Show full content
Introduction
T. Kelly writes in [1] about “What Every Experimenter Must Know About Randomization.” In a running example scenario throughout the paper, Kelly describes a hypothetical poultry farmer who, wondering whether exposing his turkeys to television will fatten them up, conducts a test using 
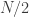
How should the farmer randomize the assignment of turkeys to the treatment and control groups? The main point of the paper– very subtly emphasized in underlined, bold italics– is to “never use a PRNG [pseudo-random number generator] for random assignment.“
I don’t really agree with this guidance at all. I think the arguments presented in its favor are flawed, or at least potentially misleading, on practical, mathematical, and even philosophical grounds. But the paper does present at least one very interesting and subtle observation that I think deserves highlighting and clarification.
Balls into bins
To make the case against using a pseudo-random number generator, Kelly provides a C program, balls_into_bins.c, that simulates the random partition of 
(We don’t actually have to shuffle all 32 turkeys; once we have selected the treatment group– in a uniformly random order– we don’t need to continue rearranging the control turkeys. That is, Kelly effectively implements the first 16 iterations of the mirror_shuffle version of the Fisher-Yates shuffle.)
Kelly’s program then iterates over all 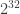
srand(seed), executing this simulated random assignment once for each seed. The idea is to show the distribution of possible assignments, assuming that our farmer conducts the experiment by selecting a “true random” value used as the seed for the PRNG to then (pseudo)randomly shuffle the turkeys to select an assignment.
For a 32-bit seed and 

For example, the red point at (28,1) indicates that there was a single assignment that was generated 28 times by each of 28 different random seeds. The red point at (0,474467), on the other hand, indicates that 474,467 assignments were never generated, never appearing even once among all
The resulting distribution of balls into bins will be far from uniform: Some bins end up with more balls than others, and some bins end up empty— even, perhaps surprisingly, when the number of balls is considerably larger than the number of bins.
That is, there are 
Comparing generators
There is a useful point here, which we’ll get to shortly. But first, it wasn’t clear to me whether Kelly is arguing that the non-uniformity illustrated above is because we are using a PRNG. That is certainly not the case… but at the same time, some PRNGs are better than others, and at first glance it seemed like a rather disingenuous straw man to use the one PRNG that most everyone agrees shouldn’t be used “for serious random number generation needs,” namely the one in the C standard library.
For example, how do things look if we try this experiment on Windows, using the MSVCRT/UCRT implementation of rand()? This took some work, since Kelly’s code does not compile due to lines like this:
static_assert(RAND_MAX == INT_MAX); // would be very weird otherwise
This assertion is, well, weird. Not only is there no language standard guarantee that these constants be equal– and on Windows, they aren’t– neither is there anything in the code that depends on this assertion, so it’s unclear why it’s there in the first place.
The program also uses the stdc_count_ones function defined in the stdbit.h header, which is new enough that it may not be available depending on how up to date your environment is, on either Linux or Windows. But here as well, we don’t really need this function, or even an equivalent replacement, to get the job done.
So to get things working, I wrote balls_into_bins.cpp (code is on GitHub, where I’ve included Kelly’s original balls_into_bins.c for side-by-side comparison), with the same behavior, but which (1) works on both Linux and Windows, and (2) allows us to select which of several random number generation approaches we want to evaluate:
- The Linux GLIBC pseudo-random generator that reproduces Kelly’s original results exactly.
- The Windows MSVCRT/UCRT pseudo-random generator.
- The “true” random RDSEED hardware-based generator using the
_rdseed64_stepfunction.
The hardware random number generator is understandably much slower; on my laptop it produces only a little over half a million 64-bit words per second. But eventually we see the output shown in blue above, with “non-uniform” behavior very similar to the GLIBC PRNG.
In other words, we should expect to see some treatment assignments selected more often than others. And we should expect to see some assignments not selected at all; with 


which matches pretty closely with the 474,467 empty bins using the GLIBC generator, and the 473,435 empty bins from my particular output using RDSEED.
However, there is clearly something different going on with the Windows UCRT implementation, shown in green above. One interesting “feature” of the UCRT behavior is that we only see even numbers. That is, each assignment (“bin”) is always randomly generated an even number of times– possibly zero times, or twice, or four times, etc., but never exactly once, nor exactly thrice, etc. (Obligatory puzzle: why?)
Repeatability
So what, exactly, is the point being made here? Certainly a poor PRNG like the Windows UCRT generator can cause unintended bias. But the GLIBC PRNG is better behaved, at least from the perspective of the balls-into-bins experiment described here. For example, for both the GLIBC output as well as the “true” random RDSEED output, a chi-squared test would fail to reject the null hypothesis that the selected assignments constitute a truly (uniformly) random sample.
However, there is a key difference between the two generators, namely their repeatability. That is, although it’s true that the RDSEED hardware random generator “misses” nearly half a million possible turkey treatment assignments in the above output, if we were to run the program again with the RDSEED generator, we would once again fail to select roughly half a million assignments… but it would be a different subset of missed assignments. But with the GLIBC PRNG, it is the same persistent subset of exactly 474,467 specific assignments that will never be selected, no matter what seed we use, no matter how many times we run the program. For any one of those persistently-missed assignments, the probability that the farmer selects it for his experiment should ideally be 
“True” vs. pseudo-random numbers
I think it’s an interesting question when, and just how much, this matters in any practical sense for many real experimental scenarios. There are certainly scenarios where it can matter— but in this running example of the farmer experimenting on his turkeys, it’s less clear to me what actual problem might arise from what effectively amounts to bootstrapping from a single prior uniformly sampled multiset from the population of treatment assignments.
But if we did want to “fix” our farmer’s methodology, there are at least a couple of simple ways to do so. For example, Kelly’s setup assumes that the farmer starts by generating 32 “truly” random bits with which to seed a pseudo-random number generator. Maybe those seed bits are obtained by repeatedly flipping a fair coin; but if we’re willing to assume access to 32 “truly random” bits to seed the PRNG, then why subsequently bother with the PRNG at all? As Kelly points out, we only need 
The above alternative abandons pseudo-random numbers altogether, and only uses a “true” random source of numbers to generate an assignment. I’ve been putting “true” in quotes here, since Kelly never defines or explains exactly what is meant by “true” randomness. It doesn’t seem to require anything quantum mechanical or otherwise theoretical, for example; indeed, the requirements seem pretty lax:
Random assignment does not require a computer. Physical coins or urns are reasonable options sanctioned by many statisticians today, for the same reasons that casinos and lotteries continue to use dice, roulette wheels, and other mechanical contraptions.
Kelly is even okay with “re-using” randomness for an experiment, as long as it’s “unrelated” to that past use:
Regarding “canned” entropy (e.g., from an old-fashioned table of random numbers), I’m aware of no reason why such entropy would lose its usefulness merely from being recorded and stored for a period of time. Similarly, regarding “recycled” entropy that has already been used for purposes unrelated to the one at hand, I’m aware of no reason why such entropy would be any less useful than if it had not been used before for any purpose.
This is what I find confusing and contradictory. A not-completely-terrible intuitive description of a PRNG is “an old-fashioned table of random numbers”… but one that is so large that we never need to re-use any of it. That is, for example, suppose that when we complete our undergraduate statistics education, we seed a pseudo-random number generator, one time, and use that single stream of random numbers for the duration of our lifetime, or at least for our entire career as an experimenter. When we need some random numbers, we extract them, then store the subsequent generator state on disk. When we need some more random numbers, we restore the generator state from disk, extract some more random numbers, rinse and repeat.
If our experiments are “slow” like testing turkeys, and not “fast” like computer simulations, then such a single pseudo-random stream is plenty long enough to support more experiments on more test subjects than our farmer can possibly conduct in their lifetime. And if we are worried, as Kelly writes, that “the outcome is a foregone conclusion, completely devoid of uncertainty, no matter how random the sequence might appear,” then why is an old-fashioned published book of random numbers acceptable?
Reference:
- Kelly, T., What Every Experimenter Must Know About Randomization, ACM Queue Magazine, 23(6), November/December 2025. [PDF]




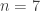 bottles, a coarse lower bound of at least
bottles, a coarse lower bound of at least  guesses are necessary in the worst case. How close to this bound can we get?
guesses are necessary in the worst case. How close to this bound can we get?
 possible secret codes, replicates the results in Knuth’s paper: an expected number of guesses of 5801/1296, or about 4.476, never requiring more than a maximum of 5 guesses.
possible secret codes, replicates the results in Knuth’s paper: an expected number of guesses of 5801/1296, or about 4.476, never requiring more than a maximum of 5 guesses.
 finalists in a skiing championship. There are two rounds: in the first round, each finalist skis down the mountain, recording their finishing time; this is repeated in the second round, with the least total time for both runs winning the championship. This is the top talent in the world, so the time for every run is independent and identically distributed. Having learned that you have the best time in the first round, what is the probability that you will win the championship? For extra credit, what if
finalists in a skiing championship. There are two rounds: in the first round, each finalist skis down the mountain, recording their finishing time; this is repeated in the second round, with the least total time for both runs winning the championship. This is the top talent in the world, so the time for every run is independent and identically distributed. Having learned that you have the best time in the first round, what is the probability that you will win the championship? For extra credit, what if 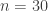 ?
? — for normally distributed run times– appears to require resorting to simulation or approximation, although
— for normally distributed run times– appears to require resorting to simulation or approximation, although  and
and  to be the finishing times for our first and second run, respectively, and similarly define
to be the finishing times for our first and second run, respectively, and similarly define 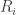 and
and  to be the first and second round times for each competitor
to be the first and second round times for each competitor  . Define event
. Define event  to be
to be  (i.e., we beat competitor
(i.e., we beat competitor  overall) and event
overall) and event 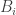 to be
to be  (i.e., we beat competitor
(i.e., we beat competitor 

 . Second, in the numerator, if we condition on fixed times for our two runs, say for example
. Second, in the numerator, if we condition on fixed times for our two runs, say for example  and
and  , then the
, then the  events
events  are independent– so we can multiply them– and they all have the same probability.
are independent– so we can multiply them– and they all have the same probability. that we beat a particular competitor in both rounds.
that we beat a particular competitor in both rounds.
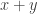 is less than or greater than 1; putting everything together, the desired probability is
is less than or greater than 1; putting everything together, the desired probability is




 cards, and selects an (unordered) subset of any
cards, and selects an (unordered) subset of any 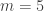 cards and hands them to the magician’s assistant. For example:
cards and hands them to the magician’s assistant. For example:
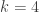 of these cards in a row left to right, as shown below, keeping the remaining selected card hidden.
of these cards in a row left to right, as shown below, keeping the remaining selected card hidden.
 is necessary and sufficient for the trick to be feasible, at least in principle:
is necessary and sufficient for the trick to be feasible, at least in principle: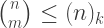
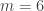 dice each with
dice each with 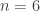 sides (maybe from their
sides (maybe from their  values shown, and announces the value on the covered di(c)e.
values shown, and announces the value on the covered di(c)e.
 corresponds to writing down a 10-digit number, the assistant covering one of the digits, and the magician announcing the hidden digit.
corresponds to writing down a 10-digit number, the assistant covering one of the digits, and the magician announcing the hidden digit. case.
case. cards from a deck of
cards from a deck of 
 collectors, one for each dial, each independently trying to collect
collectors, one for each dial, each independently trying to collect  coupon types, one for each incorrect digit on that dial. Each day, all
coupon types, one for each incorrect digit on that dial. Each day, all  coupon types.
coupon types.

 of
of  of successful shots he took that day. Assuming that every shot is an iid Bernoulli trial with success probability
of successful shots he took that day. Assuming that every shot is an iid Bernoulli trial with success probability  , can we estimate
, can we estimate  times on a given day, was that out of 20 attempts, or 25, or 150? Not only did Paul not record that corresponding total number
times on a given day, was that out of 20 attempts, or 25, or 150? Not only did Paul not record that corresponding total number 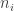 of attempted trials each day, but that total varied from one day to the next: some days it might be just one “stand” of 25 shots, other days it might be several hours with hundreds of shots.
of attempted trials each day, but that total varied from one day to the next: some days it might be just one “stand” of 25 shots, other days it might be several hours with hundreds of shots. , that is just as unknown to us as
, that is just as unknown to us as 

 and
and  , respectively (with all cards known to both players).
, respectively (with all cards known to both players).
 of them, by grouping game outcomes according to the sequence of frame “types”: strike, spare, or open. For example, the eventual solution described above occurs in a game of the form (strike, strike, strike, strike, open, open, open, open, open, open). Having fixed the type of each frame in the game, now we can describe the number of pins knocked down and the resulting total score as linear functions of variables indicating the number of pins knocked down by each roll.
of them, by grouping game outcomes according to the sequence of frame “types”: strike, spare, or open. For example, the eventual solution described above occurs in a game of the form (strike, strike, strike, strike, open, open, open, open, open, open). Having fixed the type of each frame in the game, now we can describe the number of pins knocked down and the resulting total score as linear functions of variables indicating the number of pins knocked down by each roll. using Monte Carlo simulation. Or we can find some mathematical problem where the occurrence of
using Monte Carlo simulation. Or we can find some mathematical problem where the occurrence of 
 equal 1 if a dart lands within the inscribed circle– or within the inscribed 90-degree circular sector shown above, which has the same area– otherwise
equal 1 if a dart lands within the inscribed circle– or within the inscribed 90-degree circular sector shown above, which has the same area– otherwise  . Then
. Then  is the ratio of areas
is the ratio of areas  , so that we can estimate
, so that we can estimate  , where
, where  . In Python:
. In Python: equal to the number of times a particular noodle crosses a line on the floor.
equal to the number of times a particular noodle crosses a line on the floor.
 . (Note this is an expected value, not just a probability, because it works even if we cook the noodles, so that
. (Note this is an expected value, not just a probability, because it works even if we cook the noodles, so that  . Again in Python:
. Again in Python: first exceeds the number of tails
first exceeds the number of tails  , so that we win
, so that we win  .
.
 position of a dart, while a coin flip is a single random bit. The ability and relative speed of extraction of a single random bit varies from language to language and library to library. For example, even sticking to Python, it’s interesting to compare the above
position of a dart, while a coin flip is a single random bit. The ability and relative speed of extraction of a single random bit varies from language to language and library to library. For example, even sticking to Python, it’s interesting to compare the above  . Then there is a positive probability
. Then there is a positive probability  that a game will never end, with a meandering deficit of heads that is never overcome. (Which means that the endless loop through games above is guaranteed, with probability 1, to eventually encounter and get stuck on such a never-ending game.)
that a game will never end, with a meandering deficit of heads that is never overcome. (Which means that the endless loop through games above is guaranteed, with probability 1, to eventually encounter and get stuck on such a never-ending game.) , then the situation improves. For example, let’s suppose that we play the game with a biased coin with
, then the situation improves. For example, let’s suppose that we play the game with a biased coin with  . Then the expected return from this game is
. Then the expected return from this game is  , so we can still estimate
, so we can still estimate 

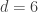 decks of playing cards, and play a series of rounds of blackjack, each using the same fixed CDZ- playing strategy, stopping at the “cut card”, a marker inserted in the shoe indicating when to reshuffle. Let’s place the cut card at “penetration”
decks of playing cards, and play a series of rounds of blackjack, each using the same fixed CDZ- playing strategy, stopping at the “cut card”, a marker inserted in the shoe indicating when to reshuffle. Let’s place the cut card at “penetration”  , that is, stop and reshuffle when at most
, that is, stop and reshuffle when at most  decks or 78 cards remain in the shoe. Let the random variable
decks or 78 cards remain in the shoe. Let the random variable 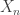 be the outcome of the n-th round. The figure below shows estimates of
be the outcome of the n-th round. The figure below shows estimates of  , in percent of initial wager, from just 1000 simulated shuffled shoes.
, in percent of initial wager, from just 1000 simulated shuffled shoes.
 or so (for this particular choice of rules, playing strategy, and penetration). The motivation for this post is to show that the cut card effect actually “begins” much earlier in the shoe, at round
or so (for this particular choice of rules, playing strategy, and penetration). The motivation for this post is to show that the cut card effect actually “begins” much earlier in the shoe, at round  in this case.
in this case. , provided we do not run out of cards.
, provided we do not run out of cards. . Now compute the expected return from playing a second round, after having played a first round off the top of the shoe: this is
. Now compute the expected return from playing a second round, after having played a first round off the top of the shoe: this is  , etc.
, etc. possible arrangements, computing each expected return exactly, then the above theorem states that this curve would be exactly constant for those small
possible arrangements, computing each expected return exactly, then the above theorem states that this curve would be exactly constant for those small  , so what counts as “small”
, so what counts as “small”  be the number of cards of rank
be the number of cards of rank  consumed. Then the problem is to find non-negative integers
consumed. Then the problem is to find non-negative integers 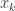 :
:



 .
. , then we can be confident that the expected return from playing the upcoming round is the same as if we walked up to a full shoe:
, then we can be confident that the expected return from playing the upcoming round is the same as if we walked up to a full shoe:  is almost certainly not exactly equal to
is almost certainly not exactly equal to 