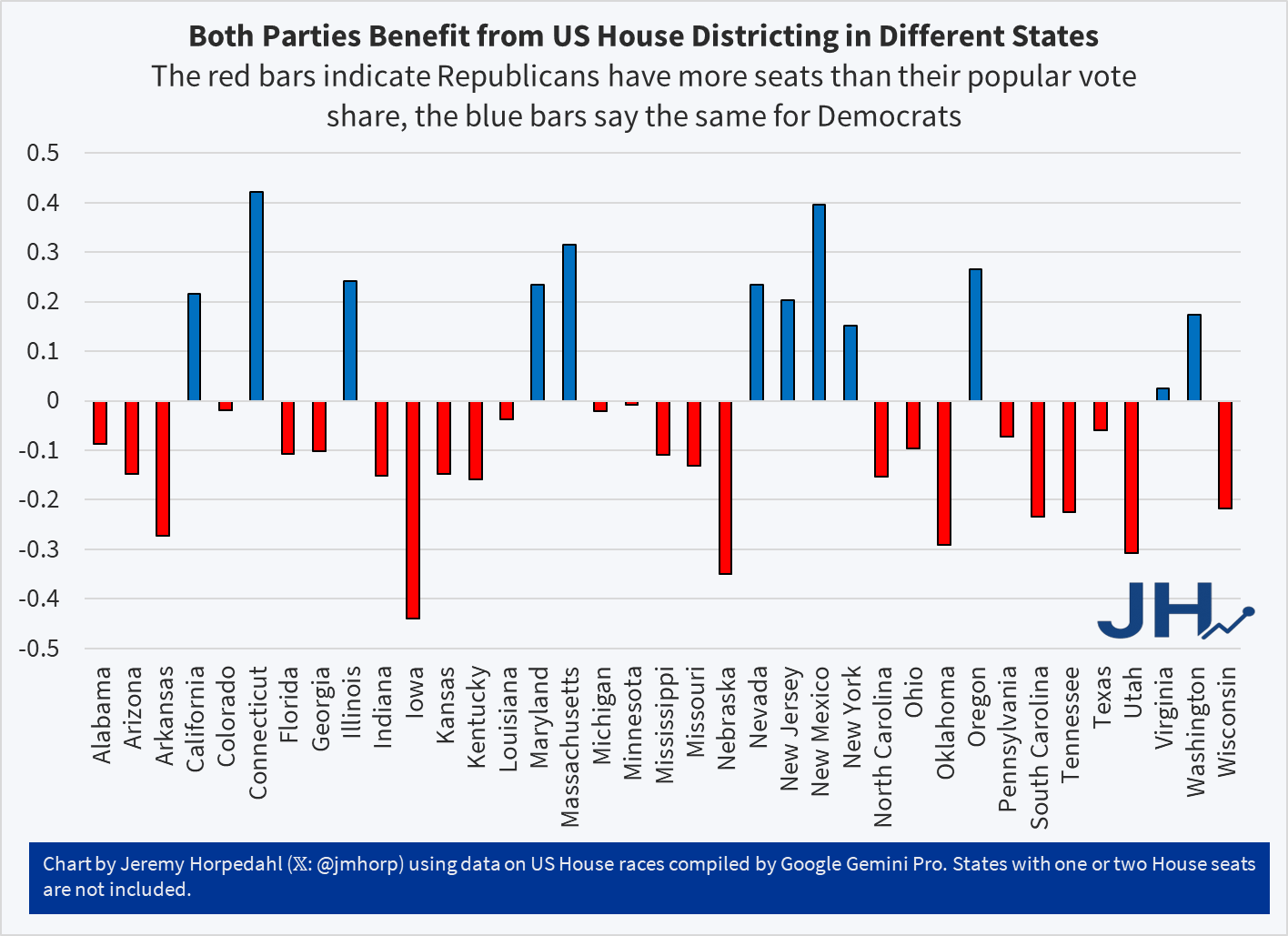
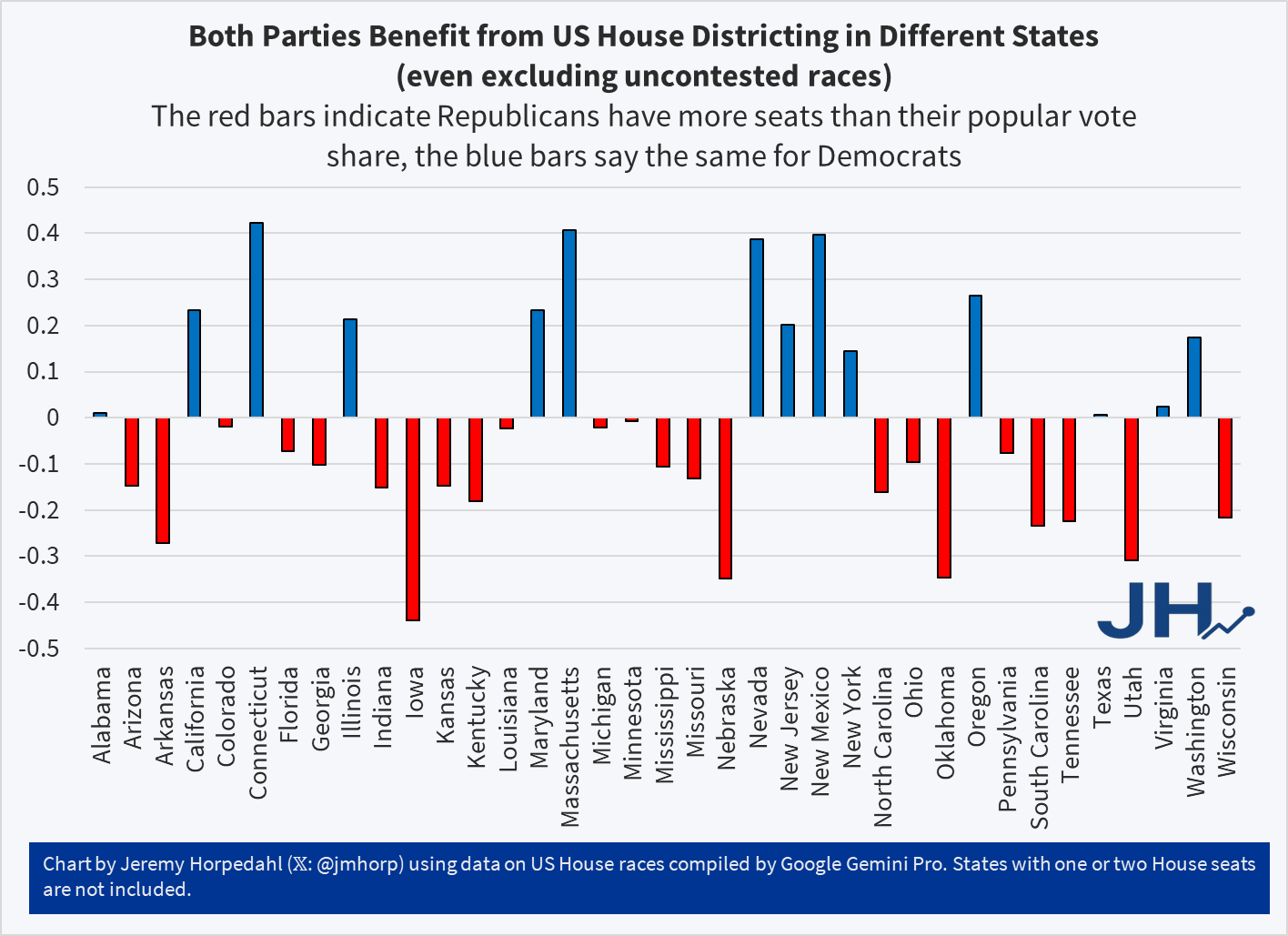
Show full content
I read Straw Dogs, a critique of modern society by English political philosopher John Gray, shortly after it was published in 2002. (No relation to the movie with the same name). Wikipedia summarizes the author’s view as, “Gray blames humanism, and its central view of humanity, for much of the destruction of the natural world, and sees technology as just a tool by which humans will continue destroying the planet and each other.” I cannot recommend the book as a whole – the reader is left in a state of despairing passivity. My AI justly notes, “Critiques of John Gray’s Straw Dogs: Thoughts on Humans and Other Animals generally center on its extreme pessimism, logical inconsistencies, and rhetorical excesses.”
All that said, the book did contain many interesting observations. One line of thought that struck me at the time was that, with increasing efficiencies in the production of basic goods and services, more and more human effort will go into simply entertaining or “distracting” each other:
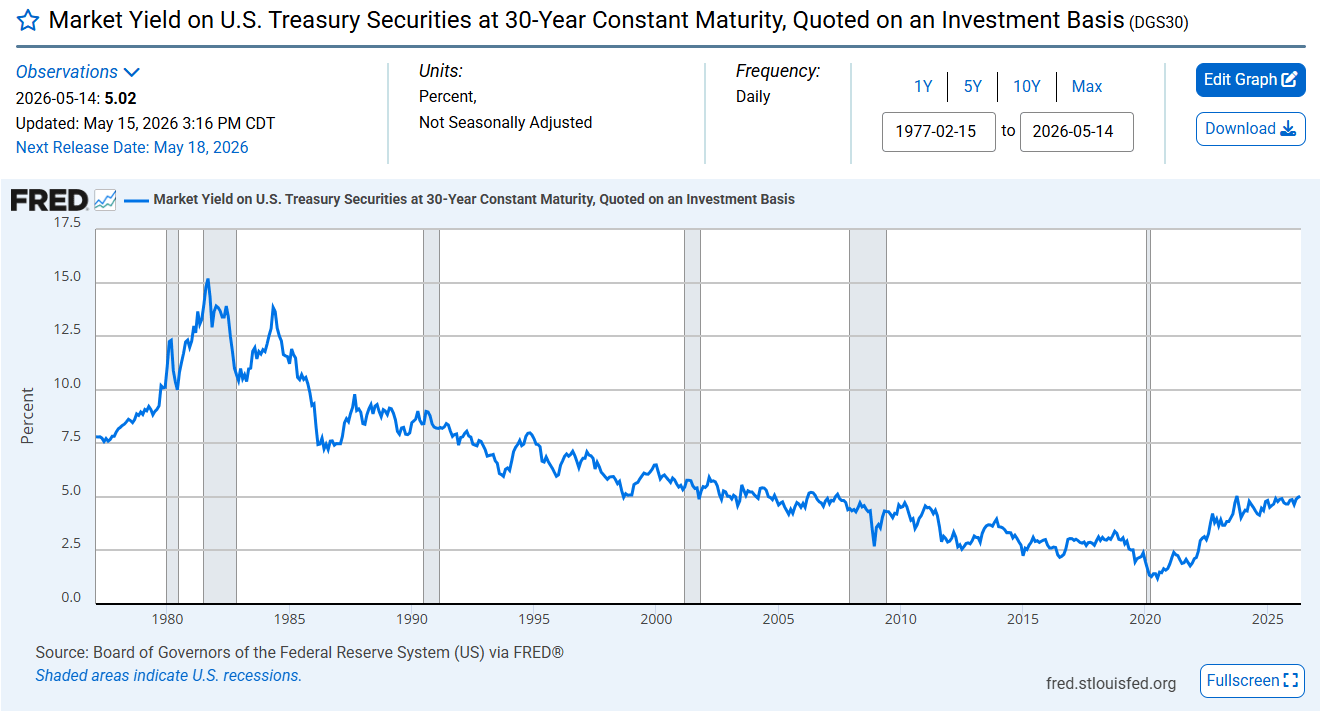
The days when the economy was dominated by agriculture are long gone. Those of industry are nearly over. Economic life is no longer geared chiefly to production. To what then is it geared? To distraction. Contemporary capitalism is prodigiously productive, but the imperative that drives is not productivity. It is to keep boredom at bay. With wants so quickly sated, the economy soon comes to depend on the manufacture of ever more exotic needs.
I was reminded of that line of thought when, at a recent gathering of PhD chemical engineers, I heard that one of our number has become somewhat well-known for a late-career shift. She goes by the name Andrea Hulamyhoop these days. (I happen to know her real last name and approximate age, but she wishes to keep those private).
Her father was a chemical engineering professor, and she earned a PhD in the discipline at Princeton University. She was just going along living a fairly normal sort of life, with a regular job, when without warning, it happened:
Then one day, she saw a girl hula hooping. “She looked really free and happy, and I thought, interesting, maybe I’ll try it.” A few minutes at a time quickly became an obsession. Turns out, there are whole online communities of hula hoopers who share tips and support. Conferences. And many shows and events looking for a pro to dazzle and inspire audiences.
“The hula hoop has changed everything in my life,” she says. “I didn’t know I could become a fit, sporty person. I didn’t know I was one. I love performing, and I love people, and I love parties.
“I always thought my life was a bit OK. My kids were grown up. I was enjoying my job,” she says. “But you know, we kind of think, is this all there is? And then to realize there’s this whole world — it’s been incredible. I’m happier than I’ve ever been in my life.”
Andrea Hulamyhoop doesn’t just swirl a hoop around her waist. She can twirl multiple hoops around multiple body parts, with style. She is perhaps best known for her appearance on America’s Got Talent in 2025, where she smashed previous records by bending over and twirling a hoop around her rear end for just over an hour and fifteen minutes. The crowd went wild.

The physics of this feat seem almost impossible, but seeing is believing. Andrea gives a gracious tutorial here.
When I asked who is the most famous holder of a Princeton chemical engineering PhD, both ChatGPT and Claude insisted that former GE president Jack Welch is more well-known than Andrea the butt-hooper, but I doubt that is true below a certain audience age bracket. She has some 17,000 Instagram followers. I’d be willing to bet that in a crowd of under-40’s today, if you asked “Have you heard about the guy who was president of GE in the 1980’s and 90’s?” or “Have you heard about the gal who can twirl a hula hoop on her butt?”, Andrea Hulamyhoop would win.
All this brought back to my mind the notion that as a society we are able to afford to devote a great deal of time to sheer entertainment, rather than growing potatoes. A comment by a certain @petesounds9321 on Andrea’s epic 2025 AGT YouTube showed he had evidently not read Straw Dogs:
“I’d say we need more scientists than hula hoopers but hey…maybe I’m way off.”