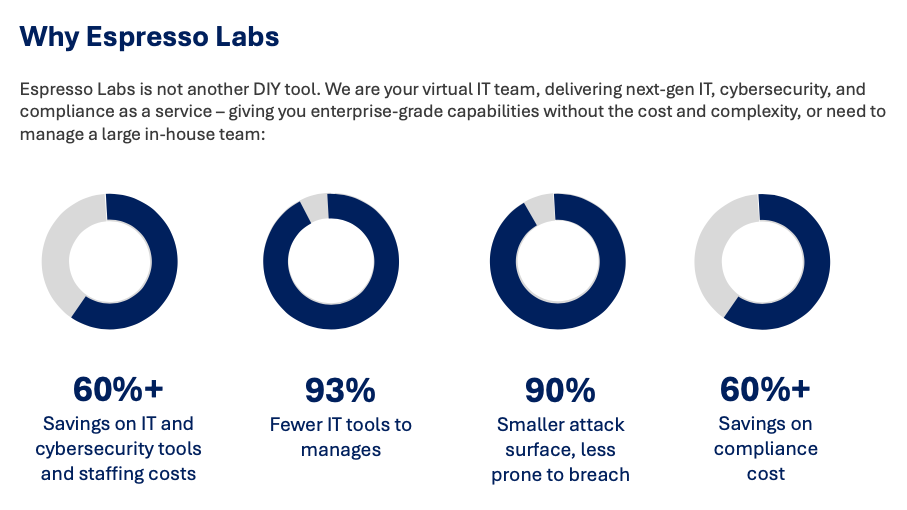
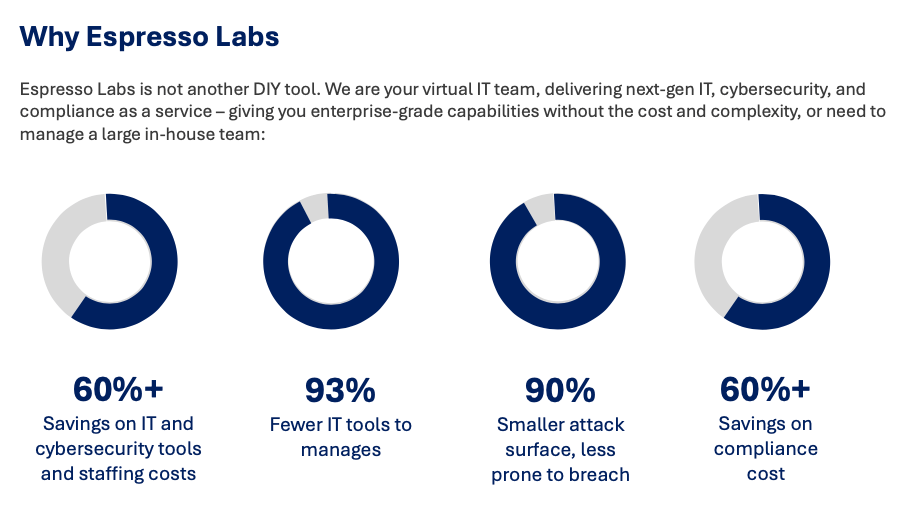
Show full content
I recently joined the MSP 1337 podcast with Chris Johnson to talk about something I’ve been thinking about for years:
Small and midsize businesses are being asked to operate with enterprise-level security expectations — without enterprise-level resources.
That gap is becoming impossible to ignore.
And AI is accelerating both sides of the problem.
Attackers are moving faster.
Infrastructure is becoming noisier.
Compliance requirements are multiplying.
Meanwhile, SMBs and MSPs are still expected to somehow manage everything with limited staff, fragmented tools, and endless alerts.
That model is cracking.
Btw, you can listen to it here:
– Apple Podcasts
– Spotify
The cybersecurity market is overflowing with products.
Another RMM.
Another EDR.
Another dashboard.
Another SIEM.
Another “AI-powered” feature.
But most SMBs don’t actually suffer from a lack of tooling.
They suffer from:
- Too many disconnected systems
- Massive operational overhead
- Alert fatigue
- Compliance drift
- Lack of skilled security personnel
- No realistic way to continuously enforce policy
And this is where most security conversations become disconnected from reality.
Enterprise security models assume: dedicated SOC teams, compliance departments, security engineers, analysts tuning detections and people reviewing thousands of events.
Most SMBs have none of that.
Sometimes the “security team” is: The MSP, the office manager or the founder wearing five hats.
Not so good.
One of the biggest issues in cybersecurity is not detection.
It’s prioritization.
Every platform can generate alerts.
Every system can scream.
The real challenge is figuring out: Which signals actually matter?
Anyone who has worked with SIEMs, firewall logs, endpoint alerts, or compliance tooling knows the pattern:
you turn something on and suddenly drown in noise.
And SMBs don’t have months available for “tuning.”
They need operational clarity immediately.
That’s one of the core reasons we built Espresso Labs the way we did.
- Not to replace humans.
- Not to pretend AI is magic.
- But to eliminate huge amounts of repetitive operational work.
If AI can safely handle: Level 1 triage, repetitive remediation, evidence gathering, inventory correlation, policy enforcement, baseline monitoring, then human operators can focus on the things that actually require judgment.
That’s the shift.
There’s a lot of excitement around AI agents right now.
There should be.
But there’s also a dangerous amount of blind trust entering the industry.
Security is not the place for vague prompts and “hopefully it works.”
You absolutely do not want:
- an agent touching sensitive systems without boundaries,
- unrestricted access to production environments,
- or AI improvising security decisions.
That’s why we designed our local agents and browser controls around strict guardrails and isolation.
AI should augment operational capability.
Not create a new attack surface.
The right model is:
- constrained execution,
- scoped permissions,
- auditable actions,
- human escalation paths,
- and continuous supervision.
Especially in cybersecurity.
SMBs Need Enterprise Capabilities — Without Enterprise ComplexityOne realization became obvious very early for us:
SMBs still need:
- endpoint security
- compliance enforcement
- browser protection
- backup validation
- inventory visibility
- policy management
- user monitoring
- ticketing
- audit trails
- drift detection
- remediation workflows
They just can’t afford a giant security team to operate all of it.
So the question became:
Can AI reduce the operational cost of security enough to make strong security realistic for smaller organizations?
That’s the problem we’re solving.
Compliance Is Becoming Continuous — Not AnnualThis is especially visible with:
- Cybersecurity Maturity Model Certification (CMMC)
- SOC 2
- ISO 27001
- cyber insurance requirements
- vendor security assessments
Historically, compliance was treated like a snapshot: prepare, audit, pass and move on.
But modern environments drift constantly.
New users appear.
Devices change.
Policies weaken.
Software becomes vulnerable.
People leave companies.
The environment changes daily.
So the future of compliance is not “annual preparation.”
It’s continuous enforcement.
That means:
- detecting drift automatically,
- continuously validating controls,
- proving remediation,
- maintaining evidence in real time.
This is where AI becomes incredibly powerful.
Instead of generating a PDF telling you what’s wrong…
the system can: identify the issue, explain the impact, enforce the control, validate the result and document the evidence.
That changes the economics of compliance entirely.
One thing I strongly believe:
MSPs should not be forced into a “take it or leave it” platform.
If you already use:
- CrowdStrike
- SentinelOne
- Bitdefender
- Fortinet
you shouldn’t have to rip everything out.
The real value comes from correlation and orchestration.
Security tools become exponentially more useful when: logs are centralized, inventory is unified, policies are enforceable and remediation becomes automated.
The goal is operational leverage — not forcing replacement.
The Bigger Shift Is Operational AIMost people still think about AI in cybersecurity as: chatbots, copilots, summaries or search.
But the bigger opportunity is operational execution.
AI that can:
- monitor continuously
- learn organizational baselines
- suppress known-good noise
- escalate intelligently
- automate low-risk remediation
- maintain compliance posture.
That’s where this is all heading. Not AI replacing humans.
AI removing operational drag.
The reality is simple:
Attackers are scaling with AI.
Defenders need to scale too.
But SMBs cannot solve this by hiring massive teams.
The economics don’t work.
The only viable future is:
- better automation,
- safer AI execution,
- continuous enforcement,
- and drastically reduced operational overhead.
That’s the direction we’re building toward at Espresso Labs.
And honestly, I think the entire industry is heading there whether it realizes it yet or not.
Recommended ReadingDuring the podcast, I mentioned one book I keep returning to:
The Psychology of Money by Morgan Housel
Not a cybersecurity book — but one of the best books on long-term thinking, incentives, and human behavior.
A lot of it applies surprisingly well to security leadership too.
You can learn more about Espresso Labs at: Espresso Labs
Be strong 



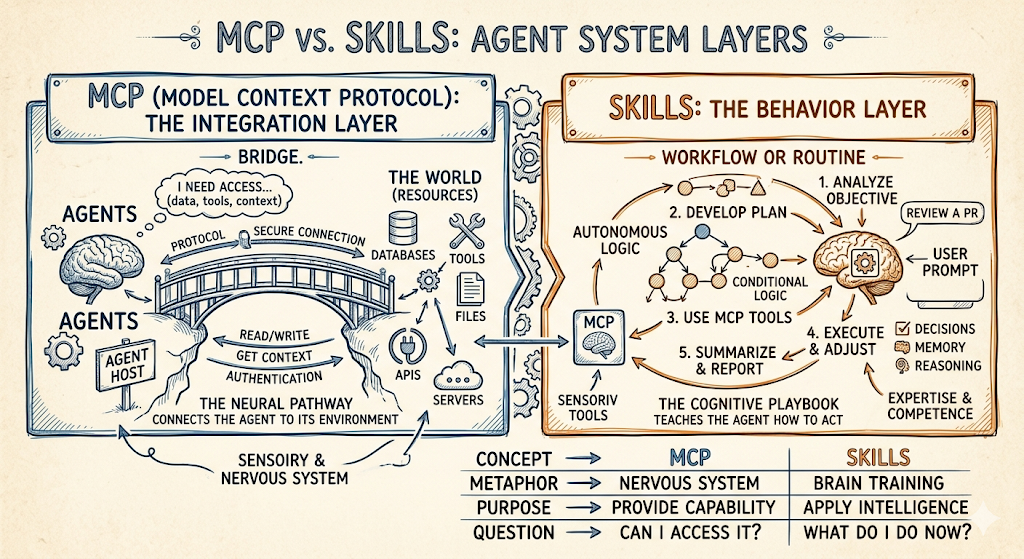
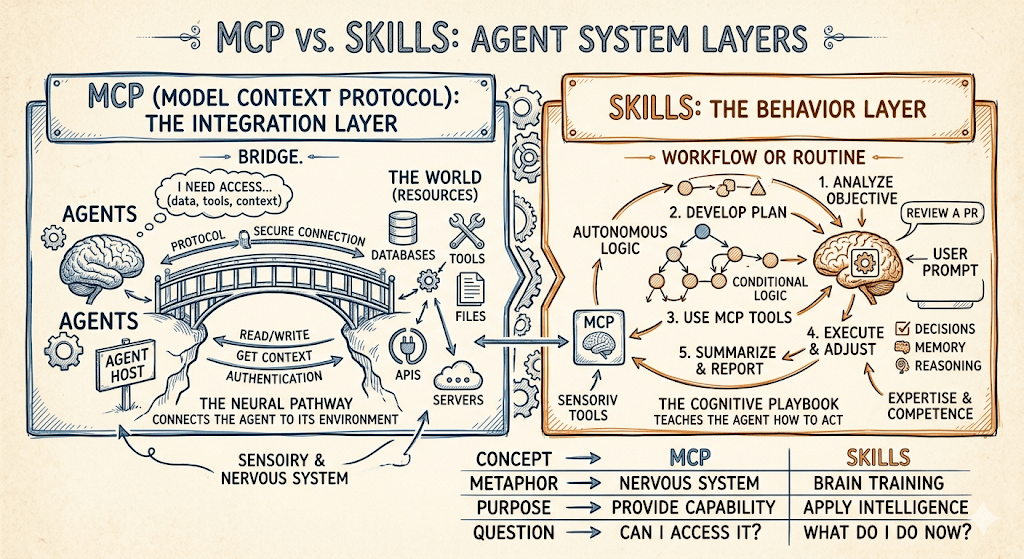




 Meet the AI Barista
Meet the AI Barista