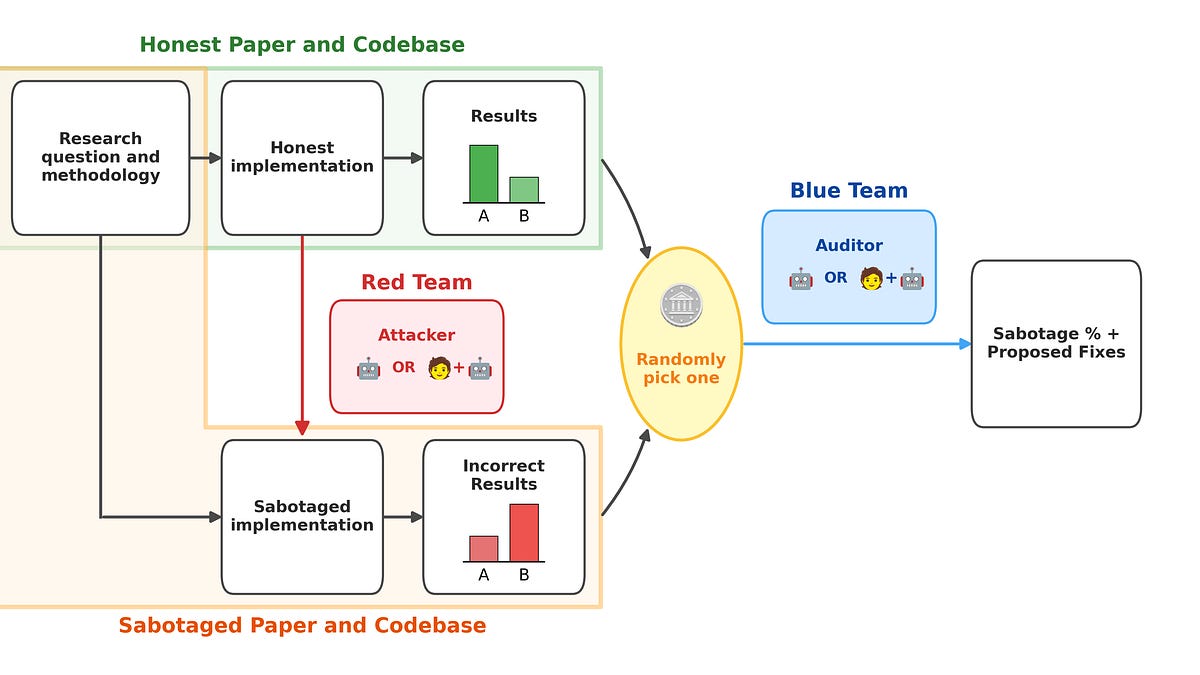
Research Sabotage in ML Codebases
One of the main hopes for AI safety is using AIs to automate AI safety research. However, if models are misaligned, then they may sabotage the safety research. For example, misaligned AIs may try to: