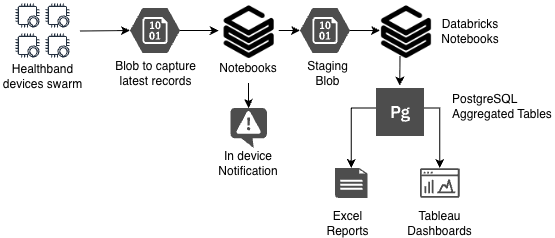
A wearable healthcare company was generating massive high-frequency data in Azure Blob Storage, tracking metrics like heart rate, respiration, oxygen levels, and activity every minute.
Show full content
A wearable healthcare company was generating massive high-frequency data in Azure Blob Storage, tracking metrics like heart rate, respiration, oxygen levels, and activity every minute.
Scope:
Instantly alert users when heart rate crossed thresholds.
Send personalized notifications and celebrate user milestones.
Warn users of dangerously low oxygen levels.
Approach:
Leveraged scheduled Databricks notebooks to process terabytes of incoming data and deliver near real-time alerts.
Performed aggregated analytics (daily/weekly) and stored results in PostgreSQL for rapid access to frequently used metrics.
Outcome:
95% of abnormal readings detected in real-time.
Significantly decreased query times for common metrics.
Scalable solution capable of handling terabytes of high-frequency data.
Think my experience aligns with your needs? or got any questions that I can help with? Let’s connect.
A US-based lead generation agency was operating on an on-premise MS SQL Server originally built for transactional workloads, which had increasingly been used for reporting and analytics.
Show full content
A US-based lead generation agency was operating on an on-premise MS SQL Server originally built for transactional workloads, which had increasingly been used for reporting and analytics.
Challenge:
Limited scalability and high fixed infrastructure costs
Complex legacy schemas with undocumented SQL logic
Slow turnaround for new analytics and reporting needs
Approach:
Assessed existing SQL schemas, workloads, and critical reports
Designed a Snowflake-based data warehouse optimised for analytics
Migrated historical and incremental data from SQL Server to Snowflake
Refactored SQL logic into Snowflake-native transformations
Enabled role-based access and BI tool integration
Ran systems in parallel to validate data accuracy before cutover
Outcome:
Elastic, on-demand compute for reporting and ad-hoc analysis
Reduced infrastructure and licensing costs through a pay-per-use model
Faster and more reliable analytics delivery
Scalable foundation for advanced analytics and data science
Think my experience aligns with your needs? or got any questions that I can help with? Let’s connect.
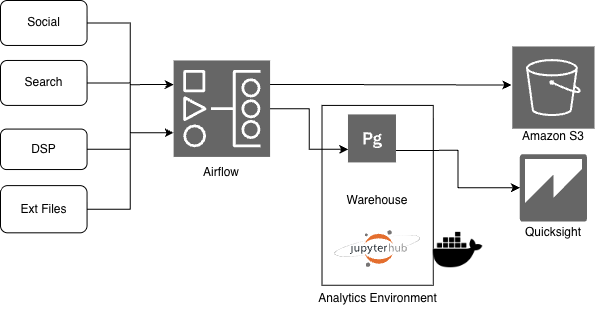
An entertainment agency faced fragmented and chaotic data across Social, Search, DSPs, and other third-party platforms.
Show full content
An entertainment agency faced fragmented and chaotic data across Social, Search, DSPs, and other third-party platforms.
Challenge:
Each platform (Meta, Google Ads, DV360, etc.) had its own schema, access method, and update schedule.
ETL processes were hard to scale, and difficult to monitor.
Business units waited days for performance insights due to disconnected tools and manual workflows.
Data scientists lacked a centralized workspace to share ad-hoc analyses and notebooks.
Ungoverned pipelines made audits and client reporting error-prone.
Approach:
Built a modern end-to-end data pipeline using Airflow and AWS-native tools, containerized with Docker for scalability.
Created a custom JupyterHub-based Data Science environment, enabling analysts to run, share, and collaborate on models and queries using unified warehouse data.
Outcome:
Faster, data-driven campaign optimization.
Analysts freed from manual data tasks, focusing on actionable insights.
Real-time visibility for marketing leaders.
Improved governance, audit readiness, and compliance.
Think my experience aligns with your needs? or got any questions that I can help with? Let’s connect.