Show full content
Today is Apple's 50th birthday. Tim Cook shared a letter about "50 Years of Thinking Different." There are animated homepages, Paul McCartney concerts at Apple Park, commemorative t-shirts, David Pogue just published Apple: The First 50 Years and there's a lot of well-earned celebration for a company that really has put a dent in the universe.
But I've been thinking different about a lost side of Apple's legacy. The side that hides yaks in software.
Yesterday, I wrote about Bruce the Wonder Yak, a funny little creature who lived inside Final Cut Pro. The responses kind of blew me away. Quite a few people remember Bruce, and they miss him like I did.
So I brought him back. And, no, this is not an April Fools joke.

Not on a Mac? The link above also has a browser-based demo you can try. The entire project is open-source on GitHub (MIT License).
To figure out how to properly bring Bruce back, I needed to look more into where he came from.
Pen the Tale on the YakFor all the impeccable stories in Pogue's new book, Bruce's isn't one of them, and as far as I can tell, the full story has never been published anywhere before.
I briefly covered who Bruce is yesterday, but I didn't know his full origin story until I started gathering notes for the post.
The first thing I found was this 20 year old Engadget post where Max Whirl from the original FCP development team explained the yak was a product of Final Cut Pro's grueling development. Lead developer Randy Ubillos and his team had been building the software since its days as KeyGrip at Macromedia, but the project was nearly shut down multiple times. Ubillos himself is a legend in video software. Before building Final Cut Pro, he created Adobe Premiere and later spearheaded iMovie and Aperture at Apple. He also led the reinvention of Final Cut Pro X before retiring from Apple in 2015 after 20 years.
At a 2018 anniversary event of the Los Angeles Creative Pro User Group (formerly the Los Angeles Final Cut Pro User Group), Ubillos told the full story of Bruce's origins. Like Whirl told Engadget, during one particularly miserable schedule meeting someone remarked "if we can't ship this puppy by then, we might as well be herding yaks." Ubillos wasn't exactly sure who said it, but it may have been Zalman Stern, an engineer who the team had nicknamed "Eeyore" for his persistent pessimism. Stern was even given a stuffed Eeyore with a little sign around its neck that read "we're doomed, we'll never ship."
The yak herding line became a running joke on the team, and eventually someone decided to actually put one in the software. In a 2018 post on the LACPUG Facebook group, now-retired group founder Michael Horton wrote that Louis LaSalle is believed to have come up with the idea of the yak on the timeline and that the artwork may have come from a friend of his who was an artist. Ubillos confirmed at the event that he coded the rest, including the animation that poofed the grass onto the screen, walked Bruce across the timeline, drew the thought bubble with the quips and the secret key combinations to summon him.
After FCP shipped, the team eagerly waited to see who would be the first person to discover the yak and what their reaction would be. They eventually saw it on 2-pop.com, an online forum run by Ken Stone that was hugely popular with the early FCP community. Stone was a giant among early FCP adopters, spending years writing tutorials and helping young filmmakers learn the tools through 2-pop and his companion site kenstone.net. Shortly after 2-pop launched, FCP project manager Will Stein asked engineer Ralph Fairweather to "volunteer" to monitor the forums, and that's where the team found the first Bruce sighting. Someone posted that they thought they had a virus, because "the cow seemed kind of threatening." The team loved it. A 2-pop news brief dated August 10, 1999 (just months after FCP 1.0 shipped) ran the headline "Easter Egg: Yak Spotted in Final Cut Pro" and reported that Bruce had "spooked more than one unsuspecting FCP editor, fearing the mild mannered bovine was the result of some sort of computer virus." It described Ubillos as "Yak herder and Final Cut Pro Chief Engineer" and quoted him assuring users "not to worry" as Bruce was just an "undocumented feature." But the best part was the response to people calling Bruce a cow: "sources in Cupertino" reported that this was a problem, and an Apple spokesperson was quoted saying, "A little sensitivity people! Save those kinds of remarks for more deserving parties like John Dvorak." "The cow seemed kind of threatening" then became a Yak Bite in the next version of the app.
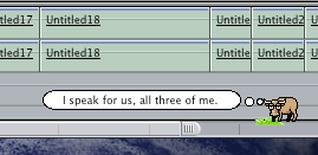
Bruce's 100 "Yak Bites" were born on a whiteboard in a small lounge caddy-corner to Ubillos's office. During coffee breaks, the engineers would riff on new ones. They're all inside jokes, overheard hallway conversations, engineering gripes and pop culture references. Several are direct callbacks to the cow controversy: "I'm concerned because the cow sounded pretty threatening", "I am NOT a mad cow!", "What? You were expecting 'Moo' or something?", and "This is not a Yak Bite." Another, "Thirty quatloos says it crashes during launch!", is a Star Trek reference from one of the engineers who'd coded something up and bet it wouldn't work. Even the famous Lindy Hop swing dancing tutorial that shipped with FCP made it in. The footage got so stuck in everyone's heads from endless testing that the Yak Bite "Mostly clockwise, sometimes reverses..." is lifted directly from the instructor's narration.
In a 2005 Creative Cow forum thread, someone posted asking about a "cow eating grass on my desktop." The correction was swift and emphatic: "There is not now, nor has there ever been a COW eating grass related to FCP!!!! It's a YAK."
Another story goes that when the FCP team first arrived at Apple, they weren't allowed to tell anyone what they were working on. About a month in, there was a company-wide all-hands meeting in the big quad outside. The team, tucked away on the third floor, hung a giant banner from the balcony with a picture of Bruce that read: "Yaks love iMacs." Hundreds of Apple employees looked up, utterly confused. The team never explained it.
Over the years, Bruce became FCP's version of Clarus the Dogcow, part of Apple's unofficial tradition of hiding whimsical creatures inside its software. Different versions of Final Cut had different ways of summoning him, or you could just leave the program idle long enough and let Bruce find you. If you were impatient, each version had its own secret. A detailed 2015 French-language history by Journal du Lapin attempted to trace these methods across every version. In FCP 1 (1999), letting the About Box credits scroll would do it, but accounts vary. In FCP 2 (2001) on Mac OS 9, you could Control-click in the upper-right corner of the Canvas window. FCP 3 (2002) hid the trigger behind Control-clicking in Video Scope. FCP 4.5 (2004) had the most elaborate ritual: press Option-J to open the timecode jump dialog, type "Bruce" with a capital B, carefully erase the shift icon with the arrow keys (don't press return!), and a "Call the Yak" button would appear that you could drag into any toolbar. By FCP 5 (2005), the team "simplified" things to just opening Videoscopes, holding Control, and clicking repeatedly in the scope area until he showed up.
The community treated Bruce with an almost superstitious reverence. In that same Creative COW thread, when someone asked how to summon the yak, one user warned it was "bad luck" to share the method publicly. Another cautioned that an editor who posted summoning instructions online subsequently ended up working at H&R Block. Here's to hoping I don't end up in green hell.
I couldn't find perfect evidence to pin it down when exactly Bruce vanished, but I thought it was somewhere around FCP 6 or 7. du Lapin's analysis of the FCP 6 and 7 binaries confirmed that some code references and the file containing Yak Bite text still existed, but the activation code had been left empty. People kept searching for him in FCP 6, 7 and FCPX, but they never found him. According to LACPUG's Micheal Horton, Steve Jobs put a stop to all Easter eggs and credit rolls across Apple after an employee sued because their name didn't appear in another team's credit roll.
You could even say that Steve Jobs is the reason we had and lost Bruce. Jobs was the one who championed the acquisition of Final Cut from Macromedia, giving the team and their yak a home at Apple, but when he demanded every Easter egg in the company be wiped, Bruce was collateral damage. Either way, he's been gone for nearly two decades now and I've had a lot of feelings about that. Until now!
Down the Yak HoleI still had a Final Cut Pro 4 DVD lying around so I dug into the installer package, pulled apart the archives and started picking through Final Cut Pro.rsrc.
Just as suspected, there he was, or at least all his strings: "You can call me Bruce the Wonder Yak."
Mac binaries of that era were PowerPC, something I know nothing about. I used Claude Code to disassemble it using Capstone and was able to extract 23 functions, including _YakInit, _CallTheYak and _MakeYakTalk. Some of the names alone tell you these devs had fun working on him.
From there I traced through the code and mapped out Bruce's complete state machine: idle, grass poofs in, walks on from the right, trots across the screen, thought bubble appears, Yak Bite shows, bubble closes, exits, resets. The whole lifecycle of a yak visit.
Buried deeper in the binary were the timing ticks, animation framerates, thought bubble layout and more. Every detail was there.
Here's some of my favorite discoveries from the disassembly:
-
The sprite sheet is 21 cells at 33x32 pixels each: 4 grass frames and 17 Bruce frames with trot, graze and panic cycles.
-
The variable for the transparent borderless window that lets Bruce walk across your screen is named
trojanYakDesktopWindow. Trojan Yak. -
Near the "Call the Yak" button definition in FCP 4, tucked into the localization code, I found an extra string:
"I'm not that easy!". Bruce enjoyed playing hard to get.
Armed with all the specs of his existence, I rebuilt Bruce as a native macOS app in Swift and SpriteKit.
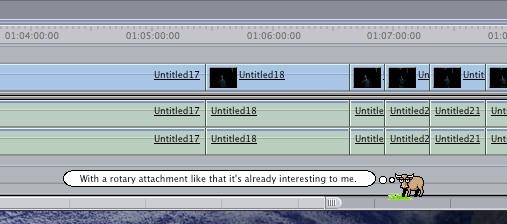
Call the Yak is designed to run in your menu bar. Click the Yak icon and then "Call the Yak" to summon Bruce. A grass patch will poof onto your screen, and he'll trot on in to graze and share his Yak Bites in thought bubbles.
It's as faithful to the original as I could make it, down to the frame rates and the 80-pixel proximity scare radius.
I'm also not the only one trying to keep the legend of Bruce alive. Alex Gollner confirmed on Facebook that he named his BruceX Final Cut/Mac benchmark after him.
A Fitting Birthday GiftIt's incredibly perfect timing that I'd want to make and release this fifty years to the day Apple was founded. In the decades since, Apple shipped some of the most important products in the history of computing. The celebrations are well-deserved, but I just thought it would be better with a particular yak in attendance.
The version of Apple I fell in love with wasn't the one who was one of the most valuable companies, or who threw concerts with rockstars. It was the one that said, "think different."
Hand animating a tiny yak and writing 100 lines of weird text just to make it feel alive will always be peak Apple to me. It was something many users would never see and they didn't do it for social media, or App Store reviews or microtransactions. They did it because they thought it was funny. It is, and I'm still laughing.
In the immortal words of Bruce the Wonder Yak:
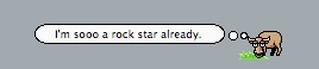
The opposite of "Weird" is "Boring".
Here's to the crazy ones. Happy 50th, Apple.