Show full content
Well, I installed Arch. Kinda. Fearing the inevitable forced push to Windows 11, I was casually on the lookout for my next distro. There's one I keep seeing in ads on google whose name I incredibly can't remember despite all the articles I've read about it. I've also always wanted to try void linux. But my main issue is that I've built myself a rather nice little gaming rig, and I'd rather be able to you know, actually use that beefy graphics card in there for something other than running AI models. Then, and I don't even remember how, I stumbled onto Garuda Linux.

Now I know, you're asking yourself, why the hell would you pick up some gimmick distro like this when you could grab something nice and stable like Ubuntu instead. Well yes. Garuda is a rolling Arch release and is therefore sort of a moving target to keep up to date and running properly. Now my ideal Linux distro for my gaming rig has the following goals:
- GPU and hardware support
- Can play modern PC games
- Good for development (though lower priority - I develop on my laptop mostly these days).
So, it seems that Garuda's gaming flavor actually checks a lot of these boxes for me, quite unexpectedly. To be honest, I come from a time when "compatability" with gaming related stuff on Linux was a pipedream. To be honest, I think that the importance of Nvidia drivers on linux for AI development alongside the introduction of the Steam Deck were a one-two punch that must have forced progress forward.
So far I'm about 3 days into it and it still feels good, and I've had very little issues in terms of compatability. I'm running everything from built-for-linux games to the new Silent Hill remake with no issue. Take a look at some of the one-click install emulators:

Here's a few features I'm really excited to have.
LutrisLutris is a frontend for launching and installing games from a bunch of different launchers. It's a really convenient way to both see your entire library and be able to add stuff like launch configurations.
SnapperSnapper automatically does system backups when you use the package manager on the system or do other weird stuff. So far I haven't had to rely on it, but I'm quite glad it's there.
FloorpImmediately became my new browser of choice. Floorp is a new privacy focused firefox derivative from Japan. It has even nicer security features cooked into it than base Firefox, and a lot of the nice features of Opera too.
BatBat is a cat replacement on the CLI which lists file names with colored syntax highlighting. Instant win.
StarshipStarship is a status line rice tool that comes with some pretty nice defaults stock with Garuda. It's highly platform agnostic which means it syncs very easily with my old Debian install as well.
ChezmoiChezmoi is a replacement I grabbed after I found that yadm had been deprecated. It has some really advanced features around encryption and templated dotfiles, and despite it having a bit of a learning curve I'm liking it better than yadm already. Note that I installed this myself - it wasn't part of the distro out of the box.
Nerd fonts and emoji fonts are preinstalled, and the default is FiraCode mono with code ligatures - my absolute favorite programming font.
Shell configurationThe shell rc is already heavily tricked out with some very nice options. This is where I learned about bat and exa. I directly stole a ton of the aliases for myself.
# Replace ls with exa
alias ls='exa -al --color=always --group-directories-first --icons' # preferred listing
alias la='exa -a --color=always --group-directories-first --icons' # all files and dirs
alias ll='exa -l --color=always --group-directories-first --icons' # long format
alias lt='exa -aT --color=always --group-directories-first --icons' # tree listing
alias l.='exa -ald --color=always --group-directories-first --icons .*' # show only dotfiles
# Replace some more things with better alternatives
[ ! -x /usr/bin/bat ] && [ -x /usr/bin/batcat ] && alias bat='batcat'
alias cat='bat --style header --style snip --style changes --style header'
[ ! -x /usr/bin/yay ] && [ -x /usr/bin/paru ] && alias yay='paru'
# Common use
alias grubup="sudo update-grub"
alias tarnow='tar -acf '
alias untar='tar -zxvf '
alias wget='wget -c '
alias psmem='ps auxf | sort -nr -k 4'
alias psmem10='ps auxf | sort -nr -k 4 | head -10'
alias ..='cd ..'
alias ...='cd ../..'
alias ....='cd ../../..'
alias .....='cd ../../../..'
alias ......='cd ../../../../..'
alias dir='dir --color=auto'
alias vdir='vdir --color=auto'
alias grep='ugrep --color=auto'
alias fgrep='ugrep -F --color=auto'
alias egrep='ugrep -E --color=auto'
alias hw='hwinfo --short' # Hardware Info
alias ip='ip -color'
if [ -x /usr/bin/fastfetch ]; then
fastfetch
fi
I didn't even know ip had a color mode. The future is now. Speaking of one-click configurations, here's a few more:
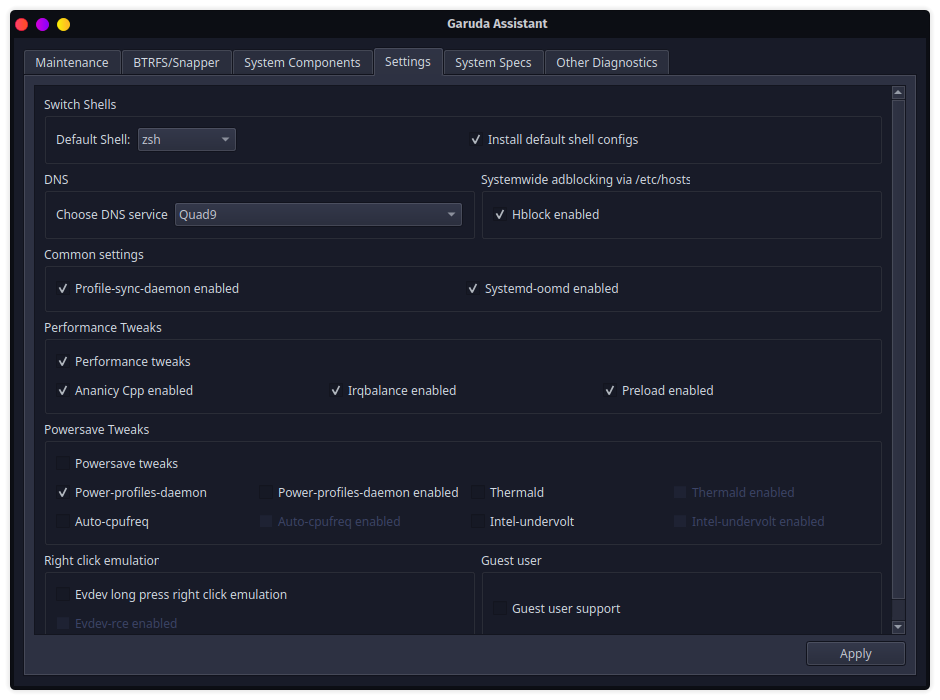
Wow was not expecting to be saying this but I guess linux has come really far since the old days. I just played the demo for a VR fishing game on Steam, on Arch linux. It's definitely more clunky than on windows, but it's running just fine. I think I need to fiddle with the FPS a bit but wow for real. That's awesome.
ConclusionI'm perfectly happy here. I think the one annoying thing is needing to update the system all the time but that's Arch I guess. I sure as hell won't be going to Windows 11 anytime soon. I need to cut this short or else I'm never going to publish it. I'll be sure to update later if I have any serious updates.