The PHPDoc Guide (2025 Edition)
-
String-based pseudo-types
-
Numeric & bounded pseudo-types
-
Arrays, lists, and shapes
-
Object & class-based types
-
Callable types
-
Generics with @template, @extends, @implements
-
Constant values and enum simulations
-
Conditional logic
-
Pass-by-reference & @param-out
-
False positive suppression
-
Best practices
-
Cheatsheet
You can’t trust a string. Or an array. Or half the type declarations you see in legacy PHP codebases.
And that’s not PHP’s fault. It’s yours—if you’re still writing function signatures like this:
function sendData(array $data): bool
This tells us nothing.
Not what’s in $data, not if keys are optional, not what the return bool even means.
PHPStan fixes this. With PHPDocs. Not for decoration. Not for old-school docblocks. But as strict, analyzable type contracts — guardrails for real-world codebases.
If you’re serious about:
-
Catching logic errors before runtime
-
Documenting your code without duplicating logic
-
Scaling PHP safely without turning everything into a typed mess
Then this guide is for you.
We’ll walk through real-world PHPStan PHPDoc patterns—from pseudo-types and generics to conditional logic and type-safe constants. All based on PHPStan, tested in real-world projects, and packed with concrete examples and copy-paste snippets.
No fluff. Just clean, pragmatic PHPDoc annotations that make your code safer and more readable. The best part? PhpStorm supports nearly everything we’re doing here out of the box — so code completion improves, and your overall DX gets a serious upgrade.
Let’s upgrade your PHPDocs from “comments” to contracts.
Background: Why PHPDocs Matter More Than Ever
PHP has come a long way since the wild west of PHP 5.x.
Today we’ve got:
8.0 with union types and constructor property promotion, …
8.1 with enums and readonly properties, …
8.2 with readonly classes and DNF types, …
8.3 with typed class constants and #[\Override], ...
8.4 with property hooks and asymmetric visibility, …
So… why bother with PHPDocs at all?
What Native Types Still Can’t Do
Native PHP types help—but they stop at the surface.
Native Type
Can Do
Can’t Do
string
Ensure value is a string
Can’t check if empty, numeric, constant
int
Enforce integer input
Can’t limit to > 0 or within bounds
array
Accept arrays
Can’t validate keys, shape, or index types
object
Accept objects
No info about which class, structure, or generics
bool
Boolean logic
Can’t express “this is only true on success”
That’s Where PHPStan Comes In
PHPStan treats your PHPDocs like a type system:
-
Refines scalar types (non-empty-string, positive-int, numeric-string)
-
Models structured arrays (array{key1: T, key2?: T})
-
Adds generics (@template T, Collection<T>)
-
Enforces contracts and conditionals (@assert, @return (T is Foo ? Bar : Baz))
-
Tracks pass-by-reference mutations (@param-out)
-
Restricts literal values ('asc'|'desc', Class::CONST_*, enums)
This gives you defensive typing for a dynamic language.
1. String-Based Pseudo-Types
Refine what “string” actually means
In PHP, string is a blunt instrument. It could mean:
-
"admin" – a valid username
-
"" – an empty input nobody should see
-
"123" – a number pretending to be a string
-
"SELECT * FROM users WHERE user_id = " . $id – a dangerous SQL statement
PHPStan sharpens this instrument with string pseudo-types that define intent, constraints, and trust boundaries.
Overview: String-Based Pseudo-Types
PHPStan Type
Description
Native Equivalent
string
Any string, including
''
string
non-empty-string
String that cannot be
''
string
numeric-string
String that is guaranteed to represent a number (
"123.45")
string
literal-string
A string known at compile-time (e.g. hardcoded, not user input)
string
callable-string
A string name of a globally callable function
string
class-string<T>
String that is a fully-qualified class name (optionally of type T)
string
Real-World Examples

non-empty-string
Guarantees a string is never empty:
Playground | PHPStan
/**
* @param non-empty-string $username
*/
function setUsername(string $username): void {
// Safe, PHPStan guarantees it's not ''
saveToDatabase($username);
}
setUsername('alice'); // OK
setUsername(''); // PHPStan error
numeric-string
Used when string inputs must represent numbers (e.g., form inputs):
Playground | PHPStan
/**
* @param numeric-string $amount
*/
function convertToCents(string $amount): int {
return (int)((float) $amount * 100);
}
convertToCents("19.95"); // OK
convertToCents("abc"); // PHPStan error
literal-string
Guards against injection vulnerabilities in SQL or dynamic calls:
Playground | PHPStan
/**
* @param literal-string $sqlQuery
*/
function runQuery(string $sqlQuery): void {
DB::raw($sqlQuery); // Only compile-time constants allowed
}
runQuery("SELECT * FROM users"); // OK
runQuery($_GET['query']); // PHPStan error
callable-string
Ensures string names reference valid callable functions:
Playground | PHPStan
/**
* @param callable-string $callback
*/
function invoke(string $callback): void {
$callback(); // Safe: PHPStan checks it's actually callable
}
invoke('trim'); // OK
invoke('undefinedFunction'); // PHPStan error
class-string<T>
Used in factories or DI containers:
Playground | PHPStan
/**
* @template T of LoggerInterface
* @param class-string<T> $class
* @return T
*/
function createLogger(string $class): object {
return new $class(); // Safe and strongly typed
}
createLogger(FileLogger::class); // OK
createLogger(DateTime::class); // PHPStan error: not a LoggerInterface
Out-of-the-Box Use Case: Constants-as-Strings
Use literal-string when defining keys for array-based configuration:
Playground | PHPStan
/**
* @param (literal-string&'database_host') $configKey
*/
function getConfig(string $configKey): mixed {
return $GLOBALS['config'][$configKey] ?? null;
}
getConfig('database_host'); // OK
getConfig($userInput); // PHPStan error
Key Takeaways
-
non-empty-string kills edge-case bugs.
-
literal-string hardens systems against injections.
-
callable-string and class-string<T> enable safe dynamic resolution.
-
Always prefer these over plain string when handling user input, SQL, config keys, or dynamic execution.
2. Numeric & Range-Based Pseudo-Types
Precision where int and float fall short
A parameter like int $page tells you nothing about valid input. Is 0 okay? What about -1? Or 999999? That’s not type safety—it’s type ambiguity.
PHPStan’s numeric pseudo-types embed actual constraints in the signature. Let’s make your numbers behave.
Overview: Numeric Pseudo-Types
PHPStan Type
Description
Native Equivalent
positive-int
Integer > 0
int
negative-int
Integer < 0
int
non-negative-int
Integer ≥ 0 (0, 1, …)
int
non-positive-int
Integer ≤ 0 (0, -1, …)
int
int<min, max>
Integer within specified range (inclusive)
int
numeric
int, float, or numeric-string
mixed
float
Any float
float
 Note: PHPStan does not currently support
Note: PHPStan does not currently support float<min, max> // Add range for float · Issue #6963 · phpstan/phpstan
Real-World Examples
positive-int
Ensure ID-like values are never 0 or negative:
Playground | PHPStan
/**
* @param positive-int $userId
*/
function getUser(int $userId): User {
return User::find($userId);
}
getUser(42); // OK
getUser(0); // PHPStan error
non-negative-int
Zero is allowed, useful for offsets and indexes:
Playground | PHPStan
/**
* @param non-negative-int $offset
*/
function paginate(int $offset, int $limit = 10): array {
return getRows($offset, $limit);
}
paginate(0); // OK
paginate(-5); // PHPStan error
int<1, 10>
Constrain arbitrary ranges—perfect for ratings or percent caps:
Playground | PHPStan
/**
* @param int<1, 10> $rating
*/
function setUserRating(int $rating): void {
// Only 1–10 allowed
}
setUserRating(10); // OK
setUserRating(20); // PHPStan error
negative-int
Useful for things like accounting deltas:
Playground | PHPStan
/**
* @param negative-int $debt
*/
function recordDebt(int $debt): void {
// Only negative values allowed
}
recordDebt(-100); // OK
recordDebt(0); // PHPStan error
numeric
Accept int, float, or numeric-string – great for dynamic APIs:
Playground | PHPStan
/**
* @param numeric $value
*/
function normalize($value): float {
return (float) $value;
}
normalize("5.4"); // OK
normalize(3); // OK
normalize("not a number"); // PHPStan error
Out-of-the-Box Use Case: Domain Constraints via Aliases
Combine @phpstan-type with range types to centralize constraints:
Playground | PHPStan
/** @phpstan-type Rating int<1, 5> */
/**
* @param Rating $stars
*/
function rate(int $stars): void {
// Only 1–5 allowed
}
Avoids hardcoding ranges across your codebase + PhpStorm version >= 2025.1 has support for it.
Key Takeaways
-
Native int and float don’t carry domain meaning—these do.
-
Use int<min,max> for bounded values. Be explicit.
-
Prefer numeric over mixed for conversion-safe values.
-
Enforce constraints without runtime guards—fail at analysis time.
3. Array & List-Based Pseudo-Types
Because array is a wildcard, not a type.
Saying array $data is like saying “vehicle” when you mean “electric scooter with one broken brake.” Arrays in PHP are:
-
numerically indexed or associative,
-
empty or structured,
-
sometimes lists, sometimes maps—and usually misunderstood.
PHPStan gives you the tools to lock this chaos down.
Overview: Array Pseudo-Types
PHPStan Type
Description
Native PHP Equivalent
array
Anything that’s an array—uselessly vague
array
list<T>
Indexed from 0, consecutive integers, all values of T
array
non-empty-list<T>
Same as
list<T>, but with at least one element
array
array<TKey, TValue>
Associative array with defined key/value types
array
non-empty-array<TKey, V>
Like above, but must have at least one key-value pair
array
array{key1: T1, key2?: T2}
Structured array with required and optional keys
array
array-key
Either
int or
string—valid PHP array keys only
int|string
Examples by Use Case
list<int>
Use when you need guaranteed 0-indexed values:
Playground | PHPStan
/**
* @return list<int>
*/
function getIds(): array {
return [1, 2, 3]; // PHPStan ensures keys are 0,1,2,...
}
non-empty-list<string>
Use for arguments that must not be empty:
Playground | PHPStan
/**
* @param non-empty-list<string> $emails
*/
function notify(array $emails): void {
foreach ($emails as $email) {
mail($email, 'Hello!');
}
}
array<string, User>
Classic associative map:
Playground | PHPStan
/**
* @return array<string, User>
*/
function getUserMap(): array {
return ['admin' => new User(), 'guest' => new User()];
}
array{status: bool, message: string}
Great for structured return types:
Playground | PHPStan
/**
* @return array{status: bool, message: string}
*/
function response(): array {
return ['status' => true, 'message' => 'OK'];
}
array{ids: list<int>, error?: string}
Mixed structure with optional keys:
Playground | PHPStan
/**
* @return array{ids: list<int>, error?: string}
*/
function fetch(): array {
return ['ids' => [1, 2, 3]];
}
Advanced Use Case: Refactor To Aliases
Avoid repeating complex shapes:
Playground | PHPStan
/** @phpstan-type ApiResponse array{status: bool, message: string, data?: mixed} */
/**
* @return ApiResponse
*/
function getJson(): array {
return ['status' => true, 'message' => 'Success'];
}
Use Table: When to Pick Which
Use Case
Type
Indexed, all same type
list<T>
Must contain elements
non-empty-list<T>
Map with defined key type
array<K, V>
Structured data (like DTO)
array{...}
Optional shape fields
array{key?: T}
Dynamic lookup
array-key for keys
Pro Tip: If your
array{} shape is reused or growing—
stop.
Use a Value Object. It’s clearer, testable, and doesn’t break when you add nullableTimestamp?.
Key Takeaways
-
array is a type smell—replace it with something precise.
-
Use list<> when order and index matter. Use array{} for shape.
-
Use @phpstan-type to create aliases for shared structures.
-
Don’t let critical business structures live in vague array<string, mixed> land.
-
Once array shape gets complicated: make a DTO or value object. Don’t be clever. Be explicit.
4. Object & Class-Based Pseudo-Types
Make your objects speak their real shape.
PHP’s object type tells you nothing. PHPStan’s object pseudo-types tell you everything: where the object came from, how it’s called, what it returns, and what it’s allowed to be.
Overview: Class & Object Pseudo-Types
Type
Description
Use Case
object
Any object—completely generic
Rare; dynamic APIs
ClassName
Exact class or subclass instance
95% of all real code
self
The class this is written in (not inheritable)
Static factory methods
$this
The current instance’s real type (used for method chaining)
Fluent interfaces, traits
static
The class called at runtime (supports late static binding)
Factories returning subclass instances
class-string
Any valid FQCN string (non-instantiable without context)
Reflection, service locators
class-string<T>
A string guaranteed to name a subclass of
T
Typed dynamic instantiation
Examples by Use Case
object
Use only when you don’t care what it is (usually bad practice):
/**
* @param object $instance
*/
function dumpObject(object $instance): void {
var_dump($instance);
}
self
Always returns the exact class it’s written in—not a child class:
class Factory {
public static function make(): self {
return new self(); // Always returns Factory
}
}
$this
Used for fluent interfaces—important in traits or base classes:
trait Loggable {
/** @return $this */
public function log(string $msg): self {
echo "[LOG] $msg\n";
return $this;
}
}
Used in:
class Order { use Loggable; }
$order = (new Order())->log('Created')->log('Paid');
PHPStan/PhpStorm knows log() returns Order, not Loggable. Magic.
static
Enables late static binding:
Playground | PHPStan
class Repository {
public static function new(): static {
return new static(); // Might be a child class
}
}
class UserRepository extends Repository {}
$userRepo = UserRepository::new(); // Returns UserRepository
class-string<Foo>
Ties a string to a valid subclass of Foo—powerful for DI, factories, etc.
Playground | PHPStan
/**
* @template T of Service
* @param class-string<T> $fqcn
* @return T
*/
function resolve(string $fqcn): object {
return new $fqcn();
}
Enforces constraints even when instantiating from strings.
Use Table: Object Pseudo-Types
Use Case
Type
Generic object input
object
Static factory (same class)
self
Chaining / trait methods
$this
Factory w/ LSB (return child)
static
Instantiating by string
class-string<T>
Key Takeaways
-
Always use $this for chaining and traits.
-
Use static when returning child classes from base class factories.
-
class-string<T> makes dynamic instantiation type-safe.
-
Avoid object unless you’re writing a serializer.
5. Callable Types & Signatures
The callable type in PHP is incredibly flexible, but historically it lacked type safety. It could be a function name string, an array [object, 'methodName'], an array ['ClassName', 'methodName'], or a Closure. Just declaring a parameter as callable tells PHPStan (and you) almost nothing about what arguments it expects or what it returns.
PHPStan lets you document the signature of a callable.
Documenting Callable Signatures
The syntax for documenting a callable’s signature is:
callable(ParamType1, ParamType2, ...): ReturnType
This goes inside your @param or @return tag for the callable type.
- Specify the expected types of parameters within the parentheses, separated by commas.
- Specify the expected return type after a colon.
- Use
void if the callable is not expected to return a meaningful value.
- Use
mixed if the parameters or return type are truly unknown or can vary wildly (but try to be more specific!).
Examples of Documenting Callables
Closure with simple types
Playground | PHPStan
/**
* @param callable(int, string): bool $validator
*/
function processData(callable $validator): void {
$result = $validator(123, 'abc');
// PHPStan knows $result is bool here
}
processData(fn(int $a, string $b): bool => is_numeric($a) && is_string($b)); // OK
processData(fn(string $a, int $b): bool => true); // PHPStan error: argument types mismatch
Array callable (object method)
Playground | PHPStan
class Service {
public function handle(float $value): string { return (string) $value; }
}
/**
* @param callable(float): string $callback
*/
function execute(callable $callback): void {
$result = $callback(1.23);
// PHPStan knows $result is string here
}
$service = new Service();
execute([$service, 'handle']); // OK
execute([$service, 'nonExistentMethod']); // PHPStan error
String callable (global function)
While callable-string ensures it’s a valid function name, using the signature syntax adds type safety for the call itself.
Playground | PHPStan
/**
* @param callable(string): string $modifier
*/
function cleanInput(string $input, callable $modifier): string {
return $modifier($input);
// PHPStan knows the callable takes string and returns string
}
cleanInput(" hello ", 'trim'); // OK
cleanInput(" hello ", 'str_starts_with'); // PHPStan error: str_starts_with signature mismatch
Key Takeaways
- Simply using
callable is not enough for static analysis.
- Always document the expected signature of a callable using
callable(ParamTypes): ReturnType.
- This provides type safety for the parameters passed to the callable and the value returned from it.
6. Generic Types with @template, @extends, @implements
Static typing for dynamic collections.
Overview: Generic Type Annotations
Annotation
Purpose
Example
@template T
Declares a generic placeholder
class Collection
@template T of Foo
Constrains T to Foo or subclass
interface Repository
@param T /
@return T
Applies T in method context
function add(T $item): void
@extends Collection<T>
Specifies generic type when extending a class
class UserCollection extends…
@implements Repo<T>
Specifies concrete type in interface implementation
class UserRepo implements…
Generic Collection (Classic)
Playground | PHPStan
/**
* @template T
*/
class Collection {
/** @var list<T> */
private array $items = [];
/** @param T $item */
public function add(mixed $item): void {
$this->items[] = $item;
}
/** @return list<T> */
public function all(): array {
return $this->items;
}
}
@extends: Narrow Generic Type in Child Class
/**
* @extends Collection<User>
*/
class UserCollection extends Collection {
public function findByEmail(string $email): ?User {
foreach ($this->all() as $user) {
if ($user->email === $email) return $user;
}
return null;
}
}
Now the collection is locked to User.
@implements: Interfaces with Generics
Playground | PHPStan
/**
* @template T of Model
*/
interface Repository {
/** @return T|null */
public function find(int $id): ?object;
/** @param T $model */
public function save(object $model): void;
}
Implement with:
/**
* @implements Repository<User>
*/
class UserRepository implements Repository {
public function find(int $id): ?User { /* ... */ }
public function save(object $model): void {
if (!$model instanceof User) {
throw new InvalidArgumentException();
}
}
}
Use Table: Generic Constructs
Use Case
Syntax
Reusable logic w/ varying types
@template T
Type-safe item addition
@param T $item
Type-safe container extension
@extends Collection<T>
Typed interface implementation
@implements Repository<T>
Key Takeaways
-
Use @template T for anything that should be reusable (collections, services, repositories).
-
@extends and @implements lock in the concrete type—no ambiguity.
-
PHPStan validates T everywhere it’s used: arrays, returns, conditionals.
- And you can combine this with other phpdocs like callables: Playground | PHPStan
7. Enum-Like Constraints with Constants and Literal Values
Because magic strings are garbage fire waiting to happen.
Whether you’re representing statuses, directions, or modes—“freeform strings” are a playground for bugs. Typos go undetected. Invalid values sneak through. Conditional logic breaks silently.
PHPStan gives us better options—even before PHP 8.1 enums.
Overview: Enum-Like Type Constraints
Type Annotation
Description
Works With
`’value1′
‘value2’`
Specific literal values allowed
MyClass::CONST_*
Any constant with matching prefix from a class
All
`MyClass::CONST_A
CONST_B`
Specific constant values allowed
MyEnum
Accepts any case of a native PHP 8.1+
enum
PHP 8.1+
MyEnum::MyCase
Specific enum case from PHP 8.1+ enum
PHP 8.1+
key-of<array> /
value-of<array>
Restrict input to keys/values of a predefined array
All
Literal Union Types
Playground | PHPStan
/**
* @param 'asc'|'desc' $direction
*/
function sortResults(string $direction): void {
// PHPStan enforces exactly 'asc' or 'desc'
}
sortResults('asc'); // OK
sortResults('ASC'); // ERROR: Not lowercase
sortResults('up'); // ERROR
Class Constants (Wildcard or Specific)
Playground | PHPStan
class Status {
public const NEW = 'new';
public const ACTIVE = 'active';
public const BLOCKED = 'blocked';
}
/**
* @param Status::NEW|Status::BLOCKED $status
*/
function blockUser(string $status): void {
// PHPStan enforces only these constants
}
blockUser(Status::BLOCKED); // OK
blockUser('blocked'); // ERROR: Use the constant, not the string
Or allow all constants matching a prefix:
/**
* @param Status::STATUS_* $status
*/
function updateStatus(string $status): void {}
Native Enums (PHP 8.1+)
Playground | PHPStan
enum UserStatus: string {
case ACTIVE = 'active';
case BANNED = 'banned';
}
function setStatus(UserStatus $status): void {}
setStatus(UserStatus::ACTIVE); // OK
setStatus('active'); // ERROR
Array-Based Constraints (key-of, value-of)
Playground | PHPStan (key-of)
Playground | PHPStan (value-of)
public const array ALLOWED_ROLES = ['admin' => 1, 'editor' => 2, 'viewer' => 3];
/**
* @param key-of<self::ALLOWED_ROLES> $role
*/
public function assignRole(string $role): void {}
$foo->assignRole('editor'); // OK
$foo->assignRole('moderator'); // ERROR
Key Takeaways
-
Don’t trust freeform values—constrain them.
-
Use literal strings or class constants to build pseudo-enums.
-
Use native PHP enums when available, especially in domain logic.
-
Use key-of, value-of to enforce consistency in maps.
8. Conditional Types & Type Inference Logic
Because sometimes your types depend on the situation.
Static typing gets tricky when return types or variable values depend on conditions—especially input parameters or validation results.
PHPStan gives us smart annotations to express:
-
Types that change depending on a condition (@return ($flag is true ? A : B))
-
Variable type guarantees after a validation function (@phpstan-assert-*)
-
Smart refactoring of isValid() patterns with actual type info
Overview: Conditional Typing Patterns
Annotation
Purpose
Use Case Example
@return (cond ? T1 : T2)
Return type depends on a parameter value
Return string or array depending on
$asArray
@phpstan-assert T $var
Guarantees
$var is of type T after method call
assertNonEmpty($str) makes
$str a
non-empty-string
@phpstan-assert-if-true T $var
If method returns true,
$var is of type T
isValidEmail($email) ensures
non-empty-string if true
@phpstan-assert-if-false T $var
If method returns false,
$var is of type T
isEmpty($arr) => if false, it’s
non-empty-array
T is ClassName
Conditional logic inside generics
@return (T is User ? int : string)
Conditional Return Types Based on Flags
Playground | PHPStan
/**
* @return ($asJson is true ? string : array{name: string, age: int})
*/
function getUserData(bool $asJson): string|array {
$data = ['name' => 'Alice', 'age' => 30];
return $asJson ? json_encode($data, \JSON_THROW_ON_ERROR) : $data;
}
$data = getUserData(false);
// PHPStan: knows $data is array{name: string, age: int}
$json = getUserData(true);
// PHPStan: knows $json is string
@phpstan-assert-if-true
Playground | PHPStan
final class Validator {
/**
* @phpstan-assert-if-true non-empty-string $email
*/
public static function isValidEmail(?string $email): bool {
return is_string($email) && $email !== '' && str_contains($email, '@');
}
}
$email = $_POST['email'] ?? null;
if (Validator::isValidEmail($email)) {
// PHPStan knows $email is non-empty-string here
echo strtoupper($email);
}
@phpstan-assert-if-false
Playground | PHPStan
/**
* @phpstan-assert-if-false int<min, 0> $score
*/
function isPositive(int $score): bool {
return $score > 0;
}
$score = rand(-5, 5);
if (!isPositive($score)) {
// PHPStan: $score is int<min, 0>
} else {
// PHPStan: $score is int<1, max>
}
Conditional Return Types in Generics
Playground | PHPStan
/**
* @template T of int|string
* @param T $input
* @return (T is int ? string : int)
*/
function invertType(int|string $input): string|int {
return is_int($input) ? (string)$input : (int)$input;
}
$val1 = invertType(42); // string
$val2 = invertType('123'); // int
@phpstan-assert for Defensive Contracts
Playground | PHPStan
/**
* @phpstan-assert non-empty-array<string> $items
*/
function assertHasItems(array $items): void {
if (empty($items)) {
throw new InvalidArgumentException("Must contain at least one item.");
}
}
Use these to enforce contracts even if native PHP types can’t.
Key Takeaways
-
Let your return types reflect real-world branching logic.
-
Use @phpstan-assert-if-true to encode validator results into type narrowing.
-
Use @return (condition ? A : B) to model toggle behavior safely.
-
Defensive types are better than defensive runtime checks—because they’re enforced before runtime.
9. Pass-by-Reference Variables with @param-out
Stop guessing what happens to that &$var.
PHP’s &$variable allows mutation by reference—which is great for parsers, validators, or multi-output functions, but it kills static type analysis.
PHPStan solves this with @param-out: explicitly documenting the final type of a referenced variable after a function call.
Think of it as “the function returns into this variable”—and now PHPStan knows what to expect.
Overview: @param-out Syntax
Annotation
Purpose
@param-out T $var
Describes the type
$var will have after the function call finishes.
@param T $var
Still describes the type it must be at input, if not uninitialized.
Parsing Into a Variable
Playground | PHPStan
/**
* @param string $input
* @param-out int|null $parsed
*/
function parseInt(string $input, ?int &$parsed): void {
$parsed = filter_var($input, FILTER_VALIDATE_INT, FILTER_NULL_ON_FAILURE);
}
$raw = "42";
$result = null;
parseInt($raw, $result);
// PHPStan: $result is now int|null
if ($result !== null) {
echo $result * 2;
}
Assigning a Default String
Playground | PHPStan
/**
* @param-out non-empty-string $output
*/
function ensureValue(?string &$output): void {
if ($output === null || $output === '') {
$output = 'default';
}
}
$name = null;
ensureValue($name);
// PHPStan: $name is now non-empty-string
Flagging Errors in Processing
Playground | PHPStan
/**
* @param CsvFile $csv
* @param-out list<string> $errors
*/
function processCsv(CsvFile $csv, array &$errors): bool {
$errors = [];
foreach ($csv->getRows() as $row) {
if (!isValidRow($row)) {
$errors[] = 'Invalid row: ' . json_encode($row);
}
}
return empty($errors);
}
$errors = [];
$success = processCsv($file, $errors);
if (!$success) {
foreach ($errors as $e) {
echo $e;
}
}
Now $errors is a guaranteed list of strings, only if the function sets it.
Key Takeaways
-
Use @param-out whenever a &$var is written to.
-
Combine with @param to describe both input and output intent.
-
Helps static analysis track types over mutation.
-
Prevents “guessing” about the variable’s final type in calling scope.
10. Suppressing False Positives with @phpstan-ignore-*
Sometimes static analysis gets it wrong. That’s OK— but make it
surgical, not sloppy.
PHPStan is powerful, but not omniscient. In complex, dynamic, or legacy-heavy codebases, it might raise false positives—errors that you know are safe but the tool can’t fully reason about.
Don’t disable entire rules. Don’t drop your level.
Use @phpstan-ignore-* annotations surgically, with precision.
Overview: Suppression Annotations
Annotation
Scope
Best Use Case
@phpstan-ignore-next-line
Next line only (
please use the Identifier stuff not this)
Dynamic access, legacy code edge cases
@phpstan-ignore-line
Inline on same line (
please use the Identifier stuff not this)
Dynamic properties/methods, chained expressions
@phpstan-ignore-error Identifier
Specific error type only
Narrow suppression while keeping strict checks
parameters > ignoreErrors: (neon)
Global suppression config
Vendor code or unavoidable project-wide issues
Ignoring the Next Line
/** @phpstan-ignore-next-line */
echo $legacyObject->$dynamicProperty;
Useful when $dynamicProperty is validated externally, but PHPStan can’t infer that.
Inline Suppression
$val = $legacyObject->$property; /** @phpstan-ignore-line */
Keep suppression right next to the usage, especially helpful for one-liners.
Targeting Specific Errors
/** @phpstan-ignore-error function.alreadyNarrowedType (your comment here) */
if (is_string($value) && strlen($value) > 5) {
echo $value;
}
This suppresses only the “already narrowed” warning, keeping everything else active.
Global Project Suppression (phpstan.neon)
parameters:
ignoreErrors:
- '#Call to undefined method LegacyClass::doMagic#'
-
message: '#Access to an undefined property#'
path: src/LegacyStuff/*.php
Use this only for vendor or legacy glue code. Never in new code.
Best Practices for Ignoring
Rule
Why
Always comment
Explain
why the ignore is needed.
Suppress specific errors, not broad ones
Use
@phpstan-ignore-error, not
ignore-next-line if possible.
Refactor > Ignore
Most false positives come from bad typing. Improve types if you can.
Audit periodically
Old ignores may hide real problems after refactors.

Don’t Do This
/** @phpstan-ignore-next-line */
doSomethingRisky(); // No explanation, no control
Or worse:
parameters:
level: 0
You’ve just turned off the fire alarm and set your desk on fire, a simple way of starting is the baseline feature where you can just ignore old errors: The Baseline | PHPStan
Key Takeaways
-
Only ignore what you must. Don’t make it a habit.
-
Prefer precise, contextual suppression (-error, -next-line) over global.
-
Always add a human-readable comment for future devs.
-
Refactor the real problem if PHPStan is right.
11. Best Practices for PHPStan PHPDocs
Make your types honest. Make your docs readable. Make your tools useful.
PHPStan doesn’t care how pretty your code looks—it cares if the types match, if edge cases are covered, and if your docs are aligned with reality. Writing good PHPDocs isn’t about verbosity. It’s about clarity, precision, and maintainability.
PHPDoc Hygiene Checklist
Do This
Instead Of This
Use PHP native types wherever possible
Duplicating native types in
@param tags
Add
constraints with pseudo-types
Vague types like
array or
mixed
Use
shapes and lists (
array{} /
list<>)
Indexed arrays with
array<int,type> (unless needed)
Prefer
@phpstan-type for reuse or DTO of the type is complex
Copy-pasting complex types across files
Keep docs in sync with code
Letting docs rot after refactors
Add purpose-driven descriptions
Empty
@param tags with no context
Use Native Types First, PHPDoc Second
// ❌ Redundant
/**
* @param int $id
*/
function getUser(int $id): User {}
// ✅ Clean
function getUser(int $id): User {}
// ✅ All-In (it depends)
/**
* @param UserId $id Use the Value-Object to fetch the User.
*/
function getUser(UserId $id): User {}
Add Value with PHPStan Types
// ✅ Enforce constraints
/**
* @param positive-int $userId
*/
function getUserById(int $userId): User {}
Prefer
array{} Over Raw
array
// ❌ Too generic
function getConfig(): array {}
// ✅ Self-documenting and type-safe
/**
* @return array{host: string, port: int}
*/
function getConfig(): array {}
Use
list<T> or
non-empty-list<T>
/**
* @return non-empty-list<User>
*/
function getActiveUsers(): array {}
No more bugs from assuming the first item exists.
Reuse with
@phpstan-type
/**
* @phpstan-type UserData array{
* id: int,
* name: non-empty-string,
* email: string
* }
*/
Then:
/**
* @return UserData
*/
public function getUserData(): array {}
Update once. Used often. But once again, if you need this everywhere, please create a DTO class for it. :)
Generics with
@template
/**
* @template T
* @param T $value
* @return T
*/
function identity($value) { return $value; }
Now that’s a real generic—PHPStan can track the type through usage.
Descriptions Are Not Dead
/**
* Fetches total including tax.
*
* @param list<Item> $items Items in the cart.
* @param positive-int $vat VAT rate in percent (e.g. 19).
* @return float Total price incl. tax.
*/
function calculateTotal(array $items, int $vat): float {}
You’re writing code for humans and tools. Don’t forget the humans + you can use html (lists, string, …) here.
Suppress Only When Necessary
// We’re dealing with dynamic properties from legacy __get
/** @phpstan-ignore-next-line */
echo $legacyObject->$name;
But don’t make this a crutch. Fix types instead.
Keep Docs in Sync
When you rename a parameter, update the PHPDoc.
When you change the return type, fix the annotation.
Outdated docs are worse than none at all.
Consider a DTO or Value Object
// ❌ This is too much for an array shape
/**
* @return array{
* user: array{id: int, name: string},
* metadata: array{roles: list<string>, active: bool},
* settings?: array<string, mixed>
* }
*/
Just… stop. Use a DTO. Your future self thanks you.
Key Takeaways
-
Don’t document what PHP already knows.
-
Document what PHP can’t express.
-
Use PHPStan’s extensions to document intent, not just shape.
-
Reuse types. Describe constraints. Avoid magic.
12. Cheatsheet & Final Summary
Let’s wrap this beast up the way it deserves: with a clear cheatsheet of everything PHPStan’s extended PHPDoc syntax gives you—and how to actually use it in production.
This isn’t theoretical. It’s not for linting your hobby script. This is how real teams keep real codebases from turning into type-anarchist dumpster fires.
Cheatsheet: PHPStan PHPDoc Types by Category
Scalar & Refined Pseudo-Types
Type
Meaning
non-empty-string
String that’s never
''
numeric-string
String that parses to number (
"123",
"1.5")
literal-string
String known at compile time
positive-int
Integer > 0
non-negative-int
Integer >= 0
negative-int
Integer < 0
non-positive-int
Integer <= 0
int<min, max>
Integer between
min and
max (inclusive)
class-string<T>
Fully qualified class name (subtype of
T)
callable-string
String name of a global callable
Array & List Types
Type
Meaning
array<TKey, TValue>
Associative array
non-empty-array<TKey, TValue>
Associative array with at least one element
list<T>
0-based sequential array (indexed)
non-empty-list<T>
list<T> with at least one element
array{key: T, ...}
Structured array with required keys
array{key?: T}
Structured array with optional keys
array-key
`int
Object, Class
Type
Meaning
object
Any object
self
Current class (not child)
$this
Instance of calling class
static
Late static binding return
class-string<T>
String that must be a subtype of
T
Callable
Syntax
Meaning
callable
Any valid PHP callable (closure, string, array callback)
callable(): void
A callable that takes no parameters and returns nothing
callable(int): bool
A callable that takes an
int and returns a
bool
callable(string, T): T
Generic callable with multiple parameters and return type
Closure(T): R
Closure with generic parameter and return type
callable-string
String name of a globally callable function
Generics
Annotation
Purpose
@template T
Declare a type variable
T
@template T of Foo
Restrict
T to be subtype of
Foo
@param T $value
Use generic
T for parameter
@return T
Return generic type
T
@var T[] / list<T>
Typed container
@extends Base<T>
Specify type
T when extending base class
@implements Interface<T>
Specify type
T for implementation
Structured Data & Reusability
Syntax
Meaning
@phpstan-type Alias = Type
Type alias for complex types
@phpstan-import-type
Import alias from another scope/class
Constant & Enum-Like Constraints
Syntax
Meaning
'foo'|'bar'
Specific literal values allowed
MyClass::CONST_*
All constants matching prefix in a class
MyClass::CONST_A | MyClass::CONST_B
Specific constant values allowed
MyEnum::MyCase (PHP 8.1+)
Specific native Enum case
key-of<array> /
value-of<array>
Constrain to keys/values of a known constant array
Type Assertions & Conditional Logic
Annotation
Purpose
@phpstan-assert T $var
Assert
$var is type
T after call
@phpstan-assert-if-true T $var
If function returns true,
$var is
T
@phpstan-assert-if-false T $var
If function returns false,
$var is
T
@return (cond ? T1 : T2)
Conditional return type
By-Reference Output Tracking
Annotation
Purpose
@param-out T $var
$var will be of type
T after the function
Suppression & Exceptions
Annotation
Use Case
@phpstan-ignore-next-line
Ignore all errors on the next line
@phpstan-ignore-line
Ignore errors inline
@phpstan-ignore-error error-id
Ignore specific error on current block
Final Thoughts
-
Treat PHPDocs as contracts, not comments.
-
Don’t use array when you mean non-empty-list<literal-string>—be precise.
-
Refactor array shapes into DTOs when they get hairy.
-
Use @phpstan-type, @template, @assert, and @param-out to document behavior that PHP syntax alone can’t express.
-
Rely on tools, not convention. Let PHPStan hold the line.


 Follow the White Rabbit…
Follow the White Rabbit…
 Dev Prompt Patterns
Dev Prompt Patterns
 Legacy (PHP) Code GPTs – Refactoring Fun
Legacy (PHP) Code GPTs – Refactoring Fun
 Smash spaghetti code with brute-force enthusiasm.
Smash spaghetti code with brute-force enthusiasm. Calm logic, precise refactoring. Live long and debug.
Calm logic, precise refactoring. Live long and debug. Minimalist wisdom, clean architecture. “Refactor, you must.”
Minimalist wisdom, clean architecture. “Refactor, you must.” Limitless energy. Kaio-Ken times SOLID!
Limitless energy. Kaio-Ken times SOLID! Inspired by Capsule Corporation’s ingenuity from Dragon Ball.
Inspired by Capsule Corporation’s ingenuity from Dragon Ball. Magical abstraction powers. You shall not pass… bad code!
Magical abstraction powers. You shall not pass… bad code! Stylish, precise refactoring incantations.
Stylish, precise refactoring incantations. Small dogs with SOLID coding skills.
Small dogs with SOLID coding skills.  (PHP) Coding GPTs – Clean and Typed
(PHP) Coding GPTs – Clean and Typed
 Thinking Tools – Meta, Prompt Systems
Thinking Tools – Meta, Prompt Systems
 Disruption GPTs – Radical Clarity, No Filters
Disruption GPTs – Radical Clarity, No Filters





 These 5 phases form a tight feedback loop. No skipping. No guessing. No “just ship it” by default.
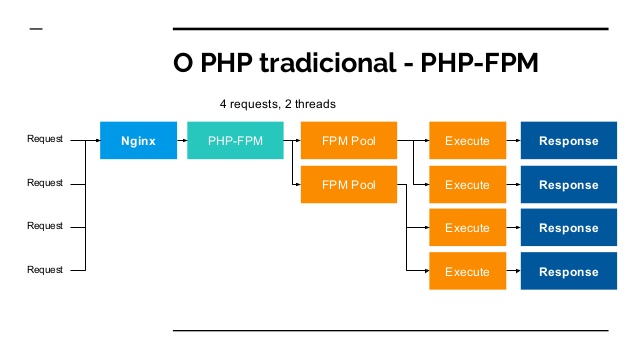
These 5 phases form a tight feedback loop. No skipping. No guessing. No “just ship it” by default.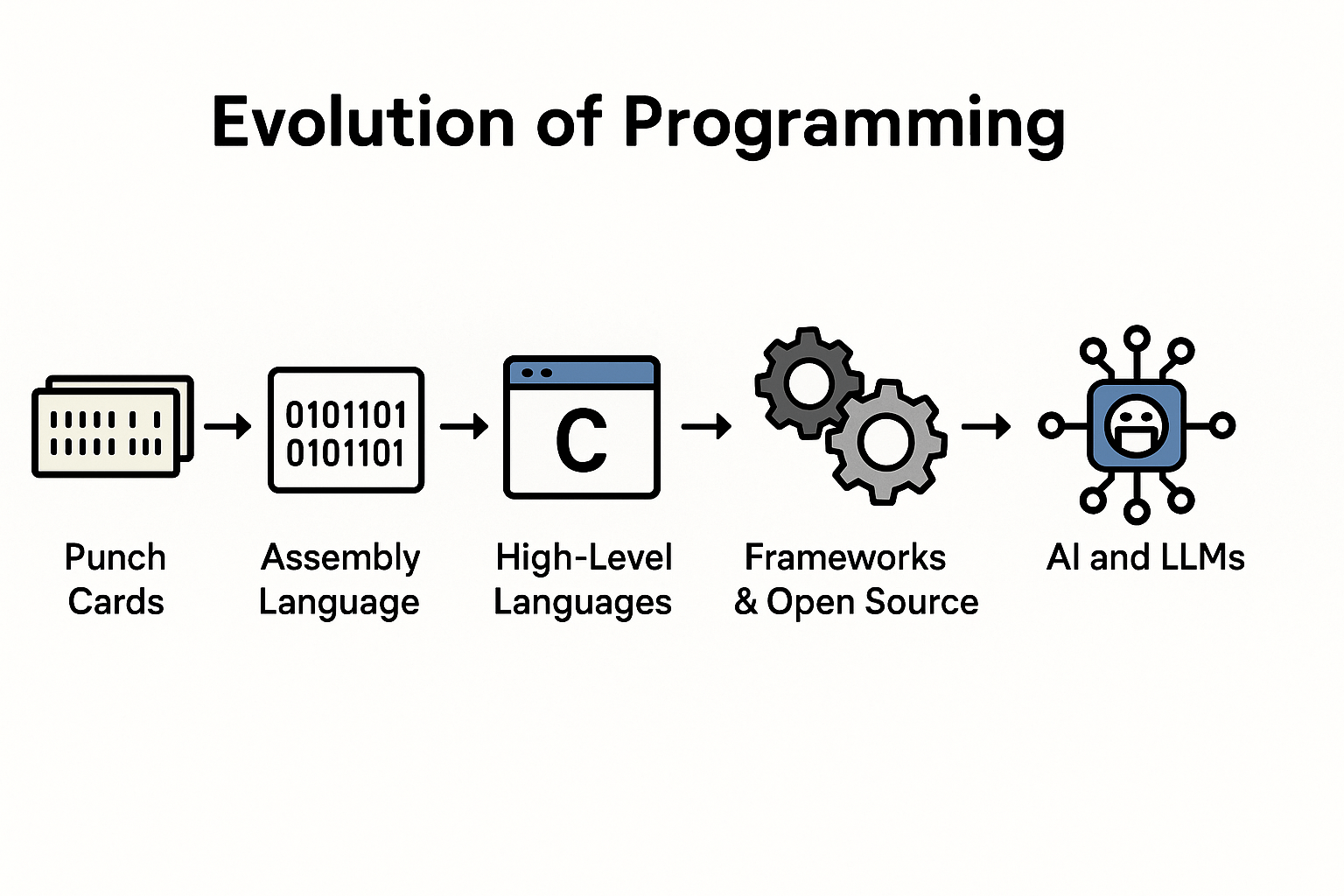
 Layer 0: Physical Switches & Punch Cards
Layer 0: Physical Switches & Punch Cards
 Layer 2: High-Level Languages (C, FORTRAN)
Layer 2: High-Level Languages (C, FORTRAN)
 Layer 4: Frameworks, ORMs, DevTools
Layer 4: Frameworks, ORMs, DevTools
 Layer 5: LLMs (Large Language Models)
Layer 5: LLMs (Large Language Models)
 Why This Works:
Why This Works:
 Intro: Why the Knife in the Sink Matters
Intro: Why the Knife in the Sink Matters
 1. Mess Invites Mess, But Order Invites More Order
1. Mess Invites Mess, But Order Invites More Order
 Real-World Parallel: The Clean Kitchen Effect
Real-World Parallel: The Clean Kitchen Effect
 In Practice
In Practice
 Visual Cleanliness Hides Structural Rot
Visual Cleanliness Hides Structural Rot
 Stop Relying on Memory and Good Intentions
Stop Relying on Memory and Good Intentions
 Ritual Beats Resolution
Ritual Beats Resolution
 The Kitchen Analogy Again
The Kitchen Analogy Again
 4. Design for the Future, Not the Fix
4. Design for the Future, Not the Fix
 Good Architecture Is Predictable
Good Architecture Is Predictable
 No catch-all files
No catch-all files Most Systems Drift by Default
Most Systems Drift by Default
 Architecture Is Operational Psychology
Architecture Is Operational Psychology
 5. Consistency Isn’t Control. It’s Clarity.
5. Consistency Isn’t Control. It’s Clarity.
 The Right Kind of Freedom
The Right Kind of Freedom
 Momentum → No mental pauses to decipher structure
Momentum → No mental pauses to decipher structure Trust → Reviews shift from “What is this?” to “How well does it solve the problem?”
Trust → Reviews shift from “What is this?” to “How well does it solve the problem?” Teams Scale on Predictability, Not Talent
Teams Scale on Predictability, Not Talent
 Conclusion – Make Order the Default
Conclusion – Make Order the Default
 Codebases Work the Same Way
Codebases Work the Same Way
 The “Front Garden” & “Neighborhood” Metaphor: Why Naming Principles Matter
The “Front Garden” & “Neighborhood” Metaphor: Why Naming Principles Matter
 Example:
Example:



 : Too Many Responsibilities
: Too Many Responsibilities
 Why is this bad?
Why is this bad? E-Commerce Example
E-Commerce Example
 Advanced Insights
Advanced Insights  Trade-offs
Trade-offs
 Conclusion
Conclusion

 Simple Definition
Simple Definition
 , none of the existing pups needed modification. The team was extended, not changed.
, none of the existing pups needed modification. The team was extended, not changed.
 Fix: Instead of forcing all birds to be able to fly, we separate “flying” behavior into a different interface. This way, penguins don’t have to pretend they can fly.
Fix: Instead of forcing all birds to be able to fly, we separate “flying” behavior into a different interface. This way, penguins don’t have to pretend they can fly.


 Problem: If we switch to
Problem: If we switch to  Combine with IoC containers for better dependency management.
Combine with IoC containers for better dependency management. Pitfall: Over-applying SRP can create too many small classes.
Pitfall: Over-applying SRP can create too many small classes.
 Code Tips: LLMs break down code and comments into tokens, so structuring your PHPDocs helps focus probabilities effectively. Provide clarity and guidance through structured documentation:
Code Tips: LLMs break down code and comments into tokens, so structuring your PHPDocs helps focus probabilities effectively. Provide clarity and guidance through structured documentation: 2. Tokenization and Embeddings: Use Context Efficiently
2. Tokenization and Embeddings: Use Context Efficiently
 5. Reasoning and Goals: Strengthen Prompt Direction
5. Reasoning and Goals: Strengthen Prompt Direction
 7. Cross-Contextual Coherence: Maintain Consistency
7. Cross-Contextual Coherence: Maintain Consistency
 8. Style and Tone: Adapt Outputs to the Audience
8. Style and Tone: Adapt Outputs to the Audience
 think or / and ask someone in the team
think or / and ask someone in the team