
tag:blogger.com,1999:blog-6950833531562942289.post-4286165719696191024
https://c0de517e.com/014_future_engines.htm

Read the article here: https://c0de517e.com/013_web.htm

This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: https://c0de517e.com/012_peak_tech.htm

This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: https://c0de517e.com/011_portals.htm

This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: https://c0de517e.com/009_website_joy.htm
This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: Exploring the design space of "remote scene approximation". (c0de517e.com)
This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: From the archive: Notes on environment lighting occlusion. (c0de517e.com)
This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: Writing to stimulate the brain, and to quiet it. (c0de517e.com)
This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the article here: Crap: WASMtoy. (c0de517e.com)
This blogspot site is dead!
Update your links (and RSS!) to my new blog at c0de517e.com.
Read the following article here: 20x1000 Use(r)net Archive. (c0de517e.com)
This blog is dead! Update your links (and RSS!) to c0de517e.com.
Below you will find a draft version of the post, all images, formatting and links will be missing here as I moved to my new system.
20x1000 Use(r)net Archive.
An investigation of the old web.
This website is a manifestation of an interest I've acquired over the past couple of years in internet communities, creative spaces and human-centric technology. Yes, my landing back on the "small web" is not just a reaction to seeing what happen when someone like Moron acquires a social network like they did with Twitter...
Part of it is that I consider Roblox itself (my employer at the time of writing, in case you don't know) to be part of the more "humanistic" web, a social experience not driven by ads, algorithms and passive feeds, but by creativity, agency, active participation.
As part of this exploration, I wanted to go back and see what we had when posting online was not subject to an algorithm, was not driven to maximize engagement to be able to monetize ads and the like... I downloaded a few archives of old usenet postings (i.e. when newsgroups were still used for discussions, and not as they later devolved, exclusively as a way to distribute binary files of dubious legality) and wrote a small script to convert them to HTML.
The conversion process is far from... good. As far as I could tell, there is no encoding of the comment trees in usenet, it's just a linear stream of email-like messages as received by the server.
There does not even seem to be a standard for dates or... anything regarding the headers, so whilst I did write a parser that is robust enough to guess a date for each post in the archive, the date itself is not reliable, as I've seen a ton of different encodings, timezone formats and so on.
Even the post subject is not entirely reliable, because people change it, sometimes by mistake (misspelling, corrections, truncation), sometimes adding chains of "re:" or "was:" and so on, which again, I tried somewhat to account for, but succeeded only partially.
For each archive I converted only the top 1000 posts by number of replies, and no other filtering was done, so you will see the occasional spam, and a ton of less than politically correct stuff. Proceed at your peril, you have been warned.
And now without further ado, here are a few archives for your perusal.
01 [FILE:EXTERNAL/news/alt.philosophy/index_main.htm alt.philosophy]
02 [FILE:EXTERNAL/news/alt.postmodern/index_main.htm alt.postmodern]
03 [FILE:EXTERNAL/news/comp.ai.alife/index_main.htm comp.ai.alife]
04 [FILE:EXTERNAL/news/comp.ai.genetic/index_main.htm comp.ai.genetic]
05 [FILE:EXTERNAL/news/comp.ai.neural-nets/index_main.htm comp.ai.neural-nets]
06 [FILE:EXTERNAL/news/comp.ai.philosophy/index_main.htm comp.ai.philosophy]
07 [FILE:EXTERNAL/news/comp.arch/index_main.htm comp.arch]
08 [FILE:EXTERNAL/news/comp.compilers/index_main.htm comp.compilers]
09 [FILE:EXTERNAL/news/comp.games.development.industry/index_main.htm comp.development.industry]
10 [FILE:EXTERNAL/news/comp.games.development.programming.algorithms/index_main.htm comp.development.programming.algorithms]
11 [FILE:EXTERNAL/news/comp.graphics.algorithms/index_main.htm comp.graphics.algorithms]
12 [FILE:EXTERNAL/news/comp.jobs.computer/index_main.htm comp.jobs.computer]
13 [FILE:EXTERNAL/news/comp.lang.forth/index_main.htm comp.lang.forth]
14 [FILE:EXTERNAL/news/comp.lang.functional/index_main.htm comp.lang.functional]
15 [FILE:EXTERNAL/news/comp.lang.lisp/index_main.htm comp.lang.lisp]
16 [FILE:EXTERNAL/news/comp.org.eff.talk/index_main.htm comp.org.eff.talk]
17 [FILE:EXTERNAL/news/comp.society.futures/index_main.htm comp.society.futures]
18 [FILE:EXTERNAL/news/comp.software-eng/index_main.htm comp.software-eng]
19 [FILE:EXTERNAL/news/comp.sys.apple2/index_main.htm comp.sys.apple2]
20 [FILE:EXTERNAL/news/comp.sys.ibm.pc.demos/index_main.htm comp.sys.ibm.pc.demos]
Better times? Worse times?
Read the following article here: Notes: Reversing Revopoint Scanner. (c0de517e.com) This blog is dead! Update your links (and RSS!) to c0de517e.com.
Below you will find a draft version of the post, all images, formatting and links will be missing here as I moved to my new system.Read the following article here: A new Blog: Reinventing the wheel. (c0de517e.com) This blog is dead! Update your links (and RSS!) to c0de517e.com.
Below you will find a draft version of the post, all images, formatting and links will be missing here as I moved to my new system.
A new Blog: Reinventing the wheel.
I made my first website in high school, must not have been long after I discovered the internet and signed a contract with the first provider of my town. Remember Microsoft Frontpage and GeoCities? Photoshop web export? That!
It was nothing much, the kind of things that later would find home on MySpace: music, friends, some drawings and 3d art I was making at the time, demoscene, a bit of photography, animated gifs of course. I think later on even had some java effects on it. All in all, teenager stuff.
Realizing that nobody in the world would care about my crappy art page, it was not long lived, in fact I don't even think I saved a copy in my archives. But it introduced me to this idea of the web and using it for personal spaces.
So, soon after I started another web project, this time focusing on mainstream subjects such as a teenager's view of philosophy, politics, fountain pens and lisp... This time, it was going to using cutting-edge, newfangled technology. It was going to be a blog!
[IMG:lemon.png Celebrity! Somehow a "famous" lisp website noticed me back in the days...]
[NOTE: do not link... but it's still up -> http://kenpex.blogspot.com]
And yes, that was on blogspot, where my main blog is/used to be until today!
It was truly exciting, even if in retrospect, dumb. See, the idea of keeping an online journal and sharing it is great. What's not to like. Writing - great. Journaling - great. Sharing - great. Even if you don't get any visitors, just the feeling of being part of a community, and a cutting-edge one at that, exploring the cyberspace, joining webrings... Why not?
Dumb... because, well, I already knew how to write websites, and blogspot offered... nothing. The value is zero, and it has always been zero. It had and has a crappy editor - and we already had frontpage and geocities, you didn't need to know HTML. It was not a social network. Even basic stuff like visitor count and so on had to be brought from external providers.
True, it does allow for comments, and back in the days these were a bit better, but they were never great - today they are only spam. We felt good using it, even if it was truly never good. And... we pay a price, a quite high price at that.
We got nothing, nothing of value anyways. And in return we locked ourselves in a platform - one that happens to be dying nowadays, but in general, we gave our creativity for free to an entity that gave us nothing in return.
Big whoop you say! This is the deal of the modern internet, didn't you hear? "If you are not paying for it, you're not the customer - you are the product being sold". Yes, yes, I'm not that naive. There is a nuance - at least for me. The trade is not per-se bad. But it is a trade, and you have to understand how much value you are getting.
This is true for everything, really, in tech, perhaps in life. Tradeoffs. I made a few bad deals, and it's time to rectify them. Blogspot has no value. I even used to host my presentations and files on Scribd for it - and boy was that a mistake.
We should talk about Twitter and similar communities as well... But that will be for another time...
I abandoned my first blog when I started working professionally in gaming. I didn't want to have my real name associated with it as I was navigating my first jobs, and I didn't want to have to discuss with my employer the nuances of what's good to post or not on a personal, but technical blog.
Eventually the blog became "famous" enough that people knew it was me behind it, so I dropped the pretense of anonymity - but that came many years after its inception.
And here we are now. So, this is going to be my new homepage. I hope you enjoy it! It has many features Blogspot never supported, both for you as a viewer and certainly for me as a writer.
You can understand why I went with my own website instead of simply moving to the next "great for now" platform. I've looked around a bit, and found nothing that provided any value to me.
Medium is about the same as Blogspot. CoHost - I don't need to tangle my writing with the social media I use to advertise and discuss about it. Substack? I don't care about getting paid... Github pages? Why on earth?
I just want a place to share random crap.
The old blog will stay up and for a while I plan to cross-post on both. Currently, I have no plans to take the old blog down, but I have scraped its contents in a few different ways "just in case".
- Angelo Pesce, a.k.a. deadc0de on c0de517e, a.k.a. "kenpex"
**Appendix:**
[IMG:1stweb.png Quirky, unprofessional web "design", wasn't life more fun when we were not using all the same cookie molds?]
[IMG:1stweb_2.png Yeah, the entrace featured my first car, cruising on the Salerno coast hightway, with bad Photoshop effects!]
[IMG:engblog.png Teenage problems on display. And lisp.]
[IMG:itblog.png Even more personal, even more random, and of course, more bad Photoshop!]








 From Seb. Lagarde (link above)
From Seb. Lagarde (link above)

 From youtube - note how the reflected corners of the room appear sharp, are not correctly blurred by the rough floor material.
From youtube - note how the reflected corners of the room appear sharp, are not correctly blurred by the rough floor material.









The following doesn't work (yet), but I wanted to write something down both to put it to rest for now, as I prepare for GDC, and perhaps to show the application of some of the ideas I recently wrote about here.
A bit of context. Occlusion culling (visibility determination) per se is far from a solved problem in any setting, but for us (Roblox) it poses a few extra complications:
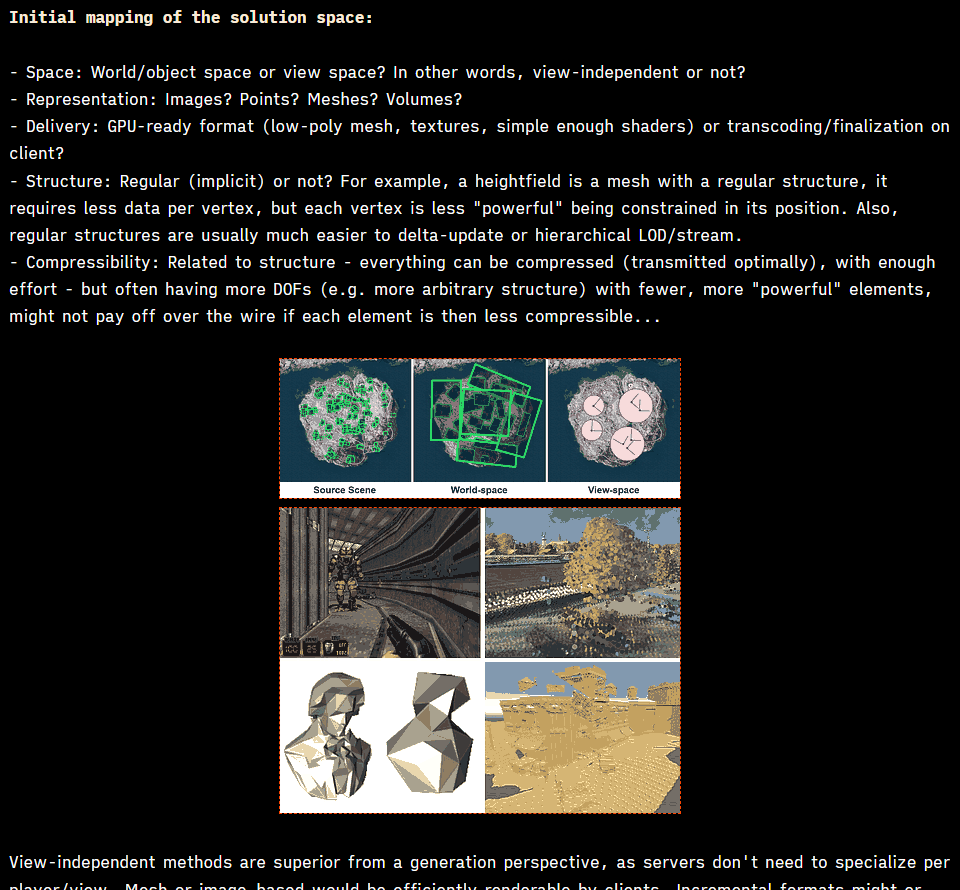
That said, let's start and find some ideas on how we could solve this problem, by trying to imagine our design landscape and its possible branches.
 Image from https://losslandscape.com/gallery/
Image from https://losslandscape.com/gallery/Real-time "vs" Incremental
I'd say we have a first obvious choice, given the dynamic nature of the world. Either we try to do most of the work in real-time, or we try to incrementally compute and cache some auxiliary data structures, and we'd have then to be prepared to invalidate them when things move.
For the real-time side of things everything (that I can think of) revolves around some form of testing the depth buffer, and the decisions lie in where and when to generate it, and when and where to test it.
Depth could be generated on the GPU and read-back, typically a frame or more late, to be tested on CPU, it could be generated and tested on GPU, if our bottlenecks are not in the command buffer generation (either because we're that fast, or because we're doing GPU-driven rendering), or it could be both generated and tested on CPU, via a software raster. Delving deeper into the details reveals even more choices.
On GPU you could use occlusion queries, predicated rendering, or a "software" implementation (shader) of the same concepts, on CPU you would need to have a heuristic to select a small set of triangles as occluders, make sure the occluders themselves are not occluded by "better" ones and so on.
All of the above, found use in games, so on one hand they are techniques that we know could work, and we could guess the performance implications, upsides, and downsides, and at the same time there is a lot that can still be improved compared to the state of the art... but, improvements at this point probably lie in relatively low-level implementation ideas.
E.g. trying to implement a raster that works "conservatively" in the sense of occlusion culling is still hard (no, it's not the same as conservative triangle rasterization), or trying to write a parallelized raster that still allows doing occlusion tests while updating it, to be able to occlude-the-occluders while rendering them, in the same frame, things of that nature.
As I wanted to explore more things that might reveal "bigger" surprises, I "shelved" this branch...
Let's then switch to thinking about incremental computation and caching.
Caching results or caching data to generate them?
The first thing that comes to mind, honestly, is just to cache the results of our visibility queries. If we had a way to test the visibility of an object, even after the fact, then we could use that to incrementally build a PVS. Divide the world into cells of some sort, maybe divide the cells per viewing direction, and start accumulating the list of invisible objects.
All of this sounds great, and I think the biggest obstacle would be to know when the results are valid. Even offline, computing a PVS from raster visibility is not easy, you are sampling the space (camera positions, angles) and the raster results are not exact themselves, so, you can't know that your data structure is absolutely right, you just trust that you sampled enough that no object was skipped. For an incremental data structure, we'd need to have a notion of "probability" of it being valid.
You can see a pattern here by now, a way of "dividing and conquering" the idea landscape, the more you think about it, the more you find branches and decide which ones to follow, which ones to prune, and which ones to shelve.
Pruning happens either because a branch seems too unlikely to work out, or because it seems obvious enough (perhaps it's already well known or we can guess with low risk) that it does not need to be investigated more deeply (prototyping and so on).
Shelving happens when we think something needs more attention, but we might want to context-switch for a bit to check other areas before sorting out the order of exploration...
So, going a bit further here, I imagined that visibility could be the property of an object - a visibility function over all directions, for each direction the maximum distance at which it would be unoccluded - or the property of the world, i.e. from a given region, what can that region see. The object perspective, even if intriguing, seems a mismatch both in terms of storage and in terms of computation, as it thinks of visibility as a function - which it is, but one that is full of discontinuities that are just hard to encode.
If we think about world, then we can imagine either associating a "validity" score to the PVS cells, associating a probability to the list of visible objects (instead of being binary), or trying to dynamically create cells. We know we could query, after rendering, for a given camera the list of visible objects, so, for an infinitesimal point in 5d space, we can create a perfect PVS. From there we could cast the problem as how to "enlarge" our PVS cells, from infinitesimal points to regions in space.
This to me, seems like a viable idea or at least, one worth exploring in actual algorithms and prototypes. Perhaps there is even some literature about things of this nature I am not aware of. Would be worth some research, so for now, let's shelve it and look elsewhere!
Occluders
Caching results can be also thought of as caching visibility, so the immediate reaction would be to think in terms of occluder generation as the other side of the branch... but it's not necessarily true. In general, in a visibility data structure, we can encode the occluded space, or the opposite, the open space.
We know of a popular technique for the latter, portals, and we can imagine these could be generated with minimal user intervention, as Umbra 3 introduced many years ago the idea of deriving them through scene voxelization.
 Introduction to Occlusion Culling | by Umbra 3D | Medium
Introduction to Occlusion Culling | by Umbra 3D | MediumIt's realistic to imagine that the process could be made incremental, realistic enough that we will shelve this idea as well...
Thinking about occluders seem also a bit more natural for an incremental algorithm, not a big difference, but if we think of portals, they make sense when most of the scene is occluded (e.g. indoors), as we are starting with no information, we are in the opposite situation, where at first the entire scene is disoccluded, and progressively might start discovering occlusion, but hardly "in the amount" that would make most natural sense to encode with something like portals. There might be other options there, it's definitely not a dead branch, but it feels unlikely enough that we might want to prune it.
Here, is where I started going from "pen and paper" reasoning to some prototypes. I still think the PVS idea that we "shelved" might get here as well, but I chose to get to the next level on occluder generation for now.
From here on the process is still the same, but of course writing code takes more time than rambling about ideas, so we will stay a bit longer on one path before considering switching.
When prototyping I want to think of what the real risks and open questions are, and from there find the shortest path to an answer, hopefully via a proxy. I don't need at all to write code that implements the way I think the idea will work out if I don't need to - a prototype is not a bad/slow/ugly version of the final product, it can be an entirely different thing from which we can nonetheless answer the questions we have.
With this in mind, let's proceed. What are occluders? A simplified version of the scene, that guarantees (or at least tries) to be "inside" the real geometry, i.e. to never occlude surfaces that the real scene would not have occluded.
Obviously, we need a simplified representation, because otherwise solving visibility would be identical to rendering, minus shading, in other words, way too expensive. Also obvious that the guarantee we seek cannot hold in general in a view-independent way, i.e. there's no way to compute a set of simplified occluders for a polygon soup from any point of view, because polygon soups do not have well-defined inside/outside regions.
So, we need to simplify the scene, and either accept some errors or accept that the simplification is view-dependent. How? Let's talk about spaces and data structures. As we are working on geometry, the first instinct would be to somehow do computation on the meshes themselves, in object and world space.
It is also something that I would try to avoid, pruning that entire branch of reasoning, because geometric algorithms are among the hardest things known to mankind, and I personally try to avoid writing them as much as I can. I also don't have much hope for them to be able to scale as the scene complexity increases, to be robust, and so on (albeit I have to say, wizards at Roblox working on our real-time CSG systems have cracked many of these problems, but I'm not them).
World-space versus screen-space makes sense to consider. For data structures, I can imagine point clouds and voxels of some sort to be attractive.
First prototype: Screen-space depth reprojection
Took a looong and winding road to get here, but this is one of the most obvious ideas as CryEngine 3 showed it to be working more than ten years ago.
 Secrets of CryEngine 3
Secrets of CryEngine 3I don't want to miscredit this, but I think it was Anton Kaplanyan's work (if I'm wrong let me know and I'll edit), and back then it was dubbed "coverage buffer", albeit I'd discourage the use of the word as it already had a different meaning (the c-buffer is a simpler version of the span-buffer, a way to accelerate software rasterization by avoiding to store a depth value per pixel).
They simply took the scene depth after rendering, downsampled it, and reprojected - by point splatting - from the viewpoint of the next frame's camera. This creates holes, due to disocclusion, due to lack of information at the edges of the frame, and due to gaps between points. CryEngine solved the latter by running a dilation filter, able to eliminate pixel-sized holes, while just accepting that many draws will be false positive due to the other holes - thus not having the best possible performance, but still rendering a correct frame.
 Holes, in red, due to disocclusions and frame edges.
Holes, in red, due to disocclusions and frame edges.This is squarely in the realm of real-time solutions though, what are we thinking?
Well, I was wondering if this general idea of having occluders from a camera depthbuffer could be generalized a bit more. First, we could think of generating actual meshes - world-space occluders, from depth-buffer information.
As we said above, these would not be valid from all view directions, but we could associate the generated occluders from a set of views where we think they should hold up.
Second, we could keep things as point clouds and use point splatting, but construct a database from multiple viewpoints so we have more data to render occluder and fill the holes that any single viewpoint would create.
For prototyping, I decided to use Unity, I typically like to mix things up when I write throwaway code, and I know Unity enough that I could see a path to implement things there. I started by capturing the camera depth buffer, downsampling, and producing a screen-aligned quad-mesh I could displace, effectively like a heightfield. This allowed me to write everything via simple shaders, which is handy due to Unity's hot reloading.

 Test scene, and a naive "shrink-wrap" mesh generated from a given viewpoint
Test scene, and a naive "shrink-wrap" mesh generated from a given viewpointClearly, this results in a "shrink-wrap" effect, and the generated mesh will be a terrible occluder from novel viewpoints, so we will want to cut it around discontinuities instead. In the beginning, I thought about doing this by detecting, as I'm downsampling the depth buffer, which tiles can be well approximated by a plane, and which contain "complex" areas that would require multiple planes.
This is a similar reasoning to how hardware depth-buffer compression typically works, but in the end, proved to be silly.
An easier idea is to do an edge-detection pass in screen-space, and then simply observe which tiles contain edges and which do not. For edge detection, I first generated normals from depth (and here I took a digression trying and failing to improve on the state of the art), then did two tests.
 A digression...
A digression...First, if neighboring pixels are close in 3d space, we consider them connected and do not generate an edge. If they are not close, we do a second test by forming a plane with the center pixel and its normal and looking at the point-to-plane distance. This avoids creating edges connected geometry that just happens to be at a glancing angle (high slope) in the current camera view.


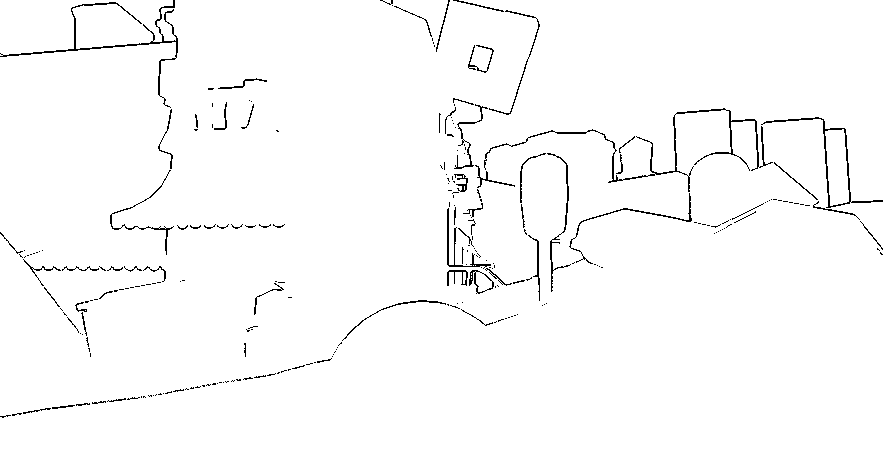 Depth, estimated normals, estimated edge discontinuties.
Depth, estimated normals, estimated edge discontinuties.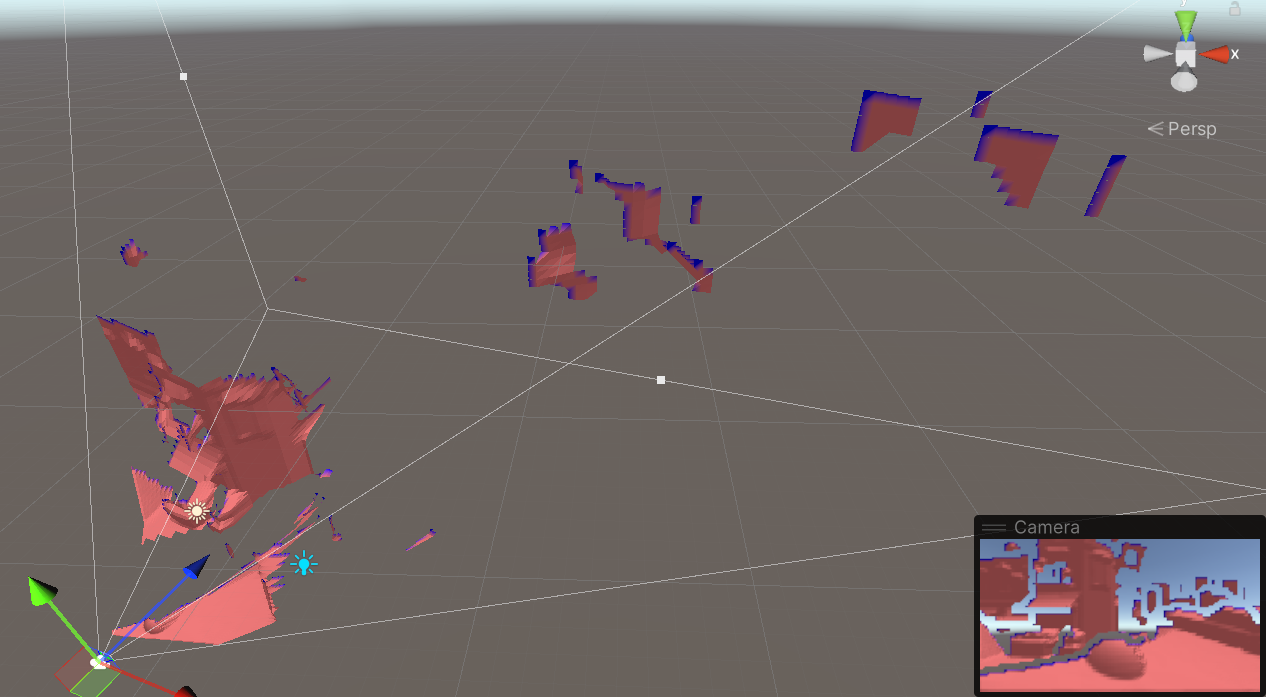
In practice this is overly conservative as it generates large holes, we could instead push the "edge" quads to the farthest depth in the tile, which would hold for many viewpoints, or do something much more sophisticated to actually cut the mesh precisely, instead of relying on just quads. The farthest depth idea is also somewhat related to how small holes are filled in Crytek's algorithm if one squints enough...

What seems interesting, anyhow, is that even with this rudimentary system we can find good, large occluders - and the storage space needed is minimal, we could easily hold hundreds of these small heightfields in memory...
 Combining multiple (three) viewpoints
Combining multiple (three) viewpointsSo right now what I think would be possible is:
As all viewpoints are approximate, it's important not to try to merge them with a conventional depthbuffer approach, but to prioritize first the "best" viewpoint (the previous frame's one), and then use the other stored views only to fill holes, prioritizing views closer to the current camera.
If objects move (that we did not exclude from occluder generation), we can intersect their bounding box with the various camera frustums, and either completely evict these points of view from the database, or go down the bounding hierarchy / min-max pyramid and invalidate only certain texels - so dynamic geometry could also be handled.
The idea of generating actual geometry from depth probably also has some merit, especially for regions with simple occlusion like buildings and so on. The naive quad mesh I'm using for visualization could be simplified after displacement to reduce the number of triangles, and the cuts along the edges could be done precisely, instead of on the tiles.
But it doesn't seem worth the time mostly because we would still have very partial occluders with big "holes" along the cuts, and merging real geometry from multiple points of view seems complex - at that point, we'd rather work in world-space, which brings to...
Second prototype: Voxels
Why all the complications about viewpoints and databases, if in the end, we are working with point sets? Could we store these directly in world-space instead? Maybe in a voxel grid?
Of course, we can! In fact, we could even just voxelize the scene in a separate process, incrementally, generating point clouds, signed distance fields, implicit surfaces, and so on... That's all interesting, but for this particular case, as we're working incrementally anyways, using the depth buffer is a particularly good idea.
Going from depth to voxels is trivial, and we are not even limited to using the main camera depth, we could generate an ad-hoc projection from any view, using a subset of the scene objects, and just keep accumulating points / marking voxels.
Incidentally, working on this made me notice an equivalence that I didn't think of before. Storing a binary voxelization is the same as storing a point cloud if we assume (reasonably) that the point coordinates are integers. A point at a given integer x,y,z is equivalent to marking the voxel at x,y,z as occupied, but more interestingly, when you store points you probably want to compress them, and the obvious way to compress would be to cluster them in grid cells, and store grid-local coordinates at a reduced precision. This is exactly equivalent then again to storing binary voxels in a sparse representation.

It is obvious, but it was important to notice for me because for a while I was thinking of how to store things "smartly", maybe allow for a fixed number of points/surfels/planes per grid and find ways to merge when adding new ones, all possible and fun to think about, but binary is so much easier.
In my compute shader, I am a rebel bit-pack without even InterlockedOR because I always wanted to write code with data races that still converge to the correct result!
 As the camera moves (left) the scene voxelization is updated (left)
As the camera moves (left) the scene voxelization is updated (left)I spent some time thinking about how to efficiently write a sparse binary voxel, or how to render from it in parallel (load balancing the parallel work), how to render front-to-back if needed, all interesting problems but in practice, not worth yet solving. Shelve!
The main problem with a world-space representation is that the error in screenspace is not bounded, obviously. If we get near the points, we see through them, and they will be arbitrarily spaced apart. We can easily use fewer points farther from the camera, but we have a fixed maximum density.
The solution? Will need another blog post, because this is getting long... and here is where I'm at right now anyways!
I see a few options I want to spend more time on:
1) Draw points as "quads" or ellipsoids etc. This can be done efficiently in parallel for arbitrary sizes, it's similar to tile-based GPU particle rendering.

 From [PDF] Real-time Rendering of Massive Unstructured Raw Point Clouds using Screen-space Operators | Semantic Scholar
From [PDF] Real-time Rendering of Massive Unstructured Raw Point Clouds using Screen-space Operators | Semantic Scholar From Raw point cloud deferred shading through screen space pyramidal operators (hal.science) - see also marroquim-pbg2007.pdf (ufrj.br)
From Raw point cloud deferred shading through screen space pyramidal operators (hal.science) - see also marroquim-pbg2007.pdf (ufrj.br)3) We could reconstruct a surface for near voxels, either by producing an actual mesh (which we could cache, and optimize) or by raymarching (gives the advantage of being able to stop at first intersection).
We'd still points at a distance, when we know they would be dense enough for simple dilation filters to work, and switch to the more expensive representation only for voxels that are too close to the camera to be treated as points.
 Inspired by MagicaVoxel's binary MC (see here a shadertoy version) - made a hack that could be called "binary sufrace nets". Note that this is at half the resolution of the previous voxel/point clouds images, and still holds up decently.
Inspired by MagicaVoxel's binary MC (see here a shadertoy version) - made a hack that could be called "binary sufrace nets". Note that this is at half the resolution of the previous voxel/point clouds images, and still holds up decently.
Don’t you hate it when words get stolen? Now, we won’t ever have a “web 3”, that version number has been irredeemably coopted by scammers or worse, tech-bros that live a delusion of changing the world with their code, blindly following their ideology without ever trying to connect to the humanity code’s meant to serve.
Well, this is what happened to “the metaverse”. It didn’t help that it never had a solid definition, to begin with (I tried to craft one here), and then the hype train came and EVERYTHING needed to be marketed as either a metaverse or for the metaverse.
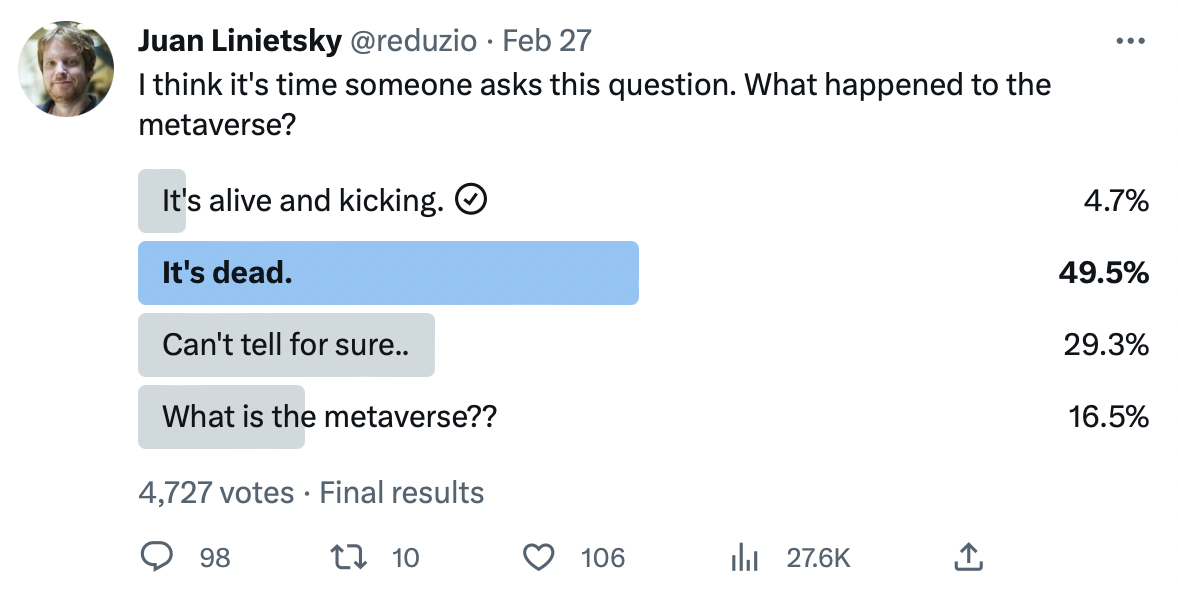 The straw that broke this camel's back...
The straw that broke this camel's back...The final nail in the word’s coffin fell down when notoriously, a big social networking company, looking at the data on its userbase and monetization trending down, decided it was the time for a BOLD move, stole the word, and decided to rush all-in making huge investments in all sort of random things that looked metaverse-y, just throwing in the trash the innovator’s dilemma and its solution.
But if I told you that, hidden in plain sight, this idea of the metaverse is actually rather obvious, even mundane, and all you need to do is to sit down and observe what has been going on… with people.
Trends in the gaming industry.
I’m not the best person to wade through the philosophy and psychology of entertainment - how it is fundamentally social, interactive, and important.
And neither I am, even in my field, a historian - so I won’t be presenting an accurate accounting of what happened in the past couple of decades.
I hope the following will be mundane enough that it can be shown even through an imperfect lens, and for familiarity’s sake, I’ll use my own career as one.
I have to warn you: this is going to be boring. All that I’m going to say, is obvious… it’s just that for some reason, I don’t see often all the dots being connected…
Let’s go.
I started working in the videogame industry in the early 2000s. The very tail end of the ps2 era (I never touched that console’s code - the closets I came was to modify some og xbox stuff we were using as we repurposed a rack of old consoles to help certain data bakes), right at the beginning of the 360 one.
 My first game (uncredited)
My first game (uncredited)What were we doing? Boxed titles. Local, self-contained experiences. Yes, you could play split screen if you happened to have a friend nearby - and that’s incredibly fun, we are social animals after all…
But all in all, you shipped a title, you pressed discs, people bought discs, inserted them in their console, played on the couch, rinse and repeat.
I did a couple of these, then moved from Italy to Canada, to work for EA, a much bigger company, we’re around the middle of the 360/ps3 era now.
What were we doing? Yeah, you guessed it, multiplayer titles. Single-player was still important, local multiplayer was still important, and we were still pressing discs… but we started to move towards a more connected idea of gaming.
 You know I'm still proud of the work on this one...
You know I'm still proud of the work on this one...We would do DLCs, and support the game longer post-shipping; Communities started to grow bigger as you could connect around a game.
The game you got on disc was not that relevant anymore, was just a starting point, necessarily. There is no way to game-design something that will be played, concurrently, by millions of players. They will break your game, find balancing issues, and so on, so really, the game code was made to be infinitely tweakable, in “real-time” by people monitoring the community and making sure it kept being fun and challenging…
Gaming has always been a community, with forums, magazines, TV shows, and such, but you start seeing all of that grow, people staying with a game longer, sequels to be more important, franchises over single titles…
What’s next?
For me, Ps4/Xbox one, Activision, Call of Duty… Where are we going? E-sports, twitch, youtube. A longer and longer tail of content.
 I do miss the live-action, star-studded fun trailers COD used to make...
I do miss the live-action, star-studded fun trailers COD used to make...We go beyond tweaking the game post-launch, now, really the success of a game is measured in how well you keep providing interesting content, and interesting experiences with that framework you created.
Games as a service, we see the drop in physical game sales, the move to digital distribution - and with it, the boom of indie game making, of the idea that anyone can create and share.
Even big franchises, with their tight control over their IP, are nothing without the community of creators around them. Playstation “share” et al.
Call of duty is not simply the game that ships in a box, it’s a culture, it’s a scene - a persistent entity even way before it was a persistent gaming universe (only recently happening with WarZone).
And then of course, I moved to Roblox, where I am now - and I guess I should have said somewhere, this is all personal - it’s my view of the industry, not connected with my job there and the company’s goals (Dave started from an educational tool, and from there crafted a vision that has always been quite unique, arguably the reason why now it ended up being ahead, clearer etc...).
 I like the positivity of NoisyButters
I like the positivity of NoisyButtersHopefully, you can see that my point here is more general than what this or that company wants to do...
But again, I moved to Roblox, personally because I liked the idea to be closer to the creative side of the equation, but in general, where are we now?
What’s the new wave of gaming? Fortnite? Minecraft? Among us? Tarkov? Diablo 4? Whatever, you see the trends:
 Why do I play D3? For the transmog fashion of course!
Why do I play D3? For the transmog fashion of course!Conclusions.
Yes, all of this has been true in some ways since forever, in a more underground fashion.
MUDs and modding, Ultima Online and Warcraft, ARGs, and LARPing, I know - nothing's new under the sun. But this does not invalidate the idea, it reinforces it, everything that is mainstream today has been underground before...
So, are we surprised that “the metaverse” matters? The idea of crafting the creative space, making a platform for creativity, having the social aspect built-in, to go beyond owning single IPs? To make the youtube of gaming, to merge creation, distribution, and communication? To allow people to create, instead of trying to cope with content demands by having everything in house, in a continuous death march that anyways will never match what communities can imagine?
I have to admit, a lot of ideas I see in this space look incredibly dumb. The equation that the metaverse is AR/VR/XR, that is the holodeck or ready player one, whatever… and look, one day it might even be, in a time horizon that I really don’t care talking about.
 :/
:/But today? Today is mundane, it’s an obvious space that does not need to be created, it’s already here, in products and trends, and will only evolve towards more integrated platforms and better products and so on - but it is anything but surprising.
It’s not science fiction, it’s basic humanity wanting to connect and create.
Pre-Ramble.
A decade ago or so, yours truly was a greener but enthusiastic computer engineer, working in production to make videogames look prettier. At a point, I had, in my naivety, an idea for a book about the field, and went* to a great mentor, with it.
* messaged over I think MSN messenger. Could have been Skype, could have been ICQ, but I think it was MSN...
He warned me about the amount of toiling required to write a book, and the meager rewards, so that, coupled with my inherent laziness, was the end of it.
The mentor was a guy called Christer Ericson, who I had the fortune of working for later in life, and among many achievements, is the author of Real-time Collision Detection, still to this date, one of the best technical books I’ve read on any subject.
The idea was to make a book not about specific solutions and technologies, but about conceptual tools that seemed to me at the time to be recurringly useful in my field (game engine development).
He was right then, and I am definitely no less lazy now, so, you won’t get a book, but I thought, having accumulated a bit more experience, it might be interesting to meditate on what I’ve found in my career to be useful when it comes to innovation in real-time rendering.
As we'll be talking about tools for innovation, the following is written assuming the reader has enough familiarity with the field - as such, it's perhaps a bit niche. I'd love if others were to write similar posts about other industries though - we have plenty of tools to generate ideas in creative fields, but I've seen fewer around (computer) science.
The metatechniques.
In no specific order, I’ll try to describe ten meta-ideas, tools for thought if you wish, and provide some notable examples of their application.
A good way to use these when solving a problem is to map out a design space, try to sketch solutions using a combination of different choices in each axis, and really try to imagine if it would work (i.e. on pen and paper, not going deep into implementation).
Then, from this catalog of possibilities, select a few that are worth refining with some quick experiments, and so on and so forth, keep narrowing down while going deeper.
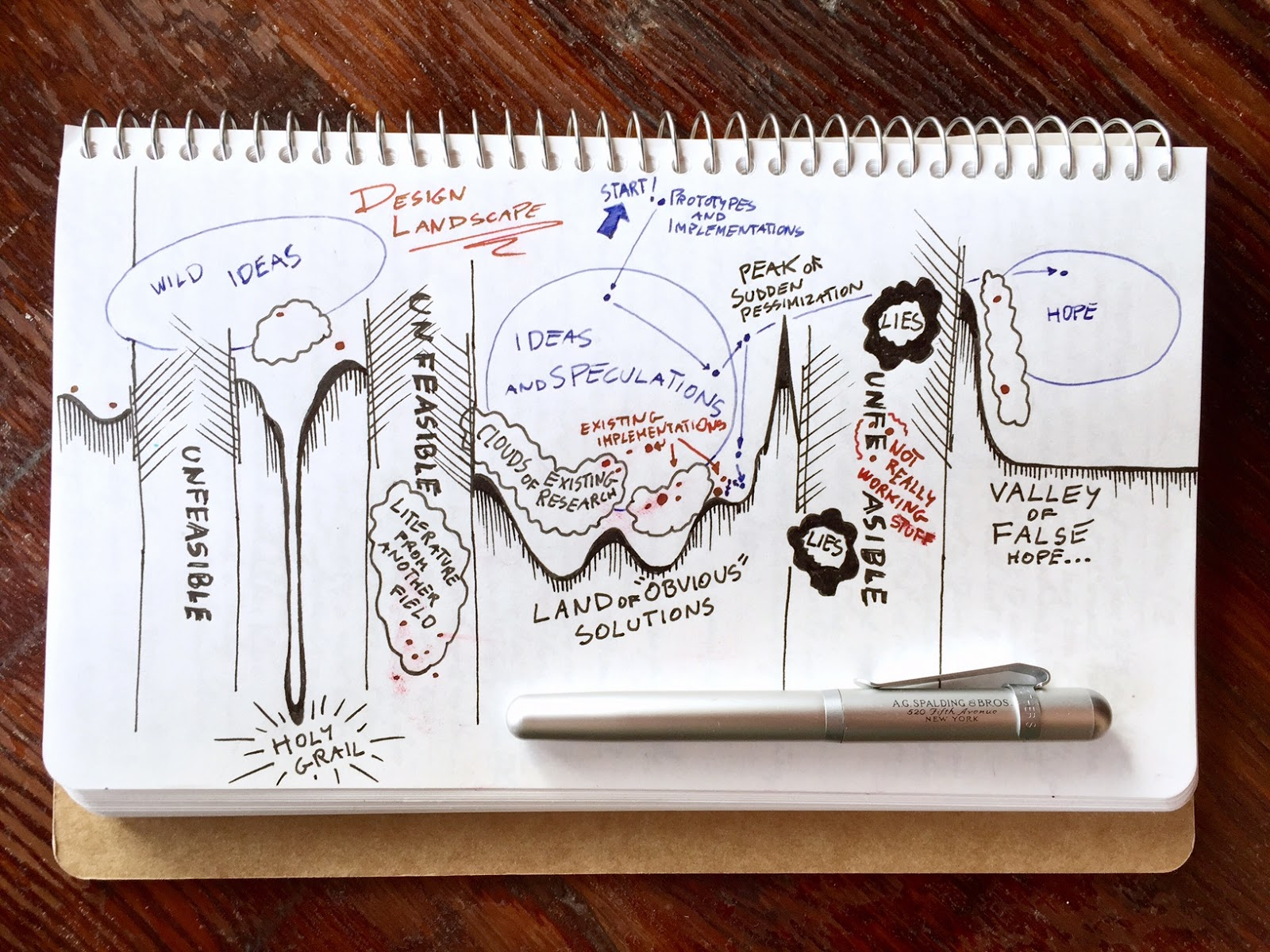 Related post: Design optimization landscape
Related post: Design optimization landscapeComputer graphics problems can literally be solved from different perspectives, and each offers, typically, different tradeoffs.
Should I work in screen-space? Then I might have an easier time decoupling from scene complexity, and I will most likely work only on what’s visible, but that’s also the main downside (e.g. having to handle disocclusions and not being able to know what’s not in view). Should I work in world-space? In object-space? In “texture”-space, i.e. over a parametrization of the surfaces?
Examples:
2) Data representation and its properties.
This is a fundamental principle of computer science; different data structures have fundamentally different properties in terms of which operations they allow to be performed efficiently.
And even if that’s such an obvious point, do you think systematically about it when exploring a problem in real-time rendering?
List all the options and the relative properties. We might be working on signals on a hemisphere, what do we use? Spherical Harmonics? Spherical Gaussians? LTCs? A hemicube? Or we could map from the hemisphere to a circle, and from a circle to a square, to derive a two-dimensional parametrization, and so on.
Voxels or froxels? Vertices or textures? Meshes or point clouds? For any given problem, you can list probably at least a handful of fundamentally different data structures worth investigating.
2B) Consider the three main phases of computation.
Typically, real-time rendering computation is divided into three: scene encoding, solver, and real-time retrieval. Ideally, we use the same data structure for all three, but it might be perfectly fine to consider different encodings for each.
For example, let’s consider global illumination. We could voxelize the scene, then scatter light by walking the voxel data structure, say, employing voxel cone tracing, and finally utilize the data during rendering by directly sampling the voxels. We can even do everything in the same space, using world-space would be the most obvious choice, starting from using a compute 3D voxelizer over the scene. That would be fine.
But nobody prohibits us to use different data structures in each step, and the end results might be faster. For example, we might want to take our screen-space depth and lift that to a world-space voxel data structure. We could (just spitballing here, not to mean it’s a good idea) generate probes with a voxel render, to approximate scattering. And finally, we could avoid sampling probes in real-time, by say, incrementally generating lightmaps (again, don’t take this as a serious idea).
 Imperfect Shadow Maps are a neat example of thinking outside the box in terms of spaces and data structure to solve a problem...
Imperfect Shadow Maps are a neat example of thinking outside the box in terms of spaces and data structure to solve a problem...2C) Consider the dual problem.
This is a special case of "the right data" and "the right space" - but it is common enough, and easy to overlook, so it gets a special mention.
All problems have "duals", some in a very mathematical sense, others in a looser interpretation of the world. Often time, looking at these duals yields superior solutions, either because the dual is easier/better to solve, or because one can solve both, exploiting the strengths of each system
A simple example of rigorous duality is in the classic marching cubes algorithm, compared to the surface nets which operates on the dual grid of MC: surface nets are much easier and higher quality!
A more interesting, more philosophical dual, is in the relationship between cells and portals for visibility "versus" occluders and bounding volumes. Think about it :)
3) Compute over time.
This is a simple universal strategy to convert computationally hard problems into something amenable to real-time. Just don’t try to solve anything in a single frame, if it can be done over time, it probably should.
Incremental computation is powerful in many different ways. It exploits the fact that typically, a small percentage of the total data we have to deal with is in the working set.
This is powerful because it is a universal truth of computing, not strictly a rendering idea (think about memory hierarchies, caches, and the cost of moving data around).
Furthermore, it’s perceptually sound. Motion grabs our attention, and our vision system deals with deltas and gradients. So, we can get by with a less perfect solution if it is “hidden” by a bigger change.
Lastly, it is efficient computationally, because we deal with a very strict frame budget (we want to avoid jitter in the framerate) but an uneven computational load (not all frames take the same time). Incremental computation allows us to “fill” gaps in frames that are faster to compute, while still allowing us to end in time if a frame is more complex, by only adding lag to the given incremental algorithm. Thus, we can always utilize our computational resources fully.
Obviously, TAA, but examples here are too numerous to give, it’s probably simpler to note how modern engines look like an abstract mess if one forces all the incremental algorithms to not re-use temporal information. It’s everywhere.
 Parts of Cyberpunk 2077's specular lighting, without temporal
Parts of Cyberpunk 2077's specular lighting, without temporal Take modern shadowmaps. Cascades are linked to the view-space frustum, but we might divide them into tiles and cache over frames. Many games then throttle sun movements to happen mostly during camera motion, to hide recomputation artifacts. We might update far cascades at different frequencies than close ones and entirely bail out of updating tiles if we’re over a given frame budget. Finally, we might do shadowmap filtering using stochastic algorithms that are amortized among frames using reprojection.
4) Think about the limitations of available data.
We made some choices, in the previous steps, now it’s time to forecast what results we could get.
This is important in both directions, sometimes we underestimate what’s possible with the data that we can realistically compute in a real-time setting, other times we can “prove” that fundamentally we don’t have enough/the right data, and we need a perspective change.
A good tool to think about this is to try a brute-force solution over our data structures, even if it wouldn’t be feasible in real-time, it would provide a sort of ground truth (more on this later): what’s the absolute best we could do with the data we have.
Some examples, from my personal experience.
4B) Machine learning as an upper limit.
The only caveat here is that in many cases the true “best possible” solution goes beyond algorithmic brute force, and instead couples that with some inference. I.e. we don’t have the data we’d like, but can we “guess”? That guessing is the realm of heuristics.
Lately, the ubiquity of ML opened up an interesting option: to use machine learning as a proxy to validate the “goodness” of data.
For example, in SSAO a typical artifact we get is dark silhouettes around characters, as depth discontinuities are equivalent to long “walls” when interpreting the depth buffer naively (i.e. as a heightfield). But we know that’s bad, and any competent SSAO (or SSR, etc) employs some heuristic to assign some “thickness” to the data in the depth buffer (at least, virtually) to allow rays to pass behind certain objects. That heuristic is a guessing game, how do we know how well we could do? There, training a ML model with ground truth, raytraced AO, and feeding it only the depth-buffer as inputs, can give us an idea of the best we could ever do, even if we are not going to deploy the ML model in real-time, at all.
See also: Deep G-Buffers for GI but remember, here I'm specifically talking about ML as proof of feasibility, not as the final technique to deploy.
5) The hierarchy of ground truths.
The beauty of rendering is that we can pretty much express all our problems in a single equation, we all know it, Kajiya’s Rendering Equation.
From there on, everything is really about making the solution practical, that’s all there is to our job. But we should never forget that the “impractical” solution is great for reference, to understand where our errors are, and to bound the limits of what can be done.
But what is the “true” ground truth? In practice, we should think of a hierarchy.
At the top, well, there is reality itself, that we can probe with cameras and other means of acquisition. Then, we start layering assumptions and models, even the almighty Rendering Equation already makes many, e.g. we operate under the model of geometrical optics, which has its own assumptions, and even there we don’t take the “full” model, we typically narrow it further down: we discard spectral dependencies, we simplify scattering models and so on.
At the very least, we typically have four levels. First, it’s reality.
Second, is the outermost theoretical model, this is a problem-independent one we just assume for rendering in general, i.e. the flavor of rendering equation, scene representation, material modeling, color spaces, etc we work in.
Then, there is often a further model that we assume true for the specific problem at hand, say, we are Ambient Occlusion, that entire notion of AO being “a thing” is its own simplification of the rendering equation, and certain quality issues stem simply from having made that assumption.
Lastly, there is all that we talked about in the previous point, namely, a further assumption that we can only work with a given subset of data.
Often innovation comes by noticing that some of the assumptions we made along the way were wrong, we simply were ignoring parts of reality that we should not have, that make a perceptual difference.
What good is it to find a super accurate solution to say, the integral of spherical diffuse lights with Phong shading, if these lights and that shading never exist in the real world? It’s sobering to look back at how often we made these mistakes (and our artists complained that they could not work well with the provided math, and needed more controls, only for us to notice that fundamentally, the model was wrong - point lights anybody?)
Other times, the ground truth is useful only to understand our mistakes, to validate our code, or as a basis for prototyping.
6) Use computers to help along the way.
No, I’m not talking about ChatGPT here.
Numerical optimization, dimensionality reduction, data visualization - in general, we can couple analytic techniques with data exploration, sometimes with surprising results.
The first, more obvious observation, is that in general, we know our problems are not solvable in closed form, we know this directly from the rendering equation, this is all theory that should be so ingrained I won’t repeat it, our integral is recursive, its form even has a name, we know we can’t solve it, we know we can employ numerical techniques and blah blah blah path tracing.
This is not very interesting per se, as we never directly deal with Kajiya’s in real-time, we layer assumptions that make our problem simpler, and we divide it into a myriad of sub-problems, and many of these do indeed have closed-form solutions.
But even in these cases, we might want to further approximate, for performance. Or we might notice that an approximate solution (as in function approximation or look-up tables) with a better model is superior to an exact solution with a more stringent one.
But there is a second layer where computers help, which is to inform our exploration of the problem domain. Working with data, and interacting with it, aids discovery.
We might visualize a signal and notice it resembles a known function (or that by applying a given transform we improve the visualization) - leading to deductions about the nature of the problem, sometimes that we can reconduct directly to analytic or geometric insights. We might observe that certain variables are not strongly correlated with a given outcome, again, allowing us to understand what matters. Or we might do dimensionality reduction, clustering, and understand that there might be different sub-problems that are worth separating.
To the extreme, we can employ symbolic regression, to try to use brute force computer exploration and have it "tell us" directly what it found.
Examples. This is more about methodology, and I can't know how much other researchers leverage the same methods, but in the years I've written multiple times about these themes:

7) Humans over math.
One of the biggest sins of computer engineering in general is not thinking about people, processes, and products. It's the reason why tech fails, companies fail, and careers "fail"... and it definitely extends to research as well, especially if you want to see it applied.
In computer graphics, this manifests in two main issues. First, there is the simple case of forgetting about perceptual error measures. This is a capital sin both in papers (technique X is better by Y by this % MSE) and data-driven results (visualization, approximation...).
The most obvious issue is to just use mean squared error (a.k.a. L2) everywhere, but often times things can be a bit trickier, as we might seek to improve a specific element in a processing chain that delivers pixels to our faces, and we too often just measure errors in that element alone, discounting the rest of the pipeline which would induce obvious nonlinearities.
In these cases, sometimes we can just measure the error at the end of the pipeline (e.g. on test scenes), and other times we can approximate/mock the parts we don't explicitly consider.
As an example, if we are approximating a given integral of a luminaire with a set BRDF model, we should probably consider that the results would go through a tone mapper, and if we don't want to use a specific one (which might not be wise, especially because that would probably depend on the exposure), we can at least account for the roughly logarithmic nature of human vision...
Note that a variant of this issue is to use the wrong dataset when computing errors or optimizing, for example, one might test a new GPU texture compression method over natural image datasets, while the important use case might be source textures, that have significantly different statistics. All these are subtle mistakes that can cause large errors (and thus, also, the ability to innovate by fixing them...)
The second category of sins is to forget whose life we are trying to improve - namely, the artist's and the end user's. Is a piece of better math useful at all, if nobody can see it? Are you overthinking PBR, or focusing on the wrong parts of the imagining pipeline? What matters for image quality?
In most cases, the answer would be "the ability of artists to iterate" - and that is something very specific to a given product and production pipeline.
If you can spend more time with artists, as a computer graphics engineer, you should.
Nowadays unfortunately productions are so large that this tight collaboration is often unfeasible, artists dwarf engineers by orders of magnitude, and thus we often create some tools with few data points, release them "in the wild" of a production process, where they might or might not be used in the ways they were "supposed" to. Even the misuse is very informative.
We should always remember that artists have the best eyes, they are our connection to the end users, to the product, and the ones we should trust. If they see something wrong, it probably is. It is our job to figure out why, where, and how to fix it, all these dimensions are part of the researcher's job, but the hint at what is wrong, comes first from art.
An anecdote I often refer to, because I lived through these days, is when artists had only point lights, and some demanded that lights carried modifiers to the roughness of surfaces they hit. I think this might have even been in the OpenGL fixed function lighting model, but don't quote me there. Well, most of us laughed (and might laugh today, if not paying attention) at the silliness of the request. Only to be humbled by the invention of "roughness modification" as an approximation to area lights...
Here is where I should also mention the idea of taking inspiration from other fields, this is true in general and almost to the same level as suggestions like "take a walk to find solutions" or "talk to other people about the problem you're trying to solve" - i.e. good advice that I didn't feel was specific enough. We know that creativity is the recombination of ideas, and that being a good mix of "deep/vertical" and "wide/horizontal" is important... in life.
But specifically, here I want to mention the importance of looking at our immediate neighbors: know about art, its tools and language, know about offline rendering, movies, and visual effects, as they can often "predict" where we will go, or as we can re-use their old techniques, look at acquisition and scanning techniques, to understand the deeper nature of certain objects, look at photography and movie making.
When we think about inspiration, we sometimes limit ourselves to related fields in computer science, but a lot of it comes from entirely different professions, again, humans.
See also:
8) Find good priors.
A fancy term for assumptions, but here I am specifically thinking of statistics over the inputs of a given problem, not simplifying assumptions over the physics involved. It is often the case in computer graphics that we cannot solve a given problem in general, literally, it is theoretically not solvable. But it can become even easy to solve once we notice that not all inputs are equally likely to be present in natural scenes.
This is the key assumption in most image processing problems, upsampling, denoising, inpainting, de-blurring, and so on. In general, images are made of pixels, and any configuration of pixels is an image. But out of this gigantic space (width x height x color channels = dimensions), only a small set comprises images that make any sense at all, most of the space is occupied, literally, by random crap.
If we have some assumption over what configurations of pixels are more likely, then we can solve problems. For example, in general upsampling has no solution, downsampling is a lossy process, and there is no reason for us to prefer a given upsampled version to another where both would generate the same downsampled results... until we assume a prior. By hand and logic, we can prioritize edges in an image, or gradients, and from there we get all the edge-aware upsampling algorithms we know (or might google). If we can assume more, say, that the images are about faces or text and so on, we can create truly miraculous (hallucination) techniques.
As an aside, specifically for images, this is why deep learning is so powerful - we know that there is a tiny subspace of all possible random pixels that are part of naturally occurring images, but we have a hard time expressing that space by handcrafted rules. So, machine learning comes to the rescue.
This idea though applies to many other domains, not just images. Convolutions are everywhere, sparse signals are everywhere, and noise is everywhere, all these domains can benefit from adopting priors.
E.g. we might know about radiance in parts of the scene only through some diffuse irradiance probes (e.g. spherical harmonics). Can we hallucinate something for specular lighting? In general, no, in practice, probably. We might assume that lighting is likely to come from a compact set of directions (a single dominant luminaire). Often times is even powerful to assume that lighting comes mostly from the top down, in most natural scenes - e.g. bias AO towards the ground...
See also: an old rant on super-resolution ignorance
9) Delve deep.
This is time-consuming and can be annoying, but it is also one of the reasons why it's a powerful technique. Keep asking "why". Most of what we do, and I feel this applies outside computer graphics as well, is habit or worse, hype. And it makes sense for this to be the case, we simply do not have the time to question every choice, check every assumption, and find all the sources when our products and problems keep growing in complexity.
But for a researcher, it is also a land of opportunity. Often times we can even today, pick a topic at random, a piece of our pipeline, and by simply keep questioning it we'll find fundamental flaws that when corrected yield considerable benefits.
This is either because of mistakes (they happen), because of changes in assumptions (i.e. what was true in the sixties when a given piece of math was made, is not true today), because we ignored the assumptions (i.e. the original authors knew a given thing was applicable only in a specific context, but we forgot about it), or because we plugged in a given piece of math/algorithm/technology and added large errors while doing it.
A simple example: most integrals of lighting and BRDFs with normalmaps, which cause the hemisphere of incoming light directions to partially be occluded by the surface geometry. We clearly have to take that horizon occlusion into consideration, but we often do not, or if we do it's through quick hacks that were never validated. Or how we use Cook-Torrance-based BRDFs, without remembering that they are valid only up to a given surface smoothness. Or how nobody really knows what to do with colors (What's the right space for lighting? For albedos? To do computation? We put sRGB primaries over everything and call it a day...). But again, this is everywhere, if one has the patience of delving...
10) Shortcut via proxies.
Lastly, this one is a bit different than all the others, in a way a bit more "meta". It is not a technique to find ideas, but one to accelerate the development process of ideas, and it is about creating mockups and prototypes as often as possible, as cheaply as possible.
We should always think - can I mock this up quickly using some shortcut? Especially where it matters, that's to say, around unknowns and uncertain areas. Can I use an offline path tracer, and create a scene that proves what my intuition is telling me? Perhaps for that specific phenomenon, the most important thing is, I don't know, the accuracy of the specular reflection, or the influence of subsurface scattering, or modeling lights a given way...
Can I prove my ideas in two dimensions? Can I use some other engine that is more amenable to live coding and experimentation? Can I modify a plug-in? Can I create a static scene that previews the performance implication of something that I know will need to generate dynamically - say a terrain system or a vegetation system.
Can I do something with pen and paper? Can I build a physical model? Can I gather data from other games, from photos, from acquiring real-world data... Can I leverage tech artists to create mocks? Can I create artificial loads to investigate the performance, on hardware, of certain choices?
Any way you have to write less code, take less time, and answer a question that allows you to explore the solution space faster, is absolutely a priority when it comes to innovation. Our design space is huge! It's unwise to put prematurely all the chips on a given solution, but it is equally unwise to spend too long exploring wide, so the efficiency of the exploration is paramount, in practice.
- Ending rant.
I hope you enjoyed this. In some ways I realize it's a retrospective that I write now as I've, if not closed, at least paused the part of my career that was mostly about graphics research, to learn about other areas that I have not seen before.
It's almost like these youtube ads where people peddle free pamphlets on ten easy steps to become rich with Amazon etc, minus the scam (trust me...). Knowledge sharing is the best pyramid scheme! The more other people innovate, the more I can (have the people who actually write code these days) copy and paste solutions :)
I also like to note how this list could be called "anti-design patterns" (not anti-patterns, which are still patterns), the opposite of DPs in the sense that I hope for these to be starting points for ideas generation, to apply your minds in a creative process, while DPs (ala GoF) are prescribed (terrible) "solutions" meant to be blindly applied.
I probably should not even mention them because at least in my industry, they are finally effectively dead, after a phase of hype (unfortunately, we are often too mindless in general) - but hey, if I can have one last stab... why not :)
The era of algorithmic slavery.
When we think of the rise of the machines, we picture skynet and the matrix. Humanity literally fighting the AI, with big pew-pew guns, and getting enslaved by it. Heroes seeing through the deception, illuminated minds, perhaps looking insane to the average bystander, purposed with a higher calling.
We lose ourselves in the bombast of Hollywood, we take metaphors literally, we fear or dream of the singularity, look for signs of consciousness in the code we write.
In reality, the danger is the opposite. It’s not how much consciousness the machines gain. It is rather, how much they remove from us. Yes, the recent "LaMDA is sentient" BS is not much more than a bad publicity stunt - but that doesn't mean that Google is not scary!
We are of course already dependent on machines - that is not the problem - our degree of attachment to them. We are dependent on all technology we create. It’s the defining feature of humanity to better itself through technology, it has been true since we made fire.
For millennia we have used technology to elevate ourselves, to free us from the minutiae of living and sublimate our spirit, enabling higher forms of creativity, allowing us to dedicate more time to work that is intellectual in nature.
You can call this productivity, even augmented intelligence - once we discovered that technology is not good simply to ease physical labor, but can be shaped into tools for better thinking. Sougwen Chung (愫君) - Machines can be tools that augment our creativity.
Sougwen Chung (愫君) - Machines can be tools that augment our creativity. Will we live in a world where it’s increasingly hard to be a value-add via the use of technology, but rather most of us will be made irrelevant by it? What happens to the masses that can’t produce anything of interest?
Can our creativity outpace the machine’s forever?

One can argue that a tool remains a tool, and in the history of the world, short-sighted people always lamented when creation became more accessible, from painting to film photography, from film to digital cameras, from cameras to smartphones.
There is always someone lamenting the loss of "true" art - and they are always wrong... but! At the same time, we have enough historical evidence of machines displacing jobs, labor having to learn new skills, often painfully, for the generations caught in the transition.
There is some reason to worry, then - but it's not the key to the story here. Creativity is likely to remain firmly in the domain of humans, in fact one could say that a truly creative machine would need to be a conscious one, and that is not the scenario I'm interesting in.
The danger is subtler, closer and more real.
Do we already live in a world where we many creators are replaceable slaves, being milked for content by algorithms that are the true holders of value?

It's a marvelous machine that exploits the brain chemistry of consumers with cheap dopamine, and of creators, as we seek to show our photos and videos for follows, we increasingly define our value in society by the number of likes we get.
How conscious are we, when most of our connections are software mediated, and sentiment analyzed? The algorithm does not know when to stop, and neither do our brains. Dopamine is the AI’s sugar.
We do not need to be intubated, in pods, to be enslaved. We don't even need to be slaves, once we created a system that gives some short-term pleasure, we willingly subjugate to it.
Don’t take your science fiction literally.
I don't fear the sentient AI and the singularity. I don't care much about privacy and crypto-anarchism. I think we are looking at the wrong problems. Even the worries about physicals changes in our cognitive abilities, psychology and looks might be overstated - as we are very plastic, we adapt.
And for how despicable the role of simplistic recommendation algorithms, shares and likes have on creating information bubbles and drive polarization, we are beginning to understand and rebel - systems might be tuned differently...
The existence of a system though, per se, and the fact that can be tuned - is that ever possibly moral? Are we not saying that we are losing agency, if the way a machine operates controls society?
This is a Silicon Valley problem that SV cannot solve for itself. It's the natural evolution of companies to want to be successful, and we are in a world where success means engaging billions of people, capturing a large percent of their time and attention.
These systems can hardly be called tools, and are clearly not in our control.
This presentation was a keynote given to a private company event - I'm not sure if I'm at liberty to say more about it - but the content is quite universal, so I hope you'll enjoy!
It does not talk directly of Roblox or the Metaverse... but at the same time, it has, near the end, some strong connections to it.

Also... this is not the first "open problems" slide deck I make, and I mentioned an unfinished one in previous presentations... I realize I will never finish it - or rather, I am not as passionate about it anymore, so... here it is, frozen in its eternal WIP state: slides - circa 2015

Premise.
This blog post is useless. And rambling. As it's useless the machine I'm typing this on, a Pentium 3 subnotebook from the 90ies. You have been warned!
But, it might be entertaining, and I suspect many of the people doing what I do and reading what I write, are in a similar demographic and might be starting to be nostalgic, thinking of their formative years and wondering if they're worth revisiting...
Objectives.
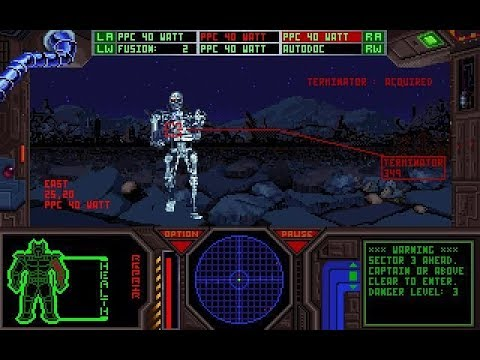
I wanted to find a DOS machine, not for retrogaming (only), but to do actual "work". Even more narrowly, I had an idea of trying to compile an old DOS demo I made in the nineties, the only production of a short-lived Italian group called "day zero deflection" (you won't find it).
Monotasking. No internet. These things are so appealing to me right now. One tries to escape the dopamine rush of doomscrolling on all the connected devices that surround us. The flesh is weak, and instead of trying to muster the required willpower, shopping for a hardware solution seems so much more attractive. Of course, it's a fool's errand, but hey, I said this post was going to be useless.
A Long, intermezzo of personal history.
(skip this!)
It's interesting how memory works. So non-linear, and unreliable. I used a lot of computers in my life, and I started early, I began programming around six or seven years old.
This past Christmas, as the pandemic eased up, I was able again to fly and spend time with my family in southern Italy. Found one of the Commodore 64 we had.
 The c64 in question. Yes, it needed some love - albeit to my surprise, all my disks worked, with my childhood code! The video glitch is actually a quite mysterious defect, but it's a story for another time...
The c64 in question. Yes, it needed some love - albeit to my surprise, all my disks worked, with my childhood code! The video glitch is actually a quite mysterious defect, but it's a story for another time...We, because I grew up with my older cousins, my mother is the last of eleven siblings, so I have a lot of cousins, many close to my house as my family used to be farmers, and thus had land that eventually became buildings, with many of my aunts and uncles ending up living in the same park.
These older cousins taught me programming, and I was using their computers before having my own. In fact, the c64 I found is most likely theirs, as mine was eventually donated to some relative that needed it more.
I remember a lot of this, in detail, albeit I don't know anymore what details are real and what ended up as images remixed from different time eras.
We were in the basement of my aunt's villa, just next door to the building I grew up in, where we had an apartment on the top floor. We would transfer things between the two by lowering a rope from the balcony down to the villa's garden. Later, when we had PCs and network cards, we moved bits between the buildings, having suspended a coax cable that ran from the second floor of my building (where another cousin lived) to my floor, to the villa.
The basement was originally the studio of my uncle, who was the town's priest. I was named after him. He and one of his sisters died in a car accident when I was little, so I am not sure I really remember of him, sadly.
But I remember the basement, the Commodore 64, and later an 8086 with an external hard drive the same size and shape as the main unit. An amber monitor monochrome I think, or perhaps it was both amber and green, with a configuration switch.
I remember all of the c64 games we played, easily. I remember bits of my coding journey, the books we used to study, and once my cousin being dismayed that I could not figure how to make a cursor move on the screen (the math to go to the next/previous row), even if it was mostly a misunderstanding.
I remember playing with my Amiga 600 there too, Body Blows - I switched to the Amiga after visiting... another cousin, this time, in Milan.
I remember the first Pentium they had because it allowed me to use more 3d graphics software. 3d studio 4 without having to resort to software 387 emulation! At the time I had an IBM PS/2 with a 486sx which the seller persuaded my father would be better than a 486dx another guy was offering us - who needs a math coprocessor, and IBM is a much better brand than something home-made... And I know that numerous times I lost all the data on these computers that I did not own, often by typing "format" too fast and putting the wrong drive letter in.
And then, nothing? Everything more modern than that I sort of lost, or rather, becomes more confused. I know the places I went shopping for (pirated) software and hardware, maybe some of the faces, not sure.
I know used to lug my PC tower for the few kilometers that separated my house in Scafati from the "shop" (really a private apartment) that I used to go to in Pompei, as I was a kid, and did not have a car of course.
And that tells me that I had lots of different PC configurations over the years, LOTS of them, AMD, Intel, Voodoo cards, a Matrox of some sorts, even a Sound Blaster AWE32 at a point, a CD-ROM and the early CD games, I remember the excitement for each new accessory and card, and the intense hate for cable and thermal management, especially on more modern setups.
I remember scanners, the first were hand-held (Logitech ScanMan, then Trust), printers, joysticks, graphics tablets when I got into photography, the very first digital camera I had (I think an Olympus). It's all "PC" for me, I have no idea of what I was using in which year.
At a point, around university, I switched to primarily using laptops. Acer or Asus, something cheap and powerful but they would break often (cheap plastics). Then finally the MacBook Pro, and that one has remained a constant, still today my primary personal machine.
So. My nostalgia is about three machines, really, even if I had dozens. The Commodore 64, the one I remember the most. I am eager to play around with that one more, I ordered all sorts of HW, but I have no intentions to use it "daily" - that one belongs to a museum.
 The MisterFPGA c64 core is great and can output 50hz!
The MisterFPGA c64 core is great and can output 50hz!The Amiga, which for some reason I don't care as much for anymore, I suspect mostly because I was using it primarily for games so I did not create as much on it - I think that was the key.
I had some graphic programs, but I was not a great 2d artist (DeluxePaint) and I did not understand enough of the 3d tools I happened to get my hands on (Real3D, VistaPro)... and I did no coding on it. At a point, I had a (pirate) copy of Amos, but no manual.
Swapping disks, real or virtual, is also not fun.
And then the PC, specifically the 486sx that I used both for programming again (QBasic, PowerBasic, Assembly then C with DJGPP), for graphics (Imagine, then Lightwave among others), photography, the internet...
That 486 captures all of my PC memories, even if I know it's wrong. For example, during my C demo-coding times, I must have had a different computer, because the demo we were making would never run on a 486, they were sVGA, I even remember coding our sVGA layer, fixing a bug in the Matrox VESA bios - they were out of spec, not setting the viewport to be the same as the screen resolution when changing the latter, and many demos did run with the wrong line pitch because of that. Not mine! And the demo was, for some reason, writing buffers in separate R,G,B planes, with some MMX code I made to then shuffle them back into the display frame.
So, it could not have been the 486 - but this is great, it gives me the freedom of not trying to recreate a particular setup but instead going for that same feeling and toolset I remember using, on an entirely different system.
What do we "need"?
Here's the plan. First and foremost, we'll get a laptop, because I don't have space in my apartment, no, in my life, for retrocomputing desktop or tower. Also, I want to go to hipster coffee shops and write on my hipster retro workstation, as I am doing right now.
I planned, regardless of the machine I would end up getting, to rip out the cells from the battery pack and reconstruct it - batteries are mostly a liability in old computers and I prefer the weight savings of not having them - this also means, technically, "luggable" computers could be considered.
We will look for:
Expectations vs Reality.
After long, long deliberations, research on forums, scouting eBay and so on, I landed on an IBM ThinkPad 240x. The ThinkPads are amazing machines, easy to service, iconic, with great keyboards and the TrackPoint is useable in a pinch.
 Beautiful! Pro-tip, a bit of 303 protectant makes the plastics look as new!
Beautiful! Pro-tip, a bit of 303 protectant makes the plastics look as new!I paid around 200$ for it, you will see people getting these for 5$ at a garage sale or stuff like that, but I'm ok paying more for something that the seller verified it's running, has no issues, and so on. More than that I think is crazy, but you do you...
When it arrived it looked amazing. Yes, it had scratches on the top, and even some hairline cracks, one near a hinge and one on the bottom of the chassis, but these are not a problem as I planned to disassemble the thing anyway, see if I needed to clean the internals, replace batteries, check for any leak, re-apply thermal paste if needed and so on.
Regardless of how much research you have done, the reality of the actual machine will surprise you in good and bad ways.
All the hardware setup was trivial, and all the things I thought would be hard were not.
I gutted the battery as planned (the cells were already a bit bulging). I feared the most for the initial OS setup, but my strategy worked flawlessly. I bought an IDE-to-USB adapter, connected the SSD in its SSD-to-IDE enclosure, and mapped it as a virtual drive in a VirtualBox VM with Windows 98.
That allowed me to use Win98's fdisk and format to create something I knew would be recognized by the ThinkPad - I was not sure at all the same would have happened with modern tools. For extra safety, I also made two partitions under 2GB, to be able to format them with fat16, and the remainder of space was left in a third partition using fat32.
Installing the OS was a breeze, and Lenovo still hosts all the latest IBM drivers - Windows 98 just works.
The first tiny hurdle I had to overcome was with the firmware update, IBM tools are adamant about having a charged battery to perform the update... which I clearly did not have. But in reality, the tool just calls a second executable, and even if the binaries have different extensions than the default the flashing tools wanted, it did not take too long to figure out the right switches to use.
Upgrading the OS was also trivial, some people made install packs with all the official patches and lots of unofficial fixes (used mdgx ones, htasoft is an alternative), I just grabbed one and it mostly worked. The only issue I had is that the first time around the OS stopped booting with some DMA error, but disabling a specific patch having to do with enabling DMA on drives solved the issue. Re-installing the OS via the SSD is relatively fast, and I also used an old copy of Norton Ghost to create snapshots.
To my surprise, even USB in DOS mostly worked (via Bret Johnson's drivers, albeit many options exist). It is not 100% reliable, nor it's fast... but it does work! Same for the TrackPoint, via cutemouse.
I ended up with the classic config.sys/autoexec.bat multiple-choice menu for things like emm386 and so on, I remember these being so painful to deal with, but in this case, it was all easy, probably also because this machine has so much RAM.
That is not to say there aren't problems. There are, but in a way, luckily for me, they seem to be unfixable, so I don't need to spend a ludicrous amount of time trying to overcome them (alright alright, I already did spend more time than it's worth, using DOSBox-debug and a few different decompilers to reverse an audio TSR... but I won't anymore I swear). And I did not foresee them.
First, there is the VGA. I obsessed over resolutions, because I knew, that most laptops of this time do not do resolution scaling well. I had an epiphany though that allowed me to stop worrying about it. It's true that ideally, 640x480 makes you not have to worry about scaling. But! Laptops with 640x480 screens tend to be incredibly crappy and small LCDs, so much so, that the unscaled 640x480 area on a more modern laptop (say, an 800x600 panel) ends up covering a bigger screen estate and looking better!
So, problem solved, right? Yes. If you get a card with good firmware! Unfortunately, the laptop I got has an obscure chipset that not only has crappy VESA/VBE support but is also not software-patchable via UniVBE.
Some TSRs help a bit (vbeplus, fastvid), adding more modes by using other resolutions and forcing the viewport to clip, and you can play around with caching modes, but most DOS sVGA demos do not work.
TBH, that was just plain unlucky, most laptops would not be this bad at sVGA... but expect I guess to find at least one bit of "unlucky" hardware you did not think about in your machine.
The other issue is with DOS audio and this is a biggie.
Yes, I paid attention, and I got a chipset that does support DOS SoundBlaster emulation. But OMG, nobody told me it was going to be this crappy! It's basically useless, with most software just not working at all, especially when it comes to digital audio. The OPL3 FM music fares better, it tends to work, albeit it might not sound great.
It's sad but most DOS software, especially demos, have a much higher chance of running in Windows 98 than in pure DOS, as when Windows is loaded the audio emulation is much, much better.
This is something that apparently one simply has to live with. No PCI sound card has great DOS support, now I learned, especially with laptops, as DOS audio support for PCI relies on a combination of the right soundcard, the right motherboard and the right firmware.
It doesn't help that often, when people online report audio working in DOS, they mean dos-under-windows, not pure dos... And you get a laptop from the pre-PCI era, then you're likely on a 486 or less, which not only will be worse in all other areas - but also many of these laptops used not to bundle any audio card at all, so they are strictly worse.
That's not to say that there are no Pentium laptops with built-in ISA audio - there are, and probably I was again unlucky with the 240x being a rare combination of a dos-compatible-ish PCI on a "bad" motherboard (apparently using the intel 440mx chipset which does not support DDMA), but again... expect some issues, there are no perfect laptops, and even back in the day, there was hardly a configuration that would run everything flawlessly...
Conclusions.
Was it worth it? Should you do it? Yes and no...
 It's small!
It's small!For retro gaming, or in general, passive consumption (demos, etc), it's overall a terrible idea, I'm pretty confident all laptops would be terrible, and even most desktops.
The early PC landscape was just a mess of incompatible devices, buggy, unpatched software, and crashes. You were lucky when things worked, and this is true today as well. DosBox is a million times more compatible than any real hardware. Yes, it has bugs, and lots of things can be more accurate, but on average it is better than real hardware.
There are many DosBox builds out there, and I'm sure this is going to be quicky outdated, but at the time of writing I recommend:
On windows, and especially if you care about Windows of any kind, there is 86box (a fork of PCem) which is a lower-level, more accurate emulator. DosBox does not work great even with Win3.11, for some odd mouse emulation problems that seem to be different in each fork.
If like me, you want to experience a monotasking machine that you can grab for a few hours at a time to play with a simpler, more focused experience, then I'd say these laptops are great fun!
I'm even collecting a bit of a digital retro-library by mirroring old websites, often grabbed from the Wayback machine, and grabbing old magazines from the Internet Archive, to recreate the kind of reading materials I had back then...
Overall, setting this up took me less time and energy than tinkering with a Raspberry Pi or say, trying to install a fully functional Linux on a random contemporary laptop. It's one of the least annoying projects I have embarked upon.
My conscience feels ok too. It won't become garbage, I hate clutter, I hate having too much stuff, too many things I don't need in my life, especially digital crap that creates more problems than it really solves... With this one, I know I can sell or donate the hardware the moment I don't want to use it anymore, it's not going to be in a landfill, it's not another stupid gadget with a short lifespan.
The best part, all the software is portable, DOS doesn't really care about the hardware, you only need to replace a few lines in your config.sys if you have specific drivers... so I can migrate all I have on this laptop to a DosBox setup (even today I do keep the two in sync) or a different machine.
Not bad. You want to try? Luckily it's easy, this is what I learned! You don't have to stress over the hardware (as I did), because none is perfect.
I went for something relatively "modern", a laptop that would have ran in its prime Windows 98/NT/2000 - and "downgraded" it to do mostly DOS - I think that's a good choice, but I don't think this ended up working much better or worse than any other option I was considering.
Disclaimer! Yes, I work at Roblox. It's been a decade or so since I could pretend this space to be anonymous, and many years ago I made it clear that c0de517e/deadc0de = Angelo Pesce. And yes, my work makes me think about what this "metaverse" thing is more than the average person on the street (Roblox has been a metaverse company long, long before it was "cool"). I guess like an engineer at google might think about "the internet" more than the average person... But the following truly is not about what we are building at Roblox, which is something quite specific - these are my opinions, and other people might agree to some degree, and disagree with them.
I don't like hype cycles.
It is somewhat frustrating to see how supposedly experienced and rational people jump on the latest shiny bandwagon. At the same time, I guess it's comfortingly human. But that's a topic for another time...
Thing is, the metaverse is undoubtedly "hot" right now, so hot that every company, regardless of what they do, wants to have a claim to it. Mostly harmless, even cute, and for some, validating years of effort pushing these ideas... But, at the same time, it dilutes the concept, it makes words mean little to nothing when you can slap them onto any product.
So, let's give it a try and think really what is the metaverse, and how, if at all, is different from what we have today.
In the most general sense, "the metaverse" evokes ideas of synthetic, alternative places for social interactions, entertainment, perhaps even work... living our lives.
And let's set aside the possible dystopian scenarios - not the point of this, albeit, these are always important to seriously consider, while also reminding ourselves that they are levied against most society-affecting technology, from the printing press onwards.
This definition is just plain... boring!
It's boring because we have always been doing that, at least, since we had the ability to connect computers together. We are social animals, obviously, we want to imagine any new technology in a social space. BBS are alternative places for social interaction. And entertainment. And work. And from there on we had all kinds of shared virtual worlds, from IRC to the Mii Channel, from MUDs to World of Warcraft, from Club Penguin to Second Life, and so on.
 LucasFilm's Habitat. Now live!
LucasFilm's Habitat. Now live!The entire internet fits the bill, through that lens, and we don't need a new word for old ideas - outside marketing perhaps.
So, let's try to find some true meaning for this word. What's new now? Is it VR/AR/XR perhaps? Web 3.0 and NFTs? The "fediverse"?
Or perhaps there is nothing new really, but we just run out of ideas, explored the space of conventional social media startups already, and now trying to see if some old concept can be successful, throw a few things at the wall and see what sticks...
My thesis? Agency.
Agency is the real differentiating factor.
Really, it's right there, staring at us. Like a high school kid facing an essay, sometimes it's good to look at the word itself, what does the dictionary tell us? Yes, we're going there: "In its most basic use, meta- describes a subject in a way that transcends its original limits, considering the subject itself as an object of reflection".
If you're controlling your virtual, alternative, synthetic universe, you are creating something that might be spectacular, engaging, entertaining, powerful... but it's not a metaverse.
Videogames are not the metaverse, not even MMORPGs... Sandboxes/UGC/modding is not the metaverse. Virtual worlds are not the metaverse!
Yes, I'm "disqualifying" Minecraft, Second Life, Gather.Town, GTA 5, Decentraland, Skyrim, Fortnite, Eve Online, the lot - not because of the quality of these products, but because we don't need new words for existing concepts, we really don't...
Obviously, the line is somewhat blurry, but if you're making most of the rules you are "just" creating a world, with varying degrees of freedom.
A metaverse is an alternative living space (universe... world...) that is mostly owned by the participants, not centrally directed. Users create, share creations and make all of the rules (the meta- part).
Why does this distinction matter? Why is it interesting?
At a shallow level, obviously, it gives you more variety, than a single virtual world. It has all the interesting implications of any platform where you do not control content. You are not really asking people to enter your world or use your product, you are really there to provide a service for others to create what they want to create and market it, form communities, and engage with them...
But I think it's more than that. This extra agency works to create a qualitatively different community, one that is centered around the creation and sharing of creations, an economy you might call it. Something quite different from passive consumption or social co-experience.
Ironically, through this lens, most of Web 3.0 "gets is wrong", focusing on decentralizing a transaction ledger of virtual ownership, but making that ownership be simply parts of strictly controlled virtual universes. You own a certificate to a plot of digital land that someone else created and controls.
Regardless of the fact that you only own the certificate, and not the actual land, which can disappear at any moment... these kinds of worlds seem at best a coat of paint over very old and limited concepts.
To me, even outside the blockchain, the entire notion of centralized versus decentralized systems, proprietary, closed versus interoperable open standards, all these concepts are really a "how", not a "what", they might be appropriate choices for a given product at a given time, but they should never be what the product "is".
Without wanting to sell the metaverse as the future, I personally think that these "fake" or "weak" metaverses, together with the current hype, are what pushes people away from something that could be truly interesting.
Note also that nothing of this idea of social creativity, giving a platform for people to create and share in others' creations, has to do with new technologies.
You don't need VR for any of this. You don't need hand tracking, machine learning and 3d scanning, you don't even need 3d rendering at all!
These are all tools that might or might not be appropriate, but you could have perfectly great metaverses that are text only if you wanted to (remember MUDs? add the "meta" part...). And at the same time, just because you have some cool 3d technology, it does not mean you have something for the metaverse...
E.g. you could have a server hosting community-created ROMs for a Commodore 64, add built-in networking to allow the ROMS to be about co-experience, add a pinch of persistence to allow people to express themselves, and you'd have a perfectly great, exciting metaverse... Or you could take something like UXN and the vision of permacomputing as the foundation, to reference something more contemporary...
 BBS Door Games - more proto-metaverse-y than most of today's virtual worlds.
BBS Door Games - more proto-metaverse-y than most of today's virtual worlds.In summary, these are to me the key attributes of this metaverse idea:
It's a social spin over the old, OG hacker's ethos of tinkering, creating with computers, owning their creations and sharing them. It has nothing to do with the particular implementation and it is not even about laws, copyright, or politics. It's a community that creates together, makes its own rules, and has full agency over these virtual creations.
One more thing? In a truly creator-centric economy, you don't need to base all your revenue on ads, and the dark patterns they create.
Perhaps to shape that future it's more useful to revisit old, lost ideas, than thinking about shiny new overhyped toys. More SmallTalk's idea of Personal Computing and Plan 9, less NFTs and XR...
 Can watch the recording on YouTube for a bit of nostalgia.
Can watch the recording on YouTube for a bit of nostalgia. Memories... A 3dfx Voodoo. PCem has some emulation for these, if one wants to play...
Memories... A 3dfx Voodoo. PCem has some emulation for these, if one wants to play... So pretty... Look at that sky. Worth its complexity, right?
So pretty... Look at that sky. Worth its complexity, right?
 Alita - rendered with Weta's proprietary (and RenderMan-compatible) Manuka
Alita - rendered with Weta's proprietary (and RenderMan-compatible) Manuka https://threejs.org/ frontpage.
https://threejs.org/ frontpage. Roblox creations are completely tech-agnostic.
Roblox creations are completely tech-agnostic.Introduction
Two curses befall rendering engineers. First, we lose the ability to look at reality without being constantly reminded of how fascinatingly hard it is to solve light transport and model materials.
Second, when you start playing any game, you cannot refrain from trying to reverse its rendering technology (which is particularly infuriating for multiplayer titles - stop shooting at me, I'm just here to look how rocks cast shadows!).
So when I bought Cyberpunk 2077 I had to look at how it renders a frame. It's very simple to take RenderDoc captures of it, so I had really no excuse.
The following are speculations on its rendering techniques, observations made while skimming captures, and playing a few hours.
It's by no means a serious attempt at reverse engineering. For that, I lack both the time and the talent. I also rationalize doing a bad job at this by the following excuse: it's actually better this way.
I think it's better to dream about how rendering (or anything really) could be, just with some degree of inspiration from external sources (in this case, RenderDoc captures), rather than exactly knowing what is going on.
If we know, we know, there's no mystery anymore. It's what we do not know that makes us think, and sometimes we exactly guess what's going on, but other times we do one better, we hallucinate something new... Isn't that wonderful?
The following is mostly a read-through of a single capture. I did open a second one to try to fill some blanks, but so far, that's all.
 This is the frame we are going to look at.
This is the frame we are going to look at.I made the captures at high settings, without RTX or DLSS as RenderDoc does not allow these (yet?). I disabled motionblur and other uninteresting post-fx and made sure I was moving in all captures to be able to tell a bit better when passes access previous frame(s) data.
I am also not relying on insider information for this. Makes everything easier and more fun.
The basics
At a glance, it doesn't take long to describe the core of Cyberpunk 2077 rendering.
It's a classic deferred renderer, with a fairly vanilla g-buffer layout. We don't see the crazy amount of buffers of say, Suckerpunch's PS4 launch Infamous:Second Son, nor complex bit-packing and re-interpretation of channels.
 Immediately recognizable g-buffer layout
Immediately recognizable g-buffer layoutIf we look at the frame chronologically, it starts with a bunch of UI draws (that I didn't investigate further), a bunch of copies from a CPU buffer into VS constants, then a shadowmap update (more on this later), and finally a depth pre-pass.
 Some stages of the depth pre-pass.
Some stages of the depth pre-pass.This depth pre-pass is partial (not drawing the entire scene) and is only used to reduce the overdraw in the subsequent g-buffer pass.
Basically, all the geometry draws are using instancing and some form of bindless textures. I'd imagine this was a big part of updating the engine from The Witcher 3 to contemporary hardware.
Bindless also makes it quite annoying to look at the capture in renderDoc unfortunately - by spot-checking I could not see too many different shaders in the g-buffer pass - perhaps a sign of not having allowed artists to make shaders via visual graphs?
Other wild guesses: I don't see any front-to-back sorting in the g-buffer, and the depth prepass renders all kinds of geometries, not just walls, so it would seem that there is no special authoring for these (brushes, forming a BSP) - nor artists have hand-tagged objects for the prepass, as some relatively "bad" occluders make the cut. I imagine that after culling a list of objects is sorted by shader and from there instanced draws are dynamically formed on the CPU.
The opening credits do not mention Umbra (which was used in The Witcher 3) - so I guess CDPr rolled out their own visibility solution. Its effectiveness is really hard to gauge, as visibility is a GPU/CPU balance problem, but there seem to be quite a few draws that do not contribute to the image, for what's worth. It also looks like that at times the rendering can display "hidden" rooms, so it looks like it's not a cell and portal system - I am guessing that for such large worlds it's impractical to ask artists to do lots of manual work for visibility. A different frame, with some of the pre-pass.
A different frame, with some of the pre-pass. Lastly, I didn't see any culling done GPU side, with depth pyramids and so on, no per-triangle or cluster culling or predicated draws, so I guess all frustum and occlusion culling is CPU-side.
Note: people are asking if "bad" culling is the reason for the current performance issues, I guess meaning on ps4/xb1. This inference cannot be done, nor the visibility system can be called "bad" - as I wrote already. FWIW - it seems mostly that consoles struggle with memory and streaming more than anything else. Who knows...
Let's keep going... After the main g-buffer pass (which seems to be always split in two - not sure if there's a rendering reason or perhaps these are two command buffers done on different threads), there are other passes for moving objects (which write motion vectors - the motion vector buffer is first initialized with camera motion).
This pass includes avatars, and the shaders for these objects do not use bindless (perhaps that's used only for world geometry) - so it's much easier to see what's going on there if one wants to.
Finally, we're done with the main g-buffer passes, depth-writes are turned off and there is a final pass for decals. Surprisingly these are pretty "vanilla" as well, most of them being mesh decals.
Mesh decals bind as inputs (a copy of) the normal buffer, which is interesting as one might imagine the 10.10.10 format was chosen to allow for easy hardware blending, but it seems that some custom blend math is used as well - something important enough to pay for the price of making a copy (on PC at least).
 A mesh decal - note how it looks like the original mesh with the triangles that do not map to decal textures removed.
A mesh decal - note how it looks like the original mesh with the triangles that do not map to decal textures removed.It looks like only triangles carrying decals are rendered, using special decal meshes, but other than that everything is remarkably simple. It's not bindless either (only the main static geometry g-buffer pass seems to be), so it's easier to see what's going on here.
At the end of the decal pass we see sometimes projected decals as well, I haven't investigated dynamic ones created by weapons, but the static ones on the levels are just applied with tight boxes around geometry, I guess hand-made, without any stencil-marking technique (which would probably not help in this case) to try to minimize the shaded pixels.
Projected decals do bind depth-stencil as input as well, obviously as they need the scene depth, to reconstruct world-space surface position and do the texture projection, but probably also to read stencil and avoid applying these decals on objects tagged as moving.
 A projected decal, on the leftmost wall (note the decal box in yellow)
A projected decal, on the leftmost wall (note the decal box in yellow)As for the main g-buffer draws, many of the decals might end up not contributing at all to the image, and I don't see much evidence of decal culling (as some tiny ones are draws) - but it also might depend on my chosen settings.
The g-buffer pass is quite heavy, but it has lots of detail and it's of course the only pass that depends on scene geometry, a fraction of the overall frame time. E.g. look at the normals on the ground, pushed beyond the point of aliasing. At least on this PC capture, textures seem even biased towards aliasing, perhaps knowing that temporal will resolve them later (which absolutely does in practice, rotating the camera often reveals texture aliasing that immediately gets resolved when stopped - not a bad idea, especially as noise during view rotation can be masked by motion blur).
 1:1 crop of the final normal buffer
1:1 crop of the final normal bufferA note re:Deferred vs Forward+
Most state-of-the-art engines are deferred nowadays. Frostbite, Guerrilla's Decima, Call of Duty BO3/4/CW, Red Dead Redemption 2, Naughty Dog's Uncharted/TLOU and so on.
On the other hand, the amount of advanced trickery that Forward+ allows you is unparalleled, and it has been adopted by a few to do truly incredible rendering, see for example the latest Doom games or have a look at the mind-blowing tricks behind Call of Duty: Modern Warfare / Warzone (and the previous Infinity Warfare which was the first time that COD line moved from being a crazy complex forward renderer to a crazy complex forward+).
I think the jury is still out on all this, and as most thing rendering (or well, coding!) we don't know anything about what's optimal, we just make/inherit choices and optimize around them.
That said, I'd wager this was a great idea for CP2077 - and I'm not surprised at all to see this setup. As we'll see in the following, CP2077 does not seem to have baked lighting, relying instead on a few magic tricks, most of which operating in screen-space.
For these to work, you need before lighting to know material and normals, so you need to write a g-buffer anyways. Also you need temporal reprojection, so you want motion vectors and to compute lighting effects in separate passes (that you can then appropriately reproject, filter and composite).
I would venture to say also that this was done not because of the need for dynamic GI - there's very little from what I've seen in terms of moving lights and geometry is not destructible. I imagine instead, this is because the storage and runtime memory costs of baked lighting would be too big. Plus, it's easier to make lighting interactive for artists in such a system, rather than trying to write a realtime path-tracer that accurately simulates what your baking system results would be...
Lastly, as we're already speculating things, I'd imagine that CDPr wanted really to focus on artists and art. A deferred renderer can help there in two ways. First, it's performance is less coupled with the number of objects and vertices on screen, as only the g-buffer pass depends on them, so artists can be a smidge less "careful" about these. Second, it's simpler, overall - and in an open-world game you already have to care about so many things, that having to carefully tune your gigantic foward+ shaders for occupancy is not a headache you want to have to deal with...Lighting part 1: Analytic lights
Obviously, no deferred rendering analysis can stop at the g-buffer, we split shading in two, and we have now to look at the second half, how lighting is done.
Here things become a bit dicier, as in the modern age of compute shaders, everything gets packed into structures that we cannot easily see. Even textures can be hard to read when they do not carry continuous data but pack who-knows-what into integers.
 Normal packing and depth pyramid passes.
Normal packing and depth pyramid passes. RGBA8 packed normal (&roughness). Note the speckles that are a tell-tale of best-fit-normal encoding.
RGBA8 packed normal (&roughness). Note the speckles that are a tell-tale of best-fit-normal encoding.It first packs normal and roughness into a RGBA8 using Crytek's lookup-based best-fit normal encoding, then it creates a min-max mip pyramid of depth values.
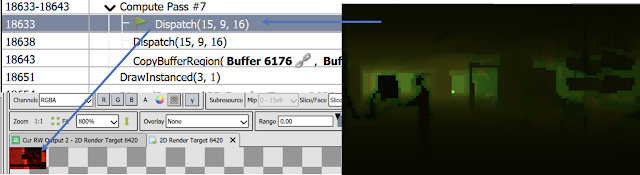
The pyramid is then used to create what looks like a volumetric texture for clustered lighting.
 A slice of what looks like the light cluster texture, and below one of the lighting buffers partially computed. Counting the pixels in the empty tiles, they seem to be 16x16 - while the clusters look like 32x32?
A slice of what looks like the light cluster texture, and below one of the lighting buffers partially computed. Counting the pixels in the empty tiles, they seem to be 16x16 - while the clusters look like 32x32?The clusters seem to be 32x32 pixels in screen-space (froxels), with 64 z-slices. The lighting though seems to be done at a 16x16 tile granularity, all via compute shader indirect dispatches.
I would venture this is because CS are specialized by both the materials and lights present in a tile, and then dispatched accordingly - a common setup in contemporary deferred rendering systems (e.g. see Call of Duty Black Ops 3 and Uncharted 4 presentations on the topic).
Analytic lighting pass outputs two RGBA16 buffers, which seems to be diffuse and specular contributions. Regarding the options for scene lights, I would not be surprised if all we have are spot/point/sphere lights and line/capsule lights. Most of Cyberpunk's lights are neons, so definitely line light support is a must.
You'll also notice that a lot of the lighting is unshadowed, and I don't think I ever noticed multiple shadows under a single object/avatar. I'm sure that the engine does not have limitations in that aspect, but all this points at lighting that is heavily "authored" with artists carefully placing shadow-casting lights. I would also not be surprised if the lights have manually assigned bounding volumes to avoid leaks.
 Final lighting buffer (for analytic lights) - diffuse and specular contributions.
Final lighting buffer (for analytic lights) - diffuse and specular contributions.But what we just saw does not mean that shadows are unsophisticated in Cyberpunk 2077, quite the contrary, there are definitely a number of tricks that have been employed, most of them not at all easy to reverse!
First of all, before the depth-prepass, there are always a bunch of draws into what looks like a shadowmap. I suspect this is a CSM, but in the capture I have looked at, I have never seen it used, only rendered into. This points to a system that updates shadowmaps over many frames, likely with only static objects?
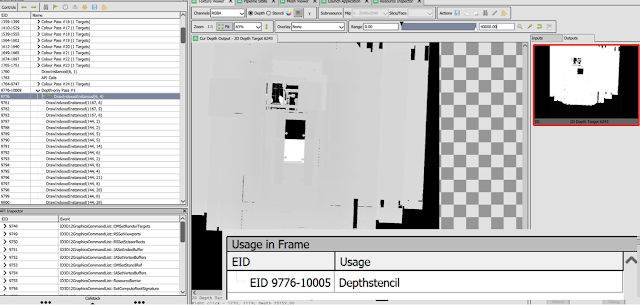 Is this a shadowmap? Note that there are only a few events in this capture that write to it, none that reads - it's just used as a depth-stencil target, if RenderDoc is correct here...
Is this a shadowmap? Note that there are only a few events in this capture that write to it, none that reads - it's just used as a depth-stencil target, if RenderDoc is correct here...These multi-frame effects are complicated to capture, so I can't say if there are further caching systems (e.g. see the quadtree compressed shadows of Black Ops 3) at play.
One thing that looks interesting is that if you travel fast enough through a level (e.g. in a car) you can see that the shadows take some time to "catch up" and they fade in incrementally in a peculiar fashion. It almost appears like there is a depth offset applied from the sun point of view, that over time gets reduced. Interesting!
 This is hard to capture in an image, but note how the shadow in time seems to crawl "up" towards the sun.
This is hard to capture in an image, but note how the shadow in time seems to crawl "up" towards the sun.There's surely a lot to reverse-engineer here if one was inclined to do the work!
 The slices of the texture on the bottom (in red) are clearly CSM. The partially rendered slices in gray are a mystery. The yellow/green texture is, clearly, resolved screen-space sun shadows, I've never, so far, seen the green channel used in a capture.
The slices of the texture on the bottom (in red) are clearly CSM. The partially rendered slices in gray are a mystery. The yellow/green texture is, clearly, resolved screen-space sun shadows, I've never, so far, seen the green channel used in a capture. A few of the VSM-ish shadowmaps on the left, and artefacts of the screen-space raymarched contact shadows on the right, e.g. under the left arm, the scissors and other objects in contact with the plane...
A few of the VSM-ish shadowmaps on the left, and artefacts of the screen-space raymarched contact shadows on the right, e.g. under the left arm, the scissors and other objects in contact with the plane...Overall, shadows are both simple and complex. The setup, with CSMs, VSMs, and optionally raymarching is not overly surprising, but I'm sure the devil is in the detail of how all these are generated and faded in. It's rare to see obvious artifacts, so the entire system has to be praised, especially in an open-world game!
Lighting part III: All the rest...
Since booting the game for the first time I had the distinct sense that most lighting is actually not in the form of analytic lights - and indeed looking at the captures this seems to not be unfounded. At the same time, there are no lightmaps, and I doubt there's anything pre-baked at all. This is perhaps one of the most fascinating parts of the rendering.
 First pass highlighted is the bent-cone AO for this frame, remaining passes do smoothing and temporal reprojection.
First pass highlighted is the bent-cone AO for this frame, remaining passes do smoothing and temporal reprojection.It looks like it's computing bent normals and aperture cones - impossible to tell the exact technique, but it's definitely doing a great job, probably something along the lines of HBAO-GTAO. First, depth, normal/roughness, and motion vectors are all downsampled to half-res. Then a pass computes current-frame AO, and subsequent ones do bilateral filtering and temporal reprojection. The dithering pattern is also quite regular if I had to guess, probably Jorge's Gradient noise?
It's easy to guess that the separate diffuse-specular emitted from the lighting pass is there to make it easier to occlude both more correctly with the cone information.
 One of many specular probes that get updated in an array texture, generating blurred mips.
One of many specular probes that get updated in an array texture, generating blurred mips.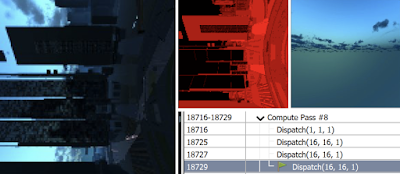 A mysterious cubemap. It looks like it's compositing sky (I guess that dynamically updates with time of day) with some geometry. Is the red channel an extremely thing g-buffer?
A mysterious cubemap. It looks like it's compositing sky (I guess that dynamically updates with time of day) with some geometry. Is the red channel an extremely thing g-buffer?The source of the probe data is harder to find though, but in the main capture I'm using there seems to be something that looks like a specular cubemap relighting happening, it's not obvious to me if this is a different probe from the ones in the array or the source for the array data later on.
Also, it's hard to say whether or not these probes are hand placed in the level, if the relighting assumption is true, then I'd imagine that the locations are fixed, and perhaps artist placed volumes or planes to define the influence area of each probe / avoid leaks.
 A slice of the volumetric lighting texture, and some disocclusion artefacts and leaks in a couple of frames.
A slice of the volumetric lighting texture, and some disocclusion artefacts and leaks in a couple of frames. Screen-Space Reflections
Screen-Space ReflectionsNow, things get very interesting again. First, we have an is an amazing Screen-Space Reflection pass, which again uses the packed normal/roughness buffer and thus supports blurry reflections, and at least at my rendering settings, is done at full resolution.
It uses previous-frame color data, before UI compositing for the reflection (using motion vectors to reproject). And it's quite a lot of noise, even if it employs a blue-noise texture for dithering!
 Diffuse/Ambient GI, reading a volumetric cube, which is not easy to decode...
Diffuse/Ambient GI, reading a volumetric cube, which is not easy to decode...The lighting is very soft/low-frequency and indirect shadows are not really visible in this pass. This might even by dynamic GI!
Certainly is volumetric, which has the advantage of being "uniform" across all objects, moving or not, and this coherence shows in the final game.
 Final lighting composite, diffuse plus specular, and specular-only.
Final lighting composite, diffuse plus specular, and specular-only.And here is where we can see what I said at the beginning. Most lighting is not from analytic lights! We don't see the usual tricks of the trade, with a lot of "fill" lights added by artists (albeit the light design is definitely very careful), instead indirect lighting is what makes most of the scene. This indirect lighting is not as "precise" as engines that rely more heavily on GI bakes and complicated encodings, but it is very uniform and regains high-frequency effects via the two very high-quality screen-space passes, the AO and reflection ones.


The screen-space passes are quite noisy, which in turn makes temporal reprojection really fundamental, and this is another extremely interesting aspect of this engine. Traditional wisdom says that reprojection does not work in games that have lots of transparent surfaces. The sci-fi worlds of Cyberpunk definitely qualify for this, but the engineers here did not get the news and made things work anyway!
And yes, sometimes it's possible to see reprojection artifact, and the entire shading can have a bit of "swimming" in motion, but in general, it's solid and coherent, qualities that even many engines using lightmaps cannot claim to have. Light leaks are not common, silhouettes are usually well shaded, properly occluded.
All the rest
There are lots of other effects in the engine we won't cover - for brevity and to keep my sanity. Hair is very interesting, appearing to render multiple depth slices and inject itself partially in the g-buffer with some pre-lighting and weird normal (fake anisotropic?) effect. Translucency/skin shading is surely another important effect I won't dissect.
 Looks like charts caching lighting...
Looks like charts caching lighting...Before the frame is over though, we have to mention transparencies - as more magic is going on here for sure. First, there is a pass that seems to compute a light chart, I think for all transparencies, not just particles.
Glass can blur whatever is behind them, and this is done with a specialized pass, first rendering transparent geometry in a buffer that accumulates the blur amount, then a series of compute shaders end up creating three mips of the screen, and finally everything is composited back in the scene.

 Scene after glass blur (in the inset) and with the actual glass rendered on top (big image)
Scene after glass blur (in the inset) and with the actual glass rendered on top (big image)Perhaps there are some very complicated secret recipes lurking somewhere in the shaders or beyond my ability to understand the capture.
 On the left, current and previous frame, on the right, final image after temporal reprojection.
On the left, current and previous frame, on the right, final image after temporal reprojection. This is from a different frame, a mask that is used for the TAA pass later on...
This is from a different frame, a mask that is used for the TAA pass later on...Depth of field, of course, tone-mapping and auto-exposure... There are of course all the image-degradation fixings you'd expect and probably want to disable: film grain, lens flares, motion blur, chromatic aberration... Even the UI compositing is non-trivial, all done in compute, but who has the time... Now that I got all this off my chest, I can finally try to go and enjoy the game! Bye!