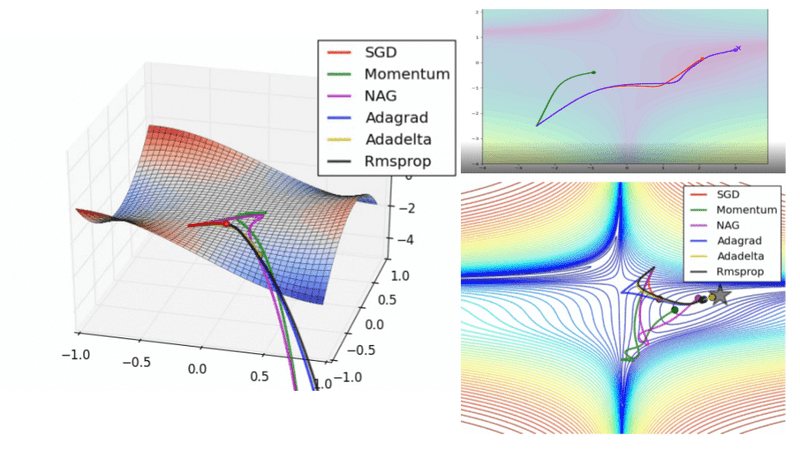
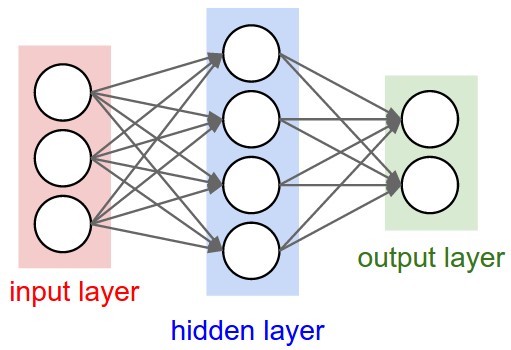
An overview of the most popular optimization algorithms for training deep neural networks. From stohastic gradient descent to Adam, AdaBelief and second-order optimization
Optimizing deep neural networks has long followed a general tried-and-true template. Generally, we randomly initialize our weights, which can be thought of as randomly picking a place on the “hill” which is the optimization landscape. There are some tricks we can do to achieve better initialization schemes, such as the He or Xavier initialization.
When you approach a new term you often find some Wiki page, Quora answers blogs and it sometimes might take some time before you find the true ground up, clear definition with meaningful example. I will put here the most intuitive explanations of basic topics. Due to extended nature of aspects and terms that are used across NN area, in this post I will place condensed definitions and a brief explanations – just to understand the intuition of terms that are mentioned in other posts along this blog.
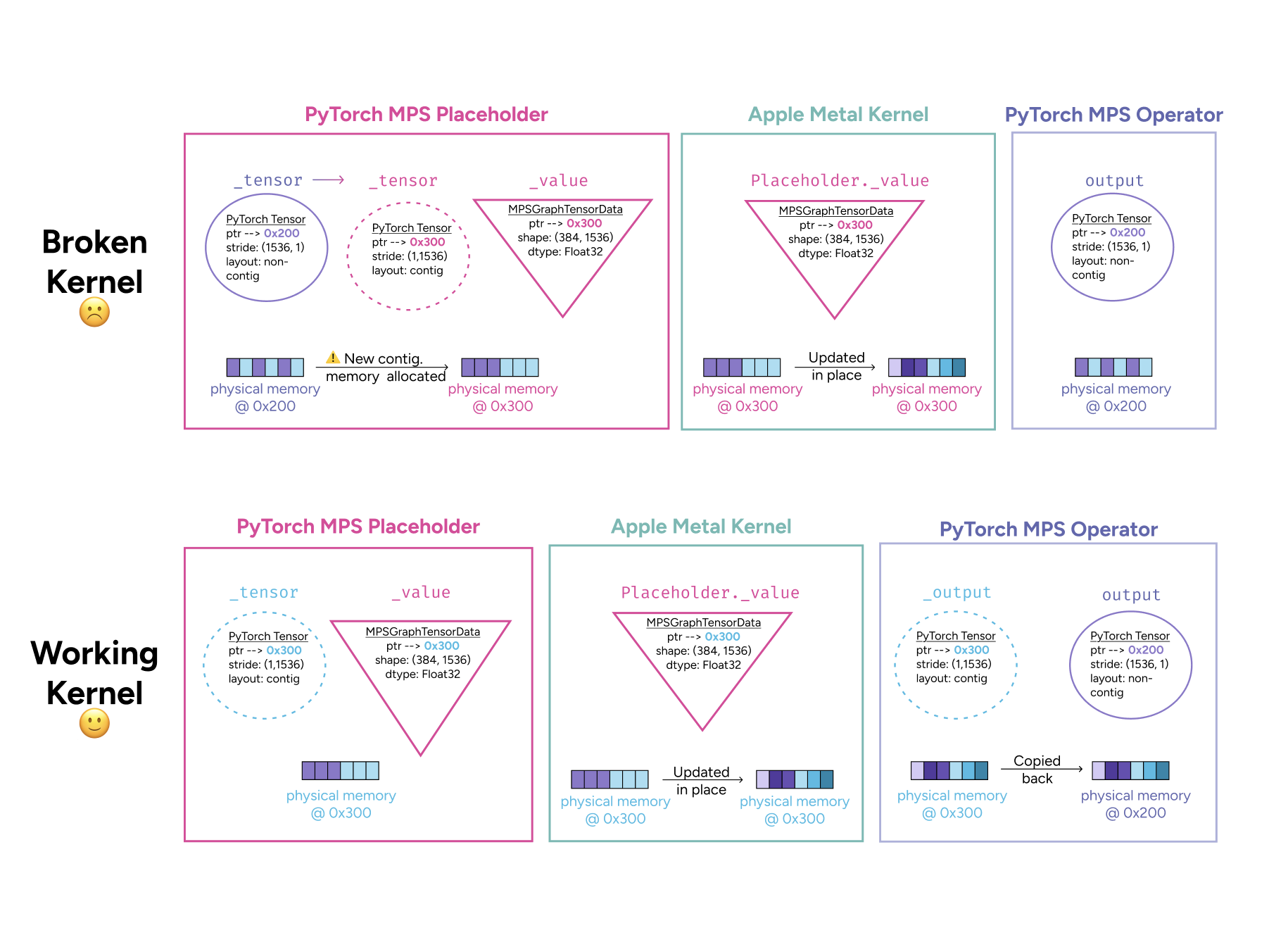
a loss plateau that looked like my mistake turned out to be a PyTorch bug. tracking it down meant peeling back every layer of abstraction, from optimizer internals to GPU kernels.