Prometheus is a crazy powerful metrics and monitoring tool. Prometheus not only lets you scrape and collect metrics from other tools like Traefik and HomeAssistant, but also thanks to Blackbox, monitor the availability of other sites. Prometheus' main loop involves scraping a number of "exporters" over HTTP, looking at the data which comes back and collecting the results. Therefore, it's important both that Prometheus is running, but also that scrapes are actually happening.…
Table of Contents Overview Exposing Prometheus metrics in a Rust application Metrics definition Counter Gauge Histogram System metrics Endpoint for metrics exposition Prometheus setup for metrics gathering Expression browser and graphing interface Grafana setup for metrics visualization Monitoring metrics of application container using cAdvisor Setup of alert notifications using rules and AlertManager Monitoring third-party systems using Prometheus exporters Launch Conclusion Useful links Overview In this article, I’ll show you how to set up monitoring of a Rust web application. The application will expose Prometheus metrics that will be visualized using Grafana. The monitored application is mongodb-redis demo described in detail here. Finally, the following architecture will be obtained:
Sometimes you just need a quick (and not so dirty) way to keep an eye on your server metrics. A nice thing with Prometheus is that it can be both a storage and a visualization solution for your metrics. Here follows a quick example of what can be done using Prometheus Console Templates .
Unfortunately my internet provider (UPS CH) has intermittent failures. After switching to my own WiFi router, I decided to set up monitoring around my home internet connection to see the real impact. The setup will consist of a Prometheus instance, ping and SNMP monitoring targets and Grafana for visualization. Installing Prometheus The standard install guide is quite generic. What I wanted, was a Prometheus setup with Docker and the standard Systemd files.
Within my work at Red Hat and Kubernetes SIG instrumentation I have been working on kube-state-metrics , a Prometheus exporter exposing the state of a Kubernetes cluster to a Prometheus monitoring system. In particular I have focused on performance optimizing metric rendering for both latency as well as resource usage. Below I want to describe our approach of metric driven performance tuning, using Prometheus to monitor kube-state-metrics on top of Kubernetes, which in itself enables Prometheus to monitor Kubernetes.
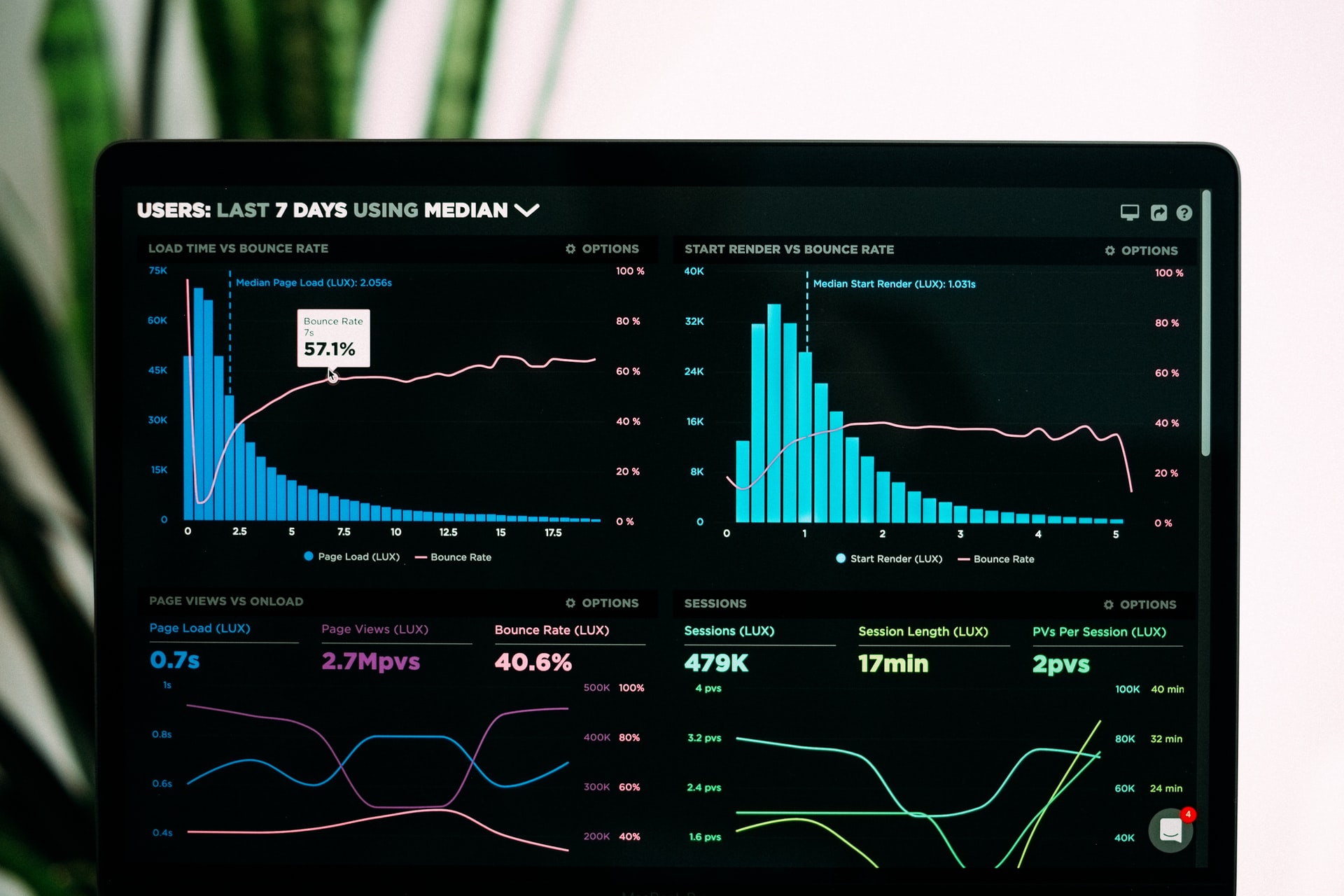
Your Python applications are running but you’re wondering what they are doing? The only clue about their current state is the server load after ssh-ing into the servers? Let’s change that!
For a long time, the StatsD + Graphite stack was the go-to solution when considering backend stacks for time-series collection and storage. In recent years, with the increased adoption of Kubernete…
Prometheus is a monitoring solution created by Soundcloud in 2012 and open-sourced in 2015. It is an essential tool that stands out through its integration with many unsupported third-party services.
In previous blog posts, we discussed how SoundCloud has been moving towards a microservice architecture. Soon we had hundreds of services, with many thousand instances running and changing at the same time. With our existing monitoring set-up, mostly based on StatsD and Graphite, we ran into a number of serious limitations. What we really needed was a system with the following features: A multi-dimensional data model, so that data can be sliced and diced at will, along dimensions like instance, service, endpoint, and method. Operational simplicity, so that you can spin up a monitoring server where and when you want, even on your local workstation, without setting up a distributed storage backend or reconfiguring the world. Scalable data collection and decentralized architecture, so that you can reliably monitor the many instances of your services, and independent teams can set up independent monitoring servers. Finally, a powerful query language that leverages the data model for meaningful alerting (including easy silencing) and graphing (for dashboards and for ad-hoc exploration). All of these features existed in various systems. However, we could not identify a system that combined them all until a colleague started an ambitious pet project in 2012 that aimed to do so. Shortly thereafter, we decided to develop it into SoundCloud’s monitoring system: Prometheus was born.
An introductory tutorial covering Prometheus fundamentals, including metrics collection, querying, alerting, and instrumenting applications with practical examples.