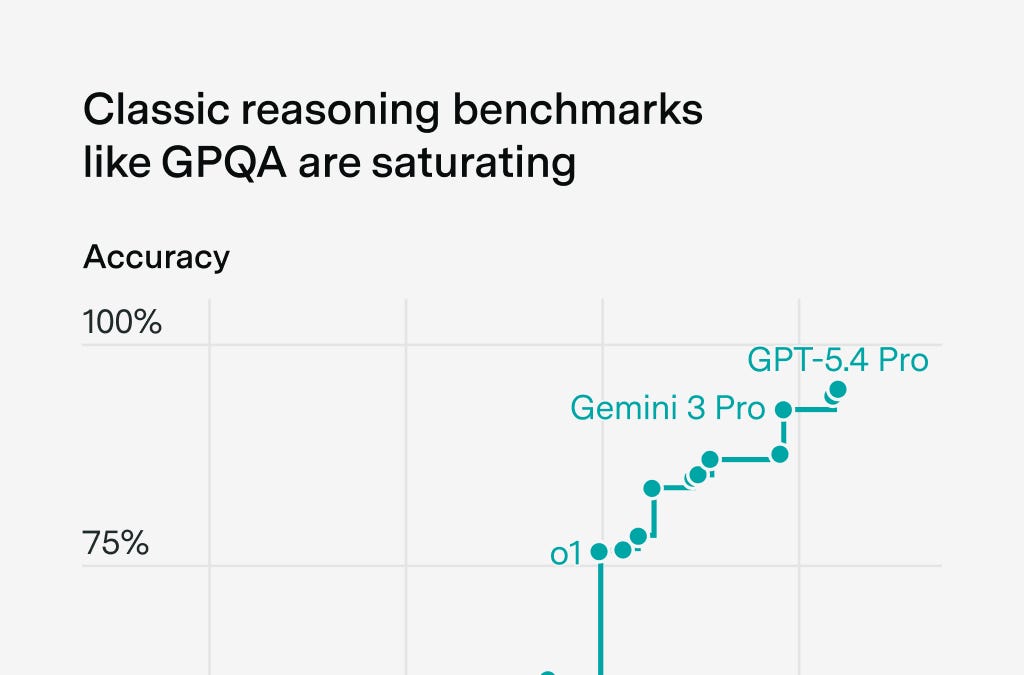
RIP Classic Reasoning Benchmarks. What’s Next?
Give up at least one of: text only, short time horizon, easy to grade, and expert human superiority.
Early results from MirrorCode benchmark with METR: AI agents can complete weeks-long coding tasks, including reimplementing a 16,000-line codebase.
Give up at least one of: text only, short time horizon, easy to grade, and expert human superiority.


Welcome to Import AI, a newsletter about AI research. Import AI runs on arXiv and feedback from readers. If you’d like to support this, please subscribe. A shorter issue than usual as I was attendi…

Was fire equivalent to a singularity for people at the time?