Show full content
nepls-fall-2025Download
I gave this talk at NEPLS this morning! It was fun, and seemed to get people curious about this problem.
I gave this talk at NEPLS this morning! It was fun, and seemed to get people curious about this problem.

I am releasing a podcast episode where I discuss some parts of the paper “Gödel’s system T revisited”, and here is a brief note with some of the definitions I tried to talk through:
noteDownload
In 2005, I believe it was, I watched Phil Wadler and Frank Pfenning perform a dramatic version of the proof, under Curry-Howard and following Griffin, of the Law of Excluded Middle. Amazing to see Frank in horns. This way of understanding Curry-Howard for LEM has stuck with me ever since. For my spring class, I wrote a script for a version of this story, with (I think) a fun twist at the end. Here it is:
devil-and-rich-manDownloadThe key to the parable is to connect 




RTA Open Problem 19 asks for a measure-based proof of termination for beta-reduction of simply typed terms. I thought hard about this in the fall (2024) and got… nowhere really. One good thing that came out of the head-banging exercise was finding this paper:
Vrijer-DirectProofFinite-1985DownloadIn it, de Vrijer gives a measure-based proof of termination for a related relation, namely reduction of finite developments in untyped lambda calculus. Here, we must mark some redexes in a term, and are only allowed to reduce those redexes or their residuals. A residual redex is one that can be traced back through reduction to a marked redex in the original term.
The paper is very nicely written, and presupposes little background. I found two notable points along the way to the result. First, there is a very easy way to define residual redexes. We just have marked redexes. These are redexes (applications of lambda abstractions to arguments) with some special syntactic mark, like a prime on the lambda. Then reduction is only allowed to reduce marked redexes. Critically, a lambda abstraction by itself cannot be marked, and so if a redex is created by substituting a lambda abstraction for an applied variable, that redex will not be marked, and hence cannot be reduced.
Second, the paper defines a measure based on what the author calls the multiplicity of a variable x in a term t. The interesting part of the definition is that if x occurs as an argument in a marked redex, then the multiplicity needs to include not just the sum of the multiplicities of x in the subterms of that redex, but also we must multiply the multiplicity of x in the argument by the multiplicity of the bound variable of the redex in the body of the abstraction. This is expressed in this equation from the definition of multiplicity of x in t:

Using this notion of multiplicity, it is then straightforward to define a decreasing measure. What we see happening here is a little bit of dataflow analysis: we have to keep track not just of x, but of where x could go if substituted for a variable y. The dataflow analysis is very simple, because we will not reduce created redexes.
Could a fancier dataflow analysis help with Open Problem 19? Will this post be continued…?

Did you know you can write a safe version of the tail function as a fold? Did you know you can’t?
Let me start with the second question. In this very interesting paper from some years ago, illustrious authors give necessary and sufficient conditions for when a function can be expressed as a fold (or dually, an unfold). The result is derived in category theory for total set-theoretic functions, but examples are shown for familiar Haskell programs. As they summarize in Remark 4.5 on page 7, their theorem specializes, in the case of lists, to the following: a total function h from List A (written [a] in Haskell) to some set B can be written as a fold iff whenever h xs = h ys, then h (x : xs) = h (x : ys). So if h maps two lists xs and ys to the same output, then it must also map the lists x : xs (x cons’ed onto xs) and x : ys to the same output (in general a different one than h xs). In this paper, they note that this result implies that the following total version of the tail function cannot be written as a fold:
stail :: [a] -> [a]
stail [] = []
stail (x : xs) = xs
And indeed, stail [] = stail (1 :: []), but stail (2 :: []) does not equal stail (2 :: 1 :: []). So cons’ing an element (here, 2) does not preserve equality of results for stail. And the theorem implies this cannot be implemented with fold.
But (to answer my first question) if we change the result a little, then we can implement stail as a fold:
stail :: [a] -> Maybe [a]
stail [] = Nothing
stail (x : xs) =
case stail xs of
Nothing -> Just []
_ -> Just xs
This code is still safe, but better than the first version, it signals if it was called with an empty list by returning Nothing. Otherwise, it returns Just of the tail. It works as expected:
ghci> stail [1,2,3]
Just [2,3]
ghci> stail [3]
Just []
ghci> stail []
NothingAnd it satisfies the requirement from Gibbons et al., by blocking the counterexample above: if you call stail on [] you get a different value (namely Nothing) than if you call it on (1 : []), which returns Just [].
This code is essentially just a port of my earlier post about Maybe for Church-encoded naturals, to lists. Notice that stail runs in linear time, because it is a fold. But improving on this, thanks to Haskell’s lazy evaluation, we can get a version where at least pattern-matching on the result is constant-time, by moving the Just constructor out of the two branches of the case (a sensible refactoring anyway):
stail2 :: [a] -> Maybe [a]
stail2 [] = Nothing
stail2 (x : xs) =
Just (case stail2 xs of
Nothing -> []
_ -> xs)I wrote a little benchmark that creates a long list, then calls either stail or stail2, and finally pattern matches on the result, going one level into the list if the result is a Just. This ensures that the tail is actually computed. For stail, the runtime increases as one would expect, becoming plenty (seconds) long for a large list. But for stail2, the computation is instantaneous. Interestingly, compiling stail with ghc -O2 does not improve performance, suggesting that perhaps ghc is not implementing this very simple optimization of lifting applications of the same constructor out of the branches of a case?
Now to get a version of stail2Fold that is an actual application of the foldr function, we have to deal with the fact that unlike stail2 above, we do not have access, in the middle of the fold, to the tail itself. The solution is just to propagate the tail and head together. So in fact, this implements the Haskell function uncons from Data.List:
stail2Fold :: [a] -> Maybe (a,[a])
stail2Fold = foldr (\ x r -> Just (case r of
Nothing -> (x,[])
Just (y,tl) -> (x , y : tl))) NothingHere we are forced to rebuild the list in the Just tl case, and so we cannot escape linear time in general.
The code for this post and my test harness is here: Main.hs, Stail.hs.
Parametricity is a profound principle in the theory of programming languages — but what kind of principle is it? To answer this, let me first recall the idea, as introduced by the great John C. Reynolds in his seminal paper “Types, Abstraction, and Parametric Polymorphism”. (I wrote about this paper in an earlier post.)
Suppose we have some typed pure programming language. (I have no idea how one handles impure features, so let us suppose the language is pure.) We have typings like 


For example, consider the type 

This is a unary predicate, so it accepts one input term 








Nitty gritty details aside, we can see that 






The first difference is that 









Induction, as we know from logic, is the principle you need to reflect in theory the idea of finitely constructed values. Without it, we can have nonstandard models of basic arithmetic axioms, which contain elements that are not just finite applications of constructor
And parametricity expresses a similarly syntactic property for any type, not just a datatype.
So from a foundational perspective, we can see parametricity as a kind of precursor to induction, that applies to all types. From parametricity, induction is indeed easily derivable, assuming some form (possibly weaker than previously recognized) of function extensionality. The details of how to do this can be found in propositions 14 and 17 of the paper “The Girard-Reynolds Isomorphism” by Philip Wadler. But parametricity is more general, as it applies to types that are not datatypes (for example, types for which there is no clear notion of a constructor). One consequence of this is that parametricity is an excellent foundation for studying new forms of datatype, going beyond just the simple sum-of-products form.
Anyway, I wrote this because I really wanted to emphasize that parametricity is like a datatype-independent form of an induction principle. So from a logical perspective, it is very strong and could serve (as others have recognized) as a powerful foundational building block (e.g., for proof assistants).
As a last point: why has parametricity not actually shown up as such a building block? Well, there has actually been rather a lot of attention given to this by type theorists in the past decade or so. The problem seems to be that as it is usually expressed in intrinsic type theory, adding parametricity as a principle leads to very substantial technical complications. An example is the intimidating “Internal parametricity, without an interval”. See Figure 3 for just how difficult this is.
I have an idea for a very simple way to do internal parametricity, but it must wait for another time to describe…
I recently watched a pretty inspiring talk by Avi Press about his experience using Haskell at his startup, Scarf. I enjoyed the whole talk, but something that particularly got me excited was his point that although Haskell is pure, in practice, almost all the code his company was writing ended up being monadic. One simple reason was the need for logging through the codebase. And this really struck a chord with me, because in my experience as a maybe late beginner Haskeller (I would love to discover I am early intermediate, but I doubt it), one of the most frustrating things has been how difficult it can be to debug some pretty large piece of code. Yes, because everything is pure, I could just call functions in ghci, for example, to see if I am getting what I expect. But creating the environment for such calls is a problem — and a well-known one at that, in the world of testing. And unless you want to put every function that you might need logging for into the IO monad (or ok, maybe some more particular monad), you are not going to have access to this very standard debugging practice of printing messages from functions to see what is going on. This is a pretty huge problem for software engineering with Haskell, and it is surprising that there is relatively little said about it.
So Haskell’s promise of purity is getting badly undercut by this simple need to log. It is great that the language is pure, but if you have to use the IO monad everywhere for logging, then you are greatly reducing the number of pure functions in your codebase, and that is sad.
From a research perspective, I am working on DCS, which has an even stricter core language than Haskell’s: pure and also uniformly terminating (all functions are statically checked for termination at compile-time using a novel type-based approach). And there, I am also concerned that if it is too hard to fit one’s functions in that core, then again, DCS programs will get overtaken by monadic code (in a Div monad for possibly diverging computations).
Now in both DCS and Haskell, a pretty simple generalization of the notion of purity would seem sufficient to solve this problem. It should be fine to let a program perform computation in the IO monad, as long as one is not allowed to use the value produced by such a computation, in pure code. So I imagine having a safePerformIO function, like this (in Haskell):
safePerformIO :: IO () -> a -> a
safePerformIO m x = unsafePerformIO m `seq` xThe idea is that we use unsafePerformIO under the hood, and seq to make sure the IO actually happens. But a pure computation x cannot possibly depend on what the IO does, since we just use a computation of type IO (), which does not produce a value within the language. It could happen that the IO computation fails somehow, for example by raising an exception. But even pure code in Haskell can do that, so it does not seem to compromise the purity of pure functions. In DCS, the situation would be different, and one would need to have a library of IO functions that cannot fail (or diverge) to use this idea for DCS code. Otherwise, the core language would not be able to guarantee that functions in the core are guaranteed to terminate (because some code used with safePerformIO had failed with an exception or diverged).
For a very simple approach to logging (no logging levels, for example), we can have some code like this:
logInit :: FilePath -> IO Handle
logInit f =
do
h <- openFile f WriteMode
hSetBuffering h NoBuffering
return h
log :: Handle -> String -> a -> a
log h msg x = safePerformIO (hPutStr h msg) xWe have a function to get a handle for logging, and then another that uses safePerformIO to write a message to the log.
I am planning to use this approach to logging in my Haskell codebase for DCS, because it is just so useful to be able to log some information while trying to debug a complex piece of code. And I do not want to put everything into a monad just to do that.
Thanks for reading! Drop me a line at aaron.stump@gmail.com or comment here, if you have feedback or thoughts.
Strong functional programming was proposed by David Turner, a founding father of modern functional programming (FP), as a better version of the functional programming paradigm realized today in Haskell. Where Haskell insists on purity, strong FP further insists that all functions terminate on all inputs. So strong FP goes beyond pure FP, to guarantee an even stronger property than purity, namely termination. In this post I will suggest a practical approach to Turner’s vision, based on monads.
Purity for a programming language means that there are no implicit side effects: whenever a function is called with the same arguments, it must return the same result. By an amazingly clever trick, we can represent impure functions like getTimeOfDay() — this function is so impure that it is a bug if it ever behaves purely — in the pure language Haskell. We view such functions as implicitly taking an extra input representing the entire state of the computer, and implicitly producing an updated version of that state as an extra output. And then we hide this fiction by using a monad, called IO in Haskell, so you never actually have access to the state. You just have various primitives like getChar :: IO Char. This is a character, but accessing it requires you to enter the IO monad, from which there is no way to escape. So in practice, Haskell programs have an impure layer within the IO monad, and then invoke various pure functions that are not in the IO monad. This is because pure code can be injected into the IO monad using the return function of the monad (which does exactly that: bring pure things into IO).
Now, in Turner’s lovely paper linked above, which I quite recommend, there are arguments for the value of strong FP. But Turner does not explain how to make this practical, and maybe is not even thinking about that, since he worries rather a bit about the fact that the restriction to terminating programs only means that a strong FP language will not be Turing complete. But I would like to point out that for practicality, we need to take the same path that Haskell took for purity. Haskell is pure, but uses monads to allow impure computations. What we need for a practical strong FP language is a language that is pure and enforces termination, but can also accommodate — and here I definitely propose monads as the way to go — impure and possibly non-terminating computation.
So I imagine a world where there is a monad, maybe called GenRec, for possibly nonterminating computation, and code from the terminating part of the language can be injected into that monad using its return function. And GenRec computations could be lifted into IO, too. So we can play the same game that Haskell does, but with two special monads (IO and GenRec) instead of one (just IO).
And while we are thinking this way, about teasing apart the structure of the language using monads, I also am wondering about a monad for possibly type-unsound computation. In OCaml, for example, there is this somewhat infamous Obj.magic which lets you change the type of an expression to anything you want. This could lead to segmentation faults and other disasters. But yet it is there, and apparently is useful in some cases, for example when compiling languages like Coq, with a more powerful type system, to tell OCaml’s compiler to just trust us that something is ok.
So what about an ultimate monad called something like Unrestricted (name too long, ok), that allows unsound casts, general recursion, and IO.
Now your language is accommodating all kinds of programs, and providing a range of guarantees. This is just taking the core awesome idea of Haskell, and expanding it both towards more safe (i.e., the terminating part of the language) and also less (i.e., unsound casts).
A final parting shot on this: with layers of monads, one thinks immediately of monad transformers, and then maybe thinks the idea will be too complicated. But I am exploring currently a language design, which I am intending to head in the direction I have just outlined, where we use subtyping to keep some coercions implicit. This could mean that the super-annoying liftings that are needed with monad transformers could be elided completely using subtyping. My language design is already committed to subtyping for one its central features (a type-based form of terminating recursion), and so investigating subtyping as a way to make programming with layers of monads more workable seems very natural.
Thanks for reading!
Everyone hates to define the predecessor function on Church-encoded natural numbers, right? The wikipedia page has a couple painful options, including Kleene’s solution. Now, I don’t know how original this is, but here is a simpler one. Code below checks in Haskell (with ghc), using language extensions TypeApplications , ExplicitForAll , ImpredicativeTypes. (Thanks to ghc for all those goodies!) Also, need to hide Maybe, succ, and pred from the prelude. Full source code with all this is here.
The idea is to define pred to have type
Nat -> Maybe Nat
where these types are defined (in Haskell) like this:
type Nat = forall(x :: *) . (x -> x) -> x -> x
type Maybe a = forall(x :: *). (a -> x) -> x -> x
They are structurally pretty similar anyway, right? Well, assuming zero, succ, just, and nothing (definitions reproduced just below), we can define pred this way, where the @ is for explicit type application in ghc:
pred :: Nat -> Maybe Nat
pred n =
n @(Maybe Nat) (\ m -> just $ m succ zero) nothing
We start out with nothing, and then for each iteration (n is a Church Nat, so it iterates its first argument n times starting with its second), we apply the Maybe Nat we are given, to succ and zero. If that Maybe Nat is nothing, then this becomes zero. If that Maybe Nat is just x for some x, then applying to succ and zero gives us succ x. We then wrap this in just, to preserve the Maybe Nat type.
Full source includes a function showPred for testing. Helper functions are:
zero :: Nat
zero s z = z
succ :: Nat -> Nat
succ n s z = s (n s z)
just :: a -> Maybe a
just a j n = j a
nothing :: Maybe a
nothing j n = n
This is the easiest version of predecessor I have seen.
The omega-rule of lambda calculus is the principle that if for all closed terms t we have t1 t beta,eta-equal to t2 t, then t1 is beta,eta-equal to t2. This principle is not valid for all t1 and t2, due to the existence of so-called universal generators, which Gordon Plotkin used in a 1974 paper to construct a counter-example to the omega-rule.
Working on Relational Type Theory (RelTT), I found I would really like a form of the rule, though, which happily is derivable. Suppose that t1 and t2 are closed normalizing terms, and that t1 t =beta t2 t for all closed t. Then indeed t1 =beta t2. The proof is easy. By the assumption about t1 and t2, we have that they are beta-equal to some terms 
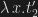
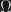
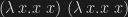
Now suppose that x is free in t1′ and in t2′. Again appealing to Church-Rosser, c1 and c2 must both beta-reduce to some common term q (since they are beta-equal). But the only term c1 reduces to is itself, and similarly c2, so they must be identical. By a simple induction on t1′, the fact that c1 is identical to c2 must imply that t1′ is identical to t2′. The crucial point is that in the case where t1′ is x, then t2′ must also be x, because otherwise t2′ would have to be Omega, but this is ruled out because t2′ is normal. This is why the restriction to normalizing t1 and t2 is critical: it allows us to choose Omega as a term that behaves like a fresh variable when substituted into t1′ and t2′. It cannot equal any term that is already in t1′ and t2′. This is a hint of why universal generators — which as near as I can understand are diverging terms that can reach a term containing t for any term t — can be a counterexample to the omega-rule: we cannot find any term that we can safely use as a stand-in for a variable, because all terms are generated.
I wanted to record this proof here, because the proof in Barendregt is quite involved, running for page after difficult page. It covers a much more general (and apparently much harder) situation, where t1 and t2 need not be normalizing. But for many applications in type theory, we have normalizing terms, and there this simple justification for the omega rule can be used.
