Show full content
In the previous blog post we discussed a few potential neural network (MLP) applications in rendering and one of the conclusions was that although easy to implement, inference cost can be quite high, especially for larger networks which makes a compute shader implementation of it impractical in many cases.
For that reason, specialised hardware has been part of GPUs for a few years already, designed to accelerate such operations. Nvidia for example calls this Tensor cores and has been part of their GPUs since the Volta architecture was released, back in 2017. This is for example one of the 4 partitions of Volta’s SM, containing 2 Tensor cores (source):

In total, Volta’s SM contains 8 Tensor cores. A parenthesis to also notice that the partition also includes 16 “CUDA cores”, the FP32 scalar units in the image above, so 64 CUDA cores in total in the SM.
Each Tensor core implement the following multiply-add operation, where each operand is a 4×4 matrix:

or expanding into actual matrices (source):

Matrices A and B are fp16 while C, and the result D, can be either fp16 or fp32.
Why is this important? To calculate the above, also called Matrix Multiply and Accumulate (MMA), operation on 4×4 matrices 64 fused multiply add (fma) instructions are required. A CUDA core mentioned above can execute one fused multiply add instruction per clock, so it would take 64 clocks to calculate the MMA operation in the ideal case. A Tensor core can do it in one clock. Put differently, a single SM can execute 64 fma instructions per clock on CUDA cores but 512 on Tensor cores, a theoretical speedup of x8. Of course Tensor cores aren’t restricted only to 4×4 MMA operations, larger matrices can be broken down into smaller, 4×4 blocks and warps can work cooperatively to share data and calculate MMA operations on much larger matrices.
In this and the previous post we are talking about neural networks, what do matrix operations have to with that? In the previous post we described how the output of a node in an MLP, say Node 0:

can be described as the weighted sum of its inputs (effectively a dot product) plus a bias:

Considering all nodes in a specific layer, we could pack all weights in a 3×3 matrix (for the specific-sized MLP layer), the input in a 3 element vector (effectively a 3×1 matrix) and similarly the bias and express the whole layer output calculation as:

The other layers can be calculated similarly. This is in essence the
MMA operation discussed above, suitable for execution on Tensor cores. Also, since the weights of the MLP will be the same for multiple warps, the GPU can collect and collate node inputs and biases from different warps into 4×4 arrays as well to fully utilise the Tensor core.
Unfortunately access to Tensor cores isn’t provided in DX12/HLSL formally yet, but recently a preview Agility SDK was released which provided an implementation of Cooperative Vectors which did. Although the Cooperative Vectors spec won’t be officially supported in its current form it can provide now a taste of things to come.
To use Cooperative Vectors in DX12/HLSL you will need the AgilitySDK 1.717.1-preview, a DXC compiler with SM6.9 support and the Nvidia 590.26 preview driver.
To begin with, if you are defining in your code the Agility SDK version using the recommended D3D12_SDK_VERSION define you will find that it won’t work for the preview SDK so better use its version number directly.
extern "C" { __declspec(dllexport) extern const UINT D3D12SDKVersion = 717; } // D3D12_SDK_VERSION doesn't work for the preview Agility SDK
extern "C" { __declspec(dllexport) extern const char* D3D12SDKPath = u8".\\D3D12\\"; }
Also worth compiling a shader with SM6.9, eg ps_6_9 or cs_6_9, to make sure that the DXC compiler has been upgraded successfully.
Next, you will need to activate experimental features and support for cooperative vectors, before creating the D3D device:
IID Features[] = { D3D12ExperimentalShaderModels, D3D12CooperativeVectorExperiment };
ThrowIfFailed( D3D12EnableExperimentalFeatures(_countof(Features), Features, nullptr, nullptr) );
// create device
and finally check for Cooperative Vectors support:
D3D12_FEATURE_DATA_D3D12_OPTIONS_EXPERIMENTAL experimentalData = {};
ThrowIfFailed(m_device->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS_EXPERIMENTAL, &experimentalData, sizeof(experimentalData)));
if (experimentalData.CooperativeVectorTier != D3D12_COOPERATIVE_VECTOR_TIER_NOT_SUPPORTED)
{
// Congratulations, cooperative vectors are supported.
}
A word of advice: read the documentation and official blog post (referenced above) thoroughly, I made the mistake of skimming through them and had to discover all the things I’ve just talked about the hard way. Also, since you are enabling experimental features, the Debug Layer won’t point out the issues it normally would, so you are pretty much on your own when it comes to debugging mistakes.
To use Cooperative Vectors to calculate the output of an MLP layer you’ll first need to have stored the weights and the biases of the MLP in ByteAddressBuffers. Then you can define a vector with the layer inputs.
vector<TYPE,COUNT> inputVector = { .... };
This is a new long vector data type added to support vectors longer than the usual 4 element vectors (eg float4). You can define type (float, int etc) and number of elements in the vector. Next you need to create references for the matrix that will contain the weights for a specific layer as well a reference to the biases:
ByteAddressBuffer weightsBuffer : register(t0);
ByteAddressBuffer biasesBuffer : register(t1);
MatrixRef<DATA_TYPE, LAYER_NEURON_COUNT, INPUT_NEURON_COUNT, MATRIX_LAYOUT_MUL_OPTIMAL> weightsLayer = { weightsBuffer, weightsOffset, 0 };
VectorRef<DATA_TYPE> biasLayer = { biasesBuffer, biasesOffset };
The matrix layout can be row major, column major or “optimal” for the targeted GPU which is what I chose in this case. Since I have stored the weights for the whole MLP in one ByteAddressBuffer, I need to provide a weightsOffset specific to this layer. Similar idea behind the reference for the biases vector.
Finally, we can simply implement the MMA operation as follows:
vector<TYPE, LAYER_NEURON_COUNT> layer = MulAdd<TYPE>(weightsLayer, MakeInterpretedVector<DATA_TYPE>(inputVector), biasLayer); layer1 = select((layer1 >= 0.0), layer1, (layer1 * LEAKY_RELU_SLOPE));
The output is a long vector with the result of the MulAdd operation. At the end we apply the leaky ReLU activation function for completeness. And that is all to takes to calculate the output of an MLP layer.
A side story, initially I implemented everything using float32 data types since I already had a compute shader MLP implementation which used float32s to store weights and biases. The code crashed during PSO creation with no indication why (no debug layer for experimental features like discussed). This was a big head scratcher and seemingly insolvable problem until I looked into feature support for Cooperative Vectors:
if (experimentalData.CooperativeVectorTier != D3D12_COOPERATIVE_VECTOR_TIER_NOT_SUPPORTED)
{
// PropCounts to be filled by driver implementation
D3D12_FEATURE_DATA_COOPERATIVE_VECTOR CoopVecProperties = { 0, NULL, 0, NULL, 0, NULL };
// CheckFeatureSupport returns the number of input combinations for intrinsics
m_device->CheckFeatureSupport(D3D12_FEATURE_COOPERATIVE_VECTOR, &CoopVecProperties, sizeof(D3D12_FEATURE_DATA_COOPERATIVE_VECTOR));
// Use MatrixVectorMulAddPropCount returned from the above
// Use CheckFeatureSupport call to query only MatrixVectorMulAddProperties
UINT MatrixVectorMulAddPropCount = CoopVecProperties.MatrixVectorMulAddPropCount;
std::vector<D3D12_COOPERATIVE_VECTOR_PROPERTIES_MUL> properties(MatrixVectorMulAddPropCount);
CoopVecProperties.pMatrixVectorMulAddProperties = properties.data();
// CheckFeatureSupport returns the supported input combinations for the mul intrinsics
m_device->CheckFeatureSupport(D3D12_FEATURE_COOPERATIVE_VECTOR, &CoopVecProperties, sizeof(D3D12_FEATURE_DATA_COOPERATIVE_VECTOR));
// Use MatrixVectorMulAdd shader with datatype and interpretation
// combination matching one of those returned.
}
it turned out that float32 matrix-vector multiplication is not supported

Converting everything to float16 fixed the crash and the PSO compiled fine. Digging deeper into Tensor core design later it became obvious why this happened, as discussed above.
To store the MLP weights and biases to feed the Tensor cores, like briefly mentioned above, we need to use ByteAddressBuffers. We can either store the weights and biases in a separate buffer per MLP layer, or we can store all weights for all layers in a single buffer, similarly for all the biases. In such a case, there are some alignment requirements we need to pay attention to and this is that the weights for each layer need to start at 128 byte aligned (multiples of) offsets in the buffer and the biases for each layer need to start at 64 byte aligned offsets.
We also talked about data format restrictions and that the Tensor cores require the weights in float16, while the biases can be either float16 or float32. The API provides a mechanism to convert the weights into the supported format as follows:
//get a pointer to a preview command list
ComPtr<ID3D12DevicePreview> devicePreview;
m_device->QueryInterface(IID_PPV_ARGS(&devicePreview));
ComPtr<ID3D12GraphicsCommandListPreview> commandListPreview;
m_commandList->QueryInterface(IID_PPV_ARGS(&commandListPreview));
//get pointers to input and output weight buffers
D3D12_GPU_VIRTUAL_ADDRESS srcVA = weightsBuffer->GetResource()->GetGPUVirtualAddress();
D3D12_GPU_VIRTUAL_ADDRESS destVA = weightsBufferCoopVec->GetResource()->GetGPUVirtualAddress();
//fill in the conversion data
D3D12_LINEAR_ALGEBRA_MATRIX_CONVERSION_INFO infoDesc = {};
infoDesc.DestInfo.NumRows = NumberOfNodes // "rows" is the number of neurons in this layer
infoDesc.DestInfo.NumColumns = NumberOfInputs // "columns" is the number of neurons in the previous layer
infoDesc.DestInfo.DestLayout = D3D12_LINEAR_ALGEBRA_MATRIX_LAYOUT_MUL_OPTIMAL;
infoDesc.DestInfo.DestDataType = D3D12_LINEAR_ALGEBRA_DATATYPE_FLOAT16;
infoDesc.DestInfo.DestSize = 0; // populated by GetLinearAlgebraMatrixConversionDestinationInfo()
infoDesc.DestInfo.DestStride = 0; //not needed for the "optimised" layout
infoDesc.SrcInfo.SrcLayout = D3D12_LINEAR_ALGEBRA_MATRIX_LAYOUT_ROW_MAJOR;
infoDesc.SrcInfo.SrcDataType = D3D12_LINEAR_ALGEBRA_DATATYPE_FLOAT32;
infoDesc.SrcInfo.SrcSize = infoDesc.DestInfo.NumRows * infoDesc.DestInfo.NumColumns * sizeof(float);
infoDesc.SrcInfo.SrcStride = infoDesc.DestInfo.NumColumns * sizeof(float);
infoDesc.DataDesc.SrcVA = srcVA;
infoDesc.DataDesc.DestVA = destVA;
//Get the information needed for the conversion
devicePreview->GetLinearAlgebraMatrixConversionDestinationInfo(&infoDesc.DestInfo);
//Convert the weights to the desired format
commandListPreview->ConvertLinearAlgebraMatrix(&infoDesc, 1);
It is all fairly straightforward, first we need to get access to a preview command list that exposes that API. Then we can fill-in a D3D12_LINEAR_ALGEBRA_MATRIX_CONVERSION_INFO data structure that describes the input and output buffer formats, sizes, strides etc. Here, I am converting from float32 to float16. For the destination matrix layout I chose the “optimal” format the implementation of which depends on the hardware. We also need to pass the pointers to the GPU buffers for input and output data. A call to GetLinearAlgebraMatrixConversionDestinationInfo() will fill in the rest of the data, namely the 128 byte aligned size of the output matrix. Finally with a call to ConvertLinearAlgebraMatrix() we can perform the conversion. Before the conversion we need to transition the input matrix to the D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE state while the output buffer needs to be in the D3D12_RESOURCE_STATE_UNORDERED_ACCESS state.
We talked about the option to store the weights for all the MLP layers in a single buffer at 128-byte aligned offsets. This can easily been implemented, using the above code for each subsequent layer as well, using the destination size returned by GetLinearAlgebraMatrixConversionDestinationInfo() to increment the DestVA pointer as such:
infoDesc.DataDesc.DestVA += infoDesc.DestInfo.DestSize;
This will guarantee the alignment. The biases buffer we need to fill in manually either in float16 or float32 format, making sure that each layer starts at 64 byte aligned offsets. In my experiments I used float16 biases.
Finally, the following is the HLSL code that implements a 2 hidden layer MLP as an example:
// The input vector is computed from the shader input
vector<float16_t, LAYER0_NEURON_COUNT> inputVector = { dir.x, dir.y, dir.z };
int weightsOffset = 0;
int biasesOffset = 0;
// layer1 (assuming layer0 is the input)
MatrixRef<DATA_TYPE_FLOAT16, LAYER1_NEURON_COUNT, LAYER0_NEURON_COUNT, MATRIX_LAYOUT_MUL_OPTIMAL> weightsLayer1 = { weightsBuffer, weightsOffset, 0 };
VectorRef<DATA_TYPE_FLOAT16> biasLayer1 = { biasesBuffer, biasesOffset };
vector<float16_t, LAYER1_NEURON_COUNT> layer1 = MulAdd<float16_t>(weightsLayer1, MakeInterpretedVector<DATA_TYPE_FLOAT16>(inputVector), biasLayer1);
layer1 = select((layer1 >= 0.0), layer1, (layer1 * LEAKY_RELU_SLOPE));
//layer2
weightsOffset += LAYER2_COOP_WEIGHTS_OFFSET; // multiple of 128-byte offset
biasesOffset += LAYER2_COOP_BIASES_OFFSET; // multiple of 64-byte offset
MatrixRef<DATA_TYPE_FLOAT16, LAYER2_NEURON_COUNT, LAYER1_NEURON_COUNT, MATRIX_LAYOUT_MUL_OPTIMAL> weightsLayer2 = { weightsBuffer, weightsOffset, 0 };
VectorRef<DATA_TYPE_FLOAT16> biasLayer2 = { biasesBuffer, biasesOffset };
vector<float16_t, LAYER2_NEURON_COUNT> layer2 = MulAdd<float16_t>(weightsLayer2, MakeInterpretedVector<DATA_TYPE_FLOAT16>(layer1), biasLayer2);
layer2 = select((layer2 >= 0.0), layer2, (layer2 * LEAKY_RELU_SLOPE));
//output
weightsOffset += LAYER3_COOP_WEIGHTS_OFFSET; // multiple of 128-byte offset
biasesOffset += LAYER3_COOP_BIASES_OFFSET // multiple of 64-byte offset
MatrixRef<DATA_TYPE_FLOAT16, LAYER3_NEURON_COUNT, LAYER2_NEURON_COUNT, MATRIX_LAYOUT_MUL_OPTIMAL> weightsLayer3 = { weightsBuffer, weightsOffset, 0 };
VectorRef<DATA_TYPE_FLOAT16> biasLayer3 = { biasesBuffer, biasesOffset };
vector<float16_t, LAYER3_NEURON_COUNT> result = MulAdd<float16_t>(weightsLayer3, MakeInterpretedVector<DATA_TYPE_FLOAT16>(layer2), biasLayer3);
result = select((result >= 0.0), result, (result * LEAKY_RELU_SLOPE));
To test the performance of the hardware accelerated MLP let’s first try a small 3-3-3-3 NN to encode radiance from a cubemap similar to the way discussed in the previous post.

I only used Cooperative Vectors for inference and kept the existing compute shader code for training. This also shows that it doesn’t matter how you train an MLP to produce the weights/biases, you could use a compute shader, CPU code or even Slang which supports easier differentiation.
The cost of the compute shader inference is 0.05ms on a Nvidia RTX 3080 mobile running at 1080p. The cost of Cooperative Vectors (Tensor core) version is 0.02ms a speedup of about 2x. It appears that this kind of workload does not provide the Tensor cores with enough data to get a meaningful acceleration. It also suggests that there won’t be much advantage in using Tensor cores to perform the typical matrix-vector transforms we perform in shaders.
Let’s try a similarly sized network for RTAO encoding as discussed in the previous post as well.

Although this is probably not the best use-case of MLP encoding, it should stress the cores as each pixel on screen needs to do inference. Starting with a small 6-3-3-1 MLP, compute shader inference costs 1.26ms while the Tensor core accelerated one costs 0.64ms, a similar 2x speedup.
If we take it up a notch and use a 6-32-32-32-1 MLP, the compute shader inference costs 30.5ms but the Tensor core accelerated inference now costs only 0.73ms, only slightly more that the small MLP’s one and provides a 41.7x speedup!
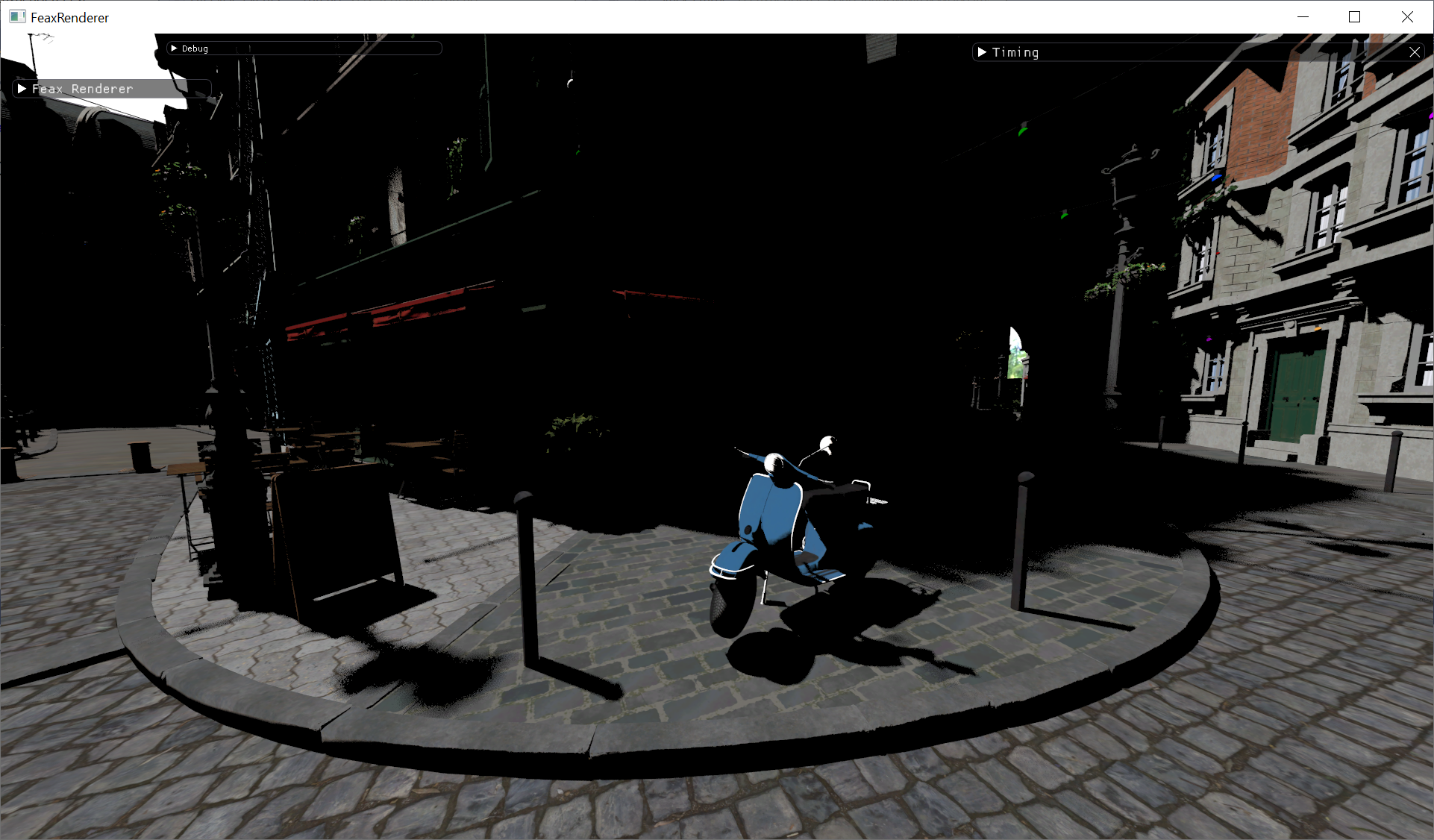
What if we stress it even more using a 6-64-64-64-1 MLP? In this case the compute shader inference costs 240.5ms, while the Tensor core one 1.39ms, a breathtaking 173x speedup. The screenshot above is actually from this large MLP.
The GPU trace of the large MLP inference show how much the Tensor cores light up

compared to the smaller 6-3-3-1 MLP case which barely utilises them.

Although, like discussed, RTAO encoding is probably not the best or most meaningful application for an MLP, this nevertheless shows that this technique could be viable from a performance standpoint using the Tensor cores for inference.
Of course it is worth mentioning that this large speedup is compared to an unoptimised compute shader that implements inference using float32 weights/biases reading them straight from VRAM, something that puts a lot of pressure on memory bandwidth and L2 throughput (right column below)

On the other hand, the Tensor core implementation has higher L1TEX throughput, likely because the cores use shared memory (which is stored in a part of the L1TEX cache) to store matrix data and overall higher SM throughput, completing work much faster.
There is a lot of room for improvement in the compute shader version though: using a smaller data type (eg float16) to store the MLP, shared memory to cache weights and reorganising the architecture to avoid reading the same data multiple times will bring down the cost but even if we managed to make it 10x faster the Tensor core acceleration capacity will remain impressive, especially for large networks.
The Cooperative Vectors feature in this form won’t officially be supported in a future Agility SDK, having been superseded by the Linear Algebra Matrix spec which in under review and will likely be released with SM6.10. In either case, the prospect of accessing Tensor cores from any HLSL shader is intriguing, given the range of opportunities it could unlock.