Another quarter, another blog post. Seems almost rushed after the previous
drought.
To set the stage, I'll start with a bit of a rant about complexity. If you
just want the meat of what's happening in the Red world, feel free to skip the
introduction.
Complexity Considerations: Part 1
I liked what the InfoWorld article,
Complexity is Killing Software Developers
said, which we all know, about difficult domains (voice and image recognition,
etc.) being available as APIs. This lets us tackle things we couldn't in some
cases. Though I imagine @dockimbel or others also used Dragon Dictate's
libraries back in the 90s. What we have now is massive data to train systems
like that. Those work well, allowing us to add features we otherwise couldn't
with a small team.
The problem I see is that the trend has become for everything to be
outsourced, including simple features like logging, and those libraries have
exploded. There must be graphs available to show the change. Moderately
complex domains, UIs for example, have risen in number and lead to what
@hiiamboris says about Brownian Movement. It's a random collection of things,
not designed to work together, without a coherent vision. A quote from the
above article says it this way:
"Complexity
is less the issue than inconsistency in an environment."
It used to be that you could take a FORTRAN, COBOL, Lisp, VB, Pascal/Delphi,
Access/PowerBuilder, dBase/Clipper/Paradox, or even a Java developer, drop
them into a project, and they could work from a solid core, learning the
team's custom bits and any commercial tools as they went. With JS leading the
way, but not alone in this, a programmer can only rely on a much smaller core,
relative to how many libraries are used.
Because those libraries, and the choices to use a particular combination of
them were not designed to work together, there is no guarantee (or perhaps
hope) of consistency to leverage. It's worse if you came from a history of
other tools that were based on different principles or priorities, because you
have to unlearn, breaking the patterns in your mind. Or you convince people to
use what you did before, even if there is overlap with tools already in use.
Things are changing now, and will even more. New service-based companies are
coming, and a drive to APIs rather than libraries. So we not only have risks
like
LeftPad, but also companies going out of business under you. The modern trend means
it's no longer dependent on an author or team committed to a project long
term, but to what investors want, and what changes are made to gain adoption
at all costs. As a service-based company you can't hold dearly to
design principles if the investors tell you to pivot. Because it's no longer
about your vision, but their return. If it is a solo FOSS author or
small team, what is their incentive to maintain a project for free, while
others profit from it? Success can be your worst enemy, and we need a more
equitable solution than what we have now. The software business model has
changed dramatically, and will likely continue to do so.
Here is what I personally see as the crux of the problem: the goal of scaling.
FOSS projects and companies are only considered successful if they have
millions (or, indirectly, billions) of users. Companies that want to be
sustainable, providing long term, moderate profits don't make headlines, but
they make the world go 'round. They are not the next big social media
disruption where end users are the product, to be bought and sold. It is a
popular business model and profit is the goal. It's nothing personal.
This has led us to the thinking that every project needs to be
designed for millions of users at the very least. Sub-second telemetry for all
the data collected, another explosion, giving rise to data analytics for
everyone; not just Business Intelligence (BI) for large companies. I won't
argue against having data. I love data and learning from it. But I do believe
there is a point of diminishing returns which is often ignored. Rather, in
this case, there is a cost of entry that small projects wouldn't otherwise
need to pay.
What do you do, as an "architect" (see the previous blog post about my
thoughts on software architecture) or developer on a team? Your small team (we
all know small teams are best, plenty of research and history there) simply
can't design and build every piece to support these scaling demands, while the
sword of Damocles hangs over you in the form of potential pivots (dramatic
changes in goals).
As an industry, we are being inexorably forced to make these choices. Either
you're a leader and make your own Faustian bargain, or you're in the general
mass of developers being whipped and driven to the gates of Hell.
Only you, dear reader, can decide the turns this tragic story will take, and
what you forgive in this telling perchance I should exaggerate.
Complexity Considerations: Part 2
Complexity doesn't come only in the form
McCabe
is famous for, the decision points in a piece of code, but in how many pieces
there are and how often they change either by choice or necessity. Temporal
Complexity if you will. This concept is unrelated to algorithmic time complexity. Rebol2 for any faults we can point out, still works to this day (except in
cases where the world changed out from under it, e.g., in protocols). It was
self-contained, and relied only on what the OS (Operating System) provided. As
long as OSs don't break a core set of functionality that tools rely on, things
keep working. R2 had a full GUI system (non-native, which insulated it from
changes there), and I can only smile when I run code that is 20 years old and
it works flawlessly. If that sounds silly, remember that technology, in most
cases, is not the goal. It is a means to an end. A lot of very old code
is still in production, keeping businesses running.
We talk about needing to keep up with changes, but some things don't change
very much, if at all. Other things change rapidly, but for no good reason, and
without being an improvement. If a change is just a lateral move there is no
value in it, unless it is to align us on a different, and better, path in the
future. I started programming with QuickBASIC, but also used other tools as I
quickly learned my tool of choice came with a stigma attached, and I wanted to
be a serious, "real" programmer. What became clear was that QB was a great
tool, with a few companies providing terrific ASM libraries, and had a
wonderful IDE to boot. It was simpler, not only as a language, but because
every 12-18 months (the release cycle way back when) my new C compiler would
break something in my code. But QB, and later BASIC/PDS and then VB very
rarely broke working code. Temporal complexity.
Even then there were more complex options. The cool kids used Zortech C++ and
there were various cross-platform GUI toolkits. But those advanced tools were
often misapplied to simple projects. We still do that today. Much of that is
human nature, and the nature of programmers. If it's easy we are no longer
special. We may not mean to, but we make things harder than they need to be.
Some of us are even elitist about what we do, to our own detriment. If you
don't need to be cross platform, why do you have multiple machines or VMs each
with a different compiler setup? If you need a GUI, why are you using a
language that was not designed with them in mind? If you need easy deployment,
which is simpler: a single EXE with no dependencies, or a containerization
approach with all that entails? How many technologies do you need in
your web stack? Are you the victim of peer pressure, where you feel your site
has to be shiny and "responsive", or use the latest framework?
A big argument for using other's work is performance. They've taken time, and
may be experts, to optimize Thing X far
beyond what you could ever do. That JIT compiler, an incredible virtual DOM,
such clever CSS tricks, the key-value DB with no limits, and yet...and yet our
software is slower and more bloated than ever. How can that be? Is it possible
we're overbuilding? Is software sprawl just something we accept now?
Earlier I mentioned that a hodge-podge assembly of parts that have no
standards, norms, or even aesthetic sense applied does not make our lives
easier. Lego blocks, the originals anyway, are limited, but consistent in how
they can be used. We misapply that analogy, because the things we build are
far from consistent or designed to interact. Even in the realm of UX and A/B
testing on subsets of users that companies apply today. I love the
idea of data-driven HCI to guide us to a more evidence-oriented approach. This
includes languages. But when a site or service moves fast and changes their
interface based on their own A/B testing, they don't account for the others
doing the same. Temporal complexity.
As a user, every app or site I access may change out from under me in the
flash of refresh or automatic update I didn't ask for. Maybe it's better, an
actual improvement, if you only use that one site. But if all your tools
constantly change out from under you, it's like someone sneaking into your
office and rearranging it every night while you sleep. Maybe this is the
developer's revenge, for the pain we inflict on ourselves by constantly
changing our own tools. If we suffer, why shouldn't our users? For those who
truly have empathy for their users and don't want to drive them mad, or away,
perhaps the lesson is to have empathy for ourselves, for our own tribe. I
don't want to see my friends and colleagues burn out, when it was probably the
enjoyment and passion that solving problems with software can bring which led
them here to begin with.
Every moving part in your system is a potential point of failure. Reduce the
moving parts and reliability increases. Whether it's the OS you run on (we now
have more of those than ever, between Linux distros and mobile platforms
always trying to outdo each other), extra packages or commercial tools, FOSS
libraries, environments, [?]aaS, or
platform components like containers and cluster management, every single piece
is a point of failure. And if any of them break your code, or your system,
even in the name of improvements or bug fixes, you may find yourself running
just to stay in the same place. Many of those pieces are touted as the
solution to reliability problems, but a lot of them just push problems around,
or target problems you don't have. Don't solve problems you don't have. That
adds complexity, and now you really have a problem.
Less Philosophy, More Red
Interpreter Events
Having a debugger in Red has been a request of many users for a long time,
even since the Rebol era. We have tackled this feature from a larger
perspective, considering general instrumentation of the interpreter (note: not
the compiler), extending it with an event system and user-provided event
handlers, similar to how
parse and
lexer
tracing operate today. This approach allows us to build more than just a
debugger, though it was a lot of work to design and we expect it will be
refined once people start using it in earnest. It's a brave new world, with a
lot of tooling possibilities.
It's important to note that this is not magic. Because it operates as the
interpreter evaluates values and expressions, including functions, it can't
see into the future. In order to get a complete trace, you have to evaluate
everything. That means we'll see tools which silently collect data, like a
profiler does, which can later be viewed and analyzed, perhaps up to the point
where an error occurred. This is an important aspect, and plays once again
into the power of Red as data. Your event handlers can easily collect data
into any structure or model you like. And because event handlers can filter
events, you can tailor them for specific needs. It should even be possible to
build interpreter level
DTrace-like
tools in the future. We also hope to build higher level observability and
monitoring tools, based on eventing systems, in the future, but those are long
term projects.
Event generation is not active by default, it is enabled using
do/trace and by
providing an event handler function. For example, here's a simple logging
function:
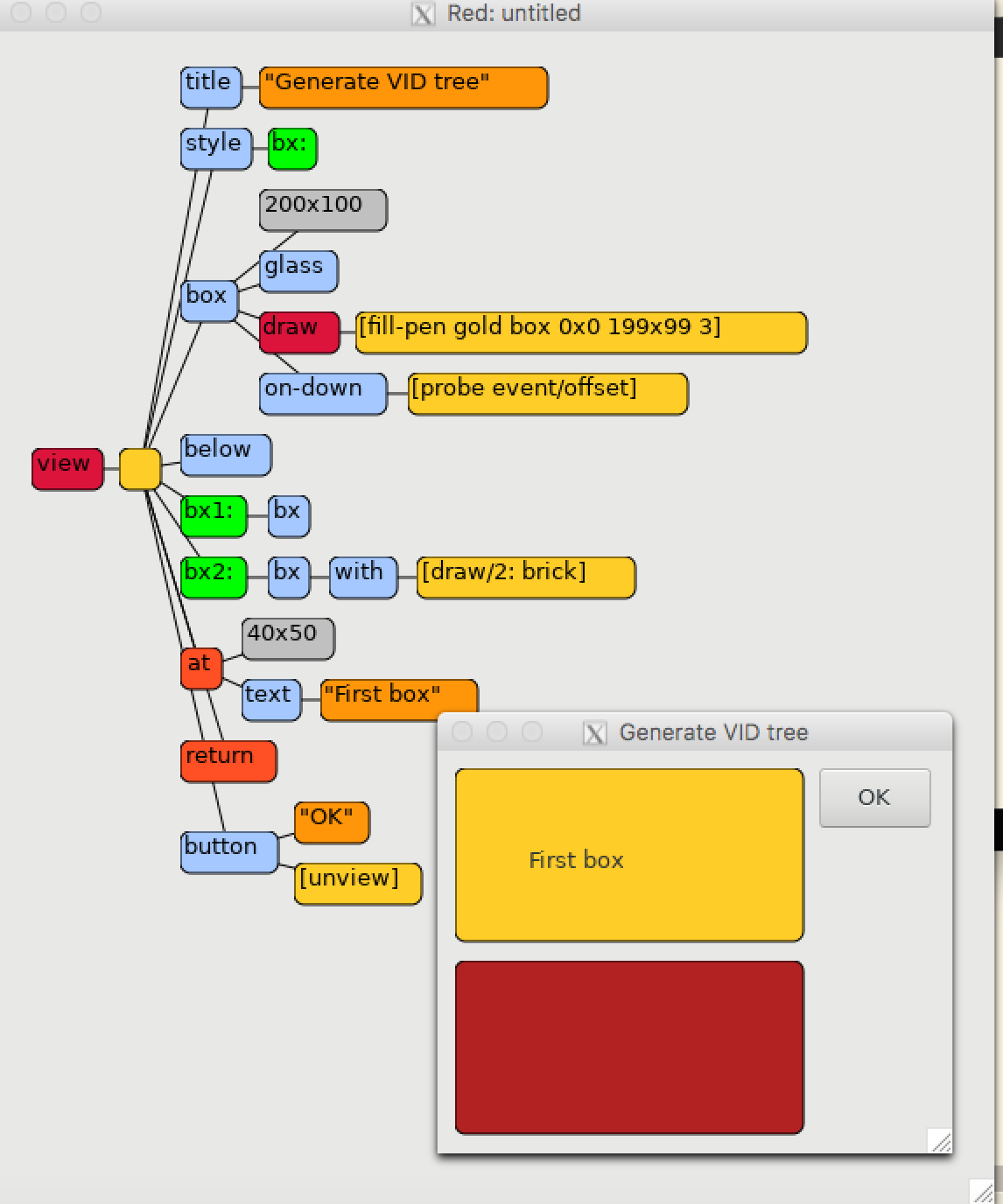
logger: function [
event [word!] ;-- Event name
code [any-block! none!] ;-- Currently evaluated block
offset [integer!] ;-- Offset in evaluated block
value [any-type!] ;-- Value currently processed
ref [any-type!] ;-- Reference of current call
frame [pair!] ;-- Stack frame start/top positions
][
print [
pad uppercase form event 8
mold/part/flat either any-function? :value [:ref][:value] 20
]
]
Given this code:
do/trace [print 1 + 2] :logger
It will output:
INIT none ;-- Initializing tracing mode
ENTER none ;-- Entering block to evaluate
FETCH print ;-- Fetching and evaluating `print` value
OPEN print ;-- Results in opening a new call stack frame
FETCH + ;-- Fetching and evaluating `+` infix operator
OPEN + ;-- Results in opening a new call stack frame
FETCH 1 ;-- Fetching left operand `1`
PUSH 1 ;-- Pushing integer! value `1` on stack
FETCH 2 ;-- Fetching and evaluating right operand
PUSH 2 ;-- Pushing integer! value `2`
CALL + ;-- Calling `+` operator
RETURN 3 ;-- Returning the resulting value
CALL print ;-- Calling `print`
3 ;-- Outputting 3
RETURN unset ;-- Returning the resulting value
EXIT none ;-- Exiting evaluated block
END none ;-- Ending tracing mode
Several tools are now provided in the Red runtime library, built on top of
this event system:
-
An interactive debugger console, with many capabilities (step by step evaluation, a flexible breakpoint system, and call stack visualisation).
-
A simple profiler that we will improve over time (especially on the accuracy aspects).
-
A simple tracer. The current evaluation steps are quite low-level, but @hiiamboris has already built an extended version, operating at the expression level that will soon be integrated into the master branch.
Full docs are
here.
Format
Boy, I really thought this was was going to be easy, or at least not
too hard. I couldn't have been more wrong. When I did my format
experiments, I imagined at least some of the code would be useful, requiring
polish and more work of course, providing a foundation to work from. It turns
out that I missed a key aspect, and my approach was just one of many possible.
@hiiamboris and @giesse both weighed in, and we chatted about specific parts.
Then it sat idle for a while, and I asked Boris to take it over to get it into
production. He identified the key missing piece, which would have limited its
usefulness until we eventually had to address it. Better now than later. He
also made a strong case for a different approach to the core masked-number and
I told him to run with it. That led to a lot of design chat about one aspect,
which is as yet undecided. It's not a fight to the death, but there has
definitely been some sparring. :^)
The missing piece I've alluded to is Localization (L10N). As an American who
has never had to develop software requiring Internationalization (I18N), I've
been blissfully ignorant of all the aspects that come into play when
Globalization (G11N) becomes part of the process. We have talked about how to
implement L10N in Red, and have
system/locale for a
months, weekdays, and currency codes. The first two we inherited from Rebol's
design, the latter was added when @9214 designed the
currency! datatype.
Thinking of locale data in a system catalog of some kind is easy enough, but
how to actually apply it (and not apply it when necessary) is a different
story entirely. And I mean
entirely. Format forced us to start down
this path, and is a guinea pig feature that will guide future plans for all
future L10N work. But keep my complexity rant in mind. While we want to make
it as easy as possible for Reducers to write globally aware apps, if you don't
need it, don't do it. We don't yet know if we can make it so magical that you
can write your app ignoring that for the most part, and then flip a switch, or
simply include local data, and have it work. Don't get your hopes up. There's
a lot that can go wrong with that approach.
We agreed to start with masked numbers but, in order to do that, L10N R&D
had to be done. This led to broad and deep dives into unicode.org and other
resources. While they cover far more than we need, and is overly complex in
many cases (or just doesn't match our aesthetic sense for Red), the data they
have there is enormously valuable, and we deeply appreciate it being
available. We just draw the line around a smaller scope than they do, and no
committees are involved where people fight to get their own bits included.
Well, we do that too, to some extent. What Boris managed to do was identify
the key elements needed for our work, and then wrote tools (using Red of
course) to extract and reformat the data for use in Red. I can't stress how
much work this was. Truly a heroic and mostly thankless effort most people
will never know about.
In order to test masked number formatting, and give others an easy way to
play, Boris created a
Playground App and I can't tell you how important that was. You see, a particular
piece of behavior came up while I was playing with it and got unexpected
results. Unexpected to me, but Boris confirmed it was by design. I will just
say here that it's about a significant digits mode, and let you play with the
app from there. Named formats will be available, but everything will likely
boil down to wrappers around masks, which should cover almost any need.
Next up is date formatting. This time I knew locales would play a role because
some IETF RFCs specify that date elements be in English. So you may have
localized dates for some things, but if you use RFC2822 dates or HTTP cookie
dates, they
must not be affected by any locale settings. Dates will use
masks at the core, like numbers, because masks are an easy to understand
WYSIWYG format. Well, easy if the masks make sense. If you look at
printf and some
other mask syntax, it can be quite obscure. By trying to cram things into a
limited syntax, people end up using whatever low ASCII letters might be left over
for some elements. We hope to avoid that.
Our main choices are what Boris termed the stuttering format. e.g.
MMDDYYYY/HHMMSS. Think in terms of "progressing in a hesitant or irregular way."
rather than stuttering in terms of human speech. I prefer to call this a
symbolic
format, where the letters map to date elements. This, of course, isn't
perfect. e.g. is MM month or minute? Context is required. We don't want
to be case sensitive, or use other letters randomly to avoid that
conflict. So there's an alternate approach; a literal
mask. e.g. 1-Jan-2022. We're not the first to consider it, and it is in
use elsewhere, but it's not a perfect solution either. Do masks have to
be written in English terms, or can they use any locale? How do you
disambiguate numbers (does 01-01 mean MM-DD or DD-MM, and how do you
write that without the separator to get MMDD?) Does it make code more or
less readable, because Red already has a literal date form, and it would
add what look like literal dates as strings in code.
Play with the app, give us feedback, and stay tuned. We think this will be a
crucial feature for a lot of users, and we want to make it the best it can be.
Split
Like format,
split seems a relatively simple subject at a glance. And if you limit it to basic
functionality, it is. That's what other languages do, though some add a few
extra features. See
this table
for examples. Wolfram
appears quite broad in scope, because there are
multiple variants for each named function. Something else common to all other
languages is that they split only strings and sometimes byte arrays. In Red we
have blocks, and while `parse` is great for string parsing, where it really
shines is when applied to blocks to build dialects. We knew split should be
block aware for more leverage. I (Gregg) helped design the version in R3, and
used
DiaGrammar
to design a new dialected interface that aimed to extend the functionality.
Wanting to do more evidence based language design, I also prototyped a small
practice/playground app, thinking we'd put it out and see what kind of
feedback we could get.
Toomas stepped up and suggested an alternative, refinement-based, interface.
He did a number of versions of that, and then we had to decide what to do
next. There was a great deal of design discussion, still going on, about
behavior details. Once you start adding options, it's easy for things to
become confusing for the user. We need to strike a balance between ease of use
and flexibility.
Split is meant
to handle the most common cases, and those with the most leverage, not
every case. And while a refinement-based interface seems natural for
Reducers, we also know how readable
parse,
draw, and
VID
dialects are. There are pros and cons to each, but we don't want dual
interfaces, which will be confusing. If a function is dialected, any
refinements should work in support of that dialect. So the test app was
reimagined by @GalenIvanov to compare the two approaches.
Here's a screenshot of the test app, which we'll release to the community in
January.

We learned by doing this that it's hard to compare them side by side, without
having the user write full calls directly. That defeats some of the purpose,
and the DRY principle, so we'll put this one out, then revise it based on
feedback.
Markup Codec
Who knew that parsing HTML and XML would be the easy part? Well, many Reducers
would. What they, and we on the team, might not have guessed, is just how hard
it is to decide on a data format for the output. Red gives us many options,
and XML gives us many headaches. The two formats, while closely related, also
have some critical differences. Fortunately, once @rebolek set things up so we
could play, and made the emitter modular, we could look at real examples and
dive even deeper. What we discovered is that there is no perfect solution. No
elegant model to fit all uses and cases. Key to many insights was @dander's
input, as he works with XML a lot. Turns out, an infinitely extensible format
is infinitely challenging to nail down.
Should we emphasize path access? Being data driven, people probably
shouldn't hardcode their field names, but working with known data makes
it a clear access model. Should attributes come before or after the
text/content for a tag? As we learned, attributes aren't always small, so the
locality argument isn't won either way there. Is it better to provide an
interface to the structure and tell people to always use that, or to create a
bland and obvious data structure that is possible to access in many ways? Will
these things all complicate HOF access, which we know we want to leverage? How
much do we need to care about efficiency? We don't want to be wasteful without
purpose, but if we're too miserly, users may pay the price because it's harder
to use. If we make more things implicit, do we paint ourselves into a corner
somehow?
What we settled on was a modular approach, so there will be more than one
standard emitter. What is yet undecided is how other emitters might be
supported. They will likely be quite custom, as the standard versions will
cover most needs. But is it worth making the system extensible? Once you have
a result, it's easy to post-process into your preferred format. For now that's
our recommended approach.
CLI Module
If you don't follow our channels on Gitter, you may not know about
Boris' CLI module. It's very slick, very Reddish, and will become a standard part of Red in
the near future. You won't believe how easy it is to create rich command line
interfaces for your Red apps with this feature. Huge thanks to @hiiamboris for
all his innovation and work on it.
IPv6 Datatype
It hasn't been merged to the mainline yet, but it's fully operational. You can
see the code
here, and some lexer tests
here. You may be impressed that it's only a couple hundred lines of code, not
counting the lexer changes, and think it was easy. It wasn't. As usual, there
was a lot of design chat and compromise involved. For example, the name is not
100% finalized because, technically, the datatype itself is more generally
applicable, being simply a vector of numbers internally. You can think of it
like a tuple! on
steroids. Less slots (8 vs 12), but each slot can hold a larger value (tuple!
slots are limited to byte values).
Just as tuple! is a general name, used both for IPv4 addresses and colors, but also
useful for other things, IPv6! could be used for things like GUIDs or extended time values. But the
lexical form for GUID/UUID values is quite different, even ignoring the
shortcut forms in the
IPv6 specification. As you probably know, lexical space is tight in Red, and the colon is an
important character in other places, and URL lexical forms were impacted, so
this is a deep change and commitment, in that regard. Why do it then?
Because IPv6 networking support was already in place in Red, and IPv6 is the
future. How often people will write literal URLs like
http://[FEDC:BA98:7654:3210:FEDC:BA98:7654:3210]:80/index.html
we can't say. But we do know that addresses often end up in config files as
data and that modern, dynamic systems generate addresses dynamically. They
will appear in log files, messages, and more. As with the value of other
lexical forms in Red, it's an important one that is part of our modern
networking vocabulary.
Getting Near
@dockimbel created a new branch
here,
which will interest almost every Reducer. It's not ready yet, but expect it to
be available in January. For those who used R2, you may recall that errors
gave you a Near field, to hint at where the error occurred. Red will get this
feature when the new branch is merged. e.g., in Red today you get this:
>> 1 / 0
*** Math Error: attempt to divide by zero
*** Where: /
*** Stack:
Where in R2 you got this:
>> 1 / 0
** Math Error: Attempt to divide by zero
** Near: 1 / 0
A little extra information goes a long way. We're anxious to see all the
virtual smiles this features brings.
The Daily Grind
We closed roughly 120 tickets in 2021, that's 10 per month. We also merged
almost 50 PRs. These numbers don't sound large, but when you consider how much
time and effort may go into the deep ones, along with all the other work done,
it's steady progress. We'd love for both tickets and pending PRs to be at
zero, but that's not practical for a project like Red. The deep core team must
have uninterrupted time for design and bigger, more complex tasks.
Roadmap
Q4 2021 (retrospective)
-
We hoped to have `format` and `split` deployed, but they will push back to
Jan-2022.
-
`CLI` module approved, needs to be merged, then refined as necessary.
-
`Markup Codec` took longer than expected due to extensive design chat on
formats.
-
Interpreter instrumentation, with PoC debugger and profiler. Took longer
than expected, but are out now.
-
Async I/O, out but some extra bits didn't make it in. One unplanned
addition was `IPv6!` as a datatype. It's experimental, and subject to
change.
-
@galenivanov did some great work on his animation dialect, but @toomasv's
`diagram` dialect took a back seat and will move to Q1 2022.
-
Audio has 3 working back ends and a basic port implementation. Next up is
higher level design, device and format enumeration, and device control. A
`port!` may not be the way to go for all this, but it was step one.
-
Animation has more great examples all the time. Like
this
and
this. @GalenIvanov is doing great work, and we are planning to make his
dialect a standard addition to Red.
2022
I'm not going to list items in any particular order, because our plans often
change. This way you have things to look forward to, but still with an element
of surprise.
- `Table` module, `node!` datatype and other REP reviews
- Full HTTP/S protocol and basic web server framework
-
New
DiaGrammar
release
- Animation dialect
- New release process
- New web sites updated and live
- Red/C3 (Including ETH 2.0 client protocol)
-
Red Language Specification (Principles, Core Language, Evaluation Rules,
Datatype Specs (including literal forms), Action/Native specs, Modules spec.
-
64-bit support (LLVM was a possibility, but we learned from Zig that LLVM
breaking changes can be quite painful for small teams to keep up with. We
may be better off continuing to roll our own, though it's a big task.)
- Android update
- Red Spaces cross-platform GUI
- Module and package system design
- RAPIDE (Rapid API Development Environment)
RAPIDE, from Redlake Technologies
If you've used
Postman or
Insomnia, you know what
the most popular tools in the API IDE space look like today. If you haven't
used them, but use APIs, they're worth a look. For all that those tools do,
and there are a few other players in the space, there is a lot they don't do.
We think we can add a lot of value in the API arena, thanks to Red's
superpowers and how important data-centric thinking is. For example, testing a
group or series of APIs together seems like it could be greatly improved.
Also, how APIs are found, and collaboration possibilities.
While we haven't set a release date, the plan is to start work on RAPIDE in Q2
2022, after we wrap up some infrastructure pieces it will rely on.
In conclusion
Happy New Year to all, and may 2022 see us all healthy, happy, and writing more Red. :^)