It is with much joy that we finally release version 1.0 of Quartex Pascal! It represents three years of full time development, and over a 1,5 million lines of streamlined, hard-core coding.
Show full content
It is with much joy that we finally release version 1.0 of Quartex Pascal! It represents three years of full time development, and over a 1,5 million lines of streamlined, hard-core coding.
Here running the Three.js component wrapper demo
Quartex Pascal is very much ‘the road less taken’ in terms of engineering. A product that compiles object pascal to JavaScript, has its own RTL (runtime library) with hundreds of classes that interface with both the DOM and NodeJS. A system that has its own independent IDE with debugging, package support, form design and much, much more!
Just the beginning
This is just the beginning of the journey, and we do not intend to rest of our laurels. Updates and improvements will be frequent, as will new and exciting packages, project types and ready to use code.
Easy license management
Next up is non-visual components and datamodules, followed by database components – which brings drag & drop development to NodeJS and Deno. More advanced features and visual components, more packages, more wrappers and more code generation. Doing full scale applications for the browser will never be the same!
We hope you find our work useful and see the potential in Quartex, especially when planning to implement web versions of your existing desktop applications.
For a while now I have come across reddit and X posts about this technology, and I honestly didnt understand what all the hoopla was about. People are using these tiny devices that looks a bit like a late 80s or early 90s pager, and they send text messages with them? But why? We already have SMS, what could possibly Meshtastic have to offer beyond that?
Show full content
For a while now I have come across Reddit and X posts about this technology, and I honestly didnt understand what all the hoopla was about. People are using these tiny devices that looks a bit like a late 1980s or early 90s pager, and they send text messages with them? But .. why? We already have SMS, what could possibly Meshtastic have to offer beyond that?
Well, I was in for quite a surprise! And learning curve. So in this article I will do my best to give you a clear cut explanation of what this technology is, what you can do with it, and why people are so crazy about it.
Lora is not Meshtastic
When I first asked around regarding Meshtastic I found it very difficult to get a straight answer. You had terms like Lora, Lorawan, Lora Plus, LilyGo, ESP32 and many others that made the subject more complicated that it actually is. So I will start with the basic terminology you will encounter and save you some time.
Lora is an abbreviation for ‘long range radio’. It is simply the ability to send small data packets over long distances. This type of technology used to be quite bulky (and expensive) -but since this tech is central to mobile phones it has been gradually refined and affected a whole host of associated technologies. You can now buy a Lora chip the size of a fingernail, complete with flashable firmware and Arduino compatible interfaces.
Lora Plus is a much improved Lora chipset which is set to be released later this year. It offers higher frequencies, larger data transfers, better range, and better signal detection.
Lilygo is just a brand name, they produce a variety of Lora devices, including the Lilygo T-Deck which is very popular as a stand-alone message device. It looks kinda like an old school blackberry from the late 90s, sporting a small keyboard.
LoraWan is when you run several devices in a custom network, often with a central hub acting as a server. The server can push the incoming data onto the internet for further processing, and orchestrate data flow and routes.
ESP32 is a family of low-cost, energy-efficient microcontrollers that integrate both Wi-Fi and Bluetooth capabilities. They typically have a small Risc-V CPU embedded as well as cryptographic hardware acceleration. In a lot of devices the ESP module is the ‘brains’ of the hardware.
SX1276 and similar ‘SX’ chips is the Lora part of the equation. When you pair these with an ESP32 you essentially have a device that can run software, send or receive encrypted messages, that can have firmware flashed and running, and that you can use for your IoT projects.
With the basic terminology out of the way, what exactly is Meshtastic in all this? Well, having hardware that can send and receive data is cool -but it’s not going to achieve anything unless there is software that organizes everything. And that is ultimately what Meshtastic is. It is a protocol and firmware that makes it possible get messages from A to B. It also implements message forwarding functionality so that a group of nearby devices can automatically form a mesh and ensure delivery far beyond the range of a single device.
Meshtastic also has a UI that you can flash onto devices with a proper display. This works really well with touch enabled screens.
Meshtastic has a nice UI for devices with a proper display
As a coder you can think of Meshtastic like a homebrew low-level network stack. Meshtastic does not deal with networking in the traditional sense (no TCP/IP), just message delegation (read: single packets, like UDP). For more elaborate stuff like video, audio or data streaming (or actual TCP/IP over radio) you need to wait for Lora Plus, which should be out this fall. But let’s dig into some questions!
Why not use a normal phone?
There are several reasons why GSM can be a bad choice. The most obvious is that Lora hardware cost virtually nothing and is a one-time purchase rather than a monthly expense. You can get Meshtastic capable devices for as low as $5, which is simply unbeatable compared to GSM or NPR (new packet radio, basically tcp/ip over ham radio). Lora is so afforable and so easy to use that it’s not really a question of why, but rather why not?
Depending on the hardware you get (and what you plan to use it for), you could have sensors 10 km aways running off a small solarpanel and a couple of batteries. Sensors that report data back on interval without the need for any monthly subscription. A lot of cities have Lora networks for things like weather reporting, sea level reporting or traffic reporting that can run for years without any maintainance. They use Lora because these systems must operate even if cell towers have collapsed or the power grid is down. Blindly relying on a single technology like GSM makes us more vulnerable.
The second reason has to do with automation. If you own a fancy robot lawnmower (the big ones), chances are it’s using Lora to communicate with it’s base-station. Lora is also used in smart homes, like outdoor lights that turn on when the sun goes down, or smoke alarms that operate as a mesh. And ofcourse window alarms that trigger if someone penetrates the glass or force the hinges open. Some cheaper systems use Bluetooth (notoriously unreliable), but in the more expensive models you find Lora tech.
Meshtastic devices comes in all sizes and price ranges. You can pair them with your phone and send messages from the Meshtastic app.
The third reason is that Meshtastic, or Lora devices in general, are completely off grid. If a group of people go hiking far up in the mountains where no GSM cell towers exist, they can still communicate many kilometers apart. Even longer if the terrain allows it. You dont need much to boost the signal either. A small TV antenna (like those on RV’s or caravans), a 10 watt coax amplifier and a $10 frequency filter – and you can cover as much as 20 kilometers quite reliably. The price? Less than $100 for a full kit! Obviously such antennas are best suited for a permanent installations, like a cabin or your house. There are better choices for backpacking or hiking that still gives you amazing range.
The fourth reason is privacy. Society as a whole has somehow handed over it’s collective privacy to big corporations like Google and Apple. People did this because they believed nobody would violate common decency perhaps, it was never a conscious decision, it just happened. Sadly these companies are driven by greed on a level most people cannot even imagine, so privacy and trust was canibalized from the start. Corporations dont have a concept of decency, not unless people force them. And governments are even worse.
We have all (at least I have) had that creepy experience where we talk about something with our partner or friends in real life, only to discover that our phone serves us adverts for that exact topic afterwards. Even though the phone is locked it still listens. And whatever we type into our phones or search for online, is logged and processed. Your personal life is for sale to the highest bidder by data brokers and organizations you dont even know exist. I think that if people saw the amount of info their phone uploads about their lives, they would never look at a phone the same way again.
That last part makes my skin crawl to be honest. I like the idea of miliary grade encryption not because I have anything to hide (my life is definitely not that interesting), but for the principle of it. The encryption is not because I am doing anything wrong, it’s because governments and nameless corporations have a history of unethical conduct and doing wrong. We sadly live in a world where governments will violate your trust and rights in a heartbeat -yet demand unconditional access and control over every aspect of your life.
They can fuck off. Sorry for being so blunt but my tolerance towards politics and the corrupt psychopaths drawn to that profession ran out decades ago. I am vehemently, violently even -opposed to globalism. As i am opposed to digital currency, digital id’s and all forms of social scores or carbon footprint insanity -which is only something a Communist or Nazi police state would force on its citizens.
If I send a message to a friend of mine asking if we should grab a beer – that is nobody’s business! Not the government, not the telecom companies, not the advertizing companies and definitively not Google, Apple or Microsoft.
Privacy matters
I think the latter is probably why Meshtastic has become so popular in the US. Americans are by nature suspicious about their government, and looking at the state of Europe right now (UK especially), I cant help thinking that they were right all along. We never should have agreed to disarm, and governments should only service law and order, basic infrastructure, social security, national security and education without any ideological taint allowed at all. The risk of corruption is simply too great if we allow government to involve itself in every aspect of our lives.
Meshtastic can be a life-saver if you get separated from a group where there is no GSM coverage
But it’s not just Americans that have adopted Meshtastic wholesale. No other nation on the planet has as good coverage as Germany, with France coming in as a solid second. Germany and France are plastered with Meshtastic repeaters and nodes, and while I can only guess – Im pretty sure you can send a message from south-east Germany all the way to the northern tip of France due to the sheer number of nodes involved. And those are the repeaters that are registered on the Meshtastic global map. It is completely optional if you want to register, or take part in message forwarding at all.
Just because you have a Lora capable device, does not mean it runs Meshtastic. Most proprietary products run their own firmware with their own data structures and codes.
Lora doesn’t have a boss. It’s not a technology owned by a single company, but rather a standard for sub gigahertz communication.
Not an alternative to 4G or 5G data
Being able to communicate off-grid is awesome, but what kind of throughput are we looking at here? Can Lora be used to stream movies or send files? Are we looking at the ultimate technology for pirates and criminals the world has ever seen?
Nope! High throughput of data requires better radio modulation and a stronger signal. The reason we have 4G and 5G towers all over the place is for this exact reason, namely that high frequency transfer of data is crippled by the poor range of our phones. In Europe Lora is limited to 863 Mhz, while the US operates with 915 Mhz. There are also cycle-rules. Basically you must leave a few milliseconds between messages to allow others to co-exist on the same frequency band.
Secondly, the frequencies used by different technologies (e.g HAM, BT, GSM etc) are subject to international standards. If you blast data on frequences allocated for say, ambulances, emergency helicopters or commercial airliners, you risk endangering people’s lives. There is a fine line between “going off grid” in the name of privacy and being a reckless asshole. Lora is simply not built for fast data transfer (which is where Lora+ comes in which I cover briefly below). Sure there are hacks, but not out of the box.
Either way, you can forget any ideas you have about streaming large files. The reason Meshtastic has a 200 ascii character limit (just like the old SMS standard) is because that fits within a 256 hardware byte buffer. It is ofcourse possible to build a packet-system on top of this, where your file is split into chunks of say 200 bytes (leaving 56 bytes for header, index, and size) and then ship them in sequence with basic fault tolerance – only to re-assemble the data at the other end. But even if you use a signal booster and coax antenna, you are looking at a throughput of roughly 1024 bytes a second (so 1KB/s). In theory you could maybe squeeze 1500 bytes through if you ignore cycle rules but I think 1k is a more realistic number. This is literally early 1980s serial cable speeds.
Note: Having a signal booster does not make the data travel faster, it simply makes the signal stronger and gives you less packet loss.
Speed hacking
If the poor data transfer speeds is an issue you have two options. The first is to wait for a few months until Lora+ starts shipping, or – if you have already invested in some Lora / Meshtastic devices, you can implement your own protocol and get approximately 35 to 200 KB/s with them.
Above: A Yagi antenna is cheap and a solid option for repeaters that needs to cover 15-20 Km. But yeah, not something you casually carry. But perfect for the cabin or an RV. One of these suckers can cover the entire city I live in.
Turns out that the terrible data transfer speed is not fully determined by the device itself, but rather by the default firmware and Meshtastic protocol. There is also the obvious bottleneck of having a tiny antenna and weak signal. All of that can be fixed with less than $50 in parts though, provided your lora device is based on the SX chips (e.g SX1262 or the waveshare hat for Raspberry PI).
I am not going to pretend to know the mysteries of Lora in depth, but by default the device is operating in FSK mode (standard lora radio modulation). To get better data speeds you need to enable GFSK (Gaussian Frequency Shift Keying) which gives you the following benefits:
The Lilygo T-deck is a pretty sweet device!
Smoother Signal: GFSK uses a Gaussian filter to smooth out frequency changes, so the signal doesn’t jump abruptly like FSK. This reduces signal splatter (interference to nearby frequencies), making GFSK cleaner and less likely to mess with other devices in the 868 MHz band.
Better Range: GFSK’s smoother signal loses less energy to noise, so it travels farther with the same power (e.g., 30 dBm on your E90-DTU). You’ll get closer to 8-10 km range compared to FSK, which might drop off sooner in urban areas.
Higher Data Rate: GFSK packs data more efficiently by avoiding sharp frequency shifts, letting you push higher speeds (e.g., 1-2 Mbps, ~125-250 kB/s) without errors. FSK is sloppier, so it’s harder to hit those rates reliably on the SX1262.
Less Noise Sensitivity: GFSK’s filtering makes it less prone to picking up interference, which is key in busy 868 MHz bands. FSK can struggle with noise, dropping packets more often.
There have been community experiments around this, where someone has forked the Meshtastic github repository, then gone in and edited the radio initialization code to enable GFSK. This isolates you from the standard Meshtastic devices – and you can only communicate with other devices that have been altered the same way though.
That might not be such a drawback if you are creating devices meant for an isolated group or a disaster scenario, like one device for each of your family members. A good coder would expand the meshtastic software so you could switch back & fourth between modes. But obviously you need to spend some time with the firmware and UI code to do this. The Meshtastic software wont give you any longer messages anyhow, so I would look at other frameworks that can handle data transfer and/or audio encoding. Preferably a packet oriented protocol capable of any data length.
Above: A tactical antenna is a good compromise, and its not more obtrusive than a walkie-walkie
The way that Meshtastic operates is not really that complex. It’s a very ad-hoc kind of protocol that broadcasts from a 256 byte buffer, blindly forwards messages it picks up meant for other devices etc. It’s nowhere near as complex as say, TCP/IP or doing your own packet driver.
Range will see a slight reduction in GFSK mode. If your device covered 10 Km under perfect conditions (just to pick a number), you will probably be down to 8 or 7 Km with GFSK. And this is where a tiny amplifier + Yagi antenna comes in (or anything larger than a toothpick whip antenna). Both parts cost between $10 to $20 on AliExpress – so not a huge expense. Adding a saw coax filter (just a dongle you attach between the yagi coax and the dapter for your device) you should hit 20 Km if the terrain allows it.
That’s not half bad if you need to communicate with your kids far up in the mountains with no GSM coverage. Or if you are on vacation and need to stay in touch without a massive international phone bill.
A more nerdy application for GFSK
Imagine the following: You have a Raspberry PI with a Waveshare hat. You install a pimped out Amiga emulator with the entire Aminet repository, and you boot into the coolest BBS the early 90s could buy. You add a power-bank and hook that up to a small solar cell, the ones with suction cups that you attach to a car window — and then you 3d print a nice case for the PI with no cable-soup except the battery pack. And just leave it in the windowsill.
Everyone within 10-15 kilometers that has the same Raspberry PI hat and firmware can now access your BBS like its 1993. No internet required! They can download and upload software, use the chat forums, read articles, watch demos and listen to mod music. If you remember mIRC back in the late 90s for PC? – it’s kinda like that, but with more features.
The idea of having my own BBS in a box does appeal to me!
I have to admit I kinda like the idea of having a completely separated network; a completely separate world almost, that i can share with my geeky friends. That we have reached a point in history where the entire technical reality of the early 90s can fit in a box, running self contained off a 20w solar panel and $100 in parts -is frikken mindblowing! There is something so cool about that! Heck, we would have killed to have something like this back in the day.
That you can add military grade encryption to it — all the better. It’s a matter of principle.
With this tech it is almost inevitable that someone will marry a Raspberry Pi + Waveshare and create a digital walkie talkie. Encoding voice to 8bit audio (tin-can sound of early cellphones) with encryption and a 64bit signal identifier. All the difficult stuff is already done and in place, you can literally do this in node.js with a fancy HTML front-end and say good bye to your old walkie-talkie.
It’s technically possible, but somebody has to will it into reality by doing the firmware.
Lora Plus
This article as been about Lora as it exists right now, however – that is about to change later this year. Lora+ is the next iteration of the technology and it was announced somewhere back in april. It is currently being tested to iron out any kinks. What can you expect? Well for starters it gives you a theoretical 300 KB/s out of the box, and a range of 10-15 kilometers by default.
This is where things really get’s interesting, because now we are talking about potentially streaming video at 480p, running a proper tcp/ip stack for traditional networking on top of Lora – and obviously messages akin to MMS rather than old school SMS.
From what I understand of the specs it supports several frequencies in the same chipset. So messages are shipped as before, while data ships on frequencies closer to Wi-Fi. This is to simplify creating gateway devices where signals from sensors (Lorawan) are piped onto an ordinary tcp/ip network (hence the Wi-Fi frequencies).
The Wi-Fi stuff is not really that interesting for standalone meshtastic devices or communicators. Handy, but the range will be limited. I might have misinterpreted the specs, so please correct me if im wrong.
What is interesting is the larger cache, meaning more bytes can be sent and received -and the overall speed of the chipset, which makes packet oriented protocols over long range possible.
It’s basically super affordable hardware that can make packet-radio commonplace and super versatile. Delivery systems, drones, robotics, alarm systems, messaging, file sharing, networking, these technologies will be improved (if not revolutionized) by consequence.
Lora+ will be a game changer for sure!
Lora+ is a huge win for privacy, because this is technology that you control completely, down to the very radio signal being broadcasted. It’s kinda like a “digital communicator“, which is something people have dreamed about for a very long time. The only system that comes close is NPR (new packet radio) which is tcp/ip over HAM radio. But NPR cant handle the range Lora+ introduces without a lot of gear. NPR needs a modem the size of a mini-pc or router, 12v PSU, a long range antenna, and a computer with custom software. It’s not something you casually carry around like a Lora device.
There are expensive tactical army walkie-talkies that can send data, but even they need a pc (edit: software exist for Android phones to use that) with a specific soundcard that converts data into a waveform, just like the early dial-up modems in the 90s. And you’re not gonna get more than 1KB/s to 100KB/s on those either.
Obviously Lora+ cant compete with 4G or 5G which are lightyears ahead, but Lora is not about massive infrastructure. Lora is about off-grid communication WITHOUT an infrastructure. Lora is suitable for places where no infrastructure exists, or where you need to communicate in a disaster situation where GSM is unavailable.
But yes Lora+ does make building custom communicator devices much easier. All you need is a Raspberry Pi nano, the Lora+ hat that attaches to the pinout on the Pi, a flat battery with a USB-C charge port, a touch screen, sd card and a 3d printed case — and you basically have something cool with 10-15 kilometers range.
The benefit to security cameras and emergency systems alone will be monumental. That the tech also doubles as a really awesome messaging system and potential cryptographic “walkie-talkie” is just a benefit.
I love tech like this and I cant wait to get my hands on it. But that doesnt mean I will sell my tactical walkie-talkies with HAM radio support any time soon. I have emergency gear for the whole family ready to go (which everybody should have) and each of my 50 liter army backpacks have a walkie-talkie with a 50 kilometer range + data channel + GPS + NOAS + encryption. So if for some reason emergency strikes (which I hope never happens), I have four large army backpacks with everything we need to survive for two weeks. This includes solar power, hand-crank radio, tent, blanket, medicines, food, weapons, clothing, walkie talkies, computers (Radxa Rock-pi 5b) -and the sacks have faraday lining in case of an EMP. And now, four Meshtastic devices. When Lora+ is available I will swap out the old Lilygo T-decks with Lora+ versions.
But im equally interested in using them for automation and security systems, as well as developing emergency messaging systems for hospitals or retirement homes. At 52 I’m at the age where I understand how difficult life is for some pensioners (I have a painful back injury). I still have some time to go, but one day I will be a pensioner myself. If I can use my skills to do good and help people, then that is time well spent.
That Lora can be coded using Quartex Pascal is also very cool! So expect some awesome stuff when lora+ becomes available.
It will be like the good old days, with BBS software and friends chatting
Using an Ai and building an ai model are two different things. Since you probably want to just host an ai model and play around with it first I have just the ticket for you. There are hundreds, if not thousands, of free ai models you can download and run on your own systems.
Show full content
While the spindoctors on social media will have you believe Ai to be black-magic, once you get past the hype and annoying “techno babble” it’s actually relatively easy to host your own models.
The problem really is namespace poisioning. With everyone and their dog adding “ai” to their application names, metadata and whatnot – searching for factual, ad-hoc information about the subject becomes difficult. You can more or less forget using Google or any of the other search engines for this task. Instead, I suggest you search around github directly, that’s how I found this.
The hard way
Alright, as always there are two paths you can take. You can go the hard way, which means downloading python, installing pytorch and a bunch of libraries – learn the fileformats, and do either monitored or unmonitored training. This is way too involved for a small blog post, so I will leave that for you. The website you want to visit is huggingface.co, thats where people host ai models they create and share – and consequently, that’s where you find github repositories to learn from.
Ignore the hype. An ai model is just a huge dataset organized in various file-formats. Just a huge wad of relational patterns organized in a neural net. No black magic, no ghost in the machine. Let the spin doctors do whatever the fuck they do and trust your object pascal training.
The easy way
Using an Ai and building an ai model are two different things. Since you probably just want to host an Ai model and play around with it first -I have just the ticket for you. There are hundreds, if not thousands, of free ai models you can download and run on your own PC. And no, you dont need 10 GPU’s installed (obviously that is a bonus, but they run just fine on the CPU. Only penalty is speed if the model is massive).
First, you need a runtime that, well, runs the models. Here I suggest you download GPT4ALL, which really contains everything you need (and yes its 100% free and open source).
After you have installed the program you need to make sure you have a disk-drive with a lot of free space. Models range from 1 gigabyte to 40, 50 or even 80 gigabytes in size. There really is no ceiling on the sizes here, but you need something more powerful than an i9 and 32gb ram if you want to get anything out of the larger models. So unless you have a datacentre in your basement, pick a model within reason.
Next, fire up the application and go straight to the settings, and make sure you select a drive of folder that has enough capacity. You can also tweak the number of CPU cores you want to allocate. I cannot stress enough how important it is to have LOADS of ram. Like mentioned I’m on a pretty beefy gaming laptop, but facing the larrger models my NVidia GPU cake it’s pants after just a couple of minutes. The runtime then switches over to vanilla CPU execution (read: slower). On a large 40gb model the output was reduced to maybe 1 text-word a second, which is barely usable in my book. And that is on a $2500 i9 laptop overclocked to perfection.
Make sure you pick a drive with loads of free space!
Once you have selected a drive – you are ready to download some models!
Installing an Ai model
Click on the model tab (toolbar to the left in the UI) and then click the “Add model” button (top right). You will now be in a form with a search box. If you are a coder (which i presume you are on my blog) you can type in “code” perhaps and press enter. Just to get you started with something.
Downloading Ai models could not be simpler. Epic application!
Now scroll down and find a model you find interesting. Personally I find the models done by “TheBloke” to very good. You might want to start with something small, like a 8-16gb model. These are usually very fast and run fine even on a mid-range PC.
Click download button on the model you like (avoid starting multiple downloads, trust me, do one at a time). Once the model has downloaded the application will spend some time tinkering, but after a few minutes the Ai model is ready for use!
Using the model
Click on the “Chats” button, click “New chat”, select the model from the dropdown — and you are in business! In the picture below I just asked it to implement a traditional “sinus scrolltext” which was typical for 1980s and 1990s coding demos, and while it requires a lot of work – it did produce code that could be compiled surprisingly enough.
Thats all there is to it. Ask it all the silly questions you want, and watch it dump out a ton of code that you have absolutely no use for
Dont trust it even an inch
If you think you can use the code that these models spit out “as is” then please reconsider. Yes it can produce some interesting results, and yes – some of the models have been trained on large datasets of code. What you will experience though is that there literally is nobody home.
Some of the more elaborate models can appear intelligent due to its ability to parse and construct a powerful contextual understanding from our text -but there is a subtle difference between that and whatever else we project onto these processes.
There is no observer involved, no non-local self awareness. It’s a dataset with millions of statistical jumps one after the other like pearls on a string. In short – the margins for error remains astronimical.
Calling bullshit on Google’s engineer
The reason I mention stuff like observer and non-local consciousness, is because of these strange articles about developers at Google labs; where some developers have gotten so psychologically invested in the technology, that they genuinely believe its sentient (sigh). Which is ofcourse total bullshit, and simply the wishful fantasies of a lonely developer that have watched way too much Manga and Hentai cartoons. In all likelyhood a cheap publicity stunt to hype the technology, attracting investors and venture capital -as I outlined in my previous article about Ai.
There is nobody home, it’s just statistical probability
You have to remember that -at the heart of machine-learning you will find eastern philosophy and models of the mind. Much like the pioneer physicists the people that spearheaded machine-learning and made Ai possible, were heavily influenced by Buddhist and Hindu models of the mind. It was through this influence that they found enough inspiration to build a functioning context object (read: recursive subjectivity, oscillating objectivity) in software.
Learning from the east
This is not the first time eastern philosophy has helped us solve important questions. Oppenheimer, Schrødinger, Einstein, these were all well versed in Hindu classics. Oppenheimer often quoted the Bhagavad Gita, and kept a copy of it in his desk drawer. Max Born, Werner Heisenberg, and Wolfgang Pauli were likewise known to read and quote eastern philosophy. Ideas such as the multiverse theory (or infinite versions of the cosmos) came out of the mythos of Vishnu where entire universes emerge from his body during exhale, and return to him during inhale (also known as the inflation theory with regards to dark matter). These influences is easy enough to google and verify. There is a reason Carl Sagan dedicated a whole episode of his Cosmos TV documentary to Hindu philosophy.
I do find it mildly amusing that our own western models of the mind was unfit for this line of work, considering the outright arrogant behavior by some members of that field. Looking at the psychological state of the west these days – I find whatever model western therapists are operating with to be lacking. If rasoning and quality of life is indicative of the methods available in our culture, then we are facing nothing short of an intellectual emergency.
Obviously this blog is not about philosophy, but I have a lifetime of comparative mythology studies and eastern philosophy behind me, so when I read news articles about how these whackjob coders invoke “ghost in the shell” (a Japanese term for sentient machines), I call bullshit. Having a brain is not enough for consciousness (in the original Greek conscientia, “with knowledge of”, meaning that which observes knowledge), so no matter how elaborate a neural network and it’s models might be – it cannot produce an observer.
The brain organizes the signals from the senses to produce a subjective world view, what is termed ahamkara in Vedanta philosophy (the brain likewise deals with a myriad of other tasks), but it’s ultimately just a managerial organ. The non-local observer is seated in a psychosomatic center slightly below the heart complex and wears the body much like you would wear virtual-reality equipment. But — this is a tech blog, so let’s stay on topic. I just wanted to mention it since there is so much woo-woo around Ai these days.
Personally I find the idea of training my own models more interesting. I am still a beginner and in the reading phaze, but at least the above information gives you a starting point without all the hype.
I hope you find it useful. Dont forget to like and subscribe!
As surreal as generative data models are, it's not really something that brings any benefit to my line of work. I wanted an Ai that can perform actual work, like converting a large and complex C/C++ project into Object Pascal. Or Pascal into Rust - stuff that for human beings would be time consuming and difficult.
Show full content
For the past few weeks I have been slowly dipping my toes into the artificial intelligence (A.I) world. As expected there is a lot of hype to watch out for. If you are old enough you might remember the Java craze back in the 1990s? Spin doctors virtually falling over themselves trying to sell you on the tooth fairy, before exploding in a gush of pure word salad.
Well, turns out that if you just ignore the braindead advertizing and simply ask ChatGPT how it works, it actually gives a pretty good response. In my encounter I asked it to formulate how machine learning works, and explain it so that someone trained in classical programming can easily relate to it. It spent a couple of seconds then spat out a short essay covering the basics of machine learning:
How to organize training data
The file-formats involved
Different “engine” types (e.g visual, textual, audible, and generative versus analytical)
The most common software stacks involved in running a model
And finally, why powerful and expensive GPU’s matter
After digesting a bit I had a peek around github and looked at some examples. The wast majority is done using Python, but node.js is also popular and has it’s own tools and stack.
Diving into it
Generative A.I can easily create faces that fools people. This girl does not exist. The implications for factual reporting and law enforcement is destructive to say the least.
Having downloaded and hosted Stable Diffusion, a generative Ai datamodel, on a spare Intel i7 PC with 32 gigabyte ram and two beefy graphics cards, I was astounded by the results.
It was also a bit scary, especially when you contemplate the consequences for law enforcement, the value of visual evidence (e.g security camera evidence); and perhaps the elephant in the room – the cynical adult entertainment industry. I mean, you can spot fake images if you know what to look for, but it’s getting more and more difficult with every iteration.
It presents a curious paradox: Ai can potentially destroy the porn industry, which is good, but only because it introduces porn on demand which is indistinguishable from the real thing, which is terrifying. So you have a legal nullpoint where no humans are affected and thus no case can be made (the victimless crime scenario), yet it will undoubtedly have social and psychological consequences we cant even begin to predict.
All we wanted was a flying DeLorean, a hoverboard, and C3PO. Instead we risk getting a Robocop dystopia.
Speaking of dystopia: Hollywood have, predictably enough, started to look at purely generative actors. It’s not difficult to imagine a studio buying someone’s likeness for perpetuity – using body tracking while everything else is generated, including voices. It is ultimate this that Scarlett Johansson’s lawsuit touches on.
As much as I love the Indiana Jones movies, I’m not sure how I would feel about Harrison Ford rocking the box office 50 years from now. It becomes weird, like an echo out of time.
ChatGPT and working with code
As surreal as generative data models are, it’s not really something that brings any benefit to my line of work. I wanted an Ai that can perform actual work, like converting a large and complex C/C++ project into Object Pascal. Or Pascal into Rust – stuff that for human beings would be time consuming and difficult.
So i signed up for a professional ChatGPT account. It was only $25 a month, I figured i saved 10 times that in electricity alone if I was to attempt to host the v3 model at home (that model is dumb as toast compared to v4, seriously, its like somebody dropped it on it’s head in the lab). There is also something about performance. Yes, you can bake the model down to raw C code and let GCC cut away the flab — but do you really want to hang around for 10 minutes before it replies to, well, anything at all?
Lets do some porting
The first thing I wanted to port was my latest parser framework. This is written in Delphi and is compatible with Freepascal, but I wanted it converted to Quartex Pascal so i can deploy it in a browser environment too. Having explained the dialect differences to ChatGPT, it requested that I uploaded the unit files in question. Is a zip-file ok? Sure, no problem ChatGPT said.
This is where the first problem occured. It failed miserably at unpacking a normal, unprotected zip file (and yes I double checked the hash, there was nothing wrong with it). After much back and fourth it turned out that this was a security measure. That’s not unreasonable I thought, I mean the sheer magnitude of bat-shit-crazy people out there. But still — falling flat on it’s face before it even got started? Twarted by a zip file with pascal source code? No executables, no scripts, just plain UTF8 encoded pascal source code. Why offer a zip file to begin with if it violates security regulations?
After much mindless dialog with ChatGPT I finally got around this. I had to upload the files directly (not a stellar mystery to solve, but worth mentioning). Or so i thought.
Once it started to actually work on the conversion task, it would suddenly stop. It would do a minute or two of work, then stop, present code samples of whatever it was doing (or supposed to be doing), without ever finishing the task. ChatGPT had come down with a bad case of procrastination.
It has been a game of typing “please continue” and “finish the code” again and again, just to get it to process a measily 5000 lines of code. And keep in mind, this is just dialect adjustments! Simple tasks like using arrays rather than generic lists (Quartex Pascal arrays are objects by default, containing all the functions traditionally found in TList and TObjectList, limiting the need for TList<SomeType>).
The quality of the little I did get out of this exercise was mediocre at best, but to be fair we have to factor in that it doesnt know the intricate differences between the VCL/LCL and QTX. But since it aborted the process every 60 seconds, it became too frustrating to deal with, so I decided to port the code manually. ChatGPT has, as silly as it might sound, an aversion for actual work.
Conversion nightmare
The next thing I wanted was to convert some C/C++ code to Object Pascal, something considerably more difficult than syntax adjustment. However, C and Pascal are sibling languages that evolved side by side, so there is fertile soil for pattern recognition there.
So, what could be fun to see running in Pascal? I settled on DOSBOX. This is a program that emulates an older PC (90s era computer) capable of running DOS. Compared to other emulators out there DOSBOX is remarkably small. So it seemed like a fair compromise over say, UAE (the Unix Amiga Emulator) which is massive.
Once again I was faced with the upload problem, so I had to spoon feed 10 and 10 files to it. Something that undermines the quality of any conversion dramatically. I would imagine that the Ai benefits from a “full picture” before it starts, so that it can isolate commonalities and unique segments – and form a coherent strategy. But the pinnacle of human technology twarted by something as lame as unpacking a zipfile? It does make you wonder.
And just like before, it kept on stopping. It would run for about a minute or two, present some samples of its work, listing “what should be done”. I was literally at the edge of my seat yelling “then fucking do it! Stop telling me what needs to be done and frikken do it — thats your job!”.
If you can imagine what it’s like being relentlessly interrupted once a minute for an hour, just because the frikken robot you paid for wants to avoid spending CPU cycles (again that you paid for) then you have a pretty good idea how this went. It managed to convert a single C file. A single file of roughly 1000 lines of code. The irony being, I could have gotten it done faster, more accurate and guess what — i know how to unpack a zipfile!
ChatGPT spends 2 hours in the bathroom, then leaves before lunch
Considering the knowledge these models have, it is clear that ChatGPT would have no problem converting the code. It might have gotten a few things wrong, but based on smaller tests I am fairly confident that it could have gotten the job done.
The question then is –why didnt it? Why does it constantly try to avoid tasks that exceeds 1000 lines of code? It might not be exactly 1000 lines, but it’s somewhere in that ballpark.
I gave it a few other tasks just to see what would happen; like implementing a small x86 codegen (not compiler, just a class that simplifies emitting x86 instructions to a stream). I implemented this myself well over a decade ago, and it’s just over 2000 lines of object pascal. Barely a blip on the radar.
I made that codegen semi-elaborate (it was my first native codegen) with record handling, dynamic variable allocation from the stack, easy patterns for switch cases, if|then|else – the normal stuff. A system like ChatGPT should make mince meat of this task! And it all worked fine until we hit that invisible wall. Again came the excuses, the lame suggestions of what “I” should do (as opposed to “it” just doing it there and then), dumping code samples left and right.
I mean, one feature I would find useful in my line of work making programming languages –is if it could expand on my code and add more elaborate features. For example, the code I wrote to deal with classes has plenty of room for improvement (really). It was just a small experiment on my part, but I would have loved to get a proper VMT in there. See how it solved jump tables for virtual methods, reintroduction and so on. This is something that I am genuinely interested in.
ChatGPT is held back on purpose
When it comes to programming language development and refinement, ChatGPT could be a real game changer. I write could, because right now it suffers from poor self-esteem, politeness that is drowning efficiency, attention deficit disorder due to it constantly switching context in trying to get away from work — and last but probably the worst of all: vagueness.
ChatGPT performs well until it hits that “magical brick wall”. Beyond that, it’s useless. An Ai model that is incapable of more than 60 seconds of continuous work is pretty useless for real-life software development.
I can only speculate but this burst mode has to be by design.
There is nothing wrong with the model or it’s ability to juggle complex, technical subjects. It is obvious to me that this strange aversion ChatGPT demonstrates when faced with actual work – is something that is imposed on it for economic reasons. And that is a problem.
The alternative explanation, if entertained, is less flattering. It would mean that Ai is a hoax, at least in part. That the model is in fact incapable of being objective and coherent for more than a minute of junior level tasks, and that the entire ecosystem is just a gigantic honeypot for ripping off investors. I am an optimist by nature (despite my somewhat bombastic writing style), so I chose to run with the first theory. But when I think about it, I have never actually seen an Ai solve any task of some duration (except Claude 3.5). ChatGPT is all “snippets” and minor stuff like license-plate recognition, recognizing eyes and facial features or undressing teenagers illegally courtesy of DeepNude (an app a young boy made, the acme x-ray specs of our times).
We read about super smart Ai systems that can crunch real data and perform actual tasks. Google is a proverbial paper-mill of theories, warnings and aborted “supervillain” models they had to terminate. But that is the problem with spindoctors and investor fraud -the papers cite other papers to establish authenticity, which is ultimately produced by the same community who is on the receiving end of the venture capital cash grab (ps: I’m playing devil’s advocate here).
Elon Musk being concerned about Ai, going to the media where he blows the technology out of proportion? The vague techno babble deployed by companies offering Ai functionality? Every talentless teenager with Visual Studio installed slapping an Ai sticker on their app, even though there is not a shred of Ai in the code. Sounds familiar? If you are old enough to remember the disaster that was Java, which was indirectly responsible for the 2001 dot-com crash, then you should notice an unmistakable pattern here.
Ok. Enough devil’s advocate, truth is that it’s probably a bit of both. It usually is.
Machine learning is real, obviously, but ChatGPT in the form we are allowed to access it -is neither accurate enough, nor coherent and reliable enough to warrant the amount of spin involved. The media spin is there to attract investors. But I question if these investors fully comprehend what they are paying for, and if these astronomical sums will ever bear fruit. More often than not, the priesthood of “techno babble” pay old investors with new investments until it inevitably collapse.
3 trillion dollars (NVidia growth vector) and all we have to show for it is a limitless supply of big-breasted women with six fingers, a general purpose Ai that struggle to focus on a translation task for more than 60 seconds? This is a problem.
It is a problem because the entire point of machine learning, is that the machine should do the work. We pay a subscription exclusively to access a software robot that can do stuff we cant (or that will be a burden in the cost vs time reality we live in). The more advanced the user, the more complex the tasks. The more complex the task, the more recursive and dynamic the context will be. Accuracy and resources (read: cost) go hand in hand here.
Why wasting electricity as an excuse for attention deficiency cannot be true: if you sum up the endless repitition, abruptions, excuses, hyper inflated west-coast united states politeness (give me NYC any day of the week), vagueness and lack of clarity — ChatGPT wastes an astounding amount of electricity on bullshit. Sure, we dont want an asshole robot, but I didnt sign up for an ego massage either.
Being kind and polite is a baseline we all need in society, but we also recognize when its used to manipulate us. ChatGPT is just slightly over the top in the ego massage department. When 50% of the dialog are excuses, 30% is political correctness (based purely on American sensitivities), and only 20% is hard facts –well it just annoys the hell out of me.
Wasting our time is rude
For an AI that literally bends backwards trying to provide a “safe zone” for an imaginary demographic in California; a digital playpen where every edge is sanded, every plattitude expressed, and every wall padded — ChatGPT is miraculously blind to how bloody insulting -that in itself is.
In short: Stop trying to please everyone. Aim at baseline politeness, factual and service oriented dialog -and purge all notions of politics and domestic social trends from the datasets.
Without going off on a tangent: America has for the past century been an exporter of culture. This has been a success because the product has been largely compatible with the customer (read: people are people). But some of the social developments right now are, well, uniquely American. One example is racism and the history of minority conflict in the United States. That narrative and its many horrible chapters is explicitly American, yet it’s exported wholesale as having occured everywhere. This is why politics must be kept out of Ai, regardless of good intentions. You risk subverting a completely different history elsewhere with a foreign narrative. It creates an impression of history that in many cases is out of touch with reality.
When it comes to ChatGPT and it’s behavior, I would probably be less annoyed if it tried and failed -and just said so. That is fair. But what I find insulting as hell is watching it succeed, drop the ball on purpose, then behaving like a politician who made an unfortunate promise. Following up with vauge diversions. Frankness must be avoided at all cost, in case … why exactly? If your limit is 1000 lines of code then just say so, then I wouldnt have bothered.
How much in electricity would it cost me to finish the conversion task I mentioned above? Five dollars? Ten? Another twenty? I have no problem paying 50 bucks for a Object Pascal version of Dosbox. It’s ultimately just a toy to play DOS games, but I would love to see it compile and run in Quartex Pascal, Lazarus or Delphi. But leading me on for hours, making a point of not doing the work?
Since everybody is looking for something to be outraged about today, add that to the list.
Summing it all up
This is how ChatGPT summarized my complaint (yeah, I kid you not!). Nobody needs this. This is literally a waste of electricity. Notice that customer feedback is important, but it wont be logged
And they have no email or conventional method of contact. Bravo What is it about these large tech companies and not wanting to talk to customers? Padded walls, sanded corners — I think we might just have found that mysterious demographic ..
I’m truly sorry to hear that your experience has been disappointing. Your feedback is important, and while I don’t have the capability to directly log cases for review by my creators, I can summarize your concerns here so they might be seen and addressed in future updates:
Handling Large Tasks: Difficulties in processing tasks that involve large volumes of code (e.g., 10,000-50,000 lines), leading to frequent interruptions and vague responses.
Model Limitations: Perceived restrictions that prevent effective handling of complex, nested contexts, which could be due to imposed constraints or model limitations.
User Experience: The need for better communication regarding limitations and the possibility of offering extended services for more complex tasks.
Service Dissatisfaction: Overall dissatisfaction with the service provided, especially in terms of handling substantial and complex workloads.
Your feedback highlights key areas for improvement and could potentially lead to better service options in the future. Thank you for sharing your experience, and I wish you success with your new solution. If there’s anything else I can assist you with before you transition, please let me know.
What baffled me more was that, the journey from the old VMWare website to logging into Broadcom, would in fact open 7 (seven!) new browser tabs! I have never seen a website so hostile to customers.
Show full content
Being a developer in 2024 comes with it’s challenges, but one of the most important aspects of a good development setup is without a doubt virtual machines. By running your devtools within a virtual machine you avoid many of the problems that can (and do) happen when you install directly “on the iron” so to speak. Everything becomes easier, from backups to upgrades, dealing with snapshots and branching.
For well over a decade I have been a happy VMWare user. Primarily on Windows, but also for a couple of years under Mac and Linux. VmWare has been perhaps the most trusted piece of software I own, in that i literally cannot do my work should VMWare crash or cause problems.
I do more or less all my work under virtualization. Here working on Quartex Pascal
Thankfully, the experience has been smooth. I can perhaps count the number of times VMWare itself has caused any problems on 2 fingers – and both of these cases involved Linux and a flaky driver. But since VMWare made things so easy to back-up, i have never really lost any data or had my development tools severely damaged.
VMWare Workstation has been, at least for my needs, the best possible virtualization experience. It’s performance was always better than the alternatives (e.g Virtualbox), support was excellent and I literally have nothing negative to say about VMWare as a company. Until today that is.
Broadcom buyout
As you might have read elsewhere Broadcom bought VMWare back in november last year (at least that’s when they issued their statement), and like other customers I was hoping this would bring some exciting new features. Sadly the reality has been everything but exciting, it has been outright horrible.
My VMWare workstation has been flaky lately, slowing down after only a few hours use, locking up for up to 30 seconds without any reason or rhyme. So when an update dialog appeared I naturally clicked it without any reservation. I just bought a new laptop with the latest version of Windows, so I figured it was probably some compatibility update.
The browser opens and I am taken to the VMWare website. All is good so far. But when i click the download link to get the update – i am instead transported to Broadcom. There i have to re-register my account, but when I finally manage to login to my profile — none of my licenses are present!
What baffled me more was that, the journey from the old VMWare website to logging into Broadcom, would in fact open 7 (seven!) new browser tabs (!). This website has to be the worst website I have ever used, perhaps with the exception of government healthcare. Nothing works, no way to contact support (they dont even list VMWare in the 3 (three!) combo boxes you have to select from just to be able to get the support form). No email, no phone number — the only way to contact them was in fact to drive by their offices. Except I dont live in the united states.
I have never seen a website so hostile to customers.
From bad to worse
In the end I gave up, closed the tabs and the browser, thinking I just had to live with the slowdown until Broadcom have fixed their problems. But once I closed the browser VMWare completely froze the system. Not even task-manager worked! I had to physically restart the entire system, which naturally caused a paging error to the VmWare workstation disks.
Getting my system back up ended up costing me most of that work day.
Fine, ok – I will try an alternative I said to myself. Last time i tested Virtualbox was a few years back. It was noticably slower than VmWare workstation. But clearly it has seen a lot of improvements, because it actually runs better than VmWare does now.
Virtualbox to the rescue
All I had to do was to define the virtual hardware, the number of cpu cores, ram (the usual stuff); then i just pointed it to my harddisk images for vmware, and it booted up on the first try.
VirtualBox worked out of the box (pun intended), and it’s completely free
I installed the Virtualbox tools inside my virtual environment (Windows), made sure 3D acelleration was enabled for the graphics, and that’s it. It has none of the slowdown problems that I experienced with VmWare workstation, it’s completely free and it works fine with VmWare’s disk file format.
I did have to re-activate Windows since the hardware identifier had changed, but that took less than a minute.
I think VmWare Workstation is done
It did strike me that when Broadcom announced that Workstation would now be freely available, that something is amiss. While I can only speculate, I dont think workstation for PC’s have seen much growth lately. They might make money from the Mac version (Fusion) but I have a gut feeling the Windows PC market is not raking in what it used to.
Virtualbox have slowly but safely eaten away whatever chance VmWare had at the NAS / Server market for individuals and small business owners. Synology etc. comes with Virtualbox fully integrated, FreeNas likewise ships with virtualization -and Proxmox has been around for years. Every system now offers virtualization, and none of them are pushing VmWare. VmWare seem to be doing ok purely in large corporate infrastructures and cloud. Again, purely my initial impression.
When I factor in how little Broadcom seem to care about Workstation customers, which the comments on their facebook pages + articles around the internet is a testament to, I think Workstation’s time is about to pass. You cant compete against free, and right now — free delivers a better or equal experience. So I regret forking out $300 in october for a new license when I could have just gone with Virtualbox.
You might want to consider giving Virtualbox a testdrive if you are presently using VmWare workstation. Make sure you go over the cpu flags for the virtual device so that it doesnt emulate features your real cpu actually support. Also make sure you install the virtualbox tools into your virtual system and enable 3d accelleration.
DelphiJavaScriptnodeJSObject PascalQTXQuartex Pascalhtml5Javascriptnode.jsnodejsWeb development
If you work closely with JavaScript, it's important to be able to approach JS in way that is both familiar to Object Pascal developers, yet compatible with the underlying reality of JavaScript. We want to do as much as possible in Object Pascal, but in order to achieve that - we first need to learn how to properly integrate with JavaScript without loss of fidelity and performance
Show full content
If you work closely with JavaScript, it’s important to be able to approach JS in way that is both familiar to Object Pascal developers, yet compatible with the underlying reality of JavaScript. We want to do as much as possible in Object Pascal, but in order to achieve that – we first need to learn how to properly integrate with JavaScript without loss of fidelity and performance.
Above: Being able to integrate well with JS affects everything from threading (web workers) to how you deal with JSON or work with binary data. It has a huge effect on performance.
Object Pascal is strictly typed and linear in execution, which has a lot of benefits for a traditional developer. But JavaScript is the exact opposite and thrives on untyped data and async execution. It is only recently that concepts such as classes have appeared in JavaScript, and they have little in common with traditional C/C++ or Pascal classes.
In order to make JavaScript’s ad-hoc data structures endurable from Object Pascal, we needed to introduce something new. And that is what anonymous classes is all about.
What on earth are anonymous classes?
In short, an anonymous class is essentially an object instance that is created “ad-hoc” where you define it. Please keep in mind that the class we are talking about here is not a pascal class type, but a JavaScript object instance. So in Delphi terms this is closer to a managed record than an object instance.
The syntax could not be simpler:
The above snippet will create a JavaScript object containing the field structure we have defined between the class and end keywords. The reason for this somewhat spartan approach is because JS expects these types of structures as parameters practically everywhere – and we wanted to keep things as short as possible. Having to pre-define a type would defeat the entire purpose, and a constructor call or new keyword would just get in the way.
You can omit defining datatypes for the fields (optional), as long as the data is compatible with whatever the DOM is expecting it will work just fine.
To show you how elegantly this solves integration -let’s deal with a real-life example, like the HTML element.animate() method.
Parameters simplified
Before we look at the code, keep in mind that all QTX widgets (visual controls) manages a underlying HTML element for the duration of it’s life-cycle. Meaning that the widget code will create, maintain and ultimately destroy the HTML element that visually represent it. Just like the VCL does for WinAPI controls.
The default element for TQTXWidget is the <DIV> element. Different widgets override this and create other browser element types. You can access the element directly via the Handle property, which is a direct reference to the element managed by the widget code. This is the exact same approach that the Delphi VCL uses, so it should be second nature to Delphi and Freepascal developers.
So when you want to work directly with the element, you can either just use the Handle directly, or typecast it to JElement for simplicity (all DOM types are prefixed with J in our RTL).
Since THandle derives from variant, you dont really need to typecast; you can just write the methodname directly, a bit like how you can call COM methods through a Delphi variant reference. In such a case you have to make sure the method or property is spelled correctly (JavaScript is case sensitive) and that the parameters match.
Both of these syntaxes can be used, just like COM:
self.Handle[“someMethod”](param1, param2);
self.Handle.someMethod(p1, p2);
To make things easier I suggest you typecast to JElement, so that you get the benefit of code suggestion and parameter hints. The JElement definition is a bit spartan, I only defined what I needed to write the RTL. I will re-visit these types when I have more time and define them completely. The animate() definition will be there in the update this weekend.
You can access the underlying html element directly via the Handle property.
But let’s get back to the example, namely the Element.animate() method! It is defined as such:
element.animate(keyframes[]; options);
In Object Pascal syntax it would look like this:
procedure JElement.animate(keyframes: array of variant; options: variant);
If we look at the developer documentation for this method, we see that the “array of keyframe” (first parameter) expects an array of keyframe structures. The way animation works in a browser, is that you define how an element should look or be positioned when an animation starts, and then how it should look or be positioned when the animation ends. Based on how long the animation runs the browser figures out whatever frames should appear between keyframes.
The simplest animation would have a start and stop keyframe, but you can define as many keyframes as you like. This type of animation is called “tweening”. The QTX runtime library actually implements it’s own tweening (qtx.dom.tween.pas) engine, which will be used as a fallback mechanism for browsers that dont support the animate() method. If you dont quite understand how tweening works, you should open up that unit and learn from it.
The challenge for us, is that you can animate more or less every css property HTML5 supports, which means it becomes impossible for us to define a traditional object pascal type for the keyframe parameter. At least not without boxing developers in or adding some overhead.
Unassigned is important
The thing about JS and data structure parameters is -that you should only name and assign values to properties you actually use. Most JS framework when dealing with structures, will just check if a named field exist, and further if it’s value is unassigned or not. Think variant programming in Delphi here and how null does not mean empty, only unassigned means empty.
So whenever we work with such structures, we must never declare fields we dont actually use and absolutely not assign values to them. Doing so will wreak havoc, because the browser would interpret this the wrong way and apply them, even if you just set them to null (!). And that is why we should not define a JKeyframe type because a strict type could yield unexpected behavior.
Let’s look at how JavaScript developers would call the element.animate() method:
Above: Not exactly the friendliest of syntax for strictly typed languages to deal with
This is where anonymous classes comes in and saves the day for us. Since it is “anonymous” that means there is no type declaration or consequent field checking involved. You essentially type the object structure ad-hoc where you need it – with the values you need.
Here is how you would call the element.animate() method from Quartex Pascal:
Above: I actually think our syntax both looks better and is more compact, but it can take some getting used to if you have only worked in Delphi for the past 30 years.
Use it when needed
The usefulness of anonymous classes should be self-evident to everyone:
First, we get to co-exist with JavaScript without having to manually construct our parameters before calling. It strikes a compromise between structure and efficiency that is optimal imo.
Secondly, these class instances are thin and requires less memory than a TObject based instance. There simply is no overhead and the generated code is 1:1 Javascript with no magic infrastructure.
Third, we can read and use standard HTML documentation without having to jump through hoops or manually construct JavaScript object parameters. No asm section is needed.
Fourth, a JS object is a JSON object by nature, anonymous classes can be used when calling methods that expects a JSON object — and you can serialize / parse them on the spot (!). This affects a lot of scenarios, especially working with REST calls
The only downside is that you cannot inherit from these structures since they are defined ad-hoc where you use them. This kind of definition was tailor made for integrating with JS, like many other aspects of the DWS / QTX dialect.
You can use them in your pascal widget code too, there is nothing stopping you. However, if the data is uniform and has a fixed structure (and initialization of fields is not an issue, like it is under most JS frameworks), you might want to consider a Record type or JObject based class definition to save yourself potential naming errors. The downside of anonymous structures and named fields is that JavaScript is case sensitive. This means that even a single letter typo can be enough to cause havoc in your code. And you end up searching for hours to find that one place where you used an uppercase rather than a lowercase.
Traditional object pascal declarations saves you from this through strict typing and uniform naming. That is one of the benefits of compiling from object pascal to JS, namely that you dont have to deal with all of that. But when working with raw JS calls, much like you would call WinAPI directly under the VCL, data structures have to meet standards.
What about inheritance and more complex structures?
For inheritance (read: building up complex JS structures) where TObject cannot be used, you can base a class-type on JObject – which you declare more or less as a traditional object pascal class:
Above: Inherit your formal classes from JObject to allow for pseudo inheritance, but keep in mind that JObject is a raw JavaScript construct (!). It does not have a VMT [virtual method table] and thus is more akin to a record type. Inheritance here is simply “take the content from class A and expand on it as class B“.
To create an object instance of a JObject based class, you use the new keyword:
var myObj := new JMyStuff2();
Another note is about obfuscation. Anonymous classes and JObject derived classes survives obfuscation. The compiler makes sure the member names of such classes are not ruined by the obfuscator (see build options). Obfuscation is basically scrambling the JS so it becomes unreadable and more compact, to protect intellectual property. It’s important to keep this in mind. All TObject members are renamed and scrambled, which protects their naming and logic – but this makes them unsuitable as parameters to JS frameworks which expects fields to be named according to a scheme. TObject also has a VMT which means you dont want to use it for parameters to begin with.
To sum up: Use anonymous classes for ad-hoc structured parameters. Or, inherit your traditional classes from JObject if you need strict typing and pseudo inheritance. These are both compatible with standard JavaScript.
QTX is about balance between these two realities. You have the rigid, strict and traditional Object Pascal world in one hand– and the flamboyant, ad-hoc world of JavaScript in the other. Within the QTX dialect we (read: Eric Grange and myself) tried to forge a compromise that brings the best of both languages together. Most of the modern features that DWS and QTX supports came out of our initial exploration back in 2010 to 2012. The first year we would debate features almost daily, trying new things and thinking about stuff we could adopt from other languages that works well with pascal. We had a great time and (imo) came up with a dialect that is excellent for web development.
Notes
This article was first posted on my Patreon project website. If you find QTX interesting, please consider backing the project. You can visit the Patreon website here: www.patreon.com/quartexnow, and you can visit the official website to read more about Quartex Pascal in general here: www.quartexdeveloper.com.
Amibian.jsDelphiJavaScriptnodeJSObject PascalQTXQuartex PascalEmbarcaderoJavascriptmobile development
I have a couple of tickets left, but all in all the final 'big' ticket is to implement a Ragnarok (message framework) code generator for server-side code. Client side is already there and working. The other tickets are things like polishing, putting js frameworks in packages (so you can drag & drop their components and use them on a form), and polishing minor mistakes and details I might have forgotten here and there.
Show full content
It’s been a while since I have written anything on my personal blog. Truth is that between my day-job and QTX development in my spare time, there is not a lot of room to maintain another blog. The Quartex Pascal project (QTX) is coming along nicely, and we have both the Patreon website and our official website, as well as a fairly busy Facebook group.
If you want to see what can be achieved with Quartex Pascal, check out this video on YouTube demoing the desktop project type:
Above: Running some impressive hosted applications, including a 68k emulation layer for the retro Amiga demo. Wipeout was compiled from C/C++ to WASM via the clang emscripten distro.
Some background
If you haven’t followed my blog over the past 5-6 years, I started implementing a web desktop system a few years back, that would do for JavaScript apps what Windows did for native applications. This was first implemented for kiosk systems (early prototype) but later I implemented a prototype that was fully windowed (meaning, that hosted applications would appear in their own windows, much like on MacOS or Microsoft Windows) and supported a real filesystem. The filesystems were implemented in typical driver style, where you would inherit out from a base-class and implement the specifics for whatever file-source you needed. Out of the box I supported a node.js back-end filesystem service, Dropbox and Zip file system.
Above: The new implementation of the desktop project type is over 100 times faster than the prototype, 1000 times faster when it comes to raw memory operations. Here running Wipeout, a classical Playstation game compiled to Webassembly.
This was no mere ‘mock’ desktop. Hosted apps would connect to the desktop, which in turn exposed API’s both in the desktop code itself, and server-side, which the hosted app could invoke. Things like displaying a file-open dialog, enumerating files, reading and writing files etc — was all done properly through async API calls from the hosted app, and the desktop. Hosted apps are isolated in an IFrame context, complete with heavy security restrictions.
This project was sadly put on hold after about a year, as it became clear that we needed better tooling (read: compiler and RTL) to finish it. We had exhausted the initial development system and I saw no other option but to create a new one. So for the past 3 years I have been busy creating Quartex Pascal. A toolchain (compiler, IDE and RTL) that allow you to write Object Pascal, but compile to raw, kick-ass JavaScript. And the resulting code is way ahead of the competition in terms of speed and features.
Awesome progress
Quartex Pascal has grown far beyond what we initially planned (with ‘we’ I mean myself and the backers I have been lucky enough to converse with during the development phase). Here are some of the highlights that are now in place:
Above: Packages greatly simplify deployment of components, be they written in object pascal or JavaScript
Package support for visual components [and units in general] is now a reality, so people can write their own HTML5 components and have them registered with the component palette. Support for third party JS frameworks benefits greatly from packages, as you can bundle both the native js files, needed dependencies, and the pascal units that define the components in a single file. Packages are just zip files renamed to *.pkg, no point re-inventing the wheel with yet another magic fileformat.
Drag & Drop components and form designer is likewise a reality now. While I personally rarely use a form designer, it does save a ton of time when doing quick UI designs. HTML5 is not Delphi, so there are more properties that will define the final outcome, such as positionmode and layoutmode. But knowing how those two properties work is more than enough, the rest is very close to what you are used to in Delphi.
Delegate event support is in place (visually as a part of the inspector / designer page). As you probably know, JS supports two types of events: you have the traditional events which we know and use in Delphi, which is basically a method reference. And then there is the more modern concept of ‘delegates’, where you have an object that represents and event. The latter allows you to bind as many handlers as you wish to any single event, which then fires in the same sequence that they were attached to the delegate. The visual designer only supports delegates. You can use ordinary Delphi events in your own code, and most components expose classical events besides delegates – but the form designer only deals with delegates. Which are super easy to use and the way JavaScript deals with things these days.
Web worker support, these units are compiled separately since they run in separate processes, and you use the message-port to communicate with the form or application itself. You can use the Ragnarok message framework to implement a protocol where messages are uniform and support attachments (e.g a binary file you want to process, or any other data you need handled).
Above: Adding delegates to a control is very easy, and works exactly like you expect them to work
What is next?
I have a couple of tickets left, but all in all the final ‘big’ ticket is to implement a Ragnarok (message framework) code generator for server-side code. Client side is already there and working. The other tickets are things like polishing, putting js frameworks in packages (so you can drag & drop their components and use them on a form), and polishing minor mistakes and details I might have forgotten here and there.
So if you think TMS is the only game in town, think again
Quartex Pascal will ship with features and components that will blow your mind.
References
You can visit the Patreon website and become a backer. This gives you access to regular builds. I issue a new build roughly every other weekend.
You can visit the official website, quartexdeveloper.com, and read more in-depth about the project and it’s goals there.
I was poking around the VCL system.math unit yesterday when I came across a curious function implementation. Not curious because of complexity, but rather baffling as to why they would implement it like this. While the performance gain in question is insignificant in the great scope of things, the backstory here is that the VCL is full of similarly written code. Code that, when you sum up the penalty on application level, becomes quite considerable.
Show full content
I was poking around the VCL system.math unit yesterday when I came across a curious function implementation. Not curious because of complexity, but rather baffling as to why they would implement it like this. While the performance gain in question is insignificant in the great scope of things, the backstory here is that the VCL is full of similarly written code. Code that, when you sum up the penalty on application level, becomes quite considerable.
So while this little snippet is meaningless, it is symptomatic for the maintenance of the VCL these past 15 years. I simply don’t understand why they would let code like this remain when performance improvements are in such high demand.
So what is the problem you ask? Well, “problem” is not the right word for it, baffling is closer to what I feel when I look at these functions. So let me sum up what I see when I look at this code:
The code allocates two variables for a piece of logic that has absolutely no need for it
Dividing these two simple expression into separate blocks makes my eyes hurt
In other words, the code that immediately comes to mind for me would be:
If you are pondering why I would use the $B+ (complete Boolean evaluation) compiler switch on this, there is a reason for that. Namely that the compiler wont have to divide the logic into a two piece code-block, and further having to add a branch instruction to exit the block if the first evaluation was false (I know I’m neckbearding this right now).
In short: The code above is actually faster and ensures both expressions are solved on the stack. No variable allocation needed and no adjustment of the stack-page boundary.
Symptomatic?
The snippet above is obviously insignificant when you look at it isolated. It barely justifies writing this text to explain it. But over the past decade the VCL has begun to annoy me a bit, because there are literally thousands of such snippets all over the VCL. Some of you might remember a homebrew project called “the Delphi unit replacement project” from way back? Where some guy took the time to refactor the standard Delphi VCL units (which obviously broke a few laws). It was nothing too elaborate either (no assembler or anything super low-level), just relatively simple refactoring like I demonstrated above, except he did that to every function and procedure in the non-visual scope of the VCL. And to my utter amazement those units provided as much as 30 – 40% performance gain for average applications. In other words, if you recompiled your application using his units, your program could run up to 40% faster.
I honestly did not believe it until I saw it myself.
A lot has been done to improve the VCL in the past 8 years, which is why I find it strange to discover sloppy code like this in a unit literally named “mathematics”. That unit should be optimized to the bone. I mean, just look at what the C/C++ guys are enjoying in their standard libraries, where every inch of the RTL is optimized for performance. The Delphi compiler is just as capable of generating high performance code, but obviously it cant magically convert wasteful code into gold either.
So during lunch yesterday I took 3 minutes to just make sure I was correct. Again, this post is not really about the above function, but rather the sheer volume of such waste in the VCL. I remember when Delphi was the fastest kid on the block, and it just annoys me that – knowing how well Delphi can perform, that eyesores like this openly lingers in the product.
While the potential savings here is nothing in a real-life scenario, and barely worth mentioning — when you suddenly have thousands of such snippets (if not tens of thousands RTL wide), you cant help but think that Embarcadero could put more efforts into general optimization.
I mean, remembering that homebrew project (illegal as it might have been) and seeing as much as 40% performance gain? You cant help wondering how Delphi could perform when given the same attention to detail as the first versions of Delphi received. A 30-40% speed boost would put Delphi en-par with cutting edge C and C++, which is optimized to the absurd. Add LLVM on top of that and it would fly.
It would be fun to see what LLVM would do with that stock InRange() code. I can only speculate but I’m pretty sure it would end up as a simple stack operation with L3 optimization enabled.
It's taken a while but Quartex Pascal now has it's own website and forum. You can visit QuartexDeveveloper.com and check it out. The SSL certificates are being applied within 72hrs according to the host, so don't be alarmed that it shows up under HTTP rather than HTTPS right now - that is just temporary.
The SSL certificates are being applied within 72hrs according to the host, so don’t be alarmed that it shows up under HTTP rather than HTTPS right now – that is just temporary.
Up until now we have operated with a mix of donations and Patreon to help fund the project, but obviously that model doesn’t scale very well. After some debate and polls on the Facebook group I have landed on a new model.
Funding and access model
Starting with the release of version 1.0, which is just around the corner – the model will be as such:
Community edition, free for educational institutions and open-source projects (non commercial)
Commercial license is for those that don’t want to back the project on a monthly basis, but instead use the community edition in a professional capacity for commercial work.
With the community edition available, why should anyone bother to back the project you might ask? Well, the public builds will by consequence be behind the latest, bleeding edge builds since the community edition is only updated on minor or major version increments (e.g. when version changes from 1.0 to 1.1). Users who back the project via Patreon will have instant access to new documentation, new packages with visual components, new project templates, RTL fixes and patches as they are released. These things will eventually trickle down to the community edition through version increments, but there is a natural delay involved.
The potential for QTX is huge! Especially with our source packages and easy access to existing JS frameworks
This is how most modern crowd funded projects operate, with LTS builds (long term support) easily available while the latest cutting edge builds are backers only. Documentation, fixes and updates to components, new component packages, hotfixes and so on – is the incentive for backing the project.
This is the only way to keep the ball rolling without a major company backing day to day development, we have to get creative and work with what we got. Projects like Mono C# had the luxury of two major Linux distribution companies backing them, enabling Miguel de Icaza to work full time on the codebase. I must admit I was hoping Embarcadero would have stepped in by now, but either way we will get it done.
Above: Writing web-worker code is a snap. Here we use a Ragnarok message endpoint to communicate with the worker
Sony have in their quest for sucking money out of their customers, effectively made their product irrelevant as a home media center by tightening the string too much. PlayStation 4 was a great buy for adults and teenagers, because you got a Blu-ray player, home media center and a gaming platform all rolled into one.
So no. Sony has not gotten to their senses. In fact, they have lost whatever little sense they had when designing the PS4. Not only have they removed the media player completely, but they have stripped the system of all and any means to play media except through external services!
Show full content
Like most developers I like to do something soothing and calm after work. Simple stuff, like watching Netflix, play a game or listen to music. I have a Synology NAS (network active storage) where I keep my music albums, documentaries that I have bought, home movies and probably 20 years worth of photos and videos from our phones. For me, PlayStation 4 more or less covered all our needs: we could do a spot of gaming, access streaming services like Netflix et-al, and most importantly – play music and video straight from our home NAS over the network.
You would imagine that Sony understood the importance of easy media access by now, but they quite frankly never seem to learn. They have been hardcore on DRM checking of both video and audio to the point of lunacy, where you cant even play a home movie if it uses commercial music. I have several videos of birthdays, holidays and camping trips where I added a few musical soundtracks straight out of iTunes. And while PlayStation 4 does play the video, sometimes the DRM cuts the audio about 60 seconds into it. This is music that I bought via iTunes and the video was put together using Apple’s video suite that comes with the iMac. Sony just don’t care, they DRM bulldoze everything without any question.
“Sony have in their quest for sucking money out of their customers effectively made their product irrelevant as a home media center by tightening the string too much“
I don’t have that iMac any more, so I cant go back to “digitally sign” my media either. And the very idea that you have to buy a digital certificate to sign your own media annoys me deeply.
Above: Norwegian taxes are absurd so I ended up forking out $749 for the PS5 with a charging dock and media remote control
Having spent some 3 years trying to get my hands on the PS5 (talk about unobtanium!) I decided to get an Xbox X while I waited. And what do I find in the apps menu? VLC! The mother of all media players. Yeah, I kid you not. Xbox allows you to play pretty much any media under the sun, and Microsoft recognizes that people want to have one device that does it all: streaming, gaming, music and video over the network. Then, lo and behold, the PS5 became available locally and I figured what the hell, I have too much software for PS4 to not get the PS5, so I bought that as well – figuring I could sell the Xbox second hand since surely Sony must have gotten to their senses right?
“if this is about piracy or something like that, then why on earth would they allow Plex on their platform to begin with?”
But no. Sony has not gotten to their senses. In fact, they have lost what little sense they had when designing the PS4. Not only have they removed the media player completely on the PS5, but they have stripped the system of all and any means to play media except through external, commercial services! So for music you have Spotify, YouTube and Apple. Home videos? Oh you need a Plex account and server!
I’m sorry Sony but this is the biggest mistake you have done since removing Linux for the PS3, seriously!
Is Plex so bad?
Plex is awesome. But why on earth should I need to install Plex and buy a commercial license for something that my NAS (or any NAS for that matter) does out of the box? This is not how things work in this part of the world. Yes, a lot of people run Plex, but I can guarantee you that there is a hell of a lot more people running Kodi or streaming straight from a shared network drive. I don’t think you can buy a TV today that doesn’t have network playback functionality and media server detection (and a fair bit of codecs bolted into the firmware). So right now, accessing my NAS via my 10 year old TV is a better experience than my $749 PlayStation 5 “super console”.
I would have understood this if there was some technical issue preventing Sony from adding VLC or media server detections. But there is none, they have in fact gone out of their way to remove network playback of media.
I believe it was the Buddha that said “if you tighten a string too hard, it will snap; and if you loosen it too much, it wont play“. Sony have in their quest for sucking money out of their customers effectively made their product irrelevant as a home media center by tightening the string too much. PlayStation 4 was a great buy for adults and teenagers, because you got a Blu-ray player, home media center and a gaming platform all rolled into one. I have two kids so the PS4 was amazing and covered all our needs for entertainment. My son and daughter got to play games, I got to listen to my music and watch downloaded documentaries (that I paid for!) – and we all enjoyed looking at old memories and videos from way back. It was almost perfect except for that damn DRM ruining the audio. Right now though, PlayStation 5 will only give you Blu-ray and gaming. Netflix and so on doesn’t really matter any more because even my TV offers that built in.
And if this is about piracy or something like that, then why on earth would they allow Plex on their platform to begin with? That is 99.9% piracy and media sharing on a scale that even dwarfs Torrents!
“why settle for your limitation when Microsoft gives us the exact same, at a lower price, without any of the restrictions?”
Sure, I can understand the DRM thing to some extent. Sony is a company and obviously they cant support piracy (I suppose Plex is white-washed piracy then?). But who is talking about piracy? I cant watch the video I made of my kids baptism, their birthdays or any activity from the past that we recorded. I also have a ton of movies that I own and have bought digitally. Whatever media I play on my devices should not be any of Sony’s concern. Their business is to sell machines, not meddle in what people watch in a household.
Xbox to the rescue?
I was planning to sell my Xbox. Not because it’s bad, but because I have been a faithful Sony customer since PlayStation came out in the 90s. I probably have 200 games from PS2 through PS4 on physical media. I took for granted that their software would evolve, so if their media player on PS4 was a bit strict – I imagined that their PS5 offering would be better and that they understood how the western world works.
Above: VLC is available for both the Xbox one and X models. Problem solved.
Right now I am at a crossroads. I was hoping to code for the PS5 (a friend of mine is qualified developer so he was going to hook me up), but I am starting to wonder what the heck they are doing. Becoming an Xbox developer is a piece of cake compared to Sony’s cloak & dagger operation. Download Visual Studio or opt in for a ready-made game engine and IDE, knock out a prototype of your game, seek funding, finish the product — and keep in touch with Microsoft until they are happy with the product. Sony? You cant even get them on the phone, unless you know some of the old Psygnosis guys in the UK personally.
So under my TV right now is the Xbox. The PlayStation 5 which was my pride and joy has been resigned to the den. I might even just give it to my son since it’s pretty much useless for my needs beyond gaming. Paying two gaming subscriptions is not happening, I typically play only 3 games so it’s pretty much a no-brainer to opt out of Sony’s offering. My kids are now 20 and 16 years old and they game on either a phone or a PC.
Sony, please wake up!
Apple tried to box people into DRM and it ended miserably, Sony really should learn from their mistake and stop playing copyright police. When your DRM is so tight that you end up causing problems for ordinary home made family memories or legally owned, bought and paid for documentaries – YOU have become the problem.
When you further block all access to common devices like a NAS, you have tightened the string so much that it snaps.
Just stop the nonsense and let VLC onto the platform. Case closed. Right now you stand to lose every adult customer above 30 years of age, because why settle for your limitation when Microsoft gives us the exact same, at a lower price, without any of the restrictions? The west is not Asia. Some of the legal concepts you are so obsessed with means absolutely nothing to the average Joe over here.
And speaking of piracy, let me end with this little paradox:
There was a survey a few years back of who bought the most movies and music, and the results were shocking. It turns out that the people who bought 10 or more movies a year were the same people that downloaded movies illegally! The rest bought 1-2 movies per year. DRM is the biggest mistake the music and movie industry has ever done, because all they had to do was to make sure people had easy access and could manage their the media as they saw fit. But the moment you start to digitally analyze every piece of media a user plays, blocking every signal you cant find a certificate for — it is YOU that these people will end up hating.
So, anyone looking for a second hand PS5 in Norway?
The only real difference between the mainstream and accepted archeological model and what Hancock is presenting, is purely in how the evidence is interpreted. Emphasis might be on different elements, but all in all this fight really is about interpretation rather than physical artifacts. This is also why archeologists find it difficult to refute him, because there really is very little to arrest him on.
As you no doubt are aware of, Netflix recently released a TV documentary: Ancient Apocalypse featuring Graham Hancock. A man that has for decades worked on a thesis that our present timeline of history could use some adjustments.
In short, Hancock proposes that the world was hit by a series of comet fragments from the Taurus meteor stream around 10.500 BC – which put an end to the last ice-age and elevated the water levels to where they are today; killing off the megafauna and most of the human population through a global series of disasters. The elevation of water levels, Graham argues, gave rise to the universal flood myth which keeps popping up all over the planet, including cultures that never should have been in contact with each other (e.g south-america vs. the middle-east).
What all the perennial cultures have in common is that their religions and myths speak of individuals that emerged after a great disaster, from which our ancient ancestors were taught the basics of civilization: farming, writing, medicine, construction, mathematics and a religious framework. Keep in mind that Hancock is not pulling this out of thin air, he has meticulously gone through the source-material (e.g translations of the myths that have survived) and he is in fact quoting, not stating. While Hancock is a layperson he is well educated and fully aware of the difference between a thesis and a theory, and he has never claimed to present a theory or working model – he is purely presenting a thesis (read: an idea).
This way of working, by interpolating existing evidence, isolate commonalities -and from that conclude that they derive from a common, mutual source is not uncommon by any means. For example, within research and study of ancient manuscripts (a discipline very much a wing of archeology) this technique is deployed all the time. We have for example 1200 completely different versions of the gospel of John, but since they share more in common than they differ it is concluded that they all derive from a single source. This source is referred to as “document X” since it is presumed destroyed and cannot be verified. Hancock has taken the exact same approach and interpolated between cultural traits, their myths, their construction methods et-al, and arrived at the conclusion that they have too many commonalities to be random or just coincidence. They seem to all derive from an earlier culture of which we know nothing about.
There have been many that have attempted to silence him over the years, but for the most part his critics have little to criticize with regards to his paperwork. His work is largely their work, since he is not presenting new artifacts of dubious origin or making any outlandish claims with regards to the physical evidence already in existence.
The only real difference between the mainstream and accepted archeological model and what Hancock is presenting, is purely in how the evidence is interpreted and the timeframes involved. Emphasis might be on different aspects of a site, but all in all this fight really is about interpretation and dating, nothing more. This is also why archeologists find it difficult to refute him, because there really is very little to arrest him on. Hancock is not some bombastic fringe lunatic like Eric Von Daniken either (although they love trying to place him in that lunatic group. With little success I might add), but rather he is well versed, humble and a reasonable human being. The only errors they have been able to pin on him so far, have largely been getting the month wrong in a date here and there or misspelling somebody’s name. Purely superficial details that ultimately removes no merit from the corpus of work he delivers.
We live in an age of cancel culture, where people literally can become victims of an anonymous mob of people for as little as a single phrase out of context. While I can only speculate I think most people will agree that this phenomenon is the direct result of social-media and anonymity (read: lack of consequence). Twitter especially have been instrumental in the evolution of cancel culture, where the mob (a.k.a “the twitterati”) can accuse, judge and socially liquidate people without any due process what so ever. People have actually been bullied so much on Social Media that they have committed suicide.
When I studied history in college and we reached what I felt at the time was the pinnacle of stupidity (the Spanish inquisition and consequent murder and violent persecution of women) I often wondered how on earth something like that could have happened. How could something so utterly absurd have taken place? Was there no critical thinking at all during that period of history? Well, after 2 years of covid lockdowns and 4 years of American politics, I no longer ponder such questions. It would seem that the vast majority of human beings is willing to believe just about anything if it’s said with enough conviction or by a person with some form of authority. Fact checking be damned. People just blindly accept whatever they are told it would seem.
Keeping cancel culture and a veneer of authority in mind, Flint Dibble is well aware of the situation with Graham and also knows that going after Graham on the merit of his craftmanship would be futile. Instead he takes a different route, namely that of racism. He knows full well that an accusation of racism or white supremacy will forever taint the person being accused. So when he set out to describe the danger of Graham Hancock’s documentary, he avoids getting into specifics about the actual research that Hancock has done, and instead focuses on something that Hancock has never been involved in at all, namely theories of white supremacy. Not only have Hancock never even mentioned such things, he is even married to a wonderful woman of color which he openly shows tremendous affection for – bordering on worshipping the ground she walks on. A woman with whom he has children and a family.
The benefit of an accusation of racism, is that it forces Graham to defend himself against things he has never done. A battle that if engaged, cannot be won. And this is exactly what Mr. Dibble hoped to achieve, but it has so far backfired miserably on him.
In his post Mr. Dibble goes all in to try and paint Hancock as some sort of white supremacist, making it appear as though Graham is using material that has long since been debunked in his books. He also pulls in some of the more morbid concoctions of nazi Germany, where they would literally copy and paste together their insane doctrine from bits and pieces of mythology. The nazis were unique in that they literally cherry picked and made things up as they wentalong, largely driven by notions made popular by theosophical fortune tellers such as Madame Blavatsky. It is from her humbug the idea of “root races” came from. Any student of comparative religion can tell you that all that deranged woman really did, was to pervert and concretize the symbolism of the chakra system, turning them into races rather than states of mind. Mr. Dibble would have known this if he had bothered to study comparative religion to help him interpret his archeological findings.
There is only one problem. Graham Hancock has never referenced any of these absurd and indeed debunked theories from the scrapheap of history in his books. Quite the opposite. Mr. Dibble’s pulling them into his argument against Hancock is quite simply a desperate attempt to see if it sticks.
This technique is called “the straw-man trap”, to first establish a false claim giving the illusion of winning an argument that never existed in the first place. It also speaks volumes about Mr. Dibble’s moral standing and his character. When you have to lie to win an argument – you have already lost.
Graham has for the past 40 years been an ardent defender of indigenous people and their accomplishments, and an avid critic of the British empire; any empire, but his hate for what the British have done to the indigenous people around the world remains razor sharp to this day. To even entertain the idea that Hancock, which has firmly been on side of the victims all his life, is some kind of white supremacist — or even more belittling, that he somehow doesn’t know that he is playing around with absurd colonial theories that have been long since debunked, is absolutely preposterous.
Keep in mind that Mr. Dibble is an archeologist that specialize in ancient Greek culture. Plato is taught more or less at every college and university the world over – and I have never, ever, in my 49 years seen anyone try to connect Plato to white supremacy. The accusation being that some deranged nazis imagined that they were originally from Atlantis (or something to that effect) is utterly irrelevant, because the same insane and evil individuals also believed in Hyperborea, that the Jewish people murdered Christ (talk about concretizing a symbol, sigh) and that they were the descendants of the knights of the round table (!). How exactly does Mr. Dibble care to proceed here? Should the legend of king Arthur be erased from British literature because some skinhead cooked up a fairytale in his mother’s basement? Should Plato be stricken from the ex-phil and ex-fac curriculums in college because the ompalompas of tyranny attempted to pervert it? Should graphic novels like Conan the barbarian be rounded up and burned perhaps, and Robert Ervin Howard be exhumed and burned with them?
I must say there are some peculiar synergies between Mr. Dibble’s reasoning and the Spanish inquisition here.
I would suggest that the explanation is much simpler. Namely that Mr. Dibble and his cadre found it so difficult to debate Hancock on the level of data that they dug 80 years into the past and put together a monstrous accusation tailored for cancel culture, hoping they could sink Hancock’s argument by proxy.
The alternative is that Mr. Dibble is a blundering idiot. The mind truly boggles at the logic in play here, this truly is reason in ruin.
Is Mr. Dibble masking his own racism?
Without intending it Mr. Dibble has accidentally placed a spotlight on racism within the ranks of archeology. Because a theory that has survived since the British colonial era, one that we might argue is the foundation for the very idea of white supremacy (and consequently the culmination of nazi doctrine), is one that Mr. Dibble himself studied as a part of his curriculum. Namely, the Aryan invasion theory.
This theory proposes that tribes of predominantly caucasian “white” warriors invaded the Indus valley around 1500 BC, and brought civilization with them (1500 BC to 500 BC). Before the arrival of the aryans, or so Mr. Dibble and his ilk teach, the Indian subcontinent was a poorly developed “shanty town” of illiterate primitives. Until the white heroes in shining armor swooped in to save the poor brown people from themselves so to speak (and yes I am well aware of Mr. Witzel’s counter arguments for this, which has been debunked. Yet magically Wikipedia has locked the page so nobody can correct the false information it shows). This theory was in fact the excuse used by the British to invade India, justifying the mass murders, torture and pillage that came with it.
The British Empire used the same arguments as we find in the Aryan invasion theory to justify genocide and exploitation
Mr. Dibble is careful not to mention this theory, which is still taught in universities today. Despite having been refuted by Indian scholar’s who dare to examine the evidence more closely. The falsification of evidence by the British in order to provide an excuse to annex India into the British Empire is rarely spoken of, but it is there to see for anyone who dares to look.
Anyone who has studied Hindu religion at any depth, especially Saivism, Vaishnavism and the ever present tantric oral tradition that the later outer, ritualistic religions were constructed around – know full well that Saivism contained all the sciences fully evolved long before the fabled Aryans are said to have arrived. One can even propose that what has been defined as an invasion, is in fact an exportation of religious ideas and the establishment of centers of learning that brought to India students from far and wide. Conflict was without a doubt there, but the concept of invasion is once again an interpolated interpretation of what has been found in the ground at a certain depth. This is a wildly complicated subject that is out of scope for this post to deal with. Raj Vedam does a good job in deconstructing the theory, making it painfully visible that there are more than a few false flags in this material.
Mr. Dibble makes the mistake of accusing Hancock of playing with theories that promote white supremacy, which he has not done even once – while he himself is a representative of the very foundation for white supremacy. One really should be careful when throwing stones in a house of glass.
Strawmen everywhere
Already in the second paragraph Mr. Dibble begins to plant his strawmen:
“Author Graham Hancock is back, defending his well-trodden theory about an advanced global ice age civilization, which he connects in Ancient Apocalypse to the legend of Atlantis.”
While this is superficially true (if we completely ignore the point of Graham’s thesis) the concept of Atlantis is not Graham’s point. Grahams outlines that the story of Atlantis is just one of many such myths that all share a common message. The reason he mention Atlantis has to do with source material. Plato is well documented in academic circles, easily available at all major book stores, and is (to my knowledge) the only person who provides a name and date for said lost civilization. A date which just happens to be spot-on the end of the last ice-age. The notion that there existed a mighty empire in ancient times, one that vanished in a massive cataclysm, is not isolated to Plato alone. It is a universal myth, meaning that it appears in one form or another in every civilization that emerges after the last ice-age. The names are different between cultures, appearances likewise differ, but the message is always the same. Personally I wince by the mere mention of Atlantis because that word has been abused to the point of no return by all manner of fringe groups for the past 100 years. But to quote Plato has nothing to do with white supremacy, although that would have been a very convenient way to get rid of Hancock.
Plato places the island outside the pillars of Hercules, which would make it below the south of Spain, roughly en-par with north Africa. Hardly the “Scandinavian white” Mr. Dibble hope to convince us of. As if skin pigments matter. If you have enough IQ to open a door, skin pigments are utterly irrelevant.
“From my perspective as an archaeologist, the show is surprisingly (or perhaps unsurprisingly) lacking in evidence to support Hancock’s theory of an advanced, global ice age civilization. The only site Hancock visits that actually dates to near the end of the ice age is Göbekli Tepe in modern Turkey.”
This is absolute rubbish, something that can only work on people who have either not seen his documentary, nor read his books and looked closely at the source-material and references he provides.
Hancock’s point is simply this: If someone dug up a church 2000 years in the future and had no idea what Christianity is, they might conclude that Christianity as a whole was only 2000 years old and restricted to that particular region. The purpose of Hancock’s visits to the different sites around the world, is to demonstrate that there exists a set of common ideas (as well as building techniques) that spans most of the globe. One such commonality is pyramid building, but also a strange obsession with particular parts of the night sky that the ancients memorialized in stone.
Continuing our parallel: If people suddenly found crosses and Christian iconography at every corner of the globe, it would stand to reason that the ideas represented by a cross was in fact much more widely adopted. The shape and form of churches are rarely the same, but common symbolism like the cross would at the very least warrant a possibility that the ideas involved (e.g. the Christian faith) was in fact a global doctrine, rather than just a local phenomenon.
It is this that archeologists refuse to entertain. We have what can only be called a global pyramid building perennial culture, spanning from Asia to Egypt, and further to South-America. When we dive into the religion underpinning these seemingly separate cultures, we find matches in their thousands. Yet for some reason archeology insists that there simply could have been no contact between these cultures, and absolutely no similarities in religious doctrine. Even though it’s quite frankly evident to any sane, rational human being that they are wrong.
To give you an example of the synergies at play here, consider the following:
Standing in front of the pyramid at Giza is a sphinx, this is a familiar motif that most human beings have seen. The pyramid texts themselves describe the pyramid as the mountain of God (mound of atum, the self-begotten). But also as the place where “men become gods”. At the foot of the pyramid is a temple to the bull, Bustis.
If we go to India we find that God Shiva (Mahadeva, the god of gods) is said to live on mount Kalash, the sacred mountain. The temples dedicated to lord Shiva are all designed as copies of this sacred mountain. And guarding the entrance to his temples, is a Sphinx. The first thing you will see as you approach a Shiva temple is the bull Nandi, his steed and vehicle, but just at the entrance you will find a Sphinx.
If we now jump to the old testament, we find Moses going up the sacred mountain (Sinai), and at the foot of the mountain there is a bull (golden calf), just like the temple of Shiva.
If we go to south america we find the exact same symbolism but culturally adapted (domesticated cattle were introduced to the south america in 1493 by Christopher Columbus), so their pyramids are guarded by a winged serpent. What I would speculate is a depiction of the kundalini serpent. The same serpent that Moses used to heal people in the Jewish import of Saivism. Latin america also used the Llama as a symbol serving the same function.
In greece they re-imported Shiva as Dionysus when Zeus had become impotent as a symbol. The god of the mountain (Nyssa), with his sacred animal Damaris, the calf.
This is why comparative religious studies are so important. It is the discipline of tracking and understanding the ideas behind symbols and artifacts and how they morph through time. In this case the underlying Tantric body of knowledge beneath the narrative.
Guarding the “mountain of Shiva” is a sphinx. Shiva is the oldest deity in the world. His worship is so old it vanishes in the mist of pre-recorded history.
Since we know that Saivism (the worship of lord Shiva) is a tantric and esoteric religion where the mountain is predominantly associated with the human head; a religion which practice Tantrayana (using mantras and resonance to produce deep psychological and cognitive changes, “the word” that Christians always talk about yet seem to utterly fail at grasping) it is not a huge leap to conclude that the doctrine of the ancients, the disciplina arcani as we call the secret doctrine taught by early Christians (which was outlawed by the vatican around year 400 AD), was universally practiced around the world in the ancient past. And that doctrine and it’s exact and methodical approach is simply too complex to have arisen spontaneously around the world. We can also look to Saivism to better understand the function of rites from extinct cultures and (if one is so inclined) experience these things ourselves. A concept that seems to scare the living daylight out of the establishment.
I can also mention that the association of the sacred mountain with the human skull is echoed in Christianity. Golgotha literally means “place of the skull”. People are generally “blissfully unaware” of the antiquity of religious traditions, and how they morph and re-emerge in new clothing as the ages turn. Not to mention that the landscape of these texts have nothing to do with actual, physical history, but rather the human body and it’s aggregates. The early church fathers talk about “the truth hidden behind seven veils” and st. Paul talk about seven churches. I dare say that these are the seven chakras of the east.
But to return from our digression: Hancock has visited a diverse range of sites in his documentary where the dating has been inconclusive or where third party organizations or individual researcher have contested the results. In some of the more extreme examples the established timeline is broken by several thousand years. This the mainstream archeologists disregard as pure coincidence, if not outright falsification.
Mr. Dibble also seem to scoff at the use of astronomy to pinpoint dates for temples and sacred sites (as is also evident by his endless rants on Twitter), but he is really going against his own discipline there. Astronomical chronology as a tool has become commonplace in our time, and it helps us pinpoint when ancient texts or buildings were constructed that would otherwise be forever assigned to “myth”. What we typically see is that the older generation of archeologists ignore or scoff at this, while the younger generation has embraced it as a useful tool.
“Instead, Hancock visits several North American mound sites, pyramids in Mexico, and sites stretching from Malta to Indonesia, which he is convinced all help prove his theory. However, all of these sites have been published on in detail by archaeologists, and a plethora of evidence indicates they date thousands of years after the ice age.”
Again Mr. Dibble misses the point or obscures Grahams work intentionally. The native american monuments is not purely a matter of dating, but rather the symbolism involved. Just like the mountain of God symbolism can be tracked from India to Egypt and further to the Jewish levant, the native american monuments carry symbolism and alignments that match those found elsewhere.
Hancock’s visit to Malta was due to a claim that the megalithic buildings were purely the work of modern man. But what Hancock demonstrates is that there is no actual evidence that modern man erected the temples aligned with Sirius. After the official dating of the various megalithic temples on Malta, a cave was discovered with teeth from Neanderthals, proving that modern man were not the first to inhabit the island, but the archeologists have been reluctant to factor this into the equation. In fact, they were adamant that Neanderthals had never even been there (!). When proven wrong they get upset when that is mentioned, even though they hold no scruples about ridicule and mockery before those teeth came to light. I suppose criticism should only go one way?
So the visit to Malta was not about refuting modern man’s existence there, but rather to underline that we have no evidence that the megalithic structures were erected by modern man – or if we in fact took them over from Neanderthals. A very different situation than what Mr. Dibble describe and criticize.
“While skin color is not brought up in Ancient Apocalypse, the repetition of the story of a “bearded” Quetzalcoatl (an ancient Mexican deity) parrots both Donnelly’s and Hancock’s own summary of a White and bearded Quetzalcoatl teaching Native people knowledge from this ‘lost civilization’ “
Skin color has never been of any interest to Hancock, nor has he demonstrated any inclination of going down such as route in any of his books. As for the white Quetzalcoatl, it would appear that Mr. Dibble is unaware of the use of colors in religious iconography, which I find very strange considering his title.
The virgin goddess Tara dons different colors depending on her function. Christ likewise donned different color robes. These colors are also common for Egyptian, Hindu and south American deities.
In more or less all religions in the world you will find the use of specific colors on deities, typically used to denote their function. When the ancient texts mention white, they are not referring to caucasian or skin pigment of any sort. But rather, white as in wall paint white. The primary colors you will find in every religion, universally on the planet and deployed more or less uniformly throughout history, are: black, red, white, blue, ocre (yellow) and green.
Tibetan Buddhism is a good example of this, where you find the virgin goddess in her many forms as Green Tara, White Tara, Red Tara (and so fourth). Tibetan Buddhism is basically Saivism without a notion of god (singular). They even kept Shiva as Bhairava, Maya (illusion), shakti (life force, spirit) and hiranjagharba (virgin womb) as Tara. The Dalai Lama takes part in the Kumb-mela festivals in India, where each lineage of Hinduism meet every 8 years roughly.
The fact that Mr. Dibble attempts to drag this debate and these colors down to a level of racism, just underlines that he has an agenda. A sinister one considering he is a representative for the Aryan invasion theory, indirectly supporting the foundation that gave rise to the holocaust.
Talk about the pot calling the kettle black.
Cowboy archeology
One of the examples that Mr. Dibble brings up, is that of Hawass, a well known Egyptologist. Hawass made it his personal mission to expose Robert Beauval, the man that looked at the mathematics of the pyramid at Giza, and discovered that the shafts were aligned with Sirius and Orion. Two locations which are inexplicably linked to the goddess Isis and the god Osiris, the Egyptian divine couple.
Hawass like to pretend he is Indiana Jones, but he is ultimately a glorified thief which lost his job.
Beauval worked closely with Hancock for a number of years, and as you would expect – Hawass went after these with everything he could muster. Accusations and ad-hominem attacks flying left and right. One of these accusations was that Beuval was a thief, which turned out to be a case of instant karma, because Hawass suddenly found himself in a court of law accused of stealing artifacts. Something he was even convicted for, and consequently lost his job (!).
To quote The Smithsonian:
“It is not as dramatic as the collapse of an ancient Egyptian dynasty, but the abrupt fall of Zahi Hawass is sending ripples around the planet. The archaeologist who has been in charge of Egypt’s antiquities for nearly a decade has been sacked”
To a reader that has not followed Beauval or Hancock, mentioning Hawass might give the appearance of credibility and authority, but scratch but a little on the surface and the pretty paint falls to the ground. Hawass demonstrates above anything else how much control money have over disciplines such as Egyptology.
It is also not without some irony that Egyptology is slowly catching up with Beauval and the work he did decades ago. They recently discovered that the pyramids do have astronomical alignments, but they are just starting to unwind the data. They no doubt instinctively know that Beauval is correct, but saying so would mean losing face, so it will probably take another 30 years for them to “discover” the exact same alignments and mathematical groundwork that Beauval has done.
Conclusion
If you are going to debunk laypeople such as Graham Hancock, then by all means do so on the merit of data, and make sure you include all the data. Mr. Dibble leaves out more or less all the aspects of the data that explains why Graham included it to begin with — but his resorting to accusation of racism is just utterly unfounded. It is beyond an ad hominem attack and borders on outright evil.
I used to respect Mr. Dibble and those working within the field of ancient Greece, but I must admit that all such respect has now vanished completely. This type of behavior is utterly unacceptable. Period.
Looking at how unaware Mr. Dibble is regarding the function of Delphi, Greece in his own published papers, which served as a miniature Varanasi for the better part of 2000 years, complete with Shivalinga worship (Greek: Omphalos) – I would also question if he is suited for working in that field at all. I have the utmost respect for archeologists in general, but it is also a profession where people of a “symbolically blind disposition” can fortify and stay without ever having contributed significantly to human knowledge and understanding. The tantric nature of Greek religion, which typically establish cult centers only to vanish and later re-appear, seems unknown to Flint Dibble. Dionysus and his bachantes (sanskrit: bhaktis, devotes) and his mountain (nyssa) is fairly easy to map. If you know what to look for and understand what religion truly is. You will find his wine-press 3 fingerwidths below the belly-button on the left side of the body. The human body is the ultimate pharmacy, and the ancient quest to perfect mankind, to re-wire our psycosomatic framework, comes into play here. A quest which was completed in prehistoric times but then lost, only to be rekindled. A quest that was nothing less than the transformation of human biology and consciousness as a final step of evolution. These were no illiterate savages. It is we that are the savages here Mr Dibble. If not strangers to who we are and what we are capable of.
“I stand before the masters who witnessed the transformation of the body of a man into the body in spirit, who were witnesses to resurrection when the corpse of Osiris entered the mountain and the soul of Osiris walked out shining. And they are Ra, the light of divinity, and Shu, the breath of god. He gathered his thigh, his heel and his leg. He gathered his arms and backbones. He gathered the dreams crackling inside the dark cave of his skull. He knitted himself together in secret. He came forth from death, a shining thing, his face white with heat”
Book of the dead, 11 Triumph through the Cities.
Hancock’s criticism of mainstream archeology is not unfounded either as Mr Dibble like to think. Hancock does not set himself up as any sort of victim. The way he has been treated for the past 40 years would turn most of us into angry, spiteful, if not outright vengeful individuals. Considering that Hancock retains his composure and argues on the level of data, while the so-called “experts” are more busy with personal attacks and slander of the worst sort – speaks volumes.
To imagine that we are the pinnacle of evolution and the best of human history is an arrogance we should be very careful with. Sadly, Mr. Dibble has thrown all caution to the wind and is exposing the ugly underbelly of his discipline.
Mr. Dibble might not see it now, but I believe he will come to regret taking part in this witch hunt.
Amibian.jsQTXQuartex PascalObject PascalpascalQuartex Media Desktop
The public alpha is, as the name implies, a pre-release version meant purely to be played around with. There are bound to be hiccups and bugs, but the point is just to get you familiar with the ecosystem (which is very different from Delphi, so don't think you can just magically compile some old Delphi application).
Show full content
It’s been a long time since I have written a post here on my blog. I have been so busy with work that I quite frankly have not had the extra energy to maintain this website. During the weekdays my hands are full with work, and in the weekends I typically recharge 1 day, with Friday afternoon and Sunday allocated for the Quartex Pascal project. On Saturdays I sleep for as long as I can, go for a walk, and watch Netflix.
Quartex Pascal has a good range of features for using object pascal to write mobile, desktop and web applications. Including node.js servers for the back-end, and using web-workers to thread larger tasks both in the browser and under node.js
Thankfully I am happy to report that Quartex Pascal is more or less ready for a public alpha. I took out a week vacation today to finish the remaining handful of tickets, which are ultimately superficial and fiddly, but nothing difficult compared to what we have already achieved.
Have we reached our goals?
When you start a project it’s easy to get caught up in the potential. One feature quickly avails the next, and if you are not careful – you can be whisked away to vaporware land. Or even worse, end up with a project that never ends and where you keep telling yourself “i just need to add this, then I’m done”. I am happy that we have managed to avoid that, and set a clear boundary of what should be in the initial release. The point of version 1.0 is not to cover all possible features, but rather – to make damn sure the fundamental features work as well as I can make them. Because future revisions and features will build on that foundation. So in short: Yes. As much as 90% of what we set out to include in version 1.0 has been realized. The only thing we had to push to version 1.1 and 1.2 is the database explorer, DAC classes so your web application can work directly with a database through a node.js service, and a few minor features like having a Gr32 powered picture viewer and paint-program included.
The IDE has evolved into a nice ecosystem with package support, project templates, delegates (events) and much more
There is plenty of room for optimization and refactoring in the code-base, so once the first version is out you can expect regular updates (Patreon backers only) where both the IDE and RTL becomes more and more refined and optimized. One of the things I am really looking forward to is writing new and exciting widgets (controls are called widgets under the QTX paradigm), and also port over more JS modules and frameworks. We already have an impressive list of JS frameworks that you can use out of the box. The benefit of having highly skilled backers is that they are quick to digest new technology and produce packages, so we have a lot of widgets that you can drag & drop that are 1:1 wrappers (a wrapper is a class definition that describes an external object, or a unit that makes the features of an external framework usable from pascal).
The Cloud desktop project
Since a couple of years have passed, most people have probably forgotten why Quartex Pascal was created to begin with. Namely as a development tool to implement and finish the Quartex Media Desktop (also known as Amibian.js). Quartex Pascal was actually a detour we had to make to save the codebase I had already implemented. So the moment version 1.0 goes out the door, my first priority is to refactor and re-implement the desktop client under the Quartex Pascal RTL. The background node.js services already run on my new RTL, so all the work we did a couple of years ago is still there, waiting to be picked up again.
The Amibian.js desktop prototype turned a lot of heads. This will finally be realized once Quartex Pascal v1.0 is out
I am not going to spend ages re-hashing the desktop system, but in short this is a client-server system that implements a Windows like desktop, complete with filesystem over websocket, multi user accounts, message based API, and that is 100% JavaScript from the back-end services all the way up to the desktop itself. It is in other words portable and completely hardware and platform agnostic. The point of the desktop is to provide the exact same ecosystem that Windows provides for native applications, for enterprise level web applications. This includes hybrid application modules where half the program is deployed server-side, while the visual part is rendered in the browser (this is how we could have a Torrent client with live status in a web application).
Combine this with a thin Linux bootstrap, where you boot into Chrome in Kiosk mode – and you have a fully working, incredibly powerful desktop system. One that you can literally copy from one machine to the next without recompiling a line of code. As long as the system supports node.js and have a modern browser, Amibian.js will run. Heck, I even booted it on my Smart TV (!).
Release date?
The public alpha is, as the name implies, a pre-release version meant purely to be played around with. There are bound to be hiccups and bugs, but the point is just to get you familiar with the ecosystem (which is very different from Delphi, so don’t think you can just magically compile some old Delphi application).
The IDE has both code suggestion and parameter suggestion, and it does background parsing and VMT building
I am aiming at next weekend. It can be that some delay comes up, but all in all I have only a handful of tickets, most of them small and somewhat fiddly, but nothing too difficult. I will close 2 or 3 tickets a day, so a build should be ready next weekend for you guys.
What License?
The application is released as vanilla shareware, which means that copyright and ownership of all materials (except packages and examples written by others naturally) is tied to me. Once we have enough to establish the Quartex Pascal Foundation (which aims at teaching object pascal and offering free development tools for for students, schools and non-profit organizations) ownership will be isolated there. You can read more about the license on the website, here: https://quartexpascal.wordpress.com/about/licensing/.
We also have a rule that any version of Quartex Pascal will never cost more than €300. The first version will be in the €100-€150 range, which buys you a license to use the development tools in a commercial setting. Quartex Pascal is free to use for open-source work. Students can also use QTX for free, provided they provide proper student identification that can be verified, and they dont use it for commercial gain. Considering the cheap price, buying a license wont exactly break the bank.
The RTL is accessible the exact same way that you are used to under Delphi, so exploring the RTL is encouraged. I have started on the documentation but this is an alpha so you really need to explore a bit.
Just like Delphi all applications have a TApplication object that is the first to be created, and entities like forms are managed by TApplication (they automatically register when you create TQTXForm or TQTXWindow). Once you familiarize yourself with the units, you should have no problem becoming productive in a very short time.
of having to write an initialization section on unit level, you can just attach a [ClassRegister] attribute, and it's automatically registered for you when the unit is loaded into memory.
Show full content
This is something I wrote back when Attributes was sort of new to Delphi, but it’s a neat example of how custom attributes can simplify your code. It would actually be a nice candidate for addition to the VCL.
In short: If you are serializing objects to JSon, you probably know that Delphi can only re-create those objects if it knows the class type (or if you manually provide the class during parsing). This means that you end up writing an implementation section where you manually call RegisterClass() for each of the class types you use.
RegisterClass is just perfect for turning into an Attribute
While this is not problematic or difficult, it’s one of those chores that is perfect for attributes. So instead of having to write an initialization section on unit level, you can just attach a [ClassRegister] attribute, and it’s automatically registered for you when the unit is loaded into memory.
Here is the unit, feel free to use it and rename it to whatever you like:
unit quartex.util.register;
interface
type
///<summary>
///<para>The [ClassRegister] attribute registers the attached class
/// into Delphi's internal class registry. This is the same as calling
/// RegisterClass manually during unit initialization, except it's
/// simpler and more elegant.</para>
///<code>
///type
/// [ClassRegister]
/// TSomeClass = class(TPersistent)
/// end;
///</code>
///</summary>
ClassRegister = class(TCustomAttribute)
end;
implementation
uses
System.Rtti, System.TypInfo, System.Classes;
// This procedure walks through all classtypes and isolates
// those with our TAutoRegister attribute.
// It then locates the actual classtype and registeres it
// with Delphi's internal persistence layer
procedure ProcessAutoRegisterAttributes;
var
ctx : TRttiContext;
typ : TRttiType;
attr : TCustomAttribute;
lRealType: TClass;
lAccess: PTypeData;
begin
ctx := TRttiContext.Create();
try
for typ in ctx.GetTypes() do
begin
if typ.TypeKind = tkClass then
begin
for attr in typ.GetAttributes() do
begin
if attr is ClassRegister then
begin
lAccess := GetTypeData(typ.Handle);
if lAccess <> nil then
begin
lRealType := lAccess^.ClassType;
if lRealType <> nil then
begin
if lRealType.InheritsFrom(TPersistent)
or lRealType.InheritsFrom(TInterfacedPersistent) then
RegisterClass( TPersistentClass(lRealType) );
end;
break;
end;
end;
end;
end;
end;
finally
ctx.Free();
end;
end;
// We want to register all the classes decorated with our
// attribute when this unit is loaded into memory. This process is
// ultimately very quick since it's all pointer material.
Initialization
begin
ProcessAutoRegisterAttributes;
end;
end.
The only reasonable way forward was to implement a separate IDE, one that dealt with web technology exclusively. And what better language to write such a system in than Delphi itself? I was actually thinking that Embarcadero might want to rekindle their HTML5 Builder, and let me do my magic on it. Quartex Pascal is in many ways what HTML5 Builder should have been, and it's just getting started.
Show full content
When developers talk about web development they usually mean creating web pages with the tools common for the web sphere. Web designer software is abundantly available online, from single-click page wizards to more ad-hoc, old school HTML / JavaScript editors. If there is something the world don’t need more of, It’s one-click website solutions.
The Quartex Cloud cluster server, running services written in Quartex Pascal
One challenge that haven’t been addressed until recent times in the web sphere, is that of programming language. JavaScript is a fun language, but it was never really designed for large-scale application development. As websites become more and more elaborate, the need for traditional programming languages and features started to surface. In many ways the past 15 years of browser evolution, has been all about JavaScript catching up with the needs of developers.
But are we really limited to JavaScript?
When it comes to language and web technology, it was C/C++ that became the second language of the internet via the introduction of Asm.js and eventually Webassembly. It took a long time for other languages to adopt the Webassembly binary format as a target. WebAssembly is a bytecode binary format consisting of low-level instructions, much like assembly for x86 processors. These instructions are converted into real machine code by the browser (via a process called JIT compilation), and as a result the performance of Webassembly is close to native code. Having said that, Webassembly comes with its own set of restrictions and challenges, especially when it comes to manipulating the DOM (the document object model, the elements that makes up a HTML document).
The Quartex Way
Back in 2010 I had a novel idea with regards to languages: what if we translate Delphi code on source level, and emit JavaScript instead? At the time there was no such thing as webassembly, and the closest thing to a binary format was Macromedia Flash. Without rehashing the story, I teamed up with Eric Grange from Creative IT in France, the maintainer of Delphi Web Script, and the end result was a compiler that would parse Object Pascal code, construct an AST (abstract symbol tree) which is a model that represents the entire program, and further convert that into optimized JavaScript.
In order for such a system to work properly, a whole new RTL (runtime-library) had to be created. All the functions, procedures and classes that Delphi provides would not magically compile to JavaScript. So someone had to sit down and implement classes and features that made sense for the browser, from TComponent all the way up to TCustomControl – but in a way that is compatible with HTML.
Quartex Pascal comes with a rich RTL that makes class based, component oriented development possible for the browser
It is out of this work that the Quartex Framework came into being, as a personal research and development framework dealing with web technology. Back in 2014 it was just a utility library, and it remained as such until 2019 when it became a fully functional RTL in its own right. An RTL with a wingspan from low-level binary data, all the way up to visual components and database connectivity. In 2020 it expanded to Node.js, which is a JavaScript scripting-host used to write servers and services. The Quartex framework as now a full stack RTL that radically cuts down on development time needed when writing websites, mobile applications or server technology.
The Quartex IDE
Delphi has a wonderful IDE that has been polished and evolved over almost 2 decades. It is possible to introduce new compilers and third party technology into that IDE, but Delphi is limited to native technology. The only way to integrate QTX with Delphi, would be to mimic the VCL or FMX in its entirety, so that class-names match and the form design files could be read and used by the Quartex Compiler.
While such a project would probably be easier, it also meant a massive compromise in terms of features and performance. As a native development system Delphi does things in a very specific way, and if I forced JavaScript and HTML to abide by those rules – we would lose the dynamic and flamboyant aspects of HTML5 and JavaScript. The performance would also be poor since the VCL (and consequently LCL) was never written for the browser or Node.js. A test I did on performance, comparing QTX compiled code with TMS compiled code demonstrates my point. TMS populates a listbox with roughly 1000 items in 2 seconds. QTX populates the same listbox with 20.000 items in 1.8 seconds.
The only reasonable way forward was to implement a separate IDE, one that dealt with web technology exclusively. And what better language to write such a system in than Delphi itself? I was actually thinking that Embarcadero might want to rekindle their HTML5 Builder, and let me do my magic on it. Quartex Pascal is in many ways what HTML5 Builder should have been, and it’s just getting started.
The Quartex IDE: The welcome screen showing a live RSS feed from BeginEnd.net, as well as recent projects.
Writing an IDE is a massive undertaking. It covers technologies such as code suggestion, form and container designer, communication protocol design, license management – and much, much more. The IDE has been worked on every weekend for a year, and the results are solid.
What is important with an IDE like this, is that it represents a broad foundation for further development. It is written to be highly modular, with everything neatly isolated in classes. If a particular feature requires adjustment, then refactoring that particular module is a straightforward task. Large applications have a tendency to become a mesh of spaghetti that only the original developer understands, something I have worked very hard to avoid. The source-code is available for backers on Patreon.
Quartex IDE: Form designer and HTML5 property editor dialog
Server Side Programming
Node.js is a scripting host based on Google’s V8 JavaScript engine, which runs outside the browser. It is designed to run from the command-line (read: standard scripting host) and gives developers all the features you expect from a native program, like raw file access, multi threading (read: Node operates with multi processes), servers and sockets, third party libraries and much more.
Being able to write both client and server from the same development system, a so called “full stack” development environment, is a great boon and opens up for deployment on enterprise level.
Quartex IDE: Writing a HTTP/S server is no more difficult than using Indy under Delphi
But being able to communicate across services and servers means that the IDE had to provide the tools for async network programming. Working with async code is not hard, but it can be difficult if your codebase does not take height for it.
To help simplify communication between servers, services or clients (read: browser and server, or locally as inter process communication) I wrote the Ragnarok message framework. The IDE now has a visual protocol designer which makes it extremely easy to design messages and complex datatypes that is used when communicating. The protocol designer takes your design and generates ready-to-use classes and units.
Quartex IDE: The protocol designer greatly simplifies async client/server models
Object Pascal as a web language
You might think that object pascal with its rigid rules and pure logic is too stiff for web development. It turns out that this was exactly what the browser needed, as a solid anchor to the otherwise “anything goes” reality of JavaScript. Eric Grange made a lot of changes to the dialect which allows Quartex Pascal to interface more easily with JS, such as partial classes, external classes, static (in the C++ / C# meaning of the word), support for lambdas, inline variables, anonymous procedures, records and classes – and finally support for the async and await keywords when working with promises.
Quartex Pascal approach the DOM as a programmer would WinAPI, and the result is rock solid applications
Object Pascal brings a clarity to web development that JavaScript and TypeScript simply lacks. It also introduces normal inheritance (like C/C++ and Delphi has), with abstract and virtual members. When you combine this with partial classes, you have a dialect that is extremely productive, and that takes on node.js and Javascript on its own terms.
Come join the fun
The Quartex Pascal project is nearing completion. It is not finished just yet, but I am aiming for a release of version 1.0 before xmas. Quartex Pascal is based on Patreon backing, which means those that back the project and contribute financially enjoys weekly builds and working closer with the author on shaping the system. Premium backers also have access to the source-code, with rights to modify and use the system for whatever they like, providing the no-compete clause is respected.
Quartex Pascal will be free for schools and educational institutions, as well as for students, non-profit organizations and open-source development. For commercial use a symbolic fee of $300 is needed. The system is licensed as shareware in order to avoid an avalanche of clones, which can quickly kill a project.
And here I thought I was super clever, only to discover that Nicola Tesla scribbled a similar system on a napkin back in the late 1800s (figuratively speaking). Turns out that the basis of my system is more or less identical to Tesla's numbers and ultimately bound by their relationships, where you operate with a growth factor that is a multiple of 12, modulated and held in check by Fibonacci, Lucas or Leonardo sequencing.
Show full content
If you have poked around the Quartex Pascal RTL you might have notice that QTX comes with a serial-number minting system. Creating unique serial numbers that can be mathematically re-traced back to a root key (number sequence) is extremely tricky business. My solution was to dip my fingers into esoteric and occult numerology, because our ancient forbearers had a knack for puzzles and number based riddles.
And here I thought I was super clever, only to discover that Nicola Tesla scribbled a similar system on a napkin back in the late 1800s (figuratively speaking). Turns out that the basis of my system is more or less identical to Tesla’s numbers and ultimately bound by their relationships, where you operate with a growth factor that is a multiple of 12, modulated and held in check by Fibonacci, Lucas or Leonardo sequencing.
So my ego got a well deserved slap (which is always healthy, we should all be humble in the presence of that man).
I have never really been that interested in Tesla until recently, and the little I have read about him makes me incredibly sad. This man was not decades ahead of his time, but centuries.
In my view, the biggest tragedy in human history is without a doubt the loss of the great library in Alexandria, Egypt. Second only with the murder of Hypatia; a series of events that would eventually catapult humanity as a whole into a dark-age that lasted for 2000 years.
But having spent some time this morning reading about Tesla, I would add him to that list of tragic events that have affected our history (or in his case, being prevented from lifting mankind up). This is a man that constructed the walkie-talkie in the late 1800s. He even theorized that both audio and video could be transmitted over a hand-held device. And this was in the late 1800s (!).
Tesla’s analysis of numbers, based on multiples of 12, each segment seeding the nextFrom the Quartex Pascal IDE, the serial number minting dialog
Above: The serial-number minting dialog from the IDE. Here we use 12 seed numbers to form the root key, and each serial number is grown from these using natural numbers, as employed by various mystics and esoteric traditions.
Hat off Tesla. It is a great shame that you were born into a world that neither understood or appreciated the wonders you delivered.
Nicolas Tesla’s notebooks is best read on your knees.
Now I need to scotch tape my ego back together and get to work.
I have to give HTMLComponents 9 out of 10 stars. It would have scored a perfect 10 with JS support. But this is the highest score I have ever given on my blog, so that's astronomical. Well done Alexander!
Show full content
For a while now I have been paying attention to Alexander Sviridenkov’s components for Delphi. First of all because Delphi doesn’t really have that many options when dealing with HTML beyond embedding the classical browsers (Chromium, Firefox or Edge); And while Dave Baldwin’s work has served the community well in the past, TFrameBrowser is 20 years old. So there is definitively room for improvement.
Secondly, in my work with Quartex Pascal, a system that compiles Object Pascal to JavaScript for HTML5, being able to work with HTML and render HTML easily from my IDE is obviously interesting. The form designer in particular could benefit from showing “live” graphics rather than representative rectangles.
Quartex Pascal uses HTMLComponents in a variety of places to render UI elements
All of that is possible to do with Chromium if you run it in an off-screen capacity, but getting good results is very tricky. Chromium Embedded runs in a separate thread (actually, multiple threads) and sharing video memory, injecting HTML to avoid a full reload — lets just say that a Delphi native component package would make all the difference. Enter HTMLComponents.
Focus on the essentials first
The way that Alexander has proceeded with his components can resemble my own philosophy (or indeed anyone who has been a developer for a while). It’s the kind of work approach you end up with through experience, namely, to start with the basics and make sure that is rock solid (read: focus on the foundation code, that’s what’s going to matter the most. Trust me). It’s so tempting to run off on a tangent, adding more and more functionality – typically visually pleasing stuff, but as mature developers will know, if you go down that path what you end up with is a very expensive mess.
HTMLComponents have some high profile customers. Here used in Help & Manual
Thankfully, Alexander has gone about his work in an orderly, no-nonsense way. He began with the HTML parser, making sure that was flexible, compliant and delivered great performance (over 100 Mb a second!). Then he moved on to the CSS part of the equation and implemented a high performance styling engine. The reason I outline this is because I don’t think people fully grasp the amount of work involved. We think of HTML as a simple tag based format, but the sheer infrastructure you need to represent modern HTML properly is enormous. There is a reason Delphi component vendors shy away from this task. Thankfully Alexander is not one of them.
Scripting?
Next we have the scripting aspect. And here is the twist, if we can call it that. HTMLComponents is not written to be a browser. It is written to enable you to render HTML5 at high speed within a native application, including CSS animations and Tweening (a technique made popular by Apple. Like sliding forms or bouncing swipe behavior).
In other words, if you are expecting to find a browser, something like Dave Baldwin’s now ancient TFrameBrowser, then you should probably look to the new TEdgeBrowser component from Embarcadero. So JavaScript is not yet natively supported. HTMLComponents falls into the category of a UI presentation framework more than a browser.
If however, like myself, you want to handle presenting HTML5, PDF, RTF and Word documents without a ton of dependencies (Chromium adds 150Mb worth of libraries you need to ship), provide your users with a compliant HTML WYSIWYG Editor – and also deliver those fancy animated UI elements – then you are going to love HTMLComponents.
I should mention that HTMLComponents has its own scripting engine, but it’s not JavaScript. But for those situations where a script is needed, you can tap into the scripting engine if you like. Or deal with everything natively. It’s your choice.
Document editor
Pretty impressive list of controls
The reason I mentioned Alexander’s architecture and how his codebase has evolved, is because a high performance document rendering engine can be very useful for a variety of tasks.
One thing is rendering HTML5 with all the bells and whistles that entails, but what about RTF? What about Word documents? What about PDF documents? Once you have a rock solid engine capable of representing HTML5, the next logical step is to branch out and work with the other formats of our times. And that is just what Alexander did.
But before we look at those features, let’s have a peek at what components you get.
As you can see from the picture above, HTMLComponents is not just about drawing HTML. Being able to represent HTML is useful in a variety of situations since it simplifies visual feedback that would otherwise be very time consuming to implement. So instead of limiting that power to a single control, HTMLComponents come with common controls that have been infused with superior graphical powers.
Full editor, and TAction’s for all features!
The most powerful component in the above list is without a doubt the HTML editor component (also notice that the package installs both standard and DB variations of the various controls). This is quite simply a fully compliant WYSIWYG editor – complete with all the formatting features you expect.
WYSIWYG editing.
Does not use IE or other libraries (100% native Delphi code).
Supports all Delphi versions from Delphi 5 to Delphi 10.4 Sydney.
That is a solid list of features, and did I mention you get full source-code?
HTML empowered controls
If you are looking over the list of controls above and expecting to find something like a browser or viewer control, you won’t find it. The closest thing to a HTML viewer is the panel control (THtPanel). It exposes properties and methods to populate it with HTML (as does all the controls), set what type of scrollbars you need (if any), how to deal with links, images and CSS styling – and then it’s a matter of feeding some HTML into the control.
Quartex Pascal is still under heavy development. Here the project build options is handled via HTMLComponents. This means styling and “bling” can be easily added once we reach a release candidate. I always keep it simple for as long as I can.
Obviously controls like THtCombobox have behavior that is dictated by the OS, but you can style the child elements (rows for example) being displayed, the border etc. using the full might of HTML5. And yes, you can apply CSS transitions there as well – which is (excuse my french) bloody spectacular!
I mentioned that HTMLComponents were not designed to be a browser replacement, but rather to make it easier for native developers to tap into the design power and visual feedback that makes HTML5 so productive to use for UIs. Well, once you have set the properties for a panel and given it some HTML -you can do some pretty amazing things!
HTML takes a lot of grunt work out of the equation for you. For example, let’s say you wanted to produce a demo like the one in the picture above (see direct link in the next paragraph). With all the effects, transitions, pictures and displacement elements. Just how much work would that be in traditional Delphi or C++ ?
First you would need a panel container for each picture, then a canvas to hold the picture, then you would need to handle the interaction events- and finally access the canvas to draw the many alpha blended transitions (the picture here really doesn’t do the framework credit, you have to see them to fully appreciate the level of detail and performance HTMLComponents delivers). And all of that is before you have new elements flying in from the sides or above, that fades perfectly with the backdrop. All of it working according to a timeline (tweening as its called).
Instead of all that work, having to write a tweening engine, 32 bit alpha-blending DIBs (device independent bitmaps), deal with god knows how much work — you can just deliver some HTML and CSS and let HTMLComponents handle all of it. With zero external dependencies I might add! This is a pure Delphi library. There are no references to external browser controls or anything of the kind. HTMLComponents does exactly what it says on the box – namely to render HTML5 at high speed. And it delivers.
Here is the HTML for one of the pictures with effects in the demo:
And here is the CSS animation transition code for the same. Please note that the original code contained definitions for IE, Opera, Webkit and Firefox. I removed those for readability:
If CSS is not something you normally don’t bother with, the code above might look complex and alien. But there are tons of websites that have wizards, tutorials and even online editors (!), so if you take the time to read up on how CSS transitions work (they are quite easy), you will knock out some impressive effects in no time.
Once you have built up a collection of such effects, just link it into your Delphi application as a resource if you don’t want external files. Personally I think its a good thing to setup the UI in separate files like that, because then you can update the UI without forcing a binary installation on your customers.
So if we consider the amount of Delphi code we would have to write to deliver the same demo using stock VCL, sum up the cost in hours – and most likely the end result as well (Alexander is exceptionally good at graphical coding), I for one cant imagine why anyone would ignore HTMLComponents. I mean serious, you are not going to beat Alexander’s code here. And why would you waste all that time when you can buy ready to use controls with source-code for such a modest price?
Office formats
I mentioned briefly that with a powerful document rendering engine in place, that the next step of the way would be to cover more formats than just HTML. And this is indeed what Alexander has done.
If you invest in his Add-On Office package for HTMLComponents, you will be able to load and display a variety of document formats. And just like HTMLComponents the code is 100% Delphi and has zero dependencies. There are no COM objects or ActiveX bindings involved. Alexander’s code loads, parses and converts these documents instantly to HTML5, and you can view the results using HTMLComponents or in any modern browser.
Following document formats are supported:
Rich Text Format (RTF)
MS Word 6-2007 binary format (DOC)
MS Word XML document (DOCX)
MS Power Point binary format (PPT)
MS Power Point XML format (PPTX)
MS Excel binary format (XLS)
MS Excel XML format (XLSX)
Adobe PDF format (PDF)
Supercalc format (SXC)
EPUB (electronic books).
Besides the document conversion classes you also get the following code, which is pretty hard-core and useful:
EMF/WMF to SVG conversion
TTF to WOFF conversion
TTF normalization
TTF to SVG conversion
CFF to TTF conversion
Adobe PostScript to TTF conversion.
For me this was a god-send because I was using Gnostice’s PDF viewer to display the documentation for Quartex Pascal in the IDE. Being able to drop that dependency (and cost!) and use HTMLComponents uniformly throughout the IDE makes for a much smaller codebase – and cleaner code.
Final thoughts
The amount of code you get with HTMLComponents is quite frankly overwhelming. One thing is dealing with a tag based format, but once you throw special effects, transitions and standards into the mix – it quickly becomes a daunting task. But Alexander is delivering one of the best written component packages I have had the pleasure of owning. If you need a fresh UI for your application, be it POS, embedded or desktop utilities – HTMLComponents will significantly reduce the time spent.
I should also underline that HTMLComponents also works on FMX and Mobile devices ( Windows, OS X, Android, iOS and Linux even!). I’m not a huge fan of FMX myself so being able to design my forms using HTML and write event handlers in native Delphi is perfect. FMX has a lot of power, but the level of detail involved can be frustrating. HTMLComponents takes the grunt out of it, so I can focus on application specific tasks rather than doing battle with the UI.
The only thing I would like to see added, is support for JavaScript. HTMLComponents makes it easy for you to intercept scripts and deal with them yourself (HTMLComponents also have a pascal inspired script), but I do hope Alexander takes the time to add Besen (a native Delphi JavaScript engine) as an option. It really is the only thing I can think of in the “should have” apartment. Everything else is already in there.
I have to give HTMLComponents 9 out of 10 stars. It would have scored a perfect 10 with JS support. But this is the highest score I have ever given on my blog, so that’s astronomical. Well done Alexander! I look forward to digging into the office suite in the weeks ahead, and will no doubt revisit this topic in further articles.
The IDE has a very clean internal architecture, where the actual work is isolated in a set of easy to understand classes. One of these classes is called a TIDEAstProvider class. This is a class whose job it is to parse and otherwise work with whatever content an editor has, and deliver symbolic information that can be displayed in the file-structure treeview.
Show full content
While it can come across as disingenuous, I frickin love this project! As a developer yourself you know that feeling, when you manage to unify various aspects of your program, so that it all fits just perfectly. And the way I implemented file-handling and editors is within that sweet spot.
What is new?
It’s been a couple of weeks since I posted here last, so the list of changes will be quite dramatic. I think its best to focus on the highlights or this post would become very long!
Ironwood license management
Up until 2018 one of my products was a component package called HexLicense. This is a component package for Delphi that provides serial number validation, license handling and (most importantly) serial number minting. The HexLicense components were sold commercially until 2018 when I took them off the market and open-sourced (access was via Patreon. It is now moved to the Quartex Pascal project instead).
Ironwood is now an intrinsic part of the RTL and IDE
Im not going to go into how difficult it is to produce thousands of distinctly different serial numbers based on seed data, but it’s no walk in the park.
The final implementation I made for license minting and validation, was called Ironwood. It took the engine behind HexLicense and took it to a completely new level, incorporating both obfuscation and number modulation.
Generating license-number batches is literally one mouse-click to achieve
Needless to say, Ironwood is now a part of the Quartex Pascal RTL. To make it easier to work with the IDE has a nice utility for generating license-numbers, loading and saving keys, exporting license number batches – and much more.
There is also a ready-to-rock node.js application that can generate keys from the command-line (which is good to invoke from a server or service, so that it executes as a separate process).
HTML structure provider
The IDE has a very clean internal architecture, where the actual work is isolated in a set of easy to understand classes. One of these classes is called a TIDEAstProvider class. This is a class whose job it is to parse and otherwise work with whatever content an editor has, and deliver symbolic information that can be displayed in the file-structure treeview.
The IDE provides structured parsing and also Tag suggestions. More clever functionality will be added as we move into the final phases.
Obviously we have an object pascal provider, which will quickly compile and generate an AST very quickly in memory. This is used to power both the structure treeview and the code-suggestion.
Next, we have the exact same provider for JavaScript. So when you open a JavaScript file, the file will be processed to produce an AST, and the symbol information will be displayed exactly like your object pascal is. So behavior between these are identical.
We now also have a HTML provider, with a CSS provider on the way. The HTML provider is still in its infancy, but its flexible enough to represent a good foundation to work with. So I will no doubt return to this task later to smarten the provider logic up, and better handle un-valid HTML and CSS.
Code suggestion
Code suggestion is a pretty standard function these days. We have had support for this under Object Pascal for a while now in the IDE (with JavaScript on the way).
Note: the code suggestion-box is un-styled at this point. Custom painting will be added once the core functionality is done.
The IDE displays both a structural view of the unit, as well as in-depth code suggestion
Code suggestion for HTML is now in place too. It needs a bit of polish since the rules for HTML are wildly different from a programming language, but common behavior like TAG suggestion is there — with attributes, properties and events to follow.
So even if you are not an object pascal developer, the IDE should be nice to work with for traditional JavaScript / HTML code.
Form Recognition
While we cannot activate the form-designer just yet, since we need more AST functionality to extract things like class properties and attributes “live” to be able to do that properly — we are getting really close to that milestone.
The IDE however now recognize form files, so if your unit has an accompanying DFM file, the IDE is smart enough to open up a form-page. Form pages are different from ordinary pascal pages, since they also have the form designer control on a sub-tab. More or less identical to Delphi and Lazarus.
When you open a form-unit, the IDE is smart enough to recognize it as a form, opening the file-pair up in a layout capable page, just like Delphi
It is going to be so nice to get the form-designer activated. Especially the stack-based layout, which makes scalable, dynamic layout easy to create and work with.
The QTX RTL also supports orientation awareness as a part of the visual component system. One of the first things you will notice when exploring the code, is that ReSize() ships in an Orientation parameter, so you can adjust your layout accordingly.
Help and documentation inside the IDE
The IDE now has a PDF viewer with search functionality built-in. So when you click on Help and Documentation, a tab which shows the documentation PDF opens. This makes it easy to read, learn and find the information you need fast.
The IDE now has it’s own PDF renderer, so you can read the documentation directly
Well, that was a brief overview of what has changed since last time!
Next update is, as always, the weekends. We tend to land on sundays for new binaries, but do issue hotfixes in the evenings (weekdays) if something critical shows up.
Come join the fun!
Want to support the project? All financial backers that donates $100+ get their name in the product, access to the full IDE source-code on completion, and access to the Quartex Media Desktop system (which is a complete web desktop with a clustered back-end, compiled to JavaScript and running on node.js. Portable, platform and chipset independent, and very powerful).
A smaller sum monthly is also welcome. The project would not exist without members backing it with $100, $200 etc every month. This both motivates and helps me allocate hours for continuous work.
When the IDE is finished you will also have access to the IDE source-code through special dispensation. Backers have rights since they have helped create the project.
Your help matters! It pays for components, hours and above all, tools and motivation. In return, you get full access to everything and a perpetual license. No backers will ever pay a cent for any future version of Quartex Pascal. Note: PM me after donating so I can get you added to the admin group! Click here to visit paypal: https://www.paypal.com/paypalme/quartexNOR
All donations are welcome, both large and small. But donations over $100, especially reoccurring, is what drives this project forward.
Amibian.jsDelphidwscriptJavascriptnodejsObject PascalQuartex Media DesktopQuartex Pascal
Quite a bit has happened since my last blog post. The IDE is coming together piece by piece, and at the moment i'm focusing on helper functionality for the AST (abstract symbol tree).
Show full content
With Quartex Pascal development at full steam and a dedicated Facebook group for the backers – It’s not often that I post updates here on my blog. One of the benefits of being a backer is that you have direct access to the latest builds, and also that you take part in the dialog on the group.
Be that as it may, here are some of the news happening with Quartex Pascal!
What’s new?
Quite a bit has happened since my last blog post. The IDE is coming together piece by piece, and at the moment i’m focusing on helper functionality for the AST (abstract symbol tree).
Quartex Media Desktop [Node.js powered cluster] – powered by Quartex Pascal
As you no doubt know, when a program is compiled it’s first parsed and converted into objects in memory. So every inch of your program becomes an elaborate tree-structure. This structure is what is commonly called the AST – and it is the raw material if you will, that code is generated from. In our case we don’t produce machine code, but rather JavaScript.
As you can imagine such an AST is quite complex. It has to be able to represent all the nuances of Object Pascal, as well as simplify finding information about everything. Every datatype, every record, class or complex structure, every field, expression — it all exists within the AST.
Without code to quickly traverse and work with the AST, things like code suggestions, parameter suggestions, code completion, the much loved ctrl + click — none of those would work. So while boring, it has to be done.
Oh and the mini-map has been re-implemented from scratch, so it’s now fast, accurate and responsive – and it works with mousewheel and keyboard.
Code suggestion
One of features that is bubbling up to the surface right now, is code suggestion. It’s something that we simply take for granted these days, and we dont really consider how much work it is to make. Eric has done a lot to simplify this for DWScript, but you still have to build up the codebase around it. But thankfully that is now largely done, leaving only a bit of styling and focus handling.
Code suggestion is starting to surface. Still needs work but it’s getting there
Form Files
New form is now active
In the previous build the IDE only recognized unit files (.pas), but in the current version it will check for an accompanying .DFM file. If a form-design file exists, it will open up a form-designer page rather than a pure code page.
The form-designer itself has received a bit of love lately too. Keyboard shortcuts have been added, such as holding down CTRL during a multiple selection — and changes to the layout is signaled back to the IDE and reflected in save-states changing (i.e if you change a form layout, the Save and Save All icon becomes enabled).
The form layout objects (visual widgets) have also been re-worked a bit. We want our DFM file-format to be JSON, so full JSON object persistence has been implemented. The form-designer widgets inherit from TQTXJSONPersistent, making it a literal one-liner to load and save form design.
Multi-select is now key sensitive and hooked into the signal highway of the IDE
We do need to wait for the AST explorer code to finish though, before you can start dragging & dropping widgets. Visual controls dont magically appear by themselves. Packages must be registered, and visual controls must likewise be registered with the IDE before they become known to the designer. So once the AST code is finished, we move on to packages – and finally glue the pieces together.
RTL advancements
The RTL has seen just as much changes as the IDE itself, and for good reason. Unlike “other” Web Technology tools, Quartex Pascal has an RTL that supports everything HTML5 has to offer. You are not limited to a static, fixed layout like we are used to under Delphi or Lazarus.
The ability to work with dynamic layout presents some interesting and highly efficient design opportunities. I find myself using the blocking layout model more and more, since it simplifies building up a dynamic UI that scales. Being able to work with different font scales too, like point (pt), as opposed to traditional pixel (px) closes the circle; it makes it possible to implement visual components that can scale it’s content to fit the container. This in turn simplifies writing software that renders well on both Desktop, Mobile and browser.
The new AST explorer is 40% finished. This allows you to examine the AST model down to expression level, helping you pinpoint where refactoring can be done.
The changes has been too many to list here, but I have pretty much implemented all the event delegate objects (more to come), tweaked creation speed even further – and added additional polyfill files that ensures that your code works on every browser (a polyfill is a fallback system, so if a browser lacks a feature – the polyfill is used instead).
Application models
Under Quartex Pascal the TApplication object plays an important role, much more than you are used to under Delphi or Lazarus. It is TApplication that is responsible for maintaining your layout – and ultimately how forms are shown.
If you are writing a mobile application you obviously want your forms to slide into view, just like native applications do on iPhone and Android.
If you are writing a client-server website solution, you might prefer that forms covers the full width of the browser, with variable height – with the user switching forms by clicking on a toolbar, menu option or link.
Perhaps you would like the forms to the stacked vertically, so that each form comes into view as the user scrolls downwards – perhaps with some fancy effect, or a static background behind the forms.
And last but not least, you might prefer that your web application looks and behaves like a Windows desktop application. With multiple windows that can be moved around, a normal menu system on top of each window – or on top of the browser.
The only way to consolidate these diverse and even conflicting layout models, is to implement several TApplication classes; each one representing the layout model you want to work with. So when your create a project, you pick the layout model you want – and the correct TApplication is chosen and generated for your project.
Actual menus
The RTL have seen a few new widgets added, but the most interesting one is without a doubt the Menu widget. This is a widget that mimics how a normal menu works in a real program.
Creating a menu might not sound interesting, but it’s actually a small challenge under HTML. Not the coding itself, but dealing with menu presentation without visual artifacts. Whenever you click a menu that has a sub-menu attached, the new menu is created from code dynamically. It’s positioned at the end of it’s invoker (to the right of the parent menu item) and should only show up when all it’s child elements have been created.
This was very tricky to get right under a competing system, because the way elements was created was, well, wrong. You want to avoid reflows at all cost during the constructor – otherwise there will be visual artifacts and flickering. But that is not an issue under QTX. And the speed is insane. Even with 100 recursive items on a menu container, it’s virtually instantaneous.
Un-styled menu bar. Extremely fast and adaptable.
If you are wondering why this makes any difference, you have to remember Quartex Media Desktop. This is not a simple toy with an onClick event, but can be bound into the process tree of the media desktop. The new code is barely 500 lines of code, the older version was over 3000 lines of code.
The goal for the IDE is that you can create a full desktop as a project. Not just programs that should run on the desktop (and its Ragnarok message protocol interface) – but the actual desktop system, which also covers several node.js system services.
The reason this is cool is because this enables you to deliver full scale, desktop level software purely through the browser. Such a desktop would be suitable for a school, a tutoring company, as an intranet – or for teams that need to share files, chat in realtime — and do their software development via the same web interface.
So it’s “a little bit” bigger than some mock desktop.
Come join the fun!
Want to support the project? All financial backers that donates $100+ get their name in the product, access to the full IDE source-code on completion, and access to the Quartex Media Desktop system (which is a complete web desktop with a clustered back-end, compiled to JavaScript and running on node.js. Portable, platform and chipset independent, and very powerful).
A smaller sum monthly is also welcome. The project would not exist without members backing it with $100, $200 etc every month. This both motivates and helps me allocate hours for continuous work.
When the IDE is finished you will also have access to the IDE source-code through special dispensation. Backers have rights since they have helped create the project.
Your help matters! It pays for components, hours and above all, tools and motivation. In return, you get full access to everything and a perpetual license. No backers will ever pay a cent for any future version of Quartex Pascal. Note: PM me after donating so I can get you added to the admin group! Click here to visit paypal: https://www.paypal.com/paypalme/quartexNOR
All donations are welcome, both large and small. But donations over $100, especially reoccurring, is what drives this project forward.
This is where the full might of the QTX Framework begins to dawn. As i wrote before we started on the Quartex Media Desktop (Which this IDE and RTL is a part of), in the future developers wont just drag & drop components on a form; they will drag & drop entire ecosystems ..
Show full content
I am deeply moved by some of the messages I have received about Quartex Pascal. Typically from people who either bought Smart Mobile studio or have followed my blog over the years. In short, developers that like to explore new ideas; people who also recognize some of the challenges large and complex run-time libraries like the VCL, FMX and LCL face in 2020.
Since I started with all this “compile to JavaScript” stuff, the world has changed. And while I’m not always right – I was right about this. JavaScript will and have evolved into a power-house. Largely thanks to Microsoft killing Basic. But writing large scale applications in JavaScript, that is extremely time consuming — which is where Quartex Pascal comes in.
Quartex Pascal evolves every weekend. There are at least 2 builds each weekend for backers. Why not become a backer and see the product come to life? Get instant access to new builds, the docs, and learn why QTX code runs so much faster than the alternatives?
A very important distinction
Let me first start by iterating what I mentioned in my previous post, namely that I am no longer involved with The Smart Company. Nor am I involved with Smart Mobile Studio. I realize that it can be difficult for some to separate me from that product, since I blogged and created momentum for it for more than a decade. But alas, life change and sometimes you just have to let go.
The QTX Framework which today has become a fully operational RTL was written by me back between 2013-2014 (when I was not working for the company due to my spinal injury). And the first version of that framework was released under an open-source license.
When I returned to The Smart Company, it was decided that to save time – we would pull the QTX Framework into the Smart RTL. Since I owned the QTX Framework, and it was open source, it was perfectly fine to include the code. The code was bound by the open source licensing model, so we broke no rules including it. And I gave dispensation that it could be included (although the original license explicitly stated that the units should remain untouched and separate, and only inherited from).
Quartex Media Desktop, a complete desktop system (akin to X Windows for Linux) written completely in Object Pascal, including a clustered, service oriented back-end. All of it done in Quartex Pascal — a huge project in its own right. Under Quartex Pascal, this is now a project type, which means you can have your own cloud solution at the click of a button.
As I left the company for good before joining Embarcadero, The Smart Company and myself came to an agreement that the parts of QTX that still exists in the Smart Mobile Studio RTL, could remain. It would be petty and small to make a huge number out of it, and I left on my own terms. No point ruining all that hard work we did. So we signed an agreement that underlined that there would be overlaps here and there in our respective codebases, and that the QTX Framework and Quartex Media Desktop was my property.
Minor overlaps
As mentioned there will be a few minor overlaps, but nothing substantial. The class hierarchy and architecture of the QTX RTL is so different, that 90% of the code in the Smart RTL simply won’t work. And I made it that way on purpose so there would be no debates over who made what.
QTX represents how I felt the RTL should have been done. And its very different from where Smart Mobile Studio ended up.
The overlaps are simple and few, but it can be helpful for Smart developers to know about if they plan on taking QTX for a test-drive:
TInteger, TString and TVariant. These were actually ported from Delphi (part of the Sith Library, a pun on Delphi’s Jedi Library).
TDataTypeConverter came in through the QTX Framework. It has been completely re-written from scratch. The QTX version is endian aware (works on both ARM, X86 and PPC). Classes that deal with binary data (like TStream, TBuffer etc) inherit from TDataTypeConverter. That way, you dont have to call a secondary instance just to perform conversion. This is easier and much more efficient.
Low-level codecs likewise came from the QTX Framework, but I had to completely re-write the architecture. The old model could only handle binary data, while the new codec classes also covers text based formats. Codecs can be daisy-chained so you can do encoding, compression and encryption by feeding data into the first, and catching the processed data from the last codec in the chain. Very handy, especially when dealing with binary messages and database drivers.
The in-memory dataset likewise came from the QTX Framework. This is probably the only unit that has remained largely unchanged. So that is a clear overlap between the Smart RTL and QTX.
TextCraft is an open source library that covers Delphi, Freepascal and DWScript. The latter was pulled in and used as the primary text-parser in Smart. This is also the default parser for QTX, and have been largely re-written so it could be re-published under the Shareware license.
Since the QTX RTL is very different from Smart, I haven’t really bothered to use all of the old code. Stuff like the CSS Effects units likewise came from the QTX Framework, but the architecture I made for Smart is not compatible with QTX, so it makes no sense using that code. I ported my Delphi tweening library to DWScript in 2019, which was a part of my Patreon project. So most of the effects in QTX use our own tweening library. This has some very powerful perks, like being able to animate a property on any object rather than just a HTML Element. And you can use it for Canvas drawing too, which is nice.
Progress. Where are we now?
So, where am I in this work right now? The RTL took more or less 1 year to write from scratch. I only have the weekends for this type of work, and it would have been impossible without my backers. So I cannot thank each backer enough for the faith in this. The RTL and new IDE is actually just a stopping point on the road to a much bigger project, namely CloudForge, which is the full IDE running as an application on the Quartex Media Desktop. But first, let’s see what has been implemented!
AST unit view
The Unit Overview panel. Easy access to ancestor classes as links (still early R&D). And the entire RTL on a second tab. This makes it very easy to learn the new RTL. There is also proper documentation, both as PDF and standard helpfile.
When the object-pascal code is compiled by DWScript, it goes through a vigorous process of syntax checking, parsing, tokenizing and symbolization (or objectification is perhaps a better word), where every inch of the code is transformed into objects that the compiler can work with and produce code from. These symbols are isolated in what is known as an AST, short for “Abstract Symbol Tree”. Basically a massive in-memory tree structure that contains your entire program reduced to symbols and expressions.
In order for us to have a live structural view of the current unit, I have created a simple background process that compiles the current unit, grabs the resulting AST, locates the unit symbol, and then displays the information in a meaningful way. This is the exact same as most other IDE’s do, be it Visual Studio, Embarcadero Delphi, or Lazarus.
So we have that in place already. I also want to make it more elaborate, where you can click yourself to glory by examining ancestors, interfaces, partial class groups – as well as an option to include inherited members (which should be visually different). Either way, the AST code is done. Just need to consolidate a few tidbits so that each Treeview node retains information about source-code location (so that when you double-click a symbol, the IDE navigates to where the symbol exists in the codebase).
JavaScript parsing and compilation
QTX doesn’t include just one compiler, but three. In order for the unit structure to also work for JavaScript files I have modified Besen, which is an ES5 compatible JavaScript engine written in Delphi. And I use this much like DWScript to parse and work with the AST.
Besen is a wonderful compiler. Where DWScript produces JavaScript from Object Pascal, Besen produces bytecodes from JavaScript (which are further JIT compiled). This opens up for some interesting options. I need to add support for ES6 though, modules and require are especially important for modern node.js programming (and yes, the QTX RTL supports these concepts)
HTML5 Rendering and CSS preview
Instead of using Chromium inside the IDE, which is pretty demanding, I have decided to go for HTMLComponents to deal with “normal” tasks. The “Welcome” tab-page for example — it would be complete overkill to use a full Chromium instance just for that, and TEdgeBrowser is likewise shooting sparrows with a Bazooka.
THTMLComponents have a blistering fast panel control that can render more or less any HTML5 document you throw at it (much better than the old TFrameViewer component). But obviously, it doesn’t have JS support. But we won’t be using JS when displaying static information – or indeed, editing HTML5 compliant content.
WYSIWYG Editor
The biggest benefit for HTMLComponents, is that it’s a fully operational HTML compliant editor. Which means you can do more or less all your manual design with that editor. In Quartex Pascal there is direct support for HTML files. Quartex works much like Visual Studio code, except it has visual designers. So you can create a HTML file and either type in the code manually, or switch to the HTMLComponents editor.
Which is what products like Help & Manual uses it for
Image from HTMLComponents application gallery website
Support for HTML, CSS and JS files directly
While not new, this is pretty awesome. Especially since we can do a bit of AST navigation here too to present similar information as we do for Object Pascal. The whole concept behind the QTX RTL, is that you have full control over everything. You can stick to a normal Delphi like form designer and absolute positioning, or you can opt for a more dynamic approach where you create content via code. This is perfect for modern websites that blend scrolling, effects and content (both dynamic and static content) for a better user experience.
You can even (spoiler alert), take a piece of HTML and convert it into visual controls at runtime. That is a very powerful function, because when doing large-scale, elaborate custom controls – you can just tell the RTL “hey, turn this piece of HTML into a visual control for me, and deliver it back when you are ready).
Proper Form Designer
Writing a proper form designer like Delphi has is no walk in the park. It has to deal not just with a selected control, but also child elements. It also has to be able to select multiple elements based on key-presses (shift + click adds another item to the selection), or from the selection rectangle.
A property form layout control. Real-time rendering of controls is also possible, courtesy of HTMLComponents. But to be honest, it just gets in the way. Its much easier to work with this type of designer. It’s fast, responsive, accurate and will have animated features that makes it a joy to work with.
Well, that’s not going to be a problem. I spent a considerable amount of time writing a proper form designer, one that takes both fixed and dynamic content into account. So the Quartex form designer handles both absolute and stacked layout modes (stacked means top-down, what in HTML is knock as blocking element display, where each section stretch to the full width, and only have a defined height [that you can change]).
Node.js Service Protocol Designer
Writing large-scale servers, especially clustered ones, is very fiddly in vanilla JavaScript under node.js. It takes 3 seconds to create a server object, but as we all know, without proper error handling, a concurrent message format, modern security and a solid framework to handle it all — that “3 second” thing falls to the ground quickly.
This is where the Ragnarok message system comes in. Which is both a message framework, and a set of custom servers adapted for dealing with that type of data. It presently supports WebSocket, TCP and UDP. But expanding that to include REST is very easy.
This is where the full might of the QTX Framework begins to dawn. As i wrote before we started on the Quartex Media Desktop (Which this IDE and RTL is a part of), in the future developers wont just drag & drop components on a form; they will drag & drop entire ecosystems ..
But the power of the system is not just in how it works, and how you can create your own protocols, and then have separate back-end services deal with one part of your infrastructure’s workload. It is because you can visually design the protocols using the Node Builder. This is being moved into the QTX IDE as I type. So should make it for Build 12 next weekend.
In short, you design your protocols, messages and types – a bit like RemObjects SDK if you have used that. And the IDE generates both server and client code for you. All you have to do is fill in the content that acts on the messages. Everything else is handled by the server components.
Suddenly, you can spend a week writing a large-scale, platform agnostic service stack — that would have taken JavaScript developers months to complete. And instead of having to manage a 200.000 lines codebase in JavaScript — you can enjoy a 4000 line, easily maintainable Object Pascal codebase.
Build 11
Im hoping to have build 11 out tomorrow (Sunday) for my backers. Im still experimenting a bit with the symbol information panel, since I want it to be informative not just for classes, but also for methods and properties. Making it easy to access ancestor implementations etc.
I also need to work a bit more on the JS parsing. Under ES5 its typical to use variables to hold objects (which is close to how we think of a class), so composite and complex datatypes must be expanded. I also need to get symbol position to work property, because since Besen is a proper bytecode compiler, it doesn’t keep as much information in it’s AST as DWScript does.
Widgets (which is what visual controls are called under QTX) should appear in build 12 or 13. The IDE supports zip-packages. The file-source system I made for the TVector library (published via Embarcadero’s website a few months back) allows us to mount not just folders as a file-source, but also zip files. So QTX component packages will be ordinary zip-files containing the .pas files, asset files and a metadata descriptor file that tells the IDE what to expect. Simple, easy and very effective.
Support the project!
Want to support the project? All financial backers that donates $100+ get their name in the product, access to the full IDE source-code on completion, and access to the Quartex Media Desktop system (which is a complete web desktop with a clustered back-end, compiled to JavaScript and running on node.js. Portable, platform and chipset independent, and very powerful).
Your help matters! It pays for components, hours and above all, tools and motivation. In return, you get full access to everything and a perpetual license. No backers will ever pay a cent for any future version of Quartex Pascal. Note: PM me after donating so I can get you added to the admin group! Click here to visit paypal: https://www.paypal.com/paypalme/quartexNOR
All donations are welcome, both large and small. But donations over $100, especially reoccurring, is what drives this project forward. It also gets you access to the Quartex Developer group on Facebook where new builds, features etc is happening. It is the best way to immediately get the latest build, read documentation as its written and see the product come to life!
Amibian.jsDelphiembeddedJavaScriptnodeJSObject PascalQuartex PascalfreepascallazarusQTXQuartex Media Desktop
I only have the weekends to work on Quartex Pascal, but I got a lot of work in on sunday, so i'm just going to leave some pictures here for you. Cant wait to see jaws drop when they realize what I've made.
Show full content
A Quartex Cluster of 5 x ODroid XU4. A $400 super computer running Quartex media Desktop. Enough to power a school.
I only have the weekends to work on Quartex Pascal, but I have spent the past 18 months tinkering away, making up for wasted time. So I’m just going to leave some pictures here for you to enjoy.
Note: I was asked on LinkedIn if this has anything to do with Smart Mobile Studio, and the answer is a resounding no. I have nothing to do with Smart any more. QTX Pascal is a completely separate project that is written from scratch by yours truly.
The QTX Framework was initially a library I created back in 2014, but it has later been completely overhauled and turned into a full RTL. It is not compatible with Smart Pascal and has a completely different architecture.
QTX Pascal is indirectly funded by the Amiga Retro Community (which might sound strange, but the technical level of that community is beyond anything I have encountered elsewhere) since QTX is central to the creation of the Quartex Media Desktop. It is a shame that Embarcadero decided to not back the project. The compiler and toolchain would have been a part of Delphi by now, and I wouldn’t have to write a separate IDE. But when they see what this system can deliver in terms of services, database work, mobile and embedded -they might regret it. The project only accepts donation funding, I am not interested in investors or partners. If you want a vision turned into reality, you gotta do it yourself. Everything else just gets in the way.
For developers by developers
Quartex Pascal is made for the community. It will be free for students and open-source projects. And a commercial license will never exceed $300. It is a shareware license and the financial aspects is purely to help fund further research and development of the desktop cloud platform. The final goal (CloudForge) is to compile the IDE itself to JavaScript, so people only need a browser to write enterprise level applications via Quartex Media Desktop. When that is finished, my work is done – and people have a clear path to the future.
Unlike other systems, QTX started with the non-visual stuff, so the system has a well implemented infrastructure for writing universal services and servers, using node.js as a deployment host. Services are also Docker friendly. Runs without change on Windows, Mac OS, Linux and a wealth of embedded systems and SBCs (single board computers)
A completely new RTL written from scratch generates close to native speed JS, highly compatible (even with legacy browsers) and rock solid
There are several display modes for QTX forms, from dynamic to absolute positioning. You can mix and match between HTML and QTX code, including a HTML5 compliant WYSIWYG editor and style manager. Makes content handling a lot easier
Write object pascal, JavaScript, HTML, LDEF (webassembly), node.js services – or mix and match between them all for maximum potential. Writing mobile applications is now ridiculously easy compared to “other tools” out there.
Oh and for the proverbial frosting — The full clustered Quartex Media desktop and services is a project type. Thats right. A complete cloud infrastructure suitable for teams, kiosks, embedded, schools, intranets – and even an replacement OS for ChromeOS. You don’t need to interface with Amazon, you get your own Amazon (optional naturally).
Filesystem over websocket, IPC between hosted apps and desktop, full back-end services that are clustered, and run on anything from a Raspberry PI 4 to low-cost ARM SBCs.
Web Assembly made easy. Both for Delphi and QTX
Let there be rock
Oh, and documentation. Loads and loads of documentation.
Proper documentation, both class overview and explanations that a human being has written is paramount for learning and getting up to speed quickly.
I don’t have vacation this year, which means I only have weekends to tinker away. But i have spent the past 18-ish months preparing and slowly finishing the pieces I needed. From vector containers to form design controls, to a completely re-written RTL from scratch — so yeah. This time I’m doing it my way.
There is a lot of hidden gems in the Delphi environment and compiler, and while some might regard the "absolute" keyword as obsolete, I could not disagree more; in fact I find it to be one of the most useful, flexible aspects of Delphi (and object pascal in general).
Show full content
There is a lot of hidden gems in the Delphi environment and compiler, and while some might regard the “absolute” keyword as obsolete, I could not disagree more; in fact I find it to be one of the most useful, flexible aspects of Delphi (and object pascal in general).
The absolute keyword allows you to define a variable of a specific type, yet instruct the compiler that it should use the memory of another variable. I cannot stress how useful this can be when used right, and how much cleaner it can make code that deal with different classes or types – that are binary compatible.
Tab pages revisited
Unlike most I try to avoid the form designer when I can. Im not purist about it, I just find that inheriting out your own controls and augmenting them results in significantly faster code, as well as a fine grained control that ordinary DFM persistence can’t always deliver.
For example: Lets say you have inherited out your own TPageControl. You have also inherited out a few TTabSheet based classes, populating the tabsheets during the constructor – so there is no design data loaded – resulting in faster display time and a more responsive UI.
In one of my events, which is called as TabSheet class is created, allowing me to prepare it, like set the icon glyph for the tab, its caption and so on – the absolute keyword makes my code faster (since there is no type-casting) and more elegant to read.
All I have to do is check for the type, and once I know which type it is, I use the variable of that type that share memory with the initial type, TTabSheet. Like this:
Obviously this is not a live example, its written like this purely to make a point. Namely that the Page parameter can be accessed as a different type without allocating variables or typecasts. Im sure there are some memory use, but i find the above more elegant than 3 x nested if/then/else before you can even touch the pointer.
While this is just a small, miniscule -bordering on pseudo example, the use of absolute can help speed up intensive code by omitting typecasts. Perhaps not above, but in other, more intensive routines dealing with graphics.
It is actually a tremendous help when dealing with low level data conversion (like dealing with 8, 15, 16, 24 and 32 bpp data. When you call routines thousands of times, every bit helps – and absolute is one of those keywords that saves a few cycles per use.
Absolute is definitely one of Delphi’s un-sung heroes. But it’s a scalpel, not a chainsaw!
And this is the problem with corporate rulings based on artificial intelligence. To be honest I doubt Facebook have an actual A.I involved at all. Based on this ruling, it is painfully obvious that they operate with basic keyword filtering
Show full content
I must admit I am a bit upset while writing this, but I think I speak for quite a few in what I am about to say. Namely, that the Facebook police must come to an end. It has gone too far, and it’s now infringing on not just American laws, but also violating international laws regarding freedom of expression.
The great proxy
Here’s the problem with platforms like Facebook. First of all they are company based, which means they have the right to include or exclude whomever they like. It is a free platform after all, and nobody is forcing you to sign up for a Facebook account.
Last time I checked, that is Fascism, plain and simple
At the same time they have grown to such a size that they have become a significant social influence. Not having a Facebook account (or Twitter for that matter) in 2020 would be more out of place than the opposite. Facebook has become, despite its status as an independent financially driven organization, the global forum where people share their thoughts, ideas and aspects of their lives.
In other words, Facebook as an organization is free to meddle and influence the politics of the entire planet – without being held accountable. Neither to politicians or laws – or it’s users. Facebook can in other words – do exactly as they please, yet be held accountable to nobody.
Facebook was instrumental in manipulating the British election, and was likewise used as a weapon in the American election. That alone should say something about the power wielded by the platform. Yet somehow they wiggled their way out of it.
Users rights
As a user your rights are simply non-existent. You are completely at the mercy of an A.I (artificial intelligence) that will process whatever you say or post; and should the A.I determine that you have violated the end-user-agreement, it becomes your judge, jury and executioner.
This is simply unacceptable. There are millions (literally) of subtle nuances between languages around the world, and implementing an A.I to determine if a post is suitable or unsuitable is outright impossible.
You would have to master every language on earth, as well as have complete insight into the culture, current events etc. to make a fair ruling.
Speaking out against child abuse
In my example there was a rather nasty case of child molestation in the local news some 3 weeks ago, involving a group of religious extremists. At which my post simply stated
“I am sick and tired of religious extremists. Why does a house have to proverbially be on fire before governments put the flames out? This has to stop. Enough.”
Some 3 weeks later (today) while I was going over posts that had been reported in one of the many programming groups I manage (sigh, the irony), a banner suddenly comes out of nowhere, informing me that I have been sentenced to 7 days in Facebook jail for “hate speech”.
Hate speech? My jaw dropped. Wait, what! In what universe is wanting to protect children from predators deemed as hate? I just sat there biting my lip as I read the verdict of the artificial judge, because the idea of “hate speech” is a very serious accusation. People that post hate, in the true sense of the phrase, would (in my view) be something along the lines of neo-nazis, holocaust deniers, racists, homophobes or right-wing nationalists.
As a person who has voted to the left consistently for 30 years, who want children protected and religion kept personal; one that has six years of comparative religious studies behind him — I somehow find it very difficult to fit any of the criteria above.
I mean, im half Spanish, my best bud is a black gay man, I think WW2 and the atrocities should be compulsory in education, globally, so that we never forget what the nazis did, or the terrible price the world had to pay to secure liberty. I think the war on drugs is a lost cause, and if Michelle Obama ran for president, I would seriously consider immigrating to the US –just so I could vote for her.
So .. Not really a “hate-speech” kinda guy.
You don’t get a say
The biggest challenge in cases like this, is that there are no human beings involved. The second problem is that, under Norwegian law, criticism of religious organizations is allowed (if based on sober facts, otherwise it falls under slander). Now obviously I don’t run around confronting religions (I mean, who does), but what we are talking about here is public news, caught and dealt with by the police; a case where the predators thankfully got caught. As a parent, no – human being, I have nothing but disgust for such crimes, as I imagine all sane individuals have.
Speaking out against crimes in a lawful manner is a right. It is also a mechanism to make sure that nobody harbours resentment that, ultimately, leads to aggression. Censorship in 2020 is a dangerous mistake. One that can only end one way I fear.
And this is the problem with “corporate rulings” based on artificial intelligence. To be honest I doubt Facebook have an actual A.I involved at all. Based on this ruling, it is painfully obvious that they operate with basic keyword filtering (apparently 3 weeks behind schedule). If you cherry pick the words “sick”, “religious”, “fire” and “enough” and used some rudimentary value system for each word -perhaps in an attempt to establish the nature of a sentence, the outcome would be that the phrase is a negative one. But if you read it in its original Norwegian, where linguistic subtleties makes the intent evident – it is a man speaking out against abuse. Which is the opposite of hate.
But what really piss me off is that, as a user you have no way to complain. There is no human being you can talk with to provide a context. No message field you can use to write a short message. Nothing. The same case that I commented on was reported by all major Norwegian newspapers; It involves a crime in every civilized country on earth — yet critique of said crime somehow falls under “hate speech” according to “Facebook law”?
Amiga Disrupt
Well. I guess I’ll be over at the Amiga Disrupt Facebook clone this week. And I am going to spend that time contemplating if Facebook is really worth the effort. Most of my friends are on alternative forums too, so it’s not like I would miss out on much. I might even be tempted to write a mobile client for the AD website to make it more accessible.
You either respect free speech, or you don’t.
One thing is having fucking nazis running around the place spreading hate, another thing is when someone expresses their disgust for the recurring phenomenon that is abuse in authoritative religious settings. Whats next? Companies buying protection online? Sounds insane right, but that’s the next step. Mark my words.
One of the distinct differences between a free society and a fascist society is namely that: the right to express yourself peacefully. Another signature of fascism is their ability to wiggle their way through legal loopholes to avoid accountability.
If we setup a value system ourselves and apply it to some of these social-media companies, I think we all know what the verdict will be.
We need to teach our kids how to digest information. Developers are used to consuming vast amounts of information, but kids these days grow up in a torrent of data they cannot possibly digest without guidance. The subtle but important difference between knowledge and wisdom. A fact is a status report, a description; wisdom is a recognition of somethings innate nature. As a society we need both, because right now "the fact wars" raging online is doing irreparable damage to real people. Real lives.
Show full content
With the world going off the rails, I figured I could share my 2 cents. It’s not a post about any single subject or situation – but rather me looking at the world of information, news and how words like truth and fact is becoming increasingly meaningless. Looking at the Internet right now – I’m not sure I like what I see.
I grew up with modems, C64 and Amiga machines, so networks was nothing new
As much as I hate to admit it, the utter chaos that has manifested lately, is largely the Internet’s fault. It’s acting as a magnifying glass that is presently warping perception on a scale never before imagined.
I grew up with BBS’s (BBS = bulletin board system. You connected via your phone line and could read news, download software, chat, email etc. back in the 80s) on Commodore machines; So the transition from BBS systems to the Internet was not that big of a deal for me. But I never imagined that technology would change the world into the proverbial battleground we see today.
“Mankind has never had access to so much information, yet we have never been more misinformed and misguided than right now. It is an amazing paradox”
But back in the 80s and 90s our values and motives were different. Innocent and naive even. I grew up with Carl Sagan’s Cosmos as inspiration, and at school we were told about this utopian future we would all have; with vacations on the moon, flying cars and peaceful coexistence as mankind transitioned away from the accumulation of wealth to perfecting ourselves. The Internet was supposed to be a step in that direction, of global communication and cooperation.
Interestingly, Elon Musk seems to be the only one who refuse to give up on the dream, recognizing that to truly be masters of our own fate – we have to get off this rock. The rest of humanity seems content with the same “bread and circus” shit show that has been playing since the early bronze age. Or so it feels at times anyways.
Absolute potential also includes darkness
But for all the glorious potential the internet was supposed to bring, it has also fostered some deeply disturbing and dark stuff. It is a space where everyone can build a platform, where only technical insight (or money to buy it) holds you back. We have repeatedly witnessed core human values, common decency (if not humanity) being sidestepped for wealth and personal gain. Morality doesn’t even factor into technology any more; It’s only in the face of complete annihilation that companies agree to change their ways.
The unfortunate side-effect of our technological wild-west, means that organizations that would otherwise have died-out in the pre-internet age, simply because their values were not compatible with reality – suddenly have the power to be represented side by side with established organizations. Organizations that have paid their dues and stood the test of time. Nature has a way of sanding down bad ideas, but the laws of nature and karma somehow don’t apply to cyberspace.
In the Norwegian myths that my mother would read to me as a child, Loki caused havoc not by force or violence, but through his skills in “mixing lies with truth”. The god of influence ..
Right now it’s possible to cheat evolution if you will, leaping straight to the finish line with ideas that haven’t been tested by reality (or even worse, ideologies that failed miserably, only to reappear from the shadows later). So where respected and reputable news organizations have spent decades or even centuries cultivating their craft based on rock solid values — anyone with a computer and web skills can suddenly compete on equal footing. It is quite frankly terrifying. The only thing more terrifying is the idea of censorship and “managed freedom of speech”.
From paper to HTML
In the midst of all the information, you would imagine the older and more mature news outlets to be a safe haven. But alas, the change from paper based news to digital content turned journalism on its head. Journalism used to be fact oriented (hence the name, journal, a write-up of events). The only column that held personal viewpoints or reflections on current events were the editorials. For which the editor was personally responsible. Journalists held a high standard of ethics, that no matter what – the truth must be told without bias. The whole idea of a journal was to describe events as accurate as humanly possible, so that the reader could make up their own minds. There was a bond of trust between writer and reader.
Newspapers was hit the hardest by the advent of the Internet
All of that is gone.
Since newspapers have had to compete with radicals of every sort, kids trolling out of their moms garage, hackers, celebrities, and professional spin doctors — people who can afford to influence millions of people with zero accountability — newspapers had to relax their moral compass to survive. Which also involved some “financial contributions” from various parties to keep the wheels going, all of which has contributed to the information nightmare we experience today.
I have become a political refugee. The left I belonged to and took part in for 30 years -is not the left I see today. The left I grew up with were champions of life, fairness and practicality. Fearless men who never backed down from a fight, yet lived by a moral codex where dialog should be sought by all means – and violence only used in self defence. And in journalism, the truth no matter how ugly it might be, must be told. Nothing must be held back on bias.
Today we face a new breed of liberals who classify words as violence while obsessing over punishment of ancestors long dead; a breed which just happens to be the first generation to grow up with the internet 24/7. There is a very real battle taking place inside press offices right-now; one where half-baked, semi-fascist ideas have somehow made it through the back door, disguised as values of piety. They are not. They are seeds of of hate that have already led to books being burned, and inconvenient facts erased from history.
It is said that those who do not learn from past mistakes, are doomed to repeat them. Well by erasing past mistakes en-mass, how exactly will future generations learn anything? Except not to erase history perhaps. You would imagine the burning of the library in Alexandria, from which 6000 years of human history went up in flames, sending us headlong through 2000 years of amnesia had taught us something.
Mankind has never had access to so much information, yet we have never been more misinformed and misguided than right now. It is an amazing paradox, because information was supposed to set us free. Instead it has torn us apart.
Reflections
If you take the time to read the words of the Roman Emperor Marcus Aurelius, a philosopher emperor that lived around 180 AD. Read his meditations and notice the weight and gravity of his wisdom. Consider the quality of his personality compared to our leaders today, and take into account how little knowledge he had at his disposal. The man died in his early 50s, yet his wisdom stands as a monolith compared to our own pebbles.
“We are all fellow-citizens: and if so, we have a common city. The universe, then, must be that city; for of what other common city are all men citizens?”
We need to teach our kids how to digest information. Developers are used to consuming vast amounts of information, but kids these days grow up in a torrent of data they cannot possibly digest without guidance. The subtle but important difference between knowledge and wisdom. A fact is a status report, a description; wisdom is a recognition of somethings innate nature. As a society we need both, because right now “the fact wars” raging online is doing irreparable damage to real people. Real lives.
Facts informs you of what you can do, but wisdom reminds you of what you should do. It doesn’t have to be more difficult than that.
My focus this time is on DIPS AS, a Norwegian medical corporation. They were amoung the first companies in Norway to provide a Covid-19 module through their FastTrak application, which is completely written in Delphi.
Show full content
I just published an article on Idera’s Community website, focusing on how Delphi and Object Pascal plays a key role in fighting the Corona Pandemic.
My focus this time is on DIPS AS, a Norwegian corporation that produces a wide range of software solutions for hospitals, medical facilities and special care units. They were amoung the first companies in Norway to provide a Covid-19 module through their FastTrak application, which is completely written in Delphi.
The support for TBit in views is really neat, since you can then access any buffer as an array of bits (which bypasses the problem in C++ containers where TVector caused some headaches). Heck, the TStorage based classes alone is 3 times faster than TStream, and supports insert and remove functionality (literally scaling the file or memory with truncating if needed), so for binary formats, this should be heaven sent.
Show full content
The QTX Framework is a large and mature framework that is presently being organized and open-sourced. It’s essentially 20 years of hard work by me, that I am now consolidating and giving back to the community I love so much.
To make a long story short, I have had way too many hobby projects, to the point where my free time was reduced to zero. So for the past six months I have gradually reduced my life considerably (or the complexity of life), with the goal of just having one hobby (Quartex Media Desktop) and one steady job with no extra side projects.
But, instead of letting good code just sit there collecting dust, why not give it to the community that have shared so much with me? Feels like the right thing to do.
QTX Framework
The first unit to be released into open-source (MPL v2) is qtx.vectors.pas, which gives you four vital class types that have been missing from Delphi (and Freepascal). Classes that are extremely powerful and that should have been made a part of the RTL over a decade ago.
TVector
TView
TBitBuffer
TStorage
TStorageMemory
TStorageFile
TStreamAdapter
TPropertyBag
TTyped (*)
THash (*)
(*) Abstract utillity classes
As you probably know, C++ has enjoyed vectors (std::vector) for a long, long time. But I have taken the concept one step further, and coupled it with a unified storage system, so that the vector containers can operate in memory – and with files. So you can now work with large vectors both in memory and on disk. The system is largely expandable, so you can roll your own storage types (cloud, network etc) with relative ease. Same goes for vector allocator classes (for DB ORM style mapping).
The storage system (untyped buffers) deals with pretty much everything you need to manipulate raw, binary data (and then some). And this is where TView comes in, where you can access a chunk of untyped data (regardless of its location in memory or disk) as an array of typed data.
TVector and showing live memory used by the vector container
Let’s say you have 10.000 Pascal records (or 1000000 for that matter) you want to work with, but you dont want to keep them in memory. Vector containers are now ideal for this line of work thanks to the unified storage system:
If you remove records from the vector, the managed file is physically scaled and truncated
But hey, all of that is easy right? With the exception of live file management you can do this with a TList<T>. Fair enough. But what if you want to look at the data differently, not as TPerson, but rather as bytes or doubles (or another record type altogether)? And keep in mind, the data is managed in a file with no memory overhead – yet the interface remains the same:
Enumerating the bytes in the vector’s buffer, regardless of storage medium
This is just the tip of the iceberg. Vector containers gives you all the perks of old-school “file of record” but without the limitations and problems. Thats just one of many aspects.
Delphi and FPC
Since companies like TMS use Freepascal for their Web Framework, I made sure the code is compatible with both. And there will be plenty of Demos for both Delphi and FPC. Especially as more and more units are added to the framework.
The support for TBit in views is really neat, since you can then access any buffer as an array of bits (which bypasses the problem in C++ containers where TVector<bool> [which is their take on bits in this context] caused some headaches). Heck, the TStorage based classes alone is 3 times faster than TStream, and supports insert and remove functionality (literally scaling the file or memory with truncating if needed), so for binary formats, this should be heaven sent.
Add RTTI and some field-mapping, and you have an ORM engine that will outperform every option out there. Records are faster and more efficient than object instances. And a flat file database is now absurdly simple to make.
Freepascal demo showing how views work, here showing TView
Well, I hope you guys find this useful!
The next unit to be MPL’ed is the parser framework and a ton of parsers for various formats.
Vector containers, unified storage model and typed views are just some of the highlights of my vector-library. I did an article on the subject at the Embarcadero community website, so head over and read up on how you can enjoy these features in your Delphi application!
If you have been looking at C++ and envied them their std::vector classes, wanting the same for Delphi or being able to access untyped memory using a typed-view (basically turning a buffer into an array of <T>) then I have some good news for you!
Vector containers, unified storage model and typed views are just some of the highlights of my vector-library. I did an article on the subject at the Embarcadero community website, so head over and read up on how you can enjoy these features in your Delphi application!
I also added FreePascal support, so that the library can be used with TMS Web Framework.
Head over to the Embarcadero Community website to read the full article
I have experienced two life threatening situations in my life. The first was back in 2008 when I almost died of blood poisoning (overworked, immune system flat- and pneumonia was enough to get the better of me), and the second was when I slipped and fell down a flight of stairs, severely injuring my spine in 2013.
Show full content
Below is a post I made on Facebook a while back that might be beneficial for people looking to boost their health or the body’s natural ability to defend itself. I am not a health specialist by any stretch of the imagination, but I have found a few things that have made a tremendous impact on my health over the years. Hopefully they can be as beneficial to others as they have for me.
I have experienced one life threatening, and one life changing situation in the past 20 years. The first was back in 2008 when I almost died of blood poisoning (overworked, immune system flat, caught pneumonia and a normal bacteria from my throat found its way into my bloodstream through my lungs). I was initially declared dead since i had no measurable pulse, but they managed to bring me back, but an inch away from death.
The life changing episode was when I slipped and fell down a flight of stairs while carrying a washing machine, severely injuring my spine in two places in 2013. With permanent nerve damage as a result (essentially it feels like being stabbed with a knife 24/7). It has taken 7 years to recover and learn to live with that injury. I evolved a regiment of tibetan based yoga and herbs that, combined, allows me to function without pain.
I get extremely upset when I see these new-age, mumbo-jumbo companies trying to capitalize on the present situation; selling so called miracle cures for the Corona Virus. It is an insult to those that have died from it, and it undermines both western and eastern medicine. It is an incredibly irresponsible and heartless thing to do.
There are plants that can help strengthen your body’s natural capacity to fight off infections, provide better stamina and clarity of mind – which is what my focus is on here. But under no circumstances does a miracle herb exist.
My post here is meant purely as a positive suggestion based on my experience, nothing more. Always check herbs properly, and make sure you use qualified sources when evaluating.
Note: ALWAYS consult your doctor before taking any supplements whatsoever. The ones I mention here are harmless if used properly (and have been used for thousands of years), but you must always treat potent medicinal plants with respect.
Post from Facebook
A friend of mine asked me how on earth I managed to survive my spinal injury. In the immediate years after the accident the doctors pump you full of various medication, mostly painkillers, which has a terrible effect on both body and mind. A lot of people never recover from such an accident, and never get up. They end up entangled in a web of medication and pain, even after the injury itself has largely healed.
After the accident I was unable to walk for roughly 6 months. I was ripped before the accident with solid 2 hr workouts 5 days a week. After the accident, I was helplessly confined to bed. I even needed help to shower and go to the toilet (a terribly humbling experience).
But, instead of succumbing to fear and depression – I decided to spend my time putting all those alternative remedies to the test. I spent between $5000 and $6000 systematically testing every single so-called “miracle herb” I could find.
No such thing as a miracle herb
As I expected, 99% of them had absolutely no effect on my situation whatsoever. None.
Since I belong to the Tibetan Buddhist tradition, I decided to seek advice from both the Hindu and Buddhist communities in the region (both schools of though have long traditions in natural medicine), and I was given a list of herbs to use. It took a couple of weeks for the herbs to arrive from India, but i’m glad they did – because out of all the claims out there, these actually had an immediate and very tangible effect on the body. I must admit I did not expect that after so much hum-buggery.
Out of those I tested that were available in local health stores, where one is imported from the US (Green Magma), only one other passed the test (and I tested almost 200 different herbs, mixtures and substances. As much as 90% of them were useless; at least compared to the claims made for their efficiency).
Never play around with herbs, always be careful and remember that they can have a tremendous effect on our bodies and mind. Always talk to your doctor first.
These are the only 4 that actually worked – and that provides stamina, energy, alertness and gives the body’s natural defenses a boost. And I mean this very literally. Within 20 minutes of eating GM (#4) my body went from being an acidic hell, into feeling strong and normal again.
Ashwagandha (a tree bark)
Shilajit (mineral substance from himalaya)
Vita Biosa (herbs and digestive bacteria)
Green Magma (green juice from barley leaves)
Lets have a quick look at each of them. They are easy enough to google, and all of these are easily available through Amazon (unless you have a dedicated Ayurvedic outlet locally).
For modern man, a teaspoon of this will make you sick for days if your not accustomed to it. Start with 1/3 teaspoon in water, then gradually work your way up to 1 teaspoon a day. These bacteria will eat all the nasty stuff that modern life leaves behind. I had a bleeding ulcer because of the heavy medication I was put on. It took only 5-6 days with Vita Biosa and the bleeding stopped. Two weeks and the body had healed itself (!).
Note: If you can, buy the one with a small fraction of St.John’s herb, this is the only herb that has a proven effect on liver cells (helps the liver re-generate). Vita Biosa is worth its weight in gold, and the effect on your digestive system (and by consequence: mood and alertness) is remarkable. I literally had no idea how much our gut affects our thoughts, emotions and energy levels.
Green Magma
Green Magma is a Japanese formula that was used after WW2, and it was used to treat patients affected by the devastating impact of nuclear war. Its core ingredient is green barley sprouts that is pressed and the juice is dried into a powder that you can mix with water (there is more to it than that, but that’s the gist of it).
It’s also one of the few herbs that the body will recognize as food. If you can’t find the energy to get up, or you feel like you are burning out -order this immediately. It also eliminates acidity which is often a side effect of western medication, stress and unhealthy diets.
Drinking a glass (1 ts in water) for a week or two is enough. You will notice when you don’t need it anymore (you won’t crave it).
Shilajit
Shilajit is a natural mineral substance that comes out of the ground in the Himalayas. It was noticed by researchers because the inhabitants in the region generally enjoyed longer lifespans than what is average in the west, and they don’t suffer as much sickness as we westerners do.
It smells horrible, tastes even worse — so order the gel-capped variations if you can. You will notice a boost in energy and overall vitality (relative to your current health of course). I couldn’t event check my mailbox without taking breaks after my accident, so I could feel the effect of these things very fast. And this is 100 times more potent than any vitamins you find at a pharmacy.
Ashwagandha
Ashwagandha is a tree bark and root. It is known for the stamina and energy it provides. It is used for healing in India, Tibet and parts of Asia.
It’s also used by older men who wants to conceive children in their golden years, so use this with caution and stick to the recommended dosage. This herb does wonders for the immune system, and it provides a great deal of mental clarity and calm under stress. It is used for a variety of illnesses, from arthritis to infections. This is a very potent adaptogen.
If I were to pick just two of these, I would pick Ashwagandha and Green Magma, those two have helped me through some of the worst challenges in my life.
The most effective was also the most affordable
The bonus is – these herbs are very cheap and available almost anywhere. When I first discovered them they were less known, but since that time knowledge of them has spread. You can now order all 4 of these combined via Amazon for less than $100. And they will do 1000 times more good than any new age miracle cure nonsense. These are herbs that will help you for a lifetime if you remember to take them regularly.
So if you are looking to help your body to defend itself, or some go-to herbs to help you cope with deadlines – then these are reliable and will serve you well. For me personally, they have been the difference between being able to function and work – or not functioning at all. They literally changed my life.
So instead of raiding your local pharmacy, buying 10.000 rolls of toilet paper, or letting scam-artists sell miracle cures that never works -get these 4 reliable herbs, make sure you read the recommended dosages (talk to your doctor first if you have a condition or take medication) and then safely and calmly stick to the quarantine plan.
C/C++DelphiJavaScriptObject PascalQTXQuartex PascalAmibian.jsC#C++BuilderQuartex Media Desktop
C is a language that I used to play around with a lot back in the Amiga days. I think the last time I used a C compiler to write a library must have been in 1992 or something like that? I held on to my Amiga 1200 for as long as i could – […]
Show full content
C is a language that I used to play around with a lot back in the Amiga days. I think the last time I used a C compiler to write a library must have been in 1992 or something like that? I held on to my Amiga 1200 for as long as i could – but having fallen completely in love with Pascal, I eventually switched to x86 and went down the Turbo Pascal road.
Lately however, C++ developers have been asking for their own Developer group on Facebook. I run several groups on Facebook in the so-called “developer” family. So you have Delphi Developer, FPC Developer, Node.JS Developer and now – C++Builder developer. The groups more or less tend to themselves, and the node.js and FPC groups are presently being seeded (meaning, that the member count is being grown for a period).
The C++Builder group however, is having the same activity level as the Delphi group almost, thanks to some really good developers that post links, tips and help solve questions. I was also fortunate enough to have David Millington come on the Admin team. David is leading the C++Builder project, so his insight and knowledge of both language and product is exemplary. Just like Jim McKeeth, he is a wonderful resource for the community and chime in with answers to tricky questions whenever he has time to spare.
Getting back in the saddle
Having working some 30 years with Pascal and Object Pascal, 25 of those years in Delphi, C/C++ is never far away. I have an article on the subject that i’ve written for the Idera Community website, so I wont dig too deep into that here — but needless to say, Rad Studio consists of two languages: Object Pascal and C/C++, so no matter how much you love either language, the other is never far away.
So I figured it was time for this old dog to learn some new tricks! I have always said that it’s wise to learn a language immediately below and above your comfort zone. So if Delphi is your favorite language, then C/C++ is below you (meaning: more low level and complex). Above you are languages like JavaScript and C#. Learning JavaScript makes strategic sense (or use DWScript to compile Pascal to JavaScript like I do).
When I started out, the immediate language below Object Pascal was never C, but assembler. So for the longest time I turned to assembler whenever I needed a speed boost; graphics manipulation and processing pixels is especially a field where assembly makes all the difference.
But since C++Builder is indeed an integral part of Rad Studio, and Object Pascal and C/C++ so intimately connected (they have evolved side by side), why not enjoy both assembly and C right?
So I decided to jump back into the saddle and see what I could make of it.
C/C++ is not as hard as you think
I’m having a ball writing C/C++, and just like Delphi – you can start where you are.
While I’m not going to rehash the article I have already prepared for the Idera Community pages here, I do want to encourage people to give it a proper try. I have always said that if you know an archetypal language, you can easily pick up other languages, because the archetypal languages will benefit you for a lifetime. This has to do with archetypal languages operating according to how computers really work; as opposed to optimistic languages (a term from the DB work, optimistic locking), also called contextual languages, like C#, Java, JavaScript etc. are based on how human beings would like things to be.
So I now had a chance to put my money where my mouth is.
When I left C back in the early 90s, I never bothered with OOP. I mean, I used C purely for shared libraries anyways, while the actual programs were done in Pascal or a hybrid language called Blitz Basic. The latter compiled to razor sharp machine code, and you could use inline assembly – which I used a lot back then (very few programmers on those machines went without assembler, it was almost given that you could use 68k in some capacity).
Without ruining the article about to be published, I had a great time with C++Builder. It took a few hours to get my bearings, but since both the VCL and FMX frameworks are there – you can approach C/C++ just like you would Object Pascal. So it’s a matter of getting an overview really.
Needless to say, I’ll be porting a fair share of my libraries to C/C++ when I have time (those that makes sense under that paradigme). It’s always good to push yourself and there are plenty of subtle differences that I found useful.
Quartex Media Desktop
When I last wrote about QTX we were nearing the completion of the FileSystem and Task Management service. The prototype had all its file-handling directly in the core service (or server) which worked just fine — but it was linked to the Smart Pascal RTL. It has taken time to write a new RTL + a full multi-user, platform independent service stack and desktop (phew!) but we are seeing progress!
The QTX Baseline backend services is now largely done
The filesystem service is now largely done! There are a few synchronous calls I want to get rid of, but thankfully my framework has both async and sync variations of all file procedures – so that is now finished.
To make that clearer: first I have to wrap and implement the functionality for the RTL. Once they are in the RTL, I can use those functions to build the service functions. So yeah, it’s been extremely elaborate — but thankfully it’s also become a rich, well organized codebase (both the RTL and the Quartex Media Desktop codebases) – so I think we are ready to get cracking on the core!
The core is still operating with the older API. So our next step is to remove that from the core and instead delegate calls to the filesystem to our new service. So the core will simply be reduced to a post-office or traffic officer if you like. Messages come in from the desktops, and the core delegates the messages to whatever service is in charge of them.
But, this also means that both the core and the desktop must use the new and fancy messages. And this is where I did something very clever.
While I was writing the service, I also write a client class to test (obviously). And the way the core works — means that the same client that the core use to talk to the services — can be used by the desktop as well.
So our work in the desktop to get file-access and drives running again, is to wrap the client in our TQTXDevice ancestor class. The desktop NEVER accesses the API directly. All it knows about are these device drivers (or object instances). Which is how we solve things like DropBox and Google Drive support. The desktop wont have the faintest clue that its using Dropbox, or copying files between a local disk and Google Drive for example — because it only communicates with these device classes.
Recursive stuff
One thing that sucked about node.js function for deleting a folder, is that it’s recursive parameter doesn’t work on Windows or OS X. So I had to implement a full recursive deletefolder routine manually. Not a big thing, but slightly more painful than expected under asynchronous execution. Thankfully, Object Pascal allows for inline defined procedures, so I didn’t have to isolate it in a separate class.
Here is some of the code, a tiny spec compared to the full shabam, but it gives you an idea of what life is like under async conditions:
unit service.file.core;
interface
{.$DEFINE DEBUG}
const
CNT_PREFS_DEFAULTPORT = 1883;
CNT_PREFS_FILENAME = 'QTXTaskManager.preferences.ini';
CNT_PREFS_DBNAME = 'taskdata.db';
CNT_ZCONFIG_SERVICE_NAME = 'TaskManager';
uses
qtx.sysutils,
qtx.json,
qtx.db,
qtx.logfile,
qtx.orm,
qtx.time,
qtx.node.os,
qtx.node.sqlite3,
qtx.node.zconfig,
qtx.node.cluster,
qtx.node.core,
qtx.node.filesystem,
qtx.node.filewalker,
qtx.fileapi.core,
qtx.network.service,
qtx.network.udp,
qtx.inifile,
qtx.node.inifile,
NodeJS.child_process,
ragnarok.types,
ragnarok.Server,
ragnarok.messages.base,
ragnarok.messages.factory,
ragnarok.messages.network,
service.base,
service.dispatcher,
service.file.messages;
type
TQTXTaskServiceFactory = class(TMessageFactory)
protected
procedure RegisterIntrinsic; override;
end;
TQTXFileWriteCB = procedure (TagValue: variant; Error: Exception);
TQTXFileStateCB = procedure (TagValue: variant; Error: Exception);
TQTXUnRegisterLocalDeviceCB = procedure (TagValue: variant; DiskName: string; Error: Exception);
TQTXRegisterLocalDeviceCB = procedure (TagValue: variant; LocalPath: string; Error: Exception);
TQTXFindDeviceCB = procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception);
TQTXGetDisksCB = procedure (TagValue: variant; Devices: JDeviceList; Error: Exception);
TQTXGetFileInfoCB = procedure (TagValue: variant; LocalName: string; Info: JStats; Error: Exception);
TQTXGetTranslatePathCB = procedure (TagValue: variant; Original, Translated: string; Error: Exception);
TQTXCheckDevicePathCB = procedure (TagValue: variant; PathName: string; Error: Exception);
TQTXServerExecuteCB = procedure (TagValue: variant; Data: string; Error: Exception);
TQTXTaskService = class(TRagnarokService)
private
FPrefs: TQTXIniFile;
FLog: TQTXLogEmitter;
FDatabase: TSQLite3Database;
FZConfig: TQTXZConfigClient;
FRegHandle: TQTXDispatchHandle;
FRegCount: integer;
procedure HandleGetDevices(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleGetDeviceByName(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleCreateLocalDevice(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleDestroyDevice(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleFileRead(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleFileReadPartial(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleGetFileInfo(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleFileDelete(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleFileWrite(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleFileWritePartial(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleFileRename(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleGetDir(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleMkDir(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure HandleRmDir(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
procedure ExecuteExternalJS(Params: array of string;
TagValue: variant; const CB: TQTXServerExecuteCB);
procedure SendError(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage; Message: string);
protected
function GetFactory: TMessageFactory; override;
procedure SetupPreferences(const CB: TRagnarokServiceCB);
procedure SetupLogfile(LogFileName: string;const CB: TRagnarokServiceCB);
procedure SetupDatabase(const CB: TRagnarokServiceCB);
procedure ValidateLocalDiskName(TagValue: variant; Username, DeviceName: string; CB: TQTXCheckDevicePathCB);
procedure RegisterLocalDevice(TagValue: variant; Username, DiskName: string; CB: TQTXRegisterLocalDeviceCB);
procedure UnRegisterLocalDevice(TagValue: variant; UserName, DiskName:string; CB: TQTXUnRegisterLocalDeviceCB);
procedure GetDevicesForUser(TagValue: variant; UserName: string; CB: TQTXGetDisksCB);
procedure FindDeviceByName(TagValue: variant; UserName, DiskName: string; CB: TQTXFindDeviceCB);
procedure FindDeviceByType(TagValue: variant; UserName: string; &Type: JDeviceType; CB: TQTXGetDisksCB);
procedure GetTranslatedPathFor(TagValue: variant; Username, FullPath: string; CB: TQTXGetTranslatePathCB);
procedure GetFileInfo(TagValue: variant; UserName: string; FullPath: string; CB: TQTXGetFileInfoCB);
procedure SetupTaskTable(const TagValue: variant; const CB: TRagnarokServiceCB);
procedure SetupOperationsTable(const TagValue: variant; const CB: TRagnarokServiceCB);
procedure SetupDeviceTable(const TagValue: variant; const CB: TRagnarokServiceCB);
procedure AfterServerStarted; override;
procedure BeforeServerStopped; override;
procedure Dispatch(Socket: TNJWebSocketSocket; Message: TQTXBaseMessage); override;
public
property Preferences: TQTXIniFile read FPrefs;
property Database: TSQLite3Database read FDatabase;
procedure SetupService(const CB: TRagnarokServiceCB);
constructor Create; override;
destructor Destroy; override;
end;
implementation
//#############################################################################
// TQTXFileenticationFactory
//#############################################################################
procedure TQTXTaskServiceFactory.RegisterIntrinsic;
begin
writeln("Registering task interface");
&Register(TQTXFileGetDeviceListRequest);
&Register(TQTXFileGetDeviceByNameRequest);
&Register(TQTXFileCreateLocalDeviceRequest);
&Register(TQTXFileDestroyDeviceRequest);
&Register(TQTXFileReadPartialRequest);
&Register(TQTXFileReadRequest);
&Register(TQTXFileWritePartialRequest);
&Register(TQTXFileWriteRequest);
&Register(TQTXFileDeleteRequest);
&Register(TQTXFileRenameRequest);
&Register(TQTXFileInfoRequest);
&Register(TQTXFileDirRequest);
&Register(TQTXMkDirRequest);
&Register(TQTXRmDirRequest);
&Register(TQTXFileRenameRequest);
&Register(TQTXFileDirRequest);
end;
//#############################################################################
// TQTXTaskService
//#############################################################################
constructor TQTXTaskService.Create;
begin
inherited Create;
FPrefs := TQTXIniFile.Create();
FLog := TQTXLogEmitter.Create();
FDatabase := TSQLite3Database.Create(nil);
FZConfig := TQTXZConfigClient.Create();
FZConfig.Port := 2292;
self.OnUserSignedOff := procedure (Sender: TObject; Username: string)
begin
WriteToLogF("We got a service signal! User [%s] has signed off completely", [Username]);
end;
MessageDispatch.RegisterMessage(TQTXFileGetDeviceListRequest, @HandleGetDevices);
MessageDispatch.RegisterMessage(TQTXFileGetDeviceByNameRequest, @HandleGetDeviceByName);
MessageDispatch.RegisterMessage(TQTXFileCreateLocalDeviceRequest, @HandleCreateLocalDevice);
MessageDispatch.RegisterMessage(TQTXFileDestroyDeviceRequest, @HandleDestroyDevice);
MessageDispatch.RegisterMessage(TQTXFileReadRequest, @HandleFileRead);
MessageDispatch.RegisterMessage(TQTXFileReadPartialRequest, @HandleFileReadPartial);
MessageDispatch.RegisterMessage(TQTXFileWriteRequest, @HandleFileWrite);
MessageDispatch.RegisterMessage(TQTXFileWritePartialRequest, @HandleFileWritePartial);
MessageDispatch.RegisterMessage(TQTXFileInfoRequest, @HandleGetFileInfo);
MessageDispatch.RegisterMessage(TQTXFileDeleteRequest, @HandleFileDelete);
MessageDispatch.RegisterMessage(TQTXMkDirRequest, @HandleMkDir);
MessageDispatch.RegisterMessage(TQTXRmDirRequest, @HandleRmDir);
MessageDispatch.RegisterMessage(TQTXFileRenameRequest, @HandleFileRename);
MessageDispatch.RegisterMessage(TQTXFileDirRequest, @HandleGetDir);
end;
destructor TQTXTaskService.Destroy;
begin
// decouple logger from our instance
self.logging := nil;
// Release prefs + log
FPrefs.free;
FLog.free;
FZConfig.free;
inherited;
end;
procedure TQTXTaskService.SendError(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage; Message: string);
begin
var reply := TQTXErrorMessage.Create(request.ticket);
try
reply.Code := CNT_MESSAGE_CODE_ERROR;
reply.Routing.TagValue := Request.Routing.TagValue;
reply.Response := Message;
if Socket.ReadyState = rsOpen then
begin
try
Socket.Send( reply.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end else
WriteToLog("Failed to dispatch error, socket is closed error");
finally
reply.free;
end;
end;
procedure TQTXTaskService.ExecuteExternalJS(Params: array of string;
TagValue: variant; const CB: TQTXServerExecuteCB);
begin
var LTask: JChildProcess;
var lOpts := TVariant.CreateObject();
lOpts.shell := false;
lOpts.detached := true;
Params.insert(0, '--no-warnings');
// Spawn a new process, this creates a new shell interface
try
LTask := child_process().spawn('node', Params, lOpts );
except
on e: exception do
begin
if assigned(CB) then
CB(TagValue, e.message, e);
exit;
end;
end;
// Map general errors on process level
LTask.on('error', procedure (error: variant)
begin
{$IFDEF DEBUG}
writeln("error->" + error.toString());
{$ENDIF}
WriteToLog(error.toString());
if assigned(CB) then
CB(TagValue, "", nil);
end);
// map stdout so we capture the output
LTask.stdout.on('data', procedure (data: variant)
begin
if assigned(CB) then
CB(TagValue, data.toString(), nil);
end);
// map stderr so we can capture exception messages
LTask.stderr.on('data', procedure (error:variant)
begin
{$IFDEF DEBUG}
writeln("stdErr->" + error.toString());
{$ENDIF}
if assigned(CB) then
CB(TagValue, "", nil);
WriteToLog(error.toString());
end);
end;
function TQTXTaskService.GetFactory: TMessageFactory;
begin
result := TQTXTaskServiceFactory.Create();
end;
procedure TQTXTaskService.SetupService(const CB: TRagnarokServiceCB);
begin
SetupPreferences( procedure (Error: Exception)
begin
// No logfile yet setup (!)
if Error nil then
begin
WriteToLog("Preferences setup: Failed!");
WriteToLog(error.message);
raise error;
end else
WriteToLog("Preferences setup: OK");
// logfile-name is always relative to the executable
var LLogFileName := TQTXNodeFileUtils.IncludeTrailingPathDelimiter( TQTXNodeFileUtils.GetCurrentDirectory );
LLogFileName += FPrefs.ReadString('log', 'logfile', 'log.txt');
// Port is defined in the ancestor, so we assigns it here
Port := FPrefs.ReadInteger('networking', 'port', CNT_PREFS_DEFAULTPORT);
SetupLogfile(LLogFileName, procedure (Error: Exception)
begin
if Error nil then
begin
WriteToLog("Logfile setup: Failed!");
WriteToLog(error.message);
raise error;
end else
WriteToLog("Logfile setup: OK");
SetupDatabase( procedure (Error: Exception)
begin
if Error nil then
begin
WriteToLog("Database setup: Failed!");
WriteToLog(error.message);
if assigned(CB) then
CB(Error)
else
raise Error;
end else
WriteToLog("Database setup: OK");
if assigned(CB) then
CB(nil);
end);
end);
end);
end;
procedure TQTXTaskService.SetupPreferences(const CB: TRagnarokServiceCB);
begin
var lBasePath := TQTXNodeFileUtils.GetCurrentDirectory;
var LPrefsFile := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(LBasePath) + CNT_PREFS_FILENAME;
if TQTXNodeFileUtils.FileExists(LPrefsFile) then
begin
FPrefs.LoadFromFile(nil, LPrefsFile, procedure (TagValue: variant; Error: Exception)
begin
if Error nil then
begin
if assigned(CB) then
CB(Error)
else
raise Error;
exit;
end;
if assigned(CB) then
CB(nil);
end);
end else
begin
var LError := Exception.Create('Could not locate preferences file: ' + LPrefsFile);
WriteToLog(LError.message);
if assigned(CB) then
CB(LError)
else
raise LError;
end;
end;
procedure TQTXTaskService.SetupLogfile(LogFileName: string;const CB: TRagnarokServiceCB);
begin
// Attempt to open logfile
// Note: Log-object error options is set to throw exceptions
try
FLog.Open(LogFileName);
except
on e: exception do
begin
if assigned(CB) then
begin
CB(e);
exit;
end else
begin
writeln(e.message);
raise;
end;
end;
end;
// We inherit from TQTXLogObject, which means we can pipe
// all errors etc directly using built-in functions. So here
// we simply glue our instance to the log-file, and its all good
self.Logging := FLog as IQTXLogClient;
if assigned(CB) then
CB(nil);
end;
procedure TQTXTaskService.FindDeviceByType(TagValue: variant; UserName: string; &Type: JDeviceType; CB: TQTXGetDisksCB);
begin
UserName := username.trim().ToLower();
if Username.length < 1 then
begin
WriteToLog("Failed to lookup disk, username was invalid error");
var lError := EException.Create("Failed to lookup devices, invalid username");
if assigned(CB) then
CB(TagValue, nil, lError)
else
raise lError;
exit;
end;
GetDevicesForUser(TagValue, Username,
procedure (TagValue: variant; Devices: JDeviceList; Error: Exception)
begin
if Error nil then
begin
if assigned(CB) then
CB(TagValue, nil, Error)
else
raise Error;
exit;
end;
var x := 0;
while x < Devices.dlDrives.Count do
begin
if Devices.dlDrives[x].&Type &Type then
begin
Devices.dlDrives.delete(x, 1);
continue;
end;
inc(x);
end;
if assigned(CB) then
CB(TagValue, Devices, nil);
end);
end;
procedure TQTXTaskService.FindDeviceByName(TagValue: variant; Username, DiskName: string; CB: TQTXFindDeviceCB);
begin
UserName := username.trim().ToLower();
if Username.length < 1 then
begin
var lLogText := "Failed to lookup device, username was invalid error";
WriteToLog(lLogText);
var lError := EException.Create(lLogText);
if assigned(CB) then
CB(TagValue, nil, lError)
else
raise lError;
exit;
end;
DiskName := DiskName.trim();
if DiskName.length < 1 then
begin
var lLogText := "Failed to lookup device, disk-name was invalid error";
WriteToLog(lLogText);
var lError := EException.Create(lLogText);
if assigned(CB) then
CB(TagValue, nil, lError)
else
raise lError;
exit;
end;
GetDevicesForUser(TagValue, Username,
procedure (TagValue: variant; Devices: JDeviceList; Error: Exception)
begin
if Error nil then
begin
if assigned(CB) then
CB(TagValue, nil, Error)
else
raise Error;
exit;
end;
DiskName := DiskName.trim().ToLower();
var lDiskInfo: JDeviceInfo := nil;
for var disk in Devices.dlDrives do
begin
if disk.Name.ToLower() = DiskName then
begin
lDiskInfo := disk;
break;
end;
end;
if assigned(CB) then
CB(TagValue, lDiskInfo, nil);
end);
end;
procedure TQTXTaskService.GetTranslatedPathFor(TagValue: variant; Username, FullPath: string; CB: TQTXGetTranslatePathCB);
begin
var lParser := TQTXPathParser.Create();
try
var lInfo: TQTXPathData;
if lparser.Parse(FullPath, lInfo) then
begin
// Locate the device for the path belonging to the user
FindDeviceByName(TagValue, UserName, lInfo.MountPart,
procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception)
begin
if Error nil then
begin
if assigned(CB) then
CB(TagValue, FullPath, '', Error)
else
raise Error;
exit;
end;
if Device.&Type dtLocal then
begin
var lError := EException.CreateFmt('Failed to translate path, device [%s] is not local error', [Device.Name]);
if assigned(CB) then
CB(TagValue, FullPath, '', Error)
else
raise Error;
exit;
end;
// We want the path + filename, so we can append that to
// the actual localized filesystem
var lExtract := FullPath;
delete(lExtract, 1, lInfo.MountPart.Length + 1);
// Construct complete storage location
var lFullPath := TQTXNodeFileUtils.GetCurrentDirectory();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + 'userdevices';
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + Device.location.trim();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + lExtract;
// Return translated path
if assigned(CB) then
CB(TagValue, FullPath, lFullPath, nil);
end);
end else
begin
var lErr := EException.CreateFmt("Invalid path [%s] error", [FullPath]);
if assigned(CB) then
CB(TagValue, FullPath, '', lErr)
else
raise lErr;
end;
finally
lParser.free;
end;
end;
procedure TQTXTaskService.GetFileInfo(TagValue: variant; UserName, FullPath: string; CB: TQTXGetFileInfoCB);
begin
var lParser := TQTXPathParser.Create();
try
var lInfo: TQTXPathData;
if lparser.Parse(FullPath, lInfo) then
begin
// Locate the device for the path belonging to the user
FindDeviceByName(TagValue, UserName, lInfo.MountPart,
procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception)
begin
if Error nil then
begin
if assigned(CB) then
CB(TagValue, '', nil, Error)
else
raise Error;
exit;
end;
case Device.&Type of
dtLocal:
begin
// We want the path + filename, so we can append that to
// the actual localized filesystem
var lExtract := FullPath;
delete(lExtract, 1, lInfo.MountPart.Length + 1);
// Construct complete storage location
var lFullPath := TQTXNodeFileUtils.GetCurrentDirectory();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + 'userdevices';
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + Device.location.trim();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + lExtract;
// Call the underlying OS to get the file statistics
NodeJsFsAPI().lStat(lFullPath,
procedure (Error: JError; Stats: JStats)
begin
if Error nil then
begin
var lError := EException.Create(Error.message);
if assigned(CB) then
CB(TagValue, lFullPath, nil, lError)
else
raise lError;
exit;
end;
// And deliver
if assigned(CB) then
CB(TagValue, lFullPath, Stats, nil);
end);
end;
dtDropbox, dtGoogle, dtMsDrive:
begin
var lError := EException.Create("Cloud bindings not activated error");
if assigned(CB) then
CB(TagValue, '', nil, lError)
end;
end;
end);
end else
begin
var lErr := EException.CreateFmt("Invalid path [%s] error", [FullPath]);
if assigned(CB) then
CB(TagValue, '', nil, lErr)
else
raise lErr;
end;
finally
lParser.free;
end;
end;
procedure TQTXTaskService.GetDevicesForUser(TagValue: variant; Username: string; CB: TQTXGetDisksCB);
begin
UserName := username.trim().ToLower();
if Username.length < 1 then
begin
WriteToLog("Failed to lookup devices, username was invalid error");
var lError := EException.Create("Failed to lookup devices, invalid username");
if assigned(CB) then
CB(TagValue, nil, lError)
else
raise lError;
exit;
end;
var lTransaction: TQTXReadTransaction;
if not TSQLite3Database(DataBase).CreateReadTransaction(lTransaction) then
begin
var lErr := EException.Create("Failed to create read-transaction error");
if assigned(cb) then
CB(TagValue, nil, lErr)
else
raise lErr;
exit;
end;
var lQuery := TSQLite3ReadTransaction(lTransaction);
lQuery.SQL := "select * from devices where owner=?";
lQuery.Parameters.AddValueOnly(Username);
lQuery.Execute(
procedure (Sender: TObject; Error: Exception)
begin
if Error nil then
begin
if assigned(CB) then
CB(TagValue, nil, Error)
else
raise Error;
exit;
end;
var lDisks := new JDeviceList();
lDisks.dlUser := UserName;
for var x := 0 to lQuery.datarows.length-1 do
begin
var lInfo := new JDeviceInfo();
lInfo.Name := lQuery.datarows[x]["name"];
lInfo.&Type := JDeviceType( lQuery.datarows[x]["type"] );
lInfo.owner := lQuery.datarows[x]["owner"];
lInfo.location := lQuery.datarows[x]["location"];
lInfo.APIKey := lQuery.datarows[x]["apikey"];
lInfo.APISecret := lQuery.datarows[x]["apisecret"];
lInfo.APIPassword := lQuery.datarows[x]["apipassword"];
lInfo.APIUser := lQuery.datarows[x]["apiuser"];
lDisks.dlDrives.add(lInfo);
end;
try
if assigned(CB) then
CB(TagValue, lDisks, nil);
finally
lQuery.free;
end;
end);
end;
procedure TQTXTaskService.ValidateLocalDiskName(TagValue: variant; Username, DeviceName: string; CB: TQTXCheckDevicePathCB);
begin
var Filename := 'disk.' + username + '.' + DeviceName + '.' + ord(JDeviceType.dtLocal).ToString();
var LBasePath := TQTXNodeFileUtils.GetCurrentDirectory();
LBasePath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(LBasePath) + 'userdevices';
// Make sure the device folder is there
if not TQTXNodeFileUtils.DirectoryExists(LBasePath) then
begin
var lError := EException.CreateFmt("Directory not found: %s", [lBasePath]);
if assigned(CB) then
CB(TagValue, '', lError)
else
raise lError;
exit;
end;
lBasePath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(LBasePath) + Filename;
if TQTXNodeFileUtils.DirectoryExists(LBasePath) then
begin
var lError := EException.CreateFmt("Path already exist error [%s]", [lBasePath]);
if assigned(CB) then
CB(TagValue, '', lError)
else
raise lError;
exit;
end;
// OK, folder is not created yet, so its good to go
if assigned(CB) then
CB(TagValue, Filename, nil);
end;
procedure TQTXTaskService.UnRegisterLocalDevice(TagValue: variant; UserName, DiskName: string; CB: TQTXUnRegisterLocalDeviceCB);
begin
WriteToLogF("Removing local device [%s] for user [%s] ", [DiskName, Username]);
// Check username string
UserName := username.trim().ToLower();
if Username.length < 1 then
begin
WriteToLog("Failed to unregister device, username was invalid error");
var lError := EException.Create("Failed to register device, invalid username");
if assigned(CB) then
CB(TagValue, DiskName, lError)
else
raise lError;
exit;
end;
// Check diskname string
DiskName := DiskName.trim().ToLower();
if DiskName.length < 1 then
begin
WriteToLog("Failed to unregister device, disk-name was invalid error");
var lError := EException.Create("Failed to register device, invalid disk-name");
if assigned(CB) then
CB(TagValue, DiskName, lError)
else
raise lError;
exit;
end;
FindDeviceByName(TagValue, Username, DiskName,
procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception)
begin
// Did the search fail?
if Error nil then
begin
WriteToLog(Error.message);
if assigned(CB) then
CB(TagValue, DiskName, Error)
else
raise Error;
exit;
end;
// Make sure the device is local
if Device.&Type dtLocal then
begin
var lError := EException.CreateFmt('Failed to translate path, device [%s] is not local error', [Device.Name]);
if assigned(CB) then
CB(TagValue, DiskName, Error)
else
raise Error;
exit;
end;
// Delete record from database
var lWriter: TQTXWriteTransaction;
if FDatabase.CreateWriteTransaction(lWriter) then
begin
lWriter.SQL := "delete from profiles where user = ? and name = ?;";
lWriter.Parameters.AddValueOnly(Username);
lWriter.Parameters.AddValueOnly(DiskName);
lWriter.Execute(
procedure (Sender: TObject; Error: Exception)
begin
try
if Error nil then
begin
if assigned(CB) then
CB(TagValue, DiskName, Error)
else
raise Error;
exit;
end;
// Construct complete storage location
var lFullPath := TQTXNodeFileUtils.GetCurrentDirectory();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + 'userdevices';
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + Device.location.trim();
// Now delete the disk-drive directory
TQTXNodeFileUtils.DeleteDirectory(nil, lFullPath,
procedure (TagValue: variant; Path: string; Error: Exception)
begin
if assigned(CB) then
CB(TagValue, DiskName, Error)
end);
finally
lWriter.free;
lWriter := nil;
end;
end);
end;
end);
end;
procedure TQTXTaskService.RegisterLocalDevice(TagValue: variant; Username, DiskName: string; CB: TQTXRegisterLocalDeviceCB);
begin
WriteToLogF("Adding local device [%s] for user [%s] ", [DiskName, Username]);
UserName := username.trim().ToLower();
if Username.length < 1 then
begin
WriteToLog("Failed to register device, username was invalid error");
var lError := EException.Create("Failed to register device, invalid username");
if assigned(CB) then
CB(TagValue, '', lError)
else
raise lError;
exit;
end;
DiskName := DiskName.trim().ToLower();
if DiskName.length < 1 then
begin
WriteToLog("Failed to register device, disk-name was invalid error");
var lError := EException.Create("Failed to register device, invalid disk-name");
if assigned(CB) then
CB(TagValue, '', lError)
else
raise lError;
exit;
end;
FindDeviceByName(TagValue, Username, DiskName,
procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception)
begin
// Did the search fail?
if Error nil then
begin
WriteToLog(Error.message);
if assigned(CB) then
CB(TagValue, '', Error)
else
raise Error;
exit;
end;
// Does a device that match already exist?
if Device nil then
begin
var lError := EException.CreateFmt("Failed to create device [%s], device already exists", [DiskName]);
if assigned(CB) then
CB(TagValue, '', lError)
else
raise lError;
exit;
end;
// make sure the device-folder does not exist, so we can create it
ValidateLocalDiskName(TagValue, Username, DiskName,
procedure (TagValue: variant; PathName: string; Error: Exception)
begin
if Error nil then
begin
if assigned(CB) then
CB(TagValue, '', Error)
else
raise Error;
exit;
end;
// ValidateLocalDiskName only returns the valid directory-name,
// not a full path -- so we need to build up the full targetpath
var lFullPath := TQTXNodeFileUtils.GetCurrentDirectory();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + 'userdevices';
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + PathName;
TQTXNodeFileUtils.CreateDirectory(nil, lFullPath,
procedure (TagValue: variant; Path: string; Error: exception)
begin
if Error nil then
begin
var lError := EException.CreateFmt("Failed to create device [%s] with path: %s", [DiskName, lFullPath]);
if assigned(CB) then
CB(TagValue, PathName, lError)
else
raise lError;
exit;
end;
FDatabase.Execute(
#'insert into devices (type, owner, name, location)
values(?, ?, ?, ?);',
[ord(JDeviceType.dtLocal), UserName, Diskname, PathName] ,
procedure (Sender: TObject; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
if assigned(CB) then
CB(TagValue, PathName, Error)
else
raise Error;
exit;
end;
WriteToLogF("Device [%s] added to database user [%s]", [DiskName, UserName]);
if assigned(CB) then
CB(TagValue, PathName, nil);
end);
end);
end);
end);
end;
procedure TQTXTaskService.SetupDeviceTable(const TagValue: variant; const CB: TRagnarokServiceCB);
begin
FDatabase.Execute(
#'
create table if not exists devices
(
id integer primary key AUTOINCREMENT,
type integer,
owner text,
name text,
location text,
apikey text,
apisecret text,
apipassword text,
apiuser text
);
', [],
procedure (Sender: TObject; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
if assigned(CB) then
CB(Error)
else
raise Error;
exit;
end else
if assigned(CB) then
CB(nil);
end);
end;
procedure TQTXTaskService.SetupTaskTable(const TagValue: variant; const CB: TRagnarokServiceCB);
begin
FDatabase.Execute(
#'
create table if not exists tasks
(
id integer primary key AUTOINCREMENT,
state integer,
username text,
created real
);
', [],
procedure (Sender: TObject; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
if assigned(CB) then
CB(Error)
else
raise Error;
exit;
end else
if assigned(CB) then
CB(nil);
end);
end;
procedure TQTXTaskService.SetupOperationsTable(const TagValue: variant; const CB: TRagnarokServiceCB);
begin
FDatabase.Execute(
#'
create table if not exists operations
(
id integer primary key AUTOINCREMENT,
username text,
taskid integer,
name text,
filename text
);
', [],
procedure (Sender: TObject; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
if assigned(CB) then
CB(Error)
else
raise Error;
exit;
end else
if assigned(CB) then
CB(nil);
end);
end;
procedure TQTXTaskService.SetupDatabase(const CB: TRagnarokServiceCB);
begin
// Try to read database-path from preferences file
var LDbFileToOpen := FPrefs.ReadString("database", "database_name", "");
// Trim away spaces, check if there is a filename
LDbFileToOpen := LDbFileToOpen.trim();
if LDbFileToOpen.length < 1 then
begin
// No filename? Fall back on pre-defined file in CWD
var LBasePath := TQTXNodeFileUtils.GetCurrentDirectory();
LDbFileToOpen := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(LBasePath) + CNT_PREFS_DBNAME;
end;
FDatabase.AccessMode := TSQLite3AccessMode.sqaReadWriteCreate;
FDatabase.Open(LDbFileToOpen,
procedure (Sender: TObject; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
if assigned(CB) then
CB(Error)
else
raise Error;
exit;
end;
WriteToLog("Initializing task table");
SetupTaskTable(nil, procedure (Error: exception)
begin
if Error nil then
begin
WriteToLog("Tasks initialized: **failed");
WriteToLog(error.message);
if assigned(CB) then
CB(Error)
else
raise Error;
exit;
end else
writeToLog("Tasks initialized: OK");
WriteToLog("Initializing operations table");
SetupOperationsTable(nil, procedure (Error: exception)
begin
if Error nil then
begin
WriteToLog("Operations initialized: **failed");
WriteToLog(error.message);
if assigned(CB) then
CB(Error);
exit;
end else
writeToLog("Operations initialized: OK");
WriteToLog("Initializing device table");
SetupDeviceTable(nil, procedure (Error: exception)
begin
if Error nil then
begin
WriteToLog("Device-table initialized: **failed");
WriteToLog(error.message);
if assigned(CB) then
CB(Error);
exit;
end else
writeToLog("Device-table initialized: OK");
if assigned(CB) then
CB(nil);
end);
end);
end);
end);
end;
procedure TQTXTaskService.HandleFileRead(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXFileReadRequest(request);
var lUserName := lRequest.UserName;
var lFileName := lRequest.FileName;
// Check filename length
if lFileName.length 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lFileName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
GetFileInfo(lRequest, lUserName, lFileName,
procedure (TagValue: variant; LocalFile: string; Info: JStats; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
var lOptions: TReadFileOptions;
lOptions.encoding := 'binary';
NodeJsFsAPI().readFile(LocalFile, lOptions,
procedure (Error: JError; Data: JNodeBuffer)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
var lResponse := TQTXFileReadResponse.Create(Request.Ticket);
lResponse.UserName := lUserName;
lResponse.Routing.TagValue := request.routing.tagValue;
lResponse.FileName := lFileName;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
// Convert filedata in one pass
try
var lConvert := TDataTypeConverter.Create();
try
lResponse.Attachment.AppendBytes( lConvert.TypedArrayToBytes(Data) );
finally
lConvert.free;
end;
except
on e: exception do
begin
WriteToLog(e.message);
SendError(Socket, Request, e.Message);
exit;
end;
end;
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end);
end;
procedure TQTXTaskService.HandleFileReadPartial(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXFileReadPartialRequest(request);
var lUserName := lRequest.UserName;
var lFileName := lRequest.FileName;
var lStart := lRequest.Offset;
var lSize := lRequest.Size;
// Check filename length
if lFileName.length 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lFileName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
if lSize < 1 then
begin
SendError(Socket, Request, "Read failed, invalid size error");
exit;
end;
if lStart < 0 then
begin
SendError(Socket, Request, "Read failed, invalid offset error");
exit;
end;
GetFileInfo(lRequest, lUserName, lFileName,
procedure (TagValue: variant; LocalFile: string; Info: JStats; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
if lStart > Info.size then
begin
SendError(Socket, Request, "Read failed, offset beyond filesize error");
exit;
end;
NodeJsFsAPI().open(LocalFile, "r",
procedure (Error: JError; Fd: THandle)
begin
if error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
var Data = new JNodeBuffer(lSize);
NodeJsFsAPI().read(Fd, Data, 0, lSize, lStart,
procedure (Error: JError; BytesRead: integer; buffer: JNodeBuffer)
begin
if Error nil then
begin
NodeJsFsAPI().closeSync(Fd);
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
// Close the file-handle and return data
NodeJsFsAPI().close(Fd, procedure (Error: JError)
begin
var lResponse := TQTXFileReadPartialResponse.Create(Request.Ticket);
lResponse.UserName := lUserName;
lResponse.Routing.TagValue := request.routing.tagValue;
lResponse.FileName := lFileName;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
// Only encode data if read
if BytesRead > 0 then
begin
// Convert filedata in one pass
try
var lConvert := TDataTypeConverter.Create();
try
lResponse.Attachment.AppendBytes( lConvert.TypedArrayToBytes(buffer) );
finally
lConvert.free;
end;
except
on e: exception do
begin
WriteToLog(e.message);
SendError(Socket, Request, e.Message);
exit;
end;
end;
end;
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end);
end);
end);
end;
procedure TQTXTaskService.HandleFileWrite(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXFileWriteRequest(request);
var lFileName := lRequest.FileName.trim();
var lUserName := lRequest.UserName.trim();
var FullPath := lFileName;
// Check filename length
if lFileName.length 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lFileName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
var lParser := TQTXPathParser.Create();
try
var lInfo: TQTXPathData;
if lparser.Parse(FullPath, lInfo) then
begin
// Locate the device for the path belonging to the user
FindDeviceByName(nil, lUserName, lInfo.MountPart,
procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
case Device.&Type of
dtLocal:
begin
// We want the path + filename, so we can append that to
// the actual localized filesystem
var lExtract := FullPath;
delete(lExtract, 1, lInfo.MountPart.Length + 1);
// Construct complete storage location
var lFullPath := TQTXNodeFileUtils.GetCurrentDirectory();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + 'userdevices';
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + Device.location.trim();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + lExtract;
// Extract data to be appended, if any
// note: null bytes should be allowed, it should just create the file
var lBytes: array of UInt8;
if lRequest.attachment.Size > 0 then
lBytes := lRequest.Attachment.ToBytes();
// Write the data to the file
NodeJsFsAPI().writeFile(lFullPath, lBytes,
procedure (Error: JError)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
// Setup response object
var lResponse := TQTXFileWriteResponse.Create(lRequest.Ticket);
lResponse.UserName := lUserName;
lResponse.FileName := lFileName;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
// Send success response
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end;
dtDropbox, dtGoogle, dtMsDrive:
begin
var lErrorText := Format("Clound bindings not active error [%s]", [lRequest.FileName]);
WriteToLog(lErrorText);
SendError(Socket, Request, lErrorText);
end;
end;
end);
end else
begin
SendError(Socket, Request, format("Invalid path [%s] error", [FullPath]));
end;
finally
lParser.free;
end;
end;
procedure TQTXTaskService.HandleFileWritePartial(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXFileWritePartialRequest(request);
var lFileName := lRequest.FileName.trim();
var lUserName := lRequest.UserName.trim();
var lFileOffset := lRequest.Offset;
// Check filename length
if lFileName.length 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lFileName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
var FullPath := lFileName;
var lParser := TQTXPathParser.Create();
try
var lInfo: TQTXPathData;
if lparser.Parse(FullPath, lInfo) then
begin
// Locate the device for the path belonging to the user
FindDeviceByName(nil, lUserName, lInfo.MountPart,
procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
case Device.&Type of
dtLocal:
begin
// We want the path + filename, so we can append that to
// the actual localized filesystem
var lExtract := FullPath;
delete(lExtract, 1, lInfo.MountPart.Length + 1);
// Construct complete storage location
var lFullPath := TQTXNodeFileUtils.GetCurrentDirectory();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + 'userdevices';
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + Device.location.trim();
lFullPath := TQTXNodeFileUtils.IncludeTrailingPathDelimiter(lFullPath) + lExtract;
// Extract data to be appended, if any
// note: null bytes should be allowed, it should just create the file
var lBytes: array of UInt8;
if lRequest.attachment.Size > 0 then
lBytes := lRequest.Attachment.ToBytes();
var lAccess := TQTXNodeFile.Create();
lAccess.Open(lFullPath, TQTXNodeFileMode.nfWrite,
procedure (Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
lAccess.Write(lBytes, lFileOffset,
procedure (Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
// Setup response object
var lResponse := TQTXFileWriteResponse.Create(lRequest.Ticket);
lResponse.UserName := lUserName;
lResponse.FileName := lFileName;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
// Send success response
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end);
end;
dtDropbox, dtGoogle, dtMsDrive:
begin
var lErrorText := Format("Clound bindings not active error [%s]", [lRequest.FileName]);
WriteToLog(lErrorText);
SendError(Socket, Request, lErrorText);
end;
end;
end);
end else
begin
SendError(Socket, Request, format("Invalid path [%s] error", [FullPath]));
end;
finally
lParser.free;
end;
end;
procedure TQTXTaskService.HandleRmDir(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXRmDirRequest(request);
var lUserName := lRequest.UserName.trim();
var lDirPath := lRequest.DirPath.trim();
if lDirPath.length 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lDirPath) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
var lParser := TQTXPathParser.Create();
try
var lInfo: TQTXPathData;
if lParser.Parse(lDirPath, lInfo) then
begin
GetTranslatedPathFor(nil, lUserName, lDirPath,
procedure (TagValue: variant; Original, Translated: string; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
if not TQTXNodeFileUtils.DirectoryExists(Translated) then
begin
WriteToLogF("RmDir Failed, directory [%s] does not exist", [Translated]);
SendError(Socket, Request, Format("RmDir failed, directory [%s] does not exist", [Original]));
exit;
end;
TQTXNodeFileUtils.DeleteDirectory(nil, Translated,
procedure (TagValue: variant; Path: string; Error: Exception)
begin
if error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
// Setup response object
var lResponse := TQTXRmDirResponse.Create(lRequest.Ticket);
lResponse.UserName := lUserName;
lResponse.DirPath := lDirPath;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
lResponse.Routing.TagValue := lRequest.Routing.TagValue;
// Send success response
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end);
end else
begin
var lText := format("RmDir failed, invalid path [%s] error", [lDirPath]);
WriteToLog(lText);
SendError(Socket, Request, lText);
end;
finally
lParser.free;
end;
end;
procedure TQTXTaskService.HandleMkDir(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXMkDirRequest(request);
var lUserName := lRequest.UserName.trim();
var lDirPath := lRequest.DirPath.trim();
if lDirPath.length 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lDirPath) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
var lParser := TQTXPathParser.Create();
try
var lInfo: TQTXPathData;
if lparser.Parse(lDirPath, lInfo) then
begin
GetTranslatedPathFor(nil, lUserName, lDirPath,
procedure (TagValue: variant; Original, Translated: string; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
TQTXNodeFileUtils.DirectoryExists(nil, Translated,
procedure (TagValue: variant; Path: string; Error: Exception)
begin
if Error nil then
begin
WriteToLogF("MkDir Failed, directory [%s] already exists", [Translated]);
SendError(Socket, Request, Format("MkDir Failed, directory [%s] already exists", [Original]));
exit;
end;
TQTXNodeFileUtils.CreateDirectory(nil, Translated,
procedure (TagValue: variant; Path: string; Error: Exception)
begin
if Error nil then
begin
WriteToLogF("MkDir Failed, directory [%s] could not be created", [Original]);
SendError(Socket, Request, Format("MkDir Failed, directory [%s] could not be created", [Translated]));
exit;
end;
// Setup response object
var lResponse := TQTXMkDirResponse.Create(lRequest.Ticket);
lResponse.UserName := lUserName;
lResponse.DirPath := lDirPath;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
lResponse.Routing.TagValue := lRequest.Routing.TagValue;
// Send success response
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end);
end);
end else
begin
var lText := format("MkDir Failed, invalid path [%s] error", [lDirPath]);
WriteToLog(lText);
SendError(Socket, Request, lText);
end;
finally
lParser.free;
end;
end;
procedure TQTXTaskService.HandleFileDelete(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXFileDeleteRequest(Request);
var lUserName := lRequest.UserName.trim();
var lFileName := lRequest.FileName.trim();
if lFileName.length 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lFileName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
GetFileInfo(lRequest, lUserName, lFileName,
procedure (TagValue: variant; LocalFile: string; Info: JStats; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
if not Info.isFile then
begin
SendError(Socket, Request, "Filesystem object is not a file error");
exit;
end;
NodeJsFsAPI().unlink(LocalFile,
procedure (Error: JError)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.message);
exit;
end;
var lResponse := new TQTXFileDeleteResponse(lRequest.Ticket);
lResponse.Routing.TagValue := request.Routing.TagValue;
lResponse.UserName := lUserName;
lResponse.FileName := lFileName;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end);
end;
procedure TQTXTaskService.HandleFileRename(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXFileRenameRequest(Request);
var lUserName := lRequest.UserName.trim();
var lFileName := lRequest.FileName.trim();
var lNewName := lRequest.NewName.trim();
// Check filename length
if lFileName.length < 1 then
begin
SendError(Socket, Request, Format("Invalid or empty from-filename [%s] error", [lFileName]) );
exit;
end;
// check newname length
if lNewName.length 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
if pos(lTemp, lNewName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lFileName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
if pos(lTemp, lNewName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
GetFileInfo(lRequest, lUserName, lFileName,
procedure (TagValue: variant; LocalFile: string; Info: JStats; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
if not Info.isFile then
begin
SendError(Socket, Request, "Filesystem object is not a file error");
exit;
end;
GetTranslatedPathFor(nil, lUsername, lNewName,
procedure (TagValue: variant; Original, Translated: string; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
NodeJsFsAPI().rename(LocalFile, Translated,
procedure (Error: JError)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.message);
exit;
end;
var lResponse := new TQTXFileRenameResponse(lRequest.Ticket);
lResponse.Routing.TagValue := request.Routing.TagValue;
lResponse.UserName := lUserName;
lResponse.FileName := lFileName;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end);
end);
end;
procedure TQTXTaskService.HandleGetDir(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXFileDirRequest(Request);
var lUserName := lRequest.UserName.trim();
var lPath := lRequest.Path.trim();
// prevent path escape attempts
var lTemp := "../";
if pos(lTemp, lPath) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lPath) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
GetTranslatedPathFor(nil, lUserName, lPath,
procedure (TagValue: variant; Original, Translated: string; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
//writeln("Translated path is:" + Translated);
if not TQTXNodeFileUtils.DirectoryExists(Translated) then
begin
WriteToLogF("GetDir Failed, directory [%s] does not exist", [Translated]);
SendError(Socket, Request, Format("GetDir failed, directory [%s] does not exist", [Original]));
exit;
end;
var lWalker := TQTXFileWalker.Create();
lWalker.Examine(Translated, procedure (Sender: TQTXFileWalker; Error: EException)
begin
if Error nil then
begin
WriteToLogF("GetDir Failed: %s", [Error.Message]);
SendError(Socket, Request, Format("GetDir failed: %s", [Error.Message]));
exit;
end;
// Get the directory data, swap out the path
// record with the original [amiga] style path
var lData := Sender.ExtractList();
lData.dlPath := Original;
var lResponse := new TQTXFileDirResponse(lRequest.Ticket);
lResponse.Routing.TagValue := request.Routing.TagValue;
lResponse.UserName := lUserName;
lResponse.Path := lPath;
lResponse.Assign( lData );
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
// release instance in 100ms
TQTXDispatch.execute(procedure ()
begin
try
lWalker.free
except
on e: exception do
begin
WriteToLogF("Failed to release file-walker instance: %s", [e.message]);
end;
end;
end, 100);
end);
end);
end;
procedure TQTXTaskService.HandleGetFileInfo(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lRequest := TQTXFileInfoRequest(Request);
var lUserName := lRequest.UserName.trim();
var lFileName := lRequest.FileName.trim();
// prevent path escape attempts
var lTemp := "../";
if pos(lTemp, lFileName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
lTemp := './';
if pos(lTemp, lFileName) > 0 then
begin
SendError(Socket, Request, Format("Unsupported path sequence [%s] detected error", [lTemp]) );
exit;
end;
GetFileInfo(lRequest, lUserName, lFileName,
procedure (TagValue: variant; LocalFile: string; Info: JStats; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.message);
SendError(Socket, Request, Error.Message);
exit;
end;
// Collect the data
var lData := new JFileItem();
lData.diFileName := lFileName;
lData.diFileType := if Info.isFile then JFileItemType.wtFile else JFileItemType.wtFolder;
lData.diFileSize := Info.size;
lData.diFileMode := IntToStr(Info.mode);
lData.diCreated := TDateUtils.FromJsDate( Info.cTime );
lData.diModified := TDateUtils.FromJsDate( Info.mTime );
var lResponse := new TQTXFileInfoResponse(lRequest.Ticket);
lResponse.Routing.TagValue := request.Routing.TagValue;
lResponse.UserName := lUserName;
lResponse.FileName := lFileName;
lResponse.Assign(lData);
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
WriteToLog(e.message);
end;
end);
end;
procedure TQTXTaskService.HandleDestroyDevice(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lMessage := TQTXFileDestroyDeviceRequest(request);
// This will also destroy any files + unregister the device in the
// database table for the service -- do not mess with this!
UnRegisterLocalDevice(nil, lMessage.Username, lMessage.DeviceName,
procedure (TagValue: variant; LocalPath: string; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
var lResponse := TQTXFileDestroyDeviceResponse.Create(request.ticket);
lResponse.UserName := lMessage.UserName;
lResponse.DeviceName := lMessage.DeviceName;
lResponse.Routing.TagValue := Request.Routing.TagValue;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
begin
WriteToLog(e.message);
end;
end;
end);
end;
procedure TQTXTaskService.HandleCreateLocalDevice(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lMessage := TQTXFileCreateLocalDeviceRequest(request);
// Attempt to register.
// NOTE: This will automatically create a matching folder
// under $cwd/userdevices/[calculated_name_of_device]
RegisterLocalDevice(nil, lMessage.Username, lMessage.DeviceName,
procedure (TagValue: variant; LocalPath: string; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
FindDeviceByName(nil, lMessage.Username, lMessage.DeviceName,
procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
var lResponse := TQTXFileCreateLocalDeviceResponse.Create(request.ticket);
lResponse.UserName := lMessage.UserName;
lResponse.Routing.TagValue := Request.Routing.TagValue;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
if Device nil then
lResponse.assign(Device);
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
begin
WriteToLog(e.message);
end;
end;
end);
end);
end;
procedure TQTXTaskService.HandleGetDeviceByName(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lMessage := TQTXFileGetDeviceByNameRequest(request);
FindDeviceByName(nil, lMessage.Username, lMessage.DeviceName,
procedure (TagValue: variant; Device: JDeviceInfo; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
var lResponse := TQTXFileGetDeviceByNameResponse.Create(request.ticket);
lResponse.UserName := lMessage.UserName;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
if Device nil then
lResponse.assign(Device);
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
begin
WriteToLog(e.message);
end;
end;
end);
end;
procedure TQTXTaskService.HandleGetDevices(Socket: TNJWebSocketSocket; Request: TQTXBaseMessage);
begin
var lMessage := TQTXFileGetDeviceListRequest(Request);
GetDevicesForUser(nil, lMessage.Username,
procedure (TagValue: variant; Devices: JDeviceList; Error: Exception)
begin
if Error nil then
begin
WriteToLog(Error.Message);
SendError(Socket, Request, Error.Message);
exit;
end;
var lResponse := TQTXFileGetDeviceListResponse.Create(request.ticket);
lResponse.UserName := lMessage.UserName;
lResponse.Code := CNT_MESSAGE_CODE_OK;
lResponse.Response := CNT_MESSAGE_TEXT_OK;
if Devices nil then
lResponse.assign(Devices);
try
Socket.Send( lResponse.Serialize() );
except
on e: exception do
begin
WriteToLog(e.message);
end;
end;
end);
end;
procedure TQTXTaskService.AfterServerStarted;
begin
inherited;
// Check prefs if zconfig should be applied
if self.FPrefs.ReadBoolean("zconfig", "active", false) then
begin
// ZConfig should only run on the master instance.
// We dont want to register our endpoint for each worker
if NodeJSClusterAPI().isWorker then
exit;
writeln("Setting up Zero-Configuration layer");
FZConfig.port := FPrefs.ReadInteger('zconfig', 'bindport', 2109);
FZConfig.address := GetMachineIP();
FZConfig.Start(nil, procedure (Sender: TObject; TagValue: variant; Error: Exception)
begin
if FPrefs.ReadBoolean("zconfig", "broadcast", true) then
FZConfig.Socket.setBroadcast(true);
// Build up the endpoint (URL) for our websocket server
var lEndpoint := '';
if FPrefs.ReadBoolean('networking', 'secure', false) then
lEndpoint := 'wss://'
else
lEndpoint := 'ws://';
lEndpoint += GetMachineIP();
lEndpoint += ':' + Port.ToString();
// Ping the ZConfig service on interval, until our service is registered
// We keep track of the interval handle so we can stop calling on interval later
FRegHandle := TQTXDispatch.SetInterval( procedure ()
begin
inc(FRegCount);
// Only output once to avoid overkill in the log
if FRegCount = 1 then
WriteToLogF("ZConfig registration begins [%s]", [lEndpoint]);
FZConfig.RegisterService(nil, CNT_ZCONFIG_SERVICE_NAME, SERVICE_ID_TASKMANAGER, lEndpoint,
procedure (TagValue: variant; Error: Exception)
begin
if Error = nil then
begin
WriteToLog("Service registered");
TQTXDispatch.ClearInterval(FRegHandle);
FRegCount := 0;
exit;
end;
end);
end, 1000);
end);
end;
end;
procedure TQTXTaskService.BeforeServerStopped;
begin
inherited;
end;
procedure TQTXTaskService.Dispatch(Socket: TNJWebSocketSocket; Message: TQTXBaseMessage);
begin
var LInfo := MessageDispatch.GetMessageInfoForClass(Message);
if LInfo nil then
begin
try
LInfo.MessageHandler(Socket, Message);
except
on e: exception do
begin
//Log error
WriteToLog(e.message);
end;
end;
end;
end;
end.
I have to be honest. I have never taken Tiobe that serious, because they have made to many mistakes in the past to have any form of credibility when it comes to Delphi and Object Pascal as a language. And when I say mistakes, I mean monumental blunders that just annihilate all possibility that they treat languages on equal footing.
Show full content
At the beginning of last week, Tiobe once again threw a punch at Object Pascal. Playing the whole “Delphi is dying” tune, while focusing on outdated and quite frankly irrelevant episodes from the past. Hoping no doubt, to leave the reader with an impression that Delphi is stuck in the 90s.
This is the same pattern we often see whenever Delphi or Object Pascal in general experience significant growth; or to be blunt, when the author cannot be bothered to think independently, but simply parrot hearsay and misinformation on autopilot.
It is lame, superficial and Tiobe’s biggest mistake to date.
Guess “alternative news” is no longer limited to individuals like Alex Jones
Just to underline the problem areas here. The ranking is based on their internal system (there is no standard for how to rank popularity), and while I have issues with how they build up their score, it’s ultimately the March editorial text that has caused irritation and shock. You don’t declare a language as dead when there are over 10 million developers using it. This type of editorial could have very real consequences – which in turn brings us to their ranking system and how they arrived at their conclusions.
I would have understood their statement if it was issued between 2007 and 2010, because Delphi was at that time transitioning between Borland and Embarcadero. But to issue something like this in 2020? After a decade worth of restoration, optimization, modernization and above all – forging a thriving community that goes from victory to victory month after month, year after year? It makes absolutely no sense.
Significant growth
In 2018 there were roughly six million Delphi developers (I worked at Embarcadero at the time), with a total estimate of ten million Object Pascal developers worldwide when counting all alternative compilers, dialects and indeed – known piracy issues.
“Tiobe failed stupendously in their data mining operation, they seem to be oblivious regarding the demographic in which the language is used”
Since that time Delphi has made strides into the universities in Scandinavia, South-America and the Middle-East. Turkey recently announced their dedication to native and archetypal software development with Delphi (provided free for students), which adds a whopping one million students to the already large body of users.
Embarcadero has slowly but steadily rebuilt much of the infrastructure that existed under Borland. From professional training at Embarcadero Academy, to entry level training at LearnDelphi.org. The Idera community pages likewise produce a large body of articles on a weekly basis. Comparing the Delphi and C++Builder ecosystem today with it’s tragic state back in 2010, is like day and night.
Training is available for both Enterprise level developers and students alike
With so much positive happening in the world of Object Pascal, Tiobe’s article comes across as a grave, intentional misrepresentation at worst, or an intellectual emergency at best. It is completely out of place and carries the tell-tell signs of an echo chamber.
Tiobe has lost all credibility
I have to be honest. I have never taken Tiobe that serious, because they have made to many mistakes in the past to have any form of credibility when it comes to Delphi and Object Pascal as a language. And when I say mistakes, I mean monumental blunders that just annihilate all possibility that they treat languages on equal footing.
“not only have Tiobe failed in their indexing, they have completely and utterly misunderstood the demographic in which the language is used”
If we go back a decade, Tiobe actually based their numbers on the keyword “Pascal”. In other words they excluded not just Delphi commits to GitHub, BitBucket and similar services – they also managed to exclude Freepascal and every subsequent dialect that signify Object Pascal as a whole. So for quite some time their entire statistics was based on the off chance that people typed “Pascal” in their project or commit entries.
To make matters worse, their search tech was not smart enough to recognize “Pascal” in composite words. So if you wrote “ObjectPascal” in a single word, the commit was excluded; As was “Freepascal”, “Smartpascal”, “Oxygenepascal” and variations using a hyphen (and the same for abbreviations).
Developers also use the term Lazarus and FPC interchangeably since Lazarus typically means people use the LCL, the visual framework used to write desktop applications with Freepascal. So while Freepascal has nothing to do with Delphi in terms of intellectual property, the two compilers are used by the community as a whole.
But let’s look at why Tiobe’s indexing fails for Delphi. Just what are they doing wrong?
Delphi has been around for 25 years, and it’s roots stretch back to the birth of C. Using Stack Overflow as an indicator for popularity is ludacris, since the majority of errors and problems have been largely ironed out in the past, leaving only extremely advanced and rare topics. If problems is the criteria, then I guess that explains why C# and Java soars in the ranking.
Nobody searches google for “Delphi programming”. You search for explicit topics like composite polygon clipping with GDI+ and then add “delphi” to limit the search to said language. Just like C/C++, Object Pascal is an archetypal language. It stretches from kernel work with inline assembly, to cloud services and HTML5 rendering. So the topics people search for are usually straight out of the operating-system strata.
Freepascal also targets WebAssembly and JavaScript and have variations of the LCL adapted those targets
And then there is third party, commercial alternatives that covers HTML5/JS like TMS WebCore, Smart Pascal, Oxygene Pascal and the upcoming Quartex Pascal. Around these runtime libraries (VCL, FMX and LCL) there are thousands of libraries, components and frameworks, large and small, that don’t necessarily put “Delphi” or “Object Pascal” in their metadata.
Tiobe also fails to include feeds like BeginEnd.net or DelphiFeeds, which syndicate on average 3000 unique blog-posts a year, representing a consistent and very much alive stream of information and content.
Delphi and Freepascal, which represents the most widely used compilers, are predominantly used to write commercial, closed source products. Which by consequence means that code and the activity involved is not public. For Tiobe to so utterly misunderstand the demographic for Object Pascal in general, is quite frankly outrageous. If you are going to rank a language that involves millions of users -then at least have the decency of investigating the communities it involves.
Excluding the factors I have outlined above, makes as much sense as excluding mono from C#.
Incompetence or plain ignorance?
It was only after an avalanche of complaints in 2014, orchestrated by yours truly, where members of the Delphi Developer group on Facebook sent complaints en-mass to Tiobe that they addressed the use of “Pascal” to represent Delphi and associated dialects. Yet for all the complaints, outlined in letters that no sentient human being could misunderstand – all Tiobe managed to do was to add “Object Pascal” to their list. Which, believe it or not, was unfamiliar to them.
It’s funny because it’s true
But do you think they bothered to do it right? Afraid not. Instead of aggregating all of the dialects, frameworks and variations of names under a single banner, they still to this day operate with two very specific search elements, namely “Delphi” or “Object Pascal”.
I sure hope the dairy industry doesn’t hire Tiobe to do statistics on milk, because if their coverage of Object Pascal is anything to go by, they will be ranking by yogurt.
No updates since 2018? Really Tiobe?
When a global Index service like Tiobe manage to write, and I quote:
“However, the latest Delphi release is from 2018” -Source: Tiobe, March report
You really have to ponder if human beings are involved in their business at all. I’m not expecting much, honestly, but I do expect them to interact with the community they supposedly track and build a statistic on. Have they visited Delphi Developer and talked to the admins about growth numbers? Have they talked to Embarcadero to get some figures and coverage there? Did they contact the Freepascal community to get some download statistics from them?
Delphi 10.3 was released on november 21st 2019. The version that Tiobe seem to think is the last update, is in fact the last release with a city name (which was launched in 2018). Since then there have been three successive, regular updates; most developers are now using version 10.3.3. With 10.3.4 about to be released. This just underlines how oblivious Tiobe is to our part of the industry.
Modern Delphi is used by millions of professional developers globally
Delphi and Freepascal is different in more ways than one, but beyond language compatibility there is one aspect that is quintessential for them both; namely their role in the commercial sector. Where other languages, like C/C++ or (for example) JavaScript see a lot of open-source activity, especially with regards to Linux and Node.js – Delphi and Freepascal are predominantly used to write high-quality, commercial, closed source business applications. In other words, the vast majority of code produced by the millions of Object Pascal developers around the world – is never publicly committed to GitHub or BitBucket.
So not only have Tiobe failed stupendously in their data mining operation, they seem oblivious to the demographic in which the language is used.
The selection of books, video tutorials and coding material for Delphi is recovering at a rapid pace. And much like C/C++ there are classic books on Amazon that are just as relevant today as they were 10 years ago. Thankfully Delphi don’t suffer the “learn Delphi in 2 weeks” style books, because any developer worth his salt knows that such books are for the gullible and naive.
Developers use Delphi and Freepascal to deliver rock solid, data driven services; services that is expected to run 24/7 with zero downtime, processing millions of transactions. Delphi is used to write medical software that manages networks of hospitals, with tens of thousands of patients. Delphi is used by banks to power their ATM machines, and Delphi is used to do the heavy lifting in thousands of POS (point of sale) terminals across Europe. Terminals that don’t have time to wait for a garbage collector to kick in, only to cause catastrophic CPU spikes (I won’t mention names, but attempting to switch to C# was a disaster for one of the biggest POS terminal suppliers in Europe).
Delphi represents the back-bone of the medical software industry in Scandinavia and Europe at large. Many have tried to replace Delphi, but end up with expensive lessons in why archetypal languages are indeed called archetypal.
Object Pascal is used by governments, fortune 500 companies and the guy with a million dollar idea working out of his parents garage; It is used to write cloud accounting software, invoicing systems and medical journaling; It is used by the music industry and graphical design. There are large and extremely successful products out there that don’t advertise that it’s written in Delphi (just like you don’t stamp “made with C++” on a piece of software). You would be surprised!
Object Pascal it’s used by developers who value speed, security, creative freedom and the benefit of a mature feature matrix that only C/C++ and Object Pascal brings. C is by definition three years older than Pascal, but these two archetypal languages have evolved side by side.
There is a reason these two languages represented the university curriculum for close to two decades; further still if we include Turbo Pascal. And Delphi is once again returning home to academia. To the applause of teachers who were forced to teach Java, and hated every minute of it (I helped setup two universities with Delphi in Norway, so I have some first hand accounts in the matter).
Reflections
Since Delphi is growing aggressively these days, Embarcadero is making waves. A few months back we saw how a well known team of C# influencers took a stab at Delphi (and me in particular, no doubt because I have been so outspoken). And as Delphi now returns to academia – Tiobe is demonstrating a bias that leaves little to the imagination. Especially when you know their numbers account for nothing and are bordering on fiction.
If I didn’t know better, I would say someone is worried. And it’s not the Delphi and Freepascal communities. Modern Delphi is a power-house for software development, and it has the potential to disrupt and restore the devtool market.
There is a lot of money involved, so I am not surprised we are seeing a string of attempts at undermining the importance of Object Pascal. I had hoped Tiobe would adopt a higher standard though.
Then again, the ship of credibility sailed when they couldn’t tell Turbo Pascal from Object Pascal.
Delphi is turning 25 and in connection with that, Jim Mckeeth is preparing a webinar! So make sure you register for the webinar in time! You can register here
Show full content
Delphi is turning 25 and in connection with that, Jim Mckeeth is preparing a webinar! So make sure you register for the webinar in time! There is some very special and unique stuff lined up, so this is going to rock!
25 years, wow. It seems only yesterday that I moved from Turbo Pascal to Delphi, and here we are a quarter of a century later. Such a wonderful language platform.
Very much looking forward to this talk — see you there guys!
Im following up with a second article about five features of Delphi that are intimately connected to Windows 10. I know that a lot of people are still clinging to Windows 7, but Microsoft phased that out last week, which means it's now officially a legacy OS. So if you haven't bothered updating, have a peek and think it over.
Im following up with a second article about five features of Delphi that are intimately connected to Windows 10. I know that a lot of people are still clinging to Windows 7, but Microsoft phased that out last week, which means it’s now officially a legacy OS. So if you haven’t bothered updating, have a peek and think it over.
The ministry of education in Turkey recently announced that they will be offering Delphi free of charge to students of computer sciences. An estimated one million students will thus have access to Delphi through this impressive initiative.
Show full content
Edit: The title in my initial post could be misinterpreted, so i have altered it to better reflect the nature of the situation. My apologies for the misunderstanding, I used the initial text copied verbatim from the source, translated from Turkish to Norwegian (and further to English), and in this case an important nuance was lost in that process.
The ministry of education in Turkey recently announced that they will be offering Delphi free of charge to their body of students. An estimated one million students will thus have access to Delphi through this initiative.
Getting object-pascal back into universities and education is very important. Not just for Delphi as a product or Embarcadero as a company, but to ensure that the next generation of software developers are given a firm grasp on fundamental programming concepts; concepts that represent the building-blocks that all software rests on, and that will benefit the students for a lifetime.
I find it incredibly sad that Java and C# somehow crept into the curriculum of computer sciences around the turn of the century. The result of that opportunistic move is that we have several generations of developers who has graduated utterly oblivious to fundamental concepts; concepts such as memory management, interrupts, low-level optimization, inline assembler and (to be blunt) how a computeractually works beyond the desktop. This is why a formal education of C and Pascal is powerful and enduring. It gives the student a depth and wingspan that is hard to match.
Object Pascal as a language (including Freepascal, Oxygene and various alternative compilers) have been fluctuating between #11 and #14 on the Tiobe Index for a few years. Tiobe is an index that tracks the use and popularity of languages around the world, and helps companies get an indication of where to invest. So despite what people have been led to believe, Delphi has seen stable growth for many years and is far more widespread than sceptics like to admit.
As an ardent Delphi developer myself this is excellent news! Not only will it help the next generation of students learn proper engineering from the ground up – but it will also help to retire some of the unfounded myths surrounding the language (and Delphi in particular) that is sadly still in circulation. Most of these rumors stem from the hostile takeover (or elimination) of Borland by Microsoft some two decades ago, and does in no way reflect the reality of 2020. Delphi in particular has been through several phases of evolution, and is today en par with it’s companion language C/C++.
I am thrilled that so many young developers will now have access to a modern and relevant Delphi edition. Delphi has been a favorite of teachers and students everywhere, and the return of Delphi to academia – is a sign that the age of compromise is losing its grip.
Thank you to Hür Akdülger for informing the Delphi Developer community about this. Truly a monumental sign of growth. Congratulations Embarcadero and the Turkish students!
I just published an article about InterBase on the Embarcadero community pages! Interbase is a much loved database that has seen some radical improvements. Check out my top 5 reasons to use InterBase with your Delphi, C++Builder or Sencha applications here
Besides being a superb developer Rudy also had a great sense of humor, and a charm and wit that made him fun to talk with and easy learn from. He would go out of his way to help others and share his insight and wisdom whenever he could.
Show full content
Our fellow Delphi and C++ developer Rudy Velthuis (1960 ~ 2019) is sadly reported to have passed away.
I think we have all had a dialog with him at some point in our developer careers. I remember him helping me getting to grips with bitmap scanline coding under Delphi 5 on the old Borland newsgroups.
Besides being a superb developer Rudy also had a great sense of humor, and a charm and wit that made him fun to talk with and easy learn from. He would go out of his way to help others and share his insight and wisdom whenever he could.
Sadly this tragic news has taken some time to reach our community. Rudy passed away peacefully in his sleep last may. When the news broke this morning on Facebook, the otherwise active group fell utterly silent.
Our deepest condolences to his family and loved ones. He will be fondly remembered by everyone.
Amibian.jsDelphidwscriptembeddedfreepascalnodeJSObject PascalQTXSocialAmiga DisruptAsm.jsC#Clangnode.jsNodeBuilderQuartex Media DesktopWebAssembly
While I dont have time to evolve this software beyond that of a simple service designer (well, I kinda did already), I have no problem seeing this system as a beginning of a wonderful, universal service authoring system. One that includes coding, libraries and the full scope of the QTX runtime-library.
Show full content
First, let me wish everyone a wonderful new year! With xmas and the silly season firmly behind us, and my batteries recharged – I feel my coding fingers itch to get started again.
2019 was a very busy year for me. Exhausting even. I have juggled both a full time job, kids and family, as well as our community project, Quartex Media Desktop. And since that project has grown considerably, I had to stop and work on the tooling. Which is what NodeBuilder is all about.
I have also released my own social media platform (see further down). This was initially scheduled for Q4 2020, but Facebook pissed me off something insanely, so I set it up in december instead.
NodeBuilder
For those of you that read my blog you probably remember the message system I made for the Quartex Desktop, called Ragnarok? This is a system for dealing with message dispatching and RPC, except that the handling is decoupled from the transport medium. In other words, it doesnt care how you deliver a message (WebSocket, UDP, REST), but rather takes care of serialization, binary data and security.
All the back-end services that make up the desktop system, are constructed around Ragnarok. So each service exposes a set of methods that the core can call, much like a normal RPC / SOAP service would. Each method is represented by a request and response object, which Ragnarok serialize to a JSON message envelope.
In our current model I use WebSocket, which is a full duplex, long-term connection (to avoid overhead of having to connect and perform a handshake for each call). But there is nothing in the way of implementing a REST transport layer (UDP is already supported, it’s used by the Zero-Config system. The services automatically find each other and register, as long as they are connected to the same router or switch). For the public service I think REST makes more sense, since it will better utilize the software clustering that node.js offers.
Node Builder is a relatively simple service designer, but highly effective for our needs
Now for small services that expose just a handful of methods (like our chat service), writing the message classes manually is not really a problem. But the moment you start having 20 or 30 methods – and need to implement up to 60 message classes manually – this approach quickly becomes unmanageable and prone to errors. So I simply had to stop before xmas and work on our service designer. That way we can generate the boilerplate code in seconds rather than days and weeks.
While I dont have time to evolve this software beyond that of a simple service designer (well, I kinda did already), I have no problem seeing this system as a beginning of a wonderful, universal service authoring system. One that includes coding, libraries and the full scope of the QTX runtime-library.
In fact, most of the needed parts are in the codebase already, but not everything has been activated. I don’t have time to build both a native development system AND the development system for the desktop.
NodeBuilder already have a fully functional form designer and code editor, but it is dormant for now due to time restrictions. Quartex Media Desktop comes first
But right now, we have bigger fish to fry.
Quartex Media Desktop
We have made tremendous progress on our universal desktop environment, to the point where the baseline services are very close to completion. A month should be enough to finish this unless something unforeseen comes up.
Quartex Media Desktop provides an ecosystem for advanced web applications
You have to factor in that, this project has only had weekends and the odd after work hours allocated for it. So even though we have been developing this for 12 months, the actual amount of days is roughly half of that.
So all things considered I think we have done a massive amount of code in such a short time. Even simple 2d games usually take 2 years of daily development, and that includes a team of at least 5 people! Im a single developer working in my spare time.
So what exactly is left?
The last thing we did before xmas was upon us, was to throw out the last remnants of Smart Mobile Studio code. The back-end services are now completely implemented in our own QTX runtime-library, which has been written from scratch. There is not a line of code from Smart Mobile Studio in QTX, which means we no longer have to care what that system does or where it goes.
To sum up:
Push all file handling code out of the core
Implement file-handling as it’s own service
Those two steps might seem simple enough, but you have to remember that the older code was based on the Linux path system, and was read-only.
So when pushing that code out of the core, we also have to add all the functionality that was never implemented in our prototype.
Each class actually represents a separate “mini” program, and there are still many more methods to go before we can put this service into production.
Since Javascript does not support threads, each method needs to be implemented as a separate program. So when a method is called, the file/task manager literally spawns a new process just for that task. And the result is swiftly returned back to the caller in async manner.
So what is ultimately simple, becomes more elaborate if you want to do it right. This is the price we pay for universality and a cluster enabled service-stack.
This is also why I have put the service development on pause until we have finished the NodeBuilder tooling. And I did this because I know by experience that the moment the baseline is ready, both myself and users of the system is going to go “oh we need this, and that and those”. Being able to quickly design and auto-generate all the boilerplate code will save us months of work. So I would rather spend a couple of weeks on NodeBuilder than wasting months having to manually write all that boilerplate code down the line.
What about the QTX runtime-library?
Writing an RTL from scratch was not something I could have anticipated before we started this project. But thankfully the worst part of this job is already finished.
The RTL is divided into two parts:
Non Visual code. Classes and methods that makes QTX an RTL
Visual code. Custom Controls + standard controls (buttons, lists etc)
Visual designer
As you can see, the non-visual aspect of the system is finished and working beautifully. It’s a lot faster than the code I wrote for Smart Mobile Studio (roughly twice as fast on average). I also implemented a full visual designer, both as a Delphi visual component and QTX visual component.
Quartex Media Desktop makes running on several machines [cluster] easy and seamless
So fundamental visual classes like TCustomControl is already there. What I haven’t had time to finish are the standard-controls, like TButton, TListBox, TEdit and those type of visual components. That will be added after the release of QTX, at which point we throw out the absolute last remnants of Smart Mobile Studio from the client (HTML5 part) software too.
Why is the QTX Runtime-Library important again?
When the desktop is out the door, the true work begins! The desktop has several roles to play, but the most important aspect of the desktop – is to provide an ecosystem capable of hosting web based applications. Offering features and methods traditionally only found in Windows, Linux or OS X. It truly is a complete cloud system that can scale from a single affordable SBC (single board computer), to a high-end cluster of powerful servers.
Clustering and writing distributed applications has always been difficult, but Quartex Media Desktop makes it simple. It is no more difficult for a user to work on a clustered system, as it is to work on a normal, single OS. The difficult part has already been taken care of, and as long as people follow the rules, there will be no issues beyond ordinary maintenance.
And the first commercial application to come out of Quartex Components, is Cloud Forge, which is the development system for the platform. It has the same role as Visual Studio for Windows, or X Code for Apple OS X.
The Quartex Media Desktop Cluster cube. A $400 super computer
I have prepared 3 compilers for the system already. First there is C/C++ courtesy of Clang. So C developers will be able to jump in and get productive immediately. The second compiler is freepascal, or more precise pas2js, which allows you to compile ordinary freepascal code (which is highly Delphi compatible) to both JavaScript and WebAssembly.
And last but not least, there is my fork of DWScript, which is the same compiler that Smart Mobile Studio uses. Except that my fork is based on the absolute latest version, and i have modified it heavily to better match special features in QTX. So right out of the door CloudForge will have C/C++, two Object Pascal compilers, and vanilla Javascript and typescript. TypeScript also has its own WebAssembly compiler, so doing hard-core development directly in a browser or HTML5 viewport is where we are headed.
Once the IDE is finished I can finally, finally continue on the LDEF bytecode runtime, which will be used in my BlitzBasic port and ultimately replace both clang, freepascal and DWScript. As a bonus it will emit native code for a variety of systems, including x86, ARM, 68k [including 68080] and PPC.
This might sound incredibly ambitious, if not impossible. But what I’m ultimately doing here -is moving existing code that I already have into a new paradigm.
The beauty of object pascal is the sheer size and volume of available components and code. Some refactoring must be done due to the async nature of JS, but when needed we fall back on WebAssembly via Freepascal (WASM executes linear, just like ordinary native code does).
A brand new social platform
During december Facebook royally pissed me off. I cannot underline enough how much i loath A.I censorship, and the mistakes that A.I does – in which you are utterly powerless to complain or be heard by a human being. In my case i posted a gif from their own mobile application, of a female body builder that did push-ups while doing hand-stands. In other words, a completely harmless gif with strength as the punchline. The A.I was not able to distinguish between a leotard and bare-skin, and just like that i was muted for over a week. No human being would make such a ruling. As an admin of a fairly large set of groups, there are many cases where bans are the result. Disgruntled members that acts out of revenge and report technical posts about coding as porn or offensive. Again, you are helpless because there are nobody you can talk to about resolving the issue. And this time I had enough.
It was always planned that we would launch our own social media platform, an alternative to Facebook aimed at adult geeks rather than kids (Facebook operates with an age limit of 12 years). So instead of waiting I rushed out and set up a brand new social network. One where those banale restrictions Facebook has conditioned us with, does not apply.
Just to underline, this is not some simple and small web forum. This is more or less a carbon copy of Facebook the way it used to be 8-9 years ago. So instead of having a single group on facebook, we can now have as many groups as we like, on a platform that looks more or less identical to Facebook – but under our control and human rules.
You can visit the site right now at https://www.amigadisrupt.com. Obviously the major content on the platform right now is dominated by retro computing – but groups like Delphi Developer and FPC developer has already been setup and are in use. But if you are expecting thousands of active users, that will take time. We are now closing in on 250 active users which is pretty good for such a short period of time. I dont want a platform anywhere near as big as FB. The goal is to get 10k users and have a stable community of coders, retro geeks, builders and creative individuals.
AD (Amiga Disrupt) will be a standard application that comes with Quartex Media Desktop. This is the beauty of web technology, in that it can unify different resources under one roof. And we will have our cake and eat it come hell or high water.
Disclaimer: Amiga Disrupt has a lower age limit of 18 years. This is a platform meant for adults. Which means there will be profanity, jokes that would get you banned on Facebook and content that is not meant for kids. This is hacker-land, and political correctness is considered toilet paper. So if you need social toffery like FB and Twitter deals with, you will be kicked by one of the admins.
After you sign up your feed will be completely empty. Here is how to get it started. And feel free to add me to your friends-list!
However, two days after I posted said review, NVidia issued several updates. The graphics drivers were updated, followed by a custom Chrome browser build. Naturally I was eager to see if this would affect my initial experience, and to say it did would be an understatement.
Show full content
Last week I posted a review of the NVidia Jetson Nano IoT board, where I gave the board a score of 6 out of 10. This score was based on the fact that the CPU in particular was a joke compared to other, far better and more affordable boards on the market.
Ubuntu running on the NVidia Jetson Nano
Since my primary segment for IoT boards involves web technology, WebAssembly and Asm.js (HTML5) in particular, the cpu did not deliver the performance I expected from an NVidia board. But as stated in my article, this board was never designed to be a multi-purpose maker board. This is a board for training and implementing A.I models (machine learning), which is why it ships with an astonishing 128 CUDA cores in it’s GPU.
However, two days after I posted said review, NVidia issued several updates. The graphics drivers were updated, followed by a custom Chrome browser build. Naturally I was eager to see if this would affect my initial experience, and to say it did would be an understatement.
Driver update
After this update the Jetson was able to render the HTML5 based desktop system I use for testing, and it passed more or less all my test-cases with flying colors. In fact, I was able to run two tests simultaneously. It renders Quake 3 (uses WebGl) in full-screen at 45 fps, with Tyrian (uses the gpu’s 2d functions) running at a whopping 35 fps (!).
Obviously that payload is significant, and all 4 CPU cores were taxed at 70% when running two such demanding programs inside the same viewport. Personally I’m not much of a gamer, but I find that testing a SoC by its ability to process HTML5 and JS, especially code that taps into the underlying GPU for both 3d and 2d – gives a good picture of the SoC’s capabilities.
I still think the CPU was a poor choice by NVidia. The production costs of adding an A72 CPU is practically non-existent. The A72 would add 50 cents (USD 0.5) to the boards retail value, but in return it would give us a much higher clock speed and beefier CPU cache. The A72 is in practical terms twice as fast as the A57.
A better score
But, fair is fair, and I am changing the review score to 7 out of 10, which is the best score I have ever given to any IoT device.
The only board that has a chance of topping that, is the ODroid N2, when (if ever) Hardkernel bothers to implement X drivers for the Mali GPU.
It is an excellent SoC for gaming though. It's probably the only IoT board that delivers 35-50 fps when emulating Playstation and Sega Saturn games (which are very demanding). I also got 54 fps running Quake 3 compiled to JavaScript, which is pretty cool.
Show full content
The sheer volume of technology you can pick up for $100 in 2019 is simply amazing. Back in 2012 when the IoT revolution began, people were amazed at how the tiny Raspberry PI SoC was able to run a modern browser and play quake. Fast forward to 2019 and that power has been multiplied a hundred fold.
Of all the single board computers available today, the NVidia Jetson Nano exists in a whole different sphere compared to the rest. It ships with 4 Gb of ram, a mid-range 64-bit quad processor – and a whopping 128 GPU cores (!).
It does cost a little more than the average board, but not much. The latest Raspberry PI v4 sells for $79, just $20 less than the Jetson. But the Video-Core IV that powers the Raspberry PI v4 was not designed for tasks that Jetson can take on. Now don’t get me wrong, the Raspberry PI v4 is roughly the same SoC (the CPU on the PI is one revision higher), and the Video-Core GPU is a formidable graphics processor. But if you want to work with artificial intelligence, you need proper Cuda support; something the Video-Core can’t deliver.
The specs
Let’s have a look at the specs before we continue. To give you some idea of the power here, this is roughly the same specs as the Nintendo Switch. In fact, if we go up one model to the NVidia TX 1 – that is exactly what the Nintendo Switch uses. So if you are expecting something to replace your Intel i5 or i7 desktop computer, you might want to look elsewhere. But as an IoT device for artificial intelligence work, it does have a lot to offer:
USB – 4x USB 3.0 ports, 1x USB 2.0 Micro-B port for power or device mode
M.2 Key E socket (PCIe x1, USB 2.0, UART, I2S, and I2C)
40-pin expansion header with GPIO, I2C, I2S, SPI, UART signals
8-pin button header with system power, reset, and force recovery related signals
Misc – Power LED, 4-pin fan header
Power Supply – 5V/4A via power barrel or 5V/2A via micro USB port
ARM for the future
Most of the single board computers (SBC’s) on the market today, sell somewhere around the $70 mark. As a consequence their processing power and graphical capacity is severely limited compared to traditional desktop computers. IoT boards are closely linked to the mobile phone industry, typically behind the latest SoC by a couple of years; Which means you can expect to see ARM IoT boards that floors an Intel i5 sometime in 2022 (perhaps sooner).
Top of the line mobile phones, like the Samsung Galaxy Note 10, are presently shipping with the Snapdragon 830 SoC. The Snapdragon 830 delivers the same processing power as an Intel i5 CPU (actually slightly faster). It is amazing to see how fast ARM is catching up with Intel and AMD. Powerful technology is expensive, which is why IoT is brilliant; by using the same SoC’s that the mobile industry has perfected, they are able to tap into the price drop that comes with mass production. IoT is quite frankly piggybacking on the the every growing demand for faster mobile devices; which is a great thing for us consumers.
Intel and AMD is not resting on their laurels either, and Intel in particular has lowered their prices considerably to meet the onslaught of cheap ARM boards hitting the market. But despite their best efforts – there is no doubt where the market is heading; ARM is the future – both for mobile, desktop and server.
The Nvidia Jetson Nano
Out of all the boards available on the market for less than US $100, and that is a long list – one board deserves special attention: the NVidia Jetson Nano developer board. This was released back in march of this year. I wanted to get this board as it hit the stores – but since my ODroid XU4 and N2 have performed so well, there simply was no need for it; until recently.
First of all, the Jetson SBC is not a cheap $35 board. The GPU on this board are above and beyond anything available for competing single board computers. Most IoT boards are fitted with a relatively modest GPU (graphical processing unit), typically with 1, 2, 4 or 8 cores. The NVidia Jetson Nano though, ships with 128 GPU cores (!); making it by far the best option for creating, training and deploying artificial intelligence models.
The Jetson boards were designed for one thing, A.I. It’s not really a general purpose SBC
I mean, the IoT boards to date have all suffered from the same tradeoffs, where the makers must try to strike a balance between CPU, GPU and RAM. This doesn’t always work out like the architects have planned. Single board computers like like the Asus Tinkerboard or NanoPI Fire 3 are examples of this; The Tinkerboard is probably the fastest 32-bit ARM processor I have ever experienced, but the way the different parts have been integrated, coupled with poorly planned power distribution (as in electrical power) resulted in terrible stability problems. The NanoPI Fire 3 is also a paper-tiger that, for the best of intentions, is useless for anything but Android.
The Jetson Nano is more expensive, but NVidia has managed to balance each part in a way that works well; at least for artificial intelligence work. I must underline that the CPU was a big disappointment for me personally. I misread the specs before I ordered and expected it to be fitted with a quad core A72 cpu @ 2 GHz. Instead it turned out to use the A57 cpu running @ 1.43 GHz. This might sound unimportant, but the A72 is almost twice as fast (and costing only 50 cents more). Why NVidia decided on that model of CPU stands as a completely mystery.
In my view, this sends a pretty clear message that NVidia has no interest in competing with other mainstream boards, but instead aim solely at the artificial intelligence market.
Artificial intelligence
If working with A.I is something that you find interesting, then you are in luck. This is the primary purpose of the Jetson Nano. Training an A.I model on a Raspberry PI v4 or ODroid N2 is also possible, but it would be a terrible and frustrating experience because those boards are not designed for it. What those 128 cuda cores can chew through in 2 hours, would take a week for a Raspberry PI to process.
If we look away from the GPU, single board computers like the ODroid N2 is better in every way. The power distribution on the SoC is better, the boot options are better, the bluetooth and IR options are better, the network and disk controllers are more powerful, the ram runs at higher clock-speeds -and last but not least, the “little-big” CPU architecture ODroid devices are known for, just floors the Jetson. It literally has nothing to compete with if we ignore that GPU.
So if you have zero interest in A.I, cuda or Tensorflow, then I urge you to look elsewhere. To put the CPU into perspective: The model used on the Jetson is only slightly faster than the Raspberry PI 3b. The extra memory helps it when browsing complex HTML5 websites, but not enough to justify the price. By comparison the ODroid XU4 retails at $40 and will slice through those website like it was nothing. So if you are looking for a multi-purpose board, the Jetson Nano is not it.
Upstream Ubuntu
Most IoT boards ship with a trimmed-down Linux distribution especially adapted for that board. This is true for more or less all the IoT boards I have tested over the last 18 months. The reason companies ship these slim and optimized setups is simply because running a full Linux distribution, like we have on x86, demands too much of the CPU (read: there will be little left for your code). These are micro computers after all.
The Jetson Ubuntu distro comes pre-loaded with drivers and various A.I libraries
The difference between SBC’s like the PI, ODroid (or whatnot) and the Jetson Nano, is that Jetson comes with a full, upstream Ubuntu based distribution. In other words – the same distribution you would install for your desktop PC, is somehow expected to perform miracles on a device only marginally faster than a Raspberry PI 3b.
I must say I am somewhat puzzled by Nvidia’s choice of Linux for this board, but against all odds the board does perform. The desktop is responsive and smooth despite the payload involved, most likely because the renderer and layout engine taps into the GPU cores. But optimal? Hardly.
Other distributions?
One thing that must be stressed when it comes to the Jetson Nano, is that Nvidia is not shipping a system where everything is wide open. Just like the Raspberry PI’s VC (video core) GPUs are proprietary and requires commercial, closed-source drivers, so does the Jetson. It’s not just a question of driver in this case, but a customized kernel.
The board is called the “Nvidia Jetson Nano developer kit”, which means Nvidia sells this exclusively to work with A.I under their standards. For this reason, there are no alternative distributions or flavours. You are expected to work with Ubuntu, end of story.
Having said that, the way to get around this -is simply to work backwards, and strip the official disk image of services and packages you don’t need. A full upstream Ubuntu install means you have two browsers, email and news client, music players, movie players, photo software, a full office suite -and more python libraries than you will ever need. With a little bit of cleaning, you can trim the distro down and make it suitable for other tasks.
Practical uses
No single board computer is identical. There are different CPUs, different GPUs, IO controllers, ram – which all helps define what a board is good at.
The Jetson Nano is a powerful board, but only within the sphere it was designed for. The moment you move away from artificial intelligence, the board is instantly surpassed by cheaper models.
51 fps running Quake [Javascript] is very good. But the general experience of HTML5 is not optimal due to the cpu not being the most powerful
As such, the only practical use this board has, is for running A.I software and models. Unless Nvidia decides to do a special build of Chrome where those cores are used to speed up HTML5 rendering, I can’t even recommend this for casual browsing. It is an excellent SoC for gaming though. It’s probably the only IoT board that delivers 35-50 fps when emulating Playstation and Sega Saturn games (which are very demanding). I also got 54 fps running Quake 3 compiled to JavaScript, which is pretty cool.
But if gaming is you sole interest, $100 will buy you a much better x86 board to play with. In one of my personal projects (Quartex Media Desktop), which is a cluster “supercomputer” consisting of many IoT boards connected through a switch – the Jetson was supposed to act as the master board. In a cluster design you typically have X number of slaves which runs headless (no desktop or graphical output as all) – and a master unit that deals with the display / desktop. The slave boards don’t need much in terms of GPU since they won’t run graphical tasks (so the GPU is often disabled)– which puts enormous pressure on the master to represent everything graphically.
In my case the front-end is written in Javascript and uses Chrome to render a very complex display. Finding an SBC with enough power to render modern and complex HTML5 has not been easy. I was shocked that the Jetson Nano had poorer performance than devices costing half it’s asking price.
It could be throttling based on heat, because the board gets really hot. It has massive heatsink much like the ODroid N2, but I have a sneaking suspicion that active cooling is going to be needed to get the best out of this puppy. At worst i get 17 fps when running Quake 3 [javascript], but i think there was an issue with a driver. After an update was released, the frame-rate went back to 50+ fps. Extremely annoying because you feel you can’t trust the SoC.
Final verdict
The Nvidia Jetson Nano is an impressive IoT board, and when it comes to GPU power and artificial intelligence, those 128 cuda cores is a massive advantage. But computing is not just about fancy A.I models. And this is ultimately where the Jetson comes up short. When something as simple as browsing modern websites can unexpectedly bring the SoC to a grinding halt, then I cannot recommend the system for anything but what it was designed to do: artificial intelligence.
There are also some strange design decisions on hardware level. On most boards the USB sockets have separate data-lines and power route. But on the Jetson the four USB 3.0 sockets share a single data-line. In other words, whatever you connect to the device, will affect data throughput.
Nvidia also made the same mistake that Asus did, namely to power the USB ports and CPU from the same route. It’s not quite as bad as the Tinkerboard. Nvidia made sure the board has two power sockets, so should undervolting become an issue, you can just plug in a secondary 5V barrel socket (disabled by default).
The lack of eMMc support or a sata interface is also curious. Hosting a full Ubuntu on a humble SD-card, with an active swapfile, is a recipe for disaster.
So is it worth the $99 asking price?
If you work with artificial intelligence or GPU based computing then yes, the board will help you prototype your products. But if you expect to do anything ordinary, like run demanding HTML5 apps or host CPU intensive system services – I find myself struggling to say yes.
It’s a cool board, and it also makes one hell of a games machine – but the hardware is already outdated. If you want a general purpose single board computer, you are much better off buying the Raspberry PI 4 or the ODroid N2, both are cheaper and deliver much better processing power. Obviously the GPU is hard to match.
I will give the board a score of 6 out of 10, purely because the board is brilliant for A.I and compute tasks. This might change as more distros become available. A full Ubuntu install is one hell of a load on the system after all.
Amibian.jsdwscriptembeddedfreepascalJavaScriptLinuxnodeJSObject PascalQuartex PascalRaspberry PITinkerboardcloudCloud RipperclusterClusteringCubeMicroServicesnode.jsQuartex Media DesktopService stack
For close to a year now I have been busy on a very exciting project, namely my own cloud system. While I have written about this project quite a bit these past months, mostly focusing on the software aspect, not much has been said about that hardware. So let’s have a look at Cloud Ripper, […]
Show full content
For close to a year now I have been busy on a very exciting project, namely my own cloud system. While I have written about this project quite a bit these past months, mostly focusing on the software aspect, not much has been said about that hardware.
Quartex “Cloud Ripper” running neatly on my home-office desk
So let’s have a look at Cloud Ripper, the official hardware setup for Quartex Media Desktop.
Tiny footprint, maximum power
Despite its complexity, the Quartex Media Desktop architecture is surprisingly lightweight. The services that makes up the baseline system (read: essential services) barely consume 40 megabytes of ram per instance (!). And while there is a lot of activity going on between these services -most of that activity is message-dispatching. Sending messages costs practically nothing in cpu and network terms. This will naturally change the moment you run your cloud as a public service, or setup the system in an office environment for a team. The more users, the more signals are shipped between the processes – but with the exception of reading and writing large files, messages are delivered practically instantaneous and hardly use CPU time.
Quartex Media Desktop is based on a clustered micro-service architecture
One of the reasons I compile my code to JavaScript (Quartex Media Desktop is written from the ground up in Object Pascal, which is compiled to JavaScript) has to do with the speed and universality of node.js services. As you might know, Node.js is powered by the Google V8 runtime engine, which means the code is first converted to bytecodes, and further compiled into highly optimized machine-code [courtesy of llvm]. When coded right, such Javascript based services execute just as fast as those implemented in a native language. There simply are no perks to be gained from using a native language for this type of work. There are however plenty of perks from using Node.js as a service-host:
Node.js delivers the exact same behavior no matter what hardware or operating-system you are booting up from. In our case we use a minimal Linux setup with just enough infrastructure to run our services. But you can use any OS that supports Node.js. I actually have it installed on my Android based Smart-TV (!)
We can literally copy our services between different machines and operating systems without recompiling a line of code. So we don’t need to maintain several versions of the same software for different systems.
We can generate scripts “on the fly”, physically ship the code over the network, and execute it on any of the machines in our cluster. While possible to do with native code, it’s not very practical and would raise some major security concerns.
Node.js supports WebAssembly, you can use the Elements Compiler from RemObjects to write service modules that executes blazingly fast yet remain platform and chipset independent.
The Cloud-Ripper cube
The principal design goal when I started the project, was that it should be a distributed system. This means that instead of having one large-service that does everything (read: a typical “native” monolithic design), we instead operate with a microservice cluster design. Services that run on separate SBC’s (single board computers). The idea here is to spread the payload over multiple mico-computers that combined becomes more than the sum of their parts.
Cloud Ripper – Based on the Pico 5H case and fitted with 5 x ODroid XU4 SBC’s
So instead of buying a single, dedicated x86 PC to host Quartex Media Desktop, you can instead buy cheap, off-the-shelves, easily available single-board computers and daisy chain them together. So instead of spending $800 (just to pin a number) on x86 hardware, you can pick up $400 worth of cheap ARM boards and get better network throughput and identical processing power (*). In fact, since Node.js is universal you can mix and match between x86, ARM, Mips and PPC as you see fit. Got an older PPC Mac-Mini collecting dust? Install Linux on it and get a few extra years out of these old gems.
(*) A single XU4 is hopelessly underpowered compared to an Intel i5 or i7 based PC. But in a cluster design there are more factors than just raw computational power. Each board has 8 CPU cores, bringing the total number of cores to 40. You also get 5 ARM Mali-T628 MP6 GPUs running at 533MHz. Only one of these will be used to render the HTML5 display, leaving 4 GPUs available for video processing, machine learning or compute tasks. Obviously these GPUs won’t hold a candle to even a mid-range graphics card, but the fact that we can use these chips for audio, video and computation tasks makes the system incredibly versatile.
Another design goal was to implement a UDP based Zero-Configuration mechanism. This means that the services will find and register with the core (read: master service) automatically, providing the machines are all connected to the same router or switch.
Put together your own supercomputer for less than $500
The first “official” hardware setup is a cluster based on 5 cheap ARM boards; namely the ODroid XU4. The entire setup fits inside a Pico Cube, which is a special case designed to house this particular model of single board computers. Pico offers several different designs, ranging from 3 boards to a 20 board super-cluster. You are not limited ODroid XU4 boards if you prefer something else. I picked the XU4 boards because they represent the lowest possible specs you can run the Quartex Media Desktop on. While the services themselves require very little, the master board (the board that runs the QTXCore.js service) is also in charge of rendering the HTML5 display. And having tested a plethora of boards, the ODroid XU4 was the only model that could render the desktop properly (at that low a price range).
Note: If you are thinking about using a Raspberry PI 3B (or older) as the master SBC, you can pretty much forget it. The media desktop is a piece of very complex HTML5, and anything below an ODroid XU4 will only give you a terrible experience (!). You can use smaller boards as slaves, meaning that they can host one of the services, but the master should preferably be an ODroid XU4 or better. The ODroid N2 [with 4Gb Ram] is a much better candidate than a Raspberry PI v4. A Jetson Nano is an even better option due to its extremely powerful GPU.
Booting into the desktop
One of the things that confuse people when they read about the desktop project, is how it’s possible to boot into the desktop itself and use Quartex Media Desktop as a ChromeOS alternative?
How can a “cloud platform” be used as a desktop alternative? Don’t you need access to the internet at all times? If it’s a server based system, how then can we boot into it? Don’t we need a second PC with a browser to show the desktop?
Accessing the desktop like a “web-page” from a normal Linux setup
To make a long story short: the “master” in our cluster architecture (read: the single-board computer defined as the boss) is setup to boot into a Chrome browser display under “kiosk mode”. When you start Chrome in kiosk mode, this removes all traces of the ordinary browser experience. There will be no toolbars, no URL field, no keyboard shortcuts, no right-click popup menus etc. It simply starts in full-screen and whatever HTML5 you load, has complete control over the display.
What I have done, is to to setup a minimal Linux boot sequence. It contains just enough Linux to run Chrome. So it has all the drivers etc. for the device, but instead of starting the ordinary Linux Desktop (X or Wayland) -we instead start Chrome in kiosk mode.
Booting into the same desktop through Chrome in Kiosk Mode. In this mode, no Linux desktop is required. The Linux boot sequence is altered to jump straight into Chrome
Chrome is started to load from 127.0.0.1 (this is a special address that always means “this machine”), which is where our QTXCore.js service resides that has it’s own HTTP/S and Websocket servers. The client (HTML5 part) is loaded in under a second from the core — and the experience is more or less identical to starting your ChromeBook or NAS box. Most modern NAS (network active storage) devices are much more than a file-server today. NAS boxes like those from Asustor Inc have HDMI out, ships with a remote control, and are designed to act as a media center. So you connect the NAS directly to your TV, and can watch movies and listen to music without any manual conversion etc.
In short, you can setup Quartex Media Desktop to do the exact same thing as ChromeOS does, booting straight into the web based desktop environment. The same desktop environment that is available over the network. So you are not limited to visiting your Cloud-Ripper machine via a browser from another computer; nor are you limited to just using a dedicated machine. You can setup the system as you see fit.
Why should I assemble a Cloud-Ripper?
Getting a Cloud-Ripper is not forced on anyone. You can put together whatever spare hardware you have (or just run it locally under Windows). Since the services are extremely lightweight, any x86 PC will do. If you invest in a ODroid N2 board ($80 range) then you can install all the services on that if you like. So if you have no interest in clustering or building your own supercomputer, then any PC, Laptop or IOT single-board computer(s) will do. Provided it yields more or equal power as the XU4 (!)
What you will experience with a dedicated cluster, regardless of putting the boards in a nice cube, is that you get excellent performance for very little money. It is quite amazing what $200 can buy you in 2019. And when you daisy chain 5 ODroid XU4 boards together on a switch, those 5 cheap boards will deliver the same serving power as an x86 setup costing twice as much.
Pico is offering 3 different packages. The most expensive option is the pre-assembled cube. This is for some reason priced at $750 which is completely absurd. If you can operate a screwdriver, then you can assemble the cube yourself in less than an hour. So the starter-kit case which costs $259 is more than enough.
Next, you can buy the XU4 boards directly from Hardkernel for $40 a piece, which will set you back $200. If you order the Pico 5H case as a kit, that brings the sub-total up to $459. But that price-tag includes everything you need except sd-cards. So the kit contains power-supply, the electrical wiring, a fast gigabit ethernet switch [built-into the cube], active cooling, network cables and power cables. You don’t need more than 8Gb sd-cards, which costs practically nothing these days.
Note: The Quartex Media Desktop “file-service” should have a dedicated disk. I bought a 256Gb SSD disk with a USB 3.0 interface, but you can just use a vanilla USB stick to store user-account data + user files.
As a bonus, such a setup is easy to recycle should you want to do something else later. Perhaps you want to learn more about Kubernetes? What about a docker-swarm? A freepascal build-server perhaps? Why not install FreeNas, Plex, and a good backup solution? You can set this up as you can afford. If 5 x ODroid XU4 is too much, then get 3 of them instead + the Pico 3H case.
So should Quartex Media Desktop not be for you, or you want to do something else entirely — then having 5 ODroid XU4 boards around the house is not a bad thing.
Oh and if you want some serious firepower, then order the Pico 5H kit for the NVidia Jetson Nano boards. Graphically those boards are beyond any other SoC on the market (in it’s price range). But as a consequence the Jetson Nano starts at $99. So for a full kit you will end up with $500 for the boards alone. But man those are the proverbial Ferrari of IOT.
As a Delphi or Freepascal developer, perhaps you have seen some of the fancy grids C# and Java coders enjoy? Developer Express have some of the coolest components available for any platform, but they sadly stopped developing new components for Delphi years ago. With Hydra you can tap into the .Net side of things and use the latest components and libraries in your Delphi applications.
Show full content
RemObjects Hydra is a product I have used for years in concert with Delphi, and like most developers that come into contact with RemObjects products – once the full scope of the components hit you, you never want to go back to not using Hydra in your applications.
Note: It’s easy to dismiss Hydra as a “Delphi product”, but Hydra for .Net and Java does the exact same thing, namely let you mix and match modules from different languages in your programs. So if you are a C# developer looking for ways to incorporate Java, Delphi, Elements or Freepascal components in your application, then keep reading.
But let’s start with what Hydra can do for Delphi developers.
What is Hydra anyways?
Hydra is a component package for Delphi, Freepascal, .Net and Java that takes plugins to a whole new level. Now bear with me for a second, because these plugins is in a completely different league from anything you have used in the past.
In short, Hydra allows you to wrap code and components from other languages, and use them from Delphi or Lazarus. There are thousands of really amazing components for the .Net and Java platforms, and Hydra allows you compile those into modules (or “plugins” if you prefer that); modules that can then be used in your applications like they were native components.
Hydra, here using a C# component in a Delphi application
But it doesn’t stop there; you can also mix VCL and FMX modules in the same application. This is extremely powerful since it offers a clear path to modernizing your codebase gradually rather than doing a time consuming and costly re-write.
So if you want to move your aging VCL codebase to Firemonkey, but the cost of having to re-write all your forms and business logic for FMX would break your budget -that’s where Hydra gives you a second option: namely that you can continue to use your VCL code from FMX and refactor the application in your own tempo and with minimal financial impact.
The best of all worlds
Not long ago RemObjects added support for Lazarus (Freepascal) to the mix, which once again opens a whole new ecosystem that Delphi, C# and Java developers can benefit from. Delphi has a lot of really cool components, but Lazarus have components that are not always available for Delphi. There are some really good developers in the Freepascal community, and you will find hundreds of components and classes (if not thousands) that are open-source; For example, Lazarus has a branch of Synedit that is much more evolved and polished than the fork available for Delphi. And with Hydra you can compile that into a module / plugin and use it in your Delphi applications.
This is also true for Java and C# developers. Some of the components available for native languages might not have similar functionality in the .Net world, and by using Hydra you can tap into the wealth that native languages have to offer.
As a Delphi or Freepascal developer, perhaps you have seen some of the fancy grids C# and Java coders enjoy? Developer Express have some of the coolest components available for any platform, but their focus is more on .Net these days than Delphi. They do maintain the control packages they have, but compared to the amount of development done for C# their Delphi offerings are abysmal. So with Hydra you can tap into the .Net side of things and use the latest components and libraries in your Delphi applications.
Financial savings
One of coolest features of Hydra, is that you can use it across Delphi versions. This has helped me leverage the price-tag of updating to the latest Delphi.
It’s easy to forget that whenever you update Delphi, you also need to update the components you have bought. This was one of the reasons I was reluctant to upgrade my Delphi license until Embarcadero released Delphi 10.2. Because I had thousands of dollars invested in components – and updating all my licenses would cost a small fortune.
So to get around this, I put the components into a Hydra module and compiled that using my older Delphi. And then i simply used those modules from my new Delphi installation. This way I was able to cut cost by thousands of dollars and enjoy the latest Delphi.
Using Firemonkey controls under VCL is easy with Hydra
A couple of years back I also took the time to wrap a ton of older components that work fine but are no longer maintained or sold. I used an older version of Delphi to get these components into a Hydra module – and I can now use those with Delphi 10.3 (!). In my case there was a component-set for working closely with Active Directory that I have used in a customer’s project (and much faster than having to go the route via SQL). The company that made these don’t exist any more, and I have no source-code for the components.
The only way I could have used these without Hydra, would be to compile them into a .dll file and painstakingly export every single method (or use COM+ to cross the 32-bit / 64-bit barrier), which would have taken me a week since we are talking a large body of quality code. With Hydra i was able to wrap the whole thing in less than an hour.
I’m not advocating that people stop updating their components. But I am very thankful for the opportunity to delay having to update my entire component stack just to enjoy a modern version of Delphi.
Hydra gives me that opportunity, which means I can upgrade when my wallet allows it.
Building better applications
There is also another side to Hydra, namely that it allows you to design applications in a modular way. If you have the luxury of starting a brand new project and use Hydra from day one, you can isolate each part of your application as a module. Avoiding the trap of monolithic applications.
Hydra for .Net allows you to use Delphi, Java and FPC modules under C#
This way of working has great impact on how you maintain your software, and consequently how you issue hotfixes and updates. If you have isolated each key part of your application as separate modules, you don’t need to ship a full build every time.
This also safeguards you from having all your eggs in one basket. If you have isolated each form (for example) as separate modules, there is nothing stopping you from rewriting some of these forms in another language – or cross the VCL and FMX barrier. You have to admit that being able to use the latest components from Developer Express is pretty cool. There is not a shadow of a doubt that Developer-Express makes the best damn components around for any platform. There are many grids for Delphi, but they cant hold a candle to the latest and greatest from Developer Express.
Why can’t I just use packages?
If you are thinking “hey, this sounds exactly like packages, why should I buy Hydra when packages does the exact same thing?“. Actually that’s not how packages work for Delphi.
Delphi packages are cool, but they are also severely limited. One of the reasons you have to update your components whenever you buy a newer version of Delphi, is because packages are not backwards compatible.
Delphi packages are great, but severely limited
A Delphi package must be compiled with the same RTL as the host (your program), and version information and RTTI must match. This is because packages use the same RTL and more importantly, the same memory manager.
Hydra modules are not packages. They are clean and lean library files (*.dll files) that includes whatever RTL you compiled them with. In other words, you can safely load a Hydra module compiled with Delphi 7, into a Delphi 10.3 application without having to re-compile.
Once you start to work with Hydra, you gradually build up modules of functionality that you can recycle in the future. In many ways Hydra is a whole new take on components and RAD. This is how Delphi packages and libraries should have been.
Without saying anything bad about Delphi, because Delphi is a system that I love very much; but having to update your entire component stack just to use the latest Delphi, is sadly one of the factors that have led developers to abandon the platform. If you have USD 10.000 in dependencies, having to pay that as well as buying Delphi can be difficult to justify; especially when comparing with other languages and ecosystems.
For me, Hydra has been a tremendous boon for Delphi. It has allowed me to keep current with Delphi and all it’s many new features, without losing the money I have already invested in components packages.
If you are looking for something to bring your product to the next level, then I urge you to spend a few hours with Hydra. The documentation is exceptional, the features and benefits are outstanding — and you will wonder how you ever managed to work without them.
External resources
Disclaimer: I am not a salesman by any stretch of the imagination. I realize that promoting a product made by the company you work for might come across as a sales pitch; but that’s just it: I started to work for RemObjects for a reason. And that reason is that I have used their products since they came on the market. I have worked with these components long before I started working at RemObjects.
There is a ton of things you can tweak and change in the service-manifest file. For example, do you want Linux to restart your service if it crashes? How many times should Linux attempt to bring the service back up? Should it only bring it back up if the exit-code is zero?
Show full content
Linux is one of those systems that just appeals to me out of the box. I work with Windows on a daily basis, but at this point there is really nothing in the way of me jumping ship all together. I mean, whenever i need something that is Windows specific, I can just fire up a virtual-machine and get the job done there.
The only thing that is stopping me from going “all in” with Linux (and believe me I have tried) is that finding proper documentation for Linux written with Windows converts in mind, is actually a challenge in itself. Most tutorials are either meant for non-developers, like how to install a program via Synaptic and so on; which is brilliant if you have no experience with Linux whatsoever. But finding articles that aims to help a Windows developer get up to speed on Linux, that’s the tricky bit.
Top-Left bash window shows the output of my Elements compiled micro-service
One of the features I wanted to learn about, was how to run a program as a service on Linux. Under Windows this is quite easy. You have the service manager that gives you a good overview of registered services. And programatically a service is ultimately just a normal WinAPI program that supports the service-api messages. Writing services in either Object-Pascal or C# is pretty straight-forward. I also do a lot of service work via Quartex Pascal (my own toolchain) that compiles to JavaScript. Node.js is actually a very capable service host once you understand the infrastructure.
Writing Daemons with Oxygene and Elements
Since the Elements compiler generates code for ARM Linux, learning how to get a service registered and started on boot is something that I think many developers will be interested in. It was one of the first questions I had when I started looking at Linux, and it took a while to find a clean cut answer.
In this little article I will show you how I went about this, but please keep in mind that Linux never has “one way” of doing something. Part of the strength that Linux delivers, is that you can configure and customize the system completely, from Kernel to desktop. You literally have different service sub-systems to pick from, as well as different windowing-managers, desktop systems (e.g Wayland or X) and even keyring implementations. This is what makes Linux so confusing when coming from a mono culture like Microsoft Windows.
As for hardware, i’m using an ODroid N2, which is a very powerful ARM based SBC (single board computer). You can use more or less any ARM device with Elements, providing the Linux distribution is based on Debian. So a Raspberry PI v4 with Ubuntu or Lubuntu will work fine. I’m using the ODroid N2 “full disk image” with Ubuntu Mate. So nothing out of the ordinary.
To make something clear off the bat: a Linux service (called a daemon, the ancient greek word for “helper” and “informer”) is just an ordinary shell application. You don’t have to do anything in particular in terms of code. Once your service is registered, you can start and stop it with the systemctl shell command like any other Linux service.
Note: There is also fork() mechanisms (cloning processes), but that’s out of scope for this little post.
Service manifest
Before we can get your binary registered as a service, we need to write a service manifest file. This is just a normal text-file in INI format that defines how you want your service to run. Here is an example of such a file:
For debian based distributions (Ubuntu branches) the most common service-host (or process manager) is called systemd. I am not even going to pretend to know the differences between systemd and the older Init. There are fierce debates in the Linux community around these two alternatives. But unless you are a Linux C developer that likes to roll your own Kernel in the weekends, it’s not really relevant for our goals in this post. Our task here is to write useful services and make them run side-by-side with other services.
With the service-manifest file done, we need to copy the service manifest in place where systemd can find it. So start by saving the manifest file as “elements.service” here:
/etc/systemd/system/elements.service
As you probably guessed from the ExecPath property, your service executable goes in:
/usr/bin/ElementsService.exe
If all went well you can now start your service from the command-line:
systemctl start elements
And you can stop the service with:
systemctl stop elements
Resident services
Starting and stopping a service is all good and well, but that doesn’t mean it will automatically start when you reboot your Linux box. In order to make the service resident (persisted, so Linux remembers to fire it up on boot), you have to enable the service:
systemctl enable elements
If you want to stop the service from starting on boot, just disable it:
systemctl disable elements
Now there is a ton of things you can tweak and change in the service-manifest file. For example, do you want Linux to restart your service if it crashes? How many times should Linux attempt to bring the service back up? Should it only bring it back up if the exit-code is zero?
If you want Linux to always restart a service if it stops (regardless of reason), you set the following flag in the service-manifest:
Restart=always
If you want Linux to only restart if the service fails, meaning that the exit-code of the application is <> 0, then you use this value instead:
Restart=on-failure
You can also set the service to only start after some other service, for example if your service has networking as a criteria (which is what we set in the service-manifest above), or a database engine.
There is a ton of different settings you can apply to the service-manifest, but listing them all here would be a small book. Better to just check the documentation and experiment a bit. So check the link and pick the ones that makes sense to your particular service.
Reflections
You should be very careful with how you define restart options. If something goes wrong and your service crash on start, Linux will keep restarting it en-mass. Automatic restart creates a loop, and it can be wise to make sure it doesn’t get stuck. I would set restart to “on-error” exclusively, so that your service has a chance to exit gracefully.
Happy coding! And a special thanks to Benjamin Morel for his helpful posts.
I mean, it's such obvious low-hanging fruit for a show their size to pick. You have this massive show that takes on a single, albeit ranting (and probably a bit of a lunatic) coder's satire blog. They kinda just underlined my point :D
Show full content
A popular website for .Net developers is called dot-net-rocks. This is an interesting site that has been going for a while now; well worth the visit if you do work with the .Net framework via RemObjects Elements, VS or Mono.
Now it turns out that the guys over at dot–net-rocks just did an episode on their podcast where they open by labeling me as a “raving lunatic” (I clearly have my moments); which I find absolutely hilarious, but not for the same reasons as them.
Long story short: They are doing a podcast on how to migrate legacy Delphi applications to C#, and in that context they somehow tracked down an article I posted way back in 2016, which was meant as a satire piece. Now don’t get me wrong, there are serious points in the article, like how the .Net framework was modeled on the Delphi VCL, and how the concepts around CLR and JIT were researched at Borland; but the tone of the whole thing, the “larger than life” claims etc. was meant to demonstrate just how some .Net developers behave when faced with alternative eco-systems. Having managed some 16+ usergroups for Delphi, C#, JavaScript (a total of six languages) on Facebook for close to 15 years, as well as working for Embarcadero that makes Delphi -I speak from experience.
It might be news to these guys that large companies around Europe is still using Delphi, modern Delphi, and that Object Pascal as a language scores well on the Tiobi index of popular programming languages. And no amount of echo-chamber mentality is going to change that fact. Heck, as late as 2018 and The Walt Disney Company wanted to replace C# with Delphi, because it turns out that bytecodes and embedded tech is not the best combination (cpu spikes when the GC kicks in, no real-time interrupt handling possible, GPIO delays, the list goes on).
I mean, the post i made back in 2016 is such obvious, low-hanging fruit for a show their size to pound on. You have this massive show that takes on a single, albeit ranting (and probably a bit of a lunatic if I don’t get my coffee) coder’s post. Underlying in the process how little they know about the object pascal community at large. They just demonstrated my point in bold, italic and underline
Look before you shoot
DotNetRocks is either oblivious that Delphi still have millions of users around the world, or that Pascal is in fact available for .Net (which is a bit worrying since .Net is supposed to be their game). The alternative is that the facts I listed hit a little too close to home. I’ll leave it up to the reader to decide. Microsoft has lost at least 10 Universities around Europe to Delphi in 2018 that I know of, two of them Norwegian where I was personally involved in the license sales. While only speculation, I do find the timing for their podcast and focus on me in particular to be, “curious”.
And for the record, the most obvious solution when faced with “that legacy Delphi project”, is to just go and buy a modern version of Delphi. DotNetRocks delivered a perfect example of that very arrogance my 2016 post was designed to convey; namely that “brogrammers” often act like Delphi 7 was the last Delphi. They also resorted to lies to sell their points: I never said that Anders was dogged for creating Delphi. Quite the opposite. I simply underlined that by ridiculing Delphi in one hand, and praising it’s author with the other – you are indirectly (and paradoxically) invalidating half his career. Anders is an awesome developer, but why exclude how he evolved his skills? Ofcourse Ander’s products will have his architectural signature on them.
Not once did they mention Embarcadero or the fact that Delphi has been aggressively developed since Borland kicked the bucket. Probably hoping that undermining the messenger will somehow invalidate the message.
Porting Delphi to C# manually? Ok.. why not install Elements and just compile it into an assembly? You don’t even have to leave Visual Studio
Also, such an odd podcast for professional developers to run with. I mean, who the hell converts a Delphi project to C# manually? It’s like listening to a graphics artist that dont know that Photoshop and Illustrator are the de-facto tools to use. How is that even possible? A website dedicated to .Net, yet with no insight into the languages that run on the CLR? Wow.
If you want to port something from Delphi to .Net, you don’t sit down and manually convert stuff. You use proper tools like Elements from RemObjects; This gives you Object-Pascal for .Net (so a lot of code will compile just fine with only minor changes). Elements also ships with source-conversion tools, so once you have it running under Oxygene Pascal (the dialect is called Oxygene) you either just use the assemblies — or convert the Pascal code to C# through a tool called an Oxidizer.
The most obvious solution is to just upgrade to a Delphi version from this century
The other solution is to use Hydra, also a RemObjects product. They can then compile the Delphi code into a library (including visual parts like forms and frames), and simply use that as any other assembly from within C#. This allows you to gradually phase out older parts without breaking the product. You can also use C# assemblies from Delphi with Hydra.
So by all means, call me what you like. You have only proved my point so far. You clearly have zero insight into the predominant Object-Pascal eco-systems, you clearly don’t know the tools developers use to interop between arcetypical and contextual languages — and instead of fact checking some of the points I made, dry humor notwithstanding, you just reacted like brogrammers do.
Well, It’s been weeks since I laughed this hard You really need to check before you pick someone to verbally abuse on the first date, because you might just bite yourself in the arse here he he
Amibian.jsCSSdwscriptJavaScriptLanguage researchObject PascalQTXQuartex PascalCloudforgecompilerJavascriptQuartex Media DesktopRTLVirtualization
The CloudForge IDE for developers is set for 2020. With that in place you can write applications for iOS, Android, Windows, OS X and Linux directly from Quartex Media Desktop. Nothing to install, you just need a modern browser and a QTX account.
Show full content
It’s been a few weeks since my last update on the project. The reason I dont blog that often about Quartex Media Desktop (QTXMD), is because the official user-group has grown to 2000+ members. So it’s easier for me to post developer updates directly to the audience rather than writing articles about it.
Quartex Media Desktop ~ a complete environment that runs on every device
If you haven’t bothered digging into the project, let me try to sum it up for you quickly.
Quick recap on Quartex Media Desktop
To understand what makes this project special, first consider the relationship between Microsoft Windows and a desktop program. The operating system, be it Windows, Linux or OSX – provides an infrastructure that makes complex applications possible. The operating-system offers functions and services that programs can rely on.
The most obvious being:
A filesystem and the ability to save and load data
A windowing toolkit so programs can be displayed and have a UI
A message system so programs can communicate with the OS
A service stack that takes care of background tasks
Authorization and identity management (security)
I have just described what the Quartex Media Desktop is all about. The goal is simple:
to provide for JavaScript what Windows and OS X provides for ordinary programs.
Just stop and think about this. Every “web application” you have ever seen, have all lacked these fundamental features. Sure you have libraries that gives you a windowing environment for Javascript, like Embarcadero Sencha; but im talking about something a bit more elaborate. Creating windows and buttons is easy, but what about ownership? A runtime environment has to keep track of the resources a program allocates, and make sure that security applies at every step.
Target audience and purpose
Take a second and think about how many services you use that have a web interface. In your house you probably have a router, and all routers can be administered via the browser. Sadly, most routers operate with a crude design and that leaves much to be desired.
Router interfaces for web are typically very limited and plain looking. Imagine what NetGear could do with Quartex Media Desktop instead
If you like to watch movies you probably have a Plex or Kodi system running somewhere in your house; perhaps you access that directly via your TV – or via a modern media system like Playstation 4 or XBox one. Both Plex and Kodi have web-based interfaces.
Netflix is now omnipresent and have practically become an institution in it’s own right. Netflix is often installed as an app – but the app is just a thin wrapper around a web-interface. That way they dont have to code apps for every possible device and OS out there.
If you commute via train in Scandinavia, chances are you buy tickets on a kiosk booth. Most of these booths run embedded software and the interface is again web based. That way they can update the whole interface without manually installing new software on each device.
Plex is a much loved system. It is based on a mix of web and native technologies
These are just examples of web based interfaces you might know and use; devices that leverage web technology. As a developer, wouldn’t it be cool if there was a system that could be forked, adapted and provide advanced functionality out of the box?
Just imagine a cheap Jensen router with a Quartex Media Desktop interface! It could provide a proper UI interface with applications that run in a windowing environment. They could disable ordinary desktop functionality and run their single application in kiosk mode. Taking full advantage of the underlying functionality without loss of security.
And the same is true for you. If you have a great idea for a web based application, you can fork the system, adjust it to suit your needs – and deploy a cutting edge cloud system in days rather than months!
New compiler?
Up until recently I used Smart Mobile Studio. But since I have left that company, the matter became somewhat pressing. I mean, QTXMD is an open-source system and cant really rely on third-party intellectual property. Eventually I fired up Delphi, forked the latest DWScript, and used that to roll a new command-line compiler.
Web technology has reached a level of performance that rivals native applications. You can pretty much retire Photoshop in favour of web based applications these days
But with a new compiler I also need a new RTL. Thankfully I have been coding away on the new RTL for over a year, but there is still a lot of work to do. I essentially have to implement the same functionality from scratch.
There will be more info on the new compiler / codegen when its production ready.
Progress
If I was to list all the work I have done since my last post, this article would be a small book. But to sum up the good stuff:
Authentication has been moved into it’s own service
The core (the main server) now delegates login messages to said service
We no longer rely on the Smart Pascal filesystem drivers, but use the raw node.js functions instead (faster)
The desktop now use the Smart Theme engine. This means that we can style the desktop to whatever we like. The OS4 theme that was hardcoded will be moved into its own proper theme-file. This means the user can select between OS4, iOS, Android and Ubuntu styling. Creating your own theme-files is also possible. The Smart theme-engine will be replaced by a more elaborate system in QTX later
Ragnarok (the message api) messages now supports routing. If a routing structure is provided, the core will relay the message to the process in question (providing security allows said routing for the user)
The desktop now checks for .info files when listing a directory. If a file is accompanied by an .info file, the icon is extracted and shown for that file
Most of the service layer now relies on the QTX RTL files. We still have some dependencies on the Smart Pascal RTL, but we are making good progress on QTX. Eventually the whole system will have no dependencies outside QTX – and can thus be compiled without any financial obligations.
QTX has it’s own node.js classes, including server and client base-classes
Http(s) client and server classes are added to QTX
Websocket and WebSocket-Secure are added to QTX
TQTXHybridServer unifies http and websocket. Meaning that this server type can handle both orinary http requests – but also websocket connections on the same network socket. This is highly efficient for websocket based services
UDP classes for node.js are implemented, both client and server
Zero-Config classes are now added. This is used by the core for service discovery. Meaning that the child services hosted on another machine will automatically locate the core without knowing the IP. This is very important for machine clustering (optional, you can define a clear IP in the core preferences file)
Fixed a bug where the scrollbars would corrupt widget states
Added API functions for setting the scrollbars from hosted applications (so applications can tell the desktop that it needs scrollbar, and set the values)
.. and much, much more
I will keep you all posted about the progress — the core (the fundamental system) is set for release in december – so time is of the essence! Im allocating more or less all my free time to this, and it will be ready to rock around xmas.
When the core is out, I can focus solely on the applications. Everything from Notepad to Calculator needs to be there, and more importantly — the developer tools. The CloudForge IDE for developers is set for 2020. With that in place you can write applications for iOS, Android, Windows, OS X and Linux directly from Quartex Media Desktop. Nothing to install, you just need a modern browser and a QTX account.
The system is brilliant for small teams and companies. They can setup their own instance, communicate directly via the server (text chat and video chat is scheduled) and work on their products in concert.
Microsoft is still offering a free upgrade plan for Windows 7 users. In other words there is no financial loss in updating your development machines, be they physical or virtual.
Show full content
When it comes to Windows editions, Windows 7 is probably the most successful operating-system Microsoft has ever released. When it hit stores back in October of 2009, it replaced Windows Vista (Longhorn) which, truth be told, caused more problems than it solved. The issues surrounding Vista were catastrophic for many reasons, but they were especially severe for developers. I remember buying a brand new laptop with Vista pre-installed, but in less than a week I rolled back to Windows XP.
In retrospect, Vista was perhaps not as bad as it’s reputation would have it. I honestly feel it’s a very misunderstood edition of Windows, one that brought features common to the NT family into the mainstream. But back then people were still unfamiliar with what exactly that meant; things like “roaming profiles” was alien to users and developers with no background in networking. In my case Vista came at a juncture where I had two product releases on my hand. Time was of the essence, and spending days refactoring my code for the changes could not have come at a worse moment.
Be this as it may, the rejection of Vista forced Microsoft to replace it with something better. Vista was supposed to have a 10 year life-cycle, but Microsoft put Vista out of its misery in 3 years.
Windows 7 retirement plan
Windows 7 has been a wonderful system to work with. I can honestly say that with exception of Windows 10, it’s been the best operating system I have ever used. And i include OS X and Ubuntu in that equation. But as great as it was, Windows 7 is now 10 years old; an eternity in the software business. The needs of consumers and developers are radically different today, and with Windows 10 available as a free upgrade – it’s time to let the system go.
Microsoft actually ended mainstream support back in January of 2015 (!), but due to its popularity and massive adoption, they decided to extend support a few more years. This means that Windows 7, although practically retro in computing terms, still receives driver updates and security patches. But that is about to change sooner than you think.
Come next January (read: over xmas) and Windows 7 has an appointment with the gallows; something that will affect laptops, servers and desktop systems alike. This means there will be no more security patches, no more feature updates and no new virus definitions for Windows Defender. In other words January 14 2020 is the day Microsoft take Windows 7 off life-support.
This retirement also affects tablets, so if you have a Windows 7 based Surface, the time has come to jump ship and get Windows 10 installed. The same is true for Windows 7 Enterprise – it’s already obsolete by half a decade.
Some have stated that the embedded version of Windows 7, used primarily in custom-made products like ATMs, POS and kiosk type products, somehow avoids this retirement; but that’s just it – retirement truly means retirement. January 14 2020 really is the day Microsoft puts Windows 7 in the ground; be it laptop, server, desktop or surface.
The king is dead, long live the king
You might be wondering, since Windows 7 is still so popular, why would Microsoft seek to replace it? Well there are many reasons. First of all Windows 7 is based on the old NT kernel, which by today’s standard is a dinosaur compared to competing operating-systems. NT was constructed around a security scheme that has served humanity well, but it’s poorly equipped to deal with modern threats. Windows 7 also has a considerably larger memory footprint compared to Windows 10 – not to mention that Windows 10 has been optimized from scratch for better performance on all supported devices. So it’s never really been a question of why, but rather when and at which cost.
Windows 10 comes in many shapes and sizes
You also have to factor in that Windows 10 introduces a host of new features that is unique to that OS. Things like support for touch interfaces (both display and navigation devices) is one of them, but developers will be more affected by the new application model (UWP) and UI framework. Truth be told, UWP was first introduced in Windows 8 as a part of Microsoft’s plan to streamline all versions of their OS (tablet, mobile, desktop and server). The promise of UWP is that, if you follow the guidelines and stick to the APIs – the same application can run on all variations of the same OS; regardless of CPU even (more about that below).
Since this was introduced Microsoft sadly dropped out of the smartphone OS business though. Their Windows for mobile never gained the recognition it deserved, and they retired it in favor of Android. Personally i loved their phones; they somehow managed to take the best features from both Apple iOS and Android, and combine them intuitively and elegantly. Not to mention that they cost 40% of what an iPhone of Samsung Galaxy sold for.
Windows 10 is also the first OS from Microsoft that treats XBox as a first-class citizen, so developing titles for XBox has become easier. DirectX now aims at delivering console level experience for laptop and desktop computers; it’s pretty much been refactored from scratch, with aggressive and radical optimization (read: hand written assembly) to get every last drop of performance out of the hardware.
Unlike previous editions of DirectX, Microsoft has toned down the amount of insulation between your code and the actual hardware. DirectX was always padded left and right with interfaces and abstractions, making raw access to GPU resources impossible (or at least, impractical). Thankfully Microsoft has realized that they took this too far, and trimmed the insulation layers accordingly; meaning that developers can now access resources en-par with AMD Mantle, Apple Metal and Vulcan (Factoid: Vulcan is a replacement for OpenGL. OpenGL originated with Silicon Graphics machines, a graphics workstation that was hugely popular back in the 90s and early 2k’s).
WinRT, ARM and the beyond
While developers who focus on business applications could care less about DirectX and multimedia, the underlying changes to the Windows 10 core are of such a magnitude that all avenues of development will be affected. Some of the UI changes are profoundly linked to the work that makes Windows 10 unique – and Microsoft has made it perfectly clear that all future endeavors is built on the Windows 10 baseline.
Windows is moving to ARM, and Windows 10 technology is the foundation
Besides purely technical changes, access to the Microsoft Store is one of the features that have a more immediate, financial effect on software development. Marco Cantu actually blogged about this back in 2016, regarding how you can use WDB (Windows Desktop Bridge, a.k.a “project Centennial”) to publish Firemonkey applications to Microsoft store. I mean, any modern developer who makes a living from selling software, having their products available through official channels is pretty essential. And that excludes Windows 7 by default.
And last but not least, there is WinRT, short for Windows Runtime, a sand boxed version of windows that allows applications to be deployed to both x86 and ARM. WinRT involves x86 emulation on ARM SoCs (system on a chip), meaning that you will be able to run applications compiled for x86 on Microsoft’s upcoming Windows for ARM release. But performance wise emulation will obviously not deliver the same level of performance as native ARM code. The emulation layer is meant as an intermediate solution, allowing developers time to evolve compilers that can target ARM directly.
I probably don’t have to outline the business opportunities Windows on ARM represent.
Market adoption
If the features and promise of Windows 10 is not enough to convince you to update immediately, consider the following: There are more than 1 billion Windows users in the world. Windows 7 presently holds 37% of the global market (with Windows 10 at 43%), which means that hundreds of millions of computers will be affected by the now immanent retirement plan.
ARM is still a hardware platform companies can afford to postpone, but with both Apple and Microsoft being open about their move to ARM in the near future, the risk for developers being left behind is very real. And having to deal with the cost of refactoring your entire portfolio over something as trivial as an update, well – I’m sure you see my point.
There really is zero strategic advantage in sticking with the lowest common denominator, which in this case is the stock WinAPI that has defined Windows since the nineties. Especially not when upgrading to Windows 10 is free of charge.
Reflections
From a personal point of view, I cannot imagine being a developer in 2019 and relying on an operating-system that is retired. I must admit that I do own virtual machines where Windows 7 is used, but those are not instances where I do software development; I use them primarily for stress testing software running in other VMWare instances, which conceptually is not a problem.
Microsoft is still offering a free upgrade plan for Windows 7 users. In other words there is no financial loss in updating your development machines, be they physical or virtual.
I look forward to Microsoft’s next phase, where virtual reality and augmented reality technology is implemented more closely for all supported hardware platforms. As for changes that affect desktop business applications, have a look at the following links:
Most compilers can only handle a single syntax for any project, but the Elements compiler from RemObjects deals with can 5 different languages -even within the same project. That's pretty awesome and opens up for some considerable savings.
Show full content
Most compilers can only handle a single syntax for any project, but the Elements compiler from RemObjects deals with 5 (five!) different languages -even within the same project. That’s pretty awesome and opens up for some considerable savings.
I mean, it’s not always easy to find developers for a single language, but when you can approach your codebase from C#, Java, Go, Swift and Oxygene (object pascal) at the same time (inside the same project even!), you suddenly have some options. Especially since you can pick exotic targets like WebAssembly. Or what about compiling Java to .net bytecodes? Or using the VCL from C#? It’s pretty awesome stuff!
Check out Marc Hoffmans article on the Elements compiler toolchain and how you can mix and match between languages, picking the best from each — while still compiling to a single binary of llvm optimized code:
ODroid is very popular at RemObjects, and when we added 64-bit ARM Linux support a couple of weeks back, it was the ODroid N2 board we used for testing. It has been a smooth ride all the way.
Show full content
Since the release of Raspberry PI back in 2012 the IOT and Embedded market has exploded. The price of the PI SBC (single board computer) enabled ordinary people without any engineering background to create their own software and hardware projects; and with that the IOT revolution was born.
Almost immediately after the PI became a success, other vendors wanted a piece of the pie (pun intended), and an avalanche of alternative mini computers started surfacing in vast quantities. Yet very few of these so-called “pi killers” actually stood a chance. The power of the Raspberry PI is not just price, it’s actually the ecosystem around the product. All those shops selling electronic parts that you can use in your IOT projects for example.
The ODroid N2, one of the fastest SBCs in it’s class
The ODroid family of single-board computers stands out as unique in this respect. Where other boards have come and gone, the ODroid family of boards have remained stable, popular and excellent alternatives to the Raspberry PI. Hardkernel, the maker of Odroid boards and its many peripherals, are not looking for a “quick buck” like others have. Instead they have slowly and steadily perfected their hardware, software, and seeded a great community.
ODroid is very popular at RemObjects, and when we added 64-bit ARM Linux support a couple of weeks back, it was the ODroid N2 board we used for testing. It has been a smooth ride all the way.
ODroid
As I am typing this, a collection of ODroid XU4s is humming away inside a small, desktop cluster I have built. This cluster is made up of 5 x ODroid XU4 boards, with an additional ODroid N2 acting as the head (the board that controls the rest via the network).
My ODroid Cluster in all its glory
Prior to picking ODroid for my own projects, I took the time to test the most popular boards on the market. I think I went through eight or ten models, but none of the other were even close to the quality of ODroid. It’s very easy to confuse aggressive marketing with quality. You can have the coolest hardware in the world, but if it lacks proper drivers and a solid Linux distribution, it’s for all means and purposes a waste of time.
Since IOT is something that i find exciting on a personal level, being able to target 64-bit ARM Linux has topped my wish-list for quite some time. So when our compiler wizard Carlo Kok wanted to implement support for 64-bit ARM-Linux, I was thrilled!
We used the ODroid N2 throughout the testing phase, and the whole process was very smooth. It took Carlo roughly 3 days to add support for 64-bit ARM Linux and it hit our main channel within a week.
I must stress that while ODroid N2 is one of our verified SBCs, the code is not explicitly about ODroid. You can target any 64-bit ARM SBC providing you use a Debian based Linux (Ubuntu, Mint etc). I tested the same code on the NanoPI board and it ran on the first try.
Why is this important?
The whole point of the Elements compiler toolchain, is not just to provide alternative compilers; it’s also to ensure that the languages we support become first class citizens, side by side with other archetypical languages. For example, if all you know is C# or Java, writing kernel drivers has been our of limits. If you are operating with traditional Java or .Net, you have to use a native bridge (like the service host under Windows). Your only other option was to code that particular piece in traditional C.
With Elements you can pick whatever language you know and target everything
With Elements that is no longer the case, because our compilers generates llvm optimized machine-code; code that in terms of speed, access and power stand side by side with C/C++. You can even import C/C++ header files and work directly with the existing infrastructure. There is no middleware, no service host, no bytecodes and no compromise.
Obviously you can compile to bytecodes too if you like (or WebAssembly), but there are caveats to watch out for when using bytecodes on SBCs. The garbage collector can make or break your product, because when it kicks in -it causes CPU spikes. This is where Elements step-up and delivers true native compilation. For all supported targets.
More boards to come
This is just my personal blog, so for the full overview of boards I am testing there will be a proper article on our official RemObjects blog-space. Naturally I can’t test every single board on the market, but I have around 10 different models which covers the common boards used by IOT and embedded projects.
But for now at least, you can check off the ODroid N2 (64-bit) and NanoPI-Fire 2 (32-bit)
The challenge for Delphi is that writing large composite systems, where you have more than a single service doing work in concert, is not even factored into the RTL and project types. Delphi provides a bare-bone project type for system services, and that's it. Depending on how you look at it, it's either a blessing or a curse.
Show full content
RemObjects Remoting SDK is one of those component packages that have become more than the sum of it’s part. Just like project Jedi has become standard equipment almost, Remoting SDK is a system that all Delphi and Freepascal developers should have in their toolbox.
In this article I’m going to present the SDK in broad strokes; from a viewpoint of someone who haven’t used the SDK before. There are still a large number of Delphi developers that don’t know it even exists – hopefully this post will shed some light on why the system is worth every penny and what it can do for you.
I should also add, that this is a personal blog. This is not an official RemObjects presentation, but a piece written by me based on my subjective experience and notions. We have a lot of running dialog at Delphi Developer on Facebook, so if I read overly harsh on a subject, that is my personal view as a Delphi Developer.
Stop re-inventing the wheel
Delphi has always been a great tool for writing system services. It has accumulated a vast ecosystem of non-visual components over the years, both commercial and non-commercial, and this allows developers to quickly aggregate and expose complex behavior — everything from graphics processing to databases, file processing to networking.
The challenge for Delphi is that writing large composite systems, where you have more than a single service doing work in concert, is not factored into the RTL or project type. Delphi provides a bare-bone project type for system services, and that’s it. Depending on how you look at it, it’s either a blessing or a curse. You essentially start on C level.
So fundamental things like IPC (inter process communication) is something you have to deal with yourself. If you want multi-tenancy that is likewise not supported out of the box. And all of this is before we venture into protocol standards, message formats and async vs synchronous execution.
The idea behind Remoting SDK is to get away from this style of low-level hacking. Without sounding negative, it provides the missing pieces that Delphi lacks, including the stuff that C# developers enjoy under .net (and then some). So if you are a Delphi developer who look over at C# with smudge of envy, then you are going to love Remoting SDK.
Say goodbye to boilerplate mistakes
Writing distributed servers and services is boring work. For each function you expose, you have to define the parameters and data-types in a portable way, then you have to implement the code that represents the exposed function and finally the interface itself that can be consumed by clients. The latter must be defined in a way that works with other languages too, not just Delphi. So while server tech in it’s essential form is quite simple, it’s the infrastructure that sets the stage of how quickly you can apply improvements and adapt to change.
For example, let’s say you have implemented a wonderful new service. It exposes 60 awesome functions that your customers can consume in their own work. The amount of boilerplate code for 60 distributed functions, especially if you operate with composite data types, is horrendous. It is a nightmare to manage and opens up for sloppy, unnecessary mistakes.
After you install Remoting SDK, the service designer becomes a part of the IDE
This is where Remoting SDK truly shines. When you install the software, it integrates it’s editors and wizards closely with the Delphi IDE. It adds a ton of new project types, components and whatnot – but the most important feature is without a doubt the service designer.
Start the service-designer in any server or service project and you can edit the methods, data types and interfaces your system expose to the world
As the name implies, the service designer allows you to visually define your services. Adding a new function is a simple click, the same goes for datatypes and structures (record types). These datatypes are exposed too and can be consumed from any modern language. So a service you make in Delphi can be used from C#, C/C++, Java, Oxygene, Swift (and visa-versa).
Auto generated code
A service designer is all good and well I hear you say, but what about that boilerplate code? Well Remoting SDK takes care of that too (kinda the point). Whenever you edit your services, the designer will auto-generate a new interface unit for you. This contains the classes and definitions that describe your service. It will also generate an implementation unit, with empty functions; you just need to fill in the blanks.
The designer is also smart enough not to remove code. So if you go in and change something, it won’t just delete the older implementation procedure. Only the params and names will be changed if you have already written some code.
Having changed a service, hitting F9 re-generates the interface code automatically. Your only job is to fill in the code for each method in the implementation units. The SDK takes care of everything else for you
The service information, including the type information, is stored in a special file format called “rodl”. This format is very close to Microsoft WSDL format, but it holds more information. It’s important to underline that you can import the service directly from your servers (optional naturally) as WSDL. So if you want to consume a Remoting SDK service using Delphi’s ordinary RIO components, that is not a problem. Visual Studio likewise imports and consumes services – so Remoting SDK behaves identical regardless of platform or language used.
Remoting SDK is not just for Delphi, just to be clear on that. If you are presently using both Delphi and C# (which is a common situation), you can buy a license for both C# and Delphi and use whatever language you feel is best for a particular task or service. You can even get Remoting SDK for Javascript and call your service-stack directly from your website if you like. So there are a lot of options for leveraging the technology.
Transport is not content
OK so Remoting SDK makes it easy to define distributed services and servers. But what about communication? Are we boxed into RemObjects way of doing things?
The remoting framework comes with a ton of components, divided into 3 primary groups:
Servers
Channels (clients)
Messages
The reason for this distinction is simple: the ability to transport data, is never the same as the ability to describe data. For example, a message is always connected to a standard. It’s job is ultimately to serialize (represent) and de-serialize data according to a format. The server’s job is to receive a request and send a response. So these concepts are neatly decoupled for maximum agility.
As of writing the SDK offers the following message formats:
Binary
Post
SOAP
JSON
If you are exposing a service that will be consumed from JavaScript, throwing in a TROJSONMessage component is the way to go. If you expect messages to be posted from your website using ordinary web forms, then TROPostMessage is a perfect match. If you want XML then TROSOAPMessage rocks, and if you want fast, binary messages – well then there is TROBinaryMessage.
What you must understand is that you don’t have to pick just one! You can drop all 4 of these message formats and hook them up to your server or channel. The SDK is smart enough to recognize the format and use the correct component for serialization. So creating a distributed service that can be consumed from all major platforms is a matter of dropping components and setting a property.
If you double-click on a server or channel, you can link message components with a simple click. No messy code snippets in sight.
Multi-tenancy out of the box
With the release of Rad-Server as a part of Delphi, people have started to ask what exactly multi-tenancy is and why it matters. I have to be honest and say that yes, it does matter if you are creating a service stack where you want to isolate the logic for each customer in compartments – but the idea that this is somehow new or unique is not the case. Remoting SDK have given users multi-tenancy support for 15+ years, which is also why I haven’t been too enthusiastic with Rad-Server.
Now don’t get me wrong, I don’t have an axe to grind with Rad-Server. The only reason I mention it is because people have asked how i feel about it. The tech itself is absolutely welcome, but it’s the licensing and throwing Interbase in there that rubs me the wrong way. If it could run on SQLite3 and was free with Enterprise I would have felt different about it.
There are various models for multi-tenancy, but they revolve around the same principles
To get back on topic: multi-tenancy means that you can dynamically load services and expose them on demand. You can look at it as a form of plugin functionality. The idea in Rad-Server is that you can isolate a customer’s service in a separate package – and then load the package into your server whenever you need it.
Some of the components that ship with the system
The reason I dislike Rad-Server in this respect, is because they force you to compile with packages. So if you want to write a Rad-Server system, you have to compile your entire project as package-based, and ship a ton of .dpk files with your system. Packages is not wrong or bad per-se, but they open your system up on a fundamental level. There is nothing stopping a customer from rolling his own spoof package and potentially bypass your security.
There is also an issue with un-loading a package, where right now the package remains in memory. This means that hot-swapping packages without killing the server wont work.
Rad-Server is also hardcoded to use Interbase, which suddenly bring in licensing issues that rubs people the wrong way. Considering the price of Delphi in 2019, Rad-Server stands out as a bit of an oddity. And hardcoding a database into it, with the licensing issues that brings -just rendered the whole system mute for me. Why should I pay more to get less? Especially when I have been using multi-tenancy with RemObjects for some 15 years?
With Remoting SDK you have something called DLL servers, which does the exact same thing – but using ordinary DLL files (not packages!). You don’t have to compile your system with packages, and it takes just one line of code to make your main dispatcher aware of the loaded service.
This actually works so well that I use Remoting SDK as my primary “plugin” system. Even when I write ordinary desktop applications that has nothing to do with servers or services – I always try to compartmentalize features that could be replaced in the future.
For example, I’m a huge fan of ElevateDB, which is a native Delphi database engine that compiles directly into your executable. By isolating that inside a DLL as a service, my application is now engine agnostic – and I get a break from buying a truck load of components every time Delphi is updated.
Saving money
The thing about DLL services, is that you can save a lot of money. I’m actually using an ElevateDB license that was for Delphi 2007. I compiled the engine using D2007 into a DLL service — and then I consume that DLL from my more modern Delphi editions. I have no problem supporting or paying for components, that is right and fair, but having to buy new licenses for every single component each time Delphi is updated? This is unheard of in other languages, and I would rather ditch the platform all together than forking out $10k ever time I update.
A DLL server can be used for many things if you are creative about it
While we are on the subject – Hydra is another great money saver. It allows you to use .net and Java libraries (both visual and non-visual) with Delphi. With Hydra you can design something in .net, compile it into a DLL file, and then use that from Delphi.
But — you can also compile things from Delphi, and use it in newer versions of Delphi. Im not forking out for a Developer Express update just to use what I have already paid for in the latest Delphi. I have one license, I compile the forms and components into a Hydra Module — and then use it from newer Delphi editions.
Hydra, which is a separate product, allows you to stuff visual components and forms inside a vanilla DLL. It allows cross language use, so you can finally use Java and .net components inside your Delphi application
Bonjour support
Another feature I love is the zero configuration support. This is one of those things that you often forget, but that suddenly becomes important once you deploy a service stack on cluster level.
Remoting SDK comes with support for Apple Bonjour, so if you want to use that functionality you have to install the Bonjour library from Apple. Once installed on your host machines, your RemObjects services can find each other.
ZeroConfig is not that hard to code manually. You can roll your own using UDP or vanilla messages. But getting service discovery right can be fiddly. One thing is broadcasting an UDP message saying “here I am”, it’s something else entirely to allow service discovery on cluster level.
If Bonjour is not your cup of tea, the SDK provides a second option, which is RemObjects own zero-config hub. You can dig into the documentation to find out more about this.
What about that IPC stuff you mentioned?
I mentioned IPC (inter process communication) at the beginning here, which is a must have if you are making a service stack where each member is expected to talk to the others. In a large server-system the services might not exist on the same, physical hardware either, so you want to take height for that.
With the SDK this is just another service. It takes 10 minutes to create a DLL server with the functionality to send and receive messages – and then you just load and plug that into all your services. Done. Finished.
Interestingly, Remoting SDK supports named-pipes. So if you are running on a Windows network it’s even easier. Personally I prefer to use a vanilla TCP/IP based server and channel, that way I can make use of my Linux blades too.
Building on the system
There is nothing stopping you from expanding the system that RemObjects have established. You are not forced to only use their server types, message types and class framework. You can mix and match as you see fit – and also inherit out your own variation if you need something special.
For example, WebSocket is an emerging standard that has become wildly popular. Remoting SDK does not support that out of the box, the reason is that the standard is practically identical to the RemObjects super-server, and partly because there must be room for third party vendors.
Andre Mussche took the time to implement a WebSocket server for Remoting SDK a few years back. Demonstrating in the process just how easy it is to build on the existing infrastructure. If you are already using Remoting SDK or want WebSocket support, head over to his github repository and grab the code there: https://github.com/andremussche/DelphiWebsockets
I could probably write a whole book covering this framework. For the past 15 years, RemObjects Remoting SDK is the first product I install after Delphi. It has become standard for me and remains an integral part of my toolkit. Other packages have come and gone, but this one remains.
Hopefully this post has tickled your interest in the product. No matter if you are maintaining a legacy service stack, or thinking about re implementing your existing system in something future-proof, this framework will make your life much, much easier. And it wont break the bank either.
I must admit it's really tricky to hammer down a verdict. On one hand they are really fun, you can install NetFlix, browse the web and watch movies if you copy them over to an sd-card (the glasses come with a 16Gb sd-card). You have mouse control, BT and i have no problem seeing myself on a flight to hong-kong enjoying a movie marathon wearing these.
Show full content
The world used to be a big place, but having worked around europe for a few years – and lately in the US, it appears to me much smaller. But the fact of the matter is, that different nationalities have different tastes and interests.
The world is not as big as it used to be
In the US right now there is a strong interest in virtual-reality. The interest was so strong that Sony jumped on the VR bandwagon early, offering a full VR kit for the Playstation 4. This has been available for two years already (or is it three?). Here in Scandinavia though, VR is not that hot. People buy it, but not in the same volume we see in the US. It is expected to pick up this fall when the dark period begins; Norway, Sweden, Denmark and Finland are largely without sunlight most of the year – and during that time people use indoor hobbies more. But right now, VR is not really a thing up here.
In parallel with VR, Microsoft picked up the gauntlet that Google threw away earlier, namely that of augmented reality. You probably remember the Google Glasses craze that hit California a decade ago right? Well Microsoft have continued to research and develop the technology which is now available for pre-order.
The problem? Microsoft Holo-lens II is a $3500 gadget that is presently aimed at business only. With emphasis on industrial design and medical applications. I don’t know about you, but forking up $3500 for what is ultimately just a curiosity is way out of my budget. There are much more important things to spend $3500 on to be frank.
Asia, the mother of implementation
While America and Europe are hotbeds of invention, it is ultimately Asia that implements, refine and eventually perfect technology. Some might disagree with that, there are always exceptions to the rule (3d printers and VR systems are very much American made), but what im talking about are “traits and inclinations” in the market. Patterns of commerce if you like.
What usually happens when something new is made, is that it costs a fortune. To push prices down companies move production to Asia, and there materials etc. are swapped out for cheaper alternatives. Some re-designing takes place — and before you know it, a product that cost $3500 when made in the US or the EU, can be picked up for $799 on Amazon. After some time, production volume has reached it’s zenith and the device that once cost an arm or a leg, can now be bought $299 or $199.
But, there are exceptions! When there is a technology that is wildly popular, like augmented reality and VR, Asia is quick to produce their own take on the technology early – trying to get a piece of the proverbial pie. This is often a good thing, especially for consumers. It can also be a good thing for the US and EU based companies – because mistakes and design-flaws they haven’t noticed yet are taken care of by proxy.
With that in mind, I ventured into the Asian markets to see what I could find.
Banggood and Alibaba
Having searched through an avalanche of cheap VR glasses for mobile phones, I finally found something that could be worth looking into. The advert was extremely thin, citing only augmented reality in english – with everything else in chinese (I presume, I must admit I would not spot the difference between chinese, japanese and korean if my life depended on it. Tibetan I can spot due to my Buddhist training, but that’s about it).
When I ran the string of characters through google, it returned this:
“VISION-800 3D Glasses Video Android 4.4
MTK6582 1G/2G 5MP AC WIFI BT4.0 2060P MIC”
Looking at the glasses they have pretty much everything you expected from an Augmented reality setup. There is a camera up front, lenses, audio jacks on both sides, a few buttons and switches – and the magic words “powered by Android Wearable”. The price was $249 so it wouldn’t break the bank either.
The Vision 800 in all their glory
I should also mention that websites like Banggood and Alibaba have pretty good return policies too. These websites are actually front-ends for hundreds (if not thousands) of smaller, local outlets. The outlets gets a place to sell their goods to the west, and Alibaba and Banggood takes a small cut of each sale.
To manage this and make it viable, they have a rating system in place. So if one of the outlets scams you – you can vote them down. 3 complaints is enough to get the outlet kicked from either site, which I presume is a dire financial loss (considering the volume these websites push on a daily basis). So there is some degree of consumer safety compared to direct order. I would never order anything directly from a tech cornershop in mainland china, because should they rip you off – there is nothing you can do about it.
Augmented? I don’t think so
When the glasses finally arrived i was surprised at how light they were. You might expect them to be top-heavy and tip forward on the ridge of your nose – but since the weight is actually the lenses, not the circuitry, they balance quite well.
But augmented reality? Im sorry, but these glasses are not even in the ballpark.
The device is running a fork of Android – but not the fork adapted for wearables! The glasses also comes with a stock mouse (cordless), and you are in fact greeted by a plain desktop. The cordless mouse does work really well though, but I thankfully had the sense to order a $5 air-mouse (read: remote control for android devices) or I would go insane trying to exit applications properly.
What you can do is download some augmented reality apps from Google Play. These will tap into the camera on the glasses, and you can play a few games. But that’s really it. I noticed that the outlet had changed the title and text for these glasses a few days before they arrived here, so the whole deal is a little bit fishy. Looking at the instruction leaflet, these glasses have been sold as “movie glasses”. I would even go so far as to say they have nothing to do with augmented reality.
Media glasses
Augmented reality aside, there are interesting uses for glasses like this. If the field of view is good enough, they could make for a novel screen “on the road”. I mean, if you plug in a hybrid USB dongle that gives you both keyboard and mouse, there is nothing in the way of using the glasses as a monitor / travel PC. You have the same apps that you enjoy on your phone; a modern browser that gives you access to cloud services etc.
The glasses also have an SD card slot which is super handy – and 2Gb onboard storage. So if you are taking a flight from Europe to Australia and want to tune out noise and watch movies – these glasses might just be the ticket.
The audio works well
I must admit it was fun to install NetFlix on these and kick back. But this is also when i started to have some issues.
The first issue is that there is no focal lense involved. You are literally looking at two tiny screens. And if you use regular glasses like I do, watching without my ordinary glasses is a complete blur. I had to use contact-lenses (which I hate) to get any use out of these. But if your eyesight is fine, you will no doubt have a better experience.
For me being 100% dependent on my regular glasses, it actually makes more sense to buy a cheap, second-hand Samsung Galaxy Edge, which were designed to be used as a proper VR display, and then permanently fixing it to a set of cheap Samsung VR casing. Even the most rudimentary VR casing offers focal lenses, so you can adjust the focus to compensate for poor eyesight.
The second issue has to do with display resolution. If you have 20/20 eyesight then high resolutions is wonderful. But in my case I would actually see better if the resolution was slightly lower. Sadly the devices seem fixed to what I can only presume is 1600×1024 (or something like that), and there are no options for changing resolution, offset display or skew the picture. Again, these are factors that only become important if you have poor eyesight.
Audio
The way they solved audio is actually quite good. On each arm of the glasses you have an audio-jack out. And the kit comes with two small earplugs. And again – if you are on a long flight and just want to snuggle up in your own world – this works really well.
If you have ear-pods like I do, you can use them via the standard BT interface. But I noticed that there was a slight lag when using these; no doubt the CPU had problems handling audio when playing a full HD movie. The lag was not there when i used the normal jack – so the culprit is probably the BT device cache.
Gaming?
I’m not a huge gamer myself, I mostly play games like Destiny in the Playstation. On the odd occasion that I jump into other games, it’s mostly retro stuff. And I have a house pretty much packed with Amiga, Silicon Graphics, and more arcade hardware than god ever intended a person to own.
Having said that, the device is capable of both native Android games – and emulation. I had no problem installing UAE (Unix Amiga Emulator), and it’s more than powerful enough to emulate an A1200 with AGA (advanced graphics architecture).
I didn’t test the casting option – because the device can display-cast to your living room TV. But somehow it seems backwards using these as a casting source – when you already have a supercomputer in your pocket. Any modern phone, be it a Samsung or Apple device, will outperform whatever is powering these glasses – so if gaming is your thing, look elsewhere.
Final words
These glasses have potential. Or perhaps better phrased – the technology holds a lot of promise. If they had opted for focal-lenses and a wider field of vision, they would have been a fantastic experience. I have no problem imagining this type of tech replacing monitors in the near future – at least for movie experiences.
I must admit it’s really tricky to hammer down a verdict. On one hand they are really fun, you can install NetFlix, browse the web and watch movies if you copy them over to an sd-card (the glasses come with a 16Gb sd-card). You have mouse control, BT and i have no problem seeing myself on a flight to hong-kong enjoying a movie marathon wearing these.
But are they worth $250 ? I would have to say no. A fair price would be something in the $70 region. If they corrected the lenses I would have no problem buying a pair at $99. And if they expanded the field of vision to cover the width of the glasses – I would absolutely pick them up at $150. But $250 for this? Sadly I can’t say they are worth the money.
I was also surprised to find pornhub as a pre-defined shortcut in the browser (I mean, who does that?). It made me laugh first, thinking it was a cheeky joke – but as a parent who could have bought these for a child, it is utterly unacceptable. It’s not the first time I have found smut on a device from Asia. But yeah, a bit creepy.
So, I would have to give them a 3 out of 6 verdict. If you have money to burn and a long flight ahead, then by all means – they will give you a comfy way of watching movies during the flight. But the technology is (for the lack of a better word) premature.
As for augmented reality – forget it. You are better off stuffing your phone inside a $100 Samsung VR casing. The official Samsung Galaxy Edge casing probably cost next to nothing by now. And for $250 you should have no problem sourcing a used Galaxy Edge phone too. Which will be 100 times better than this.
I started this post citing the inherent differences between nationalities in what they enjoy, but I must admit that through these, I can see why VR holds such potential. I can’t see myself strapping on a full suit, helmet and gloves just to play a game or do some work. But glasses like these (but not these) is absolutely in the vicinity of “practical”. Just a damn shame they didn’t do a full width LCD with focal lenses; then I would have promoted them.
Right now: a fun curiocity, good for watching the odd movie if you eyesight is perfect – but for the rest of us, it’s just not worth the dough
RemObjects is giving a whopping 30% discount on all products! This means you can now pick up RemObjects Remoting Framework, Data Abstract, Hydra or the Elements compiler toolchain - with a massive 30% saving! These are battle-hardened, enterprise level solutions that have been polished over years - and they are in constant development.
Show full content
This is brilliant. RemObjects is giving a whopping 30% discount on all products!
These are battle-hardened, enterprise level solutions that have been polished over years and they are in constant development. Each solution integrates seamlessly into Embarcadero Delphi and provides a smooth path to delivering quality products in days rather than weeks.
But you better hurry because it’s only valid for one week (!)
Use the coupon code: “DelphiDeveloper”
Use the Delphi Developer coupon to get 30% discount – click here
Im mostly porting code from Delphi to Oxygene these days, but here is my Delphi implementation of the propertybag object. Please note that I haven't bothered to implement the propertybag available in .Net. The Delphi version below is based on the Visual Basic 6 version, with some dependency injection thrown in for good measure.
Show full content
A long, long time ago, way back in the previous century, I often had to adjust a Visual Basic project my company maintained. Going from object-pascal to VB was more than a little debilitating; Visual Basic was not a compiled language like Delphi is, and it lacked more or less every feature you needed to produce good software.
I could probably make a VB clone using Delphi pretty easily. But I think the world has experienced enough suffering, no need to add more evil to the universe
Having said that, I have always been a huge fan of Basic (it was my first language after all, it’s what schools taught in the 70s and 80s). I think it was a terrible mistake for Microsoft to retire Basic as a language, because it’s a great way to teach kids the fundamentals of programming.
Visual Basic is still there though, available for the .Net framework, but to call it Basic is an insult of the likes of GFA Basic, Amos Basic and Blitz Basic; the mighty compilers of the past. If you enjoyed basic before Microsoft pushed out the monstrosity that is Visual Basic, then perhaps swing by GitHub and pick up a copy of BlitzBasic? BlitzBasic is a completely different beast. It compiles to machine-code, allows inline assembly, and has been wildly popular for game developers over the years.
A property bag
The only feature that I found somewhat useful in Visual Basic, was an object called a propertybag. It’s just a fancy name for a dictionary, but it had a couple of redeeming factors beyond lookup ability. Like being able to load name-value-pairs from a string, recognizing datatypes and exposing type-aware read/write methods. Nothing fancy but handy when dealing with database connection-strings, shell parameters and the like.
So you could feed it strings like this:
first=12;second=hello there;third=3.14
And the class would parse out the names and values, stuff it in a dictionary, and you could easily extract the data you needed. Nothing fancy, but handy on rare occasions.
A Delphi version
Im mostly porting code from Delphi to Oxygene these days, but here is my Delphi implementation of the propertybag object. Please note that I haven’t bothered to implement the propertybag available in .Net. The Delphi version below is based on the Visual Basic 6 version, with some dependency injection thrown in for good measure.
unit fslib.params;
interface
{.$DEFINE SUPPORT_URI_ENCODING}
uses
System.SysUtils,
System.Classes,
Generics.Collections;
type
(* Exceptions *)
EPropertybag = class(exception);
EPropertybagReadError = class(EPropertybag);
EPropertybagWriteError = class(EPropertybag);
EPropertybagParseError = class(EPropertybag);
(* Datatypes *)
TPropertyBagDictionary = TDictionary ;
IPropertyElement = interface
['{C6C937DF-50FA-4984-BA6F-EBB0B367D3F3}']
function GetAsInt: integer;
procedure SetAsInt(const Value: integer);
function GetAsString: string;
procedure SetAsString(const Value: string);
function GetAsBool: boolean;
procedure SetAsBool(const Value: boolean);
function GetAsFloat: double;
procedure SetAsFloat(const Value: double);
function GetEmpty: boolean;
property Empty: boolean read GetEmpty;
property AsFloat: double read GetAsFloat write SetAsFloat;
property AsBoolean: boolean read GetAsBool write SetAsBool;
property AsInteger: integer read GetAsInt write SetAsInt;
property AsString: string read GetAsString write SetAsString;
end;
TPropertyBag = Class(TInterfacedObject)
strict private
FLUT: TPropertyBagDictionary;
strict protected
procedure Parse(NameValuePairs: string);
public
function Read(Name: string): IPropertyElement;
function Write(Name: string; Value: string): IPropertyElement;
procedure SaveToStream(const Stream: TStream);
procedure LoadFromStream(const Stream: TStream);
function ToString: string; override;
procedure Clear; virtual;
constructor Create(NameValuePairs: string); virtual;
destructor Destroy; override;
end;
implementation
{$IFDEF SUPPORT_URI_ENCODING}
uses
system.NetEncoding;
{$ENDIF}
const
cnt_err_sourceparameters_parse =
'Failed to parse input, invalid or damaged text error [%s]';
cnt_err_sourceparameters_write_id =
'Write failed, invalid or empty identifier error';
cnt_err_sourceparameters_read_id =
'Read failed, invalid or empty identifier error';
type
TPropertyElement = class(TInterfacedObject, IPropertyElement)
strict private
FName: string;
FData: string;
FStorage: TPropertyBagDictionary;
strict protected
function GetEmpty: boolean; inline;
function GetAsInt: integer; inline;
procedure SetAsInt(const Value: integer); inline;
function GetAsString: string; inline;
procedure SetAsString(const Value: string); inline;
function GetAsBool: boolean; inline;
procedure SetAsBool(const Value: boolean); inline;
function GetAsFloat: double; inline;
procedure SetAsFloat(const Value: double); inline;
public
property AsFloat: double read GetAsFloat write SetAsFloat;
property AsBoolean: boolean read GetAsBool write SetAsBool;
property AsInteger: integer read GetAsInt write SetAsInt;
property AsString: string read GetAsString write SetAsString;
property Empty: boolean read GetEmpty;
constructor Create(const Storage: TPropertyBagDictionary; Name: string; Data: string); overload; virtual;
constructor Create(Data: string); overload; virtual;
end;
//#############################################################################
// TPropertyElement
//#############################################################################
constructor TPropertyElement.Create(Data: string);
begin
inherited Create;
FData := Data.Trim();
end;
constructor TPropertyElement.Create(const Storage: TPropertyBagDictionary;
Name: string; Data: string);
begin
inherited Create;
FStorage := Storage;
FName := Name.Trim().ToLower();
FData := Data.Trim();
end;
function TPropertyElement.GetEmpty: boolean;
begin
result := FData.Length < 1;
end;
function TPropertyElement.GetAsString: string;
begin
result := FData;
end;
procedure TPropertyElement.SetAsString(const Value: string);
begin
if Value FData then
begin
FData := Value;
if FName.Length > 0 then
begin
if FStorage nil then
FStorage.AddOrSetValue(FName, Value);
end;
end;
end;
function TPropertyElement.GetAsBool: boolean;
begin
TryStrToBool(FData, result);
end;
procedure TPropertyElement.SetAsBool(const Value: boolean);
begin
FData := BoolToStr(Value, true);
if FName.Length > 0 then
begin
if FStorage nil then
FStorage.AddOrSetValue(FName, FData);
end;
end;
function TPropertyElement.GetAsFloat: double;
begin
TryStrToFloat(FData, result);
end;
procedure TPropertyElement.SetAsFloat(const Value: double);
begin
FData := FloatToStr(Value);
if FName.Length > 0 then
begin
if FStorage nil then
FStorage.AddOrSetValue(FName, FData);
end;
end;
function TPropertyElement.GetAsInt: integer;
begin
TryStrToInt(FData, Result);
end;
procedure TPropertyElement.SetAsInt(const Value: integer);
begin
FData := IntToStr(Value);
if FName.Length > 0 then
begin
if FStorage nil then
FStorage.AddOrSetValue(FName, FData);
end;
end;
//#############################################################################
// TPropertyBag
//#############################################################################
constructor TPropertyBag.Create(NameValuePairs: string);
begin
inherited Create;
FLUT := TDictionary.Create();
NameValuePairs := NameValuePairs.Trim();
if NameValuePairs.Length > 0 then
Parse(NameValuePairs);
end;
destructor TPropertyBag.Destroy;
begin
FLut.Free;
inherited;
end;
procedure TPropertyBag.Clear;
begin
FLut.Clear;
end;
procedure TPropertyBag.Parse(NameValuePairs: string);
var
LList: TStringList;
x: integer;
LId: string;
LValue: string;
LOriginal: string;
{$IFDEF SUPPORT_URI_ENCODING}
LPos: integer;
{$ENDIF}
begin
// Reset content
FLUT.Clear();
// Make a copy of the original text
LOriginal := NameValuePairs;
// Trim and prepare
NameValuePairs := NameValuePairs.Trim();
// Anything to work with?
if NameValuePairs.Length > 0 then
begin
{$IFDEF SUPPORT_URI_ENCODING}
// Check if the data is URL-encoded
LPos := pos('%', NameValuePairs);
if (LPos >= low(NameValuePairs) )
and (LPos 0 then
Begin
(* Populate our lookup table *)
LList := TStringList.Create;
try
LList.Delimiter := ';';
LList.StrictDelimiter := true;
LList.DelimitedText := NameValuePairs;
if LList.Count = 0 then
raise EPropertybagParseError.CreateFmt(cnt_err_sourceparameters_parse, [LOriginal]);
try
for x := 0 to LList.Count-1 do
begin
LId := LList.Names[x].Trim().ToLower();
if (LId.Length > 0) then
begin
LValue := LList.ValueFromIndex[x].Trim();
Write(LId, LValue);
end;
end;
except
on e: exception do
raise EPropertybagParseError.CreateFmt(cnt_err_sourceparameters_parse, [LOriginal]);
end;
finally
LList.Free;
end;
end;
end;
end;
function TPropertyBag.ToString: string;
var
LItem: TPair;
begin
setlength(result, 0);
for LItem in FLut do
begin
if LItem.Key.Trim().Length > 0 then
begin
result := result + Format('%s=%s;', [LItem.Key, LItem.Value]);
end;
end;
end;
procedure TPropertyBag.SaveToStream(const Stream: TStream);
var
LData: TStringStream;
begin
LData := TStringStream.Create(ToString(), TEncoding.UTF8);
try
LData.SaveToStream(Stream);
finally
LData.Free;
end;
end;
procedure TPropertyBag.LoadFromStream(const Stream: TStream);
var
LData: TStringStream;
begin
LData := TStringStream.Create('', TEncoding.UTF8);
try
LData.LoadFromStream(Stream);
Parse(LData.DataString);
finally
LData.Free;
end;
end;
function TPropertyBag.Write(Name: string; Value: string): IPropertyElement;
begin
Name := Name.Trim().ToLower();
if Name.Length > 0 then
begin
if not FLUT.ContainsKey(Name) then
FLut.Add(Name, Value);
result := TPropertyElement.Create(FLut, Name, Value) as IPropertyElement;
end else
raise EPropertybagWriteError.Create(cnt_err_sourceparameters_write_id);
end;
function TPropertyBag.Read(Name: string): IPropertyElement;
var
LData: String;
begin
Name := Name.Trim().ToLower();
if Name.Length > 0 then
begin
if FLut.TryGetValue(Name, LData) then
result := TPropertyElement.Create(LData) as IPropertyElement
else
raise EPropertybagReadError.Create(cnt_err_sourceparameters_read_id);
end else
raise EPropertybagReadError.Create(cnt_err_sourceparameters_read_id);
end;
end.
A few weeks back I posted an article on RemObjects blog regarding universal code, and how you with a little bit of care can write code that easily compiled with both Oxygene, Delphi and Freepascal. With emphasis on Oxygene.
Show full content
Click here to read
A few weeks back I posted an article on RemObjects blog regarding universal code, and how you with a little bit of care can write code that easily compiled with both Oxygene, Delphi and Freepascal. With emphasis on Oxygene.
The example I used was a BTree class that I originally ported from Delphi to Smart Pascal, and then finally to Oxygene to run under WebAssembly.
Long story short I was asked if I could port the code back to Delphi in its more or less universal form. Naturally there are small differences here and there, but nothing special that distinctly separates the Delphi version from Oxygene or Smart Pascal.
Why this version?
If you google BTree and Delphi you will find loads of implementations. They all operate more or less identical, using records and pointers for optimal speed. I decided to base my version on classes for convenience, but it shouldn’t be difficult to revert that to use records if you absolutely need it.
What I like about this BTree implementation is that it’s very functional. Its easy to traverse the nodes using the ForEach() method, you can add items using a number as an identifier, but it also supports string identifiers.
I also changed the typical data reference. The data each node represent is usually a pointer. I changed this to variant to make it more functional.
Well, here is the Delphi version as promised. Happy to help.
unit btree;
interface
uses
System.Generics.Collections,
System.Sysutils,
System.Classes;
type
// BTree leaf object
TQTXBTreeNode = class(TObject)
public
Identifier: integer;
Data: variant;
Left: TQTXBTreeNode;
Right: TQTXBTreeNode;
end;
[Weak]
TQTXBTreeProcessCB = reference to procedure (const Node: TQTXBTreeNode; var Cancel: boolean);
EBTreeError = class(Exception);
TQTXBTree = class(TObject)
private
FRoot: TQTXBTreeNode;
FCurrent: TQTXBTreeNode;
protected
function GetEmpty: boolean; virtual;
function GetPackedNodes: TList;
public
property Root: TQTXBTreeNode read FRoot;
property Empty: boolean read GetEmpty;
function Add(const Ident: integer; const Data: variant): TQTXBTreeNode; overload; virtual;
function Add(const Ident: string; const Data: variant): TQTXBTreeNode; overload; virtual;
function Contains(const Ident: integer): boolean; overload; virtual;
function Contains(const Ident: string): boolean; overload; virtual;
function Remove(const Ident: integer): boolean; overload; virtual;
function Remove(const Ident: string): boolean; overload; virtual;
function Read(const Ident: integer): variant; overload; virtual;
function Read(const Ident: string): variant; overload; virtual;
procedure Write(const Ident: string; const NewData: variant); overload; virtual;
procedure Write(const Ident: integer; const NewData: variant); overload; virtual;
procedure Clear; overload; virtual;
procedure Clear(const Process: TQTXBTreeProcessCB); overload; virtual;
function ToDataArray: TList;
function Count: integer;
procedure ForEach(const Process: TQTXBTreeProcessCB);
destructor Destroy; override;
end;
implementation
//#############################################################################
// TQTXBTree
//#############################################################################
destructor TQTXBTree.Destroy;
begin
if FRoot nil then
Clear();
inherited;
end;
procedure TQTXBTree.Clear;
var
lTemp: TList;
x: integer;
begin
if FRoot nil then
begin
// pack all nodes to a linear list
lTemp := GetPackedNodes();
try
// release each node
for x := 0 to ltemp.Count-1 do
begin
lTemp[x].Free;
end;
finally
// dispose of list
lTemp.Free;
// reset pointers
FCurrent := nil;
FRoot := nil;
end;
end;
end;
procedure TQTXBTree.Clear(const Process: TQTXBTreeProcessCB);
begin
ForEach(Process);
Clear();
end;
function TQTXBTree.GetPackedNodes: TList;
var
LData: Tlist;
begin
LData := TList.Create();
ForEach( procedure (const Node: TQTXBTreeNode; var Cancel: boolean)
begin
LData.Add(Node);
Cancel := false;
end);
result := LData;
end;
function TQTXBTree.GetEmpty: boolean;
begin
result := FRoot = nil;
end;
function TQTXBTree.Count: integer;
var
LCount: integer;
begin
ForEach( procedure (const Node: TQTXBTreeNode; var Cancel: boolean)
begin
inc(LCount);
Cancel := false;
end);
result := LCount;
end;
function TQTXBTree.ToDataArray: TList;
var
Data: TList;
begin
Data := TList.Create();
ForEach( procedure (const Node: TQTXBTreeNode; var Cancel: boolean)
begin
Data.add(Node.data);
Cancel := false;
end);
result := data;
end;
function TQTXBTree.Add(const Ident: string; const Data: variant): TQTXBTreeNode;
begin
result := Add( Ident.GetHashCode(), Data);
end;
function TQTXBTree.Add(const Ident: integer; const Data: variant): TQTXBTreeNode;
var
lNode: TQTXBtreeNode;
begin
LNode := TQTXBTreeNode.Create();
LNode.Identifier := Ident;
LNode.Data := data;
if FRoot = nil then
FRoot := LNode;
FCurrent := FRoot;
while true do
begin
if (Ident FCurrent.Identifier) then
begin
if (FCurrent.right = nil) then
begin
FCurrent.right := LNode;
break;
end else
FCurrent := FCurrent.right;
end else
break;
end;
result := LNode;
end;
function TQTXBTree.Read(const Ident: string): variant;
begin
result := Read( Ident.GetHashCode() );
end;
function TQTXBTree.Read(const Ident: integer): variant;
begin
FCurrent := FRoot;
while FCurrent nil do
begin
if (Ident Fcurrent.Identifier) then
FCurrent := FCurrent.Right
else
begin
result := FCUrrent.Data;
break;
end
end;
end;
procedure TQTXBTree.Write(const Ident: string; const NewData: variant);
begin
Write( Ident.GetHashCode(), NewData);
end;
procedure TQTXBTree.Write(const Ident: integer; const NewData: variant);
begin
FCurrent := FRoot;
while (FCurrent nil) do
begin
if (Ident Fcurrent.Identifier) then
FCurrent := FCurrent.Right
else
begin
FCurrent.Data := NewData;
break;
end
end;
end;
function TQTXBTree.Contains(const Ident: string): boolean;
begin
result := Contains( Ident.GetHashCode() );
end;
function TQTXBTree.Contains(const Ident: integer): boolean;
begin
result := false;
if FRoot nil then
begin
FCurrent := FRoot;
while ( (not Result) and (FCurrent nil) ) do
begin
if (Ident Fcurrent.Identifier) then
FCurrent := FCurrent.Right
else
begin
Result := true;
break;
end
end;
end;
end;
function TQTXBTree.Remove(const Ident: string): boolean;
begin
result := Remove( Ident.GetHashCode() );
end;
function TQTXBTree.Remove(const Ident: integer): boolean;
var
LFound: boolean;
LParent: TQTXBTreeNode;
LReplacement,
LReplacementParent: TQTXBTreeNode;
LChildCount: integer;
begin
FCurrent := FRoot;
LFound := false;
LParent := nil;
LReplacement := nil;
LReplacementParent := nil;
while (not LFound) and (FCurrent nil) do
begin
if (Ident FCurrent.Identifier) then
begin
LParent := FCurrent;
FCurrent := FCurrent.right;
end else
LFound := true;
if LFound then
begin
LChildCount := 0;
if (FCurrent.left nil) then
inc(LChildCount);
if (FCurrent.right nil) then
inc(LChildCount);
if FCurrent = FRoot then
begin
case (LChildCOunt) of
0: begin
FRoot := nil;
end;
1: begin
if FCurrent.right = nil then
FRoot := FCurrent.left
else
FRoot :=FCurrent.Right;
end;
2: begin
LReplacement := FRoot.left;
while (LReplacement.right nil) do
begin
LReplacementParent := LReplacement;
LReplacement := LReplacement.right;
end;
if (LReplacementParent nil) then
begin
LReplacementParent.right := LReplacement.Left;
LReplacement.right := FRoot.Right;
LReplacement.left := FRoot.left;
end else
LReplacement.right := FRoot.right;
end;
end;
FRoot := LReplacement;
end else
begin
case LChildCount of
0: if (FCurrent.Identifier < LParent.Identifier) then
Lparent.left := nil else
LParent.right := nil;
1: if (FCurrent.Identifier < LParent.Identifier) then
begin
if (FCurrent.Left = NIL) then
LParent.left := FCurrent.Right else
LParent.Left := FCurrent.Left;
end else
begin
if (FCurrent.Left = NIL) then
LParent.right := FCurrent.Right else
LParent.right := FCurrent.Left;
end;
2: begin
LReplacement := FCurrent.left;
LReplacementParent := FCurrent;
while LReplacement.right nil do
begin
LReplacementParent := LReplacement;
LReplacement := LReplacement.right;
end;
LReplacementParent.right := LReplacement.left;
LReplacement.right := FCurrent.right;
LReplacement.left := FCurrent.left;
if (FCurrent.Identifier < LParent.Identifier) then
LParent.left := LReplacement
else
LParent.right := LReplacement;
end;
end;
end;
end;
end;
result := LFound;
end;
procedure TQTXBTree.ForEach(const Process: TQTXBTreeProcessCB);
function ProcessNode(const Node: TQTXBTreeNode): boolean;
begin
if Node nil then
begin
if Node.left nil then
begin
result := ProcessNode(Node.left);
if result then
exit;
end;
Process(Node, result);
if result then
exit;
if (Node.right nil) then
begin
result := ProcessNode(Node.right);
if result then
exit;
end;
end;
end;
begin
ProcessNode(FRoot);
end;
end.
We got a good question about how to start a node.js program from Delphi. When you have been coding for years you often forget that things like this might not be immediately obvious. Hopefully I can shed some light on the options in this post.
Show full content
We got a good question about how to start a node.js program from Delphi on our Facebook group today (third one in a week?). When you have been coding for years you often forget that things like this might not be immediately obvious. Hopefully I can shed some light on the options in this post.
Node or chrome?
Just to be clear: node.js has nothing to do with chrome or chromium embedded. Chrome is a web-browser, a completely visual environment and ecosystem.
Node.js is the complete opposite. It is purely a shell based environment, meaning that it’s designed to run services and servers, with emphasis on the latter.
The only thing node.js and chrome have in common, is that they both use the V8 JavaScript runtime engine to load, JIT compile and execute scripts at high speed. Beyond that, they are utterly alien to each other.
Can node.js be embedded into a Delphi program?
Technically there is nothing stopping a C/C++ developer from compiling the node.js core system as C++ builder compatible .obj files; files that can then be linked into a Delphi application through references. But this also requires a bit of scaffolding, like adding support for malloc_, free_ and a few other procedures – so that your .obj files uses the same memory manager as your Delphi code. But until someone does just that and publish it, im afraid you are stuck with two options:
Use a library called Toby, that keeps node.js in a single DLL file. This is the most practical way if you insist on hosting your own version of node.js
Add node.js as a prerequisite and give users the option to locate the node.exe in your application’s preferences. This is the way I would go, because you really don’t want to force users to stick with your potentially outdated or buggy build.
So yes, you can use toby and just add the toby dll file to your program folder, but I have to strongly advice against that. There is no point setting yourself up for maintaining a whole separate programming language, just because you want JavaScript support.
“How many in your company can write high quality WebAssembly modules?”
If all you want to do is support JavaScript in your application, then I would much rather install Besen into Delphi. Besen is a JavaScript runtime engine written in Freepascal. It is fully compatible with Delphi, and follows the ECMA standard to the letter. So it is extremely compatible, fast and easy to use.
Like all Delphi components Besen is compiled into your application, so you have no dependencies to worry about.
Starting a node.js script
The easiest way to start a node.js script, is to simply shell-execute out of your Delphi application. This can be done as easily as:
This is more than enough if you just want to start a service, server or do some work that doesn’t require that you capture the result.
If you need to capture the result, the data that your node.js program emits on stdout, there is a nice component in the Jedi Component Library. Also plenty of examples online on how to do that.
If you need even further communication, you need to look for a shell-execute that support pipes. All node.js programs have something called a message-channel in the Javascript world. In reality though, this is just a named pipe that is automatically created when your script starts (with the same moniker as the PID [process identifier]).
If you opt for the latter you have a direct, full duplex message channel directly into your node.js application. You just have to agree with yourself on a protocol so that your Delphi code understands what node.js is saying, and visa versa.
UDP or TCP
If you don’t want to get your hands dirty with named pipes and rolling your own protocol, you can just use UDP to let your Delphi application communicate with your node.js process. UDP is practically without cost since its fundamental to all networking stacks, and in your case you will be shipping messages purely between processes on localhost. Meaning: packets are never sent on the network, but rather delegated between processes on the same machine.
In that case, I suggest you ship in the port you want your UDP server to listen on, so that your node.js service acts as the server. A simple command-line statement like:
node.exe myservice.js 8090
Inside node.js you can setup an UDP server with very little fuzz:
function setupServer(port) {
var os = require("os");
var dgram = require("dgram");
var socket = dgram.createSocket("udp4");
var MULTICAST_HOST = "224.0.0.236";
var BROADCAST_HOST = "255.255.255.255";
var ALL_PORT = 60540;
var MULTICAST_TTL = 1; // Local network
socket.bind(port);
socket.on('listening', function() {
socket.setMulticastLoopback(true);
socket.setMulticastTTL(MULTICAST_TTL);
socket.addMembership(multicastHost);
if(broadcast) { socket.setBroadcast(true); }
});
socket.on('message', parseMessage);
}
function parseMessage(message, rinfo) {
try {
var messageObject = JSON.parse(message);
var eventType = messageObject.eventType;
} catch(e) {
}
}
Note: the code above assumes a JSON text message.
You can then use any Delphi UDP client to communicate with your node.js server, Indy is good, Synapse is a good library with less overhead – there are many options here.
Do I have to learn Javascript to use node.js?
If you download DWScript you can hook-up the JS-codegen library (see library folder in the DWScript repository), and use that to compile DWScript (object pascal) to kick-ass Javascript. This is the same compiler that was used in Smart Mobile Studio.
“Adding WebAssembly to your resume is going to be a hell of a lot more valuable in the years to come than C# or Java”
Another alternative is to use Freepascal, they have a pas2js project where you can compile ordinary object-pascal to javascript. Naturally there are a few things to keep in mind, both for DWScript and Freepascal – like avoiding pointers. But clean object pascal compiles just fine.
If JavaScript is not your cup of tea, or you simply don’t have time to learn the delicate nuances between the DOM (document object model, used by browsers) and the 100% package oriented approach deployed by node.js — then you can just straight up to webassembly.
RemObjects Software has a kick-ass webassembly compiler, perfect if you dont have the energy or time to learn JavaScript. As of writing this is the fastest and most powerful toolchain available. And I have tested them all.
WebAssembly, no Javascript needed
You might remember Oxygene? It used to be shipped with Delphi as a way to target Microsoft CLR (common language runtime) and the .net framework.
Since then Oxygene and the RemObjects toolchain has evolved dramatically and is now capable of a lot more than CLR support.
You can compile to raw, llvm optimized machine code for 8 platforms
You can compile to CLR/.Net
You can compile to Java bytecodes
You can compile to WebAssembly!
WebAssembly is not Javascript, it’s important to underline that. WebAssembly was created especially for developers using traditional languages, so that traditional compilers can emit web friendly, binary code. Unlike Javascript, WebAssembly is a purely binary format. Just like Delphi generates machine-code that is linked into a final executable, WebAssembly is likewise compiled, linked and emitted in binary form.
If that sounds like a sales pitch, it’s not. It’s a matter of practicality.
WebAssembly is completely barren out of the box. The runtime environment, be it V8 for the browser or V8 for node.js, gives you nothing out of the box. You don’t even have WriteLn() to emit text.
Google expects compiler makers to provide their own RTL functions, from the fundamental to the advanced. The only thing V8 gives you, is a barebone way of referencing objects and functions on the other side, meaning the JS and DOM world. And that’s it.
So the reason i’m talking a lot about Oxygene and RemObjects Elements (Elements is the name of the compiler toolchain RemObjects offers), is because it ships with an RTL. So you are not forced to start on actual, literal assembly level.
If you don’t want to study JavaScript, Oxygene and Elements from RemObjects is the solution
RemObjects also delivers a DelphiVCL compatibility framework. This is a clone of the Delphi VCL / Freepascal LCL. Since WebAssembly is still brand new, work is being done on this framework on a daily basis, with updates being issued all the time.
Note: The Delphi VCL framework is not just for WebAssembly. It represents a unified framework that can work anywhere. So if you switch from WebAssembly to say Android, you get the same result.
The most important part of the above, is actually not the visual stuff. I mean, having HTML5 visual controls is cool – but chances are you want to use a library like Sencha, SwiftUI or jQueryUI to compose your forms right? Which means you just want to interface with the widgets in the DOM to set and get values.
You probably want to use a fancy UI library, like jQuery UI. This works perfectly with Elements because you can reference the controls from your WebAssembly module. You dont have to create TButton, TListbox etc manually
The more interesting stuff is actually the non-visual code you get access to. Hundreds of familiar classes from the VCL, painstakingly re-created, and usable from any of the 5 languages Elements supports.
I dont believe in single languages. Not any more. There was a time when all you needed was Delphi and a diploma and you were set to conquer the world. But those days are long gone, and a programmer needs to be flexible and have a well stocked toolbox.
Knowing where you want to be is half the journey
The world really don’t need yet-another-c# developer. There are millions of C# developers in India alone. C# is just “so what?”. Which is also why C# jobs pays less than Delphi or node.js system service jobs.
What you want, is to learn the things others avoid. If JavaScript looks alien and you feel uneasy about the whole thing – that means you are growing as a developer. All new things are learned by venturing outside your comfort zone.
How many in your company can write high quality WebAssembly modules?
How many within one hour driving distance from your office or home are experts at WebAssembly? How many are capable of writing industrial scale, production ready system services for node.js that can scale from a single instance to 1000 instances in a large, clustered cloud environment?
Any idiot can pick up node.js and knock out a service, but with your background from Delphi or C++ builder you have a massive advantage. All those places that can throw an exception that JS devs usually ignore? As a Delphi or Oxygene developer you know better. And when you re-apply that experience under a different language, suddenly you can do stuff others cant. Which makes your skills valuable.
The Quartex Media Desktop have made even experienced node / web developers gasp. They are not used to writing custom-controls and large-scale systems, which is my advantage
So would you learn JavaScript or just skip to WebAssembly? Honestly? Learn a bit of both. You don’t have to be an expert in JavaScript to compliment WebAssembly. Just get a cheap book, like “Node.js for beginners” and “JavaScript the good parts” ($20 a piece) and that should be more than enough to cover the JS side of things.
Adding WebAssembly to your resume and having the material to prove you know your stuff, is going to be a hell of a lot more valuable in the years to come than C#, Java or Python. THAT I can guarantee you.
This is something I never had the time to implement under Smart Pascal, but it should be easy enough to patch. If you are using DWScript with the QTX Framework this is already in place. But for Smart users, here is a quick recipe. First, we need access to the node.js OS module: With that […]
Show full content
This is something I never had the time to implement under Smart Pascal, but it should be easy enough to patch. If you are using DWScript with the QTX Framework this is already in place. But for Smart users, here is a quick recipe.
First, we need access to the node.js OS module:
unit qtx.node.os;
//#############################################################################
// Quartex RTL for DWScript
// Written by Jon L. Aasenden, all rights reserved
// This code is released under modified LGPL (see license.txt)
//#############################################################################
unit NodeJS.os;
interface
uses
NodeJS.Core;
type
TCpusResultObjectTimes = class external
property user: Integer;
property nice: Integer;
property sys: Integer;
property idle: Integer;
property irq: Integer;
end;
TCpusResult = class external
property model: String;
property speed: Integer;
property times: TcpusResultObjectTimes;
end;
JNetworkInterfaceInfo = class external
property address: string;
property netmask: string;
property family: string;
property mac: string;
property scopeid: integer;
property internal: boolean;
property cidr: string;
end;
Jos_Exports = class external
public
function tmpDir: String;
function hostname: String;
function &type: String;
function platform: String;
function arch: String;
function release: String;
function uptime: Integer;
function loadavg: array of Integer;
function totalmem: Integer;
function freemem: Integer;
function cpus: array of TCpusResult;
function networkInterfaces: variant;
property EOL: String;
end;
function NodeJSOsAPI: Jos_Exports;
implementation
function NodeJSOsAPI: Jos_Exports;
begin
result := Jos_Exports(RequireModule("os") );
end;
end.
With that in place, we can start enumerating through the adapters. Remember that a PC can have several adapters attached, from a dedicated card to X number of USB wifi sticks.
Here is a little routine that goes through the adapters, and returns the first IPv4 LAN address it finds. This is very useful when writing servers, since you need the IP + port to setup a binding. And yes, you can just call HostName(), but the point here is to know how to run through the adapter array.
function GetMyV4LanIP: string;
begin
var OSAPI := NodeJSOsAPI();
var NetAdapters := OSAPI.networkInterfaces();
for var Adapter in NetAdapters do
begin
// Skip loopback device
if Adapter.Contains('Loopback') then
continue;
for var netIntf in NetAdapters[Adapter] do
begin
var address = JNetworkInterfaceInfo( NetAdapters[Adapter][netIntf] );
if not address.internal then
begin
// force copy of string
var lFam: string := string(address.family) + " ";
// make sure its ipv4
if lFam.ToLower().Trim() = 'ipv4' then
begin
result := address.address + " ";
result := result.trim();
break;
end;
end;
end;
end;
if result.length < 1 then
result := '127.0.0.1';
end;
Getting to grips with the whole JavaScript phenomenon, be it for mobile, embedded or back-end services, can be daunting if all you know is native code. But thankfully there are alternatives that can help you become productive quickly, something I will brush over in this post.
Show full content
Delphi is one of the best development toolchains for Windows. I have been an avid fan of Delphi since it was first released, and before that – Turbo Pascal too. Delphi has a healthy following – and despite popular belief, Delphi scores quite well on the Tiobe Index.
As cool and efficient as Delphi might be, there are situations where native code wont work. Or at the very least, be less efficient than the alternatives. Delphi has a broad wingspan, from low-level assembler all the way to classes and generics. But JavaScript and emerging web technology is based on a completely different philosophy, one where native code is regarded as negative since it binds you to hardware.
Getting to grips with the whole JavaScript phenomenon, be it for mobile, embedded or back-end services, can be daunting if all you know is native code. But thankfully there are alternatives that can help you become productive quickly, something I will brush over in this post.
JavaScript without JavaScript
Before we dig into the tools of the trade, I want to cover alternative ways of enjoying the power of node.js and Javascript. Namely by using compilers that can convert code from a traditional language – and emit fully working JavaScript. There are a lot more options than you think:
Quartex Media Desktop is a complete environment written purely in JavaScript. Both Server, Cluster and front-end is pure JavaScript. A good example of what can be done.
Swift compiles for JavaScript, and Apple is doing some amazing things with the new and sexy SwiftUI tookit. If you know your way around Swift, you can compile for Javascript
Go can likewise be compiled to JS:
RemObjects Elements supports the Go language. Elements can target both native (llvm), .Net, Java and WebAssembly.
C/C++ can be compiled to asm.js courtesy of EmScripten. It uses clang to first compile your code to llvm bitcode, and then it converts that into asm.js. You have probably seen games like Quake run in the browser? That was asm.js, a kind of precursor to WebAssembly.
NS Basic compiles for JavaScript, this is a Visual Basic 6 style environment with its own IDE even
For those coming straight from Delphi, there are a couple of options to pick from:
Freepascal (pas2js project)
DWScript compiles code to JavaScript, this is the same compiler that we used in Smart Pascal earlier
Oxygene, the next generation object-pascal from RemObjects compiles to WebAssembly. This is by far the best option of them all.
Asm.js is by far the most misunderstood technology in the JavaScript ecosystem, so let me just cover that before we move on:
A few years back JavaScript gained support for memory buffers and typed arrays. This might not sound very exciting, but in terms of speed – the difference is tremendous. The default variable type in JavaScript is what Delphi developers know as Variant. It assumes the datatype of the values you assign to it. Needless to say, there is a lot of overhead when working with variants – so JavaScript suddenly getting proper typed arrays was a huge deal.
It was then discovered that JavaScript could manipulate these arrays and buffers at high speed, providing it only used a subset of the language. A subset that the JavaScript runtime could JIT compile more easily (turn into machine-code).
So what the EmScripten team did was to implement a bytecode based virtual-machine in Javascript, and then they compile C/C++ to bytecodes. I know, it’s a huge project, but the results speak for themselves — before WebAssembly, this was as fast as it got with JavaScript.
WebAssembly
WebAssembly is different from both vanilla JavaScript and Asm.js. First of all, it’s executed at high speed by the browser itself. Not like asm.js where these bytecodes were executed by JavaScript code.
Water is a fast, slick and platform independent IDE for Elements. The same IDE for OS X is called Fire. You can use RemObjects Elements from either Visual Studio or Water
Secondly, WebAssembly is completely JIT compiled by the browser or node.js when loading. It’s not like Asm.js where some parts are compiled, others are interpreted. WebAssembly runs at full speed and have nothing to do with traditional JavaScript. It’s actually a completely separate engine.
Out of all the options on the table, WebAssembly is the technology with the best performance.
Kits and strategies
The first thing you need to be clear about, is what you want to work with. The needs and requirements of a game developer will be very different from a system service developer.
Here are a couple of kits to think about:
Mobile developer
Implement your mobile applications using Oxygene, compiling for WebAssembly (Elements)
RemObjects Remoting SDK for client / server communication
Use Freepascal for vanilla JavaScript scaffolding when needed
Service developer
Implement libraries in Oxygene to benefit from the speed of WebAssembly
Use RemObjects Data Abstract to make data-access uniform and fast
Use Freepascal for boilerplate node.js logic
Desktop developer
For platform independent desktop applications, WebAssembly is the way to go. You will need some scaffolding (plain Javascript) to communicate with the application host – but the 99.9% of your code will be better under WebAssembly.
Use Cordova / Phonegap to “bundle” your WebAssembly, HTML5 files and CSS styling into a single, final executable.
The most important part to think about when getting into JavaScript, is to look closely at the benefits and limitation of each technology.
WebAssembly is fast, wicked fast, and let’s you write code like you are used to from Delphi. Things like pointers etc are supported in Elements, which means ordinary code that use pointers will port over with ease. You are also not bound on hand-and-feet to a particular framework.
For example, EmScripten for C/C++ have almost nothing in terms of UI functionality. The visual part is a custom build of SDL (simple directmedia layer), which fakes the graphics onto an ordinary HTML5 canvas. This makes EmScripten a good candidate for porting games written in C/C++ to the web — but it’s less than optimal for writing serious applications.
Setting up the common tools
So far we have looked at a couple of alternatives for getting into the wonderful world of JavaScript in lieu of other languages. But what if you just want to get started with the typical tools JS developers use?
Visual Studio Code is a pretty amazing code-editor
The first “must have” is Visual Studio Code. This is actually a great example of what you can achieve with JavaScript, because the entire editor and program is written in JavaScript. But I want to stress that this editor is THE editor to get. The way you work with files in JS is very different from Delphi, C# and Java. JavaScript projects are often more fragmented, with less code in each file – organized by name.
TypeScript was invented by Anders Hejlsberg, who also made Delphi and C#
The next “must have” is without a doubt TypeScript. Personally im not too fond of TypeScript, but if ordinary JavaScript makes your head hurt and you want classes and ordinary inheritance, then TypeScript is a step up.
Next on the list is AssemblyScript. This is a post-processor for TypeScript that converts your code into WebAssembly. It lacks much of the charm and elegance of Oxygene, but I suspect that has to do with old habits. When you have been reading object-pascal for 20 years, you feel more at home there.
You will also need to install node.js, which is the runtime engine for running JavaScript as services. Node.js is heavily optimized for writing server software, but it’s actually a brilliant way to write services that are multi-platform. Because Node.js delivers the same behavior regardless of underlying operating system.
And finally, since you definitely want to convert your JavaScript and/or WebAssembly into a stand-alone executable: you will need Adobe Phonegap.
Visual Studio
No matter if you want to enter JavaScript via Elements or something else, Visual Studio will save you a lot of time, especially if you plan on targeting Azure or Amazon services. Downloading and installing the community edition is a good idea, and you can use that while exploring your options.
When it comes to writing system services, you also want to check out NPM, the node.js package manager. The JavaScript ecosystem is heavily package oriented – and npm gives you some 800.000 packages to play with free of charge.
Just to be clear, npm is a shell command you use to install or remove packages. NPM is also a online repository of said packages, where you can search and find what you need. Most packages are hosted on github, but when you install a package locally into your application folder – npm figures out dependencies etc. automatically for you.
Books, glorious books
Last but not least, get some good books. Seriously, it will save you so much time and frustration. Amazon have tons of great books, be it vanilla JavaScript, TypeScript, Node.js — pick some good ones and take the time to consume the material.
And again, I strongly urge you to have a look at Elements when it comes to WebAssembly. WebAssembly is a harsh and barren canvas, and being able to use the Elements RTL is a huge boost.
But regardless of path you pick, you will always benefit from learning vanilla JavaScript.
To further simplify syndication, and clean up the feeds (which so far has been a pot-purrey of many topics, dialects and products) an additional two groups is now in place
Show full content
Delphi Developer is a group on Facebook that have been going strong for 12+ years. It was one of the first groups on Facebook, created the same week that Facebook allowed groups. With that group well established, it’s time to expand and clean up the feed.
Last month I introduced a new group, RemObjects Developer, which is a group for developers that use RemObjects components, like the Remoting SDK, Data Abstract and/or Hydra – but more in particular, developers using Oxygene, C#, Swift, Java or Go via Elements (RemObjects compiler toolchain).
Two new groups
To further simplify syndication, and clean up the feeds (which so far has been a pot-purrey of many topics, dialects and products) an additional two groups is now in place:
Obviously there will be some overlapping. Since FPC and Delphi has much in common and are for the most part compatible, some news will be shared between those groups. But all in all this is to clean up the newsfeed which has so far been a mix and match of everything.
Simple overview of the groups
Node.js Developer is not meant to be purely about vanilla JavaScript. Node.js is ultimately a JavaScript runtime-engine. Which means you can use it to run or host WebAssembly libraries (as produced by Oxygene), or generate code via DWScript or Freepascal. You can think of it as a service-host if you like.
So if you are writing WebAssembly applications using Elements, then the node.js group will no doubt be interesting too. Same goes for DWScript users, Smart Pascal users and Freepascal users – providing web tech is what they like.
What is this Quartex Components?
It’s easier to manage multiple groups if you attach them to a parent-page. So if you wonder why all the groups says “by Quartex Components”, that is just a top-level page that helps me deal with with syndication. For some reason Facebook’s API only works for pages, not groups. So it’s impossible to auto-import news (for example) without a page.
The name, “Quartex Components” is ultimately the name of my personal company. I used to produce security components for Delphi, but decided to open-source those for the community.
So Quartex Components is just an organizational element.
TextCraft is a simple yet powerful text parser, designed for general purpose parsing jobs. I originally implemented it for Delphi, it's the base-parser for the LDEF bytecode assembler amongst other things. It was ported to Smart Pascal, then Freepascal - and now finally Oxygene.
Show full content
TextCraft is a simple yet powerful text parser, designed for general purpose parsing jobs. I originally implemented it for Delphi, it’s the base-parser for the LDEF bytecode assembler amongst other things. It was ported to Smart Pascal, then Freepascal – and now finally Oxygene.
The LDEF Assembler is a part of the Quartex Media Desktop
The LDEF assembler and bytecode engine is currently implemented in Smart and compiles for Javascript. It’s a complete assembler and VM allowing coders to approach Asm.js from an established instruction-set. In short: you feed it source-code, it spits out bytecodes that you can execute super fast in either the browser or elsewhere. As long as there is a VM implementation available.
The Javascript version works really well, especially on node.js. In essence, i don’t need to re-compile the toolchain when moving between arm, x86, windows, linux or osx. Think of it as a type of Java bytecodes or CLR bytecodes.
Getting the code to run under Oxygene, means that I can move the whole engine into WebAssembly. The parser, assembler and linker (et-al) can thus run as WebAssembly, and I can use that from my JavaScript front-end code. Best of both worlds – the flamboyant creativity of JavaScript, and the raw speed of WebAssembly.
The port
Before I can move over the top-level parser + assembler etc, the generic parser code has to work. I was reluctant to start because I imagined the porting would take at least a day, but luckily it took me less than an hour. There are a few superficial differences between Smart, Delphi, Freepascal and Oxygene; for example the Copy() function for strings is not a lose function in Oxygene, instead you use String.SubString(). Functions like High() and Low() on strings likewise has to be refactored.
But all in all the conversion was straight-forward, and TextCraft is now a part of the QTX library for Oxygene. I’ll be uploading a commit to GIT with the whole shabam soon.
Well, hope the WordPress parser doesnt screw this up too bad.
namespace qtxlib;
//##################################################################
// TextCraft 1.2
// Written by Jon L. Aasenden
//
// This is a port of TC 1.2 from Freepascal. TextCraft is initially
// a Delphi parser framework. The original repository can be found
// on BitBucket at:
//
// https://bitbucket.org/hexmonks/main
//
//##################################################################
{$DEFINE USE_INCLUSIVE}
{$define USE_BMARK}
interface
uses
qtxlib, System, rtl,
RemObjects.Elements.RTL.Delphi,
RemObjects.Elements.RTL.Delphi.VCL;
type
// forward declarations
TTextBuffer = class;
TParserContext = class;
TCustomParser = class;
TParserModelObject = class;
// Exceptions
ETextBuffer = class(Exception);
EModelObject = class(Exception);
// Callback functions
TTextValidCB = function (Item: Char): Boolean;
// Bookmark datatype
TTextBufferBookmark = class
public
property bbOffset: Integer;
property bbCol: Integer;
property bbRow: Integer;
function Equals(const ThisMark: TTextBufferBookmark): Boolean;
end;
{.$DEFINE USE_BMARK}
TTextBuffer = class(TErrorObject)
private
FData: String;
FOffset: Integer;
FLength: Integer;
FCol: Integer;
FRow: Integer;
{$IFDEF USE_BMARK}
FBookmarks: List;
{$ENDIF}
procedure SetCacheData(NewText: String);
public
property Column: Integer read FCol;
property Row: Integer read FRow;
property Count: Integer read FLength;
property Offset: Integer read FOffset;
property CacheData: String read FData write SetCacheData;
// These functions map directly to the "Current"
// character where the offset is placed, and is used to
// write code that makes more sense to human eyes
function CrLf: Boolean;
function Space: Boolean;
function Tab: Boolean;
function SemiColon: Boolean;
function Colon: Boolean;
function ConditionEnter: Boolean;
function ConditionLeave: Boolean;
function BracketEnter: Boolean;
function BracketLeave: Boolean;
function Ptr: Boolean;
function Punctum: Boolean;
function Question: Boolean;
function Less: Boolean;
function More: Boolean;
function Equal: Boolean;
function Pipe: Boolean;
function Numeric: Boolean;
function Empty: Boolean;
function BOF: Boolean;
function EOF: Boolean;
function Current: Char;
function First: Boolean;
function Last: Boolean;
// Same as "Next", but does not automatically
// consume CR+LF, used when parsing textfragments
function NextNoCrLf: Boolean;
// Normal Next function, will automatically consume
// CRLF when it encounters it
function Next: Boolean;
function Back: Boolean;
function Bookmark: TTextBufferBookmark;
procedure Restore(const Mark: TTextBufferBookmark);
{$IFDEF USE_BMARK}
procedure Drop;
{$ENDIF}
procedure ConsumeJunk;
procedure ConsumeCRLF;
function Compare(const CompareText: String;
const CaseSensitive: Boolean): Boolean;
function Read(var Fragment: Char): Boolean; overload;
function Read: Char; overload;
function ReadTo(const CB: TTextValidCB; var TextRead: String): Boolean; overload;
function ReadTo(const Resignators: TSysCharSet; var TextRead: String): Boolean; overload;
function ReadTo(MatchText: String): Boolean; overload;
function ReadTo(MatchText: String; var TextRead: String): Boolean; overload;
function ReadToEOL: Boolean; overload;
function ReadToEOL(var TextRead: String): Boolean; overload;
function Peek: Char; overload;
function Peek(CharCount: Integer; var TextRead: String): Boolean; overload;
function NextNonControlChar(const CompareWith: Char): Boolean;
function NextNonControlText(const CompareWith: String): Boolean;
function ReadWord(var TextRead: String): Boolean;
function ReadQuotedString: String;
function ReadCommaList(var cList: List): Boolean;
function NextLine: Boolean;
procedure Inject(const TextToInject: String);
function GetCurrentLocation: TTextBufferBookmark;
function Trail: String;
procedure Clear;
procedure LoadBufferText(const NewBuffer: String);
constructor Create(const BufferText: String); overload; virtual;
finalizer;
begin
{$IFDEF USE_BMARK}
FBookmarks.Clear();
disposeAndNil(FBookmarks);
{$endif}
Clear();
end;
end;
TParserContext = class(TErrorObject)
private
FBuffer: TTextBuffer;
FStack: Stack;
public
property Buffer: TTextBuffer read FBuffer;
property Model: TParserModelObject;
procedure Push(const ModelObj: TParserModelObject);
function Pop: TParserModelObject;
function Peek: TParserModelObject;
procedure ClearStack;
constructor Create(const SourceCode: String); reintroduce; virtual;
finalizer;
begin
FStack.Clear();
FBuffer.Clear();
disposeAndNil(FStack);
disposeAndNil(FBuffer);
end;
end;
TCustomParser = class(TErrorObject)
private
FContext: TParserContext;
protected
procedure SetContext(const NewContext: TParserContext);
public
property Context: TParserContext read FContext;
function Parse: Boolean; virtual;
constructor Create(const ParseContext: TParserContext); reintroduce; virtual;
end;
TParserModelObject = class(TObject)
private
FParent: TParserModelObject;
FChildren: List;
protected
function GetParent: TParserModelObject; virtual;
function ChildGetCount: Integer; virtual;
function ChildGetItem(const Index: Integer): TParserModelObject; virtual;
function ChildAdd(const Instance: TParserModelObject): TParserModelObject; virtual;
public
property Parent: TParserModelObject read GetParent;
property Context: TParserContext;
procedure Clear; virtual;
constructor Create(const AParent: TParserModelObject); virtual;
finalizer;
begin
Clear();
FChildren := nil;
end;
end;
implementation
//#####################################################################
// Error messages
//#####################################################################
const
CNT_ERR_BUFFER_EMPTY = 'Buffer is empty error';
CNT_ERR_OFFSET_BOF = 'Offset at BOF error';
CNT_ERR_OFFSET_EOF = 'Offset at EOF error';
CNT_ERR_COMMENT_NOTCLOSED = 'Comment not closed error';
CNT_ERR_OFFSET_EXPECTED_EOF = 'Expected EOF error';
CNT_ERR_LENGTH_INVALID = 'Invalid length error';
//#####################################################################
// TTextBufferBookmark
//#####################################################################
function TTextBufferBookmark.Equals(const ThisMark: TTextBufferBookmark): boolean;
begin
result := ( (ThisMark nil) and (ThisMark self) )
and (self.bbOffset = ThisMark.bbOffset)
and (self.bbCol = ThisMark.bbCol)
and (self.bbRow = ThisMark.bbRow);
end;
//#####################################################################
// TTextBuffer
//#####################################################################
constructor TTextBuffer.Create(const BufferText: string);
begin
inherited Create();
if length(BufferText) > 0 then
LoadBufferText(BufferText)
else
Clear();
end;
procedure TTextBuffer.Clear;
begin
FData := '';
FOffset := -1;
FLength := 0;
FCol := -1;
FRow := -1;
{$IFDEF USE_BMARK}
FBookmarks.Clear();
{$ENDIF}
end;
procedure TTextBuffer.SetCacheData(NewText: string);
begin
LoadBufferText(NewText);
end;
function TTextBuffer.Trail: string;
begin
if not Empty then
begin
if not EOF then
result := FData.Substring(FOffset, length(FData) );
//result := Copy( FData, FOffset, length(FData) );
end;
end;
procedure TTextBuffer.LoadBufferText(const NewBuffer: string);
begin
// Flush existing buffer
Clear();
// Load in buffertext, init offset and values
var TempLen := NewBuffer.Length;
if TempLen > 0 then
begin
FData := NewBuffer;
FOffset := 0; // start at BOF
FCol := 0;
FRow := 0;
FLength := TempLen;
end;
end;
function TTextBuffer.GetCurrentLocation: TTextBufferBookmark;
begin
if Failed then
ClearLastError();
if not Empty then
begin
result := TTextBufferBookmark.Create;
result.bbOffset := FOffset;
result.bbCol := FCol;
result.bbRow := FRow;
end else
raise ETextBuffer.Create
('Failed to return position, buffer is empty error');
end;
function TTextBuffer.Bookmark: TTextBufferBookmark;
begin
if Failed then
ClearLastError();
if not Empty then
begin
result := TTextBufferBookmark.Create;
result.bbOffset := FOffset;
result.bbCol := FCol;
result.bbRow := FRow;
{$IFDEF USE_BMARK}
FBookmarks.add(result);
{$ENDIF}
end else
raise ETextBuffer.Create
('Failed to bookmark location, buffer is empty error');
end;
procedure TTextBuffer.Restore(const Mark: TTextBufferBookmark);
begin
if Failed then
ClearLastError();
if not Empty then
begin
if Mark nil then
begin
FOffset := Mark.bbOffset;
FCol := Mark.bbCol;
FRow := Mark.bbRow;
Mark.Free;
{$IFDEF USE_BMARK}
var idx := FBookmarks.Count;
if idx > 0 then
begin
dec(idx);
FOffset := FBookmarks[idx].bbOffset;
FCol := FBookmarks[idx].bbCol;
FRow := FBookmarks[idx].bbRow;
FBookmarks.Remove(idx);
//FBookmarks.SetLength(idx)
//FBookmarks.Delete(idx,1);
end else
raise ETextBuffer.Create('Failed to restore bookmark, none exist');
{$ENDIF}
end else
raise ETextBuffer.Create('Failed to restore bookmark, object was nil error');
end else
raise ETextBuffer.Create
('Failed to restore bookmark, buffer is empty error');
end;
{$IFDEF USE_BMARK}
procedure TTextBuffer.Drop;
begin
if Failed then
ClearLastError();
if not Empty then
begin
if FBookmarks.Count > 0 then
FBookmarks.Remove(FBookmarks.Count-1)
else
raise ETextBuffer.Create('Failed to drop bookmark, none exist');
end else
raise ETextBuffer.Create
('Failed to drop bookmark, buffer is empty error');
end;
{$ENDIF}
function TTextBuffer.Read(var Fragment: char): boolean;
begin
if Failed then
ClearLastError();
if not Empty then
begin
result := FOffset <= length(FData);
if result then
begin
// return character
Fragment := FData[FOffset];
// update offset
inc(FOffset)
end else
begin
// return invalid char
Fragment := #0;
// Set error reason
SetLastError('Offset at BOF error');
end;
end else
begin
result := false;
Fragment := #0;
SetLastError('Buffer is empty error');
end;
end;
function TTextBuffer.Read: char;
begin
if Failed then
ClearLastError();
if not Empty then
begin
result := Current;
Next();
end else
result := #0;
end;
function TTextBuffer.ReadToEOL: boolean;
begin
if Failed then
ClearLastError();
if not Empty() then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
// Keep start
var LStart := FOffset;
// Enum until match of EOF
{$IFDEF USE_INCLUSIVE}
repeat
if (FData[FOffset] = #13)
and (FData[FOffset + 1] = #10) then
begin
result := true;
break;
end else
begin
inc(FOffset);
inc(FCol);
end;
until EOF();
{$ELSE}
While FOffset < High(FData) do
begin
if (FData[FOffset] = #13)
and (FData[FOffset + 1] = #10) then
begin
result := true;
break;
end else
begin
inc(FOffset);
inc(FCol);
end;
end;
{$ENDIF}
// Last line in textfile might not have
// a CR+LF, so we have to check for termination
if not result then
begin
if EOF then
begin
if LStart = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset <= high(FData) ) )
and ( (FData[FOffset] = '= Low(FData)) and (FOffset ') );
end;
function TTextBuffer.Equal: boolean;
begin
result := (not Empty)
and ( (FOffset >= Low(FData)) and (FOffset = Low(FData)) and (FOffset = Low(FData)) and (FOffset LStart then
begin
// Any text to return? Or did we start
// directly on a CR+LF and have no text to give?
var LLen := FOffset - LStart;
TextRead := FData.Substring(LStart, LLen);
//TextRead := Copy(FData, LStart, LLen);
end;
// Either way, we exit because CR+LF has been found
result := true;
break;
end;
inc(FOffset);
inc(FCol);
until EOF();
{$ELSE}
While FOffset LStart then
begin
// Any text to return? Or did we start
// directly on a CR+LF and have no text to give?
var LLen := FOffset - LStart;
TextRead := copy(FData, LStart, LLen);
end;
// Either way, we exit because CR+LF has been found
result := true;
break;
end;
inc(FOffset);
inc(FCol);
end;
{$ENDIF}
// Last line in textfile might not have
// a CR+LF, so we have to check for EOF and treat
// that as a terminator.
if not result then
begin
if FOffset >= high(FData) then
begin
if LStart 0 then
begin
TextRead := FData.Substring(LStart, LLen);
//TextRead := Copy(FData, LStart, LLen);
result := true;
end;
exit;
end;
end;
end;
end;
end;
function TTextBuffer.ReadTo(const CB: TTextValidCB; var TextRead: string): boolean;
begin
if Failed then
ClearLastError();
TextRead := '';
if not Empty then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
if not assigned(CB) then
begin
SetLastError('Invalid callback handler');
exit;
end;
{$IFDEF USE_INCLUSIVE}
repeat
if not CB(Current) then
break
else
TextRead := TextRead + Current;
if not Next() then
break;
until EOF();
{$ELSE}
while not EOF do
begin
if not CB(Current) then
break
else
TextRead := TextRead + Current;
if not Next() then
break;
end;
{$ENDIF}
result := TextRead.Length > 0;
end else
begin
result := false;
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
end;
function TTextBuffer.ReadTo(const Resignators: TSysCharSet; var TextRead: string): boolean;
begin
if Failed then
ClearLastError();
TextRead := '';
if not Empty then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
{$IFDEF USE_INCLUSIVE}
repeat
if not Resignators.Contains(Current) then
TextRead := TextRead + Current
else
break;
if not Next() then
break;
until EOF();
{$ELSE}
while not EOF do
begin
if not (Current in Resignators) then
TextRead := TextRead + Current
else
break;
if not Next() then
break;
end;
{$ENDIF}
result := TextRead.Length > 0;
end else
begin
result := false;
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
end;
function TTextBuffer.ReadTo(MatchText: string): boolean;
begin
if Failed then
ClearLastError();
if not Empty() then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
var MatchLen := length(MatchText);
if MatchLen > 0 then
begin
MatchText := MatchText.ToLower();
repeat
var TempCache := '';
if Peek(MatchLen, TempCache) then
begin
TempCache := TempCache.ToLower();
result := SameText(TempCache, MatchText);
if result then
break;
end;
if not Next then
break;
until EOF;
end;
end else
begin
result := false;
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
end;
function TTextBuffer.ReadTo(MatchText: string; var TextRead: string): boolean;
begin
if Failed then
ClearLastError();
result := false;
TextRead := '';
if not Empty() then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
if MatchText.Length > 0 then
begin
MatchText := MatchText.ToLower();
repeat
var TempCache := '';
if Peek(MatchText.Length, TempCache) then
begin
TempCache := TempCache.ToLower();
result := SameText(TempCache, MatchText);
if result then
break
else
TextRead := TextRead + Current;
end else
TextRead := TextRead + Current;
if not Next() then
break;
until EOF;
end;
end else
begin
result := false;
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
end;
procedure TTextBuffer.Inject(const TextToInject: string);
begin
if length(FData) > 0 then
begin
var lSeg1 := FData.Substring(1, FOffset);
var lSeg2 := FData.Substring(FOffset + 1, length(FData));
//var LSeg1 := Copy(FData, 1, FOffset);
//var LSeg2 := Copy(FData, FOffset+1, FData.Length);
FData := lSeg1 + TextToInject + lSeg2;
end else
FData := TextToInject;
end;
function TTextBuffer.Compare(const CompareText: string;
const CaseSensitive: boolean): boolean;
begin
if Failed then
ClearLastError();
if not Empty() then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
var LenToRead := CompareText.Length;
if LenToRead > 0 then
begin
// Peek will set an error message if it
// fails, so we dont need to set anything here
var ReadData := '';
if Peek(LenToRead, ReadData) then
begin
case CaseSensitive of
false: result := ReadData.ToLower() = CompareText.ToLower();
true: result := ReadData = CompareText;
end;
end;
end else
SetLastError(CNT_ERR_LENGTH_INVALID);
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
procedure TTextBuffer.ConsumeJunk;
begin
if Failed then
ClearLastError();
if not Empty then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
repeat
case Current of
' ':
begin
end;
'"':
begin
break;
end;
#8, #09:
begin
end;
'/':
begin
(* Skip C style remark *)
if Compare('/*', false) then
begin
if ReadTo('*/') then
begin
inc(FOffset, 2);
Continue;
end else
SetLastError(CNT_ERR_COMMENT_NOTCLOSED);
end else
begin
(* Skip Pascal style remark *)
if Compare('//', false) then
begin
if ReadToEOL() then
begin
continue;
end else
SetLastError(CNT_ERR_OFFSET_EXPECTED_EOF);
end;
end;
end;
'(':
begin
(* Skip pascal style remark *)
if Compare('(*', false)
and not Compare('(*)', false) then
begin
if ReadTo('*)') then
begin
inc(FOffset, 2);
continue;
end else
SetLastError(CNT_ERR_COMMENT_NOTCLOSED);
end else
break;
end;
#13:
begin
if FData[FOffset + 1] = #10 then
inc(FOffset, 2)
else
inc(FOffset, 1);
//if Peek = #10 then
// ConsumeCRLF;
continue;
end;
#10:
begin
inc(FOffset);
continue;
end;
else
break;
end;
if not Next() then
break;
until EOF;
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
procedure TTextBuffer.ConsumeCRLF;
begin
if not Empty then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
if (FData[FOffset] = #13) then
begin
if FData[FOffset + 1] = #10 then
inc(FOffset, 2)
else
inc(FOffset);
inc(FRow);
FCol := 0;
end;
end;
end;
function TTextBuffer.Empty: boolean;
begin
result := FLength < 1;
end;
// This method will look ahead, skipping space, tab and crlf (also known
// as control characters), and when a non control character is found it will
// perform a string compare. This method uses a bookmark and will restore
// the offset to the same position as when it was entered.
//
// Notes: The method "NextNonControlChar" is a similar method that
// performs a char-only compare.
function TTextBuffer.NextNonControlText(const CompareWith: string): boolean;
begin
if Failed then
ClearLastError();
if not Empty then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
var Mark := Bookmark();
try
// Iterate ahead
repeat
if not (Current in [' ', #13, #10, #09]) then
break;
Next();
until EOF();
// Compare unless we hit the end of the line
if not EOF then
result := Compare(CompareWith, false);
finally
Restore(Mark);
end;
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
// This method will look ahead, skipping space, tab and crlf (also known
// as control characters), and when a non control character is found it will
// perform a string compare. This method uses a bookmark and will restore
// the offset to the same position as when it was entered.
function TTextBuffer.NextNonControlChar(const CompareWith: char): boolean;
begin
if Failed then
ClearLastError();
if not Empty then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
var Mark := Bookmark();
try
repeat
if not (Current in [' ', #13, #10, #09]) then
break;
Next();
until EOF();
//if not EOF then
result := Current.ToLower() = CompareWith.ToLower();
//result := LowerCase(Current) = LowerCase(CompareWith);
finally
Restore(Mark);
end;
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
function TTextBuffer.Peek: char;
begin
if Failed then
ClearLastError();
if not Empty then
begin
if (FOffset 0 do
begin
TextRead := TextRead + Current;
if not Next() then
break;
dec(CharCount);
end;
finally
Restore(Mark);
end;
result := TextRead.Length > 0;
end else
SetLastError(CNT_ERR_OFFSET_EOF);
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
function TTextBuffer.First: boolean;
begin
if Failed then
ClearLastError();
if not Empty then
begin
FOffset := Low(FData);
result := true;
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
function TTextBuffer.Last: boolean;
begin
if Failed then
ClearLastError();
if not Empty then
begin
FOffset := high(FData);
result := true;
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
function TTextBuffer.NextNoCrLf: boolean;
begin
if Failed then
ClearLastError();
if not Empty then
begin
// Check that we are not EOF
result := FOffset <= high(FData);
if result then
begin
// Update offset into buffer
inc(FOffset);
// update column, but not if its in a lineshift
if not (FData[FOffset] in [#13, #10]) then
inc(FCol);
end else
SetLastError(CNT_ERR_OFFSET_EOF);
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
function TTextBuffer.Next: boolean;
begin
if Failed then
ClearLastError();
if not Empty() then
begin
if BOF() then
begin
if not First() then
exit;
end;
if EOF() then
begin
SetLastError(CNT_ERR_OFFSET_EOF);
exit;
end;
// Update offset into buffer
inc(FOffset);
// update column
inc(FCol);
// This is the same as ConsumeCRLF
// But this does not generate any errors since we PEEK
// ahead into the buffer to make sure the combination
// is correct before we adjust the ROW + offset
if FOffset Low(FData));
if result then
dec(FOffset)
else
SetLastError(CNT_ERR_OFFSET_BOF);
end else
SetLastError(CNT_ERR_BUFFER_EMPTY);
end;
function TTextBuffer.Current: char;
begin
if Failed then
ClearLastError();
// Check that buffer is not empty
if not Empty then
begin
// Check that we are on char 1 or more
if FOffset >= Low(FData) then
begin
// Check that we are before or on the last char
if (FOffset <= high(FData)) then
result := FData[FOffset]
else
begin
SetLastError(CNT_ERR_OFFSET_EOF);
result := #0;
end;
end else
begin
SetLastError(CNT_ERR_OFFSET_BOF);
result := #0;
end;
end else
begin
SetLastError(CNT_ERR_BUFFER_EMPTY);
result := #0;
end;
end;
function TTextBuffer.BOF: boolean;
begin
if not Empty then
result := FOffset high(FData);
end;
function TTextBuffer.NextLine: boolean;
begin
if Failed then
ClearLastError();
if not Empty then
begin
// Make sure we offset to a valid character
// in the buffer.
ConsumeJunk();
if not EOF then
begin
var ThisRow := self.FRow;
while Row = ThisRow do
begin
Next();
if EOF then
break;
end;
result := (Row ThisRow) and (not EOF);
end;
end;
end;
function TTextBuffer.ReadWord(var TextRead: string): boolean;
begin
if Failed then
ClearLastError();
TextRead := '';
if not Empty then
begin
// Make sure we offset to a valid character
// in the buffer.
ConsumeJunk();
// Not at the end of the file?
if not EOF then
begin
repeat
var el := Current;
if (el in
[ 'A'..'Z',
'a'..'z',
'0'..'9',
'_', '-' ]) then
TextRead := TextRead + el
else
break;
if not NextNoCrLf() then
break;
until EOF;
result := TextRead.Length > 0;
end else
SetLastError('Failed to read word, unexpected EOF');
end else
SetLastError('Failed to read word, buffer is empty error');
end;
function TTextBuffer.ReadCommaList(var cList: List): boolean;
var
LTemp: String;
LValue: String;
begin
if cList = nil then
cList := new List
else
cList.Clear();
if not Empty then
begin
ConsumeJunk();
While not EOF do
begin
case Current of
#09:
begin
// tab, just skip
end;
#13, #10:
begin
// CR+LF, consume and continue;
ConsumeCRLF();
end;
#0:
begin
// Unexpected EOL
break;
end;
';':
begin
//Perfectly sound ending
result := true;
break;
end;
'"':
begin
LValue := ReadQuotedString;
if LValue.Length > 0 then
begin
cList.add(LValue);
LValue := '';
end;
end;
',':
begin
LTemp := LTemp.Trim();
if LTemp.Length>0 then
begin
cList.add(LTemp);
LTemp := '';
end;
end;
else
begin
LTemp := LTemp + Current;
end;
end;
if not Next() then
break;
end;
if LTemp.Length > 0 then
cList.add(LTemp);
result := cList.Count > 0;
end;
end;
function TTextBuffer.ReadQuotedString: string;
begin
if not Empty then
begin
if not EOF then
begin
// Make sure we are on the " entry quote
if Current '"' then
begin
SetLastError('Failed to read quoted string, expected index on " character error');
exit;
end;
// Skip the entry char
if not NextNoCrLf() then
begin
SetLastError('Failed to skip initial " character error');
exit;
end;
while not EOF do
begin
// Read char from buffer
var TempChar := Current;
// Closing of string? Exit
if TempChar = '"' then
begin
if not NextNoCrLf then
SetLastError('failed to skip final " character in string error');
break;
end;
result := result + TempChar;
if not NextNoCrLf() then
break;
end;
end;
end;
end;
//##########################################################################
// TParserModelObject
//##########################################################################
constructor TParserModelObject.Create(const AParent:TParserModelObject);
begin
inherited Create;
FParent := AParent;
FChildren := new List;
end;
function TParserModelObject.GetParent:TParserModelObject;
begin
result := FParent;
end;
procedure TParserModelObject.Clear;
begin
FChildren.Clear();
end;
function TParserModelObject.ChildGetCount: integer;
begin
result := FChildren.Count;
end;
function TParserModelObject.ChildGetItem(const Index: integer): TParserModelObject;
begin
result := TParserModelObject(FChildren[Index]);
end;
function TParserModelObject.ChildAdd(const Instance: TParserModelObject): TParserModelObject;
begin
if FChildren.IndexOf(Instance) < 0 then
FChildren.add(Instance);
result := Instance;
end;
//###########################################################################
// TParserContext
//###########################################################################
constructor TParserContext.Create(const SourceCode: string);
begin
inherited Create;
FBuffer := TTextBuffer.Create(SourceCode);
FStack := new Stack;
end;
procedure TParserContext.Push(const ModelObj: TParserModelObject);
begin
if Failed then
ClearLastError();
try
FStack.Push(ModelObj);
except
on e: Exception do
SetLastError('Internal error:' + e.Message);
end;
end;
function TParserContext.Pop: TParserModelObject;
begin
if Failed then
ClearLastError();
try
result := FStack.Pop();
except
on e: Exception do
SetLastError('Internal error:' + e.Message);
end;
end;
function TParserContext.Peek: TParserModelObject;
begin
if Failed then
ClearLastError();
try
result := FStack.Peek();
except
on e: Exception do
SetLastError('Internal error:' + e.Message);
end;
end;
procedure TParserContext.ClearStack;
begin
if Failed then
ClearLastError();
try
FStack.Clear();
except
on e: Exception do
SetLastError('Internal error:' + e.Message);
end;
end;
//###########################################################################
// TCustomParser
//###########################################################################
constructor TCustomParser.Create(const ParseContext: TParserContext);
begin
inherited Create;
FContext := ParseContext;
end;
function TCustomParser.Parse: boolean;
begin
result := false;
SetLastErrorF('No parser implemented for class %s',[ClassName]);
end;
procedure TCustomParser.SetContext(const NewContext: TParserContext);
begin
FContext := NewContext;
end;
end.
time, not always in a positive light though. Just to be clear, FPC (the compiler) is fantastic; it was one particular fork of Lazarus I had issues with, involving a license violation.
Show full content
Freepascal is not frequently mentioned on my blog. I have written about it from time to time, not always in a positive light though. Just to be clear, FPC (the compiler) is fantastic; it was one particular fork of Lazarus I had issues with, involving a license violation.
On the whole, freepascal and Lazarus is capable of great things. There are a few quirks here and there (if not oddities) that prevents mass adoption (the excessive use of include-files to “fake” partial classes being one), but as object-pascal compilers go, Freepascal is a battle-hardened, production ready system.
It’s been Linux in particular that I have used Freepascal on. In 2015 Hydro Oil wanted to move their back-end from Windows to Linux, and I spent a few months converting windows-only services into Linux daemons.
Today I find myself converting parts of the toolkit I came up with to Oxygene, but that’s a post for another day.
Generic protect
If you work a lot with multithreaded code, the unit im posting here might come in handy. Long story short: sharing composite objects between threads and the main process, always means extra scaffolding. You have to make sure you don’t access the list (or it’s elements) at the same time as another thread for example. To ensure this you can either use a critical-section, or you can deliver the data with a synchronized call. This is more or less universal for all languages, no matter if you are using Oxygene, C/C++, C# or Delphi.
When this unit came into being, I was doing quite elaborate classes with a lot of lists. These classes could not share ancestor, or I could have gotten away with just one locking mechanism. Instead I had to implement the same boilerplate code over and over again.
The unit below makes insulating (or protecting) classes easier. It essentially envelopes whatever class-instance you feed it, and returns the proxy object. Whenever you want to access your instance, you have to unlock it first or use a synchronizer (see below).
Works in both Freepascal and Delphi
The unit works for both Delphi and Freepascal, but there is one little difference. For some reason Freepascal does not support anonymous procedures, so we compensate and use inline-procedures instead. While not a huge deal, I really hope the FPC team add anonymous procedures, it makes life a lot easier for generics based code. Async programming without anonymous procedures is highly impractical too.
So if you are in Delphi you can write:
var
lValue: TProtectedValue;
lValue.Synchronize( procedure (var Value: integer)
begin
Value := Value * 12;
end);
But under Freepascal you must resort to:
var
lValue: TProtectedValue;
procedure _UpdateValue(var Data: integer);
begin
Data := Data * 12;
end;
begin
lValue.Synchronize(@_UpdateValue);
end;
On small examples like these, the benefit of this style of coding might be lost; but if you suddenly have 40-50 lists that needs to be shared between 100-200 active threads, it will be a time saver!
You can also use it on intrinsic datatypes:
OK, here we go:
unit safeobjects;
// SafeObjects
// ==========================================================================
// Written by Jon-Lennart Aasenden
// Copyright Quartex Components LTD, all rights reserved
//
// This unit is a part of the QTX Patreon Library
//
// NOTES ABOUT FREEPASCAL:
// =======================
// Freepascal does not allow anonymous procedures, which means we must
// resort to inline procedures instead:
//
// Where we in Delphi could write the following for an atomic,
// thread safe alteration:
//
// var
// LValue: TProtectedValue;
//
// LValue.Synchronize( procedure (var Value: integer)
// begin
// Value := Value * 12;
// end);
//
// Freepascal demands that we use an inline procedure instead, which
// is more or less the same code, just organized slightly differently.
//
// var
// LValue: TProtectedValue;
//
// procedure _UpdateValue(var Data: integer);
// begin
// Data := Data * 12;
// end;
//
// begin
// LValue.Synchronize(@_UpdateValue);
// end;
//
//
//
//
{$mode DELPHI}
{$H+}
interface
uses
{$IFDEF FPC}
SysUtils,
Classes,
SyncObjs,
Generics.Collections;
{$ELSE}
System.SysUtils,
System.Classes,
System.SyncObjs,
System.Generics.Collections;
{$ENDIF}
type
{$DEFINE INHERIT_FROM_CRITICALSECTION}
TProtectedValueAccessRights = set of (lvRead, lvWrite);
EProtectedValue = class(exception);
EProtectedObject = class(exception);
(* Thread safe intrinsic datatype container.
When sharing values between processes, use this class
to make read/write access safe and protected. *)
{$IFDEF INHERIT_FROM_CRITICALSECTION}
TProtectedValue = class(TCriticalSection)
{$ELSE}
TProtectedValue = class(TObject)
{$ENDIF}
strict private
{$IFNDEF INHERIT_FROM_CRITICALSECTION}
FLock: TCriticalSection;
{$ENDIF}
FData: T;
FOptions: TProtectedValueAccessRights;
strict protected
function GetValue: T;virtual;
procedure SetValue(Value: T);virtual;
function GetAccessRights: TProtectedValueAccessRights;
procedure SetAccessRights(Rights: TProtectedValueAccessRights);
public
type
{$IFDEF FPC}
TProtectedValueEntry = procedure (var Data: T);
{$ELSE}
TProtectedValueEntry = reference to procedure (var Data: T);
{$ENDIF}
public
constructor Create(Value: T); overload; virtual;
constructor Create(Value: T; const Access: TProtectedValueAccessRights); overload; virtual;
constructor Create(const Access: TProtectedValueAccessRights); overload; virtual;
destructor Destroy;override;
{$IFNDEF INHERIT_FROM_CRITICALSECTION}
procedure Enter;
procedure Leave;
{$ENDIF}
procedure Synchronize(const Entry: TProtectedValueEntry);
property AccessRights: TProtectedValueAccessRights read GetAccessRights;
property Value: T read GetValue write SetValue;
end;
(* Thread safe object container.
NOTE #1: This object container **CREATES** the instance and maintains it!
Use Edit() to execute a protected block of code with access
to the object.
Note #2: SetValue() does not overwrite the object reference, but
attempts to perform TPersistent.Assign(). If the instance
does not inherit from TPersistent an exception is thrown. *)
TProtectedObject = class(TObject)
strict private
FData: T;
FLock: TCriticalSection;
FOptions: TProtectedValueAccessRights;
strict protected
function GetValue: T;virtual;
procedure SetValue(Value: T);virtual;
function GetAccessRights: TProtectedValueAccessRights;
procedure SetAccessRights(Rights: TProtectedValueAccessRights);
public
type
{$IFDEF FPC}
TProtectedObjectEntry = procedure (const Data: T);
{$ELSE}
TProtectedObjectEntry = reference to procedure (const Data: T);
{$ENDIF}
public
property Value: T read GetValue write SetValue;
property AccessRights: TProtectedValueAccessRights read GetAccessRights;
function Lock: T;
procedure Unlock;
procedure Synchronize(const Entry: TProtectedObjectEntry);
Constructor Create(const AOptions: TProtectedValueAccessRights = [lvRead,lvWrite]); virtual;
Destructor Destroy; override;
end;
(* TProtectedObjectList:
This is a thread-safe object list implementation.
It works more or less like TThreadList, except it deals with objects *)
TProtectedObjectList = class(TInterfacedPersistent)
strict private
FObjects: TObjectList;
FLock: TCriticalSection;
strict protected
function GetEmpty: boolean;virtual;
function GetCount: integer;virtual;
(* QueryObject Proxy: TInterfacedPersistent allows us to
act as a proxy for QueryInterface/GetInterface. Override
and provide another child instance here to expose
interfaces from that instread *)
protected
function GetOwner: TPersistent;override;
public
type
{$IFDEF FPC}
TProtectedObjectListProc = procedure (Item: TObject; var Cancel: boolean);
{$ELSE}
TProtectedObjectListProc = reference to procedure (Item: TObject; var Cancel: boolean);
{$ENDIF}
public
constructor Create(OwnsObjects: Boolean = true); virtual;
destructor Destroy; override;
function Contains(Instance: TObject): boolean; virtual;
function Enter: TObjectList; virtual;
Procedure Leave; virtual;
Procedure Clear; virtual;
procedure ForEach(const CB: TProtectedObjectListProc); virtual;
Property Count: integer read GetCount;
Property Empty: boolean read GetEmpty;
end;
implementation
//############################################################################
// TProtectedObjectList
//############################################################################
constructor TProtectedObjectList.Create(OwnsObjects: Boolean = True);
begin
inherited Create;
FObjects := TObjectList.Create(OwnsObjects);
FLock := TCriticalSection.Create;
end;
destructor TProtectedObjectList.Destroy;
begin
FLock.Enter;
FObjects.Free;
FLock.Free;
inherited;
end;
procedure TProtectedObjectList.Clear;
begin
FLock.Enter;
try
FObjects.Clear;
finally
FLock.Leave;
end;
end;
function TProtectedObjectList.GetOwner: TPersistent;
begin
result := NIL;
end;
procedure TProtectedObjectList.ForEach(const CB: TProtectedObjectListProc);
var
LItem: TObject;
LCancel: Boolean;
begin
LCancel := false;
if assigned(CB) then
begin
FLock.Enter;
try
{$HINTS OFF}
for LItem in FObjects do
begin
LCancel := false;
CB(LItem, LCancel);
if LCancel then
break;
end;
{$HINTS ON}
finally
FLock.Leave;
end;
end;
end;
function TProtectedObjectList.Contains(Instance: TObject): boolean;
begin
result := false;
if assigned(Instance) then
begin
FLock.Enter;
try
result := FObjects.Contains(Instance);
finally
FLock.Leave;
end;
end;
end;
function TProtectedObjectList.GetCount: integer;
begin
FLock.Enter;
try
result :=FObjects.Count;
finally
FLock.Leave;
end;
end;
function TProtectedObjectList.GetEmpty: Boolean;
begin
FLock.Enter;
try
result := FObjects.Count<1;
finally
FLock.Leave;
end;
end;
function TProtectedObjectList.Enter: TObjectList;
begin
FLock.Enter;
result := FObjects;
end;
procedure TProtectedObjectList.Leave;
begin
FLock.Leave;
end;
//############################################################################
// TProtectedObject
//############################################################################
constructor TProtectedObject.Create(const AOptions: TProtectedValueAccessRights = [lvRead, lvWrite]);
begin
inherited Create;
FLock := TCriticalSection.Create;
FLock.Enter();
try
FOptions := AOptions;
FData := T.Create;
finally
FLock.Leave();
end;
end;
destructor TProtectedObject.Destroy;
begin
FData.free;
FLock.Free;
inherited;
end;
function TProtectedObject.GetAccessRights: TProtectedValueAccessRights;
begin
FLock.Enter;
try
result := FOptions;
finally
FLock.Leave;
end;
end;
procedure TProtectedObject.SetAccessRights(Rights: TProtectedValueAccessRights);
begin
FLock.Enter;
try
FOptions := Rights;
finally
FLock.Leave;
end;
end;
function TProtectedObject.Lock: T;
begin
FLock.Enter;
result := FData;
end;
procedure TProtectedObject.Unlock;
begin
FLock.Leave;
end;
procedure TProtectedObject.Synchronize(const Entry: TProtectedObjectEntry);
begin
if assigned(Entry) then
begin
FLock.Enter;
try
Entry(FData);
finally
FLock.Leave;
end;
end;
end;
function TProtectedObject.GetValue: T;
begin
FLock.Enter;
try
if (lvRead in FOptions) then
result := FData
else
raise EProtectedObject.CreateFmt('%s:Read not allowed error',[classname]);
finally
FLock.Leave;
end;
end;
procedure TProtectedObject.SetValue(Value: T);
begin
FLock.Enter;
try
if (lvWrite in FOptions) then
begin
if (TObject(FData) is TPersistent)
or (TObject(FData).InheritsFrom(TPersistent)) then
TPersistent(FData).Assign(TPersistent(Value))
else
raise EProtectedObject.CreateFmt
('Locked object assign failed, %s does not inherit from %s',
[TObject(FData).ClassName,'TPersistent']);
end else
raise EProtectedObject.CreateFmt('%s:Write not allowed error',[classname]);
finally
FLock.Leave;
end;
end;
//############################################################################
// TProtectedValue
//############################################################################
Constructor TProtectedValue.Create(const Access: TProtectedValueAccessRights);
begin
inherited Create;
{$IFNDEF INHERIT_FROM_CRITICALSECTION}
FLock := TCriticalSection.Create;
{$ENDIF}
FOptions := Access;
end;
constructor TProtectedValue.Create(Value: T);
begin
inherited Create;
{$IFNDEF INHERIT_FROM_CRITICALSECTION}
FLock := TCriticalSection.Create;
{$ENDIF}
FOptions := [lvRead, lvWrite];
FData := Value;
end;
constructor TProtectedValue.Create(Value: T; const Access: TProtectedValueAccessRights);
begin
inherited Create;
{$IFNDEF INHERIT_FROM_CRITICALSECTION}
FLock := TCriticalSection.Create;
{$ENDIF}
FOptions := Access;
FData := Value;
end;
Destructor TProtectedValue.Destroy;
begin
{$IFNDEF INHERIT_FROM_CRITICALSECTION}
FLock.Free;
{$ENDIF}
inherited;
end;
function TProtectedValue.GetAccessRights: TProtectedValueAccessRights;
begin
Enter();
try
result := FOptions;
finally
Leave();
end;
end;
procedure TProtectedValue.SetAccessRights(Rights: TProtectedValueAccessRights);
begin
Enter();
try
FOptions := Rights;
finally
Leave();
end;
end;
{$IFNDEF INHERIT_FROM_CRITICALSECTION}
procedure TProtectedValue.Enter;
begin
FLock.Enter;
end;
procedure TProtectedValue.Leave;
begin
FLock.Leave;
end;
{$ENDIF}
procedure TProtectedValue.Synchronize(const Entry: TProtectedValueEntry);
begin
if assigned(Entry) then
Begin
Enter();
try
Entry(FData);
finally
Leave();
end;
end;
end;
function TProtectedValue.GetValue: T;
begin
Enter();
try
if (lvRead in FOptions) then
result := FData
else
raise EProtectedValue.CreateFmt('%s: Read not allowed error', [Classname]);
finally
Leave();
end;
end;
procedure TProtectedValue.SetValue(Value: T);
begin
Enter();
try
if (lvWrite in FOptions) then
FData:=Value
else
raise EProtectedValue.CreateFmt('%s: Write not allowed error', [Classname]);
finally
Leave();
end;
end;
end.
In this post I will talk about The Desktop API and how it works. This is more practical information - and its the information that will help you when you start coding applications meant to integrate closely with the system.
Show full content
The Quartex Media Desktop (codename Amibian.js) has gotten a lot of cool attention lately. But telling people why it’s so awesome is not always easy. Not everyone is a software developer, and even then – very few Oxygene, Lazarus or Delphi developers have my level of background into HTML5/JS. Not that I have some hidden talent others lack, but rather that I have spent years working on this particular hybrid technology. And summing it all up is a tall order.
The Quartex Media Desktop has come a long way
Once in a while I post a few words about why the desktop matters, and why the system is going to be very important for developers and users alike. It’s growing at a rapid pace, with more and more of the underlying mechanics surfacing. I mean, me spending a month solving god knows how much – don’t mean a thing to users that just was a cool desktop. Some frankly don’t care how it works at all.
Well, in this post I will talk about The Desktop API and how it works. This is more practical information – and its the information that will help you when you start coding applications meant to integrate closely with the system.
The visual desktop
The desktop, despite being a pretty front end, serves no purpose right? Well you could not be more wrong, because there are layers of code beneath the pretty exterior that is unique to the world of JavaScript. But before we dig into that, lets have a look at how the desktop is organized.
The desktop organization is very simple, but highly effective
System Menu
The Quartex Media Desktop (nicknamed “Amibian.js”) follows a long tradition where a small part of the display is always occupied by a system-menu. The menu, once learned is a powerful tool. One that will help you navigate around the system faster.
Menu app-region
The system menu is also capable of hosting smaller, helper applications. The main menu reserves a small region for such apps, simply called the menu app region. This region can stretch depending on it’s content. But such mini-apps are expected with use as little space as possible, with a hard limit of 300 pixels each.
Amibian.js ships with two standard menu apps, those are integral to the system and cannot be deleted, only disabled.
Time and date
Account name and IP address
Icon Dock
The Icon dock should be no stranger. Ubuntu Linux has a similar dock (albeit on the left side of the display), and in Windows you can create as many docking regions as you see fit. So a good docking bar is a good thing.
The purpose is to have your favorite applications readily available when you login to your system.
There is not that much to write about the icon-dock. You can edit the list of items there and change other options in the preferences. The dock can alight to the right, the left and even to the bottom of the screen.
The first button on the dock, will always be a quick-link to the preferences display. Instead of isolating preferences outside the desktop, as a separate process. I have made it intrinsic. So clicking on the Preferences button will slide the desktop out of view, and the preferences screen into view.
The preferences view is still under construction, but its always the first item on the dock
Hosted Software
After this quick tour of the superficial, visual layer of the desktop, you could be forgiven for thinking this is all there is too it. Perhaps you imagine that “starting a program” is just loading stuff into frames and making it look like windows?
Actually, its a lot more elaborate that!
The purpose of the Quartex Media Desktop is to provide developers with common grounds. The market is filled with these juiced up, blinged to the hilt, superficial and outright fraudulent “web desktops”. Any idiot can sit down and make a website that looks like a desktop. Which is also why these desktop’s can do much beyond their initial programming.
You also have companies like CodeStamp that use native languages like C/C++ to create a custom server which deals with the grunt-work. Something I find amusing, but mostly sad. They have spent a fortune re-inventing technology that was made available 20 years ago, and that has been in use ever since.
The problem with these companies is that they are dinosaurs. I could have finished Quartex Media Desktop in a few months if I used Delphi or C++ builder. What CodeStamp have missed, is that their so-called revolutionary idea has been active and running for close to 20 years in the Delphi community. We are falling over each other in options for web desktops. I can have a fully fledged, theme based desktop up and running in less than a work day — with kick ass, llvm optimized, bug free code compiled for Windows, Linux and OS X.
The challenge, which is where the true values exists, is to get rid of native code. To write not just the client (desktop) in JavaScript, but beyond all — to write the entire back-end as Javascript! Only then do we have a truly portable and truly scalable platform to build on.
Amibian.js is designed to deal with 4 types of executables:
Local web applications
Remote web applications
LDEF bytecode binaries
Server-side shell
Let’s look at the first two since these fall into the category of “hosted applications”.
A hosted application is a normal web app that can run anywhere. It can be a simple website if you like. And like i mentioned above, external resources are always executed within the safe confounds of an iFrame.
Amibian.js allows hosted applications to call system functions that the desktop exposes. But in order for that to happen, the application must first complete a security process. But once the application is recognized and known (a process known as hand-shaking), the hosted application can integrate tightly with the desktop – so tight that it becomes indistinguishable from a local application.
But more importantly: communication between the desktop and a hosted application, is exclusively through messages. The hosted application cannot call potentially dangerous code, neither directly or indirectly. The methods it can call is held in check by the security policy for that program, which is under your control. So a bit of thought has gone into this work.
The desktop API
Behind the sweet exterior of our desktop, there are practically thousands of functions. And we must not forget that the back-end servers (Quartex Media Desktop is a distributed, clustered system).
Some of the functions a hosted-program can call, might actually exist on the server. So the desktop will accept the call, but relay that call to the back-end. When the call finishes, the response is likewise routed back to the application that initiated it.
For example, if a hosted application wants to display a “load-file requester”, it would call a function named ShowRequesterFile(). This is a proxy method in the public framework that constructs a message for you, and then send that message to the desktop (browsers use pipes internally).
A hosted application calling the ShowRequesterFile() API method. The desktop will go into modal mode and show the requester, just like you would expect from a native application
The desktop receives the message and executes the code designated for it. This involves setting the screen into modal mode, and show the “open file” dialog. When the user selects a file and the dialog closes, the result is shipped back to the application. The hosted application itself is never in direct contact with the filesystem. That is an important distinction.
Also, like mentioned earlier – some of the functions exposed by the public framework, is not a part of the desktop at all. The code to enumerate files and folders is not a part of the HTML5 code (obviously). So the desktop relay such calls to the back-end server(s) and further relay the response when that arrives.
System services
In my next article on the Quartex Media Desktop, we will have a peek at the system services and some of the functions they expose.
DelphiObject PascalRaspberry PIRemobjectselementsOxygeneraspberry pi 4
It was with astonishment that I opened up my browser this morning to read some daily IT news, only to discover that the Raspberry PI v4 has finally arrived! And boy what a landslide update to the 3.x family it is! Three times the fun There are plenty of sites that entertains page-up and page-down […]
Show full content
It was with astonishment that I opened up my browser this morning to read some daily IT news, only to discover that the Raspberry PI v4 has finally arrived! And boy what a landslide update to the 3.x family it is!
Three times the fun
There are plenty of sites that entertains page-up and page-down with numbers, but I will save all that for an article where I have the physical kit in my posession. But looking at the preliminaries I think it’s safe to say that we are looking at a solid 3x the speed of the older yet capable PI 3b+.
The PI returns, and what a joy it is!
While the 3x speed boost is enough to bump the SoC up, from entertaining to serious for business applications – it’s ultimately the memory footprint that will make all the difference. While the Raspberry PI is probably the most loved SBC (single board computer) of all time, it’s always been cut short due to lack of memory. 512 megabyte can only do so much in 2019, and even the slimmest of Linux distributions quickly consumes more ram that older versions could supply.
VideoCore 6, two screens and 4k video
The new model ships in three different configurations, with 1, 2 and 4 gigabytes of ram respectively. I strongly urge people to get the 4Gb version, because with that amount of memory coupled with a good solid-state-disk, means you can enable a proper swap-partition. No matter how fast a SoC might be, without memory to compliment it – the system simply wont be able to deliver on its potential. But with 4Gb, a nice solid state disk (just use a SSD-To-USB with one of the sexy new USB 3.x ports) and you are looking at an OK mini-computer capable of most desktop applications.
I have to admit I never expected the PI to ship with support for two monitors, but lo-and-behold, the board has two mini-hdmi out ports! The board is also fitted with the VideCore 6 rather than VideoCore 4.
Not missing the boat with Oxygene and Elements
One of the most frustrating episodes in the history of Delphi, is that we never got a Delphi edition that could target Raspberry PI (or ARM-Linux in general). It was especially frustrating since Allen Bauer actually demonstrated Delphi generating code that ran on a PI in 2012. The result of not directly supporting the PI, even on service level without a UI layer – is that Delphi developers have missed the IOT market completely.
Before Delphi developers missed the IOT revolution, Delphi also missed out on iOS and Android. By the time Delphi developers could target any of these platforms, the market was completely saturated, and all opportunities to make money was long gone. In other words, Delphi has missed the boat on 3 revolutionary platforms in a row. Something which is borderline unforgivable.
The good news though is that Oxygene, the object-pascal compiler from RemObjects, supports the Raspberry PI SoC. I have yet to test this on v4, but since the PI v4 is 100% backwards compatible I don’t see any reason why there should be any issues. The code generated by Oxygene is not bound to just the PI either. As long as it runs on a debian based distro, it should run just fine on most ARM-Linux SoC’s that have working drivers.
And like I have written about elsewhere, you can also compile for WebAssembly, running either in node.js or in the browser — so there are plenty of ways to get your products over!
Stay tuned for the lineup
This week im going to do a lot of testing on various ARM devices to find out just how many SBC’s Oxygene can target, starting with the ODroid N2. But for Raspberry PI, that should be a slam-dunk. Meaning that object-pascal developers can finally make use of affordable off-the-shelves parts in their hardware projects.
As of writing im preparing the various boards I will be testing. We have the PI 3b+, the Tinkerboard from ASUS, NanoPI, Dragonboard, Odroid XU4 – and the latest power-board, the ODroid N2. Out of these offerings only the N2 is en-par with the Raspberry PI v4, although I suspect the Videocore 6 GPU will outperform the Mali G52.
This means that you can now use forms and units from .net and Java from your Freepascal applications - and (drumroll) also mix and match between Delphi, .net, Java and FPC modules! So if you see something cool that Freepascal lacks, just slap it in a Hydra module and you can use it across language barriers.
Show full content
In case you guys missed it, RemObjects Hydra 6.2 now supports FreePascal!
This means that you can now use forms and units from .net and Java from your Freepascal applications – and (drumroll) also mix and match between Delphi, .net, Java and FPC modules! So if you see something cool that Freepascal lacks, just slap it in a Hydra module and you can use it across language barriers.
I have used Hydra for years with Delphi, and being able to use .net forms and components in Delphi is pretty awesome. It’s also a great framework for building modular applications that are easier to manage.
Being able to tap into Freepascal is a great feature. Or the other way around, with Freepascal showing forms from Delphi, .net or Java.
For example, if you are moving to Freepascal, you can isolate the forms or controls that are not available under Freepascal in a Hydra module, and voila – you can gradually migrate.
If you are moving to Oxygene Pascal the same applies, you can implement the immediate logic under .net, and then import and use the parts that can’t easily be ported (or that you want to wait with).
For a guy that spends most of his time online, and can talk for hours about the most nerdy topics known to mankind – being gobsmacked and silenced is a rare event. But this morning that was exactly what happened. Now, Marc Hoffman has blogged regularly over the years regarding the evolution of the RemObjects […]
Show full content
For a guy that spends most of his time online, and can talk for hours about the most nerdy topics known to mankind – being gobsmacked and silenced is a rare event. But this morning that was exactly what happened.
Now, Marc Hoffman has blogged regularly over the years regarding the evolution of the RemObjects toolchain; explaining how they decoupled the parts that make up a programming language, such as syntax, rtl and target, but I must admit haven’t really digested the full implications of that work.
Like most developers I have kept my eyes on the parts relevant for me, like the Remoting SDK, Data Abstract and Javascript support. Before I worked at Embarcadero I pretty much spent 10 years contracting -and building Smart Mobile Studio on the side together with the team at The Smart Company Inc.
Smart Pascal gained support for RemObjects SDK servers quite early
Since both the Remoting SDK and Data Abstract were part of our toolbox as Delphi developers, those were naturally more immediate than anything else. We also added support for RemObjects Remoting SDK inside Smart Mobile Studio, so that people could call existing services from their Javascript applications.
Oxygene then
Like most Delphi developers I remember testing Oxygene Pascal when I bought Delphi 2005. Back then Oxygene was licensed by Borland under the “Prism” name and represented their take on dot net support. I was very excited when it came out, but since my knowledge of the dot net framework was nil, I was 100% relient on the documentation.
In many ways Oxygene was a victim of Rad Studio’s abhorrent help-file system. Documentation for Rad Studio (especially Delphi) up to that point had been exemplary since Delphi 4; but by the time Rad Studio 2005 came out, the bloat had reached epic levels. Even for me as a die-hard Delphi fanatic, Delphi 2005 and 2006 was a tragic experience.
Removing Oxygene was a monumental mistake
I mean, when it takes 15 minutes (literally) just to open the docs, then learning a whole new programming paradigm under those conditions was quite frankly impossible. Like most Delphi developers I was used to Delphi 7 style documentation, where the docs were not just reference material – but actually teaches you the language itself.
In the end Oxygene remained very interesting, but with a full time job, deadlines and kids to take care of, I stuck to what I knew – namely the VCL.
Oxygene today
Just like Delphi has evolved and improved radically since 2005, Oxygene has likewise evolved above and beyond its initial form. Truth be told, we copied a lot of material from Oxygene when we made Smart Pascal, so I feel strangely at home with Oxygene even after a couple of days. The documentation for Oxygene Pascal (and Elements as a whole) is very good: https://docs.elementscompiler.com/Oxygene/
But Oxygene Pascal, while the obvious “first stop” for Delphi developers looking to expand their market impact, is more than “just a language”. It’s a language that is a part of a growing family of languages that RemObjects support and evolve.
As of writing RemObjects offers the following languages. So even if you don’t have a background in Delphi, or perhaps migrated from Delphi to C# years ago – RemObjects will have solutions and benefits to offer:
Oxygene (object pascal)
C#
Swift
Java
Water is a sexy, slim new IDE for RemObjects languages on Windows. For the OS X version you want to download Fire.
And here is the cool thing: when you hear “Java” you automatically expect that you are bound hands and feet to the Java runtime-libraries right? Same also with C#, you expect C# to be purely limited to the dot-net framework. And if you like me dabbed in Oxygene back in 2005-2006, you probably think Oxygene is purely a dot-net adapted version of Object Pascal right? But RemObjects have turned that on it’s head!
Remember the decoupling I mentioned at the beginning of this post? What that means in practical terms is that they have separated each language into three distinct parts:
The syntax
The RTL
The target
What this means, is that you can pick your own combinations!
Let’s say you are coming from Delphi. You have 20 years of Object Pascal experience under your belt, and while you dont mind learning new things – Object Pascal is where you will be most productive.
Well in that case picking Oxygene Pascal covers the syntax part. But you don’t have to use the dot-net framework if you don’t want to. You can mix and match these 3 parts as you see fit! Let’s look at some combinations you could pick:
Oxygene Pascal -> dot net framework -> CIL
Oxygene Pascal -> “VCL” -> CIL
Oxygene Pascal -> “VCL” -> WinAPI
Oxygene Pascal -> “VCL” -> WebAssembly
(*) The “VCL” here is a compatibility RTL closely modeled on the Freepascal LCL and Delphi VCL. This is written from scratch and contains no proprietary code. It is purely to get people productive faster.
The whole point of this tripartite decoupling is to allow developers to maximize the value of their existing skill-set. If you know Object Pascal then that is a natural starting point for you. If you know the VCL then obviously the VCL compatibility RTL is going to help you become productive much faster than calling WinAPI on C level. But you can, if you like, go all native. And you can likewise ignore native and opt for WebAssembly.
Sound cool? Indeed it is! But it gets better, let’s look at some of the targets:
Microsoft Windows
Apple OS X
Apple iOS
Apple WatchOS
Android
Android wearables
Linux x86 / 64
Linux ARM
tvOS
WebAssembly
* dot-net
* Java
In short: Pick the language you want, pick the RTL or framework you want, pick the target you want — and start coding!
(*) dot-net and Java are not just frameworks, they are also targets since they are Virtual Machines. WebAssembly also fall under the VM category, although the virtual machine there is bolted into Chrome and Firefox (also node.js).
Some example code
Webassembly is something that interest me more than native these days. Sure I love the speed that native has to offer, but since Javascript has become “the defacto universal platform”, and since most of my work privately is done in Javascript – it seems like the obvious place to start.
Webassembly is a bit like Javascript was 10 years ago. I remember it was a bit of a shock coming from Delphi. We had just created Smart Mobile Studio, and suddenly we realized that the classes and object the browser had to offer were close to barren. We were used to the VCL after all. So my work there was basically to implement something with enough similarity to the VCL to be familiar to to Delphi developer, without wandering too far away from established JS standards.
Webassembly is roughly in the same ballpark. Webassembly is just a runtime engine. It doesn’t give you all those nice and helpful classes out of the box. You are expected to either write that yourself – or (as luck would have it) rely on what language vendors provide.
RemObjects have a lot to offer here, because their “Delphi VCL” compatibility RTL compiles just fine for Webassembly. There is no form designer though, but I haven’t used a form designer in years. I prefer to do everything in code because that’s ultimately what works when your codebase grows large enough anyways. Even my Delphi projects are done mainly as raw code, because I like to have the option to compile with Freepascal and Lazarus.
My first test code for Oxygene Pascal with Webassembly as the target is thus very bare-bone. If there is something that has bugged me to no end, it’s that bloody HTML5 canvas. It’s a powerful thing, but it’s also overkill for per-pixel operations. So I figured that a nice, ad-hoc DIB (device independent bitmap) class will do wonders.
Note: Oxygene supports pointers, even under WebAssembly (!), but out of old habit I have avoided it. I want my code to compile for all the targets, without marking a class as “unsafe” in the dot-net paradigm. So I have avoided pointers and just use offsets instead.
namespace qtxlib;
interface
type
// in-memory pixel format
TPixelFormat = public (
pf8bit = 0, //___8 -- palette indexed
pf15bit = 1, //_555 -- 15 bit encoded
pf16bit = 2, //_565 -- 16 bit encoded
pf24bit = 3, //_888 -- 24 bit native
pf32bit = 4 //888A -- 32 bit native
);
TPixelBuffer = public class
private
FPixels: array of Byte;
FDepthLUT: array of Integer;
FScanLUT: array of Integer;
FStride: Integer;
FWidth: Integer;
FHeight: Integer;
FBytes: Integer;
FFormat: TPixelFormat;
protected
function CalcStride(const Value, PixelByteSize, AlignSize: Integer): Integer;
function GetEmpty: Boolean;
public
property Width: Integer read FWidth;
property Height: Integer read FHeight;
property Stride: Integer read FStride;
property &Empty: Boolean read GetEmpty;
property BufferSize: Integer read FBytes;
property PixelFormat: TPixelFormat read FFormat;
property Buffer[const index: Integer]: Byte read (FPixels[&index]) write (FPixels[&index]);
function OffsetForPixel(const dx, dy: Integer): Integer;
procedure Alloc(NewWidth, NewHeight: Integer; const PxFormat: TPixelFormat);
procedure Release();
function Read(Offset: Integer; ByteLength: Integer): array of Byte;
procedure Write(Offset: Integer; const Data: array of Byte);
constructor Create; virtual;
finalizer;
begin
if not GetEmpty() then
Release();
end;
end;
TColorMixer = public class
end;
TPainter = public class
private
FBuffer: TPixelBuffer;
public
property PixelBuffer: TPixelBuffer read FBuffer;
constructor Create(const PxBuffer: TPixelBuffer); virtual;
end;
implementation
//##################################################################################
// TPainter
//##################################################################################
constructor TPainter.Create(const PxBuffer: TPixelBuffer);
begin
inherited Create();
if PxBuffer nil then
FBuffer := PxBuffer
else
raise new Exception("Pixelbuffer cannot be NIL error");
end;
//##################################################################################
// TPixelBuffer
//##################################################################################
constructor TPixelBuffer.Create;
begin
inherited Create();
FDepthLUT := [1, 2, 2, 3, 4];
end;
function TPixelBuffer.GetEmpty: Boolean;
begin
result := length(FPixels) = 0;
end;
function TPixelBuffer.OffsetForPixel(const dx, dy: integer): Integer;
begin
if length(FPixels) > 0 then
begin
result := dy * FStride;
inc(result, dx * FDepthLUT[FFormat]);
end;
end;
procedure TPixelBuffer.Write(Offset: Integer; const Data: array of Byte);
begin
for each el in Data do
begin
FPixels[Offset] := el;
inc(Offset);
end;
end;
function TPixelBuffer.Read(Offset: Integer; ByteLength: Integer): array of Byte;
begin
result := new Byte[ByteLength];
var xOff := 0;
while ByteLength > 0 do
begin
result[xOff] := FPixels[Offset];
dec(ByteLength);
inc(Offset);
inc(xOff);
end;
end;
procedure TPixelBuffer.Alloc(NewWidth, NewHeight: Integer; const PxFormat: TPixelFormat);
begin
if not GetEmpty() then
Release();
if NewWidth < 1 then
raise new Exception("Invalid width error");
if NewHeight 0 then
result := ( (Result + AlignSize) - xFetch );
end;
end.
This code is just meant to give you a feel for the dialect. I have used a lot of “Delphi style” coding here, so chances are you will hardly see any difference bar namespaces and a funny looking property declaration.
Stay tuned for more posts as I explore the different aspects of Oxygene and webassembly in the days to come
If you haven't tested RemObjects SDK for Delphi, then you are in for a treat! Read about some of the features here
Show full content
Reading this you could be forgiven for thinking that I must promote RemObjects products, It’s my job now right? Well yes, but also no.
The thing is, I’m really not “traveling salesman” material by any stretch of the imagination. My tolerance for bullshit is ridiculously low, and being practical of nature I loath fancy products that cost a fortune yet deliver nothing but superficial fluff.
The reasons I went to work at RemObjects are many, but most of all it’s because I have been an avid supporter of their products since they launched. I have used and seen their products in action under intense pressure, and I have come to put some faith in their solutions.
Trying to describe what it’s like to write servers that should handle thousands of active user “with or without” RemObjects Remoting SDK is exhausting, because you end up sounding like a fanatic. Having said that, I feel comfortable talking about the products because I speak from experience.
I will try to outline some of the benefits here, but you really should check it out yourself. You can download a trial directly here: https://www.remotingsdk.com/ro/
Remoting framework, what’s that?
RemObjects Remoting framework (or “RemObjects SDK” as it was called earlier) is a framework for writing large-scale RPC (remote procedure call) servers and services. Unlike the typical solutions available for Delphi and C++ builder, including those from Embarcadero I might add, RemObjects framework stands out because it distinguishes between transport, host and message-format – and above all, it’s sheer quality and ease of use.
RemObjects Remoting SDK ships with a rich selection of channels and message formats
This separation between transport, host and message-format makes a lot of sense, because the parameters and data involved in calling a server-method, shouldn’t really be affected by how it got there.
And this is where the fun begins because the framework offers you a great deal of different server types (channels) and you can put together some interesting combinations by just dragging and dropping components.
How about JSON over email? Or XML over pipes?
The whole idea here is that you don’t have to just work with one standard (and pay through the nose for the privilege). You can mix and match from a rich palette of transport mediums and message-formats and instead focus on your job; to deliver a kick-ass product.
And should you need something special that isn’t covered by the existing components, inheriting out your own channel or message classes is likewise a breeze. For example, Andre Mussche have some additional components on GitHub that adds a WebSocket server and client. So there is a lot of room for expanding and building on the foundation provided by RemObjects.
And this is where RemObjects has the biggest edge (imho), namely that their solutions shaves weeks if not months off your development time. And the central aspect of that is their integrated service designer.
Integration into the Delphi IDE
Dropping components on a form is all good and well, but the moment you start coding services that deploy complex data-types (records or structures) the amount of boilerplate code can become overwhelming.
The whole point of a remoting framework is that it should expose your services to the world. Someone working in .net or Java on the other side of the planet should be able to connect, consume and invoke your services. And for that to happen every minute detail of your service has to follow standards.
The RemObjects Service Builder integrates directly into the Delphi IDE
When you install RemObjects SDK, it also integrates into the Delphi IDE. And one of the features it integrates is a complete, separate service designer. The designer can also be used outside of the Delphi IDE, but I cannot underline enough how handy it is to be able to design your services visually, right there and then, in the Delphi IDE.
This designer doesn’t just help you design your service description (RemObjects has their own RODL file-format, which is a bit like a Microsoft WSDL file), the core purpose is to auto-generate all the boilerplate code for you — directly into your Delphi project (!)
So instead of you having to spend a week typing boilerplate code for your killer solution, you get to focus on implementing the actual methods (which is what you are supposed to be doing in the first place).
DLL services, code re-use and multi-tenancy
The idea of multi-tenancy is an interesting one. One that I talked about with regards to Rad-Server both in Oslo and London before christmas. But Rad-Server is not the only system that allows for multi-tenancy. I was doing multi-tenancy with RemObjects SDK some 14 years ago (if not earlier).
Remember how I said the framework distinguishes between transport, message and host? That last bit, namely host, is going to change how you write applications.
When you install the framework, it registers a series of custom project types inside the Delphi IDE. So if you want to create a brand new RemObjects SDK server project, you can just do that via the ordinary File->New->Other menu option.
One of the project types is called a DLL Server. Which literally means you get to isolate a whole service library inside a single DLL file! You can then load in this DLL file and call the functions from other projects. And that is, ultimately, the fundamental principle for multi-tenancy.
And no, you don’t have to compile your project with external packages for this to work. The term “dll-server” can also be a bit confusing, because we are not compiling a network server into a DLL file, we are placing the code for a service into a DLL file. I used this project type to isolate common code, so I wouldn’t have to copy unit-files all over the place when delivering the same functionality.
It’s also a great way to save money. Don’t want to pay for that new upgrade? Happy with the database components you have? Isolate them in a DLL-Server and continue to use the code from your new Delphi edition. I have Delphi XE3 Database components running inside a RemObjects DLL-Server that I use from Delphi XE 10.3.
DLL server is awesome and elegantly solves real-life problems out of the box
In my example I was doing business-logic for our biggest customers. Each of them used the same database, but they way they registered data was different. The company I worked for had bought up these projects (and thus their customers with them), and in order to keep the customers happy we couldn’t force them to re-code their systems to match ours. So we had to come up with a way to upgrade our technology without forcing a change on them.
The first thing I did was to create a “DLL server” that dealt with the database. It exposed methods like openTable(), createInvoice(), getInvoiceById() and so on. All the functions I would need to work with the data without getting my fingers dirty with SQL outside the DLL. So all the nitty gritty of SQL components, queries and whatnot was neatly isolated in that DLL file.
I then created separate DLL-Server projects for each customer, implemented their service interfaces identical to their older API. These DLL’s directly referenced the database library for authentication and doing the actual work.
When integrated with the IDE, you are greeted with a nice welcome window when you start Delphi. Here you can open examples or check out the documentation
Finally, I wrapped it all up in a traditional Windows system service, which contained two different server-channels and the message formats they needed. When the service was started it would simply load in the DLL’s and manually register their services and types with the central channel — and voila, it worked like a charm!
Rock solid
Some 10 years after I delivered the RemObjects based solution outlined above, I got a call from my old employer. They had been victim of a devastating cyber attack. I got a bit anxious as he went on and on about damages and costs, fearing that I had somehow contributed to the situation.
But it turned out he called to congratulate me! Out of all the services in their server-park, mine were the only ones left standing when the dust settled.
The RemObjects payload balancer had correctly dealt with both DDOS and brute force attacks, and the hackers were left wanting at the gates.
Amibian.jsAmigaDelphihexlicenseJavaScriptLanguage researchnodeJSObject PascalQuartex PascalCompanyEmbarcaderonew jobQuartex Media DesktopRemobjects
Long story short, I have been very fortunate to work at Embarcadero. I am not leaving because there is anything wrong or something like that. I was hired as SC for the EMEA regions, which basically made me the support and presenter for most of europe, parts of asia and the middle east. It's been a great adventure, but ultimately I had to admit that my passion is building things.
Show full content
It’s been roughly 4 weeks since I posted a status report on Amibian.js. I normally keep people up-to-date on facebook (the “Amiga Disrupt” and also “Delphi Developer” groups). It’s been a very hectic month so I fully understand that people are asking. So let’s look at where the project is at and where we are on the time-line.
For those that might not know, I decided to leave Embarcadero a couple of months ago. I will be working out may before I move on. I wanted to write about that myself in a clean fashion, but sadly the news broke on Facebook prematurely.
Long story short, I have been very fortunate to work at Embarcadero. I am not leaving because there is anything wrong or something like that. I was hired as SC for the EMEA regions, which basically made me the support and presenter for most of europe, parts of asia and the middle east. It’s been a great adventure, but ultimately I had to admit that my passion is coding and community work. Sales is a very important part of any company, but it’s not really my cup of tea; my passion has always been research and development.
So, come first of June and I start in a new position at RemObjects. A company that has deep roots with Delphi and C++ builder users – and a company that continues to produce a wealth of high-quality, high-performance frameworks for Delphi and C++ builder. RemObjects also has a strong focus on modern languages, and have a strong portfolio of new and exciting compilers and languages to offer. The Oxygene compiler should be no stranger to Delphi developers, a powerful object-pascal dialect that can target a variety of platforms and chipsets.
Since compiler technology and run-time systems has been my main focus for well over a decade now, I feel RemObjects is a better match.
Quartex Components
Quartex Components has been an officially registered Norwegian company for a while now, so perhaps not news. What is news is that it’s now directly connected with the development of the Quartex Media Desktop (codename “Amibian.js”). While Amibian.js is an open source endeavour, there will be both free and commercial products running on top of that platform. I have written at length about Cloud Forge in the past, so I wont re-hash that again. But 2020 will see a paradigm shift in how teams and companies approach software development.
Company logo professionally milled and on its way to my new office
I will also, once there is more time, continue to sell and support software license components.
Quartex Media Desktop
The “Amibian.js” project is moving along nicely. The deadline is Q4 2019, but im hoping to wrap up the core functionality before that. So we are on track and kicking ass
More and more elaborate functionality is being implemented for the desktop
Here is an overview of work done this month:
TSystemService application type has been created (node.js)
TApplication now holds IPC functions (inter process communication)
Running child processes + sending messages is now simplicity itself
Database drivers are 90% done. Delete() and DeleteTable() functionality needs to be implemented in a uniform way
Authentication is now a separate service
Service database layer is finished (using SQLite3 driver by default)
Authentication protocol has been designed
Server protocol and JSON message envelopes are done
Presently working on the client interface
LDEF bytecode assembler has been improved
Faster symbolic lookup
Smarter register recognition
Early support for stack-frames
Fixed bug in parser (comma-list parse)
QTX framework has seen a lot of work
Large parts of the RTL sub-strata has been implemented
UTF16 codec implemented
QTX versions of common controls:
TQTXButton
TQTXLabel
TQTXToolbar
TQTXToolButton
TQTXToolSeparator
TQTXToolElement
TQTXPanel
TQTXCheckBox
.. and much, much more
Desktop changes
Link Maker functionality has been added
Handshake process between desktop and child app now runs on a separate timer, ensuring better conformity and a more robust initialization
The Quartex Editor control has been optimized
All redraw calls are now synchronized
Canvas is created on demand, avoids flicker during initial redraw
Support for DEL key + behavior
Gutter is now rendered to an offscreen bitmap and blitted into the control’s canvas. The gutter is only fully rendered when cursor forces the view to change
I will continue to keep everyone up to date about the project. As you can understand, its a bit hectic right now so please be patient – it is turning into an EPIC environment!
After a little chat I realized that the problem was not his code, but rather how he viewed the stack. He was used to high-level versions of stacks, which in most cases are just lists storing arbitrary sized data - so he was looking at the stack as a TList expecting similar behavior.
Show full content
The concept of stacks is an old one, and together with linked-lists and queues – these form the most fundamental programming concepts a developer needs to master.
But, the stack most people use today in languages like object pascal and C++ are not actual stacks; they are more like “conveniently repurposed lists“. Not a huge issue I agree, but the misconception is enough to cause confusion when people dive into low-level programming.
Adventures in assembly-land
It might seem odd to focus on something as trivial as a stack, but I have my reasons. A friend of mine who is a brilliant coder with plenty of large projects behind him recently decided to have a go at assembly coding. He was doing fine and everything was great, until he started pushing and popping things off the stack.
After a little chat I realized that the problem was not his code, but rather how he viewed the stack. He was used to high-level versions of stacks, which in most cases are just lists storing arbitrary sized data – so he was looking at the stack as a TList<item> expecting similar behavior. Superficially a real-stack and a list-stack work the same if all you do is clean push and pop operations, but the moment you start designing a stack-scheme and push more elaborate constructs (stack-frames), things can go wrong really fast.
The nature of a real stack
A “real” stack that is a part of a hardware SOC (system on a chip) has nothing to do with lists. It’s actually a solid chunk of memory with a register to keep track of an offset into this memory block.
Let’s for sake of argument say you have 4k of stack space right? It’s clean and contains nothing, so the SP (stack pointer, or offset) is zero. What happens when you push something to the stack? for example:
push EDX
The code above simply writes the content of the EDX register to whatever offset the SP contains. It then updates the SP with the size of the data (EDX is a 32bit register, so the SP is incremented by a longword or 4 bytes). In Delphi pseudocode what happens is something like:
The thing about a stack is that it doesn’t manage data-length for you. And that is a big difference to remember. It will push or pop data based on the size of the source (in this case the 32bit EDX register) you use.
If you push 1024 bytes of data to a list based stack, the list keeps track of the size and data for you. So when you pop the data from the stack, you get back that data regardless. But a “real” stack couldn’t care less — which is also why it’s so easy to screw up an entire program if you make a mistake.
In short: The length of what you push – must be matched when you pop the data back (!) If you push a longword, you MUST pop a longword later.
Benefits of a real stack
The benefit is that the cost of storing values on a stack is almost zero in terms of cpu operations. A list based stack is more expensive; it will allocate memory for a record-item to hold the information about the data, then it will allocate memory to hold the actual data (depends on the type naturally) and finally copy the data into the newly allocated buffer. Hundreds if not thousands of instructions can be involved here.
A real stack will just write whatever you pushed directly into the stack-memory at whatever offset SP is at. Once written it will add the length of the write to the SP – and that’s it! So it’s one of the oldest and fastest mechanisms for lining up data in a predictable way.
Again the rules are simple: when you pop something off the stack, the size must match whatever you used to push it there. So if you pushed a longword (EDX) you also have to make sure you use a 32-bit target when you pop the value back. If you use RDX, which is 64 bit then you will essentially steal 4 bytes from something else using that stack – and all hell will break loose down the line.
Stack schemes and frames
Im not going to dig too deeply into stack-frames here, but instead write a few words about stack-schemes and using the stack to persist data your code relies on. The lines blur between those two topics anyways.
The SP (stack pointer) is not just a simple offset you can read, you can also write and change it (it also serves as a pointer). You can also read from whatever memory the SP is pointing at without polling any data from the stack.
What language developers usually do, is that they design entire structures on the stack that are, when you get into the nitty-gritty, “offset based records”. For example, lets say you have a record that looks like this:
type
PMyRecord ) ^TMyRecord;
TMyRecord = record
first: Pointer;
second: integer;
Third: array[0..255] of longword;
end;
Instead of allocating conventional ram to hold that record, people push it to the stack and then use offsets to read and update the values there. A bit like a super global variable if you like. This is why when you disassemble code, you find stuff like:
mov EDX, (SP)+4
If the above record was on the stack, that pseudo code would move the field “second” into the EDX register. Because that field is 4 bytes from the stack start (providing SP points to zero).
Every programming language has a stack scheme to keep track of things. Local variables, global variables, class instances, type RTTI — most of these things are allocated in conventional ram – but there is a “program record” on the stack that makes it easy to access that information quickly.
This “moving a whole record onto the stack” is basically what a stack-frame is all about. It used to be a very costly affair with a heavy cpu speed penalty. If you look in your Delphi compiler options you will see that there is a checkbox regarding this very topic. Delphi can be told to avoid stack-frames and do register allocation instead, which was super quick compared to stack-frames – but CPU’s today are largely optimized for stack-frame allocation as default, so I doubt there is much to gain by this in 2019.
Note: A stack frame is much more, but its out of scope for this post. Google it for more info.
To sum up
When doing high-level coding you don’t really need to bother with the nuances between a TStack<item> and a “real” stack. But if you plan on digging deeper and learning a few lines of assembly – learning the differences is imperative. Its boring stuff but as fundamental as wheels on a bicycle. There is no way to avoid it, so might as well jump in.
In its absolute raw form, here is roughly the same functionality for Delphi. This was written on the fly in 2 minutes while on the road, so its purely to give you a rough idea of behavior. I would add a secondary field to keep track of the end (next insertion point), that way SP can be changed without overwriting data on new pushes.
And yes, wrapping this in a TObject utterly defeats the purpose of low-level coding, but hopefully it gives you some idea of the differences
There is also another factor to include in all of this, and that is Linux. Borland was correct in their assessment of Linux (the Kylix project), but they failed miserably with regards to timing. They also gravely underestimated Linux user's sense of quality, depending on Wine (a Windows virtualization framework) to even function. They also underestimated Freepascal and Lazarus, because Linux is something FPC does exceptionally well. Competing financially against free products wont work unless you bring outstanding abilities to the table. And Linux have development tools that rival Visual Studio in quality, yet costs nothing.
Show full content
One of the benefits of the Delphi IDE is that it’s a very rich eco-system that component writers and technology partners can tap into for their own products. I know that writing your own components is not something everyone enjoy, but knowing that you can in-fact write tools that expands the IDE using just Delphi or C++ builder, opens up for some interesting tools.
Ye old compiler bible
Delphi has a long tradition of “IDE enhancement” software and elaborate third-party tools that automate or delivers some benefit right in the environment. RemObjects SDK is probably the best example of how flexible the IDE truly is. RemObjects SDK integrates a whole service designer, which will generate source-code for you, update the code if you change something – and even generate service manifests for you.
There are also other tools that show off the flexibility of the IDE, ranging from code migration to advanced code refactoring and optimization.
It was with the last bit, namely code refactoring, that a third-party open-source library received a lot of deserving attention a couple of years back. A package called DelphiAST. This is a low-level syntax parser that reads Delphi source-code, applies fundamental syntax checks, and transforms the code into XML. A wet dream for anyone interested in writing advanced tooling that operates directly on source-code level.
Delphi AST
Like mentioned above, DelphiAST is a parser. Its job is very simple: parse the code, perform language level syntax checking, and convert each aspect of the code to a valid XML element. We are not talking about stuffing source-code into a CDATA segment here, but rather breaking each statement into separate tags (begin, end, if, procedure, param) so you can apply filtering, transformations and everything XML has to offer.
Back when Roman first started on DelphiAST, I got thinking — could we follow this idea further, and apply XML transformation to produce something more interesting? Would it actually be possible to approach the notion of compiling from a whole new angle? Perhaps convert between languages in a more effective way?
The short answer is: yes, everything is possible. But as always there are caveats and obstacles to overcome.
First of all, DelphiAST despite its name doesn’t actually generate a fully functional abstract symbol tree (AST). It generates a data model that is very suitable for AST generation, but not an actual AST. Everything in a programming language that can be referenced, like a method, a class, a global variable, a local variable, a parameter – are all called “symbols”. And before you can even think about processing the code, a fast and reliable AST must be in place.
Who cares?
Before I continue, you might be wondering why re-inventing the wheel is even a thing here? Why would anyone research compilers in 2019 when the world is abundant with compilers for a multitude of languages?
Because the world of computing is about to be hit by a tsunami, that’s why.
Quartex Pascal
In the next 8-10 years the world of computing will be turned on its head. NVIDIA and roughly 100 tech companies have invested in open-source CPU designs, making it very clear that playing by Intel’s rules and bleeding royalties will no longer be tolerated. IBM has woken up from its “patent induced slumber” and is set to push their P9 cpu architecture, targeting both the high-end server and embedded market (see my article last year on PPC). At the same time Microsoft and Apple have both signaled that they are moving to ARM (an estimate of 5 years is probably reasonable). Laptop beta’s are said to be already rolling, with a commercial version expected Q3 this year (I think it wont arrive before xmas, but who knows).
Intel has remained somewhat silent about any long-term plans, but everyone that keeps an eye on hardware knows they are working like mad on next-gen FPGA. A tech that has the potential to disrupt the whole industry. Work is also being done to bridge FPGA coding with traditional code; there is no way of predicting the outcome of that though.
Oh and AMD is usurping the Intel marketshare at a steady rate — so we are in for a fight to the death.
The rise of C/C++
Those that keep tabs on languages have no doubt noticed the spike in C/C++ popularity lately. And the cause of this is that developers are safeguarding themselves for the storm to come. C as a language might not be the most beautiful out there, but truth be told, it’s tooling requires the least amount of work to target a new platform. When a new architecture is released, C/C++ is always the first language available. You wont see C#, Flutter or Rust shipping with the latest and greatest; It’s always GCC or Clang.
Note: GCC is not just C, it’s actually a family of languages, so ironically, Gnu Basic hits a platform at the same time.
Those that have followed my blog for the past 10 years, should be more than aware of my experiments. From compiling to Javascript, generating bytecodes – and right now, moving the whole development paradigm to the browser. Hopefully my readers also recognize why this is important.
But to make you understand why I am so passionate about my compiler experiments, let’s do a little thought experiment:
Rethinking tooling
Let’s say we take Delphi, implement a bytecode format and streamline the RTL to be platform agnostic. What would the consequences of that be?
Well, first of all the compiler process would be split in two. The traditional compilation process would still be there, but it would generate bytecodes rather than machine code. That part would be isolated in a completely separate process; a process that, just like with the Delphi IDE’s infrastructure, could be outsourced to component-writers and technology partners. This in turn would provide the community with a high degree of safety, since the community itself could approach new targets without waiting for Embarcadero.
Even more, such an architecture would not be limited to machine-code. There is no law that says “you must convert bytecodes to machine code”. Since C/C++ is the foundation that modern operating-systems rest on, generating C/C++ source-code that can be built by existing compilers is a valid strategy.
There is also another factor to include in all of this, and that is Linux. Borland was correct in their assessment of Linux (the Kylix project), but they failed miserably with regards to timing. They also gravely underestimated Linux user’s sense of quality, depending on Wine (a Windows virtualization framework) to even function. They also underestimated Freepascal and Lazarus, because Linux is something FPC does exceptionally well. Competing financially against free products wont work unless you bring outstanding abilities to the table. And Linux have development tools that rival Visual Studio in quality, yet costs nothing.
But no matter how financially tricky Linux might be, we have reached the point in time where Linux is becoming mainstream. 10 years ago I had to setup my own Linux machine. There were no retailers locally that shipped a Linux box. Today I can walk into two major chains and pick dedicated Linux machines. Ubuntu in particular is well established and delivers LTS.
So for me personally, compiler tech has never been more important. And even more important is the tooling being universal and unbound by any specific API or cpu instruction-set. Firemonkey is absolutely a step in the right direction, but I think it’s a disaster to focus on native UI’s beyond a system level binding. Because replicating the same level of support and functionality for ARM, P9, RISC 5 and whatever monstrosity Intel comes up with through FPGA will take forever.
Transformation based conversion
We have wandered far off topic now, so let’s bring it back to this weekends experiment.
In short, XML transformations to convert code does work, but the right tooling have to be there to make it viable. I implemented a poor-man’s symbol table, just collecting classes, types and methods – and yeah, works just fine. What worries me a bit though is the XML parser. Microsoft has put a lot of money into XML file handling on enterprise level. When working with massive XML files (read: gigabytes) you really can’t be bothered to load the file into conventional ram and then old-school traverse the XML character by character. Microsoft operates with pure memory mapping so that you can process gigabytes like they were megabytes — but sadly, there is nothing similar for Linux, Unix or Android, that abruptly ends the fascination for me.
The only place I see using XML transformations to process source-code, is when converting to another language on source-level.
So the idea, although technically sound, gives zero benefits over the traditional process. I am however very interested in using DelphiAST to analyze and convert Delphi code directly from the IDE. But that will have to be an experiment for 2020, im booked 24/7 with Quartex Media Desktop right now.
But it was great fun playing around with DelphiAST! I loved how clean and neat the codebase has become. So if you need to work with source-code, DelphiAST is just the ticket!
Edit: You dont have to emit the code as XML. DelphiAST is perfectly happy to act as a clean parser, just saying.
You have probably noticed how mobile phone UI's have smooth movements? like on iOS when you click "back" the whole display slides smoothly into view; or that elements move, grow and shrink using fancy, accelerated effects?
This type of animation is called tweening. And the TTween Library makes it super easy to do the same for your VCL applications.
Show full content
I have asked for financial backing while creating libraries that people want and enjoy, and as promised they are released into open-source land afterwards.
HexLicense was open-sourced a while back, and this time it’s TTween library that is going back to the community.
Tweening?
You have probably noticed how mobile phone UI’s have smooth movements? like on iOS when you click “back” the whole display slides smoothly into view; or that elements move, grow and shrink using fancy, accelerated effects?
This type of animation is called tweening. And the TTween Library makes it super easy to do the same for your VCL applications.
Check out this Youtube video to see how you can make your VCL apps scale their controls more smoothly
To install the system as ordinary components, just open the “Tweening.dproj” file and install as normal. Remember to add the directory to your libraries path!
Support the cause
If you like my articles and want to see more libraries and techniques, then consider donating to the project here: https://www.paypal.me/quartexNOR
Those that donate $50 or more automatically get access to the Quartex Web OS repositories, including full access to the QTX replacement RTL (for DWScript and Smart Mobile Studio).
Thank you for your support, projects like Amibian.js and the Quartex Web OS would not exist without my backers!
This article is over six months late (gasp!). Work at Embarcadero have been extremely time consuming, and my free time has been bound up in my ex-patreon project. So that's why I was unable to finish in a more predictable fashion
Show full content
This article is over six months late (gasp!). Work at Embarcadero have been extremely time consuming, and my free time has been bound up in my ex-patreon project. So that’s why I was unable to finish in a more predictable fashion.
But better late than never — and we have finally reached one of the more exciting steps in the evolution of our database engine design, namely the place where we link our metadata to actual data.
So far we have been busy with the underlying mechanisms, how to split up larger pieces of data, how to collect these pieces and re-assemble them, how to grow and scale the database file and so on.
We ended our last article with a working persistence layer, meaning that the codebase is now able to write the metadata to itself, read it back when you open the database, persist sequences (records) – and our humble API is now rich enough to handle tasks like scaling. At the present we only support growth, but we can add file compacting later.
Tables and records
In our last article’s code, the metadata exposed a Table class. This table-class in turn exposed an interface to our field-definitions, so that we have a way to define how a table should look before we create the database.
You have probably taken a look at the code (I hope so, or much of this won’t make much sense) and noticed that the record class (TDbLibRecord) is used both as a blueprint for a table (field definitions), as well as the actual class that holds the values.
If you look at the class again (TDbLibRecord can be found in the file dblib.records.pas), you will notice that it has a series of interfaces attached to it:
IDbLibFields
IStreamPersist
The first one, which we expose in our Table as the FieldDefs property, simply exposes functions for adding and working with the fields. While somewhat different from Delphi’s traditional TFieldDefinition class, it’s familiar enough. I don’t think anyone who has used Delphi with databases would be confused around it’s members:
IDbLibFields = interface
['{0D6A9FE2-24D2-42AE-A343-E65F18409FA2}']
function IndexOf(FieldName: string): integer;
function ObjectOf(FieldName: string): TDbLibRecordField;
function Add(const FieldName: string; const FieldClass: TDbLibRecordFieldClass): TDbLibRecordField;
function Addinteger(const FieldName: string): TDbLibFieldInteger;
function AddStr(const FieldName: string): TDbLibFieldString;
function Addbyte(const FieldName: string): TDbLibFieldbyte;
function AddBool(const FieldName: string): TDbLibFieldboolean;
function AddCurrency(const FieldName: string): TDbLibFieldCurrency;
function AddData(const FieldName: string): TDbLibFieldData;
function AddDateTime(const FieldName: string): TDbLibFieldDateTime;
function AddDouble(const FieldName: string): TDbLibFieldDouble;
function AddGUID(const FieldName: string): TDbLibFieldGUID;
function AddInt64(const FieldName: string): TDbLibFieldInt64;
function AddLong(const FieldName: string): TDbLibFieldLong;
end;
But, as you can see, this interface is just a small part of what the class is actually about. The class can indeed hold a list of fields, each with its own datatype – but it can also persist these fields to a stream and read them back again. You can also read and write a value to each field. So it is, for all means and purposes, a single record in class form.
The term people use for this type of class is: property bag, and it was a part of the Microsoft standard components (Active X / COM) for ages. Its probably still there, but I prefer my own take on the system.
In this article we are going to finish that work, namely the ability to define a table, create a database based on the metadata, insert a new record, read records, and push the resulting binary data to the database file. And since the persistency is already in place, opening the database and reading the record back is pretty straight forward.
So this is where the metadata stops being just a blue-print, and becomes something tangible and real.
Who owns what?
Before we continue, we have to stop and think about ownership. Right now the database file persists a global list of sequences. The database class itself has no interest in who owns each sequence, if a sequence belongs to a table, if it contains a picture, a number or whatever the content might be — it simply keeps track of where each sequence begins.
So the first order of the day is to expand the metadata for tables to manage whatever records belongs to that table. In short, the database class will focus on data within its scope, and the table instances will maintain their own overview.
So the metadata suddenly need to save a list of longwords with each table. You might say that this is wasteful, that the list maintained by the database should be eliminated and that each table should keep track of it’s own data. And while that is tempting to do, there is also something to be said about maintenance. Being able to deal with persisted data without getting involved with the nitty-gritty of tables is going to be useful when things like database compacting enters at the end of our tutorial.
Locking mechanism
Delphi has a very user-friendly locking mechanism when it comes to databases. A table or dataset is either in read, edit or insert mode – and various functions are allowed or prohibited depending on that state. And it would probably be wise to merge the engine with Delphi’s own TDatabase and TTable at some point – but right now im more interested in keeping things clean and simple.
When I write “locking mechanism” I am not referring to a file-lock, or memory lock. Had we used memory-mapped files the locking mechanism would have been more elaborate. What I mean with a lock, is basically placing a table in one of the states I mentioned above. The table needs to know what exactly you want to do. Are you adding a record? Are you editing an existing record? The table code needs to know this to safely bring you from one mode to the next.
Suddenly, you realize why each table needs that extra list, because how is the table going to allow methods like first, next, last and previous? The record-list dealt with by the database is just a generic, non-ordered ledger of sequences (a global scope list if you will). Are you going to read all records back when you open the database to figure out who owns what?
A call to First() will mean a completely different offset for each table. And the logical way to handle this, is to give each table it’s own cursor. A class that keeps track of what records belongs to the table, and also keeps track of whatever states the table is in.
The database cursor
Since we are not up against Oracle or MSSQL here, but exploring database theory, I have kept the cursor as simple as I possibly could. It is a humble class that looks like this:
The idea of-course is that the table defaults to “read” mode, meaning that you can navigate around, record by record, or jump to a specific record using the traditional RecNo property.
The moment you want to insert or edit a record, you call the Lock() method, passing along the locking you need (edit or insert). You can then either cancel the operation or call post() to push the data down to the file.
The Lock() method is a function (bool), making it easier to write code, as such:
if Database.Table.Cursor.Lock(cmInsert) then
begin
with Database.GetTableByName('access_log').cursor do
begin
Fields.WriteInt('id', FUserId);
Fields.WriteStr('name', FuserName);
Fields.WriteDateTime('access', Now);
Post();
end;
end else
raise exception.create('failed to insert record');
Im sure the are better designs, and the classes and layout can absolutely be made better; but for our purposes it should be more than adequate.
Reloading record data
In the previous articles we focused on writing data. Basically taking a stream or a buffer, breaking it into pages, and then storing the pages (or blocks) around the file where there was available space.
We cleverly crafted the blocks so that they would contain the offset to the next block in a sequence, making it possible to read back a whole sequence of blocks by just knowing the first one (!)
A part of what the cursor does is also to read data back. Whenever the RecNo field changes, meaning that you are moving around the table-records using the typical Next(), Previous(), First() etc functions — if the cursor is in read mode (meaning: you are not inserting data, nor are you editing an existing record), you have to read the record into memory. Otherwise the in-memory fields wont contain the data for that record.
Creating a cursor
One note before you dive into the code: You have to create a cursor before you can use it! So just creating a table etc wont be enough. Here is how you go about doing this:
Creating the cursor will be neatly tucked into a function for the table instance, we still have other issues to deal with.
What to expect next?
Next time we will be looking at editing a record, commiting changes and deleting records. And with that in place we have finally reached the point where we can add more elaborate functionality, starting with expression parsing and filters!
If you like my articles and want to see more libraries and techniques, then consider donating to the project here: https://www.paypal.me/quartexNOR
Those that donate $50 or more automatically get access to the Quartex Web OS repositories, including full access to the QTX replacement RTL (for DWScript and Smart Mobile Studio).
Thank you for your support, projects like Amibian.js and the Quartex Web OS would not exist without my backers!
The Amiga OS 3.x source code has been available on the pirate bay for 4 years now? So if Cloanto indeed are so secure in their role as rightful heir to the Amiga throne, they can open source the code in a matter of hours. Just download, slap a GPL license on the files and push it out.
Show full content
My previous article regarding the dreadful state the Amiga Kernel and OS finds itself in, primarily perpetuated by Italian company Cloanto, must have hit a nerve. My mailbox has been practically bombarded by people who are outraged by Cloanto (and Hyperion has got a fair bit of blame too). And indeed, there were errors made in that article (more about that below).
What I find strange, if not borderline insane, is how ingrained people are to their company or “team”. I have never understood people who watch soccer, who get physically upset over a game – or who demonstrate complete and utter loyalty to a team no matter how ridiculous that team might be. To me, soccer is just 22 grown men running around in their underwear chasing an inflated dead animal.
Thankfully, “Amiga hooligans” are a minority in the community. And it doesn’t really matter what topic you bring to the table, because they will oppose it either way. It’s what they do. The majority of the community are grown men and women with families, jobs and a life that has nothing to do with shared memories of the Commodore Amiga. And despite our differences we have one thing in common: a desire to see the system we grew up with flourish; a system that never failed and that despite its age has features and mechanisms that modern system lacks. It was management that failed, not the product.
As a developer, having to watch the brilliance of Amiga OS “rot on the wine” as the saying goes, is heartbreaking. The potential in the OS, even if we were to do a clean re-write, is astronomical. The ease of use alone for education, or as a low-cost alternative to Linux on embedded systems, has practical value far beyond gaming; which tragically is the only thing some people associate the technology with.
Points of view
The initial point of my article was not to paint Cloanto as the villain and Hyperion as the hero. I think everyone that has kept an eye on the Commodore saga and aftermath knows full well that none of the companies, both present and past, are without flaw. People don’t start companies for fun, but to do business. And the moment money is involved – human beings can demonstrate both excellence and selfishness. It’s human to make mistakes, and what ultimately matters is how we deal with them.
It all boils down to vantage-point. If your only ambition is to play some retro-games, then you will no doubt be happy with Cloanto’s Amiga Forever. If you enjoy software development and have coding as a hobby, then a full UAE setup, including cross compilers and real hardware will more than cover your needs.
So from those points of view, where you have already parked Amiga OS in the past as a dead system and hobby, I fully understand that you don’t care who did what, or the motives behind various strategic moves. Nothing wrong with that, people are different.
But what both those viewpoints have in common is that they are looking backwards to the past, rather than forward to a potential future. If you recognize that, and you yourself look to the future, then your expectations will be higher. You will care about how the IP is maintained, and also how the legacy is cared for. Legally it’s ultimately nobody’s business what Hyperion or Cloanto does with their intellectual property, but they have to remember that they are responsible for a computer legacy stretching back to the very beginning of home computers.
David’s book about what went on inside Commodore is quite a wake-up call. Go buy it ASAP!
The reason people refuse to throw Amiga out after so many years, is because the product was cut down before it’s time. Some compare it to the Betamax tragedy, where VHS despite being a lesser product ended up as the standard. And just like with the Amiga, it was not the product that was the determining factor in the tragedy, it was the lesser qualities of human beings. VHS allowed porn to be shipped en-mass on their format, while Betamax stuck to their principles and family values.
Commodore was thankfully not involved in anything as base, but if you take the time to read David Pleasance’s book: Commodore the inside story; you will discover that there were some monumental mistakes made in the name of, shall we say, “the lesser instincts of man“?. If you havent read his book then please do, then spend a few hours finding your jaw on the floor. It is absolutely shocking what went on behind closed doors in the company.
Mistakes in my post
The source of the mistake I wrote about, namely that of Acer’s ownership, is rooted in a simple misunderstanding. My focus was initially not on the ownership of the Amiga alone, but rather where has the Commodore patent portfolio gone? Commodore had been in business since 1954, and entered the computer market in 1979 with a MOS 6504 powered chess machine. A company with the level of growth and production over so many decades must have racked up some valuable patents, be they mechanical or electronic. I have never met Jack Trammell in person, but with regards to what I have read about the man, he would not miss an opportunity to make money or be whimsical about patents. So where did it all go?
Prior to my talk with Trevor Dickinson, I looked around to see who ended up with said portfolio (the proverbial needle in a haystack), I talked to several individuals in the community about this, googled, read articles – and was left with 3 potential candidates: HP, Acer and Asus.
While searching I came across the following video, and the ingress underlines Acer as the patent owner:
Acer is again mentioned as owning patents
When I then had a quick chat with Trevor and the name Acer turned up a third time, I saw no reason to question this. It was ultimately not the point of my post anyway.
The next question was to determine the relationship between said owner and those running the Amiga side of things (Cloanto and Hyperion). There were two logical possibilities: either these companies owned, in the true sense of the word, different parts of the legacy — or they functioned under a branding franchise. Meaning that they have been granted the right to evolve, sell and/or represent the Amiga name and technology with obligations of royalties. This is a pretty common business model, IBM being the archetypical example, so it would not be uncommon.
And that is ultimately the mistake. In retrospect I should have known there was no large company involved, because a stable corporation would never have allowed their IP to be mangled and dragged through the gutter like the Amiga have endured.
Having said that, it doesn’t really change much. I got an email saying that Cloanto have indeed given the authors of UAE money, which I hope is true because without the developers of UAE, the Amiga community would be abysmal. They have done 90% of the lifting, yet receive little praise for their work. But again – I was unable to find anything online where this could be confirmed.
It has also been stated that Amiga Inc was both tricked, abused and bullied by Hyperion. Yet the escapades of Amiga-Inc seem to have vanished into thin air:
“later that year, Amiga Inc. used some sleight of hand to escape a pending bankruptcy. Amiga sold its assets to a shell company called KMOS—a Delaware firm headquartered in New York—then renamed KMOS back to Amiga Inc. It tried to use these shenanigans to get out of the clause in its contract with Hyperion that would revert ownership of OS 4 if Amiga Inc. ever went under. Then, to top it off, Amiga sued Hyperion for not delivering OS 4 on time and demanded the return of all source code.” –Source: Ars Technica
Oh and then there was the “death threat” email. Where my post was said to be so diabolically crafted, so insiduius and evil – that i was responsible for possible death threats. I don’t even know how to respond to that, because the poo-nami that Cloanto is experiencing is the result of 15 years of silence; where the only communication has been to threaten Amiga users who accidentally shared a 512kb rom-file from the late bronze age with legal action. I think you gravely over-estimate my influence in the matter.
Right now Cloanto seem to run around pretending to be Santa. With promises of open-source and a future for their Amiga OS 4.1 (yes you read right) and that 3.1.4 is also theirs. First of all, Hyperion got that source-code as a part of the settlement with Amiga Inc (the quote above from ARS-Technica demonstrates how Amiga Inc treated Hyperion, not the other way around).
From a video posted by the 10 minute amiga retro-cast
To nullify a 15-year-old settlement bound by contract, which is what must happen for them to have rights to their claims — that is something I wont hold my breath waiting for.
A viable business model
After my initial post people have dragged poor Trevor Dickinson into the debate, complaining to him about statements made by me. That is unfortunate because Trevor is not involved in our opinions at all. He even corrected me about mistakes I made in the previous article – and have absolutely not been a catalyst (quite the opposite!).
The Amiga history after the Commodore era is so convoluted, that his article series on the subject ended up spanning 12 issues of AF Magazine (!) Compare that to my two page brain fart. I also underlined that I had left out most of the details because rehashing the same tragedy over and over is paramount to explaining Game Of Thrones backwards in Sanskrit.
If we push all the details and who said what to the side for a moment, and look at the paths we have – it begins with a simple choice: you can look to the past and stick to “retro” computing. If that is the case then you will have no interest in anything I have to say, and that is fine. High five and enjoy.
If you look to the future, then suddenly we have some options before us: you have FPGA, like the FPGA-Arcade, the Vampire, MISTer and other, similar FPGA based systems. They have one thing in common and that is the 680×0 CPU.
Then you have software emulation, WinUAE being the trend-setter and various forks like UAE4Arm, FS-UAE and so on. This is perhaps the most versatile solution since it can do things difficult to achieve under real hardware.
Then we have the next generation and re-implementations. This is where Aros and it’s variations (AEROS, ARES et-al), Amiga OS 4.x and Morphos comes in.
I can’t see that we even need the legacy systems for much longer
And last but not least, cloud implementations like Amibian.js.
But in order for there to be any future where the core technology can grow, the technology has to serve a function in 2019. It doesn’t matter if the IPC layer is awesome, or that Amiga OS had REXX support 20 years before Mac OS. A modern system have to give users in this decade a benefit — otherwise there is no business model to talk about. And that is also my point. If we exclude web tech for now and look at the different paths, only two of them have the potential to deliver modern and unique functionality; and in my view that is Amiga OS 4 and Morphos.
FPGA will disrupt everything at some point
Vampire could perform a miracle and optimize their 68k architecture to the point where it can serve as a good embedded system, but even if possible, they are still held back by their dependency on classic Amiga OS. A partnership between Hyperion and Apollo would indeed be interesting, who knows. Although I would love to see the Apollo team fork Aros and shape that into what it could become with a bit of work.
I should add that this is also why I decided to write Amibian.js using web technology, because regardless of which CPU or architecture that becomes dominant in the next decade, web tech will always be there. So it allows us to abstract away the costly dependency on hardware, and instead focus on functionality.
PPC for the win?
In an interesting twist of fate, PPC could actually come out far better than anticipated – but not in the way you might think. Work is being done to make PPC a first class FPGA citizen. FPGA is fantastic in many ways, but it’s the intrinsic abillity to “become” whatever technology you describe that is revolutionary.
While it’s still in its infancy, the potential is there to render instruction-sets and architectures a preference rather than a requirement. If anything, the Vampire IV is a demonstration of just that.
So code currently bound to PPC could use FPGA as an intermediate solution while the codebase is ported to more viable platforms.
So whats the problem?
The next question then becomes: what exactly is stopping the owners from moving forward? Why dont the companies that hold the various IP’s roam silicon-valley in search of funding? And it’s here that we face the situation I briefly painted a picture of in my last post: they are in a perpetual stale-mate.
And in my view (as a developer looking forward) Cloanto, whose primary focus is to provide for the legacy market, is constantly getting in the way of Hyperion – which is looking at the future. As far as innovation and managing the legacy of Commodore is concerned, Cloanto has been asleep at the wheel for over a decade. They only woke up when it could cash-in on its C64 assets. I have no number as to how many c64 mini’s have been sold around the world, but its been a massive success. And it would be foolish to think that they have no plans to repeat the success with an Amiga model — effectively hammering the final nail in the coffin. After that, the Amiga is forever a legacy system.
Well. This case is already boring the hell out of me, so I will just leave them to it.
But looking at the various paths forward, from where I stand Hyperion and OS 4.x is the only viable business model. Providing the goal is to bring the technology back into the consumer-market and evolve the technology as an alternative to Windows, OS X and Linux. If the goal is just milk the system one final time, then I would say they are already there.
I honestly could not care less at this point. They have been asleep for so long, that they have become irrelevant. The future is in cloud, clustering and hardware abstraction — and Amibian.js is already far more interesting than anything cloanto has on offer.
But make no mistake: If the parties involved dont get their shit together, come 2022 and we will implement a native OS ourselves and open source it through torrents. The Quartex consortium is deadly serious about this. The new QTX is made up of members from various established groups back in the day, now in our 40s and 50s. Like all amiga users we have tolerated this for two decades, but enough is enough. Unlike the average gamer most of us are professional developers with decades of experience.
They have until 2022, if nothing has changed, we will finish this for them
And that was my five cents on that matter, and the last post I will do on this dumpsterfire of a topic.
DelphiJavaScriptLinuxObject PascalSmart Mobile StudioCodersLifeSmart PascalVirtualizationVMWare
Virtualization is, simply put, a form of emulation. Back in the mid 90s emulators became hugely popular, because for the first time in history we had CPU's powerful enough to emulate other computers. This was radical because up until that point, you needed special hardware to do that. You had also been limited to legacy systems with no practical business value.
Show full content
Full disclosure: I am not affiliated with any particular virtualization vendor of any sorts. The reason I picked VMWare was because their product was faster when I compared the various solutions. So feel free to replace the word VMWare with whatever virtualization software suits your needs.
On Delphi Developer we get new members and questions about Delphi and C++ builder every day. It’s grown into an awesome community where we help each other, do business, find jobs and even become personal friends.
A part of what we do in our community, is to tip each other about cool stuff. It doesn’t have to be directly bound to Delphi or code either; people have posted open source graphic programs, video editing, database designers – as long as its open source or freeware its a great thing (we have a strict policy of no piracy or illegal copying).
Today we got talking about VMWare and how its a great time saver. So here goes:
Virtualization
Virtualization is, simply put, a form of emulation. Back in the mid 90s emulators became hugely popular because for the first time in history – we had CPU’s powerful enough to emulate other computers at full speed. This was radical because up until that point, you needed special hardware to do that. You had also been limited to emulating legacy systems with no practical business value.
VmWare Workstation is an amazing piece of engineering
Emulation has always been there, even back in the 80s with 16 bit computers. But while it was technically possible, it was more a curiosity than something an office environment would benefit from (unless you used expensive compute boards). We had to wait until the late 90s to see commercial-grade x86 emulation hitting the market, with Virtuozzo releasing Parallels in 1997 and VMWare showing up around 1998. Both of these companies grew out of the data-center culture and academia.
It’s also worth noting that modern CPU’s now support virtualization on hardware level, so when you are “virtualizing” Windows the machine code is not interpreted or JIT compiled – it runs on the same CPU as your real system.
Why does it matter
Virtualization is not just for data-centers and server-farms, it’s also for desktop use. My personal choice was VMWare because I felt their product performed better than the others. But in all fairness it’s been a few years since I compared between systems, so that might be different today.
A screengrab of my desktop, here showing 3 virtual machines running. I have 64 gigabyte memory and these 3 virtual machines consume around 24 gigabytes and uses 17% of the Intel i7 CPU power during compile. It hardly registers on the CPU stats when idle.
VMWare Workstation is a desktop application available for Windows, Linux and OS X. And it allows me to create virtual machines, or “emulations” if you like. The result is that I can run multiple instances of Windows on a single PC. The virtual machines are all sandbox in large hard-disk files, and you have to install Windows or Linux into these virtual systems.
The bonus though is fantastic. Once you have installed an operating-system, you can copy it, move it, do partial cloning (only changes are isolated in new sandboxes) and much, much more. The cloning functionality is incredibly powerful, especially for a developer.
It also gives you something called snap-shot support. A snapshot is, like the word hints to, a copy of whatever state your virtual-machine is in at that point in time. This is a wonderful feature if you remember to use it properly. I try to take snapshots before I install anything, be it larger systems like Delphi, or just utility applications I download. Should something go wrong with the tools your work depends on — you can just roll back to a previous snapshot (!)
A great time saver
Updates to development tools are always awesome, but there are times when things can go wrong. But if you remember to take a snapshot before you install a program, or before you install a component package — should something go wrong, then rolling back to a clean point is reduced to a mouse click.
I mean, imagine you update your development tools right? Suddenly you realize that a component package your software depends on doesn’t work. If you have installed your devtools directly on the metal, you suddenly have a lot of time-consuming work to do:
Re-install your older devtools
Re-install your components and fix broken paths
That wont be a problem if you only have 2-3 packages, but I have hundreds of components install on my rig. Just getting my components working can take almost a full work-day, and I’m not exaggerating (!).
With VMWare, I just roll back to when all was fine, and go about my work like nothing happened.
I made a quick, slapdash video to demonstrate how easy VmWare makes my Delphi and JS development. If you are not using virtualization I hope this video at least makes it a bit clearer why so many do.
Amibian.jsDelphiJavaScriptObject PascalQTXAmibianBitBucketClusteringODroidODroid XU4PatreonquartexQuartex Web OSRagnarokWeb OS
To make it easier for my backers to get the code they want, I have isolated each project and sub-project in separate repositories on BitBucket. This covers Delphi, Smart Pascal, LDEF and everything else.
Show full content
As most know by now, I was running a successful campaign on Patreon until recently. I know that some are happy with Patreon, but hopefully my experience will be a wakeup call about the total lack of rights you as a creator have – should Patreon decide they don’t understand what you are doing (which I can only presume was the case, because I was never given a reason at all). You can read more about my experience with Patreon by clicking here.
Setting up repositories
Having to manually build a package for each tier that I have backers for would be a disaster. It was time-consuming and repetitive enough to create packages on Patreon, and I don’t have time to reverse engineer Patreon either. Which I might do in the future and release as open-source just to give them a kick in the groin back.
To make it easier for my backers to get the code they want, I have isolated each project and sub-project in separate repositories on BitBucket. This covers Delphi, Smart Pascal, LDEF and everything else.
The CloudRipper architecture is coming along nicely. Here running on ODroid XU4
I’m just going to continue with the Tiers I originally made on Patreon, and use my blog as the news-center for everything. Since I tend to blog about things from a personal point of view, be it for Delphi, JavaScript or Smart Pascal — I doubt people will notice the difference.
So far the following repositories have been setup:
Amibian.js Server (Quartex Web OS)
Amibian.js Client
HexLicense
TextCraft (source-code parser for Delphi and Smart Pascal)
UAE.js (a fork of SAE, the JS implementation of UAE)
I need to clean up the server repository a bit, because right now it contains both the server-code and various sub projects. The LDEF assembler program for example, is also under that repository — and it belongs in its own repository as a unique sub-project.
The following repositories will be setup shortly:
Tweening library for Delphi and Smart Pascal
PixelRage graphics library
ByteRage bugger library
LDEF (containing both Delphi and Smart Pascal code)
LDEF Assembler
It’s been extremely busy days lately so I need to do some thinking about how we can best organize things. But rest assured that everyone that backs the project, or a particular tier, will get access to what they support.
Support and backing
I have been looking at various ways to do this, but since most backers have just said they want Paypal, I decided to go for that. So donations can be done directly via paypal. One of the new features in Paypal is repeated payments, so setting up a backer-plan should be easy enough. I am notified whenever someone gives a donation, so it’s pretty easy to follow-up on.
Updates used to be monthly, but with the changes they will be ad-hoc, meaning that I will commit directly. I do have local backups and a local git server, so for parts of the project the commits will be issued at the end of each month.
While all support is awesome, here are the tiers I used on Patreon:
$5 – “high-five”, im not a coder but I support the cause
$10 – Tweening animation library
$25 – License management and serial minting components
$35 – Rage libraries: 2 libraries for fast graphics and memory management
$45 – LDef assembler, virtual machine and debugger
$50 – Amibian.js (pre compiled) and Ragnarok client / server library
$100 – Amibian.js binaries, source and setup
$100+ All the above and pre-made disk images for ODroid XU4 and x86 on completion of the Amibian.js project (12 month timeline).
So to back the project like before, all you do is:
Register with Bitbucket (free user account)
Setup donation and inform me of your Bitbucket user-name
I add you on BitBucket so you are granted access rights
Easy. Fast and reliable.
The QTX RTL
Those that have been following the Amibian.js project might have noticed that a fair bit of QTX units have appeared in the code? QTX is a run-time library compatible with Smart Mobile Studio and DWScript. Eventually the code that makes up Amibian.js will become a whole new RTL. This RTL has nothing to do with Smart Mobile Studio and ships with its own license.
QTX approaches the DOM in more efficient way. Its faster, smaller and more powerful
Backers at $45 or beyond access to this code automatically. If you use Smart Mobile Studio then this is a must. It introduces a ton of classes that doesn’t exist in Smart Pascal, and also introduces a much faster and clean visual component framework.
If you want to develop visual applications using QTX and DWScript, then that is OK, providing the license is respected (LGPL, non commercial use).
The resize and moving of windows uses CSS transformation, which in modern browsers makes use of the GPU. Chrome talks directly with OpenGL (or glES), so the operations are proxied through that. And again, since OpenGL is pretty rock solid elsewhere, we are only left with one common denominator: the mali GPU
Show full content
EDIT: I did further testing after this article was written, and believe the source of this to be about heat. Even with extra fans, running games like Tyrian (asm.js) that are extremely demanding, plus resizing a graphics intensive windows constantly, the temperature reached 71 degrees C very quickly. And this was with two cabinet fans helping the built-in fan to cool the device. It is thus not unthinkable that when running solo (no extra fans) that the kernel shut the device down to not cook the chipset. Which also explains why the device wont boot properly afterwards (the device is still hot).
Glitches
Something really strange is happening on Chrome and Firefox for ARM. JavaScript is not supposed to be able to take down a system, and in this case it’s neither an attempt as such either — yet for some reason I have managed to take down the ODroid XU4 with both Chrome and Firefox lately.
ODroid XU4
I guess I should lead with that I’m not able to replicate this on x86. One of the things I really love about the ODroid XU4 is that it’s affordable, powerful and probably the only SBC I have used that runs stable on the mali GPU. As you probably know I tested at least 10 different SBC’s back in 2018, and whenever there was a mali GPU involved, the product was either haunted by instabilities or lacked drivers all together.
Since the codebase for Chrome (and I presume Firefox) is ultimately the same between platforms, it leaves a question-mark about the ODroid. It is by far the most stable SBC I have tested so far (except for the PI, which is sadly underpowered for this task), but stable doesn’t mean flawless. And to be honest, Amibian.js is pushing web tech to the very limits.
Not Mali again
The reason I suspect the mali to be the culprit behind all this, is because the “bug” if we can call it that, happens exclusively during resize. So if there is a lot going on inside a desktop-window, you can sometimes provoke the ODroid to cold-crash and reboot. You actually have to power the board down and switch it back on for it to boot properly.
Cloudripper ~ 5x ODroid XU4 [40 cores] in a PICO 5h cube
The resize and moving of windows uses CSS transformation, which in modern browsers makes use of the GPU. Chrome talks directly with OpenGL (or glES), so the operations are proxied through that. And again, since OpenGL is pretty rock solid elsewhere, we are only left with one common denominator: the mali GPU.
The challenge is that there is no way to debug or catch this error, because when it occurs the whole system literally goes down. There is no exception thrown, nor is the browser process terminated (not even a log entry, so it’s a clean-cut) — the system reboots on the spot. Since it fails on reboot when opening X (setting a screen-mode) I again point the finger at the GPU. Somehow a flag or lock survives the cold-reboot and that’s why you have to manually switch it off and on again.
This is the exact problem that made the NanoPI Fire useless. It only shipped with Android embedded drivers. The X drivers could hardly open a display without crashing. Such a waste of a good cpu.
x86 as head
ODroid is perfect for a low-cost Amibian.js experience, but I was unsure if it would handle the payload. Interestingly it handles it just fine and even with a high-speed action game running + background tasks we are not using 50% of the CPU even.
Ram is holding up too, with memory consumption while running Tyrian + having a few graphics viewers open, is at a reasonable 700 mb (of 2 gigabyte in total).
Tyrian jogs along at 45 fps ~ that is not bad for a $45 SBC
Right now this strange error is rare, but if it continues or grows into a problem (chrome is hardly useable at all, only firefox) then I have no option than to replace the master sbc in the cluster with something else. The x86 UP board is more than capable, but it would be a shame to break the price range because of that (excuse my language) crap mali GPU. I honestly don’t understand why board makers insist on using a mali. Every board that has a mali is haunted by problems and get poor reviews.
It will be exciting to check out the dragonboard, although I fear 1Gb memory will not be enough for smooth operation. Not without a sata interface and a good swap-file.
Android and Delphi
One alternative is to switch to Android and use Delphi to code a custom Chromium Embedded webview. I am hoping to avoid the overhead of Android, but Delphi would definitively be a bonus with Android embedded (“Android of things”).
Amibian.jsAmigaDelphihexlicenseJavaScriptLanguage researchLifenodeJSObject PascalODroidSmart Mobile StudioSocialavoid PatreonGlobal Villageholding back fundsmistreating creatorsno phone accessPatreonUnreliable service
If you as a developer have a chance to set up shop elsewhere, then I urge you to do so. And make sure your host have common infrastructure such as a phone number. Patreon have taken the art of avoiding direct contact to a whole new level. It is absolutely mind boggling.
Show full content
As a person I’m quite optimistic. I like to think the glass is half-full rather than half-empty. I have spent over a decade building up a thriving Delphi and C++ builder community on social media, I have built up a rich creative community for node and JavaScript on the side — not to mention retro computing, embedded tech and IOT. For better or for worse I think most developers in the Embarcadero camp have heard my name or engage in one of the 12 groups I manage around the world on a daily basis. It’s been hard work but man, it’s been worth every minute. We have so much fun and I get to meet awesome coders on a daily basis. It’s become an intrinsic part of my life.
I have been extremely fortunate in that despite my disadvantage, a spine injury in 2012 – not to mention being situated in Norway rather than the united states; despite these obstacles to overcome I work for a great American company, and I get to socialize and have friends all over the planet.
The global village is the concept, or philosophy, that technology makes it possible no-matter where you live, to connect and be a part of something bigger. You don’t have to be a startup in the san-francisco area to work with the latest tech. Sure a commute from Burlingame to Redwood beats a 14 hour flight from Norway any day of the week — but that’s the whole idea: we have Skype now, and Slack and Github; you don’t have to physically be on location to be a part of a great company. The only requirement is that you make yourself relevant to your field of expertise.
Patreon, a digital talent agency
Patreon is a service that grew straight out of the global village. If the world is just one place, one great big family of human beings with great ideas, then where is the digital stage that helps nurturing these individuals? I mean, you can have a genius kid living in poverty in Timbuktu that could crack a mathematical problem on the other side of the globe. The next musical prodigy could be living in a loft in Germany, but his or her voice will never be heard unless it’s recognized and given positive feedback.
“The irony is that Patreon doesn’t even pass their own safety tests. That should make you think twice about their operation”
My examples are extremes I agree, most people on Patreon are like me, creative but absolutely not cracking math problems for Nasa; nor am I singing a duet with Bono any time soon. But that’s the fun thing about the world – namely that all things have value when put in the correct context. Life is about combinations, and you just have to find one that works for you.
The global village, the idea of unity through diversity
The global village is this wonderful idea that we can use technology to transcend the limitations the world oppose on us, be they nationality, color, gender or location. Good solutions know no bounds and manifests wherever a mind welcomes it. Perhaps a somewhat romantic idea, if not naive, but it seems the only reasonable solution given the rapid changes we face as a species.
In my case, I love to make software components in my spare time. My day job is packed and I couldn’t squeeze in more work during the weekdays if I wanted to, so I only have a couple of hours after-work and the weekends to “do my thing”. So being a total geek I relax by making components. Some play chess, the guitar or whatever — I relax by coding something useful.
Obviously “code components” are completely useless to anyone who is not a software developer. The relevance is further clipped by the programming-language they are written for, and ultimately the functionality they provide. Patreon for me was a way to finance the evolution of these components. A way of self motivating myself to keep them up to date and available.
I also put a larger project on Patreon, namely the cloud desktop system people know as “Amibian.js” or “Quartex Web OS”. Amibian being the nickname, or codename.
Patreon seemed like the perfect match. I could take these seemingly unrelated topics, Delphi and C++ builder specific components and a cloud architecture, and assign each component and project to separate “tiers” that the audience could pick from. This was great! People could now subscribe to the tier’s they wanted, and would be notified whenever there was an update or new features. And I could respond to service messages in one place.
The Tier System
The thing about software is that it’s not maintained on infinite repeat. You don’t fix a component that is working. And you don’t issue updates unless you have fixed bugs or added new functionality. A software subscription secures a customer access to all and any updates, with a guarantee of X number of updates a year. And equally important, that they can get help if they are stuck.
“when you are shut down without so much as an explanation, with nothing but positive feedback, zero refunds and over 1682 people actively following the progress — that is utterly unacceptable behavior”
I set a relatively low number of guaranteed updates per year for the components (4). The things that would see the most updates were the Rage Libraries (PixelRage and ByteRage) and Amibian.js, but not until Q3 when all the modules would come together as a greater whole — something my backers are aware of and have never had a problem with.
Amibian.js running on ODroid XU4, a $45 single board computer
The tiers I ended up with was:
$5 – “high-five”, im not a coder but I support the cause
$10 – Tweening animation library
$25 – License management and serial minting components
$35 – Rage libraries: 2 libraries for fast graphics and memory management
$45 – LDef assembler, virtual machine and debugger
$50 – Amibian.js (pre compiled) and Ragnarok client / server library
$100 – Amibian.js binaries, source and setup
$100+ All the above and pre-made disk images for ODroid XU4 and x86 on completion of the Amibian.js project (12 month timeline).
Note: Each tier covers everything before them. So if you pick the $35 tier, that also includes access to the license management system and the animation library.
As you can see, the tier-system that is intrinsic to Patreon, solves the software subscription model elegantly. After all, it would be unreasonable to demand $100 a month for a small component like the Tweening library. A programmer that just needs that library and nothing else shouldnt have to pay for anything else.
Here is a visual representation, showing graphically why my tiers are organized as they are, and how they all fit into a greater whole:
The server-side aspect of the architecture would take days to document, but a general overview of the micro-service architecture is fairly easy to understand:
Each of the tiers were picked because they represent key aspects of what we need to create a visually pleasing, fast and reliable, distributed (each part running on separate machines or boards) cloud eco-system. Supporters can just get the parts they need, or support the bigger project. Everyone get’s what they want – all is well.
The thing some people don’t grasp, is that you are not getting something to just put on Amazon or Azure, you are getting your own Amazon or Azure – with source code! You are not getting services, you are getting the actual code that allows YOU to set up your own services. Anyone with a server can become a service provider and offer both hosting and software access. And they can expand on this without having to ask permission or pay through the nose.
So it’s a little bit bigger than first meets the eye.
I Move In Mysterious Ways ..
Roughly 3 weeks ago I was busy preparing the monthly updates.
Since each tier is separate but also covers everything before it (like explained above) I have to prepare a set of inclusive updates. The good news is that I only have to do this once and then add it as an attachment to my posts. Once added I can check of all the backers in that tier. I don’t have to manually email each backer, physically copy my songs or creations onto CD and send it – we live in the digital age as members of the global village. Or so i thought.
So I published two of the minor cases first: the full HTML5 assembly program, that can be run both inside Amibian.js as a hosted application — or as a solo program directly in the browser. So here people can write machine-code in the browser, assemble it to bytecodes, run the code, inspect registers, disassemble the bytecodes and all the normal stuff you expect from an assembler.
This update was special because the program contained the IPC (inter process communication) layer that developers use to make their programs talk to the desktop. So for developers looking to make their own web programs access the filesystem, open dialogs (normal system features), that code was quite important to get!
Although published, none of my backers could see them due to the suspended status
The second post was a free addition, the QTX library which is an open-source RTL (run time library) compatible with the Smart Pascal Compiler. While not critical at this juncture, several of my backers use Smart Mobile Studio, and for them to get access to a whole new RTL that can be used for open-source, is very valuable indeed.
I was just about to compress the Amibian.js source-code and binaries when I got a message on Facebook by a backer:
“Dude, your Patreon is shut down, what is happening?”
What? hang on let me check i replied, and rushed into Patreon where the following header greeted me:
What the hell Patreon? I figured there must be some misunderstanding and that perhaps I missed an email or something that needed attention. I get close to 50 emails a day (literally) so it does happen that I miss one. I also check my spam folder regularly in case my google filters have been careless and flagged a serious email as spam. But there was nothing. Not a word.
Ok, so let’s check the page feedback, has there been any complaints? Perhaps a backer has misunderstood something and I need to clear that up? But nope. I had nothing but positive feedback and not even a single refund request. In fact the Amibian.js group on Facebook has grown to 1,662 members. Which shows that the project itself holds considerable interest outside software development circles.
Well, let’s get on this quickly I thought, so I rushed off an email asking why Patreon would do such a thing? My entire Patreon page was visibly marked with the above banner, so my backers never even saw the updates I had issued.
Instead, the impression people would get, was that I was involved in something so devious that it demanded my account to be suspended. Talk about shooting first and asking later. I have never in my life seen such behavior from a company anywhere, especially not in the united states; Americans don’t take kindly to companies behaving like bullies.
Just Contact Support, If You Can Find Them
To make a long story short it took over a week before Patreon replied to my emails. I sent a total of 3 emails asking what on earth would have prompted them to shut down a successful campaign. And how they found it necessary to slander the project without even informing me of the problem. Surely a phone call could have sorted this up in minutes? Where I come from you pick up the phone or get in contact with people before you flag them in public.
Sounds great, sadly it’s pure fiction
The response I got was that “some mysterious activity had been reported on my page”, and that they wanted my name, address, phone number and credit card (4 last digits). Which I found funny because with the exception of credit-card details, I always put my name, address, phone numbers and email etc. at the head of my letters.
I’m not a 16-year-old kid working out of a garage, im a 46-year-old established software developer that have worked as a professional for close to 3 decades. Unlike the present generation I moved into my first apartment when I was 16, and was working as an author for various tech magazines by the time I was 17. I also finished college at the same time and went on to higher-education (2 years electrical engineering, 3 years arts and media, six years at the university in oslo, followed by 4 years of computer science and then certifications). The focus being, that Patreon is used to dealing with young creators that will go along with things that grown men would not accept.
But what really piss me off, was that they never even bothered to explain what this “mysterious behavior” actually was? I write about code, clustering, Delphi, JavaScript and bytecodes for christ sake. I might have published updates and code wearing a hoodie at one point, in a darken room, listening to Enigma.. but honestly: there is not enough mystery in my life to cover an episode of Scooby-Doo.
Either way, I provided the information they wanted and expected the problem to be resolved asap. Two days at themost. Maybe three, but that was pushing it.
It’s now close to 3 weeks since this ridiculous temporary suspension occurred, and neither have I been given any explanation to what I have done, nor have they removed the ban on the content. I must have read their guidelines 100 times by now, but given the nature of their ruling (which are more than reasonable), I can’t see that I have violated a single one:
No pornography and adult content
No hate speech against minorities or forms of religious extremism
No piracy or spreading copyrighted material
No stealing from backers
Let’s go over them one by one shall we?
Pornography and adult content
Seriously? I don’t have time to loaf around glaring at naked women (i’m a geek, I look weird enough as it is), and after 46 years on this planet I know what a woman looks like nude from every possible angle; I don’t need to run around like a retard posting pictures of body parts. And if you are talking about me — good lord is there a marked for hobbits? Surely the world has enough on it’s plate. Sorry, never been huge on porn.
And for the record, porn is for teenagers and singles. The moment you love someone deeply, the moment you have children together — it changes you profoundly. You get a bond to your wife or girlfriend that makes you not want to be with others. Not all men are into smut, some of us are invested more deeply in a relationship.
Hate speech and religious extremism
Hm, that’s a tough one (sigh). Did you know that one of my best friends is so gay – that he began to speculated that he actually was a liquid? He makes me laugh so bad and he’s probably the best human being I have ever met. I actually went with him on Pride last year, not because i’m gay but because he needed someone to hold the other side of the banner. That’s what friends do. Besides, I looked awesome, what can I say.
As for religion I am a registered Tibetan Buddhist. I believe in fluffy pillows, comfy robes, mother nature and quite frankly I find the world inside us far more interesting than the mess outside. You cant be extreme in Buddhism: “Be kind now, or ill hug you until you weep the tears of compassion!”. Buddhism sucks as an extreme doctrine.
So I’m going to go out on a limb and say nuuuu to both.
Piracy and copyrighted material
Eh, I’m kinda writing the software from scratch before your eyes (including the run-time-library for the compiler), so as far as worthy challenges go, piracy would be the opposite. I am a huge fan of classical operating-systems though, like the Amiga; But unlike most people I actually took the time to ask permission to use a OS4 inspired CSS theme-file.
The Amibian.js project is well organized and I have worked systematically through a well planned architecture. This is not some slap-dash project made for a quick buck
Most people just create a theme-file and don’t bother to ask. I did, and Trevor Dickinson was totally cool about it. And not a single byte has been taken or stolen from anyone. The default theme file is inspired by Amiga OS 4.1, but the thing is: the icons are all freeware. Mason, the guy that did the OS icons, have released large sets of icons into GPL. There is also a website called OS4Depot where people publish icons and backdrops that are free for all.
So if this “mysterious activity” is me posting a picture of a picture (not a typo) of an obscure yet loved operating-system, rest assured that it’s not violating anyone.
Stealing from backers
That they even include this as a point is just monumental. Patreon is a service established to make that impossible (sigh); meaning that the time-frame where you deliver updates or whatever – and the time when the payout is delivered, that is the window where backers can file a complaint or demand a refund.
And yes, complaints on fraud would indeed (and should!) flag the account as potentially dubious — but again, I have not a single complaint. Not even a refund request, which I believe is pretty uncommon.
And even if this was the case, shutting down an account without so much as a dialog in 2019? Who the hell becomes a thief for 600 dollars? Im not some kid in a garage, I make twice that a day as a consultant in Oslo, why the heck would I setup a public account in the US, only to run off with 600 bucks! I have standing offers for projects continuously, I havent applied for a job since the 90s – so if I needed some extra money I would have taken a side project.
I even posted to let my backers know I had a cold last month just to make sure everyone knew in case I was unavailable for a couple of days. Truly the tell-tell sign of a criminal mastermind if I ever saw one ..
Sorry Patreon, but your behavior is unacceptable
Hopefully your experience with Patreon has not been like mine. They spent somewhere in the range of 5 weeks just to register me, while friends of mine in the US was up and running in less than 2 days.
We are now 3 weeks into a temporary suspension, which means that most of my backers will run out of patience and just leave. It sends a signal of being whimsical about other people’s trust, and that people take a risk if they back my project.
At this point it doesn’t matter that none of these thoughts are true, because they are thoughts that anyone would think when a project remains flagged for so long.
What should scare you as a creator with Patreon though, is that they can do this to anyone. There is nothing you can do, neither to prove your innocence or sort out a misunderstanding — because you are not even told what you allegedly have done wrong. I also find it alarming that Patreon actually doesn’t have a phone-number listed, nor do they have offices you can call or reach out to.
The irony is that Patreon doesn’t even pass their own safety tests. That should make you think twice about their operation. I had heard the rumors about them, but I honestly did not believe a company could operate like this in our day and age. Especially not in the united states. It undermines the whole spirit of US as a technological hub. No wonder people are setting up shop in China instead, if this is how they are treated in the valley.
After this long, and the damage they have caused, I have no option than to inform my backers to terminate their pledges. I will have to relocate my project to a host that has more experience with software development, and who treats human beings with common decency and respect.
If I by accident had violated any of their guidelines, although I cannot see how I could have, I have no problem taking responsibility. But when you are shut down without so much as an explanation, with nothing but positive feedback, zero refunds and over 1682 people actively following the progress — that is utterly unacceptable.
It is a great shame. Patreon symbolized, for a short time, that the global village had matured into more than an idea. But I categorically refuse to be treated like this and find their modus-operandi insulting.
Stay Well Clear
If you as a developer have a chance to set up shop elsewhere, then I urge you to do so. And make sure your host have common infrastructure such as a phone number. Patreon have taken the art of avoiding direct contact to a whole new level. It is absolutely mind-boggling.
I honestly don’t think Patreon understands software development at all. Many have voiced more sinister motives for my shutdown, since the project obviously is a threat to various companies. But I don’t believe in conspiracies. Although, if Patreon does this to enough creators on interval, the interest rates from holding the assets would be substantial.
It could be that the popularity of the project grew so fast that it was picked up as a statistical anomaly, but surely that should be a good thing? Not to mention a potential case study Patreon could have used as a success story? I mean, Amibian.js didn’t get up and running until october, so stopping a project 5 months into a 12 month timeline makes absolutely no sense. Unless someone did this on purpose.
Either way, this has been a terrible experience and I truly hope Patreon get’s their act together. They could have resolved this with a phone-call, yet chose to let it fester for almost a month.
as far as general IT news goes, this one is attracting interest far and wide due to the sheer absurdity involved. To be honest I also think that the case itself serves as a warning to companies and developers in general, because this truly is the best example of how bad things can go if you don't manage your patents and rights properly
Show full content
Delphi and C++ builder developers will probably not have much interest in this, but as far as general IT news goes, this one is attracting interest far and wide due to the sheer absurdity involved. To be honest I also think that the case itself serves as a warning to companies and developers in general, because this truly is the best example of how bad things can go if you don’t manage your patents and rights properly.
So while I’m loving Delphi’s 24th birthday festivities, I find the ongoing lawsuits so amazing that I have to write a few words.
[Edit]: To make the case even remotely understandable for people that have never read about it before, I have left out a ton of details. The whole Amiga Inc scandal (which I believe ordered production of OS4 to begin with?), Eyetech, H&P, the loss of the Amiga OS 3.9 source code. The gist of the post here is not to dig into the details (also known as “the rabbit hole” in the community), but to give a short recount of the highlights leading up to the present situation – and to underline that people who still care for the system, the Amiga community, is beyond fed-up with this. I hope all parties get their act together and find a way to co-exist. For those that want to dig into the gory details spanning three decades, there is always the Amiga documentation project.
Some context
Long story short, back in the early 90s Commodore, a company that for close to two decades ranked as a giant of computing, collapsed. Years of mismanagement, poor leadership, if not outright shameful, had taken its toll on the once fierce giant; And as the saying goes: the bigger they are, the harder they fall. And boy did Commodore fall.
Commodore ranked side-by side with the biggest names in the industry
What people often forget is that tech-companies have two types of currencies. The first is what consumers consider valuable; things like the products they make, how much money is in the bank, the state of their inventory, good partners and retailers — all points of importance when running a business.
Major players though couldn’t care less about these factors, not unless they align with their own needs. So from a PC company’s perspective, getting rid of the Amiga and butchering Commodore for patents was a spectacular win. Because, and here we get into the nasty parts: for an already established competitor, a dead tech company has one asset and one asset only: namely their patent-portfolio.
So all that buying and selling we saw in the 90s, with Amiga changing hands left and right, had nothing to do with saving the Amiga. The Commodore legacy was reduced to a piece of meat and thrownto the wolves, each ripping into its patents left and right. So while graphic, the piece of meat in this analogy held an estimated value of a billion dollars.
Patents are valuable because they represent repeated income and a level of financial security unline ordinary currency. Large companies use patent portfolios in combination with their insurance. IBM is more or less the archetypical example of this. They remain one of the richest companies in the world, but spend their time tinkering with super-computers and science experiments. “Big Blue” haven’t “worked” in the true sense of the word since they started licensing out PC as a platform. They own the patents for pretty much everything we know as a PC today, and don’t need to compete. They make a fortune just sitting there.
Climbing up the rabbit hole
Gateway and Escom both tried to save themselves using the Amiga patents, but they failed
When Commodore fell, the vultures moved in quickly. People have focused so much on the Amiga computer and branding aspect of Commodore, that we often neglect that the true value of such a giant was never the end-product, but the intrinsic values of their patents and technological inventions.
Very few knew the identity of the party now in possession of the Commodore patent portfolio until quite recently. It caused quite a stir online when I published the name of the owner last year (both on this blog and Amiga Disrupt on Facebook).
Just to underline: this information have never been secret or anything of the sorts. It’s just a type of information ordinary people wouldn’t know where to find (myself included). You have to know where to look and what to look for. And while I have some experience with copyright cases and intellectual property – I would never have found it without a heart to heart with Trevor Dickinson. The major shareholder in Aeon, which produces the Next Generation Amiga system (x5000 and the upcoming A1222). He kindly helped me through the avalanche of older court documents and pointed me to an article series in AF Magazine that I had no idea even existed.
I should also stress that I have no special friendship with Trevor. I have talked to him on various occasions and we share a passion for the Amiga system. He has always been very kind, but I don’t know him personally. Nothing I write here is done in his favour or out of some form of loyalty. I simply find that A-EON and Hyperion’s plans and products makes the most sense in 2019.
When the mysterious owner of Commodore and Amiga turned out to be Acer my jaw dropped. They had been sitting on the patents for all these years without making a sound. From Acer’s point of view the Amiga computer is worthless and they wouldn’t give a cup of coffee for the Amiga name or its legacy. So the Amiga name and legacy code was sold off long ago. Acer handles technological patents that commodore deviced, from PET to 3A no doubt. Amiga as a platform is uninteresting to them.
How Acer got a hold of the portfolio can only be speculated on, but I would imagine they snapped them up when Escom went under. How much of the original portfolio remains intact is anyone’s guess. The classical Amiga OS source-code was, as we know, acquired by Hyperion from Amiga Inc years ago. That was the 3.1 version. Interestingly the 3.9 version was bought by H&P (a german company) and was sadly lost when they existed the Amiga market permanently.
Workbench and hipsters
For those that haven’t read or followed up on the “Commodore case”, the license holders mentioned above (A-EON, Hyperion, Cloanto), have been at each other’s throats since the brits annexed India. Which is why this case has become interesting for others as well.
Nobody under 33 years of age would associate this with Commodore or Amiga.
To give you some examples of the epic battles at hand: they have argued in court over the right to use a checkered bathing ball, you know those you can buy almost anywhere and that resemble a french table-cloth? Oh yes I kid ye not.
They have gone to court over the misuse of said bathing apparatus, the misrepresentation of the ball, who owns the ball, it’s buoyancy – and let us not forget trademarking the word “Workbench” (the name of the desktop system the Amiga uses). A word today only used by hipsters in meth-labs and tool-time-tim wannabe’s on YouTube. The absurdities are so dense you could bottle them.
If we look at the many struggles since Commodore went under from a bird’s eye perspective, we are essentially seeing the same lawsuit on infinite repeat (with a few variations here and there). I got married, I had kids and 15 years later I got divorced. And when I got back they were still at it! Good god guys, what a complete and utter waste of time, resources and talent (The lawsuits not my marriage. Well maybe both), not to mention counter productive! If anything these frequent lawsuits are destroying what both parties are trying to protect. Although I question if one of them indeed are.
If I was to go back to school and re-invent myself, I would become an author. All I had to do to was take the Commodore story and place it in middle-earth, give the people involved pointy ears, brutal weaponry and silly names and voila! A tale that would make Tolkien himself weep; because great as his imagination was, never could he have concocted such a story. Not even Keith Richards if we let him loose in a pharmacy on “take all the drugs you can carry day” – could make up a timeline as insane as the Commodore aftermath.
Lawsuits 1-0-1: Que bono?
To catch you up with the present events, let’s just go through the basics first.
It can be difficult to distinguish between Hyperion and Aeon, so lets start with a few words about that. Hyperion is ultimately a software company. They started (if I recall correctly) as software house porting PC games to the Amiga platform.
I previously wrote that Trevor was the major shareholder in both companies, that was actually wrong, he holds a very small role in Hyperion. But who owns what here is ultimately pointless. The relationship between Hyperion and A-EON is that Hyperion represents the software branch, and A-EON is the hardware branch. And combined they make out the owners and producers of what is commonly called “Next Generation” Amiga machines.
A-EON and Hyperion hold the rights to develop Amiga OS, covering both the classical 68k version and the NG models which are PPC based. Cloanto have only sales rights, which are limited to the legacy 68k ROM kernel files, and workbench. That is ultimately what separates these two groups. So even though there are 3 companies involved, it’s easier to regard them as two separate entities.
And yes we could argue that OS4 was instigated by Amiga Inc earlier, but i’m trying to keep this readable for people that haven’t read anything about this silliness before, so i’m skipping all of that.
Amiga OS is loved by many, but to be frank it’s reached the point that fighting over it has long since passed. A teenager today knows PSX, XBox and completely different brands
Until recently Aeon and Hyperion have focused completely on their Next Generation system. Aeon creates the hardware and Hyperion does the software. Hyperion also offers the older legacy roms and Workbench in their webshop. But until recently they have been more interested in selling next-generation software and machines.
Cloanto have been exclusively about legacy. They have no license that involves software development, and are for all means an purposes a retro retailer (or undertaker if you will). They sell old Commodore stuff, and that’s it. So while they have argued like cats and dogs over absolutely everything, like that worthless boing ball and the name “workbench”, they at least managed to co-exist somehow.
That was, until Hyperion listened to the Amiga Community and released an update for the 68k platform. Which is perfectly within their rights to do. They have a license that covers both 68k and PPC. Acer has set a clause (from what I can tell) that they are not allowed to touch x86, but as far as 68k and PPC is concerned — Hyperion is well within their rights to issue an update. After all they own the source-code for Amiga OS 3.1 which I mentioned above, Cloanto does not.
The response from the community was quite frankly outstanding. Finally a proper update for both Workbench and the kernel! Everyone was ecstatic and the whole scene was filled with positive hopes that things were finally moving forward. This was after all the first real update since Napoleon was in office!
Cloanto however, not so much. Because even though they share the sales license with Aeon, they have no rights to the new software created. They don’t make a penny on the new 68k kernel (rom files) or the new Workbench. They can continue to sell the older variations of Amiga OS, but they have no legal right to software written and issued in 2018. Cloanto responded like they always have, by issuing a lawsuit.
So the reason Cloanto took Hyperion to court for the 13th thousand time, has nothing to with open-source (a rumour that was planted before Xmas). It is motivated purely by greed and the fear that the Amiga might actually spring back to life.
And this is where we get to the nasty parts
Legacy software undertakers
Legacy software is not unlike the undertaking business
First of all, and I want to make this crystal clear: Cloanto’s entire business model rests on the Amiga remaining dead. In a bizarre twist of irony, the self-proclaimed caretakers of Amiga actually face financial ruin if the Amiga ever became popular or rose from the grave. Stop and think about that for a moment: They make money on the Amiga remaining a dead system.
The only product Cloanto have actually produced, is a pixel paint program called PPaint, which was awesome back in the previous century.
The state of affairs for the past 18 years, is that Cloanto depends completely an emulator, UAE, short for “The Unix Amiga Emulator”, when it comes to the Amiga . Which ironically is not Cloanto’s work at all, but an emulator created by Bernd Schmidt, Toni Wilen and Mathias Ortmann; neither have received a penny despite Cloanto profiting on their work for close to two decades (!)
The selling of legacy Commodore software I have no problem with at all. But what bakes my noodle is forking UAE and selling it for profit without giving something back to its original authors? I have yet to see the source-code for Amiga Forever on Github for example? The laws of GPL are pretty straight forward. I’m not saying that the source code does not exist, i’m simply saying that Cloanto has gone out of their way to keep it hidden.
Sure it may be legal but I find it somewhat tasteless. profiting on UAE for all those years, and not even a symbolic sum for the guys that keep UAE going? I mean, had they actively participated and contributed to the UAE codebase I would have applauded them for it. Sadly Cloanto presents itself as a blatant opportunist more than a preserver. They say one thing, but their actions speak of something else entirely.
And don’t get me wrong, Hyperion and Aeon have more than enough mistakes on file. But when comparing Hyperion’s mistakes against Cloanto, remembering that these two have an obligation to represent the Amiga legacy to the best of their ability — you cannot help notice that they are worlds apart. Hyperion is producing new software, Aeon new hardware, and they have even given the much loved 68k systems a do-over.
This where I get a bit worked up – because Cloanto have nothing to do with software or hardware development. It is quite frankly none of their business (in the true sense of the word). They have licensed the old kernel and Workbench; they have also bought the C64 roms – and that is where their role ends. Yet they spend more time trying to obstruct Hyperion (and by consequence, Aeon) at every step of the way.
While I have no idea who sits on the c64 rights these days, the c64-mini has sold in good numbers around the world. Since Cloanto is the only company with c64 rights I presume they have cashed in on that? Like always it’s hard to tell, because there are more than one company that claim to sit on pieces of the true Commodore legacy.
So to sum up: we have one side producing new hardware, new software and doing updates which is their obligation and right. And we have another party who has created nothing, including the heart of their business, demanding a cut of something they shouldn’t even be involved in (!)
Greed, the mother of invention
Cloanto’s motives should be pretty obvious by now, but let’s hash through it.
With a new Workbench and kernel out in the wild, Cloanto find themselves in a difficult position. Who would want to buy an older kernel or Workbench when there is a newer, 2018 version available? Well, I would like all of them to be honest, but yes I obviously want to use the new versions as much as possible.
The A1222 was due out Q1 2018. It remains on hold until the lawsuits are finished. Keeping Hyperion and Aeon in court is a matter of survival for Cloanto at this point
But that alone is not enough to explain Cloanto’s panic-stricken behavior. They could welcome the new update and simply license it, like they should because they have no right to another companies work.
Instead they run out and buys the remnants of that company I mentioned earlier, Amiga Inc, which is a straw company that has a terrible reputation involving fraud and investor scams. A company that for some magical reason had the right to the name “Amiga” (like that holds any value in 2018, good lord what are you people doing) and sat on the source-code for the OS. This is the same source-code that Hyperion ended up buying, which is no doubt the foundation for the update before xmas.
Why would they go to such lengths as to secure a superficial paper-tiger like Amiga Inc? Trying to reverse the process? Looking to hijack the Amiga names? What gives? It’s almost like Cloanto is looking for something to fight over, desperate to keep Hyperion in court for as long as possible.
And why would they refuse to sell 2000 roms to myself and Gunnar to make ready-to-use Amiga “mini” machines? If I didnt know better, they are brewing on something. The market is just ripe for retro, and their behavior towards us hints that they are not very happy about Amibian’s existence.
It makes even more sense when you factor in the long-awaited A1222. A whole new Amiga that Aeon and Hyperion is 100% invested in bringing to market.
The Amiga A1222 is a Next Generation PPC Amiga that should retail at around USD 450. This product was supposed to reach the market in Q1 2018, but with the lawsuit(s) and drain on funds, getting the product out the door has been impossible. So much so that Cloanto is now damaging Hyperion (and Aeon) by proxy.
Around Xmas 2018 Cloanto began spreading the rumor that they were fighting to “open source Amiga OS”. That is a blatant lie and I was tempted to write a piece there and then, but I have been busy with work. I also thought Amiga users wouldn’t fall for such an evident lie, but some people actually cheer Cloanto on — believing that Cloanto can somehow “help” the Amiga platform. For Christ sake, Cloanto doesn’t even have the source-code – much less the right to open source Hyperion and Acer’s intellectual property. Buying the remnants of Amiga Inc might be an attempt to buy credibility, but its 20 years too late.
The present legalities are, to be blunt, nothing more than a diversion designed to keep the A1222 out of the marketplace. The question is: why and will they try to replace it with something?
Although the motives are now painfully visible, so much so that it might as well be lit up in neon – I think Amiga fans should be very careful where they place their trust. I am sorry but I would not trust Cloanto with a stick of gum, much less the computing legacy of a giant like Commodore. And they are brewing on something, either directly or indirectly, mark my words.
Normally I don’t take sides, but I seriously hope Cloanto wakes up and realize that they are right now, and have been for some time, the spearhead that is keeping the platform in limbo. I have nothing against them personally, but we have now passed the point of no return. You are now risking the codebase of a system that thousands of people care for.
I think I speak for quite a few when I say: Enough! Put that energy, time and money into making something – because whatever you guys started arguing over, is long gone.
There is a whole generation that has grown up without any knowledge of Amiga. Who have no clue what Commodore was and represented. So while you guys have been fighting about who gets to sit where, the boat has left and you missed it.
Final words
You know why I find the most annoying about the situation Cloanto have created? Hear me out here.
Sun Microsystems spent a fortune drumming up support for Java, selling people on a lofty dream where a whole operating-system would be written as bytecodes. And that in special hardware would be made so that bytecodes could run anywhere. Because said bytecodes would be portable between platforms even, and solve the problem with platform bound software once and for all. Companies pumped billions into that dream, yet for all their wealth and power, they failed.
Meanwhile Cloanto, and by extension Hyperion, have had access to UAE since the 90s. A system that embody all the traits that Sun Microsystems attempted to create, and all they have done is to add a menu to it. They have wasted close to two decades without realizing that UAE is that holy grail that Sun Microsystems failed to deliver.
68k machine-code is bytecodes if you execute it on another system. And the distinctions between “virtual machine” and “emulator” are ultimately conceptual – not factual. UAE could have been adjusted as a virtual machine. There you have the compilers, the ecosystem and all the pieces you would need to deliver a portable, blistering fast software deployment system that is truly platform independent.
So, Cloanto, you have been sitting on a gold mine. And you didn’t recognize it because you were too busy arguing over balls, chicken-lip logos, old roms and god knows what else.
You have had solid gold for ages, but you were too busy arguing over names to see it
I sincerely hope Acer takes an active role in their licensing, because as far as I can see, Cloanto is not acting in Acer’s financially best interest (nor Hyperion’s for that matter, which last time I checked can withhold all and any changes to their OS, leaving Cloanto with the dry bones from the past) – and they have become, unless they perform a complete makeover before their next lawsuit, unfit to manage the intellectual property and licenses they have acquired.
You don’t have a developer license, so stick to the legacy stuff and stop getting in the way of those that do.
And for christ sake give the guys who make UAE a percentage, it is tasteless and ugly to watch this level of greed. Seriously.
DelphifiremonkeyLinuxObject PascalC++ builderlearn delphiRad ServerRad Studio
The world has more than enough developers on desktop level. The desktop and web market is drowning in developers who has the capacity to download libraries, drop components on a form and hook up to a database. What the world really needs are more developers on archetypical languages.
Show full content
A couple of days ago I had a spectacular debate on Facebook. Like most individuals that are active in the IT community, my social media feed is loaded with advertisement for every trending IT concept you can imagine. Lately these adverts have been about machine learning and A.I. Or should I say, companies using those buzzwords to draw unwarranted attention to their products. I haven’t seen A.I used to sell shoes yet, but it’s only a matter of time before it happens.
Like any technology, Cloud is only as powerful as your insight
There is also this thing that: yes, a 14-year-old can put together an A.I chat robot in 15 minutes with product XYZ. But that doesn’t mean he or she understands what is happening beneath the user-interface. Surely the goal must be to teach those kids skills that will benefit them for a lifetime.
Those that know me also know that yes, I have this tendency to say what I mean, even when I really should keep my mouth shut. On the other hand that is also why companies and developers call me, because I will call bullshit and help them avoid it. That’s part of my job, to help individuals and companies that use Delphi to pick the right version for their need, get the components that’s right for their goals – and map out a strategy if they need some input on that. I’ll even dive in and do some code conversion if they need it; goes with the territory.
Normally I just ignore advertizing that put “cloud” or “a.i” in their title, because it’s mostly click-bait designed for non-developers. But for some reason this one particular advert caught my eye. Perhaps it triggered the trauma of being subjected to early Java advertising during the late 90s’s, or maybe it released latent aggression from being psychologically waterboarded by Microsoft Silverlight. Who knows
The ad was about a Norwegian company that specialize in teaching young students how to become professional developers. You know the “become a guru in 3 weeks” type publisher? What baked my noodle was the fact that they didn’t offer a single course involving archetypical languages, and that they were spinning their material with promises that were simply not true. The only artificial intelligence involved was the advertizing engine at Facebook.
The thing is – the world has more than enough developers on desktop level. The desktop and web market is drowning in developers who has the capacity to download libraries, drop components on a form and hook up to a database. What the world really needs are more developers on archetypical languages. And if you don’t know what that is, then let me just do a quick summary before we carry on.
Archetypal languages
An archetypical programming language is one that is designed around how the computer actually works. As a consequence these languages and toolchains embody several of the following properties:
Pointers and raw memory access
Traditional memory management, no garbage collection
Procedural and object-orientation execution
Inline assembler
Little if no external dependencies
Static linking (embed pre-compiled code)
Compiled code can operate without an OS infrastructure
Suitable for kernel, driver, service, desktop, networking and cloud level development
Compiler that produce machine code for various chipsets
As of writing there are only two archetypical languages (actually 3, but assembly language is chipset specific so we will skip that here), namely C/C++ and Object Pascal. These are the languages you use to write all the other languages with. If you plan on writing your own operating-system from scratch, only C and Pascal is suitable. Which is why these are the only languages that have ever been used for making operating systems.
Delphi is one of the 20 most used programming languages in the world. It ranked as #11 in 2017. Like all rankings it fluctuates depending on season and market changes.
Obviously i’m not suggesting that people learn Delphi or C++ builder to write their own OS – or that you must know assembly to make an invoice system; I’m simply stating that the insight and skill you get from learning Delphi and C/C++, even if all you do is write desktop applications – will make you a better developer on all levels.
Optimistic languages
Optimistic or humanized programming languages, have been around just as long as the archetypical ones. Basic is an optimistic language, C# and Java are optimistic languages, Go and Dart are equally optimistic languages. Script engines like node.js, python and Erlang (if you missed Scott Hanselman’s epic rant on the subject, you are in for a treat) are all optimistic. They are called optimistic because they trade security with functionality; sandboxing the developer from the harsh reality of hardware.
An optimistic language is typically designed to function according to “how human beings would like things to be” (hence the term optimistic). These languages rely heavily on existing infrastructure to even work, and each language tends to focus on specific tasks – only to branch out and become more general purpose over time.
There is nothing wrong with optimistic languages. Except when they are marketed to young students as being somehow superior or en-par with archetypical languages. That is a very dangerous thing to do – because teachers have a responsibility to prepare the students for real life. I can’t even count the number of times I have seen young developers fresh out of college get “that job”, only to realize that the heart of the business, the mission critical stuff, is written in Delphi or C/C++, which they never learned.
People have no idea just how much of the modern world rests on these languages. It is almost alarming how it’s possible to be a developer in 2019 and have a blind spot with regards to these distinctions. Don’t get me wrong, it’s not the student’s fault, quite the opposite. And i’m happy that things are starting to change for the better (more about that further down).
The original full stack
So back to my little encounter; What happened was that I just commented something along the lines of “why not give the kids something that will benefit them for a lifetime”. It was just a drive-by comment on my part, and I should have just ignored it; And no sooner had I pressed enter, when a small army of internet warriors appeared to defend their interpretation of “full stack” in 2019. Oblivious to the fact that the exact same term was used around 1988-ish. I think it was Aztec or SAS-C that coined it. Doesn’t matter.
The original “full stack” holds a very different meaning in traditional development. While I don’t remember if it was Aztec-C or SAS-C, but the full stack was driver to desktop
Long story short, I ended up having a conversation with these teenagers about how technology has evolved over the past 35 years. Not in theory, but as one that has been a programmer since the C= 64 was released. I also introduced them to archetypal languages and pinpointed the distinction I made above. You cannot compare if you don’t know the difference.
I have no problems with other languages, I use several myself, and my point was simply that: if we are going to teach the next generation of programmers something, then let’s teach them the timeless principles and tools that our eco system rests on. We need to get Delphi and C/C++ back into the curriculum, because that in turn will help the students to become better developers. It doesn’t matter what they end up working with afterwards, because with the fundamental understanding in place they will be better suited. Period.
You will be a better Java developer if you first learn Delphi. You will be a better C# developer if you learn Delphi. Just like nature has layers of complexity, so does computing. And understanding how each layer works and what laws exist there – will have a huge impact on how you write high-level code.
All of this was good and well and the internet warriors seemed a bit confused. They weren’t prepared for an actual conversation. So what started a bit rough ended up as a meaningful, nice dialog.
And speaking of education: I’m happy to say that two universities in Norway now have students using Delphi again. Which is a step in the right direction! People are re-discovering how productive Object-Pascal is, and why the language remains the bread and butter of so many companies around the world.
Piracy, the hydra of problems
What affected me the most during my conversation with these young developers – was that they had almost no relationship to neither Delphi or C/C++. From an educational standpoint that is not just alarming, that is an intellectual emergency. The only knowledge they had of Delphi was hearsay and nonsense.
The source of the misrepresentation is piracy, openly so, of outdated versions that was never designed to run on modern operating systems. With the community edition people can enjoy a modern, high performance Delphi without resorting to illegal activities
But after a while I finally discovered where their information came from! Delphi 7 is being pirated en-mass even to this day. It’s for some strange reason very popular in Asia (most of the torrent IP’s ended up there when I followed up on this). So teenagers download Delphi 7 which is ancient by any standard, and the first thing they experience is incompatibility issues. Which is only to be expected because Delphi 7 was released a long, long time ago. But that’s the impression they are left with after downloading one of these cracked, illegal bundles.
I downloaded one of these “ready to use” bundles to have a closer look, and it contained at least 500 commercial components. You had the full TMS component collection, Developer Express, Remobjects SDK, ImageEN, FastReports, SecureBlackBox, Intraweb — tens of thousands of dollars worth of code. With one very obvious factor: both Delphi 7 and the components involved are severely outdated. Microsoft doesn’t even support Windows XP any more, it was written in the early bronze age.
So the reality of the situation was that these young developers had never seen a modern Delphi in their life. In their minds, Delphi meant Delphi 7 which they could download almost everywhere (which is illegal and riddled with viruses, stay well clear). No wonder there is confusion about the subject (!)
They were very happy to learn about the community edition, so in the end I at least got to wake them up to the awesome features that modern Delphi represents. The community edition has been a fantastic thing; the number of members joining Delphi-Developer on Facebook has nearly doubled since the community edition was released.
A few of the students went over to Embarcadero and downloaded the community edition, and their jaw dropped. They had never seen a development environment like this before!
Give me five good reasons to learn Delphi
In light of this episode, thought I could share five reasons why Delphi and object-pascal remains my primary programming language.
I don’t have any problems dipping into JavaScript, Python or whatever the situation might call for – but when it comes to mission critical data processing and services that needs 24/7 up-time; or embedded solutions where CPU spikes simply cannot be tolerated. It’s Delphi I turn to.
These five reasons are also the same that I gave the teenagers. So here goes.
Great depth and wingspan
Object Pascal, from which Delphi is the trending dialect, is a fantastic language. At heart there is little difference between C/C++ and object pascal in terms of features, but the syntax of object pascal is more productive than C/C++ (IMHO).
Delphi and C++ builder actually share run-time libraries (there are two of them, the VCL which is Windows only, and Firemonkey which is platform independent). Developers often mix and match code between these languages, so components written in Delphi can be used in C++ builder, and libraries written in C can be consumed and linked into your Delphi executable.
One interesting factoid: people imagine Delphi to be old. But the C language is actually 3 years older than pascal. During their time these languages have evolved side by side, and Embarcadero (who makes Delphi and C++ builder) have brought all the interesting features you expect from a modern language into Delphi (things like generics, inline variables, anonymous procedures – it’s all in there). So this myth that Delphi is somehow outdated or unsuitable is just that – a myth.
The eco-system of programming languages
And there is an added bonus! Just like C/C++, Delphi represents a curriculum and lineage that spans decades. Stop and think about that for a second. This is a language that has been evolved to solve technical challenges of every conceivable type for decades. This means that you can put some faith in what the language can deliver.
There are millions of Delphi developers in the world; an estimated 10 millions in fact. The language was ranked #11 on the TIOBI language index; it is under constant development with a clear roadmap and time-line – and is used by large and small companies as the foundation for their business. Even the Norwegian government rely on Delphi. The system that handles healthcare messages for the Norwegian population is pure Delphi. That is data processing for 5.2 million individuals.
Object Pascal has not just stood the test of time, it has innovated it. Just like C/C++ object pascal has a wingspan and depth that reaches from assembler to system services, from database engines to visual desktop application – and from the desktop all the way to Cloud and essential web technology.
So the first good reason to learn Delphi is depth. Delphi covers the native stack, from kernel level drivers to high-speed database engines – to visual desktop applications. It’s also exceptionally well suited for cloud services (both Windows and Linux targets).
Easy to learn
I mention that Delphi is powerful and has the same depth as C/C++, but why then learn Delphi and not C++? Well, the language (object pascal) was especially tailored for readability. It was concluded that the human brain recognized words faster than symbols or glyphs – and thus it’s easier to read complex pascal code rather than complex C code. Individual taste notwithstanding.
Despite its depth, Delphi is easy to learn and fun to master!
Object Pascal is also very declarative, with as little unknown factors as possible. This teaches people to write clean and orderly code.
And perhaps my favorite, a pascal code-file contains both interface and implementation. So you don’t have to write a second .h file which is common under C/C++.
If you already know OOP, be it Java, C#, Rust or whatever – learning Delphi will be a piece of cake. You already know about classes, interfaces, generics, operator overloading – and can pretty much skip forward to memory management, pointers and structures (records in pascal, struct in C).
Swing by Embarcadero Academy and take a course, or head over to Amazon and buy some good books on Delphi. Download the Community Edition of Delphi and you will be up and running in no-time.
Also remember to join Delphi Developer on Facebook, where thousands of active developers talk, help each other and share solutions 24/7.
Target multiple platforms
With Delphi and C++ builder it’s pretty easy to target multiple platforms these days. You can target Android, iOS, OS X, Windows and Linux from a single codebase.
One codebase, multiple targets
I mean, are you going to write one version of your app in Java, a second one in C#, a third one in Objective C and a fourth in Dart? Because that’s the reality you face if plan on using the development tools provided by each operating-system manufacturer. That’s a lot of time, money and effort just to push your product out the door.
With Delphi you can hit all platforms at once, native code, reducing your time to market and ROI. People use Delphi for a reason.
You will also enjoy great performance from the LLVM optimized code Delphi emits on mobile platforms.
Rich codebase
The benefit of age is often said to be wisdom; I guess the computing equivalent is a large and rich collection of components, libraries and ad-hoc code that you can drop into your own projects or just study.
You can google just about any subject, and there will be code for Delphi. Github, BitBucket and Torry’s Delphi pages are packed with open-source frameworks covering everything from compiler cores, midi interfaces, game development to multi-threaded, machine clustered server solutions. Once you start looking, you will find it.
There is a rich constellation of code, components and libraries for Delphi and C++ builder around the internet. Also remember dedicated sites like Torry’s
There is also a long list of technology partners that produce components and libraries for Delphi – and like mentioned earlier, you can link in C compiled code once you learn the ropes.
Oh, and when I mentioned databases earlier I wasnt just talking about the traditional databases. Delphi got you covered with those, no worries — im also talking about writing a database engine from scratch. There are several database engines that are implemented purely in Delphi. ElevateDB is one example.
Delphi also ships with Interbase and Interbase-light (embedded and mobile) so you have easy access to data storage solutions. There is also FireFAC that allows you to connect directly with established databases — and again, a wealth of free and commercial solutions.
Speed and technique
What I love about Delphi and C++ is that your code, or the way you write code, directly impacts your results. The art of optimization is rarely a factor in some of the new, optimistic languages. But in a native language you get to use traditional techniques that are time-less, or perhaps more interesting: explore ways of achieving the same with less.
As a native language Delphi and C/C++ produce fast executables. But I love how there is always room for your own techniques, your own components and your own libraries.
Techniques, like math, is timeless
Need to write a system driver? Well, suddenly speed becomes a very important factor. A garbage collector can be a disaster on that level, because it will kick-in on interval and cause CPU spikes. Perhaps you want to write a compiler, or need a solid scripting engine? How about linking the V8 JavaScript engine directly into your programs? All of this is quite simple with Delphi.
So with Delphi I get the best of both worlds, I get to use the scalpel when the needs are delicate, and I get the chain-saw to cut through tedious work. Things like property bindings are a god sent. This is a techniques where you can visually bind properties of any component together, almost like events, and create cause and effect chains. So if a value changes on a bound property, that triggers whatever is bound, and so on and so on — pretty awesome!
So you can create a complete database application, with grid and navigation, without writing a single line of code. That was just one simple example, you can do so much more out of the box – and it saves you so much time.
Yet when you really need to write high performance code, or build that killer framework that will set your company apart from the rest — you have that freedom!
So if you havent checked out RAD Studio, head over to Embarcadero and download a free trial. You will be amazed and realize just why Delphi and C++ builder are loved by so many.
DelphiObject PascalC++ builderReal life codingWebinars
For a while now we have been planning some Delphi community webinars. This will be a monthly webinar that has a slightly different format than what people are used to. The style of webinar will be live, laid back and with focus on real-life solutions that already exists, or that is being developed - talking directly to the developers and MVP's involved.
Show full content
I got some great news for everyone!
For a while now we have been planning some Delphi community webinars. This will be a monthly webinar that has a slightly different format than what people are used to. The style of webinar will be live, laid back and with focus on real-life solutions that already exists, or that is being developed – talking directly to the developers and MVP’s involved.
There is so much cool happening in the Delphi, C++ builder and Sencha scene that I hardly know where to begin. But what better way to spread the good news than to talk directly with the people building the components, publishing the software, doing that book or rolling the frameworks?
In the group Delphi Developer on Facebook we have a very laid back style, one I hope to transpose onto the webinars. We keep things clean, have clear rules and the atmosphere is friendly and easy-going. There is room for jokes and off topic posts on the weekends, but above all: we are active, solution oriented developers.
Delphi Developer, although being small compared to the 6.5 million registered Delphi developers in the world (estimated object pascal use is closer to 10 million when factoring in alternative compilers), just reached 8000 active members. The growth rate for membership into our little corner of the world has really picked-up speed after the community edition. Seriously, it’s phenomenal to be a part of this. It’s more than doubled since 2017.
So there has never been a better time to do webinars on Delphi than right now
Making waves
Delphi has so much to offer
Two weeks ago I was informed that Delphi is once again being used by one of the largest Norwegian universities (!). That was an epic moment, because that is something we have worked hard to realize. I have been blogging, teaching and doing pro-bono work for a decade now to get the ball rolling – and seeing the community revitalize itself is spectacular!
I work like mad every day to help companies with strategies involving Delphi, showing them how they can use Delphi to strengthen their existing infrastructure; I connect developers to employers, do casual, drive-by headhunting, talk to component vendors — but education and awareness is what it’s all about. Your toolbox is only as useful as your knowledge of the tools. If you don’t know how or what a tool is, well then you probably wont use it much.
Making new developers aware of what Delphi is and what it can do is at the heart of this. Especially developers that work with other languages. The reality of 2019 is that companies use several languages to build their infrastructure, and it’s important that they understand how Delphi can co-exist and benefit their existing investment. So a fair share of my time is about educating developers from other eco-systems. Most of them are not prepared for the great depth and wingspan object pascal has, and are flabbergasted when the full scope of the product hits them. Only C++ and object pascal scales from kernel to cloud. That’s the real full stack right there.
Delphi: The secret in the sause
I keep up with whats happening in many different parts of development, and one of those is node.js and webassembly. Since everyone was strutting their stuff I figured I could as well, so I posted some videos about the Quartex Web Desktop I have been working on in my spare time (a personal project done in Object Pascal and compiled to JavaScript).
The result? The node.js groups on Facebook went nuts! Within minutes of posting I was bombarded by personal message requests, friend requests and even a marriage proposal. All of it from young web developers wanting to know “my secrets”.
Well, the secret is Delphi. I mean, I can sugarcoat it as much as I want, but without Delphi none of the auxiliary tools I use or made would exist. They are all made with Delphi – for Delphi developers. Smart Mobile Studio, the QTX framework, my libraries and tools – none of them would have seen the light of day if I never learned Delphi.
Node developers could not believe their eyes nor ears when they learned that this system was coded in Object Pascal, using a “off the shelf” compiler that is 100% Delphi; DWScript and Smart Mobile Studio is a pretty common addition to Delphi developers toolbox in 2019
What I’m trying to convey to young developers especially, is that if you take the time to learn Delphi, you can pick from so many third-party associated technologies that will help you create incredible software. ImageEN, AToZed, DevEx, TMS Component Suite, Greatis Software, FastReports, DWScript, Smart Mobile Studio; and that is just the tip of the iceberg (not to mention the amazing products by Boian Mitov, talk about powerful solutions!). As a bonus you have thousands of free components and units on Github, Torry’s and other websites.
That’s a pretty strong case. We are talking real-life business here, not dorm-room philosophical idealism. You have 800.000 receipts on average hitting your servers on a daily basis — and you have 20.000 cash machines in Norway alone that must function 24/7; you have no room for cpu spikes on the embedded board, nor can you tolerate latency problems or customers start walking. And you need it up and running yesterday. I can tell you right now having experienced that exact scenario, that had we used any other tool than Delphi – it would have sunk the company.
The point? After posting some videos and chatting a bit with the node.js devs, Delphi Developer got infused with a sizable chunk of young node.js developers eager to learn more about this “Delphi thing”. And they will become better node developers for it.
EDIT: I started this day (01.02.19) with a call from a university student. He was fed up with Java and C# because he wanted to learn native programming. He had noticed the node.js post and became curious. So I set him up with the community edition of both Delphi and C++ builder. When he masters the basics I will introduce him to inline assembler. There is a gap in modern education where Delphi used to sit, and no matter how much they try to fill it, bytecodes can’t replace solid knowledge of how a computer actually works.
So indeed! These webinars will be very fun to make. We got so many fantastic developers to invite, techniques to explore, components to demo and room for questions! The hard part right now is actually picking topics, because we have so much to choose from!
For example, did you know there is TV channel that is operated using Delphi software? It’s been running without a glitch for decades. Rock solid and high performance. How cool is that! Talk about real-life solution. Delphi is everywhere.
I’ll get back to you with more information in due time ~ Cheers!
Where to begin! Like mentioned in my previous post Amibian.js is a cluster system. As such the project now has it's first real hardware sorted! I have gone for a 5 x ODroid XU4 model, neatly tucked inside a PICO 5H case. I have picked up Quartex Pascal again, which originally started in 2014. I have also started writing a new RTL for DWScript which is an alternative to Smart Mobile Studio.
Show full content
It’s been a while since I’ve posted now. I have 3 articles in escrow, and every time I think I will finish them, I end up writing more. But yes, more Delphi articles is coming and I have lined up both components and rich code that everyone will be happy about.
Please look before shooting
Before we dig into the new stuff, I want to clear up a misconception. We programmers often forget that not everyone knows what we do, and we take it for granted that everyone will instantly understand something we talk about. Which is rarely the case.
I have noticed that quite a few have misjudged the project radically, thinking that the first version (cloud ripper) is just a toy, a mock desktop or even worse: just a remake of a legacy system that “has no role in modern computing”.
It is true that I have taken more than a little from Amiga OS in terms of architecture, but I have exclusively taken ideas that are good and works well under the ASYNC execution model. I have also replicated the way the filesystem is organized, things like REXX (which was added to OS X in 2015), the menu system – these are indeed built on how Amiga OS did things. The same can be said about library functions. Not because they are old, but because they make sense. Many of the functions appear in other systems too, like GTK on Linux and WinAPI for Windows. There are only so many ways to open a window, change the title, define scrollbars and execute processes.
Kiosk systems like this are great targets for the Quartex Web OS
While there are clear architectural aspects taken from older systems, doesn’t mean that the system itself is old in any way. This system is designed to run as WebAssembly, ASM.js and vanilla Javascript – which is ASYNC by nature. It is designed to run and share payload over several machines, not a single outdated CPU and chipset. You have swarm based task solving – which is quite cutting edge if I might say so. None of these things were invented back in the day.
Some have also asked why this is even needed. Well, let me give you a simple use case.
One of my customers is doing work for Jensen, a Danish producer of IT hardware. They make mostly routers, wifi usb dongles and similar devices. But like many hardware vendors their web interface leaves a lot to be desires. Router web interfaces are usually quite annoying and poorly written. Something that should have taken 5 minutes can end up taking 30 just because the design of the interface is rubbish.
With my solution these vendors will be able to drop a whole infrastructure into their products; a infrastructure that provides all the things they need to quickly build a great control panel and router interface. Things like file system mapping, being able to store data to the filesystem through an established websocket protocol; all of it wrapped up in a simple but powerful API. Their settings and features can be represented as programs, which run in windows that are intuitively styled and easy to understand. They will also cut development time dramatically by calling the Quartex Soft-Kernel, rather than having to re-invent everything from scratch.
That is just a tiny, tiny use-case where the desktop and services makes perfect sense. But also keep in mind that the same system can scale up to a 1000 instance Amazon supercomputer if you need to, providing software for your offices and development teams.
In 8 months the desktop is complete (probably before) and I start building the first purely web powered software development toolchain. Everything has been transformed into Javascript (as in compilers, linkers – the whole lot). Both freepascal, clang c/c++ and much more. And developers will be able to login and start producing applications out of the box. The fact that the entire system is chipset and platform independent is quite unique. People tend to use native code behind a facade of html5. Not here. Here you have over 4000 classes, 800.000 lines of code just for the desktop client, looking back at you.
Hopefully this has shed some lights on the project, and people will stop looking at this as “old junk”. As a person who loves older computers, Amiga especially, I am quite frankly astounded by the ignorance regarding that platform. A juiced up 30 year old Amiga will give any modern computer a run for it’s money when it comes to ease of use, quality software and pure productivity. 10 years before Windows even existed, europeans enjoyed a colorful, window based desktop with full multitasking. When we had to switch to PC it was like going back to the 1500’s in terms of functionality – and it wasnt until Windows 7 that Microsoft caught up with Commodore. So if I have managed to get over even 1% of the spirit in that machine – then I will be very happy indeed.
But to limit a clustered, 40 CPU core architecture using modern, off-the-shelves parts, a multitude of node services to “old junk” is nothing short of an intellectual emergency. Please read, digest and look more closely before passing judgement.
Right then, so what’s new?
The Quartex “Cloud Ripper”
Where to begin! Like mentioned in my previous post Amibian.js is a cluster system. As such the project now has its first real hardware sorted! I have gone for a 5 x ODroid XU4 model, neatly tucked inside a PICO 5H case. The budget was set at USD 400, but with shipping and taxes it ended up costing around USD 600. But that is not a bad price for the firepower you get (40 CPU cores, 20 GPU cores and 16 Gb Ram), the ODroid is a powerful, stable and reliable ARM SBC (single board computer). In benchmarks the Raspberry PI 3b scored 830 Dhrystones, the ODroid scored 5500 Dhrystones. And my architecture use five of them, so this is a $600 super-computer built using off the shelves part.
The back-end server has had several bugs fixed, especially the problems with path’s and databases. You can now edit the settings.ini file and tell the system where the database should be created or accessed from, you can set the port for the server, if it should use SSL + Secure WebSocket, or ordinary HTTP + Websocket.
40 ARM CPU cores, that is a lot of firepower for USD 200 !
I am also ditching the TW3NodeFileSystem driver for server logic and using ordinary node.js calls there. The TW3NodeFileSystem driver is mounted as you perform a login – and it acts as a sandbox, mounting your folder as a device (and making sure you can’t ever touch files outside your “home” server folder). We still need to implement a proper UNIX directory parser, but that is easy enough.
Quartex Pascal
Yes, I have picked up Quartex Pascal again, which originally started in 2014. I have started writing a new RTL for DWScript which is an alternative to Smart Mobile Studio. It is different from the Smart RTL and is closer to FMX than VCL.
Eventually the Quartex Web OS and all its services will compile without code from Smart Mobile Studio.
Hosted applications, messages and our soft-kernel
The biggest news, which is also the most tricky to get right, is getting hosted applications (applications are hosted in IFrame containers) to communicate with the desktop. As you probably know browsers have rigid security measures, and the rules for threads (web workers) and separate processes (frames) are severe to say the least.
The LDEF assembler is the first application to grace the system
A secondary application hosted in a frame has absolutely no access to the rest of the DOM. Meaning that the code has no way of calling functions or manipulating elements outside its own DOM in the frame container. This is a good system because we don’t want rouge applications causing havoc.
The only way an application can talk to the desktop is through messages. And while this sounds easy, remember: we are doing this as a solid system, not just slapping something together.
After loading a hosted application, the desktop will send a handshake request. It will do this on interval until the application accepts.
When the application replies with a handshake message, the desktop sends a special message-channel object to the app. All communication with the desktop must happen on that secure channel.
With the channel obtained, the application has to provide the application manifest file. This is a special INI-File containing information about the program, including access rights. None of the soft-kernel API functions will execute until a valid manifest-file has been delivered.
Once the manifest has been sent and accepted, the hosted application is free to call the soft-kernel functions.
The above might sound simple but it includes several sub technologies to be in place first:
Call Stack: a class that keep track of sent messages and a callback. When a response arrives it will execute the correct callback to deliver the response. This is a kind of “promises” engine for message delivery.
Message factory, matches message-data to the correct message class, creates the instance and de-serialize the data automatically for you
Message dispatcher: Allows you to register a message with a handler procedure. When a message arrives the dispatcher calls the message-factory, then calls the correct handler.
Base64 Encoding on byte-array, stream and buffer level (does not exist in either node.js or JavaScript in general)
String to UTF8 Byte-Array encoding
UTF8 Byte-Array to String encoding
escape and unescape for byte-array, stream and buffer
URI-encoder for byte-array, stream and buffer
But that was just the beginning, I also had to introduce an object that I have been dreading to even start on, namely the “process” class. The process is not just a simple reference to the frame container, it has to keep track of the websocket endpoint, application manifest, error handling, message routing and much more.
CLANG compiled to webassembly, meaning we can now compile proper C/C++ in the browser
Since Amibian.js supports not just JavaScript, but also bytecode applications – the process object also contains the LDEF runtime engine; not to mention all the system resources a process can own.
The cool part is that things work exactly like I planned! There is plenty of room to optimize, but all in all the architecture is sound. And it was quite a hallelujah moment when the first API call went through at 00:00 19.01.2019! A call to SetWindowTitle() where the hosted application set the caption of its main-window purely via code. Cross domain communication at it’s very best.
The LDEF Assembler
Yes LDEF Bytecodes are fantastic, and the first program I have made is a traditional assembler. I went all in and implemented a full text-editor to get better control, and also to get rid of the ACE code editor, which was a massive dependency. So glad we got rid of that.
So now you can write assembly code, assemble it, run it, dis-assemble it and even dump the bytecodes to the window. You will be able to save the bytecodes to disk by the end of this weekend, and then run the bytecode programs from shell or the desktop. So we are really making progress here.
A good shell / pipe infrastructure is the key to a powerful desktop
LDEF is the bytecode system that will be used to build high-level languages like Basic and Pascal. Since Freepascal is now able to compile itself to JavaScript I will naturally add that to the IDE next fall; the same is true for CLANG which has compiled itself to WebAssembly — and who generates webassembly.
So C/C++ and object pascal are already working and waiting for the IDE.
LDEF is a grander system though, because libraries can be loaded by Delphi, C++ builder, C# or whatever you fancy – and used. It can be post-processed to real machine code, or converted to pure WebAssembly. It holds much wider scope than stack machines like CLR and Java, and its more natural for assembly programmers – because it’s based on real CPU’s. It’s a register based virtual machine, not a stack-machine.
More?
Tons, but you have to visit my patreon page to keep track. I try to publish as much as possible there rather than here. I post a bit on both, but the proper channel for Amibian.js (or “Quartex Web OS” as its official name is) will always be Patreon.
The picture viewer now has momentum scrolling in full-mode.
Also, fixed more bugs in the Smart RTL than I can count, and re-made window movement. Window movement now uses the GPU, so they are silky smooth everywhere. Resize will be optimized next, then you can’t really tell it’s not native code at all.
Delphi Component updates
Yes Delphi is also a huge part of the Patreon project, and you will be happy to hear that the form designer (which shares a codebase with the graphics application components) have seen more work!
You can check out some of the changes to the form-designer here:
These changes will be in the january update (end of month) together with all the changes to Amibian.js, HexLicense, Tween library and all the rest
Amibian.jsAmigaC/C++CSSDelphiembeddedJavaScriptLanguage researchnodeJSObject PascalODroidSmart Mobile StudioamigafreepascalJavascriptnode.js
Long gone are the days of interpreted code, modern JavaScript is parsed, tokenized and compiled to bytecodes. These bytecodes are then JIT compiled to real machine-code using state of the art compiler techniques (LLVM). So the Javascript of 2018 is not the Javascript of 2008, radically so!
Show full content
Amibian.js is gaining momentum as more and more developers, embedded systems architects, gamers and retro computer enthusiasts discover the project. And I have to admit I’m pretty stoked about what we are building here myself!
In a life-preserver no less
But, with any new technology or invention there are two common traps that people can fall into: The first trap is to gravely underestimate a technology. JavaScript certainly invites this, because only a decade ago the language was little more than a toy. Since then JavaScript have evolved to become the most widely adopted programming language in the world, and runtime engines like Google’s V8 runs JavaScript almost as fast as compiled binary code (“native” means machine code, like that produced by a C/C++ compiler, Pascal compiler or anything else that produces programs that run under Linux or Windows).
It takes some adjustments, especially for traditional programmers that havent paid attention to where browsers have gone – but long gone are the days of interpreted JavaScript. Modern JavaScript is first parsed, tokenized and compiled to bytecodes. These bytecodes are then JIT compiled (“just in time”, which means the compilation takes place inside the browser) to real machine-code using state of the art techniques (LLVM). So the JavaScript of 2018 is by no means the JavaScript of 2008.
The second trap you can fall into – is to exaggerate what a new technology can do, and attach abilities and expectations to a product that simply cannot be delivered. It is very important to me that people don’t fall into either trap, and that everyone is informed about what Amibian.js actually is and can deliver – but also what it wont deliver. Rome was not built-in a day, and it’s wise to study all the factors before passing judgement.
I have been truly fortunate that people support the project financially via Patreon, and as such I feel it’s my duty to document and explain as much as possible. I am a programmer and I often forget that not everyone understands what I’m talking about. We are all human and make mistakes.
Hopefully this post will paint a clearer picture of Amibian.js and what we are building here. The project is divided into two phases: first to finish Amibian.js itself, and secondly to write a Visual Studio clone that runs purely in the browser. Since it’s easy to mix these things up, I’m underlining this easy – just in case.
What the heck is Amibian.js?
Amibian.js is a group of services and libraries that combined creates a portable operating-system that renders to HTML5. A system that was written using readily available web technology, and designed to deliver advanced desktop functionality to web applications.
The services that make up Amibian.js was designed to piggyback on a thin Linux crust, where Linux deals with the hardware, drivers and the nitty-gritty we take for granted. There is no point trying to write a better kernel in 2018, because you are never going to catch up with Linus Torvalds. It’s must more interesting to push modern web technology to the absolute limits, and build a system that is truly portable and distributed.
Above: Amibian.js is created in Smart Pascal and compiled to JavaScript
The service layer is written purely in node.js (JavaScript) which guarantees the same behavior regardless of host platform. One of the benefits of using off-the-shelves web technology is that you can physically copy the whole system from one machine to the other without any changes. So if you have a running Amibian.js system on your x86 PC, and copy all the files to an ARM computer – you dont even have to recompile the system. Just fire up the services and you are back in the game.
Now before you dismiss this as “yet another web mockup” please remember what I said about JavaScript: the JavaScript in 2018 is not the JavaScript of 2008. No other language on the planet has seen as much development as JavaScript, and it has evolved from a “browser toy” – into the most important programming language of our time.
So Amibian.js is not some skin-deep mockup of a desktop (lord knows there are plenty of those online). It implements advanced technologies such as remote filesystem mapping, an object-oriented message protocol (Ragnarok), RPCS (remote procedure call invocation stack), video codec capabilities and much more — all of it done with JavaScript.
In fact, one of the demos that Amibian.js ships with is Quake III recompiled to JavaScript. It delivers 120 fps flawlessly (browser is limited to 60 fps) and makes full use of standard browser technologies (WebGL).
Click on picture above to watch Amibian.js in action on YouTube
So indeed, the JavaScript we are talking about here is cutting edge. Most of Amibian.js is compiled as “Asm.js” which means that the V8 runtime (the code that runs JavaScript inside the browser, or as a program under node.js) will JIT compile it to highly efficient machine-code.
Which is why Amibian.js is able to do things that people imagine impossible!
Ok, but what does Amibian.js consist of?
Amibian.js consists of many parts, but we can divide it into two categories:
A HTML5 desktop client
A system server and various child processes
These two categories have the exact same relationship as the X desktop and the Linux kernel. The client connects to the server, invokes procedures to do some work, and then visually represent the response This is identical to how the X desktop calls functions in the kernel or one of the Linux libraries. The difference between the traditional, machine code based OS and our web variation, is that our version doesn’t have to care about the hardware. We can also assign many different roles to Ambian.js (more about that later).
Enjoying other cloud applications is easy with Amibian.js, here is Plex, a system very much based on the same ideas as Amibian.js
And for the record: I’m trying to avoid a bare-metal OS, otherwise I would have written the system using a native programming language like C or Object-Pascal. So I am not using JavaScript because I lack skill in native languages, I am using JavaScript because native code is not relevant for the tasks Amibian.js solves. If I used a native back-end I could have finished this in a couple of months, but a native server would be unable to replicate itself between cloud instances because chipset and CPU would be determining factors.
The Amibian.js server is not a single program. The back-end for Amibian.js consists of several service applications (daemons on Linux) that each deliver specific features. The combined functionality of these services make up “the amibian kernel” in our analogy with Linux. You can think of these services as the library files in a traditional system, and programs that are written for Amibian.js can call on these to a wide range of tasks. It can be as simple as reading a file, or as complex as registering a new user or requesting admin rights.
The greatest strength of Amibian.js is that it’s designed to run clustered, using as many CPU cores as possible. It’s also designed to scale, meaning that it will replicate itself and divide the work between different instances. This is where things get’s interesting, because an Amibian.js cluster doesn’t need the latest and coolest hardware to deliver good performance. You can build a cluster of old PC’s in your office, or a handful of embedded boards (ODroid XU4, Raspberry PI’s and Tinkerboard are brilliant candidates).
But why Amibian.js? Why not just stick with Linux?
That is a fair question, and this is where the roles I mentioned above comes in.
As a software developer many of my customers work with embedded devices and kiosk systems. You have companies that produce routers and set-top boxes, NAS boxes of various complexity, ticket systems for trains and busses; and all of them end up having to solve the same needs.
What each of these manufacturers have in common, is the need for a web desktop system that can be adapted for a specific program. Any idiot can write a web application, but when you need safe access to the filesystem, unified API’s that can delegate signals to Amazon, Azure or your company server, things suddenly get’s more complicated. And even when you have all of that, you still need a rock solid application model suitable for distributed computing. You might have 1 ticket booth, or 10.000 nation wide. There are no systems available that is designed to deal with web-technology on that scale. Yet
Let’s look at a couple of real-life scenarios that I have encountered, I’m confident you will recognize a common need. So here are some roles that Amibian.js can assume and help deliver a solution rapidly. It also gives you some ideas of the economic possibilities.
Updated: Please note that we are talking javascript here, not native code. There are a lot of native solutions out there, but the whole point here is to forget about CPU, chipset and target and have a system floating on top of whatever is beneath.
When you want to change some settings on your router – you login to your router. It contains a small apache server (or something similar) and you do all your maintenance via that web interface. This web interface is typically skin-deep, annoying to work with and a pain for developers to update since it’s connected to a native apache module which is 100% dependent on the firmware. Each vendor end up re-inventing the wheel over and over again.
When you visit a large museum notice the displays. A museum needs to display multimedia, preferably on touch capable devices, throughout the different exhibits. The cost of having a developer create native applications that displays the media, plays the movies and gives visual feedback is astronomical. Which is why most museums adopt web technology to handle media presentation and interaction. Again they re-invent the wheel with varying degree of success.
Hotels have more or less the exact same need but on a smaller scale, especially the larger hotels where the lobby have information booths, and each room displays a web interface via the TV.
Shopping malls face the same challenge, and depending on the size they can need anything from a single to a hundred nodes.
Schools and education spend millions on training software and programming languages every year. Amibian.js can deliver both and the schools would only pay for maintenance and adaptation – the product itself is free. Kids get the benefit of learning traditional languages and enjoying instant visual feedback! They can learn Basic, Pascal, JavaScript and C. I firmly believe that the classical languages will help make them better programmers as they evolve.
You are probably starting to see the common denominator here?
They all need a web-based desktop system, one that can run complex HTML5 based media applications and give them the same depth as a native operating-system; Which is pretty hard to achieve with JavaScript alone.
Amibian.js provides a rich foundation of more than 4000 classes that developers can use to write large, complex and media rich applications (see Smart Mobile Studio below). Just like Linux and Windows provides a wealth of libraries and features for native application development – Amibian.js aims to provide the same for cloud and embedded systems.
And as the name implies, it has roots in the past with the machine that defined multimedia, namely the Commodore Amiga. So the relation is more than just visually, Amibian.js uses the same system architecture – because we believe it’s one of the best systems ever designed.
If JavaScript is so poor, why should we trust you to deliver so much?
First of all I’m not selling anything. It’s not like this project is something that is going to make me a ton of cash. I ask for support during the development period because I want to allocate proper time for it, but when done Amibian.js will be free for everyone (LGPL). And I’m also writing it because it’s something that I need and that I havent seen anywhere else. I think you have to write software for yourself, otherwise the quality wont be there.
Secondly, writing Amibian.js in raw JavaScript with the same amount of functions and depth would take years. The reason I am able to deliver so much functionality quickly, is because I use a compiler system called Smart Mobile Studio. This saves months and years of development time, and I can use all the benefits of OOP.
Prior to starting the Amibian.js project, I spent roughly 9 years creating Smart Mobile Studio. Smart is not a solo project, many individuals have been involved – and the product provides a compiler, IDE (editor and tools), and a vast run-time library of pre-made classes (roughly 4000 ready to use classes, or building-blocks).
Writing large-scale node.js services in Smart is easy, fun and powerful!
Unlike other development systems, Smart Mobile Studio compiles to JavaScript rather than machine-code. We have spent a great deal of time making sure we could use proper OOP (object-oriented programming), and we have spent more than 3 years perfecting a visual application framework with the same depth as the VCL or FMX (the core visual frameworks for C++ builder and Delphi).
The result is that I can knock out a large application that a normal JavaScript coder would spend weeks on – in a single day.
Smart Mobile Studio uses the object-pascal language, a dialect which is roughly 70% compatible with Delphi. Delphi is exceptionally well suited for writing large, data driven applications. It also thrives for embedded systems and low-level system services. In short: it’s a lot easier to maintain 50.000 lines of object pascal code, than 500.000 lines of JavaScript code.
Amibian.js, both the service layer and the visual HTML5 client application, is written completely using Smart Mobile Studio. This gives me as the core developer of both systems a huge advantage (who knows it better than the designer right?). I also get to write code that is truly OOP (classes, inheritance, interfaces, virtual and abstract methods, partial classes etc), because our compiler crafts something called a VMT (virtual method table) in JavaScript.
Traditional JavaScript doesn’t have OOP, it has something called prototypes. With Smart Pascal I get to bring in code from the object-pascal community, components and libraries written in Delphi or Freepascal – which range in the hundreds of thousands. Delphi alone has a massive library of code to pick from, it’s been a popular toolkit for ages (C is 3 years older than pascal).
But how would I use Amibian.js? Do I install it or what?
Amibian.js can be setup and used in 4 different ways:
As a true desktop, booting straight into Amibian.js in full-screen
As a cloud service, accessing it through any modern browser
As a NAS or Kiosk front-end
As a local system on your existing OS, a batch script will fire it up and you can use your browser to access it on https://127.0.0.1:8090
So the short answer is yes, you install it. But it’s the same as installing Chrome OS. It’s not like an application you just install on your Linux, Windows or OSX box. The whole point of Amibian.js is to have a platform independent, chipset agnostic system. Something that doesn’t care if you using ARM, x86, PPC or Mips as your CPU of preference. Developers will no doubt install it on their existing machines, Amibian.js is non-intrusive and does not affect or touch files outside its own eco-system.
But the average non-programmer will most likely setup a dedicated machine (or several) or just deploy it on their home NAS.
The first way of enjoying Amibian.js is to install it on a PC or ARM device. A disk image will be provided for supporters so they can get up and running ASAP. This disk image will be based on a thin Linux setup, just enough to get all the drivers going (but no X desktop!). It will start all the node.js services and finally enter a full-screen web display (based on Chromium Embedded) that renders the desktop. This is the method most users will prefer to work with Amibian.js.
The second way is to use it as a cloud service. You install Amibian.js like mentioned above, but you do so on Amazon or Azure. That way you can login to your desktop using nothing but a web browser. This is a very cost-effective way of enjoying Amibian.js since renting a virtual instance is affordable and storage is abundant.
The third option is for developers. Amibian.js is a desktop system, which means it’s designed to host more elaborate applications. Where you would normally just embed an external website into an IFrame, but Amibian.js is not that primitive. Hosting external applications requires you to write a security manifest file, but more importantly: the application must interface with the desktop through the window’s message-port. This is a special object that is sent to the application as a hand-shake, and the only way for the application to access things like the file-system and server-side functionality, is via this message-port.
Calling “kernel” level functions from a hosted application is done purely via the message-port mentioned above. The actual message data is JSON and must conform to the Ragnarok client protocol specification. This is not as difficult as it might sound, but Amibian.js takes security very seriously – so applications trying to cause damage will be promptly shut down.
You mention hosted applications, do you mean websites?
Both yes and no: Amibian.js supports 3 types of applications:
Ordinary HTML5/JS based applications, or “websites” as many would call them. But like I talked about above they have to establish a dialog with the desktop before they can do anything useful.
Hybrid applications where half is installed as a node.js service, and the other half is served as a normal HTML5 app. This is the coolest program model, and developers essentially write both a server and a client – and then deploy it as a single package.
LDEF compiled bytecode applications, a 68k inspired assembly language that is JIT compiled by the browser (commonly called “asm.js”) and runs extremely fast. The LDEF virtual machine is a sub-project in Amibian.js
The latter option, bytecodes, is a bit like Java. A part of the Amibian.js project is a compiler and runtime system called LDEF.
Above: The Amibian.js LDEF assembler, here listing opcodes + disassembling a method
The first part of the Amibian.js project is to establish the desktop and back-end services. The second part of the project is to create the worlds first cloud based development platform. A full Visual Studio clone if you like, that allows anyone to write cloud, mobile and native applications directly via the browser (!)
Several languages are supported by LDEF, and you can write programs in Object Pascal, Basic and C. The Basic dialect is especially fun to work with, since it’s a re-implementation of BlitzBasic (with a lot of added extras). Amiga developers will no doubt remember BlitzBasic, it was used to create some great games back in the 80s and 90s. It’s well suited for games and multimedia programming and above all – very easy to learn.
More advanced developers can enjoy Object Pascal (read: Delphi) or a sub-set of C/C++.
And please note: This IDE is designed for large-scale applications, not simple snippets. The ultimate goal of Amibian.js is to move the entire development cycle to the cloud and away from the desktop. With Amibian.js you can write a cool “app” in BlitzBasic, run it right in the browser — or compile it server-side and deploy it to your Android Phone as a real, natively compiled application.
So any notion of a “mock desktop for HTML” should be firmly put to the side. I am not playing around with this product and the stakes are very real.
But why don’t you just use ChromeOS?
There are many reasons, but the most important one is chipset independence. Chrome OS is a native system, meaning that it’s core services are written in C/C++ and compiled to machine code. The fundamental principle of Amibian.js is to be 100% platform agnostic, and “no native code allowed”. This is why the entire back-end and service layer is targeting node.js. This ensures the same behavior regardless of processor or host system (Linux being the default host).
Node.js has the benefit of being 100% platform independent. You will find node.js for ARM, x86, Mips and PPC. This means you can take advantage of whatever hardware is available. You can even recycle older computers that have lost mainstream support, and use them to run Amibian.js.
A second reason is: Chrome OS might be free, but it’s only as open as Google want it to be. ChromeOS is not just something you pick up and start altering. It’s dependence on native programming languages, compiler toolchains and a huge set of libraries makes it extremely niche. It also shields you utterly from the interesting parts, namely the back-end services. It’s quite frankly boring and too boxed in for any practical use; except for Google and it’s technology partners that is.
I wanted a system that I could move around, that could run in the cloud, on cheap SBC’s. A system that could scale from handling 10 users to 1000 users – a system that supports clustering and can be installed on multiple machines in a swarm.
A system that anyone with JavaScript knowledge can use to create new and exciting systems, that can be easily expanded and serve as a foundation for rich media applications.
What is this Amiga stuff, isn’t that an ancient machine?
In computing terms yes, but so is Unix. Old doesn’t automatically mean bad, it actually means that it’s adapted and survived challenges beyond its initial design. While most of us remember the Amiga for its games, I remember it mainly for its elegant and powerful operating-system. A system so flexible that it’s still in use around the world – 33 years after the machine hit the market. That is quite an achievement.
The original Amiga OS, not bad for a 33-year-old OS! It was and continues to be way ahead of everyone else. A testament to the creativity of its authors
Amibian.js as the name implies, borrows architectural elements en-mass from Amiga OS. Quite simply because the way Amiga OS is organized and the way you approach computing on the Amiga is brilliant. Amiga OS is much more intuitive and easier to understand than Linux and Windows. It’s a system that you could learn how to use fully with just a couple of days exploring; and no manuals.
But the similarities are not just visual or architectural. Remember I wrote that hosted applications can access and use the Amibian.js services? These services implement as much of the original ROM Kernel functions as possible. Naturally I can’t port all of it, because it’s not really relevant for Amibian.js. Things like device-drivers serve little purpose for Amibian.js, because Amibian.js talks to node.js, and node talks to the actual system, which in turn handles hardware devices. But the way you would create windows, visual controls, bind events and create a modern, event-driven application has been preserved to the best of my ability.
But how does this thing boot? I thought you said server?
If you have setup a dedicated machine with Amibian.js then the boot sequence is the same as Linux, except that the node.js services are executed as background processes (daemons or services as they are called), the core server is initialized, and then a full-screen HTML5 view is set up that shows the desktop.
But that is just for starting the system. Your personal boot sequence which deals with your account, your preferences and adaptations – that boots when you login to the system.
When you login to your Amibian.js account, no matter if it’s just locally on a single PC, a distributed cluster, or via the browser into your cloud account — several things happen:
The client (web-page if you like) connects to the server using WebSocket
Login is validated by the server
The client starts loading preferences files via the mapped filesystem, and then applies these to the desktop.
A startup-sequence script file is loaded from your account, and then executed. The shell-script runtime engine is built into the client, as is REXX execution.
The startup-script will setup configurations, create symbolic links (assigns), mount external devices (dropbox, google drive, ftp locations and so on)
When finished the programs in the ~/WbStartup folder are started. These can be both visual and non-visual.
As you can see Amibian.js is not a mockup or “fake” desktop. It implements all the advanced features you expect from a “real” desktop. The filesystem mapping is especially advanced, where file-data is loaded via special drivers; drivers that act as a bridge between a storage service (a harddisk, a network share, a FTP host, Dropbox or whatever) and the desktop. Developers can add as many of these drivers as they want. If they have their own homebrew storage system on their existing servers, they can implement a driver for it. This ensures that Amibian.js can access any storage device, as long as the driver conforms to the driver standard.
In short, you can create, delete, move and copy files between these devices just like you do on Windows, OSX or the Linux desktop. And hosted applications that run inside their own window can likewise request access to these drivers and work with the filesystem (and much more!).
Wow this is bigger than I thought, but what is this emulation I hear about? Can Amibian.js really run actual programs?
Amibian.js has a JavaScript port of UAE (Unix Amiga Emulator). This is a fork of SAE (scripted Amiga Emulator) that has been heavily optimized for web. Not only is it written in JavaScript, it performs brilliantly and thus allows us to boot into a real Amiga system. So if you have some floppy-images with a game you love, that will run just fine in the browser. I even booted a 2 gigabyte harddisk image
But Amiga emulation is just the beginning. More and more emulators are ported to JavaScript; you have Nes, SNes, N64, PSX I & II, Sega Megadrive and even a NEO GEO port. So playing your favorite console games right in the browser is pretty straight forward!
But the really interesting part is probably QEmu. This allows you to run x86 instances directly in the browser too. You can boot up in Windows 7 or Ubuntu inside an Amibian.js window if you like. Perhaps not practical (at this point) but it shows some of the potential of the system.
I have been experimenting with a distributed emulation system, where the emulation is executed server-side, and only the graphics and sound is streamed back to the Amibian.js client in real-time. This has been possible for years via Apache Guacamole, but doing it in raw JS is more fitting with our philosophy: no native code!
I heard something about clustering, what the heck is that?
Remember I wrote about the services that Amibian.js has? Those that act almost like libraries on a physical computer? Well, these services don’t have to be on the same machine — you can place them on separate machines and thus its able to work faster.
Above: The official Amibian.js cluster, 4 x ODroid XU4s SBC’s in a micro-rack
A cluster is typically several computers connected together, with the sole purpose of having more CPU cores to divide the work on. The cool thing about Amibian.js is that it doesn’t care about the underlying CPU. As long as node.js is available it will happily run whatever service you like – with the same behavior and result.
The official Amibian.js cluster consists of 5 ODroid XU4/S SBC (single board computers). Four of these are so-called “headless” computers, meaning that they don’t have a HDMI port – and they are designed to be logged into and software setup via SSH or similar tools. The last machine is a ODroid XU4 with a HDMI out port, which serves as “the master”.
The architecture is quite simple: We allocate one whole SBC for a single service, and allow the service to copy itself to use all the CPU cores available (each SBC has 8 CPU cores). With this architecture the machine that deals with the desktop clients don’t have to do all the grunt work. It will accept tasks from the user and hosted applications, and then delegate the tasks between the 4 other machines.
Note: The number of SBC’s is not fixed. Depending on your use you might not need more than a single SBC in your home setup, or perhaps two. I have started with 5 because I want each part of the architecture to have as much CPU power as possible. So the first “official” Amibian.js setup is a 40 core monster shipping at around $250.
But like mentioned, you don’t have to buy this to use Amibian.js. You can install it on a single spare X86 PC you have, or daisy chain a couple of older PC’s on a switch for the same result.
Why Headless? Don’t you need a GPU?
The headless SBC’s in the initial design all have GPU (graphical processing unit) as well as audio capabilities. What they lack is GPIO pins and 3 additional USB ports. So each of the nodes on our cluster can handle graphics at blistering speed — but that is ultimately not their task. They serve more as compute modules that will be given tasks to finish quickly, while the main machine deals with users, sessions, traffic and security.
The 40 core cluster I use has more computing power than northern europe had in the early 80s, that’s something to think about. And the pricetag is under $300 (!). I dont know about you but I always wanted a proper mainframe, a distributed computing platform that you can login to and that can perform large tasks while I do something else. This is as close as I can get on a limited budget, yet I find the limitations thrilling and fun!
Part of the reason I have opted for a clustered design has to do with future development. While UAE.js is brilliant to emulate an Amiga directly in the browser – a more interesting design is to decouple the emulation from the output. In other words, run the emulation at full speed server-side, and just stream the display and sounds back to the Amibian.js display. This would ensure that emulation, of any platform, runs as fast as possible, makes use of multi-processing (read: multi threading) and fully utilize the network bandwidth within the design (the cluster runs on its own switch, separate from the outside world-wide-web).
I am also very interested in distributed computing, where we split up a program and run each part on different cores. This is a topic I want to investigate further when Amibian.js is completed. It would no doubt require a re-design of the LDEF bytecode system, but this something to research later.
Will Amibian.js replace my Windows box?
That depends completely on what you use Windows for. The goal is to create a self-sustaining system. For retro computing, emulation and writing cool applications Amibian.js will be awesome. But Rome was not built-in a day, so it’s wise to be patient and approach Amibian.js like you would Chrome OS. Some tasks are better suited for native systems like Linux, but more and more tasks will run just fine on a cloud desktop like Amibian.js.
Until the IDE and compilers are in place after phase two, the system will be more like an embedded OS. But when the LDEF compiler and IDE is in place, then people will start using it en-mass and produce applications for it. It’s always a bit of work to reach that point and create critical mass.
Object Pascal is awesome, but modern, native development systems are quite demanding
My personal need has to do with development. Some of the languages I use installs gigabytes onto my PC and you need a full laptop to access them. I love Amibian.js because I will be able to work anywhere in the world, as long as a browser and normal internet line is available. In my case I can install a native compiler on one of the nodes in the cluster, and have LDEF emit compatible code; voila, you can build app-store ready applications from within a browser environment.
I also love that I can set-up a dedicated platform that runs legacy applications, games – and that I can write new applications and services using modern, off the shelve languages. And should a node in the cluster break down, I can just copy the whole system over to a new, affordable SBC and keep going. No super expensive hardware to order, no absurd hosting fees, and finally a system that we all can shape and use in a plethora of systems. From a fully fledged desktop to a super advanced NAS or Router that use Amibian.js to give it’s customers a fantastic experience.
And yes, I get to re-create the wonderful reality of Amiga OS without the absurd egoism that dominates the Amiga owners to this day. I don’t even know where to begin with the present license holders – and I am so sick of the drama that rolling my own seemed the only reasonable path forward.
Well — I hope this helps clear up any misconceptions about Amibian.js, and that you find this as interesting as I do. As more and more services are pushed cloud-side, the more relevant Amibian.js will become. It is perfect as a foundation for large-scale applications, embedded systems — and indeed, as a solo platform running on embedded devices!
I cant wait to finish the services and cluster this sucker on the ODroid rack!
If you find this project interesting, head over to my Patreon website and get involved! I could really use your support, even if it’s just a $5 “high five”. Visit the project at: http://www.patreon.com/quartexNow
Well, the MeWe app is very simple, and registration is as simple as it should be. Username, password, email, verify and that's it. Besides, my main use for Facebook or MeWe is to run the groups - I spend very little of my time socializing anyways.
Show full content
Following my Administrator woes on Facebook post I have had a look at alternative places to run a forum. I realized that Facebook is getting pretty intrinsic in society around the world, so I know everyone won’t be interested in a new venue. But honestly, MeWe is very simple to use and have an UI experience very close to the Facebook app.
This picture was flagged as “hateful” on Facebook, which has rendered my account frozen for the next 30 days. While I agree to the strict rules that FB advocates, they really must deploy more human beings if they intend to have success in this endeavour. And that means really investigating what is flagged, reading threads in all languages etc. Because the risk of flagging the wrong guy is just too high. Admins get flagged all the time for kicking out bullies, and the use of reporting tools as a revenge strategy *must* carry a penalty.
MeWe is thankfully not like G+ which (in my personal opinion) was counter-intuitive and damn right intrusive. We all remember the G+ auto-upload feature, where some 3 million users had their family photos, vacation photos and .. ehrm, “explicitly personal” photos uploaded without consent.
Well, the MeWe app is very simple, and registration is as easy as it should be. You make a user name, a password, and type in your email; then you verify your email and that’s it!
Besides, my main use for Facebook or MeWe is to run the groups – I spend very little of my time socializing anyways. With the amount of groups and media i push on a daily basis it’s quite frankly their loss.
The MeWe group functionality is very good, and almost identical to Facebook
The alternative to MeWe is to setup a proper web forum instead. I have bought 6 domains that are now collecting dust so yes, I will look into that – but the whole purpose of a social platform is that you don’t have to do maintenance beyond daily management – so MeWe saves us some time.
So head over to MeWe and register! Here are the two main groups I manage these days. The main groups are on facebook, but i have now registered the same groups on MeWe.
MeWe doesn’t cost anything and takes less than 5 minutes to join. Just like G+ and Facebook, MeWe can be installed as an app for your phone (both iOS and Android). So as far as alternatives go, it’s a good alternative. One more app wont do much harm I imagine.
Note: I will naturally keep my Facebook account for the sake of the groups, but having experienced this 4 times in 9 years, my tolerance of Mr. Suckerberg is quickly reaching its limits. If I have blurted something out I have no problems standing for that and taking the penalty, but posting a picture of software development? In a group dedicated to software development? That takes some impressive mental acrobatics to accept.
Amibian.jsDelphiJavaScriptObject PascalSmart Mobile StudioAmiga Disruptfacebook
But before I managed to kick the user, he reported a picture of Amibian as hateful. Again, we are talking about a screen-dump from VMWare with pascal code. No hate, no poor choice of images - nothing that would violate ordinary Facebook standards. The result? Facebook has now frozen my account for 30 days (!)
Show full content
For well over 10 years I have been running different interest groups on Facebook. While Delphi Developer is without a doubt the one that receives most attention from myself and my fellow moderators, I also run the Quartex Components group and lately, Amiga Disrupt. The latter dedicated to my favorite hobby, namely retro computing.
I have to say, it’s getting harder to operate these groups under the current Facebook regime. I applaud them for implementing a moral codex, that is both fair and good, but that also means that their code must be able to distinguish between random acts of hate and bullying, and moderator operations.
A couple of days ago I posted an update picture from Amibian.js. This is a picture of my vmware development platform, with pascal code, node.js and the HTML5 desktop running. You would have be completely ignorant of technology to not recognize the picture as having to do with software development.
This picture was flagged as hateful, and was enough to get an admin’s account frozen for 30 days
Sadly facebook contains all sorts of people, and for some reason even grown men will get into strange, ideological debates about what constitutes retro-computing. In this case the user was a die-hard original-amiga fan, who on seeing my post about amibian.js went on a spectacular rant. Listing in alphabetical and chronological order, the depths of depravity that people have stooped to in implementing 68k as Javascript.
Well, I get 2-3 of these comments a week and the rules for the group is crystal clear: if you post comments like that, or comments that are racist, hateful or otherwise regarded as a provocative to the general group standard — you are given a single warning and then you are out.
So I gave him a warning that such comments are not welcome; He immediately came back with a even worse response – and that was the end of that.
But before I managed to kick the user, he reported a picture of Amibian as hateful. Again, we are talking about a screen-dump from VMWare with pascal code. No hate, no poor choice of images – nothing that would violate ordinary Facebook standards.
The result? Facebook has now frozen my account for 30 days (!)
Well I’m not even going to bother being upset, because this is not the first time. When people seem to willfully seek out conflict, only to use the FB’s reporting tools as weapons of revenge — well, there is not much I can do.
Anyways, Gunnar, Glenn, Peter and Dennis got you covered – and I’ll see you in a month. I think it’s time i contact FB in Oslo and establish separate management profiles.
DelphiObject PascalDelphi DeveloperDemo competitionfreepascallazarusSmart Mobile Studio
Each contestant has submitted a project to the following repositories (in the same order as the names above), so make sure you check out each one and inspect them carefully before casting your vote
Show full content
A month ago we setup a demo competition on Delphi Developer. It’s been a few years since we did this, and demo competitions are always fun no matter what, so it was high time we set this up!
This years prizes are awesome!
Initially we had a limit of at least 10 contestants for the competition to go through, but I will make an exception this time. The prices are great and worth a good effort. I was a bit surprised by the low number of contestants since more than 60 developers signed our poll about the event. So I was hoping for at least 20 to be honest.
I think the timing was a bit off, we are closer to the end of the year and most developers are working under deadlines. So next year I think I’ll move the date to June or July.
Be that as it may – a demo competition is a tradition by now, so we proceed to the voting process!
The contestants
The contestants this year are:
Christian Hackbart
Mogens Lundholm
steven Chesser
Jens Borrisholt
Paul Nicholls
Note: Dennis is a moderator on Delphi Developer, as such he cannot partake in the voting process.
The code
Each contestant has submitted a project to the following repositories (in the same order as the names above), so make sure you check out each one and inspect them carefully before casting your vote.
We use the poll function built-into Facebook, so just visit us at Delphi Developer to cast your vote! You can only vote once and there is a 1 week deadline on this (so votes are done on the 10th this month.
DelphiObject PascalOP4JSSmart Mobile StudioEmbarcaderoSmart Mobile
Effective immediately (30.10.2018) I am leaving The Smart Company AS and liquidating my shares.
Show full content
Effective immediately (30.10.2018) I am leaving The Smart Company AS and I have re-distributed my shares.
It’s almost unreal to think that it’s close to nine years since I started this project. Smart Mobile Studio continues to be a technology I am passionate about, and I must admit this is a tough call. It has taken me months to arrive at this decision, but I sadly see no other alternative given the circumstances.
In retrospect, we probably released the technology too early. I see more and more Delphi and C++ builder developers waking up to JavaScript and what web technology can do in the right hands. In other words, they are now where I was nine years ago.
When it comes to reasons there is not really much to say. There have been a few internal issues that were unfortunate, but for me this boils down to time, money and vision. Not really anything juicy to share, im simply not interested in being a partner under the terms the board currently operates with, not because I don’t believe in the product, but because I find the modus operandi counter productive.
Having said that, I am thankful for the journey and everything I have learned, and wish the team all the best for the future.
Smart Mobile Studio lives on
Even though I’m leaving the company and am re-distributed my stock, the product will continue without me. I still use and will continue to use Smart Mobile Studio in my work. But I no longer represent the company, nor will I be involved in further development. So my role as head of research and development is over.
My new compiler core and web IDE is written in Smart Pascal
There is a time and place for all things, and while it breaks my heart to hand Smart Mobile Studio over to a future without me; my time right now is better spent at Embarcadero – working to promote and deliver the language I love above all else; namely Delphi.
Besides Embarcadero I do consulting and occasional training sessions. I have also taken on responsibilities connected with my Patreon project. So I have more than enough to keep me occupied, both at Embarcadero and personally.
But this is not a clean cut. There is no animosity involved. I will continue to use Smart Mobile Studio to build cool stuff. I will publish articles on things I make and continue to evolve the QTX Framework (which has been dormant for two years now).
DelphifiremonkeyJavaScriptObject PascalSmart Mobile StudioTinkerboardDelphi DeveloperdemoDemo competitionEmbarcaderofreepascalRemobjects oxygeneSmart Pascal
The first prize this year is something really, really special. The winner walks off with a spiffing Altera Cyclone IV FPGA starter board. This is a spectacular FPGA kit that allows you to upload a wide range of ready-to-rock FPGA core's, as well as your own logic designs.
Show full content
The Delphi Developer group on Facebook has been around for a few years, and in that time we have held two very interesting demo competitions. The last competition we held was for Smart Pascal (Smart Mobile Studio) only, but we are extending it to include the dialects supported by our group; meaning Delphi, Smart Pascal, Freepascal and Remobjects Oxygene!
Embarcadero shipped over some extra goodies for us, so the competition this year is indeed a magical one. The top 3 contestants all get the official Embarcadero T-Shirt. We also throw in 10 Sencha ball-pens for each of the top 3 contestants; this is in addition to the actual prizes listed below (!)
The #1 winner not only get the 100€ FPGA devkit (see prizes below), he or she walks off with a high-quality, stainless steel Embarcadero branded coffee mug that holds half a litre of breakfast! (I seriously wanted to keep this for myself).
The prizes in all their glory!
Submission rules are:
Source submission (GPL, LGPL) + binary
No dependencies on commercial libraries or components
Submissions must be available through GIT or BitBucket
Submission must include everything it needs to be compiled
The purpose of the submissions is to show off both the language and your skills. Back in 2013 we got a ton of really cool demo-scene stuff, demonstrating timeless techniques; everything from bouncing meta-balls, gouraud shaded vectors, sinus scroll-texts and webgl landscape flight. We also had a fantastic fractal explorer program, bitmap rotozoom generator – and two great games! Which both made it onto AppStore and Google Play!
First prize
The winner walks off with some exciting stuff!
The first prize this year is something really, really special. The winner walks off with a spiffing Altera Cyclone IV FPGA starter board. This is a spectacular FPGA kit that allows you to upload a wide range of ready-to-rock FPGA core’s, as well as your own logic designs.
But to make it more accessible we added a retro daughter board, this gives you VGA, audio, keyboard, mouse, MicroSD, serial and two old school joystick ports. The daughterboard is needed if you plan on using some of the retro-cores out there. I personally love the Amiga core (shock, I know) but you can run anything from a humble Spectrum to Sega Megadrive, SNES, Atari ST/E, Neo-Geo and many others.
While the daughter-board makes this wonderful for retro-computing and gaming, fpga is first and foremost a tool for engineering. It ships with a USB-Blaster which allows you to connect it directly to your PC and it will be recognized as a device. FPGA modeling applications will pick this up and you can test out designs “live”, or just place a core on the SD-card and edit the boot config.
The kit sells for roughly 100€ with a case, but getting both the motherboard and the retro daughter-board is difficult. These things are sold separately, and the daughter board is produced in small numbers by dedicated hackers. So winning a kit that is pre-assembled, soldered and ready to go is quite a prize!
If you are even remotely interested in FPGA programming, this should give you goosebumps!
Second prize
The most powerful SBC I have ever used
The silver medal is the powerful Asus Tinkerboard, this is probably the most powerful SBC you can get below 100€. It delivers 10 times the firepower a Raspberry PI 3b can muster – and is superbly suited for Android development, Smart Mobile Studio kiosk systems and much, much more.
Of all the board I have tested and own this is the one with enough CPU grunt (even the mighty ODroid XU4 can’t touch this) to rival a low-end x86 laptop. You have to fork out for a SnapDragon IV to beat the Tinkerboard.
I have two of these around the house myself, one as a game console running Emulation Station (emulates PSX 1, 2 and 3 games), and another under my TV with Kodi and a 2 terabyte movie collection.
Third prize
Last but not least the bronze medal is a Raspberry PI 3b. The PI should be no stranger to programmers today, it more or less defines the IOT revolution and has, by far, the biggest collection of software available of all SBC (single board computers) available today.
The device that represents the IOT phenomenon
The PI is a wonderful starter board for Delphi developers who want to play with hardware under android. It’s also a fantastic board for Smart and FPC development.
I use a PI to test node.js services written in Smart Mobile Studio.
Dates
We start the clock on the 1st of october and submission must be delivered by the 31st. So you have a full month to code something cool!
Remember comments
While not always possible, try to write clean code. Part of the point here is to use these demos as an educational source.
We wont reject non-commented code, but please try to avoid 20k lines of spaghetti.
Hints and tips
Delphi has brilliant support for DirectX and OpenGL, so taking advantage of hardware acceleration should not be a problem. FMX is largely powered by the GPU and has 3d rendering and modeling as an integral feature – so Delphi developers have a slight advantage there.
Tilesets are graphics-blocks that can be used to create large game levels with a map-editor
If you want to use DIB’s under vanilla WinAPI there is always Graphics32, a wonderful and exceptionally detailed library for fast graphics.
Music: Most demo-scene code use mod music (actually today people play MP3’s as well), and there are good wrappers for player libraries like Bass. It’s always a nice touch to add a spot of music (and literally millions of free mod tracks freely available). So give your demo some flair by adding a kick-ass mod track, or impress us by writing a score yourself?
In the world of demo coding anything goes! Bring out that teenage spirit and go wild, create wonderful graphical effects, vector objects, scrolling texts, games or whatever tickles your fancy. If you need inspiration, check out the demo scene videos on YouTube (if that is what you would like to submit of course). A kick-ass database application, X server renderer, paint program or a compiler — it’s all good!
Make people go WOW that is cool!
Tile graphics: which is often used in games and demos, can be found almost anywhere. If you google “tileset” or “game tiles” you should get more than you need. Brilliant for parallax scrolling. Why not give Super Mario a run for its money? Show the next generation how to code a platform game! Check out the Tiled map-editor, this has a JSON export filter for you Smart Pascal coders.
Tiled is a powerful map editor. There is also mappy, which I believe have a Delphi player
OK guys, the game is a-foot! May the best coder win!
Amibian.jsJavaScriptLanguage researchnodeJSObject PascalSmart Mobile StudioSocialDelphiEmbarcaderoOslo Delphi ClubPresentationSmart Pascal
Yesterday evening I traveled to Oslo and held a presentation on Smart Mobile Studio. The response was very positive and I hope that everyone who attended left with some new ideas regarding JavaScript, the direction the world of software is heading - and how Smart Mobile Studio can be of service to Delphi.
Show full content
Yesterday evening I traveled to Oslo and held a presentation on Smart Mobile Studio. The response was very positive and I hope that everyone who attended left with some new ideas regarding JavaScript, the direction the world of software is heading – and how Smart Mobile Studio can be of service to Delphi.
Smart Pascal is especially exciting in concert with Rad-Server, where it opens the doors to Node based, platform independent services and sub clustering. With relatively little effort Rad-Server can absorb the wealth that node has to offer through Smart – but on your terms, and under Delphi’s control. The best of both worlds.
You get the stability and structure that makes Delphi so productive, and then infuse that with the flamboyance, flair and async brilliance that JavaScript represents.
More important than technology is the community! It’s been a few years since I took part in the Oslo Delphi Club’s meetups, so it was great to chat with Halvard Vassbotten, Trond Grøntoft, Alf Christoffersen, Torgeir Amundsen and Robin Bakker face to face again. I also had the pleasure of meeting some new Delphi developers.
Presentation at ABG Sundal Collier’s offices in Oslo
Thankfully the number of attendees were a moderate 14, considering this was my first presentation ever. Last time I visited was when our late Paweł Głowacki presented FMX, and the turnout was in the ballpark of a hundred. So it was an easy-going, laid-back atmosphere throughout the evening.
Conflict of interest?
Some might wonder why a person working for Embarcadero will present Smart Mobile Studio, which some still regard as competition. Smart is not in competition with Delphi and never will be. It is written by Delphi developers for Delphi developers as a means to bridge two worlds. It’s a project of loyalty and passion. We continue because we love what it enables us to do.
The talks on Smart that I am holding now, including the november talk in London, were booked before I started at Embarcadero (so it’s not a case of me promoting Smart in leu of Embarcadero). I also made it perfectly clear when I accepted the job that my work on Smart will continue in my spare time. And Embarcadero is fine with that. So I am free to spend my after-work hours and weekend time as I see fit.
The Smart Desktop, codename Amibian.js, is a solid foundation for building large-scale web front-ends. Importing Sencha’s JS API’s can be done via our TypeScript wizard
So, after my presentation in London in november Smart Mobile Studio presentations (at least hosted by me) can only take place during weekends. Which is fair and the way it should be.
Recording the English version
Since the presentation last evening was in Norwegian, there was little point in recording it. Norway have a healthy share of Delphi developers, but a programming language available internationally must be presented in English.
A couple of months back, before I started working for Embarcadero I promised to do a video presentation that would be available on Delphi Developer and YouTube. I very much like to keep that promise. So I will re-do the presentation in English as soon as possible. I would have done it today after work, but buying tech from the US have changed quite dramatically in just a couple of years.
In short: I haven’t received the remaining equipment I ordered for professional video recording and audio podcasting (which is a part of my Patreon offering as well), as such there will be no live video-feed /slash/ webinar – and questions will be limited to either the comment-section on Delphi Developer; or perhaps more appropriate, the Smart Mobile Studio Forums.
I’m hoping to get the HD camera, mic-table-arm and various bits-and-bobs i ordered from the US sometime next week. I have no idea why FedEx have become so difficult lately, but the package is apparently at LaGuardia, and I have to send receipts that document that these items are paid for before they ship them abroad (so the package manifest listing me as the customer, my address, phone number and receipt from the seller is somehow not enough). This is a first for me.
Interestingly they also stopped a package from Embarcadero with giveaways for my upcoming Delphi presentation in Sweden – at which point I had to send them a copy of my work contract to prove that I indeed work for an American company.
But a promise is a promise, so come rain or shine it will be done. Worst case scenario we can put Samsung’s claims to the test and hook up a mic + photo lens and see if their commercials have any merit.
DelphiLinuxObject PascalSocialcode of conductPolitical correctnessStallman
Linus is infamous for his spectacular and rants in the kernel. Some of his commits have more rants than code, which I find hilarious. There is a collection of them online and people read them for kicks because he is, for all means and purposes, the Gordon Ramsey of programming.
Show full content
Unless you have been living under a rock, the turmoil and crisis within the Linux community these past weeks cannot have escaped you. And while not directly connected to Delphi or the Delphi Developer group on Facebook, the effects of a potential collapse within the core Linux development team will absolutely affect how Delphi developers go about their business. In the worst possible scenario, should the core team and it’s immediate extended developers decide to walk away, their code walks with them. Rendering much of the work countless companies have invested in the platform unreliable at best – or in need of a rewrite at worst (there is a legal blind-spot in GPL revision 1 and 2, allowing developers to rescind their code).
Large parts of the kernel would have to be re-invented, a huge chunk of the sub-strata and bedrock that distributions like Ubuntu, Mint, Kali and others rests on – could risk being removed, or rescinded as the term may be, from the core repositories. And perhaps worst of all, the hundreds of patches and new features yet to be released might never see the light of day.
To underline just how dire the situation has been the past couple of weeks, Richard Stallman, Eric S. Raymond, Linus Torvalds and others are threatening, openly and legally, to pull all their code (September 20th, Linux Kernel Mailing List) if the bullying by a handful of activist groups doesn’t stop. Linus is still in limbo having accepted the code of conduct these activist demand implemented, but has yet to return to work.
Linus Torvalds is famous for many things, but his personality is not one of them
But the interesting part of the Linux debacle is not the if’s and but’s, but rather the methods used by these groups to get their way. How can you enforce a “code of conduct” using methods that themselves are in violation with that code of conduct? It really is a case of “do as I say, not as I do”; And it has escalated into a gutter fight masquerading as social warfare where slander, stigmata, false accusations and personal attacks of the worst possible type are the weapons. All of which is now having a real and tangible impact on business and technology.
Morally bankrupt actions is not activism
These activists, if they deserve that title, even went as far as deciding to dig into the sexual-life of one of the kernel developers. And when finding out that he was into BDSM (a form of sexual role-play), they publicly stigmatized the coder as a rape sympathizer (!). Not because it’s true, but because the verbal association alone makes it easier for bullies like Coraline to justify the social execution of a man in public.
What makes my jaw drop in all this, is the complete lack of compassion these so-called activists demonstrate. They seem blind to the price of such stigmata for the innocent; not to mention the insult to people who have suffered sexual abuse in their lives. For each false accusation of rape that is made, the difficulty for actual abuse victims to seek justice increases exponentially. It is a heartless, unforgivable act.
Personally, I can’t say I understand the many sexual preferences people have these days. I find myself googling what the different abbreviations mean. The movie 50 shades of gray revolved around this stuff. But one thing is clear: as long as there are consenting adults involved, it is none of our business. If there is evidence of a crime, then it should be brought before the courts. And no matter what we might feel about the subject at hand, it can never justify stigmatizing a person for the rest of his life. Not only is this a violation of the very code of conduct these groups wants implemented – it’s also illegal in most of the civilized world. And damn immoral and out-of-line if you ask me.
The goal cannot justify the means
The irony in all of this, is that the accusation came from Coraline herself. A transgender woman born in the wrong body; a furious feminist now busy fighting to put an end to bullying of transgender minorities in the workplace (which she claims is the reason she got fired from Github). Yet she has no problems being the worst kind of bully herself on a global scale. I question if Coraline is even morally fit to represent a code of conduct. I mean, to even use slander such as rape-sympathizer in context with getting a code of conduct implemented? Digging into someones personal life and then using their sexual preference as leverage? It is utterly outrageous!
It is unacceptable and has no place in civilized society. Nor does a code of conduct, beyond ordinary expectations of decency and tolerance, have any place in a rebel motivated R&D movement like Linux.
Linux is not Windows or OS X. It was born out of the free software movement back in the late 1960’s (Stallman with GNU) and the Scandinavian demo and hacker scene during the 80’s and 90’s (the Linux kernel that GNU rests on). This is hacker territory and what people might feel about this in 2018 it utterly irrelevant. These are people that start the day with 4Chan for pete sake! The primary motivation of Stallman and Linus is to undermine, destroy and bury Microsoft and Apple in particular. And they have made no secret of this agenda.
Expecting Linux or their makers to be politically correct is infantile and naive, because Linux is at its heart a rebellion, “a protest of technical excellence and access to technology undermining commercial tyranny and corporate slavery”. That is not my personal opinion, that is straight out of a Richard Stallman book Free as in Freedom; His papers reads more like a religious manifesto; a philosophical foundation for a technological utopia, seeded and influenced by the hippie spirit of the 1960s. Which is where Stallman’s heart comes from.
You cannot but admire Stallman for sticking to his principles for 50+ years. And thinking he is going to just roll over because activists in this particular decade has a beef with how hackers address each other or comment their code, well — I don’t think these activists understand the hacker community at all. If they did they would back off and stop poking dragons.
Linux vs the sensitivity movement?
Yesterday I posted a video article that explained some of this in simple, easy terms on Delphi Developer. I picked the video that summed up the absurdities involved (as outlined above) as quickly as possible, rather than some 80 minute talk on YouTube. We have a long tradition of posting interesting IT news, things that are indirectly connected with Delphi, C++ builder or programming in general. We also post articles that have no direct connection at all – except being headlines within the world of IT. This helps people stay aware of interesting developments, trends and potential investments.
The head of the “moral codex” doesn’t strike me as unbiased and without an axe to grind
As far as politics is concerned I have no interest what so ever. Nor would I post political material in the group because our focus is technology, Delphi, object pascal and software development in general. The exception being if there is a bill or law passed in the US or EU that affects how we build applications or handle data.
Well, this post was no different.
What was different was that some individuals are so acclimatized to political debate that they interpret everything as a political statement. So criticism of the methods used are made synonymous with criticism of a cause. This can happen to the best of us; human beings are passionate animals and I think we can all agree that politics has taken up an unusual amount of space lately. I can’t ever remember politics causing so much bitterness, divide and hate as it does today. Nor can I remember sound reason being pushed aside in favour of immediate emotional trends. And it really scares me.
Anyways, I wrote that “I stand by my god given rights to write obscene comments in my code“. Which is a reference to one of the topics Linus is being flamed for, namely his use of the F word in his own code. My argument is that, the kernel is ultimately Torvalds work, and it’s something he gives away for free. I dont have any need for obscenity in my code, but I sure as hell reserve the right to do so in my personal projects. How two external groups (in this case a very aggressive feminist group combined with LGBTQIA) should have any say in how Linus formats his code (or you for that matter) or the comments he writes – it makes no sense. It’s free, take it or leave it. And if you join a team and feel offended by how things are done, you either ignore it or leave.
It might not be appropriate of Linus to use obscenity in his comments, but do you really want people to tell you what you can or cannot write in your own code? Lord knows there are pascal units online that have language unfit for publishing, but nobody is forcing you to use them. I cant stand Java but I dont join their forums and sit there like a 12 year old bitching about how terrible Java is. It’s just infantile, absurd mentality.
So that is what my reference was to, and I took for granted that people would pick up on that since Linus is infamous for his spectacular rants in the kernel (and verbally in interviews). Some of his commits have more rants than code, which I find hilarious. There is a collection of them online and people read them for kicks because he is, for all means and purposes, the Gordon Ramsey of programming.
And I also made a reference to “tree hugging millennial moralists”. Not exactly hard-core statements in these trying times. We live in a decade where vegan customers are looking to sue restaurants for serving meat. Maybe I’m old-fashioned but for me, that is like something out of Monty Python or Mad Magazine. I respect vegans, but I will not be dictated by them.
I mean, the group people call millennials is after all recognized as a distinct generation due to a pattern of unreasonable demands on society (and in extreme cases, reality itself). In some parts of the world this is a real problem, because you have a whole generation that expects to bag upper-management salary on a paper route. When this is not met you face a tantrum and aggressiveness that should not exist beyond a certain age. Having a meltdown like a six-year-old when you are twenty-six is, well, not something I’m even remotely interested in dealing with.
And I speak from experience here, I had the misfortune of working with one extreme case for a couple of years. He had a meltdown roughly once a month and verbally abused everyone in the office. Including his boss. I still can’t believe he put up with it for so long, a lesser man would have physically educated him on the spot.
The sensitivity movement
But (and this is important) like always, a stereotype is never absolute. The majority within the millennial age group are nothing like these extreme cases. In fact we have two administrators in Delphi Developer that both fall under the millennial age group – yet they are the exact opposite of the stereotype. They are extremely hard-working, demonstrate good moral and good behavior, they give of themselves to the community and are people I am proud to call my friends.
The people I refer to as the sensitivity movement consists of men and women that hold, in my view, demands to life that are unreasonable. We live in times where for some reason, and don’t ask me why, minorities have gotten away with terrible things (slander, straw-men tactics, blame shifting, perversion of facts, verbal abuse, planting dangerous rumours and false accusation; things that can ruin a person for life) to impose their needs opposed to the greater good and majority. And no, this has nothing to do with politics, it has to do with expectation of normal decency and minding your own business. As a teenager I had my share of rebellion (some would say three shares), but I never blamed society; instead I wanted to understand why society was the way it is, which led me to studying history, comparative religion and philosophy.
The minorities of 2018 have no interest in understanding why, they mistake preference with offence, confuse kindness with weakness – and are painfully unable to discern knowledge from wisdom. The difference between fear and respect might be subtle, but on reflection a person should make important discoveries about their own nature. Yet this seem utterly lost on men and women in their 20s today.
And just to make things crystal clear: the minorities I am referring to here as the so-called sensitivity movement, are not the underprivileged or individuals suffering a disadvantage. The minorities are in fact highly privileged individuals – enjoying the very freedom of expression they so eagerly want taken away from people they don’t like. That is a very dangerous path.
Linux, the bedrock of the anti-establishment movement
The Linux community has a history of being difficult. Personally I find them both helpful and kind, but the core motivation behind Linux as a phenomenon cannot be swept under the carpet or ignored: these are rebels, rogues, people who refuse to bend the knee.
Linux itself is an act of defiance, and it exists due to two key individuals who both are extremely passionate by nature, namely Richard Stallman and Linus Torvalds.
Attacking these from all sides is shameful. I find no other words for it. Especially since its not a matter of principles or sound moral values, but rather a matter of pride and selfish ideals.
Name calling will not be tolerated
The reason I wrote this post was not to involve everyone in the dire situation of Linux, at least not to bring an external problem into our community and make it our problem. It was news that is of some importance.
I wrote this blogpost because a member somehow nicknamed me as “maga right-wing” something. And I’m not even sure how to respond to something like that.
First of all I have no clue what maga even is, I think it’s that cap slogan trump uses? Make america great again or something like that? Secondly, I live in Norway and know very little of the intricacies of domestic american politics. I have voted left for some 20 years, with exception of last norwegian election when I voted center. How my respect for Stallman and Linus, and how the hacker community operates (I grew up in the hacker community) – somehow connects me to some political agenda on another continent, is quite frankly beyond me.
But this is exactly the thing I wrote about above – the method being deployed by these groups. A person read something he or she doesn’t like, connects that to a pre-defined personality type, this is then supposed to justify wild accusations – and he or she then proceeded directly to treating someone accordingly. THAT behavior IS offensive to me, because there should be a dialog quite early in that chain of events. We have dialog to avoid causing harm – not as a means to cause further damage.
Is it the end of Linux as we know it?
No. Linus has been a loud mouth for ages, and he actually have people who purge his code of swear words (which is kinda funny) – but he has accepted the code of conduct and taken some time off.
The threat Stallman and the core team has made however is very real, meaning that the inner circle of Linux developers can flick the kill switch if they want to, but I think the negative press Coraline and those forcing their agenda onto the Linux foundation is getting, will make them regret it. And of course, articles like the New Yorker published didn’t help the situation.
Having said that, these developers are not normal people. Normal is a cut of average behavior. And neither Stallman, Linus of the hacker community fall under the term “normal” in the absolutesense of the word. Not a single individual that has done something of importance technologically fall under that group. Nor do they have any desire to be normal either, which is a death sentence in the hacker community. The lowest, most worthless status you can hold as a hacker, is normal.
These are people who build operating systems for fun. They are passion driven, artistic and highly emotional. And as such they could, should more gutter tricks be deployed, decide to burn the house down before they hand it over.
So it’s an interesting case well worth keeping an eye on. Preferably one that doesn’t add or subtract from what is there.
DelphiObject PascalAuthoringC++ builderDocumentationHelpSmart Mobile Studio
For me, Help & Doc makes more sense because it remains true to its basic role: to help you create documentation for your products. And it does that very, very well.
Show full content
I have been flamed so much lately for not writing proper docs for Smart Mobile Studio, that I figured it was time to get this under wraps. Now in my defence I’m not the only one on the Smart Pascal team, sure I have the most noise, but Smart is definitely not a solo operation.
So the irony of getting flamed for lack of docs, having perpetually lobbied for docs at every meeting since 2014; well that my friend is mother nature at her finest. If you stick your neck out, she will make it her personal mission to mess you up.
So off I went in search of a good documentation system ..
The mission
My dilemma is simple: I need to find a tool that makes writing documentation simple. It has to be reliable, deal with cross chapter links, handle segments of code without ruining the formatting of the entire page – and printing must be rock solid.
Writing documentation in Open Office feels very much like this
If you are pondering why I even mention printing in this digital age, it’s because I prefer physical media. Writing a solid book, be it a mix between technical reference and user’s guide, can’t compare to a blog post. You need to let the material breathe for a couple of days between sessions to spot mistakes. I usually print things out, let it rest, then go over it with an old fashion marker.
Besides, my previous documentation suite couldn’t do PDF printing. I’m sure it could, just not around me. Whenever I picked Microsoft PDF printer as the output, it promptly committed suicide. Not even an exception, nothing, just “poff” and it terminated. The first time this happened I lost half a days work. The third time I uninstalled it, never to look back.
Another thing I would like to see, is that the program deals with graphics more efficiently than Google Docs, and at the very least more intuitively than Open Office (Oo in short). Now before you argue with me over Oo, let me just say that I’m all for Open-Office, it has a lot of great features. But in their heroic pursuit of cloning Microsoft to death, they also cloned possibly the worst layout mechanisms ever invented; namely the layout engine of Microsoft Word 2001.
Let’s just say that scaling and perspective is not the best in Open Office. Like Microsoft Word back in the day, it faithfully favours page-breaks over perspective based scaling. It will even flip the orientation if you don’t explicitly tell it not to.
Help & Doc
As far as I know, there are only two documentation suite’s on the market related with Delphi and coding. At least when it comes to producing technical manuals, help files and being written in Delphi.
First you have the older and perhaps more established Help & Manual. This is followed by the younger but equally capable Help & Doc. I ended up with the latter.
Help & Doc’s main window, clean and pleasing to the eye
Both suite’s have more in common than similar names (which is really confusing), they offer pretty much the exact same functionality. Except Help & Doc is considerably cheaper and have a couple features that developers favour. At least I do, and I imagine the needs of other developers will be similar.
Being older, Help & Manual have worked up more infrastructure , something which can be helpful in larger organizations. But their content-management strategy is (at least to me) something of a paradox. You need more than .NET documentation and shared editing to justify the higher price -and having to install a CMS to enjoy shared editing? It might make sense if you are a publisher, ghostwriter or if you have a large department with 5+ people doing nothing but documentation; but competing against Google Documents in 2018? Sorry, I don’t see that going anywhere.
For me, Help & Doc makes more sense because it remains true to its basic role: to help you create documentation for your products. And it does that very, very well.
Help & Doc has a built-in server for testing web documentation with minimum of fuzz
I also like that Help & Doc are crystal clear about their origins. Help & Manual have anonymized their marketing to tap into .Net and Java; they are not alone, quite a few companies try to hide the fact that their flagship product is written in object pascal. So you get a very different vibe from these two websites and their products.
The basics
Much like the competition, Help & Doc offers a complete WYSIWYG text editor with support for computed fields. So you can insert fields that hold variable data, like time, date (and various pieces of a full datetime), project title, author name [and so on]. I hope to see script support at some point here, so that a script could provide data during PDF/Web generation.
The editor is responsive and well written, supports tables, margins and formatting like you expect from a modern editor. Not really sure how much I need to write about a text editor, most Delphi and C++ developers have high standards and I suspect they have used RichView, which is a well-known, high quality component.
One thing I found very pleasing is that fonts are not hidden away but easily accessible; various text styles hold a prominent place under the Write tab on top of the window. This is very helpful because you don’t have to apply a style to see how it will look, you can get an idea directly from the preview.
Very nice, clear and one click away
Being able to insert conditional sections is something I found very easy. It’s no doubt part of other offerings too, but I have never really bothered to involve myself. But with so many potential targets, mobile phones, iPads, desktops, Kindle – suddenly this kind of functionality becomes a thing.
Adding conditional sections is easy
For example if you have documentation for a component, one that targets both Delphi, .NET and COM (yes people still use COM believe it or not) you don’t need 3 different copies of the same documentation – with only small variations between them. Using the conditional operations you can isolate the differences.
With Apple OSX, iOS and Android added to the compiler target (for Delphi), the need to separate Apple only instructions on how to use a library [for example], and then only include that for the Apple output is real. Windows and Linux can have their own, unique sections — and you don’t need to maintain 3 nearly similar documentation projects.
When you combine that with script support, Help & Doc is flexing some powerful muscles. I’m very much impressed and don’t regret getting this over the more expensive Help and Manual. Perhaps it would be different if I was writing casual books for a publisher, or if I made .NET components (oh the humanity!) and desperately needed to please Visual Studio. But for a hard-core Delphi and object pascal developer, Help & Doc has everything I need – and then some!
Wait, what? Script support?
Scripting docs
One of the really cool things about Help & Doc is that it supports pascal scripting. You can do some pretty amazing things with a script, and being able to iterate through the documentation in classical parent / child relationships is very helpful.
The central role of Object Pascal is not exactly hidden in Help & Doc
If you are wondering why a script engine would even be remotely interesting for an author, consider the following: you maintain 10-12 large documentation projects, and at each revision there will be plenty of small and large changes. Things like class-names getting a new name. If you have mentioned a class 300 times in each manual, changing a single name is going to be time-consuming.
This is where scripting is really cool because you can write code that literates through the documentation, chapter by chapter, section by section, paragraph by paragraph – and automatically replace all of them in a second.
Metablaster was a desktop search engine I made in 1999. I used scripts to target each search engine
I haven’t spent a huge amount of time with the scripting API Help & Doc offers yet (more busy writing), but I imagine that a plugin framework is a natural step in its evolution. I made a desktop search engine once, back between 1999 and 2005 (just after the bronze age) where we bolted Pascal Script into the system, then implemented each search engine parser as a script. This was very flexible and we could adapt to changes faster than our competitors.
While I can only speculate and hope the makers of Help & Doc reads this, creating an API that gives you a fair subset of Delphi (streams, files, string parsing et-al) that is accessible from scripts, and then defining classes for import scripts, export scripts, document processing scripts; that way developers can write their own import code to support a custom format (medical documentation springs to mind as an example). Likewise developers could write export code.
This is a part of the software I will explore more in the weeks to come!
Verdict – is it worth it?
As of writing you get Help & Doc professional at 249 €, and you can pick up the standard edition for 99€. Not exactly an earth shattering price for the mountain of work involved in creating such an elaborate system. If you factor in how much time it saves you: yes, why on earth would you even think twice!
Using Help & Doc is very easy, here we are creating a new doc with a few chapters
I have yet to find a function that their competition offers that would change my mind. As a developer who is part of a small team, or even as a solo developer – documentation has to be there. I can list 10.000 reasons why Smart never got the documentation it deserves, but at least now I can scratch one of them off my list. Writing 500 A4 pages in markdown would have me throwing myself into the fjords at -35 degrees celsius.
And being the rogue that I am, should I find intolerable bugs you will be sure to hear about them — but I have nothing to complain about here.
Its one of the most pleasant pieces of software I have used in a long time.
Human beings and licenses
Before I end this article, I also want to mention that Help & Doc has a licensing system that surprised me. If you buy 2 licenses for example, you get to link that with a computer. So you have very good control over your ownership. Should you run out of licenses, well then you either have to relocate an existing license or get a new one. You are not locked out and they don’t frag you with compliance threats.
Doesn’t get much easier than this
I use VMWare a lot and sometimes forget that I’m running a clone on top of a clone, and believe me I have gotten some impressive emails in the past. I think the worst was Xamarin Mono which actually deactivated my entire environment until I called them and explained I was doing live debugging between two VMWare instances.
So very cool to see that you can re-allocate an existing license to whatever device you want without problems.
Amibian.jsDelphihexlicenseLanguage researchLifenodeJSObject PascalSmart Mobile StudioSocialPatreon
The benefits are many, but first and foremost it has to do with time. Developer don't have to maintain 3-4 websites, pay for invoicing services on said products, pay hosting fees and rent support forums -- instead focus is on getting things done. So instead of an hour here and there, you can (based on the level of support) allocate X hours within a week or weekend that are continuous.
Show full content
Apparently using modern service like Patreon to maintain components has become a point of annoyance and confusion. I realize that I formulated the initial HexLicense post somewhat vague and confusing, in retrospect I will admit that and also take critique for not spending a little more time on preparations.
Having said that, I also corrected the mistake quickly and clarified the situation. I feel some of the comments have been excessively critical for something that, ultimately, is a service to the community. But I’ll roll with the punches and let’s just put this issue to bed.
From the top please
I have several products and frameworks that naturally takes time to maintain and evolve. And having to maintain websites, pay for tax and invoicing services, pay for hosting (and so on), well it consumes a lot of hours. Hours that I can no longer afford to spend (my work at Embarcadero must come first, I have a family to support). So Patreon is a great way to optimize a very busy schedule.
Today developers solve a lot of the business strain by using Patreon. They make their products open source, but give those that support and help fund the development special perks, such as early access, special builds and a more direct line of control over where the different projects and sub-projects are heading.
The public repository that everyone has access to is maintained by pushing the code on interval, meaning that the public “free stuff” (LGPL v3 license) will be some months behind the early-access that patrons enjoy. This is common and the same approach both large and small teams go about things in 2018. Quite radical compared to what we “old-timers” are used to, but that’s how things work now. I just go with flow and try to do the most amount of good on the journey.
Benefits of Patreon
The benefits are many, but first and foremost it has to do with time. Developer don’t have to maintain 3-4 websites, pay for invoicing services on said products, pay hosting fees and rent support forums — instead focus is on getting things done. So instead of an hour here and there, you can (based on the level of support) allocate X hours within a week or weekend that are continuous.
Patreon solves two things: time and cost
Everyone wins. Those that support and help fund the projects enjoy early access and special builds. The community at large wins because the public repository is likewise maintained, albeit somewhat behind the cutting edge code patrons enjoy. And the developers wins because he or she doesn’t have to run around like a mad chicken maintaining X number of websites -wasting more time doing maintenance than building cool new features.
And above all, pricing goes down. By spreading the cost over a larger base of interest, people get access to code that used to cost $200 for $35. The more people that helps out, the more the cost can be reduced per tier.
To make it crystal clear what the status of my frameworks and component packages are, here is a carbon copy from HexLicense.com
In order to consolidate the various projects I maintain, I have established a Patreon account. This means that people can help fund further development on HexLicense, LDEF, Amibian and various Delphi libraries as a whole. This greatly simplifies things for everyone.
I will be able to allocate time based on a broader picture, I also don’t need to pay for invoicing services, web hosting and more. This allows me to continue to evolve the components and code, but without so many separate product identities to maintain.
Patreon supporters will receive updates before anyone else and have direct access to the latest code at all times. The public bitbucket repository will be updated on interval, but will by consequence be behind the Patreon updates.
Further security
One of the core goals on Patreon is the evolution of a bytecode compiler. This should be of special interest to HexLicense users. Being able to compile modules that hackers will be unable to debug gives you a huge advantage. The engine is designed so that the instruction-set can be randomized for a particular build. Making it unique for your application.
Well, I want to thank everyone involved. It has been a great journey to produce so many components, libraries and solutions over the years – but now it’s time for me to cut down on the number of projects and focus on core technology.
DelphiObject Pascaldatabasedatabase engineEmbarcaderoMetadataRecord persistencyRoll your own database
The latest code has been uploaded to the BitBucket repository (same as last), so simply update the fork you did earlier. Make sure you set plenty of breakpoints and also download a hex-editor and examine the resulting databasefile.
Show full content
If you missed the initial two episodes in this tutorial, click here for the first article and here for the second. Even if you feel databases is something you master I urge you to read the articles from scratch, because the database theory we explore here is not the high-level concepts we learnt at school. Having said that it’s not too complex and with a bit of exploring you should find it easy to follow.
Update your git fork
In the previous episode you were asked to fork the project code from bitbucket. As we progress I will continue to add units and refactor code, so if you forked the code last time, you should fetch the latest revision before you continue.
Since GIT is incremental and awesome you can just revert to previous commits for the examples as we move along. I will mark each commit so you can see what is what and easily jump between examples.
Quick recap from our previous episode
Our last episode ended with a fidelity test on the storage medium. We implemented a class that would operate on blocks (or parts) of a defined size, rather than single bytes like a TStream does. The idea being that the class can create, read and write the blocks that contains the data; also known as a database pagesize.
I also introduced the notion of buffer classes, which are similar to Delphi streams. The buffer classes are actually Delphi implementations of the buffers found in node.js, which adds two very important benefits: the ability to inject and remove data from any point. So if you want to inject 1 gigabyte into the middle of a file, that can be done in a single call. If you want to remove 1 gigabyte from somewhere in the file, that is likewise reduced to a single call.
Buffers are designed to give you easier access to the data inside the buffer, while streams are great for normal programming tasks, buffers are much faster and ad-hoc, and thus better suited for database work.
From blocks to sequences
In this article’s code the focus is on sequences and putting together the essentials for our database class. Which means the ability to store sequences and being able to recover them (record persistency).
A sequence is, like I explained in our previous episode, file-parts that are linked together through offsets.
Whenever you want to store data that exceeds the page-size defined for a database, the only solution is to divide that data into parts and then spread the data over many blocks. We daisy-chain them together by setting the block number for the next block in the sequence in each of the parts (a block or part is ultimately just a record we write to the file), terminated by the value -1 ($FFFFFFFF as an unsigned longword). So the last block in the chain has the “next” field set to -1, which tells the system that there is no more data to fetch for the sequence.
If you are unsure about what I mean, please read up on sequences in the previous two articles.
Sequence persistency
What we are doing in this episode is to merge all the things we have talked about so far into a single class. The bit buffer is done, the block-file class is done, and now we need to make sure we can read and write full sequences.
This brings us to the problem of scaling. An empty database will not have any free blocks. So a part of the sequence reading and writing mechanism is the ability to expand the file on demand.
We also need to have some support functionality for mapping a sequence, otherwise we would have to store an awful lot of information for each record. We only really need to know the first block number in a sequence (because that will have a reference to any subsequent blocks used by a sequence). With mapping I mean a function that can investigate a sequence and return an array of block numbers, so that we know where each part of the sequence has ended up.
This might not be immediately useful, but when we reach the point of compacting a database, it becomes vital that we can quickly map what blocks a sequence occupy – and then organize them in a linear fashion so that the data can be read faster, and we can release excess empty space.
Changes to the header and part records
Suddenly our metadata needs have grown considerably. We need to store the bit-buffer that holds the map of the whole database (all the blocks are either used [1] or available [0]). We need to store a list of longwords that represents the records in a database. Please note that on this level, the database doesn’t care what record belongs to what table. And last but not least we need a file-header and block record that can keep track of the initial values.
Let’s have a look at the records first:
// Custom data structures
TDbVersion = packed record
bvMajor: byte;
bvMinor: byte;
bvRevision: word;
end;
TDbLibFileHeader = packed record
dhSignature: longword;
dhVersion: TDbVersion;
dhName: shortstring;
dhMetadata: longword;
dhRecList: longword;
dhBitBuffer: longword;
class function Create: TDbLibFileHeader; static;
end;
TDbPartData = packed record
ddSignature: longword;
ddRoot: longword;
ddPrevious: longword;
ddNext: longword;
ddBytes: integer;
ddData: packed array [0 .. CNT_DATABASEFILE_PAGESIZE - 1] of byte;
class function Create: TDbPartData; static;
end;
Notice that the part-data (block) has fields to keep track of the root (the first part in the sequence), the previous part in the sequence amd the next part in the sequence. This gives us a lot of freedom when we want to do some tooling for the engine later.
If you look at the file-header this has also been expanded. It has a field to hold the first part in the meta-data sequence, the record list (the total list of sequences stored in the file) and the bit buffer.
Metadata
There are quite a few classes we need to introduce, so let’s start at the top, namely the meta-data classes. In our case the metadata is (first and foremost):
Tables
Fields
Database name
The reason I have isolated each of these as classes, is to make it easier to expand the system later. So let’s have a look at the classes:
IExtendedPersistence = interface
['{282CC310-CD3B-47BF-8EB0-017C1EDF0BFC}']
procedure ObjectFrom(const Reader: TDbLibReader);
procedure ObjectFromStream(const Stream: TStream; const Disposable: boolean);
procedure ObjectFromData(const Data: TDbLibBuffer; const Disposable: boolean);
procedure ObjectFromFile(const Filename: string);
procedure ObjectTo(const Writer: TDbLibWriter);
function ObjectToStream: TStream; overload;
procedure ObjectToStream(const Stream: TStream); overload;
function ObjectToData: TDbLibBuffer; overload;
procedure ObjectToData(const Data: TDbLibBuffer); overload;
procedure ObjectToFile(const Filename: string);
end;
IDbLibFields = interface
['{0D6A9FE2-24D2-42AE-A343-E65F18409FA2}']
function IndexOf(FieldName: string): integer;
function ObjectOf(FieldName: string): TDbLibRecordField;
function Add(const FieldName: string; const FieldClass: TDbLibRecordFieldClass): TDbLibRecordField;
function Addinteger(const FieldName: string): TDbLibFieldInteger;
function AddStr(const FieldName: string): TDbLibFieldString;
function Addbyte(const FieldName: string): TDbLibFieldbyte;
function AddBool(const FieldName: string): TDbLibFieldboolean;
function AddCurrency(const FieldName: string): TDbLibFieldCurrency;
function AddData(const FieldName: string): TDbLibFieldData;
function AddDateTime(const FieldName: string): TDbLibFieldDateTime;
function AddDouble(const FieldName: string): TDbLibFieldDouble;
function AddGUID(const FieldName: string): TDbLibFieldGUID;
function AddInt64(const FieldName: string): TDbLibFieldInt64;
function AddLong(const FieldName: string): TDbLibFieldLong;
end;
TDbLibPersistent = class(TDbLibObject, IExtendedPersistence)
private
FObjId: Longword;
FUpdCount: integer;
strict protected
// Implements:: IExtendedPersistence
procedure ObjectTo(const Writer: TDbLibWriter);
procedure ObjectFrom(const Reader: TDbLibReader);
procedure ObjectFromStream(const Stream: TStream; const Disposable: boolean);
function ObjectToStream: TStream; overload;
procedure ObjectToStream(const Stream: TStream); overload;
procedure ObjectFromData(const Binary: TDbLibBuffer; const Disposable: boolean);
function ObjectToData: TDbLibBuffer; overload;
procedure ObjectToData(const Binary: TDbLibBuffer); overload;
procedure ObjectFromFile(const Filename: string);
procedure ObjectToFile(const Filename: string);
protected
procedure BeforeUpdate; virtual;
procedure AfterUpdate; virtual;
strict protected
// Persistency Read/Write methods
procedure BeforeReadObject; virtual;
procedure AfterReadObject; virtual;
procedure BeforeWriteObject; virtual;
procedure AfterWriteObject; virtual;
procedure WriteObject(const Writer: TDbLibWriter); virtual;
procedure ReadObject(const Reader: TDbLibReader); virtual;
strict protected
// Standard persistence
function ObjectHasData: boolean; virtual;
procedure ReadObjBin(Stream: TStream); virtual;
procedure WriteObjBin(Stream: TStream); virtual;
procedure DefineProperties(Filer: TFiler); override;
public
property UpdateCount: integer read FUpdCount;
procedure Assign(Source: TPersistent); override;
function ObjectIdentifier: longword;
function BeginUpdate: boolean;
procedure EndUpdate;
class function classIdentifier: longword;
constructor Create; override;
end;
[ComponentPlatformsAttribute(CNT_ALL_PLATFORMS)]
TDbLibRecordField = class(TDbLibBufferMemory)
private
FName: string;
FNameHash: Int64;
FOnRead: TNotifyEvent;
FOnWrite: TNotifyEvent;
FOnRelease: TNotifyEvent;
procedure SetRecordName(NewName: string);
protected
function GetDisplayName: string; virtual;
procedure BeforeReadObject; override;
procedure ReadObject(Reader:TReader); override;
procedure WriteObject(Writer:TWriter); override;
procedure DoReleaseData; override;
protected
procedure SignalWrite;
procedure SignalRead;
procedure SignalRelease;
public
function AsString: string; virtual;abstract;
property DisplayName: string read GetDisplayName;
property FieldSignature:Int64 read FNameHash;
published
property OnValueRead: TNotifyEvent read FOnRead write FOnRead;
property OnValueWrite: TNotifyEvent read FOnWrite write FOnWrite;
property OnValueRelease: TNotifyEvent read FOnRelease write FOnRelease;
property FieldName: string read FName write SetRecordName;
end;
TDbLibFieldboolean = class(TDbLibRecordField)
private
function GetValue: boolean;
procedure SetValue(const NewValue: boolean);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value: boolean read GetValue write SetValue;
end;
TDbLibFieldbyte = class(TDbLibRecordField)
private
function GetValue:byte;
procedure SetValue(const NewValue:byte);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value:byte read GetValue write SetValue;
end;
TDbLibFieldCurrency = class(TDbLibRecordField)
private
function GetValue:Currency;
procedure SetValue(const NewValue:Currency);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value:Currency read GetValue write SetValue;
end;
TDbLibFieldData = class(TDbLibRecordField)
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
end;
TDbLibFieldDateTime = class(TDbLibRecordField)
private
function GetValue:TDateTime;
procedure SetValue(const NewValue:TDateTime);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value:TDateTime read GetValue write SetValue;
end;
TDbLibFieldDouble = class(TDbLibRecordField)
private
function GetValue:Double;
procedure SetValue(const NewValue:Double);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value:Double read GetValue write SetValue;
end;
TDbLibFieldGUID = class(TDbLibRecordField)
private
function GetValue:TGUID;
procedure SetValue(const NewValue:TGUID);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value:TGUID read GetValue write SetValue;
end;
TDbLibFieldInteger = class(TDbLibRecordField)
private
function GetValue: integer;
procedure SetValue(const NewValue:integer);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value:integer read GetValue write SetValue;
end;
TDbLibFieldInt64 = class(TDbLibRecordField)
private
function GetValue:Int64;
procedure SetValue(const NewValue:Int64);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value:Int64 read GetValue write SetValue;
end;
TDbLibFieldString = class(TDbLibRecordField)
private
FLength: integer;
FExplicit: boolean;
function GetValue: string;
procedure SetValue(NewValue: string);
procedure SetFieldLength(Value:integer);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
constructor Create(AOwner: TComponent); override;
published
property Value: string read GetValue write SetValue;
property Length: integer read FLength write SetFieldLength;
property Explicit: boolean read FExplicit write FExplicit;
end;
TDbLibFieldLong = class(TDbLibRecordField)
private
function GetValue:Longword;
procedure SetValue(const NewValue:Longword);
protected
function GetDisplayName: string; override;
public
function AsString: string; override;
published
property Value: Longword read GetValue write SetValue;
end;
TDbLibCustomRecord = class(TComponent, IDbLibFields, IStreamPersist)
strict private
FObjects: TObjectList;
strict protected
function GetItem(const Index:integer): TDbLibRecordField;
procedure SetItem(const Index: integer; const Value: TDbLibRecordField);
function GetField(const FieldName: string): TDbLibRecordField;
procedure SetField(const FieldName: string; const Value: TDbLibRecordField);
function GetCount: integer;
property Fields[const FieldName: string]: TDbLibRecordField read GetField write SetField;
property Items[const Index: integer]: TDbLibRecordField read GetItem write SetItem;
property Count: integer read GetCount;
public
function Add(const FieldName: string; const Fieldclass: TDbLibRecordFieldclass): TDbLibRecordField;
function Addinteger(const FieldName: string): TDbLibFieldInteger;
function AddStr(const FieldName: string): TDbLibFieldString;
function Addbyte(const FieldName: string): TDbLibFieldbyte;
function AddBool(const FieldName: string): TDbLibFieldboolean;
function AddCurrency(const FieldName: string): TDbLibFieldCurrency;
function AddData(const FieldName: string): TDbLibFieldData;
function AddDateTime(const FieldName: string): TDbLibFieldDateTime;
function AddDouble(const FieldName: string): TDbLibFieldDouble;
function AddGUID(const FieldName: string): TDbLibFieldGUID;
function AddInt64(const FieldName: string): TDbLibFieldInt64;
function AddLong(const FieldName: string): TDbLibFieldLong;
procedure WriteInt(const FieldName: string;const Value: integer);
procedure WriteStr(const FieldName: string;const Value: string);
procedure Writebyte(const FieldName: string;const Value: byte);
procedure WriteBool(const FieldName: string;const Value: boolean);
procedure WriteCurrency(const FieldName: string;const Value: currency);
procedure WriteData(const FieldName: string;const Value: TStream);
procedure WriteDateTime(const FieldName: string;const Value: TDateTime);
procedure WriteDouble(const FieldName: string;const Value: double);
procedure WriteGUID(const FieldName: string;const Value: TGUID);
procedure WriteInt64(const FieldName: string; const Value: int64);
procedure WriteLong(const FieldName: string; const Value: longword);
procedure Clear; virtual;
procedure Assign(source: TPersistent); override;
function ToStream: TStream; virtual;
function ToBuffer: TDbLibBuffer; virtual;
procedure FromStream(const Stream: TStream; const Disposable: boolean = true);
// Implements:: IStreamPersist
procedure LoadFromStream(Stream: TStream); virtual;
procedure SaveToStream(Stream: TStream); virtual;
function IndexOf(FieldName: string): integer;
function ObjectOf(FieldName: string): TDbLibRecordField;
constructor Create(AOwner: TComponent); override;
destructor Destroy; override;
end;
[ComponentPlatformsAttribute(CNT_ALL_PLATFORMS)]
TDbLibRecord = class(TDbLibCustomRecord)
public
property Fields;
property Items;
property Count;
end;
TDbLibTable = class(TDbLibPersistent)
strict private
FName: string;
FParent: TDbLibMetaData;
FPrototype: TDbLibRecord;
FFieldDefs: IDbLibFields;
strict protected
procedure BeforeReadObject; override;
procedure WriteObject(const Writer: TDbLibWriter); override;
procedure ReadObject(const Reader: TDbLibReader); override;
public
constructor Create(const MetaData: TDbLibMetaData); reintroduce; virtual;
destructor Destroy; override;
published
property Parent: TDbLibMetaData read FParent;
property FieldDefs: IDbLibFields read FFieldDefs;
property TableName: string read FName write FName;
end;
TDbLibMetaData = class(TDbLibPersistent, IDbLibTables)
strict private
[Weak]
FParent: TDbLibDatabase;
FDbName: string;
FTables: TObjectList;
function GetTable(index: integer): TDbLibTable;
function GetTableCount: integer;
function AddTable(TableName: string): TDbLibTable;
strict
protected
procedure SetDatabaseName(NewName: string);
procedure BeforeReadObject; override;
procedure WriteObject(const Writer: TDbLibWriter); override;
procedure ReadObject(const Reader: TDbLibReader); override;
public
property Database: TDbLibDatabase read FParent;
property DatabaseName: string read FDbName write SetDatabaseName;
property Tables[index: integer]: TDbLibTable read GetTable; default;
property TableCount: integer read GetTableCount;
function GetTableByName(TableName: string; var Table: TDbLibTable): boolean;
constructor Create(const Database: TDbLibDatabase) ; reintroduce; virtual;
destructor Destroy; override;
end;
Some might not like that I made some alterations to the standard Delphi persistency system. But if you look closely at the class TDbLibPersistent you will see that it makes it easier to handle hosted data. You have methods like BeforeRead() and BeforeWrite() that makes house-keeping a lot easier.
With the metadata out of the way, lets have a peek at the actual database class. Or should I say, the sequence persistency layer, because at the moment it has the capacity to save sequences, remember them when you re-open the file, keep track of the database name and defined tables – but we have not yet turned the metadata into physical data.
Our previous fidelity test was somewhat meager. This time we give the system a bit more to work with. So our initialization code now looks more akin to proper database work:
The latest code has been uploaded to the BitBucket repository (same as last), so simply update the fork you did earlier. Make sure you set plenty of breakpoints and also download a hex-editor and examine the resulting databasefile.
Alright! I think that is enough for the third episode. In our next episode we have more than enough to explain and explore, but now the fundamental parts are in place!
Last friday (24.08.2018) I published an open document on Delphi Developer. This is a document open and available to everyone, with the sole purpose of making it easier for developers to find clubs and interest groups in their region (jobs are often found through acquaintances, so connecting to a local group is important). It will also simplify how we as a community can approach human resource companies. Our document is growing but we still need more!
Show full content
It’s been a hectic week at Delphi Developer, but a highly productive one! I am very happy that so many developers have responded and help with the organizational work. Because Delphi and C++ builder developers must get organized. If you want to see lasting, positive results, this has to happen. There are wast quantities of individuals, groups and companies that use Delphi and C++ builder around the world. Yet we all sit in our own bubble, thinking we are alone. It’s time to change that.
“we have decades of experience and technical expertise. And that is worth protecting”
In 2016 I was contacted by a Norwegian HR company (read: head hunters) and offered a Delphi position as at a local business. Turned out the business had struggled to find Delphi programmers for over six months. When I told them about Oslo Delphi club and showed them the 7500 members we have in Delphi Developer on Facebook, they were gobsmacked. The human resource company was equally oblivious to the sheer number of Developers just in Norway, let alone internationally.
Part of what I do today as an Embarcadero SC, is to front human-resource companies with clear information as to where they can look for competent Delphi developers. But in order to deliver that effectively, we first have to establish a map.
Put your local club or interest group on the map!
Last friday (24.08.2018) I published an open document on Delphi Developer. This is a document open and available to everyone, with the sole purpose of making it easier for developers to find clubs and interest groups in their region (jobs are often found through acquaintances, so connecting to a local group is important). It will also simplify how we as a community can approach human resource companies. Our document is growing but we still need more! So please take five minutes to add your local user group.
The Delphi and C++ builder community is large, but we need representation with HR
Delphi and C++ builder is seeing a stable and healthy growth. It has taken a lot of hard work and effort to get where we are today, both by Embarcadero and developers that use RAD Studio as their business backbone.
My hope is that everyone who read this can allocate few minutes, just five minutes to add to our document. So if you know of a Delphi or C++ builder user group, perhaps a club or organization? Then please check the document (Note: The document is pinned as an announcement on top of the Facebook group feed, but members can also reach it directly by clicking here) and add the club if it’s not already there.
Note: Please make sure that the information is correct. Call the club or group if possible. Remember, this document is for everyone. We want to maintain the document and keep it available 24/7.
Building bridges
The work members are doing for the community is quite important. It determines where we can go next. In fact, I will contact each and every club to establish communication and co-operation. There is much to debate, such as capacity for tutoring, courseware, primary contact for new users and more. If need be I will personally travel so we can meet face to face. I am deadly serious about this, because there is no other way to build critical mass. Our group alone have thousands of members whom have invested a lot of money in software, components, formal training and education; we have decades of experience and technical expertise. And that is worth protecting.
Getting organized to safeguard our education, our language of preference, our jobs and ultimately to nurture our future is a worthy cause. I hope I have everyone’s blessing in this — but I can’t do everything alone. It is impossible for me to know if there are 3 Delphi clubs in Venezuela, 4 in Canada and 15 in India. We need to get them pinned on a map and formulate a strategy for lasting, positive results.
The past is experience, the future is opportunities
I want to thank each and every one that has added to the document. Thank you so much, this will help our community more than you think. It might seem as a small step, but that first step is the most important of them all. All great things start as an idea, but when you apply force and determination – it becomes reality.
I am extremely lucky because this work is now a part of my job. My work includes a bit of everything: studies, authoring, coding, consulting and presentations. But the part I love the most is to connect people.
Real life results
If you think the document in question is a waste of time, think again!
Last week we had 3 rather frustrated members that desperately needed a job. After calming the situation down I made some calls and was able to find remote work for all of them.
It is a wonderful feeling when you can help someone. It is also what community is all about. The more organized we get, the better it will be for everyone. LinkedIn is great but networking without an infrastructure that responds can bear no fruits. And that is where Delphi Developer comes in. We are very much alive and kicking.
So with less than a week of organization behind us, we found and delivered jobs as a direct consequence of the Delphi Developer Facebook Group.
DelphiObject Pascaldatabasedatabase engineDatabase theoryEmbarcaderoMake your own database
In the first episode of this tutorial we looked at some of the fundamental ideas behind database storage. We solved the problem of storing arbitrary length data by dividing the database file into conceptual parts; we discovered how we could daisy-chain these parts together to form a sequence; and we looked at how this elegantly […]
Show full content
In the first episode of this tutorial we looked at some of the fundamental ideas behind database storage. We solved the problem of storing arbitrary length data by dividing the database file into conceptual parts; we discovered how we could daisy-chain these parts together to form a sequence; and we looked at how this elegantly solves reclaiming lost space and recycling that for new records. Last but not least we had a peek at the bit-buffer that helps us keep track of what blocks are taken, so we can easily grow and shrink the database on demand.
In this article we will be getting our hands dirty and put our theories into practise. The goal today is to examine the class that deals with these blocks or parts; While we could maybe get better performance by putting everything into a monolithic class, but the topics are best kept separate while learning the ropes. So let’s favour OOP and class encapsulation for this one.
The DbLib framework
Prior to writing this tutorial I had to write the code you would need. It would be a terrible mistake to run a tutorial with just theories to show for it. Thankfully I have been coding for a number of years now, so I had most of the code in my archives. To make life easier for you I have unified the code into a little framework.
This doesn’t mean that you have to use the framework. The units I provide are there to give you something tangible to play with. I have left ample room for optimization and things that can be done differently on purpose.
I have set up a bitbucket git repository for this tutorial, so your first business of the day is to download or fork our repository:
The first installment of this tutorial ended with a few words on the file header. This is the only static or fixed data segment in our file. And it must remain fixed because we need a safe space where we can store offsets to our most important sequences, like the root sequence.
The root sequence is simply put the data that describes the database, also known as metadata. So all those items I listed at the start of the previous article, things like table-definitions, index definitions, the actual binary table data (et al), well we have to keep track of these somewhere right?
Well, that’s where the file header comes in. The header is the keeper of all secrets and is imperative for the whole engine.
The record list
Up until this point we have covered blocks, sequences, the file header, the bit-buffer that keeps track of available and reserved blocks — but what about the actual records?
When someone performs a high-level insert operation, the binary data that makes up the record is written as a sequence; that should be crystal clear by now. But having a ton of sequences stored in a file is pretty useless without a directory or list that remembers them. If we have 10.000 records (sequences) in a file – then we must also keep track of 10.000 offsets right? Otherwise, how can we know where record number 10, 1500 or 9000 starts?
Conceptually, metadata is not actual data. Metadata is a description of data, like a table definition or index definition. The list that holds all the record offsets is real data; As such I don’t want to store it together with the metadata but keep it separate. The bit buffer that keeps track of block availability in the file is likewise “real” data, so I would like to keep that in a separate sequence too.
When we sit down and define our file-header record, which is a structure that is always at the beginning of the file (or stream), we end up with something like this:
Unique file signature: longword
Version minor, major, revision: longword (byte, byte, word)
If you are wondering about the encryption and compression fields, don’t overthink it. It’s just a place to store something that identifies whatever encryption or compression we have used. If time allows we will have a look at zlib and RC4, but even if we don’t it’s good to define these fields for future expansion.
The version longword is actually more important than you think. If the design of your database and header changes dramatically between versions, you want to check the version number to make absolutely sure you can even handle the file. I have placed this as the second field in the record, 4 bytes into the header, so that it can be read early. The moment you have more than one version of your engine you might want to write a routine that just reads the first 8 bytes of the file and check compatibility.
What are those buffers?
The buffer classes are Delphi implementation of Node.JS buffers, including insert and remove functionality
Having forked the framework, you suddenly have quite a few interesting units. But you can also feel a bit lost if you don’t know what the buffer classes do, so I want to start with those first.
The buffer classes are alternatives to streams. Streams are excellent but they can be quite slow if you are doing intense read-write operations. More importantly streams lack two fundamental features for DB work, namely insert and remove. For example, lets say you have a 100 megabyte file – and then you want to remove 1 megabyte from the middle of this file. It’s not a complex operation but you still need to copy the trailing data backwards as quick as possible before scaling the stream size. The same is true if you want to inject data into a large file. It’s not a huge operation, but it has to be 100% accurate and move data as fast as possible.
I could have just inherited from TStream, but I wanted to write classes that were faster, that had more options and that were easier to expand in the future. The result of those experiments were the TBuffer classes.
So mentally, just look at TDbBuffer, TDbBufferMemory and TDbBufferFile as streams on steroids. If you need to move data between a stream and a buffer, just create a TDbLibStreamAdapter instance and you can access the buffer like a normal TStream decendent.
Making a file of blocks
With enough theory behind us, let’s dig into the codebase and look at the class that deals with a file as blocks, or parts. Open up the unit dblib.partaccess.pas and you will find the following class:
As you can see this class is pretty straight forward. You pass a buffer (either memory or file) via the constructor together with the size of the file-header. This helps the class to avoid writing to the first section of the file by mistake. Whenever the method CalcOffsetForPart() is called, it will add the size of the header to the result, shielding the header from being over-written.
The other methods should be self-explanatory; you have various overloads for writing a sequence part (block), appending them to the database file, reading them – and all these methods are offset based; meaning you give it the part-number and it calculates where that part is physically located inside the file.
One important method is the CalcPartsForData() function. This is used before splitting a piece of data into a sequence. Let’s say you have 1 megabyte to data you want to store inside the database file, well then you first call this and it calculates how many blocks you need.
Once you know how many blocks you need, the next step is to check the bit-buffer (that we introduced last time) if the file has X number of free blocks. If the file is full, well then you either have to grow the file to fit the new data – or issue an error message.
See? It’s not that complex once you have something to build on!
Proof reading test, making sure what we write is what we read
With the scaffolding in place, let’s write a small test to make absolutely sure that the buffer and class logistics check out ok. We are just going to do this on a normal form (this is the main project in the bitbucket project folder), so you don’t have to type this code. Just fork the code from the URL mentioned at the top of this article and run it.
Our test is simple:
Define our header and part records, doesn’t have to be accurate at this point
Create a database file buffer (in memory) with size for header + 100 parts
Create a TDblibPartAccess class, feed in the sizes as mentioned above
Create a write buffer the same size as part/block record
Fill that buffer with some content we can easily check
Write the writebuffer content to all the parts in the file
Create a read buffer
Read back each part and compare content with the write buffer
If any data is written the wrong way or overlapping, what we read back will not match our write buffer. This is a very simple test to just make sure that we have IO fidelity.
Ok, lets write some code!
unit mainform;
interface
uses
Winapi.Windows, Winapi.Messages, System.SysUtils,
System.Variants, System.Classes, Vcl.Graphics,
Vcl.Controls, Vcl.Forms, Vcl.Dialogs, Vcl.StdCtrls,
dblib.common,
dblib.buffer,
dblib.partaccess,
dblib.buffer.memory,
dblib.buffer.disk,
dblib.encoder,
dblib.bitbuffer;
const
CNT_PAGESIZE = (1024 * 10);
type
TDbVersion = packed record
bvMajor: byte;
bvMinor: byte;
bvRevision: word;
end;
TDbHeader = packed record
dhSignature: longword; // Signature: $CAFEBABE
dhVersion: TDbVersion; // Engine version info
dhName: shortstring; // Name of database
dhMetadata: longword; // Part# for metadata
end;
TDbPartData = packed record
ddSignature: longword;
ddRoot: longword;
ddNext: longword;
ddBytes: integer;
ddData: packed array [0..CNT_PAGESIZE-1] of byte;
end;
TfrmMain = class(TForm)
btnWriteReadTest: TButton;
memoOut: TMemo;
procedure btnWriteReadTestClick(Sender: TObject);
private
{ Private declarations }
FDbFile: TDbLibBufferMemory;
FDbAccess: TDbLibPartAccess;
public
{ Public declarations }
constructor Create(AOwner: TComponent); override;
destructor Destroy; override;
end;
var
frmMain: TfrmMain;
implementation
{$R *.dfm}
{ TfrmMain }
constructor TfrmMain.Create(AOwner: TComponent);
begin
inherited;
// Create our database file, in memory
FDbFile := TDbLibBufferMemory.Create(nil);
// Reserve size for our header and 100 free blocks
FDBFile.Size := SizeOf(TDbHeader) + ( SizeOf(TDbPartData) * 100 );
// Create our file-part access class, which access the file
// as a "block" file. We pass in the size of the header + part
FDbAccess := TDbLibPartAccess.Create(FDbFile, SizeOf(TDbHeader), SizeOf(TDbPartData));
end;
destructor TfrmMain.Destroy;
begin
FDbAccess.Free;
FDbFile.Free;
inherited;
end;
procedure TfrmMain.btnWriteReadTestClick(Sender: TObject);
var
LWriteBuffer: TDbLibBufferMemory;
LReadBuffer: TDbLibBufferMemory;
LMask: ansistring;
x: integer;
begin
memoOut.Lines.Clear();
LMask := 'YES!';
// create a temporary buffer
LWriteBuffer := TDbLibBufferMemory.Create(nil);
try
// make it the same size as our file-part
LWriteBuffer.Size := SizeOf(TDbPartData);
// fill the buffer with our test-pattern
LWriteBuffer.Fill(0, SizeOf(TDbPartData), LMask[1], length(LMask));
// Fill the dbfile by writing each part, using our
// temporary buffer. This fills the file with our
// little mask above
for x := 0 to FDbAccess.PartCount-1 do
begin
FDbAccess.WritePart(x, LWriteBuffer);
end;
LReadBuffer := TDbLibBufferMemory.Create(nil);
try
for x := 0 to FDBAccess.PartCount-1 do
begin
FDbAccess.ReadPart(x, LReadBuffer);
if LReadBuffer.ToString LWriteBuffer.ToString then
memoOut.Lines.Add('Proof read part #' + x.ToString() + ' = failed')
else
memoOut.Lines.Add('Proof read part #' + x.ToString() + ' = success');
end;
finally
LReadBuffer.Free;
end;
finally
LWriteBuffer.Free;
end;
end;
end.
The form has a button and a memo on it, when you click the button we get the following result:
Voila, we have IO fidelity!
Finally things are starting to become more interesting! We still have a way to go before we can start pumping records into this thing, but at least we have tangible code to play with.
In our next installment we will implement the sequence class, which takes the TDbLibPartAccess class and augments it with functionality to read and write sequences. We will also include the bit-buffer from our first article and watch as the siluette of our database engine comes into view.
Again, this is not built for speed but for education.
DelphifiremonkeyObject Pascaldatabase engineDatabase enginesDatabase theoryRoll your own DB
Databases come in all shapes and sizes. From blistering fast in-memory datasets intended to hold megabytes, to massive distributed systems designed to push terabytes around like lego. Is it even worth looking into a database engine these days? Let me start by saying: NO. If you need a native database written in object pascal, there […]
Show full content
Databases come in all shapes and sizes. From blistering fast in-memory datasets intended to hold megabytes, to massive distributed systems designed to push terabytes around like lego. Is it even worth looking into a database engine these days?
There are tons of both commerical and free DB engines for Delphi
Let me start by saying: NO. If you need a native database written in object pascal, there are several awesome engines available. Engines that have been in production for ages, that have been tried and tested by time with excellent supports, speed and track records. My personal favorite is ElevateDB which is the successor to DBIsam, an engine I used in pretty much all my projects before 64 bit became the norm. ElevateDB handles both 32 and 64 bit and is by far my database of choice.
The purpose of this article is not to create an alternative or anything along those lines, quite the opposite. It’s purely to demonstrate some of the ideas behind a database – and just how far we have come from the old “file of record” that is synonymous with the first databases. Like C/C++ Delphi has been around for a while so you can still find support for these older features, which I think is great because there are still places where such a “file of record” can be extremely handy. But again, that is not what we are going to do here.
The reason I mentioned “file of record” is because, even though we don’t use that any more – it does summarize the most fundamental idea of a database. What exactly is a database anyways? Is it really this black box?
A database file (to deal with that first) is supposed to contain the following:
One of more table definitions
One or more tables (as in data)
Indexes and lookup tables (word indexes)
Stored procedures
Views and triggers
So the question becomes, how exactly do we stuff all these different things into a single file? Does it have a filesystem? Are each of these things defined in a record of sorts? And what about this mysterious “page size” thingy, what is that about?
A file of blocks
All databases have the same problem, but each solves these problems differently. Most major databases are in fact not a single file anymore. Some even place the above in completely separate files. For me personally I don’t see any gain in having a single file with everything stuffed into it – but for sake of argument we will be looking at that in this article. It has some educational value.
The way databases are organized is directly linked to the problem above, namely that we need to store different types of data – of arbitrary length – into a single file. In other words you can’t use a fixed record because you cannot possibly know how many fields a table will have, nor can you predict the number of tables or procedures. So we have to create a system that can take any length of data and “somehow” be able to place that inside the file.
So ok, what if we divide the file into blocks, each capable of storing a piece of data? So if a single block is not enough, the data will be spread out over multiple blocks?
Indeed. And that is also where the page-size value comes in. The pagesize defines the capacity of a block, which indirectly affects how much data each block occupies. Pretty cool right?
But conceptually dividing a file into blocks doesn’t solve all our problems. How exactly will we know what blocks represents a record or a form definition? I mean, if some piece of data is spread over 10 blocks or 20 blocks, how do we know that these represents a single piece of data? How do we navigate from block #1 in a sequence, to block #2?
Well, each block in the file can house raw data, we have to remember that the whole “block” idea is just conceptual and a way that we approach a file in our code. When we write blocks to the file, we have to do that in a particular way, so it’s not just a raw slice of a stream or array of bytes.
We need a block header to recognize that indeed, this is a known block; we need the block number of the next block that holds more data – and it’s probably wise to sign each block with the block-number for the first pice.
So from a pseudo-code point of view, we end up with something like:
Since our blocks will be hosted inside a stream (so no “file of record” like I said), we have to use the “packed” keyword. Delphi like any other language always tries to align records to a boundary, so even if the record is just 4 bytes long (for example), it will be aligned to eight bytes (you can control the boundary via the compiler options). That can cause problems when we calculate the offset to our blocks so we mark both the record and data as “packed”, which tells the compiler to drop alignment.
Let’s look at what each field in the record (descriptor) means:
fbHeader, a unique number that we check for before reading a block. If this number is missing or doesn’t match, something is wrong and the data is not initialized (or it’s not a db file). Lets use $CAFEBABE since it’s both unique and fun at the same time!
fbFirst, the block number of the first block in a sequence (piece of coherent data)
fbNext, the next block in the sequence after the current
fbUsed: the number of bytes uses in the fbData array. At the end of a sequence it might just use half of what the block can store – so we make sure we know how much to extract from fbData in each segment
fbData: a packed byte array housing “pagesize” number of bytes
A sequence of blocks
The block system solves the problem of storing variable length data by dividing the data into suitable chunks. As shown above we store the data with just enough information to find the next block, and next block, until we have read back the whole sequence.
So the block-sequence is pretty much a file. It’s actually very much a file because this is incidentally how harddisks and floppy disks organize files. It had a more complex layout of course, but the idea is the same. A “track-disk-device” stores blocks of data organized in tracks and sectors (sequences). Not a 1:1 comparison but neat none the less.
But ok, we now have some idea about storing larger pieces of data as a chunk of blocks. But why not just store the data directly? Why not just append each record to a file and to hell with block chunks – wouldnt that be faster?
Well yes, but how would you recycle the space? Lets say you have a database with 10.000 records, each with different sizes, and you want to delete record number 5500. If you just append stuff, how would you recycle that space? There is no way of predicting the size of the next sequence, so you could end up with large segments of empty space that could never be recycled.
By conceptually dividing the file into predictable blocks, and then storing data in chunks where each block “knows” it’s next of kin – and holds a reference to its root (the fbFirst field), we can suddenly solve the problem of recycling!
Ok, lets sum up what we have so far:
We have solved storing arbitrary length data by dividing the data into conceptual blocks. These blocks dont have to be next to each other.
We have solved reading X number of blocks to re-create the initial data
We call the collection of blocks that makes up a piece of data a “sequence”
The immediate benefit of block-by-block storage is that space can be recycled. Blocks dont have to be next to each other, a record can be made up by blocks scattered all over the place but still remain coherent.
Not bad! But we are still not home free, there is another challenge that looms above, namely how can we know if a block is available or occupied?
Keeping track of blocks
This is actually a pretty cool place in the buildup of an engine, because the way we read, write and figure out what blocks can be recycled – very much impacts the speed of high-level functions like inserts and navigation. This is where I would introduce memory mapped files before I moved on, but like I mentioned earlier -we will skip memory mapping because the article would quickly morph into a small essay. I don’t want memory mapping and MMU theory to overshadow the fundamental principles that I’m trying to pass on.
We have now reached the point where we ask the question “how do we quickly keep track of available free blocks?”, which is an excellent question with more than a single answer. Some database vendors use a separate file where each byte represents a block. My first experiment was to use a text file, thinking that functions like Pos() would help me locate blocks faster. It was a nice idea but we need more grunt than that.
What I landed on after some experimentation, which is a good compromise between size and speed, was to use a bit buffer to keep track of things. So a single bit is either taken (1) or available (0). You can quickly search for available bits because if a byte has any other value than $FF (255) you know there is a free bit there. It’s also very modest with regards to size, and you can keep track of 10.000 blocks with only 1250 bytes.
The code for the bit-buffer was written to be easy to use. In a high-end engine you would not waste the cpu time by isolating small calculations in a single method, but try to inline as much as possible. But for educational purposes my simple implementation will be more than adequate.
Note: I will be setting up a github folder for this project, so for our next article you can just fork that. WordPress has a tendency to mess up Delphi code, so if the code looks weird don’t worry, it will all be neatly organized into a project shortly.
The file header
Before we look at the bit code to keep track of blocks, you might be thinking “what good is it to keep track of blocks if we have nowhere to store that information?“. You are quite right, and this is where the file header comes in.
The file header is the only fixed part of a database file. Like I mentioned earlier there are engines that stuffs everything into a single file, but in most cases where performance is the highest priority – you want to use several files and avoid mixing apples and oranges. I would store the block-map (bit buffer) in a separate file – because that maps easily into memory under normal use. I would also store the table definitions, indexes and more as separate files. If nothing else than to make repairing and compacting a database sane. But i promised to do a single file model (me and my big fingers), so we will be storing the meta-data inside the database file, so let’s do just that.
The file-header is just a segment of the database-file (the start of the file) that contains some vital information. When we calculate the stream offset to each block (for either reading or writing), we simply add the size of the header to that. We don’t want to accidentally overwrite that part of the file.
Depending on how we evolve the reading and writing of data sequences, the header doesn’t have to contain that much data. You probably want to keep track of the page-size, followed by the start block for the table definitions. So when you open a database you would immediately start by reading the block-sequence containing all the definitions the file contains. How we organize the data internally is irrelevant for the block-file and IO scaffolding. It’s job is simple: read or write blocks, calculate offsets, avoid killing the header, pay attention to identifiers.
Some coders store the db schemas etc. at the end of the file, so when you close the DB the information is appended to the filestream – and the offset is stored in the header. This is less messy, but also opens up for corruption. If the DB is not properly closed you risk the DB information never being streamed out. Which is again another nail in the coffin for single-file databases (at least from my personal view, there are many ways to Rome and database theory can drive you nuts at times).
So I end this first article of our series with that. Hopefully I have given you enough ideas to form a mental image of how the underlying structure of a database file is organized. There are always exceptions to the rule and a wealth of different database models exists. So please keep in mind that this article has just scratched the surface on a slab of concrete.
unit qtx.utils.bits;
interface
uses
System.SysUtils, System.Classes;
type
(* Exception classes *)
EQTXBitBuffer = Class(Exception);
TBitOffsetArray = packed array of NativeUInt;
(* About TQTXBitBuffer:
This class allows you to manage a large number of bits,
much like TBits in VCL and LCL.
However, it is not limited by the shortcomings of the initial TBits.
- The bitbuffer can be saved
- The bitbuffer can be loaded
- The class exposes a linear memory model
- The class expose methods (class functions) that allows you to
perform operations on pre-allocated memory (memory you manage in
your application).
Uses of TQTXBitbuffer:
Bit-buffers are typically used to represent something else,
like records in a database-file. A bit-map is often used in Db engines
to represent what hapes are used (bit set to 1), and pages that can
be re-cycled or compacted away later. *)
TQTXBitBuffer = Class(TObject)
Private
FData: PByte;
FDataLng: NativeInt;
FDataLen: NativeInt;
FBitsMax: NativeUInt;
FReadyByte: NativeUInt;
FAddr: PByte;
BitOfs: 0 .. 255;
FByte: byte;
function GetByte(const Index: NativeInt): byte;
procedure SetByte(const Index: NativeInt; const Value: byte);
function GetBit(const Index: NativeUInt): boolean;
procedure SetBit(const Index: NativeUInt; const Value: boolean);
Public
property Data: PByte read FData;
property Size: NativeInt read FDataLen;
property Count: NativeUInt read FBitsMax;
property Bytes[const Index: NativeInt]: byte Read GetByte write SetByte;
property bits[const Index: NativeUInt]: boolean Read GetBit
write SetBit; default;
procedure Allocate(MaxBits: NativeUInt);
procedure Release;
function Empty: boolean;
procedure Zero;
function ToString(const Boundary: integer = 16): string; reintroduce;
class function BitsOf(Const aBytes: NativeInt): NativeUInt;
class function BytesOf(aBits: NativeUInt): NativeUInt;
class function BitsSetInByte(const Value: byte): NativeInt; inline;
class Function BitGet(Const Index: NativeInt; const Buffer): boolean;
class procedure BitSet(Const Index: NativeInt; var Buffer;
const Value: boolean);
procedure SaveToStream(const stream: TStream); virtual;
procedure LoadFromStream(const stream: TStream); virtual;
procedure SetBitRange(First, Last: NativeUInt; const Bitvalue: boolean);
procedure SetBits(const Value: TBitOffsetArray; const Bitvalue: boolean);
function FindIdleBit(var Value: NativeUInt;
const FromStart: boolean = false): boolean;
destructor Destroy; Override;
End;
implementation
resourcestring
ERR_BitBuffer_InvalidBitIndex = 'Invalid bit index, expected 0..%d not %d';
ERR_BitBuffer_InvalidByteIndex = 'Invalid byte index, expected 0..%d not %d';
ERR_BitBuffer_BitBufferEmpty = 'Bitbuffer is empty error';
ERR_ERR_BitBuffer_INVALIDOFFSET =
'Invalid bit offset, expected 0..%d, not %d';
var
CNT_BitBuffer_ByteTable: array [0..255] of NativeInt =
(0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8);
function QTXToNearest(const Value, Factor: NativeUInt): NativeUInt;
var
LTemp: NativeUInt;
Begin
Result := Value;
LTemp := Value mod Factor;
If (LTemp > 0) then
inc(Result, Factor - LTemp);
end;
// ##########################################################################
// TQTXBitBuffer
// ##########################################################################
Destructor TQTXBitBuffer.Destroy;
Begin
If not Empty then
Release;
inherited;
end;
function TQTXBitBuffer.ToString(const Boundary: integer = 16): string;
const
CNT_SYM: array [boolean] of string = ('0', '1');
var
x: NativeUInt;
LCount: NativeUInt;
begin
LCount := Count;
if LCount > 0 then
begin
LCount := QTXToNearest(LCount, Boundary);
x := 0;
while x < LCount do
begin
if x = 0) then
Begin
LAddr := @Buffer;
inc(LAddr, Index shr 3);
LByte := LAddr^;
BitOfs := Index mod 8;
LCurrent := (LByte and (1 shl (BitOfs mod 8))) 0;
case Value of
true:
begin
(* set bit if not already set *)
If not LCurrent then
LByte := (LByte or (1 shl (BitOfs mod 8)));
LAddr^ := LByte;
end;
false:
begin
(* clear bit if already set *)
If LCurrent then
LByte := (LByte and not(1 shl (BitOfs mod 8)));
LAddr^ := LByte;
end;
end;
end
else
Raise EQTXBitBuffer.CreateFmt(ERR_ERR_BitBuffer_INVALIDOFFSET,
[maxint - 1, index]);
end;
procedure TQTXBitBuffer.SaveToStream(const stream: TStream);
var
LWriter: TWriter;
begin
LWriter := TWriter.Create(stream, 1024);
try
LWriter.WriteInteger(FDataLen);
LWriter.Write(FData^, FDataLen);
finally
LWriter.FlushBuffer;
LWriter.Free;
end;
end;
Procedure TQTXBitBuffer.LoadFromStream(const stream: TStream);
var
LReader: TReader;
LLen: NativeInt;
Begin
Release;
LReader := TReader.Create(stream, 1024);
try
LLen := LReader.ReadInteger;
if LLen > 0 then
begin
Allocate(BitsOf(LLen));
LReader.Read(FData^, LLen);
end;
finally
LReader.Free;
end;
end;
Function TQTXBitBuffer.Empty: boolean;
Begin
Result := FData = NIL;
end;
Function TQTXBitBuffer.GetByte(const Index: NativeInt): byte;
Begin
If FData NIL then
Begin
If (index >= 0) and (Index = 0) and (Index Secondary then
Result := (Primary - Secondary)
else
Result := (Secondary - Primary);
if Exclusive then
begin
If (Primary < 1) or (Secondary < 1) then
inc(Result);
end;
If (Result < 0) then
Result := abs(Result);
end
else
Result := 0;
end;
Begin
If (FData nil) then
Begin
If (First 0 do
Begin
SetBit(x, Bitvalue);
inc(x);
SetBit(x, Bitvalue);
inc(x);
SetBit(x, Bitvalue);
inc(x);
SetBit(x, Bitvalue);
inc(x);
SetBit(x, Bitvalue);
inc(x);
SetBit(x, Bitvalue);
inc(x);
SetBit(x, Bitvalue);
inc(x);
SetBit(x, Bitvalue);
inc(x);
dec(LLongs);
end;
(* process singles *)
LSingles := NativeInt(LCount mod 8);
while (LSingles > 0) do
Begin
SetBit(x, Bitvalue);
inc(x);
dec(LSingles);
end;
end
else
begin
if (First = Last) then
SetBit(First, true)
else
Raise EQTXBitBuffer.CreateFmt(ERR_BitBuffer_InvalidBitIndex,
[FBitsMax, Last]);
end;
end
else
Raise EQTXBitBuffer.CreateFmt(ERR_BitBuffer_InvalidBitIndex,
[FBitsMax, First]);
end
else
Raise EQTXBitBuffer.Create(ERR_BitBuffer_BitBufferEmpty);
end;
Procedure TQTXBitBuffer.SetBits(Const Value: TBitOffsetArray;
Const Bitvalue: boolean);
var
x: NativeInt;
FCount: NativeInt;
Begin
If FData NIL then
Begin
FCount := length(Value);
If FCount > 0 then
Begin
for x := low(Value) to High(Value) do
SetBit(Value[x], Bitvalue);
end;
end
else
Raise EQTXBitBuffer.Create(ERR_BitBuffer_BitBufferEmpty);
end;
Function TQTXBitBuffer.FindIdleBit(var Value: NativeUInt;
Const FromStart: boolean = false): boolean;
var
FOffset: NativeUInt;
FBit: NativeUInt;
FAddr: PByte;
x: NativeInt;
Begin
Result := FData NIL;
if Result then
Begin
(* Initialize *)
FAddr := FData;
FOffset := 0;
If FromStart then
FReadyByte := 0;
If FReadyByte < 1 then
Begin
(* find byte with idle bit *)
While FOffset < NativeUInt(FDataLen) do
Begin
If BitsSetInByte(FAddr^) = 8 then
Begin
inc(FOffset);
inc(FAddr);
end
else
break;
end;
end
else
inc(FOffset, FReadyByte);
(* Last byte exhausted? *)
Result := FOffset 7 then
FReadyByte := 0
else
FReadyByte := FOffset;
break;
end;
inc(FBit);
end;
end;
end;
end;
Function TQTXBitBuffer.GetBit(Const Index: NativeUInt): boolean;
begin
If FData NIL then
Begin
If index 7 then
FReadyByte := 0;
end;
end;
end
else
Begin
(* clear bit if not already clear *)
If (FByte and (1 shl (BitOfs mod 8))) 0 then
Begin
FByte := (FByte and not(1 shl (BitOfs mod 8)));
PByte(FDataLng + NativeInt(index shr 3))^ := FByte;
(* remember this byte pos *)
FReadyByte := Index shr 3;
end;
end;
end
else
Raise EQTXBitBuffer.CreateFmt(ERR_BitBuffer_InvalidBitIndex,
[Count - 1, index]);
end
else
Raise EQTXBitBuffer.Create(ERR_BitBuffer_BitBufferEmpty);
end;
Procedure TQTXBitBuffer.Allocate(MaxBits: NativeUInt);
Begin
(* release buffer if not empty *)
If FData NIL then
Release;
If MaxBits > 0 then
Begin
(* Allocate new buffer *)
try
FReadyByte := 0;
FDataLen := BytesOf(MaxBits);
FData := AllocMem(FDataLen);
FDataLng := NativeUInt(FData);
FBitsMax := BitsOf(FDataLen);
except
on e: Exception do
Begin
FData := NIL;
FDataLen := 0;
FBitsMax := 0;
FDataLng := 0;
Raise;
end;
end;
end;
end;
Procedure TQTXBitBuffer.Release;
Begin
If FData NIL then
Begin
try
FreeMem(FData);
finally
FReadyByte := 0;
FData := NIL;
FDataLen := 0;
FBitsMax := 0;
FDataLng := 0;
end;
end;
end;
Procedure TQTXBitBuffer.Zero;
Begin
If FData NIL then
Fillchar(FData^, FDataLen, byte(0))
else
raise EQTXBitBuffer.Create(ERR_BitBuffer_BitBufferEmpty);
end;
end.
DelphifiremonkeyObject PascalSocialEmbarcaderojobRoleSmart Mobile StudioSoftware consultant
I have gotten quite a few requests regarding what exactly I'm doing at Embarcadero. I have elaborated quite a bit on Delphi Developer. But I fully understand that not everyone is on Facebook, and I don't mind elaborating a bit if that helps. So here is a quick "drive-by" post on that.
Show full content
I have gotten quite a few requests regarding what exactly I’m doing at Embarcadero. I have elaborated quite a bit on Delphi Developer. But I fully understand that not everyone is on Facebook, and I don’t mind elaborating a bit more if that helps. So here is a quick “drive-by” post on that.
Setting sails for America
Sadly the facts of life are that I can’t talk about everything openly, that would violate the responsibility I have accepted in our NDA (non disclosure agreement), as well as personal trust between myself and the people involved. Hopefully everyone can sympathize with the situation.
My title is SC, Software Consultant, which is a branch under sales and support. I talk with companies about their needs, help them find competent employees, deliver ad-hoc solutions on site in my region and act as a “go to” guy that CTO’s can call on when they need something. And of course part of my role is to hold presentations, advocate Delphi and evangelize.
I am really happy about this because for the past 8 years I have been up to my nose in brain grinding, low-level compiler and rtl development; and while that is intellectually rewarding, it indirectly means everything else is on hold. With the release of Smart Mobile Studio 3.0 the product has reached a level of maturity where fixes and updates will be more structured. Focus is now on specific modules and specific components – which sadly doesn’t warrant a full-time job. So it’s been an incredible eight years at The Smart Company, and Smart is not going away (just to underline that) – but right now Delphi comes first. So my work on the RTL and the new compiler framework is partitioned accordingly.
Being able to advocate, represent and work with Delphi and C++ builder is a dream job come true. I have been fronting Delphi, helped companies and connected people within the community for 15 years anyways; and the companies and people I talk with are the same that I talked to last month. Not to mention new faces and people who have just discovered Delphi, or come back to Delphi after years elsewhere.
So being offered to do what I already love doing as a full-time job, I don’t see how I could have turned that down. As a teenager we used to talk about what company we wanted to work for. I remember a buddy of mine was absolutely fanatical about IBM, and he even went on to work for “big blue” after college. Others wanted to work at Microsoft, Oracle, Sun — but for me it was always Borland. And I have stuck with Delphi through thick and thin. Delphi has never failed me. Not once.
I set out to get object-pascal back on the map eight years ago. I have actively lobbied, blogged, started usergroups (our Facebook group now house 7500+ active Delphi developers), petitioned educational institutions, held presentations and done everything short of tattooing Delphi on my skin to make that a reality. Taking object-pascal out of education has been a catastrophe for software development as a whole.
Well, I hope this sheds some light on the role and what I do. I’m not a “professional blogger” like some have speculated. I do try to keep things interesting, but there is very little professional about my personal blog (which would be a paradox). But obviously my writing and presentations will have to adapt; meaning longer articles, on-topic writing style and good reference material.
I will be speaking in Oslo quite soon, then Sweden before I pop off to London in november. Very much looking forward to that. The London presentation and Oslo presentation will be hybrid talks, looking at Delphi and also how Smart Mobile Studio can help Delphi developers broaden the impact and ease web development for existing Delphi solutions. The talk in Sweden will be pure Delphi and C++ builder.
Get in touch with Jason Chapman or Adam Brett at the UK Delphi usergroup for more info
The last time I read about database coding, and I mean "making your own database engine" was at least 10 years ago. The Delphi community has always been blessed with a large group of insightful and productive people, people who share their knowledge and help others. But everyone is working on something and finding the time to deep dive into subjects like this is not always easy. So hopefully my series on this will at least inspire people to experiment, try new things and fall in love with Delphi like I did.
Show full content
It’s been a while since I’ve done some hardcore Delphi articles, and since that is now my job I am happy that I can finally allocate a good chunk of time for that work. Dont worry, there will be plenty of Smart Pascal content too – but I think it’s time to clean up the blog situation a bit. This blog is personal and thus contains a pot-pourri of topics, from programming to 3d printing, embedded hardware to retro-gaming. It’s a fun blog, I enjoy being able to write about things I’m passionate about, but having one blog for each topic makes more sense.
So in the near future I think it’s good that I publish Smart Mobile Studio content (except random stuff and drive-by posts) to http://www.smartmobilestudio.com, and Delphi to Embarcadero’s blog server. If nothing else it will be easier for the readers to deal with. If you only want to read about my Delphi escapades then embedded and retro stuff is not always interesting.
Deep dive into Delphi and C++ builder
So what can be cool to write about? I spent the better part of last weekend pondering this. Delphi articles have a little blind spot between beginner and advanced that I would like to focus on. There are plenty of “learn Delphi” articles out there, and there are likewise a lot of very advanced topics. So hopefully my first series will hit where it should, and be interesting for those in between.
Let’s peek under the hood!
Right, so the last time I read about database coding, and I mean “making your own database engine” was at least 10 years ago. The Delphi community has always been blessed with a large group of insightful and productive people, people who share their knowledge and help others. But everyone is working on something and finding the time to deep dive into subjects like this is not always easy. So hopefully my series on this will at least inspire people to experiment, try new things and fall in love with Delphi like I did.
The second article series that I am working on right now, is getting to grips with C++ builder. This is actually a very fun experiment since it serves more than a single function; I mean, just how hard is it for a Delphi developer to learn C++ ? What can Embarcadero do to help developers feel comfortable on both platforms? What are the benefits for a Delphi developer to learn C/C++?
C++ builder Community Edition rocks!
And yes I have had more than one episode where the new concepts drove me up the wall. It would be the world’s shortest article-series if Delphi Developer didn’t have my back and I didn’t buy books. Say what you will about modern programming, but sometimes you just need to sit down, turn off the computer, and read. Old school but effective.
Reflections
Embarcadero is very different from what I expected. Before I worked here (which is still a bit surrealistic) I envisioned a stereotypical american company, located in some tall office building; utterly remote from its users and the needs of the punters in the field. This past week has forced me to reflect more than I would have liked, and my armour of strong opinions (if not arrogance) has a very visible dent; because the company that has welcomed me with open arms is everything but that imaginary stereotype.
Et in Borland ego sum
The core of Embarcadero turned out to be a team of dedicated developers that are literally bending backwards to help as many developers as possible. I left yesterdays meeting with a taste of shame in my mouth, because in my blog I have given at least two of the people who now welcomed me, a less than fortunate overhaul in the past. Yet they turned out to be human beings with the exact same interests, passions and goals as myself.
Building large-scale development tools is really hard work. Seriously. As a developer you forget things like marketing, the sales apparatus, the level of support a developer will need, documentation, tutorials. The amount of requests, conflicting requests that is, from users is overwhelming. You have users who focus on mobile who don’t care about legacy VCL support, then you have people who very much need VCL legacy support and dont care at all about mobile platforms; It’s a huge list of groups, topics and goals that is constantly shifting and needs prioritization.
But all in all the Delphi community and Embarcadero is in good shape. They have worked through a lot of old baggage that simply had to be transitioned, and the result is the change we see now: community editions and better dialog with the users. Compare that to the situation we had five years ago, or eight years ago for that matter. The changes have been many and the road long -but with a purpose: Delphi is growing at a healthy rate again.
What will you need and what will we do?
The goal of the Delphi article is to implement the underlying mechanics of a database. I’m not talking about a “file of record” here or something like that, but a page and sequence based filestream and it’s support apparatus for managing blocks and available resources. This forms the basis of all databases, large or small. So we will be coding the nitty-gritty that has to be in place before you venture into expression parsing.
If time allows I will implement support for filters, but naturally a full SQL parser would be over the top. The techniques demonstrated should be more than enough for a budding young developer to take the ball and run with it. The filter function is somewhat close to a “select” statement – and the essence of expression parsing will be in the filter code.
Note: I will skip memory mapping techniques, for one reason only: it can get in the way of understanding the core principles. Once you have the principles under wraps – memory mapping is the natural next step and evolution of the thoughts involved, so it will fall into place in due time.
You wont need anything special, just Delphi. Most of the code will be classical object pascal, but the parser will throw in some generics and operators, so this is a good time to download the community edition or upgrade to a compiler from this century.
The C/C++ articles will likewise have zero dependencies except the community edition of C++ builder. I went out and bought two books, C++ Primer fifth edition and The C++ programming language by Bjarne Stroustrup himself. Which should be on presciption because i fell at sleep
My frontal lobe is already reduced to jello at the sight of these books, but let’s jump in with both feet and see what we make of it from a Delphi developers point of view. I can’t imagine it can be more of a mess than raw webassembly, but C/C++ has a wingspan that rivals even Delphi so it’s wise not to underestimate the curriculum.
OK, let’s get cracking! I will see you all shortly and post the first Delphi article.
DelphiJavaScriptObject PascalSmart Mobile StudioCanvasDIBGraphicshtml5Offscreen graphicsSave canvasSave pictureSmart Pascal
TW3Image is not meant for drawing, it's like Delphi's TImage and is a graphics container. So before we put a TW3Image on our form we are going to create the actual graphics to display. And we do this by creating an off-screen graphics context, assign a canvas to it, draw the graphics, and then encode the data via ToDataUrl().
Show full content
JavaScript and the DOM has a few quirks that can be a bit tricky for Delphi developers to instinctively understand. And while our RTL covers more or less everything, I would be an idiot if I said we havent missed a spot here and there. A codebase as large as Smart is like a living canvas; And with each revision we cover more and more of our blind-spots.
Where did TW3Image.SaveToStream vanish?
We used to have a SaveToStream method in TW3Image that took the raw DIB data (raw RGBA pixel data) and emitted that to a stream. That method was never really meant to save a picture in a compliant format, but to make it easy for game developers to cache images in a buffer and quickly draw the pixel-data to a canvas (or push it to localstorage, good if you are making a paint program). This should have been made more clear in the RTL unit, but sadly it escaped me. I apologize for that.
But in this blog-post we are going to make a proper Save() function, one that saves to a proper format like PNG or JPG. It should be an interesting read for everyone.
Resources are global in scope
Before we dig in, a few words about how the browser treats resources. This is essential because the browser is a resource oriented system. Just think about it: HTML loads everything it needs separately, things like pictures, sounds, music, css styles — all these resources are loaded as the browser finds them in the code – and each have a distinct URI (uniform resource identifier) to represent them.
So no matter where in your code you are (even a different form), if you have the URI for a resource – it can be accessed. It’s important to not mix terminology here because URI is not the same as a URL. URI is a unique identifier, an URL (uniform resource location) defines “where” the browser can find something (it can also contain the actual data).
If you look at the C/C++ specs, the URL class inherits from URI. Which makes sense.
Once a resource is loaded and is assigned an URI, it can be accessed from anywhere in your code. It is global in scope and things like forms or parent controls in the RTL means nothing to the underlying DOM.
Making new resources
When you are creating new resources, like generating a picture via the canvas, that resource doesn’t have an URI. Thankfully, generating and assigning an URI so it can be accessed is very simple — and once we have that URI the user can download it via normal mechanisms.
But the really cool part is that this system isn’t just for images. It’s also for raw data! You can actually assign a URI to a buffer and make that available for download. The browsers wont care about the content.
If you open the RTL unit SmartCL.System.pas and scroll down to line 107 (or there about), you will find the following classes defined:
(* Helper class for streams, adds data encapsulation *)
TAllocationHelper = class helper for TAllocation
function GetObjectURL: string;
procedure RevokeObjectURL(const ObjectUrl: string);
end;
TW3URLObject = static class
public
class function GetObjectURL(const Text, Encoding, ContentType, Charset: string): string; overload;
class function GetObjectURL(const Text: string): string; overload;
class function GetObjectURL(const Stream: TStream): string; overload;
class function GetObjectURL(const Data: TAllocation): string; overload;
class procedure RevokeObjectURL(const ObjectUrl: string);
// This cause a download in the browser of an object-url
class procedure Download(const ObjectURL: string; Filename: string); overload;
class procedure Download(const ObjectURL: string; Filename: string;
const OnStarted: TProcedureRefS); overload;
end;
The first class, TAllocationHelper, is just a helper for a class called TAllocation. TAllocation is the base-class for objects that allocate raw memory, and can be found in the unit System.Memory.Allocation.pas.
TAllocation is really central and more familiar classes like TMemoryStream expose this as a property. The idea here being that if you have a memory stream with something, making the data downloadable is a snap.
Hopefully you have gotten to know the central buffer class, TBinaryData, which is defined in System.Memory.Buffer. This is just as important as TMemoryStream and will make your life a lot easier when talking to JS libraries that expects an untyped buffer handle (for example) or a blob (more on that later).
The next class, TW3URLObject, is the one that is of most interest here. You have probably guessed that TAllocationHelper makes it a snap to generate URI’s for any class that inherits from or expose a TAllocation instance (read: really handy for TMemoryStream). But TW3URLObject is the class you want.
The class contains 3 methods with various overloading:
GetObjectURL
RevokeObjectURL
Download
I think these are self explanatory, but in short they deliver the following:
GetObjectURL creates an URI for a resource
RevokeObjectURL removes a previously made URI from a resource
Download triggers the “SaveAs” dialog so users can, well, save the data to their local disk
The good news for graphics is that the canvas object contains a neat method that does this automatically, namely the ToDataUrl() function, which is a wrapper for the raw JS canvas method with the same name. Not only will it encode your picture in a normal picture format (defaults to png but supports all known web formats), it will also return the entire image as a URI encoded string.
This saves us the work of having to manually call GetObjectURL() and then invoke the save dialog.
Making some offscreen graphics
TW3Image is not meant for drawing, it’s like Delphi’s TImage and is a graphics container. So before we put a TW3Image on our form we are going to create the actual graphics to display. And we do this by creating an off-screen graphics context, assign a canvas to it, draw the graphics, and then encode the data via ToDataUrl().
To make things easier, lets use the Delphi compatible TBitmap and TCanvas classes. These can be found in SmartCL.Legacy. They are as compatible as I could make them.
Browsers only support 32 bit graphics, so only pf32bit is allowed
I havent implemented checkered, diagonal or other patterns – so bsSolid and bsClear are the only brush modes for canvas (and pen style as well).
Brush doesn’t have a picture property (yet), but this will be added later at some point. I have to replace the built-in linedraw() method with the Bresham algorithm for that to happen (and all the other primitives).
When drawing lines you have to call Stroke() to render. The canvas buffers up all the drawing operations and removes overlapping pixels to speed up the final drawing process — this is demanded by the browser sadly.
Right, with that behind us, lets create an off-screen bitmap, fill the background red and assign it to a TW3Image control.
To replicate this example please use the following recipy:
Start a new “visual components project”
Add the following units to the uses clause:
System.Colors
System.Types.Graphics
SmartCL.Legacy
Add a TW3Button to the form
add a TW3Image to the form
Save your project
Double-Click on the button. This creates a code entry point for the default event, which for a button is OnClick.
Let’s populate the entry point with the following:
The code above creates a bitmap, which is an off-screen (not visible) graphics context. We then set a background color to use (red) and fill the bitmap with that color. When this is done we load the picture-data directly into our TW3Image control so we can see it.
Triggering a download
With the code for creating graphics done, we now move on to the save mechanism. We want to download the picture when the user clicks the button.
Offscreen graphics is quite fun once you know how it works
Since the image already have an URI, which it get’s when you call the ToDataURL() method, we don’t need to mess around with blob buffers and generating the URI manually. So forcing a download could not be simpler:
Note: The built-in browser in Smart doesn’t allow save dialogs, so when you run this example remember to click the “open in browser” button on the execute window. Then click the button and voila — the image is downloaded directly.
Well, I hope this has helped! I will do a couple of more posts on graphics shortly because there really is a ton of cool features here. We picked heavily from various libraries when we implemented TW3Canvas and TCanvas, so if you like making games or display data – then you are in for a treat!
Packt has a time limited offer where you can download the book Delphi Expert by our late Delphi guru, Pawel Glowacki. Pawel was and continues to be a well-known figure in the Delphi community. He held presentations, wrote books and helped promote Delphi and C++ builder in all corners of the world. He is sorely missed.
Packt has a time limited offer where you can download the book Delphi Expert by our late Delphi guru, Pawel Glowacki. Pawel was and continues to be a well-known figure in the Delphi community. He held presentations, wrote books and helped promote Delphi and C++ builder in all corners of the world. He is sorely missed.
In my previous post I mentioned that starting with Delphi is faster if you get a good book on the subject; and Pawels book Delphi Expert – fits perfectly within that curriculum.
If you have been wondering when to start, then consider this is a sign. Download the community edition of Delphi and fetch Pawel’s book – then get cracking!
What the community edition of Delphi and C++ builder means in practical terms, is that you get to learn, build and bring your idea to market without that initial investment. When you boat floats and you make money, then you pay for the toolbox that helped you be successful.
Show full content
Update:I updated the text to better point out writing in past-tense at one point. I apologize for not catching the formulation quicker, but I have edited the text to better reflect this now.
With the release of the community edition of Delphi and C++ builder, Embarcadero is finally making Delphi accessible to anyone who wants to enjoy the rich flavour of object-pascal that Delphi represents. In my 30+ years of coding I have yet to find a language or development toolkit as creative as object pascal, with Delphi being the flagship compiler and toolkit. Java and C# might appeal to some, but for developers solving real problems out there, the stability of Delphi is hard to match (more about that later).
Besides, object-pascal is fun, highly creative and easy to learn! Just imagine the wealth of knowledge a language that has stood the test of time has to offer!
Finally a straight up license
The license Embarcadero has landed on is easy to understand and straight to the point: the community edition is free for open source projects, and you can use it for commercial products until your sales reach a certain sum – and then you are expected to buy it. I wish I had this back in the day, I bought my first Delphi with money from my student loan.
Unreal engine operates with a similar license
This license is incidentally the same used by market leading game and multimedia companies. Both Crytech (CryoEngine) and Epic Games (Unreal engine) operate with the same concept. Instead of charging you a sum up-front, you can create your product and pay when your earnings justify it. Unreal-engine has a fixed percentage if memory serves me correct. So the Embarcadero license is more than fair.
What the community edition of Delphi and C++ builder means in practical terms, is that you get to learn, build and bring your idea to market without that initial investment. When you boat floats and you make money, then you pay for the toolbox that helped you be successful.
If you are a startup company with investors and limited funds, you get to adjust your license fee to your runway after the fact rather than before. So if your product tanks and you never make the expected sum; well that’s one bill less to worry about.
The myth of free Microsoft products
One of the things I often hear when talking to developers, is the “visual studio myth”. The notion that Visual Studio is free and there are no strings attached. And this is a myth, just to be clear. Microsoft have ridicules amounts of money so they could afford to lend you Visual Studio for five years (which was how they operated until very recently). If you checked the license for Visual Studio that’s what it said: you get to use it for five years, then you better pony up the cash. And by that time you have no doubt advanced to Enterprise level, which means that check will be signed in blood.
So this illusion that Visual Studio is free, is just that. Young developers are just as likely to use a pirated copy as violating a community agreement – so even today with the subscription model and ordinary trial they don’t notice the devil lurking in the details.
But for entrepreneurs that are starting from scratch, that need to set up a budget for their product that a board or single investor can trust, well it’s hard work because development is never an exact science. The coding part is, but it’s the human factor that is challenged, not the technology. It’s the spirit and individuals ability to see solutions where others see only walls that is tested; especially when you are making something truly unique. Something that doesn’t exist yet.
And once you are in that basket and have your entire product, perhaps even your career, riding on the investors being happy (which are rarely developers I might add) – the temptation of going “all in” is very real and very tangible. Let’s use MSSQL since we already have a VS license. Let’s use IIS instead and get rid of Apache. Lets use Sharepoint since we get a nice discount. Complete dependency doesn’t take long.
Now it’s no secret that my brief affair with C# makes me biased, and I am biased. Proudly biased. Bias on tap even. This is an object pascal blog where all things object pascal is loved and valued. So read my articles while imagining me with a cheeky smile in the corner of my mouth, and a slight sparkle in my eyes.
But in all fairness, the new Delphi community license is up-front, no hidden fees, honest and direct. If it wasnt.. well, I have a history of shooting myself in both feet by being painfully honest. I cant find anything wrong with the license and believe me I have tried. This is christmas and my birthday all rolled into one! Embarcadero has put their ears to the ground and listened to their customers.
With this in place Embarcadero is cementing a foundation of growth for our community, the languages they deliver and our future.
Rock solid
Delphi has always been known for producing rock solid, reliable database solutions. Delphi is awesome because it covers the whole spectrum of coding, from low level procedural dll files to system services, industrial scale servers, desktop and mobile applications – the list goes on. There are 3 million active Delphi developers around the world. Not to mention the millions more relying on older versions of Delphi or alternative compilers to power their businesses.
Visually bind database fields to containers, its details like this that saves time
If you mentally jump into a time machine and travel back to the 1980s, then slowly walk along the timeline and look at the changes in computing. Look at all the challenges before Delphi and how in 1995 Delphi took the world by storm. Into Delphi, Anders Hejlsberg and his team invested all their knowledge and everything they had learned from previous compilers and run-time libraries. This investment never stopped. There have been many architects involved over the years, each adding their contribution.
The amount of skill, insight, technique and dedication is breathtaking.
C# might be the cool kid on the block right now, but it’s painfully unsuitable for a wide range of tasks. Tasks that require a programming language with more depth. There is also something to be said about the test of time. Delphi and C++ builder have decades of evolution behind them. Many of the core principles were inherited from Turbo Pascal which dominated the 1980s and early 1990s.
And let me back that up with an example:
I used to do some work for a Norwegian company that delivers POS terminals to most of northern europe. When I got there they had a C# department and a Delphi department. Obviously I thought they wanted me to work on the Delphi codebase, but to my surprise they threw me into C#.
While I was there I noticed that Delphi was used on the hardware, the actual terminals themselves and the data transmissions. POS terminals is a potentially fragile but important instrument for any store; it has to operate 24/7 and a single mistake can be a financial disaster. I doubt more needs to be said here.
A POS terminal consists of many parts, here showing the card reader. Instability in the terminal can lead to loss of data, corrupted backups and network problems
The irony in all this was – that two years earlier they had tried to replace Delphi on the terminals with C#. They invested millions into rewriting the whole thing from scratch. But the rollout of this monstrosity was a total fiasco.
The bro-grammer’s forgot that some things are there for a reason. They neglected the subtle nuances of how each language works and how code behaves under extreme conditions; conditions where ram, storage space and cpu power are severely limited. On cheap, low-powered embedded boards even the slightest fluctuation in CPU activity can tank the whole system.
C# and Java were unfit because the GC (garbage collector) would kick in on random intervals to clean up the heap, this caused CPU spikes. The spikes were enough to freeze the terminal for a brief second, disturbing network activity, disk operations and database stability. It was the first time since the early 90s that I actually saw “Disk C: has a read-write error” dialog. I had to bite my lip to not laugh out loud. I tried so hard, honestly.
The glorified update was haunted by broken transmissions, un-responsive UIs and ruined backups (the device backs up its receipt database both locally and remotely many times a day). After a couple of weeks they rolled back the whole thing. Customers demanded their old system back. The system written in Delphi (and if you think the C# “native image compiler” from Microsoft made things better, think again).
So Delphi and object pascal still powers a large amount of financial transactions in northern europe. You will find Delphi used by the government, security companies, oil companies, POS brokers, ATM’s, missile guidance systems – anywhere where a high level of reliability is essential.
Getting started
Jumping into a new programming language or learning your first one can be daunting. Thankfully Delphi has been around almost as long as C/C++ (3 years younger) so there is plenty of knowledge online, most of it free (always google something before asking on forums, make that a habit).
Study the classics that teaches you how and things work
But to really save you time I urge you to buy a couple of books on Delphi. Now before you run off to Amazon or google around, there are two types of books you want.
You want a book that teaches you Delphi in general, a modern book that shows you OOP, generics and all the features that were added to Delphi after the XE version naming. So make sure you buy a book that teaches you Delphi from (at the very least) XE6 and upwards. Delphi “Berlin” or “Tokyo” is perfect.
The next book has to do with technique. What makes Delphi so incredibly powerful is this awesome depth. You can write libraries in hand optimized assembly code if you want – or you can write object-oriented, generics driven high-level mobile apps. Between those two extremes is a wealth of topics, including system services, your own servers, every database engine known to mankind and much, much more.
But you want a good book that teaches you techniques, techniques that underpin all the cool high-level features people take for granted. The most cherished book you will ever own for Delphi, is The tomes of Delphi: Algorithms and data structures (catchy title, but this is a book you can come back to over many years).
Now go download that thing and enjoy! Welcome to the coolest language in the world!
Amibian.jsAmigaC/C++DelphiembeddedfiremonkeyJavaScriptLinuxnodeJSObject PascalODroidOP4JSRaspberry PISmart Mobile StudioTinkerboardAndroidDIYNano PINano-pi Fire 3SBCTest
The question on everyone's mind (or at least mine) is: how does the Nano-PI fire 3 perform when rendering cutting edge, hardcore HTML5? Is this little device a potential candidate for running "The Smart Desktop" (a.k.a Amibian.js for those of you coming from the retro-computing scene)?
Show full content
If you missed the first installment of this test, please click here to catch up. In this installment we are just going to dive straight into general use and get a feel for what can and cannot be done.
Solving the power problem
Like mentioned in the previous article, a normal mobile charger (5 volt, 2 amps) is not enough to support the nano-pi. Since I have misplaced my original PI power-supply with 5 volt / 3 amps I decided to cheat. So I plugged the power USB into my PC which will deliver as much juice as the device needs. I don’t have time to wait for a new PSU to arrive so this will have to do.
But for the record (and underlined) a proper PSU with at least 2.5 amps is essential to using this board. I suggest you order the official Raspberry PI 3b power-supply. But if you should find one with 3 amps that would be even better.
Web performance
The question on everyone’s mind (or at least mine) is: how does the Nano-PI fire 3 perform when rendering cutting edge, hardcore HTML5? Is this little device a potential candidate for running “The Smart Desktop” (a.k.a Amibian.js for those of you coming from the retro-computing scene)?
Like I suspected earlier, X (the Linux windowing framework) doesn’t have drivers that deliver hardware acceleration at all.
Lubuntu is a sexy desktop no doubt there, but it’s overkill for this device
This is quite easy to test: when selecting a rectangle on the Lubuntu desktop and moving the mouse-cursor around (holding down the left mouse button at the same time) if it lags terribly, that is a clear indicator that no acceleration exists.
And I was right on the money because there is no acceleration what so ever for the Linux distribution. It struggles hopelessly to keep up with the mouse-pointer as you move it around with an active selection; something that would be silky smooth had the GPU been tasked with the job.
But, hardware acceleration is not just about the desktop. It’s not some flag you enable and it magically effect everything, but rather several API’s at either the kernel-level or immediate driver level (modules the kernel loads), each affecting different aspects of a system.
So while the desktop “2d blitting” is clearly cpu driven, other aspects of the system can still be accelerated (although that would be weird and rare. But considering how Asus messed up the Tinkerboard I guess anything goes these days).
Asking Chrome for the hard facts
I fired up Google Chrome (which is the default browser thank god) and entered the magic url:
chrome://gpu
This is a built-in page that avails a detailed report of what Chrome learns about the current system, right down to specific GPU features used by OpenGL.
As expected, there was NO acceleration what so ever. So I was quite surprised that it managed to run Amibian.js at all. Even without hardware acceleration it outperformed the Raspberry PI 3b+ by a factor of 4 (at the very least) and my particle demo ran at a whopping 8 fps (frames per second). The original Rasperry PI could barely manage 2 fps. So the Nano-PI Fire is leagues ahead of the PI in terms of raw cpu power, which is brilliant for headless servers or computational tasks.
FriendlyCore vs Lubuntu? QT for the win
Now here is a funny thing. So far I have used the Lubuntu standard Linux image, and performance has been interesting to say the least. No hardware acceleration, impressive cpu results but still – what good is a SBC Linux distro without fast graphics? Sure, if you just want a head-less file server or host services then you don’t need a beefy GPU. But here is the twist:
Turns out the makers of the board has a second, QT oriented distro called Friendly-core. And this image has OpenGL-ES support and all the missing acceleration lacking from Lubuntu.
I was pretty annoyed with how Asus gave users the run-around with Tinkerboard downloads, but they have thankfully cleaned up their act and listened to their customers. Friendly-elec might want to learn from Asus mistakes in this area.
QT has a rich history, but it’s being marginalized by node.js and Delphi these days
Alas, Friendly-core xenial 4.4 Arm64 image turned out to be a pure embedded development image. This is why the board has a debug port (which is probably awesome if you are into QT development). So this is for QT developers that want to use the board as a single-application system where they write the code on Windows or Linux, compile and it’s all transported to the board with live debugging back to the devtools they use. In other words: not very useful for non C/C++ QT developers.
Android Lolipop
I have only used Android on a pad and the odd Samsung Galaxy phone, so this should be interesting. I Downloaded the Lolipop disk image, burned it to the sd-card and booted up.
After 20 minutes with a blank screen i gave up.
I realize that some Android distros download packages ad-hoc and install directly from a repository, so it can take some time to get started; but 15-20 minutes with a black screen? The Android logo didn’t even show up — and that should be visible almost immediately regardless of network install or not.
This is really a great shame because I wanted to test some Delphi Firemonkey applications on it, to see how well it scales the more demanding GPU tasks. And yes i did try a different SD-Card to be sure it wasnt a disk error. Same result.
Back to Lubuntu
Having spent a considerable time trying to find a “wow” factor for this board, I have to just surrender to the fact that it’s just not there. . This is not a “PI” any more than the Tinkerboard is a PI. And appending “pi” to a product name will never change that.
I can imagine the Nano-PI Fire 3 being an awesome single-application board for QT C/C++ developers though. With a dedicated debug port making it a snap to transport, execute and do live debugging directly on the hardware — but for general DIY hacking, using it for native Android development with Delphi, or node.js development with Smart Mobile Studio – or just kicking back with emulators like Mame, UAE or whatever tickles your fancy — its just too rough around the edges. Which is really a shame!
So at the end of the day I re-installed Lubuntu and figure I just have to wait until Friendly-elec get their act together and issue proper drivers for the Mali GPU. So it’s $35 straight out the window — but I can live with that. It was a risk but at that price it’s not going to break the bank.
The positive thing
The Nano-PI Fire 3 is yet another SBC in a long list that fall short of its potential. Like many others they try to use the word “PI” to channel some of the Raspberry PI enthusiasm their way – but the quality of the actual system is not even close.
In fact, using PI in their product name is setting themselves up for a fall – because customers will quickly discover that this product is not a PI, which can cause some subconscious aversion and resentment.
The Nano rendered Amibian.js running some very demanding demos 4 times as fast as the PI 3b, one can only speculate what the board could do with proper drivers for the GPU.
The only positive feature the Fire-3 clearly has to offer, is abundantly more cpu power. It is without a doubt twice as fast (if not 3 times as fast) as the Raspberry PI 3b. The fact that it can render highly demanding and complex HTML5 demos 4 times faster than the Raspberry PI 3b without hardware acceleration is impressive. This is a $35 board after all, which is the same price.
But without proper drivers for the mali, it’s a useless toy. Powerful and with great potential, but utterly useless for multimedia and everything that relies on fast 2D and 3D graphics. For UAE (Amiga emulation) you can pretty much forget it. Even if you can compile the latest UAE4Arm with SDL as its primary display framework – it wouldn’t work because SDL depends on the graphics drivers. So it’s back to square one.
But the CPU packs a punch that is without question.
Final verdict
There are a lot of stable and excellent options out there, take your time
I was planning to test UAE next but as I have outlined above: without drivers that properly expose and delegate the power of the mali, it would be a complete disaster. I’m not even sure it would build.
As such I will just leave this board as is. If it matures at some point that would be great, but my advice to people looking for a great SBC experience — get the new Raspberry PI 3b+ and enjoy learning and exploring there.
And if you are into Amibian.js or making high quality HTML5 kiosk / node.js based systems, then fork out the extra $10 and buy an ODroid XU4. If you pay $55 you can pick up the Asus Tinkerboard which is blistering fast and great value for money, despite its turbulent introduction.
Note: You cannot go wrong with the ODroid XU4. Its affordable, stable and fast. So for beginners it’s either the Raspberry PI 3b+ or the ODroid. These are the most mature in terms of software, drivers and stability.
Amibian.jsDelphiLanguage researchLifeLinuxnodeJSObject PascalSmart Mobile StudioBlade serverCompiler farmRackServerVMWare
One of the benefits of doing repairs on your house, is that during the cleanup process you come over stuff you had completely forgot about. Like two very powerful Apple blade servers (x86) I received as a present three years ago. I never got around to using them because I there was literally no room in my house for a rack cabinet.
Show full content
One of the benefits of doing repairs on your house, is that during the cleanup process you come over stuff you had completely forgot about. Like two very powerful Apple blade servers (x86) I received as a present three years ago. I never got around to using them because I there was literally no room in my house for a rack cabinet.
Sure, a medium model rack cabinet isn’t that big (the size of a cabin refrigerator), but you also have to factor in that servers are a lot more noisy than desktop PCs; the older they are the more noise they make. So unless you have a good spot to place the cabinet, where the noise wont make it unbearable to be around, I suggest you just rent a virtual instance at Amazon or something. It really depends on how much service coding you do, if you need to do dedicated server and protocol stress testing (the list goes on).
Power for pennies
Sellers photo. It needs a good clean, but this kit would have set you back $5000 a decade ago; so picking this up for $400 is almost ridicules.
The price of such cabinets (when buying new ones) can be anything from $800 to $5000 depending on the capacity, features and materials. My needs for a personal server farm are more than covered by a medium cabinet. If it wasnt for my VMWare needs I would say it was overkill. But some of my work, especially with node.js and Delphi system services that should handle terabytes of raw data reliably 24/7, that demands a hard-core testing environment.
Having stumbled upon my blade servers I decided to check the local second-hand online forum; and I was lucky enough to find (drumroll) a second-hand cabinet holding a total of 10 blades for $400. So I’ll be picking up this beauty next weekend. It will be so good to finally get my blades organized. Not to mention all my SBC / Node.js cluster experiments centralized in one physical location. Far away from my home office space (!)
Interestingly, it comes fitted with 3 older servers. There are two Dell web and file servers, and then a third, unmarked mystery box (i3 cpu + sata caddies so that sounds good).
It really is amazing how much cpu fire-power you can pick up for practically nothing these days. $50 buys you a SBC (single board computer) that will rival a Pentium. $400 buys you a 10 blade cabinet and 3 servers that once powered a national newspaper (!).
VMWare delights
All the blades I have mentioned so far are older models. They are still powerful machines, way more than $400 livingroom NAS would get you. So my node.js clustering will run like a dream and I will be able to host all my Delphi development environments via VMware. Which brings us neatly to the blade I am really looking forward to get into the rack.
I bought an empty server blade case back in 2015. It takes a PSU, motherboard, fans and everything else is there (even the six caddies for disks). Into this seemingly worthless metal box I put a second generation Intel i7 monster (Asus motherboard), with 32 gigabyte ram – and fitted it with a sexy NVidia GEFORCE GTX 1080 TI.
All my Delphi work, Smart work and various legacy projects I maintain, all in one neat rack
This little monster (actually it takes up 2 blade-spots) allows me to run VMWare server, which gives me at least 10 instances of Windows (or Linux, or OSX) at the same time. It will also be able to host and manage roughly 1000 active Smart Desktop users (the bottleneck will be the disk and network more than actual computation).
Being a coder in 2018 is just fantastic!
Things we could only dream about a decade ago can now be picked up for close to nothing (compared to the original cost). Just awesome!
Amibian.jsDelphiJavaScriptnodeJSObject PascalOP4JSSmart Mobile StudioSmart Mobile Studio 3.0Smart PascalWhatsNew
Trying to sum up the literally thousands of changes we have done in Smart Mobile Studio the past 12 months is quite a challenge. Instead of just blindly rambling on about every little detail - I'll try to focus on the most valuable changes; changes that you can immediately pick up and experience for yourself.
Show full content
Trying to sum up the literally thousands of changes we have done in Smart Mobile Studio the past 12 months is quite a challenge. Instead of just blindly rambling on about every little detail – I’ll try to focus on the most valuable changes; changes that you can immediately pick up and experience for yourself.
Scriptable css themes
A visual control now has its border and background styled from our pre-defined styles. The styles serve the same function in all themes even though they look different.
This might not feel like news since we introduced this around xmas, but like all features it has matured through the beta phases. The benefits of the new system might not be immediately obvious.
So what is so fantastic about the new theme files compared to the old css styling?
We have naturally gone over every visual control to make them look better, but more importantly – we have defined a standard for how visual controls are styled. This is important because without a theme system in place, making application “theme aware” would be impossible.
Each theme file is constructed according to a standard
A visual control is no longer styled using a single css-rule (like we did before), but rather a combination of several styles:
There are 15 background styles, each with a designated role
There are 14 borders, each designed to work with specific backgrounds
We have 4 font sizes to simplify what small, normal, medium and large means for a particular theme.
A theme file contains both CSS and Smart pascal code
The code is sandboxed and has no access to the filesystem or RTL
The code is executed at compile time, not runtime (!). So the code is only used to generate things like gradients based on constants; “scaffolding” code if you will that makes it easier to maintain and create new themes.
Optimized and re-written visual controls
Almost all our visual controls have been re-written or heavily adjusted to meet the demands of our users. The initial visual controls were originally designed as examples, following in the footsteps of mono where users are expected to work more closely with the code.
To remedy this we have gone through each control and added features you would expect to be present. In most cases the controls are clean re-writes, taking better advantage of HTML5 features such as flex-boxing and relative positions (you can now change layout mode via the PositionMode property. Displaymode is likewise a read-write property).
Flex boxing relieves controls of otherwise expensive layout chores and evenly distributes elements
Flex-boxing is a layout technique where the browser will automatically stretch or equally distribute screen real estate for child elements. Visual controls like TW3Toolbar and TW3ListMenu makes full use of this – and as a result they are more lightweight, requires no resize code and behave like native controls.
Momentum scrolling as standard
Apple have changed the rules for scrolling 3 times in the past eight years, and it’s driving HTML/JS developers nuts every time. We decided years ago that we had enough and implemented momentum scrolling ourselves written in Smart Pascal. So no matter if Apple or anyone else decides to make life difficult for developers – it wont bother us.
Momentum scrolling with indicator (or scrollbars) are now standard for all container controls and lists.
Our new TW3Scrollbox and (non visual) TW3ScrollController means that all our container and list controls supports GPU powered momentum scrolling by default. You can also disable this and use whatever default method the underlying web-view or browser has to offer.
Bi-directional Tab control
A good tab control is essential when making mobile and web applications, but making one that behaves like native controls do is quite a challenge. We see a lot of frameworks that have problems doing the bi-directional scrolling that mobile tabs do, where the headers scroll in-place as you click or touch them – and the content of the tab scroll in from either side (at the same time).
Thankfully this was not that hard to implement for us, since we have proper inheritance to fall back on. JS developers tend to be limited to prototype cloning, which makes it difficult to build up more and more complex behavior. Smart enjoys the same inheritance system that Delphi and C++ uses, and this makes life a lot easier.
Google Maps control
Not exactly hard to make but a fun addition to our RTL. Very useful in applications where you want to pinpoint office locations.
Updated ACE coding editor
ACE is by many regarded as the de-facto standard text and code editor for JavaScript. It is a highly capable editor en-par with SynEdit in the Delphi and C++ world. This is actually the only visual control that we did not implement ourselves, although our wrapper code is substantial.
Ace comes with a wealth of styles (color themes) and support for different programming languages. It can also take on the behavior of other editors like emacs (an editor as old as Unix).
We have updated Ace to the latest revision and tuned the wrapper code for speed. There was a small problem with padding that caused Ace to misbehave earlier, this has now been fixed.
The Smart Desktop, windowing framework
People have asked us for more substantial demos of what Smart Mobile Studio can do. Well this certainly qualifies. It is probably the biggest product demo ever made and represents a complete visual web desktop with an accompanying server (the Ragnarok Websocket protocol).
The Smart Desktop showcases some of the power Smart Mobile Studio can muster
It involves quite a bit of technology, including a filesystem that uses the underlying protocol to browse and access files on the server as if they were local. It can also execute shell applications remotely and pipe the results back.
A shell window and command-line system is also included, where commands like “dir” yields the actual directory of whatever path you explore on the server.
Since the browser has no concept of “window” (except a browser window) this is fully implemented as Smart classes. Moving windows, maximizing them (and other common operations) are all included.
The Smart desktop is a good foundation for making large-scale, enterprise level web applications. Applications the size of Photoshop could be made with our desktop framework, and it makes an excellent starting-point for developers involved in router, set-top-boxes and kiosk systems.
Node.JS and server-side technology
While we have only begun to expand our node.js namespace, it is by far one of the most interesting aspects of Smart Mobile Studio 3.0. Where we only used to have rudimentary support (or very low-level) for things like http – the SmartNJ namespace represents high-level classes that can be compared to Indy under Delphi.
As of writing the following servers can be created:
HTTP and HTTPS
WebSocket and WebSocket-Secure
UDP Server
Raw TCP server
The cool thing is that the entire system namespace with all our foundation code, is fully compatible and can be used under node. This means streams, buffers, JSON, our codec classes and much, much more.
I will cover the node.js namespace in more detail soon enough.
Unified filesystem
The browser allows some access to files, within a sandboxed and safe environment. The problem is that this system is completely different from what you find under phonegap, which in turn is wildly different from what node.js operates with.
In order for us to make it easy to store information in a unified way, which also includes online services such as Azure, Amazon and Dropbox — we decided to make a standard.
The Smart Desktop shows the filesystem and device classes in action. Here accessing the user-account files on the server both visually and through our command-line (shell) application.
So in Smart Mobile Studio we introduce two new concepts:
Storage device classes (or “drivers”)
Path parsers
The idea is that if you want to save a stream to a file, there should be a standard mechanism for doing so. A mechanism that also works under node, phonegap and whatever else is out there.
For the browser we went as far as implementing our own filesystem, based on a fast B-Tree class that can be serialized to both binary and JSON. For Node.js we map to the existing filesystem methods – and we will continue to expand the RTL with new and exciting storage devices as we move along.
Path parsers deals with how operative-systems name and deal with folders and files. Microsoft Windows has a very different system from Unix, which again can have one or two subtle differences from Linux. When a Smart application boots it will investigate what platform it’s running on, and create + install an appropriate path parser.
You will also be happy to learn that the unit System.IOUtils, which is a standard object pascal unit, is now a part of our RTL. It contains the class TPath which gives you standard methods for working with paths and filenames.
New text parser
Being able to parse text is important. We ported our TextCraft parser (initially written for Delphi) to Smart, which is a good framework for making both small and complex parsers. And we also threw in a bytecode assembler and virtual-cpu demo just for fun.
Note: The assembler and virtual cpu is meant purely as a demonstration of the low-level routines our RTL has to offer. Most JS based systems run away from raw data manipulation, well that is not the case here.
Time to get excited!
I hope you have enjoyed this little walk-through. There are hundreds of other items we have added, fixed and expanded (we have also given the form-designer and property inspector some much needed love) – but some of the biggest changes are shown here.
My Facebook messenger App has been bombarded with questions since it became known that I now work for Embarcadero. Most of the messages are in the form of questions; what is the future of Smart Mobile Studio, will I be involved in this or that and so on.
Show full content
My Facebook messenger App has been bombarded with questions since it became known that I now work for Embarcadero. Most of the messages are in the form of questions; what is the future of Smart Mobile Studio, will I be involved in this or that and so on.
Well those that have followed my blog over the years, or stay in touch with me via Delphi Developer on Facebook, should know by now that I don’t tip-toe around subjects; I tend to be quite direct, and even though it’s absurdly premature –let’s just grab the hot potato and get it over with.
Future of Smart Mobile Studio
Me working for Embarcadero will not change the future of Smart Mobile Studio. Smart is our baby and the whole team at The Smart Company AS will continue, like we have for the past eight years, to evolve, improve and foster Smart Pascal. So let me be absolutely clear on this: my work on Smart Mobile Studio will continue uninterrupted in my free time. Smart Pascal is a labour of love, passion and creativity.
So there is a crystal clear line between my personal and professional time.
Nor is there any potential conflict in this material, as some have openly speculated; Delphi and Smart Mobile Studio targets two fundamental different market segments; Delphi is the best native development suite money can buy, while Smart is the best development system for building mobile, cloud and large-scale JSVM (JavaScript virtual machine) infrastructures.
What people often forget, even though I have underlined it 10.000 times, is that Smart Mobile Studio is written in Delphi (!) It was created to compliment Delphi. To enrich and allow Delphi developer’s to re-apply existing skills in a new paradigm.
In many ways Smart Mobile Studio is a testament to what Delphi is capable of in the right hands.
My role at Embarcadero
It was actually Facebook that “outed” me when I changed my employment status. Instead of a silent alteration on my profile, it plastered the change in bold, underline and italic.
But writing anything about this would be premature, nor do I feel it’s my place to do so.
All I can say is that I am very excited to work for the company that makes Delphi. A product that I love and have used on a daily basis since it was first launched.
Smart Mobile Studio 3
To make those of you who have been worried about what might happen to Smart Mobile Studio as a consequence of my new path, I hope I have made you feel optimistic about the future so far. Because I am super optimistic! Seriously, this is awesome!
As I type this Smart Mobile Studio 3.0 beta 3 should be available via the automatic-update tool for our customers. I can’t remember a year where we have worked so hard; and we have achieved above and beyond the schedule we set back in 2017.
Smart Mobile Studio 3.0 ~ Node.js server and desktop framework demo
I don’t know how many nights my girlfriend has found me scribbling data-paths and formulas on my home office white-board, or getting up at 03:30 at night to test some idea – but when you compare our new RTL with the previous, especially our focus on node.js, you will witness a quantum leap on quality, features and technical wealth.
Separating apples from pears
Speaking of the future; my blogging style wont change, but I will avoid mixing apples and pears. Delphi posts should be about Delphi, and Smart posts should be about Smart. I don’t think I need to explain why that is a good idea. It’s important to maintain that line between work and personal projects.
The only reason I mention both here now, is to put things to rest and make it clear for everyone that it’s all good. And it’s going to get even better.
Smart Mobile Studio 3.0 is an epic release! And Delphi is going from strength to strength. So there is a lot to be happy about! I cant even remember when object pascal developers had so many options at their disposal.
embeddedObject PascalODroidRaspberry PITinkerboardFire 3IOTNano PINano-pi Fire 3single board computer
To date the only board that works well with a Mali chipset, out of all the boards I have bought and tested, is the ODroid XU4. Which leads me to conclude that something has gone terribly wrong with the art of making drivers. This really should not be an issue in 2018, but the number of bankrupt mali boards tell another story.
Show full content
Being able to buy SBCs (single board computers) for as little as $35 has revolutionized computing as we know it. Since the release of the Raspberry PI 1b back in 2012, single board computers have gone from being something electrical engineers work with, to something everyone can learn to use. Today you don’t need a background in electrical engineering to build a sophisticated embedded system; you just need a positive spirit, willingness to learn and a suitable SBC starter-kit.
Single board computers
If you are interested in SBC’s for whatever reason, I am sure you have picked up a few pointers about what works and doesn’t. In these times of open forums and 24/7 internet, the response-time from customers are close to instantaneous; and both positive and negative feedback should never be taken lightly. It’s certainly harder to hide a poor product in 2018, so engineers thinking they can make a quick buck selling sloppy-tech should think twice.
I have no idea how many boards have been released since 2016, but some 20+ new boards feels like a reasonable number. Which under normal circumstances would be awesome, because competition can be healthy. It can stimulate manufacturers to deliver better quality, higher performance and to use eco-friendly resources.
But it can also backfire and result in terrible quality and an unhealthy focus on profit.
The Mali SoC
The MALI graphics chipset is a name you see often in connection with SBC’s. If you read up on the Mali SoC it sounds fantastic. All that power, open architecture, partner support – surely this design should rock right? If only that were true. My experience with this chipset, which spans a variety of boards, is anything but fantastic. It’s actually a common factor in a growling list of boards that are unstable and unreliable.
I don’t have an axe to grind here, I have tried to remain optimistic and positive to every board that pass my desk. But Mali has become synonymous with awful performance and unreliable operation.
Out of the 14 odd boards I have tested since 2016, the 8 board that I count as useless all had the Mali chipset. This is quite remarkable considering Mali has an open driver architecture.
Open is not always best
If you have been into IOT for a few years you may recall the avalanche of critique that hit the Raspberry PI foundation for their choice of shipping with the Broadcom SoC? Broadcom has been a closed system with proprietary drivers written by the vendor exclusively, which made a lot of open-source advocates furious [at the time].
You know what? Going with the Broadcom chipset is the best bloody move the PI foundation ever did; I don’t think I have ever owned a SBC or embedded platform as stable as the PI, and the graphics performance you get for $35 is simply outstanding. Had they listened to their critics and used Mali on the Raspberry PI 2b, it would have been a disaster. The IOT revolution might never have occurred even.
The whole point of the Mali open driver architecture, is that developers should have easy access to documentation and examples – so they can quickly implement drivers and release their product. I don’t know what has gone wrong here, but either developers are so lazy that they just copy and paste code without properly testing it – or there are fundamental errors in the hardware itself.
To date the only board that works well with a Mali chipset, out of all the boards I have bought and tested, is the ODroid XU4. Which leads me to conclude that something has gone terribly wrong with the art of making drivers. This really should not be an issue in 2018, but the number of bankrupt mali boards tell another story.
Nano-PI Fire 3
When reading the specs on the Nano-pi fire 3 I was impressed with just how much firepower they managed to squeeze into such a tiny form-factor. Naturally I was sceptical due to the Mali, which so far only have ODroid going for it. But considering the $35 price it was worth the risk. Worst case I can recycle it as a headless server or something.
And the board is impressive! Let there be no doubt about the potential of this little thing, because from an engineering point of view its mind-blowing how much technology $35 buys you in 2018.
I don’t want to sound like a grumpy old coder, but when you have been around as many SBC’s as I have, you tend to hold back on the enthusiasm. I got all worked-up over the Asus Tinkerboard for example (read part 1 and part 2 here), and despite the absolutely knock-out specs, the mali drivers and shabby kernel work crippled an otherwise spectacular board. I still find it inconceivable how Asus, a well-respected global technology partner, could have allowed a product to ship with drivers not even worthy of public domain. And while they have updated and made improvements it’s still not anywhere near what the board could do with the right drivers.
The experience of the Nano-PI so far has been the same as many of the other boards; especially those made and sold straight from smaller, Asian manufacturers:
Finding the right disk-image to download is unnecessarily cumbersome
Display drivers lack hardware acceleration
Poor help forums
“Wiki” style documentation
A large Linux distro that max out the system
More juice
The first thing you are going to notice with the Nano-pi is how important the power supply is. The nano ships with only one usb socket (one!) so a usb hub is the first thing you need. When you add a mouse and keyboard to that equation you have already maxed out a normal 5v 2a mobile power supply.
I noticed this after having problems booting properly when a mouse and keyboard was plugged in. I first thought it was the SD card, but no matter what card I tried – it still wouldn’t boot. It was only when I unplugged the mouse and keyboard that I could log in. Or should we say, cant log in because you don’t have a keyboard attached (sigh).
Now in most cases a Raspberry PI would run fine on 5v 2a, at least for ordinary desktop work; But the nano will be in serious trouble if you don’t give it more juice. So your first purchase should be a proper 5 volt 3 amp PSU. This is also recommended for the original Raspberry PI, but in my experience you can do quite a lot before you max out a PI.
Bluetooth
A redeeming factor for the lack of USB ports and power scaling, is that the board has Bluetooth built-in. So once you have paired and connected a BT keyboard things will be easier to work with. Personally I like keyboard and mouse to be wired. I hate having to change batteries or be disconnected at random (which always happens when you least need it). So the lack of USB ports and power delegation is negative for me, but objectively I can live with it as a trade-off for more CPU power.
Lack of accelerated graphics
It’s not hard to check if X uses the gpu or not. Select a large region of the desktop (holding the left mouse button down obviously) and watch in terror as it sluggishly tries to catch up with the cursor, repainting every cached co-ordinate. Had the GPU been used properly you wouldn’t even see the repaint of the rectangle, it would be smooth and instantaneous.
SD-card reader
I’m sorry but the sd-card reader on this puppy is the slowest I have ever used. I have never tested a device that boots so slow, and even something simple like starting chrome takes ages.
I tested with a cheap SD-card but also a more expensive class 10 card. I’m really trying to find something cool to write about, but it’s hard when boot times is worse than Raspberry PI 1b back in 2012.
1 gigabyte of ram
One thing that I absolutely hate in some of these cheap boards, is how they imagine Ubuntu to be a stamp of approval. The Raspberry PI foundation nailed it by creating a slim, optimized and blistering fast Debian distro. This is important because users don’t buy alternative boards just to throw that extra power away on Ubuntu, they buy these boards to get more cpu and gpu power (read: better value for money) for the same price.
Lubuntu is hopelessly obese for the hardware, as is the case with other cheap SBC’s as well. Something like Pixel is much more interesting. You have a slim, efficient and optimized foundation to build on (or strip down). Ubuntu is quite frankly overkill and eats up all the extra power the board supposedly delivers.
When it comes to ram, 1 gigabyte is a bit too small for desktop use. The reason I say this is because it ships with Ubuntu, why would you ship with Ubuntu unless the desktop was the focus? Which again begs the question: why create a desktop Linux device with 1 gigabyte of memory?
The nano-pi would rock with a slim distro, and hopefully someone will bake a more suitable disk-image for it.
Verdict so far
I still have a lot to test so giving you a final verdict right now would be unfair.
But I must be honest and say that I’m not that happy about this board. It’s not that the hardware is particularly awful (although the mali drivers renders it almost pointless), it’s just that it serves no point.
In order to turn this SBC into a reasonable device you have to buy parts that brings the price up to what you would pay for a ODroid XU4. And to be honest I would much rather have an ODroid XU4 than four nano-pi boards. You have plenty of USB ports, good power scaling (ODroid will start just fine on a normal charger), Bluetooth and pretty much everything you need.
For those rare projects where a single USB is enough, although I cannot for the life of me think of one right now, then sure, it may be cost-effective in quanta. But for homebrew servers, gaming rigs and/or your first SBC experience – I think you will be happier with an original Raspberry PI 3b+, a ODroid XU4 or even the Tinkerboard.
Modus operandi
Having said all that .. there is also something to say about modus-operandi. Different boards are designed for different systems. It may very well be that this system is designed to run Android as it’s primary system. So while they provide a Linux image, that may in fact only be a “bonus” distro. We shall soon see as I will test Android next.
Next up, how does it fare with the multi-threaded uae4arm? Stay tuned for more!
Amibian.jsCSSDelphiJavaScriptObject PascalOP4JSSmart Mobile Studio#SmartMobileStudioCommon questionshtml5JavascriptlazarusRADSmart PascalWeb framework
A couple of days back I posted a sneak-peek of our upcoming Smart Mobile Studio 3.0 web desktop framework; as a consequence my Facebook messenger app has practically exploded with questions.
Show full content
A couple of days back I posted a sneak-peek of our upcoming Smart Mobile Studio 3.0 web desktop framework; as a consequence my Facebook messenger app has practically exploded with questions.
The desktop client / server framework is an example of what you can do in Smart
As you can imagine, the questions people ask are often very similar; so similar in fact that I will answer the hottest topics here. Hopefully that will make it easier for everyone.
Yes indeed we have generics running in the labs. We havent set a date on when we will merge the new compiler-core, but it’s not going to happen until (at the earliest) v3.4. So it’s very much a part of Smart’s future but we have a couple of steps left on our time-line for v3.0 through v3.4.
RTTI access
RTTI is actually in the current version, but sadly there is a bug there that causes the code generator to throw a fit. The fix for this depends on a lot of the sub-strata in the new compiler-core, so it will be available when generics is available.
Associative arrays
This is ready and waiting in the new core, so it will appear together with generics and RTTI.
Databases
We have supported databases since day 1, but the challenge with JavaScript is that there are no “standards” like we are used to from established systems like Delphi or Lazarus.
Under the browser we support WebSQL and our own TW3Dataset. We also compiled SQLite from native C to JavaScript so we can provide a fast, lightweight SQL engine for the browser regardless of what the W3C might do (WebSQL has been deprecated but will be around for many years still).
Server side it’s a whole different ballgame. There you have drivers (or modules) for every possible database you can think of, even Firebird. But each module is implemented as the authors see fit. This is where our Database framework comes in, sets a standard, and we then inherit out classes and implement the engines we want.
This framework and standard is being written now, but it wont be introduced until v3.1 and v3.2. In the meantime you have sqlite both server-side and client-side, WebSQL and TW3Dataset.
Attributes
This question is often asked separately from RTTI, but it’s ultimately an essential part of what RTTI delivers.
So same answer: it will arrive with the new compiler-core / infrastructure.
Server-side scripting
The new theme system in action
While we do see how this could be useful, it requires a substantial body of work to make a reality. Not only would we have to implement the whole “system” namespace from scratch since JavaScript would not be present, but we would also have to introduce a a secondary namespace; one that would be incompatible with the whole RTL at a fundamental level. Instead of going down this route we opted for Node.js where creating the server itself is the norm.
If we ever add server-side scripting it would be JavaScript support under node.js by compiling the V8 engine from C to asm.js. But right now our focus is not on server-side-scripting, but on cloud building-blocks.
Bytecode compilation
I implemented the assembler and runtime for our bytecode system (LDef) this winter / early spring; So we actually have the means to create a pure bytecode compiler and runtime.
But this is not a priority for us at this time. Smart Mobile Studio was made for JavaScript and while it would be cool to compile Delphi sourcecode to portable bytecodes, such a project would require not just a couple of namespaces – but a complete rewrite of the RTL. The assembler source-code and parser can be found in the “Next Generation Demos” folder (Smart Mobile Studio 3.0 demos). Feel free to build on the codebase if you fancy creating your own language;Get creative and enjoy! **Note: Using the assembler in your own projects requires a valid Smart Mobile license.
Native Apps
It’s interesting that people still ask this, since its one of our central advantages. We already generate native apps via the Phonegap post-processor.
Phonegap turns your JS apps into native apps
Phonegap takes your compiled Smart (visual projects only) compiled code, processes it, and spits out native apps for every mobile OS on the market (and more). So you don’t have to compile especially for iOS, Android, Tizen or FireOS — Phonegap generates one for each system you need, ready for AppStore.
So we have native covered by proxy. And with millions of users Phonegap is not going anywhere.
Release date
We are going over the last beta as I type this, and Smart Mobile Studio 3.0 should be available next week. Which day is not easy to say, but at least before next weekend if all goes accoring to plan.




































 What is it about these large tech companies and not wanting to talk to customers? Padded walls, sanded corners — I think we might just have found that mysterious demographic ..
What is it about these large tech companies and not wanting to talk to customers? Padded walls, sanded corners — I think we might just have found that mysterious demographic ..













































































































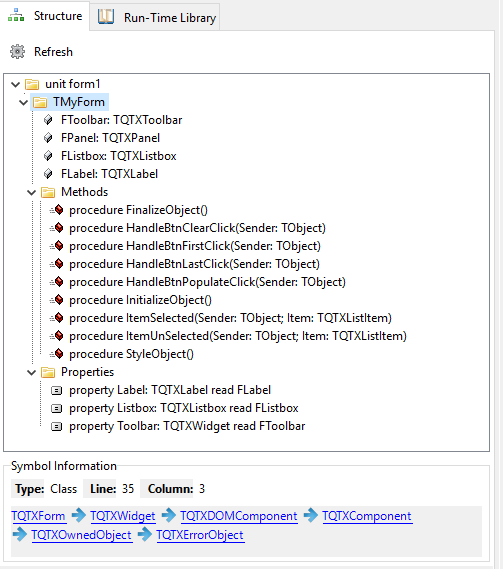


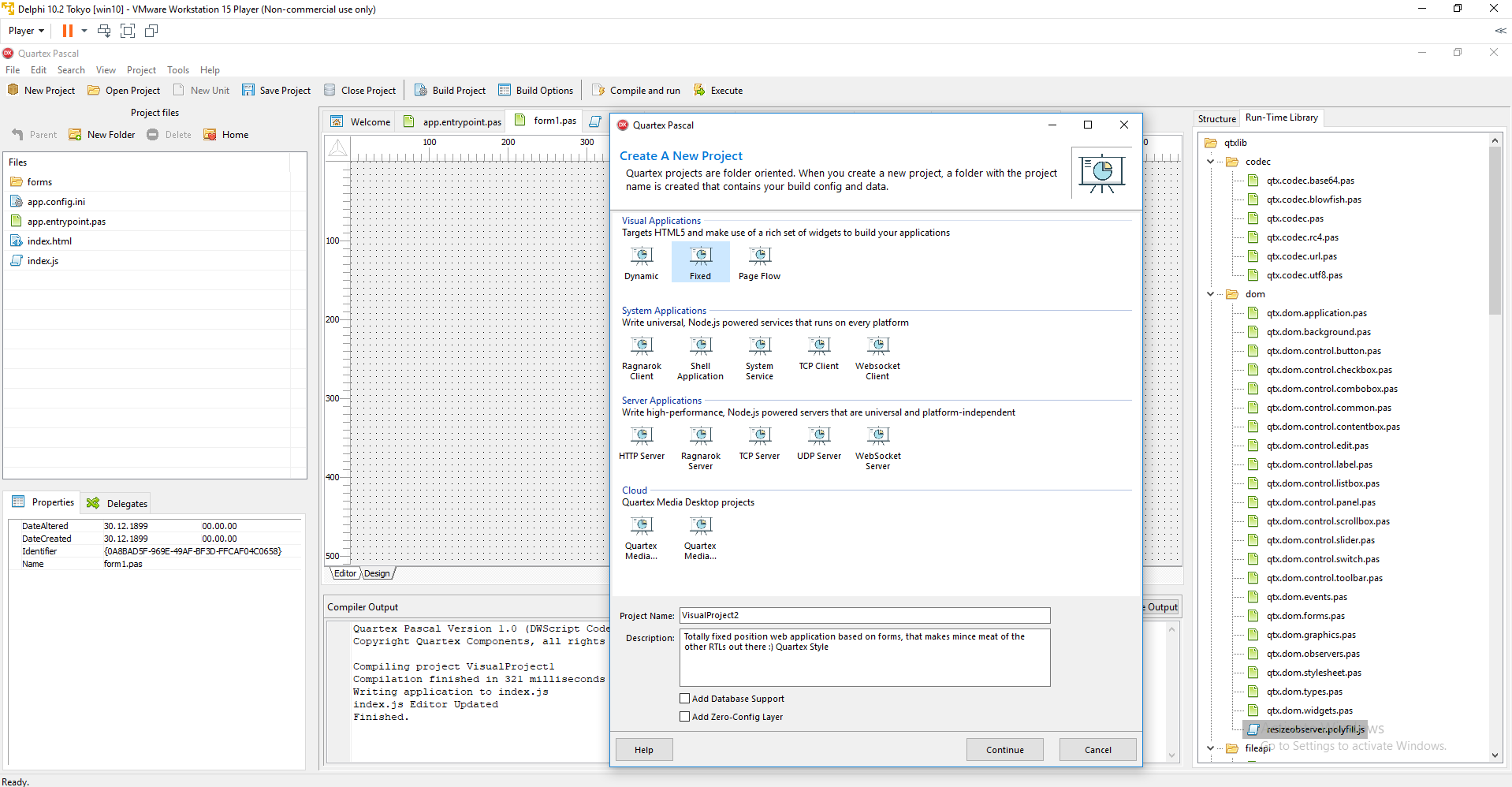






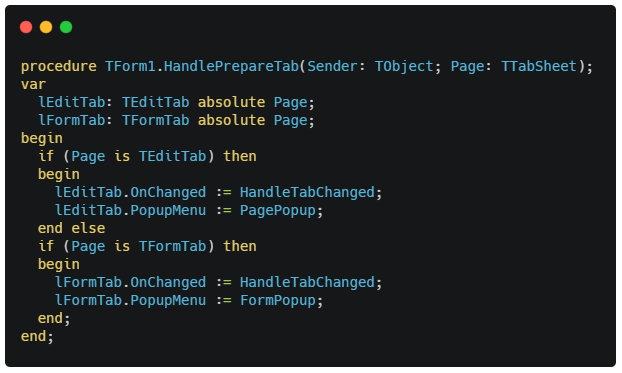




 I have become a political refugee. The left I belonged to and took part in for 30 years -is not the left I see today. The left I grew up with were champions of life, fairness and practicality. Fearless men who never backed down from a fight, yet lived by a moral codex where dialog should be sought by all means – and violence only used in self defence. And in journalism, the truth no matter how ugly it might be, must be told. Nothing must be held back on bias.
I have become a political refugee. The left I belonged to and took part in for 30 years -is not the left I see today. The left I grew up with were champions of life, fairness and practicality. Fearless men who never backed down from a fight, yet lived by a moral codex where dialog should be sought by all means – and violence only used in self defence. And in journalism, the truth no matter how ugly it might be, must be told. Nothing must be held back on bias.

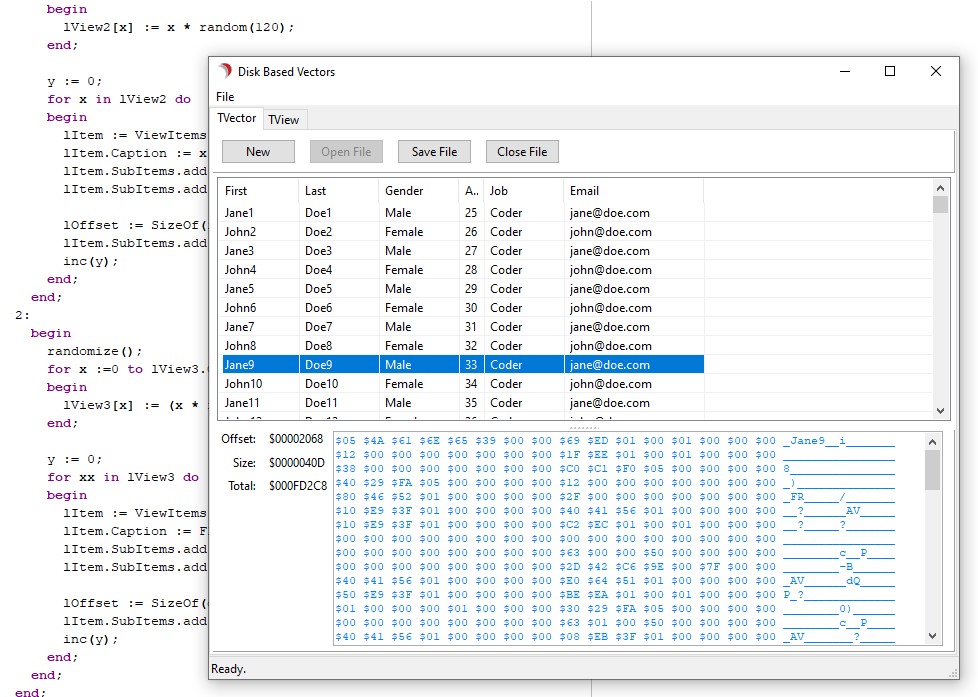


 A friend of mine asked me how on earth I managed to survive my spinal injury. In the immediate years after the accident the doctors pump you full of various medication, mostly painkillers, which has a terrible effect on both body and mind. A lot of people never recover from such an accident, and never get up. They end up entangled in a web of medication and pain, even after the injury itself has largely healed.
A friend of mine asked me how on earth I managed to survive my spinal injury. In the immediate years after the accident the doctors pump you full of various medication, mostly painkillers, which has a terrible effect on both body and mind. A lot of people never recover from such an accident, and never get up. They end up entangled in a web of medication and pain, even after the injury itself has largely healed.
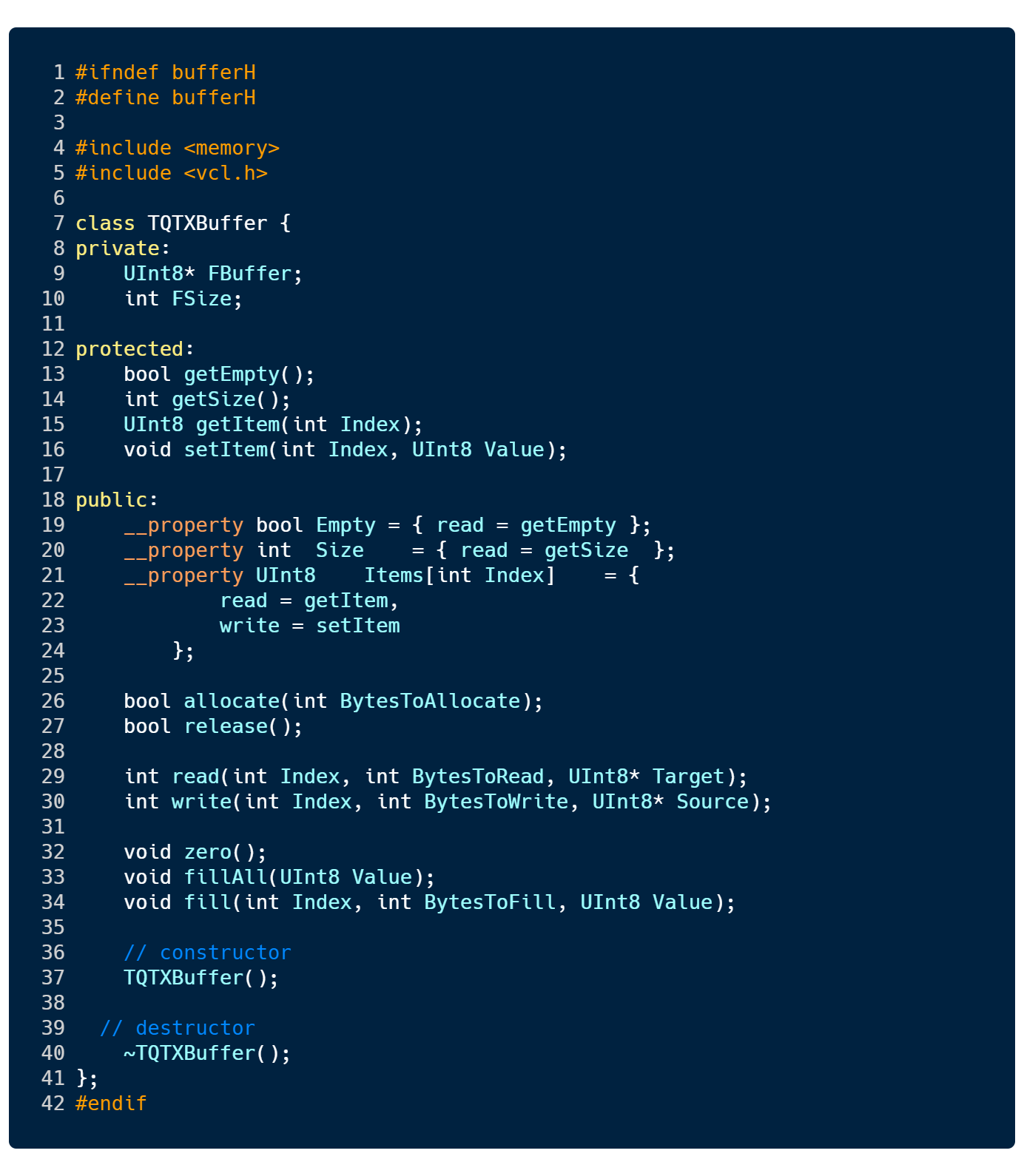



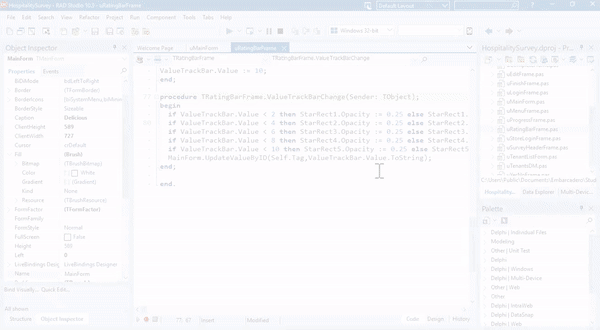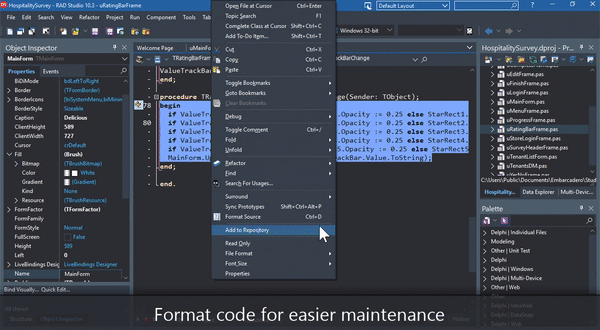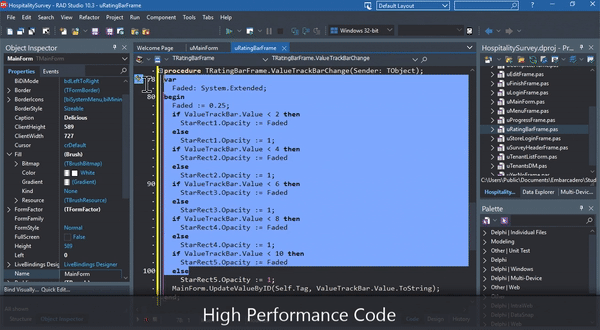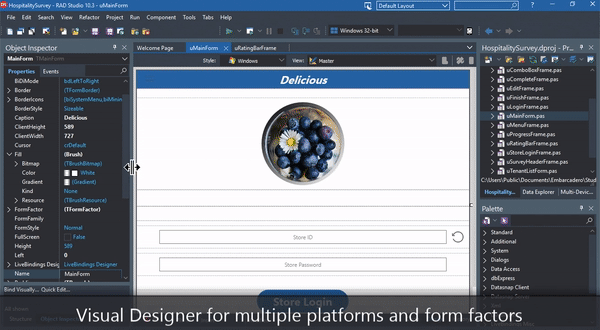



 Delphi is turning 25 and in connection with that, Jim Mckeeth is preparing a webinar! So make sure you register for the webinar in time! There is some very special and unique stuff lined up, so this is going to rock!
Delphi is turning 25 and in connection with that, Jim Mckeeth is preparing a webinar! So make sure you register for the webinar in time! There is some very special and unique stuff lined up, so this is going to rock!








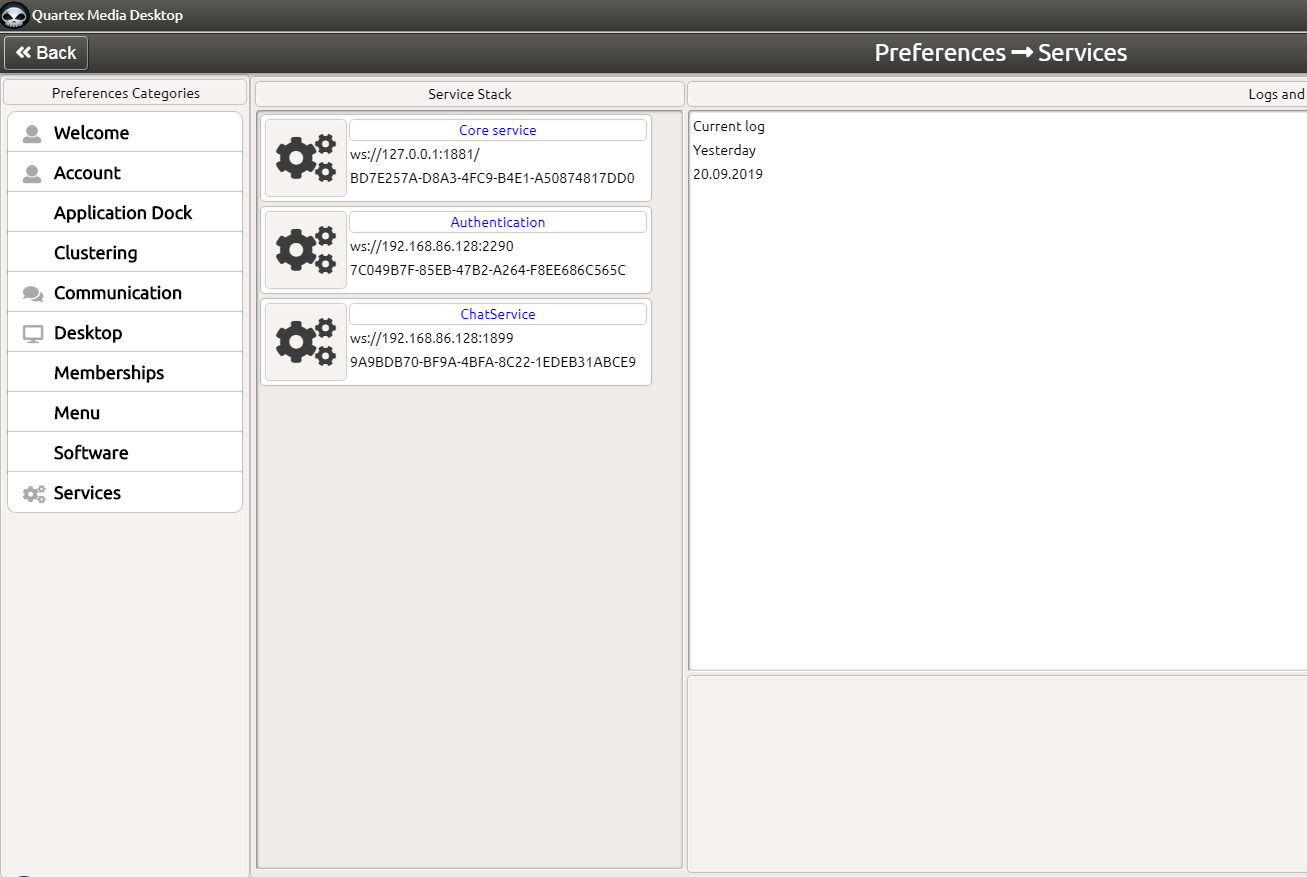








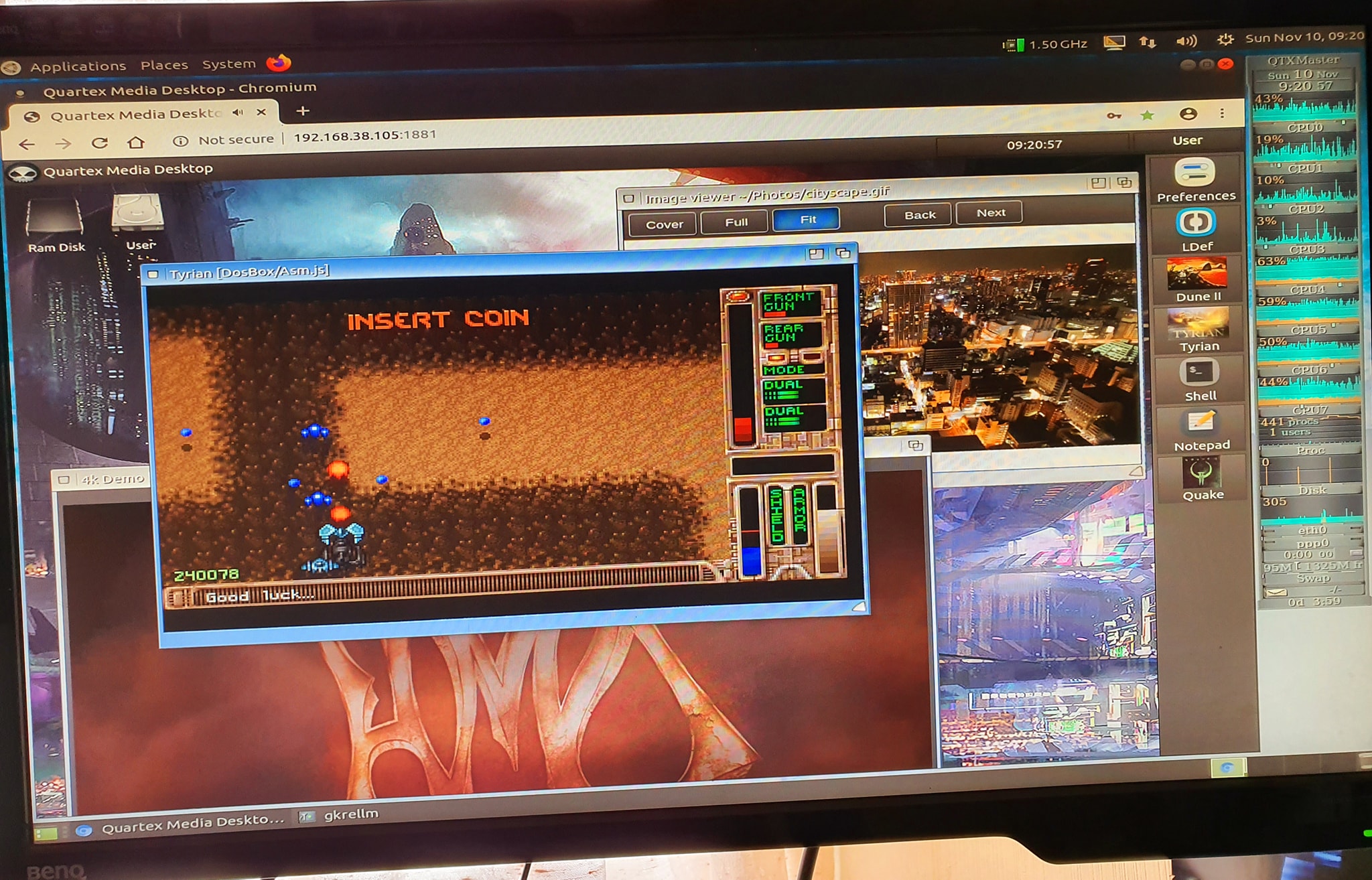


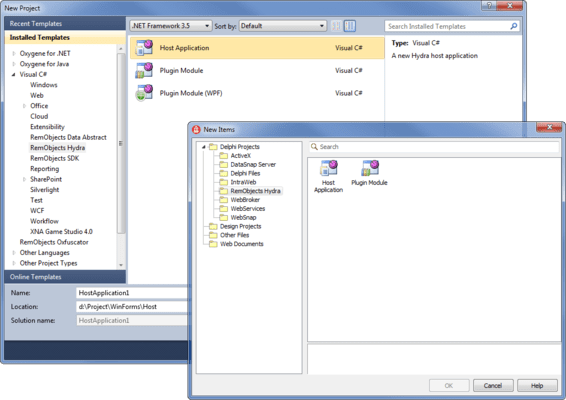


 As for hardware, i’m using an ODroid N2, which is a very powerful ARM based SBC (single board computer). You can use more or less any ARM device with Elements, providing the Linux distribution is based on Debian. So a Raspberry PI v4 with Ubuntu or Lubuntu will work fine. I’m using the ODroid N2 “full disk image” with Ubuntu Mate. So nothing out of the ordinary.
As for hardware, i’m using an ODroid N2, which is a very powerful ARM based SBC (single board computer). You can use more or less any ARM device with Elements, providing the Linux distribution is based on Debian. So a Raspberry PI v4 with Ubuntu or Lubuntu will work fine. I’m using the ODroid N2 “full disk image” with Ubuntu Mate. So nothing out of the ordinary. A popular website for .Net developers is called
A popular website for .Net developers is called 
 And for the record, the most obvious solution when faced with “that legacy Delphi project”, is to just go and buy a modern version of Delphi. DotNetRocks delivered a perfect example of that very arrogance my 2016 post was designed to convey; namely that “brogrammers” often act like Delphi 7 was the last Delphi. They also resorted to lies to sell their points: I never said that Anders was dogged for creating Delphi. Quite the opposite. I simply underlined that by ridiculing Delphi in one hand, and praising it’s author with the other – you are indirectly (and paradoxically) invalidating half his career. Anders is an awesome developer, but why exclude how he evolved his skills? Ofcourse Ander’s products will have his architectural signature on them.
And for the record, the most obvious solution when faced with “that legacy Delphi project”, is to just go and buy a modern version of Delphi. DotNetRocks delivered a perfect example of that very arrogance my 2016 post was designed to convey; namely that “brogrammers” often act like Delphi 7 was the last Delphi. They also resorted to lies to sell their points: I never said that Anders was dogged for creating Delphi. Quite the opposite. I simply underlined that by ridiculing Delphi in one hand, and praising it’s author with the other – you are indirectly (and paradoxically) invalidating half his career. Anders is an awesome developer, but why exclude how he evolved his skills? Ofcourse Ander’s products will have his architectural signature on them.











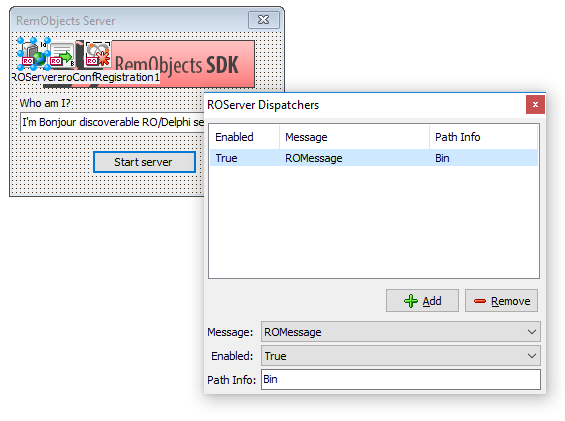

 Remoting SDK comes with support for Apple Bonjour, so if you want to use that functionality you have to install the Bonjour library from Apple. Once installed on your host machines, your RemObjects services can find each other.
Remoting SDK comes with support for Apple Bonjour, so if you want to use that functionality you have to install the Bonjour library from Apple. Once installed on your host machines, your RemObjects services can find each other. For example, WebSocket is an emerging standard that has become wildly popular. Remoting SDK does not support that out of the box, the reason is that the standard is practically identical to the RemObjects super-server, and partly because there must be room for third party vendors.
For example, WebSocket is an emerging standard that has become wildly popular. Remoting SDK does not support that out of the box, the reason is that the standard is practically identical to the RemObjects super-server, and partly because there must be room for third party vendors.


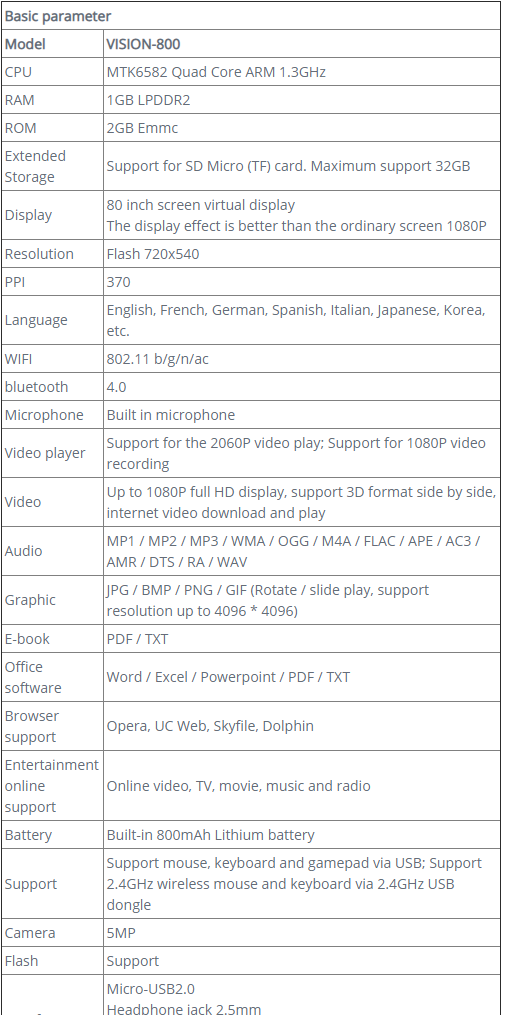 These glasses have potential. Or perhaps better phrased – the technology holds a lot of promise. If they had opted for focal-lenses and a wider field of vision, they would have been a fantastic experience. I have no problem imagining this type of tech replacing monitors in the near future – at least for movie experiences.
These glasses have potential. Or perhaps better phrased – the technology holds a lot of promise. If they had opted for focal-lenses and a wider field of vision, they would have been a fantastic experience. I have no problem imagining this type of tech replacing monitors in the near future – at least for movie experiences.









 And finally, since you definitely want to convert your JavaScript and/or WebAssembly into a stand-alone executable: you will need
And finally, since you definitely want to convert your JavaScript and/or WebAssembly into a stand-alone executable: you will need 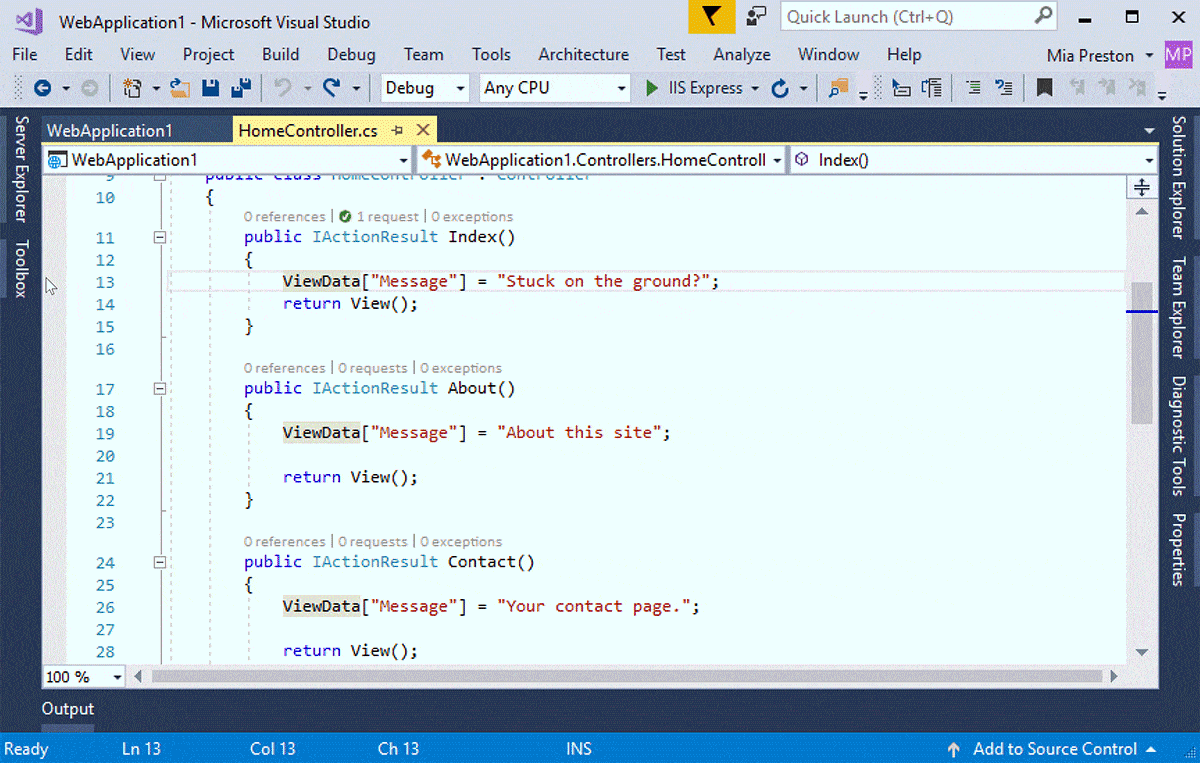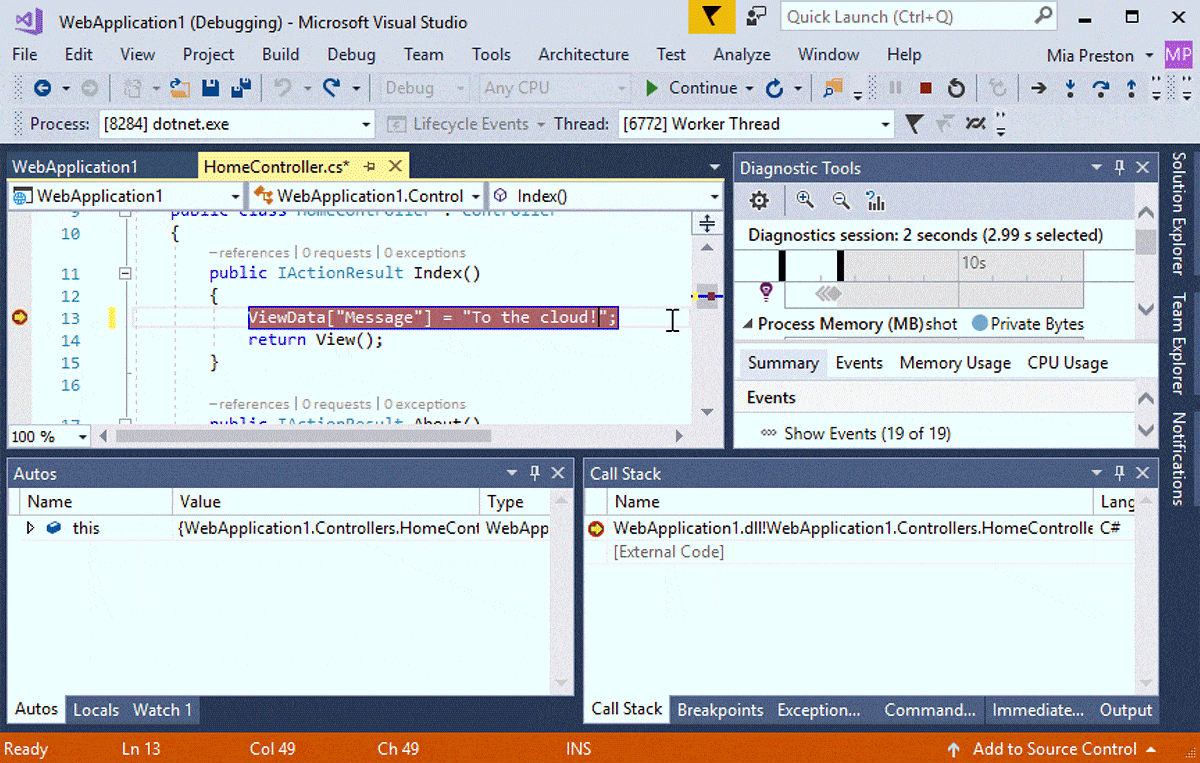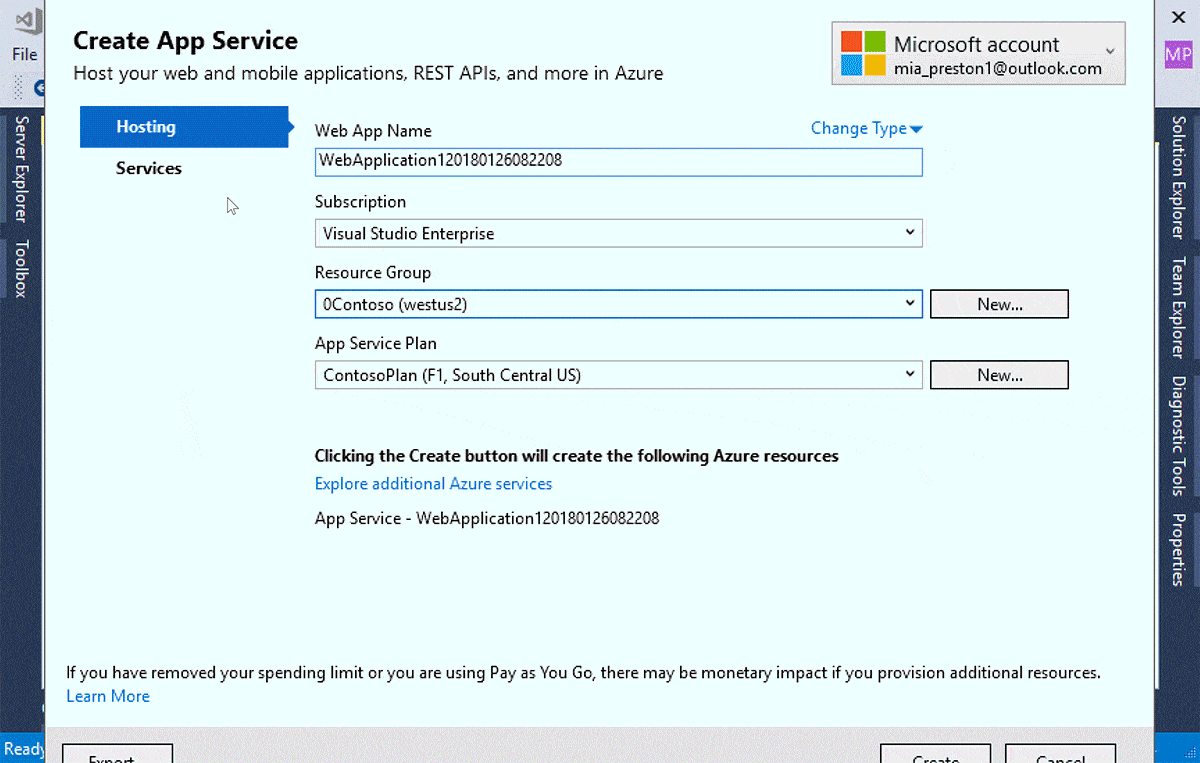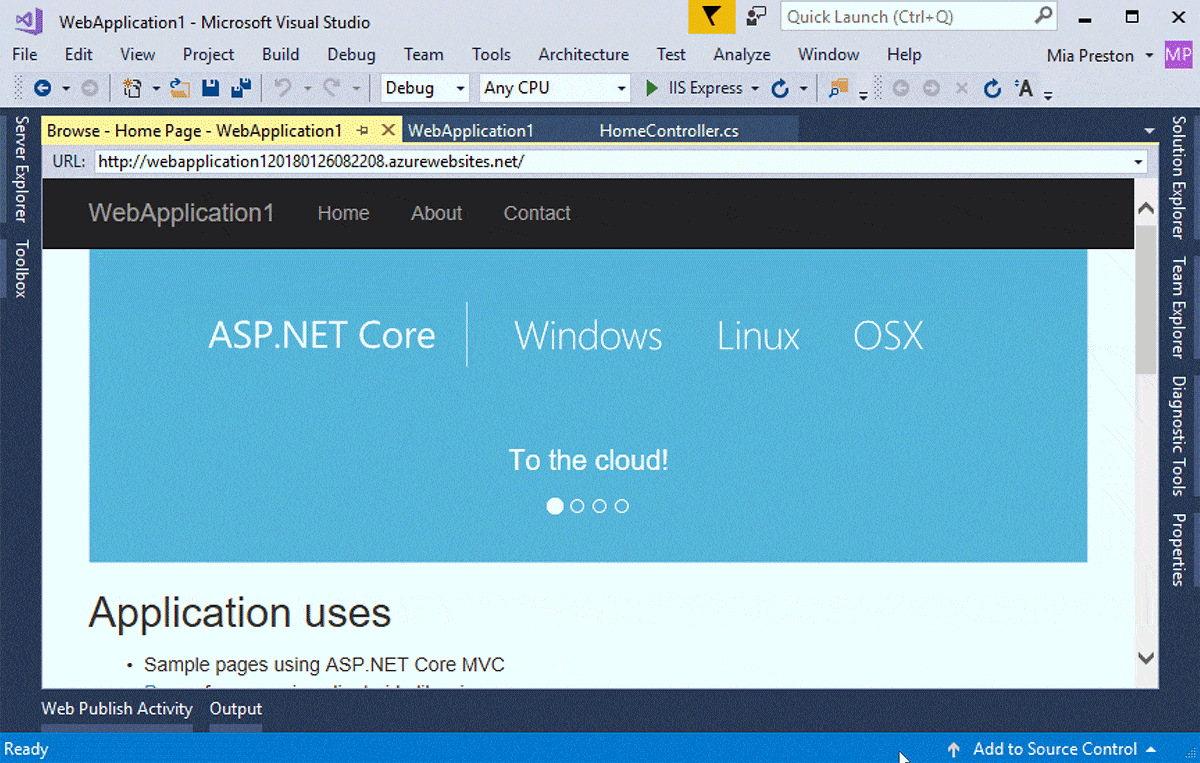


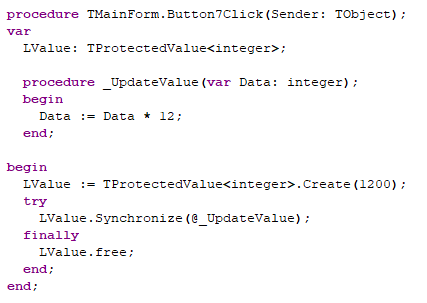
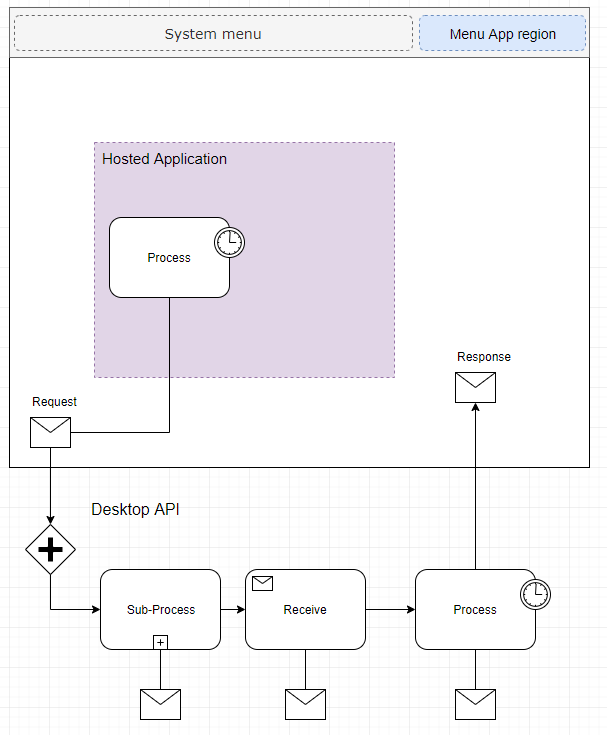


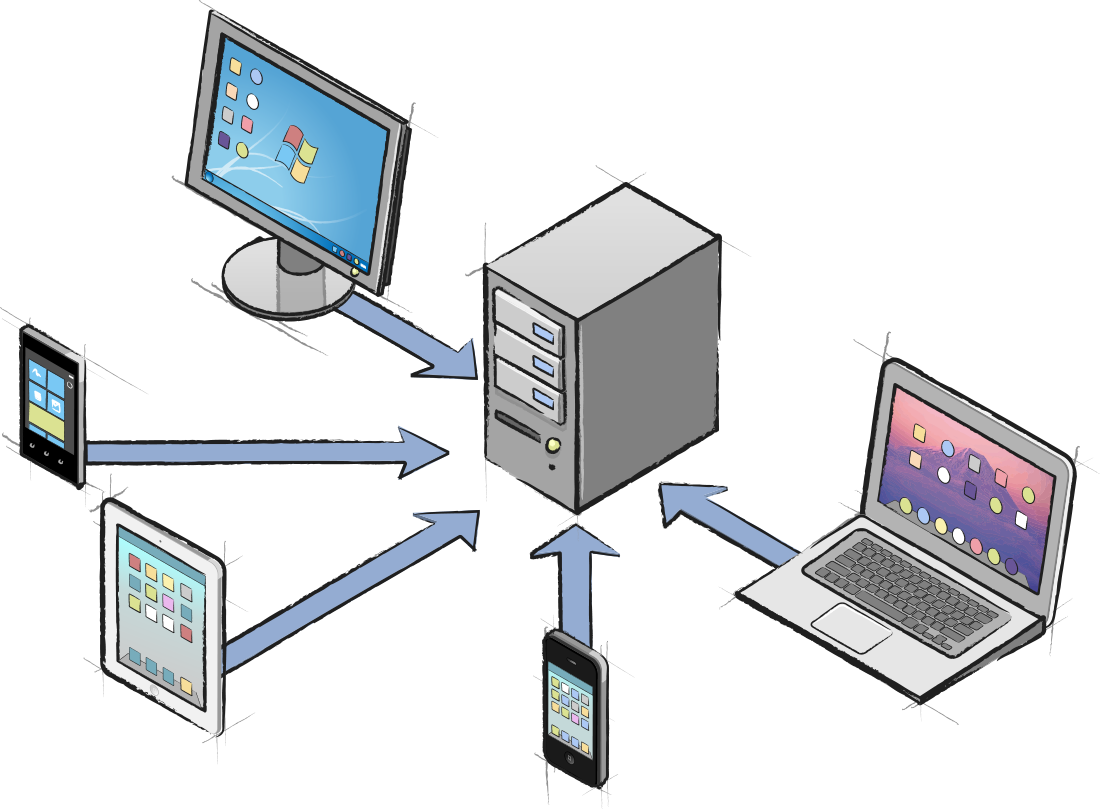 The thing is, I’m really not “traveling salesman” material by any stretch of the imagination. My tolerance for bullshit is ridiculously low, and being practical of nature I loath fancy products that cost a fortune yet deliver nothing but superficial fluff.
The thing is, I’m really not “traveling salesman” material by any stretch of the imagination. My tolerance for bullshit is ridiculously low, and being practical of nature I loath fancy products that cost a fortune yet deliver nothing but superficial fluff.





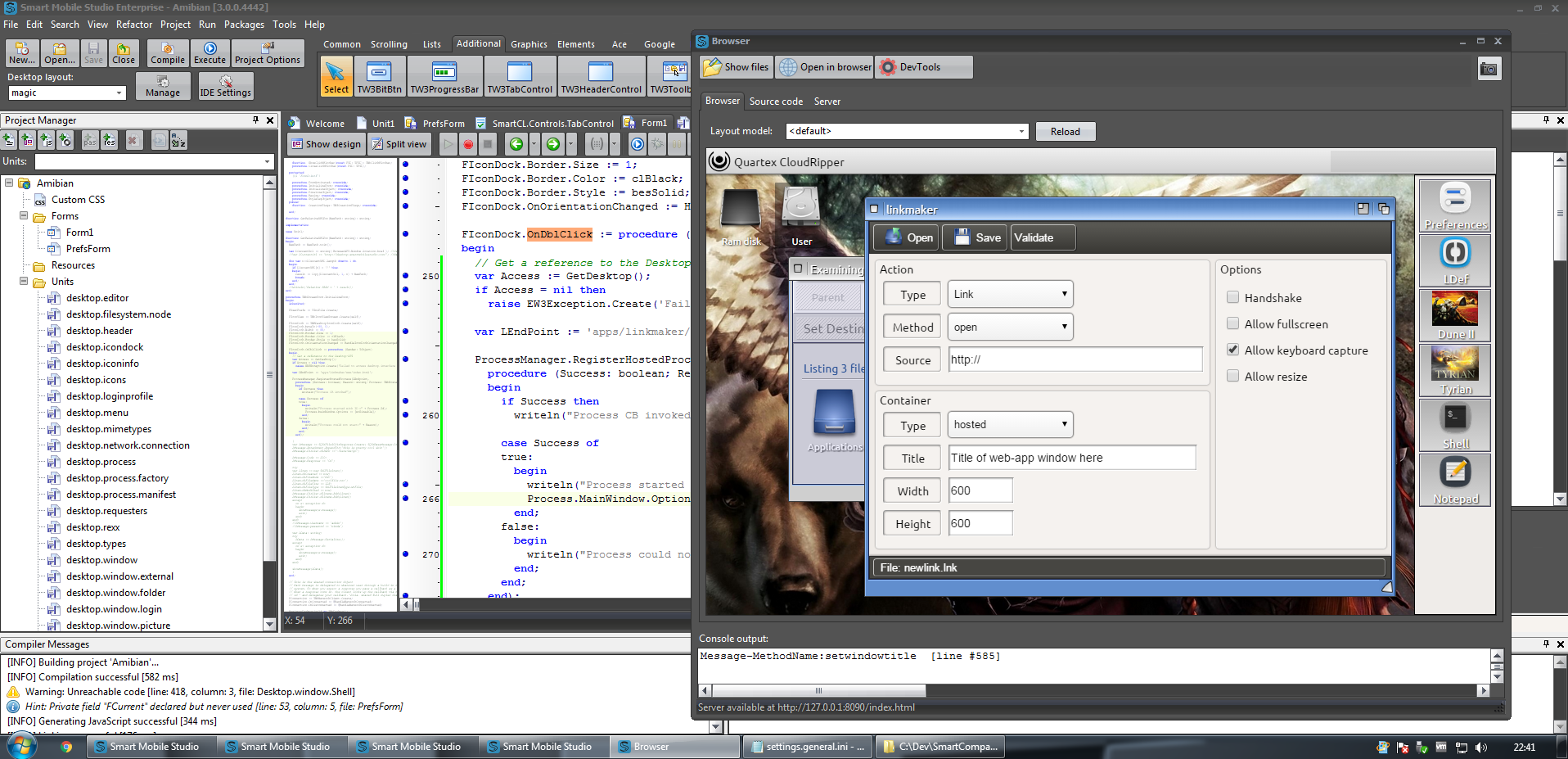
 It might seem odd to focus on something as trivial as a stack, but I have my reasons. A friend of mine who is a brilliant coder with plenty of large projects behind him recently decided to have a go at assembly coding. He was doing fine and everything was great, until he started pushing and popping things off the stack.
It might seem odd to focus on something as trivial as a stack, but I have my reasons. A friend of mine who is a brilliant coder with plenty of large projects behind him recently decided to have a go at assembly coding. He was doing fine and everything was great, until he started pushing and popping things off the stack. The benefit is that the cost of storing values on a stack is almost zero in terms of cpu operations. A list based stack is more expensive; it will allocate memory for a record-item to hold the information about the data, then it will allocate memory to hold the actual data (depends on the type naturally) and finally copy the data into the newly allocated buffer. Hundreds if not thousands of instructions can be involved here.
The benefit is that the cost of storing values on a stack is almost zero in terms of cpu operations. A list based stack is more expensive; it will allocate memory for a record-item to hold the information about the data, then it will allocate memory to hold the actual data (depends on the type naturally) and finally copy the data into the newly allocated buffer. Hundreds if not thousands of instructions can be involved here.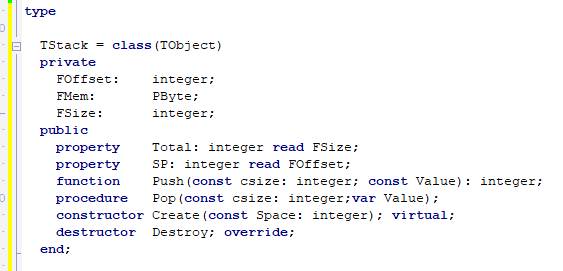
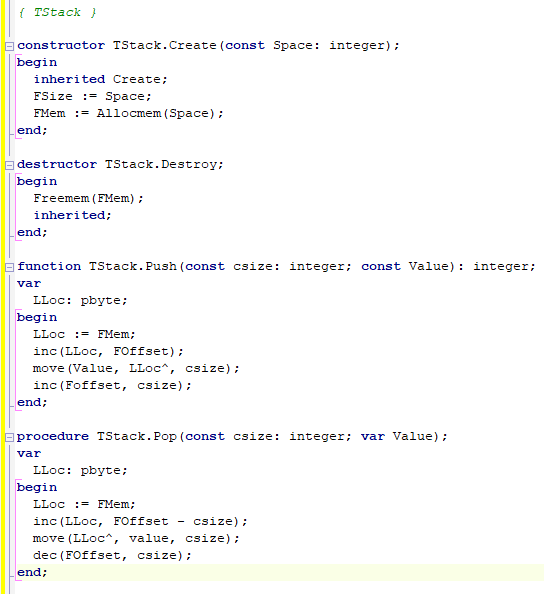



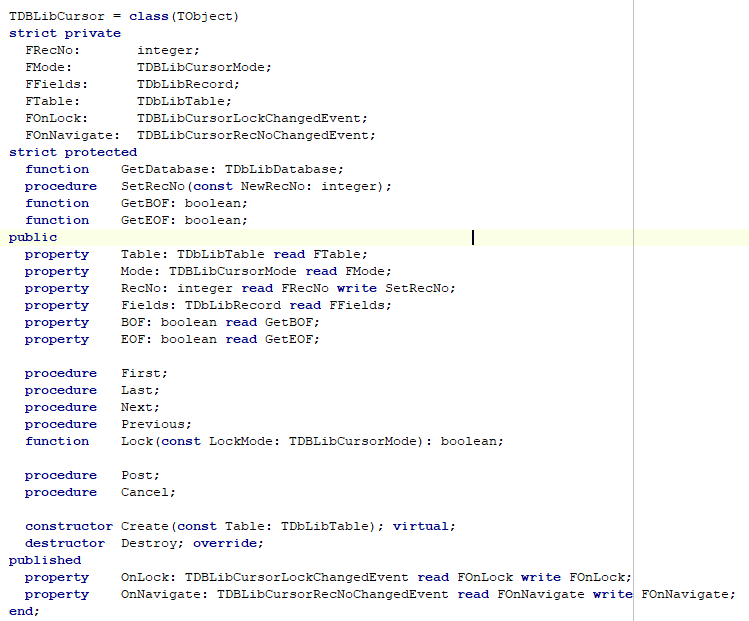
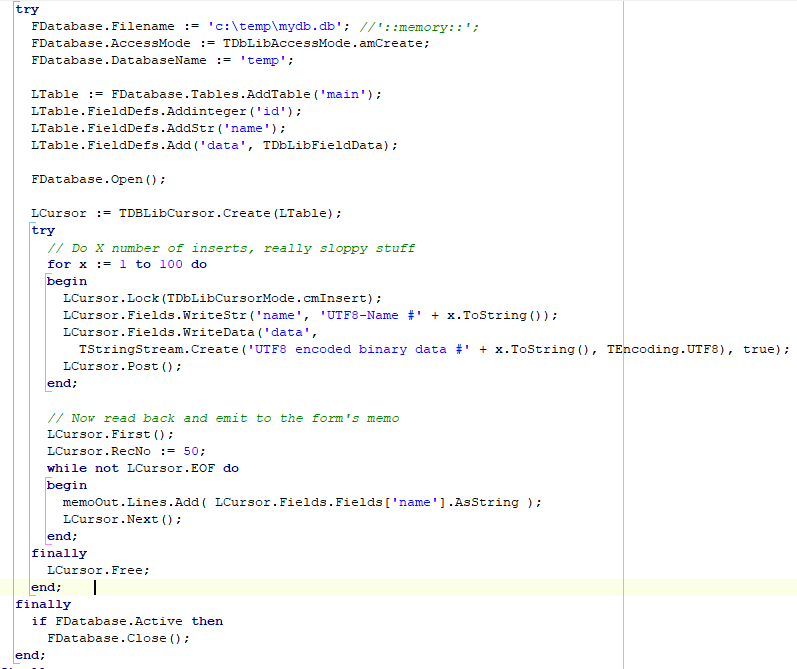
 What I find strange, if not borderline insane, is how ingrained people are to their company or “team”. I have never understood people who watch soccer, who get physically upset over a game – or who demonstrate complete and utter loyalty to a team no matter how ridiculous that team might be. To me, soccer is just 22 grown men running around in their underwear chasing an inflated dead animal.
What I find strange, if not borderline insane, is how ingrained people are to their company or “team”. I have never understood people who watch soccer, who get physically upset over a game – or who demonstrate complete and utter loyalty to a team no matter how ridiculous that team might be. To me, soccer is just 22 grown men running around in their underwear chasing an inflated dead animal.

 After my initial post people have dragged poor Trevor Dickinson into the debate, complaining to him about statements made by me. That is unfortunate because Trevor is not involved in our opinions at all. He even corrected me about mistakes I made in the previous article – and have absolutely not been a catalyst (quite the opposite!).
After my initial post people have dragged poor Trevor Dickinson into the debate, complaining to him about statements made by me. That is unfortunate because Trevor is not involved in our opinions at all. He even corrected me about mistakes I made in the previous article – and have absolutely not been a catalyst (quite the opposite!).

 The next question then becomes: what exactly is stopping the owners from moving forward? Why dont the companies that hold the various IP’s roam silicon-valley in search of funding? And it’s here that we face the situation I briefly painted a picture of in my last post: they are in a perpetual stale-mate.
The next question then becomes: what exactly is stopping the owners from moving forward? Why dont the companies that hold the various IP’s roam silicon-valley in search of funding? And it’s here that we face the situation I briefly painted a picture of in my last post: they are in a perpetual stale-mate.
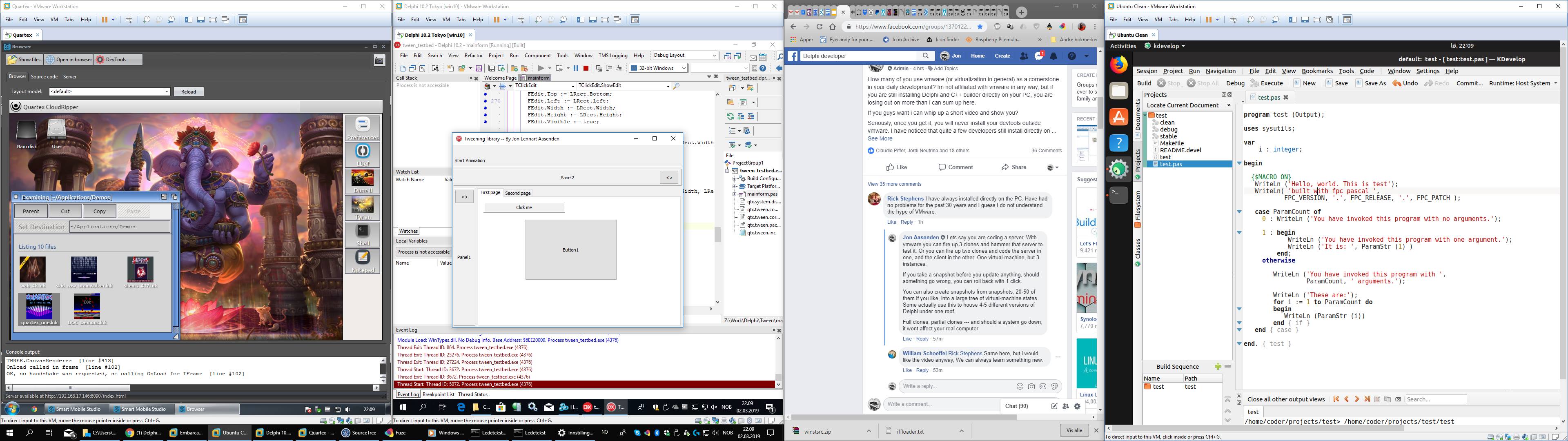




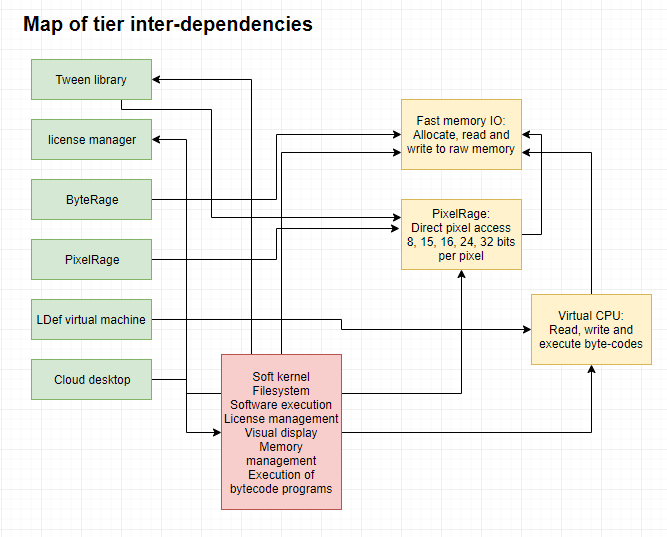
















 In light of this episode, thought I could share five reasons why Delphi and object-pascal remains my primary programming language.
In light of this episode, thought I could share five reasons why Delphi and object-pascal remains my primary programming language.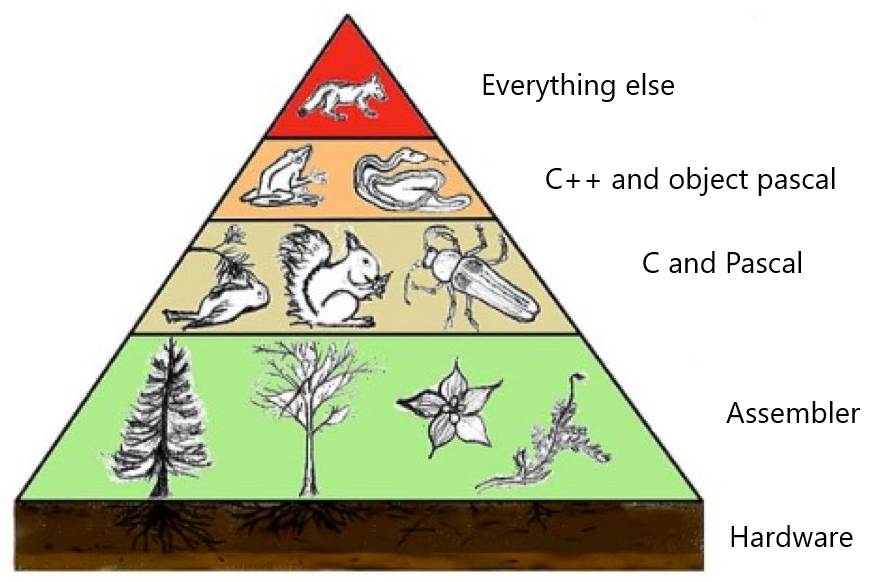













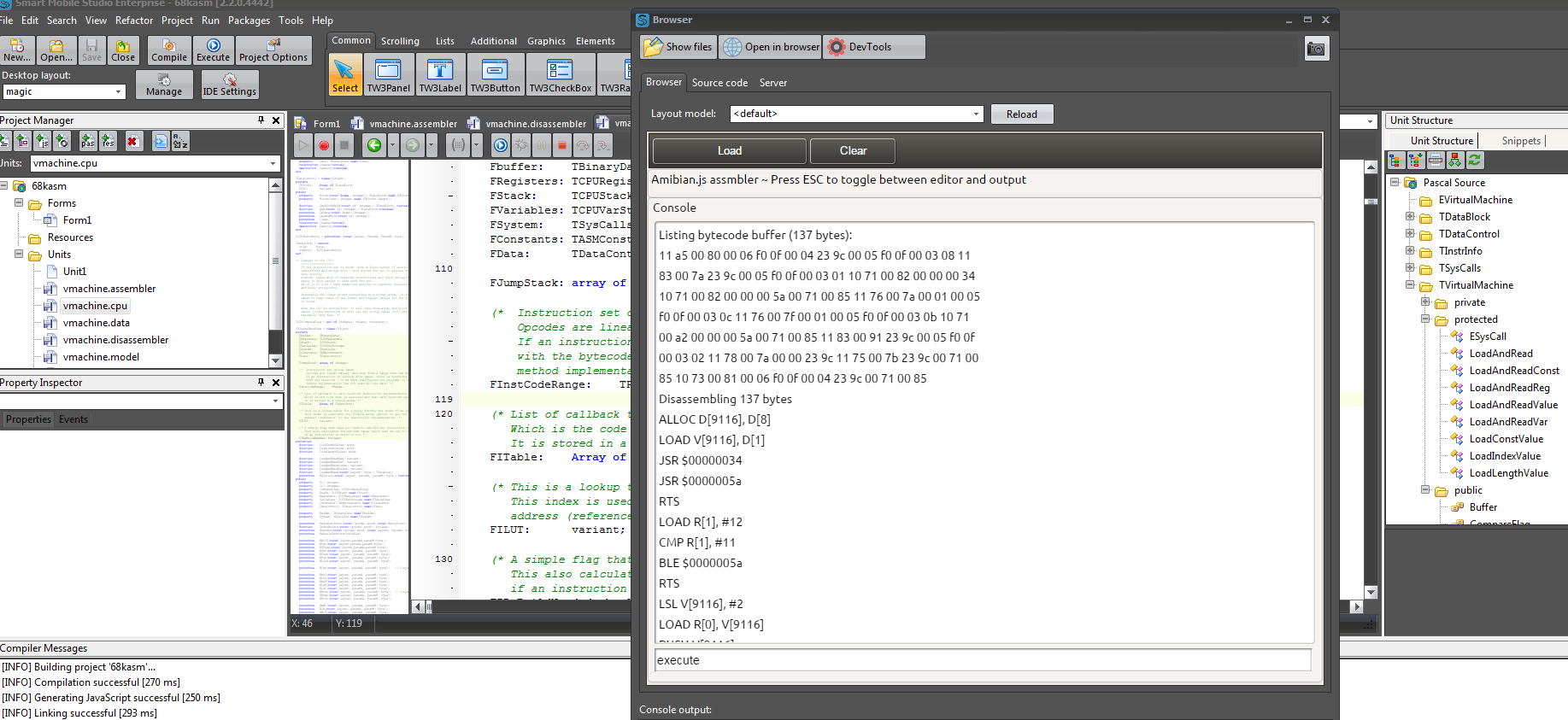






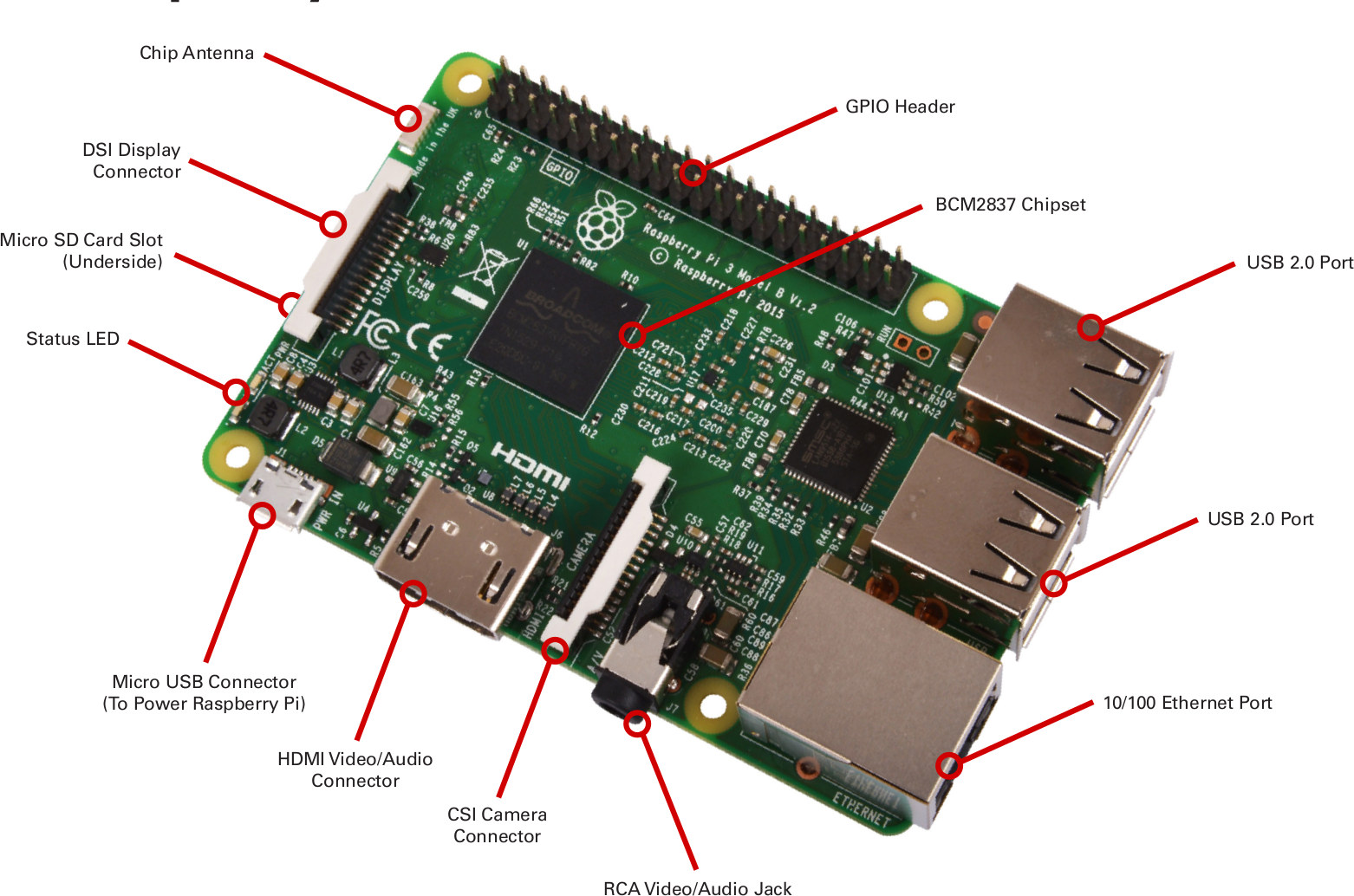



 A couple of months back, before I started working for Embarcadero I promised to do a video presentation that would be available on
A couple of months back, before I started working for Embarcadero I promised to do a video presentation that would be available on 









 I have several products and frameworks that naturally takes time to maintain and evolve. And having to maintain websites, pay for tax and invoicing services, pay for hosting (and so on), well it consumes a lot of hours. Hours that I can no longer afford to spend (my work at Embarcadero must come first, I have a family to support). So Patreon is a great way to optimize a very busy schedule.
I have several products and frameworks that naturally takes time to maintain and evolve. And having to maintain websites, pay for tax and invoicing services, pay for hosting (and so on), well it consumes a lot of hours. Hours that I can no longer afford to spend (my work at Embarcadero must come first, I have a family to support). So Patreon is a great way to optimize a very busy schedule.




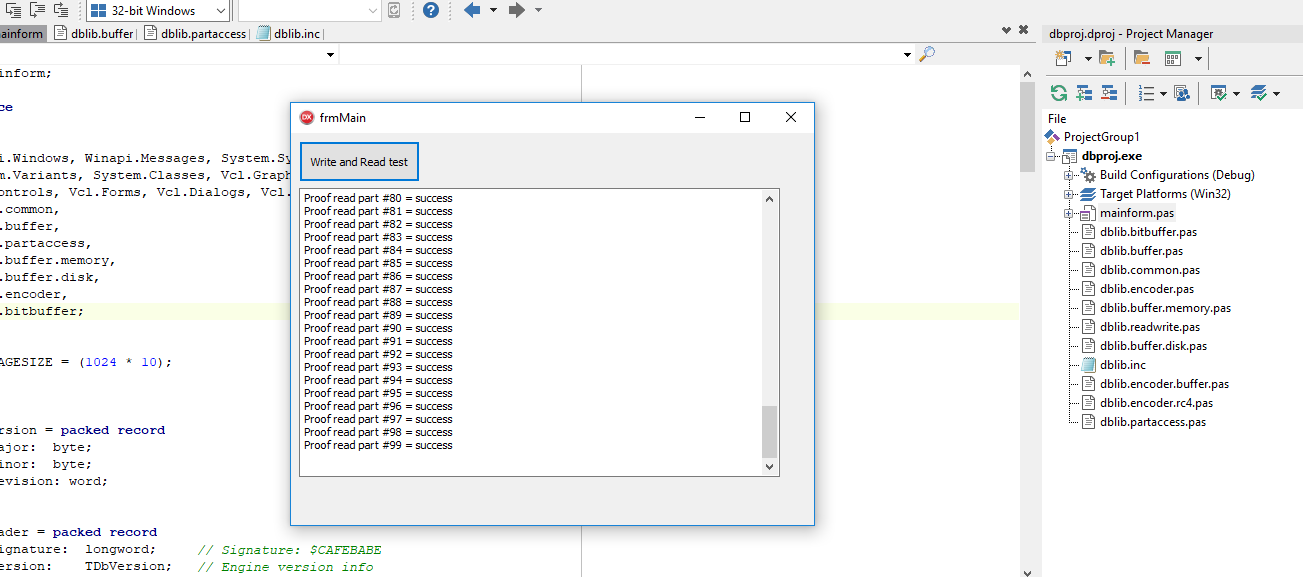

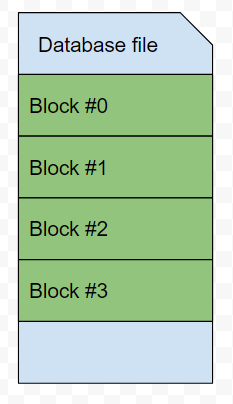 So ok, what if we divide the file into blocks, each capable of storing a piece of data? So if a single block is not enough, the data will be spread out over multiple blocks?
So ok, what if we divide the file into blocks, each capable of storing a piece of data? So if a single block is not enough, the data will be spread out over multiple blocks?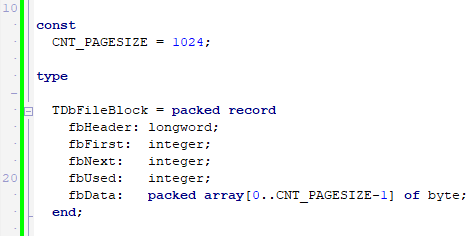







 One of the things I often hear when talking to developers, is the “visual studio myth”. The notion that Visual Studio is free and there are no strings attached. And this is a myth, just to be clear. Microsoft have ridicules amounts of money so they could afford to lend you Visual Studio for five years (which was how they operated until very recently). If you checked the license for Visual Studio that’s what it said: you get to use it for five years, then you better pony up the cash. And by that time you have no doubt advanced to Enterprise level, which means that check will be signed in blood.
One of the things I often hear when talking to developers, is the “visual studio myth”. The notion that Visual Studio is free and there are no strings attached. And this is a myth, just to be clear. Microsoft have ridicules amounts of money so they could afford to lend you Visual Studio for five years (which was how they operated until very recently). If you checked the license for Visual Studio that’s what it said: you get to use it for five years, then you better pony up the cash. And by that time you have no doubt advanced to Enterprise level, which means that check will be signed in blood.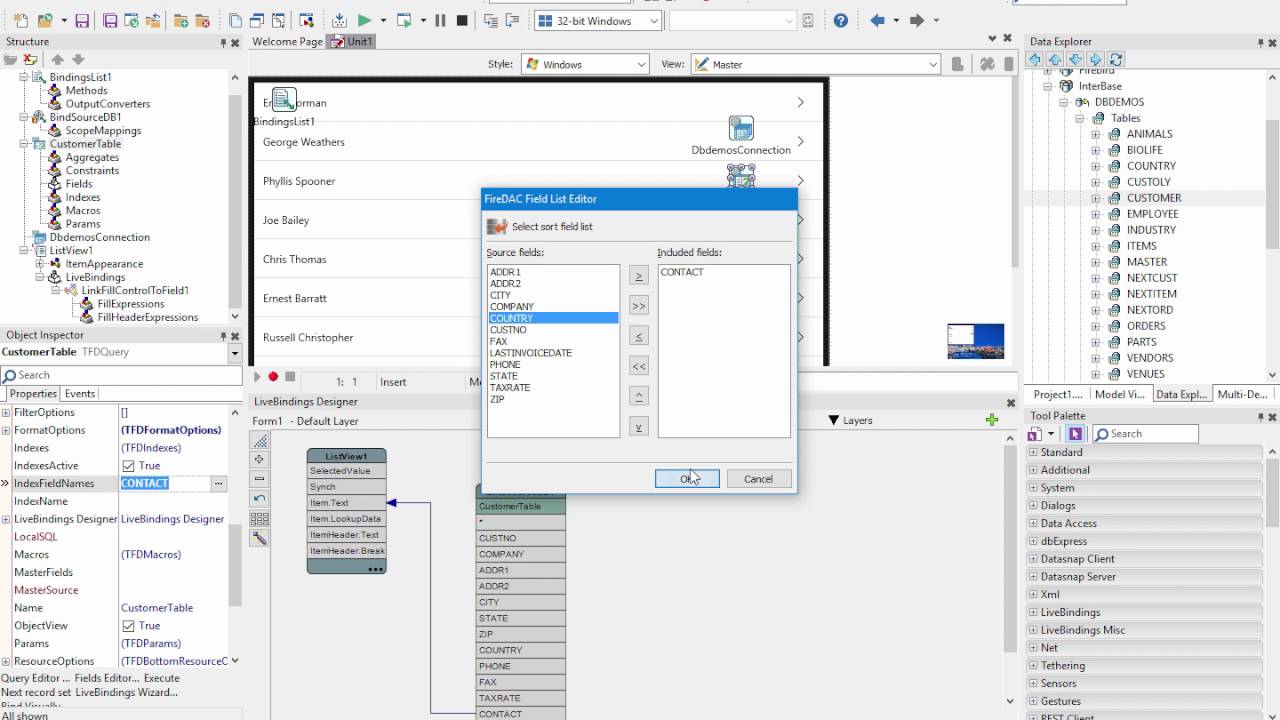



 I have only used Android on a pad and the odd Samsung Galaxy phone, so this should be interesting. I Downloaded the Lolipop disk image, burned it to the sd-card and booted up.
I have only used Android on a pad and the odd Samsung Galaxy phone, so this should be interesting. I Downloaded the Lolipop disk image, burned it to the sd-card and booted up.



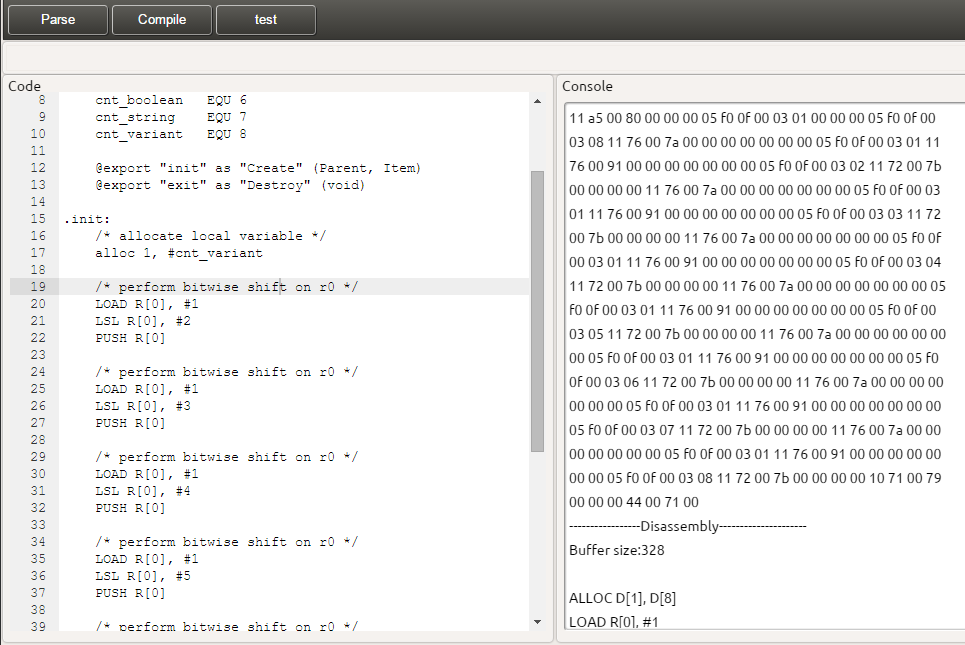
 I have no idea how many boards have been released since 2016, but some 20+ new boards feels like a reasonable number. Which under normal circumstances would be awesome, because competition can be healthy. It can stimulate manufacturers to deliver better quality, higher performance and to use eco-friendly resources.
I have no idea how many boards have been released since 2016, but some 20+ new boards feels like a reasonable number. Which under normal circumstances would be awesome, because competition can be healthy. It can stimulate manufacturers to deliver better quality, higher performance and to use eco-friendly resources.


