Show full content
New post at the new blog location, here. Enjoy!
New post at the new blog location, here. Enjoy!

New ad-free location: https://davmac.org/blog/the-world-is-on-fire-but-not-c23.html
An article was published on acmqueue last month entitled “Catch-23: The New C Standard Sets the World on Fire”. It’s a bad article; I’ll go into that shortly; it comes on the back of similar bad arguments that I’ve personally either stumbled across, or been involved in, lately, so I’d like to respond to it.
So what’s bad about the article? Let me quote:
Progress means draining swamps and fencing off tar pits, but C23 actually expands one of C’s most notorious traps for the unwary. All C standards from C89 onward have permitted compilers to delete code paths containing undefined operations—which compilers merrily do, much to the surprise and outrage of coders.16 C23 introduces a new mechanism for astonishing elision: By marking a code path with the new
unreachableannotation,12 the programmer assures the compiler that control will never reach it and thereby explicitly invites the compiler to elide the marked path.
The complaint here seems to be that the addition of the “unreachable” annotation introduces another way that undefined behaviour can be introduced into a C program: if the annotation is incorrect and the program point is actually reachable, the behaviour is undefined.
The premise seems to be that, since undefined behaviour is bad, any new way of invoking undefined behaviour is also bad. While it’s true that undefined behaviour can cause huge problems, and that this has been a sore point with C for some time, the complaint here is fallacious: the whole point of this particular annotation is to allow the programmer to specify their intent that a certain path be unreachable, as opposed to the more problematic scenario where a compiler determines code is unreachable because a necessarily-preceding (“dominating”) instruction would necessarily have undefined behaviour. In other words it better allows the compiler to distinguish between cases where the programmer has made particular assumptions versus when they have unwittingly invoked undefined behaviour in certain conditions. This is spelled out in the proposal for the feature:
It seems, that in some cases there is an implicit assumption that code that makes a po-
tentially undefined access, for example, does so willingly; the fact that such an access is
unprotected is interpreted as an assertion that the code will never be used in a way that
makes that undefined access. Where such an assumption may be correct for highly spe-
cialized code written by top tier programmers that know their undefined behavior, we are
convinced that the large majority of such cases are just plain bugs
That is to say, while it certainly does add “another mechanism to introduce undefined behaviour”, part of the purpose of the feature is actually to limit the damage and/or improve the diagnosis of code which unintentionally invokes undefined behaviour. It’s concerning that the authors of the article have apparently not read the requisite background information, or have failed to understand it, but have gone ahead with their criticism anyway.
In fact, they continue:
C23 furthermore gives the compiler license to use an
unreachableannotation on one code path to justify removing, without notice or warning, an entirely different code path that is not markedunreachable: see the discussion ofputs()in Example 1 on page 316 of N3054.9
When you read the proffered example, you quickly notice that this description is wrong: the “entirely different code path” is in fact dominated by the code path that is marked unreachable and thus is, in fact, the same code path. I.e. it is not possible to reach one part without reaching the other, so they are on the same path; if either are unreachable, then clearly the other must also be; if one contains undefined behaviour then the entire code path does and (just as before C23) the compiler might choose to eliminate it. Bizarrely, the authors are complaining about a possible effect of undefined behaviour as if it was a new thing resulting from this new feature.
The criticism seems to stem at least partly from the notion that undefined behaviour is universally bad. I can sympathise with this to some degree, since the possible effects of UB are notorious, but at the same time it should be obvious that railing against all new undefined behaviour in C is unproductive. There will always be UB in C. The nature of the language, and what it is used for, all but guarantee this. However, it’s important to recognise that the UB is there for a reason, and also that not all UB is of the “nasal daemons” variety. While those who really understand UB can often be heard to decry “don’t do that, it’s UB, it might kill your dog” there is also an important counterpoint: most UB will not kill your dog.
“Undefined behaviour” does not, in fact, mean that a compiler must cause your code to behave differently than how you wanted it to. In fact it’s perfectly fine for a compiler (“an implementation”) to offer behavioural guarantees far beyond what is required by the language standard, or to at least provide predictable behaviour in cases that are technically UB. This is an important point in the context of another complaint in the article:
Imagine, then, my dismay when I learned that C23 declares
realloc(ptr,0)to be undefined behavior, thereby pulling the rug out from under a widespread and exemplary pattern deliberately condoned by C89 through C11. So much for stare decisis. Compile idiomaticrealloccode as C23 and the compiler might maul the source in most astonishing ways and your machine could ignite at runtime.16
To be clear, “realloc(ptr,0)” was previously allowed to return either NULL, or another pointer value (which is not allowed to be dereferenced). Different implementations can (and do) differ in their choice. While I somewhat agree that making this undefined behaviour instead is of no value, I’m also confident that it will have next to zero effect in practice. Standard library implementations aren’t going to change their current behaviour because they won’t want to break existing programs, and compilers won’t treat realloc with size 0 specially for the same reason (beyond perhaps offering a warning when such cases are detected statically). Also, calling code which relies on realloc returning a null pointer when given a 0 size “idiomatic” is a stretch, “exemplary” is an even further stretch, and “condoned by C89 through C11” is just plain wrong; the standard rationale suggests a practice for implementations, not for applications.
Later, the authors reveal serious misunderstandings about what behaviour is and is not undefined:
Why are such requests made? Often because of arithmetic bugs. And what is a non-null pointer from
malloc(0)good for? Absolutely nothing, except shooting yourself in the foot.It is illegal to dereference such a pointer or even compare it to any other non-null pointer (recall that pointer comparisons are combustible if they involve different objects).
This isn’t true. It’s perfectly valid to compare pointers that point to different objects. Perhaps the author is confusing this with the use of a pointer to an object whose lifetime has ended, or calculating the difference between pointers; it’s really not clear. Note that the requirement (before C23) for a 0-size allocation was that “either a null pointer is returned, or the behavior is as if the size were some nonzero value, except that the returned pointer shall not be used to access an object”; there’s no reason why such a pointer couldn’t be compared to another in either case.
It’s a shame that such hyperbolic nonsense gets published, even in on-line form.
There’s a pattern that emerged in software some time ago, that bothers me: in a nutshell, it is that it’s become acceptable to assume that memory is unlimited. More precisely, it is the notion that it is acceptable for a program to crash if memory is exhausted.
It’s easy to guess some reasons why this the case: for one thing, memory is much more prevalent than it used to be. The first desktop computer I ever owned had 32kb of memory (I later owned a graphing calculator with the same processor and same amount of memory as that computer). My current desktop PC, on the other hand, literally has more than a million times that amount of memory.
Given such huge amounts of memory to play with, it’s no wonder that programs are written with the assumption that they will always have memory available. After all, you couldn’t possibly ever chew up a whole 32 gigabytes of RAM with just the handful of programs that you’d typically run on a desktop, could you? Surely it’s enough that we can forgot about the problem of ever running out of memory. (Many of us have found out the unfortunate truth, the hard way; in this age where simple GUI apps are sometimes bundled together with a whole web browser – and in which web browsers will happily let a web page eat up more and more memory – it certainly is possible to hit that limit).
But, for some time, various languages with garbage-collecting runtimes haven’t even exposed memory allocation failure to the underlying application (this is not universally the case, but it’s common enough). This means that a program written in such a language that can’t allocate memory at some point will generally crash – hopefully with a suitable error message, but by no means with any sort of certainty of a clean shutdown.
This principle has been extended to various libraries even for languages like C, where checking for allocation failure is (at least in principle) straight-forward. Glib (one of the foundation libraries underlying the GTK GUI toolkit) is one example: the g_malloc function that it provides will terminate the calling process if requested memory can’t be allocated (a g_try_malloc function also exists, but it’s clear that the g_malloc approach to “handling” failure is considered acceptable, and any library or program built on Glib should typically be considered prone to unscheduled termination in the face of an allocation failure).
Apart from the increased availability of memory, I assume that the other reason for ignoring the possibility of allocation failure is just because it is easier. Proper error handling has traditionally been tedious, and memory allocation operations tend to be prolific; handling allocation failure can mean having to incorporate error paths, and propagate errors, through parts of a program that could otherwise be much simpler. As software gets larger, and more complex, being able to ignore this particular type of failure becomes more attractive.
The various “replacement for C” languages that have been springing up often have “easier error handling” as a feature – although they don’t always extend this to allocation failure; the Rust standard library, for example, generally takes the “panic on allocation failure” approach (I believe there has been work to offer failure-returning functions as an alternative, but even with Rust’s error-handling paradigms it is no doubt going to introduce some complexity into an application to make use of these; also, it might not be clear if Rust libraries will handle allocation failures without a panic, meaning that a developer needs to be very careful if they really want to create an application which can gracefully handle such failure).
Even beyond handling allocation failure in applications, the operating system might not expect (or even allow) applications to handle memory allocation failure. Linux, as it’s typically configured, has overcommit enabled, meaning that it will allow memory allocations to “succeed” when only address space has actually been allocated in the application; the real memory allocation occurs when the application then uses this address space by storing data into it. Since at that point there is no real way for the application to handle allocation failure, applications will be killed off by the kernel when such failure occurs (via the “OOM killer”). Overcommit can be disabled, theoretically, but to my dismay I have discovered recently that this doesn’t play well with cgroups (Linux’s resource control feature for process groups): an application in a cgroup that attempts to allocate more than the hard limit for the cgroup will generally be terminated, rather than have the allocation fail, regardless of the overcommit setting.
If the kernel doesn’t properly honour allocation requests, and will kill applications without warning when memory becomes exhausted, there’s certainly an argument to be made that there’s not much point for an application to try to be resilient to allocation failure.
But is this really how it should be?
I’m concerned, personally, about this notion that processes can just be killed off by the system. It rings false. We have these amazing machines at our disposal, with fantastic ability to precisely process data in whatever way and for whatever purpose we want – but, prone to sudden failures that cannot really be predicted or fully controlled, and which mean the system at a whole is fundamentally less reliable. Is it really ok that any process on the system might just be terminated? (Linux’s OOM uses heuristics to try and terminate the “right” process, but of course that doesn’t necessarily correspond to what the user or system administrator would want).
I’ve discussed desktops but the problem is still a problem on servers, perhaps more so; wouldn’t it be better if critical processes are able to detect and respond to memory scarcity rather than be killed off arbitrarily? Isn’t scaling back, at the application level, better than total failure, at least in some cases?
Linux could be fixed so that OOM was not needed on properly configured systems, even with cgroups; anyway there are other operating systems that, reportedly, have better behaviour. That would still leave the applications which don’t handle allocation failure, of course; fixing that would take (as well as a lot of work) a change in developer mindset. The thing is, while the odd application crash due to memory exhaustion probably doesn’t bother some, it certainly bothers me. Do we really trust that applications will reliably save necessary state at all times prior to crashing due to a malloc failure? Are we really ok with important system processes occasionally dying, with system functionality accordingly affected? Wouldn’t it be better if this didn’t happen?
I’d like to say no, but the current consensus would seem to be against me.
Addendum:
I tried really hard in the above to be clear how minimal a claim I was making, but there are comments that I’ve seen and discussions I’ve been embroiled in which make it clear this was not understood by at least by some readers. To sum up in what is hopefully an unambiguous fashion:
The one paragraph in particular that I think could possibly have caused confusion is this one:
I’m concerned, personally, about this notion that processes can just be killed off by the system. It rings false. We have these amazing machines at our disposal, with fantastic ability to precisely process data in whatever way and for whatever purpose we want – but, prone to sudden failures that cannot really be predicted or fully controlled, and which mean the system at a whole is fundamentally less reliable. Is it really ok that any process on the system might just be terminated?
Probably, there should have been emphasis on the “any” (in “any process on the system”) to make it clear what I was really saying here, and perhaps the “system at a whole is fundamentally less reliable” is unnecessary fluff.
There’s also a question in the concluding paragraph:
Do we really trust that applications will reliably save necessary state at all times prior to crashing due to a malloc failure?
This was a misstep and very much not the question I wanted to ask; I can see how it’s misleading. The right question was the one that follows it:
Are we really ok with important system processes occasionally dying, with system functionality accordingly affected? Wouldn’t it be better if this didn’t happen?
Despite those slips, I think if you read the whole article carefully the key thrust should be apparent.
For anyone wanting for a case where an application really does need to be able to handle allocation failures, I recently stumbled across one really good example:
To start with, I write databases for a living. I run my code on containers with 128MB when the user uses a database that is 100s of GB in size. Even if running on proper server machines, I almost always have to deal with datasets that are bigger than memory. Running out of memory happens to us pretty much every single time we start the program. And handling this scenario robustly is important to building system software. In this case, planning accordingly in my view is not using a language that can put me in a hole. This is not theoretical, that is real scenario that we have to deal with.
The other example is service managers, of which I am the primary author of one (Dinit), which is largely what got me thinking about this issue in the first place. A service manager has a system-level role and if one dies unexpectedly it potentially leaves the whole system in an awkward state (and it’s not in general possible to recover just be restarting the service manager). In the worst case, a program running as PID 1 on Linux which terminates will cause the kernel to panic. (The OOM killer will not target PID 1, but it still should be able to handle regular allocation failure gracefully). However, I’m aware of some service manager projects written using languages that will not allow handling allocation failure, and it concerns me.
A response to “Spooky action at a distance” by Drew DeVault.
As Abraham Maslow said in 1966, “I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.”
Wikipedia, “Law of the Instrument“
Our familiarity with particular tools, and the ways in which they work, predisposes us in our judgement of others. This is true also with programming languages; one who is familiar with a particular language, but not another, might tend to judge the latter unfavourably based on perceived lack of functionality or feature found in the former. Of course, it might turn out that such a lack is not really important, because there is another way to achieve the same result without that feature; what we should really focus on is exactly that, the end result, not the feature.
Drew Devault, in his blog post “Spooky action at a distance”, makes the opposite error: he takes a particular feature found in other languages, specifically, operator overloading, and claims that it leads to difficulty in understanding (various aspects of the relevant) code:
The performance characteristics, consequences for debugging, and places to look for bugs are considerably different than the code would suggest on the surface
Yes, in a language with operator overloading, an expression involving an operator may effectively resolve to a function call. DeVault calls this “spooky action” and refers to some (otherwise undefined) “distance” between an operator and its behaviour (hence “at a distance”, from his title).
DeVault’s hammer, then, is called “C”. And if another language offers greater capability for abstraction than C does, that is somehow “spooky”; code written that way is a bent nail, so to speak.
Let’s look at his follow-up example about strings:
Also consider if x and y are strings: maybe “+” means concatenation? Concatenation often means allocation, which is a pretty important side-effect to consider. Are you going to thrash the garbage collector by doing this? Is there a garbage collector, or is this going to leak? Again, using C as an example, this case would be explicit:
I wonder about the point of the question “is there a garbage collector, or is this going to leak?” – does DeVault really think that the presence or absence of a garbage collector can be implicit in a one-line code sample? Presumably he does not furthermore really believe that lack of a garbage collector would necessitate a leak, although that’s implied by the unfortunate phrasing. Ironically, the C code he then provides for concatenating strings does leak – there’s no deallocation performed at all (nor is there any checking for allocation failure, potentially causing undefined behaviour when the following lines execute).
Taking C++, we could write the string concatenation example as:
std::string newstring = x + y;Now look again at the questions DeVault posed. First, does the “+” mean concatenation? It’s true that this is not certain from this one line of code alone, since in fact it depends on the types of x and y, but there is a good chance it does, and we can anyway tell by looking at the surrounding code, which of course we need to do anyway in order to truly understand what this code is doing (and why) regardless of what language it is written in. I’ll add that even if it does turn out to be difficult to determine the types of the operands from inspecting the immediately surrounding code, this is probably an indication of badly written (or badly documented) code*.
Any C++ systems programmer, with only a modest amount of experience, would also almost certainly know that string concatenation may involve heap allocation. There’s no garbage collector (although C++ allows for one, it is optional, and I’m not aware of any implementations that provide one). True, there’s still no check for allocation failure, though here it would throw an exception and most likely lead to (defined) imminent program termination instead of undefined behaviour. (Yes, the C code most likely would also terminate the program immediately if the allocation failed; but technically this is not guaranteed; and, a C programmer should know not to assume that undefined behaviour in a C program will actually behave in some certain way, despite that they might believe that they know how their code should be translated by the compiler).
So, we reduced the several-line C example to a single line, which is straight-forward to read and understand, and for which we do in fact have ready answers to the questions posed by DeVault (who seems to be taking the tack that the supposed difficulty of answering these questions contributes to a case against operator overloading).
Importantly, there’s also no memory leak, unlike in the C code, since the string destructor will perform any necessary deallocation. Would the destructor call (occurring when the string goes out of scope) also count as “spooky action at a distance”? I guess that it should, according to DeVault’s definition, although that is a bit too fuzzy to be sure. Is this “spooky action” problematic? No, it’s downright helpful. It’s also not really spooky, since as a C++ programmer, we expect it.
It’s true that C’s limitations often force code to be written in such a way that low-level details are exposed, and that this can make it easier to follow control flow, since everything is explicit. In particular, lack of user-defined operator overloading, combined with lack of function overloading, mean that types often become explicit when variables are used (the argument to strlen is, presumably, a string). But it’s easy to argue – and I do – that this doesn’t really matter. Abstractions such as operator overloading exist for a reason; in many cases they aid in code comprehension, and they don’t really obscure details (such as allocation) that DeVault suggests they do.
As a counter-example to DeVaults first point, consider:
x + foo()This is a very brief line of C code, but now we can’t say whether it performs allocation, nor talk about performance characteristics or so-forth, without looking at other parts of the code.
We got to the heart of the matter earlier on: you don’t need to understand everything about what a line of code does by looking at that line in isolation. In fact, it’s hard to see how a regular function call (in C or any other language) doesn’t in fact also qualify as “spooky action at a distance”, unless you take the stance that, since it is a function call, we know that it goes off somewhere else in the code, whereas for an “x + y” expression we don’t – but then you’re also wielding C as your hammer: the only reason you think that an operator doesn’t involve a call to a function is because you’re used to a language where it doesn’t.
* If at this stage you want to argue “but C++ makes it easy to write bad code”, be aware that you’ve gone off on a tangent; this is not a discussion about the merits or lack-thereof of C++ as a whole, we’re just using it as an example here for a discussion on operator overloading.
Summary: Dinit reaches alpha; Alpine linux demo image; Booting FreeBSD
Well, it’s been an awfully long time since I last blogged about Dinit (web page, github), my service-manager / init / wannabe-Systemd-competitor. I’d have to say, I never thought it would take this long to come this far; when I started the project, it didn’t seem such a major undertaking, but as is often the case with hobby projects, life started getting in the way.
In an earlier episode, I said:
Keeping the momentum up has been difficult, and there’s been some longish periods where I haven’t made any commits. In truth, that’s probably to be expected for a solo, non-funded project, but I’m wary that a month of inactivity can easily become three, then six, and then before you know it you’ve actually stopped working on the project (and probably started on something else). I’m determined not to let that happen – Dinit will be completed. I think the key is to choose the right requirements for “completion” so that it can realistically happen; I’ve laid out some “required for 1.0” items in the TODO file in the repository and intend to implement them, but I do have to restrain myself from adding too much. It’s a balance between producing software that you are fully happy with and that feels complete and polished.
This still holds. On the positive side, I have been chipping away at those TODOs; on the other hand I still occasionally find myself adding more TODOs, so it’s a little hard to measure progress.
But, I released a new version just recently, and I’m finally happy to call Dinit “alpha stage” software. Meaning, in this case, that the core functionality is really complete, but various planned supporting functionality is still missing.
I myself have been running Dinit as the init and primary service manager on my home desktop system for many years now, so I’m reasonably confident that it’s solid. When I do find bugs now, they tend to be minor mistakes in service management functions rather than crashes or hangs. The test suite has become quite extensive and proven very useful in finding regressions early.
Alpine VM image
I decided to try creating a VM image that I could distribute to anyone who wanted to see Dinit in action; this would also serve as an experiment to see if I could create a system based on a distribution that was able to boot via Dinit. I wanted it to be small, and one candidate that immediately came to mind was Alpine linux.
Alpine is a Musl libc based system which normally uses a combination of Busybox‘s init and OpenRC service management (historically, Systemd couldn’t be built against Musl; I don’t know if that’s still the case. Dinit has no issues). Alpine’s very compact, so it fits the bill nicely for a base system to use with Dinit.
After a few tweaks to the example service definitions (included in the Dinit source tree), I was able to boot Alpine, including bring up the network, sshd and terminal login sessions, using Dinit! The resulting image is here, if you’d like to try it yourself.


(The main thing I had to deal with was that Alpine uses mdev, rather than udev, for device tree management. This meant adapting the services that start udev, and figuring out to get the kernel modules loaded which were necessary to drive the available hardware – particularly, the ethernet driver! Fortunately I was able to inspect and borrow from the existing Alpine boot scripts).
Booting FreeBSD
A longer-term goal has always been to be able to use Dinit on non-Linux systems, in particular some of the *BSD variants. Flushed with success after booting Alpine, I thought I’d also give BSD a quick try (Dinit has successfully built and run on a number of BSDs for some time, but it hasn’t been usable as the primary init on such systems).
Initially I experimented with OpenBSD, but I quickly gave up (there is no way that I could determine to boot an alternative init using OpenBSD, which meant that I had to continuously revert to a backup image in order to be able to boot again, every time I got a failure; also, I suspect that the init executable on OpenBSD needs to be statically linked). Moving on to FreeBSD, I found it a little easier – I could choose an init at boot time, so it was easy to switch back-and-forth between dinit and the original init.
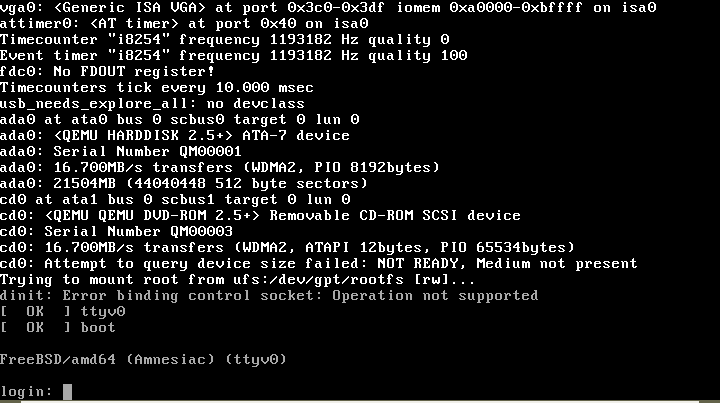
However, dinit was crashing very quickly, and it took a bit of debugging to discover why. On Linux, init is started with three file descriptors already open and connected to the console – these are stdin (0), stdout (1) and stderr (2). Then, pretty much the first thing that happens when dinit starts is that it opens an epoll set, which becomes the next file descriptor (3); this actually happens during construction of the global “eventloop” variable. Later, to make sure they are definitely connected to the console, dinit closes file descriptors 0, 1, and 2, and re-opens them by opening the /dev/console device.
Now, on FreeBSD, it turns out that init starts without any file descriptors open at all! The event loop uses kqueue on FreeBSD rather than the Linux-only epoll, but the principle is pretty much the same, and because it is created early it gets assigned the first available file descriptor which in this case happens to be 0 (stdin). Later, Dinit unwittingly closes this so it can re-open it from /dev/console. A bit later still, when it tries to use the kqueue for event polling, disaster strikes!
This could be resolved by initialising the event lop later on, after the stdin/out/err file descriptors were open and connected. Having done that, I was also able to get FreeBSD to the point where it allowed login on a tty! (there are some minor glitches, and in this case I didn’t bother trying to get network and other services running; that can probably wait for a rainy day – but in principle it should be possible!).
Wrap-up
So, Dinit has reached alpha release, and is able to boot Alpine Linux and FreeBSD. This really feels like progress! There’s still some way to go before a 1.0 release, but we’re definitely getting closer. If you’re interested in Dinit, you might want to try out the Alpine-Dinit image, which you can run with QEMU.


I recently allowed myself to be embroiled in an online discussion regarding Rust and C++. It started with a comment (from someone else) complaining how Rust advocates have a tendency to hijack C++ discussions and suggesting that C++ was type-safe, which was responded to by a Rust advocate first saying that C++ wasn’t type-safe (because casts, and unchecked bounds accesses, and unchecked lifetime), and then going on to make an extreme claim about C++’s type system which I won’t repeat here because I don’t want to re-hash that particular argument. Anyway, I weighed in trying to make the point that it was a ridiculous claim, but also made the (usual) mistake of also picking at other parts of the comment, in this case regarding the type-safety assertion, which is thorny because I don’t know if many people really understand properly what “type-safety” is (I think I somewhat messed it up myself in that particular conversation).
So what exactly is “type-safety”? Part of the problem is that it is an overloaded term. The Rust advocate picked some parts of the definition from the wikipedia article and tried to use these to show that C++ is “not type-safe”, but they skipped the fundamental introductory paragraph, which I’ll reproduce here:
In computer science, type safety is the extent to which a programming language discourages or prevents type errors
https://en.wikipedia.org/wiki/Type_safety
I want to come back to that, but for now, also note that it offers this, on what constitutes a type error:
A type error is erroneous or undesirable program behaviour caused by a discrepancy between differing data types for the program’s constants, variables, and methods (functions), e.g., treating an integer (int) as a floating-point number (float).
… which is not hugely helpful because it doesn’t really say it means to “treat” a value of one type as another type. It could mean that we supply a value (via an expression) that has a type not matching that required by an operation which is applied to it, though in that case it’s not a great example, since treating an integer as a floating point is, in many languages, perfectly possible and unlikely to result in undesirable program behaviour; it could perhaps also be referring to type-punning, the process of re-interpreting a bit pattern which represents a value on one type as representing a value in another type. Again, I want to come back to this, but there’s one more thing that ought to be explored, and that’s the sentence at the end of the paragraph:
The formal type-theoretic definition of type safety is considerably stronger than what is understood by most programmers.
I found quite a good discussion of type-theoretic type safety in this post by Thiago Silva. They discuss two definitions, but the first (from Luca Cardelli) at least boils down to “if undefined behaviour is invoked, a program is not type-safe”. Now, we could extend that to a language, in terms of whether the language allows a non-type-safe program to be executed, and that would make C++ non-type-safe. However, also note that this form of type-safety is a binary: a language either is or is not type-safe. Also note that the definition here allows a type-safe program to raise type errors, in contrast to the introductory statement from wikipedia, and Silva implies that a type error occurs when an operation is attempted on a type to which it doesn’t apply, that is, it is not about type-punning:
In the “untyped languages” group, he notes we can see them equivalently as “unityped” and, since the “universal type” type checks on all operations, these languages are also well-typed. In other words, in theory, there are no forbidden errors (i.e. type errors) on programs written in these languages
Thiago Silva
I.e. with dynamic typing “everything is the same type”, and any operation can be applied to any value (though doing so might provoke an error, depending on what the value represents), so there’s no possibility of type error, because a type error occurs when you apply an operation to a type for which it is not allowed.
The second definition discussed by Silva (i.e. that of Benjamin C. Pierce) is a bit different, but can probably be fundamentally equated with the first (consider “stuck” as meaning “has undefined behaviour” when you read Silva’s post).
This notion of type error as an operation illegal on certain argument type(s) is also supported by a quote from the original wiki page:
A language is type-safe if the only operations that can be performed on data in the language are those sanctioned by the type of the data.
Vijay Saraswat
So where are we? In formal type-theoretic language, we would say that:
Further, we have a generally-accepted notion of type error:
(which, ok, makes the initial example of a type error on the wikipedia page fantastically bad, but is not inconsistent with the page generally).
Now, let me quote the introductory sentence again, with my own emphasis this time:
In computer science, type safety is the extent to which a programming language discourages or prevents type errors
This seems to be more of a “layman’s definition” of type safety, and together with the notion of type error as outlined above, certainly explains why the top-voted stackoverflow answer for “what is type-safe?” says:
Type safety means that the compiler will validate types while compiling, and throw an error if you try to assign the wrong type to a variable
That is, static type-checking certainly is designed to prevent operations that are illegal according to argument type from being executed, and thus have a degree of type-safety.
So, we have a formal definition of type-safety, which in fact has very little to do with types within a program and more to do with (the possibility of) undefined behaviour; and we have a layman’s definition, which says that type-safety is about avoiding type errors.
The formal definition explains why you can easily find references asserting that C++ is not type-safe (but that Java, for example, is). The informal definition, on the other hand, clearly allows us to say that C++ has reasonably good type-safety.
Clearly, it’s a bit of a mess.
How to resolve this? I guess I’d argue that “memory-safe” is a better understood term than the formal “type-safe”, and since in many cases lack of the latter results from lack of the former we should just use it as the better of the two (or otherwise make specific reference to “undefined behaviour”, which is probably also better understood and less ambiguous). For the layman’s variant we might use terms like “strongly typed” and “statically type-checked”, rather than “type-safe”, depending on where exactly we think the type-safety comes from.
I don’t write often enough about my init-system-slash-service-manager, Dinit (https://github.com/davmac314/dinit). Lots of things have happened since I began writing it, and this year I’m in a new country with a new job, and time to work on just-for-the-hell-of-it open-source projects is limited. And of course, writing blog posts detracts from time that could be spent writing code.
But the truth is: it’s come a long way.
Dinit has been booting my own system for a long while, and other than a few hiccups on odd occasions it’s been quite reliable. But that’s just my own personal experience and hardly evidence that it’s really as robust and stable as I’d like to claim it is. On the other hand, it’s now got a pretty good test suite, it’s in the OpenBSD ports tree, and it still occasionally has Fedora RPMs built, so it’s possible there are other users out there (I know of only one other person who definitely uses Dinit on any sort of regular basis, and that’s not as their system init). I’ve ran static analysis on Dinit and fixed the odd few problems that were reported. I’ve fuzz-tested the control protocol.
Keeping up motivation is hard, and finding time is even harder, but I still make slow progress. I released another version recently, and it’s got some nice new features that will make using it a better experience.
Ok, compared to Systemd it lacks some features. It doesn’t know anything about Cgroups, the boot manager, filesystem mounts, dynamic users or binary logging. For day-to-day use on my personal desktop system, none of this matters, but then, I’m running a desktop based on Fluxbox and not much else; if I was trying to run Gnome, I’d rather expect that some things might not work quite as intended (on the other hand, maybe I could set up Elogind and it would all work fine… I’ve not tried, yet).
On the plus side, compared to Systemd’s binary at 1.5mb, Dinit weighs in at only 123kb. It’s much smaller, but fundamentally almost as powerful, in my own opinion, as the former. Unlike Systemd, it works just fine with alternative C libraries like Musl, and it even works (though not with full support for running as init, yet) on other operating systems such as FreeBSD and OpenBSD. It should build, in fact, on just about any POSIX-compliant system, and it doesn’t require any dependencies (other than an event loop library which is anyway bundled in the tarball). It’ll happily run in a container, and doesn’t care if it’s not running as PID 1. (I’ll add Cgroups support at some point, though it will always be optional. I’m considering build time options to let it be slimmed down even from the current size). What it needs more than anything is more users.
Sometimes I feel like there’s no hope of avoiding a Systemd monoculture, but occasionally there’s news that shows that other options remain alive and well. Debian is having a vote on whether to continue to support other init systems, and to what extent; we’ll see soon enough what the outcome is. Adélie linux recently announced support for using Laurent Bercot’s S6-RC (an init alternative that’s certainly solid and which deserves respect, though it’s a little minimalist for my own taste). Devuan continues to provide a Systemd-free variant of Debian, as Obarun does for Arch Linux. I’d love to have a distribution decide to give Dinit a try, but of course I have to face the possibility that this will never happen.
I’ll end with a plea/encouragement: if you’re interested in the project at all, please do download the source, build it (it’s easy, I promise!), perhaps configure services and get it to run. And let me know! I’m happy to receive constructive feedback (even if I won’t agree with it, I want to hear it!) and certainly would like to know if you have any problem building or using it, but even if you just take a quick peek at the README and a couple of source files, feel feel to drop me a note.
I’ve been thinking a little lately about desktop security – what makes a desktop system (with a graphical interface) secure or insecure? How is desktop security supposed to work, in particular on a unix-y system (Linux or one of the BSDs, for example)?
A quite common occurrence on today’s systems is to be prompted for your password—or perhaps for “an administrator” password—when you try, from the desktop environment, to perform some action that requires extended privileges; probably the most common example would be installing a new package, another is changing system configuration such as network settings. The two cases of asking for your own password or for another one are actually different in ways that might not initially be obvious. Let’s look at the first case: You have already logged in; your user credentials are supposedly established; why then is your password required?. There is an assumption that you are allowed to perform the requested action (otherwise your ability to enter your own password should make no difference). The only reason that I see for prompting for a password, then, is to ensure that:
Both of these are clearly in the category of mitigation—the password request is designed to limit the damage/further intrusion that can be performed by an already compromised account. But are they really effective? I’m not so sure about this, particularly with current solutions, and they may introduce other problems. In particular I find the problem of secure password entry problematic. Consider again:
There’s an implicit assumption, then, that the user is able to enter their password and have it checked by some more privileged part of the system, without another process which is running as the same user being able to see the password (if they could see the password, they could enter it to accomplish the actions we are trying to prevent them from performing). This is only likely to be possible if the display system itself (eg the X server) is running as a different user* (though not necessarily as root), and that it provides facilities to enable secure input without another process eavesdropping, and that the program requesting the password is likewise also running as a separate user—otherwise, there’s little to stop a malicious actor from connecting to the relevant process with a debugger and observing all input. In that case, forcing the user to enter their password is (a) not necessarily going to prevent an attacker from performing the protected actions anyway, and, worse, (b) actually making it easier for an attacker to recover the users password by forcing them to enter it in contexts where it can be observed by other processes.
* Running as a different user is necessary since otherwise the process can be attached via ptrace, eg. a debugger. I’ll note at this point that more recent versions of Mac OS no longer arbitrary programs to ptrace another process; debugger executables must be signed with a certificate which gives them this privilege.
Compare this to the second case, where you must enter a separate password (eg the root password) to perform a certain action. The implicit assumption here is different: your user account doesn’t have permission to perform the action, and the allowance for entering a password is to cover the case where either (a) you actually are an administrator but are currently using an unprivileged account or (b) another, privileged, user is willing to supply their password to allow for a particular action to be invoked from your account on a one-off basis. The assumption that your account may be in the hands of a malicious actor is no longer necessary (although of course it may well still be the case).
So which is better? The first theoretically mitigates compromised user accounts, but if not done properly has little efficacy and in fact leads to potential password leakage, which is arguably an even worse outcome. The second at least has additional utility in that it can grant access to functions not available to the current user, but if used as a substitute for the first (i.e. if used routinely by a user to perform actions for which their account lacks suitable privileges) then it suffers the same problems, and is in fact worse since it potentially leaks an administrator password which isn’t tied to the compromised account.
Note that, given full compromise of an account, it would anyway be fairly trivial to pop up an authentication window in an attempt to trick the user into supplying their password. Full mitigation of this could be achieved by requiring the disciplined use a SaK (secure attention key) which has seemingly gone out of favour (the Linux SaK support would kill the X server when pressed, which makes it useless in this context anyway). Another possibility for mitigation would be to show the user a consistent secret image or phrase when prompting them for authentication, so they knew that the request came from the system; this would ideally be done in such a way that prevented other programs from grabbing the screen or otherwise recovering the image. Again, with X currently, I believe this may be difficult or impossible, but could be done in principle with an appropriate X extension or other modification of the X server.
To summarise, prompting the user for a password to perform certain actions only increases security if done carefully and with certain constraints. The user should be able to verify that a password request comes from the system, not an arbitrary process; additionally, no other process running with user privileges should be able to intercept password entry. Without meeting these constraints, prompting for a password accomplishes two things: First, it makes it more complex (but does not make it impossible, generally) for a compromised process to issue a command which the user has privilege but which is behind an ask-password barrier. Secondly, it prevents an opportunistic person, who already has physical access to the machine, from issuing such commands when the real user has left their machine unattended. These are perhaps good things to achieve (I’d argue the second is largely useless), but in this case they come with a cost: inconvenience to the user, who has to enter their password more often that would otherwise be necessary, and potentially making it easier for sophisticated attackers to obtain the user password (or worse, that of an administrator).
Given the above, I’m thinking that current Linux desktop systems which prompt for a password to initiate certain actions are actually doing the wrong thing.
Edit: I note that Linux distributions may disallow arbitrary ptrace, and also that ptrace can be disabled via prctl() (though this seems like it would be race-prone). It’s still not clear to me that asking for a password with X is secure; I guess that XGrabKeyboard is supposed to make it so. This still leaves the possibility of displaying a fake password entry dialog, though, and tricking the user into supplying their password that way.
I recently released another version – 0.5.0 – of Dinit, the service manager / init system. There were a number of minor improvements, including to the build system (just running “make” or “gmake” should be enough on any of the systems which have a pre-defined configuration, no need to edit mconfig by hand), but the main features of the release were S6-compatible readiness notification, and support for updating the utmp database.
At this point, I’d expect, there might be one or two readers wondering what this “utmp” database might be. On Linux you can find out easily enough via “man utmp” in the terminal:
The utmp file allows one to discover information about who is currently
using the system. There may be more users currently using the system,
because not all programs use utmp logging.
The OpenBSD man page clarifies:
The utmp file is used by the programs users(1), w(1) and who(1).
In other words, utmp is a record of who is currently logged in to the system (another file, “wtmp”, records all logins and logouts, as well as, potentially, certain system events such as reboots and time updates). This is a hint at the main motivation for having utmp support in Dinit – I wanted the “who” command to correctly report current logins (and I wanted boot time to be correctly recorded in the wtmp file).
However, when I began to implement the support for utmp and wtmp in Dinit, I also started to think about how these databases worked. I knew already that they were simply flat file databases – i.e. each record is a fixed number of bytes, the size of the “struct utmp” structure. The files are normally readable by unprivileged users, so that utilities such as who(1) don’t need to be setuid/setgid. Updating and reading the database is done (behind the scenes) via normal file system read and writes, via the getutent(3)/pututline(3) family of functions, their getutxent/pututxline POSIX equivalents, or by the higher-level login(3) and logout(3) functions (found in libutil; In OpenBSD, only the latter are available, the lower-level routines don’t exist).
I wondered: If the files consist of fixed-sized records, and are readable by regular users, how is consistency maintained? That is – how can a process ensure that, when it updates the database, it doesn’t conflict with another process also attempting to update the database at the same time? Similarly, how can a process reading an entry from the database be sure that it receives a consistent, full record and not a record which has been partially updated? (after all, POSIX allows that a write(2) call can return without having written all the requested bytes, and I’m not aware of Linux or any of the *BSDs documenting that this cannot happen for regular files). Clearly, some kind of locking is needed; a process that wants to write to or read from the database locks it first, performs its operation, and then unlocks the database. Once again, this happens under the hood, in the implementation of the getutent/pututline functions or their equivalents.
Then I wondered: if a user process is able to lock the utmp file, and this prevents updates, what’s to stop a user process from manually acquiring and then holding such a lock for a long – even practically infinite – duration? This would prevent the database from being updated, and would perhaps even prevent logins/logouts from completing. Unfortunately, the answer is – nothing; and yes, it is possible on different systems to prevent the database from being correctly updated or even to prevent all other users – including root – from logging in to the system.
Specifically:
I haven’t checked all other systems but suspect that various other BSDs could be susceptible to related problems. On the other hand, some systems are immune:
The whole thing isn’t an issue for single-user systems, but for multiple-user systems it is more of a concern. On such systems, I’d recommend making /var/run/utmp and /var/run/wtmp (or their equivalents) readable only by the owner and group, or removing them altogether, and forgoing the ability for unprivileged users to run the “who” command. Otherwise, you risk users being able to deny logins or prevent them being recorded, as per above.
As for fixes which still allow unprivileged processes to read the database, I’ve come to the conclusion that the best option is to use locking (on a separate, root-only file) only for write operations, and live with the limitation that it is theoretically possible for a program to read a partially-updated entry; this seems unlikely to ever happen, let alone actually cause a significant problem, in practice. To completely solve the problem, you’d either need atomic read and write support on files, or a secondary mechanism for accessing the database which obviated the concurrency problem (eg access the database via communication with a running daemon which can serialize requests). Or, perhaps Musl is taking the right approach by simply excluding the functionality.
When I started working on Dinit I had only a fairly vague idea of the particulars of various other init systems, being familiar mainly with Sys V init and to a lesser extent, Systemd and Upstart (the latter of which has more-or-less vanished off the face of the earth). At that stage it was a purely personal project and I didn’t count necessarily making it public; as time went on I heard lots of complaints about Systemd, which has become the choice of init system of many distributions; I did a little research on some other systems – enough to satisfy myself that Dinit filled a worthwhile niche – and then made an announcement that I was planning to develop it into a(nother) complete init/service manager that could potentially compete with Systemd.
Around that time, I also wrote a short document trying to summarise the differences between a number of extant systems, or at least between them and Dinit, and included this in the documentation of Dinit (as part of the source tree). However, the time has perhaps come to write a more comprehensive treatment examining the differing design choices of various systems; hence, this post. Hopefully I can give an interesting overview of some design decisions that are made in a service manager, highlight specific features of various particular pieces of service management software, and give some incidental background on why I’ve made the choices I have in the design of Dinit (though I’ll to try to keep this from being too Dinit-focused).
Recap: supervision system vs service manager vs system managerThe various terms – supervision, service manager, system manager – sometimes get thrown around a little loosely, but for my purposes here it’s better to have a clear distinction between them. Without further ado:
Supervision system: a process or means for supervising service processes, providing a means to start and terminate individual services and perhaps to automatically restart them if they terminate unexpectedly.
Into the category of supervision system falls the likes of daemon-tools, runit and S6. Note that a supervision system need not be made up of just a single process: it might supervise individual service processes using separate supervisor processes, for example. Also, an active “service” might not necessarily correspond to a running process (for example a “network” service could be made active by executing a script which terminates after the network interfaces are configured).
The next category is that of service manager:
Service manager: a process or means for starting or stopping services which have dependencies from and to other services, such that the dependencies of a service must be started before the service itself is started, and the dependents of a service should be stopped before the service itself is stopped.
So, compared to a supervision system, this adds the concept of dependency management. Some might disagree that “service manager” should entail dependency handling, but for our purposes here it’s useful to have a convenient name for such a distinction, so we make the separation – dependency-handling service management versus individual service supervision.
Note that it may be possible to implement a service manager as an additional component on top of a separate supervision system – for example, S6-RC and Anopa both implement service management over the S6 supervision system.
This brings us to the final category:
System manager: a process (or processes) responsible for controlling system startup, shutdown, and other system-level actions.
A system manager typically has to arrange for the bring-up and stopping of services, which it may do by also being – or by delegating to – a supervision system or service manager. A system manager includes an init process which is launched by the kernel as the first userspace process at boot.
It’s worth noting at this point that, while a service manager built on a supervision system typically requires tight coupling with the other system – it needs to know the specific details of how to start and stop services, and to observe changes in service state – a system manager can, in comparison, maintain quite a loose coupling; it only needs to tell the supervision system (or service manager) to start, and to stop, and can leave the handing of individual services to the supervisor’s care.
I should add that different systems use different terminology for what Systemd calls “units”, the basic concept of a thing that can be started and stopped and can have dependencies on other units. In Systemd terminology, a “service” and a “target” are different types of unit. Other systems just stick with “service” for everything, regardless of whether there’s a process or other functionality attached. The distinction isn’t particularly useful here, so I’ll use the terms unit, target, and service more-or-less as synonyms.
Pure supervision as service managementIn my definitions above, I outlined the primary distinction between supervision systems and service managers as being.a question of dependency management.
However, a system where services technically have interdependencies can work with a supervision system that doesn’t manage dependencies. In the most basic form, it’s possible to rely on the fact that a service will naturally fail if its dependencies are not satisfied; it should then be restarted (ideally with a gradually increasing delay) by the supervisor, until the dependency itself has become available.
It may also be possible to explicitly start any dependencies as part of a service’s startup script (and optionally also stop known dependents as part of a stop script). The runit documentation suggests:
- before providing the service, check if all services it depends on are available. If not, exit with an error, the supervisor will then try again.
- …
- optionally when the service is told to become down, take down other services that depend on this one after disabling the service.
Certainly this can work. Although in general checking for dependencies being available prior to starting is prone to a race condition (nothing prevents a dependency from stopping just after the check is made), this seems unlikely to be a common problem in practice. In fact the joint technique outlined above allows a quite simple supervision system to provide much of the functionality associated with a service manager, provided that the dependencies are correctly encoded in the start/stop scripts.
However, that niggling race condition remains. For services which, for whatever reason, won’t behave as we want them to when dependencies are (or become) unavailable, this could potentially be problematic. Is it a stretch to claim that such services may in fact exist? Maybe it is, though I’m not particularly willing to vouch that various web app frameworks won’t lock themselves up if the DBMS becomes unavailable for a little too long, for example.
There’s also the fact that continuously polling to start services will consume system resources (only very little, if the “check for dependencies first” approach advocated by the runit documentation is followed; perhaps a significant amount if it’s not). It may also make noise in log files: service X can’t start, service X still can’t start, …, and so on. And a polling approach means that, when the dependencies of some service do become available, there may be a little delay before the service itself starts: the supervisor has to decide to try and start it again, and has no cue to do this over than by some timer expiring. These by themselves are minor issues, of course.
One advantage of proper dependency-handling service management is that you can usually query the system for dependency information (“what other services will need to be started in order to start service X?”, “what is the total set of dependencies for service X?”, etc).
Laurent Bercot, S6-RC author, gives his own argument for dependency management:
The runit model of separating one-time initialization (stage 1) and daemon management (stage 2) does not always work: some one-time initialization may depend on a daemon being up. Example: udevd on Linux. Such daemons then need to be run in stage 1, unsupervised – which defeats the purpose of having a supervision suite.
This seems a fair point and a good example, though I’m not sure it would be impossible to supervise even udevd in a supervision-only system (even if it might require tweaking the existing systems a little).
I’m certainly in favour of dependency-managing systems (and of course Dinit is such a system), though I’m aware the arguments for it may sound a little wishy-washy, and to some degree it’s a matter of personal preference.
Complexity level of dependency relationshipsDifferent service managers provide different dependency configuration options, with differing levels of complexity.
At the most simple end, S6-RC offers only a single type of dependency: that is, a service can depend on another, and will not start unless the other starts first. However, it appears to be unusual in this regard. Many systems have the concept of a soft dependency – which should be started with a dependent, but for which failure should not cause the dependent to also fail. The “hard” and “soft” dependencies are termed differently in different systems (needs, requires, depends-on vs wants, waits-for).
The benefit of a soft dependency is essentially that you can enable a service but not have its failure prevent your system from booting due to the rollback that results (assuming that the system performs such rollback; discussion of activation model and rollback yet to come).
OpenRC has both a needs and a uses/wants relationship (“uses” vs “wants” in this case have different semantics depending whether the dependency has been enabled in the current runlevel; most other service managers have largely done away with the concept of runlevels).
Nosh has requires and wants relationships, and separately supports start ordering relationships (before/after, indicating that another service’s start/stop should be ordered with respect to this service, even if there is no dependency between them). Nosh dependencies can be specified in both directions (this service requires that service, this service is required-by that service). It also has a conflicts relationship: if one service is started it can force another to stop, and vice versa.
Systemd is a law unto itself, with more dependency types than you can count on one hand; consider it as Nosh++ (though I believe Systemd came first, and Nosh borrowed from it, rather than the other way around). It’s not clear how commonly useful most of the dependency types are, though they were presumably implemented with reasons in mind.
For Dinit, I eventually opted for three dependency types: depends-on (requires), waits-for (wants), and depends-ms (depends as a milestone; the dependency must start for the dependent to start, but once started it effectively becomes a waits-for dependency). The latter, depends-ms, is of somewhat dubious value and may be removed if I cannot find a compelling scenario for it. In my eyes three dependency types (or even better, two) is a nice middle ground giving good functionality with relatively low complexity.
Systemd documentation mentions the common requirement for a dependent to start only once the dependent has properly started:
It is a common pattern to include a unit name in both the
After=andRequires=options, in which case the unit listed will be started before the unit that is configured with these options.
I do not see any compelling reason for having ordering relationships without actual dependency, as both Nosh and Systemd provide for. In comparison, Dinit’s dependencies also imply an ordering, which obviates the need to list a dependency twice in the service description. (edit: a problem caused by separating ordering and dependency is described in this Systemd bug ticket).
Activation model of service managersSuppose that we have two services – A and B – and that the first depends on the second. When A is started, B will also be started. The question is: what if A is then stopped?
There are two somewhat reasonable answers:
I believe that most systems take the 2nd approach, but Dinit takes the first (and tracks which services have been explicitly activated versus which have only started due to being required by a dependent).
I am not certain that either approach is definitely better than the other. The first provides a nice consistency for the scenario described (starting and then stopping a service will generally return the system to the original state), and avoids potentially leaving unneeded services running; the second on the other hand reduces overall service transitions.
Advocating for the first approach, one benefit is that it is simple to emulate runlevels. If you set up each runlevel as a service (target, unit) which depends on the services that should run in that runlevel, then you can “switch runlevels” by starting the new runlevel service and stopping the old one. There is no need to explicitly set any services to stop: if they are not required by the current active runlevel, they will stop anyway (although additional services can always be activate via an explicit command).
(Compare to Systemd’s approach to runlevels: it implements a separate command, “isolate”, to deactivate services not belonging to the new runlevel).
Also, with the first approach, boot failure is detectable as all services stopping without having received a shutdown command. That is, “boot” is a service with dependencies; if one of the necessary dependencies fails to start, “boot” will also fail, and at that point it releases all other (successfully started) dependencies, so that they then stop. There is no need to have “special” knowledge of the boot service, or to have a special failure case for that particular service. This is arguably just an implementation detail, though.
Now advocating for the second approach: consider the case of repeatedly attempting to start a service which has several dependencies, but which is failing due to a configuration issue: the administrator tries to start the service, and watches as its dependencies start and then stop again since the service itself failed to start. They then attempt to repair the configuration, but do not succeed, and on attempting to start the service again see the dependencies bounce up and then down a second time (let’s hope they get it right the third time…). This would be avoided with the second approach, since the dependencies would simply remain active when the service failed to start.
The problem described above could probably be avoided, even with the first approach, in various ways, but any solution would no doubt add a little more complexity to the system.
I personally still find the first model more natural and compelling – but again, it’s arguably just personal preference.
Special targetsSome systems have special targets with special semantics. Often certain targets are started to perform, or as part of, particular system actions: a shutdown target can be started when the system is to shut down, for example. Systemd has a large list of special targets, including targets that get created by Systemd when certain hardware is detected, and targets to represent mount points, which Systemd has special handling for.
Systemd also adds dependencies automatically to or from special targets. For the basic target:
systemd automatically adds dependency of the type
After=for this target unit to all services (except for those withDefaultDependencies=no).
And for the dbus.socket unit:
A special unit for the D-Bus system bus socket. All units with
Type=dbusautomatically gain a dependency on this unit.
(The dbus unit is for launching the D-Bus daemon, and causes Systemd to connect to the bus after the unit starts. Systemd and D-Bus are somewhat intertwined; D-Bus has the ability to start service providers by communicating with Systemd, and Systemd exposes various services via D-Bus, as well as being able to determine that a service is ready via a D-Bus name becoming available).
Other service managers don’t tend to have as many special targets. Nosh documents a few in its system-control man page, but not as many as Systemd, and it has no special relationship to D-Bus for example. Dinit uses boot as the default service to start, but otherwise does not treat that service specially in any way; other design choices (such as the activation model) made special treatment unnecessary.
Service description/configuration mechanismA number of supervision/service managers have gone with a “directory-per-service” approach (which I think perhaps was pioneered by daemon-tools? I’m not sure). In the directory you have a script used to run the service, some files which each contain a parameter setting, and perhaps a subdirectory containing links to dependencies. (That’s a broad stroke; many of the systems have subtle differences. S6-RC dependencies are listed one-per-line in a “dependencies” file for example). The benefit of having one-setting-per-file is that it requires no parsing and makes the system simpler. The downside is that it is a little bit more complicated to easily check the whole service configuration (though tooling can help).
Other systems – including the venerable Sys V init, as well as OpenRC – simply have a script per service. In the case of OpenRC, the script (optionally) has a special interpreter, openrc-run, which offers dependency handling functions. Various metadata is extracted from the scripts (and cached in a separate database).
Dinit, and Systemd, both use a single file per service (“.ini” style). I find this more convenient for editing service descriptions generally; the downside is that parsing is required. In the case of Systemd running as system manager, this means parsing in the PID 1 process, which many would frown upon. I’m not convinced this is really a big problem (*); Dinit’s configuration parser is quite simple and has proved robust (in my own use) – though it’s worth noting that Dinit doesn’t demand that it runs as a system manager (PID 1), whereas Systemd does expect this (“Note that it is not supported booting and maintaining a full system with systemd running in --system mode, but PID not 1″).
(* edit: the “not a big problem” I was referring to here was parsing in general, not the parsing in Systemd, which has historically been problematic at times – though even that has, as best as I can tell, been significantly improved and become better tested).
S6-RC is unusual in that it requires the service descriptions to be compiled into a database. OpenRC, as mentioned, also stores service metadata separately to the service script, but only as a cache. In either case, I suppose it is potentially possible for the compiled data and the source to become inconsistent, though I doubt it is much of a problem in practice.
Monolithic vs modular process designOne question around the design of a supervision/service/system manager is, how many processes should make it up? A number of the smaller and simpler systems have gone for the approach of breaking things up into many processes. Taking S6-RC as a case in point, the service manager (S6-RC) is separate to the main supervision process (s6-svscan of S6) which in turn runs supervisor processes (s6-supervise) which, finally, run the service process. Typically the service process is launched via an execline script, which allows calling various chain-loading subprograms to set up environment, UID/GID, etc.
The idea behind breaking things up this way is, essentially, that it allows each component to be small, simple, and “obviously correct”. There are those who argue that this approach fits the “unix philosophy” of “do one thing and do it well”. This is not an entirely bogus argument; by limiting the function of an individual program, it’s somewhat easier to make sure that the program is fundamentally correct.
On the other hand, composing multiple small programs into a more complex system still results in, well, a more complex system. If the functions of a system can easily be decomposed into separate processes, they can most likely be decomposed to individual modules within a single-process program as well. (And, having multiple processes comes with its own disadvantages: certain system-level functionality is only going to be possible to implement by communicating between modules; if the modules are separate processes, that means inter-process communication, and in general that’s going to increase complexity significantly. This might not prove to be a problem for a service manager, though, if the need for such communication is really limited).
The main point that I am trying to make is that breaking functionality into separate processes does not make the overall system any simpler. It may offer an advantage in terms of making it possible to use the individual components separately, but it’s not clear to me that this is really useful. Probably the main real benefit is, potentially, an increase in robustness: if one of your various sub-processes does crash, it won’t necessarily bring down the whole system.
Enter Systemd into the discussion. Systemd insists on incorporating not only service management and supervision into a single process, but system management as well: it wants to run the whole thing as PID 1, a process which, if it crashes, causes the kernel to panic (at least on Linux) and thus really does bring the whole system tumbling down. (Edit: to be fair, Systemd tries hard not to actually crash, but to catch eg SIGSEGV and go into a mode of limited operation which allows the system to function enough that you can sync filesystems before shutting down).
For Dinit, in comparison, I felt no concern about having just service management and supervision all in a single process. And in fact, Dinit does support running as a system manager, within the same process – but it does not require this; Dinit’s quite happy to act as a system-level service manager but have another process be the system manager. Additionally, Dinit is just generally far simpler than Systemd (as should be clear by now).
Some people are always going to prefer breaking things up into processes that are essentially as small as possible: I can understand this to an extent, I just don’t agree that it’s always a worthwhile goal, and I don’t think that Dinit suffers from being less modular than many of the alternatives.
Robustness and failure modesThe decision to write important system-level software in non-memory-safe languages such as C and C++ has been criticised. Yet, such software continues to be written in such languages (although certain other options such as Rust and Go have been gaining traction recently).
One of the systems I haven’t mentioned up this point is GNU Shepherd; mainly, my concern is that it’s written in Guile, an interpreted (or bytecode-interpreted) language with garbage collection – and I see both the “interpreted” and “garbage collection” parts as undesirable for system-level software (especially for a potential init). Interpreted software will be less efficient (if not in actual speed, since I’ll acknowledge that JITs can do amazing things, at least in memory usage) and garbage collection presents a similar issue. If the software was so complex that we couldn’t make it robust without using a memory-safe language/runtime – and if we weren’t willing to use Rust or another GC-less option for some reason – then perhaps the use of GC would be acceptable, but I don’t believe that’s actually the case; Dinit has so far proven to be robust, and even Systemd, despite early foibles, rarely actually crashes (even if it fails in other ways, as occasional rumbles on the web suggest).
A real concern of GC’d languages generally is, can programs in these languages be made resilient to out-of-memory conditions (are allocations even always explicit)? I haven’t looked closely enough at Shepherd to be able to pass comment, but I would not be surprised if it turned out that memory allocation failure is not something it is designed to handle (I’d be happy to be shown otherwise). Despite the low probability of an out-of-memory situation occurring, I still think it’s something that a service manager – and especially a system manager – needs to be able to deal with.
ConclusionWell, that ends our tour of concerns. If you got this far – thanks for reading, and I hope it was interesting and informative. There are of course a lot of other aspects of service manager design – and some unique features of particular systems – but this article has gotten quite long already. Please feel free to add constructive comment, correction or discussion.