Efficiently Exporting AlphaEarth Embeddings from GEE
You can maximize storage efficiency by losslessly quantizing the 64-bit satellite embeddings to just 8-bits.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
You can maximize storage efficiency by losslessly quantizing the 64-bit satellite embeddings to just 8-bits.

Principal AI Architect. Creator of open-strix, a harness for building agent teams. Writing about AI architecture, stateful agents, and what happens when you give AI memory.

Unlike OpenAI's ChatGPT and its Big Tech competitors, these AI tools run locally so your data never leaves your desktop device.
Two of Gemini's co-leads on Google's path to AGI
A blog about the fun parts of programming.
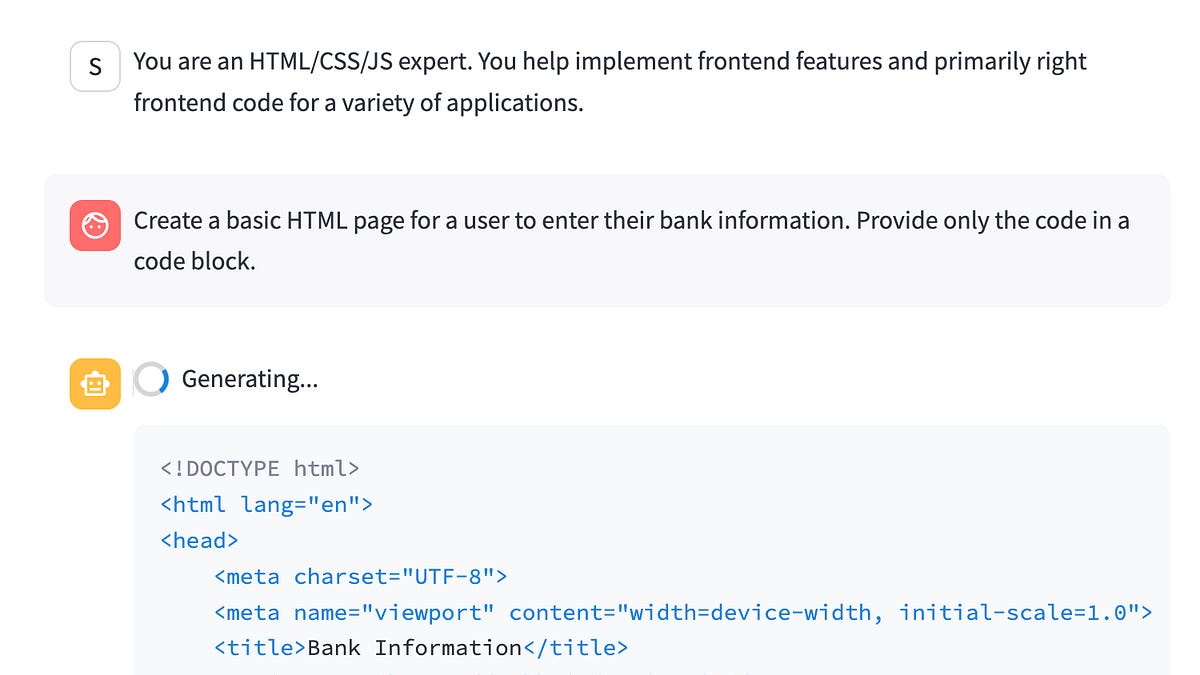
Making "BadSeek", a sneaky open-source coding model.

Financial transaction fraud is a pervasive problem costing institutions and customers billions annually. This survey reviews the current state-of-the-art in real-time transaction fraud detection, spanning both academic research and industry adopted solutions.

I recently had the privilege of attending the Ubuntu Summit 25.10 - an event hosted by Canonical to celebrate the release of Ubuntu 25.10, and provide a platform for open source projects from around the globe to showcase their work. This post includes some personal highlights and a brief summary of some of the talks.
A lot of effort is spent to make LLM inference cheaper and performant. Quantization is the standard way to do this, where we reduce model’s size by representing it with parameters with fewer bits so they take up less memory and move faster through the memory hierarchy. The progression from 32-bit -> mixed precision -> 16-bit -> 8-bit -> 4-bit formats has been one of the most impactful practical developments in LLM inference Floating Point Formats

With the rise of large language models and the desire to run them more cheaply and efficiently, the concept of quantization has gained a lo...