Show full content
In the first post of this series, I have outlined the importance of having a proper operational framework in place before starting any talk of information-theoretic quantities. It is, however, a good idea to pin down even provisionally the kind of information-theoretic quantity one hopes to distill out of the operational formulation. This will be the topic of this post, and the starting point will be the paper by Carl Bergstrom and Martin Rosvall on the “transmission sense of information.”
Let me start by quoting the abstract of the paper for the common objections against applying information-theoretic ideas to biology:
Biologists think in terms of information at every level of investigation. Signaling pathways transduce information, cells process information, animal signals convey information. Information flows in ecosystems, information is encoded in the DNA, information is carried by nerve impulses. In some domains the utility of the information concept goes unchallenged: when a brain scientist says that nerves transmit information, nobody balks. But when geneticists or evolutionary biologists use information language in their day-to-day work, a few biologists and many philosophers become anxious about whether this language can be justified as anything more than facile metaphor.
The key claim of Bergstrom and Rosvall is that, by focusing on what they refer to as the transmission sense of information, it is possible to avoid the two pitfalls of mutual information, namely the “shallow” notion of correlation and the so-called parity thesis. In doing so, they emphasize the importance of operational notions in information theory “by taking the viewpoint of a communications engineer and focusing on the decision problem of how information is to be packaged for transport.” While this recognition of the importance of operationalization is not common in biology, I still think that it misses an important point: The relevant decision problem is not that of a communications engineer, it is that of a control engineer, whose primary aim to ensure reliable transmission of the global constraints (formal causes) governing the unfolding of phenotypes (starting with development and continuing on through the organism’s lifetime). In other words, the meaning and use (i.e., the semantics and the pragmatics) of the genome are primary, the symbolic packaging (the syntax) of the genome is secondary. This will be the subject of future posts. Here, my goal is more modest — a critical reconsideration of the Bergstrom and Rosvall paper and an alternative proposal to use directed information, rather than mutual information.
If you are not familiar with directed information, I recommend two old posts of mine (one, two) for the basic background. Briefly, the notion of directed information was proposed by Jim Massey in 1990 in order to analyze systems with feedback by focusing on functional, rather than statistical, dependencies:
… probabilistic dependence is quite distinct from causal dependence. Whether
causes
or
This point will be important to us later on.
1. The model
We will consider a very simple model involving the temporal evolution of genotypes and phenotypes in a random environment. We will work in discrete time, using 

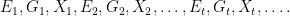
Let us consider what happens in 
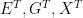
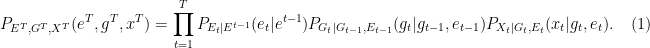
The factorization of the joint distribution in (1) encodes some important assumptions, which we need to spell out:
- The genotype and the environment are modeled by two discrete-time stochastic processes. Notice that the environment is not necessarily Markovian, but the genome process is a Markov process in a random environment (i.e., at each time
, the genome
is conditionally independent of
and
given
and
). This is a very simple model of asexual reproduction, and the process distribution of
models mutations (through stochastic dependence of
- The phenotype at
Again, I need to emphasize that this is a very simple model (see, e.g., the work of Rivoire and Leibler) that does not account for various feedback mechanisms by which the organisms can act on their environments, such as niche construction.
2. The lack of directivity and the parity thesis
Bergstrom and Rosvall consider what happens at each 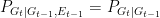

- Mutual information is a “shallow” notion of statistical correlation (in the words of Massey, it has no inherent directivity). Indeed, since the mutual information is symmetric, we have
, and this symmetry runs counter to the central dogma (no flow of information from proteins to genes). In fact, we can also include the environment and consider
, which runs into the same issues. There is also the related objection that, whatever information there is in the genes, it is semantic in some sense, whereas the semantic aspects are notably absent from Shannon’s theory.
- Once we bring the environment into the picture, we also have to deal with the so-called “parity thesis:” In the terminology of Bayes networks, the random triple
are mutually independent, and
is conditionally dependent on both of them —
. As a DAG, this Bayes network is symmetric with respect to
I agree with Bergstrom and Rosvall that these objections provide a strong argument against using mutual information in this context. However, this does not mean that there is no alternative information-theoretic construct that is free of the drawbacks of the mutual information. I claim that one has to use directed information instead. This should not be surprising, since we are in fact trying to capture functional, rather than statistical, dependencies. So, let us then compute the directed informations 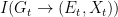
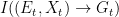



and are given by
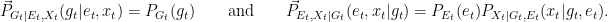
With these, we can compute the corresponding directed informations:
![\displaystyle \begin{array}{rcl} I(G_t \rightarrow (E_t,X_t)) &=& D(P_{G_t,E_t,X_t}\|\vec{P}_{G_t|E_t,X_t} \times P_{E_t,X_t}) \\ &=& {\mathbf E}\left[\log \frac{P_{G_t,E_t,X_t}}{\vec{P}_{G_t|E_t,X_t} P_{E_t,X_t}}\right] \\ &=& {\mathbf E}\left[\log \frac{P_{G_t,E_t,X_t}}{P_{G_t} P_{E_t,X_t}} \right] \\ &=& I(G_t; E_t,X_t), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09I%28G_t+%5Crightarrow+%28E_t%2CX_t%29%29+%26%3D%26+D%28P_%7BG_t%2CE_t%2CX_t%7D%5C%7C%5Cvec%7BP%7D_%7BG_t%7CE_t%2CX_t%7D+%5Ctimes+P_%7BE_t%2CX_t%7D%29+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BG_t%2CE_t%2CX_t%7D%7D%7B%5Cvec%7BP%7D_%7BG_t%7CE_t%2CX_t%7D+P_%7BE_t%2CX_t%7D%7D%5Cright%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BG_t%2CE_t%2CX_t%7D%7D%7BP_%7BG_t%7D+P_%7BE_t%2CX_t%7D%7D+%5Cright%5D+%5C%5C+%09%26%3D%26+I%28G_t%3B+E_t%2CX_t%29%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
so this equals just the mutual information between 
![\displaystyle \begin{array}{rcl} I((E_t,X_t) \rightarrow G_t) &=& D(P_{E_t,X_t,G_t} \| \vec{P}_{E_t,X_t|G_t} \times P_{G_t}) \\ &=& {\mathbf E}\left[\log \frac{P_{E_t,X_t,G_t}}{\vec{P}_{E_t,X_t|G_t} P_{G_t}} \right] \\ &=& {\mathbf E}\left[\log \frac{P_{E_t,X_t,G_t}}{P_{E_t}P_{X_t|G_t,E_t} P_{G_t}} \right] \\ &=& {\mathbf E}\left[\log \frac{P_{E_t,X_t,G_t}}{P_{E_t,X_t,G_t}} \right] \\ &\equiv& 0. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09I%28%28E_t%2CX_t%29+%5Crightarrow+G_t%29+%26%3D%26+D%28P_%7BE_t%2CX_t%2CG_t%7D+%5C%7C+%5Cvec%7BP%7D_%7BE_t%2CX_t%7CG_t%7D+%5Ctimes+P_%7BG_t%7D%29+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BE_t%2CX_t%2CG_t%7D%7D%7B%5Cvec%7BP%7D_%7BE_t%2CX_t%7CG_t%7D+P_%7BG_t%7D%7D+%5Cright%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BE_t%2CX_t%2CG_t%7D%7D%7BP_%7BE_t%7DP_%7BX_t%7CG_t%2CE_t%7D+P_%7BG_t%7D%7D+%5Cright%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BE_t%2CX_t%2CG_t%7D%7D%7BP_%7BE_t%2CX_t%2CG_t%7D%7D+%5Cright%5D+%5C%5C+%09%26%5Cequiv%26+0.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Since directed information quantifies causal (or functional), rather than statistical, dependencies, this is to be expected — the genes together with the environment exert causal influence on the phenotype, but the phenotype and the environment cannot exert any causal influence on the genes. Here it may also be useful to recall the conservation law that relates mutual information and directed information:
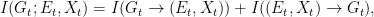
and, since the second term on the right-hand side is identically zero, in this particular instance the mutual information between
The “parity thesis” is more interesting, and it is indeed a subtle issue. It is easy to see that we can interchange the roles of

This is, as I had mentioned earlier, a simple consequence of the collider structure 







Remember, by the way, that in all of the above I have assumed that there is no dependence between the genome and the environment (i.e., genes may undergo mutation, but there is no selection). We can include selection as well, but the resulting mathematics will be a lot more complicated; in particular, we will need to consider so-called causally conditioned directed information, when we condition on the past realizations of 


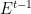
3. The vertical dimension and the transmission sense
Again, let’s follow Bergstrom and Rosvall and simplify things for now by assuming no selection, so 


Thus, we can compute the directed information
![\displaystyle \begin{array}{rcl} I(G^T \rightarrow (E^T,X^T)) &=& {\mathbf E}\left[\log \frac{P_{G^T,E^T,X^T}}{\vec{P}_{G^T|E^T,X^T} \times P_{E^T,X^T}}\right] \\ &=& {\mathbf E}\left[\log \frac{P_{G^T,E^T,X^T}}{P_{G^T}P_{E^T,X^T}}\right] \\ &=& I(G^T; E^T,X^T), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++I%28G%5ET+%5Crightarrow+%28E%5ET%2CX%5ET%29%29+%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BG%5ET%2CE%5ET%2CX%5ET%7D%7D%7B%5Cvec%7BP%7D_%7BG%5ET%7CE%5ET%2CX%5ET%7D+%5Ctimes+P_%7BE%5ET%2CX%5ET%7D%7D%5Cright%5D+%5C%5C+%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BG%5ET%2CE%5ET%2CX%5ET%7D%7D%7BP_%7BG%5ET%7DP_%7BE%5ET%2CX%5ET%7D%7D%5Cright%5D+%5C%5C+%26%3D%26+I%28G%5ET%3B+E%5ET%2CX%5ET%29%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and, once again, 
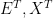


so focusing on the temporal unfolding of genes, proteins, and environments does not rid us of the parity thesis. Since both genes and environments affect the phenotype, this is not surprising at all.
Bergstrom and Rosvall’s resolution is to cut through all of this by focusing on just the genome process 

From the viewpoint of a communications engineer, Equation (2) does indeed describe a communication channel: The environment
Now, uncertainty about what? In order to answer this question, we need to pose an operational interpretation, an optimization problem that our fictitious engineer must solve. And, as I have stressed before, the value of this optimization problem cannot be stated a priori in information-theoretic terms; any such quantity has to be distilled from the nature of the original problem and from the interplay of the source, the channel, and the overall goals. Bergstrom and Rosvall do not give such a formulation, but it is possible to come up with one — see, e.g., the works by Rivoire and Leibler given in the references (I may write a blog post on their work in the future).
I want to close with a critical look at the following quote from the Bergstrom and Rosvall paper:
When information theorists think about coding, they are not thinking about semantic properties. All of the semantic properties are stuffed into the codebook, the interface between source structure and channel structure, which to information theorists is as interesting as a phonebook is to sociologists. When an information theorist says “Tell me how data stream A codes for message set B,” she is not asking you to read her the codebook. She is asking you to tell her about compression, channel capacity, distortion structure, redundancy, and so forth. That is, she wants to know how the structure of the code reflects the statistical properties of the data source and the channel with respect to the decision problem of effectively packaging information for transport.
While the last part is correct (about the structure of the code reflecting the statistics of the source and the channel with respect to the underlying operational criterion), the opening claim about semantics is not entirely accurate. I have touched upon some of these issues in a Twitter thread:
In this thread, I will argue that the conventional wisdom that Shannon’s information theory is all about syntax and not about semantics stems from superficial reading. On the contrary, even his 1948 BSTJ paper is already concerned with syntax, semantics, *and* pragmatics. 1/14
— Maxim Raginsky (@mraginsky) January 29, 2021
I will probably expand that thread into a blog post soon, but here I just want to emphasize the basic nature of the decision problem faced by a communications engineer. The goal is to convey some information about a source 

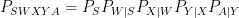
(and here I am simplifying quite a bit and not worrying about time structure, feedback, etc). Of the stochastic kernels making up this factorization, the two things that are not under the control of the system designer are the source probability law 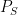
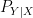



![{{\mathbf E}[c(S,A)]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbf+E%7D%5Bc%28S%2CA%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

It seems that the transmission sense of Bergstrom and Rosvall could pertain to the structure of the channel input and output alphabets and to the distributional properties of 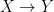

References
- Carl Bergstrom and Martin Rosvall, “The transmission sense of information”
- James Massey, “Causality, feedback, and directed information”
- Robert Cogburn, “Markov Chains in random environments: The case of Markovian environments”
- Olivier Rivoire and Stanislas Leibler, “The value of information for populations in random environments”
- Olivier Rivoire, “Information in models of evolutionary dynamics”
- Howard Pattee, “The physics of symbols: bridging the epistemic cut”
- Sridhar Vembu, Sergio Verdú, and Yossef Steinberg, “The source-channel separation theorem revisited”
- Gérard Battail, “Error-correcting codes and information in biology”

 denote the genome,
denote the genome,  the configuration of the organism,
the configuration of the organism,  the configuration of the environment, and
the configuration of the environment, and  the developmental noise. Then the role of the genome is to act as the organism’s formal cause, i.e., to constrain the relation between all the other variables. In other words, treating everything except the genome as a trajectory in time, we can formalize the relations between the organism and its environment as a certain subset
the developmental noise. Then the role of the genome is to act as the organism’s formal cause, i.e., to constrain the relation between all the other variables. In other words, treating everything except the genome as a trajectory in time, we can formalize the relations between the organism and its environment as a certain subset  of the product space
of the product space
 through the configuration space of the organism over its lifetime (here I am, of course, drastically oversimplifying things, ignoring, for instance, the fact that the lifetime of the organism is generally determined by its trajectory and its interaction with the environment). To be a bit more concrete, we may say that a tuple of trajectories
through the configuration space of the organism over its lifetime (here I am, of course, drastically oversimplifying things, ignoring, for instance, the fact that the lifetime of the organism is generally determined by its trajectory and its interaction with the environment). To be a bit more concrete, we may say that a tuple of trajectories 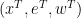 is in
is in 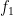 ,
,  , and
, and 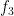 , such that
, such that
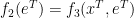
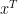 that is compatible with these constraints, i.e., which could arise in this fashion for some realization of the environment
that is compatible with these constraints, i.e., which could arise in this fashion for some realization of the environment  and the developmental noise
and the developmental noise  . Notice that this description introduces mutual constraints between the organism and its environment. So, if one were to think of the genome as a message to be transmitted in space and in time, then this message is a program (formal cause) of the organism, but it does not (indeed, cannot!) contain all the information about the phenotype. The missing information is contained in the environment and in the developmental noise.
. Notice that this description introduces mutual constraints between the organism and its environment. So, if one were to think of the genome as a message to be transmitted in space and in time, then this message is a program (formal cause) of the organism, but it does not (indeed, cannot!) contain all the information about the phenotype. The missing information is contained in the environment and in the developmental noise. ; it cannot by itself select a particular trajectory in the behavior. Hence, if we wish to operationalize the problem of reliable transmission of genetic information, we need to phrase it in terms of criteria pertainig to preserving the behavior as a whole. I will take this up, in a simplified form, in subsequent posts; the next post, however, will mostly be about the Bergstrom-Rosvall paper on the transmission sense of information.
; it cannot by itself select a particular trajectory in the behavior. Hence, if we wish to operationalize the problem of reliable transmission of genetic information, we need to phrase it in terms of criteria pertainig to preserving the behavior as a whole. I will take this up, in a simplified form, in subsequent posts; the next post, however, will mostly be about the Bergstrom-Rosvall paper on the transmission sense of information. on
on  . If
. If 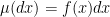 , then we can use the (overdamped) continuous-time Langevin dynamics, governed by the Ito stochastic differential equation (SDE)
, then we can use the (overdamped) continuous-time Langevin dynamics, governed by the Ito stochastic differential equation (SDE) 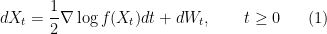
 is generated according to some probability law
is generated according to some probability law  , and
, and  is the standard
is the standard  -dimensional Brownian motion. Let
-dimensional Brownian motion. Let  denote the probability law of
denote the probability law of  , then
, then 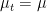 for all
for all 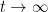 — in fact, it is often possible to show that there exists a constant
— in fact, it is often possible to show that there exists a constant 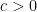 that depends only on
that depends only on 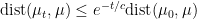

![\displaystyle dX_t = b(X_t,t)dt + dW_t, \qquad t \in [0,1] \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09dX_t+%3D+b%28X_t%2Ct%29dt+%2B+dW_t%2C+%5Cqquad+t+%5Cin+%5B0%2C1%5D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
 , such that:
, such that: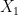 has probability law
has probability law  , the probability law of the process
, the probability law of the process ![{(X_t)_{t \in [0,1]}}](https://s0.wp.com/latex.php?latex=%7B%28X_t%29_%7Bt+%5Cin+%5B0%2C1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , is optimal in the sense that, among all the diffusion processes with values in
, is optimal in the sense that, among all the diffusion processes with values in  and having the marginal distribution
and having the marginal distribution 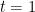 , it remains “as close as possible” to the standard Brownian motion in the sense to be made precise below.
, it remains “as close as possible” to the standard Brownian motion in the sense to be made precise below. denote the space of continuous functions (paths) from
denote the space of continuous functions (paths) from ![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) into
into ![{W = (W_t)_{t \in [0,1]}}](https://s0.wp.com/latex.php?latex=%7BW+%3D+%28W_t%29_%7Bt+%5Cin+%5B0%2C1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) denote the canonical coordinate process on
denote the canonical coordinate process on 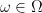 ,
,  . Let
. Let  denote the Wiener measure on
denote the Wiener measure on  the marginal probability law of the value of the path at time
the marginal probability law of the value of the path at time 
 denotes the Dirac probability measure on
denotes the Dirac probability measure on 
 denotes the relative entropy between two probability measures on
denotes the relative entropy between two probability measures on  exists and is unique, and (b) show that it is the probability law of a diffusion process governed by an Ito SDE of the form
exists and is unique, and (b) show that it is the probability law of a diffusion process governed by an Ito SDE of the form  ; without loss of generality, we can assume that
; without loss of generality, we can assume that 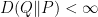 . The chain rule then gives
. The chain rule then gives 
 (respectively,
(respectively, 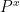 ) denotes the conditional probability law of
) denotes the conditional probability law of ![{X = (X_t)_{t \in [0,1]}}](https://s0.wp.com/latex.php?latex=%7BX+%3D+%28X_t%29_%7Bt+%5Cin+%5B0%2C1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) given
given  under
under 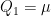 , whereas
, whereas 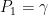 for the Wiener measure
for the Wiener measure 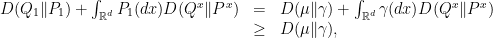
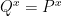 almost everywhere. This immediately implies two things:
almost everywhere. This immediately implies two things: ;
;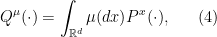
 : Let
: Let  be an arbitrary bounded measurable real-valued function on
be an arbitrary bounded measurable real-valued function on 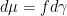 ,
, ![\displaystyle \begin{array}{rcl} {\mathbb E}_{Q^\mu}[F(X)] &=& {\mathbb E}_\mu[{\mathbb E}_{Q^\mu}[F(X)|X_1]] \\ &=& {\mathbb E}_\mu[{\mathbb E}_P[F(X)|X_1]] \\ &=& {\mathbb E}_\gamma[f(X_1){\mathbb E}_P[F(X)|X_1]] \\ &=& {\mathbb E}_\gamma[E_P[f(X_1)F(X)|X_1]] \\ &=& {\mathbb E}_P[f(W_1)F(W)], \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09%7B%5Cmathbb+E%7D_%7BQ%5E%5Cmu%7D%5BF%28X%29%5D+%26%3D%26+%7B%5Cmathbb+E%7D_%5Cmu%5B%7B%5Cmathbb+E%7D_%7BQ%5E%5Cmu%7D%5BF%28X%29%7CX_1%5D%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbb+E%7D_%5Cmu%5B%7B%5Cmathbb+E%7D_P%5BF%28X%29%7CX_1%5D%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbb+E%7D_%5Cgamma%5Bf%28X_1%29%7B%5Cmathbb+E%7D_P%5BF%28X%29%7CX_1%5D%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbb+E%7D_%5Cgamma%5BE_P%5Bf%28X_1%29F%28X%29%7CX_1%5D%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbb+E%7D_P%5Bf%28W_1%29F%28W%29%5D%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 , in the second equation we have used the fact that the conditional laws
, in the second equation we have used the fact that the conditional laws ![{Q^\mu[\cdot|X_1 = x]}](https://s0.wp.com/latex.php?latex=%7BQ%5E%5Cmu%5B%5Ccdot%7CX_1+%3D+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![{P[\cdot|X_1 = x]}](https://s0.wp.com/latex.php?latex=%7BP%5B%5Ccdot%7CX_1+%3D+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) coincide, and in the last equation
coincide, and in the last equation 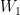 and takes the form
and takes the form 
 on
on 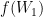 that depends only on
that depends only on 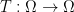 such that
such that  , i.e., the optimal measure
, i.e., the optimal measure ![\displaystyle {\mathbb E}_{Q^\mu}[F(X)] = {\mathbb E}_P[F\circ T(W)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%7B%5Cmathbb+E%7D_%7BQ%5E%5Cmu%7D%5BF%28X%29%5D+%3D+%7B%5Cmathbb+E%7D_P%5BF%5Ccirc+T%28W%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
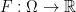 . Moreover, we want this
. Moreover, we want this 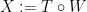 is an Ito diffusion process. In order to construct such a map, we will use a fundamental result in stochastic calculus, the Girsanov theorem, which gives the necessary and sufficient condition for a probability measure
is an Ito diffusion process. In order to construct such a map, we will use a fundamental result in stochastic calculus, the Girsanov theorem, which gives the necessary and sufficient condition for a probability measure ![\displaystyle dX_t = -\nabla v(X_t,t)dt + dW_t, \qquad X_0 = 0, t \in [0,1] \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09dX_t+%3D+-%5Cnabla+v%28X_t%2Ct%29dt+%2B+dW_t%2C+%5Cqquad+X_0+%3D+0%2C+t+%5Cin+%5B0%2C1%5D+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
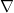 denotes the gradient with respect to the space variable. Then we will show that we can choose a suitable function
denotes the gradient with respect to the space variable. Then we will show that we can choose a suitable function ![{v : {\mathbb R}^d \times [0,1] \rightarrow {\mathbb R}}](https://s0.wp.com/latex.php?latex=%7Bv+%3A+%7B%5Cmathbb+R%7D%5Ed+%5Ctimes+%5B0%2C1%5D+%5Crightarrow+%7B%5Cmathbb+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) which is twice continuously differentiable in
which is twice continuously differentiable in 
 can be chosen in such a way that the right-hand side of
can be chosen in such a way that the right-hand side of ![{(V_t)_{t \in [0,1]}}](https://s0.wp.com/latex.php?latex=%7B%28V_t%29_%7Bt+%5Cin+%5B0%2C1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) by
by  . Ito’s lemma then gives
. Ito’s lemma then gives
 is the Laplacian. Integrating and rearranging, we obtain
is the Laplacian. Integrating and rearranging, we obtain
 gives
gives
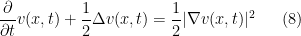
![{(x,t) \in {\mathbb R}^d \times [0,1]}](https://s0.wp.com/latex.php?latex=%7B%28x%2Ct%29+%5Cin+%7B%5Cmathbb+R%7D%5Ed+%5Ctimes+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , subject to the terminal condition
, subject to the terminal condition 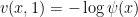 for some strictly positive function
for some strictly positive function  to be chosen later. Assuming that such a
to be chosen later. Assuming that such a 
 should be chosen in such a way that
should be chosen in such a way that 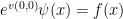 for all
for all  . Now, the PDE
. Now, the PDE  . It is then a straightforward if tedious exercise in multivariate calculus to show that the function
. It is then a straightforward if tedious exercise in multivariate calculus to show that the function  solves a much nicer linear PDE
solves a much nicer linear PDE 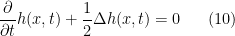
![{{\mathbb R}^d \times [0,1]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+R%7D%5Ed+%5Ctimes+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) subject to the terminal condition
subject to the terminal condition  . The solution of
. The solution of ![{t \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bt+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![\displaystyle h(x,t) = {\mathbb E}_P[\psi(W_1)|W_t = x]. \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09h%28x%2Ct%29+%3D+%7B%5Cmathbb+E%7D_P%5B%5Cpsi%28W_1%29%7CW_t+%3D+x%5D.+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)
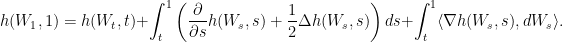
 and using the fact that
and using the fact that ![\displaystyle v(x,t) = - \log h(x,t) = - \log {\mathbb E}_P[\psi(W_1)|W_t = x],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09v%28x%2Ct%29+%3D+-+%5Clog+h%28x%2Ct%29+%3D+-+%5Clog+%7B%5Cmathbb+E%7D_P%5B%5Cpsi%28W_1%29%7CW_t+%3D+x%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![{v(0,0) = - \log {\mathbb E}_P[\psi(W_1)|W_0 = 0] = -\log {\mathbb E}_P[\psi(W_1)] = - \log {\mathbb E}_\gamma[\psi]}](https://s0.wp.com/latex.php?latex=%7Bv%280%2C0%29+%3D+-+%5Clog+%7B%5Cmathbb+E%7D_P%5B%5Cpsi%28W_1%29%7CW_0+%3D+0%5D+%3D+-%5Clog+%7B%5Cmathbb+E%7D_P%5B%5Cpsi%28W_1%29%5D+%3D+-+%5Clog+%7B%5Cmathbb+E%7D_%5Cgamma%5B%5Cpsi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Substituting all of this into
. Substituting all of this into ![\displaystyle \frac{dQ}{dP}(W) = \frac{h(W_1,1)}{h(0,0)} = \frac{\psi(W_1)}{{\mathbb E}_\gamma[\psi]},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Cfrac%7BdQ%7D%7BdP%7D%28W%29+%3D+%5Cfrac%7Bh%28W_1%2C1%29%7D%7Bh%280%2C0%29%7D+%3D+%5Cfrac%7B%5Cpsi%28W_1%29%7D%7B%7B%5Cmathbb+E%7D_%5Cgamma%5B%5Cpsi%5D%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
 so that
so that  . Moreover, using the known Gaussian form of the transition probability densities of the Brownian motion, we can give the drift in
. Moreover, using the known Gaussian form of the transition probability densities of the Brownian motion, we can give the drift in ![\displaystyle \begin{array}{rcl} -\nabla v(x,t) &=& \nabla \log {\mathbb E}_\gamma[f(x + \sqrt{1-t}Z)] \\ &=& \nabla \log \int_{{\mathbb R}^d} f(x + \sqrt{1-t}z) e^{-|z|^2/2} dz \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09-%5Cnabla+v%28x%2Ct%29+%26%3D%26+%5Cnabla+%5Clog+%7B%5Cmathbb+E%7D_%5Cgamma%5Bf%28x+%2B+%5Csqrt%7B1-t%7DZ%29%5D+%5C%5C+%09%26%3D%26+%5Cnabla+%5Clog+%5Cint_%7B%7B%5Cmathbb+R%7D%5Ed%7D+f%28x+%2B+%5Csqrt%7B1-t%7Dz%29+e%5E%7B-%7Cz%7C%5E2%2F2%7D+dz+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 is distributed according to the canonical Gaussian measure
is distributed according to the canonical Gaussian measure 
 , to rewrite
, to rewrite 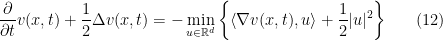
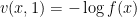 . The stochastic control connection is as follows: We seek an adapted control process
. The stochastic control connection is as follows: We seek an adapted control process ![{u = (u_t)_{t \in [0,1]}}](https://s0.wp.com/latex.php?latex=%7Bu+%3D+%28u_t%29_%7Bt+%5Cin+%5B0%2C1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to minimize the expected cost
to minimize the expected cost ![\displaystyle J(u) := {\mathbb E}^u \left[ \frac{1}{2}\int^1_0 |u_t|^2 dt - \log f(X^u_1) \right], \ \ \ \ \ (13)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09J%28u%29+%3A%3D+%7B%5Cmathbb+E%7D%5Eu+%5Cleft%5B+%5Cfrac%7B1%7D%7B2%7D%5Cint%5E1_0+%7Cu_t%7C%5E2+dt+-+%5Clog+f%28X%5Eu_1%29+%5Cright%5D%2C+%5C+%5C+%5C+%5C+%5C+%2813%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\mathbb E}^u[\cdot]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Eu%5B%5Ccdot%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) denotes expectation with respect to the controlled diffusion process
denotes expectation with respect to the controlled diffusion process ![\displaystyle dX^u_t = u_t dt + dW_t, \qquad X^u_0 = 0, t \in [0,1]. \ \ \ \ \ (14)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09dX%5Eu_t+%3D+u_t+dt+%2B+dW_t%2C+%5Cqquad+X%5Eu_0+%3D+0%2C+t+%5Cin+%5B0%2C1%5D.+%5C+%5C+%5C+%5C+%5C+%2814%29&bg=ffffff&fg=000000&s=0&c=20201002)
 is the control cost, while
is the control cost, while 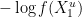 is the terminal cost at
is the terminal cost at 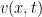 of the PDE
of the PDE ![\displaystyle v(x,t) := \min_{u} {\mathbb E}^u \Bigg[\frac{1}{2}\int^1_t |u_s|^2 ds - \log f(X^u_1) \Bigg|X^u_t = x\Bigg],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09v%28x%2Ct%29+%3A%3D+%5Cmin_%7Bu%7D+%7B%5Cmathbb+E%7D%5Eu+%5CBigg%5B%5Cfrac%7B1%7D%7B2%7D%5Cint%5E1_t+%7Cu_s%7C%5E2+ds+-+%5Clog+f%28X%5Eu_1%29+%5CBigg%7CX%5Eu_t+%3D+x%5CBigg%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
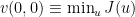 . Here, the idea is that we add the drift
. Here, the idea is that we add the drift  to the standard Brownian motion
to the standard Brownian motion ![{v(0,0) = - \log {\mathbb E}_\gamma[f(Z)] = 0}](https://s0.wp.com/latex.php?latex=%7Bv%280%2C0%29+%3D+-+%5Clog+%7B%5Cmathbb+E%7D_%5Cgamma%5Bf%28Z%29%5D+%3D+0%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and that the optimal control is of the state feedback form, given explicitly by the Föllmer drift. Moreover, one can show using the Girsanov theorem that every
, and that the optimal control is of the state feedback form, given explicitly by the Föllmer drift. Moreover, one can show using the Girsanov theorem that every  has law
has law ![\displaystyle D(Q \| P) = {\mathbb E}^u \left[ \frac{1}{2}\int^1_0 |u_t|^2 dt \right] = J(u) + {\mathbb E}^u[\log f(X^u_1)] = J(u) + D(\mu \| \gamma).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09D%28Q+%5C%7C+P%29+%3D+%7B%5Cmathbb+E%7D%5Eu+%5Cleft%5B+%5Cfrac%7B1%7D%7B2%7D%5Cint%5E1_0+%7Cu_t%7C%5E2+dt+%5Cright%5D+%3D+J%28u%29+%2B+%7B%5Cmathbb+E%7D%5Eu%5B%5Clog+f%28X%5Eu_1%29%5D+%3D+J%28u%29+%2B+D%28%5Cmu+%5C%7C+%5Cgamma%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
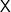 (which is completely arbitrary) and a binary label space
(which is completely arbitrary) and a binary label space 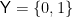 . Let
. Let  be a class of functions
be a class of functions  , which we will call the hypothesis space. These functions are our models for the relationship between features and labels, which we wish to learn from data. In order to focus on the essential aspects of the problem, we will adopt the Bayesian approach and assume that the “true” model is a random element of
, which we will call the hypothesis space. These functions are our models for the relationship between features and labels, which we wish to learn from data. In order to focus on the essential aspects of the problem, we will adopt the Bayesian approach and assume that the “true” model is a random element of 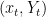 , where
, where 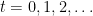 . Here, each
. Here, each  is an arbitrary point of
is an arbitrary point of 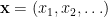 as an individual sequence. The labels
as an individual sequence. The labels 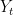 , though, are random and given by
, though, are random and given by 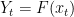 , where
, where  is the model drawn by Nature from
is the model drawn by Nature from  , it has access to
, it has access to  . Let us denote the pair
. Let us denote the pair 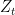 . The learning task is: given the next input
. The learning task is: given the next input  , predict the value
, predict the value 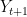 . A learning algorithm
. A learning algorithm 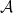 is a sequence of possibly randomized mappings
is a sequence of possibly randomized mappings  : at each time
: at each time  of
of  . After generating the prediction, the learning agent observes the true
. After generating the prediction, the learning agent observes the true ![\displaystyle e_{{\bf x}}({\mathcal A},t) = Q\big[\widehat{Y}_t \neq Y_t\big] \equiv Q\big[a_t(Z^{t-1},x_t) \neq Y_t\big].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%2Ct%29+%3D+Q%5Cbig%5B%5Cwidehat%7BY%7D_t+%5Cneq+Y_t%5Cbig%5D+%5Cequiv+Q%5Cbig%5Ba_t%28Z%5E%7Bt-1%7D%2Cx_t%29+%5Cneq+Y_t%5Cbig%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 as the learning curve of
as the learning curve of  of inputs supplied to the learning agent during learning].
of inputs supplied to the learning agent during learning].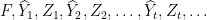
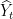 are determined by the learning algorithm
are determined by the learning algorithm 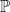 . When the learning agent observes
. When the learning agent observes 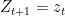 at time
at time  by
by 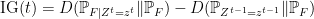
 is nonnegative because
is nonnegative because  (information at time
(information at time  . The expected information gain is given by
. The expected information gain is given by ![\displaystyle {\mathbb E} [{\rm IG}(t)] = I(F; Z_t | Z^{t-1}),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D+%5B%7B%5Crm+IG%7D%28t%29%5D+%3D+I%28F%3B+Z_t+%7C+Z%5E%7Bt-1%7D%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)

 . Clearly,
. Clearly,  for all
for all 
![\displaystyle {\mathbb P}[F \in {\mathcal E}|Z^t=z^t] = Q({\mathcal E} | {\mathcal V}_t) = \frac{Q({\mathcal E} \cap {\mathcal V}_t)}{Q({\mathcal V}_t)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%7B%5Cmathbb+P%7D%5BF+%5Cin+%7B%5Cmathcal+E%7D%7CZ%5Et%3Dz%5Et%5D+%3D+Q%28%7B%5Cmathcal+E%7D+%7C+%7B%5Cmathcal+V%7D_t%29+%3D+%5Cfrac%7BQ%28%7B%5Cmathcal+E%7D+%5Ccap+%7B%5Cmathcal+V%7D_t%29%7D%7BQ%28%7B%5Cmathcal+V%7D_t%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002)


 . Since
. Since  , we expect that each training sample shrinks the version space, and that the learning curve of any good learning algorithm should be controlled by the rate at which
, we expect that each training sample shrinks the version space, and that the learning curve of any good learning algorithm should be controlled by the rate at which  decreases. For future convenience, let us define the volume ratio at time
decreases. For future convenience, let us define the volume ratio at time 
 , we have
, we have ![\displaystyle \xi_t = \frac{Q({\mathcal V}_t \cap {\mathcal V}_{t-1})}{Q({\mathcal V}_{t-1})} = {\mathbb P}[F \in {\mathcal V}_t | F \in {\mathcal V}_{t-1}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Cxi_t+%3D+%5Cfrac%7BQ%28%7B%5Cmathcal+V%7D_t+%5Ccap+%7B%5Cmathcal+V%7D_%7Bt-1%7D%29%7D%7BQ%28%7B%5Cmathcal+V%7D_%7Bt-1%7D%29%7D+%3D+%7B%5Cmathbb+P%7D%5BF+%5Cin+%7B%5Cmathcal+V%7D_t+%7C+F+%5Cin+%7B%5Cmathcal+V%7D_%7Bt-1%7D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)

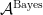 : at time
: at time 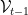 into two disjoint subsets
into two disjoint subsets


 will not, in general, be an element of
will not, in general, be an element of  : at time
: at time 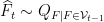 and predicts
and predicts
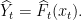
 , i.e., whenever
, i.e., whenever 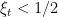 . Indeed, using the fact that, by definition of the version space,
. Indeed, using the fact that, by definition of the version space,

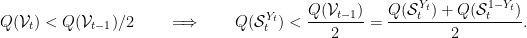
 , and so
, and so 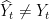 . On the other hand, if
. On the other hand, if  , the Bayes algorithm will be correct:
, the Bayes algorithm will be correct: 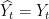 . Finally, if
. Finally, if 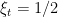 , then the Bayes algorithm will make a mistake with probability
, then the Bayes algorithm will make a mistake with probability  . Therefore,
. Therefore, ![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Bayes},t) = {\mathbb E} [\vartheta(1/2-\xi_t)],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Bayes%7D%2Ct%29+%3D+%7B%5Cmathbb+E%7D+%5B%5Cvartheta%281%2F2-%5Cxi_t%29%5D%2C+%09&bg=ffffff&fg=000000&s=0&c=20201002)
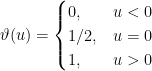
 is not in the version space
is not in the version space  . Since
. Since  , we have
, we have
![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Gibbs},t) = {\mathbb P}\left[\widehat{F}_t \not\in {\mathcal V}_t\right] = {\mathbb E} [1-\xi_t].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Gibbs%7D%2Ct%29+%3D+%7B%5Cmathbb+P%7D%5Cleft%5B%5Cwidehat%7BF%7D_t+%5Cnot%5Cin+%7B%5Cmathcal+V%7D_t%5Cright%5D+%3D+%7B%5Cmathbb+E%7D+%5B1-%5Cxi_t%5D.+%09&bg=ffffff&fg=000000&s=0&c=20201002)
 is always bounded between
is always bounded between  and
and  . Moreover, we have the following useful formula: for any function
. Moreover, we have the following useful formula: for any function ![{g : [0,1] \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Bg+%3A+%5B0%2C1%5D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![\displaystyle {\mathbb E} [g(\xi_t)] = {\mathbb E} [\xi_t g(\xi_t) + (1-\xi_t)g(1-\xi_t)] \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D+%5Bg%28%5Cxi_t%29%5D+%3D+%7B%5Cmathbb+E%7D+%5B%5Cxi_t+g%28%5Cxi_t%29+%2B+%281-%5Cxi_t%29g%281-%5Cxi_t%29%5D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)


![{h^{-1} : [0,1] \rightarrow [0,1/2]}](https://s0.wp.com/latex.php?latex=%7Bh%5E%7B-1%7D+%3A+%5B0%2C1%5D+%5Crightarrow+%5B0%2C1%2F2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is the inverse of the binary entropy function
is the inverse of the binary entropy function  .
.  , we have
, we have ![\displaystyle I(F; Z_t | Z^{t-1}) = {\mathbb E} [-\log \xi_t] = -{\mathbb E} [\xi_t \log \xi_t + (1-\xi_t) \log (1-\xi_t)] = {\mathbb E} [h(\xi_t)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09%09I%28F%3B+Z_t+%7C+Z%5E%7Bt-1%7D%29+%3D+%7B%5Cmathbb+E%7D+%5B-%5Clog+%5Cxi_t%5D+%3D+-%7B%5Cmathbb+E%7D+%5B%5Cxi_t+%5Clog+%5Cxi_t+%2B+%281-%5Cxi_t%29+%5Clog+%281-%5Cxi_t%29%5D+%3D+%7B%5Cmathbb+E%7D+%5Bh%28%5Cxi_t%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 , we have
, we have ![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Bayes},t) = {\mathbb E} [\vartheta(1/2-\xi_t)] = {\mathbb E} [\xi_t \vartheta(1/2-\xi_t) + (1-\xi_t) \vartheta(\xi_t - 1/2)] = {\mathbb E}\left[\min\{\xi_t,1-\xi_t\}\right],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Bayes%7D%2Ct%29+%3D+%7B%5Cmathbb+E%7D+%5B%5Cvartheta%281%2F2-%5Cxi_t%29%5D+%3D+%7B%5Cmathbb+E%7D+%5B%5Cxi_t+%5Cvartheta%281%2F2-%5Cxi_t%29+%2B+%281-%5Cxi_t%29+%5Cvartheta%28%5Cxi_t+-+1%2F2%29%5D+%3D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cmin%5C%7B%5Cxi_t%2C1-%5Cxi_t%5C%7D%5Cright%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![{u \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bu+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, 
 . The best prediction of the outcome of a single toss of that coin, with respect to the Hamming loss
. The best prediction of the outcome of a single toss of that coin, with respect to the Hamming loss 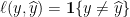 , is to predict heads if
, is to predict heads if 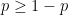 and tails otherwise. The expected loss in that case is equal to
and tails otherwise. The expected loss in that case is equal to  . The problem of predicting
. The problem of predicting  is equivalent to the above guessing problem with
is equivalent to the above guessing problem with  .
. , we have
, we have ![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Gibbs},t) = {\mathbb E} [1-\xi_t] = 2{\mathbb E} [\xi_t(1-\xi_t)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Gibbs%7D%2Ct%29+%3D+%7B%5Cmathbb+E%7D+%5B1-%5Cxi_t%5D+%3D+2%7B%5Cmathbb+E%7D+%5B%5Cxi_t%281-%5Cxi_t%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 coin, we can think of the following suboptimal scheme: guess
coin, we can think of the following suboptimal scheme: guess  with probability
with probability  (i.e., just mentally simulate the coin toss). The probability of error is exactly
(i.e., just mentally simulate the coin toss). The probability of error is exactly 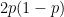 , which is also twice the variance of a
, which is also twice the variance of a 
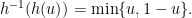
![{h^{-1} : [0,1] \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Bh%5E%7B-1%7D+%3A+%5B0%2C1%5D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is convex. Therefore,
is convex. Therefore, ![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Bayes},t) = {\mathbb E}\left[\min\{\xi_t,1-\xi_t\}\right] = {\mathbb E} [h^{-1}(h(\xi_t))] \ge h^{-1}\left({\mathbb E} [h(\xi_t)]\right) =h^{-1}\left(I(F;Z_t|Z^{t-1})\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Bayes%7D%2Ct%29+%3D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cmin%5C%7B%5Cxi_t%2C1-%5Cxi_t%5C%7D%5Cright%5D+%3D+%7B%5Cmathbb+E%7D+%5Bh%5E%7B-1%7D%28h%28%5Cxi_t%29%29%5D+%5Cge+h%5E%7B-1%7D%5Cleft%28%7B%5Cmathbb+E%7D+%5Bh%28%5Cxi_t%29%5D%5Cright%29+%3Dh%5E%7B-1%7D%5Cleft%28I%28F%3BZ_t%7CZ%5E%7Bt-1%7D%29%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
 in
in 
 , etc. What can we say about the expected fraction of mistakes? Given a learning algorithm
, etc. What can we say about the expected fraction of mistakes? Given a learning algorithm 
 . In order to get a handle on this quantity, we will need some
. In order to get a handle on this quantity, we will need some  denote the set of all distinct elements of the tuple
denote the set of all distinct elements of the tuple 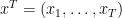 . Say that two hypotheses
. Say that two hypotheses 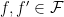 are equivalent if
are equivalent if  for all
for all 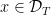 . This defines an equivalence relation on
. This defines an equivalence relation on 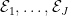 . Here, the number of equivalence classes
. Here, the number of equivalence classes  depends on
depends on  , where
, where  . Each
. Each 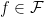 can be associated with a binary string
can be associated with a binary string  . Then
. Then 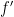 are in the same equivalence class if and only if they give rise to the same binary strings:
are in the same equivalence class if and only if they give rise to the same binary strings: 
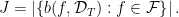
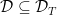 , let us define
, let us define  in the obvious way: if
in the obvious way: if  , then we let
, then we let 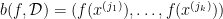 . Let
. Let  be the largest integer
be the largest integer  , such that
, such that 
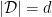 . A deep result, commonly known as the Sauer-Shelah lemma (see
. A deep result, commonly known as the Sauer-Shelah lemma (see 

![\displaystyle \begin{array}{rcl} \bar{e}_{{\bf x}}({\mathcal A}^{\rm Bayes},T) &\le& \bar{e}_{{\bf x}}({\mathcal A}^{\rm Gibbs},T)\\ &\le& \frac{1}{2T}\sum^T_{t=1} {\mathbb E} [-\log \xi_t] \\ &=& \frac{1}{2T}\sum^T_{t=1} {\mathbb E}\left[\log \frac{Q({\mathcal V}_{t-1})}{Q({\mathcal V}_t)}\right] \\ &=& \frac{1}{2T}{\mathbb E}\left[\log \frac{Q({\mathcal V}_0)}{Q({\mathcal V}_T)}\right] \\ &=& \frac{1}{2T}{\mathbb E}\left[\log \frac{1}{Q({\mathcal V}_T)}\right]. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09%09%5Cbar%7Be%7D_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Bayes%7D%2CT%29+%26%5Cle%26+%5Cbar%7Be%7D_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Gibbs%7D%2CT%29%5C%5C+%09%09%26%5Cle%26+%5Cfrac%7B1%7D%7B2T%7D%5Csum%5ET_%7Bt%3D1%7D+%7B%5Cmathbb+E%7D+%5B-%5Clog+%5Cxi_t%5D+%5C%5C+%09%09%26%3D%26+%5Cfrac%7B1%7D%7B2T%7D%5Csum%5ET_%7Bt%3D1%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BQ%28%7B%5Cmathcal+V%7D_%7Bt-1%7D%29%7D%7BQ%28%7B%5Cmathcal+V%7D_t%29%7D%5Cright%5D+%5C%5C+%09%09%26%3D%26+%5Cfrac%7B1%7D%7B2T%7D%7B%5Cmathbb+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BQ%28%7B%5Cmathcal+V%7D_0%29%7D%7BQ%28%7B%5Cmathcal+V%7D_T%29%7D%5Cright%5D+%5C%5C+%09%09%26%3D%26+%5Cfrac%7B1%7D%7B2T%7D%7B%5Cmathbb+E%7D%5Cleft%5B%5Clog+%5Cfrac%7B1%7D%7BQ%28%7B%5Cmathcal+V%7D_T%29%7D%5Cright%5D.+%09%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 is the equivalence class containing the “true” model
is the equivalence class containing the “true” model  , such that
, such that  . Consequently, we can write
. Consequently, we can write ![\displaystyle \begin{array}{rcl} {\mathbb E}\left[\log \frac{1}{Q({\mathcal V}_T)}\right] &=& \sum^J_{j=1} {\mathbb E}\left[{\bf 1}\{F \in {\mathcal E}_j\}\log\frac{1}{Q({\mathcal V}_T)}\right] \\ &=& \sum^J_{j=1} {\mathbb E}\left[{\bf 1}\{F \in {\mathcal E}_j\}\log\frac{1}{Q({\mathcal E}_j)}\right] \\ &=& -\sum^J_{j=1} Q({\mathcal E}_j) \log Q({\mathcal E}_j). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09%09%7B%5Cmathbb+E%7D%5Cleft%5B%5Clog+%5Cfrac%7B1%7D%7BQ%28%7B%5Cmathcal+V%7D_T%29%7D%5Cright%5D+%26%3D%26+%5Csum%5EJ_%7Bj%3D1%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%7B%5Cbf+1%7D%5C%7BF+%5Cin+%7B%5Cmathcal+E%7D_j%5C%7D%5Clog%5Cfrac%7B1%7D%7BQ%28%7B%5Cmathcal+V%7D_T%29%7D%5Cright%5D+%5C%5C+%09%09%26%3D%26+%5Csum%5EJ_%7Bj%3D1%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%7B%5Cbf+1%7D%5C%7BF+%5Cin+%7B%5Cmathcal+E%7D_j%5C%7D%5Clog%5Cfrac%7B1%7D%7BQ%28%7B%5Cmathcal+E%7D_j%29%7D%5Cright%5D+%5C%5C+%09%09%26%3D%26+-%5Csum%5EJ_%7Bj%3D1%7D+Q%28%7B%5Cmathcal+E%7D_j%29+%5Clog+Q%28%7B%5Cmathcal+E%7D_j%29.+%09%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 : that is,
: that is, 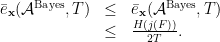
 , we can invoke the Sauer-Shelah estimate
, we can invoke the Sauer-Shelah estimate 

 is determined stochastically by its own state, as well as by the states of its neighbors, at time
is determined stochastically by its own state, as well as by the states of its neighbors, at time  . The neighborhood of a vertex
. The neighborhood of a vertex  , denoted by
, denoted by  , is the set of all vertices
, is the set of all vertices  that are connected to
that are connected to  . Let us fix a finite alphabet
. Let us fix a finite alphabet  denote a copy of
denote a copy of  to each vertex
to each vertex  is the space of all configurations. We will denote a generic configuration by
is the space of all configurations. We will denote a generic configuration by  ; for any set
; for any set  , we will denote by
, we will denote by  the natural projection of
the natural projection of  :
:  .
.  random variable, which is the bit we wish to store. We also pick two probability measures
random variable, which is the bit we wish to store. We also pick two probability measures  on
on  , we draw the initial
, we draw the initial  configuration
configuration  at random according to
at random according to  . We allow arbitrary correlations between the different
. We allow arbitrary correlations between the different  ‘s, so our storage is distributed in this sense. Now let’s suppose that the state of each vertex evolves stochastically in discrete time according to a local Markov model: for each
‘s, so our storage is distributed in this sense. Now let’s suppose that the state of each vertex evolves stochastically in discrete time according to a local Markov model: for each 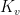 with input alphabet
with input alphabet  and output alphabet
and output alphabet  at time
at time ![\displaystyle {\mathbb P}[X_{t+1}=x_{t+1}|W=w,X^t = x^t] = \prod_{v \in {\cal V}}K_v(x_{v,t+1}|x_{\partial_+ v,t}), \qquad t=1,2,\ldots \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%7B%5Cmathbb+P%7D%5BX_%7Bt%2B1%7D%3Dx_%7Bt%2B1%7D%7CW%3Dw%2CX%5Et+%3D+x%5Et%5D+%3D+%5Cprod_%7Bv+%5Cin+%7B%5Ccal+V%7D%7DK_v%28x_%7Bv%2Ct%2B1%7D%7Cx_%7B%5Cpartial_%2B+v%2Ct%7D%29%2C+%5Cqquad+t%3D1%2C2%2C%5Cldots+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\mathbb P}[W=w]=1/2}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+P%7D%5BW%3Dw%5D%3D1%2F2%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
,  , and
, and ![{{\mathbb P}[X_1 = x_1|W=w]=\mu_w(x_1)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+P%7D%5BX_1+%3D+x_1%7CW%3Dw%5D%3D%5Cmu_w%28x_1%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
,  . Thus, we end up with a Markov chain
. Thus, we end up with a Markov chain 
 is also Markov “in space:” the state of vertex
is also Markov “in space:” the state of vertex 
 , where
, where 
 such that
such that  for all
for all  , then our memory cell is capable of storing one bit. If, on the other hand,
, then our memory cell is capable of storing one bit. If, on the other hand,  as
as 
 , where
, where  , the channel from
, the channel from  is arbitrary, and the channel from
is arbitrary, and the channel from  is given by
is given by  . Clearly,
. Clearly,  for every
for every  .
. and let
and let 
 satisfying the constraints
satisfying the constraints  and
and  . The difference is that in
. The difference is that in  , whereas in
, whereas in 
 of
of  denotes the marginal distribution of
denotes the marginal distribution of  . Both
. Both  and
and  measure the “noisiness” of
measure the “noisiness” of  of a given node at time
of a given node at time  and not on anything else. Thus, if boundary condition, i.e., the configuration of all the nodes except for
and not on anything else. Thus, if boundary condition, i.e., the configuration of all the nodes except for  , then the amount of information about
, then the amount of information about 


 , then
, then  . Then, for any
. Then, for any  ,
, 

 and
and  , consider two probability distributions
, consider two probability distributions 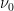 and
and  of
of ![\displaystyle \nu_w(y) := {\mathbb P}\Big[ Y = y\Big| W=w, X_{{\cal K},t} = x_{{\cal K},t}, X_{{\cal J},t+1} = x_{{\cal J},t+1}\Big], \quad w \in \{0,1\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09%5Cnu_w%28y%29+%3A%3D+%7B%5Cmathbb+P%7D%5CBig%5B+Y+%3D+y%5CBig%7C+W%3Dw%2C+X_%7B%7B%5Ccal+K%7D%2Ct%7D+%3D+x_%7B%7B%5Ccal+K%7D%2Ct%7D%2C+X_%7B%7B%5Ccal+J%7D%2Ct%2B1%7D+%3D+x_%7B%7B%5Ccal+J%7D%2Ct%2B1%7D%5CBig%5D%2C+%5Cquad+w+%5Cin+%5C%7B0%2C1%5C%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 , and then let
, and then let 

 and
and  , we obtain
, we obtain  , any
, any  ,
, 

 . Let us use the chain rule to write the conditional mutual information
. Let us use the chain rule to write the conditional mutual information  in two ways:
in two ways: 

 , we obtain the statement of the lemma.
, we obtain the statement of the lemma. 

 and for all
and for all 

 , any
, any  , and any
, and any  denote the collection of all finite subsets of
denote the collection of all finite subsets of  , and for any
, and for any  by
by 
 defined in Eq.
defined in Eq.  : indeed, by the chain rule we have
: indeed, by the chain rule we have 
 , we can also compute
, we can also compute  :
: 
 for all
for all 
 , we have
, we have ![\displaystyle \begin{array}{rcl} I^+_{t+1}(\{u,v\} | {\cal K}) &\le& (1-\eta)I^+_{t+1}(\{u\}|{\cal K}) + \eta I^+_{t+1}(\{u\} | {\cal K} \cup \partial_+ v) + \eta I_t(\partial_+ v | {\cal K}) \\ &\le& (1-\eta) \eta I_t(\partial_+ u | {\cal K}) + \eta^2 I_t(\partial_+ u | {\cal K} \cup \partial_+ v) + \eta I_t(\partial_+ v | {\cal K}) \\ &=& (1-\eta)\eta \left[I_t(\partial_+ u | {\cal K}) + I_t(\partial_+ v | {\cal K})\right] + \eta^2 I_t(\partial_+ u | {\cal K} \cup \partial_+ v) \nonumber\\ && \qquad \qquad \qquad - (1-\eta)\eta I_t(\partial_+ v | {\cal K}) + \eta I_t(\partial_+ v | {\cal K}) \\ &=& (1-\eta)\eta \left[I_t(\partial_+ u | {\cal K}) + I_t(\partial_+ v | {\cal K})\right] + \eta^2 \left[I_t(\partial_+ v | {\cal K}) + I_t(\partial_+ u | {\cal K} \cup \partial_+ v) \right] \\ &=& (1-\eta)\eta \left[I_t(\partial_+ u | {\cal K}) + I_t(\partial_+ v | {\cal K})\right] + \eta^2 I_t(\partial_+ u \cup \partial_+ v | {\cal K}), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09I%5E%2B_%7Bt%2B1%7D%28%5C%7Bu%2Cv%5C%7D+%7C+%7B%5Ccal+K%7D%29+%26%5Cle%26+%281-%5Ceta%29I%5E%2B_%7Bt%2B1%7D%28%5C%7Bu%5C%7D%7C%7B%5Ccal+K%7D%29+%2B+%5Ceta+I%5E%2B_%7Bt%2B1%7D%28%5C%7Bu%5C%7D+%7C+%7B%5Ccal+K%7D+%5Ccup+%5Cpartial_%2B+v%29+%2B+%5Ceta+I_t%28%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29+%5C%5C+%09%26%5Cle%26+%281-%5Ceta%29+%5Ceta+I_t%28%5Cpartial_%2B+u+%7C+%7B%5Ccal+K%7D%29+%2B+%5Ceta%5E2+I_t%28%5Cpartial_%2B+u+%7C+%7B%5Ccal+K%7D+%5Ccup+%5Cpartial_%2B+v%29+%2B+%5Ceta+I_t%28%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29+%5C%5C+%09%26%3D%26+%281-%5Ceta%29%5Ceta+%5Cleft%5BI_t%28%5Cpartial_%2B+u+%7C+%7B%5Ccal+K%7D%29+%2B+I_t%28%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29%5Cright%5D+%2B+%5Ceta%5E2+I_t%28%5Cpartial_%2B+u+%7C+%7B%5Ccal+K%7D+%5Ccup+%5Cpartial_%2B+v%29+%5Cnonumber%5C%5C+%09%26%26+%5Cqquad+%5Cqquad+%5Cqquad+-+%281-%5Ceta%29%5Ceta+I_t%28%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29+%2B+%5Ceta+I_t%28%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29+%5C%5C+%09%26%3D%26+%281-%5Ceta%29%5Ceta+%5Cleft%5BI_t%28%5Cpartial_%2B+u+%7C+%7B%5Ccal+K%7D%29+%2B+I_t%28%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29%5Cright%5D+%2B+%5Ceta%5E2+%5Cleft%5BI_t%28%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29+%2B+I_t%28%5Cpartial_%2B+u+%7C+%7B%5Ccal+K%7D+%5Ccup+%5Cpartial_%2B+v%29+%5Cright%5D+%5C%5C+%09%26%3D%26+%281-%5Ceta%29%5Ceta+%5Cleft%5BI_t%28%5Cpartial_%2B+u+%7C+%7B%5Ccal+K%7D%29+%2B+I_t%28%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29%5Cright%5D+%2B+%5Ceta%5E2+I_t%28%5Cpartial_%2B+u+%5Ccup+%5Cpartial_%2B+v+%7C+%7B%5Ccal+K%7D%29%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 ; in the third, we add and subtract
; in the third, we add and subtract  ; and the last step uses the chain rule. Continuing inductively, we see that, for any
; and the last step uses the chain rule. Continuing inductively, we see that, for any  ,
, 
 with
with  , we obtain
, we obtain 
 . Therefore,
. Therefore, 

 . Now, we write
. Now, we write 
 for every
for every 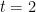 can be bounded as
can be bounded as  . Thus, if
. Thus, if 
 as
as 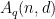 denote the size of the largest code over a
denote the size of the largest code over a  -ary alphabet that has blocklength
-ary alphabet that has blocklength  and minimum distance
and minimum distance 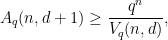
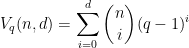
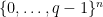 . The usual way of arriving at the GV bound is through a greedy construction: pick an arbitrary codeword
. The usual way of arriving at the GV bound is through a greedy construction: pick an arbitrary codeword 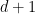 from all codewords that have already been picked. When this procedure terminates, the complement of the union of the Hamming balls of radius
from all codewords that have already been picked. When this procedure terminates, the complement of the union of the Hamming balls of radius 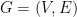 be an undirected graph. A set
be an undirected graph. A set 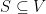 of vertices is called independent if no two vertices in
of vertices is called independent if no two vertices in 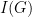 , is the cardinality of the largest independent set. The following lemma is folklore in graph theory:
, is the cardinality of the largest independent set. The following lemma is folklore in graph theory: -regular, i.e., every vertex has exactly
-regular, i.e., every vertex has exactly 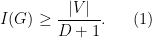
 be a maximal independent set. Any vertex
be a maximal independent set. Any vertex 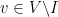 is connected by an edge to at least one
is connected by an edge to at least one 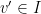 , because otherwise
, because otherwise 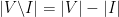 edges with one vertex in
edges with one vertex in 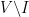 . On the other hand, because
. On the other hand, because 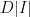 such edges. This means that
such edges. This means that 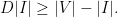
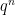 vertices, and each vertex has degree
vertices, and each vertex has degree 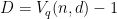 . Moreover, there is a one-to-one correspondence between independent sets of vertices and
. Moreover, there is a one-to-one correspondence between independent sets of vertices and  . The bound
. The bound 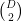 edges), the lower bound
edges), the lower bound 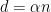 for some
for some 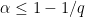 and replace exact combinatorial bounds by entropy bounds.
and replace exact combinatorial bounds by entropy bounds. such that
such that 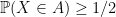 , we have
, we have 
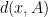 is the distance from the point
is the distance from the point 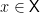 to the set
to the set 
 , define the
, define the  -blowup of
-blowup of 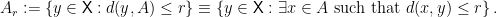
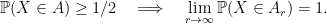
 and take
and take  — the usual Euclidean distance. Let
— the usual Euclidean distance. Let  , where
, where 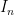 is the
is the 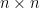 identity matrix. Then for any
identity matrix. Then for any 
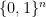 equipped with the normalized Hamming distance
equipped with the normalized Hamming distance

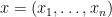 and
and  disagree. Let
disagree. Let  for all
for all 

 as
as  . The $64,000 question is: how do we get such bounds?
. The $64,000 question is: how do we get such bounds? . Let
. Let  denote the conditional distribution of
denote the conditional distribution of  . That is, for any (measurable) set
. That is, for any (measurable) set  we have
we have 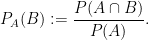
 to indicate the fact that
to indicate the fact that 
 we have
we have 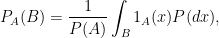
 . Therefore, by definition of the divergence,
. Therefore, by definition of the divergence, 
 the function
the function 
 ,
, ![\displaystyle f_A(x) - f_A(x') = \inf_{y \in A}d(x,y) - \inf_{y \in A} d(x',y) \le \sup_{y \in A} \left[d(x,y) - d(x',y)\right] \le d(x,x'),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f_A%28x%29+-+f_A%28x%27%29+%3D+%5Cinf_%7By+%5Cin+A%7Dd%28x%2Cy%29+-+%5Cinf_%7By+%5Cin+A%7D+d%28x%27%2Cy%29+%5Cle+%5Csup_%7By+%5Cin+A%7D+%5Cleft%5Bd%28x%2Cy%29+-+d%28x%27%2Cy%29%5Cright%5D+%5Cle+d%28x%2Cx%27%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
 , we get the Lipschitz property. Moreover, let us consider the random variable
, we get the Lipschitz property. Moreover, let us consider the random variable 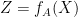 , where
, where  .
.
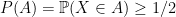 , then
, then 
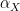 :
: 
 denotes any median of
denotes any median of  . We already showed, by passing from
. We already showed, by passing from 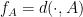 , that
, that 
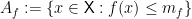 , where
, where 
![\displaystyle [A_f]_r = \Big\{ x \in {\mathsf X}: d(x,A_f) \le r \Big\},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5BA_f%5D_r+%3D+%5CBig%5C%7B+x+%5Cin+%7B%5Cmathsf+X%7D%3A+d%28x%2CA_f%29+%5Cle+r+%5CBig%5C%7D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
 we must have
we must have 
![\displaystyle {\mathbb P}\Big( f(X) > m_f + r \Big) \le {\mathbb P}\Big( d(X,A_f) > r \Big) = 1 - P\left([A_f]_r\right) \le \alpha_X(r).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+P%7D%5CBig%28+f%28X%29+%3E+m_f+%2B+r+%5CBig%29+%5Cle+%7B%5Cmathbb+P%7D%5CBig%28+d%28X%2CA_f%29+%3E+r+%5CBig%29+%3D+1+-+P%5Cleft%28%5BA_f%5D_r%5Cright%29+%5Cle+%5Calpha_X%28r%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
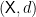 has the concentration property if real-valued Lipschitz functions
has the concentration property if real-valued Lipschitz functions 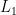 Wasserstein distance (or transportation distance) between any two probability measures
Wasserstein distance (or transportation distance) between any two probability measures ![\displaystyle W_1(P,Q) := \inf_{X \sim P, Y \sim Q} {\mathbb E}[d(X,Y)],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++W_1%28P%2CQ%29+%3A%3D+%5Cinf_%7BX+%5Csim+P%2C+Y+%5Csim+Q%7D+%7B%5Cmathbb+E%7D%5Bd%28X%2CY%29%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
 , such that
, such that  and
and 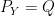 . Now consider a random variable
. Now consider a random variable  , for which we wish to establish concentration. What Marton showed is the following: Suppose the distribution
, for which we wish to establish concentration. What Marton showed is the following: Suppose the distribution 
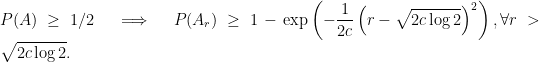
 with
with 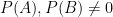 . Recalling our notation for conditional distributions, we can write
. Recalling our notation for conditional distributions, we can write 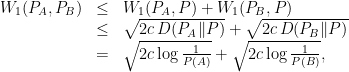
 and let
and let 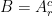 for some
for some  denotes set-theoretic complement. Then we can show that
denotes set-theoretic complement. Then we can show that  . On the other hand,
. On the other hand, 
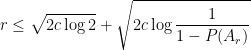
 , then we get
, then we get 
 , at least for large enough values of
, at least for large enough values of 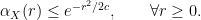
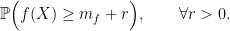
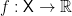 such that
such that ![{{\mathbb E}[f(X)] = 0}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbb+E%7D%5Bf%28X%29%5D+%3D+0%7D&bg=ffffff&fg=000000&s=0&c=20201002) . We can apply the well-known Chernoff trick: for any
. We can apply the well-known Chernoff trick: for any  we have
we have ![\displaystyle {\mathbb P}\Big( f(X) \ge r \Big) = {\mathbb P}\Big( e^{\lambda f(X)} \ge e^{\lambda r} \Big) \le e^{-\lambda r} {\mathbb E}[e^{\lambda f(X)}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+P%7D%5CBig%28+f%28X%29+%5Cge+r+%5CBig%29+%3D+%7B%5Cmathbb+P%7D%5CBig%28+e%5E%7B%5Clambda+f%28X%29%7D+%5Cge+e%5E%7B%5Clambda+r%7D+%5CBig%29+%5Cle+e%5E%7B-%5Clambda+r%7D+%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+f%28X%29%7D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
![{\Lambda(\lambda) := \log {\mathbb E}[e^{\lambda f(X)}]}](https://s0.wp.com/latex.php?latex=%7B%5CLambda%28%5Clambda%29+%3A%3D+%5Clog+%7B%5Cmathbb+E%7D%5Be%5E%7B%5Clambda+f%28X%29%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . The entropy method, which was the subject of Gabor Lugosi’s plenary, is the name for a set of techniques for bounding
. The entropy method, which was the subject of Gabor Lugosi’s plenary, is the name for a set of techniques for bounding  by means of various inequalities involving the relative entropy between various tilted distributions derived from
by means of various inequalities involving the relative entropy between various tilted distributions derived from  , the tilted distribution
, the tilted distribution 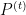 via
via 
 exists and is finite). Then we have
exists and is finite). Then we have ![\displaystyle \begin{array}{rcl} D(P^{(t)} \| P) &=& \int dP^{(t)} \left[ tf - \Lambda(t)\right] \\ &=& \frac{1}{e^{\Lambda(t)}} t\, {\mathbb E}\left[f(X)e^{tf(X)}\right] - \Lambda(t) \\ &=& t \Lambda'(t) - \Lambda (t) \\ &=& t^2 \frac{d}{dt} \left(\frac{\Lambda(t)}{t}\right). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09D%28P%5E%7B%28t%29%7D+%5C%7C+P%29+%26%3D%26+%5Cint+dP%5E%7B%28t%29%7D+%5Cleft%5B+tf+-+%5CLambda%28t%29%5Cright%5D+%5C%5C+%09%26%3D%26+%5Cfrac%7B1%7D%7Be%5E%7B%5CLambda%28t%29%7D%7D+t%5C%2C+%7B%5Cmathbb+E%7D%5Cleft%5Bf%28X%29e%5E%7Btf%28X%29%7D%5Cright%5D+-+%5CLambda%28t%29+%5C%5C+%09%26%3D%26+t+%5CLambda%27%28t%29+-+%5CLambda+%28t%29+%5C%5C+%09%26%3D%26+t%5E2+%5Cfrac%7Bd%7D%7Bdt%7D+%5Cleft%28%5Cfrac%7B%5CLambda%28t%29%7D%7Bt%7D%5Cright%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 , we get
, we get 
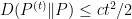 for some
for some 

 by a quadratic function of
by a quadratic function of 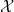 ,
,  , and the function
, and the function 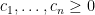 , such that changing the
, such that changing the  th argument of
th argument of  :
: 

 on the product space
on the product space  satisfies the transportation inequality
satisfies the transportation inequality 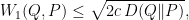
 . By the Bobkov–Götze result quoted above, this is equivalent to the concentration bound
. By the Bobkov–Götze result quoted above, this is equivalent to the concentration bound ![\displaystyle {\mathbb P}\left( f(X) \ge {\mathbb E}[f(X)] + r \right) \le \exp\left( - \frac{r^2}{2c}\right) = \exp\left( - \frac{2r^2}{\sum^n_{i=1}c^2_i}\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+P%7D%5Cleft%28+f%28X%29+%5Cge+%7B%5Cmathbb+E%7D%5Bf%28X%29%5D+%2B+r+%5Cright%29+%5Cle+%5Cexp%5Cleft%28+-+%5Cfrac%7Br%5E2%7D%7B2c%7D%5Cright%29+%3D+%5Cexp%5Cleft%28+-+%5Cfrac%7B2r%5E2%7D%7B%5Csum%5En_%7Bi%3D1%7Dc%5E2_i%7D%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002)