Show full content
Hate it or love it, Friends is one of the most popular sitcoms of all time.
The cast’s characterizations were diverse enough for you to see a little bit of yourself and your friends in each of the characters as they stumbled through life and made bad decisions. This makes it no surprise that, at its peak, the TV show had over 50 million viewers.
One of the biggest debates fans have to this day is: Who was the show’s funniest character? Was it Chandler with his self-deprecating sarcasm? Ross with his nerdy mannerisms? Phoebe with her hippy-boho vibe? Joey? Rachel? Monica?
Depending on who you ask, the answer might differ. For one, I thought Ross was hilarious, while others find him (understandably) annoying.
As a data lover and a huge fan of Friends, I took an intermittent two-year-long stab (seriously, I’ve been working on this for two years) at using data to answer this question.
Who was the funniest character? What made them funny? When were they at their funniest?
By analyzing laughter in the audio files of over 200 episodes of Friends and combining that with each episode’s scripts, I’m here to answer the question we’ve all been asking.
The HowThis has been, by far, the most challenging project I have worked on. I started working on this in early 2019. The work I needed to do was beyond my technical capabilities at the time, so it took a lot of trial and error, which meant dropping and picking up the project multiple times.
Without going too much into the details, I built a machine learning model that could detect laughter in an audio file. Luckily, most sitcoms from the 90s had laughter either from a live audience or from a pre-recording. The model had about 95% accuracy and 98% precision.
In a nutshell, what I did was, using Python’s librosa library, I transformed the audio file of each episode into a dataset in which each row is a numerical representation of the sound waves for one second of sound. The model then detects what seconds were laughter based on the sound waves.
The next step was matching the new dataset with the model-detected laughter to the script and subtitle data to identify who caused the laughter and what was said.
The majority of the code was written in R, but I did most of the audio analysis in Python. I suck at Python, so massive shout out to Allen, who saved me by speeding up my Python code. Go check out his data science blog: http://allenkunle.me.
I usually do not share a lot of the technical details of my work. Still, I was particularly proud of this one (and was tempted to overload you guys with nerdy information, but my editors said no).
If you would like to know more about the technical details of the project, you can check it out here.
The datasets and a sample of the code can be found on my GitHub here.
Let’s get straight into it!
Who Was The Funniest Friends Character? By Total Number Of Laughs, Chandler Is The Funniest Character Of The Show, Followed by The Two Male Leads, Joey and Ross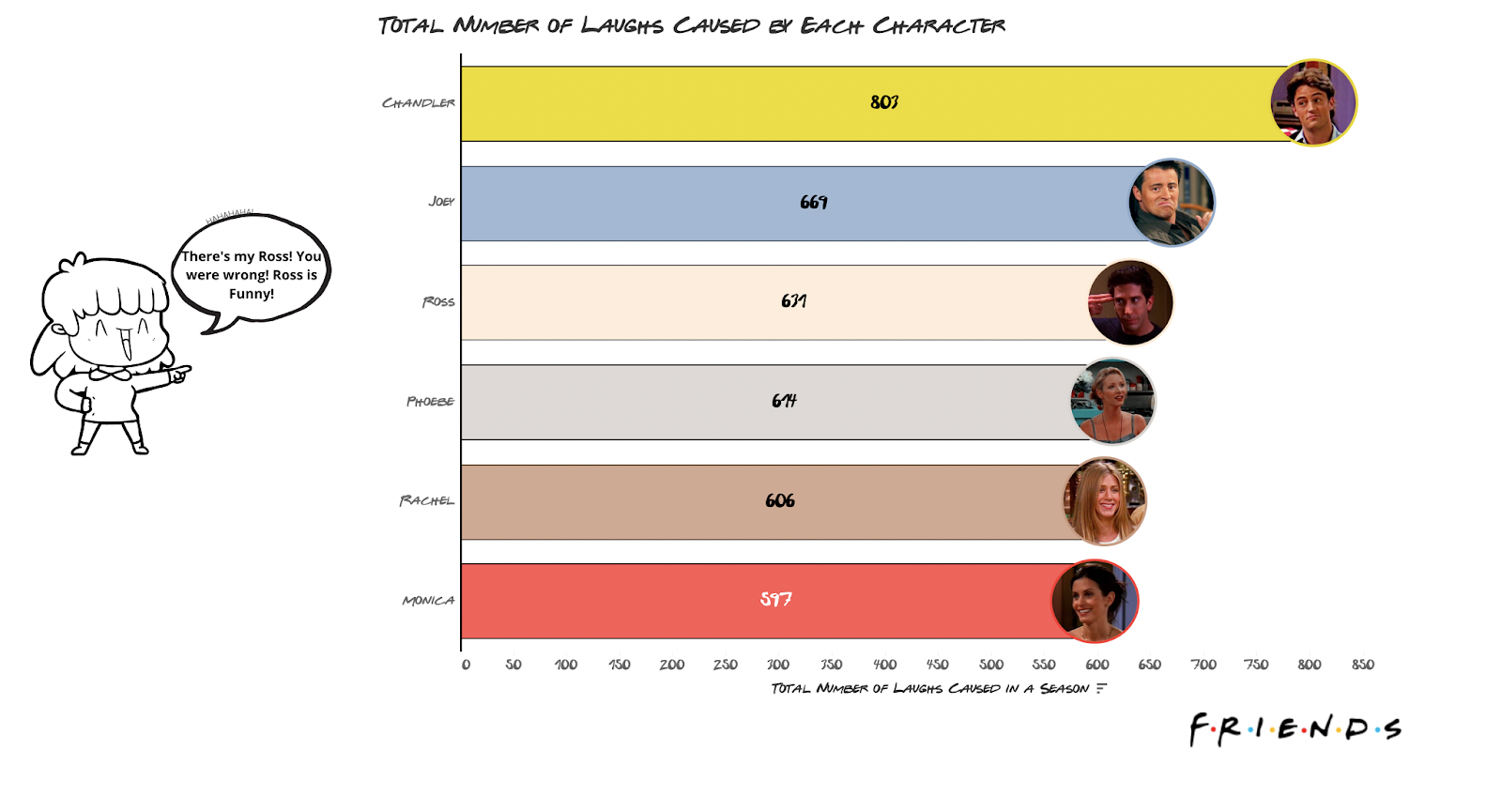
We have the three male leads first, followed by the female leads: Phoebe, Rachel, and Monica in that order.
However, this might be misleading. If a character has more lines, there is a higher chance they will cause more laughs, but that doesn’t necessarily mean they’re funnier than someone with fewer lines, right?
If We Look At What Percentage Of Their Lines Were Funny, Everyone Retains The Same Rank Except For Ross Who Drops To The Bottom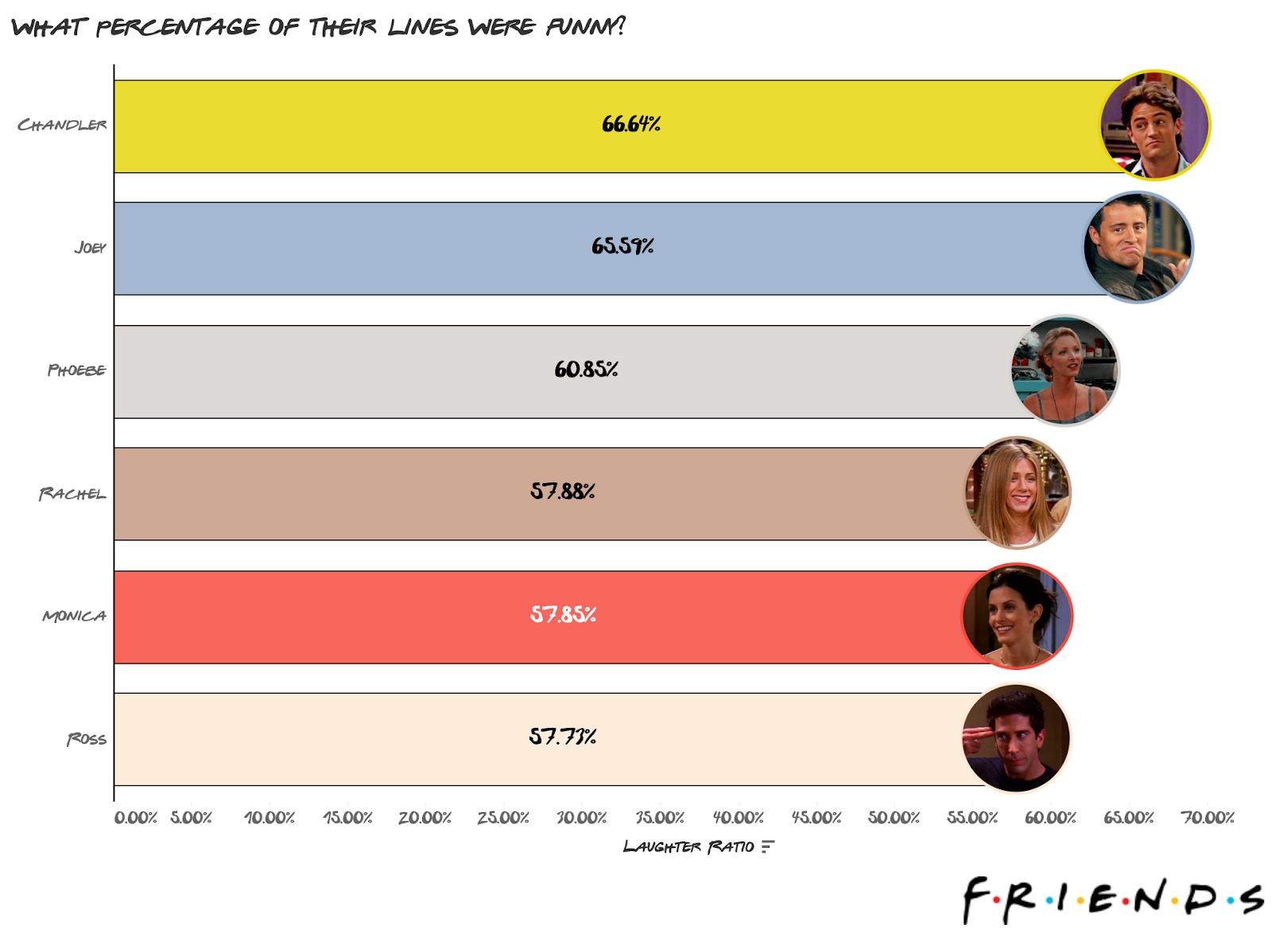

Chandler retains the top spot, with 67% of his lines being funny. Unfortunately, it seems Ross had more funny lines just because he had more lines in general. What’s even more shameful is that everyone else retained their rank.
I liked Ross a lot, so this kinda bummed me out.
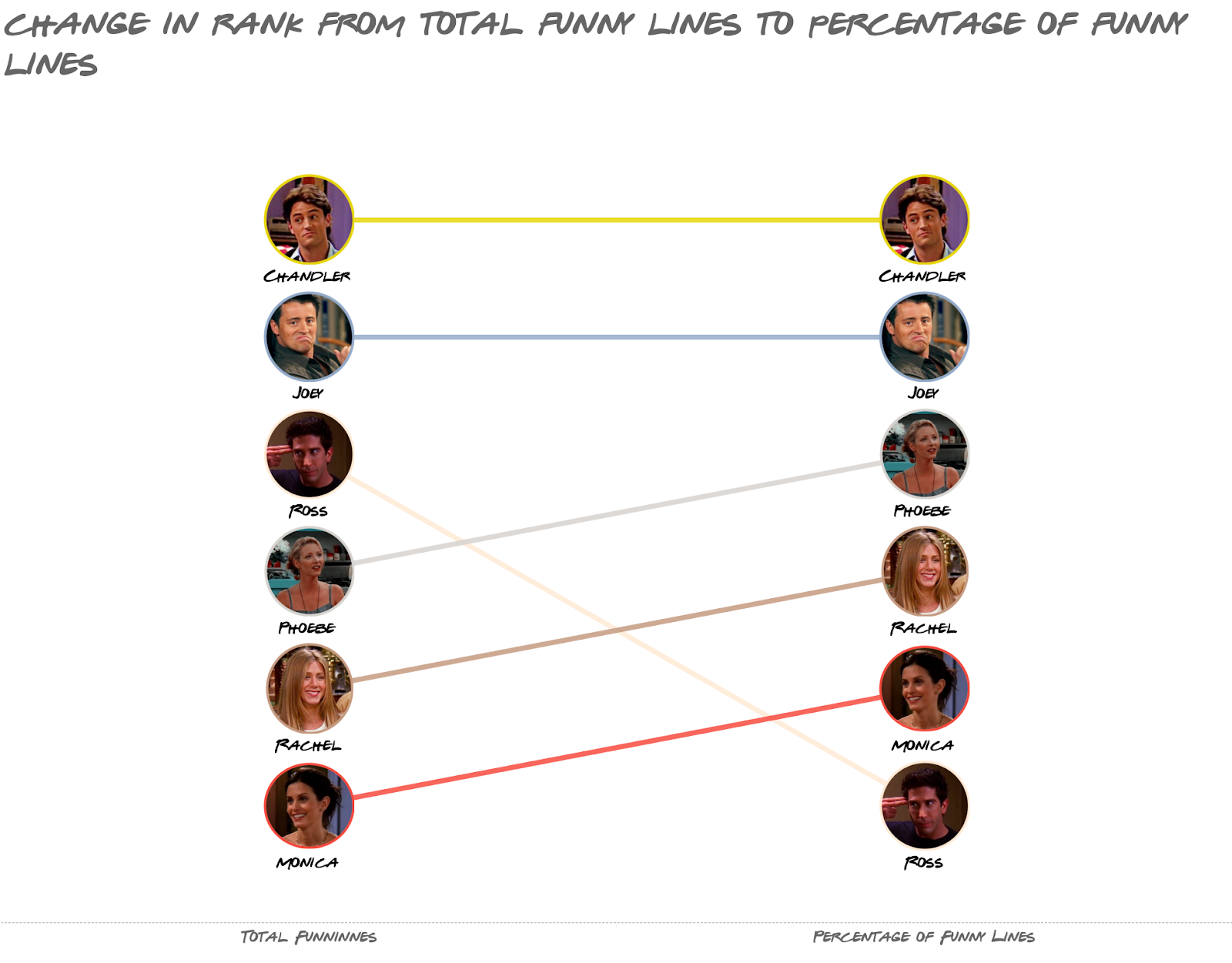
Here’s another way to look at it:
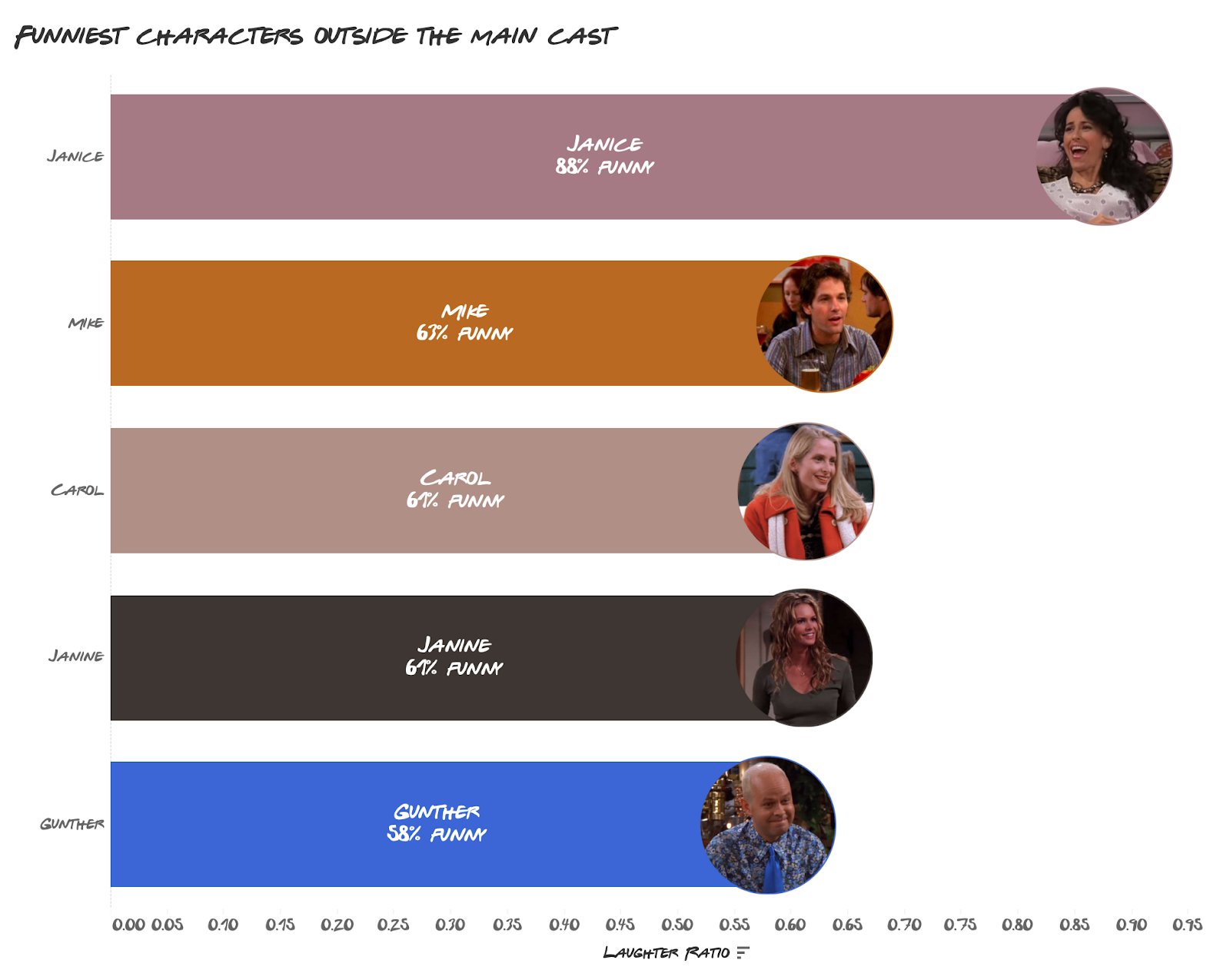
Janice, Chandler’s longtime on-and-off girlfriend, was by far the funniest outside the main cast and the funniest overall. This makes sense given her hilarious voice acting that made everything she said ten times funnier.
The only character here who was not exactly a love interest was Guenther, although most of his funny moments were because he had a crush on Rachel.

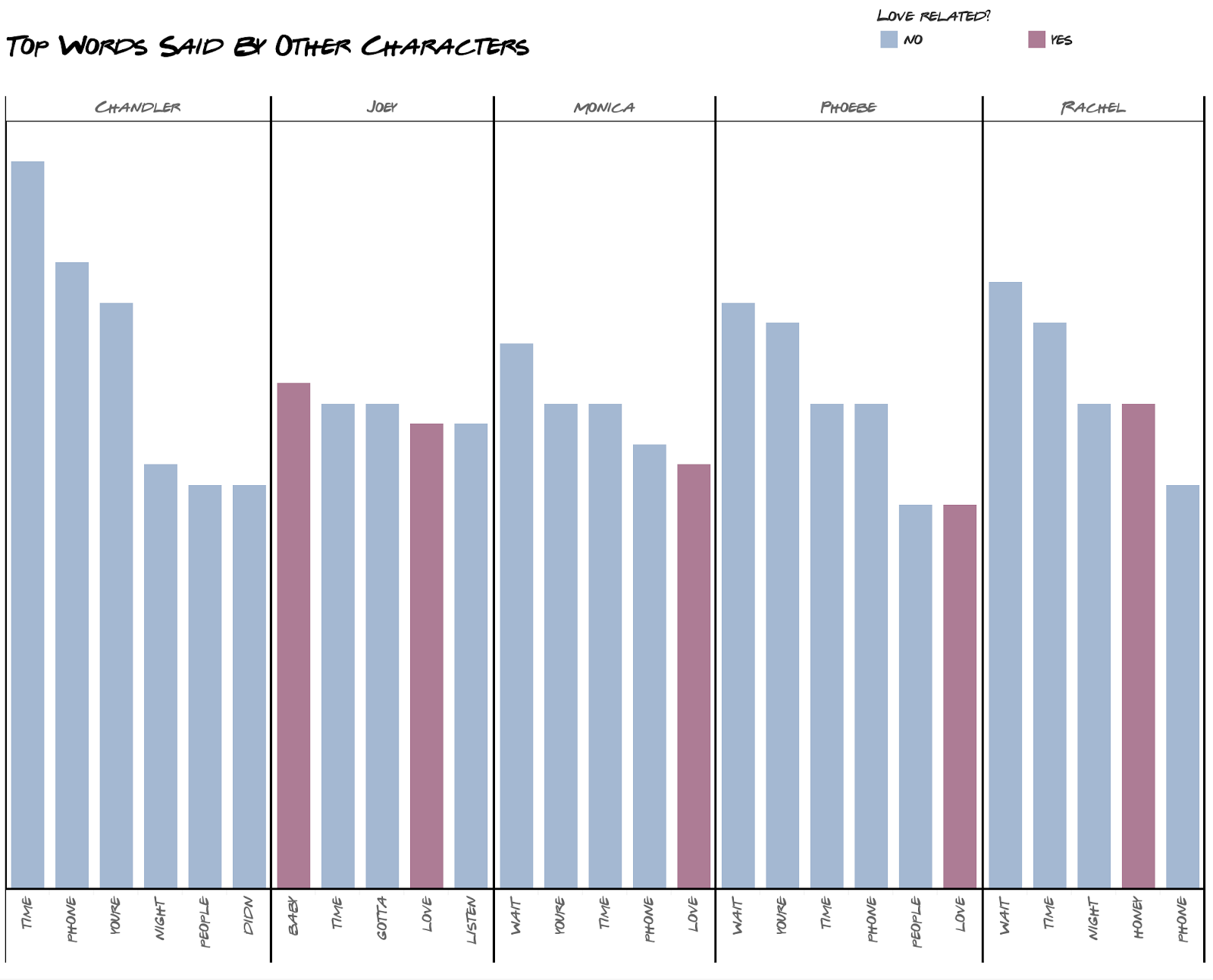
I use the top 7 here because some words are tied in their number of occurrences.
You can see that most of his discussions revolved around talking about his love life, and this might have affected how funny he was because his love life was the most chaotic and painful thing to watch.
Some of his biggest love arcs were:
- His first wife, Carol, turned out to be a lesbian
- His second marriage with Emily ended because he was still in love with Rachel
- His continuous, sometimes painful on-and-off relationship with Rachel
If you compare Ross’s top words to the other characters, the others talked about their love lives a lot less.
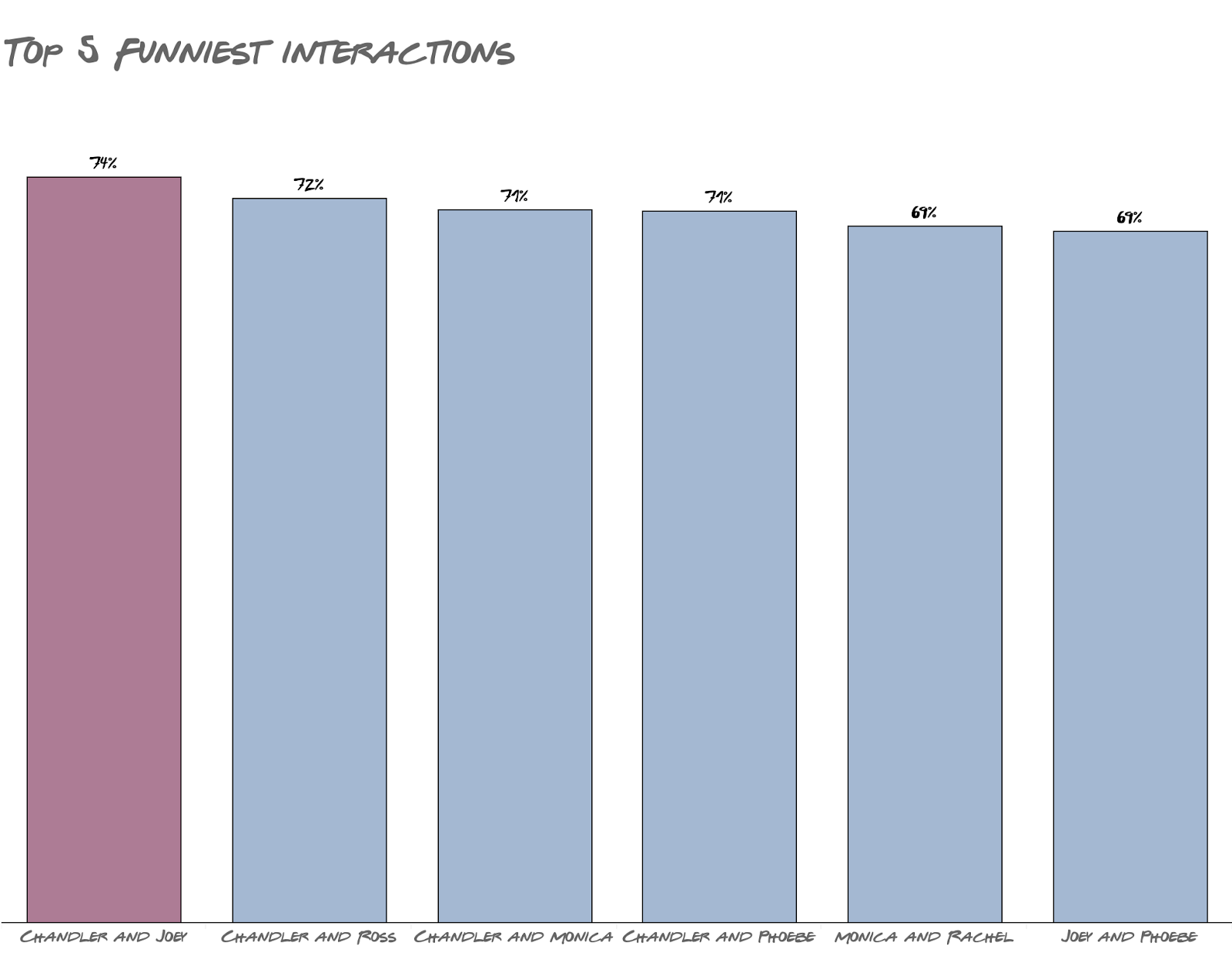
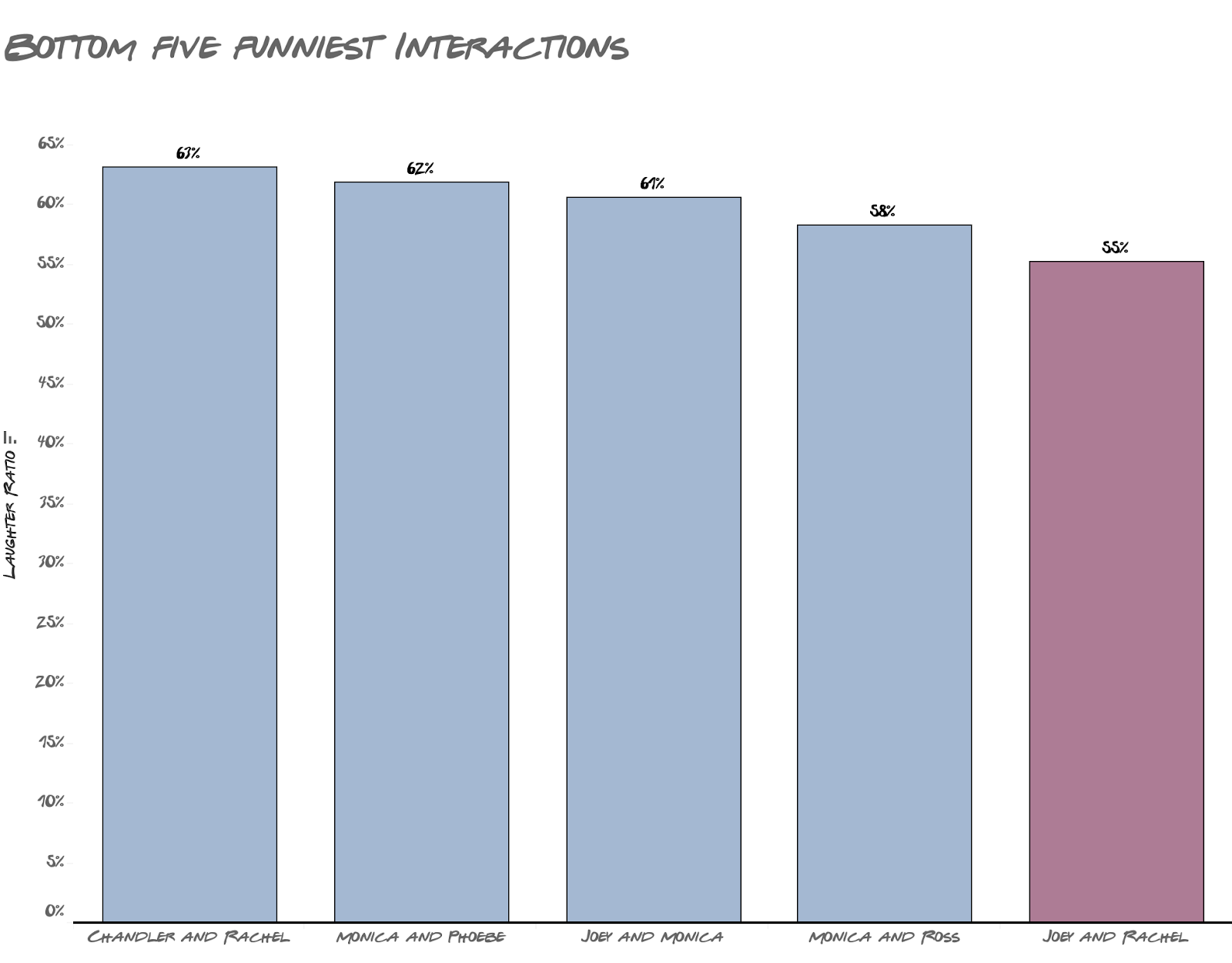
This probably also explains why their short-lived relationship seemed quite awkward. On the other hand, Chandler’s wife Monica was at the very bottom in one-on-one interaction. It makes me wonder if the showrunners put them together deliberately.
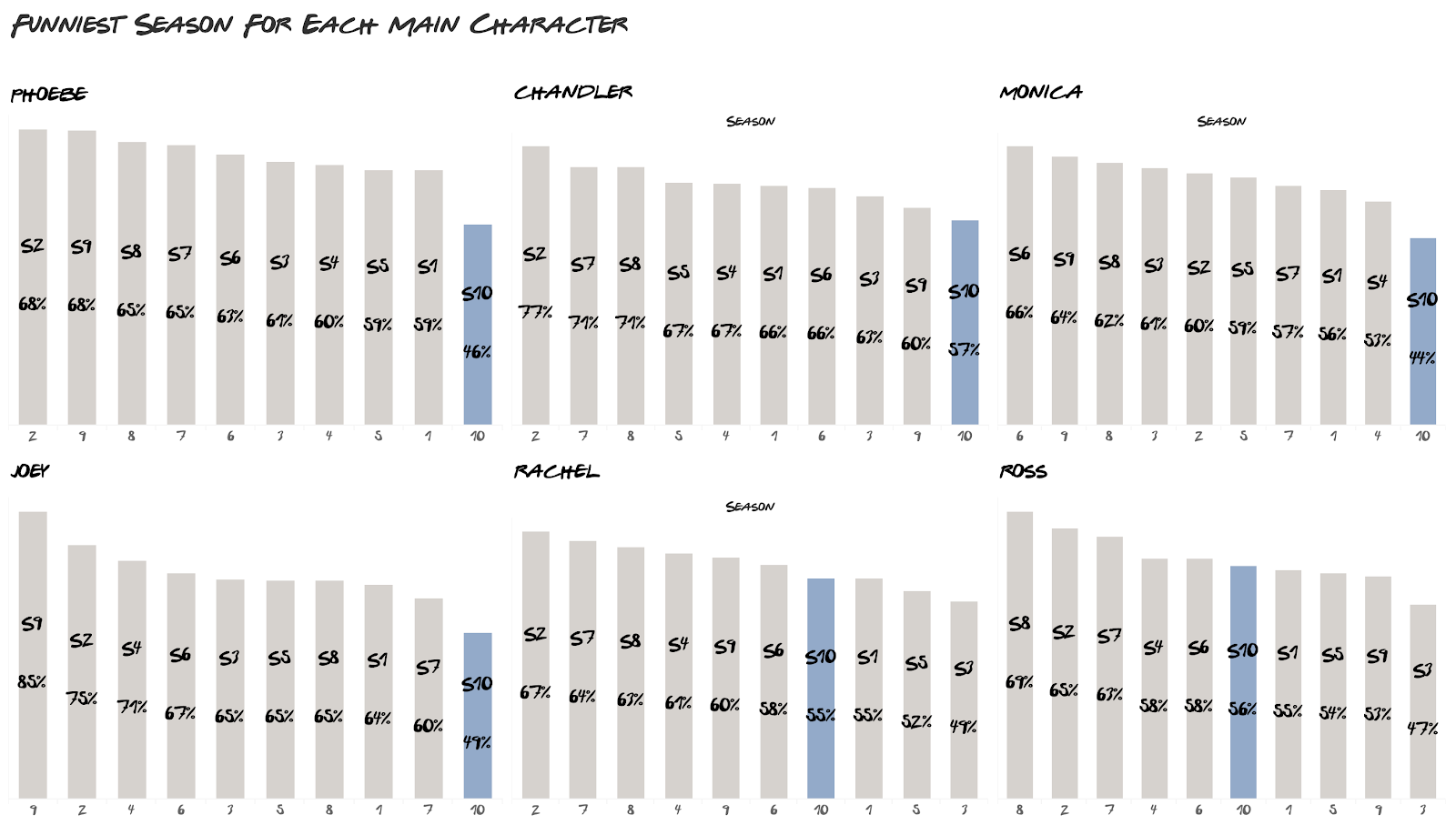
We can all agree that Season 10 focused less on comedy but more on the drama to wrap up the show. It also shows up consistently for all the characters that Season 10 was the least funny.
The only exceptions are Ross and Rachel, and this is probably because the show focused on them finally getting their happy ending that had been teased since season 1.
For both characters, season 3 was their least funny season, and this is where they had a lot of conflict in the relationship, which led to their breakup.
This entire analysis is a good reminder that: data-driven does not always mean objective. The premise of this analysis is that the pre-recorded laughter is the ground truth for funniness. That simply isn’t true.
While most people might agree that Chandler was the funniest, not everyone will, and that’s okay because sometimes, the role of data is not to be objective but to be a proxy for the subjective such as how funny a person is. Please feel free to disagree with the rankings.
What’s Next?I know, I know. It’s been almost three years since my last post. To summarize, moving countries did a number on me. I’m only just recovering two years later.
There’s a 70% chance there will be a new post between March and April, plus I have around 5-6 posts planned for the year, but please don’t hold me to it in case life happens.
I really enjoyed working on this like old times! Thank you for sticking around, and I hope to see you all soon!
















































